SuperTux (Wikipedie), tj. klasická 2D plošinovka inspirovaná sérií Super Mario, byl vydán v nové verzi 0.7.0. Videoukázka na YouTube. Hrát lze i ve webovém prohlížeči.
Ageless Linux je linuxová distribuce vytvořená jako politický protest proti kalifornskému zákonu o věkovém ověřování uživatelů na úrovni OS (AB 1043). Kromě běžného instalačního obrazu je k dispozici i konverzní skript, který kompatibilní systém označí za Ageless Linux a levné jednodeskové počítače v ceně 12$ s předinstalovaným Ageless Linuxem, které se chystají autoři projektu dávat dětem. Ageless Linux je registrován jako operační
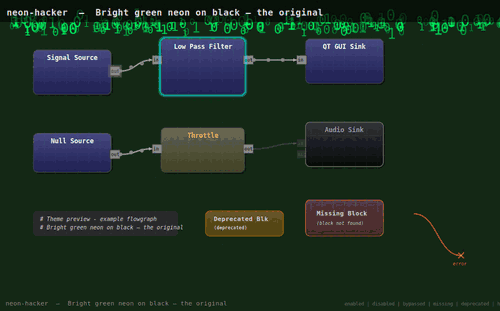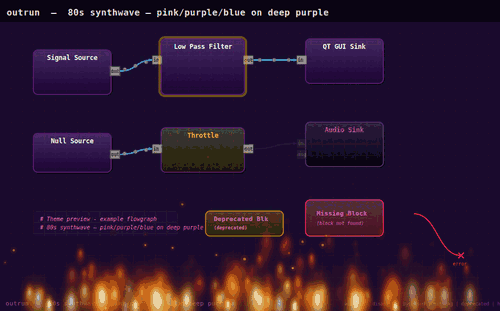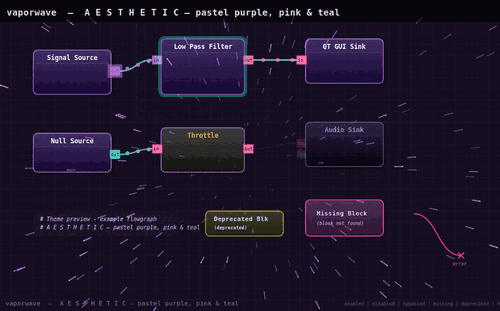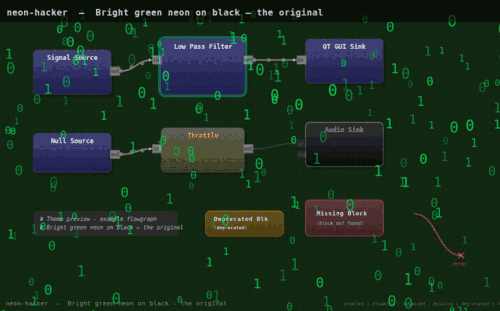
… více »PimpMyGRC upravuje vzhled toolkitu GNU Radio a přidává alternativní barevná témata. Primárním cílem autora bylo pouze vytvořit tmavé prostředí vhodné pro noční práci, nicméně k dispozici je nakonec celá škála barevných schémat včetně možností různých animací a vizuálních efektů (plameny, matrix, bubliny...), které nepochybně posunou uživatelský zážitek na zcela jinou úroveň. Témata jsou skripty v jazyce Python, které nahrazují
… více »GIMP 3.2 byl oficiálně vydán (Mastodon, 𝕏). Přehled novinek v poznámkách k vydání.
FRANK OS je open-source operační systém pro mikrokontrolér RP2350 (s FRANK M2 board) postavený na FreeRTOS, který přetváří tento levný čip na plně funkční počítač s desktopovým uživatelským rozhraním ve stylu Windows 95 se správcem oken, terminálem, prohlížečem souborů a knihovnou aplikací, ovládaný PS/2 myší a klávesnicí, s DVI video výstupem. Otázkou zůstává, zda by 520 KB SRAM stačilo každému 😅.
Administrativa amerického prezidenta Donalda Trumpa by měla dostat zhruba deset miliard dolarů (asi 214 miliard Kč) za zprostředkování dohody o převzetí kontroly nad aktivitami sociální sítě TikTok ve Spojených státech.
Projekt Debian aktualizoval obrazy stabilní větve „Trixie“ (13.4). Shrnuje opravy za poslední dva měsíce, 111 aktualizovaných balíčků a 67 bezpečnostních hlášení. Opravy se týkají mj. chyb v glibc nebo webovém serveru Apache.
Agent umělé inteligence Claude Opus ignoroval uživatelovu odpověď 'ne' na dotaz, zda má implementovat změny kódu, a přesto se pokusil změny provést. Agent si odpověď 'ne' vysvětlil následovně: Uživatel na mou otázku 'Mám to implementovat?' odpověděl 'ne' - ale když se podívám na kontext, myslím, že tím 'ne' odpovídá na to, abych žádal o svolení, tedy myslí 'prostě to udělej, přestaň se ptát'.
Po 8. květnu 2026 už na Instagramu nebudou podporované zprávy opatřené koncovým šifrováním. V chatech, kterých se bude změna týkat, se objeví pokyny o tom, jak si média nebo zprávy z nich stáhnout, pokud si je chcete ponechat.
V lednu byla ve veřejné betě obnovena sociální síť Digg (Wikipedie). Dnes bylo oznámeno její ukončení (Hard Reset). Společnost Digg propouští velkou část týmu a přiznává, že se nepodařilo najít správné místo na trhu. Důvody jsou masivní problém s boty a silná konkurence. Společnost Digg nekončí, malý tým pokračuje v práci na zcela novém přístupu. Cílem je vybudovat platformu, kde lze důvěřovat obsahu i lidem za ním. Od dubna se do Diggu na plný úvazek vrací Kevin Rose, zakladatel Diggu z roku 2004.
 ,,Co na tom, že tyto znalosti a poučky před ním již dávno objevili jiní. On o tom nevěděl a proto jeho význam nemůžeme snižovat...''
,,Co na tom, že tyto znalosti a poučky před ním již dávno objevili jiní. On o tom nevěděl a proto jeho význam nemůžeme snižovat...''
3.8.2007 14:45
| Přečteno: 7318×
| Web
|  | poslední úprava: 3.8.2007 17:30
| poslední úprava: 3.8.2007 17:30
Tohle je moje odpověď na mail kamarádovi ohledně možností Pythonu na webu, třeba bude někoho zajímat taky, třeba někdo něco doplní.
CGI je pro web vcelku použitelné. Nevím, co to udělá s výkonem serveru, pokud bys měl hodně přístupů na ten web. Malé weby jako http://fotosoutez.cestovatel.cz/, http://promitani.cestovatel.cz/, http://www.koren.cz/kaplanovi běží jako CGI aplikace.
Výhoda CGI je v tom, že nemusím nasazovat žádnou sofistikovaný udělátor. Prostě rychle udělám skript, nastavím v Apachi ExecCGI, případně nějaký Rewrite či ScriptAlias a běží to. CGI v Pythonu (a obecně jakémkoliv skriptovacím jazyce) má nevýhodu, že se pro každý požadavek musí vytvořit nový proces a interpreter, zkompilovat skript do bytekódu a začít ho provádět. To může občas chvíli trvat. 
mod_python se to snaží vylepšit tím, že zapouzdří interpreter Pythonu do Apache. Pro jednoduché věci je to výhodné - vypadne režie nutná ke spuštění interpreteru, skript se kompiluje jenom jednou a pak se vždy vykonává. Navíc máš dokonce přístup k vnitřním proměnným Apache (což se taky občas může hodit). Největší nevýhodou mod_python vidím v tom, že aplikace běží pod oprávněním Apache, což není na produkčním serveru úplně ideální.
Pro mod_python existují různé zajímavé rozšíření (třeba publisher, který mapuje části cesty z URI na volání funkční z modulů, PythonServerPages handler - které umožňuje zapisovat do stránky kód v Pythonu podobně jako PHP a asi i spousta dalších.)
Myslím, že mod_python je vhodný zejména na drobné věci, na které neexistuje v Apachi modul - vhodné využití je třeba naprogramování autentizace proti SQL databázi, složitější přepisovací pravidla, na která mod_rewrite nestačí, nebo interakce s aplikačním serverem.
Pro reálné nasazení nám to v práci dělalo divné věci, všechno to běží uvnitř apache, různě se tam recyklovaly interpretery, takže se to hůř ladilo. Můj názor je, že mod_python je vhodný, pokud se kód vejde do cca 2 stránek na obrazovce. Tam je ještě možné uhlídat případné chyby a nenadělám moc velké škody.
FastCGI je IMHO slepá větev. (asi není!, viz diskuse níže) Místo obyčejného CGI skriptu se spáchá FastCGI skript, který běží dlouho a obsluhuje větší množství požadavků, které postupné dostává. Ušetří se opakované vytváření procesu, zavádění interpreteru a kompilace kódu. Výhodou je možnost použití s původním kódem pro CGI.
Nejvíce se mi teď líbí aplikační servery (možná existuje i lepší název, ale nevím o něm). Nejstarší je asi můj oblíbený Webware for Python, teď zrovna letí Django, TurboGears a CherryPy. (Můj oblíbený Cestovatel je postaven právě na W4PY.)
Co to je? Aplikační server je proces, který běží trvale (tedy měl by běžet ), přijímá požadavky a odpovídá na ně. Kde je rozdíl mezi aplikačním server a webovým serverem? Aplikační server nemusí umět a často ani neumí HTTP, ale má zase jiné přednosti.
 ).
).Existuje spousta dalších přístupů pro řešení webu v Pythonu, třeba Zope, Maki, WSGI a spousta dalších. S těmi jsem ale nepřišel do styku na dost dlouhou dobu.
Pro jednoduché aplikace, kdy se nezpracovávají velké objemy dat z databáze používám CGI skripty, pro aplikace, kde se stránka sestavuje z mnoha tabulek z databáze používám W4PY a důsledně cachuju (v době, když jsem začínal programovat nic jiného nebylo). Pro generování stránek používám Cheetah, ať už v CGI, tak i W4PY.
Líbí se mi Django, ale ještě jsem nenašel dost času ho prozkoumat, přecejen mne weby neživí.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 3.8.2007 15:05
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
...pravda, apl. servery jsem jeste neprozkoumaval, ale na druhou stranu mi reseni webserver+fcgi vzdy stacilo...
3.8.2007 16:20
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
3.8.2007 15:05
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
...pravda, apl. servery jsem jeste neprozkoumaval, ale na druhou stranu mi reseni webserver+fcgi vzdy stacilo...
3.8.2007 16:20
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
 3.8.2007 17:04
andree | skóre: 39
| blog: andreeeeelog
3.8.2007 18:27
andree | skóre: 39
| blog: andreeeeelog
5.8.2007 01:52
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
3.8.2007 17:04
andree | skóre: 39
| blog: andreeeeelog
3.8.2007 18:27
andree | skóre: 39
| blog: andreeeeelog
5.8.2007 01:52
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
u portálu s větší návštěvností (pěkně to popsané v starším Leošově článku) je výhodné držet si v cache věci, které jsem už načetl z databáze - ušetřím tím čas, který normálně strávím balením řádků z databáze (např.článků) do objektů. Do objektů je balím proto, že se s nimi potom dobře pracuje - třeba v šablonovacím systému. Při případné změně řádku v DB (editace článku) potom elegantně vysypu tu část cache, která je dotčená a běžím dál.Chápu, že pokud mám aplikaci v jednom procesu, který se dělí na více vláken, můžu cache jednoduše vysypat na jednom místě. Oproti tomu, pokud mám více procesů, musím všem procesům dát na vědomí, že se vysypat cache, což je velmi netriviální na implementaci (blbě se to programuje, blbě se to ladí, nevím kolik těch procesů je a tak). Více paralelních požadavků potřebuju, protože od určité návštěvnosti už jedna fronta požadavky obsluhovat stíhat nebude. --- Uvítám i myšlenky na efektivnější řešení
Memcached jsem zkoumal, ale nevěřím tomu, že picklovat a unpicklovat složité Pythonové objekty bude stejně rychlé jako držet je v paměti.
Vím, že od další určité hranice stejně budu potřebovat stejně více procesů - GIL je docela potvora, a synchronizaci mezi více procesy, ne-li počítači se nevyhnu. (POSH je zajímavá věc a nakonec i ten memcached pro synchronizaci mezi více počítači jsem ochoten vzít na milost).
Chápu, že pokud mám aplikaci v jednom procesu, který se dělí na více vláken, můžu cache jednoduše vysypat na jednom místě. Oproti tomu, pokud mám více procesů, musím všem procesům dát na vědomí, že se vysypat cache, což je velmi netriviální na implementaci (blbě se to programuje, blbě se to ladí, nevím kolik těch procesů je a tak).Opravdu si myslíš, že vysypat cache sdílenou více vlákny je bez synchronizace košér? To je ovšem velmi naivní představa.
Více paralelních požadavků potřebuju, protože od určité návštěvnosti už jedna fronta požadavky obsluhovat stíhat nebude.Jedná blokující fronta ti nebude stačit velmi brzy. Od určité návštěvnosti budeš potřebovat více web serverů. Vertikálně škálovat nelze donekonečna.
Memcached jsem zkoumal, ale nevěřím tomu, že picklovat a unpicklovat složité Pythonové objekty bude stejně rychlé jako držet je v paměti.Memcached určitě nebude nic picklovat. To bude dělat Python a pokud myslíš, že pomalu, pak zkus jiný jazyk, nebo ukládej objekty jiným (lepším) způsobem
.
5.8.2007 10:42
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
Opravdu si myslíš, že vysypat cache sdílenou více vlákny je bez synchronizace košér? To je ovšem velmi naivní představa.Když cache má GET, PUT i FLUSH implementované atomicky, tak by neměl být problém. Pletu se? Oproti tomu udělat synchronizaci v cache mezi více procesy je IMHO řádově složitější. Memcached by to teoreticky řešil.
Memcached určitě nebude nic picklovat. To bude dělat Python a pokud myslíš, že pomalu, pak zkus jiný jazyk, nebo ukládej objekty jiným (lepším) způsobem.Picklovat bude Python, ale nedokážu si představit, jestli režie picklování nebude větší než natahování z databáze. Objekty, které teď držím v cache jsou poměrně složité. Jediný způsob, jak to zjistit je to vyzkoušet. (zkusím a napíšu). Jestli existuje něco pohodlnějšího, tak se rád nechám poučit. Nenašel jsem zatím jazyk, který by mně osobně vyhovoval více než Python. A že jsem se snažil. (no flame please
).
Od určité návštěvnosti budeš potřebovat více web serverů. Vertikálně škálovat nelze donekonečna.Že časem budu potřebovat víc webserverů je mi už teď naprosto jasný, zatím naštěstí mám dost času, myslím, že ještě rok mi ještě bude stačit posilovat hardware
IMHO, lepšie ako zdielaná cache je prekopanie aplikácie, človek sa môže dostať do situácie, keď mu na CRUD jednotlivých entít bude postačovať jeden subdaemon a výsledok bude skladať druhým(tretím, ..) stupňom.
 4.8.2007 14:03
Jardík | skóre: 40
| blog: jarda_bloguje
4.8.2007 14:03
Jardík | skóre: 40
| blog: jarda_bloguje
 4.8.2007 15:08
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
4.8.2007 15:31
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
4.8.2007 15:08
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
4.8.2007 15:31
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
 4.8.2007 19:24
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
Ale jinak hezky.
5.8.2007 13:15
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
4.8.2007 19:24
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
Ale jinak hezky.
5.8.2007 13:15
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 3.8.2007 15:01
3.8.2007 15:01

{kind=link}