Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
FreeCAD (Wikipedie), tj. svobodný multiplatformní parametrický 3D CAD, má nový vtipný a současně užitečný doplněk Banana For Scale (GitHub). Aktuálně umožňuje do výkresu vložit banán nebo plechovku pro porovnání a určení měřítka.
Blender Studio nedávno oznámilo plán vytvořit svůj první otevřený (open source) celovečerní film. Film by se měl jmenovat Overgrown (YouTube). Film vznikne, pokud se zajistí financování. Prvním krokem je získat 7 000 předplatitelů Blender Studia. Cena je od 11,50 eur měsíčně. Aktuálně počet předplatitelů je 5 289. Předplatné pokryje 20 % nákladů. Zbytek, 80 % nákladů, má být financován externími producenty nebo distributory.
Byl vydán Debian 13.6, tj. šestá opravná verze Debianu 13 s kódovým názvem Trixie a Debian 12.15, tj. poslední patnáctá opravná verze Debianu 12 s kódovým názvem Bookworm, k dispozici je LTS. Řešeny jsou především bezpečnostní problémy, ale také několik vážných chyb. Instalační média Debianu 13 a Debianu 12 lze samozřejmě nadále k instalaci používat. Po instalaci stačí systém aktualizovat.
V jádře Linux byla nalezena a v upstreamu již byla opravena kritická zranitelnost GhostLock aneb CVE-2026-43499. Lokálnímu uživateli umožňuje získat práva roota a také obejít kontejnerovou izolaci. Zranitelnost existovala v Linuxu 15 let, tj. od roku 2011, od Linuxu verze 2.6.39.
Evropská komise předběžně shledala, že návykový design aplikací Instagram a Facebook od americké společnosti Meta porušuje unijní nařízení o digitálních službách (DSA). Návykový design zahrnuje například takzvané nekonečné posouvání, automatické přehrávání videí, tzv. push notifikace, kdy aplikace uživatele vybízí k návratu do jejího prostředí, či vysoce personalizovaný algoritmus, který rychle pozná, co uživatele baví a snaží
… více »Byla vydána verze 1.97.0 programovacího jazyka Rust (Wikipedie). Podrobnosti v poznámkách k vydání. Vyzkoušet Rust lze například na stránce Rust by Example.
Švýcarská společnost Punkt. má nově v nabídce telefon Punkt. MC03. Telefon byl navržen ve Švýcarsku s důrazem na soukromí a digitální suverenitu a vyroben v Německu. V telefonu běží operační systém AphyOS (Apostrophy OS) založený na AOSP (Android Open Source Project) 15. Cena telefonu je 745 eur.
TypeScript (Wikipedie), tj. JavaScript rozšířený o statické typování a další atributy, byl vydán v nové verzi 7.0. Kompilátor byl kvůli výkonu přepsán z TypeScriptu do Go.
Europarlament podpořil pozměněnou verzi výjimky známé jako „chat control 1.0“ umožňující firmám skenovat soukromou komunikaci na internetu kvůli ochraně dětí před zneužitím. Pozměňovací návrhy přijaté europoslanci však počítají s tím, že z výjimky bude vyřazena šifrovaná komunikace. Výjimka přestala platit začátkem dubna poté, co se Evropský parlament a Rada EU nedokázaly shodnout na jejím prodloužení. Rada následně přijala
… více » 2.2.2019 16:13
xkucf03 | skóre: 50
| blog: xkucf03
2.2.2019 16:13
xkucf03 | skóre: 50
| blog: xkucf03
Jedna připomínka k algoritmu: pro malé soubory to funguje, ale pokud bych chtěl prohodit např. první dva řádky (nebo první a desátý) v souboru, který má milion řádků, tak musím načíst celý soubor do paměti (tam se nemusí vejít – nebo i když se vejde, tak mi to zbytečně požere moc paměti, která se dala využít jinak).
Přitom by to bylo řešitelné – načítat řádky postupně (nedávat je všechny do pole) a postupně posílat na výstup. Jen by sis předem musel udělat plán, co musíš načíst předem – např. načíst deset řádků, prohodit, vypsat, a pak už plynule vypisovat zbytek souboru. Tzn. stačí, aby se ti do paměti vešlo prvních deset řádků.
Záleží, k čemu je ten nástroj určený – pokud soubory budou dostatečně malé a RAMka dostatečně velká, tak bych to nechal, jak to je (tzn. dát přednost jednoduchosti, čitelnosti). Ale jestli je důvodem implementace studium, tak si to schválně zkus napsat tak, aby to zvládlo zpracovat třeba i ten soubor s milionem řádků a minimální paměťovou náročností (samozřejmě za předpokladu, že se nemá prohazovat třeba první a poslední řádek).
n-m musíš načíst do paměti m - n + 1 řádků. Navrhnout optimální algoritmus pro co nejvíce různých případů může být zajímavá úloha. Prvně by to asi chtělo zanalyzovat, jaké řádky se budou prohazovat (resp. jaká je mezi nimi vzdálenost) a podle toho zvolit vhodnou strategii. Pak je jednou z možností sestavit si index začátků řádků (bonusová úloha: s konstantní spotřebou RAM i pro nekonečně velké soubory; samozřejmě za cenu výkonu) a seekovat se na ně. Při streamovém zpracování by bylo nutné si nejprve vytvořit dočasný soubor.
 2.2.2019 23:18
Jendа | skóre: 78
| blog: Jenda
| JO70FB
2.2.2019 23:18
Jendа | skóre: 78
| blog: Jenda
| JO70FB
mmap je (vhodnější) alternativa k fseek, ale potřebuješ pořád ten index, jinak bys musel řádky hledat sekvenčně.
 2.2.2019 23:42
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
2.2.2019 23:42
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Aniž bych četl kontext, přijde mi, že tohle je úplně ukázková úloha na memory-mapped soubory (v Pythonu například numpy.memmap, i když osobně jsem tohle vždycky používal jenom z C, a pokud to byl Python program, tak se to dělalo v modulu připojeném přes CFFI).Tohle mě taky napadlo, ale můžeš v tom potom prohazovat ty řádky? Pokud budou různě dlouhé? Četl jsem tu něco v Jaderných novinkách o tom že linux by měl podporovat ty díry v souborech, ale nemám tušení jak to funguje v praxi.
2.2.2019 23:43
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Při streamovém zpracování by bylo nutné si nejprve vytvořit dočasný soubor.
3.2.2019 00:43
xkucf03 | skóre: 50
| blog: xkucf03
Což je podobné, jako když si to načteš do RAM – ta se může odswapovat na disk a namapovaný soubor zase může být v paměti…
Tahle úloha IMHO nemá univerzální řešení a člověk si musí vybrat jednu ze dvou možností – buď proudové zpracování a možnost transformovat dynamicky generovaná data, která nikdy v žádném souboru nebyla (takže není co mapovat) nebo pracovat na vstupu se soubory a mít k nim náhodný přístup a moci si přečíst co potřebuji, skákat na různá místa… a na výstupu může být klidně zase proud, takže tam můžu vypisovat průběžně (pokud nechci upravovat ten soubor na místě).
Což je podobné, jako když si to načteš do RAM – ta se může odswapovat na disk a namapovaný soubor zase může být v paměti…Ne, není. Když odhlédnu od toho, že 100 GB mi systém naalokovat nedovolí a swap si kvůli tomu zvětšovat (resp. zavádět, protože nemám žádný) nebudu, tak swapování prostě z principu nemůže být tak efektivní jako odkládání do souboru. (Napřed vyžereš všechnu RAM a až dojde, tak se to začně kopírovat na disk, přičemž nevím, jak si kernel ty odswapované stránky organizuje, ale nižší režii to nemůže mít ani náhodou. Mezitím trpí všechny okolní procesy, pokud jsi to tedy nespustil se správnou prioritou a nevím čím…)
Tahle úloha IMHO nemá univerzální řešení a člověk si musí vybrat jednu ze dvou možností – buď proudové zpracování a možnost transformovat dynamicky generovaná data, která nikdy v žádném souboru nebyla (takže není co mapovat) nebo pracovat na vstupu se soubory a mít k nim náhodný přístup a moci si přečíst co potřebuji, skákat na různá místaTahle úloha je hlavně k ničemu. Vzešla sice z dotazu v poradně, ale neumím si představit, jak a kde by její řešení bylo obecně uplatnitelné. Jako cvičení to ale může být docela pěkné. Přišlo by mi smysluplnější zkusit to napsat efektivněji než psát složitější Hello, world! ve dvou jazycích. Odtud můj návrh. Jinak to univerzální řešení v podstatě má: Implementuješ obě dílčí řešení, které jsi popsal (a případně další), a umožníš problémy převádět z jednoho druhu na jiný tam, kde je to výhodné.
3.2.2019 01:07
Jendа | skóre: 78
| blog: Jenda
| JO70FB
ag je o tolik rychlejší než grep -R et al.
2.2.2019 17:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jedna připomínka k algoritmu: pro malé soubory to funguje, ale pokud bych chtěl prohodit např. první dva řádky (nebo první a desátý) v souboru, který má milion řádků, tak musím načíst celý soubor do paměti (tam se nemusí vejít – nebo i když se vejde, tak mi to zbytečně požere moc paměti, která se dala využít jinak).On navíc nezpracovává soubory, ale scelé streamy. A to mu padne už na
for line in sys.stdin:
lines.append(line.rstrip())
Což mimochodem kromě toho že načítá neuvěřitelně debilním způsobem celý standardní vstup do pole navíc uřezává bílé znaky z konce řádků, což nechápu proč a pokud bude na konci mezera, nebo tabulátor, tak jí to celou sežere.
Když už ale načítat celý standardní vstup, tak spíš takhle:
lines = sys.stdin.read().splitlines()pokud tedy nechce používat
.readlines(), že na konci jsou znaky nových řádků (což vůbec nechápu proč jako vadí).
Pak taky to parsování čísel regexpama, to mi fakt připomíná ten vtip, že regexpy jsou jako buldozer, dobrý sluha, ale zlý pán. A tady jezdí buldozerem po něčem, co by šlo řešit podstatně čitelněji:
p = re.compile('(\d+)-(\d+)')
for arg in sys.argv[1:]:
m = p.match(arg)
if m:
a, b = int(m.group(1)), int(m.group(2))
což jde nahradit pomocí:
for arg in parse_args(sys.argv[1:]):
tokens = arg.split("-")
a, b = int(tokens[0]), int(tokens[1])
což teda asi automaticky nepřeskakuje špatně matchlé řádky, ale pokud to tam chceš, dá se před to dát podmínka if not all(token.isdigit() for token in tokens) and tokens != 2:, ale mluvit tady o ošetřování chyb moc nemá smysl.
Co má pak za smysl for line in lines: print(line)mi uchází. Snaží se autor snad ušetřit budget za nové řádky, nebo co? Tohle rozhodně není čitelnější. Hah, a teď mi došlo, proč odřezával ty bílé znaky z konce - asi neví, jak vypsat na standardní výstup, protože
print() tam přidává svoje \n. Řešení je jednoduché; použít sys.stdout.write(), které má mimochodem i sys.stdout.writelines();
>>> data = sys.stdin.readlines() asd bs >>> data ['asd\n', 'bs\n'] >>> sys.stdout.writelines(data) asd bs >>>
2.2.2019 17:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
if not all(token.isdigit() for token in tokens) and tokens != 2:Chtěl jsem napsat:
if not all(token.isdigit() for token in tokens) or tokens != 2: continuePřípadně to obalit
try:except: blokem.
Chtěl jsem napsat:super, jen ten regex je 10x prehlednejsi
if not all(token.isdigit() for token in tokens) or tokens != 2:
continue
Případně to obalit try:except: blokem.
 5.2.2019 16:33
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.2.2019 17:04
xkucf03 | skóre: 50
| blog: xkucf03
5.2.2019 16:33
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
5.2.2019 17:04
xkucf03 | skóre: 50
| blog: xkucf03
Obecně mixování programovacího jazyka s úplně jiným
Třeba v Perlu je to přirozená součást jazyka.
ať už je to tenhle patternmatching brainfuck
Výhodou regulárních výrazů je to, že jsou (až na drobné odlišnosti) společné pro všechna prostředí a všichni jim rozumí, takže koukneš a vidíš, co to dělá – zatímco ty příkazy nebo konstrukce konkrétního jazyka nemusíš znát z hlavy, pokud s ním běžně neděláš. Totéž SQL – to taky většina lidí zná a zorientuje se v tom, i když to uvidí uvnitř neznámého kódu. Z tohoto pohledu to přispívá čitelnosti.
Argumentem proti regulárním výrazům je výkon – řadu operací jde bez nich udělat efektivněji. Nicméně neuchyloval bych se k předčasné optimalizaci a nezbavoval se regulárních výrazů tam, kde to nepřinese žádný relevantní rozdíl ve výkonu.
Chápu tu snahu používat nativní prostředky jazyka, ale ono když proženeš text nějakou funkcí, která ti vyplivne pole řetězců a z nich si pak taháš hodnoty, tak to není jednodušší oproti regulárnímu výrazu, ze kterého si pak taháš skupiny.
nebo databázový cobol uznávám jen pokud je k tomu důvod
Předpokládám, že myslíš SQL. Ten důvod tam většinou je a dost zásadní – SQL se provádí v databázi, která má k těm datům nejblíž tzn. není potřeba je tahat do aplikace a zpracovávat třeba v tom Pythonu.
Částečně to řeší různá ORM a knihovny typu jOOQ nebo jinq, kde nemusíš psát SQL, používáš nativní prostředky svého jazyka – a to SQL se ti vygeneruje na pozadí samo.
5.2.2019 18:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Výhodou regulárních výrazů je to, že jsou (až na drobné odlišnosti) společné pro všechna prostředí a všichni jim rozumí, takže koukneš a vidíš, co to dělá – zatímco ty příkazy nebo konstrukce konkrétního jazyka nemusíš znát z hlavy, pokud s ním běžně neděláš. Totéž SQL – to taky většina lidí zná a zorientuje se v tom, i když to uvidí uvnitř neznámého kódu. Z tohoto pohledu to přispívá čitelnosti.Jak jsem psal, pokud je k tomu důvod, tak se použití regulárních výrazů nevyhýbám. Rozdělení dvou čísel pomlčkou mi ale jako důvod nepřijde. Kdybys třeba měl string, kde může být větší počet těch párů oddělených něčím jiným, tak ok, ale tady dostaneš doslova
"1-2" už z argv.
ale ono když proženeš text nějakou funkcí, která ti vyplivne pole řetězců a z nich si pak taháš hodnoty, tak to není jednodušší oproti regulárnímu výrazu, ze kterého si pak taháš skupiny.Tak to není pravda, že. Je to doslova jednodušší kód na míň řádků, je pochopitelnější co se tam děje a navíc to má větší výkon. Ta if podmínka je jen další validace, která se dá udělat navíc i podstatně jednodušeji a jinak.
Předpokládám, že myslíš SQL. Ten důvod tam většinou je a dost zásadní – SQL se provádí v databázi, která má k těm datům nejblíž tzn. není potřeba je tahat do aplikace a zpracovávat třeba v tom Pythonu.Opět bych se řídil tím, jestli je k tomu důvod, nebo ne. Když jsem dělal v uložto, tak jsem taky optimalizoval dotazy a byly tam napsané ručně v kódu, protože ORM to prostě neutáhlo a ten důvod byl jasný. Nebo když píšu něco malého nad SQLite, tak to většinou taky spíchnu jen jako string, ale pokud se tomu jde v běžném kódu vyhnout, tak si myslím že je lepší se tomu vyhnout, už jen z toho důvodu, že ORM je víc portabilní a je možné přejít napřiklad z mysql na postgre relativně bezbolestně.
Částečně to řeší různá ORM a knihovny typu jOOQ nebo jinq, kde nemusíš psát SQL, používáš nativní prostředky svého jazyka – a to SQL se ti vygeneruje na pozadí samo.Používal jsem PonyORM.
 Ale kdyz uz o tom mluvis:
Ale kdyz uz o tom mluvis:
import re
p = re.compile('(\d+)-(\d+)')
for i in range(1000000):
m = p.match("123-456")
if m:
print "a =", m.group(1), ", b =", m.group(2)
$ time python a.py > /dev/null real 0m4.021s user 0m3.727s sys 0m0.263s
for i in range(1000000):
tokens = "123-456".split("-")
if not all(token.isdigit() for token in tokens) or len(tokens) != 2: continue
print "a =", tokens[0], ", b =", tokens[1]
$ time python b.py > /dev/null real 0m4.035s user 0m3.728s sys 0m0.296s
Pokud ti v tomhle případě přijde kompilování regexpu, matchování a pak vytahování grup přehlednější, tak se asi neshodneme no.
tokens = arg.split("-")
if len(tokens) == 2 and tokens[0].isdigit() and tokens[1].isdigit():
# match
6.2.2019 17:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
- vznikle pole projedu cyklem a kazdy prvek mapuju na true/false podle toho jestli je to cislo - vysledne pole znovu projedu cyklem a zkontroluju ze mam vsude true - zkontroluju ze pole ma prave 2 prvkyTyhle 3 kroky tam mit vubec nemusis, pokud to obalis
try:except: blokem co udela continue pri chybe:
for arg in sys.argv[1:]:
try:
tokens = arg.split("-")
a, b = int(tokens[0]), int(tokens[1])
except:
continue
Slo mi o to ze kdyz nekdo prijde s tezi "regexy jsou buldozer, nabastlit si vlastni parser bude podstatne citelnejsi" tak se hodi veci uvest na pravou miru...
cituji Bystroushaaka
Pak taky to parsování čísel regexpama, to mi fakt připomíná ten vtip, že regexpy jsou jako buldozer, dobrý sluha, ale zlý pán. A tady jezdí buldozerem po něčem, co by šlo řešit podstatně čitelněji
6.2.2019 21:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Slo mi o to ze kdyz nekdo prijde s tezi "regexy jsou buldozer, nabastlit si vlastni parser bude podstatne citelnejsi" tak se hodi veci uvest na pravou miru...Vlastní parser bude skoro vždycky podstatně čitelnější, dokud nemusíš dělat stavový automat. To se ani nebavím o věcech, jako parsování emailové adresy, kde to bnf v čitelnosti vyhraje na celé čáře.
6.2.2019 21:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
tohle vypada lepe, ale zase tam chybi test jestli ty cisla jsou prave 2A je to zapotřebí? Pokud jich bude víc jak dvě, tak použije první dvě. Což teda jestli se nepletu, tak i ten regexp.
6.2.2019 17:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jestli ses chtel pochlubit ze umis pouzivat "for" a "all" tak ok, aje pro reseni tohohle konkretniho problemu je to strasliva prasarnaA muzes nejak zduvodnit proc je to prasarna? Pokud umis cist python, tak je to krasne ciste vyjadreni skoro na urovni matematiky: pro kazdy prvek plati, ze je cislem. Uznavam, ze v tomhle konkretnim pripade asi dava smysl to tam vypsat explicitne, ale pokud by tam byly uz treba tri prvky, tak by mi to prislo vyslovene blbe.
6.2.2019 21:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Prasarna je to proto ze je to slozitejsi nez by to melo byt. I kdzy jsi zvykly na ten zapis tak porad za tim musis videt jak se ty tokeny propaguji pres nekolik urovni...Nevím, jakmile se tohle naučíš používat, spolu s generátory a iterátory, tak je to prostě přirozené. Uznávám, že pro někoho kdo to běžně nepoužívá je to nepřirozené, ale to je i regexp.
Dalsi vec je ze se snazis vymyslet algoritmus ktery za tebe muze snadno udelat regex engine. A jak sam vidis tak tam opakovane delas chyby. I to je dukaz komplexity...Chyby dělám hlavně protože jsem to psal z hlavy jen do inputu tady na abclinuxu. Upřímně kdybych měl psát regexp, tak to asi dopadne mnohem hůř. Ale jinak jak jsem psal, nebráním se regexpu, pokud k tomu existuje důvod. Ten důvod u mě je například že bys musel splitnout string víc než jednou, či provádět nějaké machinace a ověřování. Specificky když chceš parsovat skupiny čísel a znaků, které jdou za sebou v nějakém pořadí a můžou se nějak opakovat, pak je regexp skutečně asi nejlepší řešení. Nadruhou stranu, jakmile ti do toho vleze třeba tak triviální věc, jako URL, tak od regexpů ruce pryč a chce to přejít na něco jiného.
Hah, a teď mi došlo, proč odřezával ty bílé znaky z konce - asi neví, jak vypsat na standardní výstup, protože print() tam přidává svoje \n.Přesně tak
O těch funkcích jsem vážně nevěděl. Tak dík.
2.2.2019 18:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
if __name__ == '__main__':. To je z toho důvodu, aby se to dalo importovat a volat samostatně. Kdybych importoval ten tvůj kód, tak se hned spustí a celé to padne.
Taky si pořid linter (pep8, pylint a pyflakes, sonarlint najednou!), všechno jsou to zdarma pluginy použitelné v editorech, kde ti budou podtrhávat a radit. Taky si zapni zobrazování bílých znaků v editoru, máš tam na konci řádků různé divné mezery (viz příloha) a v pythonu se bez toho moc nedá dělat. To umí všechny, i vim/emacs (ty lintery vim/emacs umí taky).
Importy nepiš na jeden řádek, hezky je rozepiš na víc. To má výhodu že je to jednak čitelnější, když jich tam máš víc, ale taky se dají jednotlivě zakomentovávat a vyhazovat pomocí klávesových zkratek pro mazání celého řádku, místo abys musel jít někam doprostřed řádku a mazat tam jedno slovo. A na začátek přidej shebang (#! /usr/bin/env python3) aby to bylo spustitelné.
No a taky je dobré rozdělit funkcionalitu od sebe a nedělat z toho špagety, kde na jednom místě parsuješ argumenty a zároveň provádíš hlavní algoritmus tvého kódu. Kdybych to měl po tobě v práci zrefactorovat (code review jsi teď dostal), tak by to vypadalo takhle:
#! /usr/bin/env python3
import sys
def _parse_argv(args):
for arg in args:
tokens = arg.split('-')
if len(tokens) != 2 or not all(token.isdigit() for token in tokens):
continue
yield [int(token) for token in tokens]
def switch_lines(lines, line_pairs):
for a, b in line_pairs:
lines[a], lines[b] = lines[b], lines[a]
def main(line_pairs):
lines = sys.stdin.readlines()
switch_lines(lines, line_pairs)
sys.stdout.writelines(lines)
if __name__ == '__main__':
main(_parse_argv(sys.argv[1:]))
Argumenty se parsují zvlášť, funkcionalita je zvlášť a hlavní část kódu ve funkci main je taky zvlášť. Z kódu je teď modul použitelný i v jiných programech.
Samozřejmě tohle je pořád bez toho o čem psal xkucf03, tedy toho prediktivního prohazování řádek na zároveň plánu a cacheování, jen čistě očividný refactoring toho co jsi napsal.
Zkus se zamyslet nad všemi body co jsem ti napsal a klidně se zeptej, pokud ti je něco nejasného. Cílem nebylo na tebe zamachrovat, ale udělat code review, tedy ukázat ti jak to dělat objektivně lépe.
Kolik jsem dlužen?
Ale tohle je určitě lepší kód, a kdybych psal něco většího, tak budu postupovat podobně.
Těch prázdných znaků jsem si ani nevšiml, já totiž v Pythonu odsazuji tabem a poté převádím taby na čtyři mezery, aby ten kód vypadal na abíčku stejně jako u mě, já vím, že bych mohl nastavit v IDE tab na mezery, ale zase tolik v Pythonu neprogramuju.
Na druhou stranu mi ten tvůj skript přijde na tak krátký prográmek docela roztahaný, já rád počítám řádky... A s tvými radami budu schopen ten skript v Pythonu ještě o několik řádek zkrátit, takže Python je efektivnější, než jsem myslel.
2.2.2019 19:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A s tvými radami budu schopen ten skript v Pythonu ještě o několik řádek zkrátit, takže Python je efektivnější, než jsem myslel.To je jedno z kouzel pythonu. Já i po 11 letech programování pořád objevuji jak dělat věci víc efektivněji. Třeba nedávno jsem si konečně dočetl i ty zbylé funkce (kromě contextmanager dekorátoru) v contextlibu a byl jsem docela překvapen.
2.2.2019 21:01
xkucf03 | skóre: 50
| blog: xkucf03
načítat parametry je obecně lepší pomocí argparse (to generuje i nápovědu a mám na to zastaralý builder).
Tohle zrovna řeším, byť v jiném jazyce. Ale nakonec to dělám ručně (cyklus přes argv)… Jde o to, že na vstupu je nějaký plochý seznam textových řetězců (argv) a na výstupu objekt resp. nějaká stromová struktura. Je to vlastně podobná úloha jako parsování nějakého jazyka – na vstupu máš text resp. posloupnost tokenů a na výstupu je AST.
Dokáží tohle ty nástroje, nebo dělají spíš jen nějaké jednoduché mapování na slovník nebo objekt obsahující pár seznamů?
Jde mi o to, že ty CLI parametry můžou vypadat nějak takhle:
--dělej-něco mojeÚloha1
--dělej-to-takhle xxx yyy
--použij-při-tom tohle
--dávej-při-tom-pozor-na-xyz
--dělej-něco-úplně-jiného 666 444
--dělej-něco mojeÚloha2
--dělej-to-takhle abc def
--přejmenuj-to-na zzz
--tady-máš-nějaký-globální-parametr jehoNázev jehoHodnota
--tady-máš-nějaký-globální-parametr jinýParametr jinýHodnota
--debug
--kontext kkk
Přičemž v argv je to nasypané v ploché struktuře, jeden token po druhém, ale já z toho potřebuji postavit nějaký strom, jehož struktura je výše naznačená tím odsazením. U těch „úloh“ by se při parsování mělo zachovat pořadí. U globálních parametrů a voleb jako --debug na pořadí nezáleží.
Přijde mi, že podobné knihovny mají přínos v případě, že chci třeba -abc interpretovat stejně jako -a -b -c nebo -ac -b. Nebo --dlouhý-název jako -d. Nebo třeba --xxx=zzz jako --xxx zzz. S tím mi to asi pomůže, ale co v těch případech, kdy je tam nějaký kontext, záleží na pořadí parametrů a má se z toho vyrobit stromová struktura?
2.2.2019 23:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
3.2.2019 00:19
xkucf03 | skóre: 50
| blog: xkucf03
Od jaké složitosti bys do toho šel? Ten můj kód kolem toho má nějakých čtyřicet řádků. To mi přijde snesitelnější napsat to ručně (a později to číst) než se dělat s gramatikou. Byť s nějakým PEG parserem by to bylo dost jednoduché, ale zase to znamená zatahovat do programu závislost na nějaké knihovně. A stejně to moc kódu neušetří, protože i ten parser musíš napojit na nějaké akce (které třeba zkonstruují ten objekt).
Možná by bylo zajímavé nějaké deklarativní mapování mezi CLI parametry a objekty – něco jako je JPA (ORM) nebo JAXB… ale psát se mi s moc zrovna nechce.
3.2.2019 00:32
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Od jaké složitosti bys do toho šel?Nevím, jestli je složitost ta správná metrika. U mě by záleželo jak moc bych to chtěl, s tím že jsem většinou ochotný redefinovat jak moc něco chci, když vidím že to jednoduše nejde. Tzn. je možné, že bych prostě změnil požadavky na něco jiného. Taky bych to porovnával metrikou užitek/námaha. Tohle má očividně docela velkou námahu, ale vůbec nejsem schopný posoudit užitek. Další věc, kterou je třeba zohlednit je podívat se po netu jestli už něco takového neexistuje. V pythonu je skoro vždycky případ, že ano, takže bych to zkusil založit na tom, či to forknout. V nedávné době jsem řešil například vytahování spec file z src RPM balíčků a ukázalo se, že pythonní rpmfile sice existuje, ale padá na RPM balíčcích, takže jsem nakonec použil a přebalil její neoficiální fork. To celé se mi pořád vyplatilo víc než volat externě příkaz
rpm.
Stejně tak bych se asi podíval, jestli neexistuje něco co třeba aspoň částečně řeší tvůj problém. Pokud ne, zvážil bych vytvoření opensource verze, kde bych tím třeba v budoucnosti pomohl někomu jinému. Kdybych to řešil, tak určitě PEG.
3.2.2019 01:18
xkucf03 | skóre: 50
| blog: xkucf03
Nevím, jestli je složitost ta správná metrika.
Od složitosti se odvíjí pracnost prvotní implementace a taky pracnost následné údržby. Další věc je, že když k tomu přijde někdo jiný, tak FOR cyklus a IF/SWITCH bude chápat určitě, ale co když nebude zkušený ohledně gramatik a různých nástrojů/knihoven pro práci s nimi?
Tím nechci říct, že by se to mělo přizpůsobovat těm méně schopným/zkušeným, ale chce to najít nějakou rozumnou míru. Taky už jsem viděl software, který byl navržený „sofistikovaně“ někým „geniálním“, ale postupně to šlo všechno do háje, protože do rozvoje se moc neinvestovalo, takže hodně věcí bylo už přežitých, z původního pěkného návrhu zbyla spíš už jen ta složitost a to vedlo k prodražení vývoje (i triviální úpravy zabraly dost času), v důsledku toho si zákazníci objednávali méně úprav, což vedlo k tomu, že vývojáři se věnovali jiným projektům a jejich znalost tohoto produktu se vytrácela. Když se jednou za čas objevil nějaký požadavek na implementaci něčeho nového, tak trvalo dlouho, než se do toho někdo zase dostal a vzpomněl si jak to funguje (nebo to spíš znovu objevil, protože s tím softwarem nikdy nedělal), takže to zase bylo drahé, což zákazníky demotivovalo požadovat v budoucnu další změny… je to začarovaný kruh – kdyby se dělaly změny často, tak budou mít vývojáři větší praxi a s tím sofistikovaným řešením se lépe sžijí, takže budou efektivnější a implementace změn bude levnější, takže zákazníci si jich budou moci dovolit víc. Pokud se tahle spirála rozjede tím špatným směrem, tak to odrovná i původně dobrý software. To už tedy hodně odbíhám od tématu, ale ono je dost rozdíl, dělat software, na kterém pracuje na plno několik vývojářů a dělat software, ve kterém se má jednou za půl roku udělat nějaká menší změna. A když si zvolíš technologie a postupy pro ten první scénář, tak to v tom druhém nemusí vůbec dobře fungovat.
Pak jsou tedy ještě jiná kritéria jako správnost/spolehlivost a výkon, ale ta složitost mi tady přijde nejzásadnější. Správnost ověříš testy a měla by být zaručena vždy. A na výkonu tady až tak nesejde, protože CLI parametry se parsují jen jednou (a pokud jsou složité, tak asi i program bude dělat něco celkem složitého a jeho běh bude řádově delší než doba parsování parametrů).
Tohle má očividně docela velkou námahu, ale vůbec nejsem schopný posoudit užitek. … Stejně tak bych se asi podíval, jestli neexistuje něco co třeba aspoň částečně řeší tvůj problém. Pokud ne, zvážil bych vytvoření opensource verze, kde bych tím třeba v budoucnosti pomohl někomu jinému. Kdybych to řešil, tak určitě PEG.
Ta jiná řešení ale taky nemají nulovou pracnost. Asi bych si to měl zkusit reimplementovat pomocí PEG parseru, abych to mohl porovnat, ale jen tak od boku mi přijde, že by to jednodušší nebylo, protože ten kód jsem měl napsaný za chvilku a moc to nebolelo. Ono asi i to hledání existujících řešení by zabralo víc času.
Příklad, kde jsem to použil minule: CLIParser.h. Ta současná úloha je jen o málo složitější a implementace zabrala méně času než tahle diskuse… Tu první verzi jsem nějak namastil s tím, že uvidím jak to půjde a při druhém nebo třetím použití to nějak zobecním a učešu. Nechtělo se mi vymýšlet nějakou abstrakci nebo sofistikované řešení předem – ve chvíli, kdy ještě přesně nevím, co od toho budu chtít a jak s tím budu pracovat.
Vlastně si mi tenhle způsob docela líbí – nejdřív nastřelit první verzi a pak ji postupně opracovávat. Ale jde to aplikovat v případě, kdy se můžeš vrátit zpět a předělat to. Což jde typicky u vlastních projektů. Zatímco když vyvíjíš pro někoho jiného, kdo to platí nebo dokonce řídí vývoj, tak tam je tendence už do toho nesahat, jakmile to nějak funguje (jednak ze strachu, aby se to nerozbilo, a jednak kvůli snižování nákladů, protože za krásný kód nikdo platit nechce).
3.2.2019 01:33
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tím nechci říct, že by se to mělo přizpůsobovat těm méně schopným/zkušeným, ale chce to najít nějakou rozumnou míru. Taky už jsem viděl software, který byl navržený „sofistikovaně“ někým „geniálním“, ale postupně to šlo všechno do háje, protože do rozvoje se moc neinvestovalo, takže hodně věcí bylo už přežitých, z původního pěkného návrhu zbyla spíš už jen ta složitost a to vedlo k prodražení vývoje (i triviální úpravy zabraly dost času), v důsledku toho si zákazníci objednávali méně úprav, což vedlo k tomu, že vývojáři se věnovali jiným projektům a jejich znalost tohoto produktu se vytrácela. Když se jednou za čas objevil nějaký požadavek na implementaci něčeho nového, tak trvalo dlouho, než se do toho někdo zase dostal a vzpomněl si jak to funguje (nebo to spíš znovu objevil, protože s tím softwarem nikdy nedělal), takže to zase bylo drahé, což zákazníky demotivovalo požadovat v budoucnu další změny… je to začarovaný kruh – kdyby se dělaly změny často, tak budou mít vývojáři větší praxi a s tím sofistikovaným řešením se lépe sžijí, takže budou efektivnější a implementace změn bude levnější, takže zákazníci si jich budou moci dovolit víc. Pokud se tahle spirála rozjede tím špatným směrem, tak to odrovná i původně dobrý software. To už tedy hodně odbíhám od tématu, ale ono je dost rozdíl, dělat software, na kterém pracuje na plno několik vývojářů a dělat software, ve kterém se má jednou za půl roku udělat nějaká menší změna. A když si zvolíš technologie a postupy pro ten první scénář, tak to v tom druhém nemusí vůbec dobře fungovat.
Ok, s tím souhlasím.Ta jiná řešení ale taky nemají nulovou pracnost. Asi bych si to měl zkusit reimplementovat pomocí PEG parseru, abych to mohl porovnat, ale jen tak od boku mi přijde, že by to jednodušší nebylo, protože ten kód jsem měl napsaný za chvilku a moc to nebolelo. Ono asi i to hledání existujících řešení by zabralo víc času.Pokud to už někdo vyřešil, tak to může mít třeba jen 20% pracnost.
Vlastně si mi tenhle způsob docela líbí – nejdřív nastřelit první verzi a pak ji postupně opracovávat. Ale jde to aplikovat v případě, kdy se můžeš vrátit zpět a předělat to. Což jde typicky u vlastních projektů. Zatímco když vyvíjíš pro někoho jiného, kdo to platí nebo dokonce řídí vývoj, tak tam je tendence už do toho nesahat, jakmile to nějak funguje (jednak ze strachu, aby se to nerozbilo, a jednak kvůli snižování nákladů, protože za krásný kód nikdo platit nechce).Co se mě týče, tak já pracoval vždycky v hodně agilních týmech, kde se bralo jako samozřejmost, že software není produkt, ale proces. Samozřejmě je to dané volbou mojí práce (backend), ale obecně myslím že to je asi nejpraktičtější způsob jak dosáhnout toho co chceš a kontinuálně to zlepšovat.
asi neví, jak vypsat na standardní výstup, protože print() tam přidává svojeNebo nastavit volitelný argument\n. Řešení je jednoduché; použítsys.stdout.write(), které má mimochodem isys.stdout.writelines()
end funkce print na prázdný řetězec.
 2.2.2019 18:55
wamba | skóre: 38
| blog: wamba
2.2.2019 18:55
wamba | skóre: 38
| blog: wamba
@l = (); push(@l, $_) while <STDIN>;jednoduše
my @l = <STDIN>;Nasledující
($l[$1], $l[$2]) = ($l[$2], $l[$1])lze upravit na
@l[$1,$2] = @l[$2,$1]Konečně pole můžeš přímo vytisknout
print @l
... a na zacatek use strict; use warnings;
perl -e 'print reverse <>' soubor...
Funguje to tak že operátor <> v seznamovém kontextu načte všechno do seznamu, reverse to otočí, a print to vypíše...
3.2.2019 01:26
xkucf03 | skóre: 50
| blog: xkucf03
Asi by si to chtělo přečíst víc než jen nadpis :-)
Ten program nemá obracet pořadí všech řádků, ale prohazovat libovolné dvojice řádků, které byly zadány jako parametry příkazu.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz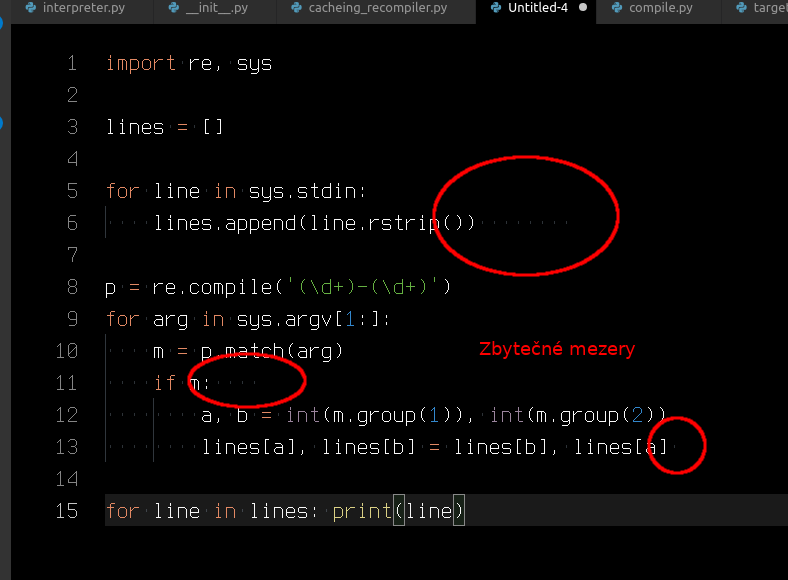{kind=link}