HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
 ). ) je mezi uzavíračem textu " nebo ne.
). ) je mezi uzavíračem textu " nebo ne.
Pred lety jsem delal v Bash prototyp streamoveho filtru.
Pak jsem to prepsal s jinou filosofii v C.
Nicmene vyvoj sel velmi rychle (stale jsem odchytaval dalsi a dalsi zverstva v tom streamu).
Myslim ze by to slo snadno priohnout.
Je to ale dost pomale....
Marek
#!/bin/bash
export IFS=""
ramecky=0
while read -rsn1 char
do
if [ $ramecky -eq 1 ]
then
case "$char" in
$'\033')
read -rsn1 char1
if [ "$char1" = '[' ]
then
read -rsn1 char2
if [ "$char2" = '1' ]
then
read -rsn1 char3
if [ "$char3" = '0' ]
then
read -rsn1 char4
if [ "$char4" = 'm' ]
then
#rozpoznana escape sequence na zapnuti ramecku
ramecky=0
echo -en "\\033[0;39m"
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
else
echo -n "$char$char1$char2"
fi
else
echo -n "$char$char1"
fi
;;
D)
echo -n '-'
;;
Z)
echo -n ','
;;
'?')
echo -n '.'
;;
'@')
echo -n '`'
;;
'Y')
echo -n "'"
;;
'3')
echo -n '|'
;;
'')
echo
;;
*)
echo -n "$char"
esac
else
case "$char" in
$'\033')
read -rsn1 char1
case "$char1" in
"d")
read -rsn1 char2
if [ "$char2" = '#' ]
then
#tady probiha tisk
read -rsn1 char3
( while [ ! "$char3" = $'\024' ]
do
[ "$char" ] || echo
echo -n "$char3"
read -rsn1 char3
done ) | /usr/local/sbin/print1
else
echo -n "$char$char1$char2"
fi
;;
'[')
read -rsn1 char2
case "$char2" in
1)
read -rsn1 char3
if [ "$char3" = '2' ]
then
read -rsn1 char4
if [ "$char4" = 'm' ]
then
#rozpoznana escape sequence na zapnuti ramecku
ramecky=1
echo -en "\\033[1;43m"
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
;;
5)
read -rsn1 char3
if [ "$char3" = ';' ]
then
read -rsn1 char4
if [ "$char4" = '1' ]
then
read -rsn1 char5
if [ "$char5" = 'i' ]
then
#rozpoznany zacatek tisku
konec=0
( while [ "$konec" -eq 0 ]
do
read -rsn1 char6
if [ "$char6" = $'\033' ]
then
read -rsn1 char7
if [ "$char7" = '[' ]
then
read -rsn1 char8
if [ "$char8" = '4' ]
then
read -rsn1 char9
if [ "$char9" = 'i' ]
then
konec=1
else
echo -n "$char6$char7$char8$char9"
fi
else
echo -n "$char6$char7$char8"
fi
else
echo -n "$char6$char7"
fi
else
[ "$char6" ] || echo
echo -n "$char6"
fi
done ) | /usr/local/sbin/print1
else
echo -n "$char$char1$char2$char3$char4$char5"
fi
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
;;
*)
echo -n "$char$char1$char2"
esac
;;
*)
echo -n "$char$char1"
esac
;;
$'\221')
echo -en "\\033[1;43m \\033[0;39m"
;;
$'\237')
echo -en "\\033[1;42m \\033[0;39m"
;;
$'\233')
echo -n "-"
;;
$'\232')
echo -n "|"
;;
'')
echo
;;
*)
echo -n "$char"
esac
fi
done
No ono to s tou pomalosti zas tak strasne neni.
Fungovalo to jako obalka pro telnet+xterm a nez ten telnet to i na starodavnych pleckach, na ktere to bylo urceno, bylo rychlejsi.
Pomalost se projevovala pouze pri tisku velkych souboru.
MarekJo a nesmelo to bufferovat, takze se muselo parsovat opravdu znakove.
sed ':a;N;$!ba;s/\("[^"]*\)\n\([^"]*"\)/\1Shit_new_line\2/g' kuk.csv
funguje to na , a " a LF na ' jsem neměl nervy to zapisovat do $quot; a escapovat, sed ':a;N;$!ba;s/\("[^"]*\)\r\n\([^"]*"\)/\1Shit_new_line\2/g' kuk.csv
Což by mohl být základ „workaround-u“ co chcete…Shit_new_line musí být unikátní v souboru se nevyskytující řetězec.
s/$quot;/\" , nebo-li $quot; mělo být " 
load data local infile 'pokus.csv' into table adresa fields terminated by ',' enclosed by '"' lines terminated by '\n' (jmeno,cislo,ulice);Vyzkoušel jsem s podobnými vstupy, funguje to. Včetně diakritiky. OpenOffice Calc to načte také.
 22.7.2011 00:33
xkucf03 | skóre: 50
| blog: xkucf03
22.7.2011 00:33
xkucf03 | skóre: 50
| blog: xkucf03
A jinak bych to asi předělal do XMLA v čem to bude lepší?
22.7.2011 10:23
xkucf03 | skóre: 50
| blog: xkucf03
xsltproc – to mi přijde rozumnější, než psát několikastránkové skripty v bashi. Nebo ty data naládovat do relační databáze a pak s tím pracovat už hezky v SQL
CSV lze specifikovat velmi jednoduše (RFC je výjimka, jenž potvrzuje pravidlo), což se o XML říct nedá.
<rejp>Napsat CSV parser dá zhruba stejně práce jako napsat hlavičku a patičku XSLT skriptu.</rejp>
CSV lze specifikovat velmi jednodušeCož bohužel znamená, že si CSV naspecifikuje každý znova a trochu jinak. Takže napsat obecný automatický parser CSV nakonec nejde, vždycky musí uživatel ze vzorku okem odhadnout, co asi budou jaké oddělovače atd.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz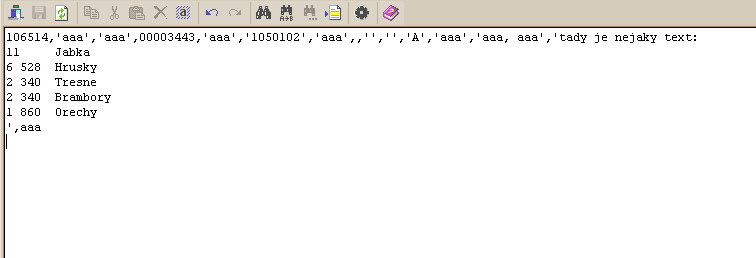{kind=link}