Spolek OpenAlt zve příznivce otevřených řešení a přístupu na 211. sraz, který proběhne v pátek 19. září od 18:00 ve Studentském klubu U Kachničky na Fakultě informačních technologií Vysokého učení technického na adrese Božetěchova 2/1. Na srazu proběhne přednáška Jiřího Eischmanna o nové verzi prostředí GNOME 49. Nemáte-li možnost se zúčastnit osobně, přednáškový blok bude opět streamován živě na server VHSky.cz a následně i zpřístupněn záznam.
Microsoft se vyhnul pokutě od Evropské komise za zneužívání svého dominantního postavení na trhu v souvislosti s aplikací Teams. S komisí se dohodl na závazcích, které slíbil splnit. Unijní exekutivě se nelíbilo, že firma svazuje svůj nástroj pro chatování a videohovory Teams se sadou kancelářských programů Office. Microsoft nyní slíbil jasné oddělení aplikace od kancelářských nástrojů, jako jsou Word, Excel a Outlook. Na Microsoft si
… více »Samba (Wikipedie), svobodná implementace SMB a Active Directory, byla vydána ve verzi 4.23.0. Počínaje verzí Samba 4.23 jsou unixová rozšíření SMB3 ve výchozím nastavení povolena. Přidána byla podpora SMB3 přes QUIC. Nová utilita smb_prometheus_endpoint exportuje metriky ve formátu Prometheus.
Správcovský tým repozitáře F-Droid pro Android sdílí doporučení, jak řešit žádosti o odstranění nelegálního obsahu. Základem je mít nastavené formální procesy, vyhrazenou e-mailovou adresu a být transparentní. Zdůrazňují také důležitost volby jurisdikce (F-Droid je v Nizozemsku).
Byly publikovány informace o další zranitelnosti v procesorech. Nejnovější zranitelnost byla pojmenována VMScape (CVE-2025-40300, GitHub) a v upstream Linuxech je již opravena. Jedná se o variantu Spectre. KVM host může číst data z uživatelského prostoru hypervizoru, např. QEMU.
V červenci loňského roku organizace Apache Software Foundation (ASF) oznámila, že se částečně přestane dopouštět kulturní apropriace a změní své logo. Dnes bylo nové logo představeno. "Indiánské pírko" bylo nahrazeno dubovým listem a text Apache Software Foundation zkratkou ASF. Slovo Apache se bude "zatím" dál používat. Oficiální název organizace zůstává Apache Software Foundation, stejně jako názvy projektů, například Apache HTTP Server.
Byla vydána (𝕏) srpnová aktualizace aneb nová verze 1.104 editoru zdrojových kódů Visual Studio Code (Wikipedie). Přehled novinek i s náhledy a videi v poznámkách k vydání. Ve verzi 1.104 vyjde také VSCodium, tj. komunitní sestavení Visual Studia Code bez telemetrie a licenčních podmínek Microsoftu.
Spotify spustilo přehrávání v bezztrátové kvalitě. V předplatném Spotify Premium.
Spoluzakladatel a předseda správní rady americké softwarové společnosti Oracle Larry Ellison vystřídal spoluzakladatele automobilky Tesla a dalších firem Elona Muska na postu nejbohatšího člověka světa. Hodnota Ellisonova majetku díky dnešnímu prudkému posílení ceny akcií Oraclu odpoledne vykazovala nárůst o více než 100 miliard dolarů a dosáhla 393 miliard USD (zhruba 8,2 bilionu Kč). Hodnota Muskova majetku činila zhruba 385 miliard dolarů.
Bylo vydáno Eclipse IDE 2025-09 aneb Eclipse 4.37. Představení novinek tohoto integrovaného vývojového prostředí také na YouTube.
Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
10.12.2018 01:40
| Přečteno: 9358×
| Obecné IT
|  | poslední úprava: 11.12.2018 15:24
| poslední úprava: 11.12.2018 15:24
Před nějakou dobou se mi dostalo do rukou zamyšlení, zdali je vlastně zapotřebí operační systém, či ne. Sám na toto téma provádím jakýsi „průzkum“ už přibližně dva roky. Rozhodl jsem se tedy, že bych mohl sepsat nosné myšlenky spolu s odkazy na některé relevantní zdroje informací.
Pozor, tento zápisek obsahuje množství textu. Pokud vás text uráží, zvažte, zda se vůbec chcete pustit do diskuze.
<možné přeskočit>Předně bych rád deklaroval, že tu mluvím sám o sobě. Když budu psát, že „je něco zapotřebí“, „možné“, nebo „schůdné“, myslím tím „zapotřebí pro mě“, „možné pro mě“, nebo „schůdné pro mě“.
Zažil jsem až příliš diskuzí na internetu, které byly způsobeny čtením mezi řádky a vztahováním čtenářovo názorů a předsudků na osobu autora. Vím, že tohle upozornění pravděpodobně nepomůže, ale zkuste se nad prezentovanými myšlenkami zamyslet s otevřenou myslí.
Pokud vám některé moje nápady přijdou kontroverzní, nesmyslné, či pokud budete mít dokonce pocit, že Vás pobuřují svou donebevolající blbostí - uklidněte se. Vzpomeňte si na výše uvedenou deklaraci. Uvědomte si, že vůbec nemluvím o vás, nemám potřebu a chuť vám něco vnucovat, měnit vám workflow, nebo pomlouvat Váš systém. Berte to jako mojí podivnost, jako možný směr, který to chce vyzkoušet a nevztahujte to o čem tu mluvím na sebe.
Jestliže v článku i poté uvidíte nedostatky a napadne Vás něco konstruktivního k věci, napište to do diskuze. Zkusme to tu pro jednou udržet v konstruktivní rovině.
Neušlo mé pozornosti, že diskuze pod většinou článků na abclinuxu trvá maximálně několik týdnů, v řídkých případech jednotky měsíců.
Jsem si vědom, že abclinuxu zobrazuje u starších článků upozornění na dlouhou dobu od vydání článku a nepovažuji to za správný nápad. Pokud máte co konstruktivního říct a přečtete si tenhle článek třeba desetiletí po jeho vydání, já jako autor stále stojím o váš názor.
Pokud ho nechcete, či nemůžete vložit do diskuze, pošlete mi ho emailem na bystrousak[]kitakitsune.org, s nějakým smysluplným předmětem. Možná Vás to překvapí, ale napsal jsem docela hodně článků s podobným upozorněním a dodneška diskutuji s lidmi co je četli, i když je to třeba 7 let od vydání. O váš názor stojím.
Osobně ovšem preferuji diskuzi zde pod článkem, neboť z ní mohou těžit i ostatní. Taky to trochu zabraňuje neustálému opakování otázek.
</možné přeskočit>V posledních letech jsem pracoval pro několik firem vytvářejících software. V některých případech jsem se zapojil do již existujících týmů, v ostatních jsem začínal spolu s několika dalšími programátory „na zelené louce“. Často jsem se přímo podílel na návrhu architektury, pokud jsem jí rovnou nevymýšlel sám.
Pracuji jako „backendový programátor“. Mým popisem práce je typicky vytvářet systémy, které načítají, zpracovávají a ukládají různá data, parsují všemožné formáty, volají různé programy, či interagují s ostatními systémy a zařízeními.
V Národní knihovně jsem v tříčlenném týmu dělal na systému pro zpracování elektronických publikací. Vytvořil jsem tam prakticky veškerý backendový kód, od ukládání dat, po komunikaci s ostatními systémy, mezi které patří například Aleph, Kramerius, nebo LTP (dlouhodobý archiv digitálních dat). Pro ukládání byl použit linuxový filesystém ext4 na CentOSu a objektová databáze ZODB vynucená Plonem, ve kterém byla frontendová část. Pro komunikaci pak všechno možné, od volání API přes REST, nahrávání XML souborů na FTP, balení věcí do ZIPu az po kopírování na sambu. Interní komponenty mezi sebou používaly RabbitMQ.
V jisté nejmenované společnosti jsem pracoval na systému k ochraně proti DDoS útokům. Kvůli NDA nemůžu rozebírat podrobnosti nad rámec popisu tehdejších pracovních inzerátů. Ty ukazují, že byl také použit linux, python, SQL i NoSQL databáze, spousta různých existujících opensource programů a na komunikaci RabbitMQ. Na velké části z toho komunikačního kódu jsem dělal přímo já.
Pro Nubium development, vytvářející asi nejznámější český filehostingový web ulož.to, jsem dělal na backendu. Zrefaktoroval jsem a částečně navrhl kusy software, které se starají o ukládání a redistribuci souborů napříč různými servery, ale i o zpracování uživatelských dat. Například ikonky, které se zobrazují u náhledů archivů a videí, jsou moje práce, kromě spousty dalších věcí, které nikde neuvidíte.
Pro pár dalších firem jsem dělal různé weby a RESTové služby. Sáhl jsem si ovšem i na exotičtější věcí, například na systém pro rozpoznání a automatické vyhodnocování záběrů z kamer v různých tunelech a k tomu přidružený machine learning.
Všude kde jsem dělal se používal linux, databáze, a většinou i nějaká forma message queue předávající strukturovaná data. Někdy šlo o SQL tabulky, jindy o JSON poslaný přes RabbitMQ.
V každé z jmenovaných firem jsem viděl ten samý vzor - nezávisle na sobě vytvořený, přibližně podobný kus software, který přirozeně vyplynul z několika požadavků:
Pokud programujete, pravděpodobně víte, kam tím mířím. Jestliže spousta programátorů vytváří nad danou knihovnou stále stejný vzor, nejedná se o chybu programátorů, ale o špatně navrženou knihovnu.
Postupně, jak jsem nad tím tak přemýšlel, jsem dospěl k názoru, že je špatně samotná architektura operačního systému. To co nám nabízí a co umožňuje nepovídá tomu co po něm chceme a co od něj očekáváme. Především z hlediska „programátorského uživatelského interface“, tedy toho, s čím jako programátor pracuji.
Když jsem byl mladší, měl jsem poměrně jasnou představu o tom, co je to operační systém: Windows přece. To je ta věc, co mají všichni na počítači, vlevo dole to má tlačítko start, a když nenaběhne a zobrazí se jen černá obrazovka, je zapotřebí napsat win.
Na střední škole mě naučili definici, podle které je operační systém „programové vybavení počítače zpřístupňující vstupně-výstupní zařízení“.
Později jsem zjistil, že operačních systémů existuje hodně a v podstatě všechny dělají to samé; vytvářejí ± jednotnou abstrakci nad hardwarem počítače, umožňují pouštět různé programy, nabízí více, či méně propracovaný filesystém, spravují paměť, řeší multitasking a uživatelská práva.
V dnešní době je operační systém pro většinu lidí to, čím pouští své prohlížeče, ve kterých koukají na youtuby a na facebooky a taky skrz to posílají emaily. Občas to umí pouštět hry a pracovat se vším možným, od CD-ROMky po klávesnici.
Pro pokročilé uživatele je to pak určitá forma databáze a API, která umožňuje spouštět jejich programy a také nabízí standardizovaný přístup ke konkrétním činnostem. Například výpis znaku, uložení souboru, navázání spojení po internetu a tak podobně.
Většinou máme tendenci vnímat operační systém jako něco neměnného, co si vybereme z relativně malé nabídky diktováné svatou trojicí (Windows, Mac, Linux), okolo které se zmateně krčí několik prakticky nepoužívaných (0.03% celkem) alternativ (*BSD, Plan9, BeOS, ..).
Z nějakého důvodu jsou všechny skutečně používané systémy až na výjimky hodně podobné. Rád bych se zamyslel, jestli je to skutečně žádaná vlastnost, nebo náhodný historický vývoj.
První počítače neměly operační systém a byly uživatelsky velmi nepříjemné. Daly se programovat pouze přímou změnou hardwarového propojení.
Pak přišly děrnoštítkové a děrnopáskové stroje. Na nich operátor nacvakal sérií přepínačů přímo do paměti binárně „zavaděč“, jenž mu umožnil načíst děrné štítky, či děrný pásek. Ten obsahoval sekvence instrukcí a data.
Systém pracoval v takzvaných dávkách. Programátor dodal médium s dávkou dat, operátor je načetl do počítače a spustil. Po dokončení běhu vrátil programátorovi výsledky, či chybovou hlášku, pokud došlo k chybě.
Jelikož se jednalo o hodně manuální činnosti, časem vznikly knihovny pomocných funkcí a různé užitečné nástroje. Například zavaděč, který se zavede automaticky po startu počítače a umožní načtení programátorova programu pouhým stisknutím patřičného tlačítka. Nebo subrutina, která při pádu programu vypíše obsah paměti. Těmto programům se říkalo monitory.
Protože tehdejší počítače byly velmi, velmi drahé, vznikl tlak na jejich použití vícero uživateli zároveň. S tím přišly první operační systémy, které sloučily funkcionalitu monitoru, přidaly podporu běhu vícero programů zároveň a také nabídly správu a paralelní přístup vícero uživatelů.
Stále komplikovanější hardware a komplexita jeho přímého ovládání způsobila narůstající tlak na univerzálnost kódu mezi různými stroji a jejich verzemi. Operační systémy začaly nabízet podporu typicky používaných zařízení. Nadále již nebylo třeba zadávat adresu paměti na disku, stačilo uložit data do pojmenovaného umístění, a později i do složek. Vznikly první souborové systémy. S podporou vícero uživatelů zároveň vyvstala také snaha oddělit jejich programy, aby si navzájem nemohly přepisovat a číst data. Také vznikly plánovače a virtuální paměť a multitasking.
Operační systémy se staly vrstvou, která stojí mezi uživatelem, jenž nadále nemusí být programátorem, a poskytuje mu standardní způsoby uložení dat, výpisu znaku na obrazovku, práci s klávesnicí, tisku na tiskárnu a spuštění jeho dávky / programu.
Později k tomu přibylo ještě grafické rozhraní a síťování. Osobní počítače nabídly plejádu zařízení, z nichž všechny musel operační systém umět používat a podporovat. Až na pár výjimek, kterým se budu věnovat dále, šlo o iterativní vývoj, který nepřinesl nic zásadně revolučního. Všechno se zlepšovalo, zefektivňovalo, samotné paradigma se však moc nezměnilo.
Nemám nejmenší problém s konceptem operačního systému jako hardwarové abstrakce. Naopak! Mám problém s konceptem OS jako uživatelského rozhraní. Tím nemyslím grafiku, ale zbytek všeho s čím interagujete, a co má nějaký tvar;
Schválně se zkuste zamyslet, co to vlastně je. Vyjde vám, že je to omezená hierarchická key-value databáze.
Omezená, protože omezuje nejen velikost a subset klíče, který je v lepším případě v UTF, ale i samotnou uloženou hodnotu na proud bajtů. To se zdá rozumné jen do chvíle, kdy si uvědomíte, že je to stromová databáze, která vám nedovoluje přímo ukládat strukturovaná data. Počet inodů (větví struktury) je navíc omezen na číslo, jenž se v horších případech pohybuje v řádu desítek až stovek tisíc, maximálně však pár milionů prvků v jednom adresáři.
Ve dvou z mých předchozích zaměstnáních jsme museli obcházet omezený počet inodů na složku retardací jako BalancedDiscStorage, či ukládáním souborů do tří podsložek složených z prvních tří písmen MD5 hashe souboru.
K tomu pro většinu operací chybí atomicita, a transakce nejsou podporovány vůbec. Paralelní zápisy a čtení fungují v různých operačních systémech různě, a ve skutečnosti není garantováno naprosto nic. Schválně si to srovnejte se světem databází, kde se ACID považuje za samozřejmost.
Filesystém je specificky omezená databáze. Každý koho znám, kdo se kdy pokusil filesystém použít pro cokoliv netriviálního, dřív nebo později tvrdě narazil. Ať už je to programátor, který si řekne, že si ty data prostě a jednoduše bude ukládat do souborů, nebo uživatel, který se v bordelu na filesystému nemůže vyznat a musí používat různé divné vyhledávání a indexování. Výkřikem techniky je, když dokáže poznat, že má poškozená data a dopočítat je zpětně ze samo-opravných kódů, pokud máte disky v RAIDu.
Samozřejmě chápu, že pointou je něco jiného. Řeší se tu sektory na disku a žurnálování, plotny a oddíly a RAIDy a celé je to super pokrok oproti původním primitivním systémům ukládání dat. Ale — není to náhodou pokrok špatným směrem?

Původní filesystémy byly metafora. Metafora pro ukládání souborů do složek, tak jako se strkají papíry do šanonů a šuplíků. Kromě mnoha technických omezení, daných stavem tehdejší výpočetní techniky, trpěly a trpí i omezením z podstaty této metafory. Přemýšlím, jestli by jsme si místo otázky „jak trochu vylepšit padesát let starou metaforu“ (třeba pomocí tagů) neměli klást spíš otázku „je to vážně ta správná metafora pro ukládání dat?“
Čistě fyzicky, programy jako takové nejsou nic jiného, než jen sekvence uložených bajtů. V podstatě ani pro operační systém nemůžou být nic jiného, neboť souborová databáze operačního systému s ničím jiným pracovat ani neumí.
Programy se prvně napíšou ve zdrojovém kódu příslušného jazyka, který se potom zkompiluje a slinkuje do jednoho bloku. Ten je následně vyděrován na děrné štítky (binární data) a zastrčen do patřičné krabice (souboru) ve správné sekci kartotéky (filesystému).
Když chce uživatel program pustit, napíše jeho jméno na příkazovém řádku, nebo někde klepne na ikonu. Poskládané děrné štítky jsou následně vyndány z kartotéky a nacpány do paměti, která se pro program tváří, jako kdyby byl v celém operačním systému sám. Kód je poté prováděn od počátečních děrných štítků k těm koncovým, s tím že program může podmíněně přeskočit na konkrétní děrný štítek v krabici, která ho tvoří.

Programy taky můžou číst parametry příkazového řádku, používat sdílené knihovny, volat API operačního systému, pracovat s filesystémem, posílat (číselné) signály různým jiným programům, reagovat na ně, vracet návratové hodnoty, nebo otevírat sockety.
Co je na tom špatně?
Nechci říct, že je koncept špatný jako takový. ALE. Opět je to stejná stará metafora, iterativním vývojem posunutá o pár kroků dál. Všechno mi přijde hrozně nízkoúrovňové. Celý ten systém se za posledních 40 let změnil jen minimálně a nemůžu se zbavit myšlenky, že než že by jsme dorazili k naprosté dokonalosti, spíš jsme někde uvázli v zákrutě lokálního maxima.
Lispovské stroje, Smalltalkovské a Selfové prostředí mě naučily, že se to dá dělat i jinak. Že programy nutně nemusí být kolekce bajtů, ale můžou to být malé samostatné objekty, které jsou (metaforou posílání zpráv) zavolatelné z ostatních částí systému, a které se dynamicky kompilují podle potřeby.
Znáte takovou tu unixovou filosofii, že je dobré používat malé programy, které dělají jednu věc, na tu se zaměřují a dělají jí dobře? Proč tu myšlenku nedotáhnout do konce a neudělat malé programy z každé funkce a metody vašeho programu? Ta by naoplátku mohla komunikovat s metodami a funkcemi ostatních programů.
Ve Smalltalku to tak funguje, dokonce není problém to verzovat, specifikovat závislosti, mít nad tím package manager, ošetření chyb, nápovědu a kdo ví co dalšího. Vážně by to nešlo dělat s programy obecně?
The whole UNIX ethos has been a huge drag on industry progress. UNIX's pitch is essentially: how about a system of small functions each doing discrete individual things... but functions must all have the signature char function(const char )? Structured data is for fools, we'll just reductively do everything as text. What we had in 1972 is fine. Let's stick with that.
A jsme zase u těch binárních dat. Na první pohled geniální myšlenka, protože nic nemůže být víc univerzální. Na další pohled už tak ne.
V čem je problém?
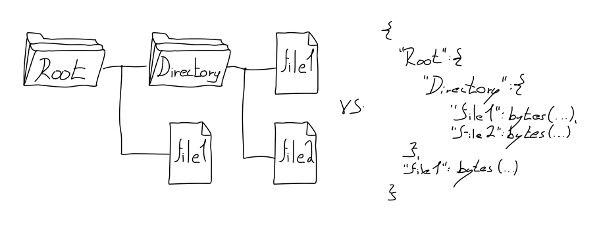
Prakticky všechna data mají svou strukturu. Kdykoliv, kdy programátoři v programovacím jazyku pracují s daty, a nejedná se jen o jejich přesunutí, tak se jim snaží dát strukturu. Namapují je na různé struct konstrukty. Vytvoří z nich strom objektů. I u streamovaných věcí, jako je třeba záznam zvuku ve formátu WAV, se iteruje skrz jednotlivé chunky.

(Struktura WAV souboru. Zdroj: https://github.com/corkami/pics/.)
Proč tedy proboha každý program vezme data, dá jim strukturu, něco nad ní udělá a tu strukturu zahodí a zkolabuje zpět na nestrukturovaná, surová binární data?
Současná počítačová kultura je posedlá parsery a externími popisy dat, jenž by však mohly nést strukturu samy o sobě. Každý den jsou nesmírná kvanta výpočetních cyklů zcela nesmyslně plýtvána na konverzi surových bajtů na struktury a zase zpět. A každý program to dělá jinak, dokonce i v různých verzích. Nemalá část mé práce jako programátora je jen o parsování a převodech dat, jenž kdyby měla strukturu, tak by byla upravitelná jednoduchou transformací. Tady vem kus stromu a přesuň ho sem. K téhle části grafu přidej tohle, jinde něco uber.
Současná situace je analogická k situaci, kde kdybych posílal poštou hrad z lega, tak bych ho rozložil na jednotlivé kostky a k balíku přibalil referenci na návod, jak si hrad složit. Příjemce by si pak návod musel někde sehnat a hrad pracně skládat. Absurdita je zřejmější, když si uvědomíme, že se to netýká jen kostek lega, ale úplně všeho. I kdybych chtěl někomu podat sklenici, tak bych jí podal jako hrst písku a příjemce by si musel sklenici vyrobit sám. Je mi jasné, že na konci se vždy musí posílat bajty, stejně jako se musí posílat kostky lega. Ale proč je neposlat už složené?
Nejde jen o nesmyslnost toho všeho. Jde o to, že zároveň s tím je to i horší. Horší pro uživatele, a horší pro programátory. Data se kterými pracujete by mohla být sebe-popisná, ale nejsou. Jednotlivé položky by mohly obsahovat datové typy, ale i dokumentaci. A nemají. Proč? Protože je v módě mít zvlášť hromadu binárních dat, a zvlášť jejich externí popis. Vážně to tak chceme, vážně to má nějaké výhody?
V minulém desetiletí bylo možné vidět masivní nárůst používání formátů jako XML, JSON a YAML. Určitě lepší než drátem do oka, ale to stále není to o čem tu mluvím. Nejde mi o konkrétní formát, jde mi o strukturu samotnou. Proč nemít strukturovaně všechna data?
Nemluvím tady o parsování XML parserem, mluvím tu o přímém načtení do paměti, ve stylu message packu, SBE, nebo FlatBuffers, či Cap’n Proto. Bez toho aniž by bylo třeba vyhodnocovat text a řešit escape sekvence a formát unicode. O tom že na strukturovaná data o Frantovi Putšálkovi v kolekci lidí přistoupím pomocí people[0].name, místo toho abych v jednom formátu dělal doc.getElementByTagName("person")[0].name.value a v druhém doc["people"][0]["name"]. O tom že si můžu k atributu přečíst nápovědu pouhým help(people), místo abych hledal dokumentaci.
Mluvím tu o tom že se neparsuji s WAVem, ale prostě iteruji přes jednotlivé chunky, které tam jsou. O tom že data popisují sebe sama přímo svou strukturou, ne externím popisem. Mluvím o přímé serializaci objektů, o jednotném systému podporovaném všemi jazyky, i když nemají objekty.
Váž ně by to bylo tak nemožné? Proč?
Všímáte si toho vzoru v mé kritice, hněvu a vášni? Je jím téma neuvědomělé struktury.
Souborové systémy nevnímáme jako databáze. Nedochází nám, že jejich struktura jsou hierarchická key-value data. Programy bereme jako binární bloby, místo klubka propojených funkcí a struktur a objektů majících potřebu komunikovat se sebou, ale i s okolním světem. Data chápeme jako mrtvé série surových bajtů, místo stromových a grafových struktur.
Co dalšího má strukturu, o čem jsem zatím nepsal? Samozřejmě komunikace. S operačním systémem. S programy. Mezi programy.
Plan9 byl úžasným krokem tímhle směrem. Poté co jsem ho prozkoumal jsem však dospěl k názoru, že tvůrci sice měli obecné povědomí o tom co dělají, ale nedošlo jim to v celé úplnosti. Možná částečně proto, že byli stále hodně ovlivněni unixem a komunikací v proudech bajtů.
Na Plan9 je úžasné, jak můžete interagovat se systémem pomocí zápisu a čtení z různých speciálních souborů. Fantastické! Revoluční! Tak úžasné, že to linux převzal například v podobě /sys subsystému a FUSE.
Víte co tomu chybí? Reflexe a struktura. Pokud si nepřečtete manuál, tak naprosto netušíte co kam zapsat.
Zde je kód pro blikání diodou na raspberry pi:
echo 27 > /sys/class/gpio/export echo out > /sys/class/gpio/export/gpio27/direction echo 1 > /sys/class/gpio/export/gpio27/value
Jak jsou řešeny chyby? Co když do /sys/class/gpio/export/gpio27/value zapíšu string „vánočka“? Dostanu zpět error kód z echa? Nebo se v nějakém jiném souboru něco objeví? Jak jsou zvládány paralelní zápisy? A co čtení, kde je popsáno co můžu dostat za hodnoty, když do /sys/class/gpio/export/gpio27/direction zapíšu „in“ místo „out“?
Prostě jak si to který modul udělá, tak to bude. Datové typy se neřeší. Pojďme postavit komunikaci se systémem na databázi, která si neuvědomuje že je databáze!
Tohle je asi největší neuvědomělá snaha o zavedení čehosi jako objektů, jakou jsem kdy viděl. Ta struktura jsou objekty. Jen ten rozdíl mezi sys.class.gpio.diode a složkou na podobném umístění je že složka je nepopsaná key-value položka, podobně jako JSON, která nemá jasně dané properties, formát dat, nápovědu, nebo třeba formát a způsob vyvolávání výjimek.
Já chápu, proč vznikly. Vážně. Ve své době to bylo naprosto racionální a nebylo nic lepšího. Ale proč proboha používat nestrukturovaný formát přenosu binárních dat i dneska, když veškerá komunikace je strukturovaná, což platí i pro zdánlivé proudy bajtů, jako streamované audio.
Vemte si, jak to vypadá, když píšete IRC bota. Navážete spojení. Super. Samozřejmě použijete select, aby jste nevytěžovali procesor. Data čtete v blocích, například 4096 bajtů. V paměti je převádíte na stringy a hledáte v nich nové „\r\n“. Musíte bufferovat a zpracovávat řádky vždy až když dorazí celé. Pak parsujete textovou strukturu a skládáte z ní zprávy o jednom řádku. A různé zprávy mají různé formáty a je třeba je parsovat různě. Hrozná zábava s reimplementací specifikace po milionté jinak. Přitom zprávy by mohly mít strukturu samy o sobě, stejnou jako zbytek všeho ostatního.
Nebo třeba HTTP. To přece přenáší strukturovaná HTML data, ne? Máte jasně daný jazyk a jeho popis a způsob parsování. Super! Co víc si přát. Myslíte ale, že HTTP používá na úrovni přenosového protokolu jako datový formát (HT/X)ML? Ani náhodou, samozřejmě, že si specifikuje vlastní protokol, který vypadá úplně jinak (key-value data hlaviček a pak způsob posílání chunků dat).
Email? Ani mě nenechte začít na téma zkaženosti emailu, jeho protokolu a formátu, kde se nejasně definovaná struktura v asi pěti standardech mísí mezi sebou a každý výrobce si to implementuje po svém. Pokud jste někdy zkoušeli zpracovávat emailové hlavičky z nějaké konference, tak určitě víte. Pokud ne, zkuste si to. Garantuji, že vám to změní pohled na svět.
A tak je to se vším. Skoro nikdy nepotřebujete proud bajtů, ale posílat zprávy, které jsou prakticky vždy hierarchie key-val dat, nebo pole. Proč tedy skoro 50 let po vynálezu socketu stále přenášíme data ve streamech a neustále si vymýšlíme vlastní textové protokoly? Není čas na něco lepšího?
Vytvoříme strukturu tady, pak jí serializujeme na surové bajty, nacpeme do socketu a pošleme systému, který musí provést deserializaci a rekonstrukci na základě externího popisu dat, který je s trochou štěstí podobný tomu našemu. Proč? Proč neposílat rovnou struktury?
ZeroMQ byla podle mého názoru krok správným směrem, ale zatím mi přijde, že se nedočkala moc vřelého přijetí.
Máte program na disku, který něco dělá. Když vynechám kliknutí a následné „ruční“ zadání dat, tak argumenty příkazové řádky jsou jeden z nejčastějších způsobů, jak programu říct, co po něm chcete. A každý druhý program si je parsuje vlastním způsobem.
Reálně neexistuje žádný standard formátu argumentů na příkazové řádce. Některé programy používají --param. Jiné -param. Další jen param. Někdy se seznamy oddělují mezerami, jindy čárkami. Už jsem dokonce zažil i JSON parametry mixované s těmi normálními.
Pokud program voláte z nějakého příkazového řádku, tak se vám do toho navíc mixuje jeho scriptovací jazyk a jeho způsob definice stringů, proměnných a bůh ví čeho dalšího (z hlavy mě napadají escape sekvence, jména funkcí, eval sekvence, wildcards znaky, -- pro ukončení wildcardů a tak podobně). Celé je to jeden velký, gigantický bordel, který si každý patlá a parsuje, jak se mu zrovna chce.
A co volání ostatních programů z jiných programů? Ani nechci vzpomínat, kolikrát jsem viděl, či psal kód ve stylu:
import subprocess sp = subprocess.Popen( ['7z', 'a', 'Test.7z', 'Test', '-mx9'], stderr=subprocess.STDOUT, stdout=subprocess.PIPE ) stdout, stderr = sp.communicate()
Naposledy nedávno, i s celou plejádou parsování free-form výstupu. A už mě to vážně nebaví.
Pokud jsou argumenty složitější, stane se z toho rychle onanie skládání stringů, kde si navíc nemůžete být jisti bezpečností, nemáte garanci podporované znakové sady, musíte sanitizovat uživatelský vstup a volané podprogramy navíc stále můžou vykazovat chování, které je všechno, jen ne triviální. Například vám zatuhne buffer při větším výstupu. Nebo program reaguje jinak v neinteraktivním režimu, než v interaktivním a není žádný způsob, jak ho přesvědčit o opaku. Případně vám cpe escape sekvence a tty formátování, kam by jste nechtěli. A jak asi přenesete strukturovaná data tam a zpět?
Přitom parametry příkazové řádky jsou většinou nějakým seznamem, nebo slovníkem s vnořenými strukturami. Chce to jednotný a na zápis jednoduchý jazyk. Něco lehčího na zápis, než JSON, ale zároveň víc expresivního.
Úplně pak vynechávám, že nutnost parametrů příkazové řádky se úplně vytratí, když můžete posílat programu strukturované zprávy podobně jako volat funkci v programovacím jazyku. Vždyť nejde o nic jiného, než o zavolání patřičné funkce / metody s konkrétními parametry, tak proč to dělat takhle divně a nepřímo?
Env proměnné jsou slovník. Doslova se tak mapují a chovají. Jenže díky chybějící struktuře jsou jen jednorozměrným slovníkem s klíči a hodnotami v podobě stringů. V D by se zapsaly jako string[string] env;. To často nestačí, protože potřebujete přenést vnořené struktury.
Má duše křičí, terorizována hláškami jako „potřebuješ předat složitější data do env proměnné? tak tam zapiš JSON, nebo odkaz na soubor!“ Proč proboha jako civilizace nezvládneme jednotný způsob předávání a ukládání dat, že musíme míchat syntaxi env proměnných v bashi s JSONem?
Ať už si to uvědomujete, nebo ne, prakticky každý netriviální program ve vašem počítači potřebuje nějakou konfiguraci. Tu si zpravidla bere z konfiguračního souboru. Víte, kde je ten soubor umístěný? V Linuxu bývá standardem je umisťovat do /etc, ale klidně můžou být taky ve vašem $HOME, nebo v $HOME/.config, nebo v libovolné podsložce (třeba $HOME/.thunderbird/).
A co formát? Hádáte správně. Může být libovolný; (pseudo)INI, XML, JSON, YAML. Nebo Lua. Nebo taky hybrid vlastního programovacího jazyka (viz postfix). Co koho zrovna napadne, to se používá.
Existuje vtip, že komplexita každého konfiguračního souborů s časem roste, dokud v něm někdo vytvoří špatně implementovanou půlku lispu. Mým oblíbeným příkladem je Ansible a jeho nedotažená, nekompletní parodie na programovací jazyk postavený nad YAMLem.
Chápu, kde se to bere. Taky jsem touhle cestou šel. Proč to ale nemůže být standardizované a stejné napříč celým systémem? Ideálně ten samý datový formát, který je zároveň jazykem, napříč vším. Proč nemůžou být konfigurací samotné objekty uložené v patřičném umístění?
U logování je typicky nutno řešit následující problémy:
Současná řešení jsou opět typicky zcela různá, tak jak koho zrovna co napadlo:
/dev/null. Celé to krásně fungovalo jen do té doby, než se pythonní RotatingFileHandler rozhodl soubor odrotovat a celá aplikace spadla.Logování mi přijde jako krásná ukázka programátorské struktury, kterou je nucen řešit prakticky každý a kterou operační systém v celé komplexitě podporuje skoro vůbec, nebo jen málo. Je to také krásná ukázka konceptu, který by si zasloužil převést na posílání strukturovaných zpráv;
Zprávy jsou objeky. Mají své datum odeslání, mají krátký text a většinou i dlouhý text a také „úroveň“ (v pythonu typicky DEBUG, INFO, WARNING, ERROR). Pokud s logy pracujete, skoro nikdy nechcete pracovat na úrovni textu. Chcete například omezit datum - jak to uděláte, když se jedná o text? Nebo úroveň - pokud chcete všechny zprávy úrovně ERROR, nechcete to grepovat textově, protože slovo „ERROR“ může být použito i v tělě zprávy v různých kontextech. Například „NO_ERROR“.
Aplikace, do které se loguje by měla přijímat zprávy, které bude uchovávat v datové struktuře fronta. Tím by nikdy nemohlo dojít místo na disku. Starší struktury by bylo možné automaticky komprimovat, ale pro uživatele by to mělo být transparentní - pokud chce vyhledávat nad komprimovanými zprávami, ani by o tom neměl vědět.
Nemělo by existovat padesát způsobů logování - pro uživatele by to měla být záležitost instancování systémového loggeru a jeho následné používání, po krátké konfiguraci, kde si zvolí politiku rotace. Pak už jen loguje standardním posláním zprávy, ať už lokálně, nebo vzdáleně z internetu.
Docker je virtualizační nástroj umožňující vám sestavovat, spravovat a spouštět kontejnery virtuálních počítačů, ve kterých je specifické programové vybavení.
Osobně mám Docker docela rád a občas ho používám k sestavování balíčků pro cílové distribuce (například .deb pro Debian a .rpm pro RHEL).
Parametrů Dockeru je nepřeberně: https://docs.docker.com/engine/reference/run/. Mojí oblíbenou částí jsou volumes, tedy složky, jenž jsou mountovány dovnitř kontejneru z vnějšího hosta.
Syntaxe je přibližně -v local_path:/docs:rw. Jako dobrá ukázka mi to přijde, protože se do jednoho parametru cpou tři různé hodnoty: cesta v počítači na kterém příkaz pouštíte (která navíc musí být absolutní!), cesta uvnitř kontejneru a práva k zápisu.
K naprosté dokonalosti to bylo dovedeno novým parametrem --mount, který dělá to samé, ale zavádí pro to úplně novou syntaxi, jenž přináší úplně jiná pravidla parsování:
--mount source=local_path,target=/docsKomplexnější ukázka může vypadat například takto:
--mount 'type=volume,src=<VOLUME-NAME>,dst=<CONTAINER-PATH>,volume-driver=local,volume-opt=type=nfs,volume-opt=device=<nfs-server>:<nfs-path>,"volume-opt=o=addr=<nfs-address>,vers=4,soft,timeo=180,bg,tcp,rw"'a zahrnuje ukázky escapování CSV parseru (!).
Z hodnot oddělených dvojtečkami se stává úplně nový formát hodnot oddělených čárkami, definující key-value hodnoty pomocí rovnítka (=), ale zároveň hodnoty jako list, protože místy tam žádné rovnítko není, a je možné používat uvozovky a celkově .. co to sakra je?
To ani nemluvím o tom jak se různě chování mění, podle toho co zrovna použijete, protože to není předmětem diskuze.
Pointou je, že místo aby se jednalo o nějak jasně definovaný objekt, kterému můžete poslat zprávu, tak je to systém hned několika konvencí skládání stringů na příkazové řádce, který je peklo snažit se nějak obalit do vašeho programu, protože se chová nekonzistentně a nepředvídatelně.
A to není všechno, pořád je tady ještě Dockerfile, protože to je samozřejmě další se vším ostatním nekompatibilní formát bez debuggeru a jasné vize a logiky.
Původní myšlenka Dockerfile byla hádám podobná, jako u makefile. Pustíme na to docker a on provede jednotlivé direktivy krok za krokem a sestaví nám „projekt“.
Původní idea byla jednoduchá - prostě soubor KEY value definic, které se budou postupně vykonávat. Může to vypadat například takto:
FROM microsoft/nanoserver
COPY testfile.txt c:\\
RUN dir c:\FROM určuje co se má použít za původní kontejner, ze kterého se bude vycházet, COPY zkopíruje soubor z počítače, na kterém je kontejner sestavován a RUN provede nějaký příkaz.
Každý kdo zná Greenspunovo desáté pravidlo asi tuší, jak se to vyvíjelo dál. Přišla definice ENV proměnných a jejich nahrazování pomocí šablonování. Definice escape znaků, .dockerignore soubor. Příkazy jako třeba CMD získaly alternativní syntaxi, takže to nemusí být jen CMD program parametr, ale i CMD ["program", "parametr"].
Věci jako LABEL umožnily definovat další key=value struktury. Samozřejmě, SAMOZŘEJMĚ, že někdo potřeboval podmíněný build, tak vznikly hacky jak ho obejít přes templatování a nastavování key value hodnot z vnějšku: https://stackoverflow.com/questions/37057468/conditional-env-in-dockerfile
Je jen otázkou času, než tam někdo přidá plnohodnotné podmínky a funkce a udělá z toho svůj vlastní zprasený programovací jazyk. Bez debuggeru, bez profileru, bez pěkných tracebacků.
Proč? Protože neexistuje žádný standard a operační systém neposkytuje nic po čem by se dalo sáhnout. Fragmentace tak pokračuje.
Nedávno jsem v práci byl nucený pracovat s OpenShiftem. Musím říct, že se mi docela líbil a myslím si, že má zářnou budoucnost. Umožňuje vytvářet pěknou hardwarovou abstrakci nad clustery počítačů, provádět relativně bezbolestný deployment aplikací na vlastním firemním cloudu.
Přesto jsem během procesu portování několika balíčků ze starého RHEL 6 formátu, který běžel na fyzických serverech do nového RHEL 7 spec formátu, který má běžet uvnitř OpenShiftu neustále kroutil hlavou ohledně specifik nastavování a konfiguraci.
Abyste tomu rozuměli, tvůrci OpenShiftu ho umožňují konfigurovat přes webové rozhraní prostě jen klikáním. K tomu navíc nabízejí REST API a také utilitu příkazové řádky oc, kterou je možné provádět to samé co z ostatních dvou rozhraní.
Kroutil jsem hlavou, protože jak v případě Webu, REST API či oc se jedná o konfiguraci nahráváním a upravováním objektů popsaných pomocí YAMLu či JSONu (formáty je možné zaměňovat).
Tyto objekty je možné definovat v takzvané template, která funguje jako svého druhu Makefile, postupně vykonává jednotlivé bloky a na konci by měl být výsledkem běžící systém. V rámci template je možné používat šablonovací systém, který umožňuje definovat a expandovat proměnné.
Tohle všechno je postavené nad YAMLem, což je poněkud méně ukecaný bratr JSONu. Ukázka template může vypadat například takto:
apiVersion: v1
kind: Template
metadata:
name: redis-template
annotations:
description: "Description"
iconClass: "icon-redis"
tags: "database,nosql"
objects:
- apiVersion: v1
kind: Pod
metadata:
name: redis-master
spec:
containers:
- env:
- name: REDIS_PASSWORD
value: ${REDIS_PASSWORD}
image: dockerfile/redis
name: master
ports:
- containerPort: 6379
protocol: TCP
parameters:
- description: Password used for Redis authentication
from: '[A-Z0-9]{8}'
generate: expression
name: REDIS_PASSWORD
labels:
redis: masterExpanze proměnných probíhají zvenčí přes parametry příkazové řádky.
Dosud dobré. Jenže jak by se dalo tušit, mám k tomu spoustu výhrad:
Naprosto zde chybějí podmínky. Aby člověk mohl například podmíněně vykonat nějakou část kódu, musí použít šablonovací systém (Jinja2 třeba) nad tímhle šablonovacím systémem.
Chybí tam taky samozřejmě definice funkcí (často opakovaných bloků) a cyklů. Kdyby se jednalo o cokoliv jiného, tak bych to asi odpustil, ale představte si úplně ukázkové použití. U nás ve firmě používáme pro každou jazykovou mutaci našeho produktu čtyři prostředí: dev, test, stage a prod. Prvně si vývojáři testují nasazení na devu, potom testeři na testu, businnesáci poté na stage a zákazníci nakonec používají prostředí na produ.
Když nasadím novou verzi programu, musí postupně projít přes všechny tyto prostředí. Tudíž by bylo dobré mít nějakou možnost například provést spuštění virtuálního stroje v rámci OpenShiftu tak, že prostě řeknu „pusť toto čtyřikrát“. Jenže OpenShift samozřejmě nic takového neumí a je třeba to dělat manuálně. To začne být velmi rychle velmi velký opruz, protože prostředí se od sebe moc nelíší, kromě trochy konfigurace, která je to jediné co by bylo třeba dynamicky upravit.
Vzpomínáte si, že jsem původně psal o různých jazykových mutacích? Protože to jsou čtyři instance per jazyk a jazykové mutace máme momentálně taky čtyři, což dává dohromady šesnáct instancí. A to máme projekty, kde je to deset instancí per vývojové prostředí, per jazyk. Tedy dohromady musí běžet 160 instancí.
Je asi jasné, že tohle nejde a tak jsme byli nuceni si nad tím postavit vlastní správu v podobě python scriptů a shellscriptů a ansible. Nemám z toho radost. A to jsem se nakonec rozhodl nepitvat, že OpenShift používá docker a je v něm nutné zároveň s jeho YAML formátem řešit i Dockerfile formát a argumenty příkazové řádky.
To vše proto, že neexistuje jednotný široce přijímaný formát konfiguračního jazyka, který by byl zároveň jazykem scriptovacím. Něco jako lisp.
Ansiblééé je krásnou ukázkou jak to dopadne, když se někdo jen tak ad-hoc pokusí podobný jazyk uvařit, aniž by nad tím nějak moc přemýšlel, nebo měl za sebou teorii programovacích jazyků.
Původně začal jako deklarační konfigurační jazyk, který popisoval co se má jak dělat, založený na JSONu.
Zde je například ukázka deklarace instalace nginxu:
- name: Install nginx
hosts: host.name.ip
become: true
tasks:
- name: Add epel-release repo
yum:
name: epel-release
state: present
- name: Install nginx
yum:
name: nginx
state: present
- name: Insert Index Page
template:
src: index.html
dest: /usr/share/nginx/html/index.html
- name: Start NGiNX
service:
name: nginx
state: startedCelé je to poměrně jednoduše čitelná YAML key-value struktura. Samozřejmě, SAMOZŘEJMĚ že nemohlo zůstat jen u tohohle a tak někoho napadlo přidat podmínky a cykly. Samozřejmě jako YAML:
Samozřejmě, že tím vznikl programovací jazyk bez jakékoliv konzistence, vnitřní logiky a smyslu. Jazyk který byl nucený jít dál a dál a nadefinovat si bloky a výjimky a ošetřování chyb a funkce a to celé postavené nad YAMLem. To celé bez debuggeru, IDE, toolingu, smysluplnných stacktrace a s naprostou ignorací šedesáti let vývoje uživatelského rozhraní programovacích jazyků.
tasks:
- command: echo {{ item }}
loop: [ 0, 2, 4, 6, 8, 10 ]
when: item > 5
Ten tenký vysoký zvuk znějící jako pištění na vysoké frekvenci, jenž můžete slyšet v dokonalém tichu třeba chvíli před spaním jsou andělé řvoucí frustrací. Je to řev mojí duše nad vší lidskou demencí, která se vrší a vrší nad sebe.
Nemůžeme se prostě domluvit nad něčím co by pro jednou dávalo smysl?
Co takhle vzít všude tam, kde se dneska používá nějaký podivný stringový formát, ať už je to předávání parametrů programům, nebo komunikace mezi nimi, a nahradit to nějakým úsporným, jednoduše zapisovatelným jazykem pro definici struktur? Jazykem, který by byl zároveň popisným formátem, jenž by chápal datové typy jako dict, list, int a string a delegaci (dědičnost). Tak aby pro člověka i program odpadla většina parsování a dohad nad strukturou, a druhý jmenovaný je dostal už rovnou ve svém nativním formátu.
Tolik tedy ke kritice. Pojďme se podívat na nápady, jak se posunout někam dál.
Když mluvím o objektech, nemám na mysli co znáte z programovacích jazyků jako třeba C++, nebo Java. Spousta lidí na to má poslední dobou alergii.
Myslím tím obecný koncept grupování funkcí s daty, nad kterými operují. K tomu není třeba class based přístup (= nemusíte psát třídy). Není k tomu třeba ani dědičnost, i když nějaká forma delegace se hodí.
GPIO podsložka filesystému /sys obsahující kontrolní soubor, jenž udává směr zápisu dat na LED diodu, a datový soubor, kterým data můžete zapsat či číst, je objekt. Má metodu (ovládací soubor) i data, nad kterými se operuje. Samozřejmě, že ideálně by bylo možné podobný objekt i kopírovat a instancovat standardním způsobem, předávat ho dalším objektům a metodám a provádět jeho introspekci. Ale i tak je to primitivní objektový systém, kde objektem je složka, daty jsou soubory, a metodami kontrolní soubory a operace nad nimi.
Samotné objekty jsou na nejnižší úrovni key-value data. Klíč způsobí provedení kódu v případě že jde o jméno metody, nebo vrácení dat, v případě že jsou v něm uloženy data. Rozdíl mezi objekty a key-value záznamem v databázi je poměrně minimální, a spočívá především v možnosti uložit kód, a také v delegaci, kde když se nenajde daný klíč v potomkovi, tak se přesune hledání do konkrétního rodiče.
Pokud tedy mluvím o objektech, mám na mysli obecné key-value struktury umožňující delegaci, referencování dalších (objektových) key-value struktur, reflexi a ideálně i nějakou formu homoikonicity.
Záměrně nemám na mysli konkrétní jazyk, ale zcela a vůbec nemám na mysli imperativní, objektově orientované a na strukturách založené jazyky, jako jsou C++, C#, Java a další podobné.
Je pro mě fascinující, že na nejnižších úrovních internetových protokolů není problém se domluvit na strukturovaném formátu zpráv. Každý TCP/IP packet má jasně danou hlavičku, jasně dané adresování a celé to funguje v naprosto masivním, celosvětovém měřítku. Proč by to tedy nemohlo fungovat na počítači, či mezi nimi i na vyšší úrovni?
Opravdu by nešlo adresovat jednotlivé metody objektů, či objekty samotné, jak v rámci jednoho počítače, tak po internetu?
Nebudu popisovat nějaký konkrétní systém. Sice jsem na tohle téma provedl pár experimentů, ale v zásadě nemám konkrétní data a zkušenosti. Shrnu pouze to co jsem napsal předtím. Tím by postupným zhušťováním a krystalizací již jednou rozebraných myšlenek mohlo vzniknout cosi jako dostatečně komprimovaný popis požadavků, aby to bylo možno brát jako nekonkrétní definici konkrétního produktu.
Přemýšlel jsem nad tím, a nevyhnutelným krokem je podle mého názoru zahodit filesystém a nahradit ho databází. Když mluvím o databázi, nemám tím na mysli konkrétní SQL databázi, ani key-value „no-SQL“ databáze. Mluvím tu o obecném strukturovaném systému uchovávání dat na záznamových médiích, který podporuje datové typy, atomicitu, indexování, transakce, žurnály a ukládání libovolně strukturovaných dat, včetně velkých bloků čistě binárních dat.
Něco kam můžete prostě hodit nějakou strukturu a ono se to postará o její uložení bez zbytečné serializace a deserializace. Já vím, že na konci jsou to vždycky jen bajty, ale právě proto nevidím moc důvodů, proč dělat signifikantní rozdíl mezi tím co je v paměti a co je na disku.
Nechci aby to vypadalo, jako že mám něco proti tradičním souborovým systémům. Jsem jejich uživatelem stejně jako všichni ostatní, ale myslím, si, že bez tohohle se není možné posunout někam signifikantně jinam. Když nejste schopni vynutit strukturu na úrovni uložených dat, bez neustálého převádění sem a tam, z formátu do formátu a reprezentací v paměti, je to jako stavět barák v bažině, na základech, které se neustále hýbou.
Jakmile máte filesystém, který vám umožňuje nativně uchovávat strukturované informace, nedává smysl mít programy jako jednu velkou sérii bajtů, která se uzavírá před světem. Naopak dává smysl z toho postavit něco podobného architektuře microservices.
Pokud se nad tím zamyslíte dostatečně abstraktně, program je objekt. Je to kolekce dat, nad kterými operují v něm obsažené funkce. Celé je to zapouzdřené a komunikuje to jen pomocí nějakých standardních způsobů (stdin/out/err, socket, signály, env, error kódy, zápisy do souborů..). Když máte filesystém umožňující tyhle objekty uchovávat nativně, nevidím důvod, proč potom nezpřístupnit jednotlivé metody tohoto objektu i z venčí.
Jakmile je zveřejníte, nepotřebujete komunikovat starými streamovými způsoby (socket, soubor, ..), stačí vám prostě vracet strukturovaná data.
Kód se může stále kompilovat, stále je možné používat různé programovací jazyky. Liší se to však výsledkem, jenž z toho vypadne. Místo binárního blobu, posílaného přímo do procesoru, jenž je izolován od ostatních procesů a zbytku systému, máte v podstatě definici API a reakcí na ně. Něco jako sdílenou knihovnu, až na to že tohle je nativní prvek systému a jeho finální podoba.
Konfigurační soubory a různé jejich formáty existují, protože filesystém neumí uložit strukturu. Kdyby to uměl, můžete prostě uložit daný slovník s danými klíči a hodnotami, a příště po nich sáhnout. Nemusíte zapisovat RUN=1 do sekce [configuration] a pak to parsovat a serializovat a deserializovat. Můžete prostě uložit samotný fakt "RUN": True na umístění configuration přímo na disku.
Nepotřebujete řešit, jestli je to JSON, nebo CSV, protože v tom pro vás není rozdíl z hlediska formátu, ale jen struktury dat (JSON typicky dict, CSV pole polí).
Parametry příkazové řádky, env proměnné, ale i všechno ostatní píšete jako datové typy zachovávající si strukturu. Programem nejsou parsovány jako text, o to se stará už systém ve chvíli kdy to uživatel dopíše. Datový formát je jednoduchý na textový zápis. Když posílá data program programu, nikde mezi nimi se neserializuje do textu, zprávy se neposílají jako stream bajtů, ale jako zprávy (ve stylu zeromq).
Předchozí popis je pořád moc dlouhý, pojďme ho proto ještě trochu víc zredukovat, tak jak se redukují třeba matematické výrazy do jednoho vzorce:
Místo filesystému strukturovaná hierarchická databáze zachovávající datové typy. V ní jak programy, uložené jako kolekce navzájem se volajících, ale i z venku zavolatelných funkcí, tak konfigurační soubory a uživatelská data. To vše formou přístupných a adresovatelných struktur. Na zápis a čtení jednoduchý, lehký textový formát, používaný všude kde je strukturovaný uživatelský vstup. Programy které ke komunikaci nepoužívají textové protokoly, ale předávají si přímo struktury.
Dost bylo iterativního vylepšování padesát let starých myšlenek. Myslím, že je čas na něco nového.
Pokud si myslíte, že jsou to všechno naivní blbosti, zkuste si přečíst něco na téma Genery:
Zjistíte, že před desítkami let existoval grafický systém splňující velkou část všeho, o čem jsem psal. Systém tak dobrý, že dodnes kolem sebe spojuje skupiny nadšenců.
Dále pak na podobná témata:
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 10.12.2018 10:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
31.12.2018 14:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 10:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
31.12.2018 14:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale kritiku syntetického filesystému ve stylu Plan 9 nelze postavit pouze na kritice /sys v Linuxu. Ten jejich 9P byl v mnohém vymyšen docela pěkně a jak sám píšeš. Zkoušel sis někdy s tím Plan 9 hrát ve virtuálu nebo psát nad tím aplikace? Ptám se, protože jsem si s tím sám nikdy seriózně nehrál, ale z popisu co jsem četl to nevypadalo úplně posixově.Právě že jsem si s tím hrál (i jsem o tom něco načetl) a sice uznávám, že je to krok správným směrem, ale potom co jsem si hrál nějakou dobu se smalltalkama a Selfem prostě jasně vidím, že to chce udělat těch kroků víc. Samo o sobě to pořád nechává spoustu problémů nevyřešených, proto si myslím, že se z toho nestalo dominantní paradigma.
10.12.2018 10:53
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 09:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.12.2018 10:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tato citace od Exuperyho se mi opravdu libi a myslim si, ze tim by se vyvoj software ridit mel, obzvlast dnes, kdy vic kodu znamena vetsi bezpecnostni riziko: It seems that perfection is attained not when there is nothing more to add, but when there is nothing more to remove.Asi bych mohl polemizovat, jestli je dokonalost to na co fakt cílíš, a jak jí budeš definovat, ale obecně s tím souhlasím. Nicméně to záleží čistě na definici toho, co vlastně chceš dělat. Pokud si jako definici dáš současný styl OS, tedy Unixový systém, tak tvoje idea dokonalosti může vypadat úplně jinak, než když si dáš za cíl třeba co nejlepší systém pro práci s informacemi, nebo co nejlepší systém pro programátora. Já si navíc hlavně nemyslím, že současný stav byl zvolen nějak racionálně, podle v současnosti smysluplných cílů. Myslím si, že je to jen historický artefakt a lokální maximum, do kterého jsme spadli. Což je mimochodem taky dobré poznamenat, že pokud chceš všechno co nejvíc univerzální a co nejvíc použitelné, tak to z principu musí optimalizovat ve více dimenzích (například právě v univerzálnosti, použitelnosti, jednoduchosti na implementaci, naučení se a tak dál). Tím to zprůměruješ níž, než systém, který by optimalizoval v méně dimenzích. Asi jako židle zprůměrovaná na průměrný zadek, versus židle udělaná přímo tobě na míru.
13.12.2018 12:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Co vlastně počítáš do OS? Co třeba libc? Já bych ji jako část OS neoznačil, ale bez ní by ten OS by byl jen těžko použitelný. Podobně na tom je třeba init (v obecném smyslu).Já jí tam počítám. Chápu, že to rozdělení jde dělat různě a právě proto jsem ho udělal čistě pragmaticky tak, že OS je to co instaluju na počítač. Tedy celá distribuce. I když je mi jasné, že v čistě pedantském smyslu to tak samozřejmě není.
Já bych řekl, že co nejlepší systém pro práci s informacemi nebo co nejlepší systém pro programátora může úplně krásně být postaven na něčem, co je současný styl OS.Do jisté míry ano. Jeden z problémů který tu vidím je spíš filosofického rázu, než čeho jiného. Je to jako když jsou programovací jazyky zpětně kompatibilní s C - lidi mají tendence to pak používat jako C, protože je to něco co znají. Jen těžko se pak posouváš někam kupředu. Můžeš si do jazyka dodělat generátory a korutiny a futures a kde co, ale pokud to uděláš zpětně kompatibilní s C, budeš jen těžko přesvědčovat ostatní, aby to používali. Proto taky vznikají nové jazyky. Ten problém je někde na úrovni vnímání světa skrz analogie. Pokud je něco skoro stejného jako něco jiného, jak budeš vysvětlovat ostatním, aby to používali úplně jinak? Ta moje představa je něco jako Python. Je to prostě trochu víc abstraktní a nabízí to nějaké další konstrukty, které standardní OS nenabízí, samozřejmě za cenu menší univerzality. Jenže to není nevýhoda, to je největší výhoda. Pokud by měl být python zpětně kompatibilní na úrovni syntaxe a funkcionality s C, tak by neexistoval moc důvod ho používat. A plně uznávám tvrzení lidí co dělají v C, že každou aplikaci, co v Pythonu naprogramuju můžou naprogramovat i v C. Jenže každý kdo dělá v Pythonu ví, že to není pointa a že ty jeho odlišnosti jsou důležité. Pokud uděláš to co jsem popsal jen jako vrstvu nad klasickým OS, tak i ty sám budeš pořád používat klasický OS. Nikdy se skutečně neponoříš do možností a schopností toho co jsi vytvořil, protože celý zbytek světa tě bude stahovat a držet zpět. Nutno teda poznamenat, že já svůj vlastní OS fakt nedělám a nemám to v plánu.
Ten systém pro programétor, nebo práci s informacemi totiž bude stejně řešit úlohy, které řeší systém v současném stylu. Objekt uložený na disku stejně pořád bude sekvence bytů, nějak zdokumentovaná (co a kde to je, apod.) na nějakém FS. Pro jeho načtení bude potřeba ovladač disku, FS, nějaké syscally, atd. Nad tím bude parser, který z bytů udělá objekt. Možná se současný styl OS úplně nehodí jako základ toho, co bys chtěl, ale to nic nemění na tom, že ten parser bude userspace záležitost.Já s tím více/méně souhlasím, až na ten rozdíl, že podle mého názoru jde o artefakt. Tak to prostě je, nikoliv že by to tak být muselo. Pokud bys měl dost prostředků, jako třeba Google, tak bys imho mohl vytvořit něco podstatně lepšího. Samozřejmě jako jednotlivec moc nemáš šanci.
13.12.2018 14:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Vezmu to od konce - co považuješ za artefakt?Věci které jsou, protože historicky dávaly smysl, případně protože pár lidí to nějak nastřelilo a ono se to osvědčilo, ale v současnosti za tím nestojí žádné racionálně podložené rozhodnutí a série experimentů, které by jasně prokázaly, že je to lepší než jiné přístupy. Souborový systém není z uživatelského hlediska nic jiného než artefakt. Je to jednoduše pochopitelná analogie, ale neexsituje důvod, proč bys mohl mít jen adresáře a soubory (a symlinky a pipy) a ne libovolně typované záznamy s relacema a triggerama a atomickým zápisem. Právě proto, že dole jsou to bajty a souborový systém to uloží tak jako tak.
Já si myslím, že těhle věcem se jednoduše nevyhneš. Můžeš je realizovat různě, i hodně odlišně od toho, jak to je aktuálně v Linuxu, ale ty vrstvy tam pořád budou. Pořád tam bude něco, co řekne disku, co číst, co to od něj přesune někam do paměti jádra, odtamtud do userspacu, něco, co to to naparsuje (udělá z toho objekt), něco, co si bude udržovat přehled, co kde je na disku atd.Já bych úplně vyhodil filesystém a přidal místo něj nativně prostě databázi s podporou ukládání objektů, key-value záznamů a možná i relací. Pořád bys mohl mít
/etc/your_app, ale neměl bys tam uložený soubor, ale samotná typovaná data. Místo stringu s ini souborem bys z toho dostal rovnou slovník. String by nevznikl nikde po cestě, nevznikl by ani na disku. Nebylo by ho třeba nikdy parsovat a zpracovávat.
13.12.2018 16:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.12.2018 18:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Mimochodem, když vyhodíš ten FS, jak jsi navrhoval a ta db ukládat data nějak přímo na block device, tak ti vznikne spousta problémů (např fragmentace), které FS řeší.Problémy ti nevzniknou, prostě se jen FS a databáze sloučí do jednoho. Nikdy jsem netvrdil, že se obejdeš bez technik, které FS používá, jen že se obejdeš bez jeho uživatelského rozhraní (soubory, složky, možnosti zápisů do nich a tak podobně).
Celkově mi přijde, že se na to koukáš tak nějak moc seshora. Myšlenka ukládat kdeco do db mi přijde celkem dobrá, ale pro realizaci mi tam tradiční FS přijde nezbytný.To upřímně nechápu proč. Naopak v případě databází je to v podstatě zbytečný mezikrok, který se stejně snažíš obcházet různým mapováním do paměti a sparse soubory a tak podobně.
Problémy ti nevzniknou, prostě se jen FS a databáze sloučí do jednoho. Nikdy jsem netvrdil, že se obejdeš bez technik, které FS používá, jen že se obejdeš bez jeho uživatelského rozhraní (soubory, složky, možnosti zápisů do nich a tak podobně).
Podle mého je to jen implementační detail, je to nepodstatné a nemá cenu se o tom hádat. Představ si, že uděláš prototyp toho tvého systému -- OS, který nabootuje do nějakého objektového světa. Je úplně jedno, jestli kdesi pod tím bude Ext4, Btrfs, XFS, nebo jejich funkcionalita reimplementovaná v nějaké spodní vrstvě té DB. Uživatel to nevidí a v zásadě ho to nezajímá.
Můžeme tedy osekat všechny zbytné kroky a vykašlat se na nějakou reimplementaci a postavit to (alespoň hypoteticky, v myšlenkách) jako nadstavbu nad stávajícím systémem. Že je pod tím POSIX resp. GNU/Linux nás nemusí trápit -- může to mít nějaké výkonnostní dopady a může to představovat zbytečnou komplexitu, ale v případě prototypu je to jedno. Tak a teď máme prázdný objektový operační systém, který nastartoval a v něm na nás bliká nějaká objektová příkazová řádka... Co dál?
13.12.2018 19:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Podle mého je to jen implementační detail, je to nepodstatné a nemá cenu se o tom hádat. Představ si, že uděláš prototyp toho tvého systému -- OS, který nabootuje do nějakého objektového světa. Je úplně jedno, jestli kdesi pod tím bude Ext4, Btrfs, XFS, nebo jejich funkcionalita reimplementovaná v nějaké spodní vrstvě té DB. Uživatel to nevidí a v zásadě ho to nezajímá.Jen pro pořádek, moje prototypy normálně pracují nad FS. To že se tu o tom hádám neznamená, že nejsem pragmatik.
Můžeme tedy osekat všechny zbytné kroky a vykašlat se na nějakou reimplementaci a postavit to (alespoň hypoteticky, v myšlenkách) jako nadstavbu nad stávajícím systémem. Že je pod tím POSIX resp. GNU/Linux nás nemusí trápit -- může to mít nějaké výkonnostní dopady a může to představovat zbytečnou komplexitu, ale v případě prototypu je to jedno. Tak a teď máme prázdný objektový operační systém, který nastartoval a v něm na nás bliká nějaká objektová příkazová řádka... Co dál?No, tohle je jeden z důvodů, proč vůbec nemám snahu ohledně čehokoliv pro uživatele. Dál jsi jako uživatel v háji. Já jako programátor si samozřejmě začnu portovat věci co tam potřebuji. Jinak přesně tuhle situaci jsem zažil se Selfem a chce to prostě zatnout svaly a prorážet si vlastní cestu. Což samozřejmě chápu, že nemůžu chtít po ostatních.
 13.12.2018 19:18
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
13.12.2018 19:18
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Naopak v případě databází je to v podstatě zbytečný mezikrok, který se stejně snažíš obcházet různým mapováním do paměti a sparse soubory a tak podobně.To je projekt od projektu. Některé DB požadují dostatečně příčetný FS a staví až nad ním. Proč by měly ztrácet čas nad řešením něčeho co už vyřešil někdo jiný. Jiné DB v minulosti měly podporu pro block device, ale opustily ji. Některé jiné storage systémy (jmenujme CEPH) se neumějí rozhodnout a za 10 let doporučují ext4, btrfs, xfs, aby se nakonec rozhodli napsat si vlastní BlueStore (což asi nebude FS ve smyslu požadavků VFS). Asi nelze říct, který přístup je lepší. Jsou projekty, které staví na již existujícím a očekávají funkční FS, ioscheduler, task scheduler, síťování a jsou projekty, které si chtějí řešit všechno sami. Výhoda prvního řešení je, že už to někdo napsal a je to k disposici a lze očekávat, že se to bude časem zlepšovat. Výhoda druhého řešení může být lepší optimalizace na konkrétní typ zátěže. V praxi vidíme oba přístupy.
Některé jiné storage systémy (jmenujme CEPH) se neumějí rozhodnout a za 10 let doporučují ext4, btrfs, xfs, aby se nakonec rozhodli napsat si vlastní BlueStore (což asi nebude FS ve smyslu požadavků VFS).V případě Cephu je to doslova cesta tam a zase zpátky, ale ve výsledku to má snad i nějakou logiku, i když se to nemusí na první pohled zdát
 Sage už ve své disertační práci (2007)
psal o EBOFS, vlastní implementaci souborového systému v user space pro potřeby Ceph OSD:
Sage už ve své disertační práci (2007)
psal o EBOFS, vlastní implementaci souborového systému v user space pro potřeby Ceph OSD:
Low-level object storage on individual OSDs is managed by EBOFS, an E xtent and B- tree based Object File System. Although a variety of distributed storage arch itectures leverage existing general-purpose file systems [14, 55] such as ext3 [95], both th e performance and the standard POSIX file system interface and safety semantics are inappro priate for RADOS. Because EBOFS is implemented entirely in user-space and interacts directly with a raw block device, it is unencumbered by an unwieldy kernel file system interface, a nd avoids interaction with the (Linux) VFS inode and page caches, which were designed aroun d a different storage abstraction and workload assumptions. This allows EBOFS to optimize specifica lly for object workloads [97]Později v roce 2009 EBOFS zahodili, protože se zdálo, že btrfs jej v budoucnu nahradí:
We dropped support for ebofs a few months back since the plan moving forward is to use btrfs and the maintenance burden wasn't deemed worthwhile. Btrfs does (almost *) everything ebofs does, and much more, and is very actively developed.Ale do produkce vždy doporučovali XFS, případně ext4. Btrfs bylo pouze experimentální a počítalo se s ním do budoucna, viz dokumentace verze z roku 2013:
We currently recommend XFS for production deployments. We recommend btrfs for testing, development, and any non-critical deployments. We believe that btrfs has the correct feature set and roadmap to serve Ceph in the long-term, but XFS and ext4 provide the necessary stability for today’s deployments. btrfs development is proceeding rapidly: users should be comfortable installing the latest released upstream kernels and be able to track development activity for critical bug fixes.S vývojem btrfs ale v Cephu asi nebyli úplně spokojení, protože se nakonec v roce 2017 na btrfs vykašlali a vrátili se k původní myšlence vlastního souborového systému v user space a napsali nový systém, Bluestore, který používá RocksDB key/value databazi. Btw Ceph s Bluestore je docela dobrý příklad, jak se na dnešním OS dá postavit storage systém, který není omezený návrhem operačního systému, co beží pod ním.
Nikdy jsem netvrdil, že se obejdeš bez technik, které FS používá, jen že se obejdeš bez jeho uživatelského rozhraní (soubory, složky, možnosti zápisů do nich a tak podobně).Tím pádem tam ale ten FS bude, jen nebude určen k přímému použití programátorem nebo uživatelem. Podobně jako teď syscally. Dají se volat přímo, ale málokterý programátor to dělá.
To upřímně nechápu proč. Naopak v případě databází je to v podstatě zbytečný mezikrok, který se stejně snažíš obcházet různým mapováním do paměti a sparse soubory a tak podobně.Nezbytný ve smyslu vrstvy, která bude řešit ty technické problémy (např. fragmentaci) při ukládání dat na disk.
17.12.2018 12:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tím pádem tam ale ten FS bude, jen nebude určen k přímému použití programátorem nebo uživatelem. Podobně jako teď syscally. Dají se volat přímo, ale málokterý programátor to dělá.Je otázka do jaké míry. Například asi nedává smysl rozdělení na soubory a složky a jejich atributy a symlinky. Naopak dává smysl ta druhá část, co jsi zmiňoval, tedy řešení fragmentace a tak dál.
18.12.2018 16:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Mě soubory a složky nepřijdou moc jako artefakt, ale spíš jako základní a velmi jednoduchý (z pohledu uživatele) způsob rozmístění dat na disku.No, tak samozřejmě, protože jsi s tím vyrůstal a celý ten koncept tu byl dýl než existuješ. Ale zamýšlel ses někdy proč ti to tak přijde? Jaké to má opodstatnění a jestli to vůbec dává nějaký smysl? Co jsou alternativní přístupy? Jestli by to třeba nešlo dělat líp, případně jaké by to přinášelo benefity?
18.12.2018 17:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nicmene zkusim jeden argument pro slozky. Jako lide jsme se vyvinuli zvykli orientovat se ve fyzickem prostoru, a proto je nam hierarchicke deleni (virtualniho) prostoru prirozene. U jinych deleni (treba kde prostor funguje jako orientovany graf, podobne jako treba kategorie na Wikipedii) ztracime prehled o tom, co a kolik toho kde mame.Tohle uznávám, ale pokud ukládáš do prototypových objektů, tak pořád máš podobné hierarchie.
Ja jsem byl taky jeden cas proti slozkam, a chtel jsem filesystem, ktery by mohl ukladat stejny soubor do libovolneho mnozstvi slozek (ci spise tagu), a adresovat ho pak na zaklade obsahu. (Tedy trochu jako hardlinky ale misto inode by byl hash toho souboru.) A samozrejme, idealne, aby stejna struktura fungovala pres ruzna zarizeni nebo i ruzne lidi.
To zní jako IPFS :-)
Nicmene zkusim jeden argument pro slozky. Jako lide jsme se vyvinuli zvykli orientovat se ve fyzickem prostoru, a proto je nam hierarchicke deleni (virtualniho) prostoru prirozene. U jinych deleni (treba kde prostor funguje jako orientovany graf, podobne jako treba kategorie na Wikipedii) ztracime prehled o tom, co a kolik toho kde mame.Ten argument pro adresare je docela validni. Umoznuji organizaci od obecnych kategorii dat, k tem specifickym. Cim zanorenejsi adresar, tim obvykle obsahuje spefictejsi data. Nic, co by lide nedelali po staleti pred tim.
U jinych deleni (treba kde prostor funguje jako orientovany graf, podobne jako treba kategorie na Wikipedii) ztracime prehled o tom, co a kolik toho kde mame.Z tohoto uhlu pohledu praktictejsi "zobecneni" (resp. zuplneni) adresaru (spis nez orientovany graf) by byl svaz, kde infimum by byl prunik tagu jednotlivych dokumentu a supremum jejich sjednoceni. Svaz (strukturu adresaru) bys pak prochazel od shora dolu a jen bys pridaval tagy (zanoroval by ses do adresaru), nez bys dosel k tem konkretnim dokumentum, co hledas.
Z tohoto uhlu pohledu praktictejsi "zobecneni" (resp. zuplneni) adresaru (spis nez orientovany graf) by byl svaz, kde infimum by byl prunik tagu jednotlivych dokumentu a supremum jejich sjednoceni. Svaz (strukturu adresaru) bys pak prochazel od shora dolu a jen bys pridaval tagy (zanoroval by ses do adresaru), nez bys dosel k tem konkretnim dokumentum, co hledas.Wow, zajímavý nápad. Ale - jestli to teda dobře chápu - stále je tam ten problém s přehledností. V tom supremu by těch položek byly strašný mraky, ne?
Ale - jestli to teda dobře chápu - stále je tam ten problém s přehlednostíTo mas do jiste miry pravdu. Cast veci je podle me resitelna, da se vyuzit ze tam jde zavest uzaverovy system, ktery ti nektere veci zjednodusi. Prakticky problem vidim v tom, ze ti vznikne velke mnozstvi kombinaci zanorenych "adresaru", ktere se budou lisit v jednom/dvou/atp. tagoch, resp. v jednom/dvou/atp. souborech. To na prehlednosti zrovna na prida. Z meho pohledu klicovejsi problem je, jak primet uzivatele, aby smysluplne tagovali jednotlive soubory.
No, tak samozřejmě, protože jsi s tím vyrůstal a celý ten koncept tu byl dýl než existuješ. Ale zamýšlel ses někdy proč ti to tak přijde? Jaké to má opodstatnění a jestli to vůbec dává nějaký smysl?Já jsem se nad tím (trochu) zamýšlel a IMHO to smysl dává a je to celkom přirozené, tedy teď myslím filesystém jako strom složek coby parent nodů a souborů coby obecných balíků dat. IMHO to celkem odpovídá přirozenému způsobu jakým člověk organizuje věci. Když se podíváš na nějakou organizovanou kancelář, archiv, knihovnu, dílnu nebo sklad, tak to v podstatě storm je. A ten soubor coby obecné 'něco' taky v podstatě odpovídá - jdeš do skladu, v sekci A-3-II najdeš na polici 'něco'. O co konkrétně se jedná, to záleží na konkrétní situaci, sklad to neřeší nebo to řeší minimálně. Tím nechci říct, že hledat alternativní postupy nemá cenu nebo že fs je vrchol poznání. Klidně může někdo přijít s nějakým lepším modelem. Chtěl jsem říct to, že ten fs sice má svoje omezení a je do jisté míry neohrabaný, ale IMHO v základu smysl celkem dává a není to jenom náhodný důsledek historického vývoje.
 18.12.2018 17:38
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.12.2018 17:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
18.12.2018 17:38
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.12.2018 17:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Čiže ďalšia vrstva, ktorá pobeží aj nad RAID, LVM, šifrovaním atď.Podle mě si pleteš systém ukládání dat a filesystém, respektive je vnímáš jako něco totožného. To první může být součástí toho druhého, není to ale nutná podmínka. Například ty vzpomínané databáze afaik můžou stále využívat RAID a LVM, přestože nepoužívají filesystém. Stejně tak ti hypoteticky nic nebrání dát smalltalkovské image jako soubor pro image prostě /dev/sda, až na to že by s ním tedy nejspíš neuměla moc efektivně pracovat (imho ukládá vždy celý image).
18.12.2018 18:43
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.12.2018 17:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Já jsem se nad tím (trochu) zamýšlel a IMHO to smysl dává a je to celkom přirozené, tedy teď myslím filesystém jako strom složek coby parent nodů a souborů coby obecných balíků dat. IMHO to celkem odpovídá přirozenému způsobu jakým člověk organizuje věci. Když se podíváš na nějakou organizovanou kancelář, archiv, knihovnu, dílnu nebo sklad, tak to v podstatě storm je. A ten soubor coby obecné 'něco' taky v podstatě odpovídá - jdeš do skladu, v sekci A-3-II najdeš na polici 'něco'. O co konkrétně se jedná, to záleží na konkrétní situaci, sklad to neřeší nebo to řeší minimálně.To je prostě hierarchické uložení dat. Ze svých zkušeností se Selfem* však z první ruky vím, že stejně můžeš organizovat i objekty (viz příloha). Zintenzivnil jsem práce na článcích, takže snad vbrzku bude počtení o něm.
To je prostě hierarchické uložení dat. Ze svých zkušeností se Selfem* však z první ruky vím, že stejně můžeš organizovat i objekty (viz příloha).Jasně. Mně tohle ani nepřijde nějak moc specifické pro Self - i v mnoha ostatních jazycích se objekty typicky používají v nějakých hierarchiích. Moderní C++, Rust a podobné jazyky mají s tímhle spjatý memory/resource management. Dokonce i v GC-ed jazycích přes určitou občasnou anarchii je typicky snaha, aby objekty "někam patřily". Nicméně objekty se od souborů liší v tom, že to nejsou obecné, i když to tak může z názvu znít. 'Objekt' implikuje nějaký datový model a v případě že bys chtěl, aby měly metody, tak i runtime. V tom je podle mě ta obtížnost a na to jsem narážel třeba s tou otázkou na VCS: Obecný objekt nemusí mít vůbec metody porovnání a diffování a i když je bude mít, tak nemusí být vhodné pro VCS. Třeba IEEE 754 čísla sice mají operátor rovnosti, ten ale není vhodný pro VCS protože NaN != NaN, i když to je ten samý NaN. Takže by nejspíše ty objekty potřebovaly operátory pro VCS a zálohovací programy (rsync, ...), což bude IMHO těžké zajistit na opravdu obecných objektech. A to je pouze jeden konkrétní use-case, který mě napadl, kdovíkolik toho ještě je, co mě nenapadlo. Další celkem (zjevný problém) je, jak čelit tomu, že ten datový/runtime model bude dříve či později nějakým způsobem pro někoho někde nedostatečný nebo nevhodný a bude potřeba ho přizpůsobovat nebo i změnit globálně...
18.12.2018 20:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jasně. Mně tohle ani nepřijde nějak moc specifické pro Self - i v mnoha ostatních jazycích se objekty typicky používají v nějakých hierarchiích. Moderní C++, Rust a podobné jazyky mají s tímhle spjatý memory/resource management. Dokonce i v GC-ed jazycích přes určitou občasnou anarchii je typicky snaha, aby objekty "někam patřily".Tohle je trochu jiné v tom že je to prototypový jazyk. Odpovídá to víc těm souborům - objekt existuje sám o sobě. Když ho někam přesuneš, tak je přesunut a tím to hasne. V C++, Rustu a tak si můžeš dělat s Objekty co chceš, ale neustále tam existuje dualita s třídami, které musíš přesunovat separátně. V Selfu je objekt v jistém smyslu svojí vlastní třídou.
Nicméně objekty se od souborů liší v tom, že to nejsou obecné, i když to tak může z názvu znít. 'Objekt' implikuje nějaký datový model a v případě že bys chtěl, aby měly metody, tak i runtime. V tom je podle mě ta obtížnost a na to jsem narážel třeba s tou otázkou na VCS: Obecný objekt nemusí mít vůbec metody porovnání a diffování a i když je bude mít, tak nemusí být vhodné pro VCS. Třeba IEEE 754 čísla sice mají operátor rovnosti, ten ale není vhodný pro VCS protože NaN != NaN, i když to je ten samý NaN. Takže by nejspíše ty objekty potřebovaly operátory pro VCS a zálohovací programy (rsync, ...), což bude IMHO těžké zajistit na opravdu obecných objektech. A to je pouze jeden konkrétní use-case, který mě napadl, kdovíkolik toho ještě je, co mě nenapadlo.Tohle jsem úplně nepochopil. Imho se na to díváš moc z pohledu kompilovaných jazyků. V Selfu si prostě vytvoříš pro daný objekt mirror (objekt obsahující reflexi mirrorovaného objektu) a pracuješ s tím.
Další celkem (zjevný problém) je, jak čelit tomu, že ten datový/runtime model bude dříve či později nějakým způsobem pro někoho někde nedostatečný nebo nevhodný a bude potřeba ho přizpůsobovat nebo i změnit globálně...No tak ho prostě přízpůsobíš nebo i změníš globálně? Moc té pointě nerozumím (což myslím zcela tak jak to píšu, nechápu v čem je podstata problému).
Tohle je trochu jiné v tom že je to prototypový jazyk. Odpovídá to víc těm souborům - objekt existuje sám o sobě. Když ho někam přesuneš, tak je přesunut a tím to hasne. V C++, Rustu a tak si můžeš dělat s Objekty co chceš, ale neustále tam existuje dualita s třídami, které musíš přesunovat separátně. V Selfu je objekt v jistém smyslu svojí vlastní třídou.Tohle trochu znám z JS, ačkoli to asi nebude úplně to samé. (JS je zmršený.) Nicméně popravdě pro téma diskuse mi to nepřijde podstatné...
Tohle jsem úplně nepochopil. Imho se na to díváš moc z pohledu kompilovaných jazyků. V Selfu si prostě vytvoříš pro daný objekt mirror (objekt obsahující reflexi mirrorovaného objektu) a pracuješ s tím.Ok, dejme tomu, že píšu VCS pro takovýhle systém. V tom případě od něj potřebuju několik věcí: 1. Možnost porovnat objekty, jestli se změnily, abych věděl, který se změnil od posledního commitu, 2. Možnost vytvořit uživatelsky přívětivý diff objektu. U toho bodu 1. stojí za povšimnutí, že takovou operaci nemusí objekt poskytovat, příklad byl ten float, který sice (ne)rovnítko definuje, ale není použitelné pro VCS. Bod 2. ten float taky nenabízí, protože např. různé NaNy nebo některá čísla by se zobrazily stejně (asi by se muselo zobrazit číslo textově a zároveň hexa nebo něco takového). Je taky otázka, jestli by tyhle operátory měl implementovat ten VCS, nebo ten object storage. Pokud ten VCS, je to nepříjemné v tom, že ten VCS musí být napsán specificky pro daný datový model. Pokud object storage, pak tenhle problém odpadá, ale zase roste komplexita object storage. Všimni si například, že třeba takový
rsync taky diffuje soubory, ale zatímco VCS diffuje za účelem zobrazení uživateli, rsync diffuje za účelem efektivity přenosu, takže rsync by nejspíše potřeboval jiný diffovací operátor nad objekty.
No tak ho prostě přízpůsobíš nebo i změníš globálně? Moc té pointě nerozumím (což myslím zcela tak jak to píšu, nechápu v čem je podstata problému).Problém je, že když tohle umožníš, ztrácí systém na obecnosti a hrozí problémy s kompatibilitou (případně EEE). Souvisí to s tím předchozím bodem - když např. bude VCS obsahovat znalost datového modelu a někdo si někde datový model změní nebo se změní globálně, co se stane s VCS? Bude se muset přízpůsobit, což může mít prodlevu nebo se na to někdo vykašle a někdo jiný pak nebude moct používat VCS apod. Precedenty pro tohle nejsou úplně dobré. Když např. vezmu v úvahu jakej porod byl Python 2 vs 3, a to přitom ani nebyly nijak velký změny. Tyhle problémy do jisté míry nastávaj i s filesystémama, třeba kódování filename, ilegální znaky ve filename, max. velikost souboru, atributy a podobně. Ale tím, že FS je obecně tak primitivní, tak se to dá zvládnout.
18.12.2018 23:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tohle trochu znám z JS, ačkoli to asi nebude úplně to samé. (JS je zmršený.) Nicméně popravdě pro téma diskuse mi to nepřijde podstatné...JS je zmršený hlavně protože Eich nezkopíroval celý Selfový objektový model, hlavně pak delegaci.
Ok, dejme tomu, že píšu VCS pro takovýhle systém. V tom případě od něj potřebuju několik věcí: 1. Možnost porovnat objekty, jestli se změnily, abych věděl, který se změnil od posledního commitu, 2. Možnost vytvořit uživatelsky přívětivý diff objektu. U toho bodu 1. stojí za povšimnutí, že takovou operaci nemusí objekt poskytovat, příklad byl ten float, který sice (ne)rovnítko definuje, ale není použitelné pro VCS. Bod 2. ten float taky nenabízí, protože např. různé NaNy nebo některá čísla by se zobrazily stejně (asi by se muselo zobrazit číslo textově a zároveň hexa nebo něco takového).V Selfu je tohle vyřešeno jednoduše: pomocí Transporteru skrz reflexi vyexportuješ všechny objekty tvořící konkrétní modul do jejich textového popisu. Ten pak můžeš diffovat a verzovat klasickým VCS. Je pravda, že ten diff nemusí být zrovna nejkrásnější, protože je to diff serializovaného kódu. To porovnávání mi přijde jako nepochopení. Neporovnáváš přímo objekty, porovnáváš jejich reflexi. Místo abys porovnával nějaký svůj vlastní objekt jeho metodami, tak si zobrazíš co v něm je za sloty a jak se změnily. Pokud bych to měl vznést na python, tak bys porovnával diff
.__dict__-u, ale taky AST všech objektů v něm referencovaných, za předpokladu, že by byly homoikonické. Ale není to úplně dobrá příměra. Na úrovni VM můžeš přímo tagovat objekty, které se změnily od poslední verze, ale to už je docela velká optimalizace.
Smalltalk to řeší komplexněji, ale přiznám se, že detaily přesně neznám, to by bylo asi spíš na Pavla.
 18.12.2018 23:57
xkucf03 | skóre: 49
| blog: xkucf03
18.12.2018 23:57
xkucf03 | skóre: 49
| blog: xkucf03
Pharo obstarává diff pro merge a nahrávání kódu samo a nespoléhá se na výstup Gitu, který o sémantice kódu neví vůbec nic.
O tom jsem přemýšlel už víckrát, sémantický diff by byl pokrok po, těch desetiletích porovnávání řádků textu. Nástroj by mohl říct: tady se přesunula metoda z jedné třídy do druhé nebo tady se zvýšilo odsazení bloku, ale ten vnitřek je stejný.
Další zajímavá věc mi přijdou sémantické transformace kódu -- něco jako patch, ale šlo by třeba vzít kus jednoho programu a transplantovat ho do jiného a v rámci toho udělat nějaké transformace. A když by se změnila verze zdrojového programu, tak by to šlo prohnat tou transformací a buď by to s celkem velkou pravděpodobností prošlo nebo by to řeklo, kde přesně to na sebe nepasuje.
tady se zvýšilo odsazení bloku, ale ten vnitřek je stejný
git diff -w ?
 19.12.2018 10:56
Josef Kufner | skóre: 70
19.12.2018 10:56
Josef Kufner | skóre: 70
Třeba v Pythonu je odsazení hodně podstatné a může zásadně měnit význam.Určitě bych nedoporučoval používat
diff -w pro Python...
například přidání importů na stejné místo na začátku souboruTo třeba v Pythonu obecně nejde, protože import může provádět kód, ie. může záležet na pořadí. Můžeš celkem oprávněně namítnout, že je to prasárna, ale obecně prostě bohužel na pořadí importů záleží. AFAIK to samé platí pro importy v JS a nejde to obecně ani u headerů v C/C++ (protože preprocessor).
Nebo třeba přidávání položek do changelogu, kde na pořadí nijak nezáleží a prostě se připisuje na konec.To si myslim, že obecně taky nebude fungovat, to bys musel mít sémantický changelog. Krom toho já třeba osobně typicky řadím položky v changelogu podle velikosti významu/dopadu.
19.12.2018 13:06
Josef Kufner | skóre: 70
19.12.2018 13:47
xkucf03 | skóre: 49
| blog: xkucf03
Jenže o to víc by ti sémantický diff pomohl. Protože kolize, která vznikne při textovém diffu, je jen náhodným vedlejším efektem toho, že oba autoři dali ty konfliktní metody zrovna na stejné místo v souboru. Ovšem kdyby dali ten konfliktní kód (např. metodu se stejnou signaturou) na dvě různá místa, tak textový diff/merge vesele projde.
19.12.2018 20:05
Josef Kufner | skóre: 70
19.12.2018 20:07
Josef Kufner | skóre: 70
To porovnávání mi přijde jako nepochopení. Neporovnáváš přímo objekty, porovnáváš jejich reflexi.To je to samé, akorát je tam mezioperátor navíc.
V Selfu je tohle vyřešeno jednoduše: pomocí Transporteru skrz reflexi vyexportuješ všechny objekty tvořící konkrétní modul do jejich textového popisu. Ten pak můžeš diffovat a verzovat klasickým VCS.Ok, tj. absence obecného porovnávní a diffu se vyřeší tím, že každý objekt/typ by měl operátor serializace do textu. Nicméně mi z toho stále není úplně jasné, jak by to fungovalo v případě toho VCS. V tom object storage systému by workspace nejspíše nebyla složka ale nějaký objekt, který bude mít fůru podobjektů. Navrhuješ serializovat celý ten workspace objekt do textu a na tom dělat diff? To doufám, že ne, ta serializace by mohla být obrovská (ie. bylo by to pomalý) a v tom diffu by se nejspíše navíc snadno ztratil kontext. V podstatě jediné, co mi dává smysl, je procházet objekty (rekurzivně) a porovnávat textovou reprezentaci až pouze u primitivních typů. Což by asi v zásadě mohlo celkem fungovat, za předpokladu, že by existoval nějaký standard množiny primitivních typů a způsobu jejich jednoznačné serializace do textu. Ale nevim, jestli jsem schopen vidět všechny důsledky a víc nad tim asi nebudu teď dumat.
Ale zamýšlel ses někdy proč ti to tak přijde? Jaké to má opodstatnění a jestli to vůbec dává nějaký smysl? Co jsou alternativní přístupy? Jestli by to třeba nešlo dělat líp, případně jaké by to přinášelo benefity?To, že je to základní a jednoduchý systém mi přijde zjevné a myslím, že z toho vychází i tvoje kritika, ne? Mě to navíc přijde intuitivní, protože se to podobá tomu, jak se věci ukládají v reálném světě - mám skřín, v ní šuplíky, v těch přihrádky, krabičky a tak (a i přesto jsem setkal s několika jinak inteligentními lidmi, kterým to dělalo problém - pravda, většinou z generace mých prarodičů). Samozřejmě, že počítač umožňuje mnohem větší abstrakci. Těch alternativ by se dalo vymyslet dost. Jenže aby nějaká měla šanci na to se uchytit, tak by musela být obdobně intuitivní. Vím, že na to koukáš jako programátor, ale aby to, co navrhuješ mělo nějaký smysl, muselo by to být hodně rozšířené, tudíž by se s tím setkali i naprostí BFU. Technicky se mi idea souborů a složek líbí proto, že je to nízkoúrovňové řešení, které mi dává větší svobodu dělat co chci, než to, co navrhuješ (třeba nad těmi soubory postavit něco na způsob toho, co navrhuješ). Cenou je samozřejmě víc práce, jak píšeš. Už několikrát u téhle diskuze jsem si vzpomněl na to, jak tohle řeší Android - hledá všechny soubory určitého typu a pak jejich seznam předá patřičné aplikaci. To je taky jedna z alternativ ke klasickému FS nad klasickým FS. Mě to sice přijde vyloženě nešikovné (třeba proto, že mezi fotky se mi neustále cpou obrázky odjinud), ale dost lidem asi to vyhovuje. Další alternativa se kterou jsem se setkal, jsou už v diskuzi zmiňované datasety na mainframu. Moc do hloubky jsem se s nimi neseznámil, ale jak tu také bylo zmíněno, tak alespoň něco z toho, co navrhuješ je v nich realizováno a bylo to tu dřív než třeba vůbec vznikl Linux.
19.12.2018 11:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To, že je to základní a jednoduchý systém mi přijde zjevné a myslím, že z toho vychází i tvoje kritika, ne? Mě to navíc přijde intuitivní, protože se to podobá tomu, jak se věci ukládají v reálném světě - mám skřín, v ní šuplíky, v těch přihrádky, krabičky a takTo právě nemáš. Současný systém odpovídá stylu, kdy máš skříň, ve které máš list papíru a další skříň, ve které máš zase list papíru. Když do ní chceš uložit špendlík, tak ho musíš převést na list papíru a když tam chceš mít krabičku třeba na šperky, tak nemůžeš a musíš místo ní použít další skříň. Tvůj systém totiž umí ukládat jen skříně a listy papíru, protože je to nejvíc univerzální a jednoduché.. Když chceš dostat zpět špendlík, tak potřebuješ program, který ti z listu papíru udělá zpět špendlík.
19.12.2018 12:16
Josef Kufner | skóre: 70
19.12.2018 12:38
xkucf03 | skóre: 49
| blog: xkucf03
Jak bys vůbec namapoval dotaz do databáze na nějakou obecnou strukturu?
Sorry, že vytahuji zase to XML :-), ale kdyby sis představil souborový systém jako obrovské XML, kde neexistuje hranice mezi adresáři/soubory a obsahem těch souborů a celé to tvoří jeden strom, tak bys nad tím mohl dělat XPath dotazy a pracovat se zcela obecnými strukturami. Je jedno, jestli by to byl textový dokument, tabulka, obrázek s metadaty... prostě to jsou stromová data, jsou tam nějaké názvy atributů a ty si nad nimi můžeš psát dotazy.
19.12.2018 13:09
Josef Kufner | skóre: 70
1.1.2019 14:31
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.1.2019 14:49
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.1.2019 15:05
xkucf03 | skóre: 49
| blog: xkucf03
Mluvím o nápadu zkonvertovat každý soubor ve filesystému do XML a pak to všechno mít jako jedno velké XML.
Tohle je nereálné -- už jen kvůli zápisům a fragmentaci dat. Muselo by se to implementovat jako nějaká stromová/grafová databáze a XML/XPath by bylo jen API (virtuální pohled na data), kterým by se k tomu dalo přistupovat. Nicméně připomínám, že to API opravdu nemusí emulovat XML a XPath -- byl to jen příklad pro představu.
1.1.2019 14:38
xkucf03 | skóre: 49
| blog: xkucf03
XML byl jen příklad, aby si to ostatní mohli nějak představit. Obecně řečeno jde ale o to, že dokument (libovolný, ne jen XML) je stromová struktura, souborový systém je taky stromová struktura. A v tomto pojetí se ztratí hranice mezi těmito dvěma stromy a stane se z nich strom jeden, se kterým jde pracovat jednotným způsobem (např. nějakým dotazovacím jazykem, kde XPath je opět jen příklad).
Z hlediska výkonu by se nad tím musely implementovat nějaké optimalizace podobné partitioningu v relačních databázích (např. máš tabulku fyzicky rozsekanou po letech, takže když dotaz pracuje jen s daty jednoho roku, databáze ví, kam sáhnout a nemusí prohledávat všechno -- ale ten logický pohled ze strany uživatele tím není nijak dotčený, ten s tím pracuje jako s jednou velkou tabulkou).
19.12.2018 15:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To je blbá analogie. Ty skříně ve FS můžou mít libovolnou velikost, ie. skřín a krabička je to samé.Krabička může být barevná, může mít různé vlastnosti, jako zdobení a vyřezávání. Skříň je uniformní a může mít tak leda název a přístupová práva. Samozřejmě tady ta analogie končí, protože co do prostoru už to moc neodpovídá.
Jinak kdyby se papír dal převádět na špendlík a zpátky tak snano jako otevření/uložení souboru nějakého typu, neviděl bych to jako velký problém.Záleží jak definuješ velký problém. Například ten list papíru se složí na různý špendlík, podle toho jestli se na něj díváš z toho či onoho programu. Navíc neplatí, že „se složí“, ale musíš ho skládat a rozkládat ty.
Krabička může být barevná, může mít různé vlastnosti, jako zdobení a vyřezávání. Skříň je uniformní a může mít tak leda název a přístupová práva.Skříň by taky mohla mít barvu, vyřezávání... nevim, tohle asi nechápu. Šlo mi o to, že ta analogie na skříň je blbá v tom, že skříň je něco nějak víceméně fixně velkého. Ale filesystémy umožǔjí skříně libovolné velikosti, ie. není to tak nešikovné, jako kdyby musel fakt na všecko mít skříň. Ale je pravdva, že se v zásadě nebudou lišit ničím krom velikosti (a nějaké ACL ale to tady neřešim).
Navíc neplatí, že „se složí“, ale musíš ho skládat a rozkládat ty.Obvykle to za mě dělá program / knihovna ¯\_(ツ)_/¯
19.12.2018 15:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Skříň by taky mohla mít barvu, vyřezávání... nevim, tohle asi nechápu.Myslel jsem že je docela jasné, že skříň je analogií složky, list papíru pak souboru. Složka nemůže sama o sobě obsahovat nic jiného, než soubory a pár atributů (práva, ..). To se liší od OO jazyků tím, že objekt agregující jiné objekty může mít sám o sobě i property a poskytovat funkcionalitu.
Obvykle to za mě dělá program / knihovna ¯\_(ツ)_/¯To že na to máš nástroj tu (zbytečnou) činnost ale neeliminuje.
19.12.2018 15:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Složka nemůže sama o sobě obsahovat nic jiného, než soubory a pár atributů (práva, ..).A další složky samozřejmě.
To že na to máš nástroj tu (zbytečnou) činnost ale neeliminuje.Mně ta činnost nepřijde zbytečná, zajišťuje, že můžu vzít 'něco' a poslat to někam do tramtárie, kde si to někdo otevře nějakým úplně jiným softwarem v jiným jazyku na jiném systému. A ten někdo ani nemusí být někdo jiný, můžu to být já za 5, 10, 20, let etc. Další věc je, že i když budeš chtít tuhle činnost eliminovat, IMHO se ti to podaří jen částečně, k nějaké transformaci formátů bude IMHO muset docházet tak jako tak, a navíc to pak taky může být vykoupeno tím, že třeba budeš moct ukládat do skříně špendlík skutečně jako špendlík, ale bude to fungovat jen u skříní Ikea a s tím špendlíkem se bude dát propichovat jen látka z Ikea v rukavicích z Ikea na pracovním stole z Ikea.
19.12.2018 16:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Mně ta činnost nepřijde zbytečná, zajišťuje, že můžu vzít 'něco' a poslat to někam do tramtárie, kde si to někdo otevře nějakým úplně jiným softwarem v jiným jazyku na jiném systému. A ten někdo ani nemusí být někdo jiný, můžu to být já za 5, 10, 20, let etc.V tom ti ale nic nebrání i tak, ne? Eliminace nucené serializace by přece nevedla k tomu, že tu serializaci nemůžeš provést vůbec.
Skříň by taky mohla mít barvu, vyřezávání... nevim, tohle asi nechápu. Šlo mi o to, že ta analogie na skříň je blbá v tom, že skříň je něco nějak víceméně fixně velkého.
Modelování a abstrakce v počítači má tu vlastnost, že neodpovídá 1:1 realitě a ani to není cílem. Cílem je vystihnout nějaké podstatné rysy a ty namodelovat v počítači a tento model použít nějakým užitečným způsobem.
Takže v případě FS je podstatné to, že máme různé skříňky, můžeme dávat jednu do druhé a dovnitř nějaké předměty. Barva skříněk, jejich velikost a omezení fyzického světa "jestli se to tam vejde" nejsou součástí modelu, abstrahujeme od nich. Naopak vznikají jiná omezení jako např. celková hmotnost (to si lze představit tak, že podlaha má nějakou nosnost a když tam těch věcí nanosíme moc, tak se propadne).
a nějaké ACL ale to tady neřešim
Zrovna to by ale chtělo. V objektovém programovacím jazyce může s objektem dělat každý cokoli -- stačí, aby měl na něj referenci. Jsou tu sice nějaké bezpečnostní mechanismy jako SecurityManager nebo role v EE javě, ale většinou se to moc neřeší a když máš referenci na objekt a zavoláš na něm metodu, tak objekt poslušně vykoná kód (resp. ono ho vykoná aktuální vlákno, ale to teď nechme stranou) a vrátí klidně i soukromá data.
Jak by to mělo být v objektovém OS? Byl by to objekt souboru, kdo by rozhodoval, zda vrátí např. obsah souboru, nebo by tam byl někdo třetí, kdo by říkal, jaké metody může kdo volat?
V objektovém programovacím jazyce může s objektem dělat každý cokoli -- stačí, aby měl na něj referenci.Ve slušných jazycích existují imutabilní reference... (Ale jasně, není to to samé, co ACL.)
19.12.2018 15:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
19.12.2018 16:55
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Asi nechápem - pro mě je špendlík a papír věc - na straně FS hromada bytů. Skřín, krabička složka. Když chci uložit špendlík dám do krabičky a tu do šuplíku. Obdobně, když chci uložit obrázek (což je z pohledu FS hromada bytů), tak ho jakožto soubor dám do složky. Takle jsem to od začátku myslel.Já chápu, že jsi to tak myslel. Ale ta tvoje krabička neumí uložit papír, nebo špendlík. Umí uložit jen papír (bajty). To jsem se právě snažil ukázat, že abys na něj mohl cokoliv uložit, musíš z toho udělat to co to umí uložit.
Obdobně, když chci uložit obrázek (což je z pohledu FS hromada bytů), tak ho jakožto soubor dám do složky.Obrázek právě vůbec není hromada bajtů. Jsou to kanály a informace o barvě a křivky a kde co. To že tvůj FS umí uložit jen hromadu bajtů je právě tak nějak celá pointa. Do složky ho skutečně dáš jako soubor (v té mé analogii papír), ale předtím z něj ten soubor musíš udělat. A kdykoliv kdy s ním chceš pracovat, tak musíš tuto činnost reverzovat. Nikoliv jen vytáhnout obrázek z umístění, ale vytáhnout z umístění papír a pak ho podle návodu převést zpět na obrázek. Co jsem se tím snažil ukázat je, že ve skutečnosti je to co obhajuješ ztrátové a záměrně tupé.
Souborový systém není z uživatelského hlediska nic jiného než artefakt. Je to jednoduše pochopitelná analogie, ale neexsituje důvod, proč bys mohl mít jen adresáře a soubory (a symlinky a pipy) a ne libovolně typované záznamy s relacema a triggerama a atomickým zápisem.
To není žádný artefakt, to je prostě řešení, které se někdo obtěžoval implementovat a které dalším připadalo natolik přínosné, že ho používají. Až (jestli) implementujete tu svou vizi (nebo si na to někoho najmete) a najde se dostatek lidí, kteří ji budou považovat za natolik užitečnou, aby ji používali, bude to po vašem. A za dalších 30 bude třeba někdo psát pojednání o tom, jak je ten váš model artefakt, ke kterému neexistuje žádný důvod, proč by to zrovna takhle mělo být.
V tradičním světě, tedy světě před Lennartem Poetteringem, bylo pravidlem, že svou životaschopnost a užitečnost nemuselo prokazovat existující řešení, ale řešení nové. Za tu "sérii experimentů" se považovalo právě to, že už příslušný model spousty uživatelů dost dlouho používají. To nové řešení muselo prokázat, že je dostatečným přínosem, aby uživatelům stálo za to na něj přejít, i když to znamená, že budou muset občas něco předělat, a že případná ztráta některých funkcí je přijatelnou obětí.
Svým způsobem je třeba i libovolná databáze příkladem toho, že může mít rozhraní, které vám umožní přistupovat k datům odlišným způsobem (a ten filesystém pod ní není ani nutný). Ale zatím se buď nikdo nepokusil použít databázi (nebo něco podobného) jako náhradu místo klasického filesystému a nebo s tou myšlenkou nebyl příliš úspěšný.
13.12.2018 16:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To není žádný artefakt, to je prostě řešení, které se někdo obtěžoval implementovat a které dalším připadalo natolik přínosné, že ho používají.Jen technická, object storage (což je tak nějak skoro to co chci, akorát to nativně ukládá XML/JSON/YAML a ne objekty) dneska vystrkuje růžky naprosto všude a v podstatě každý cloud ho poskytuje. Je jen otázka času, než to bude běžné i na desktopu.
Až (jestli) implementujete tu svou vizi (nebo si na to někoho najmete) a najde se dostatek lidí, kteří ji budou považovat za natolik užitečnou, aby ji používali, bude to po vašem. A za dalších 30 bude třeba někdo psát pojednání o tom, jak je ten váš model artefakt, ke kterému neexistuje žádný důvod, proč by to zrovna takhle mělo být. V tradičním světě, tedy světě před Lennartem Poetteringem, bylo pravidlem, že svou životaschopnost a užitečnost nemuselo prokazovat existující řešení, ale řešení nové. Za tu "sérii experimentů" se považovalo právě to, že už příslušný model spousty uživatelů dost dlouho používají. To nové řešení muselo prokázat, že je dostatečným přínosem, aby uživatelům stálo za to na něj přejít, i když to znamená, že budou muset občas něco předělat, a že případná ztráta některých funkcí je přijatelnou obětí.Jo, jo, mě tohle nezajímá. To je právě to co jsem naschvál psal na začátek. Mě je úplně jedno, co používáš ty, nebo ostatní. Klidně používej Linux, ostatně vždyť já ho taky používám. Přijde mi, že máš pocit jak kdyby ti něco ubylo. Snažím se přemýšlet nad něčím jiným. Formou slov a reakcí v diskuzi. Představ si tuhle nesmyslnost třeba v případě domu. Vysníš si a popíšeš někde hobití noru s kulatýma dveřma a spíží na koláče a pak někdo přijde a bude ti říkat, že je to nahovno, že to není životaschopné a že životaschopné to bude, až v tom bude žít víc lidí než v bytovkách. A že v bytovce můžeš mít skříň na koláče a na dveře si namalovat kolo, abys měl aspoň podobný pocit. Mně fakt upřímě naprosto vůbec nezajímá proč to nejde, ani jak se to dá obejít. Vážně. Mám přes deset let zkušeností s IT, z toho asi pět let komerčně je to moje každodenní práce. Obcházím to každou chvíli. Dělal jsem všechno od psaní v assembleru, v C, Javě, C#, Python až po common lisp. Já vím, že a proč co konkrétně jde a nejde. To že jsem sepsal tuhle kritiku není naivita, naopak je to promyšlená ignorace a fakace současného standardu.
Svým způsobem je třeba i libovolná databáze příkladem toho, že může mít rozhraní, které vám umožní přistupovat k datům odlišným způsobem (a ten filesystém pod ní není ani nutný). Ale zatím se buď nikdo nepokusil použít databázi (nebo něco podobného) jako náhradu místo klasického filesystému a nebo s tou myšlenkou nebyl příliš úspěšný.Smalltalk používal koncept image paměti a úspěšný s tím byl. Gemstone (objektová databáze) je business dodneška. Kdyby se víc soustředili na to aby to byl operační systém, místo programovací prostředí, tak by to nejspíš spousta lidí používala i poté, co
13.12.2018 16:29
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Smalltalk používal koncept image paměti a úspěšný s tím byl. Gemstone (objektová databáze) je business dodneška. Kdyby se víc soustředili na to aby to byl operační systém, místo programovací prostředí, tak by to nejspíš spousta lidí používala i poté, co.. i poté, co Smalltalk jako jazyk upadl do nemilosti a byl nahrazen javou.
13.12.2018 17:06
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Jen technická, object storage (což je tak nějak skoro to co chci, akorát to nativně ukládá XML/JSON/YAML a ne objekty) dneska vystrkuje růžky naprosto všude a v podstatě každý cloud ho poskytuje. Je jen otázka času, než to bude běžné i na desktopu.Tak na desktopu to můžeš mít už min. 13 let (CouchDB), není to nic nového. XML umí (z počátku asi zejména komerční) DB exportovat asi i déle. Dneska si můžeš vybrat hromadu "providerů" pro tyto objekty, ať buď z řady nosql db (které si většinou z CAP teorémů odstraní to C) nebo klasické transakční ACID db.
13.12.2018 17:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.12.2018 17:22
xkucf03 | skóre: 49
| blog: xkucf03
Teď jsem si vzpomněl na věci jako Nepomuk, Akonadi... myšlenky hezké, ale lidi to spíš sralo.
13.12.2018 18:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.12.2018 18:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.12.2018 19:09
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
13.12.2018 23:27
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Čili nejde jen o to, aby bylo dostupné něco lepšího, ale také aby to používala kritická masa uživatelů a vývojářů.Tak ona je otázka, zda se skutečně jedná o něco lepšího (podle jaké metriky se to měří?) a taky zda to něco lepšího využije dostatečný počet uživatelů. Jinými slovy, těch unikátních použití OS bude takové množství, že jakákoliv instalace bude pro velmi významnou skupinu nedostatečná. Podle mě je lepší dívat se na to, co je k disposici v repozitáři než na to, co je ve výchozí instalaci.
Onehdá jsem potřeboval naskriptovat otevření URL v konkrétním okně Chromu a tvrdě jsem narazil. Buď bych musel opatchovat a překompilovat X server, nebo si před něj představit proxy, protože eventům (jako je např. stisknutí klávesy), které jsem do těch oken zkoušel posílat, nastavuje flag, že ta zpráva pochází od 3rd party programu, a většina programů pak takové eventy zahazuje z bezpečnostních důvodů. A takových zkušeností mám vícero.Upřímně řečeno nevím, proč by něco takového mělo vůbec projít. Nevím, proč by měl mít program možnost posílat stisky kláves do jiného programu. To je interface vyhrazený uživateli. Pamatuji se, jak jsem byl zděšen programem od kámoše, který scanoval obraz a posílal klávesy do jiného programu (tehdy to běželo jako administrator na Windows, netuším zda by to prošlo pod omezenými právy) a viděl jsem v tom velké bezpečností riziko.
Na druhou stranu, možná právě díky tomu je diskuze pod tímto blogem mimořádně kvalitní.Souhlasím a jsem za tuto diskusi rád.
Přitom by to skoro vždy šlo popsat jedním univerzálním formátem (schématem), který jasně rozliší mezi titulkem, perexem, jménem autora, datem vydání, hlavním tělem textu, doplňujícím sloupcům s informacemi apod.Ano, ono by to šlo a nebyl by to žádný problém, ale tohle je přesně to, co vydavatelé těch zpráv nechtějí. Jak už jsem psal v jiné diskusi. I kdyby existoval dokonalý a sebepopisný formát, tak by jej stejně kritické množství zpravodajských webů nepoužívalo.
14.12.2018 00:15
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nevím, proč by měl mít program možnost posílat stisky kláves do jiného programu.Lehce OT, ale tohle mi prochází přes (Jendou porazené)
xdotool type '{}', kde {} je znak.
14.12.2018 00:28
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
14.12.2018 00:42
xkucf03 | skóre: 49
| blog: xkucf03
IMHO by to jít mělo, ovšem ne nějak mimochodem, ale řízenou cestou -- tak, abys k tomu mohl nastavit práva (a ve výchozím stavu by to bylo zakázané, zejména u těch programů jiných uživatelů). Ono i v rámci jednoho uživatele by mělo být možné pouštět programy v různých bezpečnostních kontextech/úrovních a data by neměla prosakovat mezi nimi. (takový Bell–LaPadula model)
Tak ona je otázka, zda se skutečně jedná o něco lepšího (podle jaké metriky se to měří?)Beru to čistě ze subjektivního hlediska.
a taky zda to něco lepšího využije dostatečný počet uživatelů. Jinými slovy, těch unikátních použití OS bude takové množství, že jakákoliv instalace bude pro velmi významnou skupinu nedostatečná. Podle mě je lepší dívat se na to, co je k disposici v repozitáři než na to, co je ve výchozí instalaci.To si možná nerozumíme. Myslel jsem to tak, že když si nainstaluju třeba tu CouchDB (slyším poprvé, mimochodem), tak je mi to v kontextu této diskuze k ničemu, pokud to nebude interoperabilní se zbytkem světa. Tady je cílem zřejmě zbavit se souborů z uživatelského i programátorského hlediska (je jedno, jestli to bude jen abstrakce nad FS). No a toho se ti nepodaří docílit, protože chybí software, který by na tuto hru přistoupil a opíral se jen o tu CouchDB. IMO nejde o to, jestli to je nebo není nativní součástí OS. Emacs taky není, ale přesto kolem něj existuje aktivní komunita, díky které to má reálně nějaké možnosti a výhody oproti jiným editorům. Ale kdyby neexistovala? Bylo by hezké, že existuje projekt, který teoreticky umí hromadu věcí, pokud by sis musel sám přidávat syntax highlighting pro každý soubor, který kdy otevřeš, a psát všechny pluginy. A takhle vnímám situaci okolo toho objektového desktopu.
Upřímně řečeno nevím, proč by něco takového mělo vůbec projít. Nevím, proč by měl mít program možnost posílat stisky kláves do jiného programu. To je interface vyhrazený uživateli. Pamatuji se, jak jsem byl zděšen programem od kámoše, který scanoval obraz a posílal klávesy do jiného programu (tehdy to běželo jako administrator na Windows, netuším zda by to prošlo pod omezenými právy) a viděl jsem v tom velké bezpečností riziko.Bezpečnostní riziko to je zcela určitě, což je ostatně i důvod, proč to nejde, ale to tu považuji za lehce podružný problém, protože by to šlo řešit nějakou autentizací (explicitně povolit posílání takových zpráv v konkrétních případech). Pointou je, že některé programy (často i FOSS) jsou pro mě vlastně uzavřené krabice. Co by se mi ještě vyplatilo nějak ubastlit à la AppleScript se mi už nevyplatí řešit patchem a mergnutím do mainstreamu (i kdyby byla nějaká šance, že to vývojáři akceptují).
Ano, ono by to šlo a nebyl by to žádný problém, ale tohle je přesně to, co vydavatelé těch zpráv nechtějí. Jak už jsem psal v jiné diskusi. I kdyby existoval dokonalý a sebepopisný formát, tak by jej stejně kritické množství zpravodajských webů nepoužívalo.Jsem si toho vědom, ale přesto se mi to nelíbí a pokud vím, tak Bystroushaakovi taky ne. S tím se asi nedá nic dělat, jen jsem zkoušel ze svého hlediska vysvětlit, jak chápu jeho postoj já.
14.12.2018 11:19
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Myslel jsem to tak, že když si nainstaluju třeba tu CouchDB, tak je mi to v kontextu této diskuze k ničemu, pokud to nebude interoperabilní se zbytkem světa.No jasně, jenže tato věta se dá napsat na téměř libovolný program. A podle mého názoru je způsobů použití OS tolik, že v podstatě každé jeho použití je silně menšinové a nikdy nedosáhne kritické masy k tomu, aby se vyplatilo všude by default instalovat něco. Proto taky vznikají specializované distribuce připravené pro jednu oblast (třeba do zvukového studia) a vedle toho jsou obecné distribuce, kam si může kdokoliv doinstalovat co potřebuje. Dole se někdo pozastavuje nad tím, proč neexistuje jednotný standard pro nastavení sítě, uživatelů, kvót, balíčků apod. No neexistuje, protože nelze říct, jak by to mělo správně vypadat. Zcela jiné nastavení sítě budu používat na NTB nebo na mobilu a zcela jiné na routeru nebo serveru. Hledat pro to společný nástroj bude znamenat, že to pro mobil bude příliš obrovské a komplexní, nebo pro server zase nedostatečné (což je mimochodem stav, který jsem jakožto správce serverů vnímal několik let nazpět, každý síťový manažer se snažil ulehčit připojení k wifi - na ntb dobrý, ale byl porod tam nastavit 30 IP na serveru - prostě v určité době se to kyvadlo zájmu vývojářů vychýlilo příliš na stranu mobility a na servery se trochu zapomnělo).
Tady je cílem zřejmě zbavit se souborů z uživatelského i programátorského hlediska (je jedno, jestli to bude jen abstrakce nad FS).Už jen z této diskuse je patrné, že různý lidé mají na úložiště různé požadavky. Pro někoho je FS příliš nízko a potřeboval by ukládat obecné objekty propojené do grafy, pro jiného je FS zase příliš komplexní a raději jde přímo na blockdevice (tj kdyby bylo úložiště ještě komplexnější než dnešní FS, tak tito lidi budou naštvaní ještě víc a budou mít ještě větší motivaci k tomu to univerzální úložiště nepoužívat.) Třeba já sám za sebe říkám, že nepoužívám molochy typu Gnome nebo KDE také i z toho důvodu, že s sebou neodstranitelně tahají věci, které na kompu nechci a nebudu používat a já nejsem z těch, kteří si řeknou, no však to tam nevadí, prostě si toho nevšímej. Všímám a nechci to tam. Tj kdyby někdo přišel s "univerzálním" úložištěm, tak jej patrně stejně používat nebudu, protože to bude moloch nad míru mé únosnosti.
Třeba já sám za sebe říkám, že nepoužívám molochy typu Gnome nebo KDE také i z toho důvodu, že s sebou neodstranitelně tahají věci, které na kompu nechci a nebudu používat a já nejsem z těch, kteří si řeknou, no však to tam nevadí, prostě si toho nevšímej. Všímám a nechci to tam.Problém je, že FS je univerzální rozhraní. Pokud bys to chtěl změnit na něco elementárně odlišného (tedy to objektové úložiště), ale zachovat zpětnou kompatibilitu, tak to buď nepůjde, a nebo to v podstatě nebude plnohodnotné objektové úložiště (a k tomu navazující ekosystém) dle Bystroushaakových představ. Mimochodem, já tu jeho vizi objektového úložiště dlouho nesdílel. Teprve díky zdejším úvahám xkucf03 mi zapadly do sebe chybějící části mozaiky a začal jsem v tom jistý smysl spatřovat. Přesto jsem daleko od toho, abych tu vizi obhajoval taky, protože stále neznám odpověď na otázku, jestli třeba audio nebo obrazová data musí být nutně přímo na úrovni té databáze uložená v nějaké objektové struktuře. Nevidím rozdíl oproti knihovně, která jediným příkazem takovou strukturu vyrobí z nějakého blobu. Dotaz na Bystroushaaka: Když se bavíme o databázi, co přesně od toho chceš? Co všechno chceš indexovat? Díky těm XML, jak tu zmiňoval xkucf03, jsem konečně pochopil alespoň jistý smysl té vrstvy – šlo by třeba přesouvat jednotlivé nody mezi dokumenty mnohem pohodlněji než u klasických souborů. Ale nevím, jak je tohle častý (a praktický) případ. Nejde ve výsledku fakt spíš o to, aby ty data měly jednotné schéma? K čemu ti bude objektová databáze, když každá kniha nebo článek bude mít úplně jiné položky? Asi začínám přicházet na chlup nějakým cool vlastnostem, jako třeba že místo PDFka budeš mít objekt, který se někde odkazuje na obrázky (a to jsou zase objekty, ze kterých si můžeš přečíst informace o rozlišení a barevné hloubce apod.). Nemusel bys parsovat ani tagy jako
img a načítat ty obrázky z disku, prostě bys jen mohl iterovat přes ten dokument a třeba to vykreslovat.
Autor by nebyl reprezentovaný nějakým fieldem, ale přímo referencí na entitu typu Autor. Kdyby sis chtěl někde evidovat seznam oblíbených autorů, prostě bys vytvořil objekt, do kterého bys nareferencoval ty konkrétní entity. A třeba bys přidal tomu objektu vlastnost knihy, která by vyhledala knihy všech těch nareferencovaných autorů (a nebo by se to udělalo i automaticky, pokud by někde ve schématu byla ta relace mezi knihou a autorem popsaná).
Reference (zdroje) v textu, kdyby to bylo třeba ISBN, by se mohly resolvovat rovnou na konkrétní knihy, pokud bys je měl v té své databázi, a vykreslit se jako klikatelné odkazy. Citace bys mohl řešit přímo referencováním konkrétních částí knih. Je to žádoucí? Nerozbíjelo by se to? Co když se nebude jednat o knihu, ale míň seriózní dokument, který autor aktualizuje a ty si tu změnu stáhneš a nahradíš jí původní dokument (u knihy by se změnilo přinejmenším ISBN, takkže by se reference nerozbila)?
Ale pak problém není ani tolik v existenci nebo neexistenci objektového úložiště, ale jednotného schématu. Podobně jako jsem tu v diskuzi zmiňoval to parsování novinových článků, potřeboval bys do jednotné struktury umět převést naprosto veškerá data. To je ten hlavní problém. Ale u toho audia pointu pořád nevidím. Asi by nebylo špatné to umožnit fetchnout rovnou jako objektovou strukturu, ale ukládat to tak? Indexovat to tak? Že bys pak mohl referencovat třeba konkrétní frame filmu? :D Ale to je vlastně asi spíš technikálie, protože pokud databáze tomu formátu bude rozumět, může ho prezentovat jakkoliv a umožnit nad ním libovolné operace. Hm. Zajímavé je to.
Ideálně by web nebyl nic jiného než API k takovéhle databázi a když by tě zajímal nějaký článek, nebo třeba jeho část, tak by sis to prostě naimportoval (přesunul) do svojí lokální databáze, co? A neexistovaly by tisíce formátů dokumentů, ale prostě jen tahle objektová struktura. Webový prohlížeč by se v zásadě nemusel nijak lišit od lokálního prohlížeče dokumentů, ba možná by nic jako prohlížeč dokumentů existovat nemuselo, protože bys měl prostě nějaké GUI, které umí vykreslovat vlastně výsledky vyhledávacích dotazů, ať už jsou opřené proti lokální nebo vzdálené databázi, a stačilo by jen mít několik speciálních (formátovacích) objektů jako třeba Titulek. A kdybys chtěl poslat odpověď někam do diskuze, tak bys jednoduše vytvořil objekt se svou odpovědí a exportoval ho na ten který server. Komentáře na webu by sis nemusel zobrazovat uzavřené v nějakém boxu, ale prostě bys je mohl libovolně roztahat na plochu, nebo vytvořit objekt Odpovědět a nereferencovat je do něj…
14.12.2018 16:06
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Dotaz na Bystroushaaka: Když se bavíme o databázi, co přesně od toho chceš? Co všechno chceš indexovat? Díky těm XML, jak tu zmiňoval xkucf03, jsem konečně pochopil alespoň jistý smysl té vrstvy – šlo by třeba přesouvat jednotlivé nody mezi dokumenty mnohem pohodlněji než u klasických souborů. Ale nevím, jak je tohle častý (a praktický) případ. Nejde ve výsledku fakt spíš o to, aby ty data měly jednotné schéma? K čemu ti bude objektová databáze, když každá kniha nebo článek bude mít úplně jiné položky?Myslím, že ve zbytku komentáře sis sám odpověděl líp než bych to zvládl já. Jinak děláš pořád jednu chybu s tím schématem. Když máš objekt samotný, ve smyslu instance, tak schéma je třída. Můžeš ale použít prototypové programovací jazyky, kde schéma neexistuje, je jím samotný objekt. Ten v sobě obsahuje všechny informace, od struktury po typy a dokumentaci.
Asi začínám přicházet na chlup nějakým cool vlastnostem, jako třeba že místo PDFka budeš mít objekt, který se někde odkazuje na obrázky (a to jsou zase objekty, ze kterých si můžeš přečíst informace o rozlišení a barevné hloubce apod.). Nemusel bys parsovat ani tagy jako img a načítat ty obrázky z disku, prostě bys jen mohl iterovat přes ten dokument a třeba to vykreslovat. Autor by nebyl reprezentovaný nějakým fieldem, ale přímo referencí na entitu typu Autor. Kdyby sis chtěl někde evidovat seznam oblíbených autorů, prostě bys vytvořil objekt, do kterého bys nareferencoval ty konkrétní entity. A třeba bys přidal tomu objektu vlastnost knihy, která by vyhledala knihy všech těch nareferencovaných autorů (a nebo by se to udělalo i automaticky, pokud by někde ve schématu byla ta relace mezi knihou a autorem popsaná). Reference (zdroje) v textu, kdyby to bylo třeba ISBN, by se mohly resolvovat rovnou na konkrétní knihy, pokud bys je měl v té své databázi, a vykreslit se jako klikatelné odkazy. Citace bys mohl řešit přímo referencováním konkrétních částí knih. Je to žádoucí? Nerozbíjelo by se to? Co když se nebude jednat o knihu, ale míň seriózní dokument, který autor aktualizuje a ty si tu změnu stáhneš a nahradíš jí původní dokument (u knihy by se změnilo přinejmenším ISBN, takkže by se reference nerozbila)? Ale pak problém není ani tolik v existenci nebo neexistenci objektového úložiště, ale jednotného schématu. Podobně jako jsem tu v diskuzi zmiňoval to parsování novinových článků, potřeboval bys do jednotné struktury umět převést naprosto veškerá data. To je ten hlavní problém. Ale u toho audia pointu pořád nevidím. Asi by nebylo špatné to umožnit fetchnout rovnou jako objektovou strukturu, ale ukládat to tak? Indexovat to tak? Že bys pak mohl referencovat třeba konkrétní frame filmu? :D Ale to je vlastně asi spíš technikálie, protože pokud databáze tomu formátu bude rozumět, může ho prezentovat jakkoliv a umožnit nad ním libovolné operace. Hm. Zajímavé je to.Myslím, že jsi většinu z toho pochopil. Co osobně nechápu je, proč je tahle myšlenka tak těžká na předání, možná to jen blbě vysvětluju.
To je ten hlavní problém. Ale u toho audia pointu pořád nevidím. Asi by nebylo špatné to umožnit fetchnout rovnou jako objektovou strukturu, ale ukládat to tak? Indexovat to tak? Že bys pak mohl referencovat třeba konkrétní frame filmu? :D Ale to je vlastně asi spíš technikálie, protože pokud databáze tomu formátu bude rozumět, může ho prezentovat jakkoliv a umožnit nad ním libovolné operace.Ta pointa ani není tolik o tom mít i audio jako naparsované chunky, ale prostě že nemá smysl mít cokoliv jiného. Pokud to má strukturu, tak jí tomu nechat. Nemá žádný smysl kromě ušetření pár bajtů jí pořád odebírat a zase rekonstruovat.
Ideálně by web nebyl nic jiného než API k takovéhle databázi a když by tě zajímal nějaký článek, nebo třeba jeho část, tak by sis to prostě naimportoval (přesunul) do svojí lokální databáze, co? A neexistovaly by tisíce formátů dokumentů, ale prostě jen tahle objektová struktura. Webový prohlížeč by se v zásadě nemusel nijak lišit od lokálního prohlížeče dokumentů, ba možná by nic jako prohlížeč dokumentů existovat nemuselo, protože bys měl prostě nějaké GUI, které umí vykreslovat vlastně výsledky vyhledávacích dotazů, ať už jsou opřené proti lokální nebo vzdálené databázi, a stačilo by jen mít několik speciálních (formátovacích) objektů jako třeba Titulek. A kdybys chtěl poslat odpověď někam do diskuze, tak bys jednoduše vytvořil objekt se svou odpovědí a exportoval ho na ten který server. Komentáře na webu by sis nemusel zobrazovat uzavřené v nějakém boxu, ale prostě bys je mohl libovolně roztahat na plochu, nebo vytvořit objekt Odpovědět a nereferencovat je do něj…Přesně tak. A co je docela brutální si uvědomit, tak tohle všechno Self uměl před 30 lety. Není to žádná sci-fi technologie.
Jinak děláš pořád jednu chybu s tím schématem. Když máš objekt samotný, ve smyslu instance, tak schéma je třída. Můžeš ale použít prototypové programovací jazyky, kde schéma neexistuje, je jím samotný objekt. Ten v sobě obsahuje všechny informace, od struktury po typy a dokumentaci.Šlo mi o jednotnou podobu těch dat. Abys lokálně nepoužíval slot
autor a někde na webu to nebylo author apod. Pokud to budeš muset transformovat, tak máš vlastně stávající stav. Proto jsem vydedukoval, že ten blog ve skutečnosti měl spíš kritizovat absenci patřičných standardů. Kdyby totiž takové standardy existovaly, konvertovat data do toho tvého objektového formátu by bylo triviální a celé to, co si představuješ, by bylo mnohem snáze realizovatelné. Aktuálně bys to musel řešit pro každou službu zvlášť a nevím, jak se s tím hodláš vypořádat (já bych to ale ostatně v CEMESYSu musel řešit taky, akorát do mnohem menší hloubky).
14.12.2018 18:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
15.12.2018 12:27
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Autor by nebyl reprezentovaný nějakým fieldem, ale přímo referencí na entitu typu Autor.Tak tyto úvahy nejsou nové, já jsem o tom básnil už někdy před 12 lety. Reference na objekty jsou v reálných systémech dost výjimečné. Ano, ono se to přirozeně nabízí to takto udělat, ale reálně je pouze minimum "CMS" které to dělají. Málokterý CMS umí udělat alespoň výčet článků, ve kterých se nachází daný konkrétní obrázek. Třeba MediaWiki. Vkládat různé části článků do jiných umí taky, ale nemyslím si, že by tam byl ten sémantický aparát a systém by věděl, že zrovna tohle je popis nějakého člověka (životopisný medailonek), toto je jeho jméno a toto jsou konkrétní data (datový typ datetime) událostí. Pokud se vrátím k tomu 12 let starému zápisku, tak dneska by mě vlastně úplně stačilo, kdyby existoval systém pro správu kontaktů i s jejich historií. Netuším, proč to nikde není implementováno, ale je poměrně přirozené, že se lidé stěhují, mění telefonní čísla i emaily. V každém adresáři kontaktů je tohle statické. Takže je fajn, že je v kalendáři událost z roku 2004, že jsem poslal balík někomu (a je tam proklik na kontakt), ale už nevím, na jakou to bylo adresu (vím, protože si to píšu do všeobecných poznámek ke kontaktu). To je jedna věc. Tyhle nápady nejsou jistě vůbec nové, ale jejich realizace je nulová. Ale má to i druhou stránku. Ne vždy záměrně chcete mít ta data propojitelná. Ano, z hlediska datového návrhu by jistě bylo příjemné mít autoritativní db kontaktů a všude jen používat reference, ale tohle okamžitě narazí na soukromí. Mám katalog fotek, mám tam otagované lidi (opět, katalog to bere jen jako obecný tag a neví, že je to jméno člověka), ale asi bych nechtěl tyto tagy propojit s autoritativní db osob. Nemluvě o tom, že existují fotky, které jsou záměrně otagované nickem bez strojové propojenosti na existující záznam (jistě, dneska se to dá propojit pomocí strojového rozpoznávání obličeje, ale je to práce navíc oproti pointeru do db).
15.12.2018 12:40
Josef Kufner | skóre: 70
15.12.2018 14:19
xkucf03 | skóre: 49
| blog: xkucf03
Tam trochu narážíš na problém s transparentností. Buď to bereš jako objekt a pak to musíš nějak vědomě interpretovat (skočit na ten skutečný objekt, kam reference ukazuje) a nebo se to tváří tak, že místo reference je ten cílový objekt.
A nebo se to chová někdy tak a někdy tak, aby to bylo pokud možno intuitivní. Např. tohle mi vypíše obsah fstabu, jako kdyby to byl normální soubor v aktuálním adresáři:
ln -s /etc/fstab soubor.txt cat soubor.txt
ale zároveň mám i nějakou možnost zjistit, že to není běžný soubor ale odkaz/reference.
16.12.2018 20:26
Josef Kufner | skóre: 70
už někdy před 12 lety
Když už zabrušujeme do historie, tak jsem se odtamtud nějak proklikal k tomu, jak se v roce 2010 někdo ptal:
abclinuxu.. to jeste existuje?
Tak musím říct, že i v roce 2018 stále existuje a stále se tu najdou zajímavé diskuse. :-)
Když už zabrušujeme do historieA sakra, abychom z toho nemuseli zase nějak vybrušovat!
Ano, ono se to přirozeně nabízí to takto udělat, ale reálně je pouze minimum "CMS" které to dělají. Málokterý CMS umí udělat alespoň výčet článků, ve kterých se nachází daný konkrétní obrázek.Kdyby ke každému webu existovalo standardizované API, které by tohle umělo, bylo by to samozřejmě ideální. Nic ti ale nebrání, aby to uměl tvůj lokální systém a data jsi do něj z webu prostě jen importoval (ale musíš si to do té podoby sám zkonvertovat).
Nemluvě o tom, že existují fotky, které jsou záměrně otagované nickem bez strojové propojenosti na existující záznam (jistě, dneska se to dá propojit pomocí strojového rozpoznávání obličeje, ale je to práce navíc oproti pointeru do db).Nevidím moc souvislost/problém. Nick je prostě identita a neexistuje důvod to někde globálně propojit. Je na koncových uživatelích, jestli si někde vytvoří ještě relaci N:1 a identity svážou s fyzickými osobami.
 17.2.2019 18:33
🇵🇸 | skóre: 93
| blog:
17.2.2019 18:33
🇵🇸 | skóre: 93
| blog:
Nevím, proč by měl mít program možnost posílat stisky kláves do jiného programu. To je interface vyhrazený uživateli.Třeba protože uživatel nechce jako debil datlovat na klávesnici. Nebo nejenže nechce, ale ani nemůže, protože třeba nemá ruce.
14.12.2018 00:23
xkucf03 | skóre: 49
| blog: xkucf03
Už jen něco jako AppleScript by otevřelo úplně nové možnosti.
A jak budeš vědět, co do toho skriptu máš psát? Trochu mi to připomíná makra -- ale ta si "nahraješ" (nikdy jsem to nepoužíval).
Dneska je celkem rozšířený a použitelný D-Bus.
A jsou firmy, které se živí "roboty" -- to je spíš něco jako ta makra -- naklikáš tam nějakou práci a robot ji pak opakuje. Dá se to trochu parametrizovat nebo to trochu reaguje na výstup programu. Ale tenhle přístup se mi nelíbí -- podle mého to jen fixuje současný špatný stav a oslabuje to tlak na to, aby se věci dělaly líp. V zásadě to pořád bude shnilé a smradlavé, ale lidem to bude jedno.
A jak budeš vědět, co do toho skriptu máš psát? Trochu mi to připomíná makra -- ale ta si "nahraješ" (nikdy jsem to nepoužíval).Kladl jsem si stejnou otázku, ale z ukázek na Wikipedii mi přijde, že všechny identifikátory lze odhadnout intuitivně. Osobní zkušenost nemám. Obecně to ale považuju spíš za technikálii. Pro začátek by mi stačilo posílání klávesnicových eventů.
Dneska je celkem rozšířený a použitelný D-Bus.Jo, ale tam už ti musí cílová aplikace exportovat API. Ten AppleScript jsem zmiňoval jako berličku pro případ, že neexistuje nebo nepodporuje kýženou funkcionalitu.
A jsou firmy, které se živí "roboty" -- to je spíš něco jako ty makra -- naklikáš tam nějakou práci a robot ji pak opakuje. Dá se to trochu parametrizovat nebo to trochu reaguje na výstup programu. Ale tenhle přístup se mi nelíbí -- podle mého to jen fixuje současný špatný stav a oslabuje to tlak na to, aby se věci dělali líp.Mně se to taky nelíbí, ale naskriptovat si třeba to otevírání tabů v prohlížeči (nebo hromadné přesouvání tabů) by bylo tak jednoduché, že bych to oželel. API na tohle se nedočkám a realisticky ani nemůžu po vývojářích chtít, aby ho přidali jen kvůli mě. Já jsem ochotný tomu jednorázově věnovat třeba 20 minut, ale víc prostě ne. Konkrétně jde o to, že mám prohlížeč na jedné ploše na čtení a na druhé na multimédia a chtěl jsem nastavit, aby se odkazy na YouTube otevíraly na té správné ploše. Ono se to dá vyřešit nejméně pěti různými způsoby (1. X proxy, 2. opatchovat X server, 3. doplňek do prohlížeče, 4. naklonovat prohlížeč, aby každou instanci reprezentoval jiný program, 5. protože se odkaz vždy otevře v posledním aktivním okně, tak prvně skočit na správné okno, pak zpátky na předchozí plochu a pak ten odkaz normálně otevřít – to by bylo nejjednodušší), ale nic z toho prostě nestojí za ten opruz. Takhle jsem se smířil s tím, že se mi občas budou taby otevírat na špatných plochách a když mi to hodně vadí, tak to přesunu nebo odkaz zkopíruju a otevřu ručně. Fakticky je to naprostá drobnost, ale fungovat mi prve to posílání zpráv, tak už jsem to měl vyřešené a počítač by se mi používal zase o něco pohodlněji.
17.2.2019 19:36
🇵🇸 | skóre: 93
| blog:
AppleScript
Historická reference: HyperTalk a TRON MicroScript
13.12.2018 17:19
xkucf03 | skóre: 49
| blog: xkucf03
Je jen otázka času, než to bude běžné i na desktopu.
Proč to ale lidi nepoužívají už teď? Ve většině případů to totiž je použitelné i se stávajícími technologiemi -- souborovým systémem.
Resp. ono se to v některých případech používá. Např. takový objekt "zdrojáky aplikace XY" by mohl být uložený jako blob celý v jednom souboru. Ale není -- místo toho je rozpadnutý na svoje podobjekty (např. třídy) a ty jsou uložené v samostatných souborech. Stejně tak bys mohl mít rozpadlý sešit (z LibreOffice Calc) na jednotlivé listy, které by byly v samostatných souborech. Když půjdeme ještě dál, tak můžeme rozpadnout listy na řádky a ty na buňky. A pak si odjinud (z jiné části stromu) můžeš udělat symbolický odkaz na konkrétní buňku v té tabulce. Trvalo by hodně dlouho, než bys při běžné desktopové práci narazil na limity FS. A většina lidí by na ně nenarazila vůbec. Tak proč se to takhle nepoužívá?
Šlo by implementovat FS optimalizovaný pro (sémantický) desktop, který by neměl limity jiných FS a naopak by měl různé indexy a vyhledávání, štítkování, verzování atd. Tu sadu funkcí, které definuje Jádro, by šlo rozšířit nebo by šlo postavit potřebnou sadu funkcí bokem nebo vystavit jiné API (doménový soket, virtuální adresáře atd.). Případně si to můžeš napsat přes FUSE a vůbec neřešit, jestli ti to do Jádra přijmou nebo ne.
Obávám se, že to není až tak technologický problém... protože současnými technologiemi to realizovatelné je a dá se do toho stavu dostat i evoluční cestou ze současného POSIXového systému.
Jinak já s těmi tvými představami nemám problém, asi by se mi to i celkem líbilo. Dovedu si představit OS, kde hned po bootu naběhne nějaká databáze, nebude tam žádný FS a všechny programy budou uložené jako objekty v té DB a budou se načítat a spouštět odtamtud. Asi by tam šlo udělat i abstrakci, která by smazala rozdíl mezi daty v paměti a na disku, něco jako dneska máš swap nebo soubor mapovaný do paměti. Tam bys prostě pracoval s objekty a bylo by ti jedno, jestli jsou už od minule v RAM nebo ti je OS teprve načte z disku -- bylo by to pro tebe transparentní. Tahle abstrakce samozřejmě něco stojí, ale s dnešním výkonem HW by to možné bylo (pro mnohá užití). Pak bys to taky mohl udělat síťově transparentní, aby bylo jedno, kde jsou data uložená -- všechny počítače (nebo ty, které spolu kamarádí a jsou v nějaké skupině) by tvořily jednu databázi, jeden adresní prostor, v rámci kterého by se pohybovali jak uživatelé tak běžící programy. Pak do toho můžeš zapojit Ethereum a decentralizované aplikace běžící napříč mnoha počítači a jejich kryptograficky ověřované výstupy.
Vymyslet se dá ledasco, realizovat taky. Ale otázka je, k čemu to bude dobré. Jak se říká, kompjůtr nepodojíš. Takže, co bude ten reálný výstup? Proč by tenhle software měl někdo napsat a někdo jiný používat? Nepochybuji o tom, že to někdo napsat dokáže. Trochu pochybuji o tom, jestli by to lidi dokázali mentálně uchopit a využít potenciál takové technologie. Někteří (třeba ty) ano, většina asi ne (a pro ně by nad tím zase vznikly nějaké metafory typu šanon, pracovní deska stolu atd.).
Co je vlastně cílem tvých experimentů? Jakou hypotézu testuješ, jakou otázku si kladeš? "Je to proveditelné?" nebo "K čemu to bude dobré?" nebo "Bude to užitečné?" nebo "Jak to udělat?"
17.2.2019 19:30
🇵🇸 | skóre: 93
| blog:
Asi by tam šlo udělat i abstrakci, která by smazala rozdíl mezi daty v paměti a na disku, něco jako dneska máš swap nebo soubor mapovaný do paměti. Tam bys prostě pracoval s objekty a bylo by ti jedno, jestli jsou už od minule v RAM nebo ti je OS teprve načte z disku -- bylo by to pro tebe transparentní.
Mimochodem, dívali jste se někdo, kam se vyvíjí podpora perzistentní paměti?
Jen technická, object storage (což je tak nějak skoro to co chci, akorát to nativně ukládá XML/JSON/YAML a ne objekty) dneska vystrkuje růžky naprosto všude
V pořádku, jen ať vystrkuje. Pokud bude poptávka, bude i nabídka. Jen nevidím důvod, proč by to mělo být integrováno v OS nebo dokonce považováno za ten správný způsob ukládání dat místo "zastaralého" konceptu filesystému.
Je jen otázka času, než to bude běžné i na desktopu.
To jsem tak kdysi v roce 1994, když jsem se zajímal o to, jak si na svém domácím počítači zkusit nějaký unixový systém, dostal od jednoho kamaráda informaci, že s unixem nemá smysl ztrácet čas, protože je tady zbrusu nový systém jménem Plan9, který je mnohem lépe navržen, a je jen otázka času, kdy odešle unix na smetiště dějin. Ještě o pár let dříve jsem čítal předpovědi, jak jsou ty klasické programovací jazyky přežitek a jak se v roce 2000 bude už všechno důležité dělat v Prologu a jemu podobných. Takhle bych mohl pokračovat ještě dlouho, ale doufám, že je jasné, kam mířím.
Představ si tuhle nesmyslnost třeba v případě domu. Vysníš si a popíšeš někde hobití noru s kulatýma dveřma a spíží na koláče a pak někdo přijde a bude ti říkat, že je to nahovno, že to není životaschopné a že životaschopné to bude, až v tom bude žít víc lidí než v bytovkách. A že v bytovce můžeš mít skříň na koláče a na dveře si namalovat kolo, abys měl aspoň podobný pocit.
Když si tu noru vybudujete nebo necháte vybudovat, tak je to vaše věc. Jenže mě celá tahle diskuse připadá spíš jako stesk člověka, který si vzal do hlavy, že taková hobití nora je přeci objektivně daleko praktičtější než ty houpé zděné domy, že by to tak víc vyhovovalo většině lidí a že jen ty hloupé stavební firmy a developeři to nechápou a pořád stavějí ty nepraktické domy, přestože k tomu není žádný důvod a nikdo neudělal detailní studii, která by ukazovala, že ten klasický dům je v něčem lepší (heslo "artefakt"). Přičemž ignoruje, že si takovou noru klidně může vyhloubit nebo i nechat vyhloubit, jen holt nemá žádné právo požadovat, aby to byl standard, pokud nepřesvědčí dost dalších o své vizi.
Mně fakt upřímě naprosto vůbec nezajímá proč to nejde
Nikdo netvrdil, že to nejde. Jen že poptávka není taková, jak byste si představoval. A u sebe ji necítím už vůbec. Stejně jako před lety přišli vývojáři prohlížečů s tezí, že organizovat bookmarky do adresářové struktury je vlastně nesmysl a že mnohem praktičtější je jim přiřazovat nějaké štítky a kdo víc co ještě. O něco později začali tvrdit, že vlastně i celý ten koncept bookmarků je od základu špatně a že bych měl místo toho… vlastně už ani nevím co. Místo toho dál používám bookmarky a organizuju si je do adresářové struktury. A to je celý problém IT vizionářů: vysní si svou vizi a pak se snaží ohnout uživatele, aby tu vizi přijali.
17.12.2018 14:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
V pořádku, jen ať vystrkuje. Pokud bude poptávka, bude i nabídka. Jen nevidím důvod, proč by to mělo být integrováno v OS nebo dokonce považováno za ten správný způsob ukládání dat místo "zastaralého" konceptu filesystému.
Tohle se dá vždycky otočit - já zas nevidím důvod, proč ne. Tím neříkám, že to má být ve všech, jen že by mi to přišlo zajímavé.
To jsem tak kdysi v roce 1994, když jsem se zajímal o to, jak si na svém domácím počítači zkusit nějaký unixový systém, dostal od jednoho kamaráda informaci, že s unixem nemá smysl ztrácet čas, protože je tady zbrusu nový systém jménem Plan9, který je mnohem lépe navržen, a je jen otázka času, kdy odešle unix na smetiště dějin. Ještě o pár let dříve jsem čítal předpovědi, jak jsou ty klasické programovací jazyky přežitek a jak se v roce 2000 bude už všechno důležité dělat v Prologu a jemu podobných. Takhle bych mohl pokračovat ještě dlouho, ale doufám, že je jasné, kam mířím.
Je mi to jasné a v případě konkrétních technologií se vůbec nedivím, že to nevyšlo. To že budou objektová úložiště dřív nebo později na desktopu běžná mi přijde vcelku jako samozřejmost. Osobně z toho nemám žádný „kick“, protože objektová úložiště považuji za podřadnou myšlenku k objektovým databázím.
Když si tu noru vybudujete nebo necháte vybudovat, tak je to vaše věc. Jenže mě celá tahle diskuse připadá spíš jako stesk člověka, který si vzal do hlavy, že taková hobití nora je přeci objektivně daleko praktičtější než ty houpé zděné domy, že by to tak víc vyhovovalo většině lidí a že jen ty hloupé stavební firmy a developeři to nechápou a pořád stavějí ty nepraktické domy, přestože k tomu není žádný důvod a nikdo neudělal detailní studii, která by ukazovala, že ten klasický dům je v něčem lepší (heslo "artefakt"). Přičemž ignoruje, že si takovou noru klidně může vyhloubit nebo i nechat vyhloubit, jen holt nemá žádné právo požadovat, aby to byl standard, pokud nepřesvědčí dost dalších o své vizi.
Hobití nora je objektivně daleko praktičtější než většina ostatních druhů domů. Schválně si to zkus hodit do youtube a najít na tom nějaké chyby. Kdyby se to zkombinovalo s konceptem zemělodí (earthships), tak to nemá jedinou vadu a mít na to peníze, tak do toho bez přemýšlení jdu.
Zrovna klasický dům z mnoha uhlů pohledu je docela nesmyslný (minimální soběstačnost, absurdně špatná odolnost zlému počasí, neschopnost si vyrábět vlastní energii a pořádně využívat vodu, ...), mám takový pocit, že jsem o tom zkoušel už jednou psát, ale nemám tušení, kam mi to v osobní wiki zapadlo.
Jinak to že to nechci po nikom jiném jsem zdůrazňoval nejednou v blogu a znova mnohokrát v téhle diskuzi, naposledy dokonce v předcházejícím příspěvku.
Nikdo netvrdil, že to nejde. Jen že poptávka není taková, jak byste si představoval. A u sebe ji necítím už vůbec. Stejně jako před lety přišli vývojáři prohlížečů s tezí, že organizovat bookmarky do adresářové struktury je vlastně nesmysl a že mnohem praktičtější je jim přiřazovat nějaké štítky a kdo víc co ještě. O něco později začali tvrdit, že vlastně i celý ten koncept bookmarků je od základu špatně a že bych měl místo toho… vlastně už ani nevím co. Místo toho dál používám bookmarky a organizuju si je do adresářové struktury. A to je celý problém IT vizionářů: vysní si svou vizi a pak se snaží ohnout uživatele, aby tu vizi přijali.
Tak samozřejmě. A před příchodem smartphonů byla nulová poptávka smartphonů. Ten koncept se zatím neosvědčil, protože moc nebyl nikdo kdo by ho osvědčil. Až se to stane, tak z toho možná bude nový standard. A nebo ne.
Hobití nora je objektivně daleko praktičtější než většina ostatních druhů domů. Schválně si to zkus hodit do youtube a najít na tom nějaké chyby. Kdyby se to zkombinovalo s konceptem zemělodí (earthships), tak to nemá jedinou vadu a mít na to peníze, tak do toho bez přemýšlení jdu.
Zrovna klasický dům z mnoha uhlů pohledu je docela nesmyslný (minimální soběstačnost, absurdně špatná odolnost zlému počasí, neschopnost si vyrábět vlastní energii a pořádně využívat vodu, ...), mám takový pocit, že jsem o tom zkoušel už jednou psát, ale nemám tušení, kam mi to v osobní wiki zapadlo.
Aha, tak to leccos vysvětluje. Dobrá, přidávám další (druhou) položku na seznam zdejších uživatelů, v diskusi se kterými nemůžu používat reductio ad absurdum, protože riskuji odpověď "jo, přesně tak to je".
Tak samozřejmě. A před příchodem smartphonů byla nulová poptávka smartphonů. Ten koncept se zatím neosvědčil, protože moc nebyl nikdo kdo by ho osvědčil.
Jestli ono to nebylo spíš tak, že (dnešní) smartphone nespadl jen tak z nebe, ale že telefony postupně "placatěly" a postupně jim přibývaly funkce a uživatelská základna se postupně rozšiřovala z pár nadšenců až po dnešní stav, kdy je člověk bez smartphonu za exota (ruku v ruce s poklesem ceny).
17.12.2018 16:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jestli ono to nebylo spíš tak, že (dnešní) smartphone nespadl jen tak z nebeVskutku nebylo. Asi nejsem jediný, kdo si pamatuje uvedení iPhonu a co za sračky s windows me existovalo před tím, jak hrozně se to ovládalo a jak hrozně daleko to mělo filosoficky k dnešnímu konceptu smartphone, i když hardwarově to šlo už nějakou dobu před tím.
13.12.2018 12:52
xkucf03 | skóre: 49
| blog: xkucf03
Co vlastně počítáš do OS? Co třeba libc? Já bych ji jako část OS neoznačil, ale bez ní by ten OS by byl jen těžko použitelný. Podobně na tom je třeba init (v obecném smyslu).
Podle mého jsou základní knihovna nebo init systém jednoznačně součástí OS a patří tam toho ještě víc. OS není jen jádro, OS je i řada nástrojů kolem (typicky GNU/Linux). V podstatě i desktopové prostředí se dá považovat za součást OS. Láme se to až u aplikací -- např. Gimp bych za součást OS nepovažoval (přestože je to součást distribuce), ale takový správce souborů Dolphin klidně ano.
Ta hranice není úplně ostrá, ale OS určitě není jen jádro.
Takže chápu, že by někdo chtěl nahradit tu UNIXovou horní vrstvu OS něčím objektovým a třeba by se mu s tím pracovalo líp. Možná na tom něco je... ale otázka je, jak to prakticky realizovat. Protože pokud by se z toho měl stát objektový ostrůvek, který je sice dokonalý, ale úplně odříznutý od okolního *NIXového světa, tak je to celkem k ničemu -- pár lidí nad tím bude akademicky onanovat a pak to zajde na nezájem. Už jsem to tu psal v jiném komentáři: mělo by to být k něčemu užitečné a teď hned použitelné → pak se k tomu začnou připojovat další lidé a bude se to rozvíjet. Hezká teorie ale sama o sobě nestačí.
P.S. a to jsem si vždy myslel, jaký jsem idealista :-) ale na tohle se dívám přeci jen trochu pragmaticky.
12.12.2018 16:33
xkucf03 | skóre: 49
| blog: xkucf03
být co nejjednodušší je totálně mimo ve chvíli, kdy používá OS co vůbec není jednoduchý ani omylem (žádný z běžné trojice).
To, co navrhuješ, je ale ve většině případů zesložitění POSIXu a znamenalo by to nové funkce, nové parametry funkcí, nové datové struktury. Viz třeba ty strukturované/objektové CLI parametry nebo proměnné prostředí, strukturované soubory, kterým rozumí OS. Nebo to bezpečné předávání objektových dat (místo např. prostých bajtových proudů) z jednoho programu do druhého. To by vyžadovalo napsat hodně řádků kódu a hodně zvýšit komplexitu. Ano, z dlouhodobého hlediska by se to vyplatilo a celková komplexita (OS + všechny aplikace) by klesla. Mně by se to líbilo. Ale nemyslím si, že by takový OS byl sám o sobě jednodušší než ty současné. Máš pravdu, že jsme asi uvízli v lokálním maximum/minimu, ale dokud se nepodaří přepsat všechny potřebné aplikace, tak to znamená nárůst komplexity a žádné zjednodušení.
Nechci být přehnaně kritický, ale přijde mi, že podobné snahy končí tím, že se napíše další VM (jedno z mnoha), pro něj se napíše pár programů, které v rámci tohoto svého ekosystému budou fungovat velice hezky a bude to obsahovat hezké myšlenky, ale ten ekosystém bude tak malý, že to časem ztratí tah, lidi začnou odpadat, programy zastarávat a časem to zapadne. Je otázka, jak získat tu kritickou masu, jak zařídit, aby se ta sněhová koule začala nabalovat a nikdo ji nezastavil a naopak se k ní přidávali další a další. Odpověď bohužel neznám. Schůdnější mi přijde dobře spolupracovat se stávajícím ekosystémem, být dostatečně otevřený a nedělat svět sám pro sebe. Ty hezké/revoluční myšlenky budou uvnitř tvých programů (knihoven, frameworků), ale bude existovat dostatek bran/adaptérů, kterými ten tvůj svět bude propojen s tím existujícím. Proto se dřív tolik řešily takové blbosti jako jak otevřít .doc soubor nebo jak se připojit k ICQ, protože uživatelé se nemohli od toho starého legacy světa hned odříznout, i když věděli, že je špatný.
Abys prosadil ty tvoje myšlenky (což bych ti přál), tak bys potřeboval právě takové brány/adaptéry do toho starého světa a popsat případy užití a vzory, které budou užitečné teď hned a lidi je můžou vzít a použít. Např. jak se připojit k relační databázi a zpřístupnit její obsah na webu (primitivní úloha řešená dnes a denně), jak se připojit k SOAP webové službě (a ukázat, že to v tvém paradigmatu jde efektivněji než pomocí stávajících nástrojů, např. tam elegantně využít reflexi a samopopisnost), jak se připojit k REST službě, jak si napsat IRC/XMPP bota, jak parsovat zprasené HTML a těžit z něj data (tzn. udělat z toho hnoje nějaké pěkné objekty a poskytnout k tomu šikovné funkce), jak objektově pracovat se stávajícím POSIXovým OS (něco jako jsem dělal v tom SQL-API prototypu, akorát bys nepoužíval SQL nýbrž objektový přístup), jak číst a zapisovat různé existující formáty objektově, jak se připojit k D-Bus, JMX, SNMP, jak objektově pracovat s IMAPem a SMTP, opačným směrem vytvořit třeba FUSE nebo D-Bus bránu, která umožní z POSIXového světa přistupovat do toho objektového nebo pak SOAP či SQL adaptéry, které umožní přistupovat k tvým objektům jako by to byly webové služby nebo SQL funkce. Až tohle budeš mít, tak se to začne nabalovat, budou se přidávat další lidi, přispívat k tomuto dílu. Pak začnou odpadat tyto brány/adaptéry, protože už nebudou potřeba, data nebude potřeba serializovat a deserializovat a budou víc a víc zůstávat v tom tvém objektovém světě a budou se předávat z jednoho objektového programu do druhého.
Nechci být přehnaně kritický, ale přijde mi, že podobné snahy končí tím, že se napíše další VM (jedno z mnoha), pro něj se napíše pár programů, které v rámci tohoto svého ekosystému budou fungovat velice hezky a bude to obsahovat hezké myšlenky, ale ten ekosystém bude tak malý, že to časem ztratí tah, lidi začnou odpadat, programy zastarávat a časem to zapadne. Je otázka, jak získat tu kritickou masu, jak zařídit, aby se ta sněhová koule začala nabalovat a nikdo ji nezastavil a naopak se k ní přidávali další a další.+1
13.12.2018 12:27
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To, co navrhuješ, je ale ve většině případů zesložitění POSIXu a znamenalo by to nové funkce, nové parametry funkcí, nové datové struktury. Viz třeba ty strukturované/objektové CLI parametry nebo proměnné prostředí, strukturované soubory, kterým rozumí OS. Nebo to bezpečné předávání objektových dat (místo např. prostých bajtových proudů) z jednoho programu do druhého. To by vyžadovalo napsat hodně řádků kódu a hodně zvýšit komplexitu. Ano, z dlouhodobého hlediska by se to vyplatilo a celková komplexita (OS + všechny aplikace) by klesla. Mně by se to líbilo. Ale nemyslím si, že by takový OS byl sám o sobě jednodušší než ty současné. Máš pravdu, že jsme asi uvízli v lokálním maximum/minimu, ale dokud se nepodaří přepsat všechny potřebné aplikace, tak to znamená nárůst komplexity a žádné zjednodušení.
Nejsem si jistý, jestli by mělo smysl to všechno roubovat na POSIX.
Ten OS by byl imho určitě jednodušší pro uživatele a administrátory.
Nechci být přehnaně kritický, ale přijde mi, že podobné snahy končí tím, že se napíše další VM (jedno z mnoha), pro něj se napíše pár programů, které v rámci tohoto svého ekosystému budou fungovat velice hezky a bude to obsahovat hezké myšlenky, ale ten ekosystém bude tak malý, že to časem ztratí tah, lidi začnou odpadat, programy zastarávat a časem to zapadne. Je otázka, jak získat tu kritickou masu, jak zařídit, aby se ta sněhová koule začala nabalovat a nikdo ji nezastavil a naopak se k ní přidávali další a další. Odpověď bohužel neznám.
Musíš mít buď to killer feature, nebo nějaký unikátní market. Pokud bys například vyráběl vlastní mobilní telefony, tak bys to asi dokázal protlačit.
Pak je tu ještě možnost nabídnout prostě tolik drobných vylepšení a efektivit co do vývojářského času, že lidem se například vyplatí postavit nad tím své cloudové řešení. Pokud by to bylo jednoduché na instalaci a deployment, s dobrou dokumentací a nízkou vstupní bariérou pro vývoj, tak si dokážu představit, že se to uchytí jako zázemí pro menší firmy.
Další možnost je prostě se spokojit, že cílíš na jiné publikum a jít na to Stallman stylem, tedy že k tomu přibalíš nějakou filosofii a uděláš z toho systém pro pár podobně postižených pošuků. Nevýhoda je, že pak tomu musíš obětovat život a stát se poustevníkem-prorokem tvého vlastního systému.
Abys prosadil ty tvoje myšlenky (což bych ti přál), tak bys potřeboval právě takové brány/adaptéry do toho starého světa a popsat případy užití a vzory, které budou užitečné teď hned a lidi je můžou vzít a použít. Např. jak se připojit k relační databázi a zpřístupnit její obsah na webu (primitivní úloha řešená dnes a denně), jak se připojit k SOAP webové službě (a ukázat, že to v tvém paradigmatu jde efektivněji než pomocí stávajících nástrojů, např. tam elegantně využít reflexi a samopopisnost), jak se připojit k REST službě, jak si napsat IRC/XMPP bota, jak parsovat zprasené HTML a těžit z něj data (tzn. udělat z toho hnoje nějaké pěkné objekty a poskytnout k tomu šikovné funkce), jak objektově pracovat se stávajícím POSIXovým OS (něco jako jsem dělal v tom SQL-API prototypu, akorát bys nepoužíval SQL nýbrž objektový přístup), jak číst a zapisovat různé existující formáty objektově, jak se připojit k D-Bus, JMX, SNMP, jak objektově pracovat s IMAPem a SMTP, opačným směrem vytvořit třeba FUSE nebo D-Bus bránu, která umožní z POSIXového světa přistupovat do toho objektového nebo pak SOAP či SQL adaptéry, které umožní přistupovat k tvým objektům jako by to byly webové služby nebo SQL funkce. Až tohle budeš mít, tak se to začne nabalovat, budou se přidávat další lidi, přispívat k tomuto dílu. Pak začnou odpadat tyto brány/adaptéry, protože už nebudou potřeba, data nebude potřeba serializovat a deserializovat a budou víc a víc zůstávat v tom tvém objektovém světě a budou se předávat z jednoho objektového programu do druhého.
Jo, něco takového asi. Jen pro pořádek, nedělám na vlastním OS. To že jsem napsal kritiku ještě neznamená, že se chystám udělat si vlastní OS.
10.12.2018 10:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nicmene pak se clanek z nejakyho duvodu zvrtl v popis veci, ktery jsou bezny ve _vysokourovnovych_ jazycich a jsou taky duvodem proc takovy vysokourovnovy jazyky existujou.S tím si dovolím nesouhlasit. Vysokoúrovňové jazyky existují z důvodu zvyšování abstrakce, často z důvodu větší produktivity. Vývoj operačních systémů sledoval podobný trend, pak se ale zastavil a od té doby se s výjimkou věcí jako BeOS* nikam konceptuálně. *Viz třeba What makes BeOS and Haiku unique nebo zajímavější The BeOS file system, an OS geek retrospective
A jelikoz vsechny ty koncepty co popisujes jsou jenom jednema z mnoha, ale rozhodne ne nejlepsi nebo jediny nejlepsi a uz vubec ne z dlouhodobyho hlediska, je zadouci, aby nebyly implementovany na urovni nizkourovnoveho operacniho systemu.Budeš se divit, ale s tímhle asi i souhlasím. Osobně ale nevidím důvod proč by nemohly být vysokoúrovňovou součástí operačního systému. Stejně jako je grafický systém určitou vrstvou poskytující způsob interakce s OS, tak nevidím důvod, proč by podobnou vrstvou nemohlo být i to co jsem popsal. Myšleno jako třeba distribuce, která staví nad těmi myšlenkami, ale v jádru je pořád linux.
Já vím, že na konci jsou to vždycky jen bajty, ale právě proto nevidím moc důvodů, proč dělat signifikantní rozdíl mezi tím co je v paměti a co je na disku.
Protoze mali versus velci indiani? Taky často in-memory bitmapa obsahuje daleko víc informací než serializovaná transportní podoba. Např. vypočítané délky bufferů, adresy v pointerech grafů a podobně.
10.12.2018 10:56
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 10:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Taky často in-memory bitmapa obsahuje daleko víc informací než serializovaná transportní podoba. Např. vypočítané délky bufferů, adresy v pointerech grafů a podobně.
10.12.2018 10:56
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 10:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Protoze mali versus velci indiani?Viz
mluvím tu o přímém načtení do paměti, ve stylu message packu, SBE, nebo FlatBuffers, či Cap’n Proto. Bez toho aniž by bylo třeba vyhodnocovat text a řešit escape sekvence a formát unicode.Doporučuji si to proklikat.
10.12.2018 11:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.12.2018 16:55
xkucf03 | skóre: 49
| blog: xkucf03
Taky jde o modifikace dat a fragmentaci. Pokud ta data mají být živá a chceš je upravovat, tak se ti nové hodnoty nemusí vejít na původní místo, následně to musíš buď celé smazat a vytvořit jinde nebo na původní místo, kde byl atribut vložit referenci někam jinam, kde jsou nová data. Tohle se týká jak paměti, tak disku. Vyhneš se tomu leda u extrémně primitivních objektů na úrovni céčkovských struktur, které mají všechno fixní délky.
Už jsem na to někdy koukal. Třeba takový MessagePack neumí skoro nic, ale jeho implementace má 100 000 řádků. Z takového softwaru se mi dělá na blití.
10.12.2018 10:55
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 11:31
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Kdyby to uměl, můžete prostě uložit daný slovník s danými klíči a hodnotami, a příště po nich sáhnout.Umí, xattr (což je key-value). Problém je, že to jednak skoro nic nepoužívá a pokud už to něco používá, tak o to přijdete s první diskovou operací. Jsou nástroje, které s tím umí pracovat, ale některé ne, takže pokud kopírujete data z fs, který xattr umí na fs, které je neumí (nebo má vypnuté), tak o tato data tiše přijdete. NTFS mají Alternate Streams (kdy jeden soubor má více binárních dat), opět, nikdo to nepoužívá a tiše o to přijdete. Osobně si myslím, že na FS by mělo být všechno zcela explicitně viditelné. Tj neskrývat nic v žádných skrytých streamech či atributech. FS je abstrakce nad blokovým zařízením, nic víc, nic méně. Nad touto abstrakcí lze budovat DB vyšší úrovně.
10.12.2018 11:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
* Každá data načítaná z disku nebo posílaná po síti jsou ze své podstaty binární. (Současné) disky a sítě umí posílat pouze sekvenci jedniček a nul.Ano.
To, že ta data budeme považovat za strukturovaná je vždy věcí externí interpretace.Ano, jedna z myšlenek ovšem byla, že ta externí interpretace by byla jednotná, tj všichni se domluvili +- na jedné a OS by pro to přímo měl podporu.
Tj pokud načtu binární stream, tak musím dopředu vědět, že tohle je png a tohle je xml a podle toho se k tomu chovat.Tohle podle mého názoru není pravda, respektive to platí pro současný stav. Pokud máš obecný formát na popis binárních stromů, tak nese strukturu obsaženou sám v sobě (za předpokladu, že umíš nativně pracovat s tím obecným formátem). Stejně tak může nést informace o tom co vlastně je.
Aby to fungovalo sebepopisně, tak by to musel být spustitelný program. A asi nechceme spouštět všechno, co přiteče po síti.Ne, tohle není pravda. JSON a XML taky nejsou spustitelné, přestože jsou do velké míry sebepopisné. Podmínkou reflexe není spustitelnost.
Vždy mě baví diskuse na téma "univerzální FS". Vždy, když přijde na přetřes nový FS, který má třeba nějaké další vlastnosti a třeba nějaké historické použití zvládá hůře, tak se hned objeví kritika, že to není univerzální FS. Ve skutečnosti žádný FS není ani v nejmenším univerzální. Jen si lidé zvykli obcházet určité vlastnosti "univerzálních" fs a považují to za standard. Viz třeba to nekonečné vytváření stromů pro uložení většího než malého počtu souborů.Uhm. Chápu co říkáš, ale pořád nevidím důvod proč by to mělo existovat.
* Parametry příkazového řádku. Tohle je problém implementace těch programů. Nevím kde (asi v Art of UNIX programming) se píše, že program by se měl implementovat jako knihovna a potom k tomu dodat interface. A ten může být libovolný (CLI, REST, GUI, WEB, ...). To, že je nutné donekonečna skládat parametry příkazové řádky hovoří o tom, že většina programů je prostě špatně napsaná a svazuje konkrétní rozhraní s programem. Tj. u dobře napsaných programů použiješ rovnou jejich knihovnu a cli interface se vůbec nemusíš zabývat.Četl jsem a je to hezká idea, kterou zabíjí mimo jiné i to, že programy jsou psané v různých jazycích. Sám tak ale svoje python scripty prakticky bez výjimky dělám.
Umí, xattr (což je key-value). Problém je, že to jednak skoro nic nepoužívá a pokud už to něco používá, tak o to přijdete s první diskovou operací. Jsou nástroje, které s tím umí pracovat, ale některé ne, takže pokud kopírujete data z fs, který xattr umí na fs, které je neumí (nebo má vypnuté), tak o tato data tiše přijdete. NTFS mají Alternate Streams (kdy jeden soubor má více binárních dat), opět, nikdo to nepoužívá a tiše o to přijdete.Vím o tom. Myslím, že by bylo lepší, kdyby to neexistovalo, protože je to zprasený nevážně myšlený krok mnou popisovaným směrem, který celou myšlenku v konečném důsledku diskredituje.
10.12.2018 12:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Ano, jedna z myšlenek ovšem byla, že ta externí interpretace by byla jednotná, tj všichni se domluvili +- na jedné a OS by pro to přímo měl podporu.Jasně. Otázkou je nakolik je to reálné (vidíme, že spíše ne). U některých věcí se to povedlo (a asi by bylo na studii proč zrovna v těch případech), ale ani ty nejsou časově stabilní.
Ne, tohle není pravda. JSON a XML taky nejsou spustitelné, přestože jsou do velké míry sebepopisné.Pokud mi přijde na vstupu binární stream a já ho podle nějakých heuristik prohlásím za textový (v nějakém konkrétním kódování), tak to ještě neznamená, že vím, co je to zač. A další heuristikou můžu zjistit, že to vypadá třeba jako INI, jenže potom přijde systemd s vlastním "vypadá to jako INI, ale není to INI" formátem a jsi opět víš kde. Proto i pro ty sebepopisné formáty je stále potřeba externí popis říkající který konkrétní formát to je. (Jasně, tím se opět dostáváme k předchozímu bodu, že se všichni na jednom konkrétním domluví.)
Chápu co říkáš, ale pořád nevidím důvod proč by to mělo existovat.Mělo existovat co? Univerzální FS? Však já po ničem takovém nevolám, jen poukazuju na to, že to tu nemáme ani dnes (i když si to mnozí lidé myslí).
Četl jsem a je to hezká idea, kterou zabíjí mimo jiné i to, že programy jsou psané v různých jazycích.Jo. Ono kdyby se chtělo, tak k tomu dodávají bindings (což lepší programy mají) a je to vyřešené.
Myslím, že by bylo lepší, kdyby to neexistovaloTak na tom se shodneme.
10.12.2018 12:29
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud mi přijde na vstupu binární stream a já ho podle nějakých heuristik prohlásím za textový (v nějakém konkrétním kódování), tak to ještě neznamená, že vím, co je to zač. A další heuristikou můžu zjistit, že to vypadá třeba jako INI, jenže potom přijde systemd s vlastním "vypadá to jako INI, ale není to INI" formátem a jsi opět víš kde. Proto i pro ty sebepopisné formáty je stále potřeba externí popis říkající který konkrétní formát to je. (Jasně, tím se opět dostáváme k předchozímu bodu, že se všichni na jednom konkrétním domluví.)Myslím že máme v tomhle ohledu zásadní nepochopení, možná vzniklé slovem „sebepopisný“. Představ si formát, který umíš automaticky bez nutnosti nad ním přemýšlet rozbalit do stromů / grafů, kde máš navíc uvnitř obsaženou sémantickou informaci a volitelně i pointery na externí nápovědu. INI je artefakt daný neschopností ukládat nativně strukturu - proto existuje parser a popis a specifikace způsobu jak ukládat strukturu zrovna v INI. Proto existují konfliktní implementace, třeba v tom systemd.
Mělo existovat co? Univerzální FS? Však já po ničem takovém nevolám, jen poukazuju na to, že to tu nemáme ani dnes (i když si to mnozí lidé myslí).Myslím spíš dnešní koncepty FS.
10.12.2018 12:52
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Myslím že máme v tomhle ohledu zásadní nepochopeníTo je možné.
Představ si formát, který umíš automaticky bez nutnosti nad ním přemýšlet rozbalit do stromů / grafů, kde máš navíc uvnitř obsaženou sémantickou informaci a volitelně i pointery na externí nápovědu.Tohle moc k pochopení nepřidalo. Pokud mi přijdou obecná binární data a já nevím co to je (nemám tuto externí informaci), tak nikdy s jistotou nezjistím, že je to strom, že na offsetu x je pointer na další podstrom a že tato větev zrovna obsahuje popis datového typu. Tohle je informace, kterou vždy musím vědět dopředu. (Ale jestli je celé nepochopení postaveno na tom, že se všichni shodli právě na tomto formátu dat, tak OK, další diskuse už není nutná a je to zcela jasné.)
Myslím spíš dnešní koncepty FS.Tak ono je to dané historicky. API k přístupu souboru je vlastně stejné jako API, které se používalo u pásek. Má to převzaté i ty názvy (rewind) a omezení (například nemožnost vložit další data doprostřed souboru - páska tohle fyzicky neumožňuje, to je jasné, ale blokové zařízení s tím v principu nemá problém, ale z historických důvodů je zachovaná zpětná kompatibilita a tohle tam prostě není - tuším že Reiser si dovolil něco takového naimplementovat, ale nebylo to přijato). Takže dnešní FS si lze představit jako kolekci pásek.
10.12.2018 13:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale jestli je celé nepochopení postaveno na tom, že se všichni shodli právě na tomto formátu dat, tak OK, další diskuse už není nutná a je to zcela jasné.Nejde jen o to že by se na tom všichni shodli, že se s ničím jiným ani nesetkáš. Prostě ani nemáš důvod otevřít soubor jako bajty, když ho vždycky můžeš otevřít jako záznam s jasně definovanou strukturou, což podporuje přímo OS ve volání open().
A nestačí tohle řešit na úrovni knihovny? Tohle jsem dělal v tom svém alt2xml prototypu. Načteš soubor v libovolném (podporovaném) formátu a vypadne ti z toho objektový strom, se kterým už pracuješ jednotným způsobem bez ohledu na původní formát.
Když implementuješ takovéto fragmenty cílového stavu jako knihovny použitelné v rámci stávajících systémů, tak se k tomu svému objektovému systému můžeš časem dopracovat evoluční cestou. Tzn. mít knihovnu pro práci s různými formáty, mít strojově čitelný popis CLI rozhraní atd. a časem z těchto fragmentů poskládáš celý systém resp. postupně to na něj překlopíš.
Představ si formát, který umíš automaticky bez nutnosti nad ním přemýšlet rozbalit do stromů / grafů, kde máš navíc uvnitř obsaženou sémantickou informaci a volitelně i pointery na externí nápovědu.
Přesně tohle dělá XML. Máš strom a víš, jak se jednotlivé atributy jmenují. Jejich význam je popsaný v XSD, na které se to XML ve své hlavičce odkazuje. Pokud je problém ukecanost, existují binární formy XML.
12.12.2018 17:30
xkucf03 | skóre: 49
| blog: xkucf03
Parametry příkazového řádku. Tohle je problém implementace těch programů. Nevím kde (asi v Art of UNIX programming) se píše, že program by se měl implementovat jako knihovna a potom k tomu dodat interface. A ten může být libovolný (CLI, REST, GUI, WEB, ...). To, že je nutné donekonečna skládat parametry příkazové řádky hovoří o tom, že většina programů je prostě špatně napsaná a svazuje konkrétní rozhraní s programem. Tj. u dobře napsaných programů použiješ rovnou jejich knihovnu a cli interface se vůbec nemusíš zabývat.
Ano, bylo to v téhle knize (píšu o tom v komentáři níže). Rozdělit programy na knihovnu a rozhraní je správná cesta. Ale přesto bych nezavrhoval ani to volání přes CLI z jiného programu. Často to jsou skripty, člověk si něco vyzkouší v Bashi, funguje mu to... a pak píše program třeba v Pythonu nebo Javě, tak přirozeně chce pře-použít to, co už má vyzkoušené a ví, že to funguje. Pokud je to CLI rozhraní příčetně navržené, tak se to dá úspěšně použít i jako API. Obecně to ideální není, ale někdy to může být nejlepší volba.
A nejen to je důvod, proč by bylo dobré mít nějakou reflexi a samopopisnost toho CLI API. Z takového popisu1 se pak dají krásně odvozovat podklady pro Bash completion nebo třeba napovídání pro editor skriptů2. Zároveň to může kromě samotných parametrů zobrazovat i dokumentaci. Taky to poslouží pro validaci. Bylo by krásné, kdybych mohl spustit libovolný program třeba s parametrem --describe-api a ono by mi to vyplivlo XML ve standardním formátu, které by obsahovalo popis všech CLI parametrů3, proměnných prostředí, vstupních a výstupních proudů, návratových kódů a ideálně informaci o náročnosti a stylu práce -- např. program pracuje proudově, průběžně čte i zapisuje a je tudíž schopný zpracovat teoreticky nekonečné množství dat s konstantní paměťovou náročností nebo naopak program načte všechna data do paměti, a pak teprve vyplivne výstup.
A udělat něco takového (tzn. specifikaci formátu a základní knihovny a nástroje) mi přijde užitečnější než snít o dokonalém objektovém OS. Dovedu si nad tím představit IDE nebo vizuální návrhář, ve kterém by sis naklikal hodnoty proměnných prostředí (jejich názvy by to nabízelo a zobrazovalo popis), parametrů a napojení vstupních a výstupních proudů. Něco jako GNU Radio Companion, kde by sis poskládal bloky, naparametrizoval, pospojoval a pak z toho vygeneroval program/GUI.
[1] u nás na škole o tom psal někdo bakalářku/diplomku, ale nemůžu to teď najít
[2] Umí to nějaký editor? Vždyť by to šlo i dneska, stačilo by, aby editor volal Bash completion a podle toho napovídal.
[3] včetně jejich gramatiky, tzn. jak na sebe jednotlivé parametry navazují a jaké jsou mezi nimi vztahy, nikoli co je uvnitř nich -- uvnitř by měly být jen atomické hodnoty určitého datového typu
10.12.2018 12:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
1) tak nějak naznačuješ vznik jakéhosi standardu pro ukládání a předávání dat. Hezká myšlenka, jen se obávám, že by to dopadlo nějak takto.Netvrdím, že to musí být něco nového, jen že by to mělo být něco jednotného a univerzálního.
2) jen tak pro rozšíření obzorů si zkus něco nastudovat o z/OS. Je tam spousta věcí jinak (třeba ten FS, ebcdic místo ascii).Ok.
10.12.2018 12:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
2) jen tak pro rozšíření obzorů si zkus něco nastudovat o z/OS. Je tam spousta věcí jinak (třeba ten FS, ebcdic místo ascii).Teď mám pocit, že už jsem na to kdysi koukal.
10.12.2018 12:10
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 15:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 12:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jeste jsem taky chtel zminit AS/400 - coz byl pokus mit filesystem jako databazi - ale moc o ni nevim.Ah, AS/400 jsem si kdysi trochu nastudoval. Jeden čas jsem se dokonce hlásil na pozici správce nějaké AS/400, s tím že se to naučím, ale nedostal jsem se ani k pohovoru :)
10.12.2018 13:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na mainframu (ono v podstate s tim souvisi i treba COBOL) je dlouha tradice pouzivat "strukturovana data", jak pises, ve forme posloupnosti "plochych" (nehierarchickych) zaznamu. A OS (a dokonce i hardware) to driv podporoval (namatkou nebo toto).To si myslím, že byla docela kritická chyba. Myslím, že chceš minimálně strom, ne-li rovnou graf.
10.12.2018 15:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nicmene, kdyz se podivas do z/OS (a zahrnes i middleware jako CICS, DB2, IMS, MQ), vsechno co chces tam v nejake forme je uz nekdy od 70. letTyto systemy znam jen hodne povrchne, ale neni to tim, ze je vse uzavrene v ramci jednoho velice specifickeho ekosystemu?
takze je to casto dost neelegantni.To muze hrat podstatnou roli i v adopci v jinych castech pocitacoveho sveta. Vem si WS zalozene na SOAP vs. RESTful API.
A lide si pak reknou "Uz nikdy vic schema!", a zacina se nove kolo.Jestli to nebude tim, ze reseni "one size fits all" proste neexistuje. Podstatna cast toho textu mi pak prijde jako nabeh na dalsi flame typu dynamicke vs. staticke typovani vedeny jinymi slovy. Sebepopisna data odpovidaji dynamickemu typovani (je zde vyhoda primeho pristupu k metadatum, za cenu podstatne rezie) vs. staticka typy (kdy metadata jsou ulozena bokem, se vsemi dusledky). Takze dle meho, zadne univerzalni reseni patrne neexistuje.
Tyto systemy znam jen hodne povrchne, ale neni to tim, ze je vse uzavrene v ramci jednoho velice specifickeho ekosystemu?Je to uzavrene a je to problem. Je to vlastne ten druhy problem, ze pokud se nekomu podari uspesne vyresit Bystroushaakovy problemy, tak za to chce zaplatit. A s tim souvisi, ze to nechce ani "pujcit" jen tak nekomu zdarma. On je rozdil i ve filozofii. Unix (protoze vznikl v kontrastu s Multicsem) je hodne otevreny uzivatelum (treba kazdy ma moznost pustit si shell, vyrabet si jake chce soubory a tak podobne), zatimco mainframe je centralizovane dost zamceny a na skoro vsechno jsou tam nejaka prava. Bystroushaak to chce dotahnout jeste dal, ke Smalltalku a Lispu, coz si myslim jde spis proti tomu co chteji korporace a tak. Zase - socialni problem.
Podstatna cast toho textu mi pak prijde jako nabeh na dalsi flame typu dynamicke vs. staticke typovani vedeny jinymi slovy.Mas myslim pravdu, a v podstate je to ten prvni problem, co popisuji. On je to vlastne taky zcasti, zda se mi, socialni problem - nekdo to datove schema vlastni. Mohlo to celkem dobre dopadnout tak, ze by se vsechno zpracovani (business logika) delalo nad schematem dat v databazi (treba v PL/SQL nebo necem podobnem). To by bylo blizke tomu, co Bystroushaak chce. Jenze pro zmenu schematu (a vlastne cehokoli) potrebovali programatori komunikovat s DB adminem, a to se jim nechtelo. Tak si vymysleli, ze se na DB vykaslou, kdyz je zamcena pro pristup, a budou si to delat mimo. Stejne s tim schematem jsou jen problemy.. a tak zacal ten kolobeh. Nicmene, ja si myslim, ze ty problemy jsou ve skutecnosti jeste hlubsi. Zatim neumime s temi schematy dat obecne pracovat (abychom zachovali kompletni semantiku, jakou potrebujeme), a nechat s nimi pracovat pocitace vede v lepsim pripade na NP-tezke, v horsim pripade algoritmicky ci prakticky neresitelne, problemy. Takze to zustava domenou inzenyrske vynalezavosti.
10.12.2018 15:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Bystroushaak to chce dotahnout jeste dal, ke Smalltalku a Lispu, coz si myslim jde spis proti tomu co chteji korporace a tak. Zase - socialni problem.Pozor, jak jsem deklaroval v začátku, provádím na tohle téma průzkum a výzkum, například teď dělám vlastní experimentální implementaci Selfu, kde jedním ze sedmi výstupních experimentů má být právě vyzkoušet to používat jako interface nad OS. Chci znova zdůraznit, že nemám potřebu cpát můj přístup ostatním nad rámec článku. Pokud jsou lidi spokojení se svým systémem, tak proti tomu fakt nic nemám. Jen jsem chtěl prodiskutovat některé z myšlenek kolem toho.
On je to vlastne taky zcasti, zda se mi, socialni problem - nekdo to datove schema vlastni.To je jeden pohled. Druhy, technicky, je ten, ze vytvoreni schema je krok, ktery se musi udelat v hodne casne fazi vyvoje a jakakoliv nedomyslenost nebo chybny predpokload se projevi pozdeji a je velmi tezke ji/jej vzit zpet. Proto se nedivim rozmachu ruznych schema-less databazi, kdy ti lidi sice maji v databazi neporadek, ale aspon se veci pohybuji rozumnym krokem kupredu, oproti tradicnim databazim, kdy se veci hybou dopredu pomalu a i tak to skonci tim, ze driv nebo pozdeji je v te databazi neporadek, protoze je nutne hledat ruzne ohejbaky a narovnavaky, protoze schema bylo definovano tak a tak.
Nicmene, ja si myslim, ze ty problemy jsou ve skutecnosti jeste hlubsi. Zatim neumime s temi schematy dat obecne pracovat (abychom zachovali kompletni semantiku, jakou potrebujeme), a nechat s nimi pracovat pocitace vede v lepsim pripade na NP-tezke, v horsim pripade algoritmicky ci prakticky neresitelne, problemy.Souhlas, jelikoz schemata odpovidaji typum, daji se znalosti z teto oblasti aplikovat docela primocare i na ne, a to se vsemi dusledky.
10.12.2018 20:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Druhy, technicky, je ten, ze vytvoreni schema je krok, ktery se musi udelat v hodne casne fazi vyvojeTo není obecná pravda. Například v práci generujeme swagger schéma z existujících java class, ze kterých je poté generován python interface. Obecně si dovedu představit systémy, kde by to fungovalo hladšeji.
To není obecná pravda. Například v práci generujeme swagger schéma z existujících java class, ze kterých je poté generován python interface. Obecně si dovedu představit systémy, kde by to fungovalo hladšeji.V tomto pripade neni to schema definovane explicitne, ale implicitne temi javovskymi tridami.
10.12.2018 21:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 12:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
No a co jste delali v tom Pythonu, nez vam ten Swagger vygeneroval to API? To je myslim, co ma deda.jabko na mysli tim "v casne fazi".Nedělali jsme to v pythonu, dělal to vedlejší team v Javě. My z pythonu pak jen komunikovali vygenerovaným API s tím jejich javovským kódem skrz ORM co automaticky vygeneruje swagger.
Jinak docela by me zajimalo, jake vyhody ma OpenAPI proti WSDL.Nemám tušení. Možná že není mrtvý a stojí za ním nědko konkrétní, kdo by dotahoval tooling?
12.12.2018 18:40
xkucf03 | skóre: 49
| blog: xkucf03
Nemám tušení. Možná že není mrtvý a stojí za ním nědko konkrétní, kdo by dotahoval tooling?
A za WSDL/SOAPem nestál nikdo konkrétní? Právě že stál a dokonce velké firmy. Dneska je to hotová věc, nástrojů i dokumentace je k tomu spousta, už není potřeba o tom psát osvětové články a přiživovat módní vlnu, vše už bylo napsáno a všichni o tom vědí. Akorát to některým lidem přišlo moc "složité", a tak začali vymýšlet něco "jednoduššího". OpenAPI/Swagger je akorát nová iterace téhož a časem to dopadne stejně, nabalí se na to spousta lidí, myšlenek, nástrojů, standardy nabobtnají... a pak přijdou jiní lidé a řeknou: fuj, ten Swagger je ale složitý, pojďme vymyslet něco jednoduššího. A celé to začne nanovo.
Souhlas, jelikoz schemata odpovidaji typum, daji se znalosti z teto oblasti aplikovat docela primocare i na ne, a to se vsemi dusledky.Ano. Uz jenom takovy zdanlive trivialni ukol - mame dany izomorfismus mezi dvema typy (prevod mezi dvema schematy), a chteli bychom vsechen nas kod predelat, aby se pouzival druhy typ misto toho prvniho. Teoreticky by tenhle refaktoring (v ramci celeho SW stacku!) mohl zvladnout pocitac. Ale tim by skoro vsechen kod dost zprznil. Takze to nakonec musi udelat lide a rucne.
10.12.2018 20:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Podstatna cast toho textu mi pak prijde jako nabeh na dalsi flame typu dynamicke vs. staticke typovani vedeny jinymi slovy. Sebepopisna data odpovidaji dynamickemu typovani (je zde vyhoda primeho pristupu k metadatum, za cenu podstatne rezie) vs. staticka typy (kdy metadata jsou ulozena bokem, se vsemi dusledky). Takze dle meho, zadne univerzalni reseni patrne neexistuje.Původně jsem tam měl skutečně ještě další kapitolku na přibližně podobné téma, nechtěl jsem tam ale zavést flame na téma typů, ale spíš zdůraznit (subjektivní) důležitost reflexe. Nakonec jsem se rozhodl nechat si to do jiného blogu. Myslíš že bych se do toho neměl pouštět?
Myslíš že bych se do toho neměl pouštět?Otazkou je, co by to melo prinest.
K tomu pro většinu operací chybí atomicita, a transakce nejsou podporovány vůbec. Paralelní zápisy a čtení fungují v různých operačních systémech různě, a ve skutečnosti není garantováno naprosto nic. Schválně si to srovnejte se světem databází, kde se ACID považuje za samozřejmost.Tak zkus NTFS, ten transakce umi. A co se tyce ACID, nekteri lidi s NoSQL databazema to jako samozrejmost uplne nepovazuji.
místo toho abych v jednom formátu dělal doc.getElementByTagName("person")[0].name.value a v druhém doc["people"][0]["name"].Toto neni problem dat jako takovych, ale rozhrani pro pristup k datum.
Nemluvím tady o parsování XML parserem, mluvím tu o přímém načtení do paměti, ve stylu message packu, SBE, nebo FlatBuffers, či Cap’n Proto. Bez toho aniž by bylo třeba vyhodnocovat text a řešit escape sekvence a formát unicode.Toto je opet problem rozhrani pro pristup k datum + ne vzdy je zadouci nacitat cela data do pameti. Coz by tedy slo resit tak, ze si udelas abstrakci nad ruznymi formaty a pristupy k nim a pracujes s nimi jednotne. Co ti brani si neco takoveho naprogramovat?
O tom že data popisují sebe sama přímo svou strukturou, ne externím popisem.To nemusi byt opet zadouci. Vem si treba IP paket.
Celé je to zapouzdřené a komunikuje to jen pomocí nějakých standardních způsobů (stdin/out/err, socket, signály, env, error kódy, zápisy do souborů..). ... nevidím důvod, proč potom nezpřístupnit jednotlivé metody tohoto objektu i z venčí.Odpovidas si sam. To zapouzdreni ma svuj smysl, protoze to umoznuje odstinit se od implementacnich detailu a kdykoliv dany program nahradit jinym, napr. s rozsirenymi funkcemi, opravenou chybou, jinou licenci, atp. Je to aplikace stejneho principu jako v beznych programovacich jazycich, jen o uroven abstrakce vys. Zpristupneni metod by bylo na urovni pristupu k privatnim metodam a atributum v objektovych jazycich. Pokud chce nekdo zpristupnit dilci funkce aplikace, je zde moznost aplikaci vytvorit jako knihovnu + frontend, jak navrhuje heron.
10.12.2018 13:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pravdepodobne budem opakovať, čo už niekto povedal, ale podľa mňa problém, prečo takéto teoreticky výborné koncepty nedosiahli (aspoň zatiaľ) praktické nasadenie, je ten, že v IT vývoj prebieha evolučne, nie revolučne. Väčšina súčasných princípov je starých, ale stále sa na nich niečo vylepšuje. Skoková zmena na iný koncept by bola krátkodobo veľmi drahá, tak ak za tým nie je skrytá nejaká bombová biznisová príležitosť, tak sa to jednoducho neurobí.Ony se ujaly a nikoliv nepodstatnou část historie dokonce vytvářely funkční tržní prostředí. Všechno to ale bylo umřelo s příchodem x86, který ostatní platformy vyžadující často specializovaný hardware podrtil výkonem. Viz situace okolo Genery a Smalltalku.
Skladovanie bambiliónu položiek u ulož.to je práve jeden z tých "ne-bežných" účelov...No, to právě ani moc není. Třeba můj Syncthing adresář obsahuje cca 200 000 souborů díky různým (nutno dodat že osobním) gitům. Což sice nerozbíjí počet inodů, ale rozbíjí to třeba inotify a kopírovat to z disku na disk je porod trvající dlouhé hodiny, i přestože to má jen asi 11 GB. Jinak mi přišlo zajímavé, že třeba SQLite je v různých benchmarcích o hodně rychlejší, než samotný filesystém.
10.12.2018 15:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Je otázka, či to ale mohlo vôbec byť v súčasnej spoločnosti inak.Zrovna tohle se pomalu narovnává, jednak máš tolik výkonu, že ten overhead už tě moc netrápí a taky je trendem cpát do procesorů FPGA, na které budeš moct dynamicky offloadovat různé detaily.
No ale čo sa s tým dá robiť?Srát na konvence?
10.12.2018 14:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 14:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 15:39
Josef Kufner | skóre: 70
Hezká věc je u spustitelných souborů, kdy soubor je prostě spustitelný a na prvním řádku je definováno jak. Přinést to do datových souborů by mohlo být zajímavé.Ani nie. U spustitelny suboroch to tak, lebo to tak musi. Inac to nejde. Shell skript nevykona interpret perlu. A u strukturovanych datach - niekto ma rad to spracovat v jednom programe, druhy v inom. A asi v linuxe sme si oblubili viac app na jednu subor (vid. zavistlost jedneho formatu na jednom programe). Nie najpouzivanejsie formaty (zvacsa) nie su only single app. A ak aj su, tak sa napodobnuju programy k im spracovani (napr. PDF).
10.12.2018 18:22
Josef Kufner | skóre: 70
10.12.2018 21:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud chceš strukturovaná data, jedno jak, použij databázi. SQLite je krásným příkladem. Tak jako tak ta databáze potřebuje nějaký prostor pro svá data a filesystém takový prostor poskytuje. Když bude filesystém vynucovat nějakou strukturu datům na něm uloženým, je prakticky jisté, že to nebude velké části aplikací vyhovovat a neúnosně mnoho práce bude vynaloženo na obcházení omezení takového systému. Proto filesystém poskytuje jen jmenný prostor pro surové bloby dat.To je tak nějak to k čemu jsem dospěl. Operační systém by měl být databáze. Nemám namysli nějaký konkrétní produkt. Dnešní databáze jako třeba Postgre umožňují pouštět scripty třeba v pythonu. Nevím proč nejít ještě o pár kroků dál a neudělat z nich operační systém úplně (teda ehm, SQL se na to imho fakt nehodí, ale obecně..).
ifconfig | grep -Eo 'inet (addr:)?([0-9]*\.){3}[0-9]*' | grep -Eo '([0-9]*\.){3}[0-9]*' | grep -v '127.0.0.1'
...a pak jen doufat, že někdo nezmění formát výstupu (třeba lokalizace).
Ještě by nebylo špatné spojit vlastnosti navrhovaného systému s IPFS.
ip route show|grep link|awk '{print $9}'
To sice aspoň nepoužívá příkaz, který za měsíc oslaví 20 (slovy dvacet) let své obsolentnosti, ale je to podobně křehké. Pro případ, že potřebujete výstup strojově zpracovávat, má příkaz ip v novějších verzích přepínač "-j":
mike@lion:~> ip -j route show
[{"dst":"default","gateway":"213.168.178.65","dev":"eth1","flags":[]},{"dst":"172.16.161.0/24","dev":"vmnet8","protocol":"kernel","scope":"link","prefsrc":"172.16.161.1","flags":[]},{"dst":"172.16.165.0/24","dev":"vmnet1","protocol":"kernel","scope":"link","prefsrc":"172.16.165.1","flags":[]},{"dst":"172.28.1.0/24","dev":"eth0.1","protocol":"kernel","scope":"link","prefsrc":"172.28.1.1","flags":[]},{"dst":"172.28.2.0/24","dev":"eth0.2","protocol":"kernel","scope":"link","prefsrc":"172.28.2.1","flags":[]},{"dst":"172.28.3.0/24","dev":"eth0.3","protocol":"kernel","scope":"link","prefsrc":"172.28.3.1","flags":[]},{"dst":"172.28.4.0/24","dev":"eth0.4","protocol":"kernel","scope":"link","prefsrc":"172.28.4.1","flags":[]},{"dst":"172.28.5.0/24","dev":"eth0.5","protocol":"kernel","scope":"link","prefsrc":"172.28.5.1","flags":[]},{"dst":"172.28.6.0/24","dev":"eth0.6","protocol":"kernel","scope":"link","prefsrc":"172.28.6.1","flags":[]},{"dst":"192.168.3.0/24","dev":"eth0","protocol":"kernel","scope":"link","prefsrc":"192.168.3.2","flags":[]},{"dst":"213.168.178.64/26","dev":"eth1","protocol":"kernel","scope":"link","prefsrc":"213.168.178.121","flags":[]}]
11.12.2018 09:56
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Manuál ip(8) ukazuje tragédii/komedii datových rozhraní v celé své kráse:
-br, -brief
Print only basic information in a tabular format for better
readability. This option is currently only supported by ip addr
show and ip link show commands.
-j, -json
Output results in JavaScript Object Notation (JSON).
-p, -pretty
The default JSON format is compact and more efficient to parse
but hard for most users to read. This flag adds indentation for
readability.
To jsou ty narovnáváky na ohejbáky. Předvídám, že někdo brzy dopíše -color, aby fungoval i s -json, protože -pretty bude prý málo čitelný.
jq, ale použití pak není příliš komfortní. Dalo by se to řešit aliasem, ale pak se bude výstup parsovat, formátovat a obarvovat zbytečně v případě, že se stejně jen posílá ke strojovému zpracování do dalšího nástroje. Především ale JSON, ani formátovaný a highlightovaný, není příjemný na čtení.
Podle mě by tohle měl řešit přímo shell. Do pipy automaticky posílat strojově zpracovatelný formát (třeba ten JSON je docela fajn), uživateli zobrazovat textový výstup. Pro debugování poskytnout utilitu, která zobrazí přímo surová data. Tedy:
foo # zobrazí nějaký textový výpis (klidně ASCII-formátovaná tabulka apod.) foo | bar # výstup z foo bude JSON, výstup z bar bude opět člověku srozumitelný text foo | as-json # naformátuje výstup jako JSONTam je pak nějaké jednotné rozhraní ze strany programů (nebo cmdletů, jak je nazývá Powershell) samozřejmě nezbytností. To je řešitelné. Větší otázkou je, jak by se měly chovat programy jako
grep, resp. čím je nahradit. Uvažujme něco jako:
ls | filter --key "filename" --pattern "foo"
ls vyprodukuje výpis souborů jako JSON (list). filter jej zůží jen na vyhovující položky (objekty). Potud je to v pořádku. Takovýto výstup bychom ale uživateli chtěli prezentovat nikoliv jako JSON, ale formátovat jej identicky jako to dělá ls. A to už je problém, protože:
json, text, keep. V posledním příkladu by tedy došlo ke spuštění ls, který by vyprodukoval JSON a shellu sdělil, že preferovanou metodou zobrazení je text. Protože ale následuje pipa, výstup by se ponechal jako JSON a poslal do filteru. Ten by vyprodukoval výstup opět jako JSON a shellu sdělil, že preferovanou metodou zobrazení je keep, tedy taková, jakou nastavil předchozí program v řetězci. To je v tomto případě text, kterou nastavil ls, a výstup by se proto transformoval na text podle jeho pravidel.cat, jsem už líný přemýšlet. Mohl by produkovat pole řádků, což na netextových datech nedává smysl, ale mohl by produkovat cokoliv jiného a nejspíš neexistuje způsob, jak to smysluplně rozhodnout.
12.12.2018 00:32
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.12.2018 01:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
ls něco podobného (výrazně jednoduššího) dělá dávno. Srovnej výstup ls vs. ls | cat
12.12.2018 10:44
Josef Kufner | skóre: 70
filter by ji změnit neměl, něco jako length ano.
 10.12.2018 20:42
Jendа | skóre: 78
| blog: Jenda
| JO70FB
10.12.2018 20:42
Jendа | skóre: 78
| blog: Jenda
| JO70FB
s/by jsme/bychom/g je vždy platné pravidlo, nebál bych se tímto prohnat jakýkoli text.
K první části: síťový přenos vždy bude proud bajtů prostě z toho principu jak fungují dráty, ty sis zvolil špatnou úroveň abstrakce (sockety a read+write) a na to nadáváš. O úroveň abstrakce výš přece není problém posílat po síti „objekty“ nebo jiné podobné konstrukty a tvůj jazyk/runtime/knihovna se postará o ostatní a žádné bajty nemusíš řešit. A totéž pro „chci jednoduše volat funkci z jiného programu, nechci řešit parametry příkazového řádku…“ - opět záležitost runtime běžícího nad OS…
Proč tedy proboha každý program vezme data, dá jim strukturu, něco nad ní udělá a tu strukturu zahodí a zkolabuje zpět na nestrukturovaná, surová binární data?Tak ukládej třeba něco jako pickle, ne? Nebo v lowlevel jazycích to Cap'n'Proto. Někteří lidé si zase posílají celé databáze a tváří se šťastně. Nebo tě nechápu?
Ještě jsem neviděl chytré logování, které by zvládlo odrotovat log, když hrozí, že na disku kvůli němu nezbude místosystemd-journald
. A možná to nechceš, protože se ti něco pokazí, zaplaví to logy a příčina odrotuje.
Opět problém runtime/ekosystému a že na to není knihovna. Command-line toolsubprocess.Popen(['7z', 'a', 'Test.7z', 'Test', '-mx9'])
7z není určen na automatizaci mimo ad-hoc shell skripty, v programech máš používat něco jako import py7z; py7z.compress(fooDir).
10.12.2018 20:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
K první části: síťový přenos vždy bude proud bajtů prostě z toho principu jak fungují dráty, ty sis zvolil špatnou úroveň abstrakce (sockety a read+write) a na to nadáváš. O úroveň abstrakce výš přece není problém posílat po síti „objekty“ nebo jiné podobné konstrukty a tvůj jazyk/runtime/knihovna se postará o ostatní a žádné bajty nemusíš řešit. A totéž pro „chci jednoduše volat funkci z jiného programu, nechci řešit parametry příkazového řádku…“ - opět záležitost runtime běžícího nad OS…
systemd-journaldTo je třeba krásná ukázka demence návrhu z principu. Error log bys chtěl ideálně někde vedle a nerotovat ho samozřejmě tak často jako zbytek, zatímco debug a info hlášky můžou rotovat jak chtěj.
10.12.2018 21:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
K první části: síťový přenos vždy bude proud bajtů prostě z toho principu jak fungují dráty, ty sis zvolil špatnou úroveň abstrakce (sockety a read+write) a na to nadáváš. O úroveň abstrakce výš přece není problém posílat po síti „objekty“ nebo jiné podobné konstrukty a tvůj jazyk/runtime/knihovna se postará o ostatní a žádné bajty nemusíš řešit. A totéž pro „chci jednoduše volat funkci z jiného programu, nechci řešit parametry příkazového řádku…“ - opět záležitost runtime běžícího nad OS…Dělal jsi někdy se ZeroMQ? Je to podobné jako použití třeba Queue v pythonu. Člověka to docela osvobodí od řešení přenosu a umožní mu to se zaměřit na podstatnější detaily.
Jednou z mých point bylo unifikovat to. Je ti docela málo platné, když si uděláš svůj vlastní ostrůvek nekompatibility, co reálně chceš je aby to používali všichni ostatní. Představ si, že by si třeba každý používal jeden z dvaceti protokolů pro web. Co web, to jiný pes, jiná ves. Taky by ti to oprávněně vadilo.Relevantní XKCD.
10.12.2018 21:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
10.12.2018 22:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
s/by jsme/bychom/g je vždy platné pravidlo, nebál bych se tímto prohnat jakýkoli text.
 10.12.2018 21:22
Gilhad | skóre: 20
| blog: gilhadoviny
10.12.2018 21:22
Gilhad | skóre: 20
| blog: gilhadoviny
s/by jsme/bychom/g je vždy platné pravidlo, nebál bych se tímto prohnat jakýkoli text.s/by jsme/bychom/g je vždy platné pravidlo, nebál bych se tímto prohnat jakýkoli text.
SELECT * FROM tabulka ORDER BY jsme; :-D
O úroveň abstrakce výš přece není problém posílat po síti „objekty“ nebo jiné podobné konstrukty a tvůj jazyk/runtime/knihovna se postará o ostatní a žádné bajty nemusíš řešit.
+1 podle mého většina těch myšlenek patří do nějakého frameworku/knihovny a nemusí být přímo v OS.
Přemýšlel jsem nad tím, a nevyhnutelným krokem je podle mého názoru zahodit filesystém a nahradit ho databází. Když mluvím o databázi, nemám tím na mysli konkrétní SQL databázi, ani key-value „no-SQL“ databáze. Mluvím tu o obecném strukturovaném systému uchovávání dat na záznamových médiích, který podporuje datové typy, atomicitu, indexování, transakce, žurnály a ukládání libovolně strukturovaných dat, včetně velkých bloků čistě binárních dat. (...) Programy jako kolekce adresovatelných bloků kódu v databázi Jakmile máte filesystém, který vám umožňuje nativně uchovávat strukturované informace, nedává smysl mít programy jako jednu velkou sérii bajtů, která se uzavírá před světem. Naopak dává smysl z toho postavit něco podobného architektuře microservices.Hezká představa, ale jako praktické to moc nevidim. Jeden z hlavních problémů IMO je, jak tohle realizovat aniž bys vytvořil zlatou klec á la Smalltalk nebo Lisp nebo podobně. Ie. jak zachovat tu univerzálnost a interoperabilitu "hloupých" souborů. To si myslim, že je velká otevřená otázka. Další věc, která mě napadá, je, že takovýhle systém by byl nejspíše dost náchylný na EEE choutky různých firem.
10.12.2018 21:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 11:10
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Zkus se třeba zamyslet nad tím, jak by se v takovém DB-místo-FS systému používal git nebo VCS obecně.Úplně stejně?
O programování ve SmallTalku toho moc nevim, ale AFAIK až tak často nepoužívají git a mají nějaké custom zlatoklecové řešení.V Pharu se třeba git používá. V Selfu je to trochu horší, tam se to řeší přes anotace objektů a export, ale to je celé dané tím, že to řešení napsal jeden člověk v devadesátkách a od té doby se na to nesáhlo. Principiálně nevidím důvod, proč by to nemohlo jít rovnou do gitu.
IMHO aby to nebyla zlatá klec, muselo by to mít nějaké velmi univerzální a velmi obecné API navenek, aby s tím mohly např. VCS nástroje (a mnoho dalšího) pracovat nějak podobně univerzálně jako s FS.Nebo si prostě uděláš verzování konkrétních částí DB pomocí čehosi jako triggerů naprosto jednoduše a přirozeně.
11.12.2018 11:12
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Zkus se třeba zamyslet nad tím, jak by se v takovém DB-místo-FS systému používal git nebo VCS obecně.To si dovedu představit hravě, protože btrfs od počátku používám (mimo jiné) jako verzovací nástroj velkých (stovky GB) binárních dat. Ano, nemá to všechny funkce VCS, ale některé ano a některé další by asi nebylo problém dopsat. Pokud by byl FS jako DB, tak opět není problém si tam doplnit atribut verze a příslušnost ke commitu, nebo celé snapshoty založené na vlastnosti COW.
VCS nástroje (a mnoho dalšího) pracovat nějak podobně univerzálně jako s FS.Myslím, že se na to díváš opačně. To, že tady máme nástroje jako git znamená jen tolik, že OS neposkytuje dostatečné prostředky na to, aby si funkce toho gitu dokázal každý zařídit s prostředky OS. Viz poznámka výše, moje nutnost používat git je menší právě proto, že některé jeho funkce si dovedu zařídit prostředky FS.
11.12.2018 11:37
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Myslím, že se na to díváš opačně. To, že tady máme nástroje jako git znamená jen tolik, že OS neposkytuje dostatečné prostředky na to, aby si funkce toho gitu dokázal každý zařídit s prostředky OS. Viz poznámka výše, moje nutnost používat git je menší právě proto, že některé jeho funkce si dovedu zařídit prostředky FS.Ano, bod pro tebe. Git má spoustu užitečných schopností, ale taky řeší spoustu věcí, které by mohlo řešit něco jiného. Například vlastní databázový formát.
Myslím, že se na to díváš opačně. To, že tady máme nástroje jako git znamená jen tolik, že OS neposkytuje dostatečné prostředky na to, aby si funkce toho gitu dokázal každý zařídit s prostředky OS. Viz poznámka výše, moje nutnost používat git je menší právě proto, že některé jeho funkce si dovedu zařídit prostředky FS.Já tomu rozumim, ale přijde mi to spíše negativní než pozitivní. Pokud funkcionalitu gitu nebo její část přesuneme do OS, vede to přesně k té zlaté kleci, o které jsem mluvil. Bude z toho jeden velký moloch s komplexní zabudovanou funkcionalitou, kterou nebude snadné měnit podle potřeb. Porovnání btrfs snapshotů a gitu není úplně na místě v tom, že git není určený na verzování velkých binárních dat. Pokud by ale takový nástroj existoval (tj. něco jako "git pro velká binární data", možná i existuje), preferoval bych ho oproti btrfs, protože bych ho mohl používat i jinde než na btrfs.
12.12.2018 00:30
Josef Kufner | skóre: 70
12.12.2018 00:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.12.2018 01:14
Josef Kufner | skóre: 70
OT: Proč git nepoužívá sqlite?Protože SQLite není adresována obsahem, což je klíčová optimalizace Gitu bez které by vůbec nefungoval. Sice by se se daly cpát hashe do primárního klíče, ale SQLite by se pak snažila indexovat, aby byla rychlá a zpomalovala by se. Hezká ukázka toho, že jedna databáze nestačí všem.
12.12.2018 01:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Teď jsou takové věci v knihovnách a dají se používat na různých systémech.No já nevím. To se dá říct o všem, proč potom vůbec mít třeba filesystém, když bych mohl mít knihovnu s raw přístupem k disku? Proč by ta hranice měla být zrovna tady, kromě historického vývoje.
Sice by se se daly cpát hashe do primárního klíče, ale SQLite by se pak snažila indexovat, aby byla rychlá a zpomalovala by se.To nedělá automaticky, ne?
12.12.2018 01:37
Josef Kufner | skóre: 70
A proč ne? Snaha cpát věci do user space je všude kolem už velmi dlouho, jen to není tak snadné udělat efektivně.Teď jsou takové věci v knihovnách a dají se používat na různých systémech.No já nevím. To se dá říct o všem, proč potom vůbec mít třeba filesystém, když bych mohl mít knihovnu s raw přístupem k disku? Proč by ta hranice měla být zrovna tady, kromě historického vývoje.
Když nebude mít index, jak pak ten blob najde? Mohla by mít nějaký hloupý index, který neumí řadit (a nezržuje se s tím), ale pokud vím, moc možností konfigurace to nemá.Sice by se se daly cpát hashe do primárního klíče, ale SQLite by se pak snažila indexovat, aby byla rychlá a zpomalovala by se.To nedělá automaticky, ne?
To se dá říct o všem, proč potom vůbec mít třeba filesystém, když bych mohl mít knihovnu s raw přístupem k disku?
To je v podstatě idea mikrojádra - a i v Linuxu to takhle může fungovat (FUSE). Že se to tak nedělá defaultně (nebo dokonce vždy), to je asi hlavně kvůli efektivitě.
Proč by ta hranice měla být zrovna tady, kromě historického vývoje.
Já bych ten historický vývoj nepodceňoval, ale možná bych tomu spíš říkal zkušenosti z praxe. Postupem času se potvrdilo, že filesystém v jádře má smysl, ale už není obecně vhodné snažit se tam mít výrazně víc. Samozřejmě existují výjimky, na jedné straně třeba FUSE pro specifické filesystémy, na druhé třeba již zmíněné databáze používající přímo blokové zařízení, ale jsou to výjimky a nevidím moc snahu dělat z nich pravidlo.
Ale to už jsem vlastně psal včera: podle mne ten "darwinistický" model, kdy se jednak nechají různá řešení soupeřit a "silnější přežije", jednak se nesnažíme všechno mít ideální hned od začátku, ale snažíme se začít s "dost dobrým" řešením, které pak vylepšujeme podle zpětné vazby z praxe, sice na první pohled vypadá méně efektivně než "intelligent design", ale statisticky má lepší výsledky.
12.12.2018 11:53
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale to už jsem vlastně psal včera: podle mne ten "darwinistický" model, kdy se jednak nechají různá řešení soupeřit a "silnější přežije", jednak se nesnažíme všechno mít ideální hned od začátku, ale snažíme se začít s "dost dobrým" řešením, které pak vylepšujeme podle zpětné vazby z praxe, sice na první pohled vypadá méně efektivně než "intelligent design", ale statisticky má lepší výsledky.Pokud bych se na to díval takhle, tak jsem na desktopu nikdy nepřestal používat Windows.
12.12.2018 13:08
Josef Kufner | skóre: 70
12.12.2018 19:14
xkucf03 | skóre: 49
| blog: xkucf03
OT: Proč git nepoužívá sqlite?
BTW: Existuje několik distribuovaných verzovacích systémů, které sqlite používají: Monotone, Fossil.
12.12.2018 19:09
xkucf03 | skóre: 49
| blog: xkucf03
To si dovedu představit hravě, protože btrfs od počátku používám (mimo jiné) jako verzovací nástroj velkých (stovky GB) binárních dat. Ano, nemá to všechny funkce VCS, ale některé ano a některé další by asi nebylo problém dopsat.Dá se tam nějak snadno zobrazit rozdíl mezi snapshoty?
12.12.2018 19:44
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
find-new, který ti ukáže změny na daném subvolume, potom lze jednotlivé snapshoty posílat inkrementálně pomocí send, tj btrfs ví, co se mezi snapshoty změnilo (tj dekódováním toho streamu by se dalo zjistit konkrétní rozdíly mezi snapshoty). Potom existuje možnost zobrazit sdílené bloky mezi dvěma soubory.
Píšu to takto obecně, protože nemám potřebu nic z toho používat. Vím, že rsync (měl plánu) používá hodně z vlastností btrfs, aby rychle zjistil změny a vím, že existují programy pro deduplikaci, které hledají stejné bloky v existujících souborech a promocí ioctl btrfs příkazů je mapují na stejný blok.
Ale já to používám tak, že si v rootu dané subvolume / datasetu vedu changelog, kde před každým snapshotem popíšu, co obsahuje (commit message) a případně i příkazy, které od minulého snapshotu k tomuto vedly. Skutečný diff ve smyslu git diff jsem vlastně nikdy nepotřeboval.
11.12.2018 10:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tak podstatné už padlo na začátku. Úkolem OS je poskytovat minimální abstrakci nad hardware, tak aby program bez úprav mohl běžet na různých počítačích.Vskutku. To je ale tak nějak definice kruhem. Tohle je úkolem OS, protože ukolem OS je tohle. To přece není tesané nikde ve skále a historicky to bylo naprosto různě. Například Smalltalk se docela dlouho používal jako OS a jeho úkolem byla spousta dalších věcí. Stejně tak třeba ten BeOS poskytuje spoustu dalších možností, než jen tuhle holotu. Dokonce i Windows a Linux toho dělají o hodně víc, než jen tohle.
Zakódovat tyhle high level abstrakce do OS by přineslo víc škody než užitku, bo by to přidalo příliš high level struktury, nad kterými by bylo složité vybudovat dostatečně specifické implementace. Jinými slovy, pro malý přínos velké většině aplikací (kterého se dá dosahnout na jiné úrovni) bychom limitovali použití OS pro potenciálně menší, ale rovněž klíčovou skupinu.To si podle mého názoru myslíš jen proto, že nemáš zkušenosti se systémy, které to umožňují. A subset, který jsem popsal je relativně malý A ZÁROVEŇ už tam je, jen jen implementovaný totálně volně, jak se komu zachtělo, bez standardu.
Ostatně, ohledně filesystem vs databáze - zjevně pro současné databáze je současná abstrakce už tak příliš vysokoúrovňová, takže jim neumožňuje dosáhnout maximální efektivity při implementaci databázového storage.Co je na tom zjevného? DB mají často větší výkon než filesystém, ale záleží na nastavení a optimalizacích.
Ohledně objektů místo bytes (ať už sockets či cokoliv jiného) - viz výše - data i protokoly se mění a zadrátovat něco do OS by drsně zbrzdilo rozvoj. Navíc ta cena za implementaci na vyšší úrovní je prakticky zanedbatelná. HTTP 3 jde dokonce přesně opačným směrem - zcela zahodit stremované TCP, v zásadě v souladu s tím, co jsem psal v předchozím odstavci.Proč by to mělo drsně zbrzdit rozvoj? Nikdo přece netvrdí, že ta funkcionalita nemůže být modulární.
K té prvotní motivaci - nevím, co přesně se dělo ve všech zmiňovaných projektech, ale pokud jste museli implementovat všechno znovu, tak jste se nedívali dostatečně kolem sebe. Ta abstrakce obvykle už existuje, jenom ne na úrovni OS, ale o úroveň (několik) výš. Rozjet dneska třeba web aplikaci, která komunikuje přes (z hlediska aplikace) datové objekty, má transakce a zapisuje tunu malých záznamů, je otázka jednotek hodin a pár desítek řádků kódu.Zajdi se podívat do desíti náhodně vybraných firem, kde si vyvíjejí vlastní SW řešení. Garantuji ti s neochvějnou jistotou, že uvidíš podobný, u nich vytvořený pattern v každé z těch firem. To ani nemyslím nějak hypoteticky, prostě jdi a udělej to. Já jsem to udělal.
V podstatě se připojím k tomu, co už tu padlo. Pro mne byla prvním varovným signálem věta
Jestliže spousta programátorů vytváří nad danou knihovnou stále stejný vzor, nejedná se o chybu programátorů, ale o špatně navrženou knihovnu.
S tím zásadně nesouhlasím. To, že spousta programátorů by ocenila nějakou vyšší úroveň abstrakce, aby nemuseli používat pořád stejný vzor, totiž vůbec neznamená, že by to tak vyhovovalo všem. Takže taková situace vůbec nemusí znamenat, že je ta knihovna špatně navržená, ale jen že té (byť i třeba poměrně velké) části programátorů chybí nějaká nadstavba (další knihovna) mezi touhle knihovnou a jejich aplikací. A pokud vy sám jste nad danou knihovnou opakovaně vytvářel ten samý vzor, je možná na místě otázka, proč jste si toho nevšiml a neudělal jste z toho knihovnu, kterou byste pak ve všech těch projektech (i budoucích) používal.
Stejný problém pak vidím i ve zbytku té úvahy. To, že někdo by pro svůj use case ocenil sofistikované rozhraní pro ukládání strukturovaných dat, neznamená, že by to tak vyhovovalo všem. Proto je v praxi většinou výhdodnější mít nad sebou několik vrstev s různou úrovní abstrakce (a komfortu), aby si každý mohl vybrat, která je pro daný účel nejvhodnější.
Jsou samozřejmě i situace, kdy bude vhodnější vrstvení narušit a sloučit funkce, které by mohly být oddělené, dohromady. Když už je řeč o databázích, některé umožňují obejít filesystém úplně a fungovat i nad holým blokovým zařízením. (Což lze brát i tak, že si implementují svůj vlastní filesystém optimalizovaný pro jejich potřeby.) Ale mělo by se tak dít po důkladném zvážení, co to přinese a čím za to zaplatím.
Část nedorozumění má možná na svědomí i samotný termín operační systém. Ten totiž podle kontextu může označovat buď samotné jádro nebo (historicky častěji) celý komplex jádra, základních systémových knihoven a základních systémových utilit. Třeba v případě linuxových distribucí je ta hranice, co ještě počítat do "OS", hodně neostrá. Takže proč ne, ať si "operační systém" (v tom širším smyslu) klidně implementuje object oriented storage pro komfortní práci se strukturovanými daty - ale nevidím jediný důvod, proč by to tak mělo být implementováno na té nejnižší úrovni, a hlavně proč by to mělo být jediné rozhraní.
Koneckonců i třeba v C++, na které je zvykem plivat, že není dost cool, je standardní způsob zápisu strukturovaných dat do souboru nebo socketu
var >> s
a někde jinde (nižší vrstva) se definuje, co to pro konkrétní datový typ znamená a jak ta data na disku (na drátě) budou vypadat. Na téhle úrovni abstrakce nemusím (a nechci) řešit, jestli to bude XML, JSON, netlink nebo třeba nějaký vlastní formát.
11.12.2018 10:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
S tím zásadně nesouhlasím. To, že spousta programátorů by ocenila nějakou vyšší úroveň abstrakce, aby nemuseli používat pořád stejný vzor, totiž vůbec neznamená, že by to tak vyhovovalo všem.To vskutku neznamená.
Takže taková situace vůbec nemusí znamenat, že je ta knihovna špatně navržená, ale jen že té (byť i třeba poměrně velké) části programátorů chybí nějaká nadstavba (další knihovna) mezi touhle knihovnou a jejich aplikací.To je určitě jeden z přístupů, který ale podle mého názoru vede na pyramidy z hoven a nekonečné vršení software na sebe. Nehledě na to, že to vůbec neřeší problém jednotnosti, naopak to vytváří tříštění nekompatibility mezi sebou. Konkrétní argument je jednoduchý. Představ si třeba že bys měl Windows a někdo ti vyprávěl o výhodách Unixu, kde máš spoustu malých programů a můžeš je scriptovat. A tvoje odpověď by byla, že to můžeš mít i ve Windows. Samozřejmě, můžeš. Ten rozdíl není ani tak technologický, jako filosofický. Já tady mluvím o v podstatě objektovém systému a jeho výhodách a demonstruji to ukázkami desítek nevýhod stringově orientovaných systémů. A tvoje odpověď je, že by to šlo emulovat další vrstvou, kterou můžu použít. Samozřejmě, šlo. Ale to postrádá celý ten smysl.
A pokud vy sám jste nad danou knihovnou opakovaně vytvářel ten samý vzor, je možná na místě otázka, proč jste si toho nevšiml a neudělal jste z toho knihovnu, kterou byste pak ve všech těch projektech (i budoucích) používal.Protože nechci přivést na svět další systemd? :] Hlavní problém je, že (jak jsem jasně napsal) ten vzor nevytvářím já, vytváří ho úplně všichni, ať přijdu kam přijdu. A těžko jim budu cpát nějaký přepis na svojí knihovnu.
Stejný problém pak vidím i ve zbytku té úvahy. To, že někdo by pro svůj use case ocenil sofistikované rozhraní pro ukládání strukturovaných dat, neznamená, že by to tak vyhovovalo všem.Taky to ale neznamená, že by nebylo možné uložit data i nestrukturovaně, jen by to nebyla preferovaná volba.
Jsou samozřejmě i situace, kdy bude vhodnější vrstvení narušit a sloučit funkce, které by mohly být oddělené, dohromady. Když už je řeč o databázích, některé umožňují obejít filesystém úplně a fungovat i nad holým blokovým zařízením. (Což lze brát i tak, že si implementují svůj vlastní filesystém optimalizovaný pro jejich potřeby.) Ale mělo by se tak dít po důkladném zvážení, co to přinese a čím za to zaplatím.Vím o tom.
Takže proč ne, ať si "operační systém" (v tom širším smyslu) klidně implementuje object oriented storage pro komfortní práci se strukturovanými daty - ale nevidím jediný důvod, proč by to tak mělo být implementováno na té nejnižší úrovni, a hlavně proč by to mělo být jediné rozhraní.Nevím jestli by to mělo mít jediné rozhraní, jsem však pevným zastáncem myšlenky, že by to mělo mít jednotné a konzistentní rozhraní.
a někde jinde (nižší vrstva) se definuje, co to pro konkrétní datový typ znamená a jak ta data na disku (na drátě) budou vypadat. Na téhle úrovni abstrakce nemusím (a nechci) řešit, jestli to bude XML, JSON, netlink nebo třeba nějaký vlastní formát.Ano, ale řešit to nakonec musíš. A pak pracuješ se vším, s JSONem, XML, YAMLem a pěti dalšími formáty najednou. Co to má za výhodu mi uniká, naopak je to čím dál větší fragmentace.
Pyramidy z hoven IMO nejsou způsobeny existencemi vrstev, ale tím že návrhu těch vrstev nikdo nevěnoval dost úsilí a pozornosti.Takže taková situace vůbec nemusí znamenat, že je ta knihovna špatně navržená, ale jen že té (byť i třeba poměrně velké) části programátorů chybí nějaká nadstavba (další knihovna) mezi touhle knihovnou a jejich aplikací.To je určitě jeden z přístupů, který ale podle mého názoru vede na pyramidy z hoven a nekonečné vršení software na sebe. Nehledě na to, že to vůbec neřeší problém jednotnosti, naopak to vytváří tříštění nekompatibility mezi sebou.
To vskutku neznamená.Takže souhlasíš, že na různé problém jsou potřeba různé nástroje a různé abstrakce. Ale zároven bys chtěl, aby byl ten jeden Správný(tm) univerzální database-based systém který vládne všem. To mi nějak nedává smysl.
11.12.2018 10:30
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Takže souhlasíš, že na různé problém jsou potřeba různé nástroje a různé abstrakce. Ale zároven bys chtěl, aby byl ten jeden Správný(tm) univerzální database-based systém který vládne všem. To mi nějak nedává smysl.Nikde jsem nepsal, že chci aby existoval jeden jediný systém, to sis tam doplnil sám(a). Specificky jsem začal celý článek žádostí:
Předně bych rád deklaroval, že tu mluvím sám o sobě. Když budu psát, že „je něco zapotřebí“, „možné“, nebo „schůdné“, myslím tím „zapotřebí pro mě“, „možné pro mě“, nebo „schůdné pro mě“. Zažil jsem až příliš diskuzí na internetu, které byly způsobeny čtením mezi řádky a vztahováním čtenářovo názorů a předsudků na osobu autora. Vím, že tohle upozornění pravděpodobně nepomůže, ale zkuste se nad prezentovanými myšlenkami zamyslet s otevřenou myslí. Pokud vám některé moje nápady přijdou kontroverzní, nesmyslné, či pokud budete mít dokonce pocit, že Vás pobuřují svou donebevolající blbostí - uklidněte se. Vzpomeňte si na výše uvedenou deklaraci. Uvědomte si, že vůbec nemluvím o vás, nemám potřebu a chuť vám něco vnucovat, měnit vám workflow, nebo pomlouvat Váš systém. Berte to jako mojí podivnost, jako možný směr, který to chce vyzkoušet a nevztahujte to o čem tu mluvím na sebe.Přestože mi bylo jasné, že to k ničemu nebude.
Takže souhlasíš, že na různé problém jsou potřeba různé nástroje a různé abstrakce. Ale zároven bys chtěl, aby byl ten jeden Správný(tm) univerzální database-based systém který vládne všem. To mi nějak nedává smysl.Nikde jsem nepsal, že chci aby existoval jeden jediný systém, to sis tam doplnil sám(a).
/(o) =p
Doplnil jsem si to třeba proto, že tady pořád zminuješ jednotnost vs. roztříštěnost. A že svůj vlastní dokonale úžasný systém nechceš vytvářet mimo jiné proto, že ho nevnutíš zbytku světa. Což mi naznačuje, že v utopickém světě kde se (podle tebe) software dělá Správně(r) je ten jeden systém který vládne všemu.Specificky jsem začal celý článek žádostí:Obzvlášt proto, že je to v té části která je explicitně optional :) Nebo proto, že celý ten blag má moc slov. Komprimuj. Also relevantní XKCD.Předně bych rád deklaroval, že tu mluvím sám o sobě. Když budu psát, že „je něco zapotřebí“, „možné“, nebo „schůdné“, myslím tím „zapotřebí pro mě“, „možné pro mě“, nebo „schůdné pro mě“. Zažil jsem až příliš diskuzí na internetu, které byly způsobeny čtením mezi řádky a vztahováním čtenářovo názorů a předsudků na osobu autora. Vím, že tohle upozornění pravděpodobně nepomůže, ale zkuste se nad prezentovanými myšlenkami zamyslet s otevřenou myslí. Pokud vám některé moje nápady přijdou kontroverzní, nesmyslné, či pokud budete mít dokonce pocit, že Vás pobuřují svou donebevolající blbostí - uklidněte se. Vzpomeňte si na výše uvedenou deklaraci. Uvědomte si, že vůbec nemluvím o vás, nemám potřebu a chuť vám něco vnucovat, měnit vám workflow, nebo pomlouvat Váš systém. Berte to jako mojí podivnost, jako možný směr, který to chce vyzkoušet a nevztahujte to o čem tu mluvím na sebe.Přestože mi bylo jasné, že to k ničemu nebude.
11.12.2018 11:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A že svůj vlastní dokonale úžasný systém nechceš vytvářet mimo jiné proto, že ho nevnutíš zbytku světa.V diskuzi jsem několikrát zmiňoval, že dělám experimenty na tohle téma, které mimo jiné zahrnují programování konkrétních systémů (časem o tom napíšu další blogy, tohle byl takový úvod proč vlastně). Záměrně nechci dělat nic obecně použitelného pro všechny, protože se jednak nechci omezovat obecným konsenzem, ale taky protože to že mě něco sere ještě neznamená, že tomu obětuji příštích dvacet let celý život jako Linus, kdyby to náhodou nefailnulo pro nezájem.
Nebo proto, že celý ten blag má moc slov. Komprimuj.Hah. Z druhé strany mi bylo na IRC vyčteno, že jsem to sepsal moc zkomprimované a skoro tomu nejde rozumět, protože jsem spoustu věcí moc nevysvětlil jak zapadají do sebe.
11.12.2018 10:30
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pyramidy z hoven IMO nejsou způsobeny existencemi vrstev, ale tím že návrhu těch vrstev nikdo nevěnoval dost úsilí a pozornosti.Podle mého názoru to není buď a nebo, můžou být imho způsobeny obojím.
Protože nechci přivést na svět další systemd? :]
Abych pravdu řekl, celá ta vize mi připadá, jako by byla založena na podobné myšlence jako systemd. Tedy místo přirozeně rostoucího ekosystému modulárního vertikálně (implementace rozdělená do jednotlivých vrstev) i horizontálně (u jednotlivých komponent si lze vybrat z několika alternativ) se nalajnuje Jediný Správný Univerzální Framework. Zastánci toho druhého modelu argumentují "roztříštěností" a tím, že se spousta energie "vyplýtvá" na duplicity a věci, které nakonec umřou, ale já mám ten první model stejně raději. Je to stejné jako s politikou: osvícená monarchie (diktatura) je v ideálním případě efektivnější než demokracie - ale v těch neideálních… a v praxi ten ideální případ nikdy moc dlouho nevydrží.
11.12.2018 10:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Abych pravdu řekl, celá ta vize mi připadá, jako by byla založena na podobné myšlence jako systemd. Tedy místo přirozeně rostoucího ekosystému modulárního vertikálně (implementace rozdělená do jednotlivých vrstev) i horizontálně (u jednotlivých komponent si lze vybrat z několika alternativ) se nalajnuje Jediný Správný Univerzální Framework.To ti připadá blbě no. Je to pozorování určitých vzorů, které jsou momentálně masivně fragmentované. Jejich sjednocený pod systém, který by zahrnoval unifikované principy by podle mého názoru nebylo na škodu, naopak by přineslo zjednodušení ve všech možných ohledech. Je to asi jako rozdíl mezi perlem, kde je možné dělat každou věc sto způsoby a všichni to sto způsoby dělají, a pythonem, kde většinou existuje jeden preferovaný způsob řešení, který ale lze nepoužít, pokud víš co děláš.
Zastánci toho druhého modelu argumentují "roztříštěností" a tím, že se spousta energie "vyplýtvá" na duplicity a věci, které nakonec umřou, ale já mám ten první model stejně raději.Tak ale nikdo ti ho nebere, ne? Už když jsem to psal, bylo mi naprosto jasné, že spousta lidí bude mít tuhle reakci, protože jim prostě sahám na něco oblíbeného, s čím se naučili žít. Přitom když se nad tím zamyslíš, tak nikomu nic neberu, jen jsem sepsal kritiku toho co mě sere.
Je to stejné jako s politikou: osvícená monarchie (diktatura) je v ideálním případě efektivnější než demokracie - ale v těch neideálních… a v praxi ten ideální případ nikdy moc dlouho nevydrží.Ono spíš poměřovat státní zřízení podle efektivity není nejspíš to správné měřítko. Já jsem osobně za neefektivitu a neschopnost v mnoha ohledech spíš rád, i když samozřejmě ne absolutně. Poslední dobou jsem dospěl k názoru, který jsem teda pravda převzal z několika článků a přednášek, že nejmenší zlo je je mít nějaký dialog a střídání cyklů, což je tak nějak to co máme tady v EU. Tohle jde vnímat podobně. Stejně jako se periodicky střídají třeba cykly mainframu a později osobních počítačů a později zase cloudu, tak jsi měl cykly sjednocování a fragmentace. Tohle je jen jeden možný směr opětovného sjednocování.
11.12.2018 10:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jejich sjednocený pod systém*sjednocení omg *uklání se a nabízí katanu před spácháním harakiri* Mojí omluvou je, že u toho dělám něco jiného a ještě mi agresivně někdo píše na mobil.
11.12.2018 11:02
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Hlavní problém je, že (jak jsem jasně napsal) ten vzor nevytvářím já, vytváří ho úplně všichni, ať přijdu kam přijdu.Tohle, si myslím, je spíše psychologické téma, než technické. Fakt nechci rýpat, už mě přestalo bavit poukazovat na každý výskyt použití věcí jako je MD5 nebo
ifconfig a spousty dalších věcí, spíše se už jen tiše bavím tím, kolik desítek let v IT trvá, než se něco vymýtí. Lidská setrvačnost je mnohem větší, než bych čekal.
K tomu "vytváří ho úplně všichni". Jsem technik, nejsem programátor, ale opakovaně se setkávám s tím, že někteří lidi mají odpor používat ty nástroje samotné, ale pokaždé nad tím hledají nějakou vrstvu navíc. Takže iptables téměř nikdo nechce používat, ale hrozně rádi hledají generátory pravidel. Ty generátory jsou ale buďto stejně komplexní jako použití iptables, pokud chtějí obsáhnout stejnou funkcionalitu, nebo jsou méně komplexní, ale vždy se stane, že na něco nestačí a dotyčný stejně musí sáhnout po iptables. Tj musí se naučit obě věci. Tohle vidím u iptables, ip, lvm, openssl, service(ctl), psql, mysql (cli) atd.
Nevím, zda se jedná o tentýž problém jako v případě programátorů, ale u techniků vidím problém v tom, že poměrně brzo ve svém profesním učení si zvykli používat nějaká udělátka vyšší úrovně a až na výjimky je nezajímá, co je pod tím a pokud ano, považují to za složitější.
11.12.2018 12:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
K tomu "vytváří ho úplně všichni". Jsem technik, nejsem programátor, ale opakovaně se setkávám s tím, že někteří lidi mají odpor používat ty nástroje samotné, ale pokaždé nad tím hledají nějakou vrstvu navíc. Takže iptables téměř nikdo nechce používat, ale hrozně rádi hledají generátory pravidel. Ty generátory jsou ale buďto stejně komplexní jako použití iptables, pokud chtějí obsáhnout stejnou funkcionalitu, nebo jsou méně komplexní, ale vždy se stane, že na něco nestačí a dotyčný stejně musí sáhnout po iptables. Tj musí se naučit obě věci. Tohle vidím u iptables, ip, lvm, openssl, service(ctl), psql, mysql (cli) atd.Zrovna IP tables potřebují prostě grafické rozhraní víc než co jiného. Já je osobně nepoužívám vůbec, používám
ufw.
Nevím, zda se jedná o tentýž problém jako v případě programátorů, ale u techniků vidím problém v tom, že poměrně brzo ve svém profesním učení si zvykli používat nějaká udělátka vyšší úrovně a až na výjimky je nezajímá, co je pod tím a pokud ano, považují to za složitější.Spíš všichni kdo chtějí stavět systém zjistí, že jim nedostačuje výbava vhodná pro stavění programů. Systém je něco víc než program a vyžaduje jiné vzory. A protože prostě nejsou k dispozici, tak je vytvoří. Trochu je to možné pozorovat třeba když se podíváš na různé cloudy. Tam se objektové úložiště stává v podstatě normou, stejně jako různé frameworky pro komunikaci, škálování a spouštění aplikací. Až na to že je to celé hrozný prasopes psaný lidmi co se jen snaží vyhovět nějaké potřebě, aniž by se nad tím nějak hlouběji zamysleli. Třeba na tom OpenShiftu je vidět hrozná nedodělanost, nevyzrálost a absence koncepce. Nehledě na to, že jsou to všechno frameworky na které potřebuješ celé datacentrum a nemůžeš je provozovat v malém, nebo třeba jen na jednom počítači. Celé je to deset věcí co nějak dělají nějakou úlohu (docker, elasticsearch, kibana, ..) pospojovaných dohromady izolepou z javascriptu a go a všeho co kdo kde našel do jednoho chuchle.
11.12.2018 12:38
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Zrovna IP tables potřebují prostě grafické rozhraní víc než co jiného.Dokonce až grafické. No na tom se neshodneme, iptables od počátku dělám výhradně na řádce a i různé nástavby (kdysi jsem tu psal o fireholu) jsou taky jen na řádce.
Spíš všichni kdo chtějí stavět systém zjistí, že jim nedostačuje výbava vhodná pro stavění programů.Spíš ji neznají a ani po tom nepátrají. Znám několik programátorů, kteří více či méně ostentativně dávají najevo, jak je aktuální stav a aktuální prostředky vůbec nezajímají a oni to všechno udělají pochopitelně nejlépe. V tomto vidím jednu z příčin úspěchu dockeru. Kontejnery tady existují desítky let, v linuxu jsou okamžitě použitelné, ale až docker se rozšířil a podle mě kvůli tomu, že se dotyčný nemusí zabývat instalací ničeho, jen se mu na základě dockerfile z náhodných míst (což taky nikoho netankuje) na internetu stáhnout požadované image, on tam dodá tu svou appku a ono to běží (a nezajímá ho, že třeba ta db a webserver je v každé normální distribuci nainstalovatelná jedním příkazem).
11.12.2018 12:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Dokonce až grafické. No na tom se neshodneme, iptables od počátku dělám výhradně na řádce a i různé nástavby (kdysi jsem tu psal o fireholu) jsou taky jen na řádce.Jde o kognitivní offload. Aby sis nemusel pamatovat všechny možné detaily, tak je můžeš externalizovat do grafického rozhraní. To může být klidně i na příkazové řádce, pointou je, že ti má umožnit zobrazit, prozkoumat a vybrat si možnosti které jsou k dispozici. Jeden čas jsem takhle používat například Vuurmuur.
Spíš ji neznají a ani po tom nepátrají. Znám několik programátorů, kteří více či méně ostentativně dávají najevo, jak je aktuální stav a aktuální prostředky vůbec nezajímají a oni to všechno udělají pochopitelně nejlépe.To je občas skutečně pravda, ale často je to taky tím, že prostě nic není.
V tomto vidím jednu z příčin úspěchu dockeru. Kontejnery tady existují desítky let, v linuxu jsou okamžitě použitelné, ale až docker se rozšířil a podle mě kvůli tomu, že se dotyčný nemusí zabývat instalací ničeho, jen se mu na základě dockerfile z náhodných míst (což taky nikoho netankuje) na internetu stáhnout požadované image, on tam dodá tu svou appku a ono to běží (a nezajímá ho, že třeba ta db a webserver je v každé normální distribuci nainstalovatelná jedním příkazem).Docker je rozšířil hlavně protože je udělal méně náročné, než klasické virtuály.
11.12.2018 13:05
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Docker je rozšířil hlavně protože je udělal méně náročné, než klasické virtuály.S tím by se dalo polemizovat, ale i právě proto jsem psal kontejnery. Když si připravím template kontejner (v mém případě jail, nspawn), tak jeho clon je záležitostí několika sekund a v tomto směru se to jinak neliší od dockeru. Dělám to tam běžně, něco chci vyzkoušet, tak udělám clon stávajícího kontejneru (pár sekund), otestuju a případně zahodím. Nspawn na to má od počátku i parametr, jedním příkazem lze udělat clon stávajícího systému, připojit se do něj, tam si bezpečně něco vyzkoušet a po opuštění je ten clon automaticky odstraněn. Jenže právě u jistých lidí pozoruju, že je něco tak podřadného jako linux v tom template vůbec nezajímá, to se prostě "odněkud" stáhne jako docker image.
11.12.2018 13:30
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 13:45
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
jexec).
Spousta base programů má navíc parametr --jail, takže třeba práce s balíčky v konkrétním konjterneru můžeš opět provádět z hostitelského prostředí:
pkg -j ttrss remove mc Proceed with deinstalling packages? [y/N]: y [ttrss] [1/1] Deinstalling mc-4.8.21... [ttrss] [1/1] Deleting files for mc-4.8.21: 100%Totéž pro služby,
service má opět parametr -j, tj z vnějšku můžeš spravovat služby.
Takže vlastně všechno můžeš dělat z vnějšího prostředí a to buď pomocí konkrétních příkazů, které umějí pracovat s jaily a nebo pomocí obecného jexec.
12.12.2018 20:46
xkucf03 | skóre: 49
| blog: xkucf03
Dokonce až grafické. No na tom se neshodneme, iptables od počátku dělám výhradně na řádce a i různé nástavby (kdysi jsem tu psal o fireholu) jsou taky jen na řádce.
A už si zvykáš na nftables? :-)
Osobně jsem teď na jednom systému s úlevou použil ufw. Dlouhé roky jsem oprašoval svůj skript s iptables, který jsem vždy jen trochu poupravil, ale tentokrát jsem si řekl, že místo abych konfiguroval automatické spouštění mého skriptu po startu systému, tak se zkusím naučit UFW. A ten základ jsem měl hotový hned a je to celkem fajn. Určitě to nějaká omezení má, ale zatím mi to stačí. Ke svému skriptu se můžu vrátit vždycky.
Spíš mne zamrzelo, že se objevil další způsob, jak konfigurovat síť. Původně jsem byl zvyklý na /etc/network/interfaces, pak přišel NetworkManager, pak systemd a teď se konfigurace sítě, kterou jsem zadal při instalaci, objevila v nějakém cloudovém konfiguráku. Musel jsem grepovat /etc na IP adresu, abych to našel.
12.12.2018 21:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
A už si zvykáš na nftables?Zatím ne, ale jsem poměrně nadšen (nadšení z nové věci) z PF, který používám na FreeBSD. Hlavně se mi líbí, že to umí by default množiny pro IP, porty, tj není potřeba hromada pravidel tak jak u
iptables (vím, že existují ipset). Takže třeba jedním řádkem povolit všechny potřebné služby na množině strojů:
# webservers
pass in on $iface proto tcp to {ip1, ip2, ... ip200} port { 22, 80, 443 }
Navíc je to chytré, takže pokud tam admin zadá místo množin 200*3 různých řádků, tak to zoptimalizuje a ve výpisu už jsou použity množiny. Tj to lze uložit znovu a rázem to má o 599 řádků méně.
Množiny lze i pojmenovávat a používat na různých místech fw.
(Ale jak říkám, spíš je to po letech s iptables čisté nadšení z nové věci. Určitě to bude mít svě quirky.)
Dlouhé roky jsem oprašoval svůj skript s iptables
A můžu se zeptat k čemu je potřeba skript a co je na tom k oprašování? Při instalaci nového serveru jen na FW zakážu všechno a povolím vybrané porty pro služby dostupné z netu a je hotovo.
Na routeru je těch pravidel jen o něco víc a místo INPUT se tam řeší hlavně FORWARD (nezapomenout na oba směry).
Nevím, nikdy jsem v tom větší problém neviděl. A pokud to z nějakého důvodu je větší problém, tak se vždy ukázalo, že problém byl v nevhodném návrhu sítě a také tam by se to mělo řešit. (Ale ano, znám lidi, jejichž iptables vypadají jako dvacetirozměrné bludiště a jsou náležitě hrdí na nečitelné kombinace MANGLE, NATů, hraní si s flagy a kombinací route rules. Ať si to užijou.)
Spíš mne zamrzelo, že se objevil další způsob, jak konfigurovat síť.Jo no, na tohle už jsem si taky v nějakém článku postěžoval. Linux vyrostl na síti a 20 let neměl žádné schopné nastavení sítě. V tomto směru jsem rád za
systemd-networkd, protože to je první Network Manager ( ), kde není opruz nastavit třeba 30 IP a 20 statických rout.
12.12.2018 21:58
xkucf03 | skóre: 49
| blog: xkucf03
), kde není opruz nastavit třeba 30 IP a 20 statických rout.
12.12.2018 21:58
xkucf03 | skóre: 49
| blog: xkucf03
A můžu se zeptat k čemu je potřeba skript a co je na tom k oprašování? Při instalaci nového serveru jen na FW zakážu všechno a povolím vybrané porty pro služby dostupné z netu a je hotovo.
Na každém stroji jsou jiné služby. Někde chci odmítat, někde zahazovat, někde logovat... případně tam jsou nějaké limity. Postupně se to vyvíjelo. Pak jsem začal přidávat blokování odchozího provozu (navazovat ven smějí jen vybraní uživatelé/skupiny).
Pak jsem měl pocit, že do toho systému ručně bastlím něco, co by mělo být řešeno nějak systémově, tak jsem zkusil použít nativní prostředky, které nabízí daná distribuce tzn. to ufw. Základní pravidla jsem v tom udělal a dál uvidím.
BTW: jak to spouštíš ty? Jako skript s iptables příkazy nebo to proženeš přes iptables-save a pak načítáš přes iptables-restore? Nebo píšeš vstup pro iptables-restore ručně?
12.12.2018 22:08
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
BTW: jak to spouštíš ty?Já se vždy snažím používat služeb dané distribuce. Pomocí série příkazů
iptables si nastavím FW, potom dám (v Debianu) netfilter-persistent save a je to. Tj při bootu se o načtení postará ta služba (distribuční skript). Ve (starém) centosu totéž přes service iptables save. Ve FreeBSD se PF konfiguruje souborem, takže upravím pf.conf soubor, proženu ho kontrolou a nechám načíst. Při bootu se o jeho načtení opět postará rc systém.
12.12.2018 22:16
xkucf03 | skóre: 49
| blog: xkucf03
Zrovna IP tables potřebují prostě grafické rozhraní víc než co jiného.
Já třeba považuji za ideální současný stav. Podle situace můžu použít přímo ioctl/netlink, příkaz iptables nebo nějakou více či méně cool nadstavbu (nebo si třeba napsat vlastní). Každý z těch přístupů má své výhody a nevýhody a každý se hodí na něco jiného. V tom vidím obrovskou sílu té "vertikální modularity", o které jsem mluvil předtím; prostě si vyberu, ve kterém patře nastoupím.
Koneckonců i třeba v C++, na které je zvykem plivatNeměl jsi ještě donedávna patičku utahující si z C++? (Je ale možné, že si to s někym pletu.)
jednak patřím dlouhodobě spíš k těm, kteří se C++ zastávají.Také jsem to tak dříve měl, nicméně ty poslední verze a vývoj okolo nich mi to dost ztěžují...
Mimochodem,
Počet inodů (větví struktury) je navíc omezen na číslo, jenž se v horších případech pohybuje v řádu desítek až stovek tisíc, maximálně však pár milionů prvků v jednom adresáři.
Čím je omezen?
mike@unicorn:/srv/debug/cvt/a> ls -U | wc -l 10000000 mike@unicorn:/srv/debug/cvt/a> time ls -U >/dev/null real 0m3,828s user 0m1,321s sys 0m2,507s mike@unicorn:/srv/debug/cvt/a> time cat 5769168 real 0m0,005s user 0m0,000s sys 0m0,005s
Přičemž těch 5 ms je režie okolo, stejnou hodnotu jsem dostal i v adresáři, kde je jen jeden soubor.
11.12.2018 09:58
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Čím je omezen?Implementací filesystému?
11.12.2018 10:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 11:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
[ root@sandro ~]# tune2fs -l /dev/sandro/data
...
Inode count: 469762048
11.12.2018 12:05
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 10:40
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
$ time ls -U | wc -l 958082 real 0m28.581s user 0m0.256s sys 0m1.336sDruhé čtení:
$ time ls -U | wc -l 958157 real 0m0.940sSAS HDD pole, SAS 12G Ve tvém případě ten čas odpovídá prvnímu nebo opakovanému čtení? Je také rozdíl, zda se jedná o čerstvě vytvořený adr. nebo o silně používaný. V tomto případě tímto adr prošlo stovky miliónů souborů, možná miliarda. V největším zaplnění tam bylo 12mil souborů a jen
ls | wc -l trvalo desítky minut.
Navíc ten tvůj příklad jistě trochu schválně obsahuje to -U a navíc se vůbec neptá na vlastnosti těch souborů. V typickém případě, pokud budu chtít "selectovat" např. soubory starší než, tak to znamená ještě pro každý soubor výlet do inode a tedy minimálně jeden další seek. Zatímco pro DB je select nad 12mil položkami hotový do 1s, tak tady je to na hodiny (optimálně mezi 1-2h*).
*) Mějme SAS disky, 200iops každý z nich, mějme nejlepší RAID10 na světě, 12disků = 12*200=2400iops. Mějme nejlepší FS na světě, kde výlet do inode zabere 1 iops, tedy pro 12mil souborů = 83minut. V nejideálnějším případě.
Ve tvém případě ten čas odpovídá prvnímu nebo opakovanému čtení?
V mém případě byly výsledky víceméně stejné, protože jsem ty soubory krátce předtím vytvořil. Ale to byl záměr, protože mne zajímalo, jak efektivně si s takovým počtem souborů poradí filesystém, ne jak rychle mi seekuje disk. Koneckonců se podívej na rozdíl user+sys vs. real u toho tvého prvního příkladu.
Navíc ten tvůj příklad jistě trochu schválně obsahuje to -U
Opět zcela záměrně, protože mne zajímá, jak se chová filesystém, ne jak efektivní sort má příkaz ls. Z podobného důvodu je tam i ten zahozený výstup. Bez "-U" byl výsledek asi 11.6 sekundy, přičemž prakticky celý nárůst měl podle očekávání na svědomí userspace.
a navíc se vůbec neptá na vlastnosti těch souborů
Pro "ls -lU" mám typicky real 26.9s, user 10.3s, sys 16.6s (s rozptylem v desetinách sekundy). Takže asi tak 2.7μs na položku, z toho 1.7μs v jádře. (Ano, zajímá mne, jak to zvládá filesystém, ne jak mám rychlý disk.)
V typickém případě, pokud budu chtít "selectovat" např. soubory starší než, tak to znamená ještě pro každý soubor výlet do inode a tedy minimálně jeden další seek. Zatímco pro DB je select nad 12mil položkami hotový do 1s, tak tady je to na hodiny (optimálně mezi 1-2h*).Ano, filesystém není databáze. Pokud budete potřebovat dělat takovouhle operaci často a nad filesystémem, děláte to blbě, použijte databázi. Na druhou stranu ta databáze to nedělá zázračně, ta databáze na to má index. A ten se i s rozhraním "select" dá doprogramovat i do toho filesystému, kdyby to někdo fakt hodně potřeboval.
11.12.2018 15:06
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Na druhou stranu ta databáze to nedělá zázračně, ta databáze na to má index.Zrovna na tohle není potřeba nasazovat index. Důvod, proč je tohle u toho FS tak pomalé, je nutnost seeku do každé inode. Kdyby tato metadata byla součástí adresářové struktury, tak by to bylo skoro stejně rychlé jako vypsání názvů souborů, stačilo by přečíst jen ten adresářový soubor (který by byl teda o něco větší). Full scan nad tabulkou obsahující 106 mil. podobných metadat je na pomalých sata hdd hotový za 24s. 864tis. položek potom do 400ms. Ano, rozumím, že na takto navrženém FS by se těžko realizovaly třeba hardlinky apod. a že vývoj klasických FS šel jiným směrem.
12.12.2018 21:06
xkucf03 | skóre: 49
| blog: xkucf03
Tohle všechno je ale o vnitřním uložení dat a šlo by to implementovat i jako FS, ne? Vždyť to je vlastně jen API, za kterým si můžeš naprogramovat, co chceš. Problém je spíš v tom, že to API některé věci neumožňuje -- např. prohlásit soubory za objekty a volat jejich libovolné objekty, nebo poskytnout dotazovací rozhraní (to tam jde ještě nějak dohackovat přes virtuální adresáře), nebo tu byla řeč o transakcích.
V podstatě by ale neměl být problém s tím FS komunikovat i jinou cestou a tam mít i jiné API než to klasické souborové. Třeba mít někde doménový soket a přes něj si s FS posílat zprávy nebo mít někde nějakou sadu funkcí. Přes to by šly udělat i ty transakce, triggery atd.
Proveditelné je prakticky všechno. Spíš je otázka architektury, jestli tyhle věci cpát do jádra nebo to udělat přes ExtFUSE (s eBPF) nebo na vyšší úrovni.
12.12.2018 21:39
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
$ time find Tree | wc -l 166244 real 1m27.177s user 0m0.264s sys 0m1.367sZFS ekvivalent RAID-10 nad 6x SATA disk. Aby toho nebylo málo, tak OS nevím proč ta načtená metadata velice rychle zapomene a za pár minut se tohle opakuje. A není to tím, že by to zahodil po změně (to bych ještě bral), ale v tomto případě se jedná o strom s cca 10tis dalšími adresáři v podstromech a navíc se nemění. Proč to zahazuje celé je mi záhadou. Takže ne, tohle používat fakt nebudu. Kdysi dávno jsem zkoušel exportovat těch 300mil souborů z MySQL na tehdy doporučovaný ReiserFS a po několika dnech jsem to vzdal. Prostě FS je kolekce emulovaných pásek a až nad tím se staví systémy pro ukládání dat.
(která navíc musí být v Dockerfile označená pomocí VOLUME)Nemusí.
 11.12.2018 14:59
cezz | skóre: 24
| blog: dm6
11.12.2018 16:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 15:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 14:59
cezz | skóre: 24
| blog: dm6
11.12.2018 16:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.12.2018 15:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
WORKDIR. Ale vzhmedem k tomu, že WORKDIR se může kdykoli změnit, je samozřejmě lepší mít v rámci konteineru cestu absolutní, ale třeba pro lokální Laravel development environment běžně dělám ./:./, což mi kód aplikace namountuje do adresáře který servíruje NGINX s PHP-FPM a je zároveň nastaven na WORKDIR, abych mohl přes exec volat artisan.
[mark_stopka@docker-host-01 https-lb-01-a.perlur.cloud]$ cat docker-compose.yml
version: '3'
networks:
proxy:
external: true
services:
# The reverse proxy service (Træfik)
https-lb-01-a_perlur_cloud:
image: traefik # The official Traefik docker image
container_name: https-lb-01-a.perlur.cloud
command: --api --docker # Enables the web UI and tells Træfik to listen to docker
ports:
- 80:80 # Add HTTP port
- 443:443 # The HTTPS port
expose:
- 8080
volumes:
- /var/run/docker.sock:/var/run/docker.sock # So that Traefik can listen to the Docker events
- ./conf/traefik.toml:/etc/traefik/traefik.toml # External Traefik configuration file
- ./conf/.htpasswd:/etc/traefik/traefik-ui.htpasswd # External BASIC AUTH log-in and password file for Traefik UI
labels:
- "traefik.backend=traefik"
- "traefik.enable=true"
- "traefik.frontend.rule=Host:https-lb-01-a.perlur.cloud"
- "traefik.port=8080"
- "traefik.frontend.entryPoints=http,https"
- "traefik.frontend.auth.basic.usersFile=/etc/traefik/traefik-ui.htpasswd"
networks:
- proxy
[mark_stopka@docker-host-01 https-lb-01-a.perlur.cloud]$
11.12.2018 16:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
docker run -v "./conf/:/etc/project/:z" --rm -it project
./usr/bin/docker-current: Error response from daemon: create ./conf/: "./conf/" includes invalid characters for a local volume name, only "[a-zA-Z0-9][a-zA-Z0-9_.-]" are allowed. If you intented to pass a host directory, use absolute path.Pokud tam dáš bez lomítka na konci, tak se to nenamountuje vůbec, ale neselže to (selže až aplikace, že tam nic není) a pokud to pustíš jako
docker run -v "`pwd`/conf/:/etc/project/:z" --rm -it projecttak to funguje.
[mark_stopka@docker-host-01 MarkoEscobarRoboZonky]$ cat docker-compose.yml
version: '3'
services:
# RoboZonky service
MarcoEscobarRoboZonky:
image: robozonky/robozonky:testing # The official RoboZonky Docker image
deploy:
replicas: 1
restart_policy:
condition: on-failure
volumes:
- ./conf:/etc/robozonky
- ./run:/var/robozonky
environment:
- TZ=Europe/Prague
restart: "always"
labels:
- traefik.enable=false
[mark_stopka@docker-host-01 MarkoEscobarRoboZonky]$
11.12.2018 22:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.12.2018 11:05
cezz | skóre: 24
| blog: dm6
Pokud tam dáš bez lomítka na konci, tak se to nenamountuje vůbec, ale neselže tolol, Docker v kostce.
12.12.2018 11:04
cezz | skóre: 24
| blog: dm6
12.12.2018 12:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.12.2018 14:30
cezz | skóre: 24
| blog: dm6
$ mkdir -p some/long/path $ docker run -ti --rm -v $PWD/some:/some alpine ls -R /some /some: long /some/long: path /some/long/path:
12.12.2018 14:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud tam dáš bez lomítka na konci, tak se to nenamountuje vůbec, ale neselže tojsem psal k ukázce relativní cesty
./code/. Pokud zadáš jen code, tak to nefunguje.
14.12.2018 11:31
cezz | skóre: 24
| blog: dm6
$ docker run -ti --rm -v ./some:/some alpine docker: Error response from daemon: create ./some: "./some" includes invalid characters for a local volume name, only "[a-zA-Z0-9][a-zA-Z0-9_.-]" are allowed. If you intended to pass a host directory, use absolute path.Ked nepouzijes absolutnu cestu docker predpoklada, ze chces miesto toho pouzit named volume. V priklade vyssie to zlyha, lebo su tam nejake znaky ktore sa v nazve volume nemozu vyskytovat. Cize ked urobis toto (co je myslim presne tvoj pripad):
docker run -ti --rm -v some:/some alpineTak to znamena, ze chces vytvorit volume ktory sa vola
some a pripojit ho ako /some v kontajneri:
$ docker volume ls | grep some local someCize ono to nezlyha potichu, ale urobi presne to o co si poziadal. Pouziva sa to napriklad vtedy ak chces zdielat adresar medzi dvoma kontajnermi, tak proste spustis druhy kontajner kde tiez pripojis
some..
11.12.2018 23:58
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
12.12.2018 00:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ako obyčajne som blog dal na ranu, komp potom telefón a dočítal v kompe. Asi by si mal písať knihy kámo :)Píšu (resp. teď čekám na výsledky konkrétních experimentů s tinySelfem). Jinak jsem měl tak trochu pocit, že by z toho šla udělat menší kniha, tak do sto stránek, kde by šlo myšlenky lépe rozvést a přidat různé featury, jako třeba uml diagramy a tak, ale jednak jsem to nechtěl psát dva roky a pak taky by to neplnilo účel, kterým bylo převážně vidět reakce.
12.12.2018 00:55
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
12.12.2018 01:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
☑ Thinking Forth (25€)
☑ The Victorian Internet (15€)
☑ Newton’s Principia (18€)
☑ Pragmatic Thinking and Learning: Refactor Your Wetware (Pragmatic Programmers) (19€)
☑ Technics and Human Development (vol 1.) (21€) (Kay)
☑ The Myth of the Machine (21€)
a část knížek z Alan Kay’s advice to computer science students (Envisioning Information je skvostná).
12.12.2018 15:25
xkucf03 | skóre: 49
| blog: xkucf03
Předně bych rád deklaroval, že tu mluvím sám o sobě. Když budu psát, že „je něco zapotřebí“, „možné“, nebo „schůdné“, myslím tím „zapotřebí pro mě“, „možné pro mě“, nebo „schůdné pro mě“.
Beru na vědomí.
V posledních letech jsem pracoval pro několik firem vytvářejících software. V některých případech jsem se zapojil do již existujících týmů, v ostatních jsem začínal spolu s několika dalšími programátory „na zelené louce“. Často jsem se přímo podílel na návrhu architektury, pokud jsem jí rovnou nevymýšlel sám. Pracuji jako „backendový programátor“. Mým popisem práce je typicky vytvářet systémy, které načítají, zpracovávají a ukládají různá data, parsují všemožné formáty, volají různé programy, či interagují s ostatními systémy a zařízeními.
Ano, prošel jsi řadou firem, ale pořád to reprezentuje jen zlomek způsobů, jakými se počítače používají. A teď je otázka, zda vytvářet operační systém a) pro tento zlomek (resp. pro každý zlomek jeho vlastní OS), nebo b) zcela minimalistický OS, který poskytne jen ten společný základ (např. pro 98 % případů užití) c) nastavit si ten cíl na jiném procentu případů užití a vytvořit něco, co většině poskytne většinu požadovaných funkcí a zároveň to většinu nebude obtěžovat nějakými přílišnými funkcemi navíc.
Vypadá to, že jdeme cestou c). Cesta b) by asi znamenala, osekat to na abstrakci HW (což je asi nejzásadnější funkce OS a potřebují ji všichni, kromě nějakých těch 2 % se speciálními potřebami) a zbytek ať si dodělá každý sám. Cesta a) podle mého nedává moc smysl (musel bys mít hodně speciální potřeby a hodně velký rozpočet, aby to bylo vůbec schůdné – a schůdné ještě neznamená celkově efektivní a smysluplné).
Je otázka, jestli nejít spíš cestou b) místo c). V podstatě se něco jako b) už děje, ale na jiné úrovni: máme základ operačního systému (GNU/Linux) a nad tím různá desktopová prostředí, která představují další vrstvu s vlastními abstrakcemi, funkcemi a filosofií. Teoreticky by to šlo rozříznout níž a tu hranici mít někde těsně nad HW abstrakcí – ta by byla společná a ten vršek by byl vyměnitelný tzn. někdo by si tam posadil vršek emulující současný POSIXový systém a ty by sis tam posadil třeba vršek emulující lispovský nebo smalltalkovský stroj.
Nemám na to úplně vyhraněný názor, možná by to bylo dobré, možná by to naopak vedlo k vytvoření ostrůvků, které k sobě mají daleko a těžko spolupracují. Zatímco dneska, když máš ten lisp nebo smalltalk nad POSIXem resp. GNU/Linuxem, tak přeci jen můžeš snáz spolupracovat s těmi, kteří smalltalk ani lisp nepoužívají a jedou přímo nad tím POSIXem nebo nad ním mají jiné vrstvy.
A pak je otázka, kam v tom b) umístit takové věci jako TCP a IP nebo šifrovací algoritmy – patří do toho společného základu nebo až do té nadstavby a měla by si je každá nadstavba implementovat po svém?
Ve dvou z mých předchozích zaměstnáních jsme museli obcházet omezený počet inodů na složku retardací jako BalancedDiscStorage, či ukládáním souborů do tří podsložek složených z prvních tří písmen MD5 hashe souboru.
Linux (případně jiná jádra či OS) ti poskytuje rozhraní, aby sis napsal vlastní souborový systém. Tzn. bude to schované za tou samou abstrakcí/metaforou (takže to můžou používat všichni a lze tuto vrstvu vyměňovat bez nutnosti měnit jiné vrstvy), ale bude to mít tebou požadované vlastnosti (např. možnost efektivně uložit neomezené množství souborů do adresáře a do souborového systému – takže pak můžeš rozpadnou data na tak malé kousky, abys nemusel používat datové formáty a ztratí se hranice mezi tím, kde končí hierarchie souborového systému a kde začíná hierarchie vnitřního formátu daného souboru tzn. např. místo XML textového uzlu nebo atributu budeš mít zase soubor, který bude v jedné hierarchii se všemi ostatními soubory a uzly uloženými původně v jiných souborech).
Otázka je, jak do toho zabudovat podporu transakcí, atomicitu – a tady prostor pro zlepšení vidím.
Další věc je indexování a efektivní vyhledávání – nicméně to už by šlo řešit v rámci současných API – napsal by sis vlastní FS a ten by poskytoval i virtuální adresáře, které by byly něco jako databázové pohledy nebo funkce – vlezl bys do neexistujícího adresáře jehož název by byl textem dotazu a FS by ti vrátil výsledky – něco jako cd /mnt/.dotazy; cd "SELECT * FROM soubory WHERE ..."; ls -l (případně by tam byly další virtuální podadresáře, které by představovaly parametry dotazu). A opravdu to nemusí být SQL – použil jsem ho jen pro názornost.
Proč tu myšlenku nedotáhnout do konce a neudělat malé programy z každé funkce a metody vašeho programu? Ta by naoplátku mohla komunikovat s metodami a funkcemi ostatních programů.
Co ti vlastně brání si jako PID 1 spustit (emacs|python|smalltalk|perl|self|.*) a všechny programy si implementovat jako funkce/objekty v daném jazyce? Vadí ti, že ten OS poskytuje i zbytečnou infrastrukturu, kterou nevyužiješ a která se duplikuje s tím, co by sis napsal sám v tom svém jazyce? Nebo ti tam naopak něco chybí? Co? Nebo je to jen moc práce a málo užitku? Nebo by to měl napsat někdo jiný a ty bys to jen použil? (ideální případ :-)
but functions must all have the signature char function(const char )
Ta signatura vypadá jinak. Jednak máš dva výstupní proudy bajtů (nikoli hodnotu) a jeden vstupní a jednak v té závorce není const char ale pole bajtových řetězců (a když budeme předpokládat výchozí kódování platformy, tak pole textových řetězců), což je celkem mocná struktura.
A shodou okolností se tímhle zabývám, už tu v diskusích něco prosáklo (1, 2, 3, 4, 5, 6 ). Je to ještě hodně čerstvé, ale když už je o tom řeč: Relational pipes (Relační roury).
Současná počítačová kultura je posedlá parsery a externími popisy dat, jenž by však mohly nést strukturu samy o sobě. Každý den jsou nesmírná kvanta výpočetních cyklů zcela nesmyslně plýtvána na konverzi surových bajtů na struktury a zase zpět
V zásadě jsou tam dvě úskalí 1) bezpečnost a implementace v HW (paměť, CPU), 2) lidé píší v různých programovacích jazycích. Ten druhý bod lze řešit tím, že vynutíš jeden jazyk (viz zmínka o PID 1 výše) nebo použiješ GraalVM. S tím prvním bodem nic moc dělat nejde (musel bys v podstatě zbourat celý IT obor a začít znovu nebo oželet výkon a proložit to nějakou poměrně tlustou vrstvou abstrakce, která poskytne rozhraní k úplně jinému stroji, než je ten fyzický).
Nemalá část mé práce jako programátora je jen o parsování a převodech dat, jenž kdyby měla strukturu, tak by byla upravitelná jednoduchou transformací. Tady vem kus stromu a přesuň ho sem.
Tohle je řešitelné knihovnami (aby ses nemusel vrtat v těch bitech a bajtech). Pak to chce nějakou jednotnou abstrakci, abys s těmi naparsovanými daty mohl pracovat stejným způsobem bez ohledu na původní fyzický formát. Tohle jsem dělal před čtyřmi lety jako prototyp alt2xml. Umožňuje to se na data v různých formátech dívat stejným způsobem – vždy je z toho strom uzlů (resp. před tím ještě posloupnost událostí v jednotném formátu), bez ohledu na to, zda data byla původně INI, XML, JSON, souborový systém nebo něco jiného.
Ale proč je neposlat už složené?
Odpověď je pořád stejná: používat GraalVM (případně si napsat jeho obdobu) nebo vynutit použití jednoho jazyka a uzavřít se do jeho VM místo toho, aby ses pohyboval v OS.
Data se kterými pracujete by mohla být sebe-popisná, ale nejsou. Jednotlivé položky by mohly obsahovat datové typy, ale i dokumentaci. A nemají. Proč? Protože je v módě mít zvlášť hromadu binárních dat, a zvlášť jejich externí popis. Vážně to tak chceme, vážně to má nějaké výhody?
Přibalovat ke všemu metadata je značně neefektivní. Metadata můžou zabírat víc místa než samotná data. V praxi se používají oba přístupy, jak samopopisné formáty, tak čistá data s minimem metadat. Většinou mi přijde výhodnější ta metadata (slovník/schéma) vystavit na jedno místo a jinde na něj už jen odkazovat. V OS/VM tohle můžeš udělat taky, můžeš mít nějaký registr schémat a jednotlivé předávané zprávy už budou obsahovat jen referenci do tohoto registru. V objektovém paradigmatu ten registr obsahuje neměnné objekty a zprávy jsou objekty které obsahují odkaz na objekt určitého schématu v registru. To schůdné a rozumné je. Ale přibalovat (rozkopírovat) metadata ke všem datům je ve většině případů špatný přístup.
Nemluvím tady o parsování XML parserem, mluvím tu o přímém načtení do paměti
Protože je to většinou buď závislé na platformě/jazyku nebo je to nebezpečné nebo obojí.
O tom že na strukturovaná data o Frantovi Putšálkovi v kolekci lidí přistoupím pomocí people[0].name, místo toho abych v jednom formátu dělal doc.getElementByTagName("person")[0].name.value a v druhém doc["people"][0]["name"].
Tohle řeším v tom alt2xml (ano, je to jen prototyp, ale můžeš si napsat něco lepšího).
O tom že data popisují sebe sama přímo svou strukturou, ne externím popisem.
Podle mého je lepší mít externí popis ve strojově čitelném formátu (schéma) uložený na jednom místě a jen se na něj odkazovat, než mít všechna data zahnojená spoustou metadat.
Souborové systémy nevnímáme jako databáze. Nedochází nám, že jejich struktura jsou hierarchická key-value data.
Já je takhle vnímám a někdy jsem je tak i použil. Např. pro konfiguraci je to použitelné velice dobře. Nemusíš vymýšlet nějaký formát nebo používat parsery a generátory existujících formátů a prostě jen ty objekty rozpadneš na stromovou strukturu adresářů a souborů. Pokud bys těch objektů měl opravdu hodně, tak si budeš muset napsat vlastní FS, ale to se většiny případů užití netýká a stávající FS bohatě dostačují. Ta abstrakce poskytovaná OS dostačuje taky (až na ty transakce).
Programy bereme jako binární bloby, místo klubka propojených funkcí a struktur a objektů majících potřebu komunikovat se sebou, ale i s okolním světem.
To je spíš otázka návrhu a konkrétní implementace. ESR v knize The Art of Unix Programming popisuje vzor polyvalentní program.
Ano, musíš ta rozhraní explicitně vystavit. Ale už jsme o tom jednou mluvili. Tohle není technický problém, ale spíš problém organizace práce. S vhodnými nástroji tě vystavení těch rozhraní nic nestojí, takže rozdíl oproti jazyku/platformě, která ta rozhraní vystavuje automaticky a vždy prakticky není. Zásadní ale je zpětná kompatibilita – pokud dovolíš ostatním navázat svoje programy na tvé funkce a pak jim to v příští verzi rozbiješ, protože funkce refaktoruješ, tak z tebe nebudou mít radost. Poskytnout nějaké API je velký závazek a spousta práce – ovšem problém není to realizovat technicky, ale problém je udržet tu zpětnou kompatibilitu. To je to, co vyžaduje nejvíc úsilí a u čeho nejvíc bolí hlava (jak to navrhnout tak, abys to v příští verzi nemusel nekompatibilně změnit).
Víte co tomu chybí? Reflexe a struktura. Pokud si nepřečtete manuál, tak naprosto netušíte co kam zapsat.
Tohle by se dalo řešit přes rozšířené atributy těch virtuálních souborů v tom virtuálním FS. Stačí si domluvit názvy atributů, do kterých se bude psát dokumentace a metadata. S návratovými hodnotami je trochu problém stejně jako s předáváním strukturovaných dat. Např. když budeš chtít LEDce předat dvojici hodnot (barva, intenzita), tak jak to nacpeš do funkcí, které vystavuje FS? To API nějaké limity má a je na něm vidět, že má sloužit k ukládání a čtení dat, nikoli k volání libovolných funkcí. I když z poměrně velké míry to lze k tomu volání funkcí použít. Tam, kde ti rozhraní FS přestává stačit, je potřeba sáhnout už po něčem jako D-Bus nebo JMX, které na tenhle způsob práce stavěné jsou.
Já chápu, proč vznikly. Vážně. Ve své době to bylo naprosto racionální a nebylo nic lepšího. Ale proč proboha používat nestrukturovaný formát přenosu binárních dat i dneska, když veškerá komunikace je strukturovaná
Takové SCTP jde o dost dál než TCP (nebo UDP) a mj. předává zprávy místo aby jen propojovalo dvě roury přenášející proudy bajtů. Vnitřní strukturu zpráv neřeší, ale to je podle mého dobře, protože to je úloha pro jinou vrstvu. Když zůstaneme v telco světě, tak by se tam (alespoň tehdy) použilo ASN.1 pro strukturování těch dat.
A tak je to se vším. Skoro nikdy nepotřebujete proud bajtů, ale posílat zprávy, které jsou prakticky vždy hierarchie key-val dat, nebo pole.
Je to tak, ale většinou nad tím lidé a) nepřemýšlí nebo nemají prostor (musí něco zmastit v daném čase a rozpočtu) nebo b) si myslí, že mají výrazně jiné potřeby než ostatní a vytvoří si nový formát/protokol c) přemýšlí nad tím, mají snahu, udělají obecný formát/protokol, který můžou používat i ostatní, ale ti se jim vysmějí a řeknou jim, že mají speciální potřeby a ten obecný formát/protokol je nepokrývá. Najít společnou řeč je poměrně těžké a zdaleka ne vždy se to povede.
ZeroMQ byla podle mého názoru krok správným směrem, ale zatím mi přijde, že se nedočkala moc vřelého přijetí.
O ZeroMQ jsem si koupil knížku a postupně se jí prokousávám, ale přijde mi, že to zase tak moc "zero" není a té komplexity je tam přeci jen poměrně dost. Nicméně celkem sympatické mi to je a nějaké využití pro to vidím.
Parametry příkazové řádky
To pole mi přijde jako vhodně zvolená struktura. Cokoli jednoduššího (jeden řetězec, pole bajtů) by bylo nedostatečné. A cokoli složitějšího by bylo zase příliš náročné na zpracování a na používání.
V podstatě se na to můžeš dívat jako na jazyk, který čteš lexerem/parserem, akorát můžeš vynechat ten lexer, protože data už máš rozsekaná na jednotlivé tokeny. Proto taky nemám rád parametry ve stylu "--klíč=nějaká hodnota" a jsem radši, když klíč a hodnota jsou dva po sobě jdoucí prvky pole: "--klíč" "nějaká hodnota".
Taky mne trochu mrzí, že si každý vymýšlí vlastní jazyk, pro parsování těch parametrů, ale s tím asi nic nenaděláme. Existují různá doporučení a konvence. Obecně preferuji styl "--parametr" "hodnota" "--volba-bez-parametru" případně tam může být první parametr jako (pod)příkaz: program příkaz --parametr1 ...
Když vymyslíš vhodný formát pro předávání strukturovaných dat na příkazové řádce, tak se to třeba ujme. Ta infrastruktura/API to umožňuje – řeší za tebe tokenizaci (díky tomu, že je to pole, tak máš jasně vyznačené hranice mezi jednotlivými tokeny, takže tohle nemusíš řešit).
Stejný problém máš ale u hlaviček metod/funkcí. Většina jazyků podporuje sekvenční parametry, někde můžou být výchozí hodnoty a nepovinné parametry a některé jazyky mají pojmenované parametry – takže tam je to taky pole (případně mapa). To ti nevadí? Není to málo? Nakonec se to někdy řeší tak, že metoda/funkce má právě jeden parametr a ten je typu objekt (nějaký konkrétní objekt) a až v něm jsou jednotlivé parametry. Přesto se často píší metody/funkce tak, že mají třeba tři parametry tzn. na vstupu je vlastně pole, kde víš, že na první pozici je tohle, na druhé tamto... akorát ti k tomu jazyk dává syntaktický cukr a rovnou ti prvky toho pole naplní do lokálních proměnných. Asi nejde obecně říct, který z těch přístupů je lepší. Pokud je funkce z principu jednoduchá a vím, že bude mít pořád ty tři parametry, tak ji napíši jako funkci o třech parametrech. Bude se to lépe používat. Naopak pokud tuším, že v budoucnu těch parametrů bude třeba deset, tak tam dám ten parametr jen jeden a postupně budu rozšiřovat jeho třídu.
Pokud jsou argumenty složitější, stane se z toho rychle onanie skládání stringů, kde si navíc nemůžete být jisti bezpečností, nemáte garanci podporované znakové sady, musíte sanitizovat uživatelský vstup a volané podprogramy navíc stále můžou vykazovat chování, které je všechno, jen ne triviální.
Viz vzor vzor polyvalentní program výše. Ono sice jde psát CLI rozhraní tak, aby bylo dobře použitelné jak pro člověka, tak jako API, ale není to samozřejmost. Často je lepší cesta program rozdělit na CLI rozhraní (případně GUI, síťové rozhraní atd.) a knihovnu.
BTW: ta objektovost byla původní myšlenkou GNOME: GNU Network Object Model Environment, nicméně už je to celkem dlouho, co od toho zřejmě upustili. Původně to měl být distribuovaný objektový framework.
Env proměnné
Je to podobný případ jako ty CLI parametry. Kdybys vytvářel operační systém, jak by ses rozhodoval, jestli je něco overengineering a přesložitělá abstrakce nad abstrakcí nebo zda to tam implementovat?
A co formát? Hádáte správně. Může být libovolný; (pseudo)INI, XML, JSON, YAML. Nebo Lua. Nebo taky hybrid vlastního programovacího jazyka (viz postfix). Co koho zrovna napadne, to se používá.
O tomhle jsem se v diskusích hádal už mnohokrát a taky mne ta nejednotnost mrzí. Osobně bych nejradši všude používal XML – a ne proto, že mám rád špičaté závorky a ukecanost, ale proto, že je to nejlepší dostupná (!) implementace myšlenek, které považuji za správné. Bohužel se vždy najde spousta naivních lidí, kteří si myslí, že jim bude stačit něco jednoduššího, že vystačí se strukturou klíč=hodnota... jenže nevystačí a v dalších verzích tam dobastlí něco jako INI [sekce] a příště začnou vymýšlet pod-sekce (jak to tam napsat? těch způsobů je několik...) nebo do klíčů začnou cpát různé tečky, lomítka... pak narazí na to, že potřebují nějak zapsat pole více hodnot a zase to nějak zmastí (a to i několika různými způsoby v rámci jednoho formátu). Následně dojde na jmenné prostory... Kapitola sama pro sebe je, když původně deklarativní formát postupně zmutuje ve spustitelný kód resp. imperativní programovací jazyk.
Existuje vtip, že komplexita každého konfiguračního souborů s časem roste, dokud v něm někdo vytvoří špatně implementovanou půlku lispu. Mým oblíbeným příkladem je Ansible a jeho nedotažená, nekompletní parodie na programovací jazyk postavený nad YAMLem. Chápu, kde se to bere. Taky jsem touhle cestou šel.
Co se týče otázky zda deklarativní (neživá) data nebo spustitelný (živý) kód a programovací jazyk pro popis konfigurace, tak mi přijde vhodné to rozdělit na dvě fáze. Výstupem by měla být deklarativní neživá data. A zda se k nim dobereš tak, že je přímo načteš ze souboru, kde leží v deklarativním formátu, nebo zda spustíš skript (ten může být psaný v libovolném jazyce), který tato data vygeneruje, to už je na tobě. Klidně program může podporovat oba přístupy. Pak to chce mít funkci, která ti porovná dva objektové stromy (deklarativní data), abys na základě ní mohl načíst novou konfiguraci za chodu programu. Ne vždy je to nutné, program můžeš restartovat, ale často se to hodí. Např. abys mohl přidat nový virtualhost a nemusel ani na okamžik přestat naslouchat na HTTP portu a obsluhovat jiné virtualhosty, které se nezměnily.
Logy
Vidím to podobně, štve mě spousta věcí stejně jako tebe. Nějaké snahy o standardizaci tu jsou. A já bych třeba mohl logovat do těch Relačních rour :-) Ale najít společnou řeč je těžké. Vždyť i v rámci jednoho programovacího jazyka máš často několik logovacích knihoven a API.
Syntaxe je přibližně -v local_path:/docs:rw. Jako dobrá ukázka mi to přijde, protože se do jednoho parametru cpou tři různé hodnoty: cesta v počítači na kterém příkaz pouštíte (která navíc musí být absolutní!), cesta uvnitř kontejneru a práva k zápisu.
Ano, tohle je špatně – přitom by stačilo využít stávající infrastrukturu a nechat tokenizaci na operačním systému a necpat do jednoho parametru tři hodnoty a vymýšlet si nějakou vlastní vnitřní strukturu. Je to stejné jako když někdo nacpe několik hodnot oddělených čárkou do jednoho sloupečku v databázi.
Proč? Protože neexistuje žádný standard a operační systém neposkytuje nic po čem by se dalo sáhnout. Fragmentace tak pokračuje.
Ale existuje (třeba to XML). Jen si řada lidí na začátku myslí, že to nebudou potřebovat a že to udělají "jednodušeji".
Imperativní prvky bych do konfiguráků raději nezatahoval a řešil to spíš tím rozdělením na dvě fáze, kde ta první volitelná může být skript (viz výše).
Pokud se nad tím zamyslíte dostatečně abstraktně, program je objekt. Je to kolekce dat, nad kterými operují v něm obsažené funkce.
Jak chceš řešit stavovost? V současnosti je program spíš něco jako třída a až proces (spuštěný program) je objekt. Můžeš se na to dívat tak, že třídy nejsou, nebo že i program (nespuštěný, na disku) je objekt, jehož jedna metoda vrátí jiný objekt (již spuštěný program). Má ten objekt programu nějaký stav? Jak je ten stav sdílen nebo naopak izolován mezi různými uživateli? Má každý uživatel svůj objekt (např. jinou konfiguraci) nebo je jeden objekt na systémové úrovni?
Když se na to podívám trochu pragmaticky: není reálné, že bys (ty nebo kdokoli jiný) napsal nový operační systém včetně všech těch ovladačů hardwaru a spousty nízkoúrovňové infrastruktury, tak, abys dohnal a předehnal současné operační systémy. Navíc by to bylo i hloupé a neefektivní, protože bys psal znovu něco, co už jiní napsali a vydali jako svobodný software. Takže pokud se tyhle myšlenky mají realizovat, vede to spíš na nějakou VM nad stávajícím operačním systémem. Ale v čem bude tvoje VM lepší a proč by ji měli všichni používat? Kdyby všichni používali javovské VM, tak to bude podobné resp. ty tebou požadované kvality a vlastnosti tam půjde implementovat. Totéž, kdyby všichni psali jen v Perlu, nebo jen v Pythonu, nebo jen ve Smalltalku, Lispu... problém je v tom, jak přesvědčit ostatní, aby přešli na tvůj jazyk/platformu.
Např. GraalVM se se nikoho nesnaží přesvědčit, aby začal psát v jiném programovacím jazyce a přepsal svoje programy – ale naopak přenáší různé programovací jazyky (a tím programy v nich napsané) do jednoho VM, do jednoho prostředí. Neříkám, že je to dneska bůhvíjak použitelné, ale přijde mi to jako zajímavá cesta a pokud ten projekt bude dobře veden a nevyschnou zdroje, tak to je asi budoucnost.
Když máte filesystém umožňující tyhle objekty uchovávat nativně, nevidím důvod, proč potom nezpřístupnit jednotlivé metody tohoto objektu i z venčí.
Já ten důvod vidím, viz zpětná kompatibilita API, o které píši výše. Resp. jednotlivé metody klidně zpřístupnit můžeš, technicky to není problém, ale pokud se v příští verzi nekompatibilně změní, protože je autor programu přepsal, tak praktická hodnota je nulová nebo i záporná.
Konfigurační soubory a různé jejich formáty existují, protože filesystém neumí uložit strukturu. Kdyby to uměl, můžete prostě uložit daný slovník s danými klíči a hodnotami, a příště po nich sáhnout.
Ale on to umí, psal jsem o tom výše a pro konfiguraci je to použitelné (tam na limity FS nenarazíš). Z původních souborů se stanou adresáře a z jejich atributů soubory (případně zase adresáře obsahující vnořené soubory a adresáře) a zmizí ta hranice mezi vnější hierarchií (původních) souborů a vnitřní hierarchií uvnitř souboru. Problém je leda ta transakčnost.
Parametry příkazové řádky, env proměnné, ale i všechno ostatní píšete jako datové typy zachovávající si strukturu.
Proměnné prostředí ve skutečnosti vůbec existovat nemusí. Vždyť jsou to vlastně globální proměnné a ty se obecně doporučuje nepoužívat. Pokud potřebuješ nějaký globálnější kontext, tak to může být jeden z parametrů.
P.S. Omlouvám se za tak dlouhý komentář :-) ale je to zajímavé téma resp. mnoho témat.
12.12.2018 16:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.12.2018 19:49
xkucf03 | skóre: 49
| blog: xkucf03
njn, já to začal číst k snídani a komentář odeslal až odpoledne. Ale času věnovaného těmto diskusím nelituji :-)
Další věc je indexování a efektivní vyhledávání – nicméně to už by šlo řešit v rámci současných API – napsal by sis vlastní FS a ten by poskytoval i virtuální adresáře, které by byly něco jako databázové pohledy nebo funkce – vlezl bys do neexistujícího adresáře jehož název by byl textem dotazu a FS by ti vrátil výsledky – něco jako cd /mnt/.dotazy; cd "SELECT * FROM soubory WHERE ..."; ls -l (případně by tam byly další virtuální podadresáře, které by představovaly parametry dotazu). A opravdu to nemusí být SQL – použil jsem ho jen pro názornost.Heh. Uvažoval jsem nad něčím velmi podobným. AFAIK není možné otevírat neexistující adresáře (ani ve virtuálním filesystému), ale to není tak velká překážka. Osobně jsem netoužil po vyhledávání souborů pomocí SQL dotazů, ale podle tagů – a tam jednoduše stačí něco jako
/search/prvni-tag/druhy-tag (v každém z virtuálních adresářů to zpřístupní všechny dostupné tagy, resp. ty, které ještě existují a má tedy smysl to podle nich filtrovat dál). Umí to potom jen logický AND, složitější dotazy tím neuděláš. Vždycky je tu možnost celé tokeny nahradit názvy adresářů a jít cestou /search/LPAR/prvni_tag/AND/druhy_tag/RPAR/OR/LPAR/prvni_tag/AND/treti_tag/RPAR, ale to už mi přijde lehce přitažené za vlasy. :D
Podobné projekty mimochodem existují, např. TMSU. Bohužel to ukládá databázi odděleně a ne jako rozšířené atributy souboru, takže kopírováním se to rozbije. Na to se tedy musí dávat pozor i u těch rozšířených atributů, protože pokud si správně vzpomínám, cp je zahodí a rsync je zachová jen na explicitní žádost. Pořád mi to ale přijde o kousek lepší než nemít vůbec nic (a ostatně, i kdybych si měl forknout třeba Thunar, tak je pořád jednodušší prostě kopírovat i atributy než muset tagy exportovat ze stávající databáze a importovat do nové). Jenže se pak blbě řeší zase indexování…
A taky nevím, jak TMSU reaguje na přesunutí souboru. Na podobných úvahách jsem se totiž sekl s tím, že pokud chci tagování vyřešené tak, aby to opravdu spolehlivě fungovalo alespoň v těch zcela běžných případech, musel bych patrně opatchovat půlku user space. Protože jakmile se na přesunutí souboru nedá reagovat nějakým triggerem/callbackem a patřičnou aktualizací indexu/databáze, ale musí se ty změny scannovat zpětně, tak už je to prostě špatně. Znám inotify, ale to je z mojí zkušenosti na větší počty položek spíše nepoužitelné, a co jsem se posledně díval na fanotify, tak to neumělo sledovat přesuny a mazání souborů, takže pro tenhle účel taky k ničemu.
Ten druhý bod lze řešit tím, že vynutíš jeden jazyk (viz zmínka o PID 1 výše) nebo použiješ GraalVM.
Odpověď je pořád stejná: používat GraalVM (případně si napsat jeho obdobu) nebo vynutit použití jednoho jazyka a uzavřít se do jeho VM místo toho, aby ses pohyboval v OS.
Např. GraalVM se se nikoho nesnaží přesvědčit, aby začal psát v jiném programovacím jazyce a přepsal svoje programy – ale naopak přenáší různé programovací jazyky (a tím programy v nich napsané) do jednoho VM, do jednoho prostředí. Neříkám, že je to dneska bůhvíjak použitelné, ale přijde mi to jako zajímavá cesta a pokud ten projekt bude dobře veden a nevyschnou zdroje, tak to je asi budoucnost.S GraalVM jsem si nedávno hrál a říct, že jsem byl zklamaný, by nedostatečně vystihovalo frustraci, kterou jsem u toho prožíval. Mám z toho nějaké lehce chaotické poznámky. Původně to měly být podklady pro článek, ale celé mě to rozladilo natolik, že jsem to nakonec nechal u ledu.
13.12.2018 22:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ano, prošel jsi řadou firem, ale pořád to reprezentuje jen zlomek způsobů, jakými se počítače používají. A teď je otázka, zda vytvářet operační systém a) pro tento zlomek (resp. pro každý zlomek jeho vlastní OS), nebo b) zcela minimalistický OS, který poskytne jen ten společný základ (např. pro 98 % případů užití) c) nastavit si ten cíl na jiném procentu případů užití a vytvořit něco, co většině poskytne většinu požadovaných funkcí a zároveň to většinu nebude obtěžovat nějakými přílišnými funkcemi navíc.
No a nebo mít prostě víc operačních systémů pro různá použití? Stejně tak máme mobilní operační systémy a serverové operační systémy a desktopové (které teda můžou být superset těch serverových).
Vypadá to, že jdeme cestou c). Cesta b) by asi znamenala, osekat to na abstrakci HW (což je asi nejzásadnější funkce OS a potřebují ji všichni, kromě nějakých těch 2 % se speciálními potřebami) a zbytek ať si dodělá každý sám. Cesta a) podle mého nedává moc smysl (musel bys mít hodně speciální potřeby a hodně velký rozpočet, aby to bylo vůbec schůdné – a schůdné ještě neznamená celkově efektivní a smysluplné).
Co takhle d) → přestat dělat operační systém jako svatou krávu a vzít ho jako systém modulů, které si nakonfiguruješ jak chceš?
Já vím že existuje mikrokernel a tak podobně, a taky jsem si kdysi sestavil vlastní LFS, ale tohle je imho něco trochu jiného. Například ovladače by imho nemusely nutně být psané pro konkrétní OS, ale mohl by být specifikované nějak obecně a pouze by se z nich poté generovala konkrétní implementace.
To samé plánovač úloh, to by šlo nejspíš taky nějak zobecnit, abys to mohl použít v odlišných typech „OS na míru“. V podstatě mě nenapadá žádný důvod kromě výkonnostních optimalizací, proč by to nešlo. A ty jsou imho spíš hypotetické.
Moje vize je asi do velké míry ovlivněná mými nedávnými zkušenostmi s rpythonem, což je framework pro psaní programovacích jazyků. Autoři abstrahovali věci jako JIT, garbage collector, objektové modely a tak podobně a udělali z toho knihovnu. Ty si pak napíšeš vlastní programovací jazyk a přes série dynamických transformací objektového AST flow grafu se do toho napojí tyhle highlevel featury předtím, než se to celé zkompiluje do poměrně výkonného C (je v tom psané pypy rychlejší než klasický cpython).
Říkám si nakolik by bylo možné udělat něco podobného pro operační systém.
PS: Chápu že unix je modulární a taky jsem si sestavoval vlastní jádro pro router, ale tohle je myslím o hodně dál.
Je otázka, jestli nejít spíš cestou b) místo c). V podstatě se něco jako b) už děje, ale na jiné úrovni: máme základ operačního systému (GNU/Linux) a nad tím různá desktopová prostředí, která představují další vrstvu s vlastními abstrakcemi, funkcemi a filosofií. Teoreticky by to šlo rozříznout níž a tu hranici mít někde těsně nad HW abstrakcí – ta by byla společná a ten vršek by byl vyměnitelný tzn. někdo by si tam posadil vršek emulující současný POSIXový systém a ty by sis tam posadil třeba vršek emulující lispovský nebo smalltalkovský stroj.
Nemám na to úplně vyhraněný názor, možná by to bylo dobré, možná by to naopak vedlo k vytvoření ostrůvků, které k sobě mají daleko a těžko spolupracují. Zatímco dneska, když máš ten lisp nebo smalltalk nad POSIXem resp. GNU/Linuxem, tak přeci jen můžeš snáz spolupracovat s těmi, kteří smalltalk ani lisp nepoužívají a jedou přímo nad tím POSIXem nebo nad ním mají jiné vrstvy.
Imho by se to neobešlo bez nějaké vrstvy interoperability. Tuším že MIcrosoftí COM byl podobná myšlenka, ale nemám s tím zkušenosti. Možná bych se na to měl podívat, když tak o tom čtu.
A pak je otázka, kam v tom b) umístit takové věci jako TCP a IP nebo šifrovací algoritmy – patří do toho společného základu nebo až do té nadstavby a měla by si je každá nadstavba implementovat po svém?
Imho zcela jasně patří do společného základu prostě jako importovatelná knihovna.
Linux (případně jiná jádra či OS) ti poskytuje rozhraní, aby sis napsal vlastní souborový systém. Tzn. bude to schované za tou samou abstrakcí/metaforou (takže to můžou používat všichni a lze tuto vrstvu vyměňovat bez nutnosti měnit jiné vrstvy), ale bude to mít tebou požadované vlastnosti (např. možnost efektivně uložit neomezené množství souborů do adresáře a do souborového systému – takže pak můžeš rozpadnou data na tak malé kousky, abys nemusel používat datové formáty a ztratí se hranice mezi tím, kde končí hierarchie souborového systému a kde začíná hierarchie vnitřního formátu daného souboru tzn. např. místo XML textového uzlu nebo atributu budeš mít zase soubor, který bude v jedné hierarchii se všemi ostatními soubory a uzly uloženými původně v jiných souborech).
Já mimo jiné o jedné z těhle možností (sysfs a fuse) píšu v blogu. Dělal jsem na tohle téma nějaké experimenty (ne úplně přímo na tohle, ale na něco hodně podobného) a naráží to na problém, že ty věci jsou pořád docela tupé soubory. Pokud z nich uděláš něco víc, tak ti vzniká programovací jazyk nad souborovým systémem (například necháš „soubory“ reagovat na zprávy tím že přidáš do souboru true reflexi), což mi věř, že nechceš, protože z toho vzniká něco ve všech ohledech (výkon, použitelnost, pochpitelnost, smysluplnnost, konzistence) horšího. Stringově orientované scriptování plné cat a echo.
Otázka je, jak do toho zabudovat podporu transakcí, atomicitu – a tady prostor pro zlepšení vidím.
To jsem kdysi řešil v jednom relativně podobném smyslu tak, že zpracování souborů balíku metadat nahraného na FTP probíhalo na FTP serveru teprve poté, co byl smazán soubor delete_me_to_start_import.
Další věc je indexování a efektivní vyhledávání – nicméně to už by šlo řešit v rámci současných API – napsal by sis vlastní FS a ten by poskytoval i virtuální adresáře, které by byly něco jako databázové pohledy nebo funkce – vlezl bys do neexistujícího adresáře jehož název by byl textem dotazu a FS by ti vrátil výsledky – něco jako
cd /mnt/.dotazy; cd "SELECT * FROM soubory WHERE ..."; ls -l(případně by tam byly další virtuální podadresáře, které by představovaly parametry dotazu). A opravdu to nemusí být SQL – použil jsem ho jen pro názornost.
Kdyby adresáře a soubory přinášely nějakou masivní výhodu, kromě toho že už existují, tak by mi to asi mohlo přijít jako dobrá myšlenka. Takhle si nejsem úplně jistý k čemu by to přesně mělo být.
Taky se mi nelíbí mixování databázového cobolu s bashem.
Co ti vlastně brání si jako PID 1 spustit (emacs|python|smalltalk|perl|self|.*) a všechny programy si implementovat jako funkce/objekty v daném jazyce? Vadí ti, že ten OS poskytuje i zbytečnou infrastrukturu, kterou nevyužiješ a která se duplikuje s tím, co by sis napsal sám v tom svém jazyce? Nebo ti tam naopak něco chybí? Co? Nebo je to jen moc práce a málo užitku? Nebo by to měl napsat někdo jiný a ty bys to jen použil? (ideální případ
Nějak podobně k tomu přistupuji inspirován Squeak NOS a PharoNOS.
V zásadě jsou tam dvě úskalí 1) bezpečnost a implementace v HW (paměť, CPU), 2) lidé píší v různých programovacích jazycích. Ten druhý bod lze řešit tím, že vynutíš jeden jazyk (viz zmínka o PID 1 výše) nebo použiješ GraalVM. S tím prvním bodem nic moc dělat nejde (musel bys v podstatě zbourat celý IT obor a začít znovu nebo oželet výkon a proložit to nějakou poměrně tlustou vrstvou abstrakce, která poskytne rozhraní k úplně jinému stroji, než je ten fyzický).
Imho ne. Ty mnou odkazované projekty dělají něco hodně podobného a co do bezpečnosti se to moc neliší od JSONu, či XML.
Tohle je řešitelné knihovnami (aby ses nemusel vrtat v těch bitech a bajtech). Pak to chce nějakou jednotnou abstrakci, abys s těmi naparsovanými daty mohl pracovat stejným způsobem bez ohledu na původní fyzický formát. Tohle jsem dělal před čtyřmi lety jako prototyp alt2xml. Umožňuje to se na data v různých formátech dívat stejným způsobem – vždy je z toho strom uzlů (resp. před tím ještě posloupnost událostí v jednotném formátu), bez ohledu na to, zda data byla původně INI, XML, JSON, souborový systém nebo něco jiného.
Ano, do jisté míry souhlasím. Znáš tohle: Kaitai Struct?
Odpověď je pořád stejná: používat GraalVM (případně si napsat jeho obdobu) nebo vynutit použití jednoho jazyka a uzavřít se do jeho VM místo toho, aby ses pohyboval v OS.
Tohle nějak nevidím. Pokud se bavíme o strukturách, tak ty jsou ve všech jazycích hodně podobné a to mapování z formátu uloženého na disku by mohlo být velmi rychlé a prakticky bez režie. Například namapovat nějakou strukturu na strom C struktur, nebo Python objektů. Do jisté míry by pro to šlo používat třeba to binární XML, i když já si představím spíš něco jako message pack a podobné, co jsem linkoval.
Přibalovat ke všemu metadata je značně neefektivní. Metadata můžou zabírat víc místa než samotná data. V praxi se používají oba přístupy, jak samopopisné formáty, tak čistá data s minimem metadat. Většinou mi přijde výhodnější ta metadata (slovník/schéma) vystavit na jedno místo a jinde na něj už jen odkazovat. V OS/VM tohle můžeš udělat taky, můžeš mít nějaký registr schémat a jednotlivé předávané zprávy už budou obsahovat jen referenci do tohoto registru. V objektovém paradigmatu ten registr obsahuje neměnné objekty a zprávy jsou objekty které obsahují odkaz na objekt určitého schématu v registru. To schůdné a rozumné je. Ale přibalovat (rozkopírovat) metadata ke všem datům je ve většině případů špatný přístup.
Nemusí být přibalena, můžou být referencována podobně jako v XML jak sám píšeš. Akorát zrovna u XML to sálo prdel, protože tooling saje prdel masivně (dodneška když mám něco pokročilejšího dělat s XML, tak mám chuť se zabít). A taky DTD navrhoval někdo, kdo podle mě tak úplně nebyl člověk (tím myslím promyšlenou urážku, že bych ho neklasifikoval jako člověka).
Protože je to většinou buď závislé na platformě/jazyku nebo je to nebezpečné nebo obojí.
Hele, tohle už mi někdo vysvětlete - proč by to mělo být nebezpečné? Já to fakt nevidím. Přijde ti třeba wav a jeho systém binárního chunkování paměti nebezpečný?
Tohle řeším v tom alt2xml (ano, je to jen prototyp, ale můžeš si napsat něco lepšího).
Náhodou se mi to i docela líbí, co jsem tak zběžně koukal, ale budu chtít ne něco lepšího, ale jiného (jiná cílová platforma než xml).
Podle mého je lepší mít externí popis ve strojově čitelném formátu (schéma) uložený na jednom místě a jen se na něj odkazovat, než mít všechna data zahnojená spoustou metadat.
Osobně preferuji dynamický jazyk s reflexí za externí popis toho co tam má být prakticky kdykoliv. Viděl jsi někdy třeba smalltalk? Doporučuji tohle video: https://www.youtube.com/watch?v=sIgrZyEzPe4. Ale python v intereaktivním režimu má blízkou produktivitu.
Já je takhle vnímám a někdy jsem je tak i použil. Např. pro konfiguraci je to použitelné velice dobře. Nemusíš vymýšlet nějaký formát nebo používat parsery a generátory existujících formátů a prostě jen ty objekty rozpadneš na stromovou strukturu adresářů a souborů.
Jo, tohle je v pythonu extra jednoduché, protože přes reflexi skrz __dict__ můžeš ty data rovnou cpát do JSONu. Neosvědčilo se mi to.
Jinak občas používám pro konfiguraci přímo python kód loadem přes AST.
Pokud bys těch objektů měl opravdu hodně, tak si budeš muset napsat vlastní FS, ale to se většiny případů užití netýká a stávající FS bohatě dostačují. Ta abstrakce poskytovaná OS dostačuje taky (až na ty transakce).
Jo, do chvíle než do toho potřebuješ zapisovat z víc procesů. Já jsem došel do stavu, že soubory nepoužívám přímo skoro nikdy a pro osobní potřeby skoro vždycky jedu do sqlite, kam serializuju objekty.
Ano, musíš ta rozhraní explicitně vystavit. Ale už jsme o tom jednou mluvili. Tohle není technický problém, ale spíš problém organizace práce. S vhodnými nástroji tě vystavení těch rozhraní nic nestojí, takže rozdíl oproti jazyku/platformě, která ta rozhraní vystavuje automaticky a vždy prakticky není. Zásadní ale je zpětná kompatibilita – pokud dovolíš ostatním navázat svoje programy na tvé funkce a pak jim to v příští verzi rozbiješ, protože funkce refaktoruješ, tak z tebe nebudou mít radost. Poskytnout nějaké API je velký závazek a spousta práce – ovšem problém není to realizovat technicky, ale problém je udržet tu zpětnou kompatibilitu. To je to, co vyžaduje nejvíc úsilí a u čeho nejvíc bolí hlava (jak to navrhnout tak, abys to v příští verzi nemusel nekompatibilně změnit).
Na tom že to API budeš muset udržovat se ale nic nemění ani v jednom případě.
Jinak osobně shledávám jako retardované především že musíš psát argparsery v jednom formátu, což je v podstatě značkovací jazyk pro parametry příkazové řádky, a generovat nápovědy v úplně jiném formátu (který snad ani nemá žádný jasně daný parsovatelný standard). Přitom zpravidla už máš nějaké rozhraní, které už má nápovědu, a vůči kterému by se dalo linkovat přímo. Tohle je jen mezikrok generující spoustu stringů po cestě mezi tím.
Tohle by se dalo řešit přes rozšířené atributy těch virtuálních souborů v tom virtuálním FS. Stačí si domluvit názvy atributů, do kterých se bude psát dokumentace a metadata.
A taky si k tomu přidej datové typy. A reflexi. A možnost udělat třeba (shallow) kopii. A během chvíle zase vyrábíš programovací jazyk nad souborovým systémem.
S návratovými hodnotami je trochu problém stejně jako s předáváním strukturovaných dat. Např. když budeš chtít LEDce předat dvojici hodnot (barva, intenzita), tak jak to nacpeš do funkcí, které vystavuje FS? To API nějaké limity má a je na něm vidět, že má sloužit k ukládání a čtení dat, nikoli k volání libovolných funkcí. I když z poměrně velké míry to lze k tomu volání funkcí použít. Tam, kde ti rozhraní FS přestává stačit, je potřeba sáhnout už po něčem jako D-Bus nebo JMX, které na tenhle způsob práce stavěné jsou.
No, a co teprve když chceš dvou, nebo více-cestnou komunikaci, callbacky a tak podobně.
Takové SCTP jde o dost dál než TCP (nebo UDP) a mj. předává zprávy místo aby jen propojovalo dvě roury přenášející proudy bajtů. Vnitřní strukturu zpráv neřeší, ale to je podle mého dobře, protože to je úloha pro jinou vrstvu. Když zůstaneme v telco světě, tak by se tam (alespoň tehdy) použilo ASN.1 pro strukturování těch dat.
Neznám, ale zdá se mi to od letmého pohledu podobné (použitím, ne implementací) té ZeroMQ. Dávám si do todo to pročíst.
O ZeroMQ jsem si koupil knížku a postupně se jí prokousávám, ale přijde mi, že to zase tak moc "zero" není a té komplexity je tam přeci jen poměrně dost. Nicméně celkem sympatické mi to je a nějaké využití pro to vidím.
Já jsem s ní párkrát dělal a mám s tím poměrně pozitivní zkušenosti. Rozhodně mi to pomohlo snížit komplexitu přenosové vrstvy.
To pole mi přijde jako vhodně zvolená struktura. Cokoli jednoduššího (jeden řetězec, pole bajtů) by bylo nedostatečné. A cokoli složitějšího by bylo zase příliš náročné na zpracování a na používání.
To je právě to. Proč bys to měl zpracovávat zrovna ty? Jako mě už docela jebe pořád psát parsery v poměrně vysokoúrovňovém argparse, abych z toho udělal nějaký objekt, když mi už ten objekt mohl přijít od systému, kdyby nebyl neschopný. Dokonce jsem si na to naprogramoval kdysi klikátko: http://kitakitsune.org/argparse_builder/
V podstatě se na to můžeš dívat jako na jazyk, který čteš lexerem/parserem, akorát můžeš vynechat ten lexer, protože data už máš rozsekaná na jednotlivé tokeny. Proto taky nemám rád parametry ve stylu
"--klíč=nějaká hodnota"a jsem radši, když klíč a hodnota jsou dva po sobě jdoucí prvky pole:"--klíč" "nějaká hodnota".
Já vím že můžu, ale .. tebe to kurva nesere? Jako to že po tobě někdo chce v každém programu parsovat něco, co by klidně už naparsováno mohlo být o vrstvu nad tím? Neustále zas a znova opakovat pořád ten samý pattern jen proto že někdo nedokázal napsat jednotný standard popisu argumentů?
Taky mne trochu mrzí, že si každý vymýšlí vlastní jazyk, pro parsování těch parametrů, ale s tím asi nic nenaděláme. Existují různá doporučení a konvence. Obecně preferuji styl
"--parametr" "hodnota" "--volba-bez-parametru"případně tam může být první parametr jako (pod)příkaz:program příkaz --parametr1 ...
Používám to argparse, které tohle řeší za mě.
Když vymyslíš vhodný formát pro předávání strukturovaných dat na příkazové řádce, tak se to třeba ujme. Ta infrastruktura/API to umožňuje – řeší za tebe tokenizaci (díky tomu, že je to pole, tak máš jasně vyznačené hranice mezi jednotlivými tokeny, takže tohle nemusíš řešit).
No právě že jen tokenizaci. Jako .. proč prostě. Proč tokenizaci ano, ale parsování ne?
Stejný problém máš ale u hlaviček metod/funkcí. Většina jazyků podporuje sekvenční parametry, někde můžou být výchozí hodnoty a nepovinné parametry a některé jazyky mají pojmenované parametry – takže tam je to taky pole (případně mapa). To ti nevadí? Není to málo?
No to právě nemáš stejné, protože minimálně to obsahuje datové typy a má to jasně daný formát, se kterým umí pracovat například IDE. Stejný problém bys měl, kdyby ti každá funkce při předání parametrů v té funkci dala místo nich k dispozici jen pole stringů a parsuj si je pořád zas a znova.
Viz vzor vzor polyvalentní program výše. Ono sice jde psát CLI rozhraní tak, by bylo dobře použitelné jak pro člověka, tak jako API, ale není to samozřejmost. Často je lepší cesta program rozdělit na CLI rozhraní případně GUI, síťové rozhraní atd.) a knihovnu.
Asi jediný program, kde jsem kdy viděl že by to alespoň vzdáleně fungovalo byl nmap a ani tam není žádná radost s tím pracovat.
Je to podobný případ jako ty CLI parametry. Kdybys vytvářel operační systém, jak by ses rozhodoval, jestli je něco overengineering a přesložitělá abstrakce nad abstrakcí nebo zda to tam implementovat?
Na základě toho co lidi často používají. Patterny co se často opakují bych udělal součástí OS, nebo pro ně minimálně přidal nějakou nativní podporu.
O tomhle jsem se v diskusích hádal už mnohokrát a taky mne ta nejednotnost mrzí. Osobně bych nejradši všude používal XML – a ne proto, že mám rád špičaté závorky a ukecanost, ale proto, že je to nejlepší dostupná (!) implementace myšlenek, které považuji za správné. Bohužel se vždy najde spousta naivních lidí, kteří si myslí, že jim bude stačit něco jednoduššího, že vystačí se strukturou klíč=hodnota... jenže nevystačí a v dalších verzích tam dobastlí něco jako INI [sekce] a příště začnou vymýšlet pod-sekce (jak to tam napsat? těch způsobů je několik...) nebo do klíčů začnou cpát různé tečky, lomítka... pak narazí na to, že potřebují nějak zapsat pole více hodnot a zase to nějak zmastí (a to i několika různými způsoby v rámci jednoho formátu). Následně dojde na jmenné prostory... Kapitola sama pro sebe je, když původně deklarativní formát postupně zmutuje ve spustitelný kód resp. imperativní programovací jazyk.
Jo. Já i opatrně souhlasím, s tím že pro mě není nejlepší XML, ale obecně objekty podobně tak jak je implemetuje Self (asociativní mapy s delegací).
Budu o tom v brzké době psát víc, tak bych tu diskuzi nechal tam.
Co se týče otázky zda deklarativní (neživá) data nebo spustitelný (živý) kód a programovací jazyk pro popis konfigurace, tak mi přijde vhodné to rozdělit na dvě fáze. Výstupem by měla být deklarativní neživá data. A zda se k nim dobereš tak, že je přímo načteš ze souboru, kde leží v deklarativním formátu, nebo zda spustíš skript (ten může být psaný v libovolném jazyce), který tato data vygeneruje, to už je na tobě. Klidně program může podporovat oba přístupy. Pak to chce mít funkci, která ti porovná dva objektové stromy (deklarativní data), abys na základě ní mohl načíst novou konfiguraci za chodu programu. Ne vždy je to nutné, program můžeš restartovat, ale často se to hodí. Např. abys mohl přidat nový virtualhost a nemusel ani na okamžik přestat naslouchat na HTTP portu a obsluhovat jiné virtualhosty, které se nezměnily.
Vidíš, tohle je právě k diskuzi a k experimentům. Osobně si myslím, že je možné mít spustitelný kód s možností ho nespustit a použít pouze datové sloty. Taky chci časem zkusit experiment s interpretací v dalších „dimenzích“ tak jak je to popsané v paperu A Simple, Symmetric, Subjective Foundation for Object-, Aspect- and Context-Oriented Programming (nebo v Korz: Simple, Symmetric, Subjective, Context-Oriented Programming ?) Když tam nejsou mirrors, skrz které by se to reflexí mohlo dostat ven, tak by to mohlo být bezpečné.
Ale existuje (třeba to XML). Jen si řada lidí na začátku myslí, že to nebudou potřebovat a že to udělají "jednodušeji".
No, to XML není zrovna vhodné pro libovolné interaktivní použití, kde ho máš fakt psát.
Jak chceš řešit stavovost? V současnosti je program spíš něco jako třída a až proces (spuštěný program) je objekt. Můžeš se na to dívat tak, že třídy nejsou, nebo že i program (nespuštěný, na disku) je objekt, jehož jedna metoda vrátí jiný objekt (již spuštěný program). Má ten objekt programu nějaký stav? Jak je ten stav sdílen nebo naopak izolován mezi různými uživateli? Má každý uživatel svůj objekt (např. jinou konfiguraci) nebo je jeden objekt na systémové úrovni?
V tomhle jsem inspirovaný Selfem. Budu o tom psát víc v samostatných blozích.
Např. GraalVM se se nikoho nesnaží přesvědčit, aby začal psát v jiném programovacím jazyce a přepsal svoje programy – ale naopak přenáší různé programovací jazyky (a tím programy v nich napsané) do jednoho VM, do jednoho prostředí. Neříkám, že je to dneska bůhvíjak použitelné, ale přijde mi to jako zajímavá cesta a pokud ten projekt bude dobře veden a nevyschnou zdroje, tak to je asi budoucnost.
Vím o něm a upřímně mám radost, že existuje. Zběžně jsem se na něj díval a vedl o něm pár diskuzí s Bherzetem, který je javista. On z něj nebyl moc nadšený, já si ale myslím, že za pár let to má šanci stát se silnou platformou.
Já ten důvod vidím, viz zpětná kompatibilita API, o které píši výše. Resp. jednotlivé metody klidně zpřístupnit můžeš, technicky to není problém, ale pokud se v příští verzi nekompatibilně změní, protože je autor programu přepsal, tak praktická hodnota je nulová nebo i záporná.
Ten samej problém máš úplně pokaždé, když s někým komunikuješ. I na příkazové řádce musíš udržovat zpětnou kompatibilitu. Tzn nemá to žádný problém navíc oproti současnému stavu, pokud to bereš tak, že bys nezveřejňoval všechno, ale jen subsety interface.
P.S. Omlouvám se za tak dlouhý komentář
Jsem rád že je z toho kvalitní diskuze. To byl ostatně přesně můj záměr. Který teda kromě jiného spočíval i v tom že do světa vystavíš jakýsi maják, na který se pak lapají další lidé a píšou ti zajímavé myšlenky a posílají odkazy na zajímavé projekty.
Jinak tahle diskuze technicky docela přerostla možnosti abclinuxu, třeba jen tuhle odpověď jsem musel psát v osobní wiki, protože jinak bych se z toho posral.
On z něj nebyl moc nadšený, já si ale myslím, že za pár let to má šanci stát se silnou platformou.Pokud to Oracle nepohřbí jako Nashorn. :D Z Graalu jsem byl nadšený přesně do chvíle než jsem si to nainstaloval a chvíli s tím experimentoval. Jedním slovem: otřesné.
14.12.2018 00:07
xkucf03 | skóre: 49
| blog: xkucf03
To jsem kdysi řešil v jednom relativně podobném smyslu tak, že zpracování souborů balíku metadat nahraného na FTP probíhalo na FTP serveru teprve poté, co byl smazán soubor delete_me_to_start_import.
Tohle už je vyřešené v různých frameworcích, např. Apache Camel -- dlouhotrvající operace (např. nahrávání po síti) se směřuje do jiné složky a pak se to lokálně přesune do té cílové, což už je rychlá a atomická operace. Nebo to umí sledovat velikost souboru a zjistit, kdy už se přestala měnit (dostatečně dlouho se nemění), což vyhodnotí tak, že druhá strana soubor už nahrála celý a my můžeme začít číst.
Ale líbilo by se mi, kdyby ta podpora atomicity transakcí byla už v OS a nebylo to potřeba takhle hackovat.
Kdyby adresáře a soubory přinášely nějakou masivní výhodu, kromě toho že už existují, tak by mi to asi mohlo přijít jako dobrá myšlenka. Takhle si nejsem úplně jistý k čemu by to přesně mělo být.
Pokud začneš FS chápat jako stromovou databázi, tak tohle jsou prostě nějaké virtuální uzly v tom stromu a výhoda je v tom, že s nimi pracuješ jednotným způsobem jako s těmi nevirtuálními. Na druhou stranu chápu, že složitější dotazování a parametry jsou v tom dost kostrbaté a nesedí to tam. V podstatě to naráží na stejný problém jako REST a selhává to v podobných situacích. Ve chvíli kdy tam chceš naroubovat volání procedur/metod/funkcí, tak to drhne. Ne že by to nešlo, ale je to nepřirozené, nesedí to tam.
Tady je otázka, jak se k tomu postavit. Jestli umožnit na souborech volat metody. Resp. ony to nejsou soubory, ale uzly stromu. A co je vlastně metoda? To už není uzel stromu? Kde ta hierarchie končí? Stejně jako má soubor obsah (pole bajtů) a má i nějaký název, datum, práva atd. tak by mohl mít metody. V podstatě i to datum, práva a spol. je vlastně pokračování toho stromu, jsou to poduzly toho uzlu "soubor". Mohla by tam být ikona, elektronický podpis, odkaz na zdroják atd. A vedle toho metody. Nicméně na jejich zavolání bys už potřeboval nějaké procedurální API, protože to už není čtení/zápis zdroje, ale volání něčeho s nějakými parametry a s nějakou návratovou hodnotou.
Taky se mi nelíbí mixování databázového cobolu s bashem.
Tak to si užij tohle :-P (i když SELECTy tam ještě nejsou, dneska dělám na podpoře dotazování pomocí Pythonu)
Nějak podobně k tomu přistupuji inspirován Squeak NOS a PharoNOS.
No vidíš, tak to už nějak funguje. Co tomu chybí? Tohle je asi cesta -- udělat to prakticky použitelné (aspoň pro někoho) a pak je možné postupně vyházet nějaké ty vrstvy a komponenty vespod, které tam jsou zbytečně... a časem z toho máš ten dokonalý objektový systém.
Imho ne. Ty mnou odkazované projekty dělají něco hodně podobného a co do bezpečnosti se to moc neliší od JSONu, či XML.
A jak se tam řeší fragmentace? Nebo současný přístup z více vláken/programů? Co když si v jednom programu držím referenci na nějakou hodnotu, ale odkaz z původního místa už někdo jiný nasměroval jinam? Pak přepíšu jiný kus paměti nebo jiný objekt, který už je ale určen k požrání GC, protože už na něj nikdo jiný neodkazuje.
Ano, do jisté míry souhlasím. Znáš tohle: Kaitai Struct?
jj, kdysi jsem na to koukal, to IDE je super.
Nicméně na parsování většiny formátů už nějaké knihovny jsou, takže problém není až tak něco rozparsovat, ale spíš ten výsledek nějak adaptovat, dát tomu nějakou smysluplnou strukturu a začlenit to do ekosystému. Např. když se rozhodnu, že chci umět dělat XPath dotazy (nebo SQL nebo jakékoli jiné) nad INI soubory, tak je celkem jedno, jestli použiji nějakou knihovnu pro INI soubory nebo framework jako Kaitai. Jde spíš o to, jak to poskládat dohromady, zdokumentovat, otestovat, udělat k tomu příklady, aby uživatelé věděli, jak to můžou používat atd.
Tohle nějak nevidím. Pokud se bavíme o strukturách, tak ty jsou ve všech jazycích hodně podobné a to mapování z formátu uloženého na disku by mohlo být velmi rychlé a prakticky bez režie. Například namapovat nějakou strukturu na strom C struktur, nebo Python objektů. Do jisté míry by pro to šlo používat třeba to binární XML, i když já si představím spíš něco jako message pack a podobné, co jsem linkoval.
Vždyť máš často problém přistupovat k jednomu objektu současně z více vláken téhož programu. A to je celý psaný v jednom jazyce, kompilovaný jedním kompilátorem. A lidi od toho často radši utíkají způsobem, že mají neměnné objekty a radši je pořád kopírují a zahazují, než aby je sdíleli.
V GraalVM se s tím nějak poprali a přijde mi to obdivuhodné. Rozhodně to ale nepovažuji za samozřejmost nebo něco jednoduchého.
Nemusí být přibalena, můžou být referencována podobně jako v XML jak sám píšeš. Akorát zrovna u XML to sálo prdel, protože tooling saje prdel masivně (dodneška když mám něco pokročilejšího dělat s XML, tak mám chuť se zabít).
Zato pro jiné formáty ty nástroje vůbec neexistují, takže tam není co kritizovat. Až na to, že to tam je (nebo dlouhé roky bylo) jako ve středověku a všechno se dělalo ručně nebo vůbec.
A taky DTD navrhoval někdo, kdo podle mě tak úplně nebyl člověk (tím myslím promyšlenou urážku, že bych ho neklasifikoval jako člověka).
Naštěstí DTD nemusíš používat. Já ho např. nepoužívám a dělám jen XSD schémata. Někdy jsem ještě použil RelaxNG kvůli podpoře v Emacsu. A pak je tu Schematron, ale s tím jsem si hrál naposledy na škole.
Hele, tohle už mi někdo vysvětlete - proč by to mělo být nebezpečné? Já to fakt nevidím. Přijde ti třeba wav a jeho systém binárního chunkování paměti nebezpečný?
Protože máš různé platformy, velikosti indiánů, kódování atd. A nebezpečné mi přijde sdílet paměť mezi více procesy -- které navíc můžou patřit různým uživatelům, nacházet se v různých bezpečnostních kontextech atd. Pokud se to schová za nějakou objektovou abstrakci a udělá se to dobře, tak to může fungovat, ale dost možná narazíš na problémy s výkonem a nakonec dojdeš k tomu, že by bylo jednodušší a spolehlivější ta data zase tolik nesdílet a nemapovat 1:1. Ono to zero-copy má podle mého smysl u větších a souvislejších kusů dat, ale když máš po paměti rozeseté tu nějaký uint8 támhle char a z toho si skládáš nějakou strukturu a modlíš se, aby ti to na sebe pasovalo, tak mi to moc efektivní nepřijde a asi to nadělá víc škody než užitku. A to se bavíme o neměnných datech -- jakmile do toho přijdou změny (které tam budou lítat z různých vláken/procesů) a budou tam data variabilní délky (tzn. následná fragmentace), tak se to začne sypat. Neříkám, že to teoreticky nejde udělat, ale... asi bych věnoval čas něčemu jinému.
Kdysi jsem o tomhle sdílení objektů v paměti uvažoval a s někým jsem se tu bavil... je to lákavé, ale asi bych si to nechal jen pro nějaké speciální případy a nedělal z toho integrální součást OS.
Náhodou se mi to i docela líbí, co jsem tak zběžně koukal, ale budu chtít ne něco lepšího, ale jiného (jiná cílová platforma než xml).
Dík :-) njn, XML je už taková moje úchylka. BTW: do metadat webu jsem si dal jméno <xkucf03/> a WebArchive mi to kvůli tomu neumí indexovat resp. stránky pak nejdou načíst :-/
To alt2xml jsem psal kvůli tomu, že se mi líbilo, že když už máme existující nástroje (dotazovací jazyk, transformace, schémata atd.) tak je můžeme použít i pro jiné formáty než je XML. A díky tomu, že je to standardní SaX parser, tak to můžeš zapojit do existujícího programu, který si načítá konfiguraci v XML a podstrčit tomu konfigurák v jiném jazyce (i když tam si většinou budeš muset napsat plugin, aby to na sebe logicky pasovalo, protože většina formátů neumí popsat všechno to, co umí XML).
Jinak osobně shledávám jako retardované především že musíš psát argparsery v jednom formátu, což je v podstatě značkovací jazyk pro parametry příkazové řádky, a generovat nápovědy v úplně jiném formátu (který snad ani nemá žádný jasně daný parsovatelný standard). Přitom zpravidla už máš nějaké rozhraní, které už má nápovědu, a vůči kterému by se dalo linkovat přímo. Tohle je jen mezikrok generující spoustu stringů po cestě mezi tím.
+1 Ono nějaké knihovny na to existují, ale nic dokonalého jsem ještě neviděl. Ještě zkusím najít tu diplomku/bakalářku, o které jsem tu psal... Chce to mít jazyk pro popis CLI rozhraní, ze kterého si pak všechno vygeneruješ (parser, zdrojáky, bash completion, nápovědu, GUI atd.).
No, a co teprve když chceš dvou, nebo více-cestnou komunikaci, callbacky a tak podobně.
Ale jo, sohlas, FS je primárně o čtení a zapisování, ne o volání metod. Částečně to tam napasovat jde a někdy to smysl dává a je to celkem hezké, ale má to svoje limity. Nejobecnější vzor je naopak posílání zpráv -- pomocí něj lze implementovat jakoukoli formu komunikace.
Já jsem s ní párkrát dělal a mám s tím poměrně pozitivní zkušenosti. Rozhodně mi to pomohlo snížit komplexitu přenosové vrstvy.
Z hlediska použití to jednoduché je (i když tam cítím trochu magie). Ale ta komplexita je uvnitř. Od něčeho, co se jmenuje ZeroMQ bych čekal, že to bude i vnitřně jednoduché a minimalistické. Ale není.
To je právě to. Proč bys to měl zpracovávat zrovna ty? Jako mě už docela jebe pořád psát parsery v poměrně vysokoúrovňovém argparse, abych z toho udělal nějaký objekt, když mi už ten objekt mohl přijít od systému, kdyby nebyl neschopný.
Zkus se vcítit do role autorů toho systému/návrhu. Jako vývojář tohle taky musíš řešit často. Zapomeňme teď na nějaké termíny a rozpočty dané shora, dejme tomu, že si můžeš dělat, co chceš. Ale i tak narážíš často na dilema, kolik danému úkolu dát úsilí, jestli to řešit robustněji nebo jednodušeji, jestli tam té abstrakce dát víc. Nebo se neptáš: je tohle overengineering nebo není? Já jsem to s tou abstrakcí/robustností párkrát přepálil. Nebyla to žádná tragédie, jen jsem se zpětně podíval a uvědomil si, že to sice nijak neškodí, ale vlastně se to nepoužívá. Dneska to dělám v první fázi spíš jednodušeji, pak to chvíli používám a pak se rozhodnu, jestli to přepsat robustněji nebo to nechat, jak to je. Přepsat třeba tři výskyty není problém -- když v tu chvíli víš, že tě čeká dalších padesát použití, kde ti ta vyšší abstrakce/robustnost návrhu přinese užitek.
A totéž mohli řešit autoři těch CLI argumentů -- buď mohli vymýšlet něco geniálního nebo tam prostě dát pole řetězců, což bylo celkem mocné, ale zároveň implementačně jednoduché. Navíc to odpovídá mocnosti parametrů funkcí ve většině jazyků. Akorát tady je omezení týkající se datového typu -- ty parametry můžou být jen řetězce.
Já vím že můžu, ale .. tebe to kurva nesere? Jako to že po tobě někdo chce v každém programu parsovat něco, co by klidně už naparsováno mohlo být o vrstvu nad tím? Neustále zas a znova opakovat pořád ten samý pattern jen proto že někdo nedokázal napsat jednotný standard popisu argumentů?
Sere i nesere. Jasně, že by to bylo hezké. Ale vždyť bych to mohl mít. Klidně by stačilo, abych si jako PID 1 spustil JVM, všechny programy měl implementované formou javovských tříd a rázem si mezi nimi můžu předávat objekty. Navíc to bude sdílet tu paměť, nic se nebude parsovat a serializovat a bude to super.
Ale z nějakého důvodu máme heterogenní prostředí, programy jsou psané v různých jazycích, paradigmatech, frameworcích, kompilované v různých kompilátorech, interpretované kde čím, část běží na jiných počítačích na síti... Je to nejednotný binec, ale nějak to funguje a asi je to i lepší než mít nalajnovaný jediný správný způsob. Funguje tam konkurence, testují se různé přístupy a hypotézy, probíhá evoluce.
Co kdybys zjistil, že jsi třeba na začátku návrhu udělal nějakou chybu a že místo CLI parametrů a ENV tam mělo být ještě něco dalšího nebo že tam naopak něco přebývá nebo něco je ve špatném formátu? A teď, co s tím? Jak dokopeš všechny, aby to přepsali a začali to dělat tím správným způsobem?
Dneska víš, že by místo pole řetězců bylo lepší mít stromovou strukturu (objekt) a že to tehdejší rozhodnutí byla návrhová chyba. Ale stejnou chybu můžeš udělat i ty teď a něco, co ti dneska přijde správné a buď to bereš jako samozřejmost nebo jsi nad tím naopak přemýšlel a jsi hrdý na to, jak geniálně jsi to vymyslel... tak za deset let někdo přijde a řekne, že je to blbě a že se to mělo dělat jinak.
Je to vlastně otázka, jestli evoluce nebo revoluce. Jedno za čas je asi potřeba všechno zahodit a začít znova, ale jinak by to mělo jít spíš plynule vylepšovat a nemuset zahazovat to, co se v minulosti udělalo.
No právě že jen tokenizaci. Jako .. proč prostě. Proč tokenizaci ano, ale parsování ne?
Třeba na to nedostali rozpočet, nebo honili termín. A nebo zvažovali dvě řešení a tohle bylo to složitější a lepší. Technologicky vyspělejší. Taky ten příkaz nemusel mít vůbec žádné parametry nebo mohl mít parametr jen jeden.
Asi jediný program, kde jsem kdy viděl že by to alespoň vzdáleně fungovalo byl nmap a ani tam není žádná radost s tím pracovat.
Tak to asi používáme jiné programy nebo jiný systém. Mně tohle přijde naopak jako celkem normální vlastnost. Spousta programů má nějaké API, buď je tam knihovna, nebo CLI nebo D-Bus. Jasně, když je něco jednoduché GUI klikátko, tak z toho nebudou vystavovat knihovnu. Ale tam zase narážíš na ten sociální netechnický problém -- když už to rozhraní vystavíš, tak je to závazek, abys ho udržoval zpětně kompatibilní. A co já vím, kdy budu potřebovat refaktorovat vnitřek svého programu? Jestli se v tom chce někdo vrtat, tak ať si vezme zdrojáky. Ale nechci nikomu dávat falešnou naději, že to má API, když to ve skutečnosti API nemá. API pro mne totiž není ta technologie, ale ta myšlenka a ten závazek, že to bude fungovat i v příštích verzích.
Na základě toho co lidi často používají. Patterny co se často opakují bych udělal součástí OS, nebo pro ně minimálně přidal nějakou nativní podporu.
Jenže v té době asi nepoužívali nic a nosili děrné štítky do nějaké místnosti a tam je někomu dávali do ruky. Jasně, dneska známe odpověď na to, jak se tehdy měly udělat CLI parametry. Ale známe dneska odpověď na něco, co bude lidi trápit za dvacet třicet let a budou si kvůli tomu klepat na čelo? Problém je, že ta návrhová rozhodnutí děláš v době, kdy ještě nevíš, jak to dopadne.
Ten samej problém máš úplně pokaždé, když s někým komunikuješ. I na příkazové řádce musíš udržovat zpětnou kompatibilitu. Tzn nemá to žádný problém navíc oproti současnému stavu, pokud to bereš tak, že bys nezveřejňoval všechno, ale jen subsety interface.
O tom to ale je -- vybrat nějakou podmnožinu a tu pak držet kompatibilní. Když už tu podmnožinu vybereš, tak už není rozdíl, jestli ti ji exportuje jazyk reflexí, OS, framework, D-Bus nebo někdo jiný. Pracné na tom není ta technická implementace, ale to lidské rozhodnutí, návrh toho API a výběr rozhraní, která budou veřejným API.
U těch CLI parametrů o tom lidi vědí a pokud to nejsou vyloženě idioti, tak chápou, že je nemůžou jen tak v další (minor) verzi přejmenovat. Ale pokud ti technologie jen tak mimochodem a automaticky vyexportuje vnitřnosti tvého programu skrze reflexi ven -- budeš se starat o to, aby to zůstalo kompatibilní? Ostatní to pak začnou naivně používat a v příští verzi se tahle spolupráce rozpadne.
Někdy ten přístup dovnitř dává smysl, i když nemáš jisté, že bude v budoucnu stejný, ale pak je to pro mne na podobné úrovni, jako když se debuggerem připojím k běžícímu programu. Tam se v tom taky můžu hrabat a koukat dovnitř. Tohle je prostě jen takový lepší debugger. Ale rozhodně bych tomu neříkal API a nepoužíval to tak.
Nějak podobně k tomu přistupuji inspirován Squeak NOS a PharoNOS. No vidíš, tak to už nějak funguje. Co tomu chybí? Tohle je asi cesta -- udělat to prakticky použitelné (aspoň pro někoho) a pak je možné postupně vyházet nějaké ty vrstvy a komponenty vespod, které tam jsou zbytečně... a časem z toho máš ten dokonalý objektový systém.Dovolím si se na toto téma ublognout.
17.12.2018 14:55
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tohle už je vyřešené v různých frameworcích, např. Apache Camel -- dlouhotrvající operace (např. nahrávání po síti) se směřuje do jiné složky a pak se to lokálně přesune do té cílové, což už je rychlá a atomická operace. Nebo to umí sledovat velikost souboru a zjistit, kdy už se přestala měnit (dostatečně dlouho se nemění), což vyhodnotí tak, že druhá strana soubor už nahrála celý a my můžeme začít číst.
Tady byl důvod že nahrávající si mohl kdykoliv spojení vypnout a pokračovat třeba další den. Jednalo se o větší počty souborů, které dohromady tvořily balík dat.
Pokud začneš FS chápat jako stromovou databázi, tak tohle jsou prostě nějaké virtuální uzly v tom stromu a výhoda je v tom, že s nimi pracuješ jednotným způsobem jako s těmi nevirtuálními. Na druhou stranu chápu, že složitější dotazování a parametry jsou v tom dost kostrbaté a nesedí to tam. V podstatě to naráží na stejný problém jako REST a selhává to v podobných situacích. Ve chvíli kdy tam chceš naroubovat volání procedur/metod/funkcí, tak to drhne. Ne že by to nešlo, ale je to nepřirozené, nesedí to tam.
Taky jde o to, že to nejsou objekty. Jsou to věci co umí vrátit nějaká data a do kterých jde zapsat nějaká data. Ale jak zapíšeš data třeba do adresáře? Jakože jak mu pošleš zprávu? Vytvoříš meta-soubor jen pro adresář? Celé se to začíná kroutit a deformovat a na konci pořád pracuješ s nedefinovanou textovou strukturou (co do toho souboru zapíšeš? XML?).
Osobně bych na to šel přesně naopak, prostě pracuješ s objekty v paměti, z nihž některé mají příznak persistent a dynamicky se ukládají na disk. Případně máš persistent listy a dicty, do kterých když to uložíš, tak se to uloží na disk (takhle to řeší například ZODB).
Tady je otázka, jak se k tomu postavit. Jestli umožnit na souborech volat metody. Resp. ony to nejsou soubory, ale uzly stromu. A co je vlastně metoda? To už není uzel stromu? Kde ta hierarchie končí? Stejně jako má soubor obsah (pole bajtů) a má i nějaký název, datum, práva atd. tak by mohl mít metody. V podstatě i to datum, práva a spol. je vlastně pokračování toho stromu, jsou to poduzly toho uzlu "soubor". Mohla by tam být ikona, elektronický podpis, odkaz na zdroják atd. A vedle toho metody. Nicméně na jejich zavolání bys už potřeboval nějaké procedurální API, protože to už není čtení/zápis zdroje, ale volání něčeho s nějakými parametry a s nějakou návratovou hodnotou.
Jo, já chápu tu tvojí myšlenku, jen mi to přijde jako hrozný paskvil. Tím že ohneš myšlenku souborového systému a uděláš z něj programovací jazyk ti vznikne zdeformovaný skřet, ve kterém bude peklo programovat.
Osobně na to chci jít naopak - vzít relativně jednoduchý a čistý programovací jazyk a namapovat na něj myšlenku perzistentního stromového úložiště dynamicky tak, aby se s tím uživatel nemusel moc zabývat.
Tak to si užij tohle :-P (i když SELECTy tam ještě nejsou, dneska dělám na podpoře dotazování pomocí Pythonu)
Meh. Jakožto tvůrce obskurních věcí které nikdo nepoužívá nic nenamítám, ale spíš se snažím jít cestou snižování komplexity, než opačně.
No vidíš, tak to už nějak funguje. Co tomu chybí? Tohle je asi cesta -- udělat to prakticky použitelné (aspoň pro někoho) a pak je možné postupně vyházet nějaké ty vrstvy a komponenty vespod, které tam jsou zbytečně... a časem z toho máš ten dokonalý objektový systém.
Chybí tomu 10 programátorů pracujících na tom pět let na plný úvazek s tímhle cílem. Což není tak moc.
A jak se tam řeší fragmentace? Nebo současný přístup z více vláken/programů? Co když si v jednom programu držím referenci na nějakou hodnotu, ale odkaz z původního místa už někdo jiný nasměroval jinam? Pak přepíšu jiný kus paměti nebo jiný objekt, který už je ale určen k požrání GC, protože už na něj nikdo jiný neodkazuje.
To co jsem odkazoval pořád funguje nad konceptem FS, takže nijak. Ukazuje to spíš že jde vyřešit ta druhá část, kde to někdo používá ve svém programu relativně bezbolestně a ono to dělá co má a poměrně rychle a efektivně. Jestli jde vyřešit i ta druhá část a díky tomu zahodit FS je otevřená otázka, ale věřím že ano.
jj, kdysi jsem na to koukal, to IDE je super.
Nicméně na parsování většiny formátů už nějaké knihovny jsou, takže problém není až tak něco rozparsovat, ale spíš ten výsledek nějak adaptovat, dát tomu nějakou smysluplnou strukturu a začlenit to do ekosystému. Např. když se rozhodnu, že chci umět dělat XPath dotazy (nebo SQL nebo jakékoli jiné) nad INI soubory, tak je celkem jedno, jestli použiji nějakou knihovnu pro INI soubory nebo framework jako Kaitai. Jde spíš o to, jak to poskládat dohromady, zdokumentovat, otestovat, udělat k tomu příklady, aby uživatelé věděli, jak to můžou používat atd.
Souhlasím, ale tohle je fajn i pro ty nové jazyky / systémy. Knihovny rozhodně nejsou pro všechno, například v D jsem kdysi musel spoustu věcí implenetovat, v Selfu není skoro nic, pro Pharo je toho jako šafránu. Díky tomu kaitai je možné přestat znova vynalézat kolo a prostě to generovat.
Vždyť máš často problém přistupovat k jednomu objektu současně z více vláken téhož programu. A to je celý psaný v jednom jazyce, kompilovaný jedním kompilátorem. A lidi od toho často radši utíkají způsobem, že mají neměnné objekty a radši je pořád kopírují a zahazují, než aby je sdíleli.
Nevím, já tohle řeším message passingem skrz queues a tyhle problémy prostě vůbec nemám.
V GraalVM se s tím nějak poprali a přijde mi to obdivuhodné. Rozhodně to ale nepovažuji za samozřejmost nebo něco jednoduchého.
Souhlasím s tím že GraalVM je docela obdivuhodný.
Zato pro jiné formáty ty nástroje vůbec neexistují, takže tam není co kritizovat. Až na to, že to tam je (nebo dlouhé roky bylo) jako ve středověku a všechno se dělalo ručně nebo vůbec.
To je částečně validní argument, na druhou stranu teď například v práci dělám s tím Swaggerem a přijde mi to docela fajn. Když jsem naposledy generoval python classy na základě DTD vytvořeného z C++ kódu, úroveň stresu a frustrace přesahovala dlouhodobě zvladatelné hodnoty.
Naštěstí DTD nemusíš používat. Já ho např. nepoužívám a dělám jen XSD schémata. Někdy jsem ještě použil RelaxNG kvůli podpoře v Emacsu. A pak je tu Schematron, ale s tím jsem si hrál naposledy na škole.
Používal jsem oboje v Národní knihovně (jak XSD, tak RelaxNG) a sice to bylo lepší, ale pořád hodně špatné. Celkově z toho mám pocit, jak kdyby to nebylo určené použití (rozuměj, psaní a chápání) lidmi, ale spíš jako nějaký meziformát z nějakého nástroje, který ovšem neexistuje.
Tohle mi na XML přišlo vždycky nejhorší, že prostě uživatelský zážitek z práce s ním je jen ten nejhorší, dokonce horší než u prastarých verzí Visual basicu a PHP.
Protože máš různé platformy, velikosti indiánů, kódování atd. A nebezpečné mi přijde sdílet paměť mezi více procesy -- které navíc můžou patřit různým uživatelům, nacházet se v různých bezpečnostních kontextech atd. Pokud se to schová za nějakou objektovou abstrakci a udělá se to dobře, tak to může fungovat, ale dost možná narazíš na problémy s výkonem a nakonec dojdeš k tomu, že by bylo jednodušší a spolehlivější ta data zase tolik nesdílet a nemapovat 1:1.
Uznávám, ale myslím že je to řešitelné, pokud by byla vůle. Například ten Self je co se objektového modelu týče naprostá výkonnostní katastrofa, přesto to byl jazyk rychlejší než Smalltalk, dosahující v některých benchmarcích rychlosti poloviny optimalizovaného C (v roce ~93). To vše díky chytrému použití JITování.
Pypy to samé. Python interpret psaný v Pythonu, přesto díky použití transkompilace a JITování rychlejší než C verze. Věřím tomu, že když se do problému pustí schopní lidé, tak jde optimalizovat kde co.
Ono to zero-copy má podle mého smysl u větších a souvislejších kusů dat, ale když máš po paměti rozeseté tu nějaký
uint8támhlechara z toho si skládáš nějakou strukturu a modlíš se, aby ti to na sebe pasovalo, tak mi to moc efektivní nepřijde a asi to nadělá víc škody než užitku. A to se bavíme o neměnných datech -- jakmile do toho přijdou změny (které tam budou lítat z různých vláken/procesů) a budou tam data variabilní délky (tzn. následná fragmentace), tak se to začne sypat. Neříkám, že to teoreticky nejde udělat, ale... asi bych věnoval čas něčemu jinému.
Ok. Tohle je na provedení experimentů.
Kdysi jsem o tomhle sdílení objektů v paměti uvažoval a s někým jsem se tu bavil... je to lákavé, ale asi bych si to nechal jen pro nějaké speciální případy a nedělal z toho integrální součást OS.
Já bych žádné objekty nesdílel přímo. Prostě můžeš poslat zprávu a nic víc.
To alt2xml jsem psal kvůli tomu, že se mi líbilo, že když už máme existující nástroje (dotazovací jazyk, transformace, schémata atd.) tak je můžeme použít i pro jiné formáty než je XML. A díky tomu, že je to standardní SaX parser, tak to můžeš zapojit do existujícího programu, který si načítá konfiguraci v XML a podstrčit tomu konfigurák v jiném jazyce (i když tam si většinou budeš muset napsat plugin, aby to na sebe logicky pasovalo, protože většina formátů neumí popsat všechno to, co umí XML).
Tak já kdysi taky začal programovat lisp nad XML, takže chápu kde se to bere. Jinak jak jsem psal, tomuhle se chci časem víc pověnovat v dalších textech, tak o tom pokecáme přímo tam.
Z hlediska použití to jednoduché je (i když tam cítím trochu magie). Ale ta komplexita je uvnitř. Od něčeho, co se jmenuje ZeroMQ bych čekal, že to bude i vnitřně jednoduché a minimalistické. Ale není.
Ok.
Zkus se vcítit do role autorů toho systému/návrhu. Jako vývojář tohle taky musíš řešit často. Zapomeňme teď na nějaké termíny a rozpočty dané shora, dejme tomu, že si můžeš dělat, co chceš. Ale i tak narážíš často na dilema, kolik danému úkolu dát úsilí, jestli to řešit robustněji nebo jednodušeji, jestli tam té abstrakce dát víc. Nebo se neptáš: je tohle overengineering nebo není? Já jsem to s tou abstrakcí/robustností párkrát přepálil. Nebyla to žádná tragédie, jen jsem se zpětně podíval a uvědomil si, že to sice nijak neškodí, ale vlastně se to nepoužívá. Dneska to dělám v první fázi spíš jednodušeji, pak to chvíli používám a pak se rozhodnu, jestli to přepsat robustněji nebo to nechat, jak to je. Přepsat třeba tři výskyty není problém -- když v tu chvíli víš, že tě čeká dalších padesát použití, kde ti ta vyšší abstrakce/robustnost návrhu přinese užitek.
A totéž mohli řešit autoři těch CLI argumentů -- buď mohli vymýšlet něco geniálního nebo tam prostě dát pole řetězců, což bylo celkem mocné, ale zároveň implementačně jednoduché. Navíc to odpovídá mocnosti parametrů funkcí ve většině jazyků. Akorát tady je omezení týkající se datového typu -- ty parametry můžou být jen řetězce.
Jo, to chápu, ale nemám pro bullshit toleranci.
Je to jako si položit trám do obýváku při stavbě a pak ho přeskakovat, protože prostě to tak v tu chvíli je. Ale nemá smysl ho tam přece mít položený už navždycky, s tím že každý kdo půjde kolem ho bude přeskakovat a nakonec ještě přijdou lidi, co ho budou obhajovat, že díky tomu skákání jsou všichni zdravější.
Nebo mi to připomíná tu situaci, kdy jsem si stěžoval že se mi ošlapávají boty na patě a bylo mi sděleno, že v těch botách asi blbě chodím. Chápeš? Výrobce vyrábí boty nahovno a když si někdo stěžuje, tak mu řeknou že v nich blbě chodí. Nasrat prostě.
To že nás historický vývoj nutí používat nějaký opruz přece není důvod se tomu přizpůsobovat a mít z toho radost. Od toho se systémy mají vylepšovat a posunovat, a ne že zamrzneme na padesát let s nějakou demencí, co už nikdy nikdo nezmění.
Ale z nějakého důvodu máme heterogenní prostředí, programy jsou psané v různých jazycích, paradigmatech, frameworcích, kompilované v různých kompilátorech, interpretované kde čím, část běží na jiných počítačích na síti... Je to nejednotný binec, ale nějak to funguje a asi je to i lepší než mít nalajnovaný jediný správný způsob. Funguje tam konkurence, testují se různé přístupy a hypotézy, probíhá evoluce.
No, schválně. Z jakého důvodu?
Co kdybys zjistil, že jsi třeba na začátku návrhu udělal nějakou chybu a že místo CLI parametrů a ENV tam mělo být ještě něco dalšího nebo že tam naopak něco přebývá nebo něco je ve špatném formátu? A teď, co s tím? Jak dokopeš všechny, aby to přepsali a začali to dělat tím správným způsobem?
Prostě vydáš novou verzi a necháš tam i starou pro zpětnou kompatibilitu s tím že to bude házet deprecated hlášky? Vždyť se to nijak neliší od používání API.
Dneska víš, že by místo pole řetězců bylo lepší mít stromovou strukturu (objekt) a že to tehdejší rozhodnutí byla návrhová chyba. Ale stejnou chybu můžeš udělat i ty teď a něco, co ti dneska přijde správné a buď to bereš jako samozřejmost nebo jsi nad tím naopak přemýšlel a jsi hrdý na to, jak geniálně jsi to vymyslel... tak za deset let někdo přijde a řekne, že je to blbě a že se to mělo dělat jinak.
Jo, viz co jsem psal výše.
Je to vlastně otázka, jestli evoluce nebo revoluce. Jedno za čas je asi potřeba všechno zahodit a začít znova, ale jinak by to mělo jít spíš plynule vylepšovat a nemuset zahazovat to, co se v minulosti udělalo.
Kéž by. Momentálně je to stav zakonzervovanosti, kde neprobíhá ani jedno.
Třeba na to nedostali rozpočet, nebo honili termín. A nebo zvažovali dvě řešení a tohle bylo to složitější a lepší. Technologicky vyspělejší. Taky ten příkaz nemusel mít vůbec žádné parametry nebo mohl mít parametr jen jeden.
Dobře. Plně uznávám a nemám s tím problém. Ale proč to má jako definovat životy milionů lidí i padesát let potom? Proto přece není žádná omluva.
Tak to asi používáme jiné programy nebo jiný systém. Mně tohle přijde naopak jako celkem normální vlastnost. Spousta programů má nějaké API, buď je tam knihovna, nebo CLI nebo D-Bus. Jasně, když je něco jednoduché GUI klikátko, tak z toho nebudou vystavovat knihovnu. Ale tam zase narážíš na ten sociální netechnický problém -- když už to rozhraní vystavíš, tak je to závazek, abys ho udržoval zpětně kompatibilní. A co já vím, kdy budu potřebovat refaktorovat vnitřek svého programu? Jestli se v tom chce někdo vrtat, tak ať si vezme zdrojáky. Ale nechci nikomu dávat falešnou naději, že to má API, když to ve skutečnosti API nemá. API pro mne totiž není ta technologie, ale ta myšlenka a ten závazek, že to bude fungovat i v příštích verzích.
Myslel jsem XML / JSON vstupy / výstupy. To jsem skutečně nikde jinde neviděl.
Jenže v té době asi nepoužívali nic a nosili děrné štítky do nějaké místnosti a tam je někomu dávali do ruky. Jasně, dneska známe odpověď na to, jak se tehdy měly udělat CLI parametry. Ale známe dneska odpověď na něco, co bude lidi trápit za dvacet třicet let a budou si kvůli tomu klepat na čelo? Problém je, že ta návrhová rozhodnutí děláš v době, kdy ještě nevíš, jak to dopadne.
Jo, ale my přece v té době nežijeme. Já neříkám že jdeme hned měnit unix, ale třeba v případě linuxu je to už hodně umělé udržování standardu, který nemá žádné výhody nad alternativou a ani nemá žádné zdůvodnění proč by měl existovat. Celé je to uměle navržený systém, který je možné změnit. Nejsou to neměnné zákony fyziky.
U těch CLI parametrů o tom lidi vědí a pokud to nejsou vyloženě idioti, tak chápou, že je nemůžou jen tak v další (minor) verzi přejmenovat. Ale pokud ti technologie jen tak mimochodem a automaticky vyexportuje vnitřnosti tvého programu skrze reflexi ven -- budeš se starat o to, aby to zůstalo kompatibilní? Ostatní to pak začnou naivně používat a v příští verzi se tahle spolupráce rozpadne.
No, tak to prostě nevyexportuje jen tak mimochodem, ale budeš muset povinně vybrat objekt který se použije jako interface?
17.12.2018 17:07
xkucf03 | skóre: 49
| blog: xkucf03
Chybí tomu 10 programátorů pracujících na tom pět let na plný úvazek s tímhle cílem. Což není tak moc.
Na jednu stranu těm tvým představám fandím, ale na druhou stranu si asi dovedu představit lepší využití 50 člověkoroků práce SW inženýrů. Možná by se z dlouhodobého hlediska lidstvu taková investice vyplatila. A v kontrastu s tím, na co se mrhá čas v různých startupech i korporacích, mi to přijde trochu škoda. Ale co naděláš? Deset let zadarmo ti nikdo pracovat nebude, to už je prostě za hranicí toho, co je jednotlivec ochotný investovat (když nepočítám miliardáře, kteří už jsou zajištění, nebo naopak asketické mnichy, kteří nic materiálního nepotřebují). Takže by se na to muselo složit víc lidí. Každý rok je to celkem dost peněz a těžko říct, jak tuhle myšlenku "prodat" třeba v nějaké crowdfundingové kampani, aby se na ni lidé složili.
Meh. Jakožto tvůrce obskurních věcí které nikdo nepoužívá nic nenamítám, ale spíš se snažím jít cestou snižování komplexity, než opačně.
Pokud ti to přijde jako zvyšování komplexity, tak si to zkus přečíst pořádně/znovu. Cílem je právě tu komplexitu snižovat. Určitá míra komplexity je nevyhnutelná (z podstaty řešených problémů) a tu to právě přesouvá ven z aplikací do znovupoužitelných komponent.
Jinak je to trochu podobné těm tvým objektům. Ten klasický unixový přístup na to jde sice "jednoduše" tím, že vstupem a výstupem je proud bajtů (takže to API je opravdu jednoduché), ale už neříká, co v tom proudu bajtů bude, jen se říká, že by to asi měl být text, ale neví se přesně jaký, takže to každý dělá trochu jinak. V důsledku toto "jednoduché" řešení akorát přenáší tu komplexitu dovnitř jednotlivých aplikací a každý se s ní musí potýkat znovu a znovu. Např. v inotify-tools je jakýsi vlastnoručně napsaný generátor CSV souborů. Ale obsahuje chyby, což je z velké míry důsledkem toho, že generování CSV souborů není primárním úkolem tohoto programu a tato funkce je tam implementovaná jen tak nějak mimochodem. Pokud chceš v pěti aplikacích implementovat čtyři formáty, máš to 5×4 a komplexita narůstá. A proč použít právě relační model jakožto logický/abstraktní model, je vysvětlené na tom webu.
Knihovny rozhodně nejsou pro všechno, například v D jsem kdysi musel spoustu věcí implenetovat, v Selfu není skoro nic, pro Pharo je toho jako šafránu. Díky tomu kaitai je možné přestat znova vynalézat kolo a prostě to generovat.
Fajn, zkusím v tom někdy popsat ty relační roury.
teď například v práci dělám s tím Swaggerem a přijde mi to docela fajn
Někdy to chci schválně změřit a popsat... zatím subjektivní pozorování je takové, že když chci vyřešit stejný úkol (ze strojově čitelného popisu API vygenerovat třídy), tak to v případě Swaggeru postahuje z internetu daleko více knihoven a nástrojů a ta komplexita za tím je vyšší, než v případě WSDL.
spíš jako nějaký meziformát z nějakého nástroje, který ovšem neexistuje.
Tohle je třeba důsledek toho, že spousta lidí promrhala čas vytvářením jakýchsi truc-formátů. Kdyby místo toho napsali alternativní serializaci XML infosetu nebo kompilátor do XSD, mohl na tom být obor a celé lidstvo lépe než teď.
Je to jako si položit trám do obýváku při stavbě a pak ho přeskakovat, protože prostě to tak v tu chvíli je. Ale nemá smysl ho tam přece mít položený už navždycky, s tím že každý kdo půjde kolem ho bude přeskakovat a nakonec ještě přijdou lidi, co ho budou obhajovat, že díky tomu skákání jsou všichni zdravější.
Ono se spíš stalo, že spousta lidí ten trám začala používat nějakým užitečným způsobem, a teď o něj nechtějí přijít. Tohle je zase problém se zpětnou kompatibilitou a asi se takovým návrhovým chybám (pokud to jsou tedy chyby) nedá vyhnout -- nikdo není jasnovidec a neví, jak to bude vypadat za deset let. Lidé mají různou míru intuice, zkušenosti a štěstí předvídat budoucnost, ale 100% ji nezná nikdo. Takové chyby jsou asi nedílná součást života.
A taky by se klidně mohlo stát, že kdybys ten unix navrhoval ty a udělal ty parametry objektové, tak by za chvíli odněkud vylezla skupinka lidí, kteří by začali nadávat, jak je to složité a založili by truc-operační-systém, ve kterém by měli parametry jen jako pole řetězců a všude by tvrdili, jak jsou ty objekty zbytečná komplikace a nikdo je nepotřebuje.
No, schválně. Z jakého důvodu?
Není to nějaký záměrný důvod, ale pokud shora nenadiktuješ jednotnost, tak to k tomu přirozeně směřuje -- konkurence, hledání lepších řešení, ověřování nových přístupů a hypotéz. Vstupuje do toho i entropie, z náhody může vzniknout evolucí lepší řešení.
V podstatě jakýkoli jazyk/platforma, by byl úspěšný a fungoval lépe než současný stav, kdyby byl jediný a středem vesmíru. Můžeš nabootovat do JVM, do Emacsu, Guile, PostgreSQL, Pythonu, Perlu, Selfu, Smalltalku... a pokud budeš psát všechen software v tom jednom, tak ti to bude krásně fungovat dohromady a odpadne ti spousta problémů. V zásadě není těžké udělat skvělý a jednoduchý systém, pokud si dokážeš vynutit, aby všichni psali aplikace v jednom jazyce.
Prostě vydáš novou verzi a necháš tam i starou pro zpětnou kompatibilitu s tím že to bude házet deprecated hlášky? Vždyť se to nijak neliší od používání API.
Teoreticky bys to mohl dostat i do stávajícího systému. Byla by alternativní signatura metody main(), která by místo počtu prvků a ukazatele na pole ukazatelů obsahovala jen ukazatel na nějakou strukturu. Akorát to znamená přepsat velké množství softwaru (kompilátory, shelly, knihovny, rozšířit API pro spouštění procesů atd.). Jinak to ale není až tak těžký úkol -- chce to jen vybrat/vymyslet nějaký fajn textový zápis pro příkazovou řádku a pak definovat tu datovou strukturu, ve které to bude uložené v paměti. Složité na tom jsou spíš ty věci kolem (jak se na této změně dohodnout s ostatními, jak rozšířit všechen stávající software, kterého se to týká...).
Ale proč to má jako definovat životy milionů lidí i padesát let potom? Proto přece není žádná omluva.
Opačný extrém je věci pořád předělávat. Někde jinde jsem si tu posteskl o tom, že přibyl další způsob jak konfigurovat síť. U věcí, které děláš jednou za čas, je to dost únavné, když se "pořád" mění. Resp. ony se sice nemění pořád, ale z tvého pohledu jsou, vždy když je chceš zrovna použít, jiné. S tou sítí to tak není, protože síť konfiguruji přeci jen častěji, než se objevují nové způsoby konfigurace. Ale v jiných případech nebo jiní lidé tímhle můžou docela trpět.
Oba extrémy jsou špatné a) když zakonzervuješ současný stav a zastavíš vývoj b) když věci neustále vylepšuješ (ale zároveň i rozbíjíš -- záleží na úhlu pohledu).
Nicméně ve světle toho, že máme stovky (nebo víc) distribucí GNU/Linuxu, opakovaně se přepisuje KDE, Gnome, vycházejí nové velké verze Qt, GTK, máme X souborových systémů, spousty textových editorů, programovacích jazyků, mění se postupně nástroje pro správu firewallů a sítí obecně... tak mi přijde nepatřičné si stěžovat, že prostředí je nějak extrémně konzervativní a nepřátelské vůči změnám a nedává ti prostor pro inovace.
který nemá žádné výhody nad alternativou a ani nemá žádné zdůvodnění proč by měl existovat
A brání ti někdo tu změnu navrhnout a prosadit? Pokud tu práci uděláš sám a nebo přineseš takové výhody, že to vyváží práci, kterou kvůli tvé změně budou muset udělat ostatní, tak si myslím, že šanci na úspěch máš.
No, tak to prostě nevyexportuje jen tak mimochodem, ale budeš muset povinně vybrat objekt který se použije jako interface?
S tímhle nemám problém, ale IMHO se to zásadně neliší od dnešní situace, kdy ty objekty můžeš explicitně vyexportovat přes D-Bus, JMX, SNMP, SOAP atd. nebo nějaké knihovní API.
Jestli je ten protokol a možnost exportu přímo součást jazyka nebo je to nějaký externí nástroj, který zavoláš během kompilace (či v době běhu), mi nepřijde jako zásadní rozdíl.
Akorát pokud je to součást tvého jazyka, tak narážíš na problém interoperability s jinými jazyky. Jasně, Java má svoje RMI. A tohle by bylo ve stejné roli. Ale kdo dneska používá RMI? Lidi spíš používají protokoly pro vzdálené volání / export objektů, které nejsou závislé jednom jazyce a můžeš mít na obou stranách volání programy psané v různých jazycích.
18.12.2018 23:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na jednu stranu těm tvým představám fandím, ale na druhou stranu si asi dovedu představit lepší využití 50 člověkoroků práce SW inženýrů. Možná by se z dlouhodobého hlediska lidstvu taková investice vyplatila. A v kontrastu s tím, na co se mrhá čas v různých startupech i korporacích, mi to přijde trochu škoda. Ale co naděláš? Deset let zadarmo ti nikdo pracovat nebude, to už je prostě za hranicí toho, co je jednotlivec ochotný investovat (když nepočítám miliardáře, kteří už jsou zajištění, nebo naopak asketické mnichy, kteří nic materiálního nepotřebují). Takže by se na to muselo složit víc lidí. Každý rok je to celkem dost peněz a těžko říct, jak tuhle myšlenku "prodat" třeba v nějaké crowdfundingové kampani, aby se na ni lidé složili.
Jasně no. Osobně bych znova a doufám že už naposledy rád zdůraznil, že to že provádím experimenty na tohle téma neznamená, že vytvářím alternativní operační systém. Dlouhodobě se chystám tenhle model použít ve vlastní verzi osobní wiki, kde chci ověřit nakolik je to životaschopné a nakolik je to jen fata-morgana daná tím, že jsem to prostě nikdy nepoužíval delší dobu v praxi.
Jinak je to trochu podobné těm tvým objektům. Ten klasický unixový přístup na to jde sice "jednoduše" tím, že vstupem a výstupem je proud bajtů (takže to API je opravdu jednoduché), ale už neříká, co v tom proudu bajtů bude, jen se říká, že by to asi měl být text, ale neví se přesně jaký, takže to každý dělá trochu jinak. V důsledku toto "jednoduché" řešení akorát přenáší tu komplexitu dovnitř jednotlivých aplikací a každý se s ní musí potýkat znovu a znovu. Např. v inotify-tools je jakýsi vlastnoručně napsaný generátor CSV souborů. Ale obsahuje chyby, což je z velké míry důsledkem toho, že generování CSV souborů není primárním úkolem tohoto programu a tato funkce je tam implementovaná jen tak nějak mimochodem. Pokud chceš v pěti aplikacích implementovat čtyři formáty, máš to 5×4 a komplexita narůstá. A proč použít právě relační model jakožto logický/abstraktní model, je vysvětlené na tom webu.
Já ti rozumím, jen si nemyslím, že je to správný přístup. Jak jsem psal, chci o tom časem napsat víc.
Fajn, zkusím v tom někdy popsat ty relační roury.
👍
Tohle je třeba důsledek toho, že spousta lidí promrhala čas vytvářením jakýchsi truc-formátů. Kdyby místo toho napsali alternativní serializaci XML infosetu nebo kompilátor do XSD, mohl na tom být obor a celé lidstvo lépe než teď.
Já si občas říkám, že kdybys mohl lidi ovládat jako mravence a prostě vymazat všechny jejich motivace, dalo by se do padesáti let kolonizovat hvězdy. Jenže to je takové dost k ničemu, když to úplně ignoruje lidskou podstatu.
Pokud chceš aby projekt byl úspěšný, nemá smysl na to jít nerdsky a cpát to lidem přes funkcionalitu, musíš prostě taky zvládnout design a marketing. Což většinu ajťáků tak nějak uráží, ale tak to prostě je a hádat se s tím je zbytečné.
A taky by se klidně mohlo stát, že kdybys ten unix navrhoval ty a udělal ty parametry objektové, tak by za chvíli odněkud vylezla skupinka lidí, kteří by začali nadávat, jak je to složité a založili by truc-operační-systém, ve kterém by měli parametry jen jako pole řetězců a všude by tvrdili, jak jsou ty objekty zbytečná komplikace a nikdo je nepotřebuje.
Osobně by mě to neurazilo.
V podstatě jakýkoli jazyk/platforma, by byl úspěšný a fungoval lépe než současný stav, kdyby byl jediný a středem vesmíru. Můžeš nabootovat do JVM, do Emacsu, Guile, PostgreSQL, Pythonu, Perlu, Selfu, Smalltalku... a pokud budeš psát všechen software v tom jednom, tak ti to bude krásně fungovat dohromady a odpadne ti spousta problémů. V zásadě není těžké udělat skvělý a jednoduchý systém, pokud si dokážeš vynutit, aby všichni psali aplikace v jednom jazyce.
Tak třeba python má spoustu problémů, kvůli kterým bys to takhle používat nechtěl (zkoušel jsem s ZODB tvořit perzistentní systém a celé se to rozpadlo).
Teoreticky bys to mohl dostat i do stávajícího systému. Byla by alternativní signatura metody
main(), která by místo počtu prvků a ukazatele na pole ukazatelů obsahovala jen ukazatel na nějakou strukturu. Akorát to znamená přepsat velké množství softwaru (kompilátory, shelly, knihovny, rozšířit API pro spouštění procesů atd.). Jinak to ale není až tak těžký úkol -- chce to jen vybrat/vymyslet nějaký fajn textový zápis pro příkazovou řádku a pak definovat tu datovou strukturu, ve které to bude uložené v paměti. Složité na tom jsou spíš ty věci kolem (jak se na této změně dohodnout s ostatními, jak rozšířit všechen stávající software, kterého se to týká...).
Yep.
Opačný extrém je věci pořád předělávat. Někde jinde jsem si tu posteskl o tom, že přibyl další způsob jak konfigurovat síť. U věcí, které děláš jednou za čas, je to dost únavné, když se "pořád" mění. Resp. ony se sice nemění pořád, ale z tvého pohledu jsou, vždy když je chceš zrovna použít, jiné. S tou sítí to tak není, protože síť konfiguruji přeci jen častěji, než se objevují nové způsoby konfigurace. Ale v jiných případech nebo jiní lidé tímhle můžou docela trpět.
Ano, chce to najít rozumný kompromis. Osobně si myslím že jde prostě všechno verzovat jako API a dělat některé věci deprecated, pokud s tím počítáš od začátku.
Nicméně ve světle toho, že máme stovky (nebo víc) distribucí GNU/Linuxu, opakovaně se přepisuje KDE, Gnome, vycházejí nové velké verze Qt, GTK, máme X souborových systémů, spousty textových editorů, programovacích jazyků, mění se postupně nástroje pro správu firewallů a sítí obecně... tak mi přijde nepatřičné si stěžovat, že prostředí je nějak extrémně konzervativní a nepřátelské vůči změnám a nedává ti prostor pro inovace.
Jak v čem. Já navíc nechci, aby se změnil linux. Jen by bylo fajn, aby nějaký nový operační systém (třeba fuchsia, nebo něco v tom smyslu) zkusil taky inovovat i tahle paradigmata. Třeba si dobře dokážu představit „cloudový“ OS zaměřený přímo na developery.
A brání ti někdo tu změnu navrhnout a prosadit? Pokud tu práci uděláš sám a nebo přineseš takové výhody, že to vyváží práci, kterou kvůli tvé změně budou muset udělat ostatní, tak si myslím, že šanci na úspěch máš.
Tak součástí mého prosazování je tenhle blog a diskuze pod ním. Samozřejmě jako všechno to nemá jen jeden důvod a dalším například je vysvětlit motivaci pro další věci, které mám v plánu, či rozepsané.
11.1.2019 00:45
xkucf03 | skóre: 49
| blog: xkucf03
Třeba si dobře dokážu představit „cloudový“ OS zaměřený přímo na developery.
BTW: OSv
13.12.2018 01:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
V jiných inženýrských oborech se tvrdě jede na normy, a tím je daná kompatibilita.V jinych inzenyrskych oborech take existuji profesni asociace, ktere to ustavovani a dodrzovani norem (mimo jine) zastresuji. Mozna, ze to je ten pravy problem v IT. Jenze hodne lidi to nechce, a vyhovuje jim ten chaos. Protoze by to znamenalo treba kvalifikacni zkousky a tak. Nebo by to znamenalo, ze spousta OSS by se stala v komercni sfere nepouzitelnym. Atd.
13.12.2018 14:18
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
13.12.2018 14:36
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Mozna, ze to je ten pravy problem v IT. Jenze hodne lidi to nechce, a vyhovuje jim ten chaos. Protoze by to znamenalo treba kvalifikacni zkousky a tak. Nebo by to znamenalo, ze spousta OSS by se stala v komercni sfere nepouzitelnym. Atd.Tak si to představ v praxi, že zatímco ty se snažíš certifikovat a ozkoušet pracovníky, aby jeli podle norem, tak tvoje konkurence uvede na trh stejný produkt a nechá tě v prachu za sebou, protože zákazníkům je nějaká tvoje certifikace totálně ukradená. Certifikace imho má smysl tam kde má smysl - v oblastech, kde jde o život. Všude jinde se ti víc vyplatí zaplatit lidi, co něco umí a poskytují výsledky, než lidi co mají tři certifikáty a používají to jako metriku svojí ceny. Jinak normy taky vyžadují, aby vlastně někdo mohl říct, že je něco objektivně špatně a nějak to může být objektivně lépe. To je důvod proč existují třeba normy v elektronice, kde prostě když to budeš dělat blbě, tak uhoříš, nebo umřeš po zásahu elektřinou, či se ti prostě roztečou dráty. Existuje jasně daná sada postupů, která ti zajišťuje, že se to nestane. Ale v IT? Dokážu si představit normy tak na bezpečnost, ale co se týče programování? Existují nějaké best practices, ale ty se liší podle použití a platforem. A většinou ani nejde říct že je nějaká technika objektivně lepší než jiná a neustále se to mění. Třeba před deseti lety byl jasným trendem OOP přístup, dneska hodně zažívá renesanci funckionální programování a za deset let to nejspíš bude zase něco o trochu jiného, co přináší úplně jiné výzvy. Dělat na to nějaké normy, tak než je vyvineš a adoptuješ, tak už můžeš začít dělat nové.
13.12.2018 15:04
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Tak si to představ v praxi, že zatímco ty se snažíš certifikovat a ozkoušet pracovníky, aby jeli podle norem, tak tvoje konkurence uvede na trh stejný produkt a nechá tě v prachu za sebou, protože zákazníkům je nějaká tvoje certifikace totálně ukradená.
Jinak normy taky vyžadují, aby vlastně někdo mohl říct, že je něco objektivně špatně a nějak to může být objektivně lépe. To je důvod proč existují třeba normy v elektronice, kde prostě když to budeš dělat blbě, tak uhoříš, nebo umřeš po zásahu elektřinou, či se ti prostě roztečou dráty.Jenom faktickou, jsou zákazníci, kteří chtějí revizi jen pro ten papír (protože ten papír po nich chce třeba pojišťovna) a faktická bezpečnost (elektrická, plynová, požární, chemická) je vůbec nezajímá a spoléhají na to, že to nikdy nenastane a když už, tak se jim z toho podaří vybruslit a na někoho to hodit. Takže v tomto bych vůbec nerozlišoval mezi software a elektronikou, prostě vždy se najde někdo, koho nějaká revize jen zbytečně otravuje.
Tak si to představ v praxi, [..] protože zákazníkům je nějaká tvoje certifikace totálně ukradená.Ja si to v praxi predstavit dovedu. Myslis, ze jim bude ukradene, kdyz dostanou kvalitni software, na ktery budou moci pozadovat zaruku, a ze kdyz jim nejaky dodavatel slibi, ze to bude podle standardu (na ktery treba spoleha zase jiny dodavatel), tak se to podle toho standardu take bude chovat? (Ze MS..
)
Ty jako inzenyr (pokud se tim chces honosit) bys mel usilovat o to, aby se veci delaly co nejkvalitneji, je to vec profesionalni cti. (Delat to co nejlevneji obhajuji zase jine profese.) Takze opravdu nechapu obhajobu slendrianu nekterych firem, ktere "move fast and break things", pripadne "embrace, extend and extinguish" (a to jsou jeste ty lepsi pripady). (Vubec obhajobu slendrianu s tim, jako by vydelavat penize bylo nejakym nezadatelnym lidskym pravem, cim dal tim vic povazuji za hlavni problem soucasne spolecnosti.)
Co se tyce te komory samotne. Vetsinou se ridi hlasovanim svych vlastnich clenu, takze i kdyz neni uplne vylouceno, ze si clenove zvoli do predstavenstva pana Jirsaka, zase tak pravdepodobne to neni. A ze do neceho ta komora bude mluvit? No srovnej si to s dneskem. Dnes o techto vecech rozhoduji casto manazeri, nikoli inzenyri. Je to lepsi? (Ja sam nejsem velky fanousek byrokracie, ale nekdy je to bohuzel nutne zlo.)
Ale jinak jsem koukal, existuje treba IEEE Computer Society, coz je takove embryo. Casem to urcite vznikne.. jenze zase ten zatraceny cesky konzervativismus, bohuzel nebudeme mezi prvnimi. A pak se lidi divi, ze tu neni zajimavy vyvoj.
Nicmene, doufam, ze svuj postoj jeste prehodnotis. Tim spis, ze se ti tu spousta lidi snazi naznacit, ze ve skutecnosti to co hledas jsou (casto jen poctiveji dodrzovane) standardy.
15.12.2018 12:30
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Ty jako inzenyr (pokud se tim chces honosit) bys mel usilovat o to, aby se veci delaly co nejkvalitneji, je to vec profesionalni cti.Když jsem něco podobného řekl svému známému tak před rokem a půl, tak se mi vysmál do ksichtu. Jsem rád, že nejsem ještě úplně sám s takovými zásadami.
15.12.2018 12:45
Josef Kufner | skóre: 70
Když jsem něco podobného řekl svému známému tak před rokem a půl, tak se mi vysmál do ksichtu. Jsem rád, že nejsem ještě úplně sám s takovými zásadami.Protože je to hloupost, engineering je od toho aby věci byly vytvořeny nejpraktičtěji, ne nejkvalitněji, od nejkvalitnějších věcí je akademický sektor.
17.12.2018 20:30
Josef Kufner | skóre: 70
17.12.2018 20:47
xkucf03 | skóre: 49
| blog: xkucf03
+1. Já většinou stojím na straně dlouhodobých cílů a "kvalitnějších" řešení, ale rozhodně to nejde prohlašovat za nějakou absolutní hodnotu.
Když někdo udělá mizernou/polovičatou práci a je zřejmé, že se to bude za půl roku předělávat, tak mu řeknu, ať to udělá rovnou pořádně. Ale pokud by se měl někdo dva roky piplat s "dokonalým" řešením, u kterého navíc není jisté, že tu "dokonalost" někdo ocení (a naopak je téměř jisté, že bychom během těch dvou let něco prošvihli), tak mu řeknu, ať se na to vykašle a udělá to v rámci možností (termínu, rozpočtu), jak nejlépe umí, ale ať tím netráví víc času.
Ono vidět a uvažovat jen v horizontu čtvrtletí vede do průšvihu. Ale uvažovat pořád jen v horizontu deseti a více let nedává o moc lepší výsledky. Ty dlouhodobé a krátkodobé cíle je potřeba držet v rovnováze, protože když se budeš soustředit jen na dlouhodobé, tak zkrachuješ/zemřeš dřív, než jich stihneš dosáhnout. A naopak když se budeš soustředit jen na krátkodobé, tak je to v dlouhodobějším součtu (pár po sobě jdoucích let) horší výsledek + hrozí že zkrachuješ/pojdeš dřív nebo budeš dlouhodobě živořit.
 17.12.2018 21:29
xxx | skóre: 42
| blog: Na Kafíčko
17.12.2018 21:29
xxx | skóre: 42
| blog: Na Kafíčko
Ty jako inzenyr (pokud se tim chces honosit) bys mel usilovat o to, aby se veci delaly co nejkvalitneji, je to vec profesionalni cti.je takovej ideologickej nesmysl. Nebo demeonstrace odtrzeni vedcu od inzenyrske reality. Pokud ji vezmes absolutne, pak by nikdy nevznikl Linux, ve meste by byly tak tri Francouzske restaurace, bydlel bys nejspis ve stanu a nikdy bys nevidel fotky od kamaradu. Nebo ji rozsisris o "za pouzit rozumnych prostredku a v rozumnem case". Pak se muzes hadat o tom, jak moc ti inzenyrska cest dovoli slevit z kvality. Narozdil od JS v tomto pozadavku nevidim jen diktat manageru, ale i krutou realitu toho, ze zakaznik se chce sveho zbozi nekdy dockat a ani jeho prostredky nejsou neomezene.
17.12.2018 22:54
xxx | skóre: 42
| blog: Na Kafíčko
17.12.2018 22:58
xxx | skóre: 42
| blog: Na Kafíčko
18.12.2018 10:19
xxx | skóre: 42
| blog: Na Kafíčko
18.12.2018 23:27
xxx | skóre: 42
| blog: Na Kafíčko
18.12.2018 23:42
xkucf03 | skóre: 49
| blog: xkucf03
V GNU se snaží složitější/vysokoúrovňovější věci psát funkcionálně, v Guile (implementace Scheme). GuixSD je na tom postavený. A většina Emacsu je psaná v EmacsLispu (to céčko je spíš takový zavaděč). Na druhou stranu příkazy jako ls, echo atd. budou psané v jazyce na úrovni céčka a nikomu to až tak moc nevadí.
17.12.2018 23:08
xxx | skóre: 42
| blog: Na Kafíčko
Ty jako inzenyr (pokud se tim chces honosit) bys mel usilovat o to, aby se veci delaly co nejkvalitneji, je to vec profesionalni cti. (Delat to co nejlevneji obhajuji zase jine profese.)
18.12.2018 10:26
xxx | skóre: 42
| blog: Na Kafíčko
18.12.2018 23:26
xxx | skóre: 42
| blog: Na Kafíčko
18.12.2018 00:55
xkucf03 | skóre: 49
| blog: xkucf03
S tímhle už se dá souhlasit. Ano, jako vývojář můžu říct: v tomhle čase a s těmito lidmi není možné dodat produkt a nepůjdu pod nějakou minimální kvalitu, na které jako profesionál trvám, takže buď osekáme funkcionalitu nebo posuneme termín / navýšíme rozpočet. A na osekání funkcionality se většinou dohodnout dá s tím, že v původním termínu se dodá nějaký základ, který obsahuje to nutné a zbytek se dodá v další iteraci.
(nicméně to je něco jiného než "usilovat o maximální kvalitu" -- spíš je to o tom mít nějaké meze, za které už se nejde, i kdyby se manažer/zákazník stavěl na hlavu)
17.12.2018 12:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ja si to v praxi predstavit dovedu. Myslis, ze jim bude ukradene, kdyz dostanou kvalitni software, na ktery budou moci pozadovat zaruku, a ze kdyz jim nejaky dodavatel slibi, ze to bude podle standardu (na ktery treba spoleha zase jiny dodavatel), tak se to podle toho standardu take bude chovat? (Ze MS..Myslím že velké části zákazníků to skutečně bude naprosto ukradené. Nehledě na to, že pochybuji že je vůbec v možnostech kohokoliv třeba řešit nějak plošně záruku na software. To jde u zakázek 1:1, či 1:N, kde N je rozumně malé. Pokud bude větší, tak dostaneš tak leda nějaký příslib ve stylu (někdy to opravíme), který se nijak neliší od dneška.
Ty jako inzenyr (pokud se tim chces honosit) bys mel usilovat o to, aby se veci delaly co nejkvalitneji, je to vec profesionalni cti. (Delat to co nejlevneji obhajuji zase jine profese.) Takze opravdu nechapu obhajobu slendrianu nekterych firem, ktere "move fast and break things", pripadne "embrace, extend and extinguish" (a to jsou jeste ty lepsi pripady). (Vubec obhajobu slendrianu s tim, jako by vydelavat penize bylo nejakym nezadatelnym lidskym pravem, cim dal tim vic povazuji za hlavni problem soucasne spolecnosti.)Protože z nějakého důvodu porovnáváš věci z hlediska kvality a ne efektivity. Vem si třeba moderní SSD. Ty jsou na úrovni buňek nekvalitní jak prdel. V podstatě neustále se část znich náhodně ztrácí a celé je to jen malý krůček od naprostého šumu, ze kterého to vytahují pokročilé samo-opravné mechanismy. Přesto dneska SSD používá prakticky každý. Velmi často je pro zákazníka lepší aby měl něco, co třeba funguje jen jako prototyp, než aby neměl nic. Je dobré si uvědomit, že alternativou je čekat třeba deset let na vývoj něčeho, co bude sice super kvalitní, ale už v době vydání naprosto zastaralé, nehledě na to že mu uteklo deset let zisků a ušlých příležitostí. Kvalitu totiž bez vloženého času a námahy nezískáš. A pak to ještě někdo musí zaplatit. Samozřejmě tohle neplatí plošně, ale minimálně pro větší desítky procent zákazníků ano. Důležité je, že existují minimálně tyhle dva druhy zákazníků s naprosto rozdílnými požadavky a proto vznikají třenice na jejich rozhraní.
Nicmene, doufam, ze svuj postoj jeste prehodnotis. Tim spis, ze se ti tu spousta lidi snazi naznacit, ze ve skutecnosti to co hledas jsou (casto jen poctiveji dodrzovane) standardy.Teď nevím k čemu se to přesně vztahuje (ztratil jsem kontext diskuze).
13.12.2018 17:35
xxx | skóre: 42
| blog: Na Kafíčko
13.12.2018 14:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Rozumný strojový/programátorský přístup k systémovým nástrojům - hrůza - dělal jsem systém pro identity management a provisioning, třeba takové nástroje pro kvóty jsou peklo, žádný dobře definovaný výstupní formát, v různých situacích se tam objevují nečekané znaky jako hvězdička značící překročenou kvótu, což rozbije ad-hoc parser, změny mezi verzemi... a spousta dalších.Mezi moje oblíbené patří, když se někdo pochlapí a začne posílat ten JSON, či XML na standardní vstup a výstup a pak najednou někde nějaká knihovna z pyramidy hoven pod tím ubleje třeba nějakým warningem, nebo něčím podobným a celé to rozbije. To je pak debugování jedna radost. Nedávno jsem se skvěle pohádal s týpkem co u nás zaváděl OpenShift, který chtěl, aby všechny aplikace co tam běží v Docker kontejnerech logovaly na stdout. Dalo mi šílenou práci mu vysvětlit, proč není dobré parsovat strukturované logy regexpama a že se to dřív nebo později rozbije, až tam někde vleze nějaký traceback, nebo něco. A půlka z té hadky byla jen o tom, že nemohl pochopit, že když bude víc procesů zapisovat na stdout, tak to pak nenaparsuje nikdo. Nakonec jsem to dohledával a našel jsem, že append má atomický zápis na stdout, ale jen do čtyř kilobajtů. Takže se budeme modlit, aby někdo v debug logu nelogoval víc jak 4kB, nebo se nám to překříží a polezou z toho hovna. Výsledek je, že to bude v JSONu a budem si nad tím u paralelních aplikací psát vlastní serializátor. O tom že by jsme to mohli cpát po UDP někam do sítového logovacího serveru nechtěl ani slyšet, kvůli propojům a firewallům a kde čemu.
Jinak spoustu těch věcí se pokoušel řešit nebo měl/má částečně vyřešené Microsoft. Ale moc se to neujalo. Něco už tu padlo - Registry, Powershell. Ale taky celé WMI (Windows Management Interface), system log, nebo historicky COM/DCOM. Zrovna ten DCOM byla ve své době zdánlivě super technlogie, která řešila síťově transparentní předávání objektů a volání funkcí mezi aplikacemi, včetně systémově integrované autentizace a autorizace, s celkem minimálním overheadem. Dodnes na tom běží velké aplikace, které by bylo extrémně obtížné přepsat do něčeho jiného - a do čeho vlastně? WebServices, REST? Bylo to ale Windows-only a s mizerným toolingem a nulovou možností debugování. Taková polo-technologie.Já jsem nad tím nedávno extenzivně přemýšlel a dospěl jsem k názoru, že v Microsoftu je něco hrozně špatně. Něco jako že satan tam zasel své sémě a teď tam roste jeho vejce a uplatňuje na všechno zlo, nebo tak něco. Zkoušel jsem nad tím přemýšlet racionálně a bez zaujatí, což bylo relativně těžké, ale myslím že se povedlo a prostě nemám jinou teorii, proč jsou schopni vymyslet spoustu inovativních a zajímavých technologií a pak totálně zkurvit jejich provedení. Cokoliv co vyjde z MS, i kdyby to na pohled byla dobrá myšlenka, tak nese vrstvu totální posyflenosti. Nechápu proč. Třeba te powershell, to vypadá super a ty myšlenky co fungují jsou fajn. A pak jsou tam takové drobné zkurvenosti, které nikdo neřeší, nebo které řešit ani pořádně nejdou a lidi to jen frustruje a sere. Jak kdyby nějaký inženýr navrhl dobrý projekt a satanovo vejce na něj uplatnilo svoje zlo a zohlo ho a pokroutilo. Jediná výjimka je snad Visual Studio Code, což je mimochodem ten důvod, proč jsem nad tím přemýšlel. Je to asi první produkt, kde nemám chuť něco rozmlátit asi tak každých deset minut, naopak si vcelku nemám na co stěžovat. PS: Samozřejmě je mi jasné, že to není Satan, ale mix korporátní zkurvenosti s closedsource uzavřeností a arogancí největšího hráče. Ale hypotéza by jinak čistě na základě pozorování mohla být stejně dobrá :)
Nakonec bych možná nejvíc souhlasil s názorem, že toto celé je víc sociální než technický problém. V jiných inženýrských oborech se tvrdě jede na normy, a tím je daná kompatibilita. V IT se to z určitých důvodů neujalo, vládne z tohoto pohledu anarchie, byť pokusy jako celý OSI stack a X.??? specifikace protokolů byly, bylo do nich vloženo nesmírné množství práce, ale neuspěly. Ano, používáme IP/TCP, SMTP, HTTP, což jsou takové nejmenší možné společné jmenovatele, ale ty X:??? protokoly byly rozpracované do podstatně větších detailů. Problém je možná rychlost vývoje, která vede na to, že takto komplexní normy se stávají zastaralými v okamžiku finalizace.Problém norem je, že v oboru který se vyvíjí tak rychle, jako IT jsou často doslova brzda, která stahuje ty kdo na ně jedou dolu. Neplatí to úplně, ale často ano. Taky proces, kde nějaká komise zasedne a začne vytvářet normu a pak o ní dva roky přemýšlí a rokuje a do toho se přídavají různé korporace, co tam začnou tlačit svoje zájmy a nakonec tu normu stejně implementují jen napůl, protože si tím chtějí udělat vendor lockin. Z tohohle hlediska je RFC docela fajn.
13.12.2018 14:53
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Zkoušel jsem nad tím přemýšlet racionálně a bez zaujatí, což bylo relativně těžké, ale myslím že se povedlo a prostě nemám jinou teorii, proč jsou schopni vymyslet spoustu inovativních a zajímavých technologií a pak totálně zkurvit jejich provedení.Já proto mám vysvětlení, které je úplně jednoduché a netýká se jen MS, ale v podstatě skoro každého komerčního softwarového produktu (se kterým jsem nucen pracovat). Prostě jde jen o prachy a o snahu donutit zákazníka zakoupit nejvyšší verzi licence a ve chvíli, kdy i tohle je málo, ho potom donutit znovu zaplatit za vyšší verzi a nebo za "zaručený" rovnák na ohejbák. Tenhle model jsem viděl několikrát. Některé featury jsou dostupné až v licenci Gold, ale je naprosto jasné, že musí být už implementovány v Bronze, protože jiné věci na tom závisejí. Jen to není exportované. Takto jsou mixovány vlastnosti tak, aby byl zákazník (po úspěšném vendor lock-in) donucen časem přejít na nejvyšší licenci. Totéž bugy. Sice máte licenci, ve které se píše, že budou vydávány opravy bugů, ale to je jen právničina, takže některé z technického hlediska jasné bugy nejsou bugy (takže update nebude), ale máte si koupit novou verzi, protože tam už je to opravené (to co v předchozí verzi není bug). A MS Windows není OS, to je platforma pro generování peněz. Ve Win by spousta věcí mohla být a spousta věcí tam i je, ale je to zkurvené tak, aby zákazník byl nucen dokoupit další software, který to bude řešit. Ano, nemusí to vždy nutně generovat zisk jen pro MS, ale za to se na tom napakuje spousta dalších firem prodávající různé Cleanery, Tweakery, Backupery apod. Co mě vždy zajímalo je, jak to můžou snášet ti lidi na nižších pozicích. Tj, že programují něco třeba skvělého, výkonného a stabilního, ale ve výsledném produktu je to záměrně vykastrované. Mě by to strašně frustrovalo.
13.12.2018 16:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Co mě vždy zajímalo je, jak to můžou snášet ti lidi na nižších pozicích. Tj, že programují něco třeba skvělého, výkonného a stabilního, ale ve výsledném produktu je to záměrně vykastrované. Mě by to strašně frustrovalo.Taky jsem nad tím přemýšlel při psaní té předchozí odpovědi. Asi bych to nedal. Na druhou stranu jsem pracovla na horších pozicích a vím že se to dá zvládnout filosofií „mrdat všechno“, akorát ta práce je pak už jen čistě opruz na vydělávání peněz, což je smutné.
13.12.2018 14:31
xkucf03 | skóre: 49
| blog: xkucf03
v různých situacích se tam objevují nečekané znaky jako hvězdička značící překročenou kvótu, což rozbije ad-hoc parser
To je problém, že se neodděluje obsah a forma, a výstup určený pro uživatele se pak někdo snaží parsovat strojově. V podstatě je to ukázka selhání principu textuality. Ten princip je na jednu stranu myšlen dobře a chápu i averzi k binárním formátům1, ale vytvořit formát použitelný dobře pro člověka i pro stroj prostě je problém. Proto považuji za hodně důležité, aby program poskytoval data (i) v čisté podobě a proto se zabývám těmi relačními rourami2.
[1] které byly často spojený právě s proprietárními nedokumentovanými formáty, se kterými bylo potřeba bojovat reverzním inženýrstvím
[2] odkaz už tu někde je
Ještě k těm normám. POSIX nakonec je norma, ale přijde mi, že u toho se to nějak zastavilo - řeší API na úrovni C headerů pro aplikační software a některé základní nástroje. Ale vůbec neřeší nástroje pro správu systému a jejich strojové použití.
Protože ty nástroje má používat člověk. A standardizovat člověka je těžké. Hlavičkové soubory používá stroj, proto jsou přesně definované.
Ale co skutečně nechápu je, že po takové době od vzniku POSIXu potažmo GNU/Linuxu neexistuje rozumné API pro strojovou správu systému a rychlé spolehlivé skriptování. To to nikdo nepotřebuje? Nebo to je tolik práce? Nebo se maintaineři jednotlivých nástrojů nikdy nedohodnou? Nebo to je něco pro Enterprise sféru, kde jsou na to specializované nástroje, které to nějak řeší ve svém ekosystému? Existují nástroje jako puppet, ansible a podobně, ale ty řeší spíše jen část statické konfigurace, pomocí stávajících nástrojů, a tomu odpovídá jejich komplexita a přehlednost.
Existuje standard (CIM nebo tak nějak) a výrobci pro enterprise jej nějak implementují. Ale každý jinak, takže použitelný je jen ve svém vlastním portfoliu, případně se hackuje kompatibilita s cizími produkty a je to nikdy nekončící práce s rozlobenými uživateli. Prozradím, že byl pokus přidat toto rozhraní do open source světa a, jak správně píšeš, mezivýsledkem bylo přidání DBus API a zknihovnění některých nástrojů, ale nakonec z toho nic nebylo, protože se ukázalo, že implementace klientské strany podle standardu nezaručila funkčnost s proprietárními implementacemi serverové strany. A psát vlastní serverovou stranu, která bude opět fungovat jen v jednom ekosystému, se nepovažovalo za dobrý nápad.
Příkazy pro správu sítě, uživatelů, skupin, kvót, služeb, filesystémů a podobně by snad mohly poskytovat (volitelně) jednotný interface
Je to rozdrobené. Na síť máš NETCONF/YANG. Na uživatele schémata v LDAP. Souborové systémy nemají nic. Roste libmount a udisks. Diskové kvóty nejsou jednotné ani na straně jádra (i když poslední dobou se to trochu zlepšuje). Nástroj quota je podle autora kopie BSD quoty včetně uživatelského rozhraní. Od 4.02 repquota umí výstup do XML.
Protože ty nástroje má používat člověk. A standardizovat člověka je těžké. Hlavičkové soubory používá stroj, proto jsou přesně definované.+1, navíc ono ani s tak nízkoúrovňovou věcí jako POSIX to není až tak slavné... OS, které mají POSIX certifikaci, jsou typicky mrtvé, obskurní nebo specializované. Výjimka ja macOS, u kterého mi není jasné, k čemu tu certifikaci vlastně má...
15.12.2018 14:11
xkucf03 | skóre: 49
| blog: xkucf03
Jenze, mam posledni dobou pocit, ze tato "neochota se dohodnout" svazuje jakykoli vyrazny inzenyrsky pokrok. Zda se mi, ze tam, kde se veci hybou, treba web technologie (nebo driv IETF), je to prave proto, ze vznikl nejaky standard.
Je otázka, jak měříš pokrok? Je to technická inovativnost? Revoluční myšlenka? Užitečnost?
Ty skvělé věci stejně většinou vytvoří jeden člověk a ostatní se k němu přidají až pak. Např. v CADu mi přijde zásadní pokrok1 to, že nekreslíš jednotlivé čáry2, ale že definuješ zeď, v ní okno atd. nebo nějakou hmotu, která se později vyfrézuje. Nebo kryptoměny -- to je taky obrovský pokrok až revoluce a přesto to vzniklo tak, že si nikdo nikoho na nic neptal a prostě to udělal, nezasedala3 žádná komise a nedefinovala předem standard. A platí to ve všech oborech -- pokud vymyslíš něco užitečného, co dobře slouží lidem, tak je to pokrok.4
Samozřejmě, že je dobré, když se to standardizuje a je pak možné, aby spolupracovaly programy různých autorů a zapojilo se do toho aktivně víc lidí. Ale sama o sobě ta myšlenka a její realizace je podle mého pokrok a to bez ohledu na to, zda se standardizuje nebo ne.
Resp. proč by mělo být lepší (nebo jediné správné) udělat nejdřív komisi, dohodnout standard a pak ho teprv realizovat? Proč by mělo být výrazně horší to, když někdo udělá nejdřív realizaci a až pak to teprve vydá jako otevřený standard? Nebo jsi to tak nemyslel a standardy dohodnuté dodatečně ti přijdou OK?
Ono když to člověk/firma dělá sám, tak se připravuje o výhodu "víc hlav víc ví, víc očí víc vidí" a hrozí, že v návrhu něco přehlédne, udělá v nějakou chybu, kterou by šlo v počátku snadno opravit, kdyby ho na ni někdo upozornil. Nicméně tohle se přece dá řešit i neformálním procesem a konzultacemi, ne? Na druhé straně ten formální přístup a snaha o standardizaci už od počátku má taky svoje úskalí.
Co se týče společenského rozměru: V těch komisích stejně nebývá nějaké demokratické zastoupení celé společnosti, ale většinou zástupci pár firem, které spolu zrovna kamarádí resp. mají nějaký společný zájem a došly k tomu, že protentokrát se jim vyplatí koordinovat svoji činnost místo aby mezi sebou bojovaly a snažily se předhonit jedna druhou. Tak jdou chvíli spolu, alespoň v jednom závodě z mnoha (a často s postranními úmysly a s vizí toho, že toho druhého stejně nějak obejdou a nabídnou zákazníkům konkurenční výhodu).
Nebo by v těch výborech měli sedět zástupci informatiků jakožto jednotlivců, profesionálů (a ne jen pár vybraných firem)? Ale kdo je to informatik? Člověk s diplomem? Osobně mi přijde samozřejmé si tou školou projít, ale na druhou stranu vím, že v oboru je spousta samouků, kteří žádné formální vzdělání nemají a přesto jsou úspěšní a jsou právoplatnou součástí našeho oboru. Asi by bylo správné, aby si všichni profesionálové v oboru tou VŠ prošli, ale současná situace je jiná. Pokud by se to mělo změnit, tak jak k tomu přijdou ti, kteří se rozhodovali ještě za starých pravidel a místo formálního vzdělání si vybrali samostudium a praxi? Ti budou zastoupeni nebo ne? A na druhé straně: když se nějaký kuchař nebo zedník rozhodne, že po večerech bude dělat známým webové stránky (za úplatu), tak je součástí oboru a měl by být v těch organizacích zastoupen nebo ne?
[1] dneska už je to samozřejmost, ale původně to tak nebylo
[2] což je vlastně jen staré rýsování na papír, akorát realizované v počítači
[3] tedy pokud pomineme konspirační teorii, že to vymysleli židozednáři a předem o tom dlouze diskutovali v komisích, standardizovali to a nakonec to zveřejnili pod pseudonymem Satoshi
[4] i když jsi to předem nekonzultoval v žádné komisi a nedohodl jsi příslušný standard
Je otázka, jak měříš pokrok? Je to technická inovativnost? Revoluční myšlenka? Užitečnost?Delat veci (u koncoveho zakaznika) efektivneji. Nemam pocit, ze to IT zvlada.
V těch komisích stejně nebývá nějaké demokratické zastoupení celé společnosti, ale většinou zástupci pár firemA kdo jiny tam ma byt, kdyz se inzenyri nedovedou sami dohodnout, aby tam meli vyraznejsi zastoupeni?
Resp. proč by mělo být lepší (nebo jediné správné) udělat nejdřív komisi, dohodnout standard a pak ho teprv realizovat? Proč by mělo být výrazně horší to, když někdo udělá nejdřív realizaci a až pak to teprve vydá jako otevřený standard? Nebo jsi to tak nemyslel a standardy dohodnuté dodatečně ti přijdou OK?
Prakticky žádný rozumný standard nevznikne jen tak na papíře a pak se teprve nerealizuje. S POSIXem to nebylo tak, že by někdo teoreticky nalajnoval specifikaci a pak se podle ní začaly psát operační systémy, ale přesně naopak. A vlasně ani IPv6, o které se každou chvíli nějaký mudrc otírá, že ho "vymysleli od stolu akademici odtržení od života", tímhle způsobem ve skutečnosti nevzniklo; i ten původní standard navrhli lidé, kteří měli spoustu praktických zkušeností s IPv4 a tím, jak funguje, s čím jsou problémy a co mu chybí. A pak se ty standardy ještě v mnoha ohledech upravovaly na základě zpětné vazby z praxe.
17.12.2018 12:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ty skvělé věci stejně většinou vytvoří jeden člověk a ostatní se k němu přidají až pak. Např. v CADu mi přijde zásadní pokrok1 to, že nekreslíš jednotlivé čáry2, ale že definuješ zeď, v ní okno atd. nebo nějakou hmotu, která se později vyfrézuje. Nebo kryptoměny -- to je taky obrovský pokrok až revoluce a přesto to vzniklo tak, že si nikdo nikoho na nic neptal a prostě to udělal, nezasedala3 žádná komise a nedefinovala předem standard. A platí to ve všech oborech -- pokud vymyslíš něco užitečného, co dobře slouží lidem, tak je to pokrok.4 Samozřejmě, že je dobré, když se to standardizuje a je pak možné, aby spolupracovaly programy různých autorů a zapojilo se do toho aktivně víc lidí. Ale sama o sobě ta myšlenka a její realizace je podle mého pokrok a to bez ohledu na to, zda se standardizuje nebo ne. Resp. proč by mělo být lepší (nebo jediné správné) udělat nejdřív komisi, dohodnout standard a pak ho teprv realizovat? Proč by mělo být výrazně horší to, když někdo udělá nejdřív realizaci a až pak to teprve vydá jako otevřený standard? Nebo jsi to tak nemyslel a standardy dohodnuté dodatečně ti přijdou OK?Další věc je, že jsem málokdy viděl, aby se víc jak tři lidi jen tak dohodli na něčem a nikdo neměl výhrady. Komise mají tendenci zabít produktivitu na problému konsenzu, kde se každý snaží protlačit svojí vizi.
Linux oficialne POSIX neni,De iure neni, de facto ano.
se z nej stal de fakto standard, ktery ma nova API nad ramec POSIXu. Takze misto toho, aby se vyvojari dohodli a upravili ten standard, tak proste vyrobili vlastni reseni.Ale to platilo i v minulosti. POSIX vznikl jako nejmensi spolecny jmenovatel ruznych [Uu]nixu. Takze ostatni [Uu]nixy implementovaly veci nad ramec.
A taky pochopitelne - programatori radeji programuji, nez aby vysedavali v nejakem vyboru o standardech. To druhe zni jako prace a lide to nebudou delat, pokud nebudou placeniToto si myslim, ze je trochu falesna dichotomie. Bud programovani, nebo tvorba standardu. Prijde mi, ze jsi spis pro to druhe, coz neni uplne stastne, protoze to vede k problemu design by committee. Mne se libi spis pristup, ktery se uplatnil u nekterych webovych techonologii. Implementuje se prototyp, vyzkousi se to v realnem nasazeni, a pokud se to uchyti, vytvori se standard. Mimochodem, podobnym zpusobem vznikl treba i standard Javy.
Toto si myslim, ze je trochu falesna dichotomie. Bud programovani, nebo tvorba standardu. Prijde mi, ze jsi spis pro to druhe, coz neni uplne stastne, protoze to vede k problemu design by committee.Ja nejsem proti kompromisu ani metode jake navrhujes, ale jsem spis pro to druhe, protoze mi prijde, ze mame az prilis toho prvniho. (Jak rikam, lidsky se to da pochopit, je spousta nadsencu, co programuji veci zdarma, ale nikdo nechce zdarma vysedavat v komisich o standardech.) Problem s kulturou standardu "de facto" a ne "de iure" je v tom, ze je prilis snadne nejaky standard bezduvodne zahodit, misto snahy ten standard zmenit a zlepsit. Coz se deje na muj vkus az prilis casto. (Druhy problem je pak v tom, ze pak ty standardy spis urcuji firmy na zaklade svych zajmu, tj. management, a nikoli inzenyri, na zaklade toho, co je inzenyrsky kvalitni postup.) Jinak ted nekdo na Hacker News postoval tak trochu souvisejici prednasku. Je to sice spis o tom jak se vyviji akademicka sfera, ale rekl bych, ze absence nejakeho profesionalniho telesa je s tim tak nejak spojena.
je prilis snadne nejaky standard bezduvodne zahodit, misto snahy ten standard zmenit a zlepsit.Vetsinou jsou ty standardy zahazovany ale z nejakeho duvodu. Typicky to byva, ze neodpovidaji praktickym potrebam.
Coz se deje na muj vkus az prilis casto.To je otazka vkusu. Je potreba mit na pameti, ze vyvoj v oblasti pocitacu prochazi bezprecedentnimi zmenami. Behem peti deseti lety se meni schopnosti hardwaru tak, ze to, co je v jeden okamzik povazovano ze sci-fi, je za pet let beznou realitou a za dalsich pet let uz technologii za zenitem. V takovem prostredi definovat formalni standardy, ktere budou relevantni v danem case, je znacne narocne.
(Druhy problem je pak v tom, ze pak ty standardy spis urcuji firmy na zaklade svych zajmu, tj. management, a nikoli inzenyri, na zaklade toho, co je inzenyrsky kvalitni postup.)Zalezi na tom, co jsou zajmy firem. Podle toho druheho pristupu vznikaly treba standardy XHTML 2.0, ktere jsou sice inzenyrsky pekne, ale nebyly zasazeny do realneho ramce (realnych potreb), a tak jsou v praxi nepouzitelne a misto toho nastoupil truc podnik v podobe HTML5, ktery sel vylozene po reseni praktickych problemu.
(Druhy problem je pak v tom, ze pak ty standardy spis urcuji firmy na zaklade svych zajmu, tj. management, a nikoli inzenyri, na zaklade toho, co je inzenyrsky kvalitni postup.)Kdyz jsem psal prispevek niz, jeste me napadlo srovnani CORBA vs. microservices postavene na HTTP.
16.12.2018 22:50
xkucf03 | skóre: 49
| blog: xkucf03
Já myslím, že tam je dost zásadnější rozdíl protokolu. Kdyby dnešní mikroslužby byly jen CORBA s HTTP místo IIOP, tak by nebyly tak zajímavé.
17.12.2018 00:10
xkucf03 | skóre: 49
| blog: xkucf03
To je technicky detail. V tomto prikladu mi slo o to, ze sice CORBA et al. jsou inzenyrsky dobre vymyslene veci, ale kdyz si vezmes, kolik tisicu clovekohodin se na tom zbytecne promrhalo, ... pricemz realita ukazala, ze svetu staci mnohem min.
Já naopak vnímám mikroslužby jako něco složitějšího. Je to něco jako DI a IoC, kdy vlastně obrátíš aplikaci naruby a podíváš se dovnitř resp. řídíš ji zvenku. Už to není černá skříňka a má to nějaký řád. V případě mikroslužeb jde o to, že můžeš zvenku jednotným způsobem sledovat, jak skrze systém proudí volání (funkcí/metod), a nejen, že to můžeš sledovat, můžeš to i ovlivňovat, různě směrovat provoz, upgradovat části za chodu, řešit přístupová práva, i nějaké QoS atd. Ty frameworky a nástroje kolem toho jsou moc pěkné, nebo alespoň podle svých prezentací a po vyzkoušení nějakého Hello world příkladu pěkně vypadají... Je to na jednu stranu zajímavé a jakýsi pokrok, na druhou stranu nevím, jestli to má smysl a jestli se náhodou nedělají věci složitěji, než je nutné, jestli se neřeší nějaký neexistující problém, nebo problém, který by neměl existovat a jehož příčina by se měla odstranit jinde. Další typický problém je, když se to přežene s granularitou (služba na násobení dvou čísel atd.).
Možná je za tím (podobně jako u CI/CD nebo třeba SonarQube a jiných nástrojů) i snaha netechnických lidí trochu vidět do aplikace (protože pro ně je to jinak černá skříňka, zatímco pro programátory ne) a mít pocit, že to mohou měřit a řídit.
Podobne situace byla i v oblasti superpocitacu. V minulosti, pokud byl potreba vyraznejsi vykon, resilo se specializovanymi, inzenyrsky velice dobre navrzenymi pocitaci (IBM, SGI, Cray, ...), ktere dokazaly vytahnout z tehdejsich technologii maximum. Pak prisel Google a ukazal, co dokaze cluster slozeny z beznych pocitacu
Tohle mi přijde jako naprosto validní a inženýrsky seriózní přístup. I sebekvalitnější HW má nějakou míru chybovosti a riziko selhání a jestliže dojdu k závěru, že vychází líp mít dva méně spolehlivé počítače, které se navzájem jistí, než jeden spolehlivější, tak přece budu mít ty dva a nižší pravděpodobnost chyby/výpadku. Totéž platí pro výkon. Jestliže dokáži z X kusů slabšího HW udělat celkově silnější superpočítač než z menšího počtu výkonnějších kusů HW, za jinak stejných okolností, tak to tak udělám. Jestliže někdo dokáže paralelizovat úlohu na více procesorů/strojů, tak je to taky pokrok. Navíc mi to přijde i jako správnější a dlouhodobě udržitelnější přístup: stavět na generickém HW, který mi může dodat kdokoli, než na nějaké proprietární technologii, která je sice (teoreticky) o něco lepší, ale dodává ji jen jeden výrobce.
Já naopak vnímám mikroslužby jako něco složitějšího.A ja tu mmluvim o slozitosti samotneho reseni. Jinak to, co popisujes, jde i u dalsich systemu, jen je to s nimi slozitejsi.
Tohle mi přijde jako naprosto validní a inženýrsky seriózní přístup. I sebekvalitnější HW má nějakou míru chybovosti a riziko selhání a jestliže dojdu k závěru, že vychází líp mít dva méně spolehlivé počítače, které se navzájem jistí, než jeden spolehlivější, tak přece budu mít ty dva a nižší pravděpodobnost chyby/výpadku.To proto, ze se na to divas s odstupem a overenim v praxi. Ano, HW muze mit vypadky, proto to ta drivejsi reseni resila na urovni hardwaru/OS. Je to prirozena volba, protoze to snizuje slozitost softwaru, ktery nemusi resit vypadaky HW. Google prosadil pristup, ze neni potreba resit odolnost na urovni hardware a presunul ji (v podstate neprirozene) na uroven software, i kdyz to ma primy dopad na podobu a slozitost software. S temi microservices je to podobne. Prirozene misto, kam dat vzdalena volani (a kam to driv davali ostatni), je na uroven objektoveho modelu tak, aby jednotliva volani byla pokud mozno transparentni a nezvysovalo to slozitost software. Ve skutecnosti ale microservices umistily ta volani o uroven vys, na ukor vetsi komplexity software. A stejne jako v pripade toho clusteru ala Google, to reseni neni uplne elegantni, ale je dostatecne ucinne pro prakticke pouziti.
16.12.2018 22:24
xkucf03 | skóre: 49
| blog: xkucf03
Problem s kulturou standardu "de facto" a ne "de iure" je v tom, ze je prilis snadne nejaky standard bezduvodne zahodit, misto snahy ten standard zmenit a zlepsit.
Zajímalo by mě, jak by ses postavil ke XML jako ke standardu. Jak bys vedl tu standardizaci, aby byl tento formát lepší? A pokud by přesto v první verzi byly chyby, jak bys dosáhl prosazení druhé verze, která by je odstraňovala?
Podle mého je XML téměř dokonalé1, ale něco by bylo lepší z toho vyhodit (věci kolem DTD, entit...). Trochu sporné jsou atributy (jsou duplicitní k elementům?), ale ty bych tam spíš nechal.
Ale to jsou konkrétní otázky -- o těch se nechci až tak hádat -- jde mi teď spíš o to, jak podchytit ten proces standardizace a jak dosáhnout ještě lepšího výsledku, než bylo dosaženo. Nebo XML nemělo vzniknout vůbec a měly se místo něj používat S-expressions? :-)
[1] zásadní jsou jmenné prostory, escapování je bezproblémové, navíc má člověk k dispozici i CDATA, syntaxe je jednotná, snadná na pochopení
Při čistě strojovém zpracování i generování by se odstraněním atributů asi pár věcí zjednodušilo, ale jak si poslední dobou hraju s návrhem protokolu založeném na netlinku, tak jasně vidím, jak absence atributů často věci uměle komplikuje. A to nemluvím o tom, jak by takové XHTML vypadalo bez atributů. :-)
Jinak i XML je IMHO příkladem toho, že rozumný standard nevzniká na zelené louce. Návrh XML byl inspirován především zkušenostmi se SGML (myslím že termín "overengineered" to asi vystihuje nejlépe) a prvními verzemi HTML (živelný chaos, jakýkoli pokus o standard selhal na ignoranci, nezájmu a přemíře lidové tvořivosti).
Na konfiguraci je to na muj vkus dost tezkopadne a na vymenu dat mezi pocitaci je to vylozene nevhodne.
Proč? Trochu mi to zavání antropocentrickým přístupem, tj. "hlavně aby se to dobře četlo, zpracování, validace a rozšiřitelnost jsou vedlejší".
zpracování, validace a rozšiřitelnost jsou vedlejšíHeh. Viděl jsi někdy parser XML? Na XML je fascinující mimo jiné to, že je nevhodný pro člověka i pro stroj... XML je primárně markup (tj. strukturované textové dokumenty určené převážně ke grafickému zobrazení) a vznikl z předchozích markup formátů. Už z toho by mělo být patrné, že použití XML na něco jiného než na markup IMO vůbec nedává moc velký smysl. Ten formát na to není navržen a nemá žádné moc výhody pro např. serializaci dat. Naopak spíše nevýhody, např. zbytečně vysoká komplexita, nejednoznačnost významu whitespace, nepříčetné escapování, atd. Jinak třeba u té konfigurace mi ten antropocentrický přístup přijde celkem na místě.
Heh. Viděl jsi někdy parser XML?
Nejen že viděl, ale dokonce jsem jich i pár napsal. Z principu to není o nic komplikovanější než parser jakéhokoli jiného podobně obecného jazyka pro zápis strukturovaných dat. (Pochopitelně nepočítám tu část, která je schovaná v libxml2, protože to koneckonců není moje starost.)
17.12.2018 14:56
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pochopitelně nepočítám tu část, která je schovaná v libxml2, protože to koneckonců není moje starost.Takže neviděl.
Ale kdepak, i tu jsem viděl (a žádná extra hrůza to taky není). Jenže ono to opravdu není podstatné. Vzhledem k rozšířenosti a dostupnosti nástrojů pro práci s XML mne to nemusí zajímat.To byl tvůj argument o té údajné dobré strojové zpracovatelnosti... Tak jestli tě to nezajímá, tak v pořádku, akorát jsme se tím nemuseli zabývat...
Naopak, když si místo toho budu psát vlastní parser nějakého hypercool formátu, nasekám v něm mnohem víc chyb, než jich je v libxml2.Já nevim, jestli úplně mají smysl tyhle debaty, kde cokoli, co není status quo, je "hypercool" a a-priori špatné... Pak se totiž vlastně už ani moc nebavíme o technologiích...
17.12.2018 15:02
xkucf03 | skóre: 49
| blog: xkucf03
O kousek výš píšeš o standardech a jejich zahazování...
Nebylo by tedy spíš řešením vytvořit novou alternativní formu zápisu XML? Podobně jako existuje binární XML, tak by mohla existovat nějaká jiná textová serializace XML, která by byla třeba vhodnější pro člověka. Ale ten logický abstraktní model (XML Information Set) by byl pořád stejný. Bylo by to tedy vzájemně převoditelné a nebylo by potřeba nic zahazovat. Šlo by použít stávající infrastrukturu a všechny nástroje by s novým formátem mohly pracovat po triviální úpravě nebo po přidání jednoduchého konvertoru mezi zdrojovou a cílovou komponentu. Pokrok by tak pokračoval dál a stavělo by se na tom, co se vytvořilo dřív, nebylo by potřeba znovu-vynalézat kolo a opakovat dříve odvedenou práci.
17.12.2018 18:03
xkucf03 | skóre: 49
| blog: xkucf03
Uz jsem to sem vickrat psal, pro konfiguraci se mi nejvic libi pristup Dhallu - snadne na lidsky zapis a pritom strojove velmi dobre validovatelne a rozsiritelne. To mi prijde jako vynikajici kompromis mezi (treba) Lispem a (treba) XML.
Profesionální přístup ale není o tom, co se komu subjektivně líbí, ale o tom, že je potřeba dělat i kompromisy a dohodnout se na jednotném postupu s ostatními.
Vubec nerozumim tomu, jaky problem se snazis resit. Ze se pouziva malo XML?
Tak si to přečti znovu a pokus se tomu textu porozumět.
Vzniká spousta truc formátů, které se vymezují proti XML a kritizují jeho údajnou složitost, ukecanost, vadnost... Týká se ta kritika daného abstraktního modelu (XML infosetu) nebo se týká jedné konkrétní textové serializace (ten text obsahující spoustu špičatých závorek) tohoto abstraktního modelu? Obávám se, že většina kritiků ani nedokáže oddělit tyto dvě věci (abstraktní model vs. jeho textové vyjádření).
Pokud je problém v textovém vyjádření, tak přece není potřeba zahazovat vše, co bylo vytvořeno. Stačí dohodnout alternativní (který se časem klidně může stát nejpoužívanějším) způsob serializace daného abstraktního modelu.
Pokud je chyba v samotném abstraktním modelu, tak je to horší, ale i k tomu by se mělo přistupovat (profesionálně) jinak, viz níže.
Na vymenu dat mezi stroji bych pouzil CBOR
To je jako kdyby ve světě souborových systémů přišel někdo s tím, že jeho FS nepotřebuje rozšířené atributy a datum poslední změny souboru, a navrhl kvůli tomu nové nekompatibilní API. To je přece nesmyslné spratkovské chování. Pokud je to nové podmnožinou stávajícího (CBOR přišel nějakých 17 let po XML), tak bys měl použít podmnožinu stávajícího API. Abys udělal výjimku z tohoto pravidla, tak bys k tomu měl mít nějaké vážné důvody.
Omlouvám se, jestli jsem tě špatně pochopil, ale tyhle tvoje komentáře mi přijdou nekonzistentní s tím, co prosazuješ jinde (standardizace, profesní organizace, inženýrský přístup, nezahazování stávajících věcí...).
Za součást profesionálního inženýrského přístupu považuji to, že obětuješ i trochu vlastních zájmů a uděláš nějaký kompromis v zájmu jednotnosti. Např. budeš používat metrický systém, i když ti by přišlo že jiné jednotky jsou lepší. Podobně by bylo lepší a profesionálnější používat XML než mít bambilión podobných (subjektivně lepších, alespoň z pohledu jejich autorů) textových formátů pro konfigurační soubory nebo serializaci objektových dat. Pokud se nelze dohodnout na jednotném formátu serializace (existují vážné objektivní důvody, proč pro různé účely použít různé serializace), tak bychom se měli dohodnout alespoň na tom abstraktním modelu, do kterého budou jednotlivé serializace převoditelné (XML infoset).
Zatím poslední velká profesionální inženýrská dohoda byla XML infoset jakožto abstraktní model + text se špičatými závorkami jakožto jeho konkrétní textová serializace. K tomu postupem času přibyly další možné serializace (různé formy binárního XML) a stejně tak by mohla přibýt další textová serializace původního abstraktního modelu.
Taky se může stát, že po těch dvaceti letech dojde obor k závěru, že je špatný ten abstraktní model. Pak je ale profesionální inženýrský přístup něco úplně jiného než vytvářet živelně nějaké truc-formáty a rozbíjet jednotnost (jak v rovině modelu, tak v rovině jeho konkrétní serializace). Profesionální přístup by byl, dohodnout se na novém abstraktním modelu, starý model oficiálně zavrhnout a dohodnout přechodové mechanismy a plán, jak celý obor dostat od původního modelu/formátu k novému modelu/formátu.
Týká se ta kritika daného abstraktního modelu (XML infosetu) nebo se týká jedné konkrétní textové serializace (ten text obsahující spoustu špičatých závorek) tohoto abstraktního modelu?Ano.
Pokud je problém v textovém vyjádření, tak přece není potřeba zahazovat vše, co bylo vytvořeno.Zahazovat se nic nemusí, ať se klidně XML používá - ale pokudmožno na to, na co je určeno. Zajímavé je, že ve vedlejší diskusi kritizuješ prohlížeče kvůli tomu, že se stejná technologie se používá na zobrazování dokumentů i na tvorbu interaktivních aplikací a že to je špatně. S tím se asi celkem dá souhlasit, nicméně přijde mi zvláštní, že ten velmi podobný problém u XML nepozoruješ...
17.12.2018 20:35
xkucf03 | skóre: 49
| blog: xkucf03
Protože u XML je ten rozdíl v komplexitě minimální a přijde mi lepší mít něco o trošku složitější, ale mít to jednotné. Zatímco u toho webu bych ocenil dva standardy (resp. jeden může být podmnožinou druhého): jeden pro sdělování hypertextových dat a druhý jako obecnou platformu pro psaní komplexních aplikací. Do toho prvního by se asi vešlo i odesílání jednoduchých formulářů na úrovni HTTP POST z 90. let (a i to by se dalo zjednodušit, protože ta různá kódování a multipart jsou docela bastl, dalo by se to navrhnout čistěji).
Zpátky k těm formátům: nevidím zásadní problém v tom, aby byl pro a) značkovací jazyk b) konfigurační soubory c) serializaci objektových dat jeden abstraktní model. Ve všech případech je to nějaký strom. V případě značkovacího jazyka tam máš i textové uzly, ale to je jen detail -- jeden typ uzlu navíc. I když vlastně ani to ne, protože textové uzly máš i v těch konfiguračních souborech a v objektových datech -- uzel buď obsahuje vnořenou strukturu nebo samotná data (textový uzel).
Je otázka, jestli kromě textu nezavést i další datové typy přímo na úrovni abstraktního modelu / formátu. Osobně bych byl celkem pro, ale znamená to zvýšení komplexity formátu. Proti tomu by zase řada lidí trucovala, ne?
Co se týče serializace: pokud se někomu nelíbí ostré závorky, klidně může používat kulaté: SXML.
Protože u XML je ten rozdíl v komplexitě minimální a přijde mi lepší mít něco o trošku složitější, ale mít to jednotné.No, ale to je výhodné pouze pro XML geeky s nástroji, editory a vůbec vším optimalizovaným pro XML a kterým se z XSLT nedělá špatně... Pro ostatní vidím převažující nevýhody.
V případě značkovacího jazyka tam máš i textové uzly, ale to je jen detail -- jeden typ uzlu navíc. I když vlastně ani to ne, protože textové uzly máš i v těch konfiguračních souborech a v objektových datech -- uzel buď obsahuje vnořenou strukturu nebo samotná data (textový uzel).Problém je, že např. u těhle 3 variant:
<foo> <bar> a </foo> </bar>
<foo> <bar>a</foo> </bar>
<foo><bar>a</foo></bar>
xml:space apod., ale afaik to není obecné řešení.)
Je otázka, jestli kromě textu nezavést i další datové typy přímo na úrovni abstraktního modelu / formátu. Osobně bych byl celkem pro, ale znamená to zvýšení komplexity formátu. Proti tomu by zase řada lidí trucovala, ne?Tak existují formáty, které mají množinu primitivních typů a přesto jsou o hodně jednodušší než XML... To je zas o tom, že na markup datové typy jiné než string spíše nepotřebuješ, zatímco na konfigurace spíš jo.
Co se týče serializace: pokud se někomu nelíbí ostré závorky, klidně může používat kulaté: SXML.Vůbec nevidim důvod, proč o něčem takovém pro účely konfigurace vůbec uvažovat, když TOML má parser pro buhvíkolik jazyků a, i když má svoje nevýhody, furt je na tu úlohu IMO asi tak 10× vhodnější...
Problém je, že např. u těhle 3 variant:
není jasné, jestli jsou nebo nejsou isomorfní.
Z hlediska XML je to jasné. Nejsou.
Pokud používáš XML na dokumenty, tak asi úplně ne. Pokud na konfiguraci/serializaci, tak asi ano, ale v obou případech závisí ten model na interpretaci aplikace. Což je dost na palici.
Ano, závisí to na aplikaci, protože aplikace se rozhodla, že bude ignorovat bílé znaky z kraje textových uzlů, protože lidi je tam cpou pro čitelnost, ale ji nezajímají. Až ale uživatel bude chtít vnutit krajní mezeru jako významný znak, tak bude mít smůlu. (A přijde nějaký webový matlal a zavede URI escapování).
Opět jsme u toho, jestli formát je pro člověka nebo pro stroj.
Zrovna tak aplikace, která doteď ignorovala mezery, bude mít problém se zavedením ukládání konfiguračního souboru. Uživatel se bude najedenou rozčilovat, že mu kazí jeho precizně vyladěné formátování. Podobný problém bude s komentáři (dokud nepřijde JSON).
Podle mě je problém v tom, že aplikace si na jednu stranu vybrala XML, ale na druhou stranu je pro ni příliš složité, a tak z infosetu používá jen podmnožinu. Na což doplácí uživatel, protože neví, kterou podmnožinu zrovna aplikace ignoruje. Nejlevnějším řešením je prostě to zdokumentovat. Jestli je správné nutit aplikaci k plné implementaci, když z toho nikdo nic nemá, je otazné.
18.12.2018 01:14
xkucf03 | skóre: 49
| blog: xkucf03
No, ale to je výhodné pouze pro XML geeky s nástroji, editory a vůbec vším optimalizovaným pro XML a kterým se z XSLT nedělá špatně... Pro ostatní vidím převažující nevýhody.
A tobě se líbí ten chlív, který je v konfiguračních souborech? Každý pes jiná ves, trochu jiné komentáře, trochu jiná rovnítka, uvozovky, escapování sekce... Přitom kdyby se čas nutný ke zvládání tohoto svinčíku (parsery a generátory různých formátů, zvýrazňovače syntaxe, spousta práce a chyb při ručních úpravách i pokusech o automatizaci...) věnovala tvorbě kvalitních nástrojů pro jeden formát, tak by to všem prospělo. Klidně se v tom čase mohla vytvořit alternativní serializace XML vhodnější pro konfiguráky, nebo vyvinout šikovné nástroje s CLI a TUI rozhraním, pomocí kterých bys mohl spravovat konfiguraci. A vyvinulo by se to jednou a ne pro každý program znovu.
není jasné, jestli jsou nebo nejsou isomorfní...
K tomu slouží whiteSpace.
To je zas o tom, že na markup datové typy jiné než string spíše nepotřebuješ, zatímco na konfigurace spíš jo.
Ono by se to hodilo i pro značkovací jazyky. Např. bys řekl: toto je nadpis úrovně 1. Dneska se tyhle věci řeší až na úrovni XSD. Což taky není špatné řešení. Nemám na tohle úplně vyhraněný názor.
Vůbec nevidim důvod, proč o něčem takovém pro účely konfigurace vůbec uvažovat, když TOML má parser pro buhvíkolik jazyků a, i když má svoje nevýhody, furt je na tu úlohu IMO asi tak 10× vhodnější...
A existuje k tomu SAX parser nebo ho mám dodělat do alt2xml? Vždyť by stačilo prohlásit TOML za jednu ze serializací XML infosetu (podobně jako to SXML nebo různá binární XML) a dalo by se navázat na dosavadní práci a využít stávající infrastrukturu.
A tobě se líbí ten chlív, který je v konfiguračních souborech? Každý pes jiná ves, trochu jiné komentáře, trochu jiná rovnítka, uvozovky, escapování sekce...1. Přiznám se, že ten chlív mi žíly nijak zvlášť netrhá. Občas nastane nějaká nejasnost, ale rozhodně nejsou problémy s formáty konfiguračních souborů něco, co by mě v noci vytrhávalo ze spánku. 2. I kdyby ano, XML tomuhle moc nepomáhá, protože člověk stejně musí více či méně řešit jakým způsobem daná aplikace XML používá. Zrovna ohledně toho escapování si člověk moc nepomůže. XML se snaží být agnostické ke kódování, což asi dávalo smysl v roce 98, ale dnes je to spíše problém. Setkal jsem se s aplikacemi, které např. všechny non-ascii znaky defensivně převedly na entity. A pak si to edituj ručně, že... Anebo taky v jednom případě dokonce na CDATA, což už je vůbec šílený, zaprvé syntaxe CDATA je obludnost a zadruhé to vlastně ani neřeší ten problém, protože když to pak někdo prožene přes nějaké non-unicode kódování, tak půjdou unicode znaky do kytek. Další důvod proč XML tomu chlívu v konfiguraci moc nepomůže je absence typů, např. v konfigurácích jsou časté booleany. (Ano, vím o
xs:boolean , ale záleží na aplikaci, jestli tohle podporuje nebo má vlastní řešení.)
K tomu slouží whiteSpace.O tom vím, ale to nic neřeší, protože je na aplikaci, jak si to vyloží. Je to vlastně jen takový hint.
A existuje k tomu SAX parser nebo ho mám dodělat do alt2xml?Nevim, SAX mě nezajímá.
Vždyť by stačilo prohlásit TOML za jednu ze serializací XML infosetu (podobně jako to SXML nebo různá binární XML) a dalo by se navázat na dosavadní práci a využít stávající infrastrukturu.Ne, to by nestačilo, TOML není bezztrátově konvertibilní na XML (přijdeš o datové typy) a využití stávající XML infrastruktury je pro non-XML-geeka v podstatě nanic, protože když bude chtít TOML nějak zpracovat (třeba transformovat nebo zvalidovat nebo něco) tak nahodit nějaký jednoduchý Python skript nebo něco podobného je asi tak 100× jednodušší než zápolit s XML ekosystémem. XML infoset imho nedává moc velký smysl, resp. pro ten markup je možné, že jo (ale nevim, polovině těch položek v infosetu nerozumim), pro serializaci určitě ne (chybí základní datové typy a naopak přebývají vestigiality z XML).
17.12.2018 22:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Vzniká spousta truc formátů, které se vymezují proti XML a kritizují jeho údajnou složitost, ukecanost, vadnost... Týká se ta kritika daného abstraktního modelu (XML infosetu) nebo se týká jedné konkrétní textové serializace (ten text obsahující spoustu špičatých závorek) tohoto abstraktního modelu? Obávám se, že většina kritiků ani nedokáže oddělit tyto dvě věci (abstraktní model vs. jeho textové vyjádření). Pokud je problém v textovém vyjádření, tak přece není potřeba zahazovat vše, co bylo vytvořeno. Stačí dohodnout alternativní (který se časem klidně může stát nejpoužívanějším) způsob serializace daného abstraktního modelu. Pokud je chyba v samotném abstraktním modelu, tak je to horší, ale i k tomu by se mělo přistupovat (profesionálně) jinak, viz níže.Proč myslíš, že vznikají? Četl jsi Design of everyday things? Pokud ne, tak bys měl. XML prostě saje prdel. Můžeme se bavit o tom, že objektivně má spoustu užitečných vlastností a je dotažené, ale lidi, primáti homo sapiens sapiens sledávají jeho design debilním. Vzhledem k tomu že i co do parsování to není žádný velký zázrak, tak si to chce položit otázku k čemu vlastně je. Přijde mi to jako výplod umělých úlových myslí korporací. Co se mě týče, tak: Je těžké na parsování (uznávám že na to jsou knihovny, sám jsem jednu takovou implementoval). Je těžké na zápis člověkem. Nemapuje se 1:1 na běžné datové struktury programovacích jazyků. Ba dokonce je to tak špatné, že i když člověk použije nástroje jako xmldict, tak tě neustále serou atributy a fakt, že XML tag může obsahovat string, nebo pole dalších atributů, což komplikuje kód. Tooling okolo toho je nepopsatelná sračka. Protože je parsování těžké, je i zpracování těžké a zpravidla všechno pro celý ekosystém stojí na jedné dementní staré knihovně, která jako jediná skutečně umí parsovat XML v celé jeho úplnosti DTD a XSD a kde čeho, kde může být nadefinována i nová syntaxe. Samotné DTD je mrdka takové magnitudy, že doslova nemám slov. XSD a RelaxNG na tom moc nezmění, protože zase tooling saje prdel a snad existuje jen jeden program na světě, co fakt korektně umí převést XSD na DTD. A je to nějaká mrdka v javě. Celé to propojení s Java ekosystémem je k posrání. Deformuje to celý svět XML tím že všichni opisují pár referenčních implementací API v javě, takže to pak všude vypadá stylem „nastavíme továrnu vyrábějící konfigurační singleton“ *výstřel pistole*.
Za součást profesionálního inženýrského přístupu považuji to, že obětuješ i trochu vlastních zájmů a uděláš nějaký kompromis v zájmu jednotnosti. Např. budeš používat metrický systém, i když ti by přišlo že jiné jednotky jsou lepší. Podobně by bylo lepší a profesionálnější používat XML než mít bambilión podobných (subjektivně lepších, alespoň z pohledu jejich autorů) textových formátů pro konfigurační soubory nebo serializaci objektových dat. Pokud se nelze dohodnout na jednotném formátu serializace (existují vážné objektivní důvody, proč pro různé účely použít různé serializace), tak bychom se měli dohodnout alespoň na tom abstraktním modelu, do kterého budou jednotlivé serializace převoditelné (XML infoset).S tím do jisté míry souhlasím (sám to tak v praxi dělám), ale těžko se lze divit, že vznikají věci jako Swagger a APIary (mimochodem koupený Oraclem), které se to snaží řešit.
Taky se může stát, že po těch dvaceti letech dojde obor k závěru, že je špatný ten abstraktní model.Složitost XML Infoset modelu je imho důsledek toho, že se XML snaží být jak značkovacím jazykem pro popis dokumentů (např. web stránka) tak formátem pro zápis datovych struktur a tím pádem pokrývat i všechno mezi tím. To je dost široký prostor, který v praxi vede na zcela různé způsoby práce a ukládání dat. Za dobu, co XML existuje se ukazuje, že je lidé prakticky raději použijí specializovaný nástroj (json pro dump nějakých dat, asciidoc/markdown/rst pro popis dokumentu) než všeobecné a složité XML. Navíc samotná složitost XML vede ještě k tomu, že ho většina lidí používá vyloženě špatně. Většinou z neznalosti, kdy správně řešení by bylo použít nějaký existující XML standard správným způsobem nebo vůbec XML nepoužít. A aby bylo jasno, proti schématu nebo dotazovacímu jazyku nic nemám, naopak. V případě json dat sice nakonec taky budu chtít mít tyto věci taky, ale výsledek bude v praxi oproti XML výrazně použitelnější. XML se tak hodí k popisu dokumentů (web stránka, dokumentace v docbooku) nebo jako obecný exportní formát pro strojově zpracovatelnou komunikaci, který není závislý na konkrétním use case nebo způsobu uložení dat, kdy si přijímací strana napíše nějaký importer, co z toho vytahá co je potřeba a něco s tím udělá. Tohle je případ command line toolu, co na vyžádání vypíše místo human readable výstupu xml verzi téhož, nebo xml dumpu wikipedie. Ale udržovat strukturovaná data jako XML a tak s nimi i pracovat je až na pár vyjímek špatný nápad.
31.12.2018 12:23
xkucf03 | skóre: 49
| blog: xkucf03
Složitost XML Infoset modelu je imho důsledek toho, že se XML snaží být jak značkovacím jazykem pro popis dokumentů (např. web stránka) tak formátem pro zápis datovych struktur a tím pádem pokrývat i všechno mezi tím. To je dost široký prostor, který v praxi vede na zcela různé způsoby práce a ukládání dat.
A v čem vidíš podstatu toho rozporu?
Já na XML hodně oceňuji jeho rozšiřitelnost, který vychází z jmenných prostorů. Ty umožňují propojovat struktury pocházející od různých autorů nebo z různých "světů" a předchází při tom kolizím jmen a udržují ve věci pořádek, je jasné, co kam patří. Že jsou jmenné prostory potřeba v dokumentech, ukazuje HTML5 -- ovšem jak to "vyřešili" tam, je k pláči. A že jsou potřeba v datových strukturách je snad zřejmé (tam se může jednat o různé anotace nebo metadata nebo o odlišení různých datových typů, které se můžou vyskytovat na témže místě atd.).
Takže jmenné prostory by zredukovat nešlo. Co dál?
Atributy? Tady ten rozpor teoreticky je, protože pro datové struktury nejsou potřeba (všechno může být elementem, resp. všechno se může zapisovat jednotným způsobem). Zatímco pro dokumenty jsou atributy důležité, protože bez nich by zápis byl dost nešikovný. Ovšem je existence (s struktur nadbytečných) atributů v praxi takovou překážkou a problémem? Podle mého ne.
CDATA mi přijdou dost šikovná v obou případech, takže tady opět žádný rozpor není. V dokumentu je používám pro citace zdrojových kódů. Ve strukturovaných datech a konfigurácích zase pro delší texty a taky různé vložené kódy nebo šablony.
Zredukovat by se daly některé věci kolem entit a DTD, to už jsem tu někde psal.
31.12.2018 14:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Atributy? Tady ten rozpor teoreticky je, protože pro datové struktury nejsou potřeba (všechno může být elementem, resp. všechno se může zapisovat jednotným způsobem). Zatímco pro dokumenty jsou atributy důležité, protože bez nich by zápis byl dost nešikovný. Ovšem je existence (s struktur nadbytečných) atributů v praxi takovou překážkou a problémem? Podle mého ne.Koukal jsi už na tu syntaxi Selfu? Ten na to šel trochu obráceně a naopak v podstatě všechno zredukoval jen na atributy. Ostatně obsah je taky jen atribut, když se nad tím tak zamyslíš.
A v čem vidíš podstatu toho rozporu?Ve snaze pokrýt požadavky dvou zcela různých světů: psání dokumentů a popis struktury dat. Výsledkem je systém, který není optimalizovaný ani na jedno, a který má i přes svoji šíři spoustu mezer, které omezují řešení praktických problémů. Už samotný fakt, že XML nelze přímo převést na nějakou triviální datovou strukturu běžně používanou v programovacích jazycích (kombinace slovníků a seznamů) je vážný problém. Znamená to, že programátor má tyto možnosti:
<objednávka id="42">
<polozka id="23" cena="100" jmeno="foo"/>
...
</objednávka>
<objednávka>
<id>42</id>
<polozky>
<polozka>
<id>23</id>
<cena>100</cena>
<jmeno>foo</jmeno>
</polozka>
...
</polozky>
</objednávka>
Atributy? Tady ten rozpor teoreticky je, protože pro datové struktury nejsou potřeba (všechno může být elementem, resp. všechno se může zapisovat jednotným způsobem). Zatímco pro dokumenty jsou atributy důležité, protože bez nich by zápis byl dost nešikovný. Ovšem je existence (s struktur nadbytečných) atributů v praxi takovou překážkou a problémem? Podle mého ne.Přesně, souhlasím s tím, že atributy mají smysl jen pro značkování dokumentu, ale pro popis datových struktur jsou nadbytečné. Ale jak píšu víše, tahle nadbytečnost v praxi dost překáží a způsobuje chaos.
Já na XML hodně oceňuji jeho rozšiřitelnost, který vychází z jmenných prostorů.Mě jmenné prostory připadají užitečné a neřadil bych je mezi problémy XML formátu jako takového. Nicméně pratkicky je problém v tom, že s tím lidi neumí dělat. Např. implementoval jsem generátor XML pro export do nějakého třetího systému, a použil jsem tam jméné prostory, abych oddělil samotné elementy toho jejich import xml formátu a xhtml obsahu (ze schématu vyplývalo, že je to takto ok). Ale vývojář toho projektu mě poslal někam, že to mám prostě espapovat nebo použít CDATA jako normální člověk ... eh. A tohle nebyl zdaleka jediný takový případ. Na jednu stranu je tohle vlastně problém lidí, co si nenastudovali XML standardy a neumí je používat. Ale na druhou stranu to, že ten celý ekosystém je tak složitý, že mimo lidí, co se tomu speciálně věnují, se v tom nikdo nevyzná, tomu nijak nepomáhá. Tady jsou ty jmené prostory prostě jen oběť toho, jak rozsáhlý XMl ekosystém je a tak rozsáhlé use casy se snaží pokrývat. Btw, teď jsem si vzpomněl na jeden vtipný komentář v dokumentaci pro perl knihovnu pro práci s html:
Footnote: Yes, this is misnamed. In proper SGML terminology, this is instead called a ``GI'', short for ``generic identifier''; and the term ``tag'' is used for a token of SGML source that represents either the start of an element (a start-tag like ``<em lang='fr'>'') or the end of an element (an end-tag like ``</em>''. However, since more people claim to have been abducted by aliens than to have ever seen the SGML standard, and since both encounters typically involve a feeling of ``missing time'', it's not surprising that the terminology of the SGML standard is not closely followed.Viz: http://ronald.cori.missouri.edu/~cuttsj/perl_docs/site/lib/HTML/Tree/Scanning.html A i když ten rant mířený na SGML, tak XML platí i pro XML, přes všechnu snahu XML se z tohodle použit a standard zjednoduššit.
CDATA mi přijdou dost šikovná v obou případech, takže tady opět žádný rozpor není. V dokumentu je používám pro citace zdrojových kódů. Ve strukturovaných datech a konfigurácích zase pro delší texty a taky různé vložené kódy nebo šablony.CDATA jsou ok, škoda jen, že jsem to viděl používat hlavně k prasení místo jmených prostorů. Viz víše. Ale abych to zakončil nějak pozitivně. Ve výsledku si myslím, že XML je dobrý formát na import a export dat mezi programy, které se můžou výrazně lišit v tom co a jak s daty dělají a XML používají jen jako komunikační protokol a kde odtrženost XML od fyzického uložení dat není bug, ale feature. Dump wikipedie je ideální příklad: jde o kombinaci strukturovaných dat a dokumentu, a o abstrakci samotného obsahu bez leakování interní struktury databáze wikipedie, která se může během příštích 10 let trochu změnit, zatímco XML dump formát zůstane stejný.
1.1.2019 15:00
xkucf03 | skóre: 49
| blog: xkucf03
Pokud je ale první věc, co s XML dokumentem udělám, převod na klasickou jednoduchou strukturu ze slovníků a seznamů, dávám tím najevo, že XML akorát překáží.
To je ale většinou důsledek ignorantství nebo absence vhodných nástrojů v daném jazyce. Asi jediný oprávněný důvod proč tohle dělat by bylo, že bych chtěl umět pracovat s libovolnými daty bez ohledu na jejich formát resp. sémantiku. Ovšem to většinou není ten případ. Většinou máme nějaké schéma (byť třeba není explicitně zdokumentované -- ale to je opět chyba) a uzly toho stromu na určitých místech s určitými názvy mají přiřazený nějaký konkrétní význam a podle toho s nimi budeme zacházet.
Rozumný způsob je a) XML namapovat na objekty (v Javě k tomu slouží JAXB) nebo b) zpracovat data proudově jako posloupnost SAX událostí (na základě nich můžeme např. něco konfigurovat nebo spouštět nějaké příkazy). Dá se vymyslet i nějaký hybridní model mezi tím, kde XML data zpracovávám částečně proudově a padají mi z nich objekty.
Pokud si ale někdo převede XML nejdřív na nějaký shluk seznamů a slovníků/map a až nad tím něco dělá, tak je patrně chyba někde jinde než v XML. Na první pohled se to tváří, že jde o obecnou strukturu (např. mapu, do které můžu nastrkat libovolné klíče) bez schématu, ale ve skutečnosti to tak není -- to schéma tam je (a program se rozbije, když ho poruším), jen to není pořádně zdokumentované, natož podpořené prostředky daného programovacího jazyka (typy, třídy...).
Rozšiřoval jsem kdysi dávno jeden tool, co takový převod dělal a potřeboval jsem přidat do struktury XML dokumentu element. Když jsem to ale udělal, zcela jsem rozbil celý skript kvůli tomu, jak se transformace XML do slovníku prováděla. Au. Mohl jsem ji sice na úrovni té knihovny upravit, tím se ale rozbilo něco jiného. Výsledkem bylo, že jsem to musel přepsat víc, než bych původně čekal.
Tohle je zrovna hezký příklad. Narazil jsi na časovanou bombu, kterou ti v kódu nechal někdo jiný (a nebyli to autoři XML specifikace).
XML právě tuhle rozšiřitelnost podporuje. Můžeš si vymyslet vlastní jmenný prostor, navrhnout si vlastní schéma, a přidat svoje data do jiného dokumentu. Že se něčí nástroj sesype, když narazí na element v cizím jmenném prostoru, ovšem není chyba XML. To ti naopak dává ty nejlepší prostředky, jak zajistit koexistenci více různých dat nebo metadat vedle sebe v jednom dokumentu a vyhnout se při tom kolizím.
Podobně díky složitosti XML není jasné, jak strukturovaná data vlastně modelovat. Měl bych udělat tohle:
To je zase ta klasická otázka, zda mají existovat atributy. Už se k tomu nechci vracet, tak jen stručně: má to i svoje stinné stránky, ale celkově si myslím, že je dobře, že tam atributy jsou.
A někdy žasnu, jaká očekávání lidé od technologií mají (nebo je to jen snaha si kopnout za každou cenu?). Ono totiž málokde máš jedinou správnou cestu. Jednoznačný způsob, jak namodelovat libovolnou strukturu libovolného jazyka v XML, prostě neexistuje. Ano, je to na tobě. Stejně jako je na tobě, jak budeš modelovat data v relační databázi, jaké sloupce budeš mít v CSV souboru nebo jak navrhneš céčkovské struktury a jaké datové typy v nich použiješ.
Jeho problém ale je, že je implementovaný jen v Javě a Perlu, a že na tyto implementace od roku cca 2008 nikdo nešáhl.
Možná k tomu přispěli i lidé, kteří šíří nenávist vůči XML a místo aby s něčím pomohli a napsali třeba implementaci v tvém oblíbeném jazyce, tak raději vymýšlení truc-formáty a znovu-vynalézají kolo (tzn. to, co už XML dávno má a oni na tom mohli stavět a vyvinout naopak to, co chybí).
Přesně, souhlasím s tím, že atributy mají smysl jen pro značkování dokumentu, ale pro popis datových struktur jsou nadbytečné. Ale jak píšu výše, tahle nadbytečnost v praxi dost překáží a způsobuje chaos.
IMHO nepřekážejí prakticky vůbec. Ono je totiž stejně utopie, že bys dokázal jednoznačně namapovat libovolnou strukturu libovolného jazyka na nějaký obecný serializační formát jen na základě specifikace tohoto formátu. Vždy k tomu potřebuješ nějaký popis mapování, který je specifický buď pro danou aplikaci, nebo může být specifický pro daný jazyk (popis pravidel, jak se které struktury mapují -- pak to jde a tohle máš i u toho XML, není to problém udělat).
Nicméně pratkicky je problém v tom, že s tím lidi neumí dělat.
To je možné, že řadě lidí chybí vzdělání. Nicméně: víc než psát články o tom "jak je XML na hovno" by pomohlo psát články o tom "jak správně používat jmenné prostory". Tady aspoň vidíš, jak různí lidé přispívají našemu oboru a zda je jejich motivací spíš pomáhat nebo spíš škodit či se zviditelňovat na něčí úkor.
Na jednu stranu je tohle vlastně problém lidí, co si nenastudovali XML standardy a neumí je používat. Ale na druhou stranu to, že ten celý ekosystém je tak složitý, že mimo lidí, co se tomu speciálně věnují, se v tom nikdo nevyzná, tomu nijak nepomáhá.
Ale on ten XML ekosystém vlastně není tak složitý. Resp. ona ta jeho složitost není nějak výrazně (vždy to jde udělat lépe, nic není dokonalé) vyšší, než inherentní složitost řešených problémů. Ono ve skutečnosti úkol nějak ojebat a zmastit to, není výrazně jednodušší než to udělat pořádně. On jen ten nepořádný přístup vypadá na první pohled snadněji, tak k němu někteří mají tendenci sklouznout. Ale v konečném důsledku to jednodušší není.
Pokud si ale někdo převede XML nejdřív na nějaký shluk seznamů a slovníků/map a až nad tím něco dělá, tak je patrně chyba někde jinde než v XML. Na první pohled se to tváří, že jde o obecnou strukturu (např. mapu, do které můžu nastrkat libovolné klíče) bez schématu, ale ve skutečnosti to tak není -- to schéma tam je (a program se rozbije, když ho poruším), jen to není pořádně zdokumentované, natož podpořené prostředky daného programovacího jazyka (typy, třídy...).Jo, to převádění na slovníky není přímo chyba XML, ale těch, co jim to přijde jako dobrý nápad. V takovém případě pak ale imho řešení není použít XML správně, ale použít jednodušší datový formát. Nevidím nic špatného na tom, když použiju csv pokud si s tím v daném případě vystačím. Podobně když má někdo data, která chce zpracovávat jako shluk seznamů a slovníků, ať si to tak klidně dělá. Propagovat XML i pro tyto případy je kontraproduktivní, protože je třeba věnovat dodatečné úsilí použití xml a tak to může skončit i např. tím zbastleným převodem na slovník. Tím nechci tvrdit, že ukládání dat do hromady slovníků je vždy dobrý nápad. Není, podobně jako není dobrý nápad na všecho použít XML. Ano, rozumné způsoby použití rozhodně existují. Stejně tak existuje spousta případů, kdy XML je dobrá volba. Ale jak jsem naznačoval předtím, XML má vyšší bariéru vstupu, která se mi vyplatí překonávat jen pokud XML možnosti opravdu využiju.
To je zase ta klasická otázka, zda mají existovat atributy. Už se k tomu nechci vracet, tak jen stručně: má to i svoje stinné stránky, ale celkově si myslím, že je dobře, že tam atributy jsou. A někdy žasnu, jaká očekávání lidé od technologií mají (nebo je to jen snaha si kopnout za každou cenu?). Ono totiž málokde máš jedinou správnou cestu. Jednoznačný způsob, jak namodelovat libovolnou strukturu libovolného jazyka v XML, prostě neexistuje. Ano, je to na tobě. Stejně jako je na tobě, jak budeš modelovat data v relační databázi, jaké sloupce budeš mít v CSV souboru nebo jak navrhneš céčkovské struktury a jaké datové typy v nich použiješ. IMHO nepřekážejí prakticky vůbec. Ono je totiž stejně utopie, že bys dokázal jednoznačně namapovat libovolnou strukturu libovolného jazyka na nějaký obecný serializační formát jen na základě specifikace tohoto formátu. Vždy k tomu potřebuješ nějaký popis mapování, který je specifický buď pro danou aplikaci, nebo může být specifický pro daný jazyk (popis pravidel, jak se které struktury mapují -- pak to jde a tohle máš i u toho XML, není to problém udělat).Souhlasím s tebou, že by dobré, že XML atributy má. Ale je imho to proto, aby bylo možné popsat širokou škládu dokumentů, od datově orientovaných s pevnou strukturou po dokumentově orientované (nechtěl bych zapisovat např. xhtml odkaz bez atributů). Ale v pro čistě datové XML s pevnou strukturou, toto naopak výrazně překáží. Musím vymyslet, jakým způsobem data do xml namapovat a proč. A na rozdíl např. od světa relačních databází, neexistuje žádná teorie jak to udělat a proč, a neexistuje ani žádná uznávaná konvence. Tohle pak způsobuje dodatečnou složitost a komplikuje např. způsob fyzického uložení dat a indexů v paměti nebo na disku. Ale opět, pokud využiju další možnosti XML, může se mi to i tak vyplatit. Pokud ne, XML je špatná volba.
To je možné, že řadě lidí chybí vzdělání. Nicméně: víc než psát články o tom "jak je XML na hovno" by pomohlo psát články o tom "jak správně používat jmenné prostory".Řekl bych, že by bylo dobré nepropagovat XML jako formát na všechno, ale ukázat možnosti a nedostatky XML standardů a případy, kdy se to vyplatí. A až pak řešit, jak se která věc používá.
Ale on ten XML ekosystém vlastně není tak složitý. Resp. ona ta jeho složitost není nějak výrazně (vždy to jde udělat lépe, nic není dokonalé) vyšší, než inherentní složitost řešených problémů. Ono ve skutečnosti úkol nějak ojebat a zmastit to, není výrazně jednodušší než to udělat pořádně. On jen ten nepořádný přístup vypadá na první pohled snadněji, tak k němu někteří mají tendenci sklouznout. Ale v konečném důsledku to jednodušší není.To ano. Ale ne vždy je složitost mého problému na úrovni co XML poskytuje. Např. v tom mém případě bych byl raději, kdyby ten někdo jiný prostě uložil ty data v JSONu a neprasil XML převodem na slovník :)
A v čem vidíš podstatu toho rozporu?Z pohledu serializace / konfiguráků:
2.1.2019 01:22
xkucf03 | skóre: 49
| blog: xkucf03
Z velké části souhlas. Např. ty PI by šly nahradit obyčejnými elementy, které by byly v nějakém jmenném prostoru. Tzn. když budeš chtít dělat zpracovat PI, tak si prostě uděláš nějaký preprocesor, vyhledáš si elementy z toho svého jmenného prostoru a ty si zpracuješ.
Jmenné prostory jsou opravdu zásadní věc a staví XML nad spoustu jiných formátů. Díky nim je možné tvořit rozšiřitelné formáty (ne nadarmo se to jmenuje eXtensible Markup Language) nebo vložit data v několika různých formátech do jednoho dokumentu.
Co se týče escapování, to současné mi nevadí, ale asi bych skousl i jeho nahrazení zpětným lomítkem.
Když si pak každý někde na koleně pitlíkuje, jak se serializují různá čísla, booleany, datumy a podobně, tak je to poněkud debilní.
To máš popsané tady: Datatypes.
Jmenné prostory jsou opravdu zásadní věc a staví XML nad spoustu jiných formátů. Díky nim je možné tvořit rozšiřitelné formáty (ne nadarmo se to jmenuje eXtensible Markup Language) nebo vložit data v několika různých formátech do jednoho dokumentu.Tohle si nechávám jako otevřenou otázku. Teoreticky to zní dobře, prakticky znám to použití asi jen z Inkscape, kde to zasírá SVG 4~5 různými namespacy a spousta těch vložených věcí navíc jsou kraviny...
Co se týče escapování, to současné mi nevadí, ale asi bych skousl i jeho nahrazení zpětným lomítkem.Netrvám na lomítku, to je v zásadě technikalita. Jde mi hlavně o to, aby to bylo konzistentní a robustní, aby se pokud možno atributy escapovaly stejně jako obsah elementu a aby bylo vždy jasné, co je/není potřeba escapovat (což v praxi asi znamená nepovolit jiné než Unicode kódování). Nějaká pěknější syntaxe by taky neškodila. Porovnej si přívětivost CDATA třeba s heredoc nebo s long/raw stringy v Pythonu, případně raw stringy v Rustu.
To máš popsané tady: Datatypes.Oceňuju snahu, ale já tohle nedávám, to je co do čitelnosti/srozumitelnosti někde mezi C++ standardem a Starým zákonem. Nad všelijakých těch JSONech, TOMLech apod. oceňuju mj. to, že ve specifikaci se vesměs dozvíš co potřebuješ stručně a jasně během pár odstavců. Tady z toho nevidim moc o co jde, hlavně mi z toho není jasné, jestli to je závazné pro lidi, kteří chtějí do XML serializovat, nebo jestli to je jen jedno z možných řešení...
 13.12.2018 23:29
xsubway | skóre: 13
| blog: litera_scripta_manet
14.12.2018 15:48
xkucf03 | skóre: 49
| blog: xkucf03
13.12.2018 23:29
xsubway | skóre: 13
| blog: litera_scripta_manet
14.12.2018 15:48
xkucf03 | skóre: 49
| blog: xkucf03
není bezpečné
Zásadní problém je lepení hodnot do SQL dotazů. Ale to už snad nikdo nedělá. Používají se parametrizované dotazy.
rychlé
Ještě nikdy jsem neviděl, že by tohle byl problém. Pokud bylo něco kolem databází pomalé, tak to bylo dané tím, že a) databáze byla špatně navržená, nakonfigurovaná, indexovaná b) dotaz byl špatně napsaný c) úloha byla z principu složitá a vyžadovala natahat velké množství dat z disku a optimalizovat to nešlo (asi jako nezoptimalizuješ cestu z Prahy do Brna -- pod nějaký čas už se prostě nemůžeš dostat). Oproti těmto zdrojům pomalosti je režie související s parsováním nebo přenosem SQL o několik řádů níž a naprosto zanedbatelná.
SQL by se mělo kompilovat do nějaké binární podoby ještě během kompilace programu, terý ten dotaz pak bude posílat na server.
Databázi lze vlastně přirovnat k dynamicky linkované knihovně, ke které mám nějaké hlavičkové soubory (schéma). Ty použiji při psaní programu a na ně se napojím. V době běhu se pak program spojuje s dynamickou knihovnou. Teoreticky to na sebe nemusí pasovat, pokud se změnila verze, ale s tím se dá žít.
V podstatě jde o to, kde vzít ty hlavičkové soubory a jak se na ně napojit a jak to co nejlépe integrovat s daným programovacím jazykem. Tyhle otázky řeší jOOQ nebo Jinq. A v vlastně i ORM nástroje např. implementace JPA standardu.
Jestli se nakonec ten dotaz serializuje do nějakého bajtkódu nebo do textového SQL je už celkem nepodstatný technický detail.
Takže dobrým krokem vpřed by mělo být jakési rozšíření konceptu kontextu lambda funkcí do compile timu (metaprogramování). Jakoby oddělit ten kontext ne jen v tom smyslu, že je to jiná funkce, ale oddělit to i tak, že kompilátor to bude interpretovat jako jinou gramatiku.
Nejde je o jinou gramatiku (ta by mohla být i stejná a mohl bys tam používat operátory a AND/OR syntaxi svého jazyka). Jde o to, že část toho kódu by se neměla spustit, mělo by to být něco jako lambda, ale místo spuštění by se z paměti vzal její AST a ten by se poslal po síti k vykonání na jiném počítači. Takže nejen že by funkce byla objektem, ale dokonce by ses skrze reflexi mohl dostat dovnitř ní a podívat se, jaké jsou v ní IFy, cykly, ANDy a ORy... prostě bys v době běhu viděl její rozparsovaný zdroják, mohl bys ho vzít a místo spuštění předat někam jinam.
V těchto úvahách mě hrozně inspiroval c++ proposal metaclassy (https://www.fluentcpp.com/2017/08/04/metaclasses-cpp-summary/). Ten proposal víceméně navrhuje odstranit keywordy 'struct' a 'class' s tím, že se dá programátorům možnost si nějakým deklrativním kódem nadefinovat věci jako 'class', 'struct', 'interface' a tak dále. Takže pak si nic v c++ nenaprogramujete pokud nebudete mít includnutý soubor, kde se píše, co to vlastně 'class' nebo 'struct' je. A já myslm, že by se hodilo tohle udělat s co nejvíce prvky jazyka.
To zní zajímavě.
14.12.2018 16:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Co se týče toho SQL, tak mi přijde že většinu toho co bys chtěl umí PonyORM.Krom toho, že to má ty nedostatky, co jsem uvedl výše je problém v tom, že to neumí to samé i pro všechny ty ostatní typy komunikace o kterých píšeš v blogu (persistentní úložiště, konfigurační soubory, libovolná síťová komunikace, ...). Poskytuje to sice jakýsi návod na to, jak to implementovat i pro další věci, ale to, že je to založené vpodstatě jen na runtimovém overloadování funkcí tuto možnost děsně omezuje, komplikuje a znepřehledňuje. A není to moc framework, který by zpříjemňoval psaní takových parserů.
14.12.2018 18:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Během kompilace toho jazyka by se ten relační query předkompiloval a pak by se až za běhu do něj doplnily konkrétní hodnoty nekonstantních proměnných.Tohle se treba (tradicne uz asi 40 let) dela v COBOLu nebo PL/I nebo C++ aplikaci co pracuji s DB2 na mainframu. Program se prozene preprocesorem, ktery vygeneruje kod pro praci s databazi. (Ale dotaz samotny se zapisuje v SQL. Existuji ale i jazyky, ktere jsou jako normalni programovaci jazyky - ruzne 4GL - a zaroven tak nejak zahrnuji nejaky dotazovaci jazyk.) Neco podobneho, jeste starsiho, existuje u IMS. Tam se program primo zkompiluje do podoby, aby s databazi pracoval efektivne. Ale ma to nevyhodu, IMS nema zdaleka tak flexibilni schema jako relacni databaze (zato je ale, pokud se pouzije spravne, brutalne rychla).
No nema smysl se to ucit, spousta veci je tam obludnych a mela smysl spis driv kvuli vykonu. Ale dava to cloveku zajimavou perspektivu, co uz se vsechno zkouselo.Ten preprocesor, ktery umoznuje zkrizit C s primym pristupem do DB, se relativne bezne pouzival i s Oraclem a IIRC to bylo i ve starsich verzich Postgresu (nebo Ingresu, ted opravdu nevim). Kazdopadne to z programatorskeho hlediska moc vyhra nebyla a jsem rad, ze to skoncilo v zapomneni.
15.12.2018 12:54
Josef Kufner | skóre: 70
16.12.2018 20:58
Josef Kufner | skóre: 70
Spis se znovu ujima proto, ze kazdy modernejsi jazyk nabizi typovou inferenci, ktera zapis typu dost usnadnuje.Typy protože lepší typy?
16.12.2018 22:02
Josef Kufner | skóre: 70
17.12.2018 20:46
Josef Kufner | skóre: 70
auto v C++. O to ale teď nejde. Pointa je v té příčině, proč vlastně se lidé vrací k typům a jak se vnímání a účel typového systému posunul.
17.12.2018 20:49
xkucf03 | skóre: 49
| blog: xkucf03
viz auto v C++
Zrovna tam mi to přijde jako reakce na to, jak obludné ty typy (s mnoha šablonami) někdy bývají.
Myslel jsem si, ze to muselo existovat i jindesamozrejme, mela to kazda poradna databaze - v dobe 1985-2000 se ani jinak ty programy nepsaly. V kodu se napsalo 'exec sql' a to zatim byl sql statement a promenne, kterym se rikalo host variable mely dvojtecku pred jmenem a byly to vlastne normalni c-promenne. Prelozeny c-kod mel pak v tom miste radu jednoduchych c-funkci, ktere vpodstate byly dnesnim provadecim planem. Pro jednoduche statement by to i dnes bylo jeste porad rychlejsi a jen u nejakych komplikovanych dotazu by to bylo horsi, protoze ty natvrdo prelozene prikazy se jen tezko optimalizuji. Podle meho to bylo zrovna tak hezke nebo nehezke jako ty dnesni 'sprintf', ve kterych jsou dnes ty prikazy schovane. Podle mne je ten duvod, proc se to prestalo pouzivat nastup webu a php-programovani, pri kterem by nebylo tou 'kompilacni' metodou mozno za behu generovat ty statements - ten vyse popsany postup vyzadoval prave v te fazi toho sql-preprocesoru, aby byl ten sql prikaz jiz znam. Na druhou stranu zase neexistovalo neco jako sql-injection
Jinak co se tyce toho inzenyrstvi, tak zde si myslim, ze je jeden problem v tom, ze se presne nevi co je inzenyrstvi - nebo vetsina lidi zde to jen nejasne tusi. Take si myslim, ze dnesni informatika nema s inzenyrstvim v tom klasickem smyslu moc spolecneho - to vyvozuji napr. z toho, ze vyuka v tech klasickych inzenyrskych disciplinach probiha diametralne jinak nez v informatice.
EXECUTE
Příklad z dokumentace
Nevýhodou byl (je) poměrně komplikovaný build + deployment. Precompiler totiž vyprodukoval dva artefakty: modifikované zdrojáky (které se pak ještě musely zkompilovat a slinkovat) a takzvaný package který se musel "nainstalovat" (BIND) do databáze. Tento balíček obsahovat všechny statické SQL případy, včetně případných query plans.
Schéma
To že je ten postup komplikovaný (v odborném slangu: "oser") by ještě takový problém nebyl. Horší problém nastal když optimalizace prováděcích plánů začala používat statistiky o skutečném rozložení dat. Jelikož statické SQL příkazy se kompilují v době buildu, a často používají nějakou vývojovou databázi, jsou ty statistiky naprosto nesmyslné. A i když se použijí správné produkční statistiky, tak mají omezenou platnost - za půl roku už mohou být data zcela jiná, ale aplikace bude používat pořád stejný dokud se nevydá nový release (a release jednou za půl roku? takové šílené tempo si nikdo netroufne). Plus, dnešní servery mají dost výkonu aby kompilaci a optimalizaci query planu zvládli v reálném čase (na rozdíl od osmdesátých let).
PostgreSQL tohle umí v C a AFAIK to dělá jen nějakou kontrolu syntaxe, ale nepřipravuje to prováděcí plán v době kompilace C. Píší tam:
Converted ECPG applications call functions in the libpq library through the embedded SQL library (ecpglib), and communicate with the PostgreSQL server using the normal frontend-backend protocol.
Pro Javu zase bylo SQLJ, ale tam taky nevím o tom, že by klient kecal databázovému serveru do toho, jak má provádět dotaz.
Vkládat SQL do Javy nebo C je na jednu stranu zajímavá myšlenka, ale problém je s podporou v nástrojích a v nutnosti prohnat kód přes preprocesor. Oproti tomu je ORM nebo třeba nástroj typu jOOQ mnohem elegantnější a přímočařejší. Připravíš/vygeneruješ si mapování, abys měl obraz databázových struktur ve svém jazyce a pak už pracuješ jen v něm, píšeš v Javě, C atd. a nemusíš už nic přegenerovávat a nástroje tomu rozumí, protože je to obyčejná Java nebo C.
 23.12.2018 16:51
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
23.12.2018 16:51
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
Horší problém nastal když optimalizace prováděcích plánů začala používat statistiky o skutečném rozložení dat. Jelikož statické SQL příkazy se kompilují v době buildu, a často používají nějakou vývojovou databázi, jsou ty statistiky naprosto nesmyslné.To je vecny spor mezi JIT a AOT kompilaci, a ja si myslim, ze existuje nejaka stredni cesta. Jsem presvedceny, ze JIT ani AOT optimalni neni. (U databazi se do toho problemu navic plete otazka se zpusobem ulozeni dat, treba existence indexu, ukladani po radkach nebo sloupcich apod.) Ono to s tim JITem je takova pseudovymluva prave na obhajobu pohodli programatoru - v praxi to vsichni delaji prave kvuli ni.
Dnes se vubec hodne veci dela z duvodu programatorskeho pohodli. Treba continuous delivery nebo zminene dynamicke typovani.Continous delivery se dělá z důvodů programátorského pohodlí? Tak tohle jsem ještě neslyšel. Naopak nadávání na to jak přidělává práci, toho jsem slyšel hodně.
Jak bychom se treba postavili k pracce, ktera je najednou dvakrat pomalejsi, ale bylo opravdu jednodussi ji nakreslit v CADu? A odted se tak budou delat vsecky?No jak asi: Jůů, o třetinu levnější, to beru. Samozřejmě, kreslení v CADu je špatný příměr. V případě programů je programátorská práce hlavním nákladem, takže její ušetření a zlepšení kvality (nebo alespoň dosažení konzistentní kvality) odpovídá tomu že u pračky ušetří materiál. Ergo, naprosto reálná situace.
16.12.2018 12:11
xkucf03 | skóre: 49
| blog: xkucf03
Continous delivery se dělá z důvodů programátorského pohodlí? Tak tohle jsem ještě neslyšel. Naopak nadávání na to jak přidělává práci, toho jsem slyšel hodně.
Když uděláš chybu, tak se na ni dříve či později přijde. CI/CD zařídí, že se na ni přijde hned. Někomu to může vyhovovat, někomu ne (např. má pocit, že by na chybu přišel sám a stihl ji opravit, než se projeví a všimnou si jí ostatní). Např. když budu vyvíjet pro X platforem/architektur, tak si u sebe lokálně stejně nemám šanci všechno vyzkoušet; nebo když tam bude nějaká složitější integrace s jinými komponentami. Dělat všechno lokálně by byl opruz. Považuji tedy za pohodlnější, když si lokálně pustím jen základní testy a zbytek se už udělá automaticky v CI/CD.
dynamicke typovani
Tohle bude spíš věc povahy/názoru. Mně dynamické typování přijde méně pohodlné, méně spolehlivé -- pohodlnější mi přijde, když za mně udělá kus práce kompilátor a typy pohlídá on. Někdo zase rád "prasí" a "kouzlí" a baví ho dynamické jazyky.
No jasně, to je Continous Integration. Ale od CI k CD je hodně dlouhá cesta a rozhodně bych to nemíchal. Navíc, otázka nezněla "jaké jsou výhody CI nebo CD" ale "je CD pro programátory pohodlnější"Continous delivery se dělá z důvodů programátorského pohodlí? Tak tohle jsem ještě neslyšel. Naopak nadávání na to jak přidělává práci, toho jsem slyšel hodně.Když uděláš chybu, tak se na ni dříve či později přijde. CI/CD zařídí, že se na ni přijde hned.... Považuji tedy za pohodlnější, když si lokálně pustím jen základní testy a zbytek se už udělá automaticky v CI/CD.
Continous delivery se dělá z důvodů programátorského pohodlí?Ano, programatori chteji pracovat se systemy a knihovnami, ktere nejsou "legacy", ale maji nejnovejsi vlastnosti (podobne jako v opensource). Proto tlaci na co nejrychlejsi zmeny - ke zlosti administratoru a zakazniku, kteri by spis vetsinou chteli nemenit uz funkcni a odladene. Podobne je to IMHO s microservices - zase, vyvojari se nechteji dohadovat, co komu patri a tak si aplikaci rozdeli napric siti.. za cenu nizsi efektivity (sitova komunikace navic).
případě programů je programátorská práce hlavním náklademPro dodavatelskou firmu ano, pro zakaznika ne nutne. Analogie je spravne. Spousta "inovaci" v IT je jenom o prenaseni nakladu toho, co driv clovek jednou zoptimalizoval, na pocitac, ktery to pak dela casto zbytecne opakovane na systemu zakaznika. Ale proc by to melo nekoho palit, to je ekonomicka externalita. Pritom by nebylo tak strasne tezke navrhovat systemy tak, aby se dosahlo obojiho.
WTF?Continous delivery se dělá z důvodů programátorského pohodlí?Ano, programatori chteji pracovat se systemy a knihovnami, ktere nejsou "legacy", ale maji nejnovejsi vlastnosti (podobne jako v opensource). Proto tlaci na co nejrychlejsi zmeny - ke zlosti administratoru a zakazniku, kteri by spis vetsinou chteli nemenit uz funkcni a odladene.
Aha, už chápu, oboje. Celé to stojí na předpokladu, že práci si programátoři sami vymýšlejí. Pak samozřejmě dává smysl si stěžovat na to, že si jí vymýšlejí moc a navíc tak aby je to bavilo.případě programů je programátorská práce hlavním náklademPro dodavatelskou firmu ano, pro zakaznika ne nutne. Analogie je spravne. Spousta "inovaci" v IT je jenom o prenaseni nakladu toho, co driv clovek jednou zoptimalizoval, na pocitac, ktery to pak dela casto zbytecne opakovane na systemu zakaznika. Ale proc by to melo nekoho palit, to je ekonomicka externalita. Pritom by nebylo tak strasne tezke navrhovat systemy tak, aby se dosahlo obojiho.
Ano, programatori chteji pracovat se systemy a knihovnami, ktere nejsou "legacy", ale maji nejnovejsi vlastnosti (podobne jako v opensource). Proto tlaci na co nejrychlejsi zmeny - ke zlosti administratoru a zakazniku, kteri by spis vetsinou chteli nemenit uz funkcni a odladene.To je jeden uhel pohledu. Zakaznici vetsinou chteji mit system stabilni, zaroven chteji nechat legacy kod a zaroven chteji ruzne nove blystive vlasnosti. A blbe se vysvetluje, ze to vsechno nejde moc dohromady, jelikoz v programovani je minimalni mnozstvi fyzickych a fyzikalni omezeni (na ktere by se dalo poukazat) a vec je typicky jen otazka ceny programatorske prace. Takze v konecnem dusledku se lepi jedna vec na druhou a inzenyrsky se resi, jak to udelat, aby to aspon chvilku drzelo pohromade. (Na druhou stranu, co jsem slysel historky od strojaru nebo stavaru, ani tam to neni prilis jine.)
Podobne je to IMHO s microservices - zase, vyvojari se nechteji dohadovat, co komu patri a tak si aplikaci rozdeli napric siti.. za cenu nizsi efektivity (sitova komunikace navic).Uz jsem videl mnoho ruznych technologii (a metodik), ktere chtely resit modularitu ala microservices, bez valneho uspechu... Vyhoda microservices (v dnesni podobe) je v tom, ze se jedna o snadno uchopitelne reseni, k jehoz pochopeni a pouziti nepotrebujes v podstate nic navic, nez co uz bezne pouzivas. Dal microservices neresi jen problem modularity a zodpovednosti, ale zaroven nabizi rozlozeni zateze a odolnost proti vypadku. V pripade microservices tyto funkce ziskavas temer zadarmo (z programatorskeho hlediska). A slusi se dodat, ze tyto dve vlasnosti prinasi rezii i v "inzenyrsky lepsich" reseni.
Dal microservices neresi jen problem modularity a zodpovednosti, ale zaroven nabizi rozlozeni zateze a odolnost proti vypadku. V pripade microservices tyto funkce ziskavas temer zadarmo (z programatorskeho hlediska).No, ja si myslim, ze to rozlozeni zateze a odolnost neni tak uplne zadarmo. A casto to jde na ukor celkoveho vykonu systemu nebo nakladu na jeho spravu. Mozna je to tim co delam - ale pripada mi, ze fyzikalne dava smysl nacpat co nejvic vypocetniho vykonu vedle sebe (a k distribuovanosti se uchylit az v nejnutnejsim pripade), a pokud to uz nejde, tak skalovat nejdriv spis horizontalne (rozdelit data a pridat vic monolitu) nez vertikalne (rozdelit program na vic sluzeb). (Ono tak zalezi dost od algoritmu, ale obecne mi prijde, ze se dnes vertikalni deleni pouziva az zbytecne moc. Ackoliv striktne vzato to neni uplne nova namitka.)
No, ja si myslim, ze to rozlozeni zateze a odolnost neni tak uplne zadarmo.Proto tam pisu:
A slusi se dodat, ze tyto dve vlasnosti prinasi rezii i v "inzenyrsky lepsich" reseni.A proto tam pisu z programatorskeho hlediska. Pokud chces rozlozeni zateze a odolnost proti vypadkum, vzdycky to bude znamenat dodatecnou rezii (neefektivnost). V pripade microservices uz tu rezii mas jednou zapocitanou, takze to mas temer zadarmo. I kdyz je to trochu styl nechci slevu zadarmo.
ale pripada mi, ze fyzikalne dava smysl nacpat co nejvic vypocetniho vykonu vedle sebeTo smysl dava. Ale v tomto pripade jde o spojite nadoby, kde neni jednoduche vyjadrit prinos/naklady vertikalni a soucasne horizontalniho. Z meho pohledu je velke plus vynucovani modularniho designu a zbytek je prijemny bonus. Jinak s tou efektivitou je to velice podobne tomu, jak s efektivitou trzniho hospodarstvi vs. centralne rizeneho (pujcuju si dovolenim tvuj priklad).
Myslel jsem si, ze to muselo existovat i jinde.
Jistě, třeba Firebird má embedded SQL a gpre dodnes. Ale naštěstí už se to skoro nepoužívá.
Je to asi stejne jako ten Python, co se nemusi kompilovat.
Nemusí kompilovat? Vždyť vám do buildu naopak přibude ještě jeden krok navíc. Mně to přišlo jako takový ten klasický "unuser friendly" přístup: strašně cool pro začátečníka, ale pokud zkusíte cokoli většího nebo komplikovanějšího, začnete zjišťovat, že je to vlastně hrozně nepraktické.
Nemusí kompilovat? Vždyť vám do buildu naopak přibude ještě jeden krok navíc.Ano, o to mi slo - programatori radeji zvoli pohodli (dynamicky jazyk bez AOT kompilace nebo sloziteho buildu) nez efektivnost vysledku.
23.12.2018 16:56
okbob | skóre: 30
| blog: systemakuv_blog
| Benešov
Poznámka dvě: Ta současná neustálá serializace a deserializace má podle mě důvod taky v tom, že to omezuje problém s únikem paměti.To je spis takovy vitany bonus. Podobne vitany bonus je, ze serializace/deserializace podporuje modularni navrh systemu, tj. umoznuje vytvaret moduly, ktere jsou od sebe izolovany a mohou spolu intergovat jen pres jasne definovane rozhrani. Jeden (z meho pohledu) velky zdroj chyb v OOP jsou objekty, ktere prolezaji celou aplikaci a ty nevis, jestli muzes zmenit jejich stav, protoze nevis, kdo vsechno na to drzi odkazy. Vysledny program pak muze byt velice krehky. Resi se to pomoci best-practices, kdy si clovek musi hlidat, kdo ma za co zodpovednost, apod. ale to neni 100% reseni. Z tohoto duvodu microservices nahrazuji ruzne monolity, protoze umoznuji jednoznacne rict, kde jsou hranice modulu a kazdy programator vidi, ze ta hranice je ostre dana jednotlivymi requesty (serializovanymi daty).
Nejde jen o přesun stejných problémů na jinou úroveň? A jak v tom systému zajistit diverzitu (programovacích jazyků, programů migrovaných z jiného prostředí atd... tam to bude zákonitě vždy narušovat tu eleganci jednotného řešení)?Ano, jde. Ta diverzita je pak docela problem. Hezky to jde videt na platforme Java. Virtualni stroj byl navrzeny pro (konkretni) objektovy jazyk, a pokud clovek chtel neco malinko jineho (treba Scalu nebo Clojure) musel se tomu dany jazyk vyrazne prizpusobovat.
17.12.2018 15:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
: V čem nevyhovuje ten smalltalk, třeba Squeak/Pharo/Self? Co má být v tom hypotetickém systému navíc nebo jinak?
Self je ve špatném stavu. Od doby co se mu přestal věnovat Sun na něm nikdo nic moc neudělal, když vynechám portaci na Linux. Grafické rozhraní je zastaralá záležitost napsaná napůl v Selfu a napůl v C++ nad Xlibem využívajícím funkce jen z devadesátých let. Zkoušel jsem do toho nahackovat podporu unicode a skoro se mi to povedlo, ale ta míra toho s čím vším se to chce poprat je hrozná.
Taky je to hodně akademický projekt, lidi si tam šušňají svoje kompilátory a proof of concepty všemožných teorií a nikdo moc nemá zájem na to aby se z toho stal široce použitelný systém.
Jo, a je to křehké. Interpreter a GUI jsem rozbil asi na sto různých způsobů jen první týden používání.
Co se týče Phara, tak jsem ho párkrát zkoušel a je tam vidět hodně velký progress pokaždé, když to pustím, ale pořád se mi to čas od času podaří sestřelit a stále mám pocit, že to není tam kde bych chtěl co se týče toolingu. To by se vše dalo oželit, ale rozhodl jsem se zkoušet svoje koncepty na prototypech založeném systému OOP, což Pharo není.
: Nejsem si jist, zda by ten hypotetický systém přinesl skutečně tu zamýšlenou skokovou kvalitativní změnu. Musel by řešit stejné problémy jako současné systémy a navíc prosadit jednotný přístup v tom, jak se co dělá. Nejde jen o přesun stejných problémů na jinou úroveň? A jak v tom systému zajistit diverzitu (programovacích jazyků, programů migrovaných z jiného prostředí atd... tam to bude zákonitě vždy narušovat tu eleganci jednotného řešení)?
Zkus si pročíst to odkazované PDF o Geneře. A to myslím vážně, nechci tě jen odpálkovat někam. Když jsem to četl a pak koukal na youtube videa, hodně mi to rozšířilo obzory.
Tohle je na tom to nejhorší - nejedná se o nic nového, operační systémy co by uměly prakticky úplně všechno co jsem popsal už existovaly a byly tak populární, že tlupy nadšenců se je snaží provozovat dodnes.
Důvod proč to pomřelo je veskrze vždycky stejný: stála za tím neflexibilní korporace účtující si buďto velké prachy, nebo snažící se to uzavřít na vlastní hardware (mrká na apple).
Ta současná neustálá serializace a deserializace má podle mě důvod taky v tom, že to omezuje problém s únikem paměti. Většina programů běží jen omezenou dobu a mezi běhy uloží data jako mrtvý bloby na disk. To umožní začít od nuly při spuštění programu.
Ano, to je pravda, není ale důvod, proč by ty programy nemohly běžet omezenou dobu i v tomhle systému.
: Osobně by se mi plně objektový systém líbil a ihned bych ho použil na denní bázi. Například při zpracování textů: různé programy by mohly exportovat svoje funkce jakými je např. změna velikosti písmen, korekce překlepů, obarvení nebo validace syntaxe - a já bych ty funkce pak mohl použít v libovolném programu, kde vepisuji nějaký text. To samé při práci se soubory. Něco takového sice desktop rozhraní nabízejí, ale nikdy to nefunguje zcela univerzálně a vždy to má dost omezení. Kdyby šlo v gui pracovat stejně univerzálně jako v konzoli... už to by byl pokrok. Propojit si různé komponenty individuálně dle svého workflow...
Jo, jo. Jdou dělat kruté věci: https://www.youtube.com/watch?v=Rr-GzmvW35w
Jo, jo. Jdou dělat kruté věci: https://www.youtube.com/watch?v=Rr-GzmvW35wJakožto uživatel i3 jsem z toho ježdění myši po stole dostal kopřivku. Mně skoro přijde, že udělat uživatelské rozhraní založené na podobných myšlenkách, ale tak, aby bylo použitelnější, je dost náročný úkol sám o sobě. Takhle to má určitý wow effect, ale neumím si představit tak pracovat denně. Bylo by fajn, kdyby to šlo víc ovládat z klávesnice, jenže pak zase budou problémy s těmi plovoucími okny. Nevím, přemýšlel jsi nad tímhle nějak? Myš má svůj význam, určitě bych ji nezahazoval úplně, ale ve chvíli, kdy ji používáš k aranžování oken na ploše aj., tak je to prostě naprosto neproduktivní pohyb ruky.
17.12.2018 22:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
18.12.2018 00:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Přesně, já to GUI Squeaku/Pharo nemůžu nějak překousnout. Jsem ochoten občas někam kliknout, ale vybírat v menu z množství položek bez našeptávání to už moc nedávám. Jinak mi to přijde super.A zkoušel jsi moderní Pharo? Protože tam je to fakt posunuté úplně někam jinam. Co si tak pamatuji z mého pokusu před rokem, tak to mělo kopu klávesových zkratek a našeptávání místy taky.
Osobně by se mi líbilo realizovat věci jako že bych si ve filemanageru podle určitých kritérií vybral sadu souborů (ta by se naživo aktualizovala při každé změně souborového systému), sadu souborů bych předal jako nějaký operační namespace textové editační komponentě, která by umožňovala ty soubory editovat, k editační komponentě by si připojil zvýrazňovač syntaxe a našeptávač kódu (představme si třeba, že kvalitní hinty pro našeptávač by mohl poskytovat přímo runtime toho kódu), nakonec bych bych na textový editor napojil renderer (třeba markdown renderer) a nějaké akce spouštěné při uložení souboru. Tímto postupem bych si postavil vlastní IDE. Jasně, že se o totéž snaží všechny IDE, ale tohle by mohlo být optimálně přizpůsobené pro workflow daného projektu a navíc ty komponenty by mohly být univerzálně využitelné úplně všude. Třeba mailový klient bych nepotřeboval jiný editor ani jiný systém vyhledávání - prostě bych pracoval nad setem souborů-mailů, které by poskytla komponenta pro přístup k IMAP účtu a odtud bych mohl s maily pracovat stejně jako se soubory. Prostě taková příkazová řádka přenesená do GUI. No a samozřejmě bych ty jednou propojené spletence komponent mohl uložit, kopírovat, duplikovat atd.To skoro zní jako chabý odvar toho co jde ve smalltalku ;)
Self je ve špatném stavu.Jasně, Self už je out, ptal jsem se jen na ten koncept.
Ano, to je pravda, není ale důvod, proč by ty programy nemohly běžet omezenou dobu i v tomhle systému.Pokud by byl nějaký mechanismus, jak nad tím vládnout, tak by asi nebyl problém. Ještě mě napadá - co když se mění schéma, struktura těch objektů? To musí mít nějaké definované chování - u prototypů se asi změny projeví okamžitě i u existujících instancí, nevím ale, jak je to třeba ve Pharo. Jak přemigruju existující instance na novou verzi tříd? Můžu nějak původní verzi transformovat? Popravdě ani nevím, jak to řeší existující objektové databáze - možná nějakým verzováním instancí (k objektovým databázím jsem se ještě pořád nedostal, ale přijde mi, že na soustu použití by byla objektová databáze snadnější řešení než průměrné ORM, které obsahuje z principu řadu pastí). Jinak praktický problém vidím dost v tom, že všechny tyhle experimenty jako Pharo a spol. jsou v reálu nejspíš nenasaditelné - netroufnul bych si to použít ani na malý projekt. Takže s tím lidé přijdou do styku jen pokud se zajímají o teorii, praktiky to nechává asi dost chladné. I když třeba jazyky kolem jvm to trochu mění. Scala, Clojure mi přijdou dost alternativní a přitom prakticky použitelné, podobně třeba Graalvm bourá hranice mezi jazyky, takže si někdo může lajsnout implementovat kus kódu na zkoušku v jiném jazyce, otázka spíš bude, jak dobře může fungovat spojení různých paradigmat... Jestli ten náš hypotetický systém může být jazykově nezávislý. Na Genera pdf koukám...
Ještě mě napadá - co když se mění schéma, struktura těch objektů? To musí mít nějaké definované chování - u prototypů se asi změny projeví okamžitě i u existujících instancí, nevím ale, jak je to třeba ve Pharo. Jak přemigruju existující instance na novou verzi tříd? Můžu nějak původní verzi transformovat?
Konkrétně ve Pharu se provádí migrace instancí tak, že se pro každou stávající instanci vytvoří nový prázdný objekt (basicNew:), překopírují se do nich hodnoty proměnných s odpovídajícími jmény a pak se nad všemi původními provede výměna identity na nové. Viz ShiftClassInstaller>>#migrateInstancesTo: a ShiftClassInstaller>>#copyObject:to: ve Pharo 7. V současné době žádné skutečné upozornění o tom, že je migrován, objekt nedostává, což by možná stálo za to změnit (ale pak by to bylo nutné řešit speciálně např. u proxy objektů).
Jinak praktický problém vidím dost v tom, že všechny tyhle experimenty jako Pharo a spol. jsou v reálu nejspíš nenasaditelné - netroufnul bych si to použít ani na malý projekt. Takže s tím lidé přijdou do styku jen pokud se zajímají o teorii, praktiky to nechává asi dost chladné. I když třeba jazyky kolem jvm to trochu mění. Scala, Clojure mi přijdou dost alternativní a přitom prakticky použitelné, podobně třeba Graalvm bourá hranice mezi jazyky, takže si někdo může lajsnout implementovat kus kódu na zkoušku v jiném jazyce, otázka spíš bude, jak dobře může fungovat spojení různých paradigmat... Jestli ten náš hypotetický systém může být jazykově nezávislý.
Řada velkých zákazníků Cincomu jako J.P. Morgan začíná intenzivně pracovat na konverzi jejich aplikací na Pharo (někteří to v minuloti zkoušeli jinam a pohořeli), takže v praktické nasaditelnosti se dají očekávat změny k lepšímu.
Ano, ve Pharu to udělat lze. Bez podobných schopností by nebylo možné mít smalltalkovskou image spravovanou jako živý systém 30 let.
Ale i tak lze věci zlepšovat. Zrovna včera obhajoval na toto téma svoji diplomovou práci (Dynamic Software Update for Production and Live Programming Environments) Pablo Tesone. Vedlejším produktem je nový class builder ve Pharo 7, který mimo jiné umí i stateful traits. Podpora atomických změn, jaké jsou potřeba ve vašem případě, se tam ale ještě nepropracovala, takže zatím je nutné ten proces trochu víc manuálně řídit. O něco snazší je to v případě, pokud pro instance zůstává celkový počet instančních proměnných stejný.
... prosadit jednotný přístup v tom, jak se co dělá.V tom vidím jeden z větších zádrhelů podobných myšlenek. Ty sekvenece bytů jsou vcelku primitivní, ale ani u těch není spoleh na to, že to bude všude fungovat stejně.
(až na to chybějící předávání objektů).
Jinak by totiž muselo být jedno prostředí/jeden jazyk TM a to se mi nějak nezdá... Pluralita platforem/jazyků je imho fajn zachovat (každý řeší problém různým pohledem, atd...), ale všeobecně používané prostředky pro komunikaci jsou hodně low-level a to je imho jeden z důvodů, proč se moc nekomunikuje. Snížení bariéry (pro programátory) by možná pomohlo.
19.12.2018 15:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jakmile by byl aspoň ten standard pro surové předávání objektů (objektů, nikoliv textu, binárních dat, atd... - jak je to teď), mohly by vznikat další standardy třeba pro obecný formát (nad objekty) předávání logů nějakému loggerovi, atd... aby ty aplikace spolu více komunikovaly a každá si to neřešila po svém. Myslím že neelegantní sdílení objektů napříč různými jazyky, formáty, po síti, atd... odrazuje lidi od toho to používat. Vyřešit problém, aby aplikace mezi sebou mohly sdílet objekty podobně elegantně, jako je mohou sdílet metody ve vyšších jazycích by určitě tu barieru a nechuť ke standardům snížilo (kdyby to ale byla jedna forma objektů). Otázka je, jak je to reálné / proveditelné. Jinými slovy, aby sdílení objektů mezi aplikacemi bylo podobně zakořeněné, jako třeba STDIN/STDOUT/ARGS/RETURN, se kterým každý jazyk nyní počítá.Přijde mi, že bys to rád naportoval na Unix, což si myslím že není úplně dobrý nápad. Sice poskytuje hardwarovou abstrakci, ale obecně je to úplně jiná kultura přístupu k věcem.
A nyní to, v čem se asi neshodneme. Pochopil jsem, že bys byl rád, kdyby se objekty daly předávat živé, tedy i s metodami a nelíbí se ti oddělení logiky od dat. Pak se ale síťová transparentnost a možnost zachovat jazykovou pluralitu a pluraliru prostředí hroutí. Nedokážu si moc představit, jak by to fungovalo jinde než v nějakém smalltalkovém stroji a upřímně mi to ani nepříjde užitečné.Je to řešitelné, ale nechce se mi zabíhat do podrobností (proxy objekty a oddělené sandbox dimenze namespace ala Korz).
Ty aplikace buď objekt narvou do nějakého konstruktoru DateTime třídy a hned mají všechny potřebné metody na porovnávání, atd... k dispozici nebo ve funkcionálních jazycích nad objektem přímo volají funkce, které mají implementované někde jinde (ideálně formou knihovny). Obojí je dneska imho standardní stav a příjde mi fajnJenže to předpokládá, že máš konstruktor na každý exsitující objekt. Což nemáš, že. Je to stejný problém jako s parsováním, jen ho přenášíš o úroveň jinam a neparsuješ textovou strukturu, ale konvertuješ nějakou strukturu ala naparsovaný JSON na něco čemu rozumíš a s čím umíš pracovat. Místo abys prostě rovnou pracoval s nějakým datovým typem definovaným třeba jinde.
19.12.2018 17:56
xkucf03 | skóre: 49
| blog: xkucf03
Jinak pro serializaci JSON preferuju místo XML z toho důvodu, že nemá atributy a díky tomu ve vyšších jazycích se dá přímo mapovat objekt na JSON pomocí nativních konstrukcí jazyka.
Jak řešíš případy, kdy JSON obsahuje jako klíče texty s mezerami nebo nepovolenými znaky? Není to náhodou stejné, jako kdyby sis místo atributů představil elementy začínající zavináčem? To už bych za větší problém považoval to, že v XML se ti může opakovat více podelementů stejného typu, ale může tam být i jen jeden -- takže se musíš rozmyslet, jestli to budeš modelovat jako seznam nebo obyčejný atribut třídy/objektu. Nicméně tohle máš v JSONu taky -- JSON totiž nezakazuje duplicitní klíče... Takže pokud chceš namapovat libovolný validní JSON na objekty, řešíš tam v zásadě stejné problémy, jako když chceš namapovat libovolné validní XML na objekty.
Ideální by pro mě byl nějaký uznávaný standard, který má širokou podporu pro různé jazyky (formou knihoven) a uměl by řešit efektivní výměnu
Je tu ASN.1 a dodnes se mnohde používá. I ty ji právě teď používáš :-) A protože je abstraktní, můžou existovat různé konkrétní serializace, takže bys určitě našel nebo vymyslel něco, co ti bude vyhovovat. Ale netvrdím, že je to ideální formát.
Jak řešíš případy, kdy JSON obsahuje jako klíče texty s mezerami nebo nepovolenými znaky? Není to náhodou stejné, jako kdyby sis místo atributů představil elementy začínající zavináčem? To už bych za větší problém považoval to, že v XML se ti může opakovat více podelementů stejného typu, ale může tam být i jen jeden -- takže se musíš rozmyslet, jestli to budeš modelovat jako seznam nebo obyčejný atribut třídy/objektu. Nicméně tohle máš v JSONu taky -- JSON totiž nezakazuje duplicitní klíče... Takže pokud chceš namapovat libovolný validní JSON na objekty, řešíš tam v zásadě stejné problémy, jako když chceš namapovat libovolné validní XML na objekty.
V našem API klíče splňují požadavky jsonu. Kdybych chtěl přenášet například JS objekty, jsou ty omezení i omezením JS, takže JSON stále funguje. Kdyby vznikl nějaký univerzální protokol pro přenos objektů mezi jazyky, měl by rovněž zajistit, že do většiny jazyků, které umožňují nativní přístup (třeba ten JS, ale i PHP, Python, Ruby...) to půjde serializovat, takže umělé omezení, aby klíče třeba nemohly obsahovat libovolné znaky mi furt dává smysl (a uživatelé jazyků, kde může být klíč objektu cokoliv si buď budou muset dávat pozor, nebo tam bude nějaké ošklivé escapování, apod., těžko to udělat bez limitů).
Otázka možná zní - dá se najít podmnožina formátu objektů, která ve většině jazyků půjde použít nativně a jen tam, kde to nejde se musí využívat metody nějaké knihovny místo nativních konstrukcí? XML to nesplňuje asi nikde, JSON aspoň ve (většině?) dynamicky typovaných jazycích (ale ve statických to bez metod nejde), jiné formáty nepoužívám.
Vím že se používá u certifikátů, ale jinak mi to příjde jako dost děsivá věc (i když myšlenka je asi podobná té, co navrhuju). Aby to fungovalo, musí ten protokol splnit několik podmínek:Je tu ASN.1 a dodnes se mnohde používá. I ty ji právě teď používáš :-) A protože je abstraktní, můžou existovat různé konkrétní serializace, takže bys určitě našel nebo vymyslel něco, co ti bude vyhovovat. Ale netvrdím, že je to ideální formát.
Abych to ješte víc upřesnil, idea je taková, že teď když dělám nějaký skriptík/jednoduchou C aplikaci, tak si radši logování naprogramuju sám, protože se mi s tím nechce štvát, například přesměruju výstup STDOUT do souboru. Proč? Protože STDOUT je standardní součást OS a pro její použití nemusím dělat skoro nic. Když budu psát složitější aplikaci, třeba nad tím začnu více přemýšlet a includuju si syslog libku (nebo z bashe použiju ulitu logger), ale tím jsem vyřešil jednu službu. S mým protokolem bych includoval jednu knihovnu nebo použil nějaké cli rozhraní (stejně jako v bashi teď musím použít program logger), ale mohl bych tu zprávu (objekt!) poslat komukoliv a kamkoliv s využitím stejného API.
Věřím tomu, že snížení barier by vytvořilo mnoho nových zajímavých aplikací, protože by komunikování přestalo být složité.
Nicméně neřeším Bystroushaakův sen, že by s daty přišly i metody. Takže každá aplikace by musela mít implementované, jak data zpracovat. Což je furt trochu na půl cesty, protože u dat sice už nemusím includovat knihovnu, jak data číst/posílat, ale furt musím includovat knihovnu (v případě složitějších dat) s metodami, jak data využít. Nicméně i tak bych to viděl jako velký posun.
.
19.12.2018 19:34
xkucf03 | skóre: 49
| blog: xkucf03
takže umělé omezení, aby klíče třeba nemohly obsahovat libovolné znaky mi furt dává smysl (a uživatelé jazyků, kde může být klíč objektu cokoliv si buď budou muset dávat pozor, nebo tam bude nějaké ošklivé escapování, apod., těžko to udělat bez limitů).
Tohle je validní JSON:
{
"a b c": "xxx",
"@#$^$%&*$%^{&*": "xxx"
}
přesto to nenamapuješ na objekty/atributy asi žádného jazyka. Budeš si tedy muset vymyslet nějakou obousměrnou konverzi/escapování. Nepřijde mi to v ničem lepší, než XML:
<moje-xml>
<můj-element nějaký-atribut="jeho hodnota">
<druhý>hodnota 2</druhý>
<třetí>hodnota 3</třetí>
</můj-element>
</moje-xml>
V JSONu je taky problém s těmi duplicitními klíči. V jeho specifikaci se píše:
The JSON syntax does not impose any restrictions on the strings used as names, does not require that name strings be unique, and does not assign any significance to the ordering of name/value pairs.
ale většina programů si s tím neporadí. A knihovny ti často zamíchají pořadí, což taky může být problém a už jsem viděl rovnáky na ohýbáky v JSONu, kdy se uměle něco dávalo do pole, aby se pořadí zachovalo. V XML dáš takovou věc do atributu a máš jistotu, že ji budeš mít načtenou dřív než elementy, nebo v XSD budeš vyžadovat konkrétní pořadí elementů.
Navíc objekty mají nějaké typy (jsou instancí třídy nebo jsou odvozené od nějakého prototypu) a na jednom místě můžeš mít klidně objekty různých typů -- typicky tam můžeš dát potomka místo předka. Nebo to může být něco úplně obecného jako List<Object> a můžou v tom být objekty libovolných typů. Při serializaci a deserializaci je tohle potřeba řešit a tu informaci o typu někam dát. Jak tohle řešíš v JSONu?
Otázka možná zní - dá se najít podmnožina formátu objektů, která ve většině jazyků půjde použít nativně a jen tam, kde to nejde se musí využívat metody nějaké knihovny místo nativních konstrukcí?
Dá se udělat něco jako [a-zA-Z][a-zA-Z0-9]* což se vejde do drtivé většiny jazyků a ve většině případů ti to bude fungovat. Ale i tak hrozí, že se trefíš třeba do nějakého klíčového slova. Pokud to chceš dělat obecně, tak nezbývá než specifikovat nějaké escapování a umět obousměrné bezztrátové převody. Nicméně není to až tak těžké. Pak máš ještě omezení na délku identifikátoru a to už je horší -- tam hrozí, že to bezztrátově převést nepůjde.
ale mohl bych tu zprávu (objekt!) poslat komukoliv a kamkoliv s využitím stejného API.
To je zase otázka, jestli má být schéma součástí dat nebo ne...
Osobně v dynamických datech bez schématu nevidím moc přínos, protože když nevíš, jak je máš interpretovat, tak jsou ti k ničemu. Takže většinou preferuji, když je schéma dohodnuté předem a obě strany vědí, jaká je struktura vyměňovaných zpráv. Na tohle už řada nástrojů existuje, různé generátory atd. ale i tady se dá vymyslet něco nového...
Věřím tomu, že snížení barier by vytvořilo mnoho nových zajímavých aplikací, protože by komunikování přestalo být složité.
Nějaké konkrétní příklady, kde by tě absence takového řešení blokovala? Zrovna tohle je věc, která mě taky trochu trápí, ale spíš v teoretické rovině a z jakéhosi perfekcionismu. Nicméně těch nedokonalých (ale v praxi použitelných) řešení existuje plno, takže pokud máš nějaký nápad na aplikaci, která má komunikovat s jinou aplikací, těch (celkem dobrých) prostředků jak to udělat, máš dost.
.
Tohle by byla pouze univerzální transportní vysokoúrovňová pohodlná vrstva pro předávání objektů bez metod.
Co je to objekt bez metod? Datová struktura s názvem typu? Hledáte univerzální serializační formát, kde deserializované datové struktury lze snadno zpracovávat nativními prostředky konkrétního jazyka? Před pár lety byl v Perlu překotný vývoj Serealu.
19.12.2018 21:13
xkucf03 | skóre: 49
| blog: xkucf03
A nechtěl bych, ať ty knihovny zajištují jen serializaci/deserializaci, ale i transport (do souboru, po síti, mezi aplikacemi, atd...).
Tohle by podle mého mělo být oddělené. Můžou to být klidně dva spolupracující standardy, ale mělo by jít použít jedno bez druhého. Měl bys mít možnost si ta serializovaná data posílat klidně poštovním holubem, když budeš chtít -- a nemělo by ti to nutit komplexitu nějakých přenosových protokolů a všeho, co s tím souvisí (fronty, brokeři, síťové protokoly, šifrování atd.).
. A nebo taky ne .
Přitom teď přichází doba různých IoT krabiček v domácnostech, atd... a jednoduchá komunikace by se hodila jak sůl.Na to existuje třeba MQTT. Osobně mám s touhle diskuzí (a potažmo tím blogem) problém v tom, že je to laděné příliš idealisticky. Kdyby se všeobecně používala jedna jediná struktura pro přenos dat, samozřejmě by to mělo svoje výhody. Pokud to nebude jen prostá datová struktura, ale objekty se spustitelným kódem, tak se přirozeně nabízí otázka, jak se v takovém systému bude řešit bezpečnost. Ve vedlejší diskuzi Bystroushaak uváděl příklad s datem, cituji:
Property start je očividně v ISO formátu, kde časová zóna je a stejně tak now, ale co ty ostatní? Budeš muset mít ručně nějaký externí tool, co ten zbytek projde a zaktualizuje, což je ve své podstatě procedurální programování. Funkcionalita je oddělená od dat. Kdyby to byl skutečný objekt, tak by na to měl jednoduše metodu (funkcionalita by byla s daty spojená).A takové objekty by se používaly všude – třeba i místo webu. Nějaká obdoba dnešního REST API nám pošle objekt, ale jak s ním budeme pracovat? No, asi by se to zřejmě muselo nějak sandboxovat, nebo analyticky dokázat, že ten kód nemá side-effecty. V plně dynamickém, reflexivním systému je tohle o to těžší, že veškerý (potenciálně) volaný kód je potřeba analyzovat rekurzivně, pokaždé znovu, a ještě si ohlídat, že se to z jiného vlákna nezmění, zatímco si untrusted kód něco chroupá. Ve statickém prostředí by to šlo řešit alespoň nějakými whitelisty. Ve světle Meltdown a Spectre už ovšem víme, že ani tohle stačit nemusí. Tím se to celé zužuje a komplikuje. Ošetřovat by bylo nutné naprosto každou práci s každým objektem nedůvěryhodné třetí strany. Jak to ohlídat? Ponese si každý objekt nějaký příznak, a podle toho se automaticky zvolí správná strategie provádění v něm obsaženého kódu? Ten příznak by nesměl zmizet při kopírování celého objektu ani jeho (funkční) části a odstranit jej by mělo být možné jen na explicitní žádost. A pak je tu samozřejmě druhý problém, a to jsou knihovny. Bude v objektech veškerá logika implementovaná vždy s minimem závislostí? Pokud ano, pravděpodobně to povede na duplicitní kód, a především objekty budou zbytečně velké. V opačném případě by se musel vždy přenášet celý graf závislostí. A ty by bylo potřeba uchovávat společně s těmi datovými objekty, protože jinak by to prostě nefungovalo. Skončilo by to asi tak, že Alice bude chtít Bobovi poslat objekt s aktuálním datem. Bob se Alice zeptá, co ten objekt obsahuje. Alice vygeneruje rekurzivní strom závislostí s checksumy veškerých položek (bloků kódu). Protože oba používají stejný systém ve stejné verzi, Bob si nechá poslat jen objekt samotný, protože potřebné závislosti (další volané objekty) už má. O týden později si Bob bude chtít od Alice zase nechat poslat objekt s aktuálním datem. Alice ovšem mezitím upgradovala systém, statická analýza na dotaz „co všechno by se mohlo v nejhorším možném případě volat“ vyblije ohromný strom závislostí, který si Bob narsyncuje k sobě a bude ho opečovávat v objektové databázi spolu s malou datovou položkou – timestampem a časovou zónou. Tohle jsou naprosto stěžejní otázky, bez jejichž zodpovězení nemá smysl debatovat o čemkoliv dalším tímto směrem (např. jak to realizovat). Dalo by se to zúžit třeba jen na ten shell, čímž se to asi výrazně zjednoduší, ale ta obecná podoba, jak byla naznačena původně, je příliš nedostatečně naspecifikovaná na to, aby se nad tím dalo nějak konkrétně technicky uvažovat (jsem si vědom toho, že naspecifikovat to nejspíš nebylo cílem blogu, ale mělo by to být cílem této diskuze, má-li být konstruktivní). PS: Postuji to sice jako odpověď tobě (se mi nějak rozproudily myšlenky), ale vím, že ty ses zrovna k míchání kódu a dat stavěl skepticky. Je to jen příspěvek do rozpravy, který nemá konkrétního adresáta.
20.12.2018 12:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
IIRC Bystroušák tohle v nějaké diskusi nazval vertikálním peklem podle nějaké knížky. IMHO se jedná o prostý denial.Podle knížky Vertikální peklo ;)
Z toho důvodu IMHO je potřeba přijít s konkrétním technickým návrhem už od začátku (a následně iterovat ke zlepšení), ne obráceně.S tím ovšem naprosto souhlasím! Ostatně v blogu snad doufám nedeklaruji nic jiného.
20.12.2018 13:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
20.12.2018 12:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jinak ten problem s temi zapouzdrenymi objekty by se nejak dal resit, podobne jako to dela ten Dhall. Tedy bylo by mozne nejak serializovat transformaci zapouzdreneho objektu na zname objekty, za predpokladu, ze by tu transformaci bylo mozne popsat totalnim algoritmem v nejakych predem dohodnutych primitivach.To mě taky napadlo, ale nejsem si úplně jistý, jak moc by to fungovalo u komplexních aplikací.
.
20.12.2018 12:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
No, asi by se to zřejmě muselo nějak sandboxovat, nebo analyticky dokázat, že ten kód nemá side-effecty.Už jsem tu několikrát zmiňoval Korz, což více popisují následující papery:
.__class__, umožníš reflexi jedině tak, že máš speciální metodu, která ti po zavolání vrátí mirror, skrz který můžeš objekt zkoumat a upravovat.
Pokud si nadefinuješ dimenzi sanboxu tak, že tam tahle reflexivní metoda není, tak ten objekt prostě nemá možnost reflexi používat.
Myšlenka, která stojí za zvážení může být upravit VM ještě tak, že umožní spustit metodu objektu v konkrétní sanboxové dimenzi, ale zpět dovolí přijmout pouze objekt bez kódu, nebo ho otagovat tak, aby žádná z metod nešla pustit mimo sandbox ani omylem.
Netvrdím, že to je řešení všech problémů, ale osobně bych chtěl vidět výsledky experimentů, jak moc to dokáže zvednout bezpečnost.
Skončilo by to asi tak, že Alice bude chtít Bobovi poslat objekt s aktuálním datem. Bob se Alice zeptá, co ten objekt obsahuje. Alice vygeneruje rekurzivní strom závislostí s checksumy veškerých položek (bloků kódu). Protože oba používají stejný systém ve stejné verzi, Bob si nechá poslat jen objekt samotný, protože potřebné závislosti (další volané objekty) už má. O týden později si Bob bude chtít od Alice zase nechat poslat objekt s aktuálním datem. Alice ovšem mezitím upgradovala systém, statická analýza na dotaz „co všechno by se mohlo v nejhorším možném případě volat“ vyblije ohromný strom závislostí, který si Bob narsyncuje k sobě a bude ho opečovávat v objektové databázi spolu s malou datovou položkou – timestampem a časovou zónou.Tohle je ovšem stejný příklad, jako v případě klasických programů. Alice bude chtít Bobovi poslat obrázek vytvořený v photoshopu. Bob si musí nainstalovat photoshop. O týden později upgraduje Alice svůj photoshop, vytvoří v něm nový obrázek a uloží ho ve formátu, který bob není schopný zpracovat. Bob si musí photoshop upgradovat, stejně jako v tom tebou popsaném případě. Ten je totiž taky jen o updatu verzí. Důvod proč ti to přijde jako velký problém je, že sis vybral něco jednoduchého, konkrétně datum. Což ti přijde, že se dá běžně poslat jednoduše, jenže si představ analogickou situaci, že posíláš datum v jednom formátu, pak updatuješ na nějnovější ISO 210010 standard, který posílá datum v úplně jiném formátu a pošleš ho Bobovi, který nemá parser na ISO 210010 a tudíž mu to na tom padne. Jaký v tom bude rozdíl? V pádu aplikace? Ten můžeš v případě tvojí Alice a Boba udělat úplně stejně.
20.12.2018 17:27
xkucf03 | skóre: 49
| blog: xkucf03
A pak je tu samozřejmě druhý problém, a to jsou knihovny. Bude v objektech veškerá logika implementovaná vždy s minimem závislostí? Pokud ano, pravděpodobně to povede na duplicitní kód, a především objekty budou zbytečně velké. V opačném případě by se musel vždy přenášet celý graf závislostí. A ty by bylo potřeba uchovávat společně s těmi datovými objekty, protože jinak by to prostě nefungovalo.
Nechci teď hodnotit, jestli je takové předávání objektů dobrý nápad nebo ne, ale čistě k té proveditelnosti:
Šlo by to řešit tím, že by se dohodla rozhraní a proložilo by se to nějakou továrnou/funkcí, která by vracela konkrétní implementaci daného rozhraní. Objekt by si pak nedržel referenci na knihovnu, ale na někoho, kdo mu tu knihovnu implementující rozhraní, poskytne. Teď jde o to, jak ty reference prohodit a po přesunu na jiný počítač to přepojit. V podstatě by tam musel existovat nějaký globální kontext, ze kterého by se ty továrny braly, nebo by bylo potřeba opatchovat všechny přenesené objekty a aktualizovat některé jejich reference.
Ve výsledku by to ale mohlo fungovat tak, že objekt by chtěl třeba zobrazit dialogové okno, a na jednom systému by se k tomu použila GTK knihovna a na jiném Qt, podle toho, co preferuje uživatel. Rozhraní by bylo stejné. Jenže už z toho je vidět, jak složitý úkol to je.
20.12.2018 17:32
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Objekt by si pak nedržel referenci na knihovnu, ale na někoho, kdo mu tu knihovnu implementující rozhraní, poskytne. Teď jde o to, jak ty reference prohodit a po přesunu na jiný počítač to přepojit.Tohle je zrovna v Selfu triviální, prostě jen změníš parenta, na kterého se to deleguje. Ono to s prototypovými jazyky celkově funguje imho líp.
20.12.2018 17:47
xkucf03 | skóre: 49
| blog: xkucf03
A nemíchá se tam pak dohromady vztah rodič-potomek (dědičnost) a vlastník (jako třeba v Qt) nebo kontext? Pro mě jsou tohle dvě/tři dimenze a dává mi smysl mít objekt poděděný z nějaké třídy, ale zároveň žijící v nějakém jiném kontextu.
Tohle je validní JSON, přesto to nenamapuješ na objekty/atributy asi žádného jazyka.
$ irb
irb(main):001:0> require 'json'
=> true
irb(main):002:0> text = <<EOT
irb(main):003:0" {
irb(main):004:0" "a b c": "xxx",
irb(main):005:0" "@#$^$%&*$%^{&*": "xxx"
irb(main):006:0" }
irb(main):007:0" EOT
=> "{\n \"a b c\": \"xxx\",\n \"@\#$^$%&*$%^{&*\": \"xxx\"\n}\n"
irb(main):008:0> json = JSON.parse(text)
=> {"a b c"=>"xxx", "@\#$^$%&*$%^{&*"=>"xxx"}
irb(main):009:0> json.class
=> Hash
irb(main):016:0> json['a b c']
=> "xxx"
irb(main):017:0> json['@#$^$%&*$%^{&*']
=> "xxx"
A nebavíme se tady o žádném obskurním jazyku, ale o Ruby
21.12.2018 14:21
xkucf03 | skóre: 49
| blog: xkucf03
To je ale mapa -- do ní to jde dát v kterémkoli jazyce, který podporuje mapy s textovými klíči (nebo to může být metoda, ono je celkem jedno, jestli píšeš ["klíč"] nebo .get("klíč") -- to první je víceméně jen syntaktický cukr). Namapováním na objekty jsem ale myslel to, že pak můžeš psát:
x = json.abc;
x = json.a b c;
x = json.@#$^$%&*$%^{&*;
Z toho ti ale bude fungovat jen ten první případ, protože v každém jazyce jsou nějaká pravidla, která musí identifikátor splňovat. A pokud ta pravidla splníš (nebo si identifikátory během mapování escapuješ, aby pravidla splňovaly), tak není důvod, proč by něco mělo jít pro JSON a nemělo to jít pro XML.
Výjimkou, o které vím, je SQL, kde můžeš být v identifikátorech i hodně kreativní (akorát si je pak dáš do uvozovek, ale proveditelné to je a je to pořád identifikátor a pracuje se s ním stejně, jen je v uvozovkách):
SELECT "První sloupeček", "druhý #$^%#$%^", "atd." FROM "Moje krásná tabulka";
(příklad) A opět je to stejné pro JSON i XML.
Připomínám kontext diskuse:
Můžu udělat childs[0].age a nikoliv něco jako xmlDoc.querySelector('childs').childNodes[0].querySelector('age');
@#$^$%&*$%^{&* nesežere ani Ruby.
21.12.2018 15:03
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
(příklad)Trochu OT, ale neuvažoval jsi o zkracovadle URL? Že bys string toho SQL příkladu uložil do db a v url bys na něj měl jen ID nebo pár náhodných písmenek?
21.12.2018 15:58
xkucf03 | skóre: 49
| blog: xkucf03
Ta služba je navržena jako bezestavová.1 Takhle je celá informace obsažená v URL a odkazy budou fungovat a jsou případně přenositelné i na jinou instalaci aplikace. Chápu, že URL jsou takhle někdy dlouhé a nemusí se do nich vejít všechno, ale přijde mi to takhle lepší. Databázi můžu kdykoli smazat a aplikaci přeinstalovat a nikoho se to nedotkne.
[1] je tam sice historie dotazů, ale tu občas promazávám a nikdo asi nečeká, že mu tam zůstane navěky
objeckt["ěšíčáýěš €€€ íčáěščýě"](...argumenty...);
21.12.2018 16:23
xkucf03 | skóre: 49
| blog: xkucf03
Hezké... ale pointa byla spíš v tom, že když mapujeme nějakou externí serializaci na objekty nějakého jazyka, je z tohoto pohledu jedno, jestli je tou externí serializací JSON nebo XML, protože v obou případech budeme řešit stejné problémy. (resp. tahle diskuse se rozvinula na základě výroku, že JSON je v tomto ohledu údajně nějak lepší než XML)
Naopak v případě JSONu ty problémy budou častější nebo hůře řešitelné, protože pravidla pro pojmenování XML elementů/atributů jsou dost podobná identifikátorům v programovacích jazycích (jen je tam ta dualita atribut/element, což lze řešit tak, že si místo atributu xxx představíš element @xxx a dále je to stejné jako v JSONu), zatímco u JSONu do těch "klíčů" můžeš namastit libovolný text, který ve většině jazyků na indentifikátory 1:1 nenamapuješ.
Ve vedlejší diskusi se bavíme o duplicitních záznamech... docela vtipné je, že dle standardu je { "a" : "b", "a" : "c" } platný JSON, ale není tam definované, jak se s tím má pracovat. To moc na objekt nenamapuješ resp. nevíš, jestli máš vyhodit výjimku, přepsat hodnotu "b" hodnotou "c" (nebo naopak? na pořadí totiž nezáleží), nebo z "a" udělat pole a dát do něj dvě hodnoty :-). Záludné je to, že většina lidí si myslí, že JSON data jsou objekt a že JSON je jednoduchý. V případě XML naopak všichni vědí, že element stejného typu se může opakovat a nezaskočí je to -- je na autorovi konkrétního schématu, aby definoval násobnost a další pravidla a popsal formát nad XML postavený.
Ve vedlejší diskusi se bavíme o duplicitních záznamech... docela vtipné je, že dle standardu je { "a" : "b", "a" : "c" } platný JSON, ale není tam definované, jak se s tím má pracovat
Jj, je to tak. Pokud bys to chtěl řešit, můžeš se inspirovat JavaScriptem. Ale nevim, jestli to má standardizováno.
To moc na objekt nenamapuješAno, a v čem je pointa? Zaprvé bych ani nečekal, že by obecný JSON nebo XML nebo i další formáty byly mapovatelné na objekty OOP jazyků. Tys ani nespecifikoval, jaké objekty to vlastně mají být. U staticky typovaných jazyků to zjevně nejde, u dynamických možná ... třeba JSON → JS objekt jde afaik vždy, u jiných jazyků bych to spíše nečekal.
Záludné je to, že většina lidí si myslí, že JSON data jsou objekt a že JSON je jednoduchý.JSON data jsou JSON objekt nebo JSON pole. Nic víc, nic míň. Rozhodně se nedá říct, že by JSON data byly třeba C++ objekt, to mi ale přijde naprosto zjevné. A ano, je to celkem velmi jednoduchý formát, někdy až moc (např. nepodporou komentářů).
U staticky typovaných jazyků to zjevně nejdeAle lze. Kdyby se do contant poolu v
*.class souboru vešlo víc než 216 položek, tak bych ti to ukázal. :D
21.12.2018 22:51
Josef Kufner | skóre: 70
14.2.2019 13:05
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.2.2019 20:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale myšlenka postavit databázi přímo nad fyzickými disky mi přijde imho nepraktická. Je pravda, že při běžném použití mezi databázi a disk vkládám další vrstry operačního systému (raid, lvm, ...), ale pokud bych tyto vrstvy chtěl vyhodit, tak pak musím jejich funkcionalitu implementovat přímo v databázi.To je pravda, ale nevím proč by to mělo vadit. Přijde mi, že momentálně je otázka sémantiky. Prostě databázím říkáme jinak než operačním systémům. Když implementuješ nový filesystém, tak taky musíš implementovat lowlevel funkcionalitu a nikdo se nad tím nepozastavuje a neříká „božínku, to by přece nešlo“. Tak proč u databází jo?
Prostě databázím říkáme jinak než operačním systémům.Jeden výrazný rozdíl mezi databází a operačním systémem je ten, že storage kód operačního systému běží v kernelu, zatímco databáze v user space. Tento rozdíl má důsledky pro spoustu věcí, od složitosti vývoje a údržby takového kódu, po možnosti, co se dá implementovat v kterém případě implementovat.
14.2.2019 21:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale myšlenka postavit databázi přímo nad fyzickými disky mi přijde imho nepraktická.A proto (komercni) databaze bezne nabizi moznost ukladat data na samostatny oddil.
Je pravda, že při běžném použití mezi databázi a disk vkládám další vrstry operačního systému (raid, lvm, ...), ale pokud bych tyto vrstvy chtěl vyhodit, tak pak musím jejich funkcionalitu implementovat přímo v databázi.Ty vrstvy muzou byt nekdy hodne otravne (napr. kecat o tom, ze ty data ulozila) a zpomalovat. Obecne FS jsou navrzeny na obecnou zatez, a pokud mas nejak specificky workload, muze specificky (pro databaze) optimalizovany pristup k disku prinaset pozitivni vysledky, ktere bys s bezny FS neziskal.
21.2.2019 16:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
11.3.2019 11:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Stavíte ale ještě nějaké servery s procesory ARM, že?-- Seznam staví vlastní servery, je to levnější, říká Vlastimil Pečínka (root.cz)Inspirovali jsme se Turrisem a stavíme vlastní armový server velikosti SSD. K němu přidáme jedno SSD a dáme do šuplíku kompatibilního s našim serverovým šasim. Výsledkem je jakýsi chytrý disk, na kterém spustíme Linux a softwarového agenta, který vytvoří malou objektovou storage. Původně to bylo řešení plánované pro náš e-mail, kde používáme proprietární objektovou storage – to je největší žrout místa. Snižujeme tím náklady na úložiště, protože používáme tenhle malý serveřík. Jeho cena je vlastně zanedbatelná vůči ceně samotného disku, takže jde o velmi levné řešení – jsme prakticky na ceně za disk. Ukázalo se, že existují i další aplikace. Plánujeme tedy stejné řešení nasadit na Ceph a plánujeme podobným způsobem zajistit i Hadoop – měli bychom obrovské množství méně výkonných Hadoop clusterů.To je plně vaše řešení?Ano, desku si navrhujeme sami a necháváme ji osazovat tady v Čechách.Nápad pochází od vás?Inspirovali jsme se u Seagate, ale dnes to dělají všichni velcí dodavatelé disků. Zjistili od velkých zákazníků, že je tu poptávka po objektovém úložišti s ethernetovým portem, do kterého se přes API dá objekt uložit, načíst a smazat. Tím se obejde spousta nadbytečných vrstev jako souborový systém. My jsme to udělali po svém a říkáme tomu Dataholder.
11.6.2019 13:23
xkucf03 | skóre: 49
| blog: xkucf03
Asi to znáš, ale pro jistotu: náhodou jsem teď narazil na The Merlin Object-Oriented System – Self/R, Neo Smalltalk…
11.6.2019 13:38
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
28.11.2019 12:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Nevím už jak jsem na Internetu narazil na Váš příspěvek „Programátorova kritika chybějící struktury OS“. Při četbě jsem si v duchu učinil pár poznámek, které jsem se nakonec rozhodl sepsat a nabídnout Vám k zamyšlení. Nejprve jen krátké představení mé osoby: Jsem již poněkud zaprášený ročník, ale mou nepopiratelnou komparativní výhodou byla překvapivě maminka, která měla v Astronomickém ústavu na starost poměrně masivní výpočty a byvši žákyní pana doc. Antonína Svobody, byla propagátorkou výpočetní techniky. Tím se stalo, že zatímco moji vrstevníci tu a tam něco zaslechli o kalkulačkách, já si mohl u mámy v práci a někdy i doma pohrát s kalkulátorem programovatelným. Díky tomu mám na dnešní poměry poměrně dlouhou programátorskou praxi (přes 45 roků) a možná i zcela unikátní možnost pohledu do historie computerové techniky. Ve srovnání s Vámi se nemohu pochlubit takovou řadou zářezů na pažbě, a také jsem během svých studií na MFF UK zběhnul z cesty programátorské a věnoval se profesně fysice, takže můj pohled je, jak jinak, hodně subjektivní a také, jak ochotně přiznám, v lecčems nekvalifikovaný, neboť přes veškeré vzdělání, jsem v programovaní de-facto samouk. V čem se však lišíme velmi podstatně, je skutečnost, že jsem díky fysice a zachycením pionýrských počátků docela dobře obeznámen s hardwarem computerů a to až po kvantové jevy v polovodičových strukturách, o nichž se obecně tuší jen tak povrchně něco o elektronech a o dírách. Tento vhled do skutečného života jedniček a nul mi umožňuje poměrně dobře odhadnout, co je ještě fysikálně možné. Takže kupříkladu zmenšování šířky kanálu pod 10nm mě naplňuje spíše skepsí než jásáním. Ale vraťme se prozatím k Vaší kritice. I když přece jen na moment odbočím ještě k objektům. Víte já jsem toho poměrně hodně naprogramoval ve strojovém kódu resp. v assembleru (různých assemblerech) a nezřídka jsem i ladil ten strojový kód, aby stíhal příslušné mikrosekundy diktované sledovaným experimentem, takže nesdílím přílišné nadšení z módních manter, kterými se postupně staly „strukturované programování“ a „objektové programování“. Nikomu to nadšení neberu, ale GOTO a vypočtený skok prostě k výbavě programátora patří a znalost hardwaru neuškodí. Pročetl jsem z pilnosti mnohé příručky – tenké i tlusté – o objektovém programování (mimo jiné i o jednom prvobytně pospolném objektovém jazyku SIMULA 67) a hledal jsem v nich jasný příklad srovnání zápisu zdrojového a přeloženého kódu nějaké ne zcela triviální úlohy standardně a objektově. Na nic zřetelného natož průkazného jsem však zatím nenarazil. Pro mne se programovací jazyk stává použitelným pouze pokud je na první pohled dostatečně srozumitelný (což je samozřejmě při používání rovněž otázka hygieny psaní dobrých komentářů) a opatřený kvalitním manuálem. Těch kvalitních manuálů jsem však za svůj život potkal velmi málo. Většina příruček se totiž po rozbředlém úvodu o výhodách dědičnosti a přetěžování ani nezmíní o základních syntaktických pravidlech a rovnou pokračuje abecedním přehledem příkazů a funkcí. I tady bych uvítal mnohem více strukturovaný popis, kde by se příkazy hledaly podle účelu. A zpátky na koleje: kdysi jsem pracoval pro grafická studia, kde se alespoň zpočátku hojně používaly Apple Macintoshe. I tam jsem zanechal několik svých programů a nevím, zda pro Vás v neznámém, jazyce Apple Script. Ten totiž uměl právě to, po čem stále toužíte – uměl komunikovat přímo s programy, které nabízely slovníky svých objektů a metod, takže šlo jednoduše zatáhnout do nějaké úlohy několik různých programů včetně Sytému a „souborového manažeru“ jménem Finder. Jazyk byl (tedy on vlastně ještě stále je) velmi srozumitelný ve svých anglicky vypadajících názvech akcí: jen namátkou, tedy pokud si to ještě správně vzpomenu, tell application "Finder" to close every window tell application "Finder" to set the sidebar width of Finder window 1 to 240 tell application "Photoshop" to open "IMG001.JPG" set folderName to "My New Folder" set folderLocation to desktop po deklaraci můžeme rovnou požádat Finder: tell application "Finder" make new folder with properties {name:folderName, location:folderLocation} end tell Samozřejmě se k deklaraci (přiřazení) mohl specifikovat cílový typ set dnesniDatum to systemtime as text Ostatně mnohem podrobnější a kvalifikovanější informace o AppleScriptu lze nalézt na Internetu. Nevím jak dnes, kdy Mac OS převzal BSD jádro, ale do verse Mac OS 9 byl dvorní souborový systém HFS velmi blízko tomu, po čem ve své kritice vlastně voláte: základem byla b-tree databáze, kde lístky na b-tree stromu obsahovaly kompletní informaci o souboru, tedy nejen název (na koncovky si Apple nehrál), různé časové značky, dva čtyřbajtové atributy CREATOR a TYPE (což Finderu umožňovalo snadno nalézt applikaci, která soubor umí otevřít), název adresáře, ve kterém se soubor nachází (ano, ano, adresáře jako abstrakce vůbec fysicky neexistovaly a Finder je sestavil ad hoc právě z informací o souborech), x/y souřadnice umístění v okně adresáře atd. atp. Soubory vždy obsahovaly dvě součásti: „Data Fork“ a „Resource Fork“, přičemž první byla nositelkou vlastních dat se strukturou dle uznávaných konvencí (třeba TIFF, JPEG) a druhá byla přesně tím, co si neustále přejete: kontejnerem objektů, které soubor v Mac OS doprovázely: ikony souboru zobrazované na ploše v různých velikostech a barevných provedeních včetně masky, informace o jazykové mutaci souboru a dalších mnoha a mnoha užitečných drobnostech. A píši-li objektů, mám na mysli kompletní objekty včetně potřebných kusů programů. Pochopitelně i applikace měla svou „Resource Fork“, a není divu, že u většiny ta část „Data Fork“ zcela atrofovala, protože nebyla potřeba. Když jsem se začal o Apply zajímat, utratil jsem tehdy hříšných 7 tisíc za program ResEdit, který uměl strukturu resourců pěkně zobrazit a ty, které měly známou strukturu uměl i editovat. V rámci resourců byly dohledatelné i všechny grafické prvky oken a nabídky, včetně klávesových zkratek. Opravil jsem si takto velmi jednoduše rozložení klávesnice, nebo i systemovou utilitu na formátovaní disků, která původně „neuměla“ formátovat disky nezakoupené od Apple. Myslím, že to byla nejlepší investice kterou jsem kdy do Applu vložil. Zajímavé na tomto rozdělení bylo to, že když se nějaký soubor z Applu překopíroval na disketu s FATkou, uložila se na ni pouze Data Fork, takže v případě většiny programů vlastně nic. Pokud však bylo potřeba přes neApplovská media nebo třeba Internet přenést celou strukturu, bylo nutné použít archivátor (tuším StufIt), který soubor zabalil rovnou do Base64 formátu se vším všudy. Tak tohle byla jen taková mimoděčná reakce na to Vaše volání po ukládání neserialisovaných dat přímo na disk. Pohleďme nyní pravdě do tváře a přiznejme si, že souborový systém vpodstatě prorůstá z diskového prostoru až do RAM, kde je jednak přítomen ve formě různých keší a bufferů nebo i celých RAM-disků. Z ryze hardwarového hlediska jakýkoliv program v dnešní době je aktivně zpracováván pouze a výhradně v L1 cache procesorového jádra. Rychlost zpracování úlohy je naprosto principiálně ovlivněná schopností programátora (nebo compilátoru) kód i data vhodně segmentovat a šetřit jinak ztrátové blokové přenosy mezi L1/L2/L3 a RAM neřku-li pevným diskem. O významu L1 keše jsem se kdysi přesvědčil na zajímavém příkladu: Když Apple přešel od CPU řady Motorola/68000 na IBM/PowerPC, objevily se pro starší modely ještě s motorolou upgradovací kity třetích stran s CPU PowerPC, které využívaly procesorový slot v počítačích Quadra. Aby přinesly alespoň něco navíc, měly tyto rozšiřovací karty se stejným CPU jaký dal Apple do svých nových modelů (PowerPC 601) 4x větší L1 cache. Oproti Applu s 256KB a hodinové frekvenci 80MHz měl upgrade Quadry 1MB cache, i když hodinová frekvence byla jen tatáž jakou měla původní Quadra – 33MHz. Při vykreslování obrysových písem se běžně používal doplněk systému ATM=Adobe Type Manager. Pokud se na stránce použilo nějaké tvarově složitější písmo v malé velikosti, takže na stránku se vešlo mnoho znaků, originální PoweMacy se s vykreslováním A4 stránky mořily i několik minut, zatímco nominálně „slabší“ upgradované Quadry stránku vyhodily na obrazovku jak zednickou lžící. Možná se s těmito myšlenkami namáhám zbytečně, protože je Vám tato skutečnost dostatečně jasná, ale mnozí lidé, a programátoři věru nejsou výjimkou, o takových principech nic netuší a vesele přetěžují i zdánlivě bombasticky nabušené stroje. Jiný příklad z mnohem vzdálenější minulosti poodhaluje závislost efektivity softwaru na hardwarové základně: někdy kolem roku 1985 se na zámku v Bechyni konala mezinárodní konference o počítačové fysice. Kromě velmi zajímavých informací o výkonnosti architektury RISC, byla pro mne nejzajímavější přednáška o výpočetním výkonu různých hw komponent při výpočtech zobrazování částí tzv. Mandelbrotovy množiny. Pro podrobnosti o definici této množiny prosím vizte kupř. wikipaedii. Podstatou výkladu bylo to, že konkrétní výsek komplexní roviny o velikosti 320x200 bodů propočítával Intel 286 přibližně dva týdny, po doplnění systému o aritmetický koprocessor i287 se doba zkrátila na cca 22 hodin, ale při použití nominálně slabšího čtyřjádrového trnasputeru pro stejný výřez bylo hotovo za pár minut! To prosím není sci-fi, ale jen prostý výsledek optimalisace procesu s využitím koordinovaného multiprocesingu, který komplexní vzorec rozložil na postupné kroky, a každý krok prováděl jiný transputer. Tento způsob oproti současně používanému konkurenčnímu multitaskingu příp. vícevláknovému zpracování úloh, využívá stejné fígle, jako kdysi první skutečně masivně nasazená „programovatelná“ výpočetní technika, kterou postavil v Los Alamos Howard Aiken. Nejen sofistikovaný pipelining, ale předávání výsledků z výstupu jednoho výpočetního celku druhému přímo na vstup, takže pak jeden celek (jedno jak jej nazveme – jádro, SOC, transputer) může provádět tentýž výpočet (tutéž úlohu) dokola s různými přicházejícími vstupy, aniž by se zatěžoval ztrátovým vyměňováním svého programu. Je pravda, že transputery se nadále vyrábějí a tedy i používají, ale mezi programátory nejsou moc oblíbené, protože naprogramovat a vlastně i načasovat správně takové pole o 64 transputerech je celkem fuška a nevím, zda jsou při takovém doslova „kom-pilování“ objekty nějak nápomocné či vůbec použitelné. Někde jsem kdysi zahlédl srovnání různých technologií při filtrování audiosignálu pomocí FFT. Zaujalo mne, že Intely v testech zcela propadly, mezi CPU dominovaly IBM POWER (hm, ale v testech nebyly ARMy), velmi dobře se ukázaly FPGA – ty ovšem nejsou skutečnými počítači a nejde tedy o programování, ale o konfiguraci – transputerové pole však všechno ostatní strčilo do kapsy. A jsem konečně u své myšlenky: Stížnosti na zastaralá paradigmata v oblasti operačních systémů, souborových systémů a programovacích nástrojů jsou legitimní, ačkoliv poněkud necitlivé, protože současné NIXy a MSWindowsy byly koncipovány a fungovaly na strojích řádově pomalejších – paradoxem je, že přidáváním zbytných fíčur se na o několik řádů rychlejších strojích dosahuje z hlediska uživatele téměř stejných pomalostí. Trochu té hw pomalosti kdysi programátory nutilo ke snaze o optimalisaci kódu, a to zas možná formovalo jejich analytickou práci. Dnešní upachtěná snaha rozchodit kdejakou pitomost, na kterou si manažeři vzpomenou (často bez kvalitní analýzy, jen na základě marketingových blábolů), a to v co nejkratším čase – jak si žádá trh, plodí nespolehlivé „rudé obry“, které si však všichni pochvalují, „protože je lze rychle opravovat a vylepšovat“. Nejsem proti pokroku, většinu svého života jsem jej obhajoval a prosazoval, ale také jsem si všiml, že právě business má na pokrok neblahý vliv. Pod vidinou snadného zisku se dopouští i v počítačové oblasti zvěrstev, která na roky vzdálí skutečně potřebné změny v technologiích, ale i v myšlení. Pokud bych Vás rád někam nasměroval, pak k faktu, že od vzniku mikroprocessoru se do jeho architektury ještě zdaleka nepodařilo vpašovat všechny geniální fígle, které usnadňovaly a urychlovaly chod počítačů s processory klasickými (sálové počítače ještě občas fungují pod jménem superpočítače). Vlivem nekompetence i chamtivosti se v hardwaru počítačů prosadily takové padělky jako jsou právě CPU Intel, přestože byla již mnohokrát prokázána jejich nízká výkonnost oproti jiným architekturám. Ostatně co si mohu myslet o součástce, která na zpracování jedné instrukce potřebuje 30 hodinových cyklů, byť jsou to hodiny třígigahertzové. RISCový processor o frekvenci 600 MHz bude stejně výkoný nebo možná i rychlejší; a co teprve RISC na třech GHz. Ale to nejdůležitější na celkové koncepci současných CPU je naprostý nedostatek reflexe nejmodernějších programátorských potřeb. Dokud nebudou k disposici processory, nebo lépe - výpočetní systémy, které na jedné straně nebudou muset řešit různorodost periferií, protože periferie budou nuceny naplňovat nějaké definice standardů (jedno-li ISO/IEEE/RFC) a zaručit tak samy kompatibilitu se systémem - oč jednodušší pak bude kernel! - ale na druhé straně budou obsahovat základní nutnou podporu pro práci s objekty - tedy příslušné struktury „nadregistrů“, které budou použitelné přímo k vytváření objektových prototypů a budou podporovat alespoň základní operace nad objekty (replikace/instancování) tím myslím replikaci na jednu instrukci CPU ať už ji bude subsystém řešit jak dlouho bude třeba, systémy, které budou schopny jednoduchého předávání výsledků k dalšímu zpracování jinou částí (skutečné roury mezi jádry namísto těch abstraktních, které jsou realizované přes pomalou RAM nebo dokonce disk), dokud nebude jádro vedle registrů obsahovat i skutečný stack a nikoliv jen stackpointer, a dokud se systémy kromě aritmetických koprocessorů nerozšíří i o jednoduše programovatelné FSA (finite state automata) případně FPGA s nějakými prekonfiguracemi . . . Prostě do té doby je diskuse na téma OS/FS vpodstatě předčasná. Uvědomte si, kolik důležitých pojmů, na kterých funkčnost OS a programovacích jazyků stojí je stále jen abstrakcí, s obtížemi realizovanou na úrovni hw architektury a jak pomalu. Pokud zůstávají pojmy stack, pipe, fronta, hromada, asociativní paměť a podobně jen v rovině abstrakce, nedošlo v počítačové technologii k žádnému positivnímu zvratu. Voláte-li po chytrém zápisu na disk, já volám po nové architektuře samotného výpočetního stroje. Zatím se však spoléháme nadále na hrubou výpočetní sílu, jejíž limity už jsou blízko. Na závěr jen drobná ilustrace: pracoval jsem příliš dlouho pro grafiky a sazeče, abych si nevšiml, že ti nejvýkonnější, velmi málo používali myš. Naopak, využívali klávesové zkratky a často přišli s požadavkem, nějakou potřebnou doplnit. Podívejte se na vývoj nabízeného ovládání takového hodně rozšířeného „MS-Wordu“. Klasické nabídky a klávesové zkratky mizí a produktivita práce také. Kecy o tom, jak budou počítače v budoucnu ovládané hlasem, očima a myšlenkami se hodí na politická řečniště tak jako bajky o světovém míru. Až nové technologie dodají vojákům flintu bez spušťadla s ovládáním na dotykové obrazovce (a s dotazem: Opravdu chcete vystřelit?), bude na čase přenechat svět barbarům.
28.11.2019 13:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jsem již poněkud zaprášený ročník, ale mou nepopiratelnou komparativní výhodou byla překvapivě maminka, která měla v Astronomickém ústavu na starost poměrně masivní výpočty a byvši žákyní pana doc. Antonína Svobody, byla propagátorkou výpočetní techniky. Tím se stalo, že zatímco moji vrstevníci tu a tam něco zaslechli o kalkulačkách, já si mohl u mámy v práci a někdy i doma pohrát s kalkulátorem programovatelným.Zajímavé, o Antonínovi Svobodovi jsem četl, ta jeho cesta do ameriky a vývoj protiletadlových systémů mi vždy přišla jako velmi zajímavý příběh.
Ve srovnání s Vámi se nemohu pochlubit takovou řadou zářezů na pažbě, a také jsem během svých studií na MFF UK zběhnul z cesty programátorské a věnoval se profesně fysice, takže můj pohled je, jak jinak, hodně subjektivní a také, jak ochotně přiznám, v lecčems nekvalifikovaný, neboť přes veškeré vzdělání, jsem v programovaní de-facto samouk.Nevím jak to přesně vyznělo v tom článku, ale já se taky považuji převážně za samouka. Ta trocha co jsem pochytil na střední a později vysoké škole byla sice podstatná, ale stejně je to jen kapka v moři všeho co jsem se učil sám později.
V čem se však lišíme velmi podstatně, je skutečnost, že jsem díky fysice a zachycením pionýrských počátků docela dobře obeznámen s hardwarem computerů a to až po kvantové jevy v polovodičových strukturách, o nichž se obecně tuší jen tak povrchně něco o elektronech a o dírách. Tento vhled do skutečného života jedniček a nul mi umožňuje poměrně dobře odhadnout, co je ještě fysikálně možné. Takže kupříkladu zmenšování šířky kanálu pod 10nm mě naplňuje spíše skepsí než jásáním.Určitě se v tom lišíme, ale neřekl bych že zas tak podstatně. Moje střední škola byla elektronická a fyzika mě vždy hodně zajímala. Samozřejmě jsem v tom jen laik, ale řekněme že mám přehled jak to chodí od těch vysokoúrovňových jazyků, přes kompilované věci, v assembleru jsem si taky svého času něco zaprogramoval a půlka střední školy byla o stavění logických obvodů z hradel. Na vysoké škole jsem pak poměrně dlouho koumal jak postavit počítač z relátek inspirován videii Harryho Portera, který o tom později vydal pěknou prezentaci: - http://web.cecs.pdx.edu/~harry/Relay/ - http://web.cecs.pdx.edu/~harry/Relay/RelayPaper.pdf Na to taky navazovaly předměty jako návrh číslicových počítačů, kde jsme šli poměrně hluboko do hloubky a například se byli podívat kousek za hranicemi v IHP, kde mikročipy na zakázku stále vyrábějí. Samozřejmě v porovnání s někým kdo studoval fyziku neobstojím, a taky už je to skoro deset let a spousta se mi z toho z hlavy vykouřila, ale nějaké povědomí mám.
Ale vraťme se prozatím k Vaší kritice. I když přece jen na moment odbočím ještě k objektům. Víte já jsem toho poměrně hodně naprogramoval ve strojovém kódu resp. v assembleru (různých assemblerech) a nezřídka jsem i ladil ten strojový kód, aby stíhal příslušné mikrosekundy diktované sledovaným experimentem, takže nesdílím přílišné nadšení z módních manter, kterými se postupně staly „strukturované programování“ a „objektové programování“.Tomu vůbec nemám problém uvěřit, osobně jsem v assembleru dělal taky, specificky pro různá embeded zařízení, postavená většinou na 8051 / Atmelu. Taky jsem si na VŠ trochu sáhl na Tecomaty, které používají na zásobníku založený assembler trochu ve stylu forthu. Programátoři jako komunita mají obecně tendence hledat něco co se v angličtině označuje jako „silver bullet“, tedy stříbrná kulka. Obecně se tím myslí řešení všech problémů. Strukturované programování mi dává smysl, ostatně i když jsem dělal v assembleru, tak jsem do velké míry používal stejný styl dělení programu jako třeba v C. Objektové programování ve své současné podobně mi zas tak velký smysl nedává, ale to je spíš tím, že jsem viděl jeho původní podobu (smalltalk, self) a dodnes stále ještě úplně nechápu, proč a jak se to zvrhlo do současného stavu. Obě dvě techniky mi pak dávají smysl z hlediska psychologie. Řekl bych, že práce programátora ve firmě je o programování jen asi tak z 30-50%. Kód slouží jako vyjádření myšlenky nejen pro počítač, ale taky pro komunikaci myšlenky v dostatečně konkrétním stavu s dalšími lidmi. Zde má strukturované a objektové programování nesporné výhody, v podstatě je to takový seznam vzorů a používaných slovíček, které definuji sdílený kontext, na kterém můžou lidé stavět mosty vzájemné komunikace.
Na nic zřetelného natož průkazného jsem však zatím nenarazil. Pro mne se programovací jazyk stává použitelným pouze pokud je na první pohled dostatečně srozumitelný (což je samozřejmě při používání rovněž otázka hygieny psaní dobrých komentářů) a opatřený kvalitním manuálem. Těch kvalitních manuálů jsem však za svůj život potkal velmi málo. Většina příruček se totiž po rozbředlém úvodu o výhodách dědičnosti a přetěžování ani nezmíní o základních syntaktických pravidlech a rovnou pokračuje abecedním přehledem příkazů a funkcí. I tady bych uvítal mnohem více strukturovaný popis, kde by se příkazy hledaly podle účelu.Můžu obecně doporučit knihu Smalltalk-80: The Language and its Implementation od Adele Goldberg.
A zpátky na koleje: kdysi jsem pracoval pro grafická studia, kde se alespoň zpočátku hojně používaly Apple Macintoshe. I tam jsem zanechal několik svých programů a nevím, zda pro Vás v neznámém, jazyce Apple Script.Nikdy jsem v něm nedělal, ale není mi úplně neznámý. Mnohem víc mě však zaujal Telescript, který kdysi Apple vytvořil pro Newton a podobná zařízení. V něm se zrcadlí několik zajímavých myšlenek ohledně distribuovaného programování, které jsou myslím do dnešní doby z větší části nevyužity.
Tak tohle byla jen taková mimoděčná reakce na to Vaše volání po ukládání neserialisovaných dat přímo na disk. Pohleďme nyní pravdě do tváře a přiznejme si, že souborový systém vpodstatě prorůstá z diskového prostoru až do RAM, kde je jednak přítomen ve formě různých keší a bufferů nebo i celých RAM-disků. Z ryze hardwarového hlediska jakýkoliv program v dnešní době je aktivně zpracováván pouze a výhradně v L1 cache procesorového jádra. Rychlost zpracování úlohy je naprosto principiálně ovlivněná schopností programátora (nebo compilátoru) kód i data vhodně segmentovat a šetřit jinak ztrátové blokové přenosy mezi L1/L2/L3 a RAM neřku-li pevným diskem. O významu L1 keše jsem se kdysi přesvědčil na zajímavém příkladu: Když Apple přešel od CPU řady Motorola/68000 na IBM/PowerPC, objevily se pro starší modely ještě s motorolou upgradovací kity třetích stran s CPU PowerPC, které využívaly procesorový slot v počítačích Quadra. Aby přinesly alespoň něco navíc, měly tyto rozšiřovací karty se stejným CPU jaký dal Apple do svých nových modelů (PowerPC 601) 4x větší L1 cache. Oproti Applu s 256KB a hodinové frekvenci 80MHz měl upgrade Quadry 1MB cache, i když hodinová frekvence byla jen tatáž jakou měla původní Quadra – 33MHz. Možná se s těmito myšlenkami namáhám zbytečně, protože je Vám tato skutečnost dostatečně jasná, ale mnozí lidé, a programátoři věru nejsou výjimkou, o takových principech nic netuší a vesele přetěžují i zdánlivě bombasticky nabušené stroje.Ah. Osobně je mi to jasné a vím že to tak je. Na druhou stranu nebudu tvrdit, že umím programovat tak, abych nepatřil mezi prasata. Do velké míry je to dané jazykem, kde v pythonu tohle ani člověk moc nemá možnost ovlivnit.
Jiný příklad z mnohem vzdálenější minulosti poodhaluje závislost efektivity softwaru na hardwarové základně: někdy kolem roku 1985 se na zámku v Bechyni konala mezinárodní konference o počítačové fysice. Kromě velmi zajímavých informací o výkonnosti architektury RISC, byla pro mne nejzajímavější přednáška o výpočetním výkonu různých hw komponent při výpočtech zobrazování částí tzv.Mandelbrotovy množiny. Pro podrobnosti o definici této množiny prosím vizte kupř. wikipaedii. Podstatou výkladu bylo to, že konkrétní výsek komplexní roviny o velikosti 320x200 bodů propočítával Intel 286 přibližně dva týdny, po doplnění systému o aritmetický koprocessor i287 se doba zkrátila na cca 22 hodin, ale při použití nominálně slabšího čtyřjádrového trnasputeru pro stejný výřez bylo hotovo za pár minut! To prosím není sci-fi, ale jen prostý výsledek optimalisace procesu s využitím koordinovaného multiprocesingu, který komplexní vzorec rozložil na postupné kroky, a každý krok prováděl jiný transputer. Tento způsob oproti současně používanému konkurenčnímu multitaskingu příp. vícevláknovému zpracování úloh, využívá stejné fígle, jako kdysi první skutečně masivně nasazená „programovatelná“ výpočetní technika, kterou postavil v Los Alamos Howard Aiken. Nejen sofistikovaný pipelining, ale předávání výsledků z výstupujednoho výpočetního celku druhému přímona vstup, takže pak jeden celek (jedno jak jej nazveme – jádro, SOC, transputer) může provádět tentýž výpočet (tutéž úlohu) dokola s různými přicházejícími vstupy, aniž by se zatěžoval ztrátovým vyměňováním svého programu. Je pravda, že transputery se nadále vyrábějí a tedy i používají, ale mezi programátory nejsou moc oblíbené, protože naprogramovat a vlastně i načasovat správně takové pole o 64 transputerech je celkem fuška a nevím, zda jsou při takovém doslova „kom-pilování“ objekty nějak nápomocné či vůbec použitelné. Někde jsem kdysi zahlédl srovnání různých technologií při filtrování audiosignálu pomocí FFT. Zaujalo mne, že Intely v testech zcela propadly, mezi CPU dominovaly IBM POWER (hm, ale v testech nebyly ARMy), velmi dobře se ukázaly FPGA – ty ovšem nejsou skutečnými počítači a nejde tedy o programování, ale o konfiguraci – transputerové pole však všechno ostatní strčilo do kapsy.Zajímavé.
A jsem konečně u své myšlenky: Stížnosti na zastaralá paradigmata v oblasti operačních systémů, souborových systémů a programovacích nástrojů jsou legitimní, ačkoliv poněkud necitlivé, protože současné NIXy a MSWindowsy byly koncipovány a fungovaly na strojích řádově pomalejších – paradoxem je, že přidáváním zbytných fíčur se na o několik řádů rychlejších strojích dosahuje z hlediska uživatele téměř stejných pomalostí. Trochu té hw pomalosti kdysi programátory nutilo ke snaze o optimalisaci kódu, a to zas možná formovalo jejich analytickou práci. Dnešní upachtěná snaha rozchodit kdejakou pitomost, na kterou si manažeři vzpomenou (často bez kvalitní analýzy, jen na základě marketingových blábolů), a to v co nejkratším čase – jak si žádá trh, plodí nespolehlivé „rudé obry“, které si však všichni pochvalují, „protože je lze rychle opravovat a vylepšovat“.Asi souhlasím, ale vidím mnoho prostoru pro vytvoření něčeho nového, i kdyby to mělo silně těžit například z Linuxu. Například v tom článku, na který reagujete jsem nastínil, jak si představuji že by to mohlo vypadat. Ty představy jsou z velké míry dané právě tím na co narážím v praxi a tím co vidím že ostatní řeší. Seznam požadavků je jaksi „tam venku“, skoro zralý na to aby ho někdo sklidil a vytvořil produkt který ho bude uspokojovat.
Pokud bych Vás rád někam nasměroval, pak k faktu, že od vzniku mikroprocessoru se do jeho architektury ještě zdaleka nepodařilo vpašovat všechny geniální fígle, které usnadňovaly a urychlovaly chod počítačů s processory klasickými (sálové počítače ještě občas fungují pod jménem superpočítače). Vlivem nekompetence i chamtivosti se v hardwaru počítačů prosadily takové padělky jako jsou právě CPU Intel, přestože byla již mnohokrát prokázána jejich nízká výkonnost oproti jiným architekturám. Ostatně co si mohu myslet o součástce, která na zpracování jedné instrukce potřebuje 30 hodinových cyklů, byť jsou to hodiny třígigahertzové. RISCový processor o frekvenci 600 MHz bude stejně výkoný nebo možná i rychlejší; a co teprve RISC na třech GHz. Ale to nejdůležitější na celkové koncepci současných CPU je naprostý nedostatek reflexe nejmodernějších programátorských potřeb.S tím souhlasím. S opatrným optimizmem koukám na konec „honby za nanometrama“, kde poté co firmy narazí na fyzikální limity velikosti tranzistorů, jenž by snad mohla zase donutit firmy inovovat směrem k zajímavějším architekturám.
Dokud nebudou k disposici processory, nebo lépe - výpočetní systémy, které na jedné straně nebudou muset řešit různorodost periferií, protože periferie budou nuceny naplňovat nějaké definice standardů (jedno-li ISO/IEEE/RFC) a zaručit tak samy kompatibilitu se systémem - oč jednodušší pak bude kernel! - ale na druhé straně budou obsahovat základní nutnou podporu pro práci s objekty - tedy příslušné struktury „nadregistrů“, které budou použitelné přímo k vytváření objektových prototypů a budou podporovat alespoň základní operace nad objekty (replikace/instancování) tím myslím replikaci na jednu instrukci CPU ať už ji bude subsystém řešit jak dlouho bude třeba, systémy, které budou schopny jednoduchého předávání výsledků k dalšímu zpracování jinou částí (skutečné roury mezi jádry namísto těch abstraktních,které jsou realizované přes pomalou RAM nebo dokonce disk), dokud nebude jádro vedle registrů obsahovat i skutečný stack a nikoliv jen stackpointer, a dokud se systémy kromě aritmetických koprocessorů nerozšíří i o jednoduše programovatelné FSA (finite state automata) případně FPGA s nějakými prekonfiguracemi . . . Prostě do té doby je diskuse na téma OS/FS vpodstatě předčasná. Uvědomte si, kolik důležitých pojmů, na kterých funkčnost OS a programovacích jazyků stojí je stále jen abstrakcí, s obtížemi realizovanou na úrovni hw architektury a jak pomalu. Pokud zůstávají pojmy stack, pipe, fronta, hromada, asociativní paměť a podobně jen v rovině abstrakce, nedošlo v počítačové technologii k žádnému positivnímu zvratu. Voláte-li po chytrém zápisu na disk, já volám po nové architektuře samotného výpočetního stroje. Zatím se však spoléháme nadále na hrubou výpočetní sílu, jejíž limity už jsou blízko.Souhlasím plně. Pro mě je v tomhle velkou inspirací architektura počítače Alto, na kterém běžely původní Smalltalky. Ten přestože měl relativně malý výkon, tak spoustu věcí doháněl speciálním hardwarem, který například uměl akcelerovat právě to vytváření objektů.
Na závěr jen drobná ilustrace: pracoval jsem příliš dlouho pro grafiky a sazeče, abych si nevšiml, že ti nejvýkonnější, velmi málo používali myš. Naopak, využívali klávesové zkratky a často přišli s požadavkem, nějakou potřebnou doplnit. Podívejte se na vývoj nabízeného ovládání takového hodně rozšířeného „MS-Wordu“. Klasické nabídky a klávesové zkratky mizí a produktivita práce také. Kecy o tom, jak budou počítače v budoucnu ovládané hlasem, očima a myšlenkami se hodí na politická řečniště tak jako bajky o světovém míru. Až nové technologie dodají vojákům flintu bez spušťadla s ovládáním na dotykové obrazovce (a s dotazem: Opravdu chcete vystřelit?), bude na čase přenechat svět barbarům.Mhm.
18.2.2020 17:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz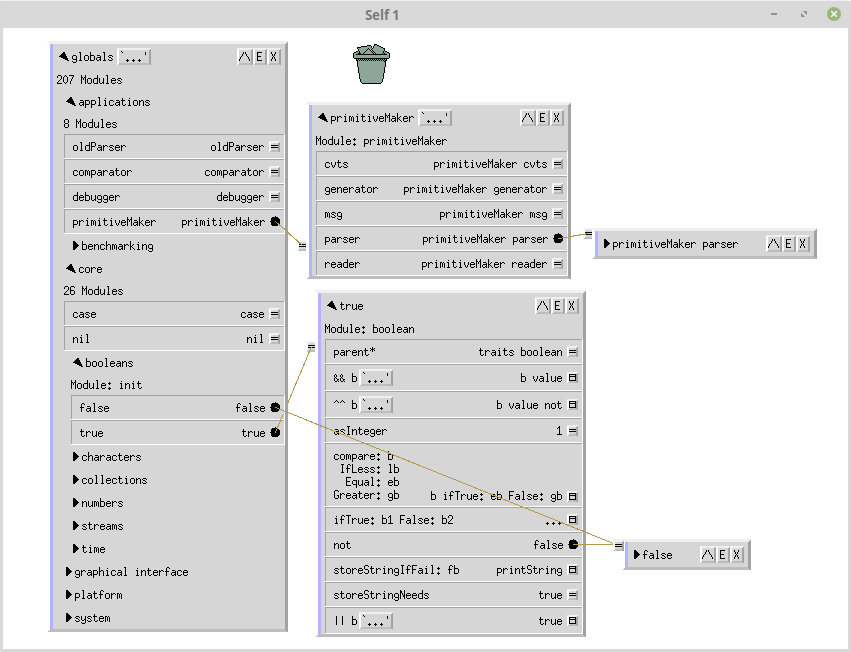{kind=link}
{kind=link}