Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefoxu s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
Samba, svobodná implementace síťového protokolu SMB/CIFS, byla vydána ve verzích 4.24.5, 4.23.10 a 4.22.11. Řešeno je 6 zranitelností.
Přední technologické společnosti (Adobe, Cadence, Capital One, Cisco, Cloudera, Cloudflare, Cognition, CrowdStrike, Databricks, Dell Technologies, DoorDash, Elastic, HPE, Hugging Face, IBM, LangChain, Linux Foundation, Microsoft, NAVER, NetApp, Nous Research, NVIDIA, OpenClaw, Palantir, Palo Alto Networks, Red Hat, Reflection AI, Salesforce, SAP, ServiceNow, Siemens, SK Telecom, Snowflake, SpacexAI, Synopsys, Thinking
… více »Řešení dotazu:
 12.10.2013 10:24
Jendа | skóre: 78
| blog: Jenda
| JO70FB
12.10.2013 10:24
Jendа | skóre: 78
| blog: Jenda
| JO70FB
htop uvádí pro jednotlivá jádra naprosto jiné údaje o záteži. A samozřejmě takové, které nejdou vysvětlit libovolným přečíslováním jader.
Měřáky se berou z /proc/stat.
Zátěž není spojitá veličina, natož spojitě diferencovatelná. V daném časovém okamžiku je u jednoho procesoru vždy buď 0% nebo 100%. Tedy celkové zatížení systému například se 4 procesory je v daném okamžiku vždy přesně 0%, 25%, 50%, 75% nebo 100%.
Protože diferenciálně krátký okamžik je celkem nezajímavý a o ničem příliš nevypovídá, všechny utility zobrazují průměrnou zátěž za delší dobu. Jednoduše řečeno, odhadne se doba, kterou procesory strávily prací a kterou strávily nicneděláním. Zátěž je pak doba strávená prací během určitého časového intervalu dělená délkou tohoto intervalu. To například znamená, že pokud čtyři procesory strávily během jedné vteřiny dohromady 150% času prací, celková zátěž systému bude 150% / 400%, tedy 37,5%. Například mohly 3 z nich pracovat každý 50% času, případně všechny čtyři 37,5% času nebo třeba jeden na 100%, dva další na 25% a ten poslední během dané vteřiny nepracoval.
Odhad času, který procesory tráví prací, se dá provádět dvěma způsoby.
Primitivní způsob, který s několika modifikacemi používá Linux, využívá pravidelný tik hodin ke kontrole stavu procesorů. Když nachytá procesor při nicnedělání, zaznamená to. Když najde na procesoru běžící vlákno, přidá celý hodinový interval do časového účetnictví daného vlákna. Poté, co byl pravidelný hodinový tik odstraněn, bylo samozřejmě nezbytné postarat se o správné počítání času i na procesorech, které si dlouhodobě žádný timer nenaplánují. Nicméně hodnoty v souboru /proc/stat stále předstírají, jako by každý procesor zpracovával 100 tiků za vteřinu a u každého tiku zaznamenával aktuální stav. Odhad celkové zátěže je na Linuxu (nepřesně řečeno) tím přesnější, čím víc je procesorů, tedy například na 32-procesorovém stroji přibude do první řádky /proc/stat celkově 3200 tiků každou vteřinu, zatímco na dvouprocesoru pouze 200 tiků.
Tento jednoduchý způsob má samozřejmě své chyby, protože vlákno ve skutečnosti může běžet po dobu mnohem kratší než doba mezi tiky hodin, ať už kvůli vypršení plánovacího kvanta, kvůli migraci na jiný procesor nebo kvůli uspání z velmi široké škály možných důvodů. Idea je ovšem taková, že i přes drobné nepřesnosti bude v průměru a z dlouhodobého hlediska účtování času korektní, tedy pravděpodobnost výrazných systematických odchylek je z pohledu statistiky velmi malá.
Přesnější, ale náročnější způsob účtování času má například Solaris (Illumos, OpenIndiana) a AIX. V těchto systémech se při každé změně stavu procesoru explicitně přečte vhodný nanosekundový čas (tj. časomíra s velkým rozlišením, kterou většina moderních platforem implementuje) a na základě tohoto času se pak přesně počítá, jak dlouho byl procesor v userspace, jak dlouho byl v systému, jak dlouho obsluhoval interrupty, jak dlouho provozoval virtuální stroje — každý interval mezi dvěma sousedními změnami stavu se dá zaúčtovat velmi přesně. V Solarisu se to jmenuje microstate accounting. Tohle ovšem s sebou nese vysokou daň v podobě doby potřebné pro přečtení přesného času. Jakkoliv se to může zdát překvapivé, čtení přesného času je drahé a odpovídá desítkám až stovkám aritmetických instrukcí. (Důvodem je, že se zpravidla jedná o čítač tiků procesoru, který musí fungovat jako pipeline, protože inkrementace čítače se obecně nedá realizovat v jednom tiku. Čtení čítače vyžaduje čekání na dosažení definovaného a čitelného stavu a navíc různá opatření, která kompenzují vliv čtení na rychlost postupu čítače.) Jestliže se tedy například Linux chlubí, že přerušení dělí od příslušného handleru pouze 18 instrukcí (což se člověk dočte ve slavné zprávě „Have you ever kissed a girl?“; dnes už to bude zcela jistě úplně jinak), přidání přesného časovače by mohlo způsobit za jistých okolností zhoršení výkonnosti. (Dlužno připomenout například registrová okénka na platformě SPARC, o jejichž správu a přepínání se musí postarat kernel, když na to přijde, a může na to přijít velmi často.) (Jakmile ovšem musí handler přerušení sáhnout kamkoliv do paměti, která není zrovna v lokální cache na procesoru, cena takového přístupu odpovídá stovkám až tisícům aritmetických instrukcí, takže zůstává otázkou, jak moc velký negativní vliv vlastně microstate accounting má.)
Ať už je způsob měření času jakýkoliv, vždy nakonec dojde na průměrování přes delší časový úsek. Právě volba tohoto delšího časového úseku vede k různým výsledkům pro různé utility. Například průměr za dobu jedné minuty by jistě všechny utility vypočítaly téměř stejně. Jenže tento průměr příliš nevypovídá o změnách zátěže během té minuty. Naopak průměr za sto milisekund velmi rychle (z lidského hlediska) reaguje na změny zátěže, ale potíž je v tom, že je extrémně nestabilní a těžko se z něj (pouhým okem) odhaduje nějaký průměr nebo trend.
Monitorovací utilita v KDE (ksysguard) implicitně vykresluje zátěž pro každý procesor zvlášť. Ta bude samozřejmě mnohem méně stabilní než celkový průměr. Často bude některý z procesorů pravidelně skákat na 100%, protože například zrovna zpracovává data související s šifrováním filesystémů, SSH, VPN, dekódováním hudby a tak podobně, zatímco ostatní procesory budou častěji idle. Tedy to, co vidíš na tom screenshotu, je naprosto normální. V ksysguard si lze u každého sešitu nastavit interval měření, tedy ten interval, přes který se zátěž průměruje. Pak bude vidět, že dlouhý interval produkuje pěkný hladký průběh, ale neukazuje rychlé fluktuace zátěže, zatímco pro krátký interval platí přesný opak. Je méně stabilní, ale změny zátěže (i krátkodobé) jsou hned vidět. Tedy je to věc jakéhosi kompromisu.
Lepší způsob výpočtu zátěže (je-li třeba odhad zátěže aktualizovat často a nepravidelně) je založený na exponenciálním klouzavém průměru, jehož vzorec se trochu poupraví pro „práci se zlomky“ (extrémně vágně řečeno). Výhodou takového postupu je absence pravidelného intervalu, který by přinášel nestabilitu, a možnost aktualizovat odhad zátěže libovolně často. Nicméně i klouzavý průměr potřebuje předem znát konstantu, která představuje kompromis mezi rychlou odezvou na změnu zátěže a stabilitou hlášených hodnot. Nepřítomnost předělů mezi časovými intervaly s sebou ovšem nese jistou daň v podobě malého rezidua z minulosti, bez kterého by ovšem odhad neměl „hladší“ průběh. Pokud vím, současné utility pro měření zátěže klouzavé průměry nepoužívají. Použil jsem tuto techniku v projektech, u kterých byl hladký a zároveň přijatelně přesný odhad zátěže velmi důležitý a kde nebylo žádoucí měřit zátěž v předem daných pravidelných intervalech.
Sečteno a podtrženo, zátěž není žádná přesná a spojitá veličina; je to něco, co se dá mnoha různými způsoby definovat, mnoha různými způsoby měřit a odhadovat. Proto dává každý měřák jiné hodnoty.
 16.10.2013 17:34
rADOn | skóre: 44
| blog: bloK
| Praha
16.10.2013 17:34
rADOn | skóre: 44
| blog: bloK
| Praha
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz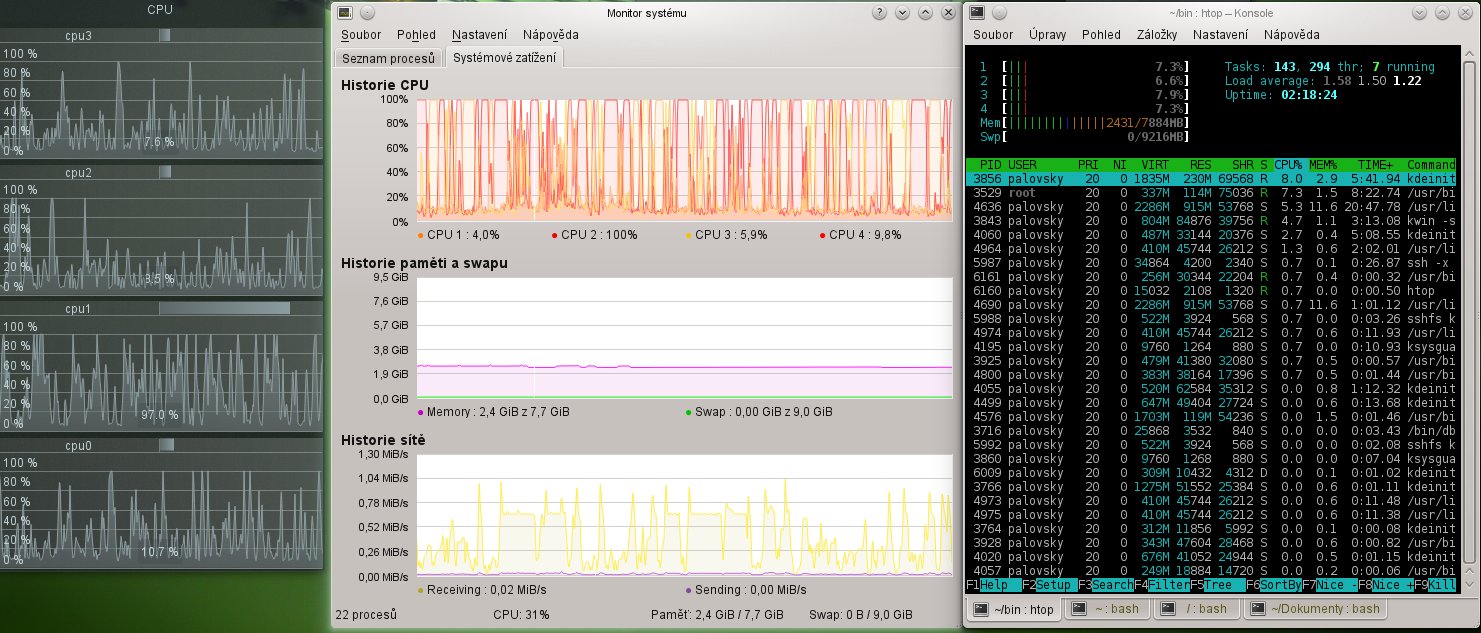{kind=link}