Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na Seznam nepovolených internetových her (Wikipedie) se k 13. 7. 2026 dostala predikční platforma Polymarket.
Nová čísla časopisů od nakladatelství Raspberry Pi zdarma ke čtení: Raspberry Pi Official Magazine 167 (pdf) a Hello World 30 (pdf).
Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »
16.10.2020 20:31
| Přečteno: 1406×
| Žumpa
|  | poslední úprava: 17.10.2020 16:04
| poslední úprava: 17.10.2020 16:04
get_all_articles.py vám stiahne z Wikipedie všetky názvy slovenských článkov.LANGUAGE = "sk"
a do main_categories stačí vložiť názvy kategórí z hlavnej stránky Wikipedie v danom jazyku.cat list/list.txt | wc -l 215128
sort list/list.txt | uniq -c | sort -nr | head
545 Imagine_Peace_Tower
189 Super_Jamato_(trieda_lodí)
189 Rimava_(rieka)
174 Slaná
165 Sovetskij_Sojuz_(trieda_lodí)
165 Scharnhorst_(trieda_lodí)
165 Jamato_(trieda_lodí)
165 Bismarck_(trieda_lodí)
163 Šinano_(lietadlová_loď)
157 Cirocha
Možno existuje nejaké elegantnejšie riešenie pre stiahnutie článkov z Wikipedie, ale neviem o ňom.
Takže som si extrahoval len unikátne názvy:
awk '!seen[$0]++' list/list1.txt > list/list-uniq.txtPočet jedinečných článkov je v skutočnosti 15723.
cat list/list-uniq.txt | wc -l 15723
download.py.
Všetky články sa sťahujú do priečinku articles. Ak sa z nejakého článku nepodarí extrahovať text,
tak sa zaloguje do errors/error_save_article.txt. (články sa u mńa práve sťahujú)echo Dom | ./majka -f w-lt.sk.fsa dom:k1gInSc1 dom:k1gInSc4 dom:k1gInSc5 dom:kATo nám to vypľuje, že je to Substantivum, rod mužsḱý neživotný, číslo jednotné v páde 1, 4 a 5. Do ľudského jazyka si to dekódujete pomocou tejto nápovedy.
 Ale napríklad sa dá vyskúšať
miniature GPT
, LSTM, alebo čo vás napadne.
Najviac sa tešim, že by to mohlo celkom dobre fungovať, so slovnými druhmi + LSTM a nejaké hranie sa s tým.
Momentálne mám v pláne iné veci, ale chcel som si pripraviť aspoň nejaké dáta.
Ale napríklad sa dá vyskúšať
miniature GPT
, LSTM, alebo čo vás napadne.
Najviac sa tešim, že by to mohlo celkom dobre fungovať, so slovnými druhmi + LSTM a nejaké hranie sa s tým.
Momentálne mám v pláne iné veci, ale chcel som si pripraviť aspoň nejaké dáta.
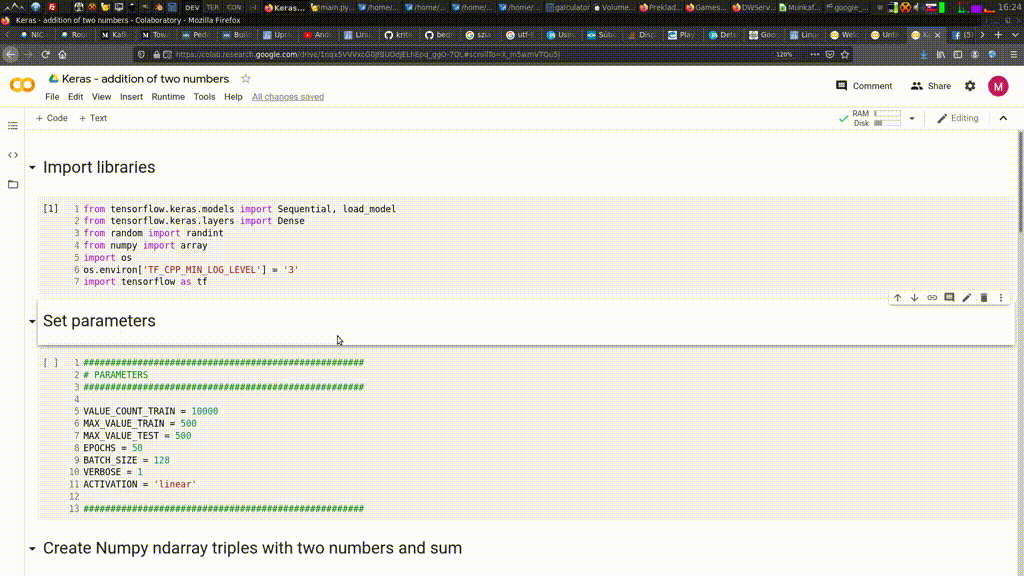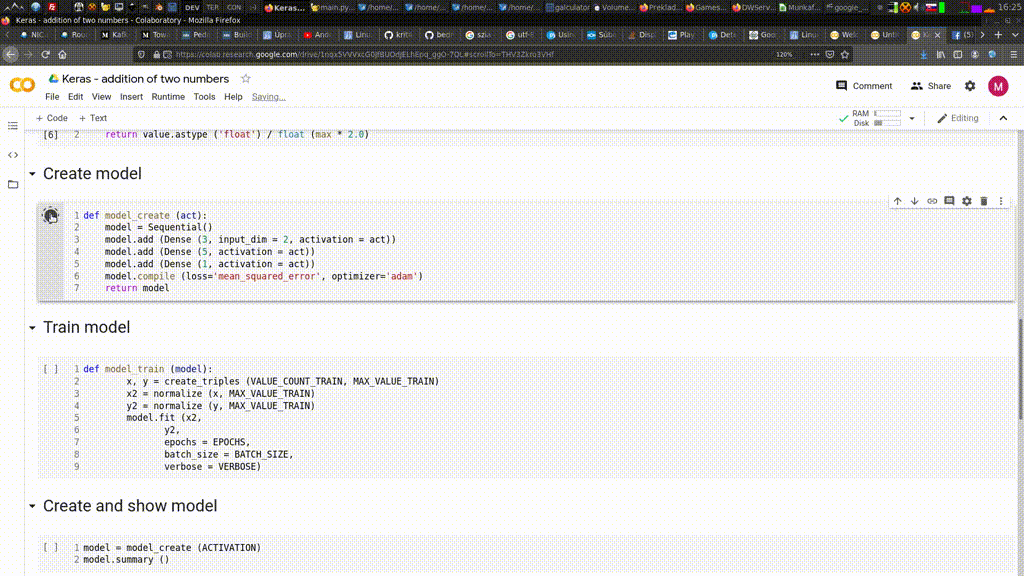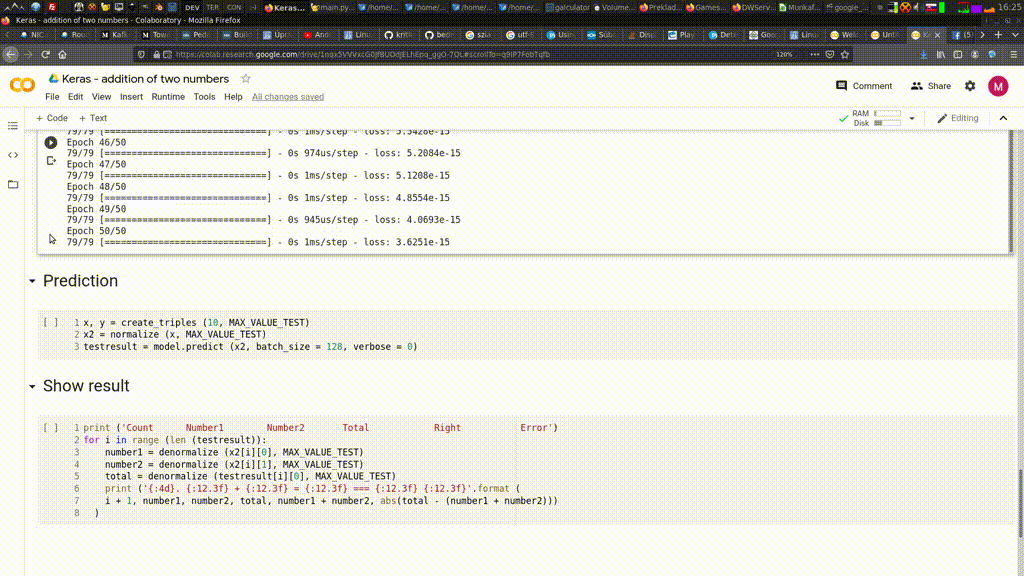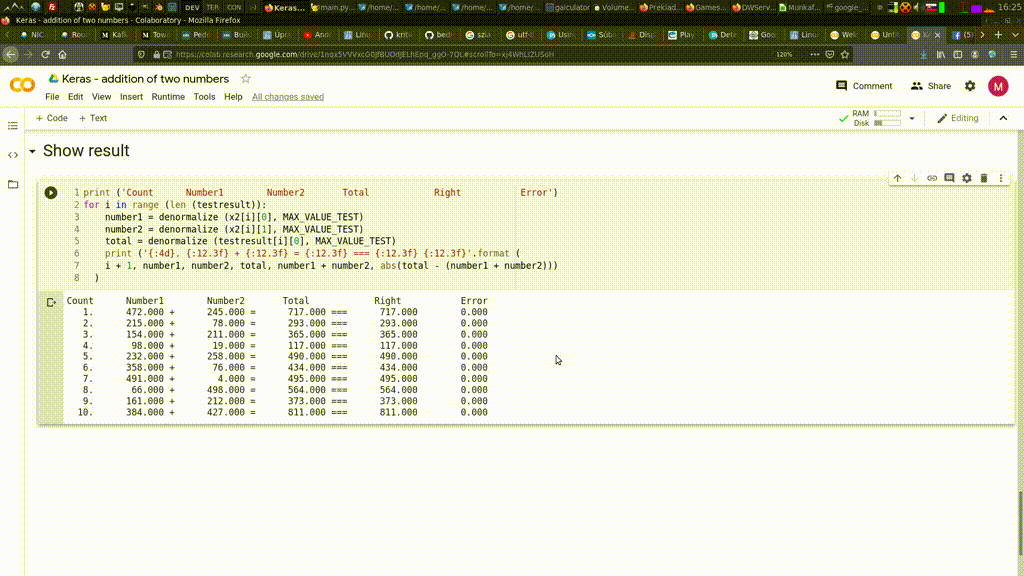
get_all_articles_special.py a stiahol 307149 názvov strániek. Na záver sa zacyklil , takže som skript musel vypnúť ručne. Nemajú to vyvhytané, pretože posledná stránka sa opakuje stále dookola. Teraz sa stánky sťahujú, mno kopec z nich sú obsahovo prázdne, ako je vidieť na obrázku nižšie.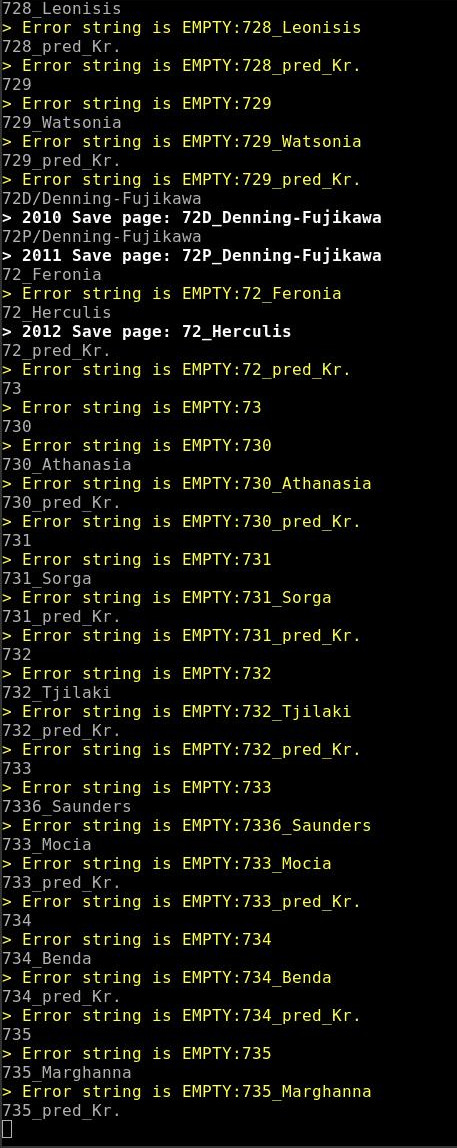


Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 16.10.2020 21:13
cbrpnk | skóre: 10
| blog: bl0gium
16.10.2020 21:13
cbrpnk | skóre: 10
| blog: bl0gium
 16.10.2020 21:24
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
16.10.2020 21:48
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
16.10.2020 22:16
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
17.10.2020 13:51
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
17.10.2020 10:06
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
16.10.2020 21:24
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
16.10.2020 21:48
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
16.10.2020 22:16
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
17.10.2020 13:51
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
17.10.2020 10:06
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
To je najlepšie.
Stiahneš: stiahneš
Výpis a spracovanie (nič extra ťažké): wiki.openzim.org/wiki/Zimlib
 17.10.2020 15:22
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
17.10.2020 15:22
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
bliká to jako když vomylem máčknu banner s čínskou reklamou :O :O :D ;D
18.10.2020 16:51
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
nóó tak vod nás angelinu pozdravuj :D ;D
17.10.2020 16:07
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
Na záver sa zacyklil , takže som skript musel vypnúť ručne. Nemajú to vyvhytané, pretože posledná stránka sa opakuje stále dookola.Majú vychytané. Viď poslednú stránku toho zoznamu.
Teraz sa stánky sťahujú, mno kopec z nich sú obsahovo prázdne, ako je vidieť na obrázku nižšie.Ak dáš tie a la prázdne stránky editovať, tak zistíš, že nie sú prázdne. Máš označené, že prázdná stránka, ale tá stránka má a la užitočný text pre používateľa (myslený text vľavo v článku).
17.10.2020 16:40
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
17.10.2020 20:21
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.10.2020 16:53
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
na nvidii nejlíp :D ;D
18.10.2020 10:16
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.10.2020 14:32
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
Mno jelikoz ses evidentne debil, kterej neumi stahnout databazi, a pripadne si ji nalejt do vlastni instance mediawikiNechcem si inštalovať softvér ktorý nebudem používať. Uvítal by som klasické zipko všetkých stránok. Niečo som dal teraz sťahovať, ale netuším čo v ňom bude (https://dumps.wikimedia.org/backup-index.html). Inak používam knižnicu, ktorá používa officiálne Wikipedia API, takže to robí trafic medzi 50 - 100kbit/s. To robím väčší DDOS, keď si pustím niečo na YT. 99% požiadaviek aj tak vybaví keš.
 ).
Nicmene, porizeni/sestaveni vhodnych vstupnich dat je asi nejslozitejsi cast vsech AI projektu. Takze je jasne, ze na tom nejaky cas stravis.
20.10.2020 04:12
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.10.2020 19:29
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
).
Nicmene, porizeni/sestaveni vhodnych vstupnich dat je asi nejslozitejsi cast vsech AI projektu. Takze je jasne, ze na tom nejaky cas stravis.
20.10.2020 04:12
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
18.10.2020 19:29
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}