Byly zveřejněny informace o kritické zranitelnosti CVE-2026-64600 pojmenované RefluXFS (technické detaily) v XFS. Je tam již od verze Linuxu 4.11, tj. rok 2017. Jedná se o lokální eskalaci práv. Neprivilegovaný uživatel může editovat libovolný soubor, například klidně zrušit rootovské heslo v /etc/passwd. Videoukázka na Vimeo. V upstreamu je zranitelnost opravena.
OpenAI / ChatGPT má dnes výpadky (OpenAI Status, DownDetector).
Poskytovatel hostingu svobodných/open-source projektů Codeberg po hlasování na valné hromadě vydal stanovisko k využívání LLM. Kvůli vytěžování infrastruktury a rostoucím cenám hardwaru, ale také hrozbám pro spolupráci v komunitě se k LLM staví kriticky. Nebude poskytovat hosting projektů vytvářených LLM agenty.
Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
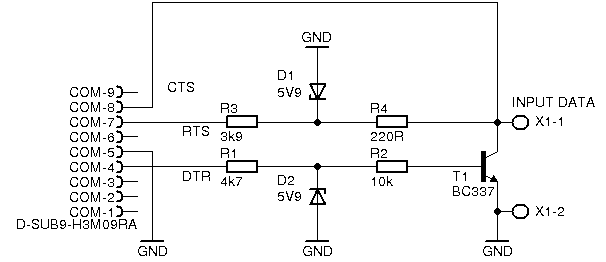
#define PORT 0x3f8
#define OFFSET_RIZENI_M 4
outb (0x00, PORT+OFFSET_RIZENI_M); //nuluj registr rizeni modemu
log1 (PORT+OFFSET_RIZENI_M); // inicializace sbernice a poskytnuti napajeni po dobu 1ms
usleep (1000);
log0 (PORT+OFFSET_RIZENI_M); //-|master reset
usleep (500); //_|
log1 (PORT+OFFSET_RIZENI_M); //-uvolnit sbernici
usleep (70);
statusCTS=inb (PORT+OFFSET_STAV_M);
if ((statusCTS & CTS_BIT)==0x00) //-je nula na sbernici
printf ("Ozval se\n");
Řešení dotazu:
void __usleep_test02 (int usecond) {
struct timeval ts,te; //ts-time start; te-time end
gettimeofday(&ts, NULL); //read start time in usec
do {
gettimeofday(&te, NULL); //read end time in usec
} while (te.tv_usec<ts.tv_usec+usecond); //when te(time end) < ts(time start) + usecond
} Ten cyklus ma spravny v pripade, ze nebude mit cekani delsi nez 1s (v pripade, ze mu to nekdo preplanuje a ono to pretece, tak uz na tom vlastne nezalezi a casem se mu to vzbudi stejne).Ne, zatuhne to. Dejme tomu: ts.tv_usec == 999999 a usecond == 3: bude se čekat až te.tv_usec >= 1000002, což nemůže nikdy nastat. Doporučuji alespoň následující, s tím, že nemůžete zadat usecond > 999999.
void __usleep_test02(int usecond) {
struct timeval tv;
time_t target_sec;
suseconds_t target_usec;
gettimeofday(&tv, NULL);
target_sec = tv.tv_sec;
target_usec = tv.tv_usec + usecond;
if (target_usec >= 1000000) {
target_sec++;
target_usec -= 1000000;
}
while ((tv.tv_usec < target_usec) || (tv.tv_sec < target_sec)) {
gettimeofday(&tv, NULL);
}
}
Ta pasaz s casovacem mne velmi zaujala a poprosil bych o rozvedeni. Mikrosekunda je z puhledu systemu cca 1000-2000 instrukci CPU a to neni az tak mnoho.No, základem všeho je si zajistit RT prioritu procesoru (SCHED_FIFO), jinak se můžete jít koulet - jádro do Vaší čekačky přepne jiný proces a místo 2 us čekáte třeba 20 ms. Pokud máte RT prioritu, tak se to nestane, na druhou stranu jelikož standardní jádro není hard-RT, tak stejně nemáte 100% jistotu, ale už máte aspoň něco, s čím se dá rámcově počítat. Samotné čekání pak můžete udělat metodou busy wait - tj. tak jak to je naznačeno výše, čekáním v úzké smyčce na ten správný okamžik. Zablokujete tím kompletně jedno jádro procesoru, proto je potřeba vážit kdy a jak se tento postup nasadí. V defaultním nastavení linuxu je proti kompletnímu zablokování pojistka:
$ cat /proc/sys/kernel/sched_rt_period_us 1000000 $ cat /proc/sys/kernel/sched_rt_runtime_us 950000... což znamená, že i přes RT prioritu bude váš proces donucen ke spánku pokud sežere více než 950000 us z 1000000 us okna (hodnoty v proc lze samozřejmě upravovat). To znamená že na jednoprocesorovém stroji budete mít šanci odladit tu chybně napsanou funkci na čekání :) Otázkou může být jak je jádro schopné říct kolik je přesně gettimeofday(). V linuxu jsou 2 časovače - clock source a event source. První lze jen číst a druhý lze i programovat na odeslání interruptu za nějakou dobu. Event source je obvykle podstatně méně přesný. Klasický časovač má 1000 Hz, HPETy mají v řádu MHz. Clock source má v optimálním případě přesnost 1 cyklu procesoru. Funkce gettimeofday() funguje tak, že se podívá na globální proměnnou kde je informace o čase posledního eventu a přičte k ní aktuální offset z clock source. Samozřejmě než se poté vyšaší přepnutí z kernel režimu do userspace atd. tak ještě nějaký čas uteče ale obvykle je to o dost méně než ta 1 us která nás zajímá. (Pro ultra přesné časování nesmíte volat funkce kernelu, ale vystačit si třeba s čtením TSC přímo v programu, což je zdroj dalšího opruzu...) Na druhou stranu pokud zavoláte nanosleep() tak si jádro dá určitou práci s tím, aby nastavilo event source jak nejlépe to jde (tam je toho dost, je potřeba váš časovač zařadit do RB stromu a kdovíco ještě) a pak si dá CPU voraz, takže skutečně tu mikrosekundu spíte. Bohužel kvůli různým overheadům a granularitě event sourcu budete mít trochu horší výsledky než u busy wait, na druhou stranu šetříte lesy :) Udělal jsem nějaké rychlé testy (viz přiložený program) a zdá se, že se výše popsané potvrzuje. Busy wait sežere 100% cpu a do 2ms okna se netrefí třeba 200x ze 100 000 pokusů. Na druhou stranu nanosleep nežere skoro nic, ale má overhead, se kterým musíte dopředu počítat a díky tomu trochu větší rozptyl.
kdezto aktivni cekani se netrefi v cca 6% pripadu... aspoň je vidět, že ani tahle metoda neni samospásná.
na jake verzi jadraPokud se pamatuju dobře, tak precizní časování se předělávalo někde kolem verze 2.6.17.
na takove kratke useky je aktivni cekani vhodnejsiStaré glibc uměly při volání nanosleep automaticky aktivně čekat do 2 mikrosekund pokud měl program RT prioritu, z novějších verzí to vyhodili.
Cist TSC bych radeji nedoporucoval, protoze se chova na ruznych architekturach jinakNení to věc architektury ale konkrétního modelu CPU. Já mám jeden celkem nový amd64 procesor a používá se dynamická změna rychlosti a TSC funguje dobře.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 16.7.2010 10:07
16.7.2010 10:07
{kind=link}