Portál AbcLinuxu, 27. června 2026 14:07
Webový prohlížeč bych nepoužíval bez podpory pro:
| taby/karty/listy |
|
91% (2068) |
| ukládání sezení |
|
37% (848) |
| klávesové zkratky |
|
38% (862) |
| gesta myší |
|
18% (407) |
| pluginy (Flash apod.) |
|
61% (1377) |
| rozšíření |
|
27% (613) |
| blokování reklam |
|
45% (1017) |
| témata/skiny |
|
4% (96) |
| AJAX |
|
40% (897) |
| jiné |
|
8% (171) |
Celkem 2267 hlasů
Vytvořeno: 12.6.2009 03:08
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 12.6.2009 03:20
thingie | skóre: 8
12.6.2009 03:20
thingie | skóre: 8
 12.6.2009 10:09
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
12.6.2009 10:09
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
 15.6.2009 16:31
rADOn | skóre: 44
| blog: bloK
| Praha
16.6.2009 13:02
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
15.6.2009 16:31
rADOn | skóre: 44
| blog: bloK
| Praha
16.6.2009 13:02
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
všechny další technologie (AJAX, JS, PHP, Flash, IE...) jsou nádorem na tváři programátorůHere we go (here comes the Prozac): konkrétně tvoje výhrady proti JavaScriptu by mne zajímaly. Podle mne je to velmi pěkný a čistý dynamicky typovaný jazyk, takový Lisp pro masy
 Problémy jsou s implementacemi v prohlížečích a zejména s vazbou na DOM, ale to je jiná pohádka. Dějí se v něm teď pravda divné věci (třídy? Vlastnosti? Dejte pokoj!), ale současný stav není vůbec špatný.
Problémy jsou s implementacemi v prohlížečích a zejména s vazbou na DOM, ale to je jiná pohádka. Dějí se v něm teď pravda divné věci (třídy? Vlastnosti? Dejte pokoj!), ale současný stav není vůbec špatný.
 12.6.2009 11:04
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
12.6.2009 11:04
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
Chyba není v JavaScriptu, ale v jeho často špatném použití – neřeknu u webových aplikací, tam je JS samozřejmost, ale u obyčejných stránek, mi vadí, když bez něj nefungují – neměl by se cpát tam, kde nepřináší žádnou hodnotu. Jednak brání v používání některým uživatelům a jednak je není deklarativní (tenhle kus textu je <a> a jeho atribut href je http://…), ale musí se to v něm naprogramovat (v případě onclick na tomto textu proveď tento kód – kód, který programově zavolá přechod na jinou stránku) – což dost znepříjemňuje údržbu a rozvoj aplikace nebo nějaké další zpracování.
12.6.2009 11:30
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
Já si ale nestěžuju na to, že JavaScript není deklarativní, ale že ta stránka kvůli jeho použití není
Což je škoda, v případě, že se bez JS dá při zachování funkčnosti obejít – pak jeho použití považuji za chybu. Ale pokud má JS nějaké odpodstatnění, ať se použije. Teď třeba píšu aplikaci, která bez JS nefunguje vůbec – ale je to aplikace a ne stránka. A taky funguje jen v některých prohlížečích
To ovšem samo o sobě nevadí, pokud je možné ten skript ignorovat. Osobně jsem toho názoru, že stránka musí fungovat bez JavaScriptu, ale může klidně o něco líp (vyšší uživatelský komfort, typicky třeba našeptávač ve vyhledávacím poli) fungovat s ním.
Podle mne je to velmi pěkný a čistý dynamicky typovaný jazykTam jsem chtěl ještě napsat (a nějak jsem na to zapomněl): s funkcionálními prvky
V JavaScriptu jsou hlavně prvotřídní ( ) ) funkce. A současné webové JS frameworky jich docela využívají, v čemž jsou tedy weboví programátoři napřed oproti zatuchlým mainstreamovým developrům, kteří považují předání funkce do funkce za vysokou magii a funkce jako návratová hodnota funkce je straší v nejčernějších snech Iterátorové metody jsou třeba v Prototype a myslím, že se chystají do další verze jazyka. Milión map jako v Haskellu tam asi nebude (avoid success at all costs!), nejspíš tam nebude rozlišeno ani foldl a foldr, ale to nepovažuju za klíčové.
(At na to koukam, jak na to koukam, i s teorii nastudovanou, tohle je proste syntax error :o)
...3K by na tom měl být o chlup lépe...
Naivko, Guido dodstává kopřivku už při samotném slově Labda a za tail call optimalisation jdeš do kladby.
Na druhou stranu tu zazněl jen jeden argument proti JavaScriptu jako takovému, totiž dynamické typování, ostatní jsou akorát nějaké implementační detaily. (U koho jsem to jen slyšel, algoritmy bez implementace? ) Mimochodem dovedu si představit takový staticky typovaný JavaScript (vlastně nad něčím podobným přemýšlím už delší dobu), to by byla paráda!
), podporu paralelismu v jazyce (paralelní algebry?), nebo tak trapnou věc, jako inkrementální paralelní garbage collectory. O syntaxi nemluvím, tam jsou zásadní věci vlastně hotové (i když predikátové gramatiky taky vypadají zajímavě – kvůli nim jsem se nakonec rozhodl koupit si i The Definitive ANTLR Reference).
Všechna ta teorie ovlivňuje (může ovlivňovat) praxi dosti silně. Proto si myslím, že je zcela legitimní vést diskusi na všech úrovních: o statickém versus dynamickém typování (statické, statické, statické!! ), o interpretech versus kompilátorech nebo automatické správě paměti, nebo čistě o vlastnostech JavaScriptu versus vlastnostech C++ bez ohledu na konkrétní implementaci. Beru to tak, že tvůj názor na JS je mnohem pragmatičtější než ten můj
Z webových aplikací mám smýšené pocity – na jednu stranu jsou příkladem toho, jak Internet díky NATům a zbytečným firewallům zdegeneroval. Na druhou stranu zbavují uživatele závislosti na operačním systému, což je z pohledu Linuxu velké plus. Dneska je totiž už hodně uživatelů, kteří potřebují jen webové aplikace + pár multiplatformních, a tak pro ně změna OS není problém. Současně taky snižují náklady na správu, není potřeba nic instalovat na klientech.
OMFG: smíšené :o)
To je akorát důvod k používání Affero GPL licencí. Za přečtení také stojí: Why you shouldn't use the Lesser GPL for your next library. Uzavřenost webových aplikací není vlastnost této platformy (webu), ale můžou za ni autoři těch programů (něchtějí zveřejnit zdrojové kódy) a autoři těch knihoven (dovolí jim to používáním příliš svobodných licencí pro svoje knihovny).
 13.6.2009 00:57
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
13.6.2009 00:57
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
Ja bych za nejvetsi nador oznacil XML. I kdyz fakt je, ze moda webovych aplikaci je taky IMHO strasna, protoze se prave stavi na technologiich (HTML, CSS, JS), ktere k vyrobe plnohodnotnych uzivatelskych rozhrani vubec nebyly urceny (ale spis k tvorbe dokumentu a interaktivniho obsahu).
Tak za prve, doporucuji k precteni tento odkaz:
http://www.defmacro.org/ramblings/lisp.html
Za druhe, XML je dost spatne navrzene i pro svou puvodni domenu (zapis dokumentu aka docbook), protoze se opravdu spatne cte (myslim, ze by byla mnohem pohodlnejsi treba LaTeX nebo nejaka wiki syntaxe). Kazdopadne, tam to je jeste docela ujde. Co je uz ovsem uplne zvrhle je XML jako format na vymenu dat mezi aplikacemi, nebo jako konfiguracni format. Tam uz jeho slozitost (treba mixed elementy, nebo dichotomie element/atribut, ktera zpusobuje znacnou duplikaci kodu parseru, generatoru a schemat) opravdu ztraci smysl. Uz jen fakt, ze je to (silne redundantni) text je zbesily.
 13.6.2009 01:10
xkucf03 | skóre: 50
| blog: xkucf03
13.6.2009 01:10
xkucf03 | skóre: 50
| blog: xkucf03
Tohle už jsme tu jednou řešili ne? To srovní je dost mimo – alespoň tenhle příklad:
int add(int arg1, int arg2)
{
return arg1 + arg2;
}
versus
<define-function return-type="int" name="add">
<arguments>
<argument type="int">arg1</argument>
<argument type="int">arg2</argument>
</arguments>
<body>
<return>
<add value1="arg1" value2="arg2" />
</return>
</body>
</define>
Programovací jazyk je něco jiného než dokument. Kód != data.
Programovací jazyk je něco jiného než dokument. Kód != data.
Ale konfigurak k Antu neni dokument. Proste, tvrzeni, ze se v takovem pripade nehodi plnohodnotny programovaci jazyk je diskutabilni. Kazdopadne, ja jednak odpovidal Eregonovi na otazku a navic o tomhle vubec nesla rec, protoze i kdybychom Lispovy zapis pouzivali jen jako datovy format, stale by byl jednodussi nez XML (z duvodu ktere jsem jiz strucne uvedl predtim).
 13.6.2009 21:21
default | skóre: 22
| Madrid
13.6.2009 21:21
default | skóre: 22
| Madrid
Výsledkem je, že lidé programují v XML (ant...). Takové lidi prostě nemám rád
Hale! Chlapče! Až budeš mít něco univerzálního na sestavování programů aspoň tak rozšířeného jako Ant, pak si mě neměj rád. Ale dokud máš prd, tak mi nefušuj do řemesla. 
OKi. Tak opět a polopatě: Co je přehlednější? Co se lépe spravuje? Pár XML souborů, které jsou by design deskriptivní, nebo megabajty shelových nesmyslů (configure skripty), Makefily volající programy v Perlu, které generují další programy v něčem jiném? Nebo něco úplně jinýho, co musíš extra stahovat, aby sis sestavil program a v případě problémů se učil něco, co nikdy nepoužiješ (cmake)?
takový nabubřelý "kód" je proti vrozené pohodlnosti programátorů a jejich snaze o zkratky.
Tady je ta chyba. Zkratky, zkratky a zase jen zkratky. Proč? Kód musí být čitelný na první pohled. Snáze uděláš chybu ve zkratkách a snáze ji i přehlédneš, než v celých slovech.
Ti, co se vyžívají ve zkratkách, nechtějí, aby jejich kód byl čitelný. Mají potřebu být nepostradatelní?
13.6.2009 22:36
xkucf03 | skóre: 50
| blog: xkucf03
Teď jsi na to kápnul – problém je v lidech a nevhodném použití → není to vada formátu (XML).
Považuji za naprosto stupidní, když někdo srovnává zdrojový kód v programovacím jazyce s jedním formátem* založeným na XML a z toho vyvodí, že XML (jako takové) je špatné.
*) který se snaží dělat něco jako programování (což ale není smysl toho formátu, jedná se spíš o jeho zvrhlé využití)
Ano. XML formát má jen jedinou vadu: příliš málo míst, kde je vhodné ho nasadit
Vražedná? Kolik lidí zemřelo v souvislosti s XML? Kolik projektů bylo neúspěšných jen proto, že se v nich použilo XML?
Problem komunismu je take v lidech a jeho nevhodnem pouziti, takze nejde o chybu komunismu. :-)
Kazdopadne, rad bych slysel o nejakem nasazeni, kde se XML hodi vic nez jine reseni. Krome dokumentu (a to jeste se skripenim zubu) o zadnem nevim. Samozrejme, taky jde o modu - ze mate parser ve standardni knihovne nic nevypovida o kvalitach toho formatu. Tim chci rict, ze nechci slyset argument typu: Pokud programujete v Jave, nejlepsi je pouzit XML, protoze se to tak proste dela.
Kazdopadne, rad bych slysel o nejakem nasazeni, kde se XML hodi vic nez jine reseni.Dokumenty, jak sám píšete, a pak různé komunikační protokoly, konfigurace, sdílená data. Samozřejmě, kdybyste nahradil špičaté závorky kulatými, dostanete stejně vhodný formát, ale o tom se snad spor nevede. Jinak má XML všechny podstatné vlastnosti – dokument vytvořený na základě alespoň průměrně navrženého schématu je samopopisný, je možné používat jmenné prostotry a kombinovat různá schémata, existuje standardní jazyk pro popis schémat, formát je snadno čitelný i snadno editovatelný. Samozřejmě jsou tam i věci, které jsou řešeny nešťastně – třeba CDATA nebo entity. Ale pořád tu nemáme žádný lepší formát, než je XML, tak je asi rozumné zatím používat XML, a ne ještě horší formáty.
13.6.2009 21:34
default | skóre: 22
| Madrid
OKi, dost možná. Největší výhoda XML je, že podporuje hierarchii. Ta se dá udělat i v properties souborech, ale je to nepřehledné a též redundandní. Redundandnosti se můžeš zbavit skupinami. Tím se ale dostaneš do situace, kdy "šipičaté" závorky nahradíš hranatými.
Nebo si můžeš udělat úplně nový formát, napsat si pro něj gramatiku, parser, generátor… Proč ne, že?
A když se tak nad tím zamýšlím, myslím, že je opravdu jednodušší nevymejšlet kolo a použít to, co je "standardní":
Je to nejjednodušší a každý se v tom vyzná. Pravděpodobnost chyby zanedbatelná ve srovnání s vlastním parserem a tunou dalšího balastu. Nevýhoda: musíš umět XML.
OKi, dost možná. Největší výhoda XML je, že podporuje hierarchii. Ta se dá udělat i v properties souborech, ale je to nepřehledné a též redundandní. Redundandnosti se můžeš zbavit skupinami. Tím se ale dostaneš do situace, kdy "šipičaté" závorky nahradíš hranatými.
Co třeba YAML, JSON, s-výrazy, INI, conf soubory. První tři řešení umí stromové struktury a mají určitě menší redundanci než XML. Navíc knihovny podporující tyto formáty jsou již hotové.
A když se tak nad tím zamýšlím, myslím, že je opravdu jednodušší nevymejšlet kolo a použít to, co je "standardní":
Kontrola v XSD je na značně primitivní úrovni, takže si občas stejně budu muset napsat vlastní kód pro validaci. Mj. všimněte si, že když si udělám vlastní jednoduchý formát, tak je v něm typicky mnohem méně míst, na nichž lze udělat chybu (syntaktickou), zato v XML je těchto míst mnohem více.
Je to nejjednodušší a každý se v tom vyzná.
Tak s tímto absolutně nesouhlasím, viz třeba WSDL nebo SOAP. Např. ve WSDL vám popis funkce string name(string query) zabere pomalu půl stránky a podstatu lze vyjádřit na 1 řádek. Oboje akorát zbytečně zatěžuje servery, klienty a přenosové linky. Stačilo by jen nelpět tolik na XML.
A nakonec k tomu dotazování. Na ty jednoduché formáty typicky postačí grep, je to mnohem jednodušší, rychlejší a kratší.
13.6.2009 23:25
default | skóre: 22
| Madrid
Co třeba YAML, JSON, s-výrazy, INI, conf soubory. První tři řešení umí stromové struktury a mají určitě menší redundanci než XML. Navíc knihovny podporující tyto formáty jsou již hotové.
Vyžadují externí knihovny. XML mám v základní výbavě. Tým podpory aplikace se musí učit specifika jen pro mou aplikaci. XML umí každý.
Kontrola v XSD je na značně primitivní úrovni, takže si občas stejně budu muset napsat vlastní kód pro validaci.
S tím počítám. Přečti si ten seznam prosím ještě jednou.
Mj. všimněte si, že když si udělám vlastní jednoduchý formát, tak je v něm typicky mnohem méně míst, na nichž lze udělat chybu (syntaktickou), zato v XML je těchto míst mnohem více.
Nějak jsem si s dovolením nevšimnul. Obojí mi přijde nastejno.
Tak s tímto absolutně nesouhlasím, viz třeba WSDL nebo SOAP. Např. ve WSDL vám popis funkce string name(string query) zabere pomalu půl stránky a podstatu lze vyjádřit na 1 řádek.
Mám tady před sebou WSDL jedný integračky, kterou jsem dělal. Mám tam mnohem složitější volání a stále se vejdu do patnácti řádek. Pardon.
A nakonec k tomu dotazování. Na ty jednoduché formáty typicky postačí grep, je to mnohem jednodušší, rychlejší a kratší.
Ještě lepší! V aplikaci budu volat grep.
Tímto s dovolením diskuzi uzavírám.
13.6.2009 23:48
default | skóre: 22
| Madrid
Hm. A jak to řeší problém s nepřehledností a redundancí XML?
Docela by mě zajímalo, jak si ten váš parser poradí s DTD, s XML deklarací, s komentáři, s CDATA sekcí, s escapováním znaků <> atd.
14.6.2009 23:34
thingie | skóre: 8
Tým podpory aplikace se musí učit specifika jen pro mou aplikaci.
Podívat se na specifikaci nějakého triviálního formátu vám může zabrat maximálně půl hodiny. Naopak číst XSD nebo jiné nepřehledné schéma vám může zabrat i déle.
XML umí každý.
Nevím, jak jste na to přišel. Co kdybych se zeptal, kterými z následujících znaků může začínat název tagu: "-", ".", "_", "2", ":", ",". Myslíte, že na to každý odpoví správně bez toho, aby to hledal ve specifikaci.
Mám tady před sebou WSDL jedný integračky,...
No nevím, tady je WSDL, co generuje .NET automaticky pro tento kod. Je tam spousta balastu, který je úplně zbytečný, obvzláště, když je možné podstatu napsat na dva řádky, které budou kratší, než jsou názvy jmenných prostorů.
Nějak jsem si s dovolením nevšimnul. Obojí mi přijde nastejno.
Vemte si například XML dokument s SQL dotazy, co tady ukázal kolega. Snadno mohu zapomenout uvozovku, uzavřít tag, otevřít tag apod. Vzhledem k tomu, jaké je tam množství tagů, tak těch chyb mohu udělat docela dost. Zatímco v tom mém formátu mohu nanejvýš zapomenout dvojtečku za názvem SQL dotazu nebo zapomenout zapsat název SQL dotazu (to se týká pouze prvního SQL dotazu).
Ještě lepší! V aplikaci budu volat grep
Ne, ten budu volat z příkazové řádky, v aplikaci použiji nějakou funkci na prohledávání textu, která bude mnohem rychlejší než XPath.
14.6.2009 09:36
default | skóre: 22
| Madrid
Podle mě hledáš problémy pro řešení. A to není moc konstruktivní.
Kolega tady uvedl příklad SQL dotazů v konfiguračních souborech. Jenže to je jen jeden z tisíce příkladů, kde se dá XML použít.
Já jsem třeba na jednom projektu XML použil také a dost nám to pomohlo. Všechny informace jsme měli v Enterprise Architektu. Úplně všechno. Od requirementů až po class diagramy a další implementační nesmysly.
Když se produkt instaloval nebo upgradoval, vyexportoval se z éáčka XMI soubor (též XML) a sadou XSLT transformaček se vygenerovaly XML konfiguráky a další věci. Mezi nimi třeba i nějaký věci v PL/SQL.
Ty transformačky na XML konfiguráky byly jednoduchý a přehledný. To se o těch ostatních říct nedá.
Teď třeba dělám na jiném projektu, kde z XML konfiguráků generuji specifikace a dokumentaci. Jednoduchý jak facka. Vpodstatě jen přejmenovávám elementy a design řeším v CSS. Je to něco podobnýho jako JavaDoc. Se schválně podívej, jak je JavaDoc složitý a jak je složitá XML-to-XML transformace.
A ta složitost, to je ten prapůvod všech problémů. Než abych tady po večerech generoval parsery a ladil již hotové knihovny, použiji to, co je již léta stabilní a umím s tím. Večery radši věnuji vlastní aplikaci. Ano, to parsování je pomalý, ale to zpomalení o 100 ms považuji jako tu nejlepší cenu za ušetřený čas. Navíc, když započítám výše uvedené výhody, opravdu není co řešit. Navíc si ty datový struktury vygenerovaný z konfiguráků beztak serializuju na disk, takže se ty konfigurační soubory prasují jen jednou po každé změně.
Řídím se jednoduchým pravidlem: Každý software obsahuje chyby. Čím víc řádek kódu, tím víc chyb. Jak minimalizovat počet chyb? Jednoduše — moc toho nenapsat.
Já jsem třeba na jednom projektu XML použil také a dost nám to pomohlo. Všechny informace jsme měli v Enterprise Architektu. Úplně všechno. Od requirementů až po class diagramy a další implementační nesmysly...
Já netvrdím, že se to nemá používat. Výhoda XML je, že je mnoho programů, co to podporují (zejména jako formát pro import/export dat a samosebou je to lepší než nějaký nesrozumitelný binární formát). Nevýhoda je přílišná univerzalita -- často lze najít jednodušší a přehlednější řešení (třeba již zmíněné INI soubory).
Například místo SOAPu můžete používat JSON -- pro většinu aplikací plně dostačující, méně redundantní, jednodušší na parsování. Asi proto vznikl SOAPjr.
Řídím se jednoduchým pravidlem: Každý software obsahuje chyby. Čím víc řádek kódu, tím víc chyb. Jak minimalizovat počet chyb? Jednoduše — moc toho nenapsat.
S tím souhlasím. Nicméně XML parser je docela velký kus kódu, je pravda, že ten kód je odzkoušený, takže v něm asi moc chyb nebude. Na druhou stranu, když si napíšu parser INI souborů, který budu používat několik let, tak ty chyby tam pravděpodobně vychytám všechny.
třeba již zmíněné INI soubory
INI soubory jsou zlo. Při čtení wikipedie jsem se skvěle povavil:
„Interpretation of whitespace varies. Most implementations … Some implementations allow values … Some software supports the use of the number sign (#) as … Some implementations allow a colon (:) as the name/value delimiter … Some implementations also offer varying support for an escape character, typically with the backslash (\). … Most commonly, INI files have no hierarchy of sections within sections. Some files appear to have a hierarchical naming convention, however. … The INI file format is not well defined“
Ale zase tak zábavné to není, když si člověk uvědomí, že s takovými soubory musí občas pracovat, ať chce nebo ne. Nejvíc mi na něm vadí nestandardnost, implementace se vzájemně liší. Hierarchie sice chybí, ale člověk se může setkat s často až zrůdnými příklady toho, jak se do těchto souborů někdo snažil hierarchii našroubovat. Pokud někomu vadí redundantnost v XML, měla by mu mnohem víc vadit redundantnost v INI souborech – zatímco v XML jsou redundantní jen značky (musím psát nejen otevírací, ale i uzavírací), v INI souborech jsou redundantní data (musím opakovat uživatelem vložená data, např. název sekce, abych mohl vyjádřit její zanoření).
Co se týče javascriptu a JSONu – ve svém posledním projektu jsem javascriptovou vrstvu minimalizoval, slouží jen jako zobrazovač HTML, které se generuje na serveru (pomocí JSPX) a JSON nepoužívám vůbec – je to o dost přehlednější a spolehlivější.
Pro inspiraci: Jiří Kosek: XML už je všude (mluví tam i o JSONu).
Nevýhoda je přílišná univerzalita -- často lze najít jednodušší a přehlednější řešen. Na druhou stranu, když si napíšu parser INI souborů, který budu používat několik let, tak ty chyby tam pravděpodobně vychytám všechny.
Nemám tolik času nazbyt, abych mohl používat jednoduché formáty – ono to sice někdy vypadá, že by jednodušší formát stačil a XML je v daném případě kanón na vrabce, ale pokud bude v softwaru potřeba dělat změny (a to je potřeba vždycky) a vzroste jeho složitost a složitost dat, nejsem v případě XML ničím omezen, umožňuje aplikaci plynule růst, zvyšovat složitost, aniž by bylo potřeba měnit mechanismy pro práci s daty. Potřebuji přidat hierarchii? Potřebuji různá kódování? Potřebuji do dokumentu přiložit binární data? … XML mě v tom neomezuje.
Specielně ta binární data. Ta jsou v XML opravdu KISS.
Properties hodnoty = new Properties(); InputStream fis = trida.getResourceAsStream(soubor); hodnoty.loadFromXML(fis);
versus
Specifikaci bych mohl napsat, když bych chtěl. Stejně tak ten parser. Oboje dohromady nebude záležitost víc jak 20 řádků.
Co z toho je jednodušší? Víc KISS?
(Jen připomenu, že v prvním případě nepoužívám žádné dodatečné knihovny, nýbrž standardní prostředky jazyka. Aby někdo neřekl, že je to záležitost specifická pro Javu a nepřenositelná jinam, tady je totéž v PHP.)
foreach ($mojeXML->entry as $hodnota) {
echo("<tr><td>");
vypis($hodnota["key"]);
echo("</td><td>");
vypis($hodnota);
echo("</td></tr>");
}
Těším se až někdo navrhne zapisovat i datové struktury javy v xml (vždyť je tak obecné a hierarchické...).
Těším se až někdo navrhne zapisovat i datové struktury javy v xml (vždyť je tak obecné a hierarchické...).
http://java.sun.com/j2se/1.5.0/docs/api/java/beans/XMLEncoder.html
INI soubory jsou zlo.
Rozhodně menší než ukládat jednoduchou konfiguraci do XML. A proč by to měla být nevýhoda, že INI nemá jednu specifikaci?
Pokud někomu vadí redundantnost v XML, měla by mu mnohem víc vadit redundantnost v INI souborech
To jsem nepochopil. Mj. já INI soubory používám na ukládání konfigurace programů a ne serializaci nějakých stromových struktur.
Pro inspiraci: Jiří Kosek: XML už je všude (mluví tam i o JSONu).
Pan Kosek neuvádí nic nového. Podívejte se třeba na 1, 2. Navíc "parsování" JSONu pomocí funkce eval již není třeba, moderní prohlížeče implementují vlastní nativní parser, který je jistě rychlejší než XML parser. Navíc já neměl na mysli použití v prohlížeči -- JSON můžete používat i bez JavaScriptu.
pokud bude v softwaru potřeba dělat změny (a to je potřeba vždycky) a vzroste jeho složitost a složitost dat, nejsem v případě XML ničím omezen, umožňuje aplikaci plynule růst, zvyšovat složitost, aniž by bylo potřeba měnit mechanismy pro práci s daty.
XML mne omezuje jako cokoliv jiného. Pokud myslíte, že ne, ukažte mi, v čem jsem méně omezen třeba oproti s-výrazům. Výhoda vlastního formátu je ta, že je takový, jaký ho potřebuju.
na ukládání konfigurace programů a ne serializaci nějakých stromových struktur.
Jenže konfigurace programu je stromovou struktura velice často. Např. mám v konfiguračním souboru uložené odkazy (odkaz má URL, název a popis) taky tam mám uložená databázová spojení (spojení má typ DB, ip adresu, jméno, heslo a sadu dalších parametrů). Odkazů i spojení tu samozřejmě může být 0 až n. Stromová struktura jak vyšitá (a to jsme ještě u hodně jednoduché konfigurace).
Konkrétně to, co popisujete, mohu uložit do INI souboru -- přehledněji a s menší redundancí než v XML. A jak už jsem psal mohu použít YAML nebo i nějaký jiný formát, v němž to bude přehlednější.
14.6.2009 11:48
default | skóre: 22
| Madrid
Na druhou stranu, když si napíšu parser INI souborů, který budu používat několik let, tak ty chyby tam pravděpodobně vychytám všechny.
Jo, a pak ti na stole přistane change request nebo feature request a budeš to hákovat. Samotnýmu se mi to stalo. Prostě jsem vsadil na špatného koně. Bylo třeba do konfiguráku přidat volbu pro replacement sekvenci. Ta byla zpravidla mezerou. Standardní Javí properties formát toto neumí, protože mezery se zahazují. Navíc ten formát nemá definován žádný encapsulator natož escape sekvenci. Apachí Commons Configuration je na tom ještě hůř. Chyb jak máku, vedlejší efekty… Takže jsem to musel vohákovat metodicky. Kdybych hned na začátku zvolil XML, byl bych vklidu.
Takže abys mohl použít INI soubory, tak bys ten formát musel ndefinovat a naimplementovat tak, aby podporoval nejen současné požadavky, ale i ty, které můžou přijít a zpravidla i přijdou. Takže by ses beztak dopracoval k něčemu ohromnýmu jako je právě XML (co se komplexnosti týče). JSON a podobný věci se v Javě pro tyto účely nepouživají, tak je ani já nebudu používat. A vymejšlet kolo s vlastním formátem? To jsme zase na začátku, viď?
Účelem vývoje software není ukázat světu, jak jsem dobrej, co všechno umím vymyslet a jak geniálně to naimplementovat. Účelem je vyprodukovat jednoduchý program, který je plně funkční a jednoduše spravovatelný. Čím míň nestandardních konstrukcí použiji, tím lépe. Ušetřím čas nejen druhým, ale hlavně sobě — nebudu muset lidem vysvětlovat, že se tady musí napsat čárka, tady zase ne a proč.
Jo, a pak ti na stole přistane change request nebo feature request a budeš to hákovat.
Ano, nebo mohu použít jiný formát. Ale může se také stát, že to ten můj jednodušší formát bude stále zvládat, pak nemusím nic dělat.
aby podporoval nejen současné požadavky, ale i ty, které můžou přijít a zpravidla i přijdou.
Ale nemusel, já byh prostě počkal, dokud nepřijdou. A jak už jsem řekl, já se XML nebráním, takže pokud by přišly takové požadavky, že by bylo vhodné změnit formát, bral bych XML v úvahu.
A vymejšlet kolo s vlastním formátem? To jsme zase na začátku, viď?
Formáty už jsou vymyšlené, takže bych se buď inspiroval, anebo použil něco existujícího. Nicméně nemám důvod volit komplexní formát od začátku, když to třeba nikdy nebude potřeba.
Účelem je vyprodukovat jednoduchý program, který je plně funkční a jednoduše spravovatelný.
Zde se shodnem.
Ušetřím čas nejen druhým, ale hlavně sobě — nebudu muset lidem vysvětlovat, že se tady musí napsat čárka, tady zase ne a proč.
Když je ten formát jednoduchý, tak to lze popsat na jeden odstavec. A typicky není nutné vysvětlovat všechny detaily, protože na ně mnohdy nedojde. Když je složitější, XML nevylučuji.
14.6.2009 17:16
default | skóre: 22
| Madrid
Ale nemusel, já byh prostě počkal, dokud nepřijdou. A jak už jsem řekl, já se XML nebráním, takže pokud by přišly takové požadavky, že by bylo vhodné změnit formát, bral bych XML v úvahu.
Jsem rád, že mě chápeš. Ale situace, kterou popisuješ, se ti může pěkně vymstít. Příklad, který se mi stal. Pár dnů před nasazením nové verze za mnou přišel správce produktu, že business chce odesílat určitá data po dávkách. Tedy né všechno na jednou, ale postupně během dne.
Když jsem tu komponentu na export těch nesmyslů vyvíjel, vzhledem k povaze dat mi došlo, že takováto feature by mohla být do budoucna dobrá. Takže změna pro mě znamenala releasnout nový konfigurák a projekt nebyl ohrožen. Byl to totiž velice důležitý požadavek.
Teď si představ, že by nějaká podobná změna pro Tebe znamenala přejít na nový konfigurační model. Měl bys na to čas? Třeba ano. Ale refaktoroval bys v časovém presu a ve stresu. A jak je známo, stres má velmi negativní dopady na kvalitu.
Podle mě druhá úroveň vývojáře je, že dokáže ze současných požadavků vyčíst mezi řádky, co přijde v následující iteraci vývoje a současné řešení na to již připravit. Jak moc připravit? To závisí na kvalitě vývojáře. Ale z osobních zkušeností musím říct, že sázka na správného koně s jistotou výhry vede k cíli. Když to převedu na problém XML versus INI, tak ze začátku — v prvních releasech — možná konfigurák vypadá divně: pět elementů. Ale v druhém či třetím release — jako když najdeš. Supportní tým se jen naučí další konfigurační volby ve stejném stylu. Člověk není za debila: "Nó, víte, ééé. Nějak jsem to na začátku neodhadnul, tak jsem to teď musel celý přebušit." To nepůsobí moc profesionálně. (Tím nemám na mysli, že člověk nesmí udělat chybu. Naopak. Tomu zabránit nejde. A také člověk tu chybu musí umět přiznat. Ale moc (ne)přiznaných chyb také škodí.)
Ale na mě nehleď. Já jsem extrémista a jsem schopen zrefaktorovat celý systém jen kvůli tomu, abych měl proměnné stejně pojmenované, aby bylo na první pohled vidět, o co vlastně jde. Možná jsem masochista. Ale zatím se mi to vyplatilo a několikanásobně vrátilo.
No nevím, tady je WSDL, co generuje .NET automaticky pro tento kod.
Sorry, ale tohle mi přijde, jako kdybys zavrhnul HTML formát na základě toho, jaké HTML dokumenty lezou z MS Wordu. („Podívejte jaký mám hezký jednoduchý .doc jen s pár formáty textu a nadpisem – a jaké hnusné HTML z toho vylezlo! HTML je tedy špatný formát!“)
Vemte si například XML dokument s SQL dotazy, co tady ukázal kolega. Snadno mohu zapomenout uvozovku, uzavřít tag, otevřít tag apod. Vzhledem k tomu, jaké je tam množství tagů, tak těch chyb mohu udělat docela dost.
Ještě se mi nestalo, že bych při tomto způsobu ukládání SQL udělal syntaktickou chybu. Kdyby se mi to přece jen povedlo, zjistil bych to už během editace souboru – ne až při kompilaci nebo spuštění aplikace. Toto chování editoru je umožněno právě tím, že existuje formální strojově čitelná definice formátu – specifikace nejenže existuje, ale rozumí jí kromě člověka také počítač (editor). Navíc se jedná o syntaxi, se kterou se lidé setkávají často (např. při psaní HTML), takže v ní dělají méně chyb než v syntaxi, která se používá jen v jednom konkrétním případě a kterou se teprve nedávno naučili.
Zatímco v tom mém formátu mohu nanejvýš zapomenout dvojtečku za názvem SQL dotazu
A na to se přijdu kdy? Až začne aplikace při běhu vykazovat divné chování a já budu složitě pátrat, co je špatně?
funkci na prohledávání textu, která bude mnohem rychlejší než XPath.
Ne vždy tomu tak je – po načtení XML už pracuji v podstatě s objekty, strukturovanými daty, zatímco v případě práce s textem pracuji pořád s nějakými poli znaků a ten formát vlastně parsuji při každém průchodu funkce na prohledávání textu.
Hlavně ale rychlost není všechno – pozor na optimalizaci na nesprávném místě, ta nadělá víc škody než užitku. Pokud se nějaký kód vykonává milionkrát denně nebo při každém kliknutí uživatele, má smysl řešit jeho rychlost a zamýšlet se nad nějakou optimalizací. Ale pokud se ten kód pustí jen párkrát za den nebo třeba jen jednou při startu aplikace, jsou mnohem důležitější věci než rychlost.
Sorry, ale tohle mi přijde, jako kdybys zavrhnul HTML formát na základě toho, jaké HTML dokumenty lezou z MS Wordu. („Podívejte jaký mám hezký jednoduchý .doc jen s pár formáty textu a nadpisem – a jaké hnusné HTML z toho vylezlo! HTML je tedy špatný formát!“)
Rozdíl je jen v tom, že Word se dnes na tvorbu stránek běžně nepoužívá. A i kdyby to mělo pět řádek, je to stále mnoho.
Ještě se mi nestalo, že bych při tomto způsobu ukládání SQL udělal syntaktickou chybu. Kdyby se mi to přece jen povedlo, zjistil bych to už během editace souboru – ne až při kompilaci nebo spuštění aplikace. Toto chování editoru je umožněno právě tím, že existuje formální strojově čitelná definice formátu – specifikace nejenže existuje, ale rozumí jí kromě člověka také počítač (editor).
Stejně dobře, jako XML umí zkontrolovat váš editor, tak to moje dokáže zkontrolovat třeba VIM, tím, že zavolá příslušnou funkci programu. Mj. program by se nechoval divně, ale oznámil chybu. Navíc jak moje, tak vaše kontrola je jen poloviční, protože SQL dotaz se nekontroluje.
Ale pokud se ten kód pustí jen párkrát za den nebo třeba jen jednou při startu aplikace, jsou mnohem důležitější věci než rychlost.
Třeba u těch konfiguračních souborů je důležitá přehlednost.
14.6.2009 12:14
xkucf03 | skóre: 50
| blog: xkucf03
tak to moje dokáže zkontrolovat třeba VIM, tím, že zavolá příslušnou funkci programu.
Kdo tu funkci napíše? Kdo mi nakonfiguruje VIM, aby ji volal? Kdo se postará o to, aby byl VIM tuto funkci viděl a mohl ji volat? Tohle všechno je práce navíc, která odvádí moji pozornost od vlastního programování, zbytečná režie navíc. U XML napíšu akorát DTD/Schéma (nebo použiji hotové) a zabiju tím několik much jednou ranou – kontrola v editoru, kontrola v programu, definice formátu pro spolupracovníky nebo externí partnery… Jasně všechno jde i v případě VIMu a vlastního formátu, ale za jakou cenu?
kontrola je jen poloviční, protože SQL dotaz se nekontroluje.
Ona se správnost SQL dost špatně kontroluje, když nemám k dispozici databázový software (PostgreSQL, MySQL…) a data (tabulky a další databázové objekty)
Třeba u těch konfiguračních souborů je důležitá přehlednost.
U XML se mi při editaci ukazuje hezký stromeček (viz příloha – okno „web.xml – Navigator“), barvení syntaxe, automatické odsazování, napovídání možných značek… a to všechno umí editor pro jakýkoli formát založený na XML, ne jeden specifický, pro který byl napsán. BTW: ty záložky „General“, „Servlets“, „Filters“ obsahují GUI pro jednotlivé části toho dokumentu – to už není vlastnost XML, ale díky XML je vznik takového GUI méně pracný a tudíž pravděpodobnější (než vznik GUI pro nějaký zvláštní textový formát).
Kdo tu funkci napíše? Kdo mi nakonfiguruje VIM, aby ji volal? Kdo se postará o to, aby byl VIM tuto funkci viděl a mohl ji volat?
Tu funkci jsem již napsal -- je to ta v Haskellu. Konfigurace je záležitost jednoho řádku. Haskell má interpretr, takže s voláním není problém.
U XML se mi při editaci ukazuje hezký stromeček (viz příloha – okno „web.xml – Navigator“), barvení syntaxe, automatické odsazování, napovídání možných značek… a to všechno umí editor pro jakýkoli formát založený na XML, ne jeden specifický, pro který byl napsán.
To je jistě výhoda, ale třeba u delších dokumentů v docbooku to moc přehledné stejnak není -- TeX je přehlednější (nemluvím o typografii). Nebo editovat v tom MathML...
Navíc jak moje, tak vaše kontrola je jen poloviční, protože SQL dotaz se nekontroluje.
Možná by nebylo od věci místo debatování nad zlým XML napsat gramatiku pro SQL a PL/SQL.
12.6.2009 13:31
xkucf03 | skóre: 50
| blog: xkucf03
Otázka je k čemu XML vlastně je. Na to, aby to člověk ručně editoval to moc vhodné není (nepřehlednost), a na to, aby s tím pracovaly různé programy to moc vhodné také není (složitost formátu a redundance) - pro tento účel jsou mnohem vhodnější třeba s-výrazy z lispu, které by mnoha programům určitě postačovaly.
S ruční editací XML nemám problém – píšu JSPX a XHTML. Je to velmi příjemná práce, protože editor mi nabízí značky a atributy, které v daném kontextu mohu použít, a také mám k dispozici online kontextovou nápovědu (např. popisy značek a atributů, které právě píšu, jejich přípustné hodnoty atd.).
Složitost formátu může být překážkou jen nějakých malých zařízení (jednočipy, hloupé automaty na kafe…), které mají hlavně omezenou paměť, takže se vyplatí data ukládat jinak. Ale všude jinde, od serverů přes PC po mobily, je XML použitelné velmi dobře.
s-výrazy z lispu, které by mnoha programům určitě postačovaly.
Výhodou XML je právě ta nezávislost na programovacím jazyku, platformě, aplikaci. I kdyby postačovaly mnoha programům, stále bude existovat mnoho programů, kterým stačit nebudou.
Složitost formátu může být překážkou jen nějakých malých zařízení (jednočipy, hloupé automaty na kafe…), které mají hlavně omezenou paměť, takže se vyplatí data ukládat jinak. Ale všude jinde, od serverů přes PC po mobily, je XML použitelné velmi dobře.
Složitost formátu implikuje pomalost parsování.
s-výrazy z lispu, které by mnoha programům určitě postačovaly.Výhodou XML je právě ta nezávislost na programovacím jazyku, platformě, aplikaci. I kdyby postačovaly mnoha programům, stále bude existovat mnoho programů, kterým stačit nebudou.
IMO většina programů využívá XML jen na to, aby uložily stromovou strukturu do souboru a věci jako namespacy, komentáře, transformace a další podobné věci vůbec nepotřebují, tudíž je pro ně XML nevhodné (dle mého názoru).
Jenže rychlost zpracování je jen jedno z mnoha kritérií – a často ani není nejdůležitější. Při dnešních cenách HW a práce vývojářů je lepší mít aplikaci, která žere o nějaké procento víc CPU, ale dá se snadno udržovat a rozšiřovat. Než nějaký bastl, který za přesně daných podmínek funguje rychleji, ale jakákoli změna je obrovksky nákladná nebo i nemožná bez přepsání většího množství kódu.
Pokud někdo do XML ukládá jen stromové struktury (to je ale nakonec všechno), využívá z XML jen malou část (standardizované kódování, escapování). Ale i v takto jedoduchých případech není XML na škodu. Příkladem takového primitivního využití je ukládání SQL dotazů do XML – není potřeba žádné zvláštní DTD, ani transformace, v podstatě se jedná jen o strukturu klíč=hodnota (jednotlivé SELECTy jsou pojemnované a pak se na ně odkazuji z aplikace). Někdo by na takový úkol zvolil ne-XML formát, ale já považuji i na takto jednoduchou práci XML za vhodné – můžu do těch SQL dotazů bez obav psát unicode znaky, nemusím řešit kódování. Když chci napsat komentář, nemusím zkoumat, jak se v daném formátu komentáře píší, nebo zda v něm vůbec jsou podporované, prostě napíšu komentář jako v <!-- HTML -->, v XML. Pokud si chci SQL dotaz rozložit na více řádek, nemusím zjišťovat jestli se v daném formátu má na konec řádku psát lomítko, které značí pokračování řádku nebo co, prostě jen odentruji, jak mi to vyhovuje a vím, že to bude fungovat. Rychlost zpracování je v takovém případě naprosto nepodstatná, protože data se načtou jen při startu aplikace a dále se s tím XML už nepracuje.
Jenže rychlost zpracování je jen jedno z mnoha kritérií – a často ani není nejdůležitější. Při dnešních cenách HW a práce vývojářů je lepší mít aplikaci, která žere o nějaké procento víc CPU, ale dá se snadno udržovat a rozšiřovat. Než nějaký bastl, který za přesně daných podmínek funguje rychleji, ale jakákoli změna je obrovksky nákladná nebo i nemožná bez přepsání většího množství kódu.
Nevidím důvod, proč by se aplikace nepoužívající XML měla hůře rozšiřovat a udržovat. A už vůbec nevidím důvod, proč by taková aplikce měla být nějaký bastl -- resp. jakou to má souvislost s tím, jestli pužívám XML nebo jiný formát, který je vhodnější pro konkrétní aplikaci.
Malý příklad:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<-- Vytáhne z databáze náhodný tip (radu, citát). -->
<entry key="NAHODNY_TIP">
SELECT *
FROM tip
ORDER BY random()
LIMIT 1;
</entry>
<-- Vybere tip podle zadaného ID. -->
<entry key="TIP_PODLE_ID">
SELECT *
FROM tip
WHERE id = ?;
</entry>
</properties>
Nemusel jsem psát vlastní DTD či schéma, jelikož to už někdo udělal přede mnou. Pro čtení i zápis použiji standardní prostředky jazyka (např. v Javě nepotřebuji ani žádnou dodatečnou knihovnu). Kdo chce zdrojáky, jak se to používá, může si je stáhnout z mercurialu. Tento formát je zdokumentovaný a může ho používat každý, bez ohledu na programovací jazyk. Není problém, tyhle konfigurační soubory zpracovávat třeba v PHP nebo v Pythonu (či jiném jazyce).
Pro srovnání bych uvítal ukázku zápisu v nějakém ne-XML formátu.
BTW: hodnoty běžně obaluji <![CDATA[ …hodnota… ]]> abych v nich mohl používat < > atd. a nemusel je složitě escapovat – v příkladě jsem tyto značky pro jednoduchost vypustil.
Třeba takto:
# Vytáhne z databáze náhodný tip (radu, citát).
NAHODNY_TIP:
SELECT *
FROM tip
ORDER BY random()
LIMIT 1;
# Bla bla.
TIP_PODLE_ID:
SELECT *
FROM tip
WHERE id = ?;
Domnívám se, že je to přehlednější než XML. Navíc žádné escapování nepotřebuji.
12.6.2009 17:02
xkucf03 | skóre: 50
| blog: xkucf03
A jak v tom zapíši tento SQL dotaz?
SELECT 1::boolean AS pravda, 0::boolean AS nepravda, true AS taky_pravda, 'true' AS "Textový řetězec" WHERE 'xxx # tohle není komentář ' <> 'xxx TIP_PODLE_ID: bzum bzum' -- ne tohle není začátek dalšího selektu. -- nějaké blbé komentáře
Toto je normální platné SQL, které se bez chyb provede třeba v databázi PostgreSQL (vrací jeden řádek se čtyřmi sloupečky). Kde najdu nějakou formální specifikaci tvého formátu, abych věděl, co v něm můžu zapsat a jak? Existuje vůbec, nebo se budu muset podívat na implementaci parseru a z ní usuzovat, co a jak napsat?
Jednoduše. Trik je v tom, že to, co je SQL dotaz, je odsazené o alespoň jednu mezeru, takže stačí každý řádek odsadit o jednu mezeru.
Kde najdu nějakou formální specifikaci tvého formátu, abych věděl, co v něm můžu zapsat a jak? Existuje vůbec, nebo se budu muset podívat na implementaci parseru a z ní usuzovat, co a jak napsat?
Specifikaci bych mohl napsat, když bych chtěl. Stejně tak ten parser. Oboje dohromady nebude záležitost víc jak 20 řádků. Mj. nemám problém s tím, aby se v dotazech vyskytovalo něco typu "]]>" nebo "<" nebo ">".
12.6.2009 18:58
xkucf03 | skóre: 50
| blog: xkucf03
Dobrý trik, v tomhle případě by asi i fungoval.*
Takže musím si musím napsat specifikaci nového formátu + napsat parser + naučit všechny, kteří s tím formátem přijdou do styku, jak na to.
A co tím získám? Když se mi všechno povede, bude to funguvat stejně dobře (při prostém načítání) jako současné řešení s XML. Bude moje aplikace startovat rychleji? Přiznám se, že to je mi úplně jedno – aplikace už teď nastartuje asi během jedné vteřiny, což je rychlé až až – na to, že ji člověk jednou spustí a pak nechá běžet třeba měsíce (webová aplikace).
Co když k tomu někdo přijde poprvé? V případě XML formátu může použít svoje znalosti, které už má (např. z psaní XHTML stránek), kdežto v případě tvého formátu se ho musí teprve učit**.
Znaky < > se dají zapsat – stačí obalit text <![CDATA[ … ]]>, pokud budu chtít dovnitř zapsat text <
BTW: Co se ti bude líp psát ve VIMu?
Tohle: n\u011bjak\u00fd text s \u010de\u0161tinou a \u0111\u0110[]\u0110[\u00b6\u0167\u2193[\u0110j zvl\u00e1\u0161tn\u00edmi znaky
nebo XML soubor v libovolném kódování?
Jistě. Šlo by to "menežovat" i pomocí regulárních výrazů. Ale tady se musím těch Properties trošku zastat. Je to jen API, které uživatele orpošťuje od vlastní reprezentace dat. Je to to samé, jako streamy. Prostě čteš a zapisuješ data a je ti v zásadě jedno, zda je to soubor či síťové spojení.
Když neabstrahuješ od podkladového formátu (XML) a pracuješ s ním přímo, vypadá to asi jako v tom PHP příkladě, co jsem dával -- tzn. taky žádná velká věda, na počet řádek to vyjde přibližně nastejno.
BTW: asi zkusím napsat knihovnu pro textový formát (který by netrpěl neduhy původních .properties), který by nahradil to ošklivé XML -- a schválně kolik lidí ji bude používat (a kolik lidí radši sáhne po XML)
(ono myslím i něco takového existuje, ale lidi nakonec radši použijí to XML...)
Tak se na to mám vykašlat? To byl jen takový pokus, abych dokázal, že i když tu jednoduchý textový formát™ bude, lidi budou stejně radši používat XML.
libconfig, jejich formát imho skutečně není o nic lépe čitelný než XML. To už radši to XML xorg.conf, to je teprv naprostá šílenost, tam by xml sedlo jako prdel na hrnec...
Section "Screen"
Identifier "Screen1"
Device "ATI Radeon HD4870"
Monitor "Monitor1"
DefaultDepth 24
SubSection "Display"
Depth 16
Modes "1440x900"
EndSubSection
SubSection "Display"
Depth 24
Modes "1440x900"
EndSubSection
EndSection
<Screen>
<Screen1 Device="ATI Radeon HD4870"
Monitor="Monitor1" DefaultDepth="24&">
<Display Depth="16" Modes="1440x900" />
<Display Depth="24" Modes="1440x900" />
</Screen1>
</Screen>
xorg.conf...
To mě praštilo do očí. Mít Screen1 jako název elementu je nesmysl. Degraduje to XML. Ta jednička (nebo „Screen1“) by měla být atributem nebo jako hodnota vnořeného elementu. Na tomhle příkladě je vidět, že se XML často používá nesprávně a někteří z zoho pak nesprávně usuzují, že XML je špatné. To je jako kdyby někdo zapřáhl Porshe za pluh a chtěl s ním orat pole – taky mu to nepůjde, ale o kvalitách toho auta to nevypovídá vůbec nic.
Výhodou XML je, že to zná úplně každej. (#195)Třeba. Asi to nebude tak žhavé.
<Screens>
<Screen id=1 Device="ATI Radeon HD4870" Monitor="Monitor1" DefaultDepth=24>
<Display Depth=16> <mode X=1440 Y=900 /> ... </Display>
<Display Depth=24> <mode X=1440 Y=900 /> ... </Display>
</Screen>
<Screen id=2 ...
</Screens>
Takhle by to mohlo být celkem ok ne?
<screens> by tam asi ani být nemuselo...
Kořenový element, ne? Nebo můžeme předpokládat, že to bude celé uzavřené v něčem jako <xorg> … </xorg> (což asi bude).
xorg.conf také nic takového není.
Chybí ti tam uvozovky u atributů. To je ale drovnost – na to by tě upozornil editor, hned jak bys takový soubor začal vytvářet
Jinak chválím rozklad rozlišení na X a Y – tak je to správně – je totiž poněkud hloupé, aby atributy měly ještě nějakou vnitřní strukturu (v tomto případě dvě čísla oddělená „x“), když máme XML → teď se dá přistupovat k jednotlivým složkám toho rozlišení pomocí standardních nástrojů a člověk nemusí parsovat nějaký další formát (byť v tomto případě velice jednoduchý).*
Pak bych měl ještě poznámku k velikosti písmen: na velikosti záleží – takže je víc než dobré mít jednotný styl, aby se to lidem nepletlo. Já bych to psal jako proměnné v Javě – první malé a začátky dalších slov velýma: <třebaNějakTakhle> – ale piš si to jak chceš… jen prostě jednotně.
*) Pro rýpaly: kdyby tam bylo např. PSČ, tak to se naopak nevyplatí rozkládat na čísla před a za mezerou (PSČ nás bude zajímat jen jako celek) – v tomto případě definujeme povolené hodnoty pomocí regulárního výrazu.
Viz Filip. Jednoduchost XML je prostě v tom, že kdejaký admin může naparametrizovat aplikaci a nemusíš se bát, že tam omylem zapomene dát odsazení nebo uvozovku. Stačí, aby věděl co chce udělat (jakému parametru dát jakou hodnotu), ale už nemusí přemýšlet jak to napsat (protože ta syntaxe je mu důvěrně známá).
Návrh XML schémat je naopak netriviální záležitost a měl by to dělat zkušenější vývojář/analytik. (což ale platí i pro návrh jakéhokoli ne-xml formátu nebo specifikace).
(BTW: z pohledu vývojáře – zadši nechám svoji aplikaci startovat o pár milisekund déle, než sledovat otrávené xichty adminů, kteří jsou naštvaní, že se musí učit sto padesátou syntaxi konfiguráků – zatímco u XML jim stačí dát schéma a do dokumentace napsat názvy parametrů a rozsahy hodnot – popisovat závorky, uvozovky, odsazení a další blbosti není potřeba).
Někdo zase neumí ani zapnout počítač – ale to taky neřešíme.
Rozhodně je větší šance, že někdo bude znát syntaxi XML než nějakého speciálního konfiguráku. A když ji nezná, tak se ji poprvé naučí a pak se mu tahle zkušenost může hodit ještě hodněkrát (ale znalost nějaké jedinečné syntaxe se mu dost možná už nikdy hodit nebude).
tak kdovíco. Achjo.
Zkus xmlstarlet.
XF86ConfigPtr).Zrovna v těchto případech bych upřednostnil YAML, který je pro člověka přehlednější.
Tomu nerozumím. Následující zápis mi přijde přehlednější než zápis v XML:
Screen:
Identifier: Screen1
Device: ATI Radeon HD4870
Monitor: Monitor1
DefaultDepth: 24
Display:
Depth: 16
Modes: 1440x900
Display:
Depth: 16
Modes: 1440x900
Máte pravdu, on to není úplně validní YAML -- display by tam nemohlo být dvakrát, to jsem si neuvědomil.
Osobně se mi ale formáty, jenž jsou závislé na odsazování, zdají přehlednější.
Ke jmenným prostorům: Myslím si, že v převážné většině konfiguračních souborů jsou zbytečné.
K validaci: pokud si udělám vlastní formát, tak si k němu mohu dopsat i funkce pro validaci a editor nastavit tak, aby je volal. Mj. YAML má nějaká schémata.
Osobně se mi ale formáty, jenž jsou závislé na odsazování, zdají přehlednější.Mně se zdají nepřehlednější – stačí, že se začnou kombinovat mezery a tabulátory, a je konec. Raději mám formáty, kde si můžu odsazovat podle svého – mimo jiné proto, že každému vyhovuje jiné odsazování.
Ke jmenným prostorům: Myslím si, že v převážné většině konfiguračních souborů jsou zbytečné.zrovna konfigurační soubor pro X server je příklad, kde se jmenné prostory hodí. Modul by mohl mít svou konfiguraci v jiném jmenném prostoru, mohl by poskytnout schéma – a hned by se konfigurák editoval líp, než když tam teď máte spoustu
Optionů, které mají různou vnitřní strukturu, kterou musíte hledat v dokumentaci.
K validaci: pokud si udělám vlastní formát, tak si k němu mohu dopsat i funkce pro validaci a editor nastavit tak, aby je volal.Jistě že můžu pro nový formát udělat tu samou infrastrukturu, která dnes existuje pro XML. Ale výhoda XML je právě v tom, že tohle všechno už existuje – stačí otevřít XML soubor s odkazem na schéma v libovolném editoru, který se umí schématy řídit, a můžu jej editovat. Nemusím proto psát nový editor ani nový validátor. Každý formát, který bude umět to samé, jako XML, bude XML velmi podobný – opravdu jde jenom o to, zda budou závorky kulaté nebo hranaté. Většina formátů, které jsou na první pohled jednodušší, než XML, dříve či později skončí ve stavu, kdy se v rámci daného formátu začnou vyvíjet různé subformáty – třeba různé
Option v xorg.conf, přepisovací pravidla v apache.conf atd. Kdyby se rovnou použilo XML, bylo by to pro všechny zúčastněné jednodušší. Pak existují případy, kdy stačí skutečně jen jednoduchá mapa klíč->hodnota. Kdyby pro to existoval jeden používaný formát, proč ne, ať se používá – XML je v takovém případě opravdu kanón na vrabce. Ale kolik je takových formátů, kde opravdu nehrozí, že se od nich v budoucnosti bude vyžadovat něco složitějšího?
XML by samozřejmě mohlo vypadat jinak, má samozřejmě své mouchy. Ale samotný fakt, že je to široce používaný formát, je velké plus. A vymýšlet spoustu dalších formátů jenom proto, aby byly jiné, to je podle mne nesmysl.
Ale kolik je takových formátů, kde opravdu nehrozí, že se od nich v budoucnosti bude vyžadovat něco složitějšího?
Pokud přijde něco složitějšího a XML se mi bude zdát vhodné, tak ho určitě použiji. Někdy však nic složitějšího nepřijde.
A vymýšlet spoustu dalších formátů jenom proto, aby byly jiné, to je podle mne nesmysl.
S tím také souhlasím. Ale vymýšlet je proto, aby se rychleji parsovaly, aby byly kompaktnější, aby byly přehlednější už smysl má -- toť můj názor.
Pokud přijde něco složitějšího a XML se mi bude zdát vhodné, tak ho určitě použiji. Někdy však nic složitějšího nepřijde.Záleží na tom, zda si můžete formát jen tak měnit. Měnit dnes formát konfiguračních souborů Apache, X serveru a dalších by asi bylo obtížné.
S tím také souhlasím. Ale vymýšlet je proto, aby se rychleji parsovaly, aby byly kompaktnější, aby byly přehlednější už smysl má -- toť můj názor.Kompaktnější – má dneska smysl šetřit pár bajtů konfiguráku? Rychlejší parsování – takový formát se typicky parsuje nějakým parserem sestaveným na koleně případně soustavou regulárních výrazů, takže bude často pomalejší, než obecný XML parser. A přehlednost? Pokud u každého souboru musím znova a znova odhadovat, jaký formát vlastně používá, těžko mluvit o přehlednosti. Navíc XML si v editoru umím zformátovat, odsadit, zabalit nezajímavé větve. Pro kolik dalších formátů tohle editory umí?
Záleží na tom, zda si můžete formát jen tak měnit. Měnit dnes formát konfiguračních souborů Apache, X serveru a dalších by asi bylo obtížné.
Pokud bude v XML potřeba změnit strukturu konfigurace tak, že staré konfigurační souboru nebudou kompatibilní s novými, tak to bude stejné jako změnit formát, ne?
Kompaktnější – má dneska smysl šetřit pár bajtů konfiguráku? Rychlejší parsování – takový formát se typicky parsuje nějakým parserem sestaveným na koleně případně soustavou regulárních výrazů, takže bude často pomalejší, než obecný XML parser.
Teď jsem měl na mysli i použití mimo konfigurační soubory, např. v protokolu SOAP nebo pro serializaci datových struktur, kde kompaktnost určitě není na škodu. Porovnám-li XML s s-výrazy, tak ty parsery jsou jednodušší a rychlejší (i když si ho napíšu na koleně).
Navíc XML si v editoru umím zformátovat, odsadit, zabalit nezajímavé větve. Pro kolik dalších formátů tohle editory umí?
To já nevím. To je však dáno jen rozšířeností XML. Když se rozšíří jiný formát (třeba nějaký vhodnější), tak to editory pro něj budou také umět.
Pokud bude v XML potřeba změnit strukturu konfigurace tak, že staré konfigurační souboru nebudou kompatibilní s novými, tak to bude stejné jako změnit formát, ne?Jak často k takové změně struktury dochází? Pokud se program normálně vyvíjí, je potřeba pouze přidávat nové konfigurační volby, a k tomu stačí přidávání dalších elementů do schématu. Pokud třeba nejprve umí program zacházet jen s jednou obrazovkou, a pak se naučí používat více monitorů, jenom se povolí opakování elementu. V jednoduchém textovém souboru
screen.width=640 screen.height=480jste ale v koncích, a musíte začít vymýšlet nějaký nový formát, který umožní opakování – a nejspíš dospějete k něčemu, co bude stejně „složité“ jako XML, ale horší. A nebo budete dál „vylepšovat“ ten textový formát, donutíte uživatele obrazovky očíslovat souvislou řadou přirozených čísel od jedničky – ale to už není ten původní jednoduchý formát, to už je bastl poslepovaný tak, aby to nějak fungovalo.
Teď jsem měl na mysli i použití mimo konfigurační soubory, např. v protokolu SOAP nebo pro serializaci datových struktur, kde kompaktnost určitě není na škodu. Porovnám-li XML s s-výrazy, tak ty parsery jsou jednodušší a rychlejší (i když si ho napíšu na koleně).Ano, v tomto případě by se nějaký binární formát hodil, ale nejlépe kdyby to bylo binární XML, a bylo možné mezi binárním a textovým XML přepínat. Opravdu je nesrovnatelné pohodlí při vývoji s XMl formátem, který si můžu prohlédnout v libovolném prohlížeči textových souborů, a vyvíjet třeba s ASN.1, který si v lepším případě vydumpujete do textové podoby nějakou utilitou, v horším počítáte bajty v hexaeditoru.
To já nevím. To je však dáno jen rozšířeností XML. Když se rozšíří jiný formát (třeba nějaký vhodnější), tak to editory pro něj budou také umět.A jak by takový vhodnější formát měl vypadat? Co by v něm mělo být jinak než v XML? To je věc, kterou jsem se ještě nikdy od odpůrců XML nedozvěděl.
A jak by takový vhodnější formát měl vypadat? Co by v něm mělo být jinak než v XML?
Takový formát by neměl obsahovat zbytečnosti, které aplikace nepotřebuje. Tím pádem se bude snáze zpracovávat. V mnoha aplikacích, kde je potřeba ukládat stromové struktury lze XML nahradit s-výrazy.
A co je na s-výrazech jiné? Menší redundance: žádné koncové tagy (jen závorky), žádné atributy. Díky tomu se to lépe a rychleji zpracovává.
Jak často k takové změně struktury dochází?
Já myslím, že dost často. Např. mám následující konfiguraci
<config> ... </config>
a v další verzi programu zjistím, že bych chtěl uživateli umožnit více konfiguračních profilů, takže bych chtěl udělat strukturu
<profiles> <profile>...</profile> <profile>...</profile> </profiles>
Podobných příkladů najdete spousty. Jiným problémem může být, že se nějaká hodnota ukládá do atributu a v další verzi je potřeba uložit více podobných hodnot, takže je lepší to udělat jako seznam elementů -- je pravda, že ten atribut tam může zůstat kvůli zpětné kompatibilitě, ale tím si trošku ztížíte zpracování.
žádné koncové tagy (jen závorky)Tím se výrazně zhorší čitelnost. Problém většiny formátů zmíněných v této diskuzi je mimo jiné v tom, že nemají koncové tagy.
žádné atributyOpět, zhoršení čitelnosti. Místo, abyste třeba jednotku nebo jazyk dal do atributu, musíte přidat obalující tag a do něj přidat tag s onou hodnotou.
Díky tomu se to lépe a rychleji zpracovává.Počítači. Ovšem hůře se s tím pak pracuje člověku. Je zvláštní, že se na internetu prosadily zrovna textové protokoly jako HTTP nebo SMTP, které jsou pro počítače neefektivní, ale lépe se s nimi pracuje lidem. Podobně třeba s formáty dokumentů – mnohem lépe se vám bude pracovat s ODT (zazipované XML) než s blobem DOC.
Podobných příkladů najdete spousty. Jiným problémem může být, že se nějaká hodnota ukládá do atributu a v další verzi je potřeba uložit více podobných hodnot, takže je lepší to udělat jako seznam elementů -- je pravda, že ten atribut tam může zůstat kvůli zpětné kompatibilitě, ale tím si trošku ztížíte zpracování.To vše se dá snadno řešit zpětně kompatibilním XML. Naproti tomu INI soubor asi XML parserem zpracujete těžko. Zatímco u zpětně kompatibilního formátu může uživatel soubor postupně přepisovat, jak bude používat nové vlastnosti, při nekompatibilní změně formátu musí soubor zcela přepsat (nebo mu k tomu musíte poskytnout konverzní nástroj).
<screen> v XML mohlo být jednobajtové číslo (které by si příslušná aplikace našla v číselníku), mohlo by v HTTP místo hlavičky Host: být jiné číslo. Například. Všechny ty dvojtečky, mezery, konce řádků, celá slova – to je pro počítače zbytečné. Ale velice to usnadňuje čtení a zápis lidem.
<Host>www.example.com</Host> je s výjimkou koncového tagu o znak kratší, než Host: www.example.comCRLF. Přičemž ten „přebývající“ koncový tag umožňuje snadno zapisovat hierarchické struktury, což protokol HTTP s tvarem klíč: hodnota neumožňuje. Parsování obou variant je taky stejně náročné, tak nevím, proč jedna je efektivní a druhá není.
Přičemž ten „přebývající“ koncový tag umožňuje snadno zapisovat hierarchické struktury, což protokol HTTP s tvarem klíč: hodnota neumožňuje.To bude možná ten vtip. On to totiž ani moc nepotřebuje. Hlavně by to neměl chtít potřebovat, pokud chce být na parsování jednodušší než XML.
Content-Type: text/html; UTF-8 je ve skutečnosti
<content> <type>text</text> <sub-type>html</sub-type> <encoding>UTF-8</encoding> </content>V „originálním“ protokolu HTTP tak máte jeden formát pro hlavičky (oddělovač je dvojtečka), v něm vložený formát pro typ a kódování (oddělovačem je středník), a třetí formát pro mime-typ (oddělovačem je lomítko). A rázem ten báječný jednoduchý parser musí být 3 parsery vnořené do sebe. A to jsem vybral jednu hlavičku, můžete si vzít další a zjistíte, že se tam používají další a další formáty pro strukturovaný zápis dat.
Musím si napsat tři různé regulární výrazy, abych vyzobnul tři texty z jednoho textu.
V případě XML použiji třikrát stejnou metodu, akorát ji zavolám s jiným parametrem (název atributu/elementu). Vstupní text se parsuje jen jednou a pak už se pracuje s objekty v daném programovacím jazyku.
XML nemá žádné magické vlastnosti které by zachraňovaly všechno co se tady píše.To nemá. Ale žádný zde zmíněný formát nemá ani ty vlastnosti, které má XML. A samozřejmě je možné vymyslet tisíce formátů, které budou mít stejné vlastnosti, jako XML, ale jednou z velkých výhod je právě i to, že je to jeden formát.
Například mít konfigurační soubory v programovacím jazyce stejném jako daný software je též zajímavé, a taky to mnoho řeší.Mít konfigurační soubory v nějakém imperativním jazyce je pěkná hloupost. Výhoda deklarativních konfiguárků je, že se dají snadno kontrolovat případně automaticky upravovat. Někdy je samozřejmě vhodné mít možnost program nastavit nějakým jiným programem, ale tomu už bych pak neříkal konfigurační soubor, ale třeba konfigurační skript.
16.6.2009 22:07
xkucf03 | skóre: 50
| blog: xkucf03
jj, konfigurák by měl být statická deklarativní záležitost, ne nějaký program, procedura.
Program může mít možnost spustit při startu (nebo jiných událostech) uživatelský skript, ale určitě bych ho oddělil od konfiguráku – jako máme třeba v Linuxu /etc/rc.local a vedle toho statické konfiguráky, které jsou pasivně načítány (samy o sobě nic nedělají, nevykonávají se, jsou to jen nějaké serializované objekty/struktury).
Mít konfigurační soubory v nějakém imperativním jazyce...
Já si teda rýpnu, co to mít ve funkcionálním jazyce Konkrétně mám na mysli okenní správce xmonad (v Haskellu), který se takto konfiguruje. Je to naprostá bomba -- mohu si tam klidně dopsat nějaké funkce a zaběhu se to umí překompilovat a tím i načíst novou konfiguraci -- geniální, ne?
Jinak musím podotknout, že u PHP aplikací se to běžně dělá.
/proc a parametry jádra a modulů jsou také pohodlnější, než konfigurovat linuxové jádro z Céčka. I když do Grubu by se určitě nějaký ten kompilátor C schoval
Celkově na celé zpracování toho regulárního výrazu až po výsledek spotřebujete nesrovnatelně víc procesorového času, než kolik spotřebuje XML parser.No ty vole! (Co na tohle proboha člověk má říct? To je jako by mi řekli… já nevím co. To je tak neuvěřitelné.)
thingie, že když mám v jednom řádku HTTP odpovědi tři různé formáty, napíšu na to přeci 3 různé regulární výrazy a mám hotovo, protože regulární výrazy má počítač vyhodnocené hned.
yaccem. Jenže u spousty konfiguračních souborů zjistíte, že vám z toho lezou výrazy jako ^clanek-(.*) skript.php?id=$1 [R] nebo 1280x1024,1280x1024; 1024x768,1024x768, které musíte zpracovat dalším parserem nebo regulárním výrazem.
A případný jednoduchý konfigurák něčím takovým +- i je.Jako odstrašující příklad je možné uvést jednoduchou syntaxi MediaWiki, která je také řešitelná smečkou regulárních výrazů.
yaccem či bisonem v úchvatné unixové tradici jsou to nejhorší, co člověka může potkat. Jestli někdo mluví o čitelnosti pro člověka a pak generuje praser takovou zrůdou, měl by se nad sebou vážně zamyslet, protože ošetřování chyb je v takovém případě zcela typické: nehorázně dementní. Uživatelé yaccu a bisonu: jděte k šípku!
IMO naopak, když se zruší koncové tagy a dokument se odsadí (což se stejně často dělá), tak to přehlednost rozhodně nezhorší. S těmi "tagy" místo atributů to je podobné, délka bude stejná, jako kdybych použil XML atribut a přehlednost bude záviset na formátování dokumentu.
...ale lépe se s nimi pracuje lidem.
S tím souhlasím, proto vznikl JSON-RPC nebo SOAPjr.
Podobně třeba s formáty dokumentů – mnohem lépe se vám bude pracovat s ODT (zazipované XML) než s blobem DOC.
Já neříkám, že se má místo XML použít binární formát, stačí s-výrazy, které jsou dobře čitelné a kratší.
To vše se dá snadno řešit zpětně kompatibilním XML.
U toho INI souboru to vyřeším jednoduše: mohu udělat druhý konfigurační soubor pro novou verzi programu, v případě jeho přítomnosti se použije ten, jinak se použije ten starý. Formát toho starého může zůstat nezměněn. Navíc alespoň nemíchám starou a novou konfiguraci dohromady a později snadno odstraním podporu pro staré konfigurační soubory.
IMO naopak, když se zruší koncové tagy a dokument se odsadí (což se stejně často dělá), tak to přehlednost rozhodně nezhorší.Zhorší. Představte si desátý zanořený tag a 200 řádků. Jak v tom budete hledat, kde je ten tag ukončen? Ostatně, stačí si udělat malý test. Patří tag
<Option> v následujícím úryvku konfiguráku do sekce Screen nebo Display?
</>
</>
</>
<Option name="DPI">112</Option>
Já neříkám, že se má místo XML použít binární formát, stačí s-výrazy, které jsou dobře čitelné a kratší.Nemají koncové tagy, jsou hůře čitelné.
U toho INI souboru to vyřeším jednoduše: mohu udělat druhý konfigurační soubor pro novou verzi programu, v případě jeho přítomnosti se použije ten, jinak se použije ten starý. Formát toho starého může zůstat nezměněn. Navíc alespoň nemíchám starou a novou konfiguraci dohromady a později snadno odstraním podporu pro staré konfigurační soubory.Takže uživatel bude s každou novou verzí konfigurační soubor přepisovat do nového formátu? To vám poděkuje.
Content-Type nebo Authorization a další u HTTP, Option v xorg.conf nebo RewriteRule v httpd.conf. A najednou prostá mapa klíč:hodnota nestačí, je potřeba košatější struktura. Takže buď můžete do stávajícího formátu vymyslet nějaký nový formát, kterým tu strukturu popíšete (a pak budete mít v jednom konfiguračním souboru několik různých formátů zápisu), nebo rovnou použijete nějaký formát, který umí popisovat a takovéto složitější struktury (třeba právě XML). A někdo tady argumentoval tím, že od mapy k XML je možné přejít vždy, že se problém s upgradem konfiguráku nějak vyřeší. Jenže ten problém v normálních případech vůbec nemusí nastat, protože normální je, že se konfigurační soubor vyvíjí postupně a je zpětně kompatibilní. Tj. s novou verzí programu můžu přidat konfiguraci nových funkcí, a nebo konfigurák nechám, jak je. Nějaké automatické úpravy konfiguráky jsou jenom obcházením problému, řešením je pouze ten problém uměle nevyrábět. Tj. hned na začátku vybrat formát, který je rozšiřitelný. A to je to, o čem se tady neustále bavíme. Buď je možné používat jednorázově splácané formáty, které pak bobtnají a bobtnají, nedají se pořádně udržovat a rozšiřovat, a nebo je možné použít rovnou pořádný a dobře navržený formát. Je to stejné, jako využití existující knihovny, nebo psaní vlastní – buď můžete použít udržovanou a dobře navrženou knihovnu, kterou používá spousta dalších vývojářů, nebo si můžete napsat „na míru“ vlastní, která bude přece přesně pokrývat vaše požadavky a bude tedy lepší. Ve skutečnosti ale nebude nikdy hotová, bude v ní spousta chyb a nebude umět pořádně ani to minimum, co od ní potřebujete.
klíč:hodnota a kde by v hodnotě nebyly ukryté další formáty.
home=/home/user
somepath=%{home}/somedir
což už se mi párkrát zdálo jako dobrá věc, i když průměrného javistu tak.ová.nějAká.dlouHá.cestaNěkamNe.Překvapí, sou na to zvyklí.
S tím ukrývámím formátů souhlasím, pokud chcete (jako že chcete) uživateli předat nějaké atomické výstupy tak tím se ten parser může zkomplikovat, ale že bych to považoval za nějaké drama, to nemyslím. Ale ano, je to komplikace.
Zhorší. Představte si desátý zanořený tag a 200 řádků. Jak v tom budete hledat, kde je ten tag ukončen?
Stačí mít lepší editor (to co je mezi závorkami je šedě zvýrazněné) a hned to vidím. Ale osobně bych v s-výrazech napsal všechny ukončující závorky na jednu řádku, čímž se zkrátí délka dokumentu a snáze se v něm budu orientovat.
Patří tag<Option>v následujícím úryvku konfiguráku do sekceScreenneboDisplay?
To, kam tag patří, nevím. Tato výhoda však platí jen tehdy, nejsou-li názvy tagů stejné. Navíc když je dokument dlouhý a před tagem Option jsou další tagy a za ním také, tak koncové názvy tagů jsou též někdě mimo obrazovku, takže si příliš nepomohu.
Takže uživatel bude s každou novou verzí konfigurační soubor přepisovat do nového formátu? To vám poděkuje.
To ne, já v novější verzi budu podporovat i starší verzi konfiguračního souboru. A není problém, aby to program sám konvertoval nebo to program uživateli nabídl při prvním spuštění nebo k programu byl přiložen nástroj pro konverzi. Navíc se formát souboru nemusí měnit s každou novou verzí.
Stačí mít lepší editor (to co je mezi závorkami je šedě zvýrazněné) a hned to vidím.Mně se tedy 100 řádků nevejde na obrazovku v sebelepším editoru. A speciální editor pak můžu mít i na binární formát. Tyhle s-výrazy a další jsou takové podivné hybridy – potřebuju na to speciální programy, ale zase je to oproti binárnímu formátu zbytečně ukecané. To radši použiju binární formát tam, kde jde skutečně o maximální úsporu místa nebo maximální rychlost parsování, a dopřeju si luxus dobře čitelného XML v ostatních případech.
To, kam tag patří, nevím. Tato výhoda však platí jen tehdy, nejsou-li názvy tagů stejné. Navíc když je dokument dlouhý a před tagem Option jsou další tagy a za ním také, tak koncové názvy tagů jsou též někdě mimo obrazovku, takže si příliš nepomohu.Prohlížím XML dokument, narazím na sekci
<Device> a vím, že ta mne nezajímá. Tak jí snadno přeskočím tak, že najdou nejbližší </Device> a pokračuju za ním – což udělám snadno i v Notepadu. Pokud bych si musel odpočítávat úrovně zanoření, byl bych tu možná ještě za týden. A přitom tohle je nejčastější případ prohlížení XML dokumentů. Už jsem zkoušel používat zkrácený zápis koncového tagu u formátu, který to povoloval – a hodně rychle jsem tam ty plné koncové tagy dopisoval, aby to zůstalo srozumitelné.
Názvy tagů (nebo kombinace názvu a atributů) u dobře navržených formátů stejné nejsou, protože pokud by byly stejné i se stejným obsahem, znamenalo by to, že vás ten formát nutí neustále něco kopírovat, místo abyste použil odkaz.
To ne, já v novější verzi budu podporovat i starší verzi konfiguračního souboru. A není problém, aby to program sám konvertoval nebo to program uživateli nabídl při prvním spuštění nebo k programu byl přiložen nástroj pro konverzi. Navíc se formát souboru nemusí měnit s každou novou verzí.Což ale pořád jen více či méně úspěšně a komplexně řešíte problém, který vůbec nemusel nastat.
Mně se tedy 100 řádků nevejde na obrazovku v sebelepším editoru.
Já měl na mysli postup, že si kurzorem zajedu třeba na začátek toho "tagu", co mě zajímá, editor šedě zvýrazní vše, co k tomuto tagu patří, a já se podívám, je-li "podtag" šedě zvýrazněn nebo ne. Nebo ve vimu je možné použít procento, které mě přesune na odpovídající závorku.
To radši použiju binární formát tam, kde jde skutečně o maximální úsporu místa nebo maximální rychlost parsování, a dopřeju si luxus dobře čitelného XML v ostatních případech.
Tak já si radši dopřeju dobře formátované s-výrazy, které se mi budou snadno a také rychle parsovat. S čitelností na tom IMO budu podobně jako XML.
Už jsem zkoušel používat zkrácený zápis koncového tagu u formátu, který to povoloval – a hodně rychle jsem tam ty plné koncové tagy dopisoval, aby to zůstalo srozumitelné.
Pravda je, že byly návrhy toto přidat i do XML, ale zatím se to tam nepodařilo prosadit (prý kvůli (ne)přehlednosti).
Názvy tagů (nebo kombinace názvu a atributů) u dobře navržených formátů stejné nejsou, protože pokud by byly stejné i se stejným obsahem, znamenalo by to, že vás ten formát nutí neustále něco kopírovat, místo abyste použil odkaz.
Viděl jsem HTML dokumenty, které měly docela dost vnořených divů nebo třeba příklad z manuálu docbooku (je to na konci stránky).
Což ale pořád jen více či méně úspěšně a komplexně řešíte problém, který vůbec nemusel nastat.
To nemusel, stějně tak dobře jako nemusí nastat potřeba měnit formát konfiguračního souboru.
IMO naopak, když se zruší koncové tagy a dokument se odsadí (což se stejně často dělá), tak to přehlednost rozhodně nezhorší.
Ne nadarmo se v mnoha HTML stránkách vyskytují komentáře typu <!-- levý sloupec - začátek --> a nakonci zase <!-- levý sloupec - konec -->. Je to tím, že někdy kodérovi pro orientaci nestačí vědět, že tady končí </div>, ale chce vědět jaký → tak si tam napíše komentář. Neříkám, že je to dobře nebo špatně, to by bylo na jiný flamewar, ale kdybys mu sebral koncové značky, nejen že by nevěděl, který např. sloupec tam končí, ale on by ani nevěděl, jestli tam končí <div> nebo třeba <p> odstavec.
-- Chudáci programátoři.
Já si takové komentáře do HTML také dělám, ale pak je mi k ničemu vědět, že tam končí div nebo něco jiného -- když vedle mám stejně napsáno, že končí hlavička, což je to podstatné. Navíc, kdyby ten editor byl byl o něco lepší, tak by mi třeba ukázal i začátek (mám na mysli oblast kolem začátečního tagu).
<Screen>
<Screen1 Device="ATI Radeon HD4870"
Monitor="Monitor1" DefaultDepth="24&">
<Display Depth="16" Modes="1440x900" />
<Display Depth="24" Modes="1440x900" />
</Screen1>
</Screen>
(je neprůchozí, protože nebude umět tagy <Moje screen 1>
V praxi to bude (a neříkej že nebude:) :
<Screen>
<Identifier>Screen1</Identifier>
<Device>ATI Radeon HD4870</Device>
<Monitor>Monitor1</Monitor>
<DefaultDepth>24</DefaultDepth>
<Display>
<Depth>16</Depth>
<Modes>
<Mode>1440x900<Mode>
<Mode>1280x1060<Mode>
</Modes>
</Display>
<Display>
<Depth>24</Depth>
<Modes>
<Mode>1440x900</Mode>
</Modes>
</Display>
</Screen>
Porovnej oproti xorg.conf:
Section "Screen"
Identifier "Screen1"
Device "ATI Radeon HD4870"
Monitor "Monitor1"
DefaultDepth 24
SubSection "Display"
Depth 16
Modes "1440x900"
EndSubSection
SubSection "Display"
Depth 24
Modes "1440x900"
EndSubSection
EndSection
Porovnal jsem přehlednost těchto formátů v editorech vim a mcedit – viz příloha. Moje postřehy:
vim zvýrazňuje XML syntaxi, takže tento formát je docela dobře čitelný. Člověk navíc nemusí řešit, co a jak odsadit, jestli má psát uvozovky, nebo je psát nemusí či nemá (u čísel). Píše všechno do stejných <závorek>.xorg.conf se také zvýrazňuje. Musím uznat, že barevné pojetí má vim v případě xorg.conf hezčí než v případě XML. Na druhou stranu potřebuji mít znalosti syntaxe specifického konfiguráku.konfigurák.conf nebo konfigurák.txt nebo xorg.conf-), vim už syntaxi nezvýrazňuje. Je zřejmé, že podporu zvýrazňování xorg.conf musel do vimu někdo naprogramovat.mceditu tam podporu tohoto konkrétního formátu nikdo nenaprogramoval, takže je značně nepřehledný.Xka jsou tak rozšířená, že je jejich syntaxe podporována alespoň některými editory. Ale těžko si dovedu představit, že by každý editor podporoval konfiguráky každé aplikace. Jako autor formátu bych musel poslat patche s podporou autorům editorů. Nebo bych si jako uživatel musel do svého oblíbeného editoru dobastlit podporu svých oblíbených formátů pomocí nějakých skriptů a volání nějakých funkcí – což by sice šlo, ale je to práce navíc.
Takže jak z toho ven? Přijde mi logické dohodnout si nějaký společný podkladový formát – díky tomu můžeme implementovat např. zvýrazňování syntaxe v editoru. A potom si dohodnout formát pomocí kterého budeme formálně (strojově čitelně) zapisovat specifikace zvláštních formátů založených na tom společném podkladovém – díky tomu budeme moci používat validaci a další „nadstandardní“ funkce (napovídání klíčových slov). Tím si ušetříme práci (v editoru bude stačit implementovat podporu jednoho formátu) a získáme větší pohodlí (při editaci budeme mít dostupné „pokročilé“ funkce pro všechny formáty, aniž bychom pro to museli vynakládat zvláštní úsilí).
Co bude tím společným formátem je mi celkem jedno, zatím se ale jako nejlepší volba jeví právě XML. Jestli si někdo myslí, že dokáže vytvořit lepší formát, který by se mohl stát společným jazykem, tak jen do toho
BTW: ne vždy znamená menší pořet řádek a textu větší přehlednost (což platí i při programování).
V praxi to bude (a neříkej že nebude:) :
<Screen>
<Identifier>Screen1</Identifier>
<Device>ATI Radeon HD4870</Device>
<Monitor>Monitor1</Monitor>
<DefaultDepth>24</DefaultDepth>
<Display>
<Depth>16</Depth>
<Modes>
<Mode>1440x900<Mode>
<Mode>1280x1060<Mode>
</Modes>
</Display>
<Display>
<Depth>24</Depth>
<Modes>
<Mode>1440x900</Mode>
</Modes>
</Display>
</Screen>
Nevím, proč by to mělo být zrovna takhle. Napsal jsi to nepřehledně jak to jen šlo...<modes> je tam naprosto redundantní. Nevím, proč by to nemohlo být, jak jsem to napsal já (kromě toho Screen1 samozřejmě...) Voni tam ty atributy v tom XML nejsou jen tak pro nic za nic. To že to lidi nepoužívaj a místo toho cpou tady kde se dá, je jiná věc...
<Identifier>Screen1</Identifier>
<Device>
ATI Radeon HD4870
</Device>
...
jde o to že tak jak jsi to psal ty by to (teoreticky) mohlo být, ale prakticky jak někdo začne dělat s xml, tak mu jde hlavně o to, jak to mít co nejrychleji hotové, snaží se využít existující prostředky, a na čitelnost vzniklého konfiguráku kašle, takže začne vytvářet jeden element za druhým. Tedy rozhodně nebude řešit (jo, je to o lidech) kde přesně by bylo možné dát něco do atributu a kde už je potřeba element. A to dopadne třeba takto (náhodně nalezeno). XML konfiguráky jsou prostě pro stroje, lidé se jimi nezabývají, sice se za jejich výhodu udává že "jsou čitelné", ale prakticky to znamená že "nejsou binární", o čitelnosti lze často s úspěchem pochybovat, protože se jimi nikdo příliš nezabývá (na rozdíl od konfiguráků na které si musí napsat parser takže se s nimi trochu pomazlí), stará se o jiné věci (např. programuje GUI pro klikače aby ten konfigurák dokázaly vytvořit lamky co nemají čas číst a učit se syntaxi). Nechci aby to znělo nabubřele, ale je to asi trend.
Modes jsem tam dal, protože se dá očekávat, že když někde může být víc módů (xorg.conf to odděluje mezerou což mu připadá dostatečné) tak to programátor nejspíš uzavře do nějakého grupelementu, aby se mu to snáž dostávalo. Jinak ano, mohly by tam ty elementy mode být naházené různě napřeskáčku mezi ostatními, o tom žádná :)
14.6.2009 23:54
thingie | skóre: 8
15.6.2009 00:05
thingie | skóre: 8
15.6.2009 09:29
default | skóre: 22
| Madrid
Výhra XML je přibližně v obrovské sadě neuvěřitelně špatných nástrojů, hoře neuvěřitelně ošklivých existujících formátů, a zástupu lidí co jim někdo nakukal, že to je dobrá věc.
A taky je strašně hnusný. Ale to ví všichni.
On je odcela rozdíl datlit XHTML které použává celá planeta, a datlit nějaký konfigurák nebo nějakou XML zprávu pro kterou žádné vychytávky […] rozjodně nenabízí.Woot? Můj editor mi nabízí značky a zobrazuje dokumentaci při editaci každého XML, ke kterému má schéma. Třeba v poslední době konfigurák Compassu (kde je bohužel dokumentace jenom asi tak k polovině elementů
). Ten kromě XML a programové konfigurace nabízí ještě .properties soubor – a díky, zlatým bych ho rozhodně nenazval!
label=value label2=value3 ...kde label může být cokoliv a value taky. že vám to jako po napsání rovnítka nabídne uvozovky? :D A stejně budou příznivci XML říkat "to musíš napsat jedině v XML, ať je to univerzální a přenositelný a může to naparsovat i Pepa Vomáschka z Oregonu". Jo že to nikdy nikdo nikam přenášet nebude a Pepa Vomáschka už je dávno mrtvej, a kdyby byl živej tak by ho ten soft stejně nezajímal, to jim uniká.
No nevím, jestli je třeba konfigurace dbusu optimální. Krátký úryvek:
<limit name="max_incoming_bytes">1000000000</limit> <limit name="max_outgoing_bytes">1000000000</limit> <limit name="max_message_size">1000000000</limit> <limit name="service_start_timeout">120000</limit>
Navíc, když to editujete z terminálu bez nějakého IDE, to je bašta
<limit name="max_incoming_bytes">1000000000</limit> <limit name="max_outgoing_bytes">1000000000</limit> <limit name="max_message_size">1000000000</limit> <limit name="service_start_timeout">120000</limit>Ono by to ale klidně mohlo vypadat i takhle:
<limits>
<max_incoming_bytes>1000000000</max_incoming_bytes>
<max_outgoing_bytes>1000000000</max_outgoing_bytes>
<max_message_size>1000000000</max_message_size>
<service_start_timeout>120000</service_start_timeout>
</limits>
Tady už jde doplňovat, validovat, dokumentovat. Může to mít nějakou logickou strukturu. XML schéma a XML vůbec samozřejmě má svoje meze (a obecně souhlasím s tím, co už myslím v téhle diskusi zaznělo, totiž že XML je vhodné pro komunikaci mezi stroji, jakmile je do toho zapletený člověk, začínají trable), ale přece jen jsou trochu dál
Tohle je právě nepochopení XML – vtip je v tom, že neměním editor, nemusím do něj instalovat nějaké pluginy pro konkrétní formát. Teď jsem si v Netbeansech založil třeba DocBookový dokument – a Netbeans mi napovídají značky, které jsou přípustné v docbooku – prostě si stáhnou příslušné DTD a podle něj mi radí. Stejně tak bych si mohl otevřít nějaký XML, který jsi definoval ty a editor by mi zase pomáhal.
Takže zatímco specifikace nějakého úžasného textového formátu bude několik stránek volného textu (obtížně pochopitelného i člověkem), tak specifikace formátu založeného na XML bude DTD nebo XML Schéma, které je strojově zpracovatelné – tzn. můžu si ho načíst do editoru ten mi radí (což je jen jeden z mnoha způsobů využití XML).
Upravovat takové konfiguráky apache nebo /etc/sudoers bez znalostí syntaxe těchto specifických formátů je fakt peklo. Těžko říct, co je horší – v případě XML mám jasno aspoň v syntaxi, ta je jednoznačná, i když nevím, jak se jednotlivé elementy a atributy mají jmenovat. V případě specifického formátu neznám ani syntaxi, ani názvy položek.
A co je lepší? Neznat jen názvy nebo neznat názvy a syntaxi?
Představ si, že přijdu k tomuto formátu, nebo k tomuto formátu – úplně poprvé, bez nějakých znalostí těch formátů. XML syntaxi mám šanci znát z dřívějška, ale jak si vycucám z prstu, že hodnoty musí být odsazené alespoň o jednu mezeru?
 12.6.2009 03:31
|🇵🇸 | skóre: 94
| blog:
12.6.2009 03:31
|🇵🇸 | skóre: 94
| blog:
 12.6.2009 08:11
otasomil | skóre: 39
| blog: puppylinux
12.6.2009 08:11
otasomil | skóre: 39
| blog: puppylinux
Ja taby pro otevirani novych stranek pouzivam vyhradne. Dnes uz nechapu jak moh nekdo pouzivat IE 6.
Az jednou bude ve webovych strankach tolik reklamniho bordelu tak radi vsichni prejdou na proste cteni textu (viz blokovani reklam).
Jednoho takovýho znám ... a je to fakt hrůza, i v době kdy už má updatováno na IE8, tak stejne má plnou start nabídku spuštěných jednotlivých IE, hroznej bordel
No a to byste se divil, kolik uživatelů používá IE6 ještě dnes. Tuhle jsem byl účastníkem jedné soutěže, kde lidé posílali Print Screeny a řekl bych, že tak polovina měla IE6 a reálně v něm pracovali. Vždycky se snažím lidem poradit, doporučit něco jiného, ale když je odjakživa synonymum pro internet IE, tak je to těžký... Nehledě na bezbečnost takto zabezpečeného počítače.
No a to byste se divil, kolik uživatelů používá IE6 ještě dnes.Hlavně ve firmách, kde je často z nerůznějších důvodů upgrade na IE7+ zamezen, protože by pak přestaly fungovat pro firmu důležité aplikace. Co jsem zjišťoval, je to většinou z důvodl využívaní ActiveX u intranetových aplikací. Často jsou to strašilvé bastly, ve kterých se už nikdo pořádně nevyzná, takže se jen udržují, protože je to pořád levnější než je nechat předělat. Četl jsem názor, že pro většinu vedení ve firmách je koruna ušetřená dnes mnohem důležitější než deset korun ušetřených někdy v budoucnu, protože v budoucnu budou už dávno za vodou (zatímco dnes jsou hodnoceni podle aktuálního zisku). Obávám se, že je až nebezpečne blízko pravdě. A což teprve u politiky ...
 12.6.2009 09:54
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
To snad nema ani smysl resit, ne?
Jinak co se tyce blokovani reklam, tak aniz bych to do sebe kdy rekl, prestal jsem s tim. Jednak chci mit ve svem hlavnim prohlizeci naproste minimum rozsireni (aktualne 0; u Firefoxu, jakozto pouze vyvojoveho nastroje je mi to celkem fuk), pak jsem zjistil, ze nastesti navstevuju pouze weby, kde je to jeste snesitelne a nakonec ti provozovatele serveru taky musi z neceho zit, ze...
Ovsem abych rekl pravdu, zrovna tady na Abicku bych si jednu reklamu zablokoval s velikou chuti -- ten skyscraper vlevo ve zpravickach
12.6.2009 09:54
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
To snad nema ani smysl resit, ne?
Jinak co se tyce blokovani reklam, tak aniz bych to do sebe kdy rekl, prestal jsem s tim. Jednak chci mit ve svem hlavnim prohlizeci naproste minimum rozsireni (aktualne 0; u Firefoxu, jakozto pouze vyvojoveho nastroje je mi to celkem fuk), pak jsem zjistil, ze nastesti navstevuju pouze weby, kde je to jeste snesitelne a nakonec ti provozovatele serveru taky musi z neceho zit, ze...
Ovsem abych rekl pravdu, zrovna tady na Abicku bych si jednu reklamu zablokoval s velikou chuti -- ten skyscraper vlevo ve zpravickach  Kluci, najdete nejake lepsi misto, prosim
Kluci, najdete nejake lepsi misto, prosim
ten skyscraper vlevo ve zpravickachEh... chápu. Nějaké návrhy?
12.6.2009 16:18
otasomil | skóre: 39
| blog: puppylinux
Musi to byt takova obluda ?
Nastesti je to tematicka reklama na tomto webu takze jakstaks OK.
Neni schudnejsi (po domluve se zadavatelem reklamy) pouzivat textove reklamy po vzoru Google ?
Je to jednoduche, prakticke, profesionalni.
12.6.2009 16:36
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
Pod zpravicky nad jobs.cz by to asi neslo, ze?
12.6.2009 16:52
|🇵🇸 | skóre: 94
| blog:
 12.6.2009 16:53
Jendа | skóre: 78
| blog: Jenda
| JO70FB
12.6.2009 16:58
|🇵🇸 | skóre: 94
| blog:
12.6.2009 17:22
otasomil | skóre: 39
| blog: puppylinux
12.6.2009 16:53
Jendа | skóre: 78
| blog: Jenda
| JO70FB
12.6.2009 16:58
|🇵🇸 | skóre: 94
| blog:
12.6.2009 17:22
otasomil | skóre: 39
| blog: puppylinux
*IBM, zeměkoule... Máš Flash?*
Vzdyd je to jen animovany gif
12.6.2009 17:26
Jendа | skóre: 78
| blog: Jenda
| JO70FB
12.6.2009 17:35
|🇵🇸 | skóre: 94
| blog:
12.6.2009 21:41
otasomil | skóre: 39
| blog: puppylinux
Asi jo ja mam pri pravokliku dialog jako na jakemkoli obrazku. Tedy nikoli jak vy.
12.6.2009 17:34
|🇵🇸 | skóre: 94
| blog:
12.6.2009 21:44
otasomil | skóre: 39
| blog: puppylinux
Nedelejte si ze me p***l.
12.6.2009 21:53
|🇵🇸 | skóre: 94
| blog:
13.6.2009 07:10
otasomil | skóre: 39
| blog: puppylinux
* ale to už hodně spekuluji.*
Nespekulujete
Je to tak Pokud mate flashplugin zakazan tak je to gif a pokud je povolen tak je to flash.
13.6.2009 07:47
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
(Mám flash povolený, ale ukazuje se mi jen obdélníček se spouštěcím buttonkem, GIF pod ním není.)
webový prohlížeč bych nepoužíval bez webu.
+1
 12.6.2009 12:29
m1c4a1 | skóre: 2
12.6.2009 12:29
m1c4a1 | skóre: 2
Je mi to vcelku jedno, ale nepoužíval bych ho, pokud by měl problémy se zobrazováním většiny webů.
12.6.2009 16:27
otasomil | skóre: 39
| blog: puppylinux
A jsme u toho proc jsou weby tak zbytecne slozite a monstrozni kdyz to pro samotnou informacni hodnotu nema vubec zadny prinos. Html dle standardu pojede v kazdem prohlizeci. Pokud nekdo neco ubastli ze to tak nejak jede jen treba v IE tak je to jeho boj.
Zacinam mit cimdal vetsi dojem ze www neni k tomu aby slouzilo lidem ale aby lide slouzili mu (tocili navstevnost stranek a provozovatel webu se ohanel mnozstvim loadu a prokliku. Vsechny tyto prvky komplikuji pouzivani rozmanitych prohlizecu.
12.6.2009 16:35
|🇵🇸 | skóre: 94
| blog:
12.6.2009 22:14
Jendа | skóre: 78
| blog: Jenda
| JO70FB
 12.6.2009 18:41
Jezekus | skóre: 19
| blog: jezkova_nora
Aby byly nahrazene nesmyslnymi videi, reklamami a podobnym svinstvem.
12.6.2009 18:41
Jezekus | skóre: 19
| blog: jezkova_nora
Aby byly nahrazene nesmyslnymi videi, reklamami a podobnym svinstvem.
No, rict, ze bych webovy prohlizec bez techto veci nepouzival, je trochu silne. Ale nektere z tech vynalezu jsou uzitecne, a pro ty jsem take hlasoval. Ale chybi mi tam par podstatnych veci - kesovani stranek, doplnovani formularu, pamatovani hesel.
...rychlosti!
BTW, Opera 10 je subjektivně opět o něco rychlejší a zdá se, že už se ani tolik nezasekává při čekání na načtení nějakého prvku. Dobré zkušenosti se zrychlením prohlížení mám taky ve spolupráci s OpenDNS + dnsmasq na serveru ve vedlejší síťové zásuvce.
 21.6.2009 23:12
David Watzke | skóre: 74
| blog: Blog...
| Praha
Naštěstí, s příchodem desítky se to výrazně zlepšilo (vím, o čem mluvím, musím teď přechodně pracovat na počítači se 768 MiB RAM místo 4 GiB ).
21.6.2009 23:12
David Watzke | skóre: 74
| blog: Blog...
| Praha
Naštěstí, s příchodem desítky se to výrazně zlepšilo (vím, o čem mluvím, musím teď přechodně pracovat na počítači se 768 MiB RAM místo 4 GiB ).
 15.6.2009 20:08
unknown_ | skóre: 30
| blog: blog
15.6.2009 20:08
unknown_ | skóre: 30
| blog: blog
ISSN 1214-1267, (c) 1999-2007 Stickfish s.r.o.
 12.6.2009 18:19
12.6.2009 18:19
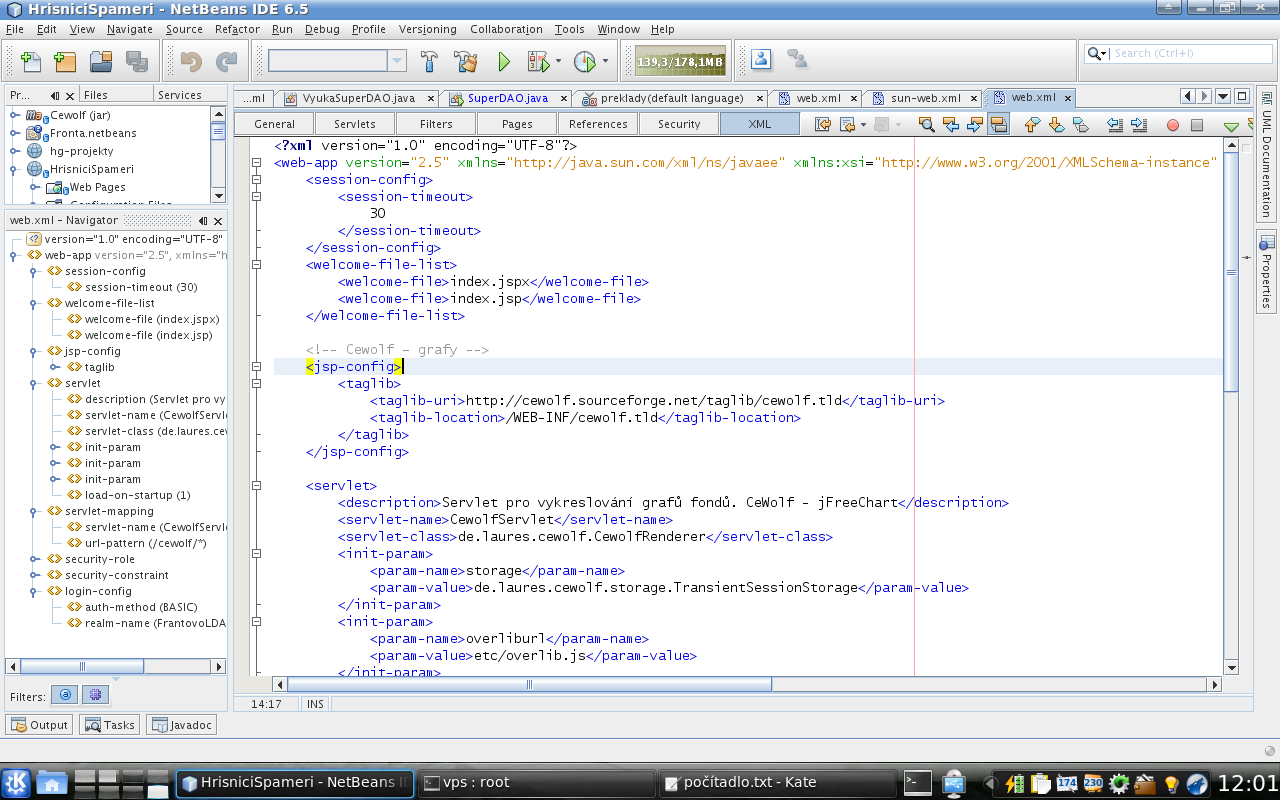{kind=link}
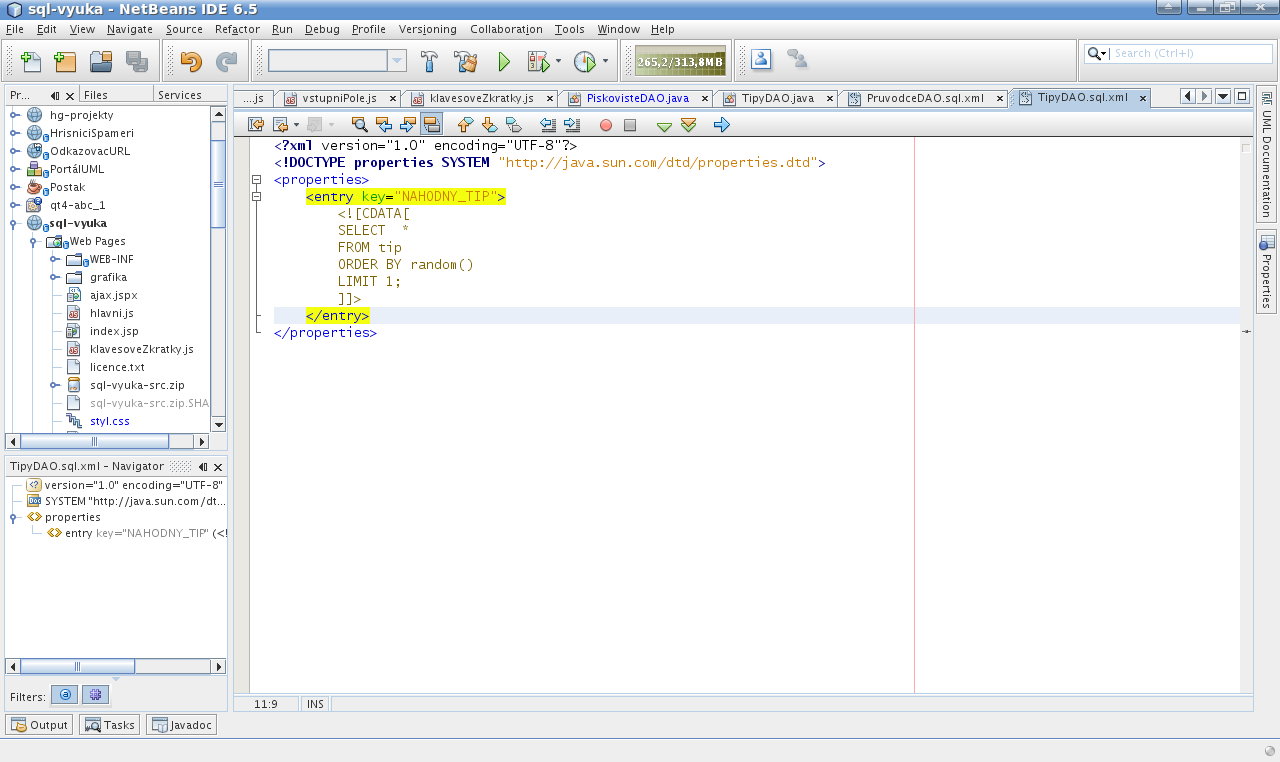{kind=link}
{kind=link}
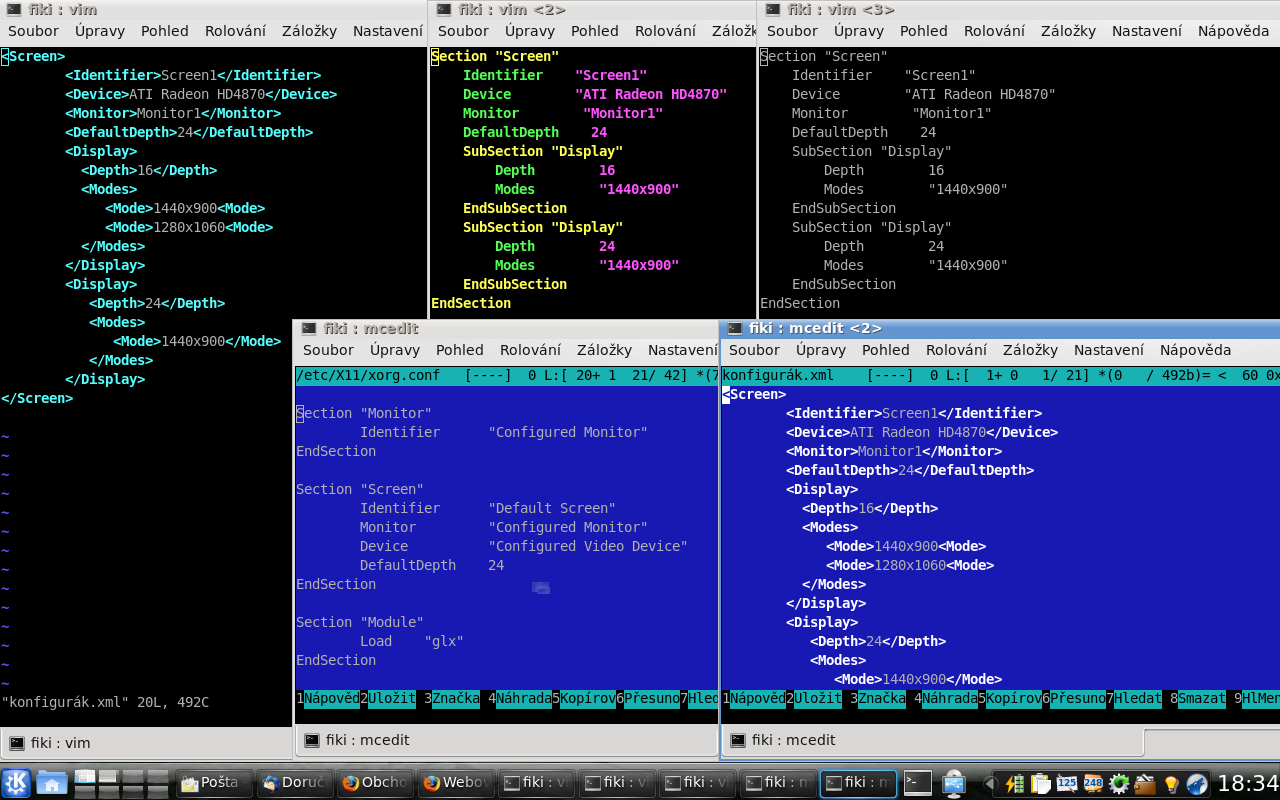{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}