Vládní CERT upozorňuje (𝕏) na kritické zranitelnosti v produktech VMware: CVE-2026-59309, CVE-2026-59310 a CVE-2026-47876. Zranitelnosti v VMware vCenter umožňují vzdálenému útočníkovi se síťovým přístupem obejít autentizaci a získat neoprávněný přístup k vCenter, případně zneužít directory traversal ke spuštění libovolného kódu na vCenter.
Společnost Coinkite upozorňuje na bezpečnostní chybu svých hardwarových kryptopeněženek Coldcard. Jedná se o kritickou chybu v generování náhodných čísel (RNG). Místo hardwarového generátoru náhodných čísel (TRNG) byl omylem používán softwarový fallback (PRNG).
Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
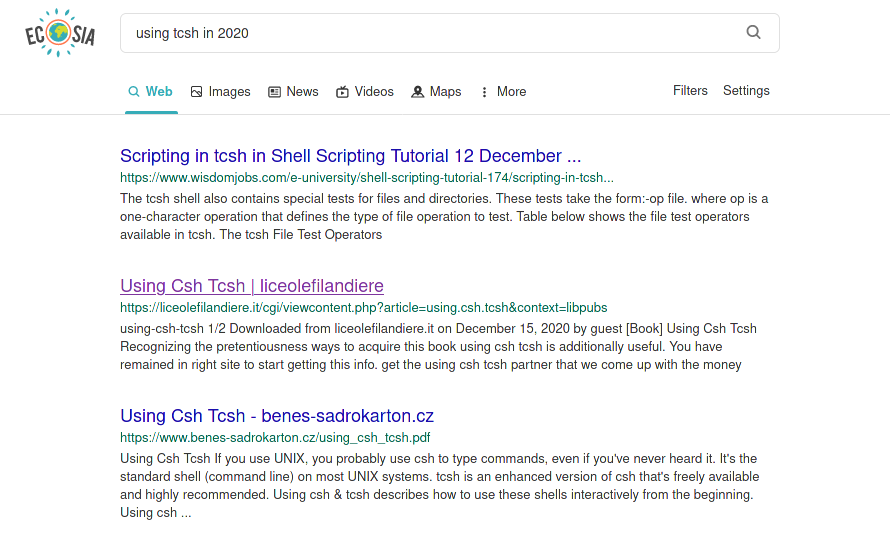
... ale na stránkach Benes-sadrokarton by som niečo takéto nehľadal (viď screenshot).
Ale ako to už obvykle býva, vysvetlenie je jednoduché. Prepadnutá doména, špekulant, nie je to odkaz na pdf ale na stránku ktorá ponúka stiahnutie "zaručene pravej a legálnej verzie" knižky (mám ju doma v papierovej podobe, celkom podarená na pomery O'Reilly).
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 31.12.2020 16:54
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
31.12.2020 16:54
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
 20.12.2020 20:26
xkucf03 | skóre: 50
| blog: xkucf03
20.12.2020 20:26
xkucf03 | skóre: 50
| blog: xkucf03
Bohužel, web je čím dál více zamořený bezcenným automaticky generovaným obsahem. Často narazíš na „články“ náhodně poskládané z nakradených nebo vygenerovaných textů, do kterých jsou vložené (opět nakradené) obrázky. Na první pohled to vypadá relevantně, ale když to začneš číst, tak zjistíš, že to nedává smysl, že to neobsahuje žádnou hodnotnou informaci a že to ani nepsal člověk. Něco je strojově přeložené z jednoho jazyka do jiného, ale často nedával smysl ani ten původní text, ze kterého se překládalo. Do toho máš různé popisy produktů, programů, formátů atd. – opět automaticky vygenerované věty, aby toho bylo víc – z pár údajů které někde automaticky stáhli vyrobí odstavce textu.
apt-get install xyz a autor si prostě nahání e-ego.
21.12.2020 12:03
xkucf03 | skóre: 50
| blog: xkucf03
Dokud je autorem živá bytost, tak to má alespoň nějakou samoregulaci. Jistě, miliardy lidí na planetě dokáží vygenerovat spoustu zbytečného obsahu, ale stále je to řádově někde jinde, než když ten zbytečný obsah generuje počítač/AI.
Otázka je, jak ten obsah klasifikovat a najít v něm něco užitečného. Tady opět jsme/budeme odkázáni na nějakou AI. A to může vést k dost nepříjemným situacím. Ono už sama závislost na tak komplexní technologii je problém. Pak jde o to, kdo tu AI vytvoří, za jakým účelem a na jakých datech ji bude trénovat. To může vést k různým nežádoucím odchylkám (vývoje lidstva) a manipulacím.
Alternativou k AI může být nějaký reputační systém nebo fragmentace. Když např. budu vědět, že distribuce XY má hezky zpracovanou wiki plnou užitečných informací, tak můžu vyhledávat některé věci rovnou tam a ne na webu obecně. Tzn. rozpad na nějaké (polo)uzavřené skupiny a světy, se kterými budu mít zkušenost, že vědí něco zajímavého o určitém tématu. Tím se ten problém dělí do dvou kroků: nejdřív se ke mně musí dostat informace typu „o tématu X vědí něco skupiny/lidé A, B a C“, a pak už hledám konkrétní informaci u A, B a C.
Ono dost možná ten současný přístup, kdy zadám pár slov do jednoho univerzálního vyhledávacího pole, stisknu jedno univerzální tlačítko a čekám, že na první stránce výsledků dostanu to, co hledám, není dlouhodobě udržitelný a optimální.
 21.12.2020 17:23
Josef Kufner | skóre: 70
21.12.2020 17:23
Josef Kufner | skóre: 70
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 20.12.2020 17:13
20.12.2020 17:13