Spolek OpenAlt zve příznivce otevřených řešení a přístupu na 209. brněnský sraz, který proběhne tento pátek 16. května od 18:00 ve studentském klubu U Kachničky na Fakultě informačních technologií Vysokého učení technického na adrese Božetěchova 2/1. Jelikož se Brno stalo jedním z hlavních míst, kde se vyvíjí open source knihovna OpenSSL, tentokrát se OpenAlt komunita potká s komunitou OpenSSL. V rámci srazu Anton Arapov z OpenSSL
… více »GNOME Foundation má nového výkonného ředitele. Po deseti měsících skončil dočasný výkonný ředitel Richard Littauer. Vedení nadace převzal Steven Deobald.
Byl publikován přehled vývoje renderovacího jádra webového prohlížeče Servo (Wikipedie) za uplynulé dva měsíce. Servo zvládne už i Gmail. Zakázány jsou příspěvky generované pomocí AI.
Raspberry Pi Connect, tj. oficiální služba Raspberry Pi pro vzdálený přístup k jednodeskovým počítačům Raspberry Pi z webového prohlížeče, byla vydána v nové verzi 2.5. Nejedná se už o beta verzi.
Google zveřejnil seznam 1272 projektů (vývojářů) od 185 organizací přijatých do letošního, již jednadvacátého, Google Summer of Code. Plánovaným vylepšením v grafických a multimediálních aplikacích se věnuje článek na Libre Arts.
Byla vydána (𝕏) dubnová aktualizace aneb nová verze 1.100 editoru zdrojových kódů Visual Studio Code (Wikipedie). Přehled novinek i s náhledy a videi v poznámkách k vydání. Ve verzi 1.100 vyjde také VSCodium, tj. komunitní sestavení Visual Studia Code bez telemetrie a licenčních podmínek Microsoftu.
Open source platforma Home Assistant (Demo, GitHub, Wikipedie) pro monitorování a řízení inteligentní domácnosti byla vydána v nové verzi 2025.5.
OpenSearch (Wikipedie) byl vydán ve verzi 3.0. Podrobnosti v poznámkách k vydání. Jedná se o fork projektů Elasticsearch a Kibana.
PyXL je koncept procesora, ktorý dokáže priamo spúštat Python kód bez nutnosti prekladu ci Micropythonu. Podľa testov autora je pri 100 MHz približne 30x rýchlejší pri riadeni GPIO nez Micropython na Pyboard taktovanej na 168 MHz.
Grafana (Wikipedie), tj. open source nástroj pro vizualizaci různých metrik a s ní související dotazování, upozorňování a lepší porozumění, byla vydána ve verzi 12.0. Přehled novinek v aktualizované dokumentaci.
 ). ) je mezi uzavíračem textu " nebo ne.
). ) je mezi uzavíračem textu " nebo ne.
Pred lety jsem delal v Bash prototyp streamoveho filtru.
Pak jsem to prepsal s jinou filosofii v C.
Nicmene vyvoj sel velmi rychle (stale jsem odchytaval dalsi a dalsi zverstva v tom streamu).
Myslim ze by to slo snadno priohnout.
Je to ale dost pomale....
Marek
#!/bin/bash
export IFS=""
ramecky=0
while read -rsn1 char
do
if [ $ramecky -eq 1 ]
then
case "$char" in
$'\033')
read -rsn1 char1
if [ "$char1" = '[' ]
then
read -rsn1 char2
if [ "$char2" = '1' ]
then
read -rsn1 char3
if [ "$char3" = '0' ]
then
read -rsn1 char4
if [ "$char4" = 'm' ]
then
#rozpoznana escape sequence na zapnuti ramecku
ramecky=0
echo -en "\\033[0;39m"
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
else
echo -n "$char$char1$char2"
fi
else
echo -n "$char$char1"
fi
;;
D)
echo -n '-'
;;
Z)
echo -n ','
;;
'?')
echo -n '.'
;;
'@')
echo -n '`'
;;
'Y')
echo -n "'"
;;
'3')
echo -n '|'
;;
'')
echo
;;
*)
echo -n "$char"
esac
else
case "$char" in
$'\033')
read -rsn1 char1
case "$char1" in
"d")
read -rsn1 char2
if [ "$char2" = '#' ]
then
#tady probiha tisk
read -rsn1 char3
( while [ ! "$char3" = $'\024' ]
do
[ "$char" ] || echo
echo -n "$char3"
read -rsn1 char3
done ) | /usr/local/sbin/print1
else
echo -n "$char$char1$char2"
fi
;;
'[')
read -rsn1 char2
case "$char2" in
1)
read -rsn1 char3
if [ "$char3" = '2' ]
then
read -rsn1 char4
if [ "$char4" = 'm' ]
then
#rozpoznana escape sequence na zapnuti ramecku
ramecky=1
echo -en "\\033[1;43m"
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
;;
5)
read -rsn1 char3
if [ "$char3" = ';' ]
then
read -rsn1 char4
if [ "$char4" = '1' ]
then
read -rsn1 char5
if [ "$char5" = 'i' ]
then
#rozpoznany zacatek tisku
konec=0
( while [ "$konec" -eq 0 ]
do
read -rsn1 char6
if [ "$char6" = $'\033' ]
then
read -rsn1 char7
if [ "$char7" = '[' ]
then
read -rsn1 char8
if [ "$char8" = '4' ]
then
read -rsn1 char9
if [ "$char9" = 'i' ]
then
konec=1
else
echo -n "$char6$char7$char8$char9"
fi
else
echo -n "$char6$char7$char8"
fi
else
echo -n "$char6$char7"
fi
else
[ "$char6" ] || echo
echo -n "$char6"
fi
done ) | /usr/local/sbin/print1
else
echo -n "$char$char1$char2$char3$char4$char5"
fi
else
echo -n "$char$char1$char2$char3$char4"
fi
else
echo -n "$char$char1$char2$char3"
fi
;;
*)
echo -n "$char$char1$char2"
esac
;;
*)
echo -n "$char$char1"
esac
;;
$'\221')
echo -en "\\033[1;43m \\033[0;39m"
;;
$'\237')
echo -en "\\033[1;42m \\033[0;39m"
;;
$'\233')
echo -n "-"
;;
$'\232')
echo -n "|"
;;
'')
echo
;;
*)
echo -n "$char"
esac
fi
done
No ono to s tou pomalosti zas tak strasne neni.
Fungovalo to jako obalka pro telnet+xterm a nez ten telnet to i na starodavnych pleckach, na ktere to bylo urceno, bylo rychlejsi.
Pomalost se projevovala pouze pri tisku velkych souboru.
MarekJo a nesmelo to bufferovat, takze se muselo parsovat opravdu znakove.
sed ':a;N;$!ba;s/\("[^"]*\)\n\([^"]*"\)/\1Shit_new_line\2/g' kuk.csv
funguje to na , a " a LF na ' jsem neměl nervy to zapisovat do $quot; a escapovat, sed ':a;N;$!ba;s/\("[^"]*\)\r\n\([^"]*"\)/\1Shit_new_line\2/g' kuk.csv
Což by mohl být základ „workaround-u“ co chcete…Shit_new_line musí být unikátní v souboru se nevyskytující řetězec.
s/$quot;/\" , nebo-li $quot; mělo být " 
load data local infile 'pokus.csv' into table adresa fields terminated by ',' enclosed by '"' lines terminated by '\n' (jmeno,cislo,ulice);Vyzkoušel jsem s podobnými vstupy, funguje to. Včetně diakritiky. OpenOffice Calc to načte také.
 22.7.2011 00:33
xkucf03 | skóre: 49
| blog: xkucf03
22.7.2011 00:33
xkucf03 | skóre: 49
| blog: xkucf03
A jinak bych to asi předělal do XMLA v čem to bude lepší?
22.7.2011 10:23
xkucf03 | skóre: 49
| blog: xkucf03
xsltproc – to mi přijde rozumnější, než psát několikastránkové skripty v bashi. Nebo ty data naládovat do relační databáze a pak s tím pracovat už hezky v SQL
CSV lze specifikovat velmi jednoduše (RFC je výjimka, jenž potvrzuje pravidlo), což se o XML říct nedá.
<rejp>Napsat CSV parser dá zhruba stejně práce jako napsat hlavičku a patičku XSLT skriptu.</rejp>
CSV lze specifikovat velmi jednodušeCož bohužel znamená, že si CSV naspecifikuje každý znova a trochu jinak. Takže napsat obecný automatický parser CSV nakonec nejde, vždycky musí uživatel ze vzorku okem odhadnout, co asi budou jaké oddělovače atd.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz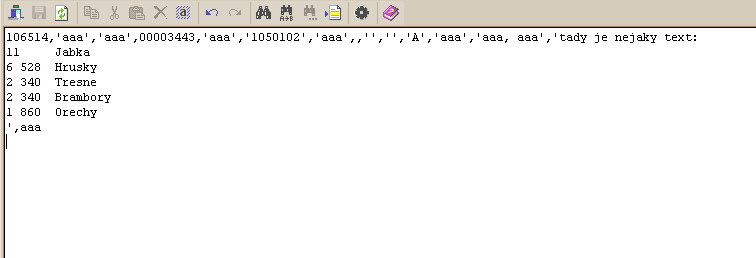{kind=link}