Přední technologické společnosti (Adobe, Cadence, Capital One, Cisco, Cloudera, Cloudflare, Cognition, CrowdStrike, Databricks, Dell Technologies, DoorDash, Elastic, HPE, Hugging Face, IBM, LangChain, Linux Foundation, Microsoft, NAVER, NetApp, Nous Research, NVIDIA, OpenClaw, Palantir, Palo Alto Networks, Red Hat, Reflection AI, Salesforce, SAP, ServiceNow, Siemens, SK Telecom, Snowflake, SpacexAI, Synopsys, Thinking
… více »Krabix.cz je online 3D konfigurátor krabiček pro 3D tisk s exportem do STL. Běží přímo v prohlížeči. Nic se neposílá na server.
Nadace Open Home Foundation spustila veřejnou preview verzi komunitní databáze zařízení pro Home Assistant. Má fungovat jako „Wikipedie pro chytrá zařízení".
Na stránce nového panelu Firefoxu přibudou nové widgety. Například denně aktualizována interaktivní křížovka.
PGSimCity (GitHub) je webová 3D vizualizace vnitřního fungování databázového systému PostgreSQL v podobě města. Vytvořena pomocí umělé inteligence.
UBports, nadace a komunita kolem Ubuntu pro telefony a tablety Ubuntu Touch, vydala Ubuntu Touch 24.04-2.0 a 24.04-1.4. Nová verze 24.04-2.0 již počítá s výřezy pro fotoaparát (notch) a zaoblenými rohy displeje. Webový prohlížeče Morph přešel z Chromia 87 na Chromium 134. Do shellu Lomiri byl přidán editor snímků obrazovky.
Byly zveřejněny informace o kritické zranitelnosti CVE-2026-64600 pojmenované RefluXFS (technické detaily) v XFS. Je tam již od verze Linuxu 4.11, tj. rok 2017. Jedná se o lokální eskalaci práv. Neprivilegovaný uživatel může editovat libovolný soubor, například klidně zrušit rootovské heslo v /etc/passwd. Videoukázka na Vimeo. V upstreamu je zranitelnost opravena.
OpenAI / ChatGPT má dnes výpadky (OpenAI Status, DownDetector).
Poskytovatel hostingu svobodných/open-source projektů Codeberg po hlasování na valné hromadě vydal stanovisko k využívání LLM. Kvůli vytěžování infrastruktury a rostoucím cenám hardwaru, ale také hrozbám pro spolupráci v komunitě se k LLM staví kriticky. Nebude poskytovat hosting projektů vytvářených LLM agenty.
Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
<objekt>
<vlastnost-1 hodnota="hodnota 1"/>
<vlastnost-123 hodnota="hodnota 123"/>
<vlastnost-9999 hodnota="hodnota 9999"/>
</objekt>
Před <vlastnost… bude tabulátor a před hodnota="… budou mezery.
*) osobně jsem spíš proti zarovnávání, protože při přidání nové (delší) položky je potřeba změnit všechny ostatní řádky a mj. to dělá bordel ve verzovacím systému.
 31.10.2012 15:57
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
31.10.2012 15:57
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
 31.10.2012 12:59
FrostyX | skóre: 27
| blog: Frostyho_blog
| Olomouc
31.10.2012 12:59
FrostyX | skóre: 27
| blog: Frostyho_blog
| Olomouc
 31.10.2012 14:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
31.10.2012 14:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 31.10.2012 15:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
31.10.2012 15:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 31.10.2012 15:29
Člověk z Horní Dolní
| blog: blbeczhornidolni
31.10.2012 16:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
31.10.2012 15:29
Člověk z Horní Dolní
| blog: blbeczhornidolni
31.10.2012 16:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 1.11.2012 21:11
Josef Kufner | skóre: 70
1.11.2012 21:11
Josef Kufner | skóre: 70
 1.11.2012 21:21
xkucf03 | skóre: 50
| blog: xkucf03
1.11.2012 21:21
xkucf03 | skóre: 50
| blog: xkucf03
if (a == 1) {
System.out.println("a == 1");
System.exit(0);
} else if (a == 0) {
System.out.println("a == 0");
System.exit(1);
}
a jinde:
if (a == 1) {
System.out.println("a == 1");
System.exit(0);
} else if (a == 0) {
System.out.println("a == 0");
System.exit(1);
}
a formátování se nerozbije, jen se přizpůsobí nastavení daného uživatele.
 2.11.2012 14:38
pavlix | skóre: 54
| blog: pavlix
2.11.2012 14:38
pavlix | skóre: 54
| blog: pavlix
spravne odsazeni dodatecneho textu na radce asi rozumne udrzovat nejde jinak nez s pouzitim tabulatoru.Vzhledem k tomu, že to nejde ani s použitím tabu, tak je to dost irelevantní.
2.11.2012 21:42
pavlix | skóre: 54
| blog: pavlix
 ? K čemu jsou dobré mezery?
31.10.2012 14:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
? K čemu jsou dobré mezery?
31.10.2012 14:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 31.10.2012 14:17
bambas | skóre: 20
| blog: bambasovo
31.10.2012 14:17
bambas | skóre: 20
| blog: bambasovo
class MyClass
⇥: public MyOtherClass
{
public:
⇥MyClass()
⇥⇥: field(0)
⇥{}
⇥~MyClass();
⇥MyClass& setField(int value,
⇥⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽⍽bool checkIfZero)
⇥{
⇥⇥if (checkIfZero && value == 0) {
⇥⇥⇥throw std::exception("FIeld is not zero");
⇥⇥}
⇥⇥this->field = value;
⇥}
protected:
⇥int field;
};
31.10.2012 15:20
Člověk z Horní Dolní
| blog: blbeczhornidolni
31.10.2012 15:21
Člověk z Horní Dolní
| blog: blbeczhornidolni
31.10.2012 17:03
Člověk z Horní Dolní
| blog: blbeczhornidolni
31.10.2012 18:42
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
1.11.2012 11:47
Člověk z Horní Dolní
| blog: blbeczhornidolni
1.11.2012 12:30
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
context[ conf-file-rule: [any[ newline | _comment | date-header | purl ] to end ] white: [#" " | #" "] _comment: [#"#" to newline] date-header: [ #"[" copy parsed-date to #"]" newline (parsed-date: to-date parsed-date) ] purl: [ [ thru #" " | thru #" "] copy parsed-url to newline ( parsed-url: to-url trim to-string parsed-url print rejoin [parsed-date " : " parsed-url] ) ] parse/all d conf-file-rule ]To by mě dřív ani nenapadlo. Pořád jsem ale nepřišel na to, jestli má smysl se rebol učit, nebo ne :)
1.11.2012 14:50
Člověk z Horní Dolní
| blog: blbeczhornidolni
1.11.2012 15:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud to má přímo vestavěnou podporu pro BNF, tak to je zajímavá vlastnost, to se může občas hodit.Jo, parse.
O Rebolu jsem jednou už tuším slyšel, měl jsem toho pocit, že to je jeden z jazyků, které mají několik originálních nápadů, ale v praxi má smysl je používat jenom na relativně malou skupinu problémů :)No, já už o něm přečetl pár desítek článků a pár knih a pořád nevím, jestli jo, nebo ne :)
Coz o to, delit veci do funkci bych se potreboval naucit (ja mam v podstate tendenci tvorit novou funkci jen v pripade, ze ji volam z vice mist, coz neni idealni).
Ale i tak je to problem, a nejhorsi je to prave na tech operatorech, jak zminuje BzHD vyse. Aritmeticky vyraz pak vypada jako rozsypany caj. Ale ono staci napsat let, if, progn a jste hned v pulce stranky.
31.10.2012 18:42
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
>-------switch(x) {
>-------case 1:
>------->-------q();
>------->-------...
>-------case 2:
>------->-------x
>------->-------y
>------->-------...
>-------}
V podstate me napadaji 2 reseni, ktere ale obe zbytecne pridavaji uroven zanoreni:
1:
>-------switch(x) {
>------->-------case 1: {
>------->------->-------int a;
>------->------->-------qwe
>------->-------}
>------->-------case 2:
>------->------->-------x
>------->------->-------y
>------->------->-------...
>-------}
>-------switch(x) {
>-------case 1:
>------->-------{
>------->------->-------int a;
>------->------->-------qwe
>------->-------}
>-------case 2:
>------->-------x
>------->-------y
>------->-------...
>-------}
31.10.2012 23:18
pavlix | skóre: 54
| blog: pavlix
1.11.2012 00:33
xkucf03 | skóre: 50
| blog: xkucf03
case 1: a case 2: mi tam chybí. A odsazovat o 8 mi přijde moc – zkus nastavit šířku tabulátoru na 4 a nebude to tak „hluboké“.
class xyz {
public:
>-------...
};
nebo goto:
int process() {
>-------...
error:
>-------...
}
Pokud jde o { na vlastnim radku, tak premyslel jsem i nad timhle:
>-------switch(x) {
>-------case 1: {
>------->------->-------int a;
>------->------->-------qwe
>------->-------}
to je pokud jde o { konzistentejsi, ale zase radek s } neni odsazeny stejne jako radek s { takze je to taky mirne nekonzistentni.
Taky jsem premyslel nad timhle, ale to by nemuselo vypadat dobre pri hodne kratkym tabulatoru:
>-------switch(x) {
>-------case 1: {
>--------------int a;
>--------------qwe
>------- }
Zatim nejvic inklinuju k puvodni moznosti c 2. Musim se uz konecne rozhodnout a delat tohle konzistentne. Momentalne to mam pokazdy jinak jak se furt nemuzu rozhodnout Ale ne ze by tech switchu psal nejak moc...
1.11.2012 10:50
pavlix | skóre: 54
| blog: pavlix
Líbí se mi první. U druhého nechápu, proč dáváš { } na nové řádky, když to jinak neděláš – IMHO zbytečnost.Podle mě } na nový řádek dává za všech okolností a { spojuje pouze s řídící konstrukcí, na kterou se vážou (i z hlediska jazyka).
>-------switch(x) {
a tohle:
>-------case 1:
>------->-------{
mi nepřijde konsistentní.
>-------switch(x) {
>-------case 1: {
>------->-------x...
>-------}
>-------}
tzn. prvni } by bylo odsazene stejne jako case. Proto me prijde lepsi byt trochu nekonzistentni a { dat na vlastni radek.
1.11.2012 11:36
pavlix | skóre: 54
| blog: pavlix
Chybně očekáváš, že se labely a řídící příkazy budou zapisovat stejně.Nemyslím, že je to chybný předpoklad, spíš logický. Ano, v kódu si můžu udělat blok { } jen tak, třeba abych omezil rozsah proměnných nebo si nějak „označil“ nějaké místo* a pak tu { nepřidávám na konec předešlého řádku, protože tam žádný takový není a i kdyby byl, nedávalo by to smysl. Ale když je to uvnitř switche, smysl to dává – logický význam a to, co tím kódem chce člověk říct, je podobné jako u IFu, proto by se to mělo i stejně odsazovat. Příklad:
if (a == 1) {
…
}
obdobně:
switch(a) {
case 1: {
…
}
*) moc se to nepoužívá a lepší bude ten blok vyčlenit do samostatné metody/funkce/procedury
1.11.2012 13:39
pavlix | skóre: 54
| blog: pavlix
Nemyslím, že je to chybný předpoklad, spíš logický.Typicky se labely zapisují takto:
... hlavička funkce ...
{
...
goto konec;
...
konec:
...
}
A bloky vložené do jiných bloků tuším typicky takto:
{
...
{
...
}
...
}
Ale samozřejmě máš možnost to psát zcela libovolně narozdíl od Python apod.
1.11.2012 23:57
pavlix | skóre: 54
| blog: pavlix
switch(a) {
case 1:
x++;
y++;
{
int i;
...
}
z++;
...
}
Kdyz z takoveho kodu ty prvni dva prikazy eliminuju, je konzistentni zachovat stejne odsazeni bloku:
switch(a) {
case 1:
{
int i;
...
}
z++;
...
}
2.11.2012 14:41
pavlix | skóre: 54
| blog: pavlix
int a = 0;
switch (a) {
case 0: {
System.out.println("0");
}
break;
case 1: {
System.out.println("1");
}
break;
default: {
System.err.println("chyba");
}
}
Dokonce jsem i zjistil, že tohle je výchozí (automatické) formátování v Netbeans
Případně bych dal ještě:
} break;Asi nemá cenu zbytečně sklouzávat k osobním útokům…
Ty vtiskáváš do odsazení své nepřesné vnímání fukce prvků jazyka.Proč by to tak mělo být? Konvence pro psaní kódu jsou z významné části věcí estetiky a osobního vkusu (proto se o nich také vedou nekonečné flamewary). Kdybych chtěl být ošklivý, tak řeknu, že ty zase podléháš iluzi, že odsazování by mělo být odvozeno čistě z technické specifikace jazyka bez ohledu na lidi, kteří ten kód píší a čtou.
2.11.2012 21:53
pavlix | skóre: 54
| blog: pavlix
Zatím jsem to nikdy nepotřeboval, ale napsal bych to takhle:Já ne, už jen proto, že nemám ve zvyku přidávat hromadu složených závorek jen tak pro okrasu.
Asi nemá cenu zbytečně sklouzávat k osobním útokům…Nevím, jak jsi na to přišel, ale doufám, že se toho budeš držet :).
Proč by to tak mělo být?Těkžo se mi vysvětluje věc, která mi připadá tak jednoduchá a samozřejmá. Měl jsem za to, že se shodujem v tom, že ti nevyhovuje sémantika céčkovského switche a omezuješ ji na určitou podmnožinu (zjednodušuješ) a takto zjednodušeně ji vnímáš. A toto vnímání vtiskáváš i do formátování. Když mi pomůžeš specifikovat, co je na tom nejasné, tak zkusím nějak reagovat.
Kdybych chtěl být ošklivý, tak řeknu, že ty zase podléháš iluziAno, to už zní ošklivě. Máš důvod být ošklivý?
 31.10.2012 21:48
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
31.10.2012 21:48
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
Netbeans? Bouchnu tabulátor, udělá se tabulátor. Dám backspace a maže to po jednom znaku místo celýho tabulátoru
31.10.2012 22:00
xkucf03 | skóre: 50
| blog: xkucf03
1.11.2012 15:43
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
Pokusim se to najít, myslel jsem že je to hardcoded feature 
Rozhodně někdo smazal konfiguraci, takže to má celej ČVUT zase v defaultu
1.11.2012 21:31
xkucf03 | skóre: 50
| blog: xkucf03
1.11.2012 10:56
pavlix | skóre: 54
| blog: pavlix
1.11.2012 00:48
xkucf03 | skóre: 50
| blog: xkucf03
Přeformátovat odsazení cizího zdrojáku jde i při odsazování mezerami.Jenže to znamená zásah do souboru, změnu prakticky všech řádků…˙Šířka tabulátorů je oproti tomu čistě věc zobrazení a nemusím do souboru nijak zasahovat. Někdo odsazuje o 2, normální lidi o 4, extrémista i o 8… každému vyhovuje něco jiného (liší se i podle jazyka). S tabulátory si to každý nastaví podle svého a přitom můžou všichni editovat ten samý soubor. Když na to špatně uvidím, zvýším si šířku tabulátoru, udělám potřebné změny a odešlu je (měním jen některé řádky). Ale když dostanu po někom zdroják s odsazením o 2 mezery a bude se mi to špatně číst (záleží na jazyku, někde je to OK), tak to budu muset nějak přetrpět nebo to přeformátovat, ale pak budou v nové verzi změněné všechny řádky, což dělá jednak bordel ve verzovacím systému a jednak tím budu otravovat ty, kterým odsazení o 2 mezery vyhovovalo. Totéž platí pro 8 nebo 3 (i takoví exoti se najdou).
1.11.2012 09:27
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Odsazení, podle toho, jestli mi vyhovuje odsazení o 2,4, 8, či jiný počet udělám bez ohledu na to, zda je odsazováno mezerami nebo tabulátory.
To bude mať autor pôvodného kódu radosť, že mu niekto rozrýpal odsadzovanie aké jemu vyhovuje. Nehovoriac o následnom merge cez VCS, ktoré kvôli odsadeniu nebude fungovať, takže bude musieť mergovať ručne.
Tedy programátor odsazující tabelátory pracuje stylem „nevadí, že se víc nadřu bez jakéhokoli smyslu“.
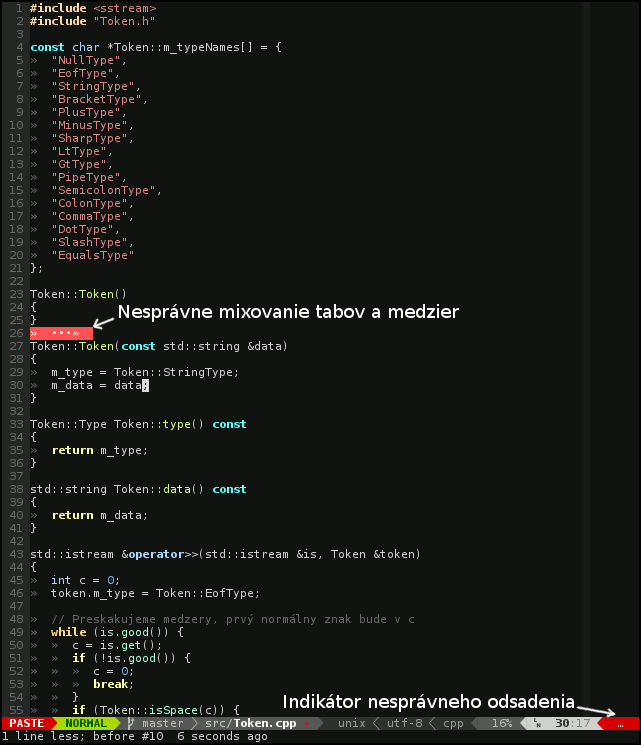
Alebo nevadí mi, že pri zmenšení odsadenia musím 4x (alebo 2x, 3x, 8x, 6x ...) ťuknúť do backspace namiesto 1, že. Inak o zobrazovanie tabulátorov a medzier a ich správne mixovanie (taby na indent, medzery na zarovannie) by sa mal starať editor pokiaľ sa nemýlim (príloha).
Při luštění cizích zdrojáků jste nuceni překousnout tolika věcí, že odsazování je to nejmenší
Škoda, že neviem práve vyhrabať štúdiu, ktorá hovorí presný opak.
1.11.2012 10:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Alebo nevadí mi, že pri zmenšení odsadenia musím 4x (alebo 2x, 3x, 8x, 6x ...) ťuknúť do backspace namiesto 1, že.Většina editorů co jsem kdy v životě používal tohle implementuje pomocí shift+tab.
1.11.2012 11:01
pavlix | skóre: 54
| blog: pavlix
1.11.2012 16:01
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
1.11.2012 16:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
2.11.2012 00:09
pavlix | skóre: 54
| blog: pavlix
6.11.2012 10:08
pavlix | skóre: 54
| blog: pavlix
1.11.2012 11:00
pavlix | skóre: 54
| blog: pavlix
Škoda, že neviem práve vyhrabať štúdiu, ktorá hovorí presný opak.Tak si jí vycucej z prstu stejně jako kdokoli, kdo mohl takovou studii vyplodit (nejspíš, pokud to myslel vážně, tak se v ní píše úplně něco jiného, než n mezer odsazení je čitelných, zatímco m ne).
1.11.2012 09:09
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
1.11.2012 21:41
xkucf03 | skóre: 50
| blog: xkucf03
nemyslel jsem to nijak zle. Dvě jsou relativně málo, ale někdy se to celkem dá a i jsem si na to zvykl (Pascal). Liché číslo mi přijde takové divné a 4 jako akorát.
31.10.2012 23:16
pavlix | skóre: 54
| blog: pavlix
Výhoda tabulátora je práve v tom, že na odsadzovanie textu bol navrhnutý a vie zarovnať stĺpce.Vážně umí zarovnat sloupce? V některém z běžně používaných editorů? A vážně byl navržen na odsazování kódu? Tomu moc nevěřím.
 1.11.2012 00:43
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.11.2012 00:48
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.11.2012 00:52
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.11.2012 00:40
xkucf03 | skóre: 50
| blog: xkucf03
1.11.2012 00:43
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.11.2012 00:48
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.11.2012 00:52
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.11.2012 00:40
xkucf03 | skóre: 50
| blog: xkucf03
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}
{kind=link}