FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
FreeCAD (Wikipedie), tj. svobodný multiplatformní parametrický 3D CAD, má nový vtipný a současně užitečný doplněk Banana For Scale (GitHub). Aktuálně umožňuje do výkresu vložit banán nebo plechovku pro porovnání a určení měřítka.
Programovací jazyk Java přináší ve své 8 verzi řadu zajímavých novinek a také rozšíření možností jazyka směrem k funkcionálnímu programování. Zejména lambda výrazům a funkčním rozhraní se věnuje autor úvodního článku Java 8: novinky jazyka na blogu Frantovo.cz.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 10.9.2014 16:48
xkucf03 | skóre: 50
| blog: xkucf03
10.9.2014 16:48
xkucf03 | skóre: 50
| blog: xkucf03

V Javě 8 můžou rozhraní obsahovat i neabstraktní metody, tedy metody, obsahující implementaci, ne jen hlavičku.
 To bylo nějakejch keců o tom, jak dědičnost implementace a multiple inheritance jsou největší zlo atd. atd. ... A po letech v tom Java jede taky. Mimochodem, tohle znamená, že už i Java teď umožňuje dreaded diamond, ne?
10.8.2014 11:56
xkucf03 | skóre: 50
| blog: xkucf03
To bylo nějakejch keců o tom, jak dědičnost implementace a multiple inheritance jsou největší zlo atd. atd. ... A po letech v tom Java jede taky. Mimochodem, tohle znamená, že už i Java teď umožňuje dreaded diamond, ne?
10.8.2014 11:56
xkucf03 | skóre: 50
| blog: xkucf03
final nebo alespoň efektivně final.
int x = 123; final int y = 456; int z = 789; Function<Integer, Integer> fx = (i) -> i + x; // tohle nejde přeložit Function<Integer, Integer> fy = (i) -> i + y; // y je (explicitně) final Function<Integer, Integer> fz = (i) -> i + z; // z je efektivně final x = 666; // důvod, proč x není efektivně final
To bylo nějakejch keců o tom, jak dědičnost implementace a multiple inheritance jsou největší zlo atd. atd.Proti dědičnosti implementace jsem nikdy nic neměl – nepatřím zrovna k fanatikům, kteří dědičnost zavrhují a všechno by řešili kompozicí.
A po letech v tom Java jede taky. Mimochodem, tohle znamená, že už i Java teď umožňuje dreaded diamond, ne?Umožňuje, ale kompilátor ti nedovolí přeložit nejednoznačný kód. V té třídě, kde se to spojuje, si musíš vybrat jednoho z předků, jehož metoda se použije, nebo si napsat její vlastní implementaci nezávislou na předcích.
public class Třída implements Aa, Ab {
@Override
public String metoda1() {
return Aa.super.metoda1();
}
}
(metoda1() je implementována v obou rozhraních Aa i Ab)
Proti dědičnosti implementace jsem nikdy nic neměl – nepatřím zrovna k fanatikům, kteří dědičnost zavrhují a všechno by řešili kompozicí.Jj, já vím, to nemělo být na tebe (možná to tak vyznělo - pardon
 ).
).
Umožňuje, ale kompilátor ti nedovolí přeložit nejednoznačný kód. V té třídě, kde se to spojuje, si musíš vybrat jednoho z předků, jehož metoda se použije, nebo si napsat její vlastní implementaci nezávislou na předcích.Jasný, čili je to v podstatě stejné jako v ostatních jazycích. Ono to nejspíš bude v Javě fungovat stejně/velmi podobně jako virtual inheritance v C++...
$x = 1;
$f = function($i) use (& $x) { return $i + $x; };
$x = 2;
echo "f(3) = ", $f(3), "\n";
Tak nedostanu "f(3) = 5", ale mám smůlu?
10.8.2014 14:51
xkucf03 | skóre: 50
| blog: xkucf03
Nejde o to zvládnout/nezvládnout. Samozřejmě, že by to šlo. Ale jde o to, jaký by to mělo vliv na čitelnost kódu, předvídatelnost výsledku.
Na tohle jsem narážel už v úvodu toho článku: jazyk, kde jde všechno možné != nejvhodnější jazyk.
10.8.2014 16:08
xkucf03 | skóre: 50
| blog: xkucf03
Je to vlastně trochu jako používat globální proměnné – řídit se jimi uvnitř funkcí a měnit podle nich jejich chování – a pak si před voláním funkce nastavovat globální proměnné tak, aby ta funkce udělala, co chceš… jenže s tím vedlejším efektem, že v tu chvíli ovlivníš všechna použití té funkce (třeba v jiných vláknech) nebo jiné na první pohled nesouvisející věci. Což může vést k chybám, které se hodně těžko hledají a opravují.
Když už chceš takhle měnit chování funkce, tak vhodnější přístupy IMHO jsou:
f.setParametr(2); // změníme chování funkce f.apply(3); // zavoláme funkci a vrátí nám 5
[1] ne na nějaké proměnné kdesi kolem, která s tou funkcí na první pohled nesouvisí – kdo to má vědět, že ovlivňuje chování té funkce?
$sum = 0;
$graph->walk(function ($node) use (& $sum) { $sum += $node->value; });
echo "Total: ", $sum, "\n";
10.8.2014 16:37
xkucf03 | skóre: 50
| blog: xkucf03
int proměnné můžeš mít objekt, který bude mít metody pro zvýšení a přečtení hodnoty, a proměnná, která na tento objekt ukazuje bude final.
10.8.2014 17:15
xkucf03 | skóre: 50
| blog: xkucf03
Objekt právě neměníš – jen ho používáš, voláš jeho rozhraní, metody.
10.8.2014 17:27
xkucf03 | skóre: 50
| blog: xkucf03
final je právě ta proměnná, což znamená že odkazuje pořád na stejný objekt – vnitřní stav toho objektu se ale měnit může.
Javovská logika mně nepřestane fascinovat...
10.8.2014 17:48
xkucf03 | skóre: 50
| blog: xkucf03
null nebo místo ní podstrčit instanci jinou.final to dělá velmi slabé omezení. const/immutable v jiných jazycích typicky zaručují*, že stav objektu zůstane nezměněný. Což může být dost užitečné. V některých jazycích dokonce je immutable výchozí a deklaruje se naopak mutable.
*) s nějakou rozumnou spolehlivostí - ne, že by se to taky nedalo tak nebo onak obejít
#include <iostream>
using namespace std;
class Foo
{
private:
int v;
public:
int value() const
{
return v;
}
int setValue(int value)
{
v = value;
}
};
int main()
{
Foo foo;
foo.setValue(3); // ok
const Foo *constfoo = &foo; // const pointer
auto lambda = [constfoo](int x) // capture constfoo
{
cout << x * constfoo->value() << endl; // ok
constfoo->setValue(15); // error - non-const member function
};
lambda(2);
}
A k čemu je mi odkaz na objekt, když nemůžu volat metody toho objektu? Mě nezajímá, co si ten objekt dělá uvnitř, jestli si nějak mění stav, to je jeho věc – od toho máme zapouzdření.
const. IMHO se stává poměrně často, že člověk někam předává referenci na objekt s tím, že ví, že objekt nebude (neměl by být) nijak měněn. V takovém případě je dobrý použít const, protože to nedovolí nechtěnou změnu stavu objektu (a afaik to umožňuje i nějaké optimalizace).
10.8.2014 19:11
xkucf03 | skóre: 50
| blog: xkucf03
Takže gettery udělám const a celý objekt pak taky předám jako const? To zní rozumně. Ono na tom C++ něco je (jen je jako celek strašně složité a rozsáhlé1).
Akorát budu mít smůlu, když bych v tom getteru chtěl mít třeba počítadlo. A z těch const metod můžu volat zase jen const metody?
[1] což má za důsledek obrovskou variabilitu kódu v něm napsaného a obecně horší čitelnost
jen je jako celek strašně složité a rozsáhléTo naprosto souhlasim, učící křivka tohohle jazyka je příšerná a možností, jak si pod sebou podřezat větev, je bohužel hodně... Navíc existuje X různých stylů jak psát a každý ti řekne, že ten jeho je ten správný
Akorát budu mít smůlu, když bych v tom getteru chtěl mít třeba počítadlo.Ano, to je určitý omezení.
A z těch const metod můžu volat zase jen const metody?Přesně tak, to const u té member funkce v podstatě nastavuje konstantnost parametru
this, takže volání non-const memberu s konstaním this je stejná situace jako v tom příkladu výše - v obojím nesouhlasí typ parametru. Je to podobný jako předat funkci místo integeru string.
10.8.2014 19:27
xkucf03 | skóre: 50
| blog: xkucf03
Tak to se mi líbí
Otázka je, jak dostat do jazyka (třeba Javy) všechny tyhle hezké vlastnosti a přitom z toho neudělat takové monstrum, jako je C++. Kéž by se to někomu povedlo
Foo + rozhraní ConstFoo nebo tak něco) a předávat objekt přes tohle rozhraní. Ale je to trochu práce navíc...
@Deprecated nebo @Override jazyk takhle rozšiřují – kompilátor díky nim hlídá další vazby v kódu. Různé knihovny přidávají další, třeba @NotNull/@Nullable – zrovna u tohohle mi není jasné, proč se taková anotace nestala součástí runtime knihovny, když už tam je java.util.Optional.
 10.8.2014 19:25
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
10.8.2014 19:25
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Alebo definovať počítadlo ako mutable.
Akorát budu mít smůlu, když bych v tom getteru chtěl mít třeba počítadlo.Ne tak docela,
mutable to řízeně dovolí:
/*
* use: g++ -pedantic -W const.cpp -o const.bin && ./const.bin
*/
#include <iostream>
class MyClass{
private:
mutable int counterGet;
mutable int counterSet;
int var;
public:
MyClass() : counterGet(0),counterSet(0),var(42){
}
virtual ~MyClass(){
/* nothing to do */
}
int getVar() const {counterGet++; return var;};
void setVar(int new_var) {counterSet++; var=new_var;};
int getCounterGet() const {return counterGet;};
int getCounterSet() const {return counterSet;};
};
int main( int argc, const char* argv[] ){
const MyClass constMyClass;
MyClass myClass;
std::cout << std::endl;
std::cout << "const:" << std::endl;
std::cout << " constMyClass.getVar(): " << constMyClass.getVar() << std::endl;
/* not possible */
/* constMyClass.setVar(10); std::cout << " constMyClass.setVar(10)" << std::endl; */
std::cout << " constMyClass.setVar(10) - compilation not possible" << std::endl;
std::cout << " constMyClass.getVar(): " << constMyClass.getVar() << std::endl;
std::cout << " constMyClass.getCounterGet(): " << constMyClass.getCounterGet() << std::endl;
std::cout << " constMyClass.getCounterSet(): " << constMyClass.getCounterSet() << std::endl;
std::cout << std::endl;
std::cout << "no-const:" << std::endl;
std::cout << " myClass.getVar(): " << myClass.getVar() << std::endl;
/* possible*/
myClass.setVar(10); std::cout << " myClass.setVar(10)" << std::endl;
std::cout << " myClass.getVar(): " << myClass.getVar() << std::endl;
std::cout << " myClass.getCounterGet(): " << myClass.getCounterGet() << std::endl;
std::cout << " myClass.getCounterSet(): " << myClass.getCounterSet() << std::endl;
return 0;
}
12.8.2014 16:43
xkucf03 | skóre: 50
| blog: xkucf03
Nejtypičtějším příkladem je asi, zamykání při multithreading, daný např. mutex je mutable aby (nejenom) všechny gettery mohli být thread-safe, ale stále const.
mutable je vhodné/určené na věci co nedefinují stav objektu, ale je třeba s tím šetřit.
final je věc, kterou může kompilátor kontrolovat. const chápu tak, že je to nějaký příznak, který nastaví programátor - ale nijak není zaručeno, že ta metoda stav objektu skutečně nemění.
Pokud chci v Javě něco takového, jako const, vytvořím pro to buď zvláštní interface, který bude mít jen to metody, které nemění stav, nebo potomka, který metody měnící stav bude mít přetížené a budou vyhazovat výjimku. Úplně stejně pak budu postupovat, pokud potřebuju nějak označit metody jiným příznakem - třeba ty, které je bezpečné volat vícevláknově.
const také kontroluje kompilátor, je to součást typu - non-cost typ je implicitne konvertibilní na const typ, ale zpět už pochopitelně ne. Že const proměnná/objekt nebude změněn je zaručeno, dá se to obejít pouze hacky jako const_cast, mutable nebo manipulací s pamětí na místě, kde je proměnná/objekt uložen.
const metody není možné volat žádnou non-const metodu ani na jiném objektu? To asi musí být dost omezující, ne? Každopádně final field v Javě zaručuje jenom to, že se hodnota proměnné nastaví právě jednou – tj. v případě objektu ukazuje reference stále na tentýž objekt, ale nedává to žádné omezení na objekt samotný.
Takže z const metody není možné volat žádnou non-const metodu ani na jiném objektu?Ne, s jinými objekty to nemá nic společnýho. Viz vysvětlení výše, specifikuje se tím, jestli je parametr
this v předpisu member funkce const, nebo ne.
11.8.2014 17:50
xkucf03 | skóre: 50
| blog: xkucf03
Takže když použiji kompozici a jeden objekt by měl zastřešovat více dalších objektů, tak změnu stavu těch vnitřních objektů mi to neohlídá?
const metoda na tom vloženém objektu buď může zavolat cokoli, a pak ta aktuální instance není zas tak moc immutable. A nebo const metoda nemůže volat nic jiného než zase const metody.
final v C++ by byl Foo &const foo, tj. const se nedá k typu, ale až k té referenci, takže vznikne immutable reference na mutable typ. Nicméně afaik se to moc nepoužívá. Jde taky obohe skombinovat (tj. const reference na const typ), ale ani to se afaik moc nepoužívá...
final v Javě, to jsem si blbě pamatoval. Nicméně pokud člověk používá smart pointery (osobně raw pointery prakticky nepoužívám), tak ty const correctness zachovávají správným způsobem.
Jinak komu nestačí const, tak možnost vytvářet interfacy je samozřejmě taky. Nevim přesně, co jsou ty anotace v Javě, ale jestli to chápu správně, tak to bude podobné jako atributy v C++11...
11.8.2014 10:28
xkucf03 | skóre: 50
| blog: xkucf03
vytvořím pro to buď zvláštní interface, který bude mít jen to metody, které nemění stav, nebo potomka, který metody měnící stav bude mít přetížené a budou vyhazovat výjimku
Potomek má nevýhodu, že na něj nemůžu konvertovat existující objekt. A rozhraní si zase může někdo přetypovat zpátky a používat všechny metody – je otázka, jestli být takhle paranoidní – třeba před reflexí se bránit moc nedá, to už je extrém, hack, ale přetypování je relativně standardní činnost, se kterou by se asi mělo počítat. Bezpečnější než rozhraní bude adaptér, který původní objekt obalí a zpřístupní jen vybrané metody.
Foo * const constfoo = &foo;Je ekvivalent tohoto v Javě:
final Foo constfoo = ...
10.8.2014 17:24
xkucf03 | skóre: 50
| blog: xkucf03
final AtomicReference<Integer> počet = new AtomicReference<>(0); počet.set(1); int x = počet.updateAndGet(i -> i + 1); int y = počet.getAndUpdate(i -> i + 1); System.out.println(počet.get());
10.8.2014 19:17
xkucf03 | skóre: 50
| blog: xkucf03
final AtomicReference<Integer> počet = new AtomicReference<>(0); // int počet = 0; počet.set(1); // počet = 1; int x = počet.updateAndGet(i -> i + 1); // int x = ++počet; int y = počet.getAndUpdate(i -> i + 1); // int y = počet++; System.out.println(počet.get()); // System.out.println(počet);
 11.8.2014 10:33
Saljack | skóre: 28
| blog: Saljack
| Praha
11.8.2014 10:33
Saljack | skóre: 28
| blog: Saljack
| Praha
#include <iostream>
using namespace std;
int main()
{
int foobar = 0;
auto lambda = [&foobar]()
{
foobar = 3; // <- Takhle
};
lambda();
cout << foobar << endl;
return 0;
}
int main()
{
int foobar = 0;
auto lambda = [&foobar]()
^^^^^^^- Takhle
{
foobar = 3;
};
lambda();
cout << foobar << endl;
return 0;
}
12.8.2014 15:55
Saljack | skóre: 28
| blog: Saljack
| Praha
díky za připomenutí.
Většinou mají přístup pouze k omezenému prostředí, případně se v některých jazycích (např. C++) dá specifikovat, které přesně proměnné patří do closures a s jakým přístupem.To je ale spis znouzectnost. Plne, neomezene closures jsou totiz nekompatibilni s tim, jak bezne jazyky implementuji lexikalni promenne a zasobnik volani. Prirozena implementace zasobniku volani pro jazyk s plnymi closures je takova, ze vnorene environements tvori spojovy seznam podrizeny GC. Takove closures maji 'tu spravnou' semantiku, ktera se od nich ocekava, ale vetsinou vyhody takoveho pristupu neprevazi nevyhody s tim spojene (napr. nizsi efektivita a daleko problematictejsi foreign function interface pri kombinaci s 'beznymi' jazyky), takze se to casto nejak osidi, aby se vlk nazral a koza zustala cela.
 10.8.2014 11:18
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.8.2014 13:23
xkucf03 | skóre: 50
| blog: xkucf03
10.8.2014 11:18
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
15.8.2014 13:23
xkucf03 | skóre: 50
| blog: xkucf03
Nevím, jak ty, ale já si Javu instaluji přes standardní balíčkovací systém své distribuce. Ani s aktualizacemi nemám problém.
Btw. Java to uz ma asi za sebou a zatim tezi jen ze setrvacnosti v relativne konzervativni korporatni sfere. U novych projektu jsem posledni dobou daleko vic videl C#, F#, Erlang nebo Scalu a u mobilnich Objective-C.
 10.8.2014 16:22
Václav "Darm" Novák | skóre: 26
| blog: Darmovy_kecy
| Bechyně / Praha
10.8.2014 16:22
Václav "Darm" Novák | skóre: 26
| blog: Darmovy_kecy
| Bechyně / Praha
Btw. Java to uz ma asi za sebou a zatim tezi jen ze setrvacnosti v relativne konzervativni korporatni sfere....Heh tak dobre som sa uz davno nezasmial. Ani nemate potuchy kde vsade je java pouzivana a v akom rozsahu. Korporatna sfera je prave iba mala cast oblasti kde je java pouzivana. Ono totiz netreba brat javu iba ako jazyk ale ako celu platformu. Co sa tyka scaly tak to je iba modny trend a nastastie sa uz zacinaju objavovat ludia, ktory nahlas hovoria aku ma scala sprasenu syntax. Java tu s nami bude este pekny par desatroci takze sa nemusite bat.
19.4.2024 21:56
xkucf03 | skóre: 50
| blog: xkucf03
Java to uz ma asi za sebou a zatim tezi jen ze setrvacnosti v relativne konzervativni korporatni sfere.Po skoro deseti letech bych rád doplnil, že Java se používá stále :-)
Ne že by na nich bylo něco špatného, ale na Javě si nejvíc cením jednoduchosti jazyka.Tohle mi uz rikalo vic lidi. Ale je to trochu omyl - Java neni jednoducha ani nahodou. Kdyby nekdo opravdu touzil po jednoduchosti, musel by se totiz vzdat OOP.
11.8.2014 11:33
xkucf03 | skóre: 50
| blog: xkucf03
OOP, které umí rozesílat zprávy všem a ne jen jednomu objektu.Nejaky priklad?
11.8.2014 13:59
xkucf03 | skóre: 50
| blog: xkucf03
A co ti brání mít objekt, u kterého se zájemci zaregistrují a on jim ty události bude přeposílat? Na to nepotřebuješ žádnou podporu v jazyce.
Bez přihlášení se k odběru událostí/zpráv, tak aby všechno chodilo všem, by to stejně nedávalo smysl.
11.8.2014 14:49
xkucf03 | skóre: 50
| blog: xkucf03
Ten objekt se nemusí registrovat sám, prostě jen existuje a vystavuje svoje rozhraní. Pak jsou jiné objekty, které můžou emitovat události/zprávy. Tyhle objekty nemůžou posílat události jen tak do vzduchoprázdna. Takže už musí něco umět – musí mít třeba metodu pro zaregistrování posluchače. U nich se zaregistruje nějaký prostředník a bude přeposílat zprávy těm prvním objektům.
11.8.2014 14:55
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Perfektne vystihnutý dôvod prečo by sa java nemala používať na výuku OOP.
11.8.2014 15:15
xkucf03 | skóre: 50
| blog: xkucf03
Jo, zatímco jinde to funguje sluníčkově samo a všechno se to propojí, jak chceš, aniž bys musel psát nějaké řádky kódu :-P
11.8.2014 15:30
xkucf03 | skóre: 50
| blog: xkucf03
BTW: když si správně navrhneš ty třídy (dost pomůžou generika), tak pak můžeš dělat klidně něco jako:
m.connect(a.x(), b.x());
Kde m je objekt, který to řídí, zprostředkovává, a emituje události, b je přijímá a x je typ události. To všechno se silnou typovou kontrolou a bez nějakého dynamického šamanismu. A ten propojovací kód je taky hezky čitelný (i když to nemá vyloženě podporu v jazyce nebo nějaké DSL).
IMHO není snad ani tak problém v tom, že se začně u Javy, ale spíš v tom, že se Javou i skončí. Co se týče OOP, poprvé jsem k němu přičuchl u Object Pascalu / DelphiPerfektne vystihnutý dôvod prečo by sa java nemala používať na výuku OOP.
Co vy?
Pak jsou jiné objekty, které můžou emitovat události/zprávy. Tyhle objekty nemůžou posílat události jen tak do vzduchoprázdna.Např. v tom Qt můžou. Příkaz
emit prostě vyšle signál a jestli je k němu připojeno 100 nebo 0 jiných objektů je šumák.
Má to bezesporu svoje výhody, nicméně mně osobně tenhle koncept "zasílat zprávy kdykoli kamkoli" případně nějaké message busy zas tak extra skvělý nepřijde. Imho z toho celkem snadno může vyústit kód typu "spaghetti with meatballs". Navíc vzhledem k tomu, že signály se navazují v runtime, může být dost těžké dohledat, co kde vyvolává jakou činnost...
11.8.2014 17:56
xkucf03 | skóre: 50
| blog: xkucf03
No právě, emitovat události někam do vzduchoprázdna s tím, že se to pak nějak magicky napojí a nasměruje, kam má, to je tak trochu prasárna. Tomu Qt se to ještě dá odpustit, svým způsobem je to výjimečný projekt, vlastní styl programování, nadstavba jazyka, ale moc si nedovedu představit, že by tohle byla běžná praxe a že by se ti v programu sešlo třeba pět knihoven, kde každá takhle nějak emituje svoje události do vzduchoprázdna a pak si je zase nějak magicky odchytává a zpracovává.
Proto mi přijde lepší ten model, kde emituješ událost směrem k nějakému prostředníkovi a ten už se postará o zbytek.
12.8.2014 16:53
xkucf03 | skóre: 50
| blog: xkucf03
Osobně nevidím na modelu událostí a registrací k událostem nic tak špatného.
To já taky ne. Ale signály a sloty jsou o něco flexibilnější a líp se to řídí zvenku.
Při registraci posluchače často registruje ten objekt sám sebe (svoji vnitřní třídu), ale i když ho registruje (propojuje zdroj a cíl událostí) někdo zvenku, je potřeba uvnitř toho cílového objektu rozhodovat, co s danou událostí udělat – pokud máme od každého typu událostí jen jednu, je to jednoduché. Ale pokud máme např. typ události „tlačítko stisknuto“, musíme uvnitř toho posluchače mít větvení, které bude řešit, které tlačítko bylo stisknuto a co se tudíž má dělat.
Oproti tomu ten přístup, co jsem popisoval výše nebo:
a.x().connect(b.x());
umožňuje propojit libovolný zdroj událostí určitého typu s libovolným cílem stejného typu.
Resp. technicky to funguje podobně, jen je rozdíl v granularitě – navenek jsou vystavené jednotlivé posluchače (více pro stejný typ události) pro různé cílové akce – místo jednoho posluchače pro jeden typ události, kde by to větvení bylo až uvnitř něj.
To já taky ne. Ale signály a sloty jsou o něco flexibilnější a líp se to řídí zvenku.Měl jsem za to, že o nich se právě bavíme.
Ale pokud máme např. typ události „tlačítko stisknuto“, musíme uvnitř toho posluchače mít větvení, které bude řešit, které tlačítko bylo stisknuto a co se tudíž má dělat.Ne. Žádné větvení tam právě není třeba, protože připojíš každému tlačítku na svou vlastní obsluhu.
12.8.2014 22:21
xkucf03 | skóre: 50
| blog: xkucf03
OMFG, vždyť o tom právě píšu, že je to výhoda signálů/slotů resp, toho přístupu, co jsem psal výše:
m.connect(a.x(), b.x()); // nebo: a.x().connect(b.x());
oproti klasickým posluchačům a případu, kdy přijímající objekt implementuje rozhraní daného posluchače (tím pádem umí přijímat daný jeden typ události) a pak si to větvení dělá uvnitř.
A ne, není těžké dohledat jak je co spojené. Stačí se kouknout na volání funkce connect().Jo, jenže
connect() může být v kódu praticky kdekoli, klidně někde úplně jinde, než kde jsou definované ty zúčastněné objekty. Navíc těch connectů může bejt větší množství a dále se může situace komplikovat použitím disconnect(), QSignalMapper a dalších vymožeností.
#if FIRST_MEANING
template<bool >
class foo
{ };
#else
static const int foo = 0;
static const int bar = 15;
#endif
static int foobar( foo < 2 ? 1 < 1 : 0 > & bar );
Java je jednoducha (az primitivne jednoducha) co se tyce syntaxe jazyka. Diky tomu se snadno parsuje a snadne se cte.Znaková sada Unicode k jednoduchosti a snadné čitelnosti zrovna nepřispívá. Např. (specifikace, část 3.8):
Two identifiers are the same only if they are identical, that is, have the same Unicode character for each letter or digit. Identifiers that have the same external appearance may yet be different.A pak jazyk není jen syntax.
12.8.2014 20:42
xkucf03 | skóre: 50
| blog: xkucf03
Děláš, jako kdybys na takový kód narážel denně. Je fakt, že já někdy píšu česky a to jsem za exota navíc háčky a čárky na první pohled poznáš.
Ale tu spoustu vlastností a konstrukcí nabízených C++ lidi reálně používají a každý používá trochu jinou podmnožinu, takže abys byl obecně schopný číst C++, musíš umět úplně všechno.
Děláš, jako kdybys na takový kód narážel denně.
Problém je, že v některých jazycích může dojít k problémům velmi snadno:
public class Boo {
static int Сena = 1;
public static void main(String[] args) {
int Cena = 2;
System.out.println(Сena);
}
}
Program samozřejmě vypíše 1, ale proč? S ASCII je podobných problémů mnohem méně.
12.8.2014 21:33
xkucf03 | skóre: 50
| blog: xkucf03
Ale proč by to někdo psal? Leda naschvál, ze zlomyslnosti. V tom je ten rozdíl. Ale ty věci z C++ lidi používají běžně a s dobrými úmysly – vlastně to jsou často i dobré věci – jen jich je prostě hodně.
Totéž třeba ten Perl – občas si v něm něco napíšu, docela jsem si ho i oblíbil a dobře mi slouží. Používám jen jeho malou podmnožinu. Ale číst něco po jiných? To už tak snadné není.
P.S. z té proměnné s velkým písmenem na začátku mě bolí oči. Fuj.
Ale proč by to někdo psal?
Stačí jednou identifikátor zkopírovat z internetu a podruhé ručně napsat.
12.8.2014 22:14
xkucf03 | skóre: 50
| blog: xkucf03
Proč by to psal někdo blbě na ten Internet? Teď pominu že jen tak kopírovat cizí kód je blbost. Spíš bys to kopíroval třeba z interní wiki, ale tam by to musel zase špatně napsat leda nějaký zlomyslný kolega, tohle fakt není normální.
Když něco zkopíruješ z webu, tak ti budou pasovat ty proměnné na ty, které už tam máš, že dojde k té záměně? Spíš by se stalo, že tam takovou proměnnou nemáš a když ji napíšeš ručně, tak to nepůjde zkompilovat, IDE ti podtrhne chybu a ty si všimneš, že jsi zkopíroval chybný text.
A nevím, proč se tu vlastně hádáme, když C++ unicode v identifikátorech umožňuje, stejně jako mnohé další jazyky.
Problémy budou i s češtinou:
public class Boo {
public static void main(String[] args) {
int čau = 2;
int čau = 1;
System.out.println(čau);
}
}
12.8.2014 21:43
xkucf03 | skóre: 50
| blog: xkucf03
Jo a taky se plete 1 a l a když přeházíš písmenka uvnitř slova, tak, aby začátek a konec zůstaly stejné, tak to většina lidí přečte jako to původní slovo.
Kritika Javy je často nesmyslná, ale zatím asi vedeš
Jo a taky se plete 1 a l a když přeházíš písmenka uvnitř slovaJenže 1 a l můžete rozlišit pomocí fontu, ale v příkladu s čau to udělat nemůžete, protože oba identifikátory jsou ekvivalentní - viz Unicode Standard Annex #15 - Unicode Normalization Forms (část 1.1):
The Unicode Standard defines two equivalences between characters: canonical equivalence and compatibility equivalence. Canonical equivalence is a fundamental equivalency between characters or sequences of characters that represent the same abstract character, and when correctly displayed should always have the same visual appearance and behavior.
Kritika Javy je často nesmyslná, ale zatím asi vedeš.Dík, a to jsme teprve ve 3. kapitole standardu z 19.
A v tom je Java (bohuzel) napredNemyslím si, že by tu šlo o nějakou časovou osu ani že by byl jasně nastavený trend, ke kterému by všichni směřovali.
12.8.2014 22:48
xkucf03 | skóre: 50
| blog: xkucf03
Ano, vzhledem k historickému dědictví těch jazyků to často není možné a asi se toho nedočkáme nikdy.
13.8.2014 08:12
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Blbosť. Osobne používam na dopĺňanie frontend kompilátora (áno preste ten parser ktorý používa kompilátor), takže všetky vlastnosti jazyka ktoré vie kompilátor vie teraz aj môj editor bez ohľadu na komplexnosť jazyka. Doba kedy si každé IDE muselo písať vlastný parser a synchronizovať sa so štandardom jazyka je dávno preč.
Ale i kdyz je to pekne hnusny, tak kdyz v Eclipse kliknu na tu promennou tak se mi kurzor prenune na jeji deklaraci. V pripade C++ toho dosahnou jen tak, ze mi kompilator behem prekladu vygeneruje metadata.C++ IDE tohle umí taky.
ttyp<int> mi to normálně pomocí F3 skočí.
13.8.2014 13:09
xkucf03 | skóre: 50
| blog: xkucf03
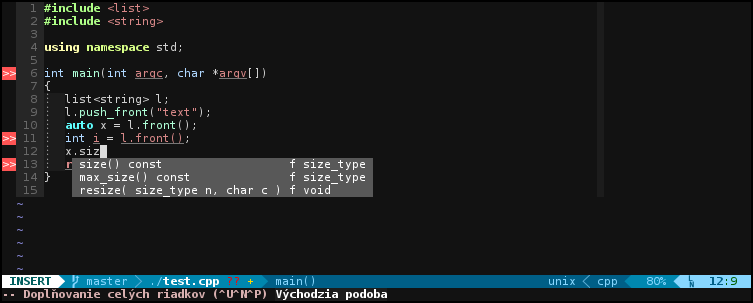
Např. v Qt Creatoru můžeš napsat tohle
list<string> l;
l.push_front("text");
int i = l.front();
a IDE proti tomu nic nenamítá – chybu ti oznámí až kompilátor.
Zatímco třeba u Netbeans a Javy by ti IDE oznámilo chybu už během psaní a taky by ti při doplňování nabízelo jen ty metody, které dávají v daném kontextu smysl (vrací typ nebo podtyp proměnné, do které přiřazuješ, nebo parametru metody, který plníš atd.)
Jo tak to nic nenamítá ani Eclipse Luna.
(Ale přece nebudu psát kraviny :))
13.8.2014 13:41
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
"wtf" = "ftw";A notepad proti tomu nič nemá.
13.8.2014 13:55
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
a IDE proti tomu nic nenamítá – chybu ti oznámí až kompilátor.Tak C++ IDE opravdu nemají ve zvyku hledat chyby a principielně to imho ani není možný. Osobně mi to ale naprosto vyhovuje, u Eclipse mě štvalo, že jsem psal kód a v průběhu psaní mi IDE neustále zvýrazňovalo nějaký chyby prostě proto, že kód nebyl ještě úplný.
Mě tedy IDE (Eclipse) 90% chyb odhalí i bez kompilace…
Když mi něco vadí, tak to vypnu
// prazdna trida = nil
class Empty {};
// ze dvou trid vybere tu ktera neni prazdna
template<class A, class B>
class TraitsSelector
{
public:
typedef A selected;
};
template<class B>
class TraitsSelector<Empty, B>
{
public:
typedef B selected;
};
// base class pro dedeni vlastnich Traits
template<class ImplTraits>
class CustomTraitsBase
{
public:
typedef Empty AllocPolicyType;
typedef Empty StringType;
};
// base Traits, obsahuje implicitni prirazeni typu
template< template<class ImplTraits> class UserTraits >
class TraitsBase
{
public:
typedef typename TraitsSelector< typename UserTraits<TraitsType>::AllocPolicyType,
DefaultAllocPolicy
>::selected AllocPolicyType;
typedef typename TraitsSelector< typename UserTraits<TraitsType>::StringType,
std::string
>::selected StringType;
};
// tady podedim a definuju vlastni alokator
template<class ImplTraits>
class MyUserTraits : public CustomTraitsBase<ImplTraits>
{
public:
typedef MyUserAllocPolicy AllocPolicyType;
};
// MyLexerTraits - kdyz se to vsechno spoji tak:
// MyLexerTraits::AllocPolicyType ::= MyUserAllocPolicy
// MyLexerTraits::StringType ::= std::string
typedef TraitsBase<MyUserTraits> MyLexerTraits;
typedef BaseLexer<MyLexerTraits> MyLexer;
MyLexer lex;
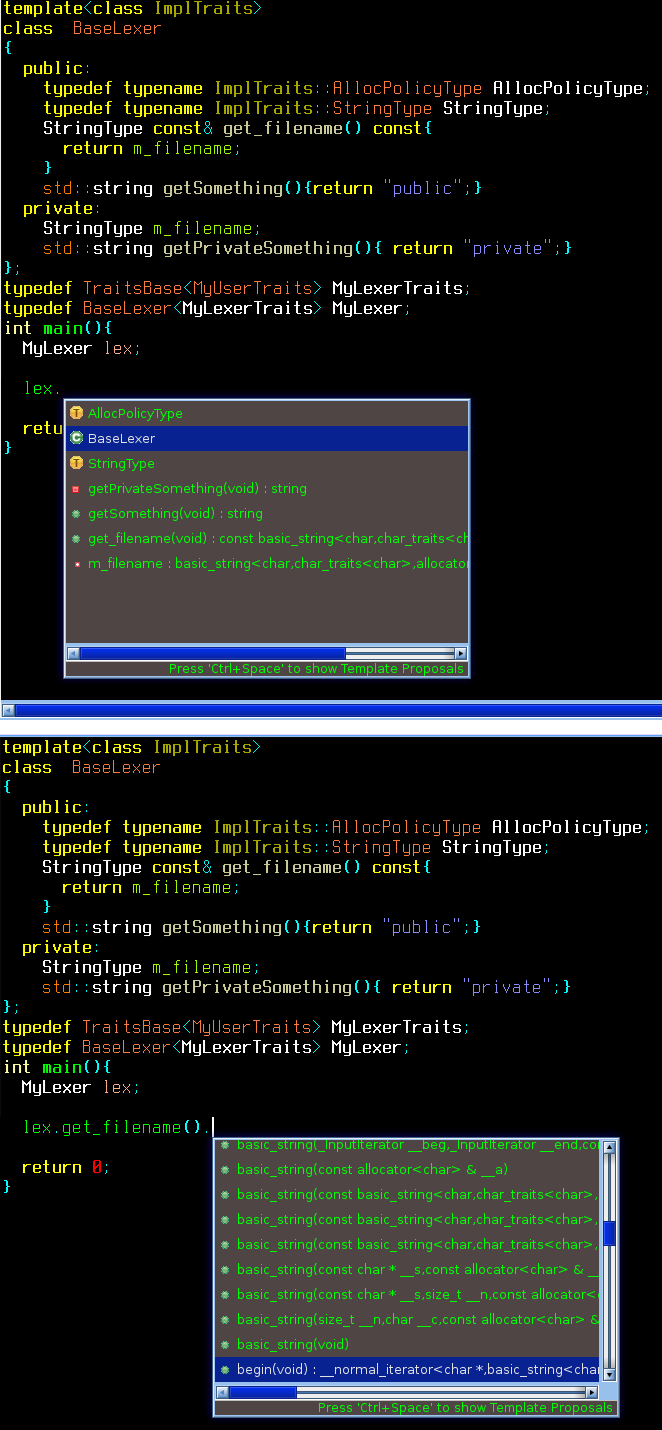
Ted mam promennou lex ktera odsahuje prvky typu StringType, coz je vlastne std::string. Nikdo o tom ale nevi. Stejne tak nikdo nevi ze MyLexer obsahuje vlastni alokator a pres IDE (CDT) se nijak nedostanu k implementaci jeho metod.
13.8.2014 14:07
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Mne to funguje.
Nic ti neuniklo - prave naopak umis se rychle orientovat v kodu :) BaseLexer je trida (sablona definovana jinde) cely je to vykously z vetsiho kusu kodu a hodne zjednoduseny. Editor tohodle webu je na me zlej a nechce mi povolit psat mensitka ani do tagu pre a code, takze jsem to po chvili vzdal.
template<class ImplTraits>
class BaseLexer
{
public:
typedef typename ImplTraits::AllocPolicyType AllocPolicyType;
typedef typename ImplTraits::StringType StringType;
StringType const& get_filename() const;
private:
StringType m_filename;
}
BaseLexer je trida ktera opravdu neco dela(ma metody a prvky). V realu cela ta saskarna s Traits slouzi k tomu abych ji mohl vnutit typy, se kteryma pracuje, konstanty, ktery ovlivni jeji chovani a treba i predka od kteryho dedi.
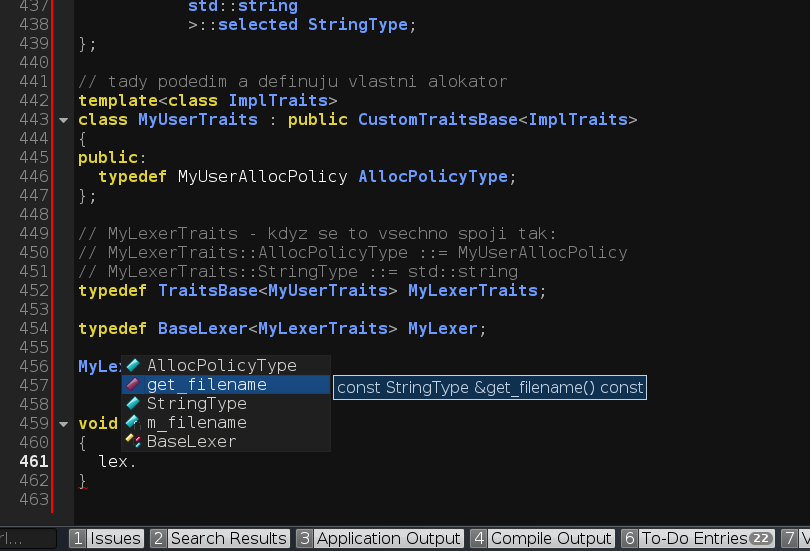
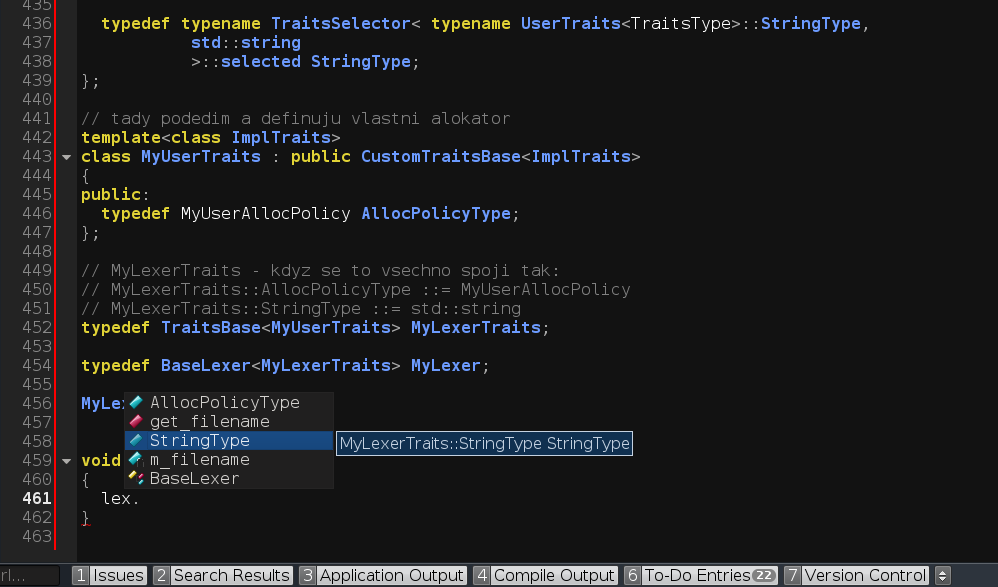
Tak jsem si to schválně zkopíroval doplnil to co schází a v eclipse juno viz příloha.
PS:
& " < >na webu píšeme jako
& " < >
Dokonce ví, že ImplTraits jsou v tomhle případě MyLexerTraits ...
#include<stdio.h>
main()
{
int xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxoxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx = 1;
int xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxoxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx = 2;
printf("%d", xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxoxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx);
}
Nečitelný kód lze totiž napsat v libovolném jazyce.
12.8.2014 00:21
xkucf03 | skóre: 50
| blog: xkucf03
22.1.2015 02:24
xkucf03 | skóre: 50
| blog: xkucf03
18.8.2014 18:20
xkucf03 | skóre: 50
| blog: xkucf03
Na to je jednoduchy lek: Naucit se nebo aspon trochu poznat vic jazyku, nejlepe ruznych paradigmat a syntaxi (ja doporucuji: C, Java, Javascript, Python, sh, Common Lisp, Haskell, Prolog, Forth, assembler, VHDL - lze zamenit za podobne podle vkusu).
Jak moc do hloubky bys doporučoval jít? Za jak dlouho se to dá stihnout?
Např. já dělám převážně v té Javě (jaké překvapení), pak SQL (včetně procedurálního), XML (a související jazyky), skriptování v Perlu a Bashi, občas nějaký JavaScript nebo Python, když musím, a pak trochu C a C++ …a to je asi tak všechno, pro co jsem našel nějaké praktické využití. Pro ty ostatní jazyky (Common Lisp, Haskell, Prolog, Forth, assembler, VHDL) jsem ho zatím nenašel – co s tím? Mám si v tom cvičně střihnout nějaký projekt? Nebo si o tom přečíst knihu, když zatím ani netuším, co bych v tom napsal? Možná by ještě tak byla nějaká motivace pro EmacsLisp kvůli psaní doplňků pro editor, ale u těch ostatních jazyků fakt nevím. To už si spíš najdu čas na C++, tam mám aspoň představu, co bych v tom chtěl napsat.
Prolog jsem zatim nezvladl, ale snad se k nemu doberu, takze zatim nic nemohu doporucit.
A vidis, SQL jsem zapomnel - tusil jsem, ze tam neco chybi.
Co SWI-Prolog?To je strašná věc.
Na úlohy by se ten možná jazyk hodil, ale ještě by byla potřeba slušná implementace s možností nějakého rozumného debuggingu, aby to celé dávalo dohromady smysl.Hlavní věc je, IMHO, že to nemá smysl jako samostatný jazyk / samostatný program. Užitečnější by to bylo jako knihovna integrovatelná s programem v některém z obecně použitelných jazyků, který by Prolog používal jako DSL podobným způsobem jako se používají regexpy, SQL apod.
Měli jsme to ve škole asi semestr, možná dva, imho je to v podstatě jen ne moc intuitivní rozhraní k prohledávání do hloubky.Dnešní implementace v podstatě obsahují 3 jazyky: Prolog, CLP a CHR.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 10.8.2014 14:36
10.8.2014 14:36
 10.8.2014 21:31
10.8.2014 21:31
 12.8.2014 19:36
12.8.2014 19:36
{kind=link}
{kind=link}
{kind=link}
{kind=link}