Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více » 28.12.2019 20:38
xkucf03 | skóre: 50
| blog: xkucf03
28.12.2019 20:38
xkucf03 | skóre: 50
| blog: xkucf03
Je to asi jako kdyby sis stěžoval, že silniční kolo není silniční, protože se s ním dá jezdit i po poli.
Nebo taky někdy v mceditu upravuji binární soubory (a kupodivu to i funguje). Budeš kvůli tomu tvrdit, že mcedit není textový editor?
A jakej je v linuxu rozdil mezi textovym a binarnim souborem?Nebo taky někdy v
mceditu upravuji binární soubory (a kupodivu to i funguje). Budeš kvůli tomu tvrdit, žemceditnení textový editor?
30.12.2019 09:54
xkucf03 | skóre: 50
| blog: xkucf03
Z hlediska OS nebo souborového systému v tom rozdíl není. Ty soubory se liší obsahem – textový soubor by měl obsahovat pouze platné posloupnosti bajtů v daném kódování (např. UTF-8). Textový editor běžně předpokládá, že v něm budeš editovat textové soubory, takže pokud v něm otevřeš binární soubor s náhodnými bajty, výsledkem může být chyba (editor odmítne soubor otevřít nebo uložit) nebo ztráta či poškození dat. Ale někdy se textovým editorem podaří upravit i binární soubor, aniž by k poškození došlo (povede se ti přepsat jen ty bajty, které jsi přepsat chtěl).
Nebo taky někdy v mceditu upravuji binární soubory (a kupodivu to i funguje). Budeš kvůli tomu tvrdit, že mcedit není textový editor?On editor musi byt jen textovy? man mcedit: mcedit - Internal file editor of GNU Midnight Commander.
Je to asi jako kdyby sis stěžoval, že silniční kolo není silniční, protože se s ním dá jezdit i po poli.Ono silnicni kolo z definice musi jezdit jen po silnici? Mne porad nejde do hlavy, proc se v tom projektu za kazdou cenu ohanis temi relacemi, kdyz to relace nejsou a ani nijak nevyuzivas jejich vlastnosti.
30.12.2019 09:48
xkucf03 | skóre: 50
| blog: xkucf03
Obe ty prirovnani kulhaji. … On editor musi byt jen textovy? … Ono silnicni kolo z definice musi jezdit jen po silnici?
Kolo primárně určené pro jízdu po silnici se nazývá silniční, přestože s ním někdo může jezdit i mimo silnici.
Editor určený primárně k úpravám textu se nazývá textový, přestože s ním někdo může editovat i binární soubory.
Formát nebo nástroj primárně určený k práci s relačními daty se nazývá relační, přestože ho někdo může použít i pro nerelační data.
Je to asi jako kdyby sis stěžoval, že silniční kolo není silniční, protože se s ním dá jezdit i po poli.Kdyz budes mluvit o silnicim kole a budes tim myslet libovolne kolo (protoze prece vsechno jezdi po silnici), tak ti (v lepsim pripade) lidi nebudou spravne rozumet, (v horsim) te budou mit za ignoranta, co to nerozumi. Vsimni si, ze silnici kolo je specialni pripad (obecneho) kola, stejne jako na relaci lze nahlizet jako na specialni pripad (obecne) tabulky.
28.12.2019 23:12
xkucf03 | skóre: 50
| blog: xkucf03
V blogu o nich píši poprvé (nepřímo se toho týkaly i zápisky z 9. 6. 2018 a 21. 7. 2017). A zpráviček o tom za rok vyšlo šest, což je v průměru jedna za dva měsíce. Je to moc?
Klidně pritlač. Na blogu, kde Golis sere jeden nečitelný zápisek o hovne za druhým, má každý rozumný anglický nebo český zápisek cenu zlata.
V anketě chybí Python
29.12.2019 09:42
xkucf03 | skóre: 50
| blog: xkucf03
Dal jsem tam to, co je reálně použitelné. Modul relpipe-tr-python sice existuje, ale je hodně nezralý. Je potřeba vymyslet, jak by se tam měl ten výraz zapisovat a jak mapovat proměnné.
K tomu zápisu výrazu: v AWK je to takto:
--relation "policy" \ --where 'policy == "allow" && user != "root"'
v SQL:
--relation "policy" \ "SELECT * FROM policy WHERE policy = 'allow' AND user <> 'root'"
a v Guile:
--relation policy \ --where '(and (string= $policy "allow") (not (string= $user "root")) )'
Kromě toho lze dělat i transformace (volba --for-each). Chci to předělat, aby to v Pythonu bylo podobně, jako v těch ostatních jazycích.
 29.12.2019 11:08
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
29.12.2019 11:08
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 29.12.2019 12:39
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
29.12.2019 12:39
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Jaký jazyk je vám nejbližší pro jednoduché filtrování?Z nabízených možností jen SQL a to hlavně pokud jsou potřeba joiny, groupy a agregační funkce; pokud se jedná o případ, kde by nad jednou tabulkou byl jen jednoduchý logický výraz (WHERE user == 'pepa' AND event='login') tak bych SQL ani nepoužil a filtroval si to rovnou pomocí prostředků daného jazyka (bud naivně jako if neco, nebo pomocí map, filter nástrojů).
29.12.2019 14:42
xkucf03 | skóre: 50
| blog: xkucf03
Chápu, že cílem příkladu bylo ukázat modulárnost toho filtrovacího nástroje, na druhou stranu kdyby ten filter se o to filtrování postaral zcela ve vlastní režii (například systém predikátů / testů jak má find), tak by si na awk nikdo ani nevzpomněl.
Zrovna na filtrování XML je ideální XQuery, což je vlastně takové SQL pro stromové struktury (a nakonec to jde použít i pro ne-XML data a ne-XML výstupy). Případně by šlo to filtrování udělat už na úrovni XPath dotazů v rámci toho relpipe-in-xmltable.
Nicméně u těch relačních rour je pointa v tom, že se ty kroky (vstup, transformace, výstup) rozdělí a můžeš je libovolně skládat a řetězit. A pak používáš jazyk, který ti je nejbližší (AWK, SQL, Scheme, regulární výrazy…) bez ohledu na to, odkud ta data přišla. Zároveň pořád zůstáváš v shellu a pracuješ s proudem bajtů, který můžeš kdykoli nasměrovat do souboru nebo poslat po síti a jinde/jindy to odtamtud zase načíst.
Co se týče efektivity, dalo by se to optimalizovat tak, že se na tu rouru nebudeš dívat jako na kód v Bashi, ale jako na nějakou vlastní gramatiku, která je jeho podmnožinou, a celé to pak buď interpretovat v rámci jednoho procesu nebo dokonce zkompilovat do jedné binárky. Dalo by se tam hezky využít GraalVM a mít tam líné vyhodnocování, díky kterému by se nepočítala/nenačítala data, se kterými se později už nepracuje (zatímco v té současné implementaci s klasickými rourami jednotlivé kroky neví, co následuje po nich a je potřeba načíst všechna data, i když se pak třeba v dalším kroku zahodí). Ale to je poměrně vzdálená budoucnost – nejdřív je potřeba dotáhnout tu specifikaci a vydat v1.0.
A pokud se mi nechce se pachtit s vlastními pravidly, tak to třeba hodím do sqlite a udělám nad tím potřebný select
To v relpipe-tr-sql1 můžeš udělat taky – jsou tam volby --file a --file-keep a data ti pak zůstanou ve standardním .sqlite souboru nebo se odtamtud načtou. Smysl to může mít kvůli těm vstupním a výstupním filtrům pro různé formáty, které už jsou hotové a nemusíš je psát, a kvůli parametrizovaným dotazům, díky kterým lze bezpečně předat data zvenku a nehrozí SQL injection.
V příští verzi v0.15 to ještě nebude, ale ve v0.16 chystám podporu libovolných RDBMS, ne jen SQLite.
Z nabízených možností jen SQL a to hlavně pokud jsou potřeba joiny, groupy a agregační funkce; pokud se jedná o případ, kde by nad jednou tabulkou byl jen jednoduchý logický výraz (WHERE user == 'pepa' AND event='login') tak bych SQL ani nepoužil a filtroval si to rovnou pomocí prostředků daného jazyka (bud naivně jako if neco, nebo pomocí map, filter nástrojů).
Mám to podobně, SQL je mi hodně blízké, nebo na ta stromová data se mi líbí XQuery. Samozřejmě, že lze psát i if, map atd. v libovolném jazyce, to je normální programování, ale často se mi nic programovat nechce, chci jen ad-hoc něco vyřešit, a pak se mi líbí, když to můžu udělat na jednom řádku v shellu, mám tam bash completion a z terminálového okna a Bashe se vlastně stává IDE, mám tam napovídání a můžu to ladit tím, že si data v určitém kroku nasměruji do souboru nebo tam rouru přeruším a dám tam relpipe-out-tabular a podívám se, co tam je za data. Dá se to distribuovat i na víc počítačů a část té roury přes SSH pouštět jinde. Což tedy není nic revolučního, je to klasický unixový shell se vším, na co jsme zvyklí, jen s drobným vylepšením, kterým je ten datový formát umožňující spolehlivě předávat strukturovaná data nebo i více sad různých dat v jednom proudu. Ostatně jedna z hlavních myšlenek je nevymýšlet nic moc nového, napsat minimum kódu a jen poskládat dohromady ty osvědčené fungující věci.
Mimochodem, předcházel tomu prototyp SQL-API (a taky trochu alt2xml) z roku 2014 – v těch prezentacích jsem vysvětloval tu motivaci za tím (i když nevím, jestli je to z těch slajdů bez přednášky úplně pochopitelné). Ty myšlenky by se měly postupně objevit v implementaci Relačních rour (např. pohled na systémové procesy, uživatele, disky atd. formou relací, nad kterými lze pak provádět SQL dotazy, nebo AWK, Scheme, Python, dle vkusu každého… zatím je implementovaný jen pohled na fstab/mtab jako ukázka). A zároveň to musí zůstat minimalistické a modulární (ty moduly mají běžně nižší stovky řádků, což je ve srovnání s jinými projekty nic – a to je tam ještě dost prostoru pro refaktoring a čištění, takže v budoucnu by ta komplexita měla ještě trochu klesnout). Taky je tam nějaká konvergence s SQL-DK… a už dneska můžeš přes SQL-DK vytahat data z libovolné DB a poslat je do relační roury. Hodí se to např. pro offline/lokální dotazy, kdy si přeliješ nějakou podmnožinu dat třeba ze vzdáleného PostgreSQL do lokální SQLite databáze, a pak si s těmi daty hraješ, aniž bys potřeboval server, ale máš stále k dispozici SQL (a navíc i jiné dotazovací/transformační jazyky).
[1] existuje i symlink/režim relpipe-in-sql, který má na vstupu SQL skript s CREATE TABLE, INSERT… – takže jde psát SELECTy nad DDL/DML skriptem: cat skript.sql | relpipe-in-sql …
29.12.2019 15:34
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
29.12.2019 16:39
xkucf03 | skóre: 50
| blog: xkucf03
Plánuješ k tomu udělat i persistentní storage
Ne, viz:
What Relational pipes are not?
…
Database system, DBMS – we focus on the stream processing rather than data storage. Although sometimes it makes sense to redirect data to a file and continue with the processing later.
Je to v první řadě datový formát pro předávání strukturovaných dat (relací) ve formě proudu bajtů. Kdo ten proud bude generovat a kdo ho bude číst, to už je na tobě. Ano, jsou k tomu i nástroje, ale primární je ten formát. Takže svým způsobem ano – v centru jsou data a až kolem nich vznikají nějaké nástroje. Ale tato data neleží na jedné hromadě, nýbrž tečou odněkud někam.
Persistenci si uděláš tak, jak potřebuješ – můžeš to jednoduše přesměrovat do souboru (ten ale není nijak indexovaný), nebo skrze relpipe-tr-sql uložit do .sqlite souboru, ten už indexovaný bude, nebo to můžeš (v přespříští verzi) poslat třeba do PostgreSQL databáze. Nebo to proženeš skrz XML/Recfile/CSV/ODS nebo jiný filtr, který to převede na textový formát, a budeš to verzovat v Mercurialu, Gitu atd. a můžeš si pak hezky porovnávat, co se v kterých verzích změnilo a jaká je historie jednotlivých záznamů (což by třeba u toho SQLite nešlo a musel by sis historii implementovat sám v rámci SQL) nebo to jednoduše distribuovat posíti pomocí push/pull příkazů příslušného DVCS.
Pokud je pro tebe centrální bod relační databáze, tak ti Relační roury můžou posloužit jako vstupně/výstupní filtr pro různé formáty případně jako řádkový SQL klient. Pak je ale spousta lidí, kteří relační databáze (včetně takové SQLite) považují za příliš komplexní software a snaží se mu vyhýbat – a pro ně zase dává smysl si ta data ukládat třeba v některém z těch textových formátů. Někdo zase nemá rád XML – tak ho nemusí používat, prostě ten XML modul bude ignorovat, nebude ho ani stahovat a použije nějaké jiné moduly. Někdo zase nesnáší polskou notaci, tak místo Guile modulu použije AWK. Každý si z toho může vzít to, co mu vyhovuje – a zároveň můžou mezi sebou komunikovat společným jazykem (datovým formátem).
29.12.2019 18:32
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Pokud je pro tebe centrální bod relační databázeTo ani ne, pro mě je centrální bod libovolné úložiště splňující určitá kritéria. Používal jsem hromadu jednoduchých knihoven, viz ty BerkleyDB, trivial db apod. Snadno použitelné key-value storage, ještě před tím, než to bylo cool a hype. To, že se dlouhodobě ukazuje, že PostgreSQL je pro mě nejlepší univerzální úložiště, ještě neznamená, že nutně potřebuju relační databázi. Vlastnosti vycházející z relační algebry nejsou pro mě až tak důležité, jako třeba ACID (zejména teda atomicita a persistence). PostgreSQL předběhl v rychlosti třeba i dokumentovou MongoDB, což je pikantní, protože tyto db vznikaly právě proto, že SQL je "pomalé a k ničemu". Nakonec je PostgreSQL i jednou s nejrychlejších nosql db. Ale to jsem odbočil. Pro mě jsou zkrátka primární data a až potom k nim vymýšlím funkce. Data se snažím rozdělovat tak, aby šla jednoduše nezávisle na sobě zpracovat. Ty máš primární přenosný datový formát a k tomu proudové funkce. Jasně, obojí je možné i když asi na různá použití. Jen mě přišlo jako dobrý nápad k těm proudům poskytovat i storage. Ale to tam máš / budeš mít, ale jinak a modulárně. Jasně, proč ne.
 29.12.2019 18:53
Josef Kufner | skóre: 70
29.12.2019 18:53
Josef Kufner | skóre: 70
Vlastnosti vycházející z relační algebry nejsou pro mě až tak důležité, jako třeba ACID (zejména teda atomicita a persistence)Kdyz uz rypu do xkucf, tak ACID opravdu nevychazi z vlastnosti relacni algebry. Jsou to ortogonalni (silne zadouci) koncepty, napr. jsou KV-uloziste, ktere (ne)jsou ACID, a jsou RDBMS, ktere (ne)jsou ACID.
20.6.2020 17:26
xkucf03 | skóre: 50
| blog: xkucf03
Od verze v0.16 jde konečně s relačními rourami používat nejen SQLite, ale libovolnou relační databázi, takže lze napojit i přímo ten PostgreSQL nebo třeba MySQL.
(to jen pro doplnění, před tím půlrokem to ještě nešlo)
Já ti furt nevím. Na jednu stranu je super, co jsi ukázal v tom skriptu, že lze v každém kroku použit rozmanité množství možností (tři filtry, 6 výstupů) bez jakékoliv změny jinde, na druhou stranu nějak pořád nevidím ten správný "sweet spot", kde by to mělo uplatnění. Všechny ty příklady mi zatím přijdou dost umělé a šly by vyřešit mnohem jednodušeji jinak.+1 Tady je to napraseno v Py:
#!/usr/bin/python3
import sys
import xml.etree.ElementTree as ET
tree = ET.parse(sys.stdin)
pols = [pol for pol in tree.getroot().iter('policy') if pol.get('user') != 'root']
rules = [{
'name': pol.attrib.get('user', '[{}]'.format(pol.attrib.get('context'))),
'send_destination': rule.attrib.get('send_destination'),
'send_interface': rule.attrib.get('send_interface'),
} for pol in pols for rule in pol.iter('allow')]
for rule in rules:
print('{name:<20} {send_destination} {send_interface}'.format(**rule))
a výsledek je tabulka, která se blbě zobrazuje na webu (protože fonty)...Tak výsledek si můžeš hodit do čeho chceš. Já v Pythonu používám Tabulate. S konverzí na web jsem neměl problém. Používám
aha, který umí vzít výstup na terminál i včetně barev a udělat z toho html.
30.12.2019 16:19
xkucf03 | skóre: 50
| blog: xkucf03
A jsi schopný ten Python kód napsat z hlavy a bez dokumentace? Protože ty Relační roury z hlavy nebo maximálně s bash completion psát jde.
Mimochodem, ten tvůj skript se nečte zrovna nejlíp, když některé části je potřeba číst od konce (přemýšlím, kde se bere proměnná rule a pak koukám, že někde za tím je for pol in pols for rule in … a jinde je zase klasický for cyklus, kde deklarace proměnných předchází jejich použití).
A znovu připomínám, že cílem není až tak nástroj, jako spíš datový formát, který půjde používat napříč různými nástroji a jazyky a propojí je dohromady. Jinak je celkem nesporné, že když se člověk omezí na jeden programovací jazyk, dá se vymyslet i něco elegantnějšího. Klidně by to mohl být framework v Javě1, kde budeš nějak šikovně řetězit metody, používat lambdy atd.
je to výřečné
To je schválně. Viz Use --long-options. Psaní ti ušetří bash completion a při čtení ti to pomůže, protože celé slovo ti řekne víc než nějaká kryptická jednopísmenková zkratka.
je na to potřeba nainstalovat desítky balíčků
Důležitější metrika mi přijde počet řádků kódu. V podstatě všechny podobné projekty mají řádově vyšší komplexitu a navíc nejsou modulární, takže si z nich nemůžeš vybrat jen to, co tě zajímá, a musíš to vzít jako celek i se všemi závislostmi.
výsledek je tabulka, která se blbě zobrazuje na webu (protože fonty)...
Nemáš to spíš nějaké rozbité u sebe? Koukal jsem na to teď ve čtyřech prohlížečích a ve všech se to zobrazuje správně. Viz příloha.
Nicméně výstup relpipe-out-tabular je určený primárně pro terminál (taky je to obarvené pomocí ANSI sekvencí). Jasně, dá se vložit (tím se ty ANSI sekvence oříznou) do e-mailu, na web, nebo kamkoli, kde lze použít neproporcionální písmo. Ale zrovna na web by se hodila víc HTML tabulka – tzn. použít relpipe-out-xml a prohnat to triviální XSLT šablonou, která ti to nastyluje přesně, jak potřebuješ.
Přitom ten nápad filtrovat data SQL-like dotazováním v zásadě není špatná.
Taky si myslím. Ale pro někoho je (jakékoli) SQL (nebo srovnatelná technologie) přehnaně komplexní a někdy i takové SQLite je příliš těžkotonážní. Jindy zase potřebuješ pracovat s XML, relačními databázemi atd. A ten společný formát je způsob, jak tyhle světy s diametrálně odlišnou mírou komplexity propojit.
Generovat data v tomhle formátu je triviální, tudíž to můžeš dělat i v programu, do kterého si nic komplexního zatahovat nechceš. Ale konzumovat tato data už pak může kdokoli, jakýmkoli nástrojem – někdo si je může filtrovat jen pomocí regulárních výrazů, někdo pomocí SQL, někdo v Guile nebo AWKu… to ale toho, kdo ta data generuje, nemusí zajímat a nijak ho to neomezuje. Případně můžeš generovat CSV, XML nebo Recfile – to se do té relační roury dá taky dobře zapojit. Spoustě programům bohužel dodnes chybí výstup ve strojově čitelném formátu. A spousta programů řeší vlastním kódem, jak „hezky“ naformátovat data v konsoli. Přitom by bylo daleko lepší na výstup poslat data ve strojově čitelném formátu a vizualizaci nechat už na někom jiném – prostě klasické: dělat jednu věc a dělat ji pořádně. Před lety jsem např. narazil na chybu v inotify-tools v generování CSV, které tam někdo nasmolil v Céčku. Přitom by stačilo, kdyby ten nástroj posílal na výstup hodnoty oddělené nulovým bajtem – a ty by sis to načetl a zpracovat třeba ve for cyklu v Bashi nebo nějakým jiným nástrojem.
Proč to ale raději nenapsat jako LINQ-like rozšíření do nějakého zavedeného ekosystému jako třeba ten Py nebo JS?
Takových nástrojů v různých jazycích existuje už dost, ne? Kromě toho, že normálně programuji, mám hodně rád i unixové roury a myšlenku psaní jednoduchých skriptů ve kterých pospojuješ různé nástroje dohromady. A v podstatě jediná věc, která mi tam chybí a která mne štve, je absence standardního formátu pro popis strukturovaných dat. Hrozně dlouho se omílalo, jak je bezva, že jsou to textové proudy a předstíralo se, že pomocí nich lze předávat data, aniž by formát byl nějak specifikovaný… ale to je omyl nebo z nouze ctnost. Funguje to jen u triviálních případů a to víceméně náhodou. Pro spolehlivější fungování potřebuješ aspoň CSV (RFC 4180), ve kterém se ti aspoň hodnoty nebudou náhodně slívat a rozpadat ve chvíli, kdy se v nich objeví nějaký „nečekaný“ znak. Ale pořád je to málo, protože s CSV přeneseš v jednom proudu jen jednu relaci (či tabulku) a chybí ti tam záhlaví (nerozlišíš ho od prvního řádku hodnot) a datové typy… Taky ta averze k binárním formátům je historický omyl vycházející z negativních emocí a dávné neblahé zkušenosti s nějakými proprietárními formáty. Bohužel si spousta lidí vypěstovala asociaci binární-proprietární – což jsou ale ve skutečnosti ortogonální kategorie.
Ta absence strukturovaných formátů/rozhraní se řešila i pod Bystroušákovými blogy o objektovém OS. Objektový přístup by se mi taky líbil, ale je to výrazně složitější na implementaci. Oproti tomu ty relace jsou jednodušší, omezenější a dají se implementovat snadno jen drobným vylepšením stávajících OS a programů (resp. OS ani shelly kvůli tomu ani není potřeba upravovat, použijí se tak, jak jsou, a stačí rozšířit jednotlivé programy tak, aby uměly generovat a číst strukturovaná data).
[1] i když tam už něco na ten způsob existuje – Apache Camel
A jsi schopný ten Python kód napsat z hlavy a bez dokumentace? Protože ty Relační roury z hlavy nebo maximálně s bash completion psát jde.Úplně bez dokumentace nejsem schopný psát ani jedno. A pokud ti jde o napovídání, na to je IDE.
A v podstatě jediná věc, která mi tam chybí a která mne štve, je absence standardního formátu pro popis strukturovaných dat.Důvod, proč takový formát neexistuje je velmi jednoduchý - viz xkcd #927.
Ale pro někoho je (jakékoli) SQL (nebo srovnatelná technologie) přehnaně komplexní a někdy i takové SQLite je příliš těžkotonážní. Jindy zase potřebuješ pracovat s XML, relačními databázemi atd. A ten společný formát je způsob, jak tyhle světy s diametrálně odlišnou mírou komplexity propojit.Tomu moc nerozumim, vzhledem k tomu, že ani XML ani SQL na ten formát moc nepasuje... Třeba u toho XML musíš, jestli tomu dobře rozumim, ručně nadefinovat transformaci XML na tabulky...
Objektový přístup by se mi taky líbil, ale je to výrazně složitější na implementaci.Nerozumim použití pojmu 'objektový přístup' v kontextu serializačního formátu, leda bys chtěl serializovat s daty i kód.
Nemáš to spíš nějaké rozbité u sebe? Koukal jsem na to teď ve čtyřech prohlížečích a ve všech se to zobrazuje správně. Viz příloha.Je to rozbitý v Chromiu, nevim proč, ale vzpomínám si, že to tu psal i někdo jinej než já...
30.12.2019 18:56
xkucf03 | skóre: 50
| blog: xkucf03
Je to rozbitý v Chromiu
Pak tedy nechápu, proč píšeš:
výsledek je tabulka, která se blbě zobrazuje na webu (protože fonty)...
Používám tam standardní Box-drawing character z Unicodu a jestli se v nějaké kombinaci prohlížeče/písma zobrazují špatně, tak by to chtělo nahlásit spíš u toho prohlížeče nebo u distribuce, než si stěžovat tady (navíc stylem, kdy to prezentuješ jako chybu těch Relačních rour).
Je to rozbitý v Chromiu, nevim proč, ale vzpomínám si, že to tu psal i někdo jinej než já...psal
31.12.2019 00:01
xkucf03 | skóre: 50
| blog: xkucf03
Jaké máš v tom Chromiu nastavené písmo? Já jsem si teď schválně pustil Chromium s čistým profilem:
chromium-browser --user-data-dir=xxxx
což zjevně zafungovalo, protože nevidím záložky a další svoje nastavení. A ty tabulky se mi zobrazují v pořádku. Když kouknu do nastavení, tak tam je:
Písmo s pevnou šířkou: Monospace
Písmo s pevnou šířkou: MonospaceTo je jen obecný font selektor, z toho se moc nedozvíš. Když chceš vědět, jakej font je reálně v tom použitej, tak je potřeba otevřít danej html node v devtools a podívat se do Computed styles úplně dolů, kde jsou vypsaný použitý fonty. Když z toho pre tagu vyhodim ty tabulky, tak mi to píše Droid Sans Mono. Když je tam vrátim, tak k němu přibude ještě Liberation Serif. Usuzuju z toho, že problém je v tom, že Droid Sans Mono je default monospace font, ale neobsahuje některý ty box drawing znaky, a tak ten engine doplní znaky z jinýho fontu, kterej není monospace nebo má jinej rozměr.
31.12.2019 01:22
xkucf03 | skóre: 50
| blog: xkucf03
U mě to vypadá takhle. Nicméně vzhledem k tomu, že ti to zlobí i na Ábíčku a asi i kdekoli jinde (?), tak s tím těžko něco udělám a přijde mi to jako chyba Chromia nebo jeho konfigurace.
a přijde mi to jako chyba Chromia nebo jeho konfigurace.Není to chyba Chromia, je to chyba toho konkrétního fontu. Když si nastavim DejaVu Sans Mono, tak je to v pořádku. Ale ve chvíli, kdy ten font ten znak nemá, jako třeba ten Droid Sans Mono, tak to Chromium lépe vyřešit prostě nemůže - i kdyby chytřeji našlo třeba jinej monospace font, ze kterýho by vzalo ty chybějící znaky, tak to obecně nepomůže, protože jinej monospace font může mít jinou šířku znaku, a tudíž by to stejně bylo rozbitý. To prostě nemá dobrý řešení. S tou tabulkou zkrátka spoléháš na to, že použitý font ty znaky má, což obecně bohužel nemusí vždy platit...
31.12.2019 11:43
xkucf03 | skóre: 50
| blog: xkucf03
Není to chyba Chromia, je to chyba toho konkrétního fontu.
A kdo rozhoduje o tom, jaké písmo Chromium použije? Distribuce? Desktopové prostředí? Chromium? Podle mého je chyba použít jako výchozí písmo takové, které tyto základní znaky neobsahuje. Hlavně, že jsou všude samé pošahané obskurní emoji, ale klasické rámečky, které se používaly už v počítačovém pravěku, nebudou?
je to chyba toho konkrétního fontu.
Že někdo vytvoří písmo, ve kterém takové znaky chybí – budiž. Ale chyba podle mého je, když někdo takové písmo nastaví jako výchozí.
To prostě nemá dobrý řešení. S tou tabulkou zkrátka spoléháš na to, že použitý font ty znaky má, což obecně bohužel nemusí vždy platit...
Ano. A když píši s diakritikou, tak čekám, že čtenář bude mít taky nastavené písmo, které ty české znaky obsahuje. To bychom taky mohli psát všechno v ASCII, pro jistotu. Ale protože máme rok 2019 (2020) a Box-drawing characters jsou globálně používané (není to nějaké lokální specifikum, jako třeba české háčky a čárky), tak mi přijde normální se jim nevyhýbat.
Na vlastních webech můžu přibalit .woff písmo, u kterého budu mít vyzkoušené, že tam ty znaky jsou. Ale tohle moc rád nemám – dávám přednost tomu, když autor webu jen řekne, co má být neproporcionálním nebo jiným písmem… a konkrétní font si nastaví uživatel dle svých potřeb a vkusu. Chápu, že je to v rozporu s moderním pojetím webu, kde je snaha, aby web vypadal na všech počítačů stejně a grafik to měl vše pod kontrolou. Ale mně se líbí spíš ten klasický přístup, kdy web má primárně obsah, zatímco o formě (spolu)rozhodne uživatel a jeho prohlížeč.
ale klasické rámečky, které se používaly už v počítačovém pravěkuTyhle rámečky se ale nepoužívaly už v počítačovém pravěku. Způsob, jakým terminál kreslí rámečky, jsem ti tady už posledně psal. S unicode box-drawing znakama to nemá vůbec nic společného. Jestli relpipes tohle kreslí do terminálu, tak to je docela rarita.
Ale chyba podle mého je, když někdo takové písmo nastaví jako výchozí.vs
a konkrétní font si nastaví uživatel dle svých potřeb a vkusuOk, takže uživatel si může nastavit písmo jaké chce, ale musí to spávné, které obsahuje ty znaky, které potřebuješ... Já nevim, odkud se u mě vzalo to nastavení toho písma jako výchozího, možná jsem si to nastavil sám někdy v minulosti, protože se mi líbilo. Fakt si to nepamatuju. Zatím jsem se na webu kromě relational pipes s použitím box-drawing znaků nesetkal.
31.12.2019 14:31
xkucf03 | skóre: 50
| blog: xkucf03
Způsob, jakým terminál kreslí rámečky, jsem ti tady už posledně psal.
Vím, že jsi to psal. Ale když se podívám na výstup třeba mc (což je asi nejpoužívanější aplikace tohoto typu) pomocí hd, tee nebo strace, tak tam žádnou magii (že by mc říkal terminálu, odkud kam má kreslit přímku) nevidím – najdu tam znaky jako e2 94 80, což je BOX DRAWINGS LIGHT HORIZONTAL' (U+2500) ─ a tytéž bajty generuji i v tom relpipe-out-tabular. Viz příloha a strace -ttf -o mc.strace -s 4096 -xx mc. Ty bajty se normálně zapisují na FD 1.
Ok, takže uživatel si může nastavit písmo jaké chce, ale musí to spávné, které obsahuje ty znaky, které potřebuješ...
V době kdy se běžně do Unicodu a písem cpou různé skládané emoji znaky typu růžový poník s duhovým pérem a zeleným kloboukem na hlavě, tak bych čekal, že tak základní věc jako textové rámečky tam budou taky. Ale možná toho chci moc :-)
31.12.2019 14:35
xkucf03 | skóre: 50
| blog: xkucf03
31.12.2019 15:45
Josef Kufner | skóre: 70
Vím, že jsi to psal. Ale když se podívám na výstup třebaMáš pravdu,mc(což je asi nejpoužívanější aplikace tohoto typu) pomocíhd,teenebostrace, tak tam žádnou magii (že bymcříkal terminálu, odkud kam má kreslit přímku) nevidím – najdu tam znaky jakoe2 94 80, což je BOX DRAWINGS LIGHT HORIZONTAL' (U+2500)
mc používá Unicode. Ale třeba weechat to dělá tím tradičním způsobem. (Můžeš si to zkusit tak, že když v Konsole nastavíš non-Unicode kódování, tak v mc se to rozbije, zatímco ve weechatu ne.)
Ono v terminálu ten Unicode až tak nevadí, protože emulátor to buď umí interpretovat a vykreslit po svém (konsole, iirc), nebo to minimálně nevadí, protože tam je vždy dodržena ta mřížka.
V době kdy se běžně do Unicodu a písem cpou různé skládané emoji znaky typu růžový poník s duhovým pérem a zeleným kloboukem na hlavě, tak bych čekal, že tak základní věc jako textové rámečky tam budou taky. Ale možná toho chci mocNo však emojis mi taky často nefungujou.
31.12.2019 23:23
xkucf03 | skóre: 50
| blog: xkucf03
Pravda. Když spustím:
LANG=cs_CZ.ISO-8859-2 strace -ttf -o mc.strace -s 4096 -xx mc
tak to rozbije háčky a čárky, ale rámečky jsou v pořádku. A v logu už ty Unicode rámečky, které tam byly, nejsou.
"\e(0", "\e)0", "\e*0" nebo "\e+0" ...
30.12.2019 18:54
Josef Kufner | skóre: 70
Taky ta averze k binárním formátům je historický omyl …Kdepak. Je to nedostatkem nástrojů a omezenými zdroji prakticky všude – bavíme se o době, kdy editor ed byl špičková technologie a kabelový přenos spočíval v roli děrného pásku či balíku disket odneseným v kabele. Na debugovaní textového protokolu stačí komunikaci sypat na terminál či na klávesnici ručně naťukat. Nemusíš vyvíjet ladicí nástroje, nemusíš je distribuovat, nezabírají místo. Například HTTP server nebo POP3 server oťukáš velmi snadno telnetem a hned víš, co se kde rozbilo. FTP se dokonce po telnetu dá reálně používat (i když bych to asi dobrovolně nedělal). Také se záznam takové komunikace dobře popisuje a vysvětluje v papírové knize. Teprve s rozvojem všech nástrojů a zvýšením výpočetního výkonu nad úroveň kalkulačky se celkem nedávno přišlo na to, že binární věci mohou být také docela použitelné.
30.12.2019 16:22
xkucf03 | skóre: 50
| blog: xkucf03
Všechny ty příklady mi zatím přijdou dost umělé a šly by vyřešit mnohem jednodušeji jinak.
Já sám to používám docela dost, ale často to jsou různé interní věci, které (ještě) nechci zveřejňovat nebo je to hodně specifické, co by vytržené z kontextu jako příklad nebylo moc pochopitelné. Jinak ale souhlasím a snažím se vymýšlet praktičtější příklady.
Teď zrovna to používám tak, že mám CSV soubor a v něm si vytvářím nějaká data. Momentálně je zadávám v LibreOffice Calc, protože je to nejpohodlnější, ale tím, že je to obyčejný textový soubor v jednoduchém formátu, tak nejsem závislý na žádném komplexním softwaru, jako je kancelářský balík, a vím, že kdykoli můžu pokračovat v práci v Emacsu, mceditu nebo čemkoli jiném. A tenhle CSV soubor si čtu pomocí relpipe-in-csv a pak z něj můžu něco generovat, spouštět pro každý řádek nějaký shellový příkaz, mít k tomu nějaké testy/kontroly pro zajištění konzistence, filtrovat to, řadit, kreslit diagram v GraphVizu nebo grafy v Gnuplotu atd. Jde taky o to, že na začátku často nevím, co všechno s těmi daty budu dělat a jak robustní to chtít mít – takhle se dá začíst s málem, jedním CSV souborem, a buď to u něj zůstane, nebo postupně přidám další věci kolem toho, jak je potřeba.
Tzn. může to sloužit i pro různé osobní agendy nebo jako pomocný nástroj při tvorbě něčeho dalšího.
30.12.2019 16:57
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
30.12.2019 17:49
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
relpipe-in-xmltable \
--relation 'policy' \
--records '/busconfig/policy/allow|/busconfig/policy/deny' \
--attribute 'policy' string 'name()' \
--attribute 'user' string '../@user'
...
\
Toto je proste hrozné jak celé XML
Ja som programoval niečo podobné, ale s tým že si to vyťahalo všetky tagy a atribúty samo (proste jeden príkaz) a potom na to môžeš nasadiť hocijaký GNU nástroj.
Čo sa týka Heronovej kritiky ("sweet spot"), tak má pravdu. Ale chápem ťa, už par krát som robil prezentáciu nejakých projektov a vždy z toho vyliezlo niečo čomu chýbal ťah na bránu. Proste všetko dobré a chýba tomu aby ľudia vstali zo stoličiek a tlieskali.
Good luck.
30.12.2019 23:50
xkucf03 | skóre: 50
| blog: xkucf03
Toto je proste hrozné jak celé XML
A jak bys jinak řešil převod stromu na relace? Tohle je ještě dost přívětivé – jedním XPath výrazem vybereš záznamy a dalšími XPath dotazy vybereš atributy. Tohle nelze namapovat nějak automaticky – některé atributy (relační) hledáš v elementech, některé v atributech (XML), některé někde hlouběji v potomcích, jiné zase v nadřazených uzlech. Ostatně totéž se používá v databázích a i se to i stejně jmenuje.
Ja som programoval niečo podobné, ale s tým že si to vyťahalo všetky tagy a atribúty samo (proste jeden príkaz) a potom na to môžeš nasadiť hocijaký GNU nástroj.
Jasně, jde to celé nasypat do jednoho seznamu1 obsahujícího klíče a hodnoty. Jenže z toho si pak záznamy splňující určitou podmínku jen tak negrepneš, protože ten záznam je zapsaný na více řádcích. Šlo by to nějak v AWKu nebo Perlu, kde bys pracoval nad těmi více řádky, ale rozhodně by to nebylo jednodušší než tohle.
A pak je samozřejmě možnost se na nějaké relace vykašlat a pracovat s tou původní stromovou strukturou. V případě XML je to často nejlepší možnost – napíšeš jeden XQuery FLWOR výraz a máš hotovo.
Čo sa týka Heronovej kritiky ("sweet spot"), tak má pravdu. Ale chápem ťa, už par krát som robil prezentáciu nejakých projektov a vždy z toho vyliezlo niečo čomu chýbal ťah na bránu. Proste všetko dobré a chýba tomu aby ľudia vstali zo stoličiek a tlieskali.
Největší problém je, že to přichází s asi dvaceti- nebo třicetiletým zpožděním. Ale podle mého to má smysl i dnes. A před těmi třiceti lety jsem fakt nebyl schopný nic takového napsat :-) ani před dvaceti. Přitom podobné myšlenky se v průběhu těch let opakovaně objevovaly.2 Akorát to nikdo nedotáhl do široce použitelného stavu. Tak uvidíme, jestli se to povede mně.
[1] záměrně nepíši mapa, protože záleží na pořadích a to se v mapách většinou ztrácí
[2] a je zajímavé, jak těžké je to v hlubinách internetu najít – samozřejmě jsem si na začátku dělal rešerši existujících řešení, ale hodně jsem jich našel až v průběhu práce a víceméně náhodou
31.12.2019 10:05
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Přitom podobné myšlenky se v průběhu těch let opakovaně objevovaly.Což vůbec neznamená, že jsou správné. Naopak, pokud se běžná praxe bez nich obešla, tak to znamená, že jejich potřeba je dost nízká až mizivá. Jako admin jsem zažil mnoho situací, kdy někdo přišel s nějakým nástrojem (velmi pěkně zpracovaným) a přesvědčoval nás, že to nutně potřebujeme a vyřeší to všechny naše problémy. Pokud už se to ze zvědavosti nasadilo, tak to vydrželo tak den a druhej to šlo pryč a za 14 dnů už si na to nikdo ani nevzpomněl. Úplně nejhůř bylo ve chvílích, kdy byl šéf o jejich prospěšnosti marketingem přesvědčen natolik, že se to nasadilo trvale. A ten problém není v těch nástrojích. Já nemám pochybnost o jejich kvalitě (no, i když...). Problém je v tom, že se totálně míjí s běžnou praxí a s běžnými potřebami těch adminů. A krásně je to vidět na pořadech typu DragonsDen. Lidé bez dlouhé praxe v daném oboru většinou přijdou s výrobkem možná hezky zpracovaným, ale totálně mimo. Když si půjčím jiný tvůj komentář:
Ty myšlenky by se měly postupně objevit v implementaci Relačních rour (např. pohled na systémové procesy, uživatele, disky atd. formou relací, nad kterými lze pak provádět SQL dotazy, nebo AWK, Scheme, Python, dle vkusu každého… zatím je implementovaný jen pohled na fstab/mtab jako ukázka).Já jsem nikdy nepotřeboval žádný "relační" pohled na tato data. Na běžném systému adminovi stačí
ps aux, cat /etc/fstab, mount, koukne a vidí. A pokud je některých položek větší než malé množství (třeba těch uživatelů), tak už dneska na to existují řešení (třeba ldap). Ale stejně se v 99% případů použije standardní id.
31.12.2019 11:24
xkucf03 | skóre: 50
| blog: xkucf03
Já jsem nikdy nepotřeboval žádný "relační" pohled na tato data. Na běžném systému adminovi stačí ps aux
A jak v těch procesech vyhledáváš? Běžně se používá:
ps aux | grep …
ale to ti najde i spoustu věcí, které nechceš, včetně procesu toho grepu, kterým právě hledáš. Takže tu máme trik s regulárním výrazem:
ps aux | grep [j]ava
čímž se ten proces grepu odfiltruje, ale stále tam máš všechny procesy, u kterých se kdekoli, třeba v parametrech nebo ve jménu uživatele vyskytuje slovo java. A zrovna jeden z mých uživatelských účtů má v názvu java.
Pak si můžeš vzít na pomoc AWK:
ps aux | awk '($11 ~ /java$/)'
ale tam si zase musíš pamatovat pozice jednotlivých sloupců.
A pokud se v názvu (nebo jiném sloupci, který prohledáváš) vyskytuje mezera, tak se ti to celé rozpadne, vyhledáváš jen v části před mezerou a následující „sloupce“ se posunou, přečíslují. Ten systém v tobě vlastně vzbuzuje nějaké naděje, že to je jednoduché a spolehlivé, ale když to začneš reálně používat, tak narážíš na další a další případy, kdy to nefunguje a už to není tak skvělé a jednoduché, jak to vypadalo na začátku.
Přijde mi, že kvůli těmto „drobným nedokonalostem“ spousta lidí utíká od unixu ke klasickému programování. Podle mého je to škoda a ten potenciál unixových systémů bych rád využíval a odstranil některé jeho chyby. Nebo se můžeme na celý unix, příkazy, roury a virtuální souborové systémy poskytující různé informace vykašlat a mít jen nějaké objektové či funkcionální API, které se bude volat třeba z toho Pythonu nebo jiného programovacího jazyka.
Potom v procps-ng existuje volba -C, kterou lze vyhledávat podle příkazu. Ale třeba ve FreeBSD volba -C znamená „Change the way the CPU percentage is calculated…“. A i když máme v systému zrovna ps s volbou -C, která hledá, tak to znamená, učit se pro každý příkaz jeho specifickou syntaxi pro filtrování. To je taky v rozporu s doporučením, že by jeden program měl dělat jednu věc a měl by ji dělat dobře. Tam, kde je dat málo a není potřeba nějak extra optimalizovat, je mi daleko bližší přístup, kdy se to oddělí: 1) příkaz, který získává/generuje data a 2) univerzální filtrovací příkaz – u kterého se člověk jednou naučí jeho syntaxi a může pak hledat v libovolných datech.
cat /etc/fstab, mount, koukne a vidí
Příkaz mount nebo cat /etc/mtab mi na první pohled moc neřekne – ty řádky splývají dohromady a nedokáži očima/hlavou snadno parsovat jednotlivé hodnoty oddělené mezerami. Ale když si dám:
cat /etc/mtab | relpipe-in-fstab | relpipe-out-tabular
tak v tom mnohem lépe najdu, co potřebuji, většinou to vidím na první pohled a už to nemusím filtrovat žádným nástrojem.
Totéž platí pro ten /etc/fstab. Většinou to tedy ručně zarovnávám do sloupců pod sebe, aby se v tom dalo aspoň trochu vyznat, ale to je ruční práce navíc – a někdy je ten soubor generovaný nebo ho psal někdo jiný, takže je to nepřehledné. Pak můžu udělat:
ssh example.com cat /etc/fstab | relpipe-in-fstab | relpipe-out-tabular
a zase to vidím mnohem přehledněji. V cyklu se to dá udělat pro více serverů a pak výsledky nějak agregovat… Samozřejmě netvrdím, že čtení fstabu je nějak zábavná nebo významná činnost – je to jen příklad a ukázka toho principu – a chtěl jsem začít s něčím co nejjednodušším.
Ještě co se týče toho vykašlání se na unix: celkem souhlasím s Bystroušákem – taky by se mi líbil objektový OS. Ale je to implementačně výrazně složitější, než unix vylepšený o datový formát, kterým se dají rourami předávat relační data.
31.12.2019 12:17
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
A jak v těch procesech vyhledáváš?Přesně jak jsi popsal. Pokud je výpis
ps, top, htop příliš komplikovaný (což většinou není), tak | grep zafunguje na drtivou většinu zbylých případů. Ty jednotky zbývajících případů se vyřeší jinak.
Navíc s nástupem kontejnerů je použití filtrů potřeba ještě méně. Ve FreeBSD mám všechno v jailech a když dám v jailu ps aux, tak se to pohodlně vejde na jednu obrazovku a jsou tam jen služby, které jsou v tom jailu, tedy typicky jedna až dvě:
[root@backup ~]# ps aux USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND root 61929 0.1 0.0 13208 3904 0 SJ 11:36 0:00.01 /usr/local/bin/bash -i root 34211 0.0 0.0 11356 1676 - IsJ 4Dec19 0:04.80 /usr/sbin/syslogd -s backuppc 34271 0.0 0.0 28552 11428 - IJ 4Dec19 0:17.34 /usr/local/bin/perl /usr/local/bin/BackupPC -d root 34277 0.0 0.0 16808 2916 - SsJ 4Dec19 0:50.89 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34280 0.0 0.0 16832 4140 - IJ 4Dec19 0:00.01 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34282 0.0 0.0 16832 3988 - IJ 4Dec19 0:00.01 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34284 0.0 0.0 16756 2804 - IJ 4Dec19 0:00.00 /usr/local/sbin/httpd -DNOHTTPACCEPT root 34288 0.0 0.0 11272 1452 - SsJ 4Dec19 0:09.13 /usr/sbin/cron -s backuppc 34319 0.0 0.0 16808 2928 - IJ 4Dec19 0:00.00 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34323 0.0 0.0 16860 4064 - IJ 4Dec19 0:00.00 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34324 0.0 0.0 16808 2928 - IJ 4Dec19 0:00.00 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34326 0.0 0.0 16860 4192 - IJ 4Dec19 0:00.01 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34327 0.0 0.0 16860 4172 - IJ 4Dec19 0:00.01 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34328 0.0 0.0 16808 2928 - IJ 4Dec19 0:00.00 /usr/local/sbin/httpd -DNOHTTPACCEPT backuppc 34329 0.0 0.0 16808 2928 - IJ 4Dec19 0:00.00 /usr/local/sbin/httpd -DNOHTTPACCEPT root 61930 0.0 0.0 11772 2764 0 R+J 11:36 0:00.00 ps auxNa první pohled:
apache a backuppc + omáčka jako cron a syslog, konec.
Výpis procesů na hostitelském systému ps aux -J 0, tedy bez jailů, obsahuje vlastně jen kernel thready a ssh (+ syslog a cron). Na to nepotřebuju filter.
Ten systém v tobě vlastně vzbuzuje nějaké naděje, že to je jednoduché a spolehlivé, ale když to začneš reálně používat, tak narážíš na další a další případy, kdy to nefunguje a už to není tak skvělé a jednoduché, jak to vypadalo na začátku.Já to reálně používám už asi 20let a fakt to není problém. A díky jiným postupům je tlak na to filtrování ještě mnohem menší. Rozdělení do virtuálek, kontejnerů apod. logické rozdělení, které přináší i mnoho dalších jiných výhod a které zjednodušuje i některé věci původně možná složité nebo nepřehledné
Nebo se můžeme na celý unix, příkazy, roury a virtuální souborové systémy poskytující různé informace vykašlatTo je podle mě chybný závěr. Unixový přístup je skvělý, ale
bash není jediný způsob, jak jej docílit. Dělat malé jednoduché a snadno komunikující programy lze i jinak, než nutně jen pipe v shellu. Třeba ten můj příklad s workery na síti, které používají centrální frontu a centrální úložiště. Každý worker si udělá jen tu svou část a výsledek uloží do úložiště a klidně může do fronty přidat další krok a následně se ukončí. Malé prográmky, které si udělají to svoje a komunikují mezi sebou. Není to jediný koncept, funguje to na data, která chci zpracovávat (tedy nezávislé datové balíky) ale je to unixové stejně jako pipe v shellu. Které pochopitelně nezatracuju a využívám také, ale nejsou pro mě svatý grál.
Totéž platí pro ten /etc/fstab. Většinou to tedy ručně zarovnávám do sloupců pod sebe, aby se v tom dalo aspoň trochu vyznat, ale to je ruční práce navíc – a někdy je ten soubor generovaný nebo ho psal někdo jiný, takže je to nepřehledné.To tam máš stovky položek vygenerovaných z různých zdrojů? Takto vypadá fstab na mém soukromém největším serveru na FreeBSD:
# Device Mountpoint FStype Options Dump Pass# /dev/ada0p2 / ufs rw 1 1 fdesc /dev/fd fdescfs rw 0 0 proc /proc procfs rw 0 0 /dev/ufs/ports-system /usr/ports ufs rw 0 2 /dev/ufs/ports-svn /usr/ports-svn ufs rw 0 2Jsou tam tři device a dva virtuální fs. Kdybych neměl oddělený port tree na samostatných oddílech, je tam reálně jeden, první, řádek. Data jsou na ZFS a ten se do fstabu vůbec nezapisuje. Na linuxu je to ještě jednodušší. Jeden rootfs na btrfs. Tečka. Díky tomu, že btrfs subvolume se v user space tváří stejně jako adresáře, tak není potřeba mít ve fstabu žádné další extra položky. Díky těmto technologiím fstab prakticky postupně ztratil smysl. Kdyby kernel uměl zjistit, který btrfs fs (pokud je jich tam víc) má být rootfs, tak může být fstab prázdný. Pokud je tam jen jeden, tak je default subvolume jen jedna (A freshly created filesystem is also a subvolume, called top-level, internally has an id 5. This subvolume cannot be removed or replaced by another subvolume. This is also the subvolume that will be mounted by default, unless the default subvolume has been changed (see subcommand set-default).) a je to rootfs.
a zase to vidím mnohem přehledněji. V cyklu se to dá udělat pro více serverů a pak výsledky nějak agregovat… Samozřejmě netvrdím, že čtení fstabu je nějak zábavná nebo významná činnost – je to jen příklad a ukázka toho principu – a chtěl jsem začít s něčím co nejjednodušším.Ano, to je super příklad, a za celou praxi jsem to potřeboval asi tak 3x, kdy jsem měl za úkol to zpracovat pro někoho jiného, kdo si myslel, že ta data nutně potřebuje a nemůže bez nich žít. Pochopitelně nepotřeboval a ani se v nich nevyznal. Protože kdyby se v nich vyznal, tak by současně i věděl, jak si je zjistit sám. Napsat
for přes seznam serverů a ssh $server command umí každý levou zadní.
31.12.2019 13:21
Josef Kufner | skóre: 70
31.12.2019 13:52
Josef Kufner | skóre: 70
31.12.2019 14:31
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
ale pokud by se roury trochu překopalyAle proč by se měly překopávat? Roury umožňují přenést libovolný "protokol" a kdo chce (třeba Franta) si může kolem toho postavit vlastní utility, které budou komunikovat domluveným protokolem přes roury (a to klidně i přes net cat nebo rourou do nebo z ssh).
Tedy o kousek vedle je ještě menší minimum, ale cesta vede přes kopec práce.Otázkou je, jestli to vedlejší minimum není minimem pro mnohem menší množinu případů, než to aktuální.
31.12.2019 14:40
Josef Kufner | skóre: 70
31.12.2019 15:08
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
a proto každý program má hromady přepínačů na různé formátování výstupuNo, ehm, ono je to totiž strašně jednoduché. Já sám nemám rád programy s přeplácanými volbami, ale u jednodnoho programu jsem doplnil výstup json (protože to někdo chtěl), takhle extrémně složitě:
with open(filename, 'w') as work_file:
json.dump(self.dataset, work_file, indent=4)
O pár modulů vedle zase někdo chtěl CSV:
csv_file = StringIO()
csv_writer = csv.writer(csv_file, quoting=csv.QUOTE_NONNUMERIC)
dataset = self.dbs.export_data()
for record in dataset:
csv_writer.writerow(record)
print(csv_file.getvalue())
csv_file.close()
Jako ono je to fakt trivka, přes Click přidat další volbu cli --export-json a napsat dva řádky.
31.12.2019 15:33
xkucf03 | skóre: 50
| blog: xkucf03
Jako ono je to fakt trivka, přes Click přidat další volbu cli --export-json a napsat dva řádky.
Jen pro zajímavost: ta knihovnička pro parsování CLI parametrů má více řádků kódu než všechny moduly Relačních rour dohromady (a to chci řadu věcí ještě pročistit a refaktorovat, občas je tam duplicitní kód).
31.12.2019 15:51
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Jen pro zajímavost: ta knihovnička pro parsování CLI parametrů má více řádků kódu než všechny moduly Relačních rour dohromadyAno, to je možné. A? Pro mě je počet řádků zajímavý až teprve po té, co ten program nebo modul dělá co má. A jestli Click potřebuje více řádků kódu než jiný projekt, není pro mě nijak podstatné. (Navíc ten modul dělá o hodně víc, než jen parsing cli parametrů.) A dělá to skvěle, na rozdíl třeba od ArgParse ve standardní knihovně. Počty řádků začnu porovnávat teprve až tehdy, až tu bude jiný projekt, který bude umět min. totéž. a stejně dobře. Aby bylo co srovnávat.
31.12.2019 15:58
Josef Kufner | skóre: 70
+1. Implementovat si protokol pro roury určitě je možné, ale IMO to nemá moc smysl - roury na tohle IMO nejsou dobrá úroveň abstrakce. Roury jsou primitivní ze své definice. Pokud chce někdo pracovat s proudy strukturovaných dat, tak na to jsou určené programovací jazyky, v kontextku diskuze by mohl být vhodný např. nějaký funkcionální skriptovací jazyk. "Překopat roury", tak jak tu někteří píší, by v podstatě IMO vedlo nutně k vytvoření něčeho takového. Proč radši místo toho nestáhnout třeba PureScript nebo tak něco a nezačít vesele hackovat?ale pokud by se roury trochu překopalyAle proč by se měly překopávat?

Asi všichni, co tu jsme umíme programovat. Nicméně síla rour je v možnosti vytváření jednoduchých jednořádkových programů.Souhlasim, nicméně IMO ty programy jsou jednoduché a jednořádkové právě mj. díky primitivnosti rour, resp. obecně těch rozhraní... Jakmile začneš řešit složitější věci, dojdeš celkem rychle k momentu, kdy to v nějakém skriptovátku typu Python je snazší... Samozřejmě je možné znásilňovat roury, grepy, sedy, awky atd. ad infinitum (koneckonců, třeba sed a awk jsou jistě turing-complete) ... ale elegantního na tom není IMO vůbec nic ...
Byly navržené v době, kdy nadupané počítače měly 256MB pamětiJsi o pár řádů vedle
Jelikož jsou tyto nástroje primitivní, tak jsou pro složitější věci nevhodné. Ale primitivní být nemusí.No já si právě myslim, že by měly zůstat primitivní. Jakmile primitvní nebudou, tak už nebudou mít ten hodně obecný záběr, obecnou použitelnost a kompatibilitu...
31.12.2019 14:22
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
roury v Unixu jsou nestrukturovanéJe to primitivum pro spojení stdout jednoho procesu se stdin druhého. Co si ty programy budou posílat už je na nich. Tradičně to byl textový výstup, já osobně mnohem více posílám binární data (
cat /dev/sda | lzop | nc backup). To je dělá univerzálními a obecně použitelnými. (Nehledě na fakt, že se takto jednoduše bez práce dosáhne určité paralelizace, protože všechny procesy běží současně a na pipe je buffer, o který se stará shell.)
v důsledku toho má každá utilita vyšší desítky přepínačůÚplně nechápu, jak počet parametrů souvisí s rourama. Jako že kdyby roury fungovaly jinak, bylo by možné programy rozdělit na menší a propojit je? To jistě u některých bude možné, ale nikoliv obecně.
Pokud má člověk trochu technického citu, tak by měl vnímat jak je vše přeplácané, překomplikované, jak chybí jednotící koncepty.S tou přeplácaností a komplikovaností nevím, ale možná je to tím, že pracuju v jiné podmnožině. Nářky na jednotící koncept jsou slyšet poměrně často, ale ještě nikdo neřekl, co vlastně chce a jak by to fungovalo napříč všemi nasazeními linuxu. Já to vnímám tak, že dnešní linux / unix poskytuje kostičky lega, které možná nejsou dokonalé, ale lze jimi vyplnit celý prostor. Některé "sjednocené" koncepty by možná byly vhodnější pro nějaká konkrétní nasazení, ale ne pro celek.
Unix je geniální koncept - ale skoro padesát let starý. Skoro všechno na něm by stálo za revizi a to brutální (posledních pár let jsem si hrál s terminálovými aplikacemi, a když se člověk dostane dost blízko, tak je to taková hromada sraček, že se člověk dost musí divit, že to přesto funguje. Vyžaduje to enormní úsilí pár lidí, kteří to nějak udržují při životě. Bohužel, dokud to úplně nespadne, tak se do toho nikdo nepustí, protože by se musela zahodit zpětná kompatibilita a znamenalo by to desítky let vývoje.O tom bych si rád přečetl něco víc. Vím, že jste dělal
pspg , možná by stálo za to sepsat něco ze zákulisí.
31.12.2019 16:29
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Hezké by to bylo, ale je otázka, jestli si to hafo potřebné práce na sebe vydělá, tj. jestli se najde dost lidí, kterým to práci ušetří tak často, aby to mělo cenu vyrábět. Nejsme v matematice, abychom něco dělali, protože je to hezké... Protože když někdo používá "zdroj | sum(xx) groupby(yyy) | graph bar" tak často, aby se vyplatilo řešit nějaké přenášení metadat, nejspíš už si pamatuje, že má použít --i-want-xx --want-yyy-tooNo hlavně to jde napsat triviálně už dnes (
psql -c 'select sum(x) from neco where ... group by ...' | graph bar') s tím, že má k disposici kompletní bohatost jazyka SQL, která by se pomocí pipe a předávání metadat dost těžko v shellu dosahovala. A navíc je otázkou, kolik lidí by nový způsob používalo místo SQL, které by ale stejně museli umět.
31.12.2019 16:13
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Zdroj by dostal jiným kanálem informaciOsobně dávám vždy přednost explicitnímu před implicitním. Takže pokud napíšu
zdroj | filter, tak očekávám, že zdroj pošle všechna data i kdyby si z nich filter vzal jeden byte (krom případu, že se filter ukončí a tím zruší i tu pipe a ten proces před ním). Neočekávám, že se stane zdroj --filter neco. Nemám rád ani automatickou detekci istty(), kdy program vypisuje něco jiného na terminál a něco jiného do roury nebo přesměrování.
Protože všechny tyhle implicitnosti vedou k chybám. Triviální příklad. Pokud by někdo vylepšil roury o předávání informací, tak by se mohlo stát, že příkaz cat /dev/sda > /dev/null by se prostě nevykonal, protože by systém usoudil, že to nemá žádný výstup, tak nebude zatěžovat storage, cache apod. Ale někdo takto může kontrolovat stav storage a to, zda jdou přečíst všechny bloky. A takových nulových příkazů s netriviálním vlivem je víc.
K tomu terminálu, co dodat. Myslel jsem si, že ncurses to řeší kompletně. Přijde mi divné, že se dneska musí speciálně řešit věci jako stín pod menu, to uměl Turbo Pascal v roce 1990 v dosu. (V roce 1997 jsem psal tui rozhraní v pascalu, ale pravda, netuším, co všechno řešila ta knihovna a bylo to tehdy jen v dosu, dnešní rozmanitost terminálů je asi fak šílená.)
netuším, co všechno řešila ta knihovnaJá bych si tipnul, že všechno. Jednou jsem si říkal, že když taková věc existovala už takhle od pradávna, napsat dneska něco v ncurses nemůže být tak těžké. Chtěl jsem napsat jednoduchý prográmek, kterým bych si ušetřil něco práce. Nakonec jsem si ji ušetřil tak, že jsem se na to po několika hodinách snažení vykašlal.
31.12.2019 17:02
Josef Kufner | skóre: 70
31.12.2019 17:15
xkucf03 | skóre: 50
| blog: xkucf03
Na stránce tvision.sourceforge.net píší:
This port is a port of the C++ version for the DOS, FreeBSD, Linux, QNX, Solaris and Win32 platforms.
To by teoreticky stálo za vyzkoušení.
31.12.2019 17:06
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
31.12.2019 17:18
xkucf03 | skóre: 50
| blog: xkucf03
31.12.2019 17:23
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
1.1.2020 14:42
xkucf03 | skóre: 50
| blog: xkucf03
Nemám rád ani automatickou detekci istty(), kdy program vypisuje něco jiného na terminál a něco jiného do roury nebo přesměrování.
Vím, že je to trochu ošemetné, ale někdy podle mého úprava chování dle toho, zda vstup/výstup je terminál, má smysl.
Co si třeba myslíš o programech, které při příliš dlouhém výstupu spustí jako podproces less a nasměrují výstup do něj, místo aby ti zahltily terminál?
Návrh b) v komentáři #65 je tomu hodně podobný.
Protože všechny tyhle implicitnosti vedou k chybám. Triviální příklad. Pokud by někdo vylepšil roury o předávání informací, tak by se mohlo stát, že příkaz cat /dev/sda > /dev/null by se prostě nevykonal, protože by systém usoudil, že to nemá žádný výstup, tak nebude zatěžovat storage, cache apod.
Např. pro localhost/loopback je v jádře nějaká zkratka a funguje to trochu jinak než komunikace s jinými adresami (byť na stejném počítači). Zkoušel jsem to hledat a nemůžu to najít, myslím, že o tom byla před pár lety zprávička. Nemáte někdo odkaz?
1.1.2020 14:46
xkucf03 | skóre: 50
| blog: xkucf03
Možná tohle: net-tcp: TCP/IP stack bypass for loopback connections, ale spíš si myslím, že to byla nějaká novější změna než v roce 2012.
1.1.2020 15:14
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Vím, že je to trochu ošemetné, ale někdy podle mého úprava chování dle toho, zda vstup/výstup je terminál, má smysl.Jasně, já jsem to taky jednou použil pro program, jehož výstup jsem často strojově zpracovával a místo parametru mi přišlo jednodušší (na implementaci) istty, ale obecně to považuju za chybu návrhu. A úprava výstupního formátu tak, aby to bylo pěkné jak pro člověka, tak pro stroj, mi přišla příliš náročná. To už je fakt lepší udělat --export-csv a mít výstup pro člověka a stroj kompletně oddělený.
Co si třeba myslíš o programech, které při příliš dlouhém výstupu spustí jako podproces less a nasměrují výstup do něj, místo aby ti zahltily terminál?Tohoto je plný freebsd a lezu z toho po zdi. Je tam nějaké dvě stě tisíc let staré
more, neumí to barvy, neumí to hledat. Naštěstí | less zafunguje. Ale obecně ne, nemělo by se to dělat. To less si tam přidá každý, navíc tmux i screen umí vlastní scrooling a emulátor terminálu také. Prostředků na volitelný paging je dost a ne každému může ten použitý vyhovovat.
Návrh b) v komentáři #65 je tomu hodně podobný.Nebrat. Pokud má nějaký program binární výstup a admin jej nechá vypsat na terminál, má se to vypsat na terminál (s tím, že ho to rozhodí a potom je poslepu nutné psát
reset (neplést s reboot )). Ještě je akceptovatelné, pokud se program zeptá, podobně jako less:
less pribeh.pdf "pribeh.pdf" may be a binary file. See it anyway?Automatický převod binárního výstupu na hezký textový výstup by mohl vést k chybám typu:
* * * * * relpipe-in- >> /var/log/pretty.log, což jsem za svou praxi taky viděl několikrát. Program pracoval, úloha se spouštěla, ale log se plnil nesmyslama.
Např. pro localhost/loopback je v jádře nějaká zkratka a funguje to trochu jinak než komunikace s jinými adresami (byť na stejném počítači). Zkoušel jsem to hledat a nemůžu to najít, myslím, že o tom byla před pár lety zprávička. Nemáte někdo odkaz?Na tohle je expert mikrotik. Některé packety některé chainy kompletně obcházejí, někdy se do fw nedostanou vůbec a mk to řeší přes ten switchovací čip apod. Jasně, z důvodu výkonu to má smysl, ale je každopádně dobré to dobře zdokumentovat. Jinak to mi připomnělo chování db klientů. Je rozdíl mezi
localhost a 127.0.0.1. Takže někteří admini si nastaví fw, nastaví si grant apod a potom se tam "ani z lokálu" nejde připojit. Rozdíl je ten, že localhost se připojuje přes unix socket, zatímco 127.0.0.1 přes TCP socket (stejně jako každé jiné spojení po síti). Připojení přes UNIX socket je u PG výhodné, protože dokáže identifikovat uživatele klienta a připojit jej automaticky (pokud je to v pg_hba.conf povoleno). U 127.0.0.1 to "najednou" chce heslo.
1.1.2020 16:21
xkucf03 | skóre: 50
| blog: xkucf03
Tohoto je plný freebsd a lezu z toho po zdi. Je tam nějaké dvě stě tisíc let staré more, neumí to barvy, neumí to hledat. … ne každému může ten použitý vyhovovat.
Od toho je proměnná $PAGER:
PAGER="more" hg log PAGER="more" man man PAGER="less" hg log PAGER="less" man man
Někdo si tam nastavuje dokonce VIM… (PAGER="/usr/share/vim/vim80/macros/less.sh" nebo něco vlastního).
navíc tmux i screen umí vlastní scrooling a emulátor terminálu také
Třeba v Konsoli je myslím výchozí nastavení 1 000 řádků. Často zjistíš, že by sis měl nastavit víc, až ve chvíli, kdy o nějaký zajímavý výstup přijdeš. Ten less (ať už explicitní nebo automatický) má výhodu v tom, že data nezahodí, ani když jsou moc dlouhá.
Nebrat. Pokud má nějaký program binární výstup a admin jej nechá vypsat na terminál, má se to vypsat na terminál (s tím, že ho to rozhodí a potom je poslepu nutné psát reset (neplést s reboot
Mně se do toho taky moc nechce. Uživatel by měl vědět, že výstupem relpipe-in-* a relpipe-tr-* jsou binární strojově čitelná data určená k tomu, aby se zpracovávala nějakým dalším nástrojem. Tzn. nechci zatemňovat tu obecnou logiku zdroj-dat | transformace | výstupní-formátování. Ale možná přidám nějakou proměnnou prostředí, kterou když si uživatel nastaví, tak pak zafunguje ta automatika. Tzn. nebude to výchozí chování, ale když si o to uživatel výslovně řekně, tak to může mít.
Jinak to mi připomnělo chování db klientů. Je rozdíl mezi localhost a 127.0.0.1. Takže někteří admini si nastaví fw, nastaví si grant apod a potom se tam "ani z lokálu" nejde připojit. Rozdíl je ten, že localhost se připojuje přes unix socket, zatímco 127.0.0.1 přes TCP socket (stejně jako každé jiné spojení po síti). Připojení přes UNIX socket je u PG výhodné, protože dokáže identifikovat uživatele klienta a připojit jej automaticky (pokud je to v pg_hba.conf povoleno). U 127.0.0.1 to "najednou" chce heslo.
Na tohle už jsem taky někdy narazil a nelíbí se mi to. Je to takové upřednostnění pohodlnosti (slovo localhost si pamatuje každý, ale kolik lidí zná z hlavy cestu k patřičnému unixovému soketu?) před spolehlivostí a transparentností.
1.1.2020 16:53
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Od toho je proměnná $PAGER:Vím, tu nemám nastavenou. Ony to dělají jen některé programy jako
portmaster a freebsd-update, u toho portmasteru to ani není jeho vina, ale děje se to i u make install v případě, kdy port chce sdělit nějaký text adminovi. Takže tato komponenta.
Často zjistíš, že by sis měl nastavit víc, až ve chvíli, kdy o nějaký zajímavý výstup přijdeš.Tak výpisy by měly být idempotentní, takže si to můžeš nechat vypsat znovu do lessu. (Muhehe, toto je téma na flame, už to tady bylo jednou u doporučení spouštět dlouho běžící programy přes
systemd-run a výpis číst v journalu  )
)
Ale možná přidám nějakou proměnnou prostředí, kterou když si uživatel nastaví, tak pak zafunguje ta automatika. Tzn. nebude to výchozí chování, ale když si o to uživatel výslovně řekně, tak to může mít.Jo. Nebo parametr. Dával bych přednost parametru před env.
Jo. Nebo parametr. Dával bych přednost parametru před env.Spíš obojí. Parametr s nejvyšší prioritou, pak env, pak zakompilovaný default. Tady je vhodné se inspirovat přepínači --color, které jsou docela dobře zavedené v mnoha programech. A klidně bych udělal výchozí pager s formátováním. Pokud vynecháš výstupní formátování a pošleš to rovnou do terminálu, tak by se automaticky spustilo něco rozumného a less. Samozřejmě by o tom měl být odstaveček hned na začátku dokumentace a řádek v --help, aby se člověk nedivil, ale nějak mne nenapadá situace, kdy bych chtěl vypsat ten binární bordel do terminálu. Spíš mi přijde fajn, že by šlo psát tu kolonu postupně a neřešit už od začátku konec. Na druhou stranu, pokud si takový výstup někam přesměruju s tím, že si ho chci uložit, bude to trochu podivné, ale asi to za to stojí a jde to řešit drobným varováním na začátku automaticky formátovaného výpisu, které půjde vypnout.
31.12.2019 16:51
xkucf03 | skóre: 50
| blog: xkucf03
Pokud bych měl v Unixu filtr, který dokáže agregovat a grupovat podle nějakých atributů, tak by bylo hezké abych mohl napsat "zdroj | sum(xx) groupby(yyy) | graph bar". Zdroj by dostal jiným kanálem informaci, že se po něm požadují atributy xxx, yyy. Tím by mohla odpadnout parametrizace zdroje i finálního konzumenta (protože ten by jiným kanálem dostal metadata).
V objektovém (případně funkcionálním) světě by tohle šlo řešit pomocí líného vyhodnocování. I když pořád by to vlastně byl full table scan, jen s tím, že by se některé hodnoty nemusely načítat (nebo ty dynamické vypočítávat), ale nepodporovalo by to indexy. To posílání predikátu vzdálenému/cizímu zdroji je zajímavější a vlastně jsem se s tím už párkrát setkal (posílal se popis filtru a z něj se na druhé straně generoval dotaz do LDAPu nebo relační databáze). Ale asi to moc nepatří do operačního systému a vede to na poměrně složitá rozhraní1, která patří spíš na úroveň aplikací nebo nějakého middlewaru. Asi by to musel být nějaký OS, který s tímhle počítá už od začátku.
[1] když to srovnám se složitostí unixových/posixových C API, tak mi to tam vyloženě nesedí
jak je vše přeplácané, překomplikované, jak chybí jednotící koncepty
| relpipe-in-cli generate-from-stdin relation_from_stdin 3
\ a integer
\ b string
\ c boolean
Takže tohle je lepší?
31.12.2019 15:21
xkucf03 | skóre: 50
| blog: xkucf03
Tohle je jeden z nejstarších modulů a jeho syntaxe se bude měnit, aby byl v souladu s ostatními příkazy a taky nebudeš muset psát tu 3 (počet atributů).
Ale bez ohledu na to:
Takže tohle je lepší?
Lepší než co? Tenhle příkaz převádí data (oddělená nulovým bajtem čtená ze standardního vstupu) na relaci. Těžko vymyslíš něco jednoduššího, vzhledem k tomu, že:
string)Ve výsledku to bude vypadat asi nějak takto:
relpipe-in-cli --relation "relation_from_stdin" --attribute "a" "integer" --attribute "b" "string" --attribute "c" "boolean"
případně:
relpipe-in-cli --relation "relation_from_stdin" --attribute "a" --type "integer" --attribute "b" --type "string" --attribute "c" --type "boolean"
s tím, že bys mohl typy nechat výchozí:
relpipe-in-cli --relation "relation_from_stdin" --attribute "a" --attribute "b" --attribute "c"
n.b. názvy atributů jsou libovolné řetězce, které můžou klidně začínat znaky "--".
1.1.2020 20:34
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
A jak bys jinak řešil převod stromu na relace? Tohle je ještě dost přívětivé – jedním XPath výrazem vybereš záznamy a dalšími XPath dotazy vybereš atributy. Tohle nelze namapovat nějak automaticky – některé atributy (relační) hledáš v elementech, některé v atributech (XML), některé někde hlouběji v potomcích, jiné zase v nadřazených uzlech. Ostatně totéž se používá v databázích a i se to i stejně jmenuje.Nerobil som úplné riešenie, pretože nejaký automat nad XML je vôbec problém napísať. Páč nad:
<clovek>
<meno>
Franta
</meno>
<sex>
man
</sex>
</clovek>
Je ten parser jednoduchý.
Ale proste XML je ideálny formát ako dáta prasiť a to vo večšine XML je:
<clovek>
<meno>
Franta
</meno>
<prasime attribute="sex" value="man">
</prasime>
</clovek>
Toto proste nemá logické riešenie.
protože ten záznam je zapsaný na více řádcích. Šlo by to nějak v AWKu ...(G)AWK vie práve spracovávať hocijaký vstup, mno zrejme to neskončí s nejakoým triviálnym zápisom.
Největší problém je, že to přichází s asi dvaceti- nebo třicetiletým zpožděním.Mno keď to bude viac ľudskejšie ako som písal, je úplne jedno kedy to príde, nežijeme v minulosti ale teraz :)
1.1.2020 21:06
xkucf03 | skóre: 50
| blog: xkucf03
Toto proste nemá logické riešenie.
Proto existuje XPath, se kterým je to řešitelné snadno:
<lide>
<clovek>
<meno>
Franta
</meno>
<prasime attribute="sex" value="man">
</prasime>
<prasime attribute="city" value="Praha">
</prasime>
</clovek>
<clovek>
<meno>
Winona
</meno>
<prasime attribute="sex" value="woman">
</prasime>
<prasime attribute="born" value="1971">
</prasime>
</clovek>
</lide>
Skript:
cat lide.xml \
| relpipe-in-xmltable \
--relation lide \
--records '/lide/clovek' \
--attribute 'name' string 'normalize-space(meno)' \
--attribute 'sex' string 'prasime[@attribute="sex"]/@value' \
--attribute 'city' string 'prasime[@attribute="city"]/@value' \
--attribute 'born' string 'prasime[@attribute="born"]/@value' \
| relpipe-out-tabular
Výsledek:
lide: ╭───────────────┬──────────────┬───────────────┬───────────────╮ │ name (string) │ sex (string) │ city (string) │ born (string) │ ├───────────────┼──────────────┼───────────────┼───────────────┤ │ Franta │ man │ Praha │ │ │ Winona │ woman │ │ 1971 │ ╰───────────────┴──────────────┴───────────────┴───────────────╯ Record count: 2
Mimochodem, totéž můžeš dělat v databázích (např. PostgreSQL), kde je funkce xmlTable(), kterou je ten relpipe-in-xmltable inspirovaný (tzn. opět se snažím nevynalézat kolo a raději použít řešení, které se už osvědčilo jinde).
1.1.2020 22:14
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
--attributes 'prasime[@attribute="%%"]/@value'Něco jako matchování regexpem, ale v XPath. (Což asi bude docela oříšek implementovat.)
2.1.2020 12:59
xkucf03 | skóre: 50
| blog: xkucf03
… a ve výsledku to bude složitější a méně přehledné, než tam těch pár atributů vyjmenovat explicitně a říct počítači přesně, co chceš, a ne ho nechat hádat.
2.1.2020 14:44
xkucf03 | skóre: 50
| blog: xkucf03
Dobře, trochu to rozvedu.
Na slušnější XML by asi šlo udělat automatiku, která by vzala první potomky jako řádky tabulky a druhé jako sloupečky.
XML popisuje stromovou strukturu, jeho přirozený datový model je strom uzlů. Pokud se ti to nedaří (snadno) napasovat na relaci (nebo jinou datovou strukturu či model), neznamená to, že by to XML bylo neslušné.
A už vůbec nemůžeš čekat, že to XML bude ve tvaru:
<tabulka>
<řádek>
<sloupec1>hodnota1</sloupec1>
<sloupec2>hodnota2</sloupec2>
<sloupec3>hodnota3</sloupec3>
</řádek>
<řádek>
…
</řádek>
</tabulka>
tzn. že ty řádky budou hned v první úrovni pod kořenovým elementem. Běžně můžou být zanořené hlouběji. A i když jde dané XML logicky namapovat na několik relací, neznamená to, že to bude takhle přímočaré. Některé atributy (relační) se můžou brát z rodičovských elementů nebo hledat někde hlouběji atd. To je normální zdravé XML.
Ten relační pohled na XML je fajn, protože často stačí a dá se to namapovat. A nebo někdy potřebuješ jen podmnožinu původních dat, kterou dokážeš namapovat. Tam vidím potenciál xmlTable(). Kromě toho jsou i případy, kdy to rozumně namapovat nejde a ty relace v tom prostě (z logického pohledu) nejsou. A pak nemá cenu to znásilňovat a je lepší použít třeba to XQuery.
automatiku, která by vzala první potomky jako řádky tabulky a druhé jako sloupečky
Dovedu si představit nějakou heuristiku, která by v XML hledala opakující se struktury a ty pak prohlásila za záznamy jednotlivých relací. A k nim by bylo nutné připojit i hodnoty z elementů a atributů nadřazených uzlů jako např. user="root" nebo context="default" z příkladu v blogu.
Tohle by mi dávalo smysl v rámci nějakého interaktivního průvodce pro import dat, který by ti navrhl mapování, ty by sis ho zkontroloval a převedl data. Výstupem by mohly být i parametry pro funkci xmlTable(), takže bys to mohl používat opakovaně.
Ale určitě bych nechtěl, aby to takhle automagicky fungovalo v rámci nějakého příkazu/skriptu, na který uživatel nedohlíží a nemá ho vždy pod kontrolou. Pak se totiž stane, že v XML třeba přibudou nové elementy a automatika najednou detekuje jiné relace než minule. Nebo autor nástroje vylepší heuristický algoritmus, což bude dávat sice lepší, ale jiné, výsledky a původní skript, se rozpadne.
Tohle je přesně způsob uvažování, který nemám rád – na první pohled se tváří, že věci zjednodušuje a šetří práci, ale ve skutečnosti zavádí skrytou komplexitu a snižuje spolehlivost systému. Ten je potom křehký a funguje nepředvídatelně. A takových případů je v dnešním softwaru bohužel hodně – jsou to časované bomby, které nečekaně bouchnou a rozbijí to, co dříve fungovalo.
Pak by také mohlo jít použít placeholder pro sloupečky, např: …˙Něco jako matchování regexpem, ale v XPath. (Což asi bude docela oříšek implementovat.)
Regulární výrazy v Relačních rourách používám docela dost. Tohle by nebylo tak těžké implementovat, prostě bys zadal jen jeden XPath v --records a místo dalších XPath výrazů v --attribute bys zadal jen regulární výraz, který by hledal přímé potomky1 (elementy a atributy) v elementech nalezených pomocí --records a mapoval je na relační atributy stejného názvu. Potíž je v tom, že struktura relace je odvozená od vstupních dat. Takže pokud v XML budou některé hodnoty chybět, relace bude mít najednou méně atributů (místo aby byly jen prázdné). A u té automatiky ti můžou zmizet dokonce celé relace, pokud v XML na vstupu zrovna dané uzly nebodu.
[1] podle názvu – akorát tím regulárním výrazem nedokážeš popsat jmenné prostory, takže je to hodně omezené
30.12.2019 23:52
xkucf03 | skóre: 50
| blog: xkucf03
O to jsem se naštěstí nikdy nepokoušel (což nás asi naučil Kosek ve škole, že tudy cesta nevede).
31.12.2019 13:54
Josef Kufner | skóre: 70
31.12.2019 15:04
xkucf03 | skóre: 50
| blog: xkucf03
Je to binární formát, který má být úsporný, není cílem ho nějak optimalizovat pro čitelnost člověkem nebo „nerozdrbání“ terminálového výstupu. Od toho jsou výstupní filtry.
Nad čím jsem ale uvažoval:
a) Dát na začátek nějaké jedinečné magické číslo (což asi udělám tak jako tak). A pak by šlo napsat rozšíření do terminálu, které když odchytí tuhle posloupnost bajtů, tak data nějak uživatelsky přívětivě vykreslí (případně by to mohlo být i nějak interaktivní, nabídnout to různé formáty nebo vykopírování/odeslání dat jinam). Ale to by byla spíš taková specialita pro někoho, kdo to používá hodně a není to pro něj obecný emulátor terminálu ale spíš jakési rozhraní pro práci s daty (něco jako RKWard GUI pro R). Ostatně stejně tak by nějaký specializovaný terminál mohl třeba vykreslovat bitmapové nebo vektorové obrázky, když přijdou ze standardního výstupu nějakého příkazu.
b) Příkazy, které generují relační data (relpipe-in-* a relpipe-tr-*) by se mohly podívat, jestli je STDOUT terminál a pokud je, tak by spustily podproces relpipe-out-tabular (případně jiný, třeba na základě proměnné prostředí), jeho výstup napojily na STDOUT a na jeho vstup poslaly relační data (která měla jít původně na STDOUT).
b) Příkazy, které generují relační data (relpipe-in-* a relpipe-tr-*) by se mohly podívat, jestli je STDOUT terminál a pokud je, ...Možná jedna z věcí, co obecně chybí, je lepší možnost obousměrné signalizace na rouře než prosté isatty(). Např. aby mohla konzumující strana roury signalizovat podporované/preferované formáty dat straně generující. Nebo i v dopředném směru předat volitelně nějaká další metadata. Tohle by šlo udělat plně zpětně kompatibilní, ale asi ta potřeba není nějak silná.
31.12.2019 15:46
xkucf03 | skóre: 50
| blog: xkucf03
Ano, tohle by bylo zajímavé vylepšení. V podstatě by stačilo procesům na FD 0, 1 a 2 nastavit místo rour sokety. Pak by se proces podíval, jestli je to roura, terminál nebo soket. A v případě soketu by mohl do STDIN i zapisovat (a poslat tam třeba ty podporované formáty). Akorát tam bude trochu jinak fungovat zavírání.
A taky by bylo potřeba definovat, kdo má kdy komunikovat, aby se to nezaseklo na tom, že oba procesy čekají, co řekne druhá strana (např. když v „protisměru“ nepřijde ten seznam podporovaných formátů). Nebo tam mít nějakou signalizaci formou systémových volání nebo knihovních funkcí, které to nějak propojí bokem.
Asi bys potřeboval vědět, jestli daný program toto rozšíření podporuje, ještě než zavoláš exec() a spustíš ho.
IMHO to je něco, co vypadá na první pohled jednoduše, ale když to začneš implementovat, tak zjistíš, že to triviální není.
tycat.
relpipe-out-tabular.
relpipe-*), pošlou se binární data tak, jak jsou.
RELPIPES_TTY=1). Bod 4 by se hodil při logování dat (můžu prohlížet i na počítači, kde nemám nainstalované relpipes), ale je to spíš jen takový divný nápad. Asi by bylo lepší to nechat jako samostatný program.
31.12.2019 16:42
Josef Kufner | skóre: 70
31.12.2019 16:53
Josef Kufner | skóre: 70
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz
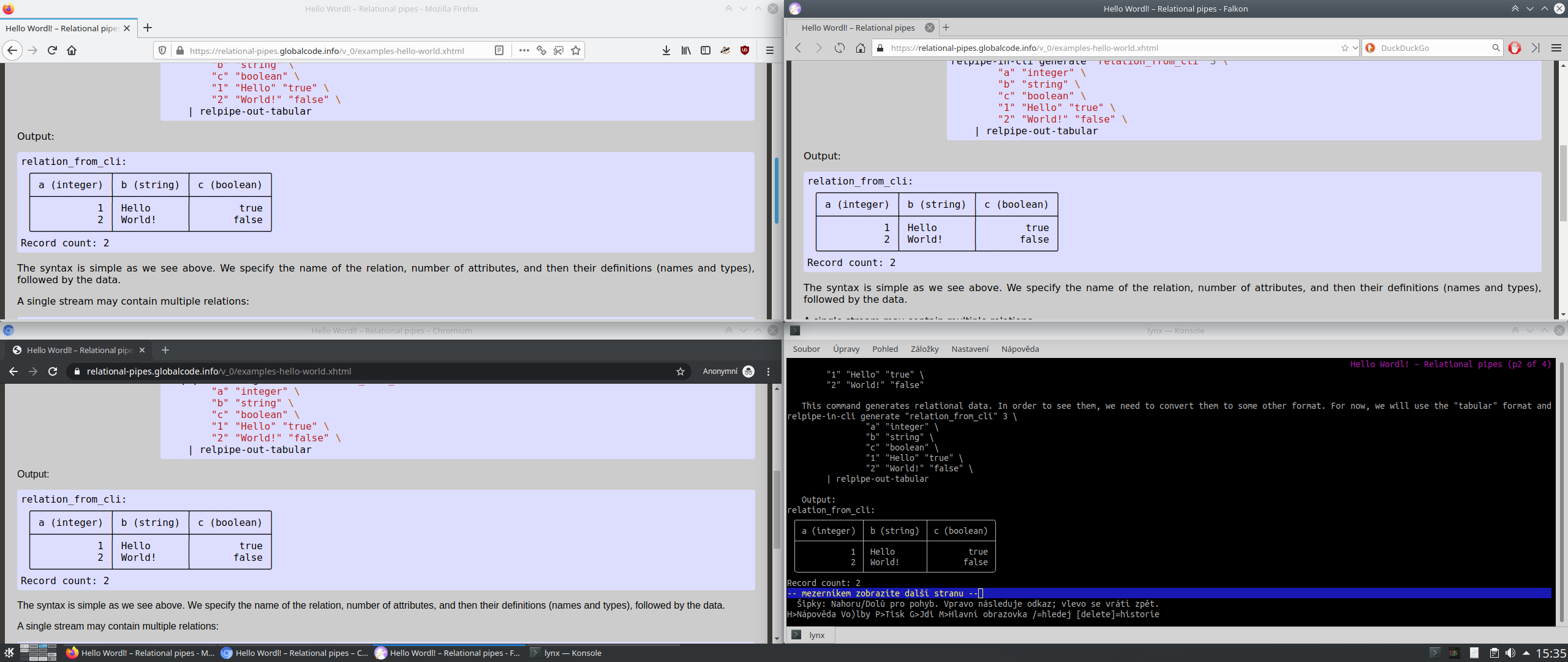{kind=link}
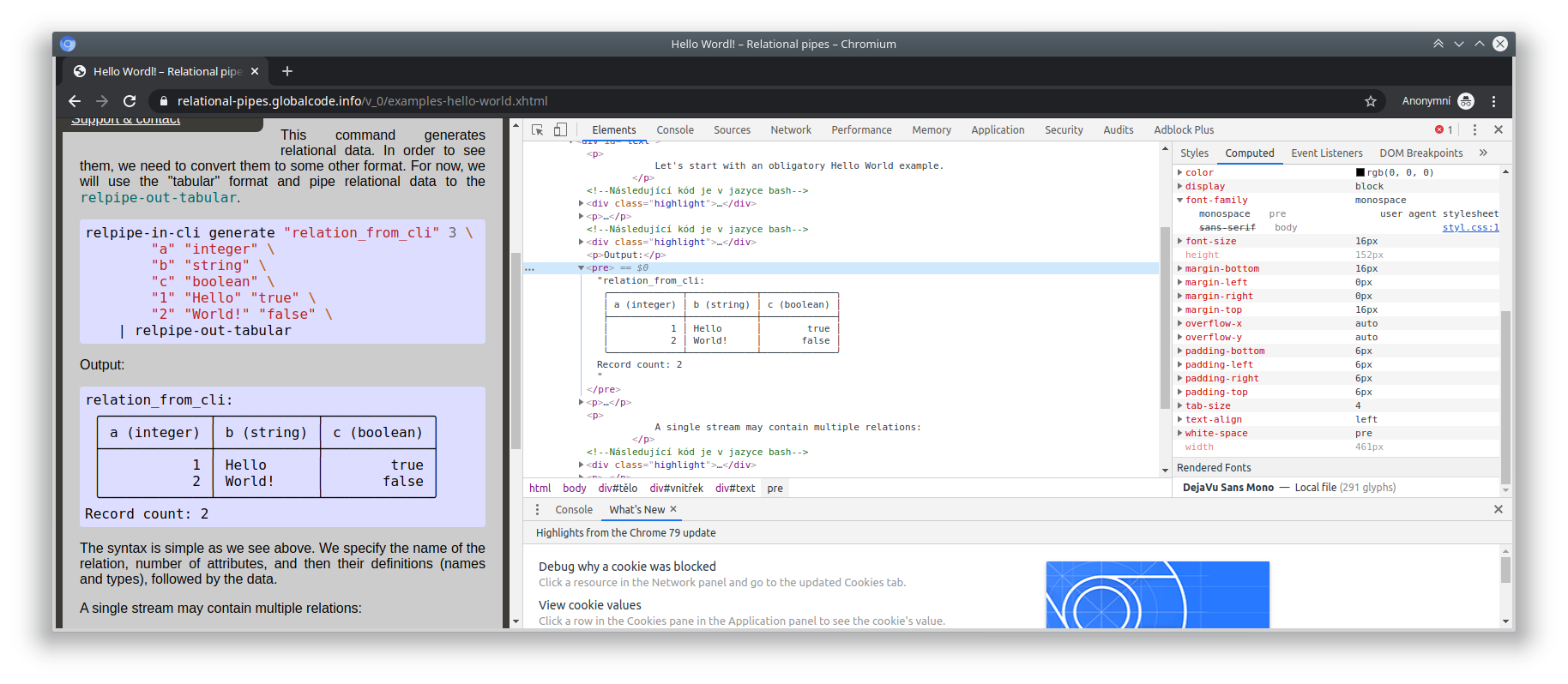{kind=link}
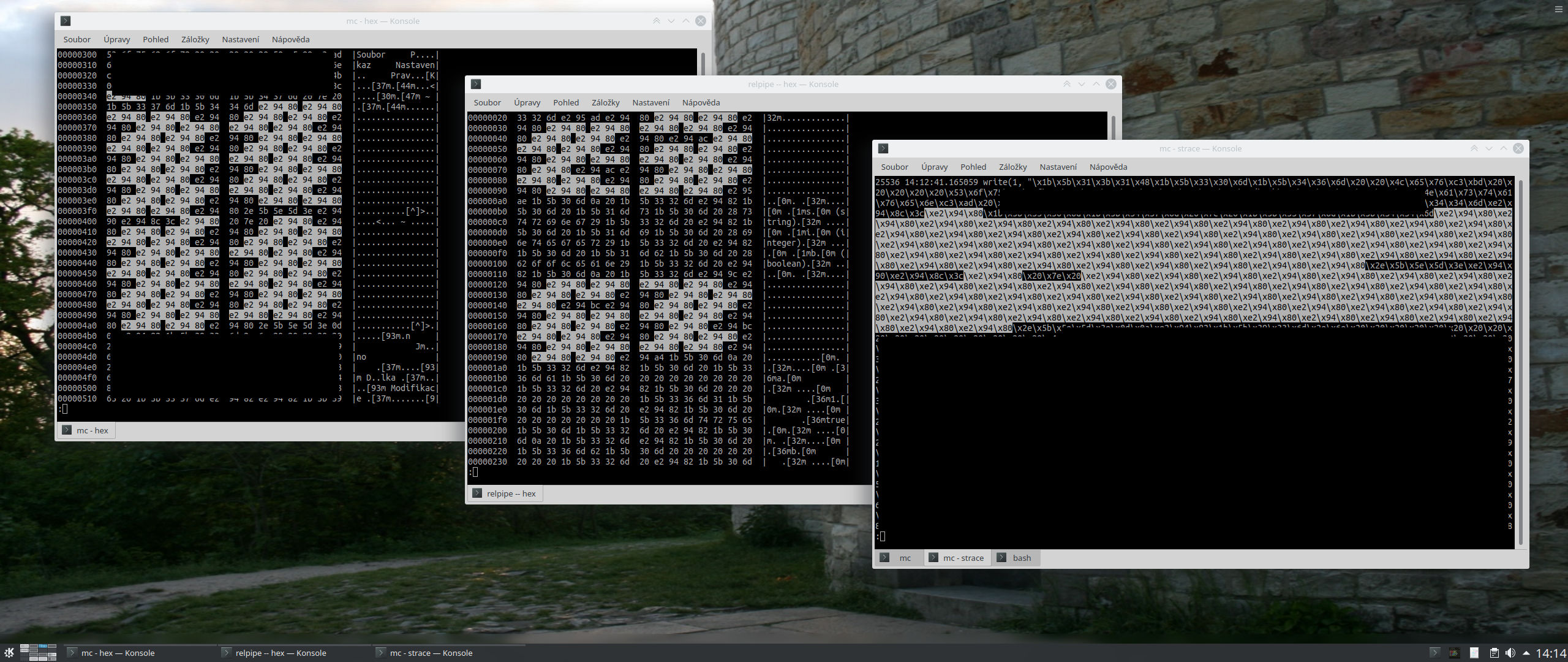{kind=link}