Eric Lengyel dobrovolně uvolnil jako volné dílo svůj patentovaný algoritmus Slug. Algoritmus vykresluje text a vektorovou grafiku na GPU přímo z dat Bézierových křivek, aniž by využíval texturové mapy obsahující jakékoli předem vypočítané nebo uložené obrázky a počítá přesné pokrytí pro ostré a škálovatelné zobrazení písma, referenční ukázka implementace v HLSL shaderech je na GitHubu. Slug je volným dílem od 17. března letošního
… více »Sashiko (GitHub) je open source automatizovaný systém pro revizi kódu linuxového jádra. Monitoruje veřejné mailing listy a hodnotí navrhované změny pomocí umělé inteligence. Výpočetní zdroje a LLM tokeny poskytuje Google.
Cambalache, tj. RAD (rapid application development) nástroj pro GTK 4 a GTK 3, dospěl po pěti letech vývoje do verze 1.0. Instalovat jej lze i z Flathubu.
KiCad (Wikipedie), sada svobodných softwarových nástrojů pro počítačový návrh elektronických zařízení (EDA), byl vydán v nové major verzi 10.0.0 (𝕏). Přehled novinek v příspěvku na blogu.
Letošní Turingovou cenu (2025 ACM A.M. Turing Award, Nobelova cena informatiky) získali Charles H. Bennett a Gilles Brassard za základní přínosy do oboru kvantové informatiky, které převrátily pojetí bezpečné neprolomitelné komunikace a výpočetní techniky. Jejich protokol BB84 z roku 1984 umožnil fyzikálně zaručený bezpečný přenos šifrovacích klíčů, zatímco jejich práce o kvantové teleportaci položila teoretické základy pro budoucí kvantový internet. Jejich práce spojila fyziku s informatikou a ovlivnila celou generaci vědců.
Firefox 149 dostupný od 24. března přinese bezplatnou vestavěnou VPN s 50 GB přenesených dat měsíčně (s CZ a SK se zatím nepočítá) a zobrazení dvou webových stránek vedle sebe v jednom panelu (split view). Firefox Labs 149 umožní přidat poznámky k panelům (tab notes, videoukázka).
Byla vydána nová stabilní verze 7.9 webového prohlížeče Vivaldi (Wikipedie). Postavena je na Chromiu 146. Přehled novinek i s náhledy v příspěvku na blogu.
Dle plánu byla vydána Opera GX pro Linux. Ke stažení je .deb i .rpm. V plánu je flatpak. Opera GX je webový prohlížeč zaměřený na hráče počítačových her.
GNUnet (Wikipedie) byl vydán v nové major verzi 0.27.0. Jedná se o framework pro decentralizované peer-to-peer síťování, na kterém je postavena řada aplikací.
Byly publikovány informace (technické detaily) o bezpečnostním problému Snapu. Jedná se o CVE-2026-3888. Neprivilegovaný lokální uživatel může s využitím snap-confine a systemd-tmpfiles získat práva roota.
V minulém díle jsme načítali data ze souboru. Pokud data v souboru reprezentují měření, může nás zajímat, jak v nich odhalit matematickou závislost.
To nebudeme dělat nijak sofistikovaně pomocí specializovaných funkcí, ale prostě tak, že ručně trefíme nějaké křivky, až to bude vypadat hezky.
Dělal jsem analogový záznam barevné fotografie černobílou tiskárnou na papír a potřeboval jsem zjistit, jak reaguje laserová tiskárna na různé úrovně šedé, abych ji mohl simulovat v matematickém modelu. Pomocí modelu jsem pak mohl obejít nutnost výsledek při ladění pokaždé vytisknout a naskenovat, což stojí peníze.
V GIMPu jsem vyrobil černobílý gradient a ditheroval ho Floyd-Steinbergem na 1200x1200 DPI 1bitově. To jsem pak na 1200x1200 DPI ČB laserovce vytiskl a vzniklou flekatou zrnitou hrůzu naskenoval. Obrázek jsem zmenšil na velikost 1x256, čímž se částečně zprůměrovaly fleky a zrnění.
Jenže co teď? Jak dostat obrázek z GIMPu do GNU R? Prošel jsem ukládací funkce GIMPu a vidím, že štěstěna nás naštěstí obšťastnila formátem PGM, kde je možné při ukládání zvolit variantu ASCII. První zhruba tři řádky hlavičky se pak v textovém editoru smažou a získáme soubor CSV, který již z minulých dílů umíme načíst. Ušetříme si tak eventuální googlování, zda a jak GNU R podporuje nahrávání dat přímo z bitmap.
Data vypadají tak, že je soubor s 256 řádky, na každém řádku číslo od 0 do 255. My se budeme pokoušet trefit nějakou matematickou funkci. Nejdříve to tedy nahrajeme:
a=read.table("transfer_fine.csv")
Zkusíme co udělá tohle:
plot(a)
Výsledek je opravdu hlubokomyslný:
Aby nám to vytisklo použitelný graf, je třeba vygenerovat ještě nějakou sadu čísel pro osu x:
x=0:255 plot(x,a$V1)
Teď už se nám rýsuje něco, co skutečně připomíná průběh jasu na papíře. Vidíme, že to je očividný nesmysl – křivka není monotónní. Od tiskárny bych čekal, že když se dá tmavší vstup, tak vyleze taky tmavší výstup. Boule před stovkou je výrazný světlý pruh, co na tisku byl. Zřejmě takový ten pruh od válců, co tiskárny rády dělají. On jí taky už docházel toner. Budu tedy tuto bouli ignorovat. Tohle myslím demonstruje typickou situaci při práci s GNU R – člověk se musí vždy nějak rozhodnout, které vlastnosti naměřených dat brát vážně a které zavrhnout jako nepřesnost měření.
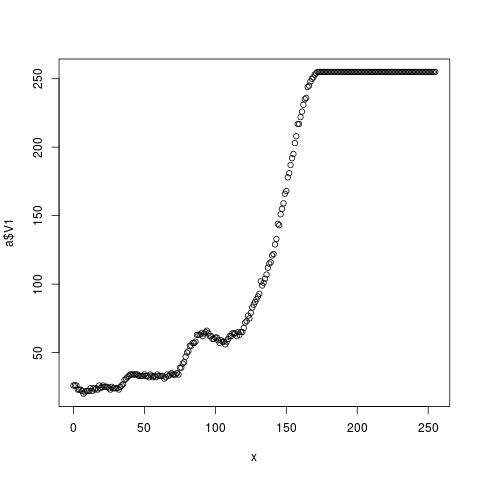
Na to se teď pokusíme napasírovat nějakou křivku. Smyslem toho není něco rigorózního, ale hlavně, aby simulace nemusela pracovat s nějakými arbitrárními 256 hodnotami, které by navíc byly do očí bijícím způsobem fyzikálně nesmyslné (nemonotónní).
Nejdřív mě tak od oka napadlo, že by to mohla být křivka kvadratická. Sám jsem to dělal ručně, ale pro zjednodušení článku nadefinuju nějakou funkci
> f=function(a,b,c){plot(x,a$V1)}
> f
function(a,b,c){plot(x,a$V1)}
> f()
Error in xy.coords(x, y, xlabel, ylabel, log) :
argument "a" is missing, with no default
Nejdřív „zavolání“ funkce f bez závorek nefungovalo, místo toho to vypsalo její kód. Zdá se, že v R je funkce jakási hodnota, něco jako číslo, jen místo numera je v tom spustitelný kód! Napodruhé při zavolání se závorkami se to zase rozbilo! Protože jsem si nevšiml, že jsem si předefinoval proměnnou a, ve které jsem měl ta naměřená data! No tak to opravíme přejmenováním proměnných:
> f=function(b,c,d){plot(x,a$V1)}
> f()
Vytisklo nám to stejný obrázek jako předtím, i když jsme funkci dali příliš málo parametrů! Z toho plyne mravní ponaučení, že v R se dají funkce volat i s nedostastkem parametrů. Teď tam dodělám nějaké dokreslování té domnělé matematické funkce pomoci funkce lines, která domaluje do již existujícího grafu nějakou křivku:
g=function(b,c){x1=x/c;x2=x1*x1;krivka=b+(255-b)*x2;lines(x,krivka)}
f()
g(30,200)
g(24,200)
g(24,150)
g(24,170)
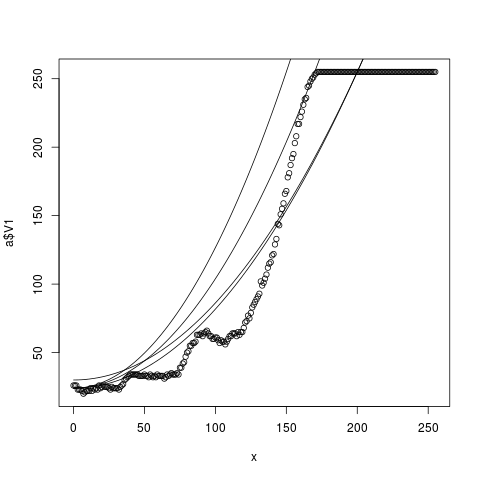
f() g(24,170)
Parametr b reprezentuje jakýsi podstavec na kterém je křivka, tedy hodnotu na levém kraji, a parametr c reprezentuje hodnotu x, pro kterou má křivka dát maximální y, tedy 255. Čísla v parametrech jsem nějak odhadl a postupně je přizpůsobil podle toho, jak to vypadalo. Podařilo se nám křivku napasovat na začátku a na konci, ale je pořád nějak moc napnutá! Proto mě napadá, co použít vyšší mocninu než druhou? Ty jsou takové více promáčklé:
g=function(b,c,d){x1=x/c;x2=x1^d;krivka=b+(255-b)*x2;lines(x,krivka)}
f()
g(24,170,3)
g(24,170,4)
g(24,170,5)
g(24,165,5)
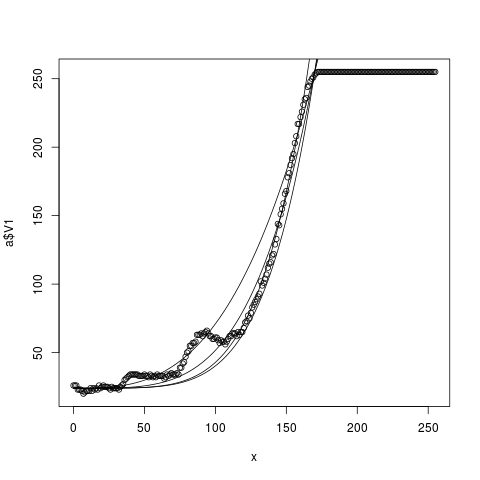
g=function(b,c,d){x1=x/c;x2=x1^d;krivka=b+(255-b)*x2;lines(x,krivka)}
f()
g(24,165,5)
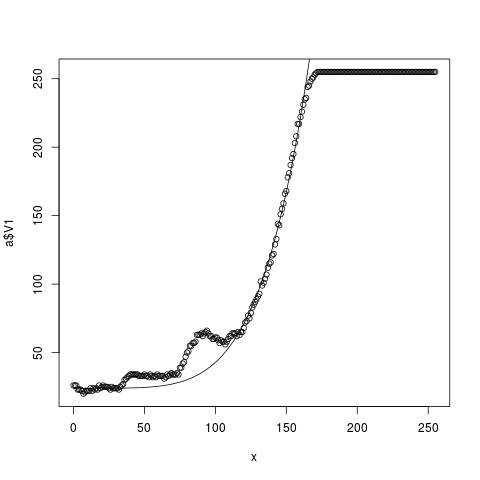
Přijde mi to už slušné, ale nelíbí se mi, že v levé dolní části se to drží příliš dlouho na nízkých hodnotách. A tu pravou strmou část to nějak ne úplně vystihne. Napadá mě tedy použít exponenciálu. Ta se v přírodě vyskytuje všude možně. Parametr b bude reprezentovat podstavec exponenciály, c bude mít stejný význam jako předtím a d bude škálovat osu x:
g=function(b,c,d){krivka=b+(255-b)*exp((x-c)/d);lines(x,krivka)}
f()
g(12,170, 20)
g(12,170, 40)
g(24,170, 30)
g(22,168, 30)
g(22,165, 30)
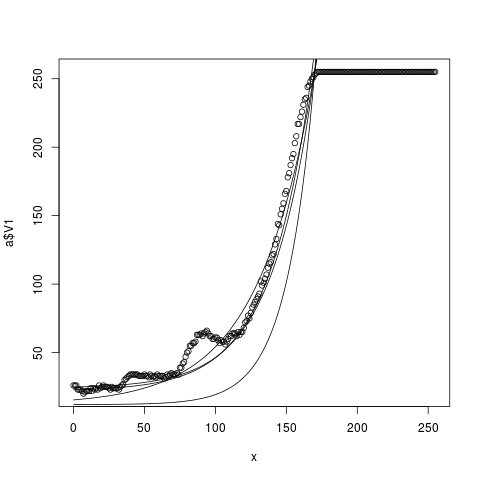
g=function(b,c,d){krivka=b+(255-b)*exp((x-c)/d);lines(x,krivka)}
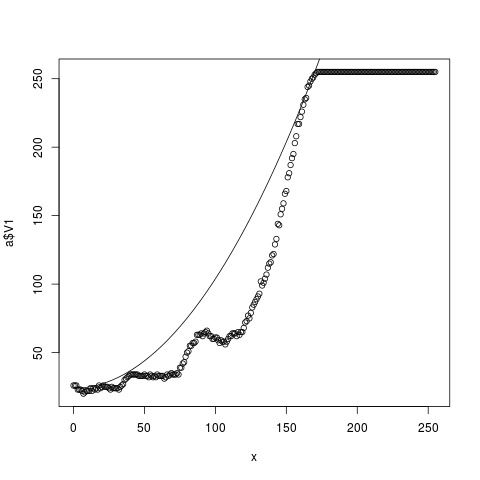
f()
g(22,165, 30)
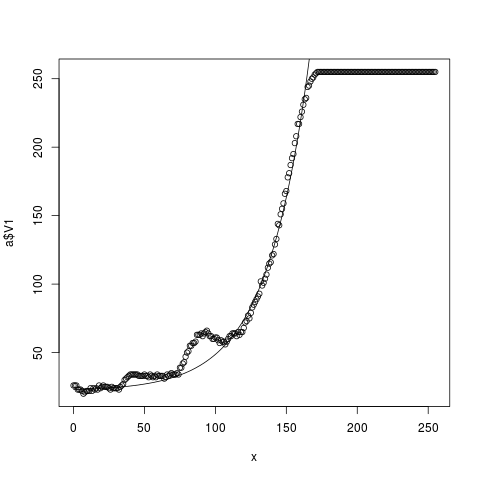
Sláva! Podařilo se na naměřená data napasírovat křivku k mojí spokojenosti. Teď už stačí jen koeficienty přenést do nějaké programátorské implementace např. v jazyce C:
/* Vstupni i vystupni hodnoty v rozsahu sede 0-255 */
float sim_printer(float x)
{
float rv;
float b=22, c=165, d=30;
rv=b+(255-b)*exp((x-c)/d);
if (rv>255) rv=255;
return rv;
}
Tato funkce nám simuluje i to rovné plato vpravo nahoře. Můžeme ji zapojit do simulace tiskárny a budeme to mít hezky hladké bez těch boulí a nemonotonicity v naměřených datech.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()

F=inline(" pin(1).*x^2 + pin(2).*x + pin(3) ","x","pin");
pak nastavime prvopocatecni odhad (musi byt vzdy, u slozitejsich funkci na tom bude zaviset kvalita fitu, ale u takovehle jednoduche muze byt prvni odhad cokoliv krome nuly):
pin=[1 1 1];
a fit se provede:
[fcomp,p,kvg,iter,corp,covp,covr,stdresid,Z,r2]=leasqr(datax,datay,pin,F);
koeficienty polynomu jsou v promenne p. Jak vykreslit, a v ktere promenne jsou residua fitu, jiz necham na laskavem ctenari (pouzijte help plot, help leasqr).
Tak a abclinuxu ma dalsi clanek :)
Nejmensi usili je prave pouzit nejakou fitovaci metoduJe to nejmensi usili pro vas, protoze to uz znate. Pokud byste to neznal, tak nastudovat si teorii o aproximaci a pak i pouziti rozhodne neni mensi usili nez zkusmo nastreli jednoduchou funkci, kterou autor zna a po par iteracich mit vysledek, ktery je vyhovujici. Je to debata o nicem ...
 22.1.2015 13:29
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
22.1.2015 13:29
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Vetsinou mam pochopeni pro zacinajici autory
Pokud to není jen shoda jmen, což podle tématu a formy článků nevypadá (potom by to byla opravdu obrovská náhoda), tak bych spíše doporučoval si zjistit, kdo daný autor je a potom psát nějaké soudy. 
23.1.2015 20:53
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Ja autora neznam a jeho jmeno mi nic nerika.
Njn, já jsem si až dodnes myslel, že k3b je počítačový software a nikoliv diskutér na abíčku .
Podle urovne clanku jsem jen usoudil
Těžko říct, co bylo původním záměrem autora. Jestli pobavit, tak alespoň u mě se to 100% podařilo. (Při představě, že někdo ručně mění koeficienty podle toho jak ne/pasuje graf.) Je to možná tím, že já nemám rád články, které nenechávají čtenáři žádný prostor. Cílová skupina článků o Rku je (podle mě) ta skupina lidí, která rozhodně ví, co je to metoda nejmenších čtverců (ví to samozřejmě i autor), a nejspíše zná jiný software (nejčastěji asi matlab) a cílem je jim nabídnout alternativu z OSS. Alespoň tak to vidím já. Já Rko neznám. Vím, že existuje, ale na grafy a fitování jsem vždy používal GNUplot. Opravdu nepotřebuju vědět, jakou metodu mám použít, ale je pro mě dobré vědět, že existuje další nástroj, ve které ji mohu použít.
 23.1.2015 22:00
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
23.1.2015 22:00
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 Článok rozhodne nepokladám za zlý, ale skôr nepochopenie autora ako sa vtipom dostal k želanému výsledku.
Článok rozhodne nepokladám za zlý, ale skôr nepochopenie autora ako sa vtipom dostal k želanému výsledku.
library(mgcv)
model.zavislosti <- gam(zmerena.data ~ s(data.na.x)
Ocekavanou hodnotu pak v neznamych bodech dostanu:
predpovezene.hodnoty <- predict(model.zavislosti, data.na.x.kde.mne.zajima.predpoved)
sigmoidni.model <- nls(zmerena.data ~ SSlogis(data.na.x, a, b, c))
summary(sigmoidni.model)
?nls
pokud chcete kreslit predikovane cary
?plot
?predict
Pokud se chcete naucit s Rkem trochu zachazet a potrebujete to cesky (jinak built-in manuals, google):
navody Pavla Drozda.
Kurzu, navodu, kucharek,... je na R na internetu plno, mirenych od uplnych zacatecniku po lidi s pozadavky na ruzne specialni typy analyz.
Jde k tomu nějak přidat požadavek, aby funkce byla neklesající?kdyz mi jde jen o prepocet a nepotrebuju znat parametry funkce ktera jsou za tim
library(mgcv) model.zavislosti <- gam(zmerena.data ~ s(data.na.x)Ocekavanou hodnotu pak v neznamych bodech dostanu:
predpovezene.hodnoty <- predict(model.zavislosti, data.na.x.kde.mne.zajima.predpoved)
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 29.1.2015 11:37
29.1.2015 11:37