Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
 30.1.2017 19:08
Josef Kufner | skóre: 70
30.1.2017 19:08
Josef Kufner | skóre: 70
\|&* vedle levého shiftu na mém Thinkpadu. Dokonce je to v KDE v nastavení klávesnice snadno nastavitelné  30.1.2017 19:33
Josef Kufner | skóre: 70
30.1.2017 19:33
Josef Kufner | skóre: 70
man xcompose
30.1.2017 19:36
Josef Kufner | skóre: 70
/usr/share/X11/locale/*/Compose.
 30.1.2017 20:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
30.1.2017 20:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Díky, konečně mám využití pro klávesuJá jí třeba používám takhle:\|&*vedle levého shiftu na mém Thinkpadu. Dokonce je to v KDE v nastavení klávesnice snadno nastavitelné
! troll klavesa keycode 94 = U201E U201C 1 1 U201A U2018Tedy na psaní „“‚‘
 2.2.2017 01:09
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
3.2.2017 14:15
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
2.2.2017 01:09
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
3.2.2017 14:15
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
 31.1.2017 11:51
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
1.2.2017 06:42
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
31.1.2017 11:51
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
1.2.2017 06:42
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
 1.2.2017 07:38
|🇵🇸 | skóre: 94
| blog:
31.1.2017 11:56
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
1.2.2017 07:38
|🇵🇸 | skóre: 94
| blog:
31.1.2017 11:56
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
(mimochodem věděli jste, že slovenská abeceda je ze všech nejrozsáhlejší?).Těžko.
všechny abecedy založené na latinceU fonetické abecedy bych si netroufnul tvrdit, že je založená na latince ("založená" chápu minimálně jako výraznou podobnost syntaxe, sémantiky, vizuální reprezentace). Fonetická abeceda toto nemůže splnit, protože diverzita řečí nezaložených na latince je výrazně vyšší než řečí založených na latince a tudíž fonetická abeceda zachycuje především výslovnost řečí nezaložených na latince. Příště raději upřesním, že se jedná o národní abecedy (nikoliv mezinárodní).
1.2.2017 09:24
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
Viz.Asi nemám moc představu, co znamenají pojmy syntaxe a sémantiky v případě abecedy, kromě toho, že se dá psát zprava doleva, shora dolů atp. či třeba v blocích – v tomto smyslu fonetická abeceda funguje úplně stejně jako latinka (píše se zprava doleva, řádky se řadí shora dolů). Co se týče visuální representace, podoba drtivé většiny znaků je založena na latince, několik málo znaků vychází z řeckého písma (ɛ, ɜ, ɸ, β, θ) a u ještě menšího počtu znaků na první pohled těžko říci ( ɣ, ɰ).všechny abecedy založené na latinceU fonetické abecedy bych si netroufnul tvrdit, že je založená na latince ("založená" chápu minimálně jako výraznou podobnost syntaxe, sémantiky, vizuální reprezentace).
Fonetická abeceda toto nemůže splnit, protože diverzita řečí nezaložených na latince je výrazně vyšší než řečí založených na latince a tudíž fonetická abeceda zachycuje především výslovnost řečí nezaložených na latince.To jsou z mnoha pohledů dost pochybná tvrzení.
…je to výrazně jednodušší a rychlejší než to co popisuje autor v článku.Nejsem si jist. Unikly vám přinejmenším dva fakty: 1, Nemám potřebu psát ty znaky neustále, pouze občas. 2, Nechci žádný extra soft, extra klávesnicový layout, ani žádnou speciální úpravu výchozího nastavení. To co popisuji má k dispozici každý uživatel, který si nainstaluje standardní Debian s českým prostředím. Jediný uživatelský zásah je max. to, že si přemapuje některou z kláves aby fungovala jako Multi_key – pokud to potřebuje.
Unikly vám přinejmenším dva fakty: 1, Nemám potřebu psát ty znaky neustále, pouze občas.Nezáleží jak často. Záleží jak komfortně (v článku popisujete, že kvůli komfortu jste přestal kopírovat znaky z gucharmap).
Pokud však narážíte na přepínání layoutů, tak stačí spočítat množství stisků jednotlivých kláves a přepínání layoutů vyjde výrazně lépe než metody popsané v článku. Pochopitelně malé množství stisků kláves není ekvivalentní úplné metrice komfortu, avšak je v tomto případě zdaleka nejvýraznějším faktorem.
2, Nechci žádný extra soft, extra klávesnicový layout, ani žádnou speciální úpravu výchozího nastavení. To co popisuji má k dispozici každý uživatel, který si nainstaluje standardní Debian s českým prostředím. Jediný uživatelský zásah je max. to, že si přemapuje některou z kláves aby fungovala jako Multi_key – pokud to potřebuje.Chápu a souhlasím. V článku jsem však tuto intenci nenalezl, a proto jsem si dovolil zmínit ULKL.
Multi_key, ale dead_caron, dead_tilde či další „mrtvé” klávesy. Ani s pomocí xev se mi je však nedaří na mé klávesnici identifikovat. Poradíte?
1.2.2017 11:45
|🇵🇸 | skóre: 94
| blog:
Ale zároveň to byla pro mne příležitost na jednom místě souhrně uvést co je a není pomlčka.
Hmm. Dosud mi přišlo snazší se prostě odkázat na UJČ, vraždu (strana 25 v PDF), potažmo v případě vysvětlování rozložení na klávesnici na Wikipedii (a v případě psaní unikódu konkrétně na článek Unicode input).
 2.2.2017 21:57
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
2.2.2017 21:57
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Bylo by zajímavé doplnit slovníky českými názvy znaků, přepnout vstupní metodu, napsat české jméno požadovaného znaku, potvrdit a pokračovat v psaní. Rozhodně lepší než tohle harakiri a potřeby pamatovat si jakési klávesové komba.
2.2.2017 21:59
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
2.2.2017 22:16
|🇵🇸 | skóre: 94
| blog:
2.2.2017 22:26
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
2.2.2017 22:47
|🇵🇸 | skóre: 94
| blog:
3.2.2017 14:43
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
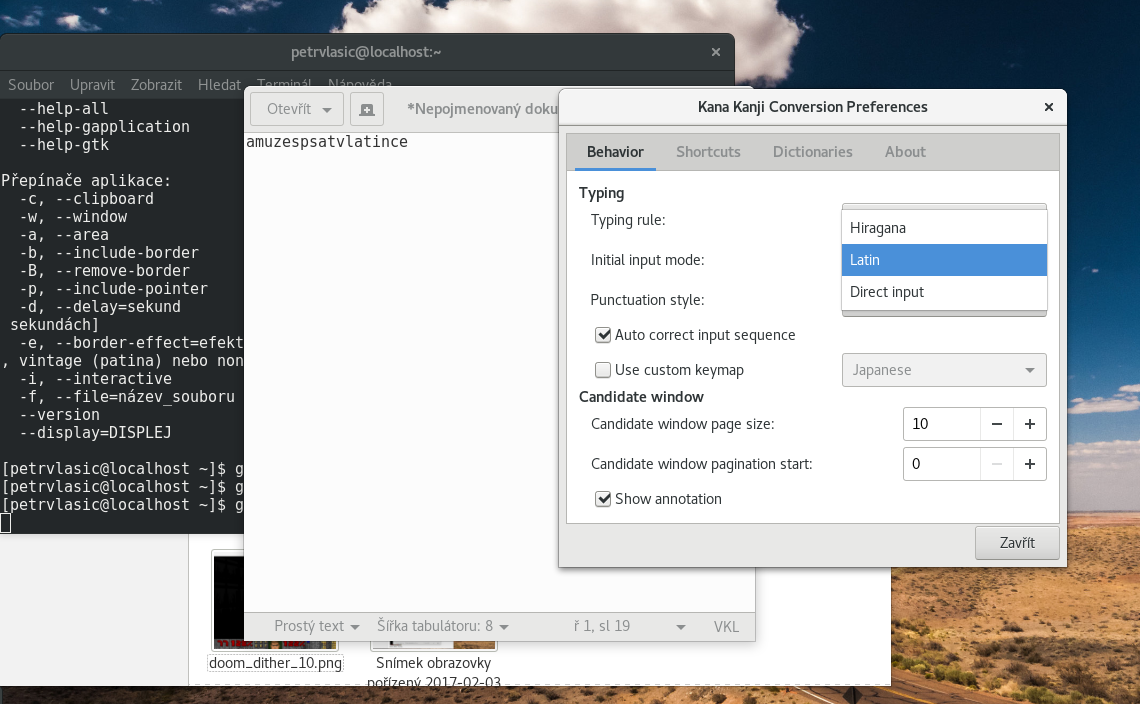
Je to na pytel, protože potřebuješ vizuální kontrolu.Nezapomeň že kana je pro ně to stejné co pro nás latinka. Oni tu vizuální kontrolu mají. Nepředpokládám že by to tam drtili v rōmaji jako my. Ale jinak si to přepni na latinku (viz screenshot) a můžeš v ní jednotlivé segmenty psát, nebude ti to převádět do kany.
Konečně, u češtiny narazíš na flexi, což u kandži/chan-c' vlastně neexistuje.Nepředpokládal jsem samozřejmě o použití téhle vstupní metody pro celou češtinu či angličtinu. Pouze ty sázecí znaky (jeden znak = jeden unicode a je šumák jestli je to kandži nebo sázecí znak, jméno musí mít tak jako tak). To by byla spíš morzeovka než rozumné psaní když by si to tam frkal v segmentech, doplňoval mezerníkem a ještě potvrzoval. Navíc jak říkáš, to může rozumně fungovat pouze u logogramů (když už nic, snadno se vizuálně hledají v seznamu). Navíc bych nic takového nechěl, sám vidíš co mi dělá auto korekce s textem, když by to ještě automaticky doplňovalo, tak už by se to po mě nedalo přečíst vůbec (nejsem pozorný).
3.2.2017 14:55
|🇵🇸 | skóre: 94
| blog:
Oni tu vizuální kontrolu mají.Nutnost vizuální kontroly je při psaní kontraproduktivní.
Nepředpokládám že by to tam drtili v rōmaji jako my.Třeba Číňani dneska velmi často (možná i většinou) píšou pchin-jin, místo aby šli po radikálech.
3.2.2017 15:01
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Počkat, já přestávám rozumět, oč ti vlastně jde.Nejde mi o automatickou expanzi psaného textu, pouze o vyhledávání sázecích znaků vypsáním jejich jména (takhle funguje anthy, nakonec cokoliv napíšeš převede na znak či znaky i když ne sázecí ale čínské logogramy). Různé komba či hexakódy se pro různé znaky špatně pamatují, se jménem (i když by to mělo být anglické jméno) už je to lepší.
3.2.2017 15:42
|🇵🇸 | skóre: 94
| blog:
shrugs<klapka> pro expanzi na ¯\_(ツ)_/¯.
3.2.2017 19:24
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
3.2.2017 19:25
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
3.2.2017 08:53
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
3.2.2017 14:44
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}
{kind=link}