Příspěvek na blogu Google Security popisuje, jak tým Chrome Security využívá umělou inteligenci k zásadnímu zrychlení a zlepšení procesu odhalování, třídění a opravování bezpečnostních chyb v prohlížeči Chrome. Díky AI byla nalezena kritická chyba, která byla v kódu přes 13 let. Ve verzích Chrome 149 a 150 bylo opraveno více chyb než v předchozích 23 verzích dohromady.
Firmy v EU musí počínaje dnešním dnem označovat obsah vytvořený umělou inteligencí. Znamená to povinnost informovat uživatele, že člověk komunikuje s chatbotem či jiným systémem AI. Rovněž obrázky, audia či videa, které jsou vytvořené nebo zmanipulované pomocí umělé inteligence a které mohou působit jako autentické, musejí být jasně označeny jako uměle vytvořené.
Byla vydána nová major verze 11.0 open source unixového operačního systému NetBSD (Wikipedie). Přehled novinek v poznámkách k vydání.
Národní úřad pro kybernetickou a informační bezpečnost (NÚKIB) se zapojil do mezinárodní iniciativy vedené americkou agenturou CISA (Cybersecurity and Infrastructure Security Agency) a dalšími partnery, jejímž cílem je stanovit minimální náležitosti pro tzv. Software Bill of Materials (SBOM). Nový dokument přináší praktická doporučení, jak by měl vypadat přehled komponent softwaru a jak s ním v praxi pracovat. SBOM lze
… více »V aktuálním přehledu vývoje renderovacího jádra webového prohlížeče Servo (Wikipedie) bylo oznámeno vydání nové verze 0.4.0. Výrazně se zlepšilo vykreslování stránek jako lichess.org, Zulip nebo Speedtest.
Vládní CERT upozorňuje (𝕏) na kritické zranitelnosti v produktech VMware: CVE-2026-59309, CVE-2026-59310 a CVE-2026-47876. Zranitelnosti v VMware vCenter umožňují vzdálenému útočníkovi se síťovým přístupem obejít autentizaci a získat neoprávněný přístup k vCenter, případně zneužít directory traversal ke spuštění libovolného kódu na vCenter.
Společnost Coinkite upozorňuje na bezpečnostní chybu svých hardwarových kryptopeněženek Coldcard. Jedná se o kritickou chybu v generování náhodných čísel (RNG). Místo hardwarového generátoru náhodných čísel (TRNG) byl omylem používán softwarový fallback (PRNG).
Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
 13.11.2013 01:03
Josef Kufner | skóre: 70
13.11.2013 01:03
Josef Kufner | skóre: 70
 ). Krom nějaké vestavěné podpory exportu existuje i nástroj eLyxer, který produkuje velice slušné výsledky (celý jeho web je v něm udělaný). Dokonce i s matematikou si docela poradí a není to povětšinou nijak tragické.
A mimochodem, tag <title> je v HTML povinný.
). Krom nějaké vestavěné podpory exportu existuje i nástroj eLyxer, který produkuje velice slušné výsledky (celý jeho web je v něm udělaný). Dokonce i s matematikou si docela poradí a není to povětšinou nijak tragické.
A mimochodem, tag <title> je v HTML povinný.
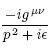 13.11.2013 10:25
egg | skóre: 20
| Praha
13.11.2013 10:25
egg | skóre: 20
| Praha
Dokonce i s matematikou si docela poradí a není to povětšinou nijak tragické.Nic moc. MathJax to umí lépe.
13.11.2013 10:43
Josef Kufner | skóre: 70
 13.11.2013 14:21
xkucf03 | skóre: 50
| blog: xkucf03
13.11.2013 14:21
xkucf03 | skóre: 50
| blog: xkucf03
Mathjax má zabalený nějakých 17 MB
OMG. A i bez toho mi přijde lepší generovat ty vzorečky offline – vyrobit z nich jednorázově nějakým generátorem HTML+CSS+JS+SVG a ne to renderovat všechno až na klientovi.
 13.11.2013 13:15
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 16:30
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 13:15
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 16:30
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
<span class="cmti-10">regul</span><span class="cmti-10">á</span><span class="cmti-10">rn</span><span class="cmti-10">í</span>tenhle problém řeším v make4ht s pomocí filtrů
13.11.2013 21:31
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
13.11.2013 14:24
xkucf03 | skóre: 50
| blog: xkucf03
Tohle je určitě zajímavý postup.
Zajímavý je a rád jsem si to přečetl. Ale vyrobit PDF a z něj pak vytáhnout zase prostý text, mi nepřijde jako moc čisté řešení.
13.11.2013 13:17
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Dílem proto, že konverze z TeXu není v principu možná bez stejné interpretace textu, jakou provádí TeX samotný: TeX si totiž pomocí přečtených maker sám určuje, jakým způsobem bude číst další řádky zdrojového textu a jak je bude interpretovat.Ano, musi to delat nejaky TeX backend, ktery ma informaci jak interpretovat co chtel autor textu rici.
Pomocí pdfTeXu vytvořím PDF soubor, který obsahuje kompletní HTML kód. Pak stačí pomocí příkazu ... z něj udělat HTML soubor.Tohle sice funguje, v mezich mozneho je to i elegantni, nicmene je to stale drbani se levou nohou za pravym uchem.
 13.11.2013 14:32
|🇵🇸 | skóre: 94
| blog:
13.11.2013 14:32
|🇵🇸 | skóre: 94
| blog:
Podotknul bych pouze, že řešení, které ze skoro každého vzorečku vygeneruje pro HTML stránku obrázek, mi připadá poněkud humpolácké: textové písmo pak ve www prohlížeči vizuálně nenavazuje na písmo ve vzorečku. Konverze do MathML nebo něčeho podobného je tedy žádoucí. Bohužel ani 15 let po vzniku MathML není tento jazyk implementován ve všech běžných webových prohlížečích, což odrazuje od dalších aktivit.
Ačkoli jsem matematik, osobně se vyhýbám vzorečkům v HTML stránkách jako čert kříži. Takže ani v následující ukázce tento problém neřeším. Důvody byly řečeny před chvílí.
Hlavu do písku samozřejmě strkat můžeme, ale popularita malých čteček podporujících EPUB a současně nevhodných pro prohlížení PDF je prostě fakt. Vzhledem k nepodpoře MathML ve WebKitu a velikosti/náročnosti skriptů jsou obrázky celkem jasná volba.
13.11.2013 17:06
|🇵🇸 | skóre: 94
| blog:
Už jsem se na to ptal minule: šlo by udělat SAX parser pro TeX? Který by četl zdrojový soubor TeXu a emitoval události typu:
Takže ze zdroje:
\sec Nadpis text
by vylezlo např.
<command name="sec">Nadpis</command> <paragraph>text</paragraph>nebo lépe
<sec>Nadpis</sec> <paragraph>text</paragraph>
(samozřejmě ne jako textový výstup ale jako SAXové události)
Nemuselo by se jít nijak do hloubky, dovnitř maker – stačilo by zpracovat značkování, které je přímo ve zdrojovém dokumentu. Případně by se nějak definovala makra, která se ještě mají interpretovat (např. makro, které vypisuje název firmy, ano, zatímco jiná makra ne).
Kdyby existoval takovýhle obecný nástroj, tak by se daleko lépe daly psát další konvertory, které by tyhle jednoduché události zpracovaly a generovaly různé další formáty.
Ale přijde mi to celkem složité, protože to není jen \něco, ale i \něco[…]{…}, \něco[a=1, b=2, …]{…} nebo třeba \verb|…| případně \scalebox{-1}[1]{F} atd.
Jde mi o tu myšlenku generování různých výstupů z jednoho vstupního formátu – proto se taky ptám pod tímhle článkem.  I když musím říct, že se čím dál víc taky uchyluji myšlence: DocBook nebo nějaký vlastní XML formát jako obecný zdroj + generování různých výstupů (z nichž jeden je TeX/LaTeX a následně PDF).
I když musím říct, že se čím dál víc taky uchyluji myšlence: DocBook nebo nějaký vlastní XML formát jako obecný zdroj + generování různých výstupů (z nichž jeden je TeX/LaTeX a následně PDF).
Akorát je pak trochu potíž, když napíšeš třeba diplomku, vygeneruješ si z ní ten LaTeX a PDF a zjistíš, že by tady ještě chtěla typografie nějak doladit, manuálně zasáhnout do vygenerovaného .tex souboru. U té diplomky to ještě jde, tu vydáš jednou a hotovo, ale třeba taková firemní dokumentace – tu je potřeba aktualizovat, vydávat nové a nové verze. Tam pro manuální zásahy není prostor, to by člověka umořilo a stejně by na to občas zapomněl.
Tohle by mělo jít řešit pomocí něčeho jako instrukce pro zpracování (nebo přímo pomocí nich), kde byl uvedl příkazy/kód pro ten který výstupní formát a při generování ostatních by se to ignorovalo – takže by šlo do zdrojového formátu vložit kus i TeXu nebo kus XHTML, pokud by to bylo potřeba. A ručním změnám generovaného výstupu by se šlo teoreticky úplně vyhnout.
git diff je v pohodě čitelný. Výstup do PDF je v podstatě čistý LaTeX (a můžeš vkládat přímo kusy LaTeXu v editoru). Výstup do HTML skrz (na začátku diskuse zmíněný) eLyxer je docela pěkný (včetně obrázků), asi by to jen chtělo přidat "firemní" CSS. Ale krom toho má LyX i nativní export do HTML, který je mnohem zajímavější, pokud to s ním myslíš vážně. V LyXu totiž je k layoutu (odstavec, nadpis, seznam,…) definováno, jak bude vypadat v LyXu (WYSIWYG editoru), jak v LaTeXu a jak v HTML (a možná i v něčem dalším). Takže můžeš přidávat vlastní konstrukce (styly) do dokumentu a přitom nepřijdeš o možnosti exportu.
Druhou možností na psaní dokumentace, o které uvažuju, je Markdown. Je docela rozšířený a pokud jde o text přiložený přímo k programu a zobrazovaný v něm (nápověda), je nepraktické vyžadovat LyX či podobné "velké" nástroje. Ale zas Markdown není rozšiřitelný a kdo si má pamatovat, jak se co vlastně formátuje.
13.11.2013 21:33
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Druhou možností na psaní dokumentace, o které uvažuju, je Markdown.Zmineny reStructuredText a Sphinx.
zjistíš, že by tady ještě chtěla typografie nějak doladit
Tvoje starosti a Rothschildovy prachy...
Jde mi o tu myšlenku generování různých výstupů z jednoho vstupního formátu – proto se taky ptám pod tímhle článkem.Protože XSLT je ještě o něco méně čitelné, než TeXová makra?
<xsl:template match="a[ starts-with(@href, 'http://') or starts-with(@href, 'https://') or starts-with(@href, 'ftp://') or starts-with(@href, 'mailto:') ]"> … </xsl:template>a ostatní se zpracují buď jinou šablonou nebo se přeskočí nebo z nich zbude jen text. Jde tohle udělat pomocí TeXového makra? Nebo bych musel předefinovat celý příkaz (bez ohledu na jeho parametry/obsah) např.
\url a dovnitř nacpat nějaké IFy?
V tomhle má obrovskou výhodu XML a XHTML (případně i olomítkované HTML5), kde nemusíš rozumět významu značek a přitom to můžeš zpracovat.Hahaha!
13.11.2013 21:32
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Jenže co když se mi v tom PDF objeví třeba poznámky pod čarou nebo po straně nebo něco jiného, s čím jsem při tvorbě HTML maker nepočítal? To mi pak úplně rozbije ten výstup, který vznikne převodem PDF na prostý text.
Ten SAX parser by právě umožňoval ty věci, kterým navazující nástroj nerozumí (nebo nechce rozumět) prostě přeskočit, ignorovat a odchytávat si jen ty značky/příkazy, které mě zajímají a které umím v tom kterém výstupním formátu vykreslit.
Poznamky pod carou by se daly nechavat v pameti
Jenže na se právě musím připravit předem – nejde to použít na obecný TeXový dokument.
Ještě mne napadla jedna věc: z TeXu se přece dají volat shellovské skripty nebo obecně příkazy, ne? Tak bych mohl předefinovat jen vybraná makra (která chci generovat v tom výstupním formátu) a na nich vždycky zavolat příkaz operačního systému, který by nějak obalená data poslal do souboru nebo nějaké roury – nezajímal by mě pak výstup pdflatexu, ale výstup těch příkazů postupně volaných z maker. Akorát by to znamenalo postupně spustit spoustu procesů (pro každý TeXový příkaz/makro, pro každý odstavec…).
Pak by tomu šlo podstrčit libovolný dokument v TeXu a filtrem by prolezlo jen to, co bych předem definoval – ostatní formátování by se zahodilo/přeskočilo.
Já měl vždycky poznámky pod čarou na konci dané stránky, ale i bez toho, bys tam měl1, což by ti pak zaplevelilo to HTML, které bys chtěl získat převodem PDF na text, a vlastně i ty poznámky na konci knihy by tam dělaly bordel.
[1] to číslo v textu, které odkazuje na poznámku
Moc jsme to nezkoumal, ale ConTeXt umí XML...
http://tex.stackexchange.com/questions/43052/converting-context-document-to-html
% Hlavička HTML:
\def\html{{\everypar={}\parskip=0pt\Blue {\typoscale[700/700]
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN"
"http://www.w3.org/TR/1998/REC-html40-19980424/strict.dtd" >\endgraf
\tag{html lang="cs"}\endgraf
\tag{head}
<meta http-equiv="Content-Type" content="text/html; charset=UTF8">\endgraf
\noindent\tag{title}Mathjax test\tag{/title}\endgraf
\tag{script type="text/x-mathjax-config"} % MathJax
\mjcode\endgraf
\tag{/script}
\tag{script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML\string_HTMLorMML"}
\tag{/script}
\tag{/head}\endgraf}
\tag{body}\endgraf\Black}\bigskip\bigskip}
% Inicializační kód MathJaxu
\def\readmeaning#1->#2\end{#2}
\def\mjcode{\bgroup\catcode`\#=12 \mjcodeA}
\def\mjcodeA#1{\def\mjcode{#1}%
\xdef\mjcode{\expandafter\readmeaning\meaning\mjcode\end}\egroup} % de-tokenizace
\mjcode{
MathJax.Hub.Config({tex2jax: {inlineMath: [["\\$","\\$"]]}});
MathJax.Hub.Config({ TeX: { Macros: {
"\(": "\\left(",
"\)": "\\right)",
bold: ["{\\bf #1}",1]
} } });
}
% Použití MathJaxu: \mj$...matika...$ nebo \mj$$...display matika...$$
\def\mj$#1${\if^#1^\expandafter\displaymj \else \printmj{\string\$}{#1}\fi}
\def\displaymj#1$${\endgraf \notagindent\printmj{\string$\string$}{#1}}
{\catcode`&=12
\gdef\printmj#1#2{\def\tmpb{#2}%
\edef\tmpb{\expandafter\readmeaning\meaning\tmpb\end}% de-tokenizace
\replacestrings{&}{&}% citlivé HTML znaky nahradím entitami
\replacestrings{<}{<}\replacestrings{>}{>}%
{\tt#1\tmpb#1}}
}
Makra předpokládají, že před každým vzorečkem ve zdrojovém textu je napsáno \mj, tedy \mj$...matika...$ nebo \mj$$...matika...$$. Mohl bych to sice dát do \everymath a \everydisplay, ale někdy je lepší to mít pod vlastní kontrolou. Do html stánky přepíše makro doslova stejný vzoerec obalený \$...\$ nebo $$...$$. Je to jiné, než v TeXu, protože v html potřebuji, aby se samotný $ choval normálně. Návrh v dokumentaci MathJaxu použít \(...\) jsem nevyužil, protože tyto sekvence používám na zvětšovací závorky.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 13.11.2013 19:20
13.11.2013 19:20