Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na Seznam nepovolených internetových her (Wikipedie) se k 13. 7. 2026 dostala predikční platforma Polymarket.
Nová čísla časopisů od nakladatelství Raspberry Pi zdarma ke čtení: Raspberry Pi Official Magazine 167 (pdf) a Hello World 30 (pdf).
Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SELECT COUNT(id) FROM data id select_type table type possible_keys key key_len ref rows Extra 1 SIMPLE data index NULL jiny_boolean_key 1 NULL 74695 Using index
SELECT COUNT(*) FROM data id select_type table type possible_keys key key_len ref rows Extra 1 SIMPLE data index NULL jiny_boolean_key 1 NULL 72276 Using indexje to normální vlastnost ?
select sum(if(nova,1,0)), /*nová*/ sum(1), /*vše*/ sum(if(stav=2),1,0) /*přečtená*/ from dataTakto by se mezi operacemi s tabulkou odlehčilo s počítáním. Je fakt, že po změně tabulky chce člověk většinou(uživatel vždy) vědět stav, takže by se stejně countovalo. V každém případě by toto asi ulehčilo tak jak tak. Ale zas takový dotaz proleze tabulku celou, i když jen jednou.
select sum(nova,1,0), /*nová*/ sum(1), /*vše*/ sum(stav=2) /*přečtená*/ from data
SELECT /*!40001 SQL_NO_CACHE */ * FROM `data`;Je to zápis tohoto dotazu nebo mi unikl nějaký divný dotaz tohoto zápisu?
Time Action Message Duration / Fetch 3 1 08:49:32 select count(*) from data LIMIT 0, 1000 1 row(s) returned 0.062 sec / 0.000 sec 3 2 08:49:48 select count(id) from data LIMIT 0, 1000 1 row(s) returned 0.047 sec / 0.000 sec 3 3 08:50:07 select count(1) from data LIMIT 0, 1000 1 row(s) returned 0.047 sec / 0.000 sec 3 4 08:50:34 select count(*) from data_pozn LIMIT 0, 1000 1 row(s) returned 0.421 sec / 0.000 secdata 7293 data_pozn 386047 Kámoš mi to testoval teď přes EMS(s i bez limitu) a opět kolem 1,4s. EMS se zdá kapánek brzda. Tzn. že mám věřit profilování v phpmyadmin, kde po součtu vychází cca stejné časy jak u workbench ?
count(*)nad pár záznamy, prostě nemůže trvat sekundu, když si pustím tento dotaz jako první nad nepoužívanou DB:
mysql> SELECT count(*) FROM generator_1m; +----------+ | count(*) | +----------+ | 1048576 | +----------+ 1 row in set (0.01 sec)
SET profiling = 1;a pak při zobrazení:
SHOW PROFILES;či
SHOW PROFILE;A pokud by nešlo věřit tomu, tak už není čemu…
Všimněte si, že v obou případech se jede přes jeden a ten samý index. Tento index je nad typem boolean (null nejspíše není povoleno) a lze se oprávněně domnívat že boolean index bude menší než libovolný jiný index (například nad integer sloupcem). Proto správně optimizer vyhodnotil že pro count(<něco co není null>) bude nejlevnější právě tento index. Zkuste si dohledat velikosti indexů a uvidíte.
@Kit: cena funkce count (stejně jako ostatních agregačních funkcí) závisí na velikosti zdrojové množiny a také na tom kolik máte cílových agregačních skupin daných frází GROUP BY. V tomto případě je počet skupin pouze jedna a cena je v zásadě rovna ceně operace "full index scan" indexu nad non null sloupci.
Je nesmysl aby uvedený dotaz nad 7500 řádky trval 1,5 s. Buď máte extrémně zatížený stroj (ve smyslu IO operací), nebo extrémně pomalý disk (starý 20+ let), nebo jinou fatální chybu v konfiguraci ( virtualizace, konfigurace paměti, ...). Podělte velikost zjištěného boolean indexu rychlostí cca 10MB/s ( pomalejší disk asi nemáte ) a dostanete přibližný response time na který by jste se měl dostat. V popisovaném případě lze čekat odpověď do 10ms (=načtení cca 75kB dat). V případě zásahu do cache (=opakované dotazy) by pak měl být response time do 2ms (=zpoždění sítě).
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz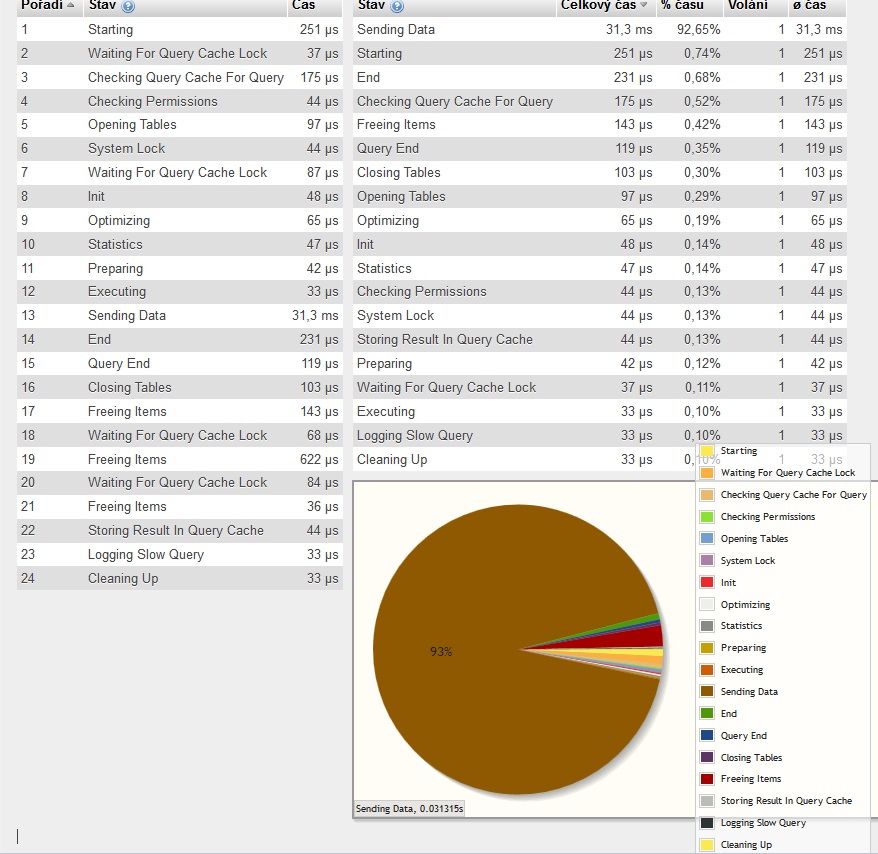{kind=link}