Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Disk /dev/sda: 1000.2 GB, 1000204886016 bytes
255 heads, 63 sectors/track, 121601 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sda1 1 310 2490043+ fd Linux raid autodetect
/dev/sda2 311 375 522112+ fd Linux raid autodetect
/dev/sda3 392 121601 973619325 fd Linux raid autodetect
výpis z mdsat :
Personalities : [linear] [raid0] [raid1] [raid6] [raid5] [raid4]
md2 : active raid5 sda3[0] sdb3[1] sdc3[2] sdd3[3]
723165696 blocks level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3]
522048 blocks [4/4] [UUUU]
md0 : active raid1 sda1[0] sdb1[1] sdc1[2] sdd1[3]
2489920 blocks [4/4] [UUUU]
Aby se pole zvětšilo musím tedy použít :
mdadm -G /dev/md2 --size maxJelikož sda3 je v md2. Je to tak ? A druhá moje otázka je jestli to mohu udělat za chodu . Nerada bych to spustila a ztratila data :) . Děkuji za případné rady .
 29.1.2014 09:52
pavlix | skóre: 54
| blog: pavlix
29.1.2014 09:53
pavlix | skóre: 54
| blog: pavlix
29.1.2014 10:00
pavlix | skóre: 54
| blog: pavlix
29.1.2014 10:08
pavlix | skóre: 54
| blog: pavlix
29.1.2014 10:09
pavlix | skóre: 54
| blog: pavlix
29.1.2014 09:52
pavlix | skóre: 54
| blog: pavlix
29.1.2014 09:53
pavlix | skóre: 54
| blog: pavlix
29.1.2014 10:00
pavlix | skóre: 54
| blog: pavlix
29.1.2014 10:08
pavlix | skóre: 54
| blog: pavlix
29.1.2014 10:09
pavlix | skóre: 54
| blog: pavlix
mdadm -G /dev/md2 --size max
/dev/md2 on /volume1 type ext3Ok chápu , takže když v budoucnu dokoupím další 3ks 1TB disky, tak postupně budu dopočítavat pole a pak zvětším souborový sytém pomocí
resize2fs -p /dev/md2
sfdisk -d /dev/sda | sfdisk /dev/sdbA následně na sdb poslední partišnu smažu (fdisk, cfdisk) a vytvořím novou, přes celý zbytek disku.
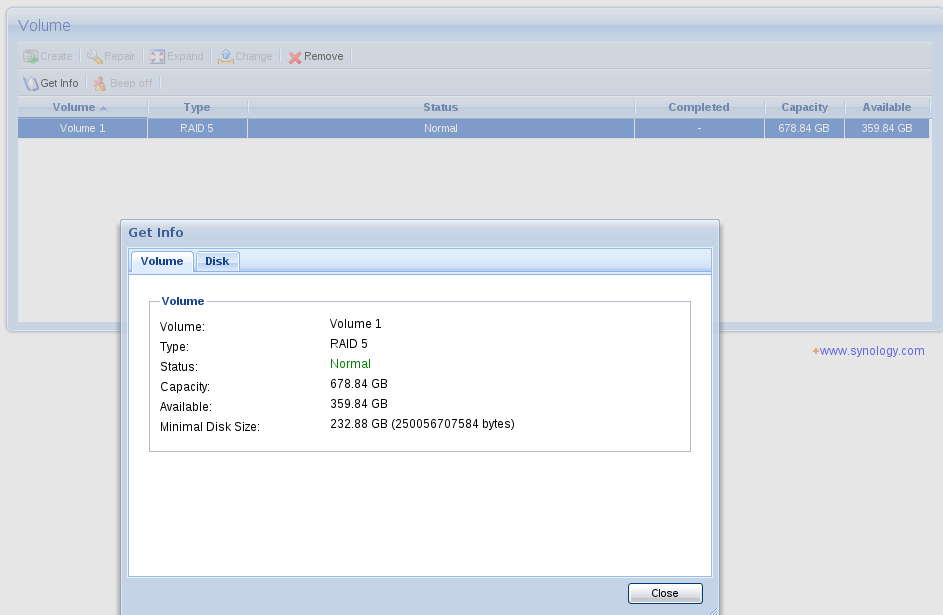
md2 má 723165696 bloků, myslím že bloky jsou klasické po 512 Bytech tak to pole má dohromady 370260836352 bytů tedy 370GB? Takže na jeden disk je cca 150G? Jen tak málo? Nízké kapacity jsou o dost dražší za GB prostě proto, že obal a mechanika hlav je téměř konstantní nákladová položka moc nezávisející na kapacitě. Nejefektivnější na GB jsou v současnosti 3TB disky, které jsou v ceně cca 1Kč/1GB (1TB je cca 1,5Kč/1GB) na druhou stranu pokud je to Synology natolik staré nemusí být schopno uřídit 3TB disky. Kde má to Synology firmware na discích nebo ve firmware? Uvažoval bych o přechodu na zcela nové disky, 2x 1TB disk v RAID1 by dalo mnohem větší kapacitu.
Další možnost k úvaze je taková: Na 1TB disku udělat přesně takové oddíly (s přesností na sektor, o sektor menší oddíl nejde zařadit do RAIDu, větší oddíl jsou zbytečné ztráty) jako jsou na ostatních discích. Na těchto oddílech vytvořit RAID s ostatními disky v Synology. Zbytek 1TB disku udělat samostatný oddíl a zapojit ho jako samostatný filesystem. Měl by se dát udělat na synology dostupný, nebyl by v RAIDu, takže na méně důležitá data, ale byl by využíván. Přesně takto jsem postupoval, když u mého pole havaroval 1,5TB disk v RAID 5 poli, a takové disky se již nedělají tak jsem koupil větší, jeho 1,5TB část zapojil do pole a na zbytku mám neRAID oddíl.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz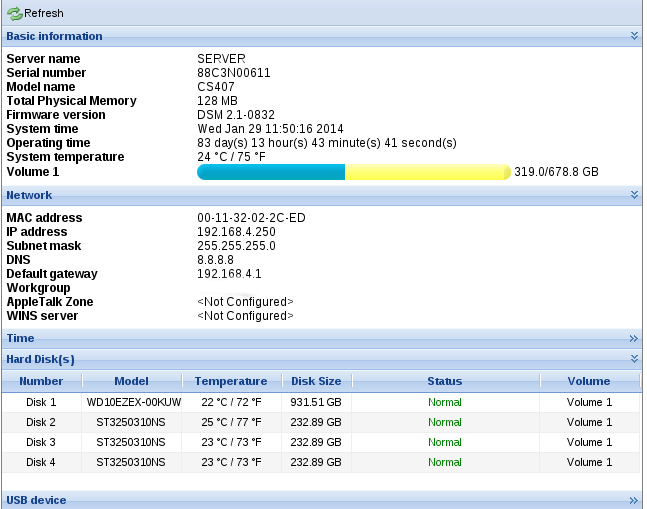{kind=link}
{kind=link}