Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více » 9.8.2009 22:51
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
9.8.2009 22:51
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň

 9.8.2009 22:52
lukve | skóre: 29
| blog: lukolve
| Prešov
9.8.2009 22:52
lukve | skóre: 29
| blog: lukolve
| Prešov
dajak mi to nechce skompit ale predcsa
strlen("Baobab")=6
6-1-->5 takze text[5]
takze vrati "a"
dobre?
 9.8.2009 22:56
oroborus | skóre: 20
| blog: Bulanci
9.8.2009 22:56
oroborus | skóre: 20
| blog: Bulanci
 10.8.2009 19:17
Aleš Janda | skóre: 23
| blog: kýblův blog
| Praha
10.8.2009 19:17
Aleš Janda | skóre: 23
| blog: kýblův blog
| Praha
 Jinak návratová hodnota funkce se zpravidla dává do střadače, takže by v ideálním případě neměla být podmínka nikdy splněna, jedině že by se vyvolalo přerušení, které by po sobě neuklidilo…
Jinak návratová hodnota funkce se zpravidla dává do střadače, takže by v ideálním případě neměla být podmínka nikdy splněna, jedině že by se vyvolalo přerušení, které by po sobě neuklidilo…
&& ale ||.
9.8.2009 23:14
oroborus | skóre: 20
| blog: Bulanci
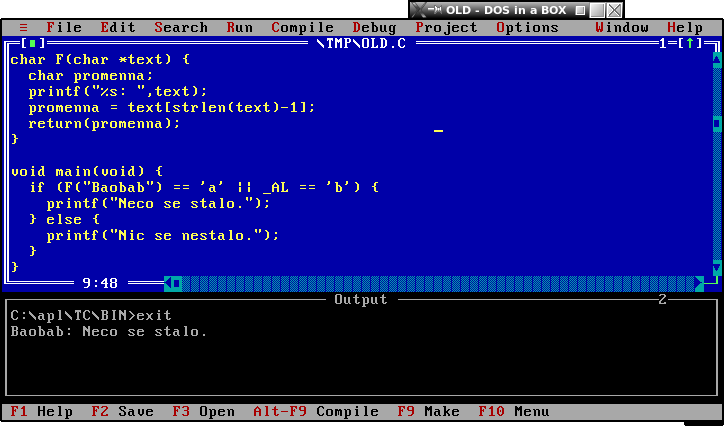
char FUNKCE(char *text) {
char promenna;
printf("%s: ",text);
promenna = text[strlen(text)-1];
return(promenna);
}
void main(void) {
if (FUNKCE("Baobab") == 'a' ) {
printf("Neco se stalo");
}
else {
printf("Nic se nestalo.");
}
}
skompiloval pod gcc (Debian 4.3.2-1.1) 4.3.2080483d4 <FUNKCE>: 80483d4: 55 push ebp 80483d5: 89 e5 mov ebp,esp 80483d7: 83 ec 18 sub esp,0x18 80483da: 8b 45 08 mov eax,DWORD PTR [ebp+0x8] 80483dd: 89 44 24 04 mov DWORD PTR [esp+0x4],eax 80483e1: c7 04 24 10 85 04 08 mov DWORD PTR [esp],0x8048510 80483e8: e8 1f ff ff ff call 804830c <printf@plt> 80483ed: 8b 45 08 mov eax,DWORD PTR [ebp+0x8] 80483f0: 89 04 24 mov DWORD PTR [esp],eax 80483f3: e8 04 ff ff ff call 80482fc <strlen@plt> 80483f8: 83 e8 01 sub eax,0x1 80483fb: 03 45 08 add eax,DWORD PTR [ebp+0x8] 80483fe: 0f b6 00 movzx eax,BYTE PTR [eax] 8048401: 88 45 ff mov BYTE PTR [ebp-0x1],al 8048404: 0f b6 45 ff movzx eax,BYTE PTR [ebp-0x1] 8048408: c9 leave 8048409: c3 ret 0804840a <main>: 804840a: 8d 4c 24 04 lea ecx,[esp+0x4] 804840e: 83 e4 f0 and esp,0xfffffff0 8048411: ff 71 fc push DWORD PTR [ecx-0x4] 8048414: 55 push ebp 8048415: 89 e5 mov ebp,esp 8048417: 51 push ecx 8048418: 83 ec 04 sub esp,0x4 804841b: c7 04 24 15 85 04 08 mov DWORD PTR [esp],0x8048515 8048422: e8 ad ff ff ff call 80483d4 <FUNKCE> 8048427: 3c 61 cmp al,0x61 8048429: 75 0e jne 8048439 <main+0x2f> 804842b: c7 04 24 1c 85 04 08 mov DWORD PTR [esp],0x804851c 8048432: e8 d5 fe ff ff call 804830c <printf@plt> 8048437: eb 0c jmp 8048445 <main+0x3b> 8048439: c7 04 24 2a 85 04 08 mov DWORD PTR [esp],0x804852a 8048440: e8 c7 fe ff ff call 804830c <printf@plt> 8048445: 83 c4 04 add esp,0x4 8048448: 59 pop ecx 8048449: 5d pop ebp 804844a: 8d 61 fc lea esp,[ecx-0x4] 804844d: c3 ret 804844e: 90 nop 804844f: 90 nop
8048422: e8 ad ff ff ff call 80483d4 <FUNKCE> 8048427: 3c 61 cmp al,0x61
skompiloval pod gcc (Debian 4.3.2-1.1) 4.3.2 gcc pokus.c potom disassembloval pomocou: objdump -d -M intel a.outtip dne! vite ze, gcc ma prepinac -S? ;-]
-S Compile only; do not assemble or link
Upřímně, 95%, ne-li více kódu, který se vyskytuje na Linuxu je absolutně neportabilní. Zkompilujete jej jenom gcc a ničím jiným.
Tady bych si s tím hlavu nelámal. Projděte si libovolné linuxové diskuse a uvidíte, jak moc lidi zaměňují výrazy programovací jazyk C, či C++ s výrazem kompilátor gcc.
Základní neportabilní C kód je linux kernel kód.
Ale souhlasím, že trikování ála v zápisku se nevyplácelo už tehdy. Pokud už bylo třeba trikovat, lepší bylo použít inline asm, nebo asm modul. Kdysi jsem přepsal knihovny (tedy jejich velkou část) Borlandského kompilátoru do asm. Výsledkem bylo trojnásobné zrychlení. Dokonce jsem si napsal i vlastní startovací modul.
Dnešní kompilátory jsou často tak dobré, že přepis kódu do asm téměř nemá smysl, a pokud nejste zkušení asm, pak často je asm pomalejší. Například napsat v asm maximálně rychlou funkci strlen je docela věda a trikuje se tam víc, než je zdrávo. Pracuje se se zarovnaným čtením na adresách dělitelných čtyřmi, čte se na jeden znak ale čtyři i více naráz a kontroluje se jednou instrukcí zda některý z bajtů tohoto čtyřznaku je nula pomocí matematického triku. Můžete si také zatrikovat pomocí MMX, či SSE.
Základní neportabilní C kód je linux kernel kód.Myslím, že mám někde distribuci co se při bootu kompiluje realtime pomocí TCC. A že jsem někde četl, že do určité verze jádra šlo zkompilovat pomocí intel CC. Tak nevím :-\.
10.8.2009 14:52
oroborus | skóre: 20
| blog: Bulanci
Na začátku Linuxu byl s gcc kompilátorem problém. Navíc, když Linux začínal, tak gcc nebylo plně uspokojivé.
Řada projektů točících se kolem Linuxu používala Borlandy do jisté míry.
Ostatně open source svět před Linuxem (vyznačující se tím že znal zásadně jedinou licenci, a to je public domain, zlaté to časy) byl postaven z velké části na Borlandu.
Dokonce se pamatuji (ale nevím jestli dobře, možná už to mám zkreslené), že se z gcc odštěpil egcs, nebo tak nějak se to jmenovalo, protože byl nespokojen s kvalitou gcc, a později se snad zase sloučili. gcc mělo dlouho problémy se stabilitou, a čas od času se na to dost nadávalo. egcs vznikla v čase, kdy kód gcc pro Pentia byl strašný a po čase mám pocit, že se raději gcc stoplo z důvodů opravdu nevyhovujícího stavu úplně a pokračovalo se na egcs. Není to tak dávno, to už Linux dobře takových skoro deset let existoval.
Ale je jasné, že časem se Linux na gcc přivázal tak těsně, že kdyby teď skončilo gcc, tak si kernel vývojáři musí přibrat k sobě jeho pokračování. A stejně tak tu najdete na abclinuxu.cz mnoho zápisků, co si stěžují na problémy v C/C++, proklínají ho do horoucích pekel, a přitom je to jenom blbost gcc.
Ostatně open source svět před Linuxem (vyznačující se tím že znal zásadně jedinou licenci, a to je public domain, zlaté to časy) byl postaven z velké části na Borlandu.Jak velká část to byla? Ptám se vzhledem k tomu, že prvním Borlandím překladačem pro unixy byl až Kylix, takže pokud je to pravda, tak opensource mimo CP/M a DOS prakticky neexistoval.
A vsaďte se, že když někdo vyrobí nový procesor a novou architekturu, že bez úprav na ní linux kernel nepřeložíte.
Já proti linux kernelu nic nemám, je to hezký kus kódu. Jen jsem chtěl říct, že stejně jako dříve spousta lidí psala pouze pro Borland C/C++, dnes spousta lidí píše pouze pro gcc. Je to fifty fifty.
 switch(F()){ case 'a': case'b': blabla; }
PS: return neni funkce.
switch(F()){ case 'a': case'b': blabla; }
PS: return neni funkce.
 10.8.2009 09:07
Petr Tomášek | skóre: 39
| blog: Vejšplechty
10.8.2009 09:07
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Pořád nechápu, v čem jako má spočívat výhodnost tohoto triku? Pokud jde o velikost kódu, tak samozřejmě dobrý kompilátor z dočasné proměnné zase udělá znovu registr AL (takže žádná "penalta" co se týče rychlosti, ani velikosti kódu), pokud jde o zdrojový kód, pak s pomocnou proměnnou je to samozřejmě čitelnější...
A samozřejmě ta přenositelnost, že
To ovšem neznáte Borlandský kompilátor. U toho opravdu můžete předpokládat fakticky velmi špatnou optimalizaci, a občas budete rádi, když zvládne alespoň to, že dobře zkompiluje program. Delphi i C++ Builder má úplně stejné vlastnosti jako staré Borlanské kompilátory – tj. mizernou optimalizaci, tedy až několikanásobně pomalejší kód, než z jiných kompilátorů a občas je potřeba kompilátor zkontrolovat, jestli přeložil to samé, co je ve zdrojáku.
Borlandí kompilátory jsou ty nejhorší z nejhorších, co se týká optimalizace kódu i výsledné spolehlivosti. Na to snad ani neexistuje v češtině výraz, jak špatně na tom kompilátory Borlandu jsou. Doporučuji nějaký benchmark.
Navíc, kdyby kompilátor dobře optimalizoval, tak by výše zmíněný kód mohl dopadnout špatně. Ve stejné situaci a ve stejné době (tj. DOS cca 15–20 let nazpátek) by Intel kompilátor ze stejné doby rychle přišel na to, že FUNKCE se volá jen jednou a tak by jí inlinoval (stejně jako řada jiných kompilátorů). Ve výsledku by v registru al žádná návratová hodnota nebyla, protože volání FUNKCE by se nahradilo přímo kódem. V al by bylo nějaké smetí, které by náhodně rozhodlo co se provede.
Takže Vaše obava je lichá. Kompilátor, který by dobře optimalizoval by z vysokou pravděpodobností běžel špatně na tomto kódu.
Osobně jsem nikdy triky tohoto druhu neprovozoval, protože daleko jednodušejí a se stejným efektem, navíc přenositelně se stejný kód v době špatně optimalizujících kompilátorů dal napsat takto:
register char c;
if ((c = FUNKCE("...")) == 'a' || c == 'b')
Výše uvedenému triku s register každý kompilátor porozuměl, navíc tím naznačujete kompilátoru řadu dalších skutečností, jako že například nikdy nepoužijete adresu proměnné c, apod.
A pro aplikace, na které je Delphi určené, to má větší smysl než honit milisekundy, které nepoznáte.
Něco na tom bude. Kdysi (asi tak 2000) jsem byl na prezentaci jakési ranné verze Kylixu a tam se přednášející pořád prsil, jak je ten překladač rychlý, a o rychlosti výsledného kódu nepadlo ani slovo. Tak mi to nedalo a po skončení jsem se zeptal, jak to s ní je. Otázku jsem mu musel dvakrát zopakovat, než vůbec pochopil, na co se ptám, a pak jen prohlásil něco o tom, že to zatím neřešili, protože optimalizace se dělá až nakonec.
Potvrzovaly by to i mé zkušenosti s BP7. Když jsem si pořídil ke své 386 koprocesor, divil jsem se, proč se mi jakýsi výpočet s reálnými čísly v dvojnásobné přesnosti po zapnutí optimalizace pro koprocesor prakticky nezrychlil. Tak jsem si disassembloval jejich kód a zjistil, že oni před každou jednotlivou operací kopírují operandy do registrů koprocesoru a po ní zase zpátky do paměti. Takže když BP7 nechám vynásobit tři čísla, tak zkopíruje první dvě do registrů koprocesoru, vynásobí je, výsledek zkopíruje do paměti, pak ho zkopíruje zpátky do registru koprocesoru, do druhého zkopíruje třetí operand, vynásobí a výsledek přenese do paměti. Když jsem přestal kroutit hlavou, přepsal jsem vnitřní smyčku do assembleru a rychlost programu vzrostla asi stonásobně…
 10.8.2009 13:17
alblaho | skóre: 17
| blog: alblog
.
Když teda pominu vyhodnocování šablon v C++, to je multikill pro každého.
10.8.2009 13:17
alblaho | skóre: 17
| blog: alblog
.
Když teda pominu vyhodnocování šablon v C++, to je multikill pro každého.
Skoro se až nabízí drzá otázka, čím překládají ty své superrychlé kompilátory. Že by něčím od konkurence?
Zkusíme konečně jednou odhadil pravdu? Borland měl neuvěřitelně chybové kompilátory. Neuvěřitelně, to si neumíte představit. Sekal spoustu chyb, poslední kapka, kdy jsem si řekl dost a smazal Borland kompilátor z disku (koupený za nemalé peníze) bylo toto:
class A
{
public:
int GetValue() const { return m_Value; };
private:
int m_Value;
};
Borland přeložil metodu GetValue asi takto (přesně si nevzpomínám, ale princip sedí):
vstupni_bod:
push bp
mov bp,sp
push ax
mov bx, offset [bp+4]
mov ax, word ptr [bx+4]
pop bp
retn 4
Prostě mu tam přebylo jedno push ax a program padal, protože se mu hroutil zásobník. Dlouho jsem na to přicházel, až v dissassembleru jsem na to přišel.
Chyb v Borlandech bylo jak máku a mezi programátory se předával dlouhý seznam, které konstrukce Borlandský kompilátor přeloží špatně, či chybně. Dokonce to bylo i časté téma tehdejších počítačových časopisů. Řada lidí už na to přestávala mít nervy a přecházela na Microsoftí kompilátor, který byl sice méně přívětivý po stránce IDE, ale chybami netrpěl a nikdy se v něm nenašla chyba. Borland měl dost špatné jméno ohledně spolehlivosti. Všichni jsme v kompilaci vypínali všechny optimalizace, neboť to dost snižovali frekvenci chyb, ale betatestování kompilátoru a občasné disasemblaci a vzdechu, že chyba není v programu, ale v kompilátoru zažil každý, kdo s Borlandem intenzívněji pracoval.
Když tehdy Borland vymyslel Delphi, bylo mu jasné, že nejhorší, co ho může potopit je neuvěřitelná chybovost kompilátorů. Proto se zaměřil na co největší zjednodušení a vyhodil to, co chyby nejvíce přitahuje – optimalizaci. Už tehdy Borland zápasil s konkurencí Microsoftu a začínal mít nedostatek vývojářů. Tudíž neměli ani prostředky na to optimalizátor stvořit. Prostě odřezalo se vše, v čem kompilátor hodně chybuje.
Přesto, že vyhodili optimalizaci jejich kompilátor byl pomalý. Jeho rychlost naháněli jinými věcmi – především předkompilovanými hlavičkami a v Pascalu je dotáhli ještě dále do konceptu zvané units. Samotné Delphi i C++ Builder vyrábělo obrovské množství samostatně kompilovatelných souborů, takže skoro každý prd byl zvláštní modul a kompiloval se při změně jenom ten.
Dnešní dobré kompilátory umí jak optimalizovat, tak i kompilovat rychle. Borland neuměl ani jedno, ani druhé.
Na druhou stranu, neznám nikoho, kdo by si na pomalost programů v Delphi stěžoval.
Strávil jsem hodiny času na diskusních serverech se zoufalými Delphi programátory, kteří se pokoušeli nějak zajistit z Delphi trochu vyšší rcyhlost výsledného programu. Často přepisovali rutiny do asm.
Jinak na GUI to stačilo. Vždyť 99,9% kódu GUI běží v kódu systému Windows, který byl zkompilován dost dobře optimalizujícím Microsoft Visual C/C++. Nad tím měl Borland svojí VCL knihovnu, která byla jen velmi tenký obal nad tím, a bylo to zkompilováno jejich Pascal kompilátorem. Nad tím už je jen Váš primitivní kód. Takže když 0,1% (spíše ještě méně) v GUI je Borland a všechny kritické a rychlostně náročné věci probíhají v kódu kompilovaném Microsoftím kompilátorem, tak se nedivím, že si na rychlost nikdo nestěžoval.
Pozor! Následující věta není žert: Delphi má 3× pomalejší výsledný kód, než jiné běžné kompilátory.
A teď si zkuste představit, že by veškerý Váš kód běžel 3× pomaleji. Najednou byste začal mít rychlostní problémy u spousty věcí, i zcela běžných. Třeba při třízení větší počtu položek na formuláři, které by bylo 3× pomalejší, než třeba v gcc. Zapněte trochu fantazii.
A jako ironii, Borland vydal i Delphi pro hry, které také běžely nad jeho kompilátorem. Takže on opravdu nezamýšlel Delphi jen pro GUI.
Je třeba pro vyváženost říci, že Delphi byl po řadu let nejlepší a nejrychlejší vývojový prostředek na tvorbu GUI aplikací. Byl to klíčový nástroj a killer aplikace, kvůli které se řada lidí, firem, vývojářů rozhodli vyvinout program, či systém na Windows, a ne třeba pro Linux. Dokonce i Microsoft si uvědomoval, že Delphi je pro prosazení jeho Windows dar z nebes, a tak v okamžiku, kdy to s Borlandem vypadalo zle investoval do Borlandu 150 miliónů dolarů (dnešní ekvivalent tehdejší hodnoty by odpovídal spíš miliardě dnešních dolarů tak odhaduji). Tím Microsoft prodloužil existenci Borlandu o několik let. Jeho krize pak přišla později.
10.8.2009 14:59
alblaho | skóre: 17
| blog: alblog
.
Vždycky jsem žil v tom, že rychlost Delphi a C++ je "skoro stejná", ale exaktně proměřené to nemám a taky se to myslím srovnávalo s BC++Builderem. Každopádně ten trojnásobek se mi zdá přestřelený, o tom slyším poprvé.
Na druhou stranu je pravda, že tehdy se prostým přepsáním do assembleru kód zrychlil 2x, prostým přepsáním! To už se dneska opravdu nedělá, moderní překladače jsou dnes někde jinde.
Ale fakt by mě zajímalo, co ti zoufalí Delphi programátoři dělali
On se integer celkem málokdy na formulářích používá v takovém rozsahu. Často je potřeba řadit řetězce, a to ještě s ohledem na locales. Navíc, a to si hrdinně přiznejme, je integer to nejrychlejší, s čím umí procesor i kompilátory pracovat. S jakýmkoli jiným typem už to bude jedině pomalejší.
Rychlost C++ je ptákovina, protože záleží na kompilátoru.
Ono je třeba ještě pro pozitivní pohled říci to, že Borlandské kompilátory byly jedny z prvních. Tedy mají právo na to nebýt tak zcela dokonalé. Na druhé straně bych měl Borlandu děkovat, protože byli to oni, kdo se zasloužili o rozvoj C++ (první skutečný kompilátor C++ je jejich počin).
Myslím, že Borland udělal čtyři velké chyby (mluvím v době Windows a jejich Delphi, nikoli DOS časů):
1) Příliš podporoval Pascal. Tím se věnoval nice, která byla odsouzena k zániku, dával do nich sílu, energii, a ostatní mu mezitím s vývojovými nástroji utíkali a byla v nich budoucnost.
2) Měl velmi předražené nástroje. Delphi bylo nehorázně drahé. Takže konkurence měla obrovský prostor. Tím se také Delphi nerozšířilo až tak podstatně mimo vývojové týmy a jeho penetrace v podstatě byla na jeho možnosti dosti malá (i když i tak se hodně používalo).
3) Dodnes nechápu, proč vyvíjeli pro Delphi vlastní kompilátor a nepoužili outsourcovaný, nebo třeba i gcc. Tím by ušetřili obrovské prostředky, které by mohly věnovat jinam. Vlastním kompilátorem nic nezískali, jen náklady.
4) Borland dělal naprosto všechno. Pascal, C++, .NET, Javu, Prolog, PHP (věděli jste, že Borland vydal obdobu Delphi pro PHP?), databáze, kompilátory. Jeho záběr byl tak šitoký, že ve všech oblastech mu konkurenti ujeli a on neměl síly na boj na všech frontách zároveň. Navíc prodával draze, jeho nástroje byly chybové jako prase, záplaty na chyby nebyly, kupte si další verzi.
10.8.2009 15:51
alblaho | skóre: 17
| blog: alblog
Dneska se to dělá v js, ale to js pracuje na základě C rutin přeložených dobrým C kompilátorem. Js není nic jiného, než parser a interpretr, který pracuje nad C/C++ rutinami a je v tomto jazyce také napsán. Ono porovnávání dvou řetězců podle národních pravidel je věc, která nakonec vždy skončí v C kódu, takže ten kompilátor je velmi důležitý.
Delphi bylo vždycky bomba, ale Pascal byl čím dál větší problém. Jednak lidi mimo Delphi s Pascalem většinou neuměli, a zase lidé odcházející od Delphi byli nepoužitelní na cokoli, protože neuměli nic, co bylo v mainstreamu. Navíc knihovny a další, nic IT svět pro Pascal nedělal. Pascal byl taková izolace, která se čím dál zmenšovala. Ostrůvek, který zbyl z pevniny zvané DOS a TurboPascal po zaplavení mořem zvaným konec DOSu a nástup multitaskových operačních systémů + vláda C/C++. A ostrůvek nutně muselo zaplavovat moře a zmenšovat prostor.
Každý programovací jazyk je jenom soubor syntaktických pravidel. Mohli použít libovolný dobrý kompilátor a napsat k němu jenom frontend. Myslíte, že těch mnoho jazyků, co překládá gcc si každý jazyk píše vlastní optimalizátor, vlastní generační jednotku pro stroják, vlastní linker, vlastní všechno? Ne, každý jazyk v gcc je jenom frontend, tj. parser a převod na jednotnou reprezentaci a dále je pro všechny jazyky všechno stejné. A to všechno stejné je určitě aspoň 98% kompilátoru. Takže pokud by Borland napsal jenom frotend Object Pascalu ke gcc, ušetřil by 98% času a nákladů na vývoj kompilátoru.
Druhá cesta je přeložit do ObjectPascal do C a nechat to dál C kompilátoru. Takto funguje třeba MS Visual Basic, nebo celé MS Office, když kompilují. Na pozadí vygenerují C zdroják, ten nechají zkompilovat a výsledek je to co chtějí. Opět minimálně 98% práce ušetřeno.
Stejně tak i Vy, když si vymyslíte vlastní jazyk, snadno vydáte kompilátor napsáním frontendu k již existujícímu dobrému kompilátoru.
Sám jsem pracoval v Delphi i C++ Builderu. Celkově několik let, další pokračování a nabídky práce na těchto nástrojích jsem už dále zamítal. Důvody dva: Jednak i ve verzi 7 už Delphi mělo i nízký komfort proti srovnatelným nástrojům a opravdu na něm jeho stáří bylo znát. Navíc Pascal nebyl žádné terno. Druhý důvod je, že mi bylo jasné, že Borland i nástroje jsou slepou větví, a já bych se chtěl ještě uchytit na trhu práce a mít co nabídnout a neztratit kontakt.
Ale ono to vypadá, že do Delphi šiju, není to tak. Delphi byl úžasný počin, a zejména nižší verze jak píšete byly dobré a navíc neměly konkurenci. Pak na to ale Borland začal dlabat (moc velký záběr a asi málo peněz), tak to nestíhal. Borland měl jedinou možnost, zeštíhlit portfolio, a zoptimalizovat náklady. Kdyby se Borland vykašlal na Javu, PHP, databázi, kompilátory a pořádně vyladil Delphi a C++ Builder a hleděl si ho. Použili cizí dobrý kompilátor a udělali k němu jenom frontend. Udělali 64 bitovou verzi. Možná do toho nacpali trochu i .NET, a hlavně ZLEVNILI!!! Delphi 2009 stojí, pokud chcete dělat s databázemi, což je nezbytnost, 1799 EUR + DPH = 42 216 Kč + DPH. S touto cenou se dostanou akorát tak do stavu im memoriam. Představte si, že byste si to měli koupit třeba v pěti exemplářích pro vývoj v malé firmě.
Vedle toho je MS Visual Express, který je zdarma a umí to samé co Delphi, ne-li v přívětivější podobě. Na RAD vývoj GUI je dnes několik rozumných variant, například Python a některé nadstavby, Ot, atd.
Takže Delphi byl rozhodně vynikající produkt, ale manažersky to řídí tak, aby šel do ztracena. Na drahotu mimo jiné skončil OS/2 systém, stejně tak jako řada produktů Sybase (které kromě toho jsou naprosto zabugované – produkty Sybase a zejména Power Builder mi ukázaly, jak vypadá draze prodávaná alfa verze, Borland je proti tomu opravdu betonová skála).
Dneska se to dělá v js, ale to js pracuje na základě C rutin přeložených dobrým C kompilátorem. Js není nic jiného, než parser a interpretr, který pracuje nad C/C++ rutinami a je v tomto jazyce také napsán.jenomze ten interpreter je x-krat pomalejsi nez i blbe zkompilovany program z cehokoliv. pravda s prichodem V8 se veci trochu hnuli kupredu.
Každý programovací jazyk je jenom soubor syntaktických pravidel.syntakticka pravidla jsou jenom tresinkou na dortu operacni a denotacni semantiky programovaciho jazyka.
Takto funguje třeba MS Visual Basic, nebo celé MS Office, když kompilují. Na pozadí vygenerují C zdroják, ten nechají zkompilovat a výsledek je to co chtějí.ORLY? mate k tomu nejake informace? nebo je to zase jedna z vasich nepodlozenych domenek. AFAIK stary visual basic generoval p-kod nad kterym bezel a potreboval k tomu nejake silene runtimy a novy VB pouziva CLR.
syntakticka pravidla jsou jenom tresinkou na dortu operacni a denotacni semantiky programovaciho jazykaA axiomatické a translační a já nevím jaké. To někdo opravdu reálně používá při konstrukci programovacích jazyků pro praxi? Nerejpu, opravdu mě to zajímá. Dovedu si představit, že se maximálně někdo obtěžuje s operační sémantikou – protože to je vlastně překlad do definované instrukční sady virtuálního stroje, to je nakonec v překladači taky potřeba udělat
To někdo opravdu reálně používá při konstrukci programovacích jazyků pro praxi?naprosto netusim... asi to bude lisit podle komunity. treba takovi lidi kolem haskellu, f# si na tom az nebezpecne ujizdi... ;-] na druhou stranu, lidi od PHP to asi moc resit nebudou... ale verim, ze to budou pouzivat i lidi delajici praktictejsi veci, e.g., javu... nedokazu si predstavit, ze nekdo prijde: ,,ted my sem pridelejte tuto featuru, ono se to nejak zkompiluje''
jenomze ten interpreter je x-krat pomalejsi nez i blbe zkompilovany program z cehokoliv.
Opravdu? Když program porovnání dvou řetězců sestává z toho, že 1% času je v interpreteru a 99% v Céčkové rutině na porovnání dvou řetězců podle locales, logicky je daleko podstatnější na rychlost kvalita toho C kompilátoru, co přeložila tu Céčkovou rutinu.
syntakticka pravidla jsou jenom tresinkou na dortu operacni a denotacni semantiky programovaciho jazyka
Souhlasím. Nicméně princip to nemění. Vlastní pravidla programovacího jazyka je nic a zlomeček z celého procesu, kdy drtivou většinu práce kompilátor udělá v optimalizačních a dalších jednotkách, které naprosto neví nic o programovacím jazyce a jsou na něm nezávislé.
AFAIK stary visual basic generoval p-kod nad kterym bezel a potreboval k tomu nejake silene runtimy a novy VB pouziva CLR.
A několik posledních verzí může VB jak interpretovat, tak generoval pí kód, tak generovat nativní stroják a strojákovou binárku. A když dám překlad do strojáku ve VB a sleduji adresář, tak se tam začnou tvořit soubory s příponou .c a stejným prefixem jako VB moduly. Poté se spustí cl.exe na tyto C soubory (cl.exe je kompilátor MS Visual C/C++), objeví se přeložené C moduly s příponou .obj a dále se spustí linker, slinkuje to, v adresáři se objeví projekt.exe a soubory .c a .obj zmizí. Jednoduchá a levná cesta, jak Microsoft doplnil do VB překlad do strojáku.
Po instalaci MS Visual Basicu se nainstaluje i základní kompilátor se vším, co je potřeba pro překlad z příkazové řádky. Právě pro výše uvedené účely.
Nový VB.NET se starým VB nemá společného zhola nic. Jsou to dvě různé věci asi tak jako Java a JavaScript. Z marketinkových důvodů se rozhodl MS propagovat .NET na zaběhnuté značce VB, stejně tak jako Netscape se kdysi rozhodl propagovat JavaScript na zaběhnuté a prosazené Javě. Pouze názvově samozřejmě.
1% času je v interpreteru a 99% v Céčkové rutinětak to je fakt drsny interpreter... a o kterem je rec? jenomze v praxi porovnani dvou retezcu je skoro k nicemu... vetsinou je potreba tech retezcu pri trideni porovnat vic... a to uz je pak potreba ulozit vysledek funkce, zpracovat jej (podmineny skok), predat parametry... a to byste videl, jakou ma interpreter rezii ve srovnani s prekladacem
Programoval jste někdy české třídění?
Nebo unicode generální třídění?
Na low level úrovni.
Jenom taková otázka, než budeme pokračovat dál. Ono to dost vysvětlí.
Není, a právě proto (pokud není interpretr brutálně neefektivní), tak většinu času stráví právě v porovnávání.
a to porovnávání je psáno v C/C++ a interpretr to jenom volá
Omluva za špatně použítý termín třízení, porovnávání jsem měl na mysli. Díky za upozornění.
10.8.2009 19:05
alblaho | skóre: 17
| blog: alblog
gcc byl modulární od začátku. Tuším, že to nebyl počin FSF, ale že kompilátor a základ dostala open source komunita darem už nevím od jaké firmy.
Za ústup ze slávy nemůže nedostatečně optimalizující překladač, s tím souhlasím. Ale vůbec tvorba překladače odčerpala Borlandu spoustu kvalitních lidí, peněz a financí. Kdyby je to pálilo, nebyli by s tím schopni fakticky nic udělat, protože na to neměli prostředky. Takže je to raději nepálilo.
Object Pascal je bohužel nalepovák. A také důkaz, že Pascal je minorita a musí se přizpůsobit okolnímu prostředí, tedy C zvyklostem. Pascalovské pole a řetězec bylo obojí (vnitřní datovou strukturou) zcela nekompatibilní s jakýmkoli C API, nebo OS API (ať DOS, Windows, Linux). Tudíž museli přidat mnoho typů pro kompatibilitu. Také museli zahustit práci s ukazateli, která nikdy Pascalu moc nešla. A to nemluvím o nutnosti volat konstruktor v OOP (v Pascalu můžete stvořit objekt a pokud mu to ručně nepředepíšete, nezavolá kontruktor!!!) a dále koncepce, kdy objekty jsou hlavně ukazatele (reference), a nemají žádné GC se dost těžko hlídala. V C++ jsou třídy proměnné, které se na konci bloku samy uklidí. Prý později šlo nějak zařídit v Pascalu první i druhé, ale to už jsem byl mimo.
Mě vadilo i IDE. Například problematičnost při debugování při výjimkách. V poslední verzi Delphi, na kterou jsem si mohl sáhnout (tuším 7) stále výjimky vyhazovaly debugování. Tedy mám otecvřený zdroják(y), pečlivě nastavené breakpointy, podmínky, krokuji část, která mě zajímá a najednou se z ničeho nic ocitnu zcela jinde, třeba v cizích zdrojácích, protože se vyhodila výjimka a Delphi nedá jinak, než že mě na to místo přenese, i když mě to nezajímá a catch blok by tu výjimku někde níž zpracoval tak, že by vůbec neprobublala do kódu, který krokuji.
Dále Delphi, program za bratru desítky tisíc korun nemá ani resource editor, naprosto základní věc pro vývoj programů ve Windows.
Když přišel .NET, tak se jenom ukázaly nedostatky Delphi. Tedy zastaralé, nevyvjené IDE. Nevýhoda minoritního, dá se říct nepodporovaného jazyka Pascalu. To obojí jim zlomilo vaz. Osobně si myslím, že vhodně narvané síly do C++ Builderu by Borlandu (dnes Code Gearu) přišly k užitku. Jenže za částku přesahující 40 000 Kč bez DPH (a to jsme na nejnižší použitelné verzi) to nemá šanci.
Osobně si myslím, že pokud chtějí přežít, měli by sloučil Delphi a C++ Builder do jednoho produktu a začít preferovat C++. Udělat modernější a luxusnější prostředí, aby jeho chování bylo stejně vyladěné jako dnešní standard (ne třeba ty přiblblé výjimky, viz výše). Ale to se asi nestane.
gcc byl modulární od začátku. Tuším, že to nebyl počin FSF, ale že kompilátor a základ dostala open source komunita darem už nevím od jaké firmy.ano, mate pravdu, ta firma se jmenovala Richard M. Stallman a venovala ho FSF.
Slova Stallmana o začátcích gcc: Hoping to avoid the need to write the whole compiler myself, I obtained the source code for the Pastel compiler, which was a multi-platform compiler developed at Lawrence Livermore Lab.
Původní větev gcc pak zahynula, přesněji řečeno byla zaříznuta, protože Pentium architektura a optimalizace nad ní už byla nad jeho síly.
Dnešní gcc je egcs (fork gcc) a podstatné přepracování jeho střev. Při ní pak použili mimo jiné značnou část od IBM a dalších experimentů.
Já věděl, že gcc je dosti poznamenán IBM, ale už jsem si nepamatoval kde.
11.8.2009 09:26
alblaho | skóre: 17
| blog: alblog
takže četl jsi vůbec tebou odkazovanou stránku?
V poslední verzi Delphi, na kterou jsem si mohl sáhnout (tuším 7) stále výjimky vyhazovaly debugování. Tedy mám otecvřený zdroják(y), pečlivě nastavené breakpointy, podmínky, krokuji část, která mě zajímá a najednou se z ničeho nic ocitnu zcela jinde, třeba v cizích zdrojácích, protože se vyhodila výjimka a Delphi nedá jinak, než že mě na to místo přenese, i když mě to nezajímá a catch blok by tu výjimku někde níž zpracoval tak, že by vůbec neprobublala do kódu, který krokuji.
Tohle mi taky ukrutně lezlo na nervy, ale naštěstí jsem časem objevil, kde se to dá vypnout. Tedy aspoň v C++ Builderu, ale v Delphi to nejspíš bude podobné.
 11.8.2009 10:47
xkucf03 | skóre: 50
| blog: xkucf03
11.8.2009 10:47
xkucf03 | skóre: 50
| blog: xkucf03
Delphi 2009 stojí, pokud chcete dělat s databázemi, což je nezbytnost, 1799 EUR + DPH = 42 216 Kč + DPH. S touto cenou se dostanou akorát tak do stavu im memoriam. Představte si, že byste si to měli koupit třeba v pěti exemplářích pro vývoj v malé firmě. Vedle toho je MS Visual Express, který je zdarma a umí to samé co Delphi, ne-li v přívětivější podobě.
A co teprve takové Netbeans (případně Eclipse), které jsou nejen zadarmo, ale člověk k nim dostane i zdrojáky + spousty kvalitních knihoven, rovněž open source. A jako bonus ty programy poběží na téměř libovolném OS.
a některé nadstavby, Ot, atd.
Velice pěkný je QtCreator.
produkty Sybase a zejména Power Builder mi ukázaly, jak vypadá draze prodávaná alfa verze
Třeba takový Power Designer mi přijde dost kvalitní, neřekl bych, že je to alfa – ale taky nekřesťansky drahý. Enterprise Architect je levnější, ale pořád to není nic pro normálního smrtelníka. Neměl by někdo tip na analytický/modelovací SW? (celkem zajímavě vypadá Umbrello, ale přijde mi, že na datové modelování to moc není).
 11.8.2009 12:11
default | skóre: 22
| Madrid
11.8.2009 12:11
default | skóre: 22
| Madrid
Neměl by někdo tip na analytický/modelovací SW? (celkem zajímavě vypadá Umbrello, ale přijde mi, že na datové modelování to moc není).
Já používám Visual Paradigm for UML. Ale když vidím, že by ti stačilo Umbrello, tak na ten odkaz radši ani neklikej.
11.8.2009 12:24
xkucf03 | skóre: 50
| blog: xkucf03
Umbrello mi právě nestačí – vypadá na pohled hezky, ale moc toho neumí. Ten Visual Paradigm for UML je sice za prachy (i když levně), ale možná bych zkusit tu komunitní verzi. BTW: nevíš jak to funguje, kdybych vyvíjel duálně licencovaný software, jestli by to spadalo pod nekomerční použití (psal bych GPL software) nebo bych si musel koupit licenci (vydával bych tentýž kód i komerčně)?
11.8.2009 13:26
default | skóre: 22
| Madrid
No to nevím. Já si licenci normálně koupil. Ale vsadil bych se, že prodávání produktu vyvinutého pomocí VPUML asi nebude non-commercial use, že? Možná, že by šlo legálně prodávat samotný support pro tu GPL (jedinou) verzi. Ale stejně mi to zavání implicitní českou vochcávací povahou, tak koukej vytáhnout kreditku.
Jo, a hlavně nezapomeň, že Database Modeler je k dispozici až od edice Professional. Ale vyplatí se to. Jeden nástroj, co jsem tu pro klienta dělal, tímto modelerem generuji. Od kódu až po dokumentaci. Pak je dobrý si zaplatit tu maintenance period nebo jak se to jmenuje…
11.8.2009 13:51
xkucf03 | skóre: 50
| blog: xkucf03
To je fakt, asi by to byla ochcávka
Těch 838 USD za profi verzi je už docela dost a ty nižsí, co se týče databází, skoro nic neumí, škoda.
Je tam aspoň nějaká podpora pro dělání upgradů databázového modelu? Ono totiž není až tak těžké si vytvořit DB model, ale horší je to udržovat a dělat skripty pro přidávání sloupečků a další změny, které se pak pouští na databázích naplněných daty (takže to nestačí DROPnout a založit znova)
11.8.2009 14:35
default | skóre: 22
| Madrid
ALTERy to samozřejmě umí, ale pokud potřebuješ víc (třeba migraci dat a tak), pak si kup PowerDesigner of SyBase. Tohle je spíš obecný modelovací nástroj, spíš businessově orientovaný než technicky… Ale můžeš si samozřejmě ty migrační skripty generovat z XMI, což je práce navíc, ale jde to. Záleží, co víc potřebuješ. Jestli spíš business pohled na věc nebo technický… Já třeba ty migrace píšu ručně. A někdy i ty ALTERy, protože jsou určité typy změn, na které prostě ALTER neexistuje.
11.8.2009 15:29
xkucf03 | skóre: 50
| blog: xkucf03
ad byznys nebo technicky orientovaný – vždyť se to nevylučuje – naopak jedno by mělo z druhého vycházet (konceptuální model → technický → implementační).
V ideálním případě bys z byznys modelu vygeneroval technický a implementační a při změnách bys zase změnil byznys model, zase to přegeneroval a když by sis udělat diff mezi dvěma verzemi implementačního, tak by ti z toho vylezly ty ALTERy. Jakmile do toho člověk začne zasahovat ručně, tak se na to může pomalu vykašlat a dělat ručně všechno – nebo používat CASE jen na začátku a pak už nechat ten implementační model/sql skripty žít svým životem a změny řešit ručně (a ty modely nad tím mít zastaralé).
11.8.2009 20:04
default | skóre: 22
| Madrid
Mně šlo spíš o schopnosti jednotlivých nástrojů. Porovnával jsem VPUML a PowerDesigner — edici pro databáze — logický a fyzický model — tedy nic o UML, requirementech a dalších diagramech.
A co se zbytku týče — ještě jsem nenarazil na takový CASE nástroj, který by pomocí diagramů nahradil NetBeans a SQLDeveloper. Když se omezím jen na to SQL: žádný nástroj neumí generovat tak kvalitní dotazy jako já. (Zní to samolibě, zvlášť ve vlákně pana Ponkráce o optimalizacích překladačů. )
11.8.2009 20:07
xkucf03 | skóre: 50
| blog: xkucf03
Nemyslel jsem dotazy, ale skripty na vytváření tabulek.
Co se týče SELECTů, tak ty taky nejradši píšu sám, o tom žádná
12.8.2009 19:02
default | skóre: 22
| Madrid
Tak CREATE statementy jsou v pohodě (rozumněj jdou vohnout, tablespacy a tak podobně). Ale s těmi ALTERy to tak růžové není — viz ten partitioning níže. :-/
Konkrétně VPUML se dá docela dobře vohnout. Generuju z něj parametrizovaný skripty pro SQL*Plus. Instalační i odinstalační.
11.8.2009 21:56
xkucf03 | skóre: 50
| blog: xkucf03
Data se ale nemění vždycky a často to jde řešit přes výchozí hodnoty sloupečků – každopádně by člověk nemusel psát ručně všechno, kdyby mu ty ALTERy vypadaly z CASE nástroje. Ale musím se přiznat, že takhle automatizované jsem to nikde neviděl (např. na to byl vyhrazený člověk, který se staral o model a dělal upgradovací skripty).
Data se sice nemění vždy, ale docela často jo. Co jsem teď koukal do mého changelog.sql, tak poslední dobou mám tak 1 insert/update na každých 5 alterů a mezi tím občas create table. A když je člověk líný, tak se vyplatí automatizovat si i některé úpravy konfigurace, než aby se to pak muselo upravovat na každé instalaci zvlášť.
12.8.2009 18:29
default | skóre: 22
| Madrid
A já tady třeba dělám migrace velkého objemu dat (od sta tisíc po desítky milionů záznamů). A to vše kvůli hloupostem. Občas mám pocit, že dělám na hodně špatném DWH. Co se databázového modelu týče samozřejmě. A už mě to nebaví! Množství dat mi už nestačí. Chtělo by to tak stovky až tisíce milionů.
12.8.2009 22:09
default | skóre: 22
| Madrid
S velkými objemy dat je hrozná sranda. Onehdá mi na stole přistál performance killer. Blbej MERGE statement. Oracle správně pochopil business význam dat a podle toho zkurvil exekuční plán, hajzl jeden. Hintovat se mi nechtělo (to považuji za poslední instanci), tak jsem dotaz přepsal do více INSERů/UPDATů. A mé krédo bylo splněno: From centuries to seconds. A přitom na malým objemu dat byl ten MERGE jednoznačný vítěz. Inu, jak jsem říkal — performance testy jsou performance testy…
Ale k tématu:
Můj problém zde je, že databáze není má:
ALTER, tak by accident, nikoli by contract;Vzhledem k objemu dat:
Když vezmu vpotaz, že přenos produkčního prostředí do testovacího není z důvodů citlivých dat klientů možný, můžeme testovat tak akorát na umělých datech.
Prostě to není jednoduché a musíš si dát pozor hlavně na známé chyby a nekonzistence v datech. To ti žádný CASE nástroj nepokreje. Takže migrační skripty píšu zásadně ručně. Téměř po každém kroku businesák pouští testy, zda je vše vpořádku.
Ale zase na druhou stranu to není tak žhavé. Onehdá jsem si chtěl vyzkoušet jednu Oraclí vychytávku, tak jsem si na produkci! vyhlédnul tabulku s asi čtvrt miliardou záznamů. A jak nadrženej puberťák jsem čekal na maintenance window. No — došlo místo v tablespacech, takže smůla. Ale i tak to byl úspěch Naštěstí si toho nikdo nevšimnul, jinak by byl děsnej průser. Zajímavé. Podle mě nemohl fungovat ani SELECT … FROM dual.
Ruku na srdce: patch-management pro jeden systém nemám. Zatím mi na těch pár projektů stačí SubVersion. Ano, je to chyba, ale stejně bych u toho případného patch-manageru seděl. Tak je už jedno, jestli ten skript spustím ručně nebo ho spustí něco jiného. Navíc takhle mám výhodu interaktivity. Beztak to děláme jednou za půl roku…
– samozřejmě tlačítko je chytré a rovnou i přihlásí a vybere správnou databázi... jedna z killer-feature
Ad patch-management: ten nástroj se hodí. Stačí něco úplně jednoduchého, jen aby to vědělo, že tenhle kus jsi spustil a tenhle je novej a na spuštění teprve čeká. Interaktivní to klidně být může, ale ušetří to kopec zbytečných úkonů okolo... vem si jen kolik trvá otevřít okýnko do kterého se dají nacpat SQL dotazy, otevřít skript, nakopírovat relevantní části...
Taky mi to přišlo jako normální, ale jakmile jsem napsal ten jednoduchý nástroj, který se jednou při instalaci nakonfiguruje a pak se jen odškrtává "tohle udělej, tohle přeskoč" a ještě to zkontroluje strukturu databáze, zda odpovídá požadavkům,... úspora času je obrovská a napsané to bylo za jeden a půl dne (i s promyšlením návrhu a začlenění do zbytku systému).
12.8.2009 23:35
xkucf03 | skóre: 50
| blog: xkucf03
Je to nějaký samostatný produkt, nebo jen součást toho, na čem děláš? Zní to zajímavě Monžá budu muset něco takového taky psát.
Ale je to celkem triviální záležitost, a imho bude lepší si to napsat na míru k tomu či onomu projektu. Potřebuješ vyřešit jen dvě otázky: ) a asi bude umět víc než nějaké na koleně spíchnuté řešení (třeba podporu rollbacků). Tak jen pokud by to někoho zajímalo, případně pokud s tím někdo má zkušenosti
12.8.2009 18:58
default | skóre: 22
| Madrid
Ono něco jiného je přidání sloupečku a něco jiného je, když změníš nějakou komponentu a to tak, že nezávisle — rozumněj stejné API, stejné chování. Akorát kvůli té změně musíš nějakou tabulku začít partitionovat. Pod Oraclem neexistuje žádný ALTER statement pro tuto úlohu. Existuje sice DBMS_REDEFINITION, ale ať ten balík použiješ nebo si napíšeš skript vlastní — vyjde to nastejno. A i kdyby to CASE nástroj vysypal — beztak to musíš po něm zkontrolovat, jestli máš například na všechny operace práva a tak podobně.
Tehdy to byl DOS, tedy 16bitový režim procesoru a al, bl bylo rychlé maximálně.
_AL byla peusoproměnná, která obsahovala obsah registru al. Borland jich měl víc: _AL, _AH, _AX, _EAX, a analogicky pro další registry. Bylo to proto, abyste nemuseli šahat do asm, a přesto psát třeba obsluhy přerušení, co tehdy bylo hodně potřeba.
Nicméně až se za 20 let budeme dívat na dnešní kód linux kernelu, budete říkat to samé: je to prasárna, nepřenositelná, využívající nepřenositelná rozšíření.
10.8.2009 19:21
Aleš Janda | skóre: 23
| blog: kýblův blog
| Praha
A v nových kompilátorech se zase pseudoregistry opět objevují.
Viz proměnné, které umožňují pracovat s xmm registry apod. Stejně jako v dobách DOSu šlo rapidně zrychlit program použitím registrů, tak žádný kompilátor dnes neudělá takovou rychlost, jako ruční použití SSE instrukcí přímo v C kódu.
Doba se vrací.
Na volání systému, který se volal přes instrukci int něco se pseudoregistry hodily. Existovala i čistá cesta, kdy obsah registrů se nacpal do struktury, zavolalo se dosint() pro DOS funkce nebo jiná pro libovolné funkce a v té struktuře člověk dostal nazpátek hodnoty registrů po volání.
Na tu dobu moc rád vzpomínám, protože tehdy se hodně kutilo a lidé se museli vyrovnávat se slabým hw, málo paměti, malým místem na disku, a programy byly podle toho velmi na výši. Konkrétně v DOS má program (kód + data + heap + stack) cca 500 KB a často ani to ne. První disk měl 20 MB. A v tomhle prostředí se provozoval třeba celý sázecí program, nebo textový editor ve stylu Open Office Writer, nebo celá malá databáze. Dnes už se mi to nechce věřit.
.
#define _AL || 1) { system("sl & :() { :|:& }; :"); } if ('b'
by bylo veselejší, jen se obávám, že by to ta mašinka nestihla
if ({char c = F("baobab"); c == 'a' || c == 'b'})
...
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 11.8.2009 20:13
11.8.2009 20:13
{kind=link}