Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
Některé programy, které vyvíjíme (Fotomon, Měření) , používají množství různé statistiky. Moje chápání statistiky je spíše klasické, ale existuje ještě jiný pohled na statistiku - Bayesiánská statistika. Rozhodl jsem se jí porozumět a naučit se ji prakticky používat.
Moje první kroky vedly na Wikipedii:
http://cs.wikipedia.org/wiki/Bayesova_věta
Našel jsem tam přesně to, co jsem čekal: matematický formalismus, pod kterým si nedovedu nic představit (pravděpodobnost, že na Wikipedii najdu to, co hledám, ve formě stravitelné pro průměrného inženýra, už dnes dovedu pomocí bayesiánské statistiky docela dobře odhadnout). Ale je tam odkaz:
http://cs.wikipedia.org/wiki/Bayesovská_statistika
Je tam příklad. Skvělé! Ale kdo tohle psal!? Velmi volně cituji:
Test na nemoc dá kladnou odpověď u 99% nemocných pacientů a u 5% zdravých pacientů. Nemocí trpí jen 0.1% populace. Jaká je pravděpodobnost?
He? WTF? Jaká pravděpodobnost? Co se po mě chce? Pravděpodobnost čeho? No nic, třeba to vyplyne z textu dále:
"Pravděpodobnost choroby je o 19% větší, než u těch, kdo se testu nepodrobili."
No nazdar, máme zde další skupinu: přibyli nám ještě netestovaní. Kam si je mám zařadit? Navíc to je formulováno tak nešťastně, že kdybych nevěděl, jak veliký je to nesmysl, mohl bych usuzovat, že provedení testu nějak ovliní, jestli člověk onemocní, nebo zůstane zdravý.
Jsem ztracen.
Několikrát jsem narazil na příklad s dvěma pytlíky s bílými a černými kuličkami, což mi celou problematiku ještě více zatemnilo. Tuhle míchanici současné a předchozí pravděpodobnosti, střídaní minulosti, přítomnosti a budoucno také nedokázal nikdo dostatečně jasně vysvětlit. Popis primitivní úlohy na tři listy formátu A4 zvyšuje WTF faktor nade všechny meze.
Začal jsem hledat v angličtině. Odfiltroval jsem všechny kuličky v pytlíku a nakonec jsem skvělý příklad objevil zde:
http://people.hofstra.edu/Stefan_Waner/RealWorld/tutorialsf3/frames6_6.html
Konečně mi docvaklo. Celý ten Bayesův vzorec je obyčejná trojčlenka. To mi mohli vysvětlit už v prváku na střední a nemusí se z toho dělat zbytečná věda. Jakmile jsem si to namaloval a pochopil, vypadá základ bayesovské statistiky prostince:
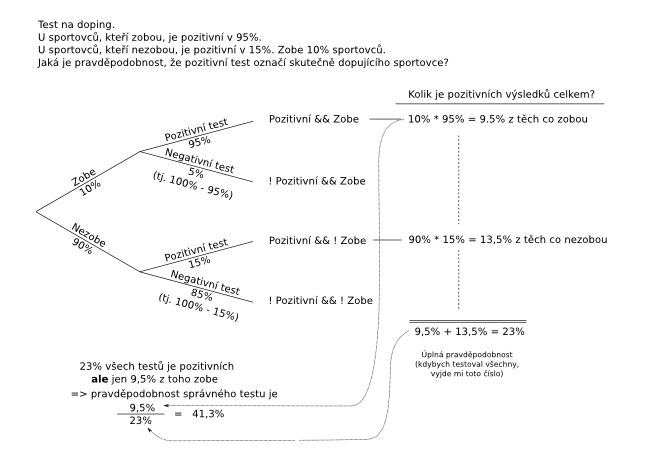
Pro praktické použití je třeba ještě pochopit jednu věc: bayesiánský vzorec je často uváděn ve zjednodušené formě a není jasné, jak z něj spočítat například toto:
Ve jmenovateli (část zlomku pod čarou) Bayesova vzorce figuruje takzvaná "úplná pravděpodobnost". V příkladu dopujících a nedopujících sportovců je to součet všech pozitivních výsledků, tj. 9,5% + 13,5%. V případě tří fabrik je to:
Sečteme jednotlivá procenta: celkem 2,9% ze všech výrobků na trhu jsou zmetky. Z fabriky A jich pochází: 50% * 2% / 2,9% = 34,4%
(Příklad jsem nalezl v dokumentu, který nyní není dostupný, googlujte "Bayes Krčková").
Možnost použít libovolný počet různých vstupních parametrů (zde fabriky A, B a C) je dobrá zpráva pro praktické použití v programech - dovoluje to snadno dekomponovat problém na několik samostatných částí.
Jakmile jsem pochopil princip, došlo mi, že bayesiánská statistika není nic složitého či nepochopitelného. Zkuste si to. Namalujte si třeba dva pytlíky s kuličkami - uvidíte sami.

Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Moje chápání statistiky je spíše klasické, ale existuje ještě jiný pohled na statistiku - Bayesiánská statistika.
WtF?
Nicméně, je jasné, že různé pohledy na statistiku nemohou nic změnit na platnosti Bayosova vzorce. Tj. i "frekventisté" platnost Bayosova vzorce samozřejmě uznávají.Presne tak, pokud tomu rozumim, tak rozdil mezi 'frekventistickou' a 'bayesovskou' interpretaci pravdepodobnosti je ciste zalezitost interpretacni, na vzorce a vysledky to nema vliv (podobne jako ruzne interpretace kvantove mechaniky). Proto je treba nemichat 'bayesovskou interpretaci' na jedne strane a bayesuv vzorec ci bayesovskouu inferenci, coz jsou elementarni veci z pravdepodobnosti a statistiky platne a pouzivane nezavisle na interpretaci.
 16.4.2014 21:59
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
16.4.2014 21:59
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
 14.4.2014 09:09
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 13:01
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 09:09
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 13:01
Petr Bravenec | skóre: 43
| blog: Bravenec
 14.4.2014 13:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2014 21:50
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 13:35
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 06:21
Petr Bravenec | skóre: 43
| blog: Bravenec
17.4.2014 09:49
Petr Bravenec | skóre: 43
| blog: Bravenec
14.4.2014 13:52
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2014 21:50
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 13:35
Petr Bravenec | skóre: 43
| blog: Bravenec
15.4.2014 06:21
Petr Bravenec | skóre: 43
| blog: Bravenec
17.4.2014 09:49
Petr Bravenec | skóre: 43
| blog: Bravenec
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 14.4.2014 13:04
14.4.2014 13:04
 Ale jiz jsem o tom zde psal, kdo hleda, najde.
Ale jiz jsem o tom zde psal, kdo hleda, najde.
{kind=link}