Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »Byla vydána nová verze 1.58 sady nástrojů pro správu síťových připojení NetworkManager. Novinkám se v příspěvku na blogu NetworkManageru věnuje Josephine Pfeiffer. Vypíchnout lze možnost nmtui zobrazit nastavení Wi-Fi jako QR kód nebo podporu CLAT (464XLAT) a tunelů GENEVE (Generic Network Virtualization Encapsulation).
Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Vládní CERT upozorňuje (𝕏) na zranitelnost ve WordPress Core: CVE-2026-63030 s přezdívkou wp2shell. Zranitelnost typu vzdálené spuštění kódu (RCE) bez nutnosti autentizace umožňuje útočníkovi spouštět libovolný kód prostřednictvím endpointu WordPress REST API Batch. Ke zneužití není vyžadován platný uživatelský účet ani interakce uživatele. Úspěšné zneužití může vést ke kompletnímu kompromitování webové stránky a souvisejících dat. Zranitelnost postihuje verze WordPress 6.9.0 až 6.9.4 a 7.0.0 až 7.0.1.
Evropská komise (EK) vyměřila čínskému internetovému prodejci AliExpress pokutu 550 milionů eur (13,3 miliardy korun) za porušení povinností vyplývajících z nařízení o digitálních službách (DSA). Platforma podle EK řádně neposuzovala a neomezovala rizika související s prodejem nelegálních, nebezpečných nebo padělaných výrobků na svém internetovém tržišti. Komise zároveň firmě nařídila přijmout nápravná opatření. Podle AliExpressu je pokuta nepřiměřená.
Ruffle, tj. open source emulátor Flash Playeru napsaný v Rustu, byl vydán ve verzi 0.4.0. Ke stažení je také na Flathubu. Přímo ve webovém prohlížeči lze vyzkoušet online dema nebo vlastní swf soubory.
Máme faktury a faktury mívají přílohy. Proces importu faktur do DMS je následovný :
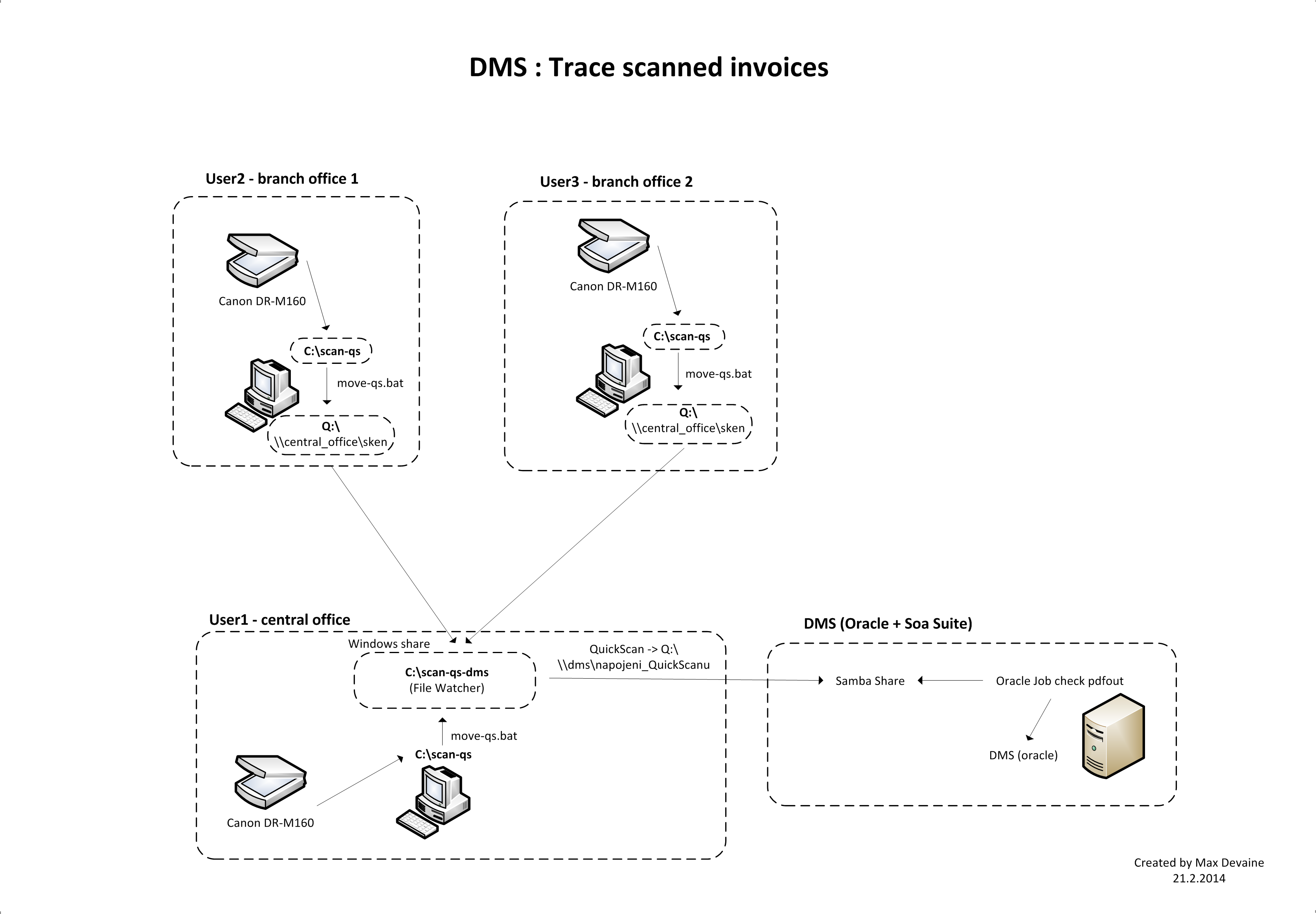
PDF jde k záznamu v DMS párovat i ručně, nebo načíst z PC. Celý proces vypadá docela složitě, ale na druhou stranu je mnohem jednodušší, jak kdyby vše kolovalo v papírové formě a je to rozhodně přehledné. Taktéž se do DMS ukládají dokumenty, které jsou v SAPu, nebo v našem IS. DMS tedy spíš nefunguje jako takový SharePoint, ale jako čistě backend pro uložiště dokumentů. Ona firma i konečně dodává plugin do MS Office, aby šlo dokumenty upravovat přímo z DMS (něco jako má SharePoint), prostě ťuknu ve web ksichtu na dokument, otevře se word, upravím ho a dám "commit to dms" a je tam včetně nové revize. Nojo, za toto chce ta firma asi 40kkč :), takže zatím fakt ne a nelze tedy DMS uživatelsky takovým způsobem používat, což je docela škoda :-/.
Největší problém tohoto řešení je skenování dokumentů, resp. QuickScan. Tento sw dělá tři nemilé věci :
(program se spouští jako baťák s parametry : IF EXIST C:\scan-qs-dms\*.tif. ("C:\Program Files (x86)\EMC Captiva\QuickScan\QuickScn.exe" /scan profile=01-BW,overwrite=overwriteall))
Jinými slovy, QuickScan nám kazí celý proces. Náš dodavatel tvrdí, že se supportem není kloudná řeč, že to nehodlají opravovat a možná už se QuickScan nebude dál vyvíjet. Znají OCR sw, který toto umí, ale stojí třeba 40kkč i více.
Nabízí se tedy otázka, zda někdo nezná lepší způsob, jak toto řešit. Nebo zda někdo nezná "levnou" náhradu za QuickScan, popř. i opensourcovou? :). Já to vidím tak, že nám firma dodala nefunkční řešení (QuickScan), tudíž to je na jejich bedrech. Osobně ale neznám pozadí (smlouvy apod. věci), takže jelikož jsem byl požádán o návrh řešení (samozřejmě jsem reagoval ve stylu, že to by měla navrhnout ona firma), tak sonduji. Nevadí, když to bude placený pro win, nebo pro lin, hlavní je funkčnost a cena :). Samozřejmě bych dal přednost nějakému OSS řešení.
Požadavky tedy jsou :
- schopnost číst čárový kód (třeba i pootočený)
- na základě čárového kódu vyjmout z tiff souboru všechny stránky tak, jak jdou za sebou a převést je do pdf do té doby, než narazí na další čárový kód, poté vytvořit nový soubory zase do něj nasypat všechny stránky, co jsou za ním atd.
- umožnit filtrování čárových kódů (nejlépe tedy podle začátku - prefixu a podle délky, prostě tak, aby nedocházelo k neřešitelným kolizím)
Pro zajímavost, přemýšlelo se jednu dobu i nad Alfresco DMS, který má SAP connector, ale jednak by to vyšlo ve výsledku asi i dráž, ale hlavně se hledělo na to, aby nám to byla schopna rozchodit nějaká firma, co s podobnými procesy má zkušenosti a má ověřené funkční řešení, tedy nic, co by někdo řešil za pochodu. Pokud by měl někdo dotazy v podobnéch duchu, tak věřte, že budou nezodpovězeny, jelikož já jsem malý červ a výběr řešení a další věci připadli někomu jinému, takže ani nevím, co vše bylo ve hře, z čeho všeho se vybíralo atd.
Zdar Max
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 21.2.2014 17:14
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 17:14
Max | skóre: 73
| blog: Max_Devaine
 21.2.2014 18:12
Josef Kufner | skóre: 70
21.2.2014 18:23
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 18:25
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 18:12
Josef Kufner | skóre: 70
21.2.2014 18:23
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 18:25
Max | skóre: 73
| blog: Max_Devaine
 22.2.2014 11:14
stativ | skóre: 54
| blog: SlaNé roury
22.2.2014 13:07
Josef Kufner | skóre: 70
22.2.2014 17:37
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 17:52
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 18:13
Josef Kufner | skóre: 70
21.2.2014 18:22
Max | skóre: 73
| blog: Max_Devaine
22.2.2014 13:13
Josef Kufner | skóre: 70
22.2.2014 11:14
stativ | skóre: 54
| blog: SlaNé roury
22.2.2014 13:07
Josef Kufner | skóre: 70
22.2.2014 17:37
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 17:52
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 18:13
Josef Kufner | skóre: 70
21.2.2014 18:22
Max | skóre: 73
| blog: Max_Devaine
22.2.2014 13:13
Josef Kufner | skóre: 70

 21.2.2014 20:19
xkucf03 | skóre: 50
| blog: xkucf03
21.2.2014 20:19
xkucf03 | skóre: 50
| blog: xkucf03
Už jsem podobné řešení viděl jinde, takže mne to ani moc nepřekvapuje, ale neodpustím si komentář: myslím, že tohle pěkně ukazuje, jak jde současný svět do prdele – máme rychlé připojení k Internetu resp. propojení skoro všech počítačů na planetě, máme rychlé mnohajádrové procesory, terabajtové disky, spousty GB operační paměti… a co s tím děláme? Tiskneme a posíláme si papírové faktury, zaměstnáváme člověka, který je strká do skeneru, OCRkujeme, rozpoznáváme čárový kód (který jsme předtím vytiskli a nalepili) a pak to stejně asi někdo opisuje z bitmapy do formuláře nebo minimálně kontroluje jestli se to OCRkovalo správně… Místo aby jedna firma poslala druhé třeba jednoduché XMLko opatřené elektronickým podpisem, na druhé straně se to automaticky spárovalo s objednávkou a automaticky nebo ručně schválilo a zadal se automaticky příkaz k proplacení. Tohle se mohlo dělat už v devadesátých letech na 486kách nebo dřív, kdyby lidi nebyli blbci a nepoužívali počítače jako psací stroje.
21.2.2014 22:28
Max | skóre: 73
| blog: Max_Devaine
)
22.2.2014 13:16
Josef Kufner | skóre: 70
)
 Velký firmy si tyhle data (objednávky, faktury atp.) vyměnujou elektronicky poměrně běžně(EDIFACT, XML, Pyšvejcův výměnný formát...)
Velký firmy si tyhle data (objednávky, faktury atp.) vyměnujou elektronicky poměrně běžně(EDIFACT, XML, Pyšvejcův výměnný formát...)
Místo aby jedna firma poslala druhé třeba jednoduché XMLkoNekdo uz zminil ten EDIFACT, tedy presne to co pisete. Je to bohuzel nezaplatitelne a kdo to nekdy zavadel vi, jak komplikovana zalezitost to je. Bezna praxe dnes je, ze mala firma posila i nadale papirovou fakturu a 'specializovany prostrednik' ma lidi, kteri to prectou a vytvori ta strukturovana data a ty pak posilaji dal. To samozrejme take neco stoji a zazil jsem pripady, kdy firma obchod s nejakym zakaznikem radeji vzdala, nez by platila tu 'infrastrukturu' pri zasilani faktury.
na druhé straně se to automaticky spárovalo s objednávkoutohle vyzaduje umelou inteligenci - to je proste v praxi u vetsiny firem nemozne. Jeste tak v pripadech, kdy je predmetem obchodu jedna polozka.
22.2.2014 11:23
xkucf03 | skóre: 50
| blog: xkucf03
tohle vyzaduje umelou inteligenci - to je proste v praxi u vetsiny firem nemozne. Jeste tak v pripadech, kdy je predmetem obchodu jedna polozka.
Co mi chodí faktury (i od celkem malých obchodů) tak tam bývá kromě čísla faktury i číslo objednávky1, takže bych si to v pohodě spárovat mohl. A v ISDOCu je taky políčko pro odkaz na objednávku – příklad:
<OrderReferences>
<!--Nepovinná hlavičková kolekce objednávek pro případnou vazbu -->
<OrderReference>
<!--Objednávka #1-->
<SalesOrderID>OP-111222/2008</SalesOrderID>
<!--Vlastní ident. objednávky přijaté u dodavatele-->
<ExternalOrderID>OV-123111/2008</ExternalOrderID>
<!--Ext.č.obj.přijaté, typicky obj.vydaná odběratele-->
<IssueDate>2008-01-03</IssueDate>
<!--Datum vystavení objednávky přijaté u dodavatele-->
</OrderReference>
<OrderReference>
<!--Objednávka #2-->
<SalesOrderID>OP-111223/2008</SalesOrderID>
<ExternalOrderID>OV-123112/2008</ExternalOrderID>
<IssueDate>2008-01-20</IssueDate>
</OrderReference>
</OrderReferences>
A pak jsou případy, kdy chodí faktury bez objednávky2 – např. pravidelné účty za elektřinu nebo telefon – a tam zase stačí nastavit pravidlo, že pokud se částka vejde do nějakého měsíčního limitu, tak se faktura automaticky schválí a zaplatí, jinak to dostane někdo k ručnímu schválení/revizi.
Tragikomické na tom je, že všechny potřebné údaje v těch počítačích máme, často i ve strojově čitelné formě v nějaké databázi, jen se pak cestou ta informace ztratí, převede na strojově nečitelnou – a pak se to na druhé straně musí zase pracně převádět zpět, aby tomu druhý informační systém rozuměl.
[1] které znám, protože jsem to objednával, akorát ho nemám zanesené v žádném systému, protože toho je málo a řeším vše ručně
[2] resp. tam zase může být číslo smlouvy, podle kterého se to spáruje
22.2.2014 17:41
Max | skóre: 73
| blog: Max_Devaine
22.2.2014 18:34
Josef Kufner | skóre: 70
 22.2.2014 19:21
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
22.2.2014 19:21
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
Otázka je jak bude vypadat trh práce, když zničehonic příjdou o práci stovky opisovačů
21.2.2014 22:17
Max | skóre: 73
| blog: Max_Devaine
21.2.2014 22:23
Max | skóre: 73
| blog: Max_Devaine
 21.2.2014 23:40
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.2.2014 11:31
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
21.2.2014 23:40
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.2.2014 11:31
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 22.2.2014 14:02
xxxs | skóre: 25
| blog: vetvicky
22.2.2014 20:25
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.2.2014 19:10
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
22.2.2014 14:02
xxxs | skóre: 25
| blog: vetvicky
22.2.2014 20:25
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.2.2014 19:10
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
zbar - http://zbar.sourceforge.net/ - čtení čárových kódů mnoha typů. Umí číst jak ze souboru, tak ze zařízení (webkamera). Jednou dobou jsem webkamerou scanoval QR kódy z Androidu a funguje to na jedničku. Má to GUI, ale může běžet i v konzoli. Buď se ukončí po přečtení prvního kódu, nebo čte kontinuálně (natočím webkameru na další kód a ten se vypíše na konzoli).
Konkrétně QR kód jsem zkoušel vytisknout, naskenovat a předat obrázek programu. Pod 200dpi byly občas problémy se čtením, při 300dpi fungovalo čtení na jedničku i když jsem QR kód přečmáral propiskou. Myslím že by stálo za pokus zařadit do cesty imagemagick a skenovat jen výřez místa, kde by měl být kód - zbaru chvilku trvalo, než se tím obřím souborem prokousal.
22.2.2014 19:30
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
K požadavkům:
- zbar, volitelně imagemagick
- imagemagick
- grep, wc, možná sed
....a všechno samozřejmě poslepovat pořádným lepidlem - BASH.
a nešlo by ty dokumenty dělit prostě jen podle toho prefixu. To OCR by mohlo rozeznávat znaky lépe než čárový kód, píšete, že jste omezili identifikační oblast, takže by mělo jít jen o dostatečně exotický prefix.
23.2.2014 22:54
Max | skóre: 73
| blog: Max_Devaine
Jinak, to dělení dokumentu je fakt dobrá finta.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}
{kind=link}
{kind=link}