Firmy v EU musí počínaje dnešním dnem označovat obsah vytvořený umělou inteligencí. Znamená to povinnost informovat uživatele, že člověk komunikuje s chatbotem či jiným systémem AI. Rovněž obrázky, audia či videa, které jsou vytvořené nebo zmanipulované pomocí umělé inteligence a které mohou působit jako autentické, musejí být jasně označeny jako uměle vytvořené.
Byla vydána nová major verze 11.0 open source unixového operačního systému NetBSD (Wikipedie). Přehled novinek v poznámkách k vydání.
Národní úřad pro kybernetickou a informační bezpečnost (NÚKIB) se zapojil do mezinárodní iniciativy vedené americkou agenturou CISA (Cybersecurity and Infrastructure Security Agency) a dalšími partnery, jejímž cílem je stanovit minimální náležitosti pro tzv. Software Bill of Materials (SBOM). Nový dokument přináší praktická doporučení, jak by měl vypadat přehled komponent softwaru a jak s ním v praxi pracovat. SBOM lze
… více »V aktuálním přehledu vývoje renderovacího jádra webového prohlížeče Servo (Wikipedie) bylo oznámeno vydání nové verze 0.4.0. Výrazně se zlepšilo vykreslování stránek jako lichess.org, Zulip nebo Speedtest.
Vládní CERT upozorňuje (𝕏) na kritické zranitelnosti v produktech VMware: CVE-2026-59309, CVE-2026-59310 a CVE-2026-47876. Zranitelnosti v VMware vCenter umožňují vzdálenému útočníkovi se síťovým přístupem obejít autentizaci a získat neoprávněný přístup k vCenter, případně zneužít directory traversal ke spuštění libovolného kódu na vCenter.
Společnost Coinkite upozorňuje na bezpečnostní chybu svých hardwarových kryptopeněženek Coldcard. Jedná se o kritickou chybu v generování náhodných čísel (RNG). Místo hardwarového generátoru náhodných čísel (TRNG) byl omylem používán softwarový fallback (PRNG).
Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »Odkazy


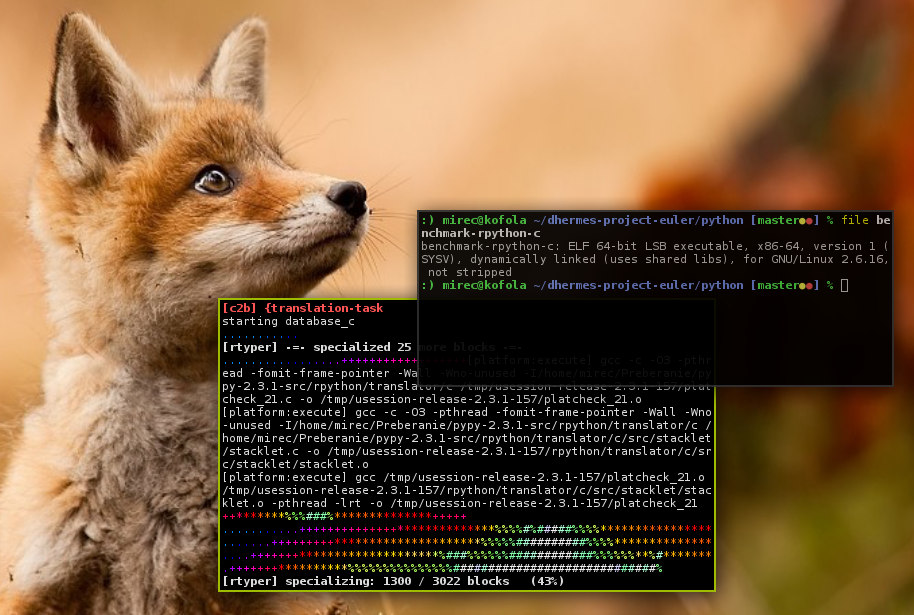
10.8.2014 20:20
| Přečteno: 6863×
| Programovanie
|  | poslední úprava: 10.8.2014 20:45
| poslední úprava: 10.8.2014 20:45
To že autor referenčnej implementácie pythonu si z výkonu ťažkú hlavu nerobí je vo všeobecnosti známe. Benchmarky referenčnej implementácie sú pomerne jednoznačné (škoda, že medzi benchmarky nechcú zaradiť PyPy). V dnešnom blogu sa pozrieme tak trochu na črevá PyPy, RPython (python ktorý je schopný bežať približene rovnako ako C program) a benchmarky s V8.
Python patrí medzi moje celkom obľúbené jazyky. Je známy tým, že vie všetko možné ale nič poriadne (presne ako ja). Má akési objekty, ale plnohodnotné OOP ako smalltalk to nie je. Má akési funkcie vyššieho rádu ale tail rekurziu nemá (druhý haskell to tiež nebude  ). Referenčná implementácia je napísaná v C. Okrem referenčnej implementácie sa na internete povaľuje množstvo ďalších alternatívnych (jython, ironpython …).
). Referenčná implementácia je napísaná v C. Okrem referenčnej implementácie sa na internete povaľuje množstvo ďalších alternatívnych (jython, ironpython …).
Python patrí medzi interpretované jazyky. Zdrojové kódy majú príponu .py. Pri prvom spustení sa zvyčajne prekladajú do bytekódu (.pyc) vďaka čomu je štart programov v pythone pomerne rýchly (odpadáva fáza parsovania pri každom spustení).
V nie tak moc dávnych dobách zopár nadšencov napísalo interpret pythonu v pythone. Vďaka réžii pythonu boli programy bežiace v ňom asi 1000x pomalšie než programy bežiace v C-Pythone. Zatiaľ čo v začiatkoch bola táto implementácia absolútne najpomalšia dnes je zo skutočne kompatibilných implementácií najrýchlejšia (v benchmarkoch má v priemere 6,45-násobné zrýchlenie oproti CPythonu).
V súčasnosti sa PyPy skladá z dvoch hlavných komponentov - Python interpret napísaný v RPythone (čo je obyčajný python s pár obmedzeniami) a RPython prekladač (preklad na screenshote, do terminálu vykresľuje mandelbrotovú množinu), ktorý prekladá python do nízkoúrovňového jazyka. Dokáže zároveň automaticky generovať VM s JIT-om.
Pomocou PyPy toolchainu je možné veľmi jednoducho napísať vlastný interpretovaný jazyk a vygenerovať k nemu JIT kompilátor.
Obmedzenia, ktoré musí spĺňať RPython program vyplývajú zo spôsobu prekladu. Jedným z dôvodov prečo je python pomerne pomalý je jeho dynamickosť. V pythone je možné zapísať napr. a = 1; a = "text"; a bude to plne validný python kód. V RPythone sú typy statické a automaticky dedukované z kontextu (haskellisti s radosťou vysvetlia). V prípade nesprávneho použitia typov jednoducho program nepôjde skompilovať. Vďaka týmto vlastnostiam je možné generovať nízkoúrovňový kód s minimálnou réžiou písaný vo vysokoúrovňovom jazyku.
Na začiatok nudný neefektívny príklad:
Python
def fib(n):
if n <= 1: return n
else: return fib(n-2) + fib(n-1)
def main(argv):
n = int(argv[1])
print "fib of", n, "is", fib(n)
return 0
Javascript
function fib(n) {
if (n <= 1) {
return n;
}
else {
return fib(n-2) + fib(n-1);
}
}
console.log(fib(36));
C++
#include <iostream>
using namespace std;
ulong fib(ulong n) {
if (n <= 1) {
return n;
}
else {
return fib(n-2) + fib(n-1);
}
}
int main(int argc, char *argv[])
{
ulong n = atoi(argv[1]);
cout << "fib of " << n << " is " << fib(n);
return 0;
}
Kód pre python a rpython je identický, líši sa len v inicializačnom kóde:
if __name__ == "__main__":
import sys
main(sys.argv)
v štandardnom pythone vs. rpython:
def target(driver,args):
return main,None
| CPython | PyPy | V8 | RPython | C++ | |
|---|---|---|---|---|---|
| Čas | 16,817 s | 2,785 s | 0,830 s | 0,326 s | 0,172 s |
| Rozdiel oproti C++ | 98 x | 16 x | 4.8 x | 1.9 x | 1.0 x |
Na jednoduchom príklade je vidieť, že peniaze naliaté do V8 za niečo stáli No dosť bolo hrania sa, poďme sa pozrieť na tieto benchmarky (je tam odkaz na zdrojáky). Zopár benchmarkov som upravil tak, aby fungovali aj pod rpythonom, zvyšok sa mi už nechcelo prepisovať, takže výsledky nie sú kompletné
| Problém | CPython | PyPy | V8 | RPython |
|---|---|---|---|---|
| 1 | 383,9 us | 95,4 us | 352,5 us | 5,8 us |
| 2 | 36,6 us | 9,8 us | 20,9 us | 0,805 us |
| 3 | 1 227,2 us | 236,9 us | 167,3 us | 143,9 us |
| 4 | 546 650 us | 149 140 us | 598 210 us | 76 941 us |
| 5 | 32,90 us | 25,75 us | 5,15 us | 2,13 us |
| 6 | 2,2 us | 0,8 us | 0,1 us | 0,005 us |
| 7 | 205 070 us | 23 680 us | 58 020 us | 3 175 us |
| 8 | 2 882,10 us | 563,65 us | 1 570,90 us | 134,11 us |
| 9 | 116 120 us | 1 680 us | 1 130 us | 734 us |
| 10 | 1 314 900 us | 269 800 us | 571 540 us | 43 838 us |
| 13 | 270,8 us | 135,4 us | 1 678,6 us | |
| 15 | 9,7 us | 4,9 us | 3,6 us | |
| 16 | 392,6 us | 196,3 us | 86,9 us | |
| 18 | 432,1 us | 216,1 us | 275,3 us | |
| 19 | 503,5 us | 251,8 us | 63,8 us | |
| 20 | 229,7 us | 114,9 us | 1 804,7 us | |
| 24 | 39,8 us | 19,9 us | 13,1 us | |
| 28 | 1 948,2 us | 974,1 us | 19,7 us | |
| 40 | 84,3 us | 42,2 us | 12,9 us | |
| 45 | 4,1 us | 2,1 us | 0,1 us |
Mierne upravené zdrojáky tak aby išli pod rpythonom sú dostupné v mojom klone.
Z výsledkov je vidieť, že JIT v PyPy funguje diametrálne odlišne od V8. Nedá sa jednoznačne povedať, že niektorý z nich je rýchlejší / pomalší. Ak by mimochodom niekoho zaujímalo ako funguje V8 a prečo je delete príšerné pomalý tak tento blog je pre vás.
Samozrejme v priamom porovnaní medzi jazykmi so statickými typmi a dynamickými typmi je rozdiel vo výkone jednoznačný. Statické typy je však možné s určitými obmedzeniami dostať aj do jazyka ako je python a to bez akéhokoľvek písania hintov. Na podobnom princípe funguje aj typový systém haskellu.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 10.8.2014 21:42
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
10.8.2014 21:42
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
 .
10.8.2014 21:55
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
).
.
10.8.2014 21:55
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
).
 10.8.2014 22:05
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
10.8.2014 22:23
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
10.8.2014 22:05
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
10.8.2014 22:23
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Na také bežné matematické blbnutie je python celkom rýchly. Numpy je pekne optimalizované, používa vektorové operácie a s pomerne rýchlym backendom je fakt super tam, kde sa python používa len ako lepidlo medzi knižnicami. Nedávno so sa tak dokonca hral s OpenCV a spracovaním videa, ale nakoniec som to aj tak prepísal do C++ (nie kvôli výkonu, ale ako príprava na jeden menší článok).
10.8.2014 22:33
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
10.8.2014 22:46
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
11.8.2014 11:41
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Ten thunk leak je jedna z vecí ktoré sa mi dosť na haskelli nepáčia (prekvapilo ma to u funkcií ako fold), ale vlastne to celkom vyplýva z lenivosti vykonávania.
Čo sa týka typov ... rpython (aspoň čo som si všimol) všetko kompletne prekladal na natívne typy, žiadne obaľovanie. Typ majú nie len premenné, ale aj polia (homogénne), tuple (pevná veľkosť, nemôže sa na jednom mieste vo funkcii vrátiť ("a", 1) a (1, "a"), položky musia mať rovnaký typ) ...
foldr negeneruje thunky, takze smysl ma psat jen striktni verzi foldl, pokud je potreba vyhodnocovat z leva.
Zavrhovat (TC) rekurzi je nesmysl, jen je potreba si uvedomit jaka struktura rekurzivnim volanim vznika a podle toho se zaridit - aplikaci striktniho vyhodnoceni na parametr(y) a/nebo v kombinaci s guard rekurzi.
Pokud k tomu neni hodne dobry duvod, tak je lepsi na vhodnych mistech vynutit predcasne vyhodnoceni nebo upravit algoritmus a vystacit si s vychozim stackem. Velkou cast optimalizace zvladne i prekladac GHC, ale nelze se spolehat ze vyresi veskery nevhodne napsany kod.
Má akési objekty, ale plnohodnotné OOP ako smalltalk to nie je.Konkrétně?
11.8.2014 22:38
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
11.8.2014 23:11
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Nič to nemení na tom, že skutočné vynútené zapuzdrenie nemá.To ovšem tvůrce pythoních programů nijak neomezuje, naopak jim to umožňuje dělat věci, které by jinak dělat nemohli a nejspíše ani neměli. Ale to je obecná vlastnost pythonu, že součástí jeho návrhnu není ochrana proti nekompetentním programátorům. Nicméně tato vlastnost (volný přístup k privátním datům) lze podle mě implementovat i pro libovolný jiný jazyk a i se to tak pro účely debuggerů dělá. Stejnětak není problém přidat kompilátoru volbu, aby zapouzdření nevynucoval. Řešení, které používá python, vede k tomu, že se stírají technické rozdíly mezi standardním během, testováním a debugováním. Samozřejmě každá sranda něco stojí a toto rozhodnutí má i své nevýhody, jen podle mě nespočívají v tom, že by byl programátor jazykem nějak omezován.
Na druhou stranu tvrzení, že je RAII vlastností objektového paradigmatu podle mě narazí na to, že různí lidé chápou objektové paradigma různěPříkladně Alan Kay: OOP to me means only messaging, local retention and protection and hiding of state-process, and extreme late-binding of all things. Kde se v tom skrývá RAII fakt netuším.
 12.8.2014 13:28
rADOn | skóre: 44
| blog: bloK
| Praha
12.8.2014 10:22
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
12.8.2014 13:28
rADOn | skóre: 44
| blog: bloK
| Praha
12.8.2014 10:22
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
RPython nie je moc známy pretože je to interný projekt PyPy určený na implementáciu interpretovaného jazyka. Ja som ho zneužil na trochu iné veci hlavne zo zvedavosti a chcel som ľuďom tak trochu predstaviť práve tento projekt lebo moc sa o ňom nepíše a pritom je to najrýchlejšia implementácia pythonu kde nie je potrebné zadávať hinty.
Samozrejme cython je vďaka kompilácii kritických častí rýchlejší len ... treba dopísať hinty a odekorovať.
12.8.2014 11:06
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
bez toho, aniž byAle fuj.
). Dokaze optimalizovat jen podmnozinu pythonu, u cisel vetsich nez uint64 se stejne pouzije pythonni kod (ktery vola gmp) a pomale volani funkci a omezeni behu jen na jedno vlakno zustava. Ma smysl jen u omezenych pripadu pri vypoctech, ktere se pokud mozno provadi jen v ramci jedne fce/metody.
To uz je rozumnejsi misto CPythonu pouzit Jython nebo PyPy, ale co jsem mel moznost testovat, zatim o moc lepsi vysledky nedavaji, nekdy dokonce i horsi nez CPython. Dynamicke typovani ma proste svou dan, kterou nelze nezaplatit.
 13.8.2014 22:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.8.2014 22:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 11.8.2014 22:18
11.8.2014 22:18