Byly zveřejněny informace o kritické zranitelnosti CVE-2026-64600 pojmenované RefluXFS (technické detaily) v XFS. Je tam již od verze Linuxu 4.11, tj. rok 2017. Jedná se o lokální eskalaci práv. Neprivilegovaný uživatel může editovat libovolný soubor, například klidně zrušit rootovské heslo v /etc/passwd. Videoukázka na Vimeo. V upstreamu je zranitelnost opravena.
OpenAI / ChatGPT má dnes výpadky (OpenAI Status, DownDetector).
Poskytovatel hostingu svobodných/open-source projektů Codeberg po hlasování na valné hromadě vydal stanovisko k využívání LLM. Kvůli vytěžování infrastruktury a rostoucím cenám hardwaru, ale také hrozbám pro spolupráci v komunitě se k LLM staví kriticky. Nebude poskytovat hosting projektů vytvářených LLM agenty.
Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
Originál tohoto článku pro LWN.net napsala Valerie Aurora (dříve Hensonová).
… Na takový komentář [viz perex] většinou nebude žádná přímá odpověď a konverzace bude tiše plynout okolo něj, jako proud okolo inkoustově černého balvanu. Proč to tak je? Jde o čisté NIH (Not Invented Here, vynalezeno někým jiným) na straně vývojářů Linuxu (a Solarisu a OS X a AIX a ...) nebo jde o něco hlubšího? Proč jsou měkké aktualizace tak slavné a přitom tak zřídka implementované? V tomto článku budu dokazovat, že měkké aktualizace jsou jednoduše řečeno příliš těžko pochopitelné, implementovatelné a udržovatelné na to, aby mohly být součástí hlavního proudu vývoje souborových systémů – přičemž se zároveň pokusím vysvětlit, jak fungují. Ó, ta ironie!
Měkké aktualizace jsou jedna z technik pro udržování konzistence souborového systému na disku. Základním problémem je to, že souborový systém není vždy ukončen čistě – řekněme kvůli pádu operačního systému nebo výpadku napájení – a když k tomu dojde uprostřed jeho aktualizace (například při mazání souboru), stav souborového systému na disku může být nekonzistentní (poškozený). Původním řešením tohoto problému bylo spustit fsck na celý souborový systém a nekonzistence najít a opravit; příkladem souborového systému, který používá tento přístup, je ext2. (Všimněte si, že toto použití fsck – obnova po nečistém ukončení – je odlišné od použití fsck ke kontrole a opravě souborového systému, který byl poškozen z nějakého jiného důvodu.)
Přístup fsck má zjevné nevýhody (trvá dlouho, je možná ztráta dat), takže vývojáři souborových systémů vyvinuli nové techniky. Nejpopulárnější a dobře známé je logování nebo žurnálování: Předtím, než začneme do souborového systému zapisovat změny, zapíšeme krátký popis této změny (záznam v žurnálu) do oddělené oblasti na disku (žurnál). Když systém padne uprostřed zápisu změn, jednoduše změny dokončíme přehráním záznamů v žurnálu při příštím připojení souborového systému.
Měkké aktualizace místo toho používají dvoukrokový přístup k obnově po pádu. První je, že se zápisy na disk pečlivě řadí tak, aby v případě pádu (či v jakékoliv jiné situaci) jediné možné inkonzistence spočívaly v tom, že je nějaká struktura souborového systému alokována, když se ve skutečnosti nepoužívá. Druhý je ten, že po pádu se na pozadí spustí fsck nad snímkem [snapshot] souborového systému (o tom více později), který vyhledá a uvolní struktury v souborovém systému, které jsou chybně označeny jako alokované. Měkké aktualizace zjednodušeně řadí zápisy na disk tak, že jsou možné pouze relativně neškodné inkonzistence, které se následně na pozadí opraví kontrolou a opravou celého souborového systému. Výsledky benchmarků jsou poměrně ohromující: U běžných pracovních zátěží je často odchylka výkonnosti od souborového systému uloženého v paměti do 5 %. Starší verze FFS, která k poskytnutí stejné spolehlivosti používala synchronní zápisy a fsck na popředí, často běží o 20-30 % pomaleji než souborový systém uložený v paměti.Prvním krokem implementace měkkých aktualizací je zjistit, jak seřadit zápisy na disk tak, aby byly po pádu jedinou možnou chybou inody a bloky, které jsou chybně označeny jako alokované (přestože jsou ve skutečnosti volné). Aby se dosáhlo tohoto cíle, autoři nejprve určují nějaká pravidla, která je potřeba dodržovat, když se změny zapisují na disk. Cituji z pojednání:
Nikdy se nesmí ukazovat na strukturu předtím, než je zinicializována (tj. inode musí být inicializován předtím, než se na něj odkazuje záznam v adresáři).
Zdroj se nikdy nesmí znovuvyužít předtím, než se vynulují všechny předchozí odkazy na něj (tj. ukazatel inodu na datový blok musí být vynulován předtím, než lze znovu alokovat nový inode na tomto diskovém bloku).
Nikdy neresetovat starý ukazatel na používaný zdroj předtím, než je nastaven nový ukazatel (tj. když je soubor přejmenováván, neodstraňovat staré jméno inodu do doby, než se zapíše nové).
Páry změn, kde jedna změna musí být zapsána na disk předtím, než lze zapsat druhou změnu podle pravidel výše, jsou nazývány závislosti aktualizace. Další příklady závislostí aktualizace si můžeme vzít ze situace, kdy je poprvé zapisován první blok v souboru. První závislost aktualizace je ta, že v blokové bitmapě, která obsahuje informaci o tom, které bloky se používají, musí být zaznamenáno, že blok se používá, předtím, než se nastaví ukazatel na blok v inodu. Pokud by v tomto okamžiku došlo k pádu, jedinou inkonzistencí by byl bit, který v blokové bitmapě ukazuje, že je blok alokován, přičemž ve skutečnosti není. Jde o únik zdroje, který je potřeba nakonec opravit, ale souborový systém může i s touto chybou pracovat korektně, pokud mu nedojdou volné bloky.
Další závislostí aktualizace je, že data v samotném bloku musí být zapsána předtím, než lze nastavit ukazatel na blok v inodu (společně s navýšením velikosti inodu a s tím spojenými aktualizacemi časových značek). Pokud by to tak nebylo, pád v tomto okamžiku by mohl způsobit, že se v souboru objeví nesmysly – to je také potenciální bezpečnostní díra, pokud tyto nesmysly pocházely z jiného souboru. S tímto řazením pád povede k úniku bloku (označen jako alokovaný, ale není), který náhodou obsahuje data, která jsme se pokoušeli zapisovat. Výsledkem je, že zápis do bitmapy a zápis dat do bloku musí být (v libovolném pořadí) dokončen předtím, než se zapíší aktualizace ukazatele na blok v inodu, velikost a časové značky.
Tato pravidla pro řazení zápisů nejsou u měkkých aktualizací nová; původně byla vytvořena pro zápisy v "normálním" souborovém systému FFS. V původním kódu FFS je řazení zápisů vynuceno synchronními zápisy – to znamená, že probíhající operace v souborovém systému (create, unlink atd.) čekají na to, než se každý řazený zápis dostane na disk, než přejdou k dalšímu kroku. Když zápis probíhá, buffer operačního systému obsahující diskový blok, o který se jedná, je zamčen. Jakákoliv další operace, která potřebuje tento buffer změnit, musí počkat, než se dostane na řadu. Výsledkem je, že mnoho operací s metadaty probíhá rychlostí práce disku (tj. vražedně pomalu).
Zatím jsme určili, že synchronní zápisy do zamčených bufferů jsou pomalým, nepříjemným způsobem vynucení řazení zápisů do souborového systému. Synchronní zápisy jsou nicméně pro většinu operací v souborovém systému nadbytečné; kromě fsync() většinou nechceme záruku, že výsledek již byl zapsán na stabilní úložiště předtím, než se systémové volání vrátí; jak jsme viděli, kód souborového systému se obvykle zajímá jenom o to, jak jsou zápisy řazeny, nikoliv kdy se dokončí. Co chceme, je zaznamenat změny metadat společně se s nimi spojenými omezeními pro řazení; skutečné zápisy pak můžeme naplánovat dle libosti. Žádný problém, že? Prostě přidáme pár ukazatelů na každý paměťový buffer obsahující metadata, čímž ho spojíme s blokem před a za ním.
Ukazuje se, že problém tu je: Cyklická závislost. Na disk musíme zapisovat po jednotlivých blocích a každý blok může potenciálně obsahovat metadata ovlivněná více než jednou operací s metadaty. Pokud dvě různé operace ovlivňují stejný blok, může to snadno vést ke konfliktním požadavkům: Operace A vyžaduje, aby byl blok 1 zapsán před blokem 2, kdežto operace B potřebuje, aby byl blok 2 zapsán před blokem 1. Takže není možné zapsat žádné změny bez porušení stanoveného řazení. Co s tím?
Většina lidí se v tomto bodě rozhodne použít žurnálování nebo kopírování při zápisu [copy-on-write] a tím problém vyřešit. Obě techniky seskupují související změny do transakcí – do sady zápisů, které musí začít platit naráz – a zapisují je na disk takovým způsobem, aby začaly platit atomicky. Když jste ale Greg Ganger a Yale Patt, přijdete se schématem zaznamenávajícím jednotlivé modifikace bloků (jako je aktualizace jediného bitu v blokové bitmapě) a jejich vztahem s ostatními jednotlivými změnami (jedna změna vyžaduje nejprve zapsat jinou změnu). Poté, když zapisujete blok, zamknete ho a procházíte záznamy jednotlivých změn tohoto bloku. Každou jednotlivou změnu, jejíž závislosti ještě nebyly vyřešeny, vezmete zpět a výsledný blok zapíšete. Když je zápis dokončen, změny znovu aplikujete (dopředné přehrávání [roll forward]), odemknete a pokračujete k dalšímu zápisu. Zápis, který jste právě dokončili, mohl vyřešit závislosti aktualizace jiných bloků, takže nyní můžete použít stejný proces (zamčení, zpětné přehrání [roll back], zápis, dopředné přehrání, odemčení) pro tyto bloky. Nakonec jsou všechny závislosti vyřešeny a všechno je zapsáno na disk – to vše, aniž byste narazili na jakékoliv cyklické závislostí. To je v kostce to, čím jsou měkké aktualizace tak unikátní.
Jak tedy záznam změn metadat a s nimi spojených závislostí aktualizace ve skutečnosti vypadá na úrovni datových struktur? Zaprvé je zde dvanáct (podle pojednání z roku 1999) oddělených struktur, které zaznamenávají jednotlivé typy závislostí:
| Struktura | Sledovaná závislost |
|---|---|
| bmsafemap | bitmapy bloku/inodu |
| inodedep | inode |
| allocdirect | bloky, na které se odkazuje přímými ukazateli na blok |
| indirdep | nepřímý blok |
| allocindir | bloky, na které se odkazuje nepřímými ukazateli na blok |
| pagedep | přidávání/odstraňování záznamu v adresáři |
| mkdir | vytváření nového adresáře |
| dirrem | odstranění adresáře |
| freefrag | fragment, který se má uvolnit |
| freeblks | blok, který se má uvolnit |
| freefile | inode, který se má uvolnit |
Každý druh struktury sledující závislost obsahuje ukazatele, které jí umožňují připojení do seznamů spojených s buffery obsahující relevantní struktury na disku. Tyto seznamy kód měkkých aktualizací prochází během operací zpětného a dopředného přehrání u bloku, který je zapisován na disk. Každá struktura závislosti má sadu příznaků popisujících stav závislosti. Příznaky určují, jestli je závislost v současnosti aplikována na s ní spojený buffer, jestli všechny zápisy, na nichž závisí, byly dokončeny a jestli aktualizace popsané v samotné struktuře sledování závislostí byly zapsány na disk. Když jsou nastaveny všechny tři tyto příznaky (aktualizace je aplikována na buffer v paměti, všechny zápisy, na kterých závisí, byly dokončeny a aktualizace je zapsána na disku), strukturu závislosti lze zahodit.
Na straně 7 pojednání o měkkých aktualizacích z roku 1999 [PDF] začínají popisy specifických druhů struktur závislostí aktualizace a jejich vzájemnými vztahy. Toto pojednání jsem četla nejméně patnáctkrát a pokaždé, když se dostanu na stránku 7, se cítím vcelku dobře a myslím si: „Jo, fajn, asi jsem chytřejší, než když jsem to četla minule, protože to tentokrát chápu“ – pak otočím na stranu osm a vybuchne mi hlava. Zde je obrázek z této stránky:
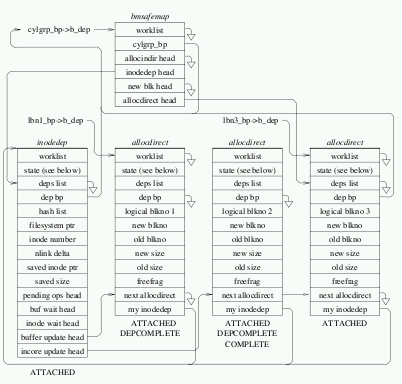
A to je obrázek pouze z levého sloupce. Na pravé straně je jenom o trochu méně složitý špagetogram. To pokračuje na šesti stránkách, které popisují každý druh závislosti aktualizace a její postup přes různé seznamy spojené s buffery a strukturami souborového systému a, což je nejdůležitější, jiné struktury závislostí aktualizace. Snažíte se propracovat textem a zápasíte s odstavci jako:
Zkuste to říci třikrát rychleji!
Nejde o to, že jsou detaily měkkých aktualizací pro pouhé lidi příliš složité na porozumění (i když já osobně bych si nevsadila na to, že Greg Ganger není nadčlověk). Jde o to, že tato složitost odráží nedostatek obecnosti a abstrakce v návrhu měkkých aktualizací jako celku. U měkkých aktualizací musí být všechny operace souborového systému jednotlivě analyzovány, aby se u nich zjistily závislosti aktualizace, každá struktura na disku musí mít zvlášť navrženou strukturu pro sledování závislostí a každá aktualizační operace musí alokovat jednu z těchto struktur a připojit se do sítě dalších zvlášť navržených struktur pro sledování závislostí. Pokud do souborového systému přidáte novou vlastnost, třeba rozšířené atributy, nebo změníte formát na disku, musíte začít od začátku a zjistit relevantní závislosti, navrhnout novou strukturu a napsat rutiny pro zpětné/dopředné přehrání. To je piplavá a zdlouhavá práce a její obtížnost spotřebu pracovních hodin programátorů nijak nevylepšuje.
Porovnejme vysoce specifický návrh měkkých aktualizací s rozhraním transakcí, které se používá ve většině žurnálovacích souborových systémech a souborových systémech používajících kopírování při zápisu. Když zahájíte logickou operaci (jako je vytvoření souboru), vytvoříte manipulátor [handle] transakce. Pak pro každou strukturu na disku její buffer přidáte do seznam bufferů touto transakcí změněných. Když jste hotovi, transakci uzavřete a předáte ji subsystému žurnálování (nebo kopírování při zápisu), který zjistí, jak ji sloučit s ostatními transakcemi a správně ji zapsat na disk. Uživatel rozhraní transakcí musí jenom vědět, jak otevřít, zavřít a přidat bloky v transakci, zatímco kód transakcí musí pouze vědět, které bloky jsou součástí stejné transakce. Přidání nové zápisové operace nevyžaduje žádné zvláštní znalosti nebo analýzu kromě zapamatování si, že se změněné bloky mají přidat do transakce.
Nedostatek abstrakce a zobecnění se ukáže znovu, když vystrčí hlavu kombinace řazení závislosti aktualizací a příslušného formátu disku a způsobí podivné chování viditelné pro uživatele. Nejvýraznější příklad se ukáže, když se odstraňuje adresář; dodržování pravidel pro závislosti aktualizace znamená, že záznam „..“ v adresáři nemůže být odstraněn, dokud adresář sám o sobě není na disku odpojen [unlink]. Řetěz závislostí aktualizací občas vyústí v to, že je mezi návratem z volání rmdir() a odpovídajícím snížením počtu odkazů nadřazeného adresáře dvouminutové zpoždění. Mezi jinými věcmi to může rozbít i jednoduché rekurzivní rm -rf. Opravou je zfalšovat druhý počet odkazů, který je hlášen do uživatelského prostoru, ale skutečným problémem je příliš těsné spojení mezi strukturami na disku, systémem pro udržování konzistence na disku a strukturami viditelnými pro uživatele. Dlouhé řetězce závislostí aktualizací způsobují problémy jinde, konkrétně během odpojování [unmount] a fsync().
Nicméně počkejte, je toho víc! Druhou fází obnovení je u měkkých aktualizací spuštění fsck na pozadí při bootu, přičemž se používá snímek [snapshot] metadat souborového systému. Snímky souborového systému jsou ve FFS implementovány vytvořením řídkého [sparse] souboru o velikosti souborového systému – souboru snímku. Kdykoliv je blok metadat změněn, původní data jsou nejprve zkopírována do odpovídajícího bloku souboru snímku. Čtení nezměněných bloků ve snímku přesměrovává na originál. fsck analyzuje snímek metadat, hledá uniklé bloky a inody. Jakmile doběhne, použije fsck zvláštní systémové volání, které tyto bloky a inody opět označí jako volné.
Takto implementované fsck za běhu má vážná omezení. První je, že obnovení po pádu stále vyžaduje čtení a zpracování metadat celého souborového systému – sice na pozadí, ale stále jde o spoustu I/O. (Plánování volných bloků (freeblock scheduling) připojuje I/O o nízké prioritě, jako je například to pocházející od fsck běžícího na pozadí, k I/O o vysoké prioritě běžícímu na popředí, aby co nejméně překáželo „skutečné“ práci, ale to moc nepotěší.) Zadruhé to není kompletní kontrola a oprava souborového systému, pouze se hledají uniklé bloky a inody – očekávané inkonzistence. Celý koncept spouštění fsck na souboru snímku, jehož bloky jsou alokované na stejném souborovém systému, předpokládá, že souborový systém není poškozen způsobem, který ponechává bloky označené jako volné, i když jsou ve skutečnosti alokované.
Koncept měkkých aktualizací lze vysvětlit stručně – řadit zápisy podle několika jednoduchých pravidel, sledovat aktualizace bloků metadat, zpětně přehrávat aktualizace s nevyřešenými závislostmi před zápisem bloku na disk, poté aktualizace zase dopředně přehrát. Když dojde na implementaci, pouze programátoři s hlubokými, encyklopedickými znalostmi formátu souborového systému na disku mohou určit správná pravidla řazení a vytvořit s nimi spojené datové struktury a síť závislostí. Toto těsné spojení datových struktur na disku a jejich aktualizací a pro uživatele viditelných datových struktur a jejich aktualizací může vyústit v podivné, neintuitivní chování, které musí být pokryto dalším kódem.
Celkově jsou měkké aktualizace sofistikovaný a rozumný nápad – a evolučně slepá ulička. Žurnálovácí souborové systémy a souborové systémy s kopírováním při zápisu se snáze implementují, potřebují méně kódu pro zvláštní účely a vyžadují mnohem méně programátorské práce na rozhraní.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Krásným potvrzením toho, jak jsou soft updates složité, je bug, který jsem hlásil na konci roku 2006. Opraven byl teprve letos na jaře ve FreeBSD 7.2, trvalo to tedy dva a půl roku.
It seems waiting for a minute before remount helps.vidím nějakou souvislost s:
Řetěz závislostí aktualizací občas vyústí v to, že je mezi návratem z volání rmdir() a odpovídajícím snížením počtu odkazů nadřazeného adresáře dvouminutové zpoždění
Není, pokud všechny vrstvy od FS níž (bloková, SCSI, NCQ) respektují "IO bariéry". Bariéra je obecné označení pro speciální příkaz, kterým se zakazuje přehazovat pořadí běžných IO příkazů dopředu/dozadu přes tuto bariéru. Bariéra je z IO fronty odstraněna ve chvíli, kdy se fyzicky sync()nou všechny příkazy, které šly před ní. Taky už jsem slyšel, že to některé disky nerespektují, aby měly v benchmarcích lepší výsledky... A třeba v linuxový DeviceMapper na bariéry kašle.
 7.8.2009 11:24
Jakub Lucký | skóre: 40
| Praha
7.8.2009 11:24
Jakub Lucký | skóre: 40
| Praha

 7.8.2009 19:46
Rezza | skóre: 25
| blog: rezza
| Brno
7.8.2009 19:46
Rezza | skóre: 25
| blog: rezza
| Brno
Ta holka nema rada, kdyz ji nekdo prirovnava k blondatemu prislusenstvi na gauc :D Ale jako jinak klobouk dolu.
BTW, zase jednou klobouk dolů před autorem českého překladu. Tohle je práce pro korejského kata. Běžná profesionálka s diplomem z fildy by si na tom osumkrát vylámala zuby.
 7.8.2009 09:04
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
7.8.2009 09:04
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
Běžná profesionálka s diplomem z fildy by si na tom osumkrát vylámala zuby.Taková nějaká ženská z fildy mě "učila" angličtinu na ČVUT a člověk musel mít neustále nastartovaný Google, aby jí mohl ukazovat, že to mám fakt dobře a ten jazyk jí jde hůř než půlce třídy :-/
A byla aspoň hezká? Musela být z učení na ČVUT nešťastná. Nešťastná hezká holka je snesitelnější, než naštvaná zapšklá větev...
 7.8.2009 17:05
stativ | skóre: 54
| blog: SlaNé roury
7.8.2009 17:05
stativ | skóre: 54
| blog: SlaNé roury
Přesně tak - jde o precizní znalost spisovného cílového jazyka a zároveň o znalost odborné stránky. Slovník oborové terminologie nestačí, chce to taky věcně chápat, o čem je řeč, mít přehled o problematice. Překládat dlouhá odborná souvětí slovo od slova nedává dobrý výsledek - lepší postup je, přečíst a pochopit třeba odstavec (případně dohledat a dostudovat širší kontext), a pak to věcně správně "přebásnit" do cílového jazyka tak, aby se to dobře četlo. Problém je v tom, že ten mlčky předpokládaný kontext okolo, potřebný pro dobrý překlad, je leckdy docela rozsáhlý (střeva filesystémů jsou docela dobrý příklad). Případná konzultace s expertem předně musí u překladatele padnout na úrodnou půdu - jinak by to ten expert mohl rovnou překládat celé sám.
Proto mi srdce vždycky poskočí radostí, když vidím dobře zvládnutý odborný překlad. Velmi často se totiž setkávám s překlady, které překládal nějaký studovaný filolog, třeba i s odborným slovníkem, ale s naprostou neznalostí cílového oboru. Když odborný slovník nabídne tři varianty překladu konkrétního slova (pro různé kontexty), má překladatel třetinovou šanci, že se trefí správně aspoň do toho izolovaného slovíčka, nemluvě o kontextu
Mimochodem, rozhodně bych neřekl, že ten text je obsahově jednoduchý. Je to docela pokročilý level programátorštiny. Připouštím, že není nijak přehnaně nápaditý a zašmodrchaný v ohledu jazykozpytném
Slušný překladatel ví sám nejlíp, na který obor stačí, a na který konkrétní materiál stačí. Třeba já jako šroubovák počítačovej si příležitostně docela dobře počtu v různých anglicky psaných výzkumných zprávách z "medicínských" oborů (když nějaký "Journal of" něco bezplatně vystaví), nacházím tam metodické hnidy typu špatně označené osy v grafech, nevhodně volený typ grafu, ošklivě poskládaná tabulka apod. Kromě toho ti výzkumníci mají občas trochu problém se srozumitelně a gramaticky správně vyjadřovat. Nemluvě o autorech, pro které Angličtina není rodnou řečí... Zato když občas u svého doktora dostanu zprávu z vyšetření (v češtině, mé rodné řeči) a snažím se ji přečíst, jdou mi z toho oči šejdrem - je to jak oborově specifický těsnopis Překlad takové zprávy bych si nikdy nelajsnul.
Vám přijde termín "měkké aktualizace" dobrý? Mě to teda docela vyděsilo...
. A jen bych podotkl, že je pro mne český název docela podstatný, kdyby mi ho nepředložil autor, něco si vymyslím sám. Protože "přemýšlím" v češtině.
 7.8.2009 09:55
Josef Kufner | skóre: 70
7.8.2009 09:55
Josef Kufner | skóre: 70
Nemam rad taketo optimalizacie ktore sposobuju strasidelne programatorske finty kombinovane s uzamknutim celeho FS proti rozsirovaniu o nove vlastnosti. Naozaj mame tie disky take pomale ze to nestaci?
Nie je skor riesenim nejaky HW napr pridanim dalsieho cachovacieho mechanizmu medzi pamat a disk? Co takto bateriovo zalohovana RAM. Vlastne vsetko sluzi iba na to aby sa predislo poskodeniu pri odpojeni napajania. Pritom by ale stacil nejaky mechanizmus ktory by zabezpecil ze ked sa odpoji napajanie tak zostane nejaka cast pamate stale zapamatana alebo niekde bude dostatok elektriny na to aby sa zmeny z medzicache zapisali na HD.

Jenže tohle není ten případ - o výpočetní výkon tu vůbec nejde, protože při operacemi s disky nejvíc času zabírá čekání na ten disk.
Ale princip je stejný, nebo ne? Namísto jemné implementace se využije síly dnešních počítačů.
A navíc tady se jedná o implementaci souborového systému nějakým způsobem, který zajišťuje konzistenci po pádu. O ladění výkonu nebyla řeč.
V úvodním odstavci je zmíněn pokles výkonu vůči ramdisku jen o 5% (oproti 20-30% u žurnálu). Pochopil jsem to tak, že výkon je hlavní motivací pro měkké aktualizace. Konzistenci zajišťuje žurnál stejně tak.
Ale princip je stejný, nebo ne? Namísto jemné implementace se využije síly dnešních počítačů.Není. Neexistuje tady nic jako jemná implementace a využívání síly dnešních počítačů. Prostě jde o dva různé způsoby zajištění konzistence souborového systému. A i kdyby - jak už jsem řekl, nejvíc času při operaci s disky zabere čekání na ten disk. Takže i když uděláš superoptimalizovanou implementaci, která bude o polovinu rychlejší, než neoptimalizovaná, v celkovém čase se to projeví o pár procent - zbytek času se bude optimalizovaně čekat, až disk udělá, co je mu poručeno.
V úvodním odstavci je zmíněn pokles výkonu vůči ramdisku jen o 5% (oproti 20-30% u žurnálu). Pochopil jsem to tak, že výkon je hlavní motivací pro měkké aktualizace. Konzistenci zajišťuje žurnál stejně tak.Já jsem z toho textu nějak nevyčetl to, že by FFS používal žurnál.
Vycházel jsem z tohoto ostavce:
U běžných pracovních zátěží je často odchylka výkonnosti od souborového systému uloženého v paměti do 5 %. Starší verze FFS, ...
Chápu Vás tedy dobře, že stejný souborový systém implementovaný žurnálem také dosáhne pouze 5% poklesu výkonosti oproti ramdisku?
8.8.2009 10:08
Josef Kufner | skóre: 70
Souhlas. Dnešní disky mají cache maximálně 32-64 MB, při sekvenční rychlosti u středu řekněme 60 MBps. Takže by disk potřeboval energii na seek ke středu plotny (v nejhorším případě odhadem 20 ms) a na 1 s sekvenčního zápisu. Možná by to bylo levnější než po nějakou dobu udržovat baterkou obsah DRAM cache. Jedna vteřina provozu se seekem směrem k parkovací poloze. Kolik to může stát energie, 20 J? Superkondenzátory mívají přirozené jmenovité napětí okolo 2.5 V na článek. To by vycházelo řádově na 10 F potřebné kapacity, spíš trochu víc (nešel by využít až k 0 V). Ten koďan by nebyl úplně malej Třeba tenhle 25F kousek od Maxwellu je váleček průměr 16 krát 25 mm.
http://www.maxwell.com/pdf/uc/datasheets/DATASHEET_HC_series_1013793.pdf
Tomuhle dobrému nápadu by mohlo docela pomoct, kdyby disk měl šanci se okamžitě dozvědět, že napájecímu zdroji počítače vypadla šťáva na vstupu (zhasla střídavina). Kdyby si disk musel sám zjišťovat, že došlo k nějakému poklesu napájecích větví, tak už propásne příležitost využít energii, která ještě zůstala naakumulovaná v napájecím zdroji. Nejvíc energie akumuluje primár napájecího zdroje (aspoň u zdrojů se vstupem 230V st.). Fakt je, že když uvažuju jako optimistický případ třeba 470uF kondík a zdroj s aktivním PFC schopný pracovat v rozsahu 100-240V st. napájený ze sítě 240V st., vychází mi využitelná akumulovaná energie na cca 20 Joulů (Watt*Sekunda), což je řekněme 100 ms provozu celého kompu. To by ten koďan na primáru zdroje musel být řádově větší Taky kdyby tomu výpadku předcházelo podpětí v té vstupní střídavině, koďan na primáru by ve chvíli výpadku neměl skoro žádnou zbytkovou energii...
Když by superkondenzátor zabudovaný do disku měl krmit zmíněný nouzový zápis, potřeboval by patrně jako doprovod ještě nějaký spínaný zdroječek/stabilizátor a taky odpojovací FET v každé napájecí větvi na vstupu disku, aby nekrmil zpátky už chcíplý počítač Celé to znamená docela dost součástek navíc.
Stejnak to problém bezezbytku neřeší, protože hodně dat bude v okamžiku výpadku v bufferech OS...
Nezapomínejte na druhou situaci, kdy jsou soft updates nebo jejich ekvivalent potřeba: pád systému.
Jo, jasně V současnosti určitě jediný možný pragmatický přístup. Přesto mě okouzluje teoretická představa, že by si disk stihl zapsat svojí cache na plotnu, ať se děje co se děje. Superkondík by měl stejnou životnost jako disk. Baterky v UPSce mají životnost tak dva roky bůhví jestli. Kolik já už viděl UPSek co měly baterku dávno sušenou, nebo se historickým vývojem přihodilo, že se časem dostaly do zóny přetížení... To jistě nebyly zodpovědně správcované UPSky - nicméně to byla realita 
Uz jsem videl take par vyhorelych UPS ...
Nejefektnejsi to bylo v datovem centru, kde u jedne masiny odkracel zdroj a zpusobil kolaps UPS pro cely sal.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 8.8.2009 03:19
8.8.2009 03:19