Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
Po síti se potulují nejrůznější konvertítka z nejrůznějších formátů do jiných, HTML mezi nimi nevyjímaje. Do jaké míry jsou schopny splnit očekávání, musíte posoudit sami. Mé očekávání nesplnilo zatím žádné. Dílem proto, že konverze z TeXu není v principu možná bez stejné interpretace textu, jakou provádí TeX samotný: TeX si totiž pomocí přečtených maker sám určuje, jakým způsobem bude číst další řádky zdrojového textu a jak je bude interpretovat. Dílem taky proto, že v dokumentacích kladou konvertítka často rovnost TeX=LaTeX a to mě vždy natolik vytočí, že dál už se tím ani nezabývám. Ve většině případů také ta konvertítka považují za výchozí formát něco jiného než zdrojový text k TeXu a konverzi do LaTeXu používají jen jako skrytý mezistupeň k vygenerování PDF.
Osobně za výchozí formát dokumentu považuji zdrojový text TeXu. S tímto
formátem interaktivně pracuji jako autor nebo sazeč, tj. vytvářím
jej v textovém editoru, dívám se na něj, modifikuji jej. Tento formát
také archivuji. V případě seriálu na abclinuxu mám archivován text
v souborech tex1.tex, tex2.tex až tex5.tex
(zde) a pokud budu chtít v budoucnu tento
text použít (například sestavit knihu), nebudu mít problém. Ostatní formáty
považuji za (de)generované. Někdo může mít jiný názor a tudíž jiné požadavky na
případné konvertítko.
O konverzi matematických vzorečků zrovna nedávno pojednal jeden článek na AbcLinuxu, takže se k tomu nebudu podrobně vracet. Podotknul bych pouze, že řešení, které ze skoro každého vzorečku vygeneruje pro HTML stránku obrázek, mi připadá poněkud humpolácké: textové písmo pak ve www prohlížeči vizuálně nenavazuje na písmo ve vzorečku. Konverze do MathML nebo něčeho podobného je tedy žádoucí. Bohužel ani 15 let po vzniku MathML není tento jazyk implementován ve všech běžných webových prohlížečích, což odrazuje od dalších aktivit.
Mezi sémantickým značkováním vzorce (jako v MathLM) a značkováním pro potřeby sazby (jako v TeXu) existují principiální rozdíly, které konverzi oběma směry komplikují nebo dokonce znemožňují. Sémantické informace (např. zda ve vzorečku f(x+1) je f označení funkce nebo je to násobící koeficient) se při konverzi do TeXu ztratí. Naopak TeX nabízí plno nástrojů na vylepšení vizuálního vzhledu vzorce (podpěry, fantómy, korekční mezerování, atd.), kterým se věnuje celá kapitola 18 TeXbooku resp. sekce 6.8 v TeXu pro pragmatiky. Ty zas nejsou konvertovatelné do sémantického značkování. Navíc většina matematiků si zjednoduší psaní vzorečků různými vlastními více či méně obskurními makry. Na takovém zdrojovém textu si pak tupé konvertítko matematických vzorců většinou vyláme zuby.
Ačkoli jsem matematik, osobně se vyhýbám vzorečkům v HTML stránkách jako čert kříži. Takže ani v následující ukázce tento problém neřeším. Důvody byly řečeny před chvílí.
Toto konvertítko je zajímavé tím, že používá pro konverzi ze zdrojového souboru TeXu přímo TeX. Má připravenou modifikovanou sadu LaTeXových balíčků, která je TeXu podstrčena místo originálních balíčků a která je zaměřena na problematiku přípravy DVI souboru pro další zpracování do HTML. Dále se na výstupní DVI vrhne postprocesor, který má zase připravenu sadu jakoby-fontů (místo skutečných fontů), ze kterých zjistí, jaká HTML entita přísluší které pozici daného fontu. Celé mi to připadá zbytečně komplikované, centrem je 8bitové DVI, ze kterého se pak akcentované znaky rodí jako HTML entity. Navíc je to pro plainTeX ne zcela fungující. Takže ani tuto možnost jsem nevyužil.
Pomocí pdfTeXu vytvořím PDF soubor, který obsahuje kompletní HTML kód. Pak stačí pomocí příkazu
pdftotext -nopgbrk tex5.pdf tex5.html
z něj udělat HTML soubor. Konvertor pdftotext exportuje do textu
v kódování UTF-8, takže stačí do preambule HTML napsat
<meta http-equiv="Content-Type" content="text/html; charset=UTF8">
a není nutné řešit HTML entity jednotlivých znaků.
Zdrojový text je označkován obvyklým
způsobem, jak to dělám při použití OPmac. Rozdíl je jen v tom, že je navíc
načtena sada maker pomocí \input abchtml.
Rozebereme si nyní některá makra ze souboru
abchtml.tex podrobněji. Například
\sec Nadpis (titulek je ukončen prázdným řádkem) se má proměnit na
<h2>Nadpis</h2>. K tomu stačí předefinovat makro
\sec takto:
\def\sec#1\par{\tag{h2}#1\unskip\tag{/h2}}
Makro \sec si přečte svůj parametr #1 až po
\par (to je interní reprezentace prázdného řádku) a vloží jej
mezi \tag{h2} a \tag{/h2}. Mezi koncem parametru
a \tag{/h2} je \unskip, aby se odstranila mezera
z konce titulku. Ve skutečnosti je makro \sec mírně složitější,
vrátíme se k tomu později.
Pomocné makro \tag má jeden parametr bez separace (tj. parametr se
píše do složených závorek) a je definováno takto:
\def\tag#1{\hbox{\localcolor\Red\tt<#1>}}
Makro \tag tedy vkládá svůj parametr mezi znaky <
a >, ale navíc to celé vytiskne uvnitř boxu (\hbox)
červeně (\localcolor\Red). To je jen mírný bonus navíc, aby bylo výstupní
PDF více přehledné. Po konverzi pomocí pdftotext pochopitelně
barvy nemají vliv. Analogicky jako \tag je definováno makro
\ent{text}, které vytiskne zeleně HTML entitu &text;.
Zabývejme se nyní sazbou odstavce. Ve zdrojovém textu jsou odstavce odděleny
prázdnými řádky, které (jak bylo řečeno) jsou v TeXu interně reprezentovány
pomocí \par. Stačí tedy definovat:
\def\par{\unskip\tag{/p}\endgraf}
a každý prázdný řádek připojí do sazby tag konce odstavce
</p> a následně pomocí \endgraf skutečně ukončí
odstavec. Toto řešení ovšem způsobí, že více prázdných řádků pod sebou se projeví
větším počtem ukončovacích tagů. To není dobré. Skutečné makro je tedy
ještě vylepšeno podmínkou, zda TeX je ve stavu rozpracovaného odstavce
\ifhmode. Není-li v tomto stavu, žádný tag netiskne.
\def\par{\ifhmode\unskip\tag{/p}\fi\endgraf}
Máme už každý odstavec ukončen správným tagem. Ještě je potřeba ho taky správně
zahájit. K tomu slouží v TeXu registr \everypar, kam můžeme
napsat, co má TeX udělat na začátku každého odstavce:
\everypar={\tag{p}}
Hladká sazba (tj. sazba odstavců) je tím vyřešena. Dále pomocí makra vlna.tex, který je součástí encTeXu, vkládám automaticky za každou neslabičnou předložku vlnku. Uživatel ji nemusí psát. Vlnka je v TeXu definována jako nedělitelná mezera. Je potřeba ji pro potřeby výstupu do HTML jen předefinovat:
\def~{\ent{nbsp}}
Zatím zmíněná makra nám ušetří při psaní HTML kódu už hodně práce. Není potřeba psát otravné tagy na začátek a konec každého odstavce. Ve zdrojovém dokumentu TeXu stačí prázdný řádek, tedy bouchnout do klávesy Enter. A o neslabičné předložky se taky nemusíme starat.
V tomto seriálu používám často slovo TeX (a někdy i LaTeX) a do
zdrojového textu zapisuji \TeX resp. \LaTeX. Tato makra
implicitně tisknou logo se sníženým E. Pro potřeby HTML to není žádoucí, takže
definuji:
\def\TeX{TeX}
\def\LaTeX{LaTeX}
Mohl bych sice definovat \def\TeX{T\tag{sub}E\tag{/sub}X}, ale moc se mi
toto řešení nelíbí.
Když chci něco v TeXu zdůraznit kurzívou, píšu {\it text}.
V případě konverze do HTML chci, aby se takový zápis přeměnil na
<i>text</i>. K tomu stačí předefinovat makro \it
takto:
\def\it{\tag{i}\aftergroup\etagi}
\def\etagi{\tag{/i}}
Toto makro lze číst takto: \it vytiskne tag <i>
a po skončení skupiny spustí \etagi. Skupina je ukončena ukončovací
závorkou }. V tomto místě \etagi vytiskne ukončovací
tag </i>. Podobně je předefinováno makro \bf pro přechod
na tučný font.
Vrátíme se k makru \sec, které bylo již vysvětleno, ale ve
skutečnosti je definováno takto:
\def\sec#1\par{\medskip\notagindent \tag{h2}{\tenbf#1}\unskip\tag{/h2}\endgraf\medskip}
Příkaz \medskip udělá vertikální mezeru, \notagindent zahájí
odstavec bez vstupního tagu <p>, dále \tenbf nastaví
tučný font (jen pro přehlednost), \endgraf ukončí odstavec bez
ukončovacího tagu </p> a \medskip vloží další
vertikální mezeru.
V tomto duchu jsou v souboru abchtml.tex naprogramována
i ostatní použitá makra. Celý dokument je vytištěn ve strojopisu písmem Cursor
(\input cs-cursor), aby se neslilo f a i do ligatury fi.
Soubor abchtml.tex obsahuje zhruba 70 řádků docela srozumitelných maker. Pokud někdo chce pro svou webovou prezentaci svých dokumentů tento přístup použít, může. Stačí makra trošičku modifikovat dle potřeb konkrétního webu, tedy například zohlednit, na jaké to bude konkrétně navazovat kaskádové styly anebo PHP. Je také možné navázat na použitý JavaScript, tj. například již zmíněnou matematiku dělat MathJaxem.
Je zřejmé, že podobná sada maker by mohla posloužit ke konverzi do reStructuredText, na který by se pak dala použít většina dostupných konvertítek do všemožných dalších formátů.
Do zdrojového textu mohu napsat například $\alpha$ a na webové
stránce po konverzi vidím α. Přitom znak α je do PDF vytištěn pomocí matematického
fontu z pozice, která vůbec neodpovídá Unicode tohoto znaku. To ale nevadí.
Font vložený do PDF má totiž ke každému znaku přidělenu nejen pozici znaku, ale
i jeho název. A konvertor pdftotext se ptá na název znaku.
Zjistí, že v tomto případě je název alpha a v Unicode
tabulce najde tento název pod číslem U+03B1. Na základě toho ví, že má pro tento
znak vytvořit UTF-8 kód 0xCE 0xB1 a vše funguje, jak má.
Pokud ve zdrojovém kódu tex5.tex
zakomentuji příkaz \input abchtml a místo toho napíšu
třeba \hyperlinks\Blue\Red \let\perex=\relax, dostanu
obvyklý výstup, který je připraven pro další
zpracování. Sazeč dále rozhodne, jaký použije font, jaké nastaví zrcadlo
a další parametry sazby, jak upraví nadpisy. Taky zatáhne neslabičné předložky
(např. pomocí vlna.tex) a vyřeší
přetečený řádek. Toto je typická ukázka, jak rozličný výstup lze získat ze
stejného textu, jen při použití jiných maker.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 13.11.2013 01:03
Josef Kufner | skóre: 70
13.11.2013 01:03
Josef Kufner | skóre: 70
 ). Krom nějaké vestavěné podpory exportu existuje i nástroj eLyxer, který produkuje velice slušné výsledky (celý jeho web je v něm udělaný). Dokonce i s matematikou si docela poradí a není to povětšinou nijak tragické.
A mimochodem, tag <title> je v HTML povinný.
). Krom nějaké vestavěné podpory exportu existuje i nástroj eLyxer, který produkuje velice slušné výsledky (celý jeho web je v něm udělaný). Dokonce i s matematikou si docela poradí a není to povětšinou nijak tragické.
A mimochodem, tag <title> je v HTML povinný.
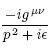 13.11.2013 10:25
egg | skóre: 20
| Praha
13.11.2013 10:25
egg | skóre: 20
| Praha
Dokonce i s matematikou si docela poradí a není to povětšinou nijak tragické.Nic moc. MathJax to umí lépe.
13.11.2013 10:43
Josef Kufner | skóre: 70
 13.11.2013 14:21
xkucf03 | skóre: 50
| blog: xkucf03
13.11.2013 14:21
xkucf03 | skóre: 50
| blog: xkucf03
Mathjax má zabalený nějakých 17 MB
OMG. A i bez toho mi přijde lepší generovat ty vzorečky offline – vyrobit z nich jednorázově nějakým generátorem HTML+CSS+JS+SVG a ne to renderovat všechno až na klientovi.
 13.11.2013 13:15
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 16:30
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 13:15
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 16:30
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
<span class="cmti-10">regul</span><span class="cmti-10">á</span><span class="cmti-10">rn</span><span class="cmti-10">í</span>tenhle problém řeším v make4ht s pomocí filtrů
13.11.2013 21:31
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 14:24
xkucf03 | skóre: 50
| blog: xkucf03
Tohle je určitě zajímavý postup.
Zajímavý je a rád jsem si to přečetl. Ale vyrobit PDF a z něj pak vytáhnout zase prostý text, mi nepřijde jako moc čisté řešení.
13.11.2013 13:17
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Dílem proto, že konverze z TeXu není v principu možná bez stejné interpretace textu, jakou provádí TeX samotný: TeX si totiž pomocí přečtených maker sám určuje, jakým způsobem bude číst další řádky zdrojového textu a jak je bude interpretovat.Ano, musi to delat nejaky TeX backend, ktery ma informaci jak interpretovat co chtel autor textu rici.
Pomocí pdfTeXu vytvořím PDF soubor, který obsahuje kompletní HTML kód. Pak stačí pomocí příkazu ... z něj udělat HTML soubor.Tohle sice funguje, v mezich mozneho je to i elegantni, nicmene je to stale drbani se levou nohou za pravym uchem.
 13.11.2013 14:32
|🇵🇸 | skóre: 94
| blog:
13.11.2013 14:32
|🇵🇸 | skóre: 94
| blog:
Podotknul bych pouze, že řešení, které ze skoro každého vzorečku vygeneruje pro HTML stránku obrázek, mi připadá poněkud humpolácké: textové písmo pak ve www prohlížeči vizuálně nenavazuje na písmo ve vzorečku. Konverze do MathML nebo něčeho podobného je tedy žádoucí. Bohužel ani 15 let po vzniku MathML není tento jazyk implementován ve všech běžných webových prohlížečích, což odrazuje od dalších aktivit.
Ačkoli jsem matematik, osobně se vyhýbám vzorečkům v HTML stránkách jako čert kříži. Takže ani v následující ukázce tento problém neřeším. Důvody byly řečeny před chvílí.
Hlavu do písku samozřejmě strkat můžeme, ale popularita malých čteček podporujících EPUB a současně nevhodných pro prohlížení PDF je prostě fakt. Vzhledem k nepodpoře MathML ve WebKitu a velikosti/náročnosti skriptů jsou obrázky celkem jasná volba.
13.11.2013 17:06
|🇵🇸 | skóre: 94
| blog:
Už jsem se na to ptal minule: šlo by udělat SAX parser pro TeX? Který by četl zdrojový soubor TeXu a emitoval události typu:
Takže ze zdroje:
\sec Nadpis text
by vylezlo např.
<command name="sec">Nadpis</command> <paragraph>text</paragraph>nebo lépe
<sec>Nadpis</sec> <paragraph>text</paragraph>
(samozřejmě ne jako textový výstup ale jako SAXové události)
Nemuselo by se jít nijak do hloubky, dovnitř maker – stačilo by zpracovat značkování, které je přímo ve zdrojovém dokumentu. Případně by se nějak definovala makra, která se ještě mají interpretovat (např. makro, které vypisuje název firmy, ano, zatímco jiná makra ne).
Kdyby existoval takovýhle obecný nástroj, tak by se daleko lépe daly psát další konvertory, které by tyhle jednoduché události zpracovaly a generovaly různé další formáty.
Ale přijde mi to celkem složité, protože to není jen \něco, ale i \něco[…]{…}, \něco[a=1, b=2, …]{…} nebo třeba \verb|…| případně \scalebox{-1}[1]{F} atd.
Jde mi o tu myšlenku generování různých výstupů z jednoho vstupního formátu – proto se taky ptám pod tímhle článkem.  I když musím říct, že se čím dál víc taky uchyluji myšlence: DocBook nebo nějaký vlastní XML formát jako obecný zdroj + generování různých výstupů (z nichž jeden je TeX/LaTeX a následně PDF).
I když musím říct, že se čím dál víc taky uchyluji myšlence: DocBook nebo nějaký vlastní XML formát jako obecný zdroj + generování různých výstupů (z nichž jeden je TeX/LaTeX a následně PDF).
Akorát je pak trochu potíž, když napíšeš třeba diplomku, vygeneruješ si z ní ten LaTeX a PDF a zjistíš, že by tady ještě chtěla typografie nějak doladit, manuálně zasáhnout do vygenerovaného .tex souboru. U té diplomky to ještě jde, tu vydáš jednou a hotovo, ale třeba taková firemní dokumentace – tu je potřeba aktualizovat, vydávat nové a nové verze. Tam pro manuální zásahy není prostor, to by člověka umořilo a stejně by na to občas zapomněl.
Tohle by mělo jít řešit pomocí něčeho jako instrukce pro zpracování (nebo přímo pomocí nich), kde byl uvedl příkazy/kód pro ten který výstupní formát a při generování ostatních by se to ignorovalo – takže by šlo do zdrojového formátu vložit kus i TeXu nebo kus XHTML, pokud by to bylo potřeba. A ručním změnám generovaného výstupu by se šlo teoreticky úplně vyhnout.
git diff je v pohodě čitelný. Výstup do PDF je v podstatě čistý LaTeX (a můžeš vkládat přímo kusy LaTeXu v editoru). Výstup do HTML skrz (na začátku diskuse zmíněný) eLyxer je docela pěkný (včetně obrázků), asi by to jen chtělo přidat "firemní" CSS. Ale krom toho má LyX i nativní export do HTML, který je mnohem zajímavější, pokud to s ním myslíš vážně. V LyXu totiž je k layoutu (odstavec, nadpis, seznam,…) definováno, jak bude vypadat v LyXu (WYSIWYG editoru), jak v LaTeXu a jak v HTML (a možná i v něčem dalším). Takže můžeš přidávat vlastní konstrukce (styly) do dokumentu a přitom nepřijdeš o možnosti exportu.
Druhou možností na psaní dokumentace, o které uvažuju, je Markdown. Je docela rozšířený a pokud jde o text přiložený přímo k programu a zobrazovaný v něm (nápověda), je nepraktické vyžadovat LyX či podobné "velké" nástroje. Ale zas Markdown není rozšiřitelný a kdo si má pamatovat, jak se co vlastně formátuje.
13.11.2013 21:33
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Druhou možností na psaní dokumentace, o které uvažuju, je Markdown.Zmineny reStructuredText a Sphinx.
zjistíš, že by tady ještě chtěla typografie nějak doladit
Tvoje starosti a Rothschildovy prachy...
Jde mi o tu myšlenku generování různých výstupů z jednoho vstupního formátu – proto se taky ptám pod tímhle článkem.Protože XSLT je ještě o něco méně čitelné, než TeXová makra?
<xsl:template match="a[ starts-with(@href, 'http://') or starts-with(@href, 'https://') or starts-with(@href, 'ftp://') or starts-with(@href, 'mailto:') ]"> … </xsl:template>a ostatní se zpracují buď jinou šablonou nebo se přeskočí nebo z nich zbude jen text. Jde tohle udělat pomocí TeXového makra? Nebo bych musel předefinovat celý příkaz (bez ohledu na jeho parametry/obsah) např.
\url a dovnitř nacpat nějaké IFy?
V tomhle má obrovskou výhodu XML a XHTML (případně i olomítkované HTML5), kde nemusíš rozumět významu značek a přitom to můžeš zpracovat.Hahaha!
13.11.2013 21:32
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Jenže co když se mi v tom PDF objeví třeba poznámky pod čarou nebo po straně nebo něco jiného, s čím jsem při tvorbě HTML maker nepočítal? To mi pak úplně rozbije ten výstup, který vznikne převodem PDF na prostý text.
Ten SAX parser by právě umožňoval ty věci, kterým navazující nástroj nerozumí (nebo nechce rozumět) prostě přeskočit, ignorovat a odchytávat si jen ty značky/příkazy, které mě zajímají a které umím v tom kterém výstupním formátu vykreslit.
Poznamky pod carou by se daly nechavat v pameti
Jenže na se právě musím připravit předem – nejde to použít na obecný TeXový dokument.
Ještě mne napadla jedna věc: z TeXu se přece dají volat shellovské skripty nebo obecně příkazy, ne? Tak bych mohl předefinovat jen vybraná makra (která chci generovat v tom výstupním formátu) a na nich vždycky zavolat příkaz operačního systému, který by nějak obalená data poslal do souboru nebo nějaké roury – nezajímal by mě pak výstup pdflatexu, ale výstup těch příkazů postupně volaných z maker. Akorát by to znamenalo postupně spustit spoustu procesů (pro každý TeXový příkaz/makro, pro každý odstavec…).
Pak by tomu šlo podstrčit libovolný dokument v TeXu a filtrem by prolezlo jen to, co bych předem definoval – ostatní formátování by se zahodilo/přeskočilo.
Já měl vždycky poznámky pod čarou na konci dané stránky, ale i bez toho, bys tam měl1, což by ti pak zaplevelilo to HTML, které bys chtěl získat převodem PDF na text, a vlastně i ty poznámky na konci knihy by tam dělaly bordel.
[1] to číslo v textu, které odkazuje na poznámku
Moc jsme to nezkoumal, ale ConTeXt umí XML...
http://tex.stackexchange.com/questions/43052/converting-context-document-to-html
% Hlavička HTML:
\def\html{{\everypar={}\parskip=0pt\Blue {\typoscale[700/700]
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN"
"http://www.w3.org/TR/1998/REC-html40-19980424/strict.dtd" >\endgraf
\tag{html lang="cs"}\endgraf
\tag{head}
<meta http-equiv="Content-Type" content="text/html; charset=UTF8">\endgraf
\noindent\tag{title}Mathjax test\tag{/title}\endgraf
\tag{script type="text/x-mathjax-config"} % MathJax
\mjcode\endgraf
\tag{/script}
\tag{script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML\string_HTMLorMML"}
\tag{/script}
\tag{/head}\endgraf}
\tag{body}\endgraf\Black}\bigskip\bigskip}
% Inicializační kód MathJaxu
\def\readmeaning#1->#2\end{#2}
\def\mjcode{\bgroup\catcode`\#=12 \mjcodeA}
\def\mjcodeA#1{\def\mjcode{#1}%
\xdef\mjcode{\expandafter\readmeaning\meaning\mjcode\end}\egroup} % de-tokenizace
\mjcode{
MathJax.Hub.Config({tex2jax: {inlineMath: [["\\$","\\$"]]}});
MathJax.Hub.Config({ TeX: { Macros: {
"\(": "\\left(",
"\)": "\\right)",
bold: ["{\\bf #1}",1]
} } });
}
% Použití MathJaxu: \mj$...matika...$ nebo \mj$$...display matika...$$
\def\mj$#1${\if^#1^\expandafter\displaymj \else \printmj{\string\$}{#1}\fi}
\def\displaymj#1$${\endgraf \notagindent\printmj{\string$\string$}{#1}}
{\catcode`&=12
\gdef\printmj#1#2{\def\tmpb{#2}%
\edef\tmpb{\expandafter\readmeaning\meaning\tmpb\end}% de-tokenizace
\replacestrings{&}{&}% citlivé HTML znaky nahradím entitami
\replacestrings{<}{<}\replacestrings{>}{>}%
{\tt#1\tmpb#1}}
}
Makra předpokládají, že před každým vzorečkem ve zdrojovém textu je napsáno \mj, tedy \mj$...matika...$ nebo \mj$$...matika...$$. Mohl bych to sice dát do \everymath a \everydisplay, ale někdy je lepší to mít pod vlastní kontrolou. Do html stánky přepíše makro doslova stejný vzoerec obalený \$...\$ nebo $$...$$. Je to jiné, než v TeXu, protože v html potřebuji, aby se samotný $ choval normálně. Návrh v dokumentaci MathJaxu použít \(...\) jsem nevyužil, protože tyto sekvence používám na zvětšovací závorky.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 13.11.2013 19:20
13.11.2013 19:20