HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Výhodou tabulkového procesoru je snadnost práce s velkým množstvím dat. A protože dáváme do tabulek data, která spolu zpravidla souvisí, není od věci je seřadit. K tomu je třeba připravená data označit a následně jít v menu na Data | Řadit..., kde se otevře okno s nastavením řazení, které má dvě karty.
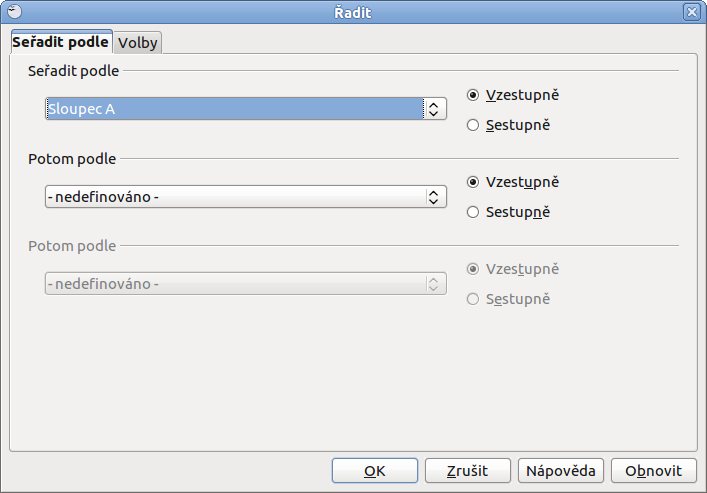
Na první kartě Seřadit podle si vybíráte, podle kterých sloupců chcete vybraná data řadit. Omezení v podstatě neexistuje a jakmile nastavíte první a druhé řazení podle, odemkne se další řazení Potom podle a tak dále. Samozřejmě po pravé straně ještě nesmíte zapomenout na možnost Vzestupně, či Sestupně.
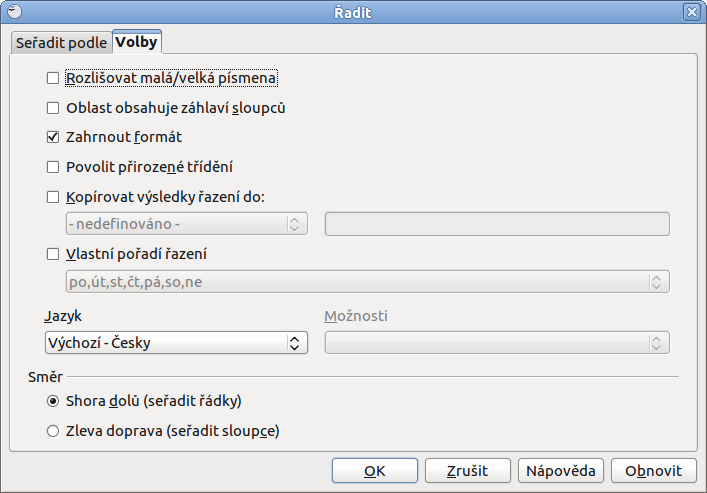
Naopak na kartě Volby si pak dolaďujete jednotlivé podrobnosti, které mohou být užitečné. Pokud jste si například označili tabulku i s jejím záhlavím, pak je třeba označit možnost Oblast obsahuje záhlaví sloupců. Stejně tak se pracuje s Rozlišovat malá/velká písmena, pokud s nimi v tabulce počítáte.
V řazení snad není třeba nic obsáhle vysvětlovat. Prostě si jen na kartě Seřadit podle vyberete sloupec, podle kterého chcete řadit. Nejčastěji se pochopitelně řadí podle data, číselné hodnoty, kategorie nebo abecedy. Jednotlivá řazení lze samozřejmě libovolně kombinovat a dosáhnout tak požadovaného výsledku.
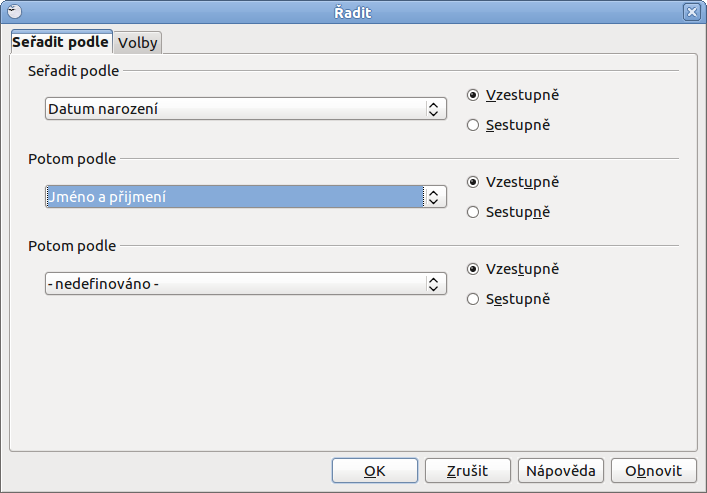
Pokud tedy chcete srovnat seznam osob nejdříve dle data a pak podle abecedy, postupujte následovně. V řadit vyberte nejdříve sloupec Datum narození, který vyberete po rozkliknutí Seřadit podle. Za druhé už stačí jen v Potom podle vybrat sloupec, kde je Jméno a příjmení a svou volbu potvrdit tlačítkem OK.
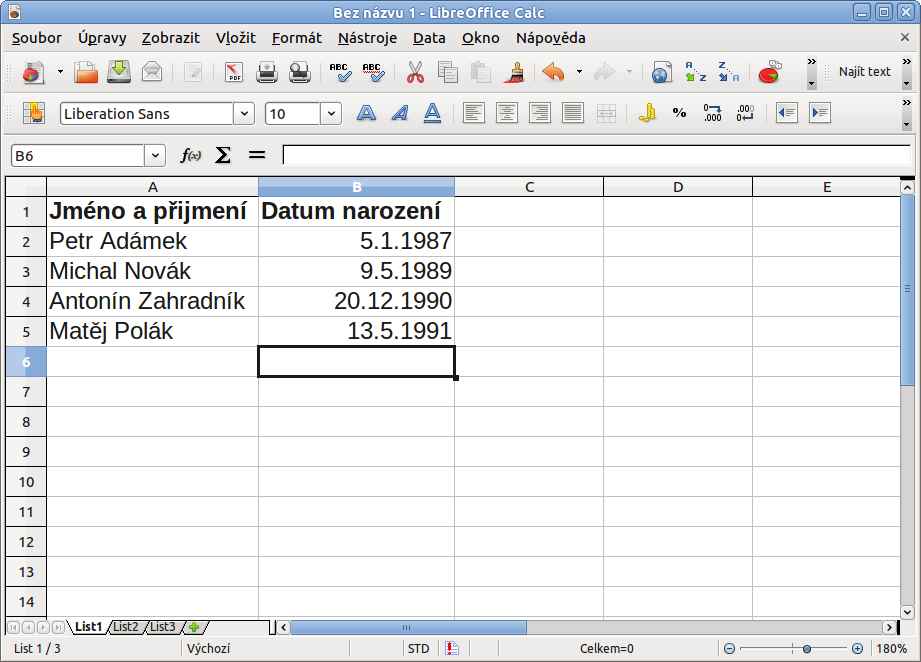
Filtry vám mohou práci skutečně usnadnit, jelikož z vybrané oblasti dat umožňují jednoduchou filtraci dat podle určitého parametru. Nejjednodušším použitím filtru je Automatický filtr. Ten vyvoláte po označení dat (včetně záhlaví, respektive popisků). Najdete jej stejně jako všechny ostatní typy filtrů v Data | Filtr – Automatický filtr.
Filtr se vytvoří zcela automaticky bez jakéhokoliv dalšího okna s nastavením a poznáte to podle tlačítka s šipkou vždy po pravé straně dané buňky. Na tlačítko stačí jen levým tlačítkem myši kliknout a můžete vybírat filtr dle zvolených kategorií (v tabulce, nejedná se o statický parametr automatického filtru jako takového). Vedle toho ale můžete vyfiltrovat horních 10 (dle nějaké hodnoty), případně lze rovnou spustit Standardní filtr.
Asi úplně nejjednodušší příklad k automatickému filtru je ten s knihovnou. Máte obrovský seznam knih v řádech stovek až tisíců a chcete vybrat jen ty, které napsal určitý autor. Není nic jednoduššího, než si klidně napořád udělat automatický filtr. V prvním řádku máte v jednotlivých sloupcích například název knihy, autor, rok vydání, žánr a ISBN.
Pak už si stačí například rozkliknout autora a vybrat si jej. V seznamu můžete k rychlému najetí na písmeno použít danou klávesu, takže ani nemusíte rolovat. Po vybrání se autor rázem vyfiltruje. Pokud se chcete vrátit k celé tabulce, není nic jednoduššího, než si opět kliknout na tlačítko se šipkou a vybrat Vše. Jednotlivé filtry mezi sebou můžete kombinovat, například autora s rokem vydání.
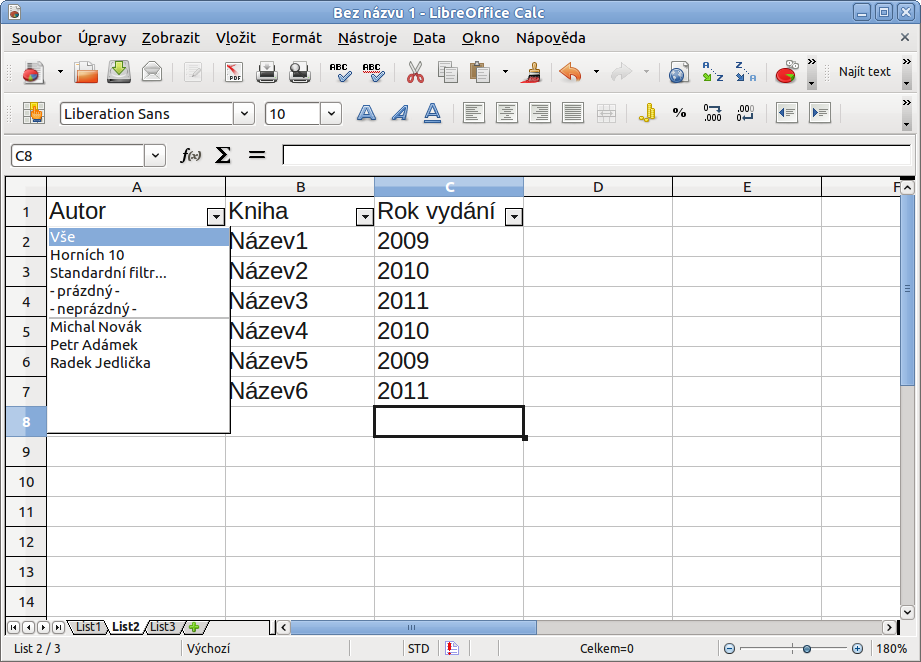
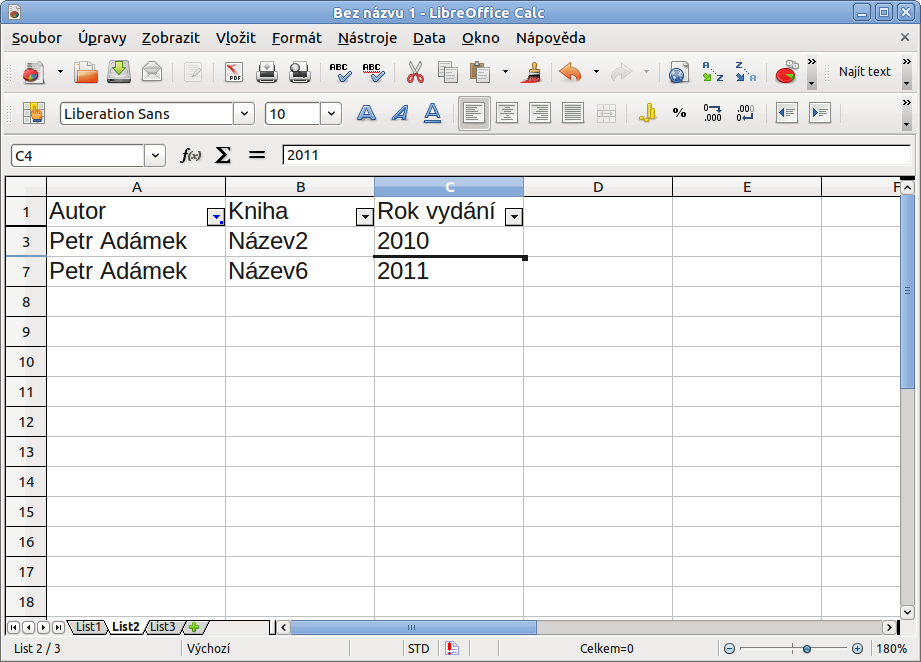
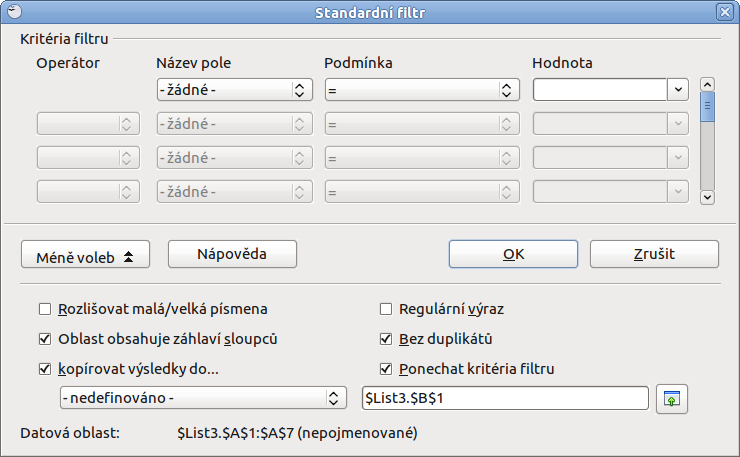
Nabízí oproti Automatickému především širší možnosti nastavení hned při jeho tvorbě a nikoliv až dodatečně. Pokud tedy víte, že vám nejednodušší filtr stačit nebude, tak standardní filtr je jasným východiskem.
Standardní filtr obsahuje především Kritéria filtru, kde si vyberete Název pole a pro něj dále už jen naklikáváte podmínky a hodnoty, které lze pomocí operátoru AND (a) nebo OR (nebo) libovolně kombinovat.
Po rozkliknutí tlačítkem Více voleb navíc zobrazíte další možnosti k nastavení filtru. Opět se jedná o podobné možnosti jako u řadit a je tu také možnost kopírovat výsledky filtru do zvolených buněk, které mohou být přitom i v jiné záložce nebo dokonce souboru, stejného typu samozřejmě. K tomu stačí kliknout na tlačítko okna se zelenou šipkou mířící nahoru a pak už jen označit tažením buňky, které se hned zobrazí v poli obsaženém v okně. Potvrzujete jednoduše enterem.
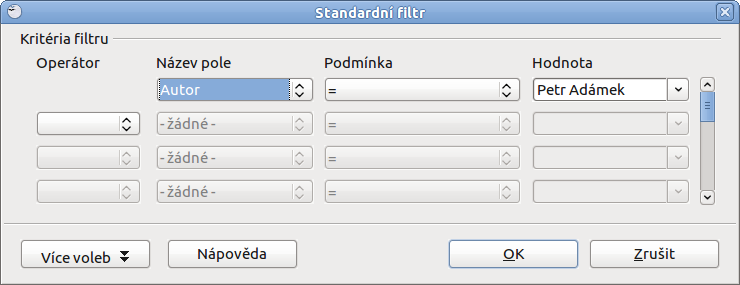
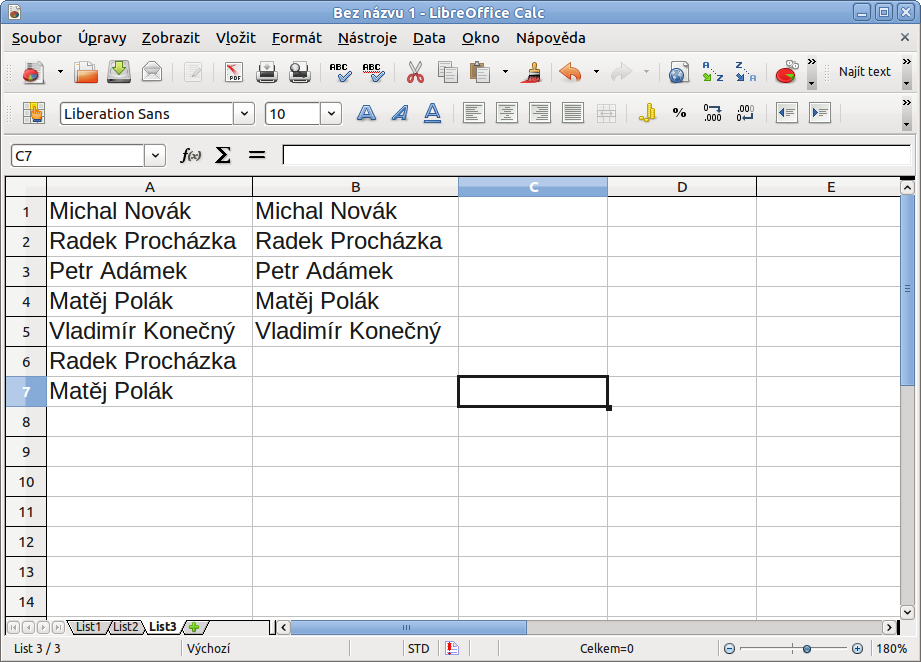
Velice užitečné může být odstranění duplicity, tedy opakujících se stejných záznamů jedné a té věci. Může se to hodit například u dlouhého seznamu lidí, jejich kontaktů, který je sbírán průběžně (sám jsem se setkal s tím, že někteří lidé jsou schopni se registrovat na jedinou věc hned několikrát) a to může být problém, pokud chcete mít přesný počet položek nebo nechcete e-mail odesílat jednomu člověku vícekrát.
Proto si označte váš seznam (jednotlivé buňky) a vytvořte si Standardní filtr. V něm stačí jen zaškrtnout možnost Bez duplikátů a způsobem výše popsaným vybrat buňky, kam nakopírovat vyfiltrovaný výsledek bez duplicit. Sice budete mít dva seznamy, ale jeden z nich bude zcela v pořádku a umístit jej můžete klidně do jiného listu (vizte přepínání vlevo dole).
Mezisoučet je velice užitečnou funkcí Calcu, která je svým způsobem unikátní. Jejím úkolem je sečíst hodnotu více položek, které jsou stejné. V podstatě se jedná o duplicity v podobě názvu (například položky, produktu), ale k nimž přísluší rozdílný údaj v hodnotě. Nejčastěji se jedná buď o počet nebo o celkovou hodnotu v penězích. Máte-li velký seznam, kde se jednotlivé položky v různém množství opakují a potřebujete je sečíst – použijte funkci mezisoučtu.
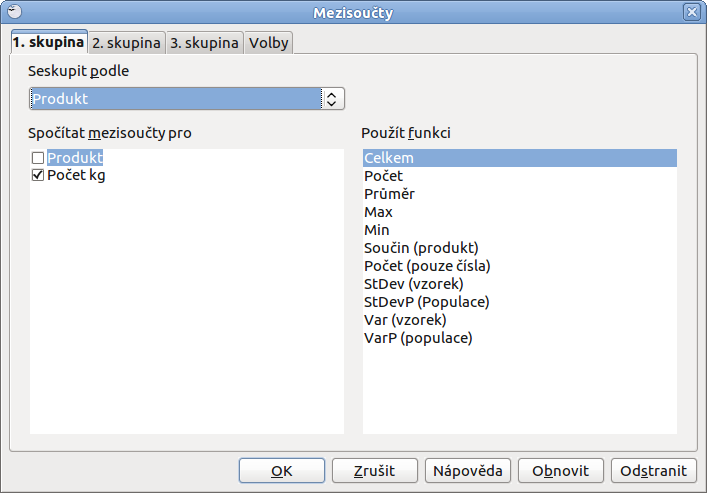
Pokaždé je třeba si před mezisoučtem data seřadit tak, aby názvy položek, které chcete sčítat, byly pod sebou. To uděláte pomocí klasického řazení, které bylo vysvětleno výše a pak už jdete na Data | Mezisoučty..., kde je primární si vybrat, podle čeho hodláte počítat mezisoučty. Navíc je třeba nezapomenout na názvy sloupců, bez nich by celá operace neprobíhala zcela v pořádku.
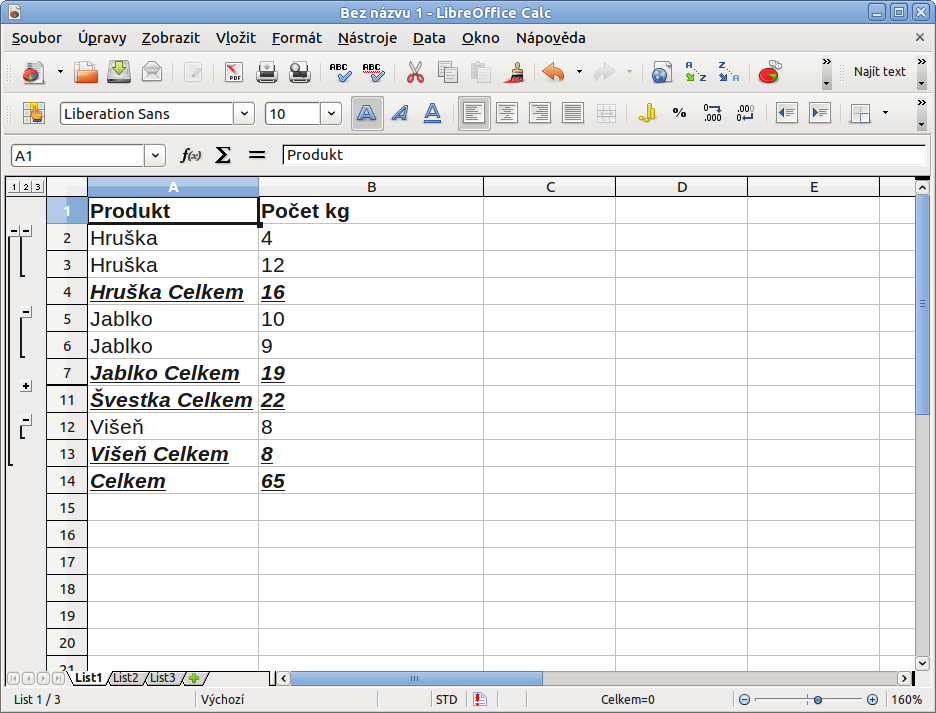
Dejme tomu, že máme výčet mnoha položek, z nich mnoho z nich je stejných a u každého je jiný počet prodaných kusů, respektive kilogramů (konečný výsledek můžete vypočítat až po celkovém sečtení). Nejdříve si takovou tabulku je třeba seřadit, jak bylo připomenuto výše. Poté už můžete jít na Data | Mezisoučty, kde vpravo vyberete, z čeho přesně onen mezisoučet chcete spočítat, a vpravo, jakou funkci chcete použít.
Poté potvrďte tlačítkem OK a v tabulce se po levé straně vytvoří tlačítka mínus, mezi nimiž jsou dostupné zmíněné součty. Pokud kliknete na -, pak zůstane celkový součet a mezisoučty nebudou zobrazeny. Takový výsledek pak lze samozřejmě zkopírovat a dle potřeby vložit do jiného dokumentu, e-mailu a podobně.
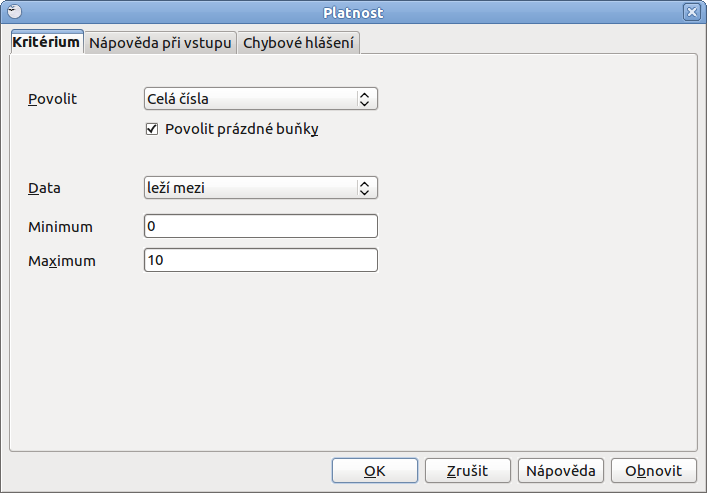
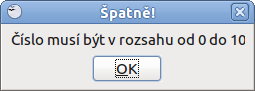
Neméně užitečnou funkcí je kontrola vstupních dat. Ta slouží k ohlídání toho, co do dané buňky vyplňujete a pokud se to neslučuje s nastavenou podmínkou, je uživatel upozorněn, že nic takového psát nemůže. Ideálním příkladem je například dotazník, kde chcete ohodnotit jednotlivé položky body od 0 do 10. Pokud uživatel napíše vyšší číslo, tak není zapsáno.
Uveďme tedy úplně na závěr jednoduchý příklad, který jsem zmínil o odstavec výše. V dotazníku jsou jednotlivá hodnocení, na která odpovídáte číslicí od nuly do desíti včetně. Nechcete však, aby uživatel za žádných okolností zvolil hodnocení vyšší, jelikož tak stupnice není nastavena.
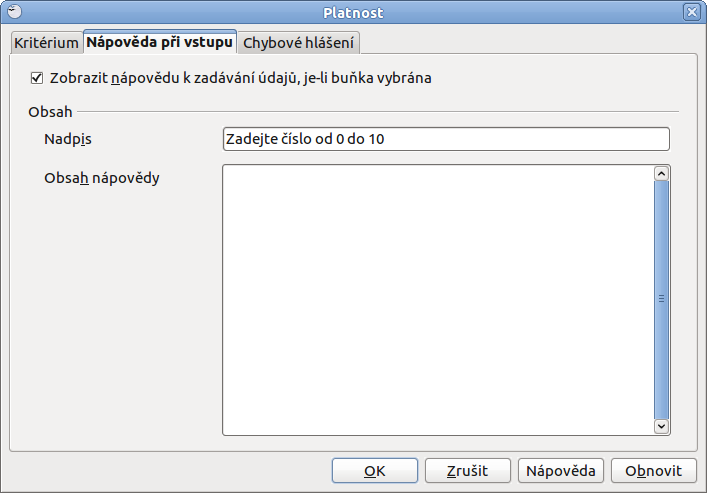
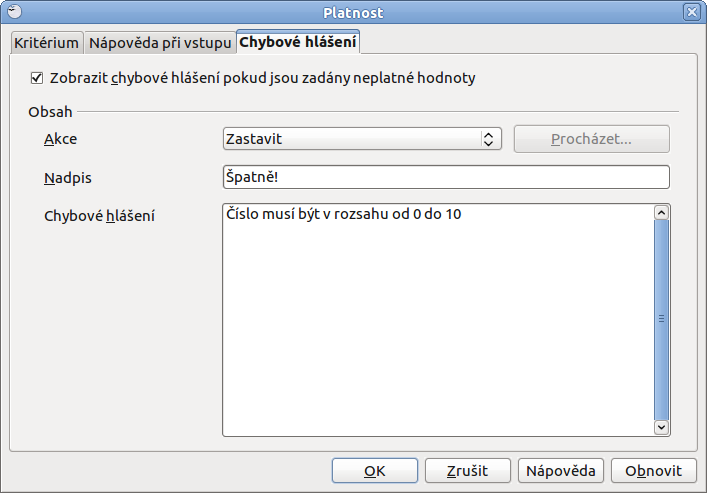
V okně platnost a na kartě kritérium proto vyberte pod Dovolit rozmezí a zvolte jeho rozsah. Dále zaškrtněte Zobrazit seznam pro výběr a Seřadit záznamy vzestupně. Na druhé kartě Nápověda při vstupu už zadáte jen libovolný text nápovědy jako například Hodnocení, respektive Vyberte číslo od 0 do 10 a přepněte se na kartu Chybové hlášení. Zde naopak nechte zaškrtnutou položku Zobrazit chybové hlášení pokud jsou zadány neplatné hodnoty a vyberte Akci, kterou má Calc provést, dojde-li k nesprávnému zadání hodnot.
A to už je k dnešnímu článku opravdu všechno. Cílem bylo představit hned několik funkcí pro práci s daty i na praktických příkladech a ukázat tak nejen to, že Calc je skutečně kvalitní aplikací.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz