V Amsterdamu probíhá Blender Conference 2025. Videozáznamy přednášek lze zhlédnout na YouTube. V úvodní keynote Ton Roosendaal oznámil, že k 1. lednu 2026 skončí jako chairman a CEO Blender Foundation. Tyto role převezme současný COO Blender Foundation Francesco Siddi.
The Document Foundation, organizace zastřešující projekt LibreOffice a další aktivity, zveřejnila výroční zprávu za rok 2024.
Byla vydána nová stabilní verze 7.6 webového prohlížeče Vivaldi (Wikipedie). Postavena je na Chromiu 140. Přehled novinek i s náhledy v příspěvku na blogu.
Byla vydána verze 1.90.0 programovacího jazyka Rust (Wikipedie). Podrobnosti v poznámkách k vydání. Vyzkoušet Rust lze například na stránce Rust by Example.
GNUnet (Wikipedie) byl vydán v nové major verzi 0.25.0. Jedná se o framework pro decentralizované peer-to-peer síťování, na kterém je postavena řada aplikací.
Byla vydána nová major verze 7.0 živé linuxové distribuce Tails (The Amnesic Incognito Live System), jež klade důraz na ochranu soukromí uživatelů a anonymitu. Nově je postavena je na Debianu 13 (Trixie) a GNOME 48 (Bengaluru). Další novinky v příslušném seznamu.
Společnost Meta na dvoudenní konferenci Meta Connect 2025 představuje své novinky. První den byly představeny nové AI brýle: Ray-Ban Meta (Gen 2), sportovní Oakley Meta Vanguard a především Meta Ray-Ban Display s integrovaným displejem a EMG náramkem pro ovládání.
Po půl roce vývoje od vydání verze 48 bylo vydáno GNOME 49 s kódovým názvem Brescia (Mastodon). S přehrávačem videí Showtime místo Totemu a prohlížečem dokumentů Papers místo Evince. Podrobný přehled novinek i s náhledy v poznámkách k vydání a v novinkách pro vývojáře.
Open source softwarový stack ROCm (Wikipedie) pro vývoj AI a HPC na GPU od AMD byl vydán ve verzi 7.0.0. Přidána byla podpora AMD Instinct MI355X a MI350X.
Byla vydána nová verze 258 správce systému a služeb systemd (GitHub).
/dev/sda:
Timing buffered disk reads: 398 MB in 3.01 seconds = 132.28 MB/sec
/dev/sdb:
Timing buffered disk reads: 526 MB in 3.01 seconds = 175.02 MB/sec
/dev/sdc:
Timing buffered disk reads: 366 MB in 3.01 seconds = 121.64 MB/sec
/dev/sdd:
Timing buffered disk reads: 528 MB in 3.00 seconds = 175.97 MB/sec
/dev/sde:
Timing buffered disk reads: 314 MB in 3.01 seconds = 104.25 MB/sec
/dev/sdf:
Timing buffered disk reads: 356 MB in 3.00 seconds = 118.58 MB/sec
Řešení dotazu:
 1.9.2020 13:16
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
1.9.2020 13:16
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Ano, dříve k tomu byla potřebná normální síťovka (tj vypnout integrovanej realtek a dát tam třeba Intel)
A teď kacířská otázka: proč vlastně? Samozřejmě vím, že se to doporučuje, ale spíš by mne zajímal nějaký technický důvod. Checksum offloading (Tx i Rx) r8169 zvládne, scatter-gather taky, TSO taky, na GRO není podpora v hardware potřeba (a LRO je stejně většinou potřeba vypnout). Někomu by se možná hodil vlan tagging/stripping, ale zdaleka ne každému a na výkon to u gigabitu až takový vliv mít stejně nebude. Multiqueue… na serveru by se to hodit mohlo, ale, levnější NIC od Intelu (typicky ty s e1000 nebo e1000e driverem) mají jen jednu frontu, takže je potřeba něco "serverového", co stojí zhruba dvakrát tolik (aby ty fronty byly aspoň dvě).
To doporučení pochází ještě z doby 100Mb/s karet s 8139 chipsetem. Ne že by s těmi gigabitovými problémy nebyly, ale ty se týkají spíš power managementu a střídavého zakazování a povolování ASPM pro jednotlivé varianty, protože výrobce nespolupracuje a informace, co přesně má kde fungovat a jak, neposkytuje.
1.9.2020 16:17
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
spíš by mne zajímal nějaký technický důvodJá ho neznám. Podle mě za to tehdy mohly drivery nebo firmware. Netuším, nikdy jsem to nezkoumal, prostě jsem místo toho koupil jinou kartu. Vím, že si někdo kompiloval vlastní drivery (jestli je sehnal přímo na realteku nevím), ale to je zase problém s update kernelu (a pokud se jedná o vzdálený síťový server, tak je to problém ještě větší).
Přesně kvůli tomuhle jsem zdůrazňoval, že mne zajímají technické důvody, ne citové. Performance je složitá věc obecně a síťování není výjimkou; nahrazovat analýzu problému cargo kultem není správná cesta.
Mně se prostě nelíbí, když kvůli tomu, že někdy před 20 lety 100Mb/s NIC Realteku neměly některé základní funkce, lidé dnes bez rozmyslu aplikují tuto zkušenost na dnešní gigabitové NIC s úplně jiných chipsetem a doporučují ostatním nahrazovat je "desktopovými" kartami od Intelu, které toho typicky budou umět tolik, co ten Realtek. Víc toho budou umět až "serverové" varianty, ale ty už jsou přeci jen trochu dražší a většina uživatelů stejně rozdíl nepozná, určitě ne na rychlosti jednoho TCP spojení po lokálním ethernetu (tj. bez ztrát a s minimální latencí).
Vůbec tím nechci říct, že aktuální stav kolem Realteku je ideální. Výrobce moc nespolupracuje, takže typicky chvíli trvá, než mainline driver začne podporovat nové verze chipsetů, a chronické problémy s (ne)fungováním ASPM a s tím související reverty revertů revertů jsou už tak trochu legendou. Ale pokud někomu integrovaný adaptér funguje, není obvykle důvod ho nahrazovat - a už vůbec ne jen proto, že "se to říká". Pokud člověk tak jako tak potřebuje přidat kartu, tak je to samozřejmě něco jiného, ale pokud má integrovaný adaptér a ten mu funguje, není důvod se plašit.
Sorry, ale jaksi zapomínáš že vše má svou režii, takže těžko dosáhneš stejných rychlostí, jako při použití testu. Podle všeho to vypadá na rotační disky, možná SSHD.To jsem samozřejmě zvážil a proto jsem psal třeba u gigabitu jen 80 % kapacity média. Proto jsem psal rychlosti disků, i kdyby se 20 % ztrácelo na arbitráž apod. Pořád je to hrozně pomalé.
No já bych začal nejprve s testováním propustnosti sítě pomocí iperf, je pro Linux i Windows.Děkuji, že mi pomáháš. Tohle vypadlo.
Client connecting to 192.168.1.102, TCP port 5001
TCP window size: 85.0 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.1.22 port 53218 connected with 192.168.1.102 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 852 MBytes 715 Mbits/sec
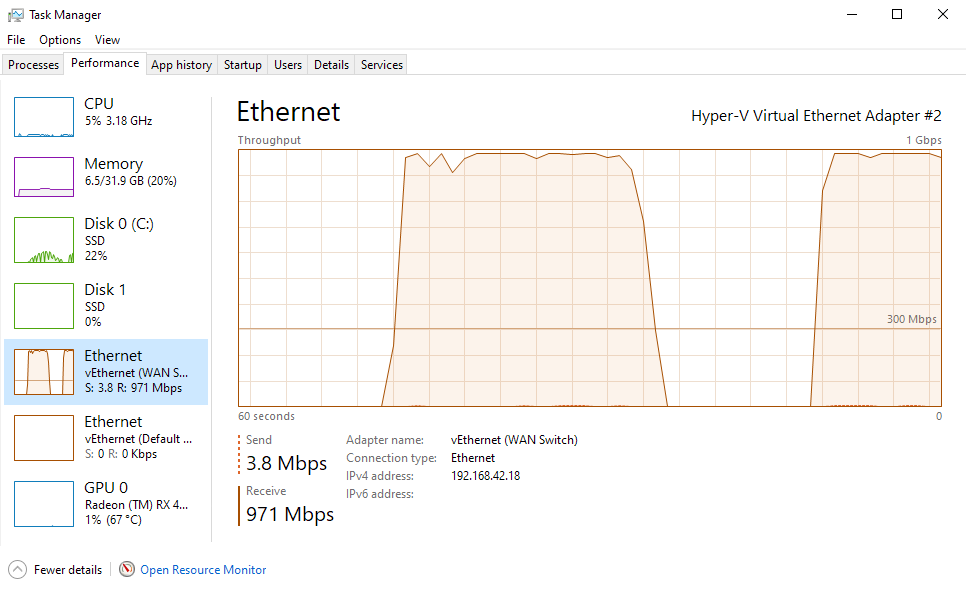
Takže kolem těch 700 Mb/s by to mělo zvládnout.
Promiň jestli to blbě čtu, ale 715 Mbits/sec rozhodně nedá 700 Mb/s (715 Mbit = 89.375 MB)...No já bych začal nejprve s testováním propustnosti sítě pomocí iperf, je pro Linux i Windows.Děkuji, že mi pomáháš. Tohle vypadlo.Client connecting to 192.168.1.102, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 192.168.1.22 port 53218 connected with 192.168.1.102 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 852 MBytes 715 Mbits/secTakže kolem těch 700 Mb/s by to mělo zvládnout.
Pokračoval bych testováním maximální rychlosti zápisu souboru velikosti 4 GB a více do pole pomocí dd (dd if=/dev/zero of=/cesta/k/adresáři/samby/test1.img bs=4G count=1 oflag=dsync) - nemělo by v tom výpisu být něco jako "md0", když se jedná o raid?
AAA:~# time dd if=/dev/zero of=/Video/PHOTOGRAPHY/image.iso bs=4G count=1 oflag=dsync 0+1 records in 0+1 records out 2147479552 bytes (2.1 GB, 2.0 GiB) copied, 42.1266 s, 51.0 MB/s real 0m42.290s user 0m0.000s sys 0m4.203szápis na RAID1 pole se dvěma disky. /Video namontováno jako RAID1 pole.
AAA:~# time dd of=/dev/null if=/Video/PHOTOGRAPHY/image.iso bs=4G count=1 oflag=dsync 0+1 records in 0+1 records out 2147479552 bytes (2.1 GB, 2.0 GiB) copied, 1.58343 s, 1.4 GB/s real 0m1.672s user 0m0.000s sys 0m1.668s
1.9.2020 16:21
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Ten zápis je podezřele pomalej. Čtení evidentně běží z iocache, tj ram. Hele, co to je za HW?
16 GB RAM
AMD Phenom(tm) II X6 1055T Processor, 1312 MHz
Realtek RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
AMD Family 10h Processor Miscellaneous Control
AMD Family 10h Processor Address Map
AMD RS780/RS880 PCI to PCI bridge (int gfx)
ATI SB7x0/SB8x0/SB9x0 LPC host controller
AMD RS880 Host Bridge
AMD Family 10h Processor Link Control
AMD Family 10h Processor DRAM Controller
ATI SB700/SB800/SB900 PCI to PCI bridge (PCIE port 0)
AMD Family 10h Processor HyperTransport Configuration
ATI SBx00 PCI to PCI Bridge
AMD RS780/RS880 PCI to PCI bridge (PCIE port 5)
Uvnitř je 8 disků na SATA - systém SATA 1 TB RAID1 (2 disky) 2x 4 TB RAID1 (2 disky) 2x 3 TB obyčejný mount na další disk bez RAID (1x 1,5 TB) disk: /dev/sdf WDC WD30EFRX-68E /dev/sdd WDC WD40EZRZ-00G /dev/sdb WDC WD40EZRZ-00G /dev/sde SAMSUNG HD154UI /dev/sdc WDC WD30EFRX-68E /dev/sda ST2000VX002-1AH1
Podle té rychlosti u druhého příkazu to vypadá, že jste ho spustil hned po tom prvním, takže bylo všechno ještě v page cache a z toho pole se nečetlo vůbec nic. Zkuste buď přidat ještě iflag=direct nebo mezi těmi dvěma příkazy spustit
echo 3 >/proc/sys/vm/drop_caches
OK, udělal jsem: Výsledek:Podle té rychlosti u druhého příkazu to vypadá, že jste ho spustil hned po tom prvním, takže bylo všechno ještě v page cache a z toho pole se nečetlo vůbec nic. Zkuste buď přidat ještě
iflag=directnebo mezi těmi dvěma příkazy spustitecho 3 >/proc/sys/vm/drop_caches
AAA:~# time dd if=/dev/zero of=/Video/PHOTOGRAPHY/image.iso bs=4G count=1 oflag=dsync 0+1 records in 0+1 records out 2147479552 bytes (2.1 GB, 2.0 GiB) copied, 31.4933 s, 68.2 MB/s real 0m31.603s user 0m0.004s sys 0m3.929s AAA:~# echo 3 >/proc/sys/vm/drop_caches AAA:~# time dd of=/dev/null if=/Video/PHOTOGRAPHY/image.iso bs=4G count=1 oflag=dsync 0+1 records in 0+1 records out 2147479552 bytes (2.1 GB, 2.0 GiB) copied, 25.5666 s, 84.0 MB/s real 0m26.106s user 0m0.008s sys 0m4.505s
Jak chceš saturovat 1 GB síť, když máš rychlost zápisu na disk 68.2 MB/s nebo 84.0 MB/s? To je nějak málo na RAID10, ne?OK, udělal jsem: Výsledek:Podle té rychlosti u druhého příkazu to vypadá, že jste ho spustil hned po tom prvním, takže bylo všechno ještě v page cache a z toho pole se nečetlo vůbec nic. Zkuste buď přidat ještě
iflag=directnebo mezi těmi dvěma příkazy spustitecho 3 >/proc/sys/vm/drop_cachesAAA:~# time dd if=/dev/zero of=/Video/PHOTOGRAPHY/image.iso bs=4G count=1 oflag=dsync 0+1 records in 0+1 records out 2147479552 bytes (2.1 GB, 2.0 GiB) copied, 31.4933 s, 68.2 MB/s real 0m31.603s user 0m0.004s sys 0m3.929s AAA:~# echo 3 >/proc/sys/vm/drop_caches AAA:~# time dd of=/dev/null if=/Video/PHOTOGRAPHY/image.iso bs=4G count=1 oflag=dsync 0+1 records in 0+1 records out 2147479552 bytes (2.1 GB, 2.0 GiB) copied, 25.5666 s, 84.0 MB/s real 0m26.106s user 0m0.008s sys 0m4.505s
Jak chceš saturovat 1 GB síť, když máš rychlost zápisu na disk 68.2 MB/s nebo 84.0 MB/s? To je nějak málo na RAID10, ne?Celou dobu mluvím o RAID 1. A i kdyby, disky mají 130 MB čtení, je to RAID, takže těch 130 MB bych velice rád dosáhl ve čtení. A hledám cestu, jak.
1.9.2020 18:58
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Myslel jsem, že RAID 10 přidá výkon, čte se z obou najednou.Hele, možná by ten dotaz chtělo strukturovat a napsat celý znovu. V původním dotazu se píše o raid10 a kopírování se testuje na 1.3GB souboru. Potom uvádíš raw fotky a Lr a teď raid1. Do toho se motá samba, síť, disky. V tomhle se nikdo nevyzná. Takže teď je evidentní, že je problém v pomalosti pole, zatímco disky se zdají být v pořádku. Btw, co smart? Jsou ty disky skutečně ok?
Myslel jsem, že RAID 10 přidá výkon, čte se z obou najednou.Hele, možná by ten dotaz chtělo strukturovat a napsat celý znovu. V původním dotazu se píše o raid10 a kopírování se testuje na 1.3GB souboru. Potom uvádíš raw fotky a Lr a teď raid1. Do toho se motá samba, síť, disky. V tomhle se nikdo nevyzná. Takže teď je evidentní, že je problém v pomalosti pole, zatímco disky se zdají být v pořádku. Btw, co smart? Jsou ty disky skutečně ok?
Ale je jedno, jestli je to 4GB file nebo 100x40MB, pokaždé (podle toho, jak se dívám na síťové rozhraní a zápis na lokální dost a čtení ze serveru, je to cca 50 MB/s).
Právě proto se motám dokola a nevím, kde začít rozmotávat.
Disky mají kolem 150 MB/s (kromě jednoho, který není v RAIDu a ten mě nezajímá)
Síť má propustnost dostatečnou na 700 Mb/s
Zůstává mi něco v samba...Takže vyzkoušet nějaké FTP?
1.9.2020 19:46
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Zůstává mi něco v samba...Jak se to může týkat samby, když to pole má při lokálním testu zápis 68 a čtení 84MB/s? Ano, v sambě může být ještě nějaký další problém, ale pokud je to pole takto pomalé, tak je nutné vyřešit nejdřív toto. Na 150MB/s diskách není normální mít 68MB/s zápis na pole. Co na to říká
mdadm --detail /dev/pole? Ať víme, jak je sestavené.
Co na to říká mdadm --detail /dev/pole? Ať víme, jak je sestavené.
/dev/md0:
Version : 1.2
Creation Time : Sat Jul 29 10:54:04 2017
Raid Level : raid1
Array Size : 2930134016 (2794.39 GiB 3000.46 GB)
Used Dev Size : 2930134016 (2794.39 GiB 3000.46 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Tue Sep 1 16:31:55 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : bitmap
Name : debian:0
UUID : e65ce113:bd09ac82:0513cda0:0f13218d
Events : 6095
Number Major Minor RaidDevice State
0 8 33 0 active sync /dev/sdc1
1 8 81 1 active sync /dev/sdf1
A
/dev/md33:
Version : 1.2
Creation Time : Sat Jun 15 07:37:46 2019
Raid Level : raid1
Array Size : 3906884608 (3725.90 GiB 4000.65 GB)
Used Dev Size : 3906884608 (3725.90 GiB 4000.65 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Tue Sep 1 17:33:25 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : bitmap
Name : nadarnas:33 (local to host nadarnas)
UUID : 27e349df:93320b5b:4075bad2:5cca8808
Events : 57147
Number Major Minor RaidDevice State
0 8 49 0 active sync /dev/sdd1
2 8 17 1 active sync /dev/sdb1
Na 150MB/s diskách není normální mít 68MB/s zápis na pole.
Ne do pole, ale do filesystému na tom poli, to může být rozdíl. Další potenciální problém je ten nešťastný parametr "bs=4G". Nedíval jsem se do zdrojáků, ale vůbec bych se nedivil, kdyby chudák dd musel nejdřív naalokovat 4 GB paměti, ze které pak půlku opravdu použil (při čtení; při zápisu asi všechno). Jestli při tom bylo potřeba flushnout nějaké stránky (na tytéž disky), aby se udělalo místo, tak to na klasickém disku s pomalým seekem taky na rychlosti nepřidá.
Možná by stálo za to zkusit ten test zopakovat s rozumnější velikostí bloku ("bs=1M count=4M" by mělo bohatě stačit).
("bs=1M count=4M" by mělo bohatě stačit).
Oops, samozřejmě "bs=1M count=4K"
1.9.2020 13:02
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
pv ten_soubor > /dev/null nebo třeba jen cat a změřit čas?
A vedle toho nezávisle změřit průchod sítě (komentář výše).
1.9.2020 13:05
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Ano, skutečně lze dosáhnout reálné rychlosti 117MB/s. Samba může bez problémů saturovat gigabit. (Fakt nechápu v roce 2020 komentáře, že 30MB/s je ok. To nebylo ani v roce 2008.) Jaký je původ těch souborů? Nebyly staženy torrentem (a tedy jsou značně fragmentované), lze na tom nasku pustit něco jakoSoubory jsou z fotoaparátu, tedy kolem 30-40 MB. Jsou to RAWy. Načítá je na stanici LIghtroom přes samba ze serveru.pv ten_soubor > /dev/nullnebo třeba jencata změřit čas? A vedle toho nezávisle změřit průchod sítě (komentář výše).
1.9.2020 16:29
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
socket options = TCP_NODELAY IPTOS_LOWDELAY SO_RCVBUF=8192 SO_SNDBUF=8192 SO_KEEPALIVE
1.9.2020 16:58
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Load smb config files from /usr/local/etc/smb4.conf Loaded services file OK. WARNING: socket options = TCP_NODELAY IPTOS_LOWDELAY SO_RCVBUF=8192 SO_SNDBUF=8192 SO_KEEPALIVE This warning is printed because you set one of the following options: SO_SNDBUF, SO_RCVBUF, SO_SNDLOWAT, SO_RCVLOWAT Modern server operating systems are tuned for high network performance in the majority of situations; when you set 'socket options' you are overriding those settings.
Linux in particular has an auto-tuning mechanism for buffer sizes (SO_SNDBUF, SO_RCVBUF) that will be disabled if you specify a socket buffer size. This can potentially cripple your TCP/IP stack.
Getting the 'socket options' correct can make a big difference to your performance, but getting them wrong can degrade it by just as much. As with any other low level setting, if you must make changes to it, make small changes and test the effect before making any large changes.
SO_RCVBUF=8192 SO_SNDBUF=8192Slovy klasika: to dává slovu hrůza nový rozměr. Nejhorší na tom asi je, že to druhé je dodnes v smb.conf(5) jako příklad…
Co tahle sem dát smb.conf. Není tam například něco takovéhoSocket mám zakomentovanýsocket options = TCP_NODELAY IPTOS_LOWDELAY SO_RCVBUF=8192 SO_SNDBUF=8192 SO_KEEPALIVE
#socket options = TCP_NODELAY SO_RCVBUF=16384 SO_SNDBUF=16384
Myslel jsem, že RAID 10 přidá výkon, čte se z obou najednou.Toť otázka. I v případě že algoritmus RAID1 bude optimálně číst u čistě sekvenčního IO pouze polovinu dat z každého členu (u RAID0 musí), při malé (typické) velikosti stripe vůči kapacitě tracku budou oba HDD trávit čas na stejném tracku čekaním než se jim pod hlavou protočí všechny "jejich" sektory. Což bude o obou členů znamenat typicky jednu celou otáčku.
net.core.rmem_default = 31457280 net.core.rmem_max = 12582912 net.core.wmem_default = 31457280 net.core.wmem_max = 12582912 net.core.somaxconn = 4096 net.core.netdev_max_backlog = 65536 net.core.optmem_max = 25165824 net.ipv4.tcp_mem = 65536 131072 262144 net.ipv4.udp_mem = 65536 131072 262144 net.ipv4.tcp_max_tw_buckets = 1440000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_sack = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_no_metrics_save = 1 net.core.rmem_max=8388608 net.core.wmem_max=8388608 net.core.rmem_default=65536 net.core.wmem_default=65536 net.ipv4.tcp_rmem=4096 87380 8388608 net.ipv4.tcp_wmem=4096 65536 8388608 net.ipv4.tcp_mem=8388608 8388608 8388608 net.ipv4.route.flush=1do /etc/samba/smb.conf pridat do [global]
socket options = TCP_NODELAY SO_RCVBUF=524288 SO_SNDBUF=524288 IPTOS_LOWDELAY socket options = SO_RCVBUF=131072 SO_SNDBUF=131072 TCP_NODELAY IPTOS_LOWDELAY SO_SNDBUF=65535 SO_RCVBUF=65535 read raw = yes write raw = yes max connections = 65535 max open files = 65535 write cache size = 1809715200 read cache size = 1809715200 read raw = Yes write raw = Yes min receivefile size = 16384 use sendfile = true aio read size = 96384 aio write size = 96384a daj vysledok ci pomohlo

net.ipv4.tcp_no_metrics_save = 1Jestli tazatel opravdu kopíruje soubory o velikosti 30-40 MB (tj. relativně malé), tak by tohle mohl být trochu problém, záleží na tom, jestli samba používá dlouhodobě jedno spojení nebo jestli opakovaně otevírá nová.
socket options = TCP_NODELAY SO_RCVBUF=524288 SO_SNDBUF=524288 IPTOS_LOWDELAY socket options = SO_RCVBUF=131072 SO_SNDBUF=131072 TCP_NODELAY IPTOS_LOWDELAY SO_SNDBUF=65535 SO_RCVBUF=65535
Neznám z hlavy syntaxi smb.conf, abych byl schopný říct, která z těch tří velikostí bufferu se nakonec použije, ale pokud by to byla ta poslední, tak vás to začne limitovat už při RTT kolem 0.5 ms. Vzhledem k tomu, že typické hodnoty v nezatížené domácí gigabitové síti mívám někde kolem 0.2 ms, tak to není moc velká rezerva.
<net.ipv4.tcp_no_metrics_save = 1Jestli tazatel opravdu kopíruje soubory o velikosti 30-40 MB (tj. relativně malé), tak by tohle mohl být trochu problém, záleží na tom, jestli samba používá dlouhodobě jedno spojení nebo jestli opakovaně otevírá nová.
Je to velice různé, z 20-30 procent kopíruju velké archívy, námi natočené videa, stovky MB až jednotky GB. A pak ze 70 procent soubory, 40 MB každý
Ale výkon je pořád do těch 50 MBDvě věci. 1. Jaké je vytížení procesoru 2. Verze protokolu samby.1. kolem 30 až 50 procent (max) 2. Version 4.7.6-Ubuntu, protokol
client min protocol = SMB2 client max protocol = SMB3
 3.9.2020 12:07
AraxoN | skóre: 47
| blog: slon_v_porcelane
| Košice
3.9.2020 12:07
AraxoN | skóre: 47
| blog: slon_v_porcelane
| Košice
Potvrdzujem - po porovnávacom teste Samba vs NFS som nakoniec dlho používal NFS (prakticky až do prechodu na Ceph).To asi nepomůže, když mám na straně klienta Widle
 3.9.2020 18:49
k3dAR | skóre: 63
3.9.2020 18:49
k3dAR | skóre: 63
Bylo tu několik rad ohledně síťovin. Tuším nebyl zmíněn tenhle atribut: net.ipv4.tcp_slow_start_after_idle=0 Ten jsem sice našel v souvislosti s NFS, ale odhadem Sambě by taky mohl pomoct.Zkusím díky
Co je to za filesystém? Ext4? Mountujete ho s opšnou "noatime"? Jaký IO scheduler? Co to je za Linux?Nee mám tohle ve fstab
/dev/md0 /Video ext4 defaults,nofail,discard 0 0
/dev/md33 /home ext4 defaults,nofail,discard 0 0
Obecně bych ještě doporučil, poladit chování VM = povolit větší využití volné systémové RAM pro cachování diskových operací, a možná zkusit přepnout IO scheduler na "deadline" a třeba ho ještě taky trochu poladit. Rychlosti čtení to asi moc nepomůže, ale jestli máte hodně RAMky, měl byste vidět její efekt (hlavně při zápisu, kdy se uplatní write-back buffering).Díky kouknu se TP
client min protocol = SMB3 client max protocol = SMB3viz odkaz na konfiguraci.
Jakmile jsem pořídil nový HW ASROCK J5040-ITX, na to 8 GB paměti (poloviční než ten původní) a rozšiřující kartu AXAGON PCES-SA2, abych měl potřebných 6 SATA III portů. IHNED to běhá 100-110 MB/s při čtení i zápisu na SAMBA.
Takže někde mezi HW desky, síťovkou a rozhraním SATA byl problém.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz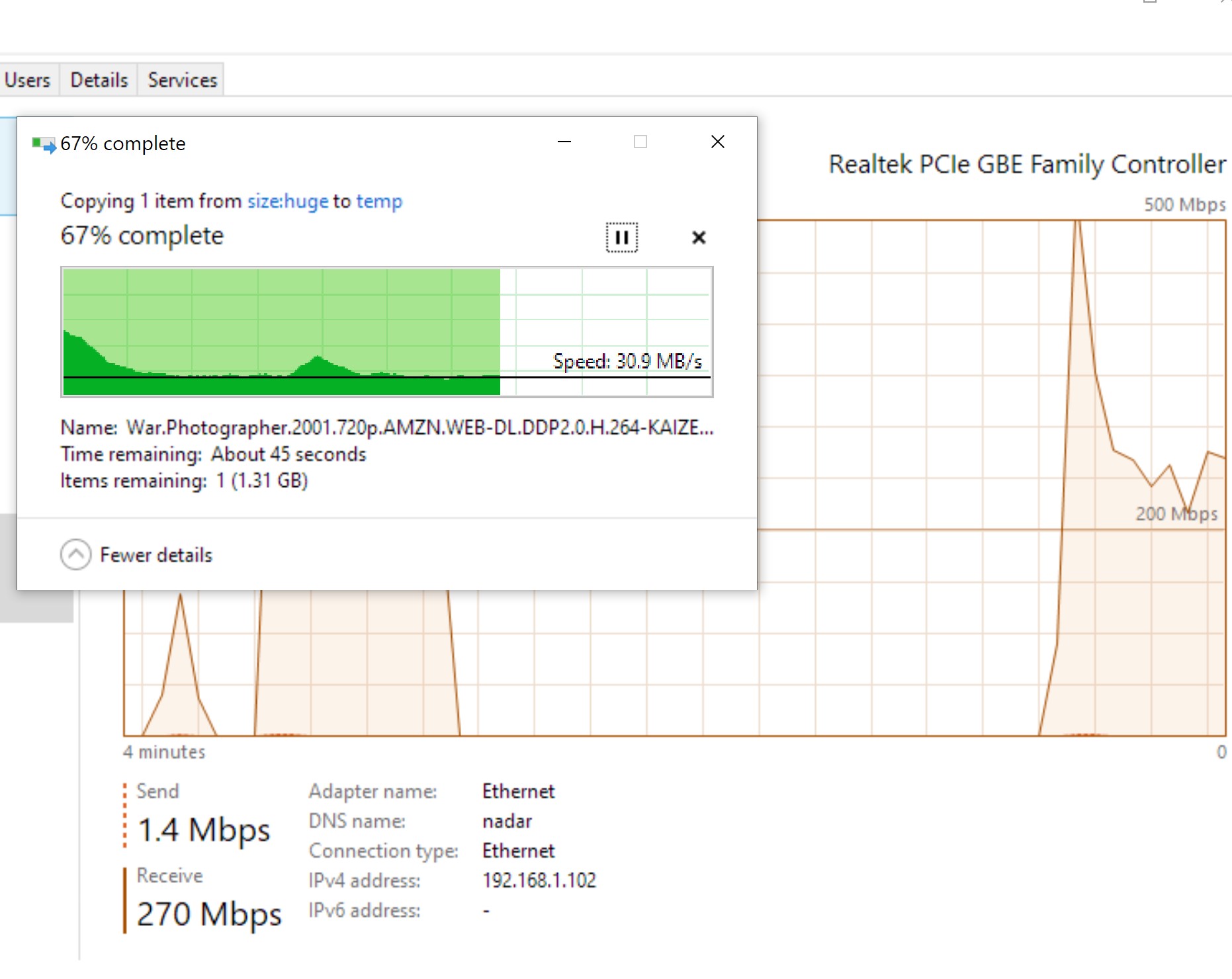{kind=link}
{kind=link}