Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
Samba, svobodná implementace síťového protokolu SMB/CIFS, byla vydána ve verzích 4.24.5, 4.23.10 a 4.22.11. Řešeno je 6 zranitelností.
Přední technologické společnosti (Adobe, Cadence, Capital One, Cisco, Cloudera, Cloudflare, Cognition, CrowdStrike, Databricks, Dell Technologies, DoorDash, Elastic, HPE, Hugging Face, IBM, LangChain, Linux Foundation, Microsoft, NAVER, NetApp, Nous Research, NVIDIA, OpenClaw, Palantir, Palo Alto Networks, Red Hat, Reflection AI, Salesforce, SAP, ServiceNow, Siemens, SK Telecom, Snowflake, SpacexAI, Synopsys, Thinking
… více »Krabix.cz je online 3D konfigurátor krabiček pro 3D tisk s exportem do STL. Běží přímo v prohlížeči. Nic se neposílá na server.
Nadace Open Home Foundation spustila veřejnou preview verzi komunitní databáze zařízení pro Home Assistant. Má fungovat jako „Wikipedie pro chytrá zařízení".
Na stránce nového panelu Firefoxu přibudou nové widgety. Například denně aktualizována interaktivní křížovka.
PGSimCity (GitHub) je webová 3D vizualizace vnitřního fungování databázového systému PostgreSQL v podobě města. Vytvořena pomocí umělé inteligence.
UBports, nadace a komunita kolem Ubuntu pro telefony a tablety Ubuntu Touch, vydala Ubuntu Touch 24.04-2.0 a 24.04-1.4. Nová verze 24.04-2.0 již počítá s výřezy pro fotoaparát (notch) a zaoblenými rohy displeje. Webový prohlížeče Morph přešel z Chromia 87 na Chromium 134. Do shellu Lomiri byl přidán editor snímků obrazovky.
Pojmem strom se zpravidla označuje neorientovaný graf, jehož každé dva vrcholy jsou spojeny právě jednou cestou (pokud nerozumíte, zkuste se podívat třeba do wiki - graf, strom).
Strom může reprezentovat vybranou hierarchickou (stromovou) strukturu a ta je předmětem toho článku. Kde že jste mohli strom mimo park zahlédnout? Zajisté jste se s nimi setkali minimálně v diskusních fórech ABCLinuxu.cz, nebo při nakupování v internetovém obchodě, na jehož kategoriích výrobků si budeme práci se stromovou strukturou prezentovat. Důvodem je několik "zajímavých" akcí, jež se v internetovém obchodě provádějí. Uložištěm našeho stromu bude RDBMS komunikující jazykem SQL (konkrétně MySQL a v jednom případě i PostgreSQL).
V perexu jsem naznačil, že si ukážeme celkem tři příklady reprezentace stromu v SQL. Než si z nich vůbec začneme vybírat, měli bychom si ujasnit to, co od stromu budeme očekávat. Aplikace typu internetový obchod může provádět následující akce:
Operací s hierarchickou strukturou bude pravděpodobně více a mnohé mohou být efektivněji provedeny na aplikační úrovni (např. načtením celé struktury a jejím zpracováním namísto několika SQL dotazů). Ponechme je ale stranou a zkusme se podívat, co nám nabízí samotné SQL. Vzhůru do lesů!
Prvním způsobem uložení hierarchické struktury v SQL tabulce budou tzv. sebereferenční tabulky, definující strom seznamem následníků. Sebereferenční tabulky využívají vazby rodič-syn/dcera v hierarchické struktuře přítomné. Pro jednoduchost budeme předpokládat, že každý uzel má nanejvýš jednoho rodiče.
Uvažujme následující hierarchii kategorií:
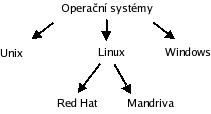
SQL tabulka by mohla být vytvořena příkazem:
CREATE TABLE categories( id INT NOT NULL PRIMARY KEY, name VARCHAR(32), parent INT NOT NULL);
a její obsah by vypadal takto:
+----+---------------------+--------+ | id | name | parent | +----+---------------------+--------+ | 1 | Operační systémy | 0 | | 2 | Unix | 1 | | 3 | Linux | 1 | | 4 | Windows | 1 | | 5 | Red Hat | 3 | | 6 | Mandriva | 3 | +----+---------------------+--------+
Jak vidíte, každý uzel má unikátní identifikátor (číslo ID) a také jsme mu přiřadili rodiče. Všimněte si, že kategorie "Operační systémy" má ve sloupci parent nulu, i když žádná taková kategorie v tabulce není. Její syny budeme označovat jako kořenové kategorie a pro ni samotnou nebudeme požadovat rodiče.
Podívejme se teď na operace, které nás při práci se stromovou strukturou budou otravovat.
CRUD operace jsou vcelku triviální. Vkládání zajistí prostý INSERT. Při odebírání bychom měli dbát na to, abychom dle potřeby rekurzivně smazali i uzly-syny, což je v košatém stromě docela náročné. Přesun uzlu (a celého jeho podstromu!) v rámci stromu, tj. změnu jeho rodiče, realizujeme jednoduchým UPDATE.
Zobrazení podstromu provedeme podobně jako smazání - rekurzivně vybereme všechny potomky právě zpracovávaného uzlu. Podotkněme, že výhoda načtení celého stromu a jeho zpracováním aplikací sice ušetří práci databázi, ale nelze ji dost dobře použít při získávání všech výrobků patřících do kategorií podstromu, kterých může být velmi mnoho.
Rozbalení stromu dle vybrané kategorie je variací na téma zobrazení podstromu s tím, že do hloubky jdeme jen po cestě od kořene k rozbalovanému uzlu. Nalezení této cesty je při této reprezentaci znovu náročné.
Předností sebereferenčních tabulky je jejich jednoduchost - při práci s ní si bohatě vystačíte se znalostí rekurze. Cenou ovšem bude neúměrné zatížení databázového serveru zvláště v případě, že se stromem budete pracovat často, což se u internetového obchodu děje obvykle s každou zobrazenou stránkou, či když strom bude hezky košatý (uzly mají mnoho potomků) a vysoký (mnoho generací potomků). Odlehčit si můžete jistou úrovní cachování stránek, nicméně časem se nejspíš poohlédnete po výkonnějším řešení.
A narazíte možná na genealogické stromy. Genealogický strom také využívá vazbu rodič-syn mezi uzly, ale navíc pro každý uzel definuje i tzv. genealogický identifikátor. Tento identifikátor je unikátní pro každý uzel a dají se z něj vyčíst informace o jeho předcích (rodičích, prarodičích, prapra...) i potomcích. Identifikátor potomka totiž získáme tak, že za identifikátor předka připojíme identifikátor potomka.
Zvolíme-li za identifikátor písmeno abecedy, pak bude naše rozšířená tabulka obsahovat tyto záznamy:
+----+---------------------+--------+------+ | id | name | parent | path | +----+---------------------+--------+------+ | 1 | Operační systémy | 0 | A | | 2 | Unix | 1 | AA | | 3 | Linux | 1 | AB | | 4 | Windows | 1 | AC | | 5 | Red Hat | 3 | ABA | | 6 | Mandriva | 3 | ABB | +----+---------------------+--------+------+
CRUD operace tentokrát váže několik nepříjemných podmínek. Jednou z nich je omezení počtu potomků dle volby uložení identifikátoru (v případě písmen abecedy smít uzel mít "jen" 26 přímých potomků). Vložení nového uzlu do stromu provedeme tak, že zjistíme genealogický identifikátor rodiče a za identifikátor uzlu zvolíme nejmenší možné písmeno abecedy, které je na dané úrovni volné (úrovní rozumíme množinu přímých potomků rodiče). Zaveďme proto požadavek, aby na sebe identifikátory sourozenců lexikálně navazovaly.
Odstraňení uzlu je velmi snadné. Stačí smazat všechny uzly, jejichž genealogický identifikátor začíná identifikátorem odstraňovaného uzlu. Pokud bychom v naší hierarchii chtěli z nabídky odstranit podstrom s kořenovou kategorií "Linux", provedli bychom SQL příkaz:
DELETE FROM categories WHERE genealogical LIKE 'AB%';
Tím nám ovšem může vzniknout mezera na úrovni mazaného uzlu (Linux), což si nepřejeme a musíme proto po smazaní uzlu aktualizovat identifikátory postižených uzlů.
Přesun uzlu provedeme příslušnou změnou umístění (změna rodiče) a následnou aktualizací identifikátorů.
Poznamenejme, že návaznost identifikátorů se nakonec zdá být spíše na škodu, jelikož nám práci docela komplikuje, nicméně se bez procedury na odstranění hluchých míst ve stromu nejspíš neobejdeme.
Zobrazení kompletního podstromu je poněkud svízelné. Sice nám postačí
SELECT s klauzulí ORDER BY genealogical, aplikace ovšem často
požaduje,
aby byl výstup abecedně setříděn. Tuto komplikaci lze vyřešit už během CRUD
operací, totiž vkládáním nových uzlů na správné místo. Cenou je bohužel
režie spojená s tříděním a následnou aktualizací identifikátorů.
Chcete-li si ušetřit nepříjemnosti s nedostatkem písmen a přepočítáváním po mazání, můžete použít jiný identifikátor. V praxi se často používá např. speciální oddělovač následovaný číselnou sekvencí. Identifikátor uzlu Red Hat by byl "/1/3/5&qout;.
Konečně nalezení cesty k uzlu zařídí:
SELECT * FROM categories WHERE 'ABB' LIKE genealogical||'%' nebo SELECT * FROM categories WHERE 'ABB' LIKE concat(genealogical, '%')
Posledním a dle mého názoru nejvýkonnějším řešením je tzv. nested set reprezentace stromu. (Pozn.: Tento název používá Joe Celko a z různých článku se zdá, že není sám. Ačkoli podstatu uložení informace o uzlech charakterizuje čitelně i pro základních grafových algoritmů neznalé, lepší název by mohl být DFS strom.) Podívejme se nejprve na tabulku:
+----+---------------------+--------+------+-------+ | id | name | parent | left | right | +----+---------------------+--------+------+-------+ | 1 | Operační systémy | 0 | 1 | 12 | | 2 | Unix | 1 | 2 | 3 | | 3 | Linux | 1 | 4 | 9 | | 4 | Windows | 1 | 10 | 11 | | 5 | Red Hat | 3 | 5 | 6 | | 6 | Mandriva | 3 | 7 | 8 | +----+---------------------+--------+------+-------+
Vychází ze sebereferenční tabulky, kterou rozšiřuje atributy left a right. Jejich hodnoty jsou získány průchodem stromu DFS (depth first search) algoritmem. Pseudokód algoritmu:
DFS(graf)
foreach uzly_grafu as uzel do
uzel->barva = bila
done
cas = 0
foreach uzly_grafu as uzel do
if uzel->barva = bila
DFS-PROJDI(uzel)
done
end
DFS-PROJDI(uzel)
uzel->barva = seda
cas = cas + 1
uzel->nalezen = cas
foreach sousede[uzel] as soused do
if soused->barva = bila
DFS-PROJDI(soused)
done
uzel->barva = cerna
uzel->opusten = cas
Algoritmus začíná voláním funkce DFS, které je předán zkoumaný graf. Ta nastaví barvu všech uzlů na bílou (uzel dosud nebyl navštíven), seřídí čas a následně prochází uzly grafu s tím, že pokud je uzel bílý, zavolá funkci DFS-PROJDI. DFS-PROJDI přebarví uzel na šedou (byl navštíven, ale dosud se zpracovává), zvedne čas o jedničku a použije jej jako čas navštívení uzlu a poté rekurzivně prochází dosud nenavštívené sousedy uzlu předaného jako parametr. Jakmile jsou všichni sousedé zpracování, přebarví uzel na černou (zpracování dokončeno), nastaví čas opuštění uzlu a vrací se.
Čas navštívení a opuštění uzlu se použijí jako hodnoty atributů left resp. right v SQL tabulce. Lepší představu o výsledku můžete získat z obrázku.
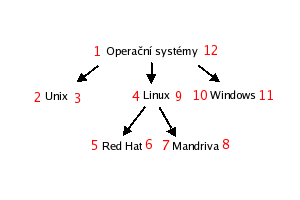
Všimněte si, že interval <left;right> libovolného uzlu je podintervalem intervalu vlastního rodiče (odtud nested set = vnořené množiny). Tato vlastnost plyne z toho, jak DFS prochází strom a ukladá časy a právě ona nám ulehčí práci s hierarchickou strukturou v SQL.
Podívejme se na operace, které chceme nad strukturou provádět. Všechny podkategorie zvolené kategorie získame jednoduchým SELECTem:
SELECT * FROM categories WHERE left >=x AND right <=y
Oproti rekurzi sebereferenčních tabulek podmíněnou mnoha dotazy či spíše přenosem většího množství dat jsme ve výhodě, ovšem genealogický identifikátor umožňuje totéž, ač s nutností použití pomalejšího operátoru LIKE. Získat výstup setříděný podle názvu uzlů je tentokrát o něco jednodušší. Po každé CRUD operaci totiž musíme aplikovat DFS algoritmus na celý strom znovu. Aby DFS generoval časy s ohledem na abecední pořadí uzlů, stačí naštěstí jen vhodně připravit pořadí uzlů, ve kterém jsou algoritmem zpracovávány (nezapomeňte abecedně setřídit i pole sousede[uzel]).
Cestu k uzlu nalezneme také velmi jednoduše. Stačí si uvědomit, že každý předek uzlu byl navštíven dříve a opuštěn později než uvažovaný uzel.
SELECT * FROM categories WHERE left <= x AND right >=y
DFS strom se zdá být velmi vhodný pro statické, či málo upravované struktury. Uplatnění si však zajisté najde i v případě potřeby vyhledávání ve velmi rozsáhlých hierarchických strukturách.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
deb http://ftp.cz.debian.org/debian jessie main contrib non-free
 11.1.2006 09:25
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
11.1.2006 09:25
Věroš | skóre: 24
| blog: Co není v hlavě
| 49.29 s.š., 16.54. v.d.
 A to jsem si na něj ráno taky vzpomněl.
.
A to jsem si na něj ráno taky vzpomněl.
.
def Renumber (node, counter):
node.left = counter; counter++
for i in node.get_child_list ():
counter = Renumber (i, counter)
node.right = counter; counter++
return counter
Renumber (root, 1)
Na začiatok sa chcem poďakovať za článok. Zhodou okolností práve píšem bakalársku prácu na rovnakú tému, preto by som sa chcel spýtať, či by mi niekto nevedel poradiť vhodnú literatúru. Vyšlo niečo k stromovým dátam aj v češtine alebo slovenčine?, za odpoveď vopred ďakujem.....
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 11.1.2006 10:07
11.1.2006 10:07
