Byla vydána nová verze 1.58 sady nástrojů pro správu síťových připojení NetworkManager. Novinkám se v příspěvku na blogu NetworkManageru věnuje Josephine Pfeiffer. Vypíchnout lze možnost nmtui zobrazit nastavení Wi-Fi jako QR kód nebo podporu CLAT (464XLAT) a tunelů GENEVE (Generic Network Virtualization Encapsulation).
Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Vládní CERT upozorňuje (𝕏) na zranitelnost ve WordPress Core: CVE-2026-63030 s přezdívkou wp2shell. Zranitelnost typu vzdálené spuštění kódu (RCE) bez nutnosti autentizace umožňuje útočníkovi spouštět libovolný kód prostřednictvím endpointu WordPress REST API Batch. Ke zneužití není vyžadován platný uživatelský účet ani interakce uživatele. Úspěšné zneužití může vést ke kompletnímu kompromitování webové stránky a souvisejících dat. Zranitelnost postihuje verze WordPress 6.9.0 až 6.9.4 a 7.0.0 až 7.0.1.
Evropská komise (EK) vyměřila čínskému internetovému prodejci AliExpress pokutu 550 milionů eur (13,3 miliardy korun) za porušení povinností vyplývajících z nařízení o digitálních službách (DSA). Platforma podle EK řádně neposuzovala a neomezovala rizika související s prodejem nelegálních, nebezpečných nebo padělaných výrobků na svém internetovém tržišti. Komise zároveň firmě nařídila přijmout nápravná opatření. Podle AliExpressu je pokuta nepřiměřená.
Ruffle, tj. open source emulátor Flash Playeru napsaný v Rustu, byl vydán ve verzi 0.4.0. Ke stažení je také na Flathubu. Přímo ve webovém prohlížeči lze vyzkoušet online dema nebo vlastní swf soubory.
HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
Řešení dotazu:
 12.10.2013 10:24
Jendа | skóre: 78
| blog: Jenda
| JO70FB
12.10.2013 10:24
Jendа | skóre: 78
| blog: Jenda
| JO70FB
htop uvádí pro jednotlivá jádra naprosto jiné údaje o záteži. A samozřejmě takové, které nejdou vysvětlit libovolným přečíslováním jader.
Měřáky se berou z /proc/stat.
Zátěž není spojitá veličina, natož spojitě diferencovatelná. V daném časovém okamžiku je u jednoho procesoru vždy buď 0% nebo 100%. Tedy celkové zatížení systému například se 4 procesory je v daném okamžiku vždy přesně 0%, 25%, 50%, 75% nebo 100%.
Protože diferenciálně krátký okamžik je celkem nezajímavý a o ničem příliš nevypovídá, všechny utility zobrazují průměrnou zátěž za delší dobu. Jednoduše řečeno, odhadne se doba, kterou procesory strávily prací a kterou strávily nicneděláním. Zátěž je pak doba strávená prací během určitého časového intervalu dělená délkou tohoto intervalu. To například znamená, že pokud čtyři procesory strávily během jedné vteřiny dohromady 150% času prací, celková zátěž systému bude 150% / 400%, tedy 37,5%. Například mohly 3 z nich pracovat každý 50% času, případně všechny čtyři 37,5% času nebo třeba jeden na 100%, dva další na 25% a ten poslední během dané vteřiny nepracoval.
Odhad času, který procesory tráví prací, se dá provádět dvěma způsoby.
Primitivní způsob, který s několika modifikacemi používá Linux, využívá pravidelný tik hodin ke kontrole stavu procesorů. Když nachytá procesor při nicnedělání, zaznamená to. Když najde na procesoru běžící vlákno, přidá celý hodinový interval do časového účetnictví daného vlákna. Poté, co byl pravidelný hodinový tik odstraněn, bylo samozřejmě nezbytné postarat se o správné počítání času i na procesorech, které si dlouhodobě žádný timer nenaplánují. Nicméně hodnoty v souboru /proc/stat stále předstírají, jako by každý procesor zpracovával 100 tiků za vteřinu a u každého tiku zaznamenával aktuální stav. Odhad celkové zátěže je na Linuxu (nepřesně řečeno) tím přesnější, čím víc je procesorů, tedy například na 32-procesorovém stroji přibude do první řádky /proc/stat celkově 3200 tiků každou vteřinu, zatímco na dvouprocesoru pouze 200 tiků.
Tento jednoduchý způsob má samozřejmě své chyby, protože vlákno ve skutečnosti může běžet po dobu mnohem kratší než doba mezi tiky hodin, ať už kvůli vypršení plánovacího kvanta, kvůli migraci na jiný procesor nebo kvůli uspání z velmi široké škály možných důvodů. Idea je ovšem taková, že i přes drobné nepřesnosti bude v průměru a z dlouhodobého hlediska účtování času korektní, tedy pravděpodobnost výrazných systematických odchylek je z pohledu statistiky velmi malá.
Přesnější, ale náročnější způsob účtování času má například Solaris (Illumos, OpenIndiana) a AIX. V těchto systémech se při každé změně stavu procesoru explicitně přečte vhodný nanosekundový čas (tj. časomíra s velkým rozlišením, kterou většina moderních platforem implementuje) a na základě tohoto času se pak přesně počítá, jak dlouho byl procesor v userspace, jak dlouho byl v systému, jak dlouho obsluhoval interrupty, jak dlouho provozoval virtuální stroje — každý interval mezi dvěma sousedními změnami stavu se dá zaúčtovat velmi přesně. V Solarisu se to jmenuje microstate accounting. Tohle ovšem s sebou nese vysokou daň v podobě doby potřebné pro přečtení přesného času. Jakkoliv se to může zdát překvapivé, čtení přesného času je drahé a odpovídá desítkám až stovkám aritmetických instrukcí. (Důvodem je, že se zpravidla jedná o čítač tiků procesoru, který musí fungovat jako pipeline, protože inkrementace čítače se obecně nedá realizovat v jednom tiku. Čtení čítače vyžaduje čekání na dosažení definovaného a čitelného stavu a navíc různá opatření, která kompenzují vliv čtení na rychlost postupu čítače.) Jestliže se tedy například Linux chlubí, že přerušení dělí od příslušného handleru pouze 18 instrukcí (což se člověk dočte ve slavné zprávě „Have you ever kissed a girl?“; dnes už to bude zcela jistě úplně jinak), přidání přesného časovače by mohlo způsobit za jistých okolností zhoršení výkonnosti. (Dlužno připomenout například registrová okénka na platformě SPARC, o jejichž správu a přepínání se musí postarat kernel, když na to přijde, a může na to přijít velmi často.) (Jakmile ovšem musí handler přerušení sáhnout kamkoliv do paměti, která není zrovna v lokální cache na procesoru, cena takového přístupu odpovídá stovkám až tisícům aritmetických instrukcí, takže zůstává otázkou, jak moc velký negativní vliv vlastně microstate accounting má.)
Ať už je způsob měření času jakýkoliv, vždy nakonec dojde na průměrování přes delší časový úsek. Právě volba tohoto delšího časového úseku vede k různým výsledkům pro různé utility. Například průměr za dobu jedné minuty by jistě všechny utility vypočítaly téměř stejně. Jenže tento průměr příliš nevypovídá o změnách zátěže během té minuty. Naopak průměr za sto milisekund velmi rychle (z lidského hlediska) reaguje na změny zátěže, ale potíž je v tom, že je extrémně nestabilní a těžko se z něj (pouhým okem) odhaduje nějaký průměr nebo trend.
Monitorovací utilita v KDE (ksysguard) implicitně vykresluje zátěž pro každý procesor zvlášť. Ta bude samozřejmě mnohem méně stabilní než celkový průměr. Často bude některý z procesorů pravidelně skákat na 100%, protože například zrovna zpracovává data související s šifrováním filesystémů, SSH, VPN, dekódováním hudby a tak podobně, zatímco ostatní procesory budou častěji idle. Tedy to, co vidíš na tom screenshotu, je naprosto normální. V ksysguard si lze u každého sešitu nastavit interval měření, tedy ten interval, přes který se zátěž průměruje. Pak bude vidět, že dlouhý interval produkuje pěkný hladký průběh, ale neukazuje rychlé fluktuace zátěže, zatímco pro krátký interval platí přesný opak. Je méně stabilní, ale změny zátěže (i krátkodobé) jsou hned vidět. Tedy je to věc jakéhosi kompromisu.
Lepší způsob výpočtu zátěže (je-li třeba odhad zátěže aktualizovat často a nepravidelně) je založený na exponenciálním klouzavém průměru, jehož vzorec se trochu poupraví pro „práci se zlomky“ (extrémně vágně řečeno). Výhodou takového postupu je absence pravidelného intervalu, který by přinášel nestabilitu, a možnost aktualizovat odhad zátěže libovolně často. Nicméně i klouzavý průměr potřebuje předem znát konstantu, která představuje kompromis mezi rychlou odezvou na změnu zátěže a stabilitou hlášených hodnot. Nepřítomnost předělů mezi časovými intervaly s sebou ovšem nese jistou daň v podobě malého rezidua z minulosti, bez kterého by ovšem odhad neměl „hladší“ průběh. Pokud vím, současné utility pro měření zátěže klouzavé průměry nepoužívají. Použil jsem tuto techniku v projektech, u kterých byl hladký a zároveň přijatelně přesný odhad zátěže velmi důležitý a kde nebylo žádoucí měřit zátěž v předem daných pravidelných intervalech.
Sečteno a podtrženo, zátěž není žádná přesná a spojitá veličina; je to něco, co se dá mnoha různými způsoby definovat, mnoha různými způsoby měřit a odhadovat. Proto dává každý měřák jiné hodnoty.
 16.10.2013 17:34
rADOn | skóre: 44
| blog: bloK
| Praha
16.10.2013 17:34
rADOn | skóre: 44
| blog: bloK
| Praha
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz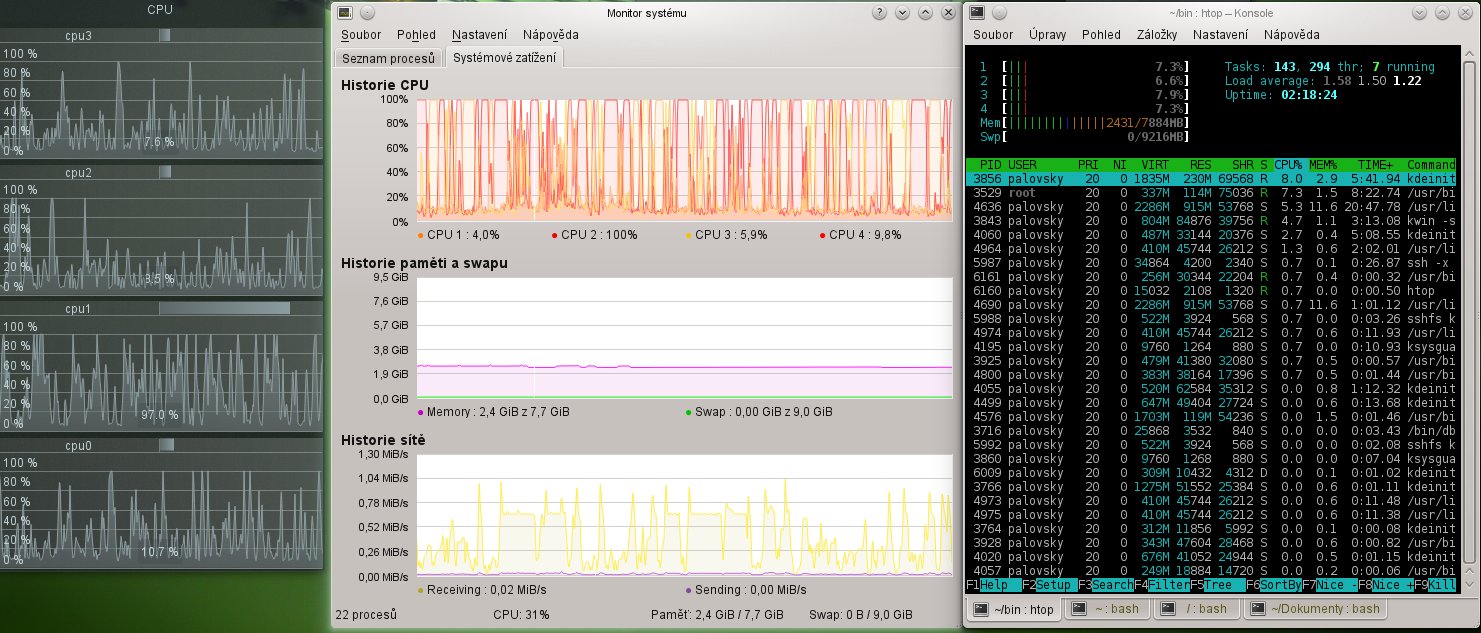{kind=link}