Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Vládní CERT upozorňuje (𝕏) na zranitelnost ve WordPress Core: CVE-2026-63030 s přezdívkou wp2shell. Zranitelnost typu vzdálené spuštění kódu (RCE) bez nutnosti autentizace umožňuje útočníkovi spouštět libovolný kód prostřednictvím endpointu WordPress REST API Batch. Ke zneužití není vyžadován platný uživatelský účet ani interakce uživatele. Úspěšné zneužití může vést ke kompletnímu kompromitování webové stránky a souvisejících dat. Zranitelnost postihuje verze WordPress 6.9.0 až 6.9.4 a 7.0.0 až 7.0.1.
Evropská komise (EK) vyměřila čínskému internetovému prodejci AliExpress pokutu 550 milionů eur (13,3 miliardy korun) za porušení povinností vyplývajících z nařízení o digitálních službách (DSA). Platforma podle EK řádně neposuzovala a neomezovala rizika související s prodejem nelegálních, nebezpečných nebo padělaných výrobků na svém internetovém tržišti. Komise zároveň firmě nařídila přijmout nápravná opatření. Podle AliExpressu je pokuta nepřiměřená.
Ruffle, tj. open source emulátor Flash Playeru napsaný v Rustu, byl vydán ve verzi 0.4.0. Ke stažení je také na Flathubu. Přímo ve webovém prohlížeči lze vyzkoušet online dema nebo vlastní swf soubory.
HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
13.3.2019 20:05
| Přečteno: 2867×
|  | poslední úprava: 13.3.2019 23:27
| poslední úprava: 13.3.2019 23:27
Pokud jste někdy viděli nápaditou přednášku Breta Victora The Future of Programming, určitě si pamatujete na pasáž, ve které popisuje procesor jako spoustu udřených tranzistorů, které se mohou přetrhnout, zatímco tranzistory operačních pamětí se většinu doby vyloženě flákají. A pokud chcete z vašeho křemíku dostat maximum, měli byste jít cestou velkého množství malých výpočetních jader, každým opatřeným malou, ale dostatečnou paměťovou kapacitou.
Tato úvaha má zcela realistický základ. Dříve se uvádělo, že k tomu, abyste si vyrobili poměrně schopný 32-bitový RISC procesor bez vyrovnávacích pamětí, potřebujete stejnou plochu křemíku, jakou vyžaduje asi 100 KiB RAM (půl megabytu v případě, že má obsahovat i podporu floating-point aritmetiky). Skutečným výpočtům je tak vyčleněno maximálně několik jednotek procent křemíkové plochy, kterou konvenční počítače využívají.
Dnes si bohužel počítač s tisícovkami jader ještě jen tak nekoupíte, to ovšem neznamená, že by tuto cestu někdo nezkoušel prošlapat. V roce 1986 začaly na MIT práce na přípravu masivně paralelního počítače jménem J-Machine (Jellybean-Machine), který se v roce 1992-3 dočkal realizace v podobě dvou strojů. Jeden měl 512 výpočetních uzlů a druhý dokonce 1024. Každý z uzlů byl složen z čipu obsahujícího 36-bitový procesor, 4 kiloslova SRAM (obdoba 18 KiB) a podpůrné komunikační obvody. K ruce měl ještě každý 1 MB DRAM. Plochou čipu i počtem tranzistorů (1,1 milionu) byl srovnatelný s 486-kou. Celá síť uzlů většího stroje tak měla méně tranzistorů než A8 z iPhone 6. Hodinová frekvence uzlů byla poměrně malá, 12,5 MHz. Výkonem byly někde na úrovni horší 386-ky. J-Machine zvládla přibližně 1000 MIPS. Čipy byly kompaktně uloženy na vertikálně propojených deskách po 64 kusech na jedné a při spotřebě 1,5W na uzel se jednalo o relativně úsporné zařízení.

Čím je ale J-Machine nejzajímavější, je způsob komunikace jednotlivých uzlů. Ten byl založen na zasílání zpráv. Jejich specializovaný čip obsahoval malý směrovač určený pro zasílání zpráv dalším kolegům a procesor pro to rovněž obsahoval zvláštní instrukci, která byla schopna vysílat zprávy do 3D sítě dle jejich délky v řádu jednotek cyklů. Přijatá zpráva se uložila do fronty dle priority a v případě, že jí nic nestálo v cestě, stačily pouhé čtyři cykly k tomu, aby se spustil příslušný kód.
Z 36-bitového slova byly 4 bity vyhrazeny pro typovou informaci. Mohli jste tak specifikovat, jestli daná hodnota je zpráva, integer, adresa, symbol a podobně. Dokonce bylo možné danou hodnotu označit jako future, protože procesor měl jejich hardwarovou podporu. Přepnul se na další úlohu a ta stávající čekala, až mu nějaký jiný uzel dodá požadovanou hodnotu.
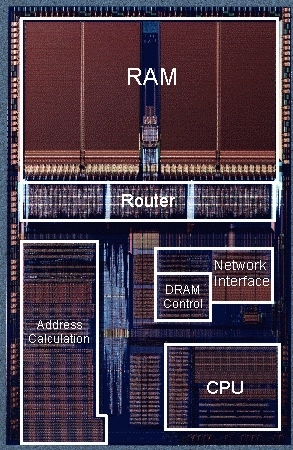
Když se posílala do sítě zpráva, nejdříve se vyslala hlavička (číslo typu MSG) následovaná daty. Zprávy měly být co nejkratší, ideálně v řádu jednotek slov. Vše bylo ošetřeno tak, aby se mohla zpráva již spouštět, zatímco její argumenty ještě přicházely ze sítě. Pokud nastala chyba přenosu, provedla se operace podobná přerušení. Bylo možné posílat uzlům zprávy bez požadavku na následnou odpověď nebo nechat odpověď poslat zcela jinému uzlu.
Přístup do lokální paměti uzlů byl řešen přes hardwarově akcelerované indexové tabulky, takže bylo možné s fyzickým umístěním dat hýbat a tak třeba provádět stlačení haldy. RISCová architektura procesorů kódovala v jednom slově hned dvě instrukce, na něž stačil většinou jen jeden takt, případně dva, pokud bylo potřeba načíst operandy z interní paměti. Počet registrů byl velmi malý. Používaly se čtyři datové registry, čtyři adresové a dále několik registrů na obsluhu fronty zpráv či uchování čísla uzlu. Adresové registry rovnou obsahovaly i délku adresovaných dat, takže přístupy do paměti mohly být automaticky kontrolovány na meze.

Programování J-Machine byla samozřejmě zajímavá výzva. Používal se buď přímo Assembler, upravená varianta C nebo Concurent Smalltalk, což byla zvláštní kompilovaná varianta Scheme s pořádnou porcí smalltalkovské sémantiky, která je pro systém založený na zasílání zpráv velice přirozená. Oproti lispovské tradici neobsahoval ani primitivy pro first (car), prostě jste si vyrobili třídu pair s instančními proměnnými car a cdr a automaticky vygenerovanými přistupovými metodami. U třídního objektového modelu se zasíláním zpráv ale také podobnost se Smalltalkem končí, což vzhledem k dostupné paměti na uzel nepřekvapí. Kompilátor tohoto jazyka byl napsán v Common Lispu. O správu paměti a práci s uzly se staraly rutiny operačního systému.
Z dostupných publikovaných výsledků se dá říct, že si tento zajímavý stroj vedl velmi slušně především díky efektivní komunikaci mezi uzly a celkově působí dojmem úspěšného experimentu. Synchronizační režie u něj se zvětšujícím se počtem uzlů rostla pomaleji než u konvenčnějších architektur. Amdahlův zákon ale jen tak obejít nejde, takže i pro J-Machine platila doporučení pro udržení co největší lokality dat snižování nutnosti vzájemné komunikace.
K lepšímu praktickému uplatnění chyběla především lepší podpora výpočtů v plovoucí řádové čárce, větší interní paměť procesorů a nevalný zájem ze strany komerčního sektoru. Svět masivně paralelních systémů se ubíral jiným směrem a vývoj procesorů šel především cestou instrukčního paralelismu, díky čemuž moderní procesory zvládají zpracovávat až 180 instrukcí naráz, ale jako nevítaný bonus se musíme potýkat s bezpečnostními problémy, jako je Meltdown a Spectre.
Jellybean-Machine vyzkoušela v praxi řadu zajímavých nápadů, které není špatné si v době, kdy se konečně začíná zvyšovat počet jader i na běžných strojích, znovu připomenout.
Zdroje:
http://cva.stanford.edu/projects/j-machine/
https://pdfs.semanticscholar.org/69aa/a426bb5bca9039e138a139c7be154f74945a.pdf
https://apps.dtic.mil/dtic/tr/fulltext/u2/a202182.pdf
https://people.eecs.berkeley.edu/~kubitron/courses/cs252-S07/handouts/papers/noakes93jmachine.pdf
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 13.3.2019 21:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.3.2019 21:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Asi by stálo za to se zamyslet nad odlišnostmi od současně používaných grafických karet. Je tu někdo fundovaný kdo by to dokázal srovnat?Fundovanost level: přečetl si v rychlosti specifikace r100, r600 a amdgpu když se snažil opravit radeon driver v kernelu, ale už většinu zapoměl
 .
No kromě mnohem vyšších rychlostí, větší paměti a těsnější komunikací v GPU mají jádra GPU většinou přístup do hlavní RAM (a ne lokální paměti, kromě obyč. cache). Moderní GPU jádra mě přijdou jako "obyčejné" RISCy. Kdežto ty procesory v jellybeanu (nebo transputeru) mě přijdou jako dost omezené na naprogramování, takže nějaká úloha, která by potřebovala velké množství lokální paměti by byla velmi pomalá, protože by se muselo přistupovat přes externí komunikaci k nějakému nejbližšímu uzlu RAM (pokud to takovej stroj měl). V CM se navíc ten jeden 1bit "procesor" musel vždycky nějak naprogramovat co měl počítat. Na parallele bylo nějaké raytraceovací demo (16 jader RISC epiphany, lokální pamět a externí sběrnice do DDR řadiče na FPGA Zynq). Ale ta epiphany architektura je moderní věc, i tak by to mělo problémy s reálným použití jako GPU, protože ty jednotlivé nody mají prostě málo paměti pro GPU operace nad texturama.
Ale jelikož jsou všechny ty architektury (no možná až na ten CM) turingovsky kompletní. Tak jde jen o rychlosti vypočítání daných úloh. Asi by i šlo na ně naportovat opencl .
.
.
No kromě mnohem vyšších rychlostí, větší paměti a těsnější komunikací v GPU mají jádra GPU většinou přístup do hlavní RAM (a ne lokální paměti, kromě obyč. cache). Moderní GPU jádra mě přijdou jako "obyčejné" RISCy. Kdežto ty procesory v jellybeanu (nebo transputeru) mě přijdou jako dost omezené na naprogramování, takže nějaká úloha, která by potřebovala velké množství lokální paměti by byla velmi pomalá, protože by se muselo přistupovat přes externí komunikaci k nějakému nejbližšímu uzlu RAM (pokud to takovej stroj měl). V CM se navíc ten jeden 1bit "procesor" musel vždycky nějak naprogramovat co měl počítat. Na parallele bylo nějaké raytraceovací demo (16 jader RISC epiphany, lokální pamět a externí sběrnice do DDR řadiče na FPGA Zynq). Ale ta epiphany architektura je moderní věc, i tak by to mělo problémy s reálným použití jako GPU, protože ty jednotlivé nody mají prostě málo paměti pro GPU operace nad texturama.
Ale jelikož jsou všechny ty architektury (no možná až na ten CM) turingovsky kompletní. Tak jde jen o rychlosti vypočítání daných úloh. Asi by i šlo na ně naportovat opencl .
.
Dříve se uvádělo, že k tomu, abyste si vyrobili poměrně schopný 32-bitový RISC procesor bez vyrovnávacích pamětí, potřebujete stejnou plochu křemíku, jakou vyžaduje asi 100 KiB RAM (půl megabytu v případě, že má obsahovat i podporu floating-point aritmetiky).Bez cachí mě to stále přijde strašně moc. pokud se tou RAM myslím SRAM, takže 6 tranzistorů na buňku, tak to je ekvivalent až 4.8 miliónů tranzistorů (spíš míň, protože to nebude tak kompaktní struktura jako SRAM). RISC procesor by měl jít vyrobit byť jen z diskrétních hradel. První ARM měl myslím jen pár desítek tisíc tranzistorů max. Zajímavý o jellybeanu jsem nějak moc nevěděl. Koukal ses i na jiné superstroje? Takovej Connection Machine byl taky super. Měl až 64ki jednobitovejch nodů (původně měli snad cíl 1 milion), spojení přes 12 rozměrovou hyperkrychli a router jim částečně navrhoval Richard Feynman. Ale pak to chcíplo na tom, že je převálcovalo PC a že neměli pořádnou myšlenku komu to prodávat. Super architektura byla taky transputer. Což bylo něco jako 16/32bit MCU+RAM na 20MHz (v polovině 80.let). Vtip byl v tom, že ty hodiny měly různé fáze a tak měl ten čip efektivně až 80MHz. Co se týče superpočítačovosti, tak každej čip měl komunikaci s okolím po 4 sériových linkách (takže šla vytvořit síť). Dokonce to přes ty sériové linky mohlo bootovat (jiné IO tam víceméně nebylo, čipy mají strašně málo pinů). Díky jedné aukci na aukru jsem si kdysi asi 3 transputery koupil
. U transputerů byl problém, že nebyl hnedka dostupný C překladač a asi i náklady musely být dost vysoký.
ale jako nevítaný bonus se musíme potýkat s bezpečnostními problémy, jako je Meltdown a Spectre.Tak on by i ten CM měl problém leakování informace přes timing nodů. Akorát v té době ještě nebyl multitasking nějak extra rozšířený. Tyhle počítače fungovaly spíš tak, že se do nich z ovládacího PCčka nahrála nějaká úloha (simulace počasí, výbuchu atomovky) a pak se počítalo jen to. Takže vlastně takový dnešní GPU. Ony i ty dnešní GPU jsou docela paralelní architektura. Jinak Adapteva chtěla udělat i 1024 jádrovou verzi. Ale měli pak problémy se zaplacením výroby té FPGA desky (navrhli desku na RAM, výrobce je přestal vyrábět, museli navrhovat znova), takže to nějak vyšumělo (relativně, 1024 procesor by měl mít mnohem větší hype
 ).
Jinak mám takové hobby že jsem měl nápad na navrhnutí podobné architektury jako mělo CM, ale nemám na to moc času. Je to spíš takové duševní cvičení, ta architektura by byla extra pomalá, ale zase by měla extra málo tranzistorů.
).
Jinak mám takové hobby že jsem měl nápad na navrhnutí podobné architektury jako mělo CM, ale nemám na to moc času. Je to spíš takové duševní cvičení, ta architektura by byla extra pomalá, ale zase by měla extra málo tranzistorů.
Bez cachí mě to stále přijde strašně moc. pokud se tou RAM myslím SRAM, takže 6 tranzistorů na buňku, tak to je ekvivalent až 4.8 miliónů tranzistorů (spíš míň, protože to nebude tak kompaktní struktura jako SRAM). RISC procesor by měl jít vyrobit byť jen z diskrétních hradel. První ARM měl myslím jen pár desítek tisíc tranzistorů max.
Ten odhad docela sedí i s novějšími technologiemi. Když budeme počítat hustotu DRAM 0.2 Gb/mm2 (26214 KiB/mm2), hustotu tranzistorů cca 7 milionů/mm2 (22nm proces), ARM1 měl 25000 tranzistorů, pak to vychází, že na plochu potřebnou pro ARM1 se vejde 93 KiB DRAM. Je to sice takové střílení hausnumery od boku, ale...
Když budeme počítat hustotu DRAM 0.2 Gb/mm2 (26214 KiB/mm2), hustotu tranzistorů cca 7 milionů/mm2 (22nm proces)V tomhle by pak měla dram hustotu tranzistorů 200 miliónů/mm^2. Takže vlastně je většina čipu jenom volná plocha nebo dráty mezi tranzistory
(a po počítám jen tu tranzistorovou vrstvu, ne ty prokovy nad tím).
 23.3.2019 00:09
Josef Kufner | skóre: 70
.
23.3.2019 00:09
Josef Kufner | skóre: 70
.
0.2 je asi hodně nadsazené, mělo by to být spíš 0.05-0.1, což je itak překvapivě velká hustota.
64 KiB SRAM potřebuje podobný počet tranzistorů jako Pentium. Je smutné, že ač je SRAM tak cenný zdroj, moderní architektury nabízí jen velmi omezené prostředky, jak s ním programově nakládat. Dnešní procesory vlastně používají interně Harvardskou architekturu a malé hierarchické paměti, ale programově se to přímo řídit nedá.
Škoda, že z Epiphany-V nic nebude, byla by to hodně zajímavý procesor.
64 KiB SRAM potřebuje podobný počet tranzistorů jako Pentium.Jj dobrý peklo. A to bude jádro v pentiu možná v dynamické logice, takže bude zabírat míň tranzistorů než klasická CMOS zapojení co se učí ve škole.
Je smutné, že ač je SRAM tak cenný zdroj, moderní architektury nabízí jen velmi omezené prostředky, jak s ním programově nakládat.On je problém, že SRAM je cenná protože se používá v místech kde je minimální latence. To ovšem dost omezuje možnosti přístupu.
Škoda, že z Epiphany-V nic nebude, byla by to hodně zajímavý procesor.No když jsem o něm slyšel naposled tak dělal na nějakým superpočítačovým AI projektu od DARPy, takže možná časem
.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz![[1]](https://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:DRAM_Cell_Structure_(8F2).PNG){kind=link}
![[2]](https://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:DRAM_Cell_Structure_(4F2).PNG){kind=link}