Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
Sťahovací bot začína sťahovať nejakou úvodnou stránkou a všetky vyhovujúce odkazy pridá do zoznamu URL na indexovanie (pokiaľ nie je už priradená na indexovanie alebo už nebola stiahnutá). Typ zoznám URL na indexovanie je FIFO. Sťahovanie skončí ak zoznám URL na indexovanie nemá žiadnu položku na sťahovanie.
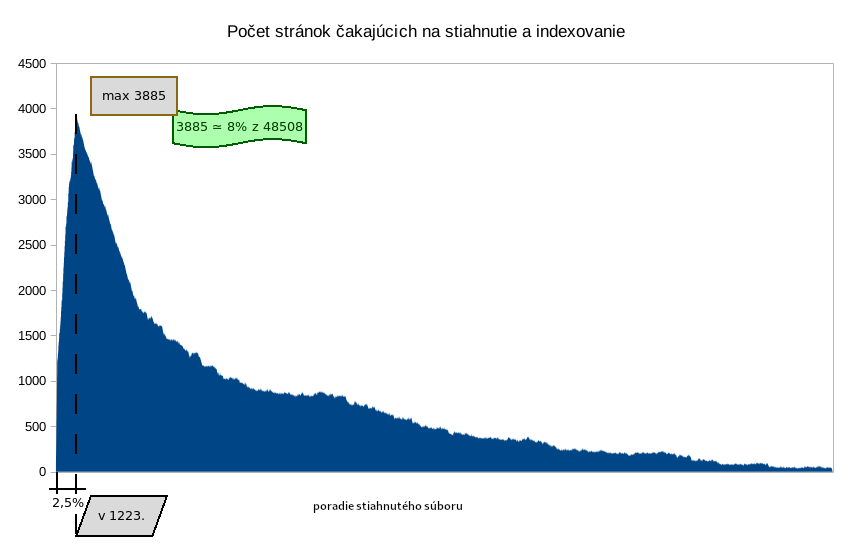
Oprava 2) - zoznamu URL na indexovanie bol v skutocnosti FIFO a nie LIFO.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
wgetříká se tomu rekurzivní stahování a umí to i třeba wgetAno, ale dokaze len urcitu url (trebars podla regularneho vyrazu) a dokaze ak, dam viac naraz stahovat priradit pre kazdu URL vlastny nazov?
mícháš dohromady velikost jedné stránky a počet stránek ke staženíSlovo vela sa mysli ak to pouzivam ako mnoho (napr. V skupine je vela /ako mnozstvo/ muzov. A potom v skupine je vela velkych /ako mohutnych/ muzov). Prepisal som to na lepsie.
indexování znamená sestavování (databázového) indexu, ty to jen stahuješ a přímo zpracováváš/cachuješAko sa to vezme - zaindexuje to vyhlavac (stiahne si kopiu). Mozno priamo nie je mojim zamerom indexovanie, ale aj tak to robim. Stahujem vsetky temy. Cize mam index vsetkych tem fora na stranke. Ale jasne, indexujem aj stiahnutu stranku, lebo aj tam mozu byt odkaci (co na tej konkretnej aj stranke boli - widget "Podobne temy").Ale indexujem iba co ma zaujima. Napr. vyhlavac na obrazky nebude predsa spracuvavat mp3.
 30.8.2020 21:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
30.8.2020 21:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ano, ale dokaze len urcitu url (trebars podla regularneho vyrazu) a dokaze ak, dam viac naraz stahovat priradit pre kazdu URL vlastny nazov?Dokáže stahovat podle regexpu, včetně blacklistů a whitelistů. Nevím co je přiřadit pro každou URL vlastní název. Ukládá to na disk podle názvu / cesty a možná umí i nějaké další vymyšleniny. Na paralelní stahování je afaik lepší aria2.
Ako sa to vezme - zaindexuje to vyhlavac (stiahne si kopiu). Mozno priamo nie je mojim zamerom indexovanie, ale aj tak to robim. Stahujem vsetky temy. Cize mam index vsetkych tem fora na stranke. Ale jasne, indexujem aj stiahnutu stranku, lebo aj tam mozu byt odkaci (co na tej konkretnej aj stranke boli - widget "Podobne temy").Ale indexujem iba co ma zaujima. Napr. vyhlavac na obrazky nebude predsa spracuvavat mp3.Imho ta terminologie pochází z toho že dřív než vyhledávače byly na světě indexy; stránky které fungovaly jako rozcestníky se spoustou kategorií (lycos?). Když se přidávala nová stránka, jednalo se o indexování; akt přidávání do indexu. Pak přišly vyhledávače a prostě už se tomu tak říkalo, protože se pořád přidávaly stránky do indexu, i když automaticky. To co děláš ty je prostě jen rekurzivní stažení webu, které technicky vzato fakt s indexováním nemá nic společného, ale whatever, imho není úplně terminologicky špatné to takhle nazývat.
Nevím co je přiřadit pro každou URL vlastní název.Myslel som toto. Priklad je pre 1 subor.
wget https://www.abclinuxu.cz/blog/analyza_greenie_20_04/2020/8/ako-dlho-bude-trvat-indexovanie-stranok -O https:__www.abclinuxu.cz_blog_analyza_greenie_20_04_2020_8_ako-dlho-bude-trvat-indexovanie-stranok
30.8.2020 21:45
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
blog/analyza_greenie_20_04/2020/8/ako-dlho-bude-trvat-indexovanie-stranok. Tedy do podsložek (jde to afaik vypnout).
30.8.2020 22:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ano, ale dokaze len urcitu url (trebars podla regularneho vyrazu) a dokaze ak, dam viac naraz stahovat priradit pre kazdu URL vlastny nazov?Dokáže stáhnout stránku, sesbírat z ní odkazy a ty pak rekurzivně procházet. Proto se tomu říká rekurzivní stahování a ne typ sťahovania sťahovanie webovej stránky/domény s množstvom stránok, ani stahování velikostí stránek, nebo co jsi to tam měl původně.
Slovo vela sa mysli ak to pouzivam ako mnoho (napr. V skupine je vela /ako mnozstvo/ muzov. A potom v skupine je vela velkych /ako mohutnych/ muzov). Prepisal som to na lepsie.Já vím, co znamená slovo vela, ale nevím, jak to souvisí.
Ako sa to vezme - zaindexuje to vyhlavac (stiahne si kopiu).1. Ty píšeš vyhledáváč? 2. Stažení kopie není totéž co indexování.
Mozno priamo nie je mojim zamerom indexovanie, ale aj tak to robim.Jakou používáš databázi? Jak je nakonfigurovaná? Na jakém hardwaru běží? Abych se z toho článku tedy dozvěděl, jak dlouho ti to indexování trvá…
Ale jasne, indexujem aj stiahnutu stranku, lebo aj tam mozu byt odkaci (co na tej konkretnej aj stranke boli - widget "Podobne temy").Říkej si tomu jak chceš, ale mimo tvojí hlavu to nebude dávat smysl, protože indexování všude jinde znamená něco jiného.
Jakou používáš databázi? Jak je nakonfigurovaná? Na jakém hardwaru běží? Abych se z toho článku tedy dozvěděl, jak dlouho ti to indexování trvá…Ziadny databaza a la MySql or PostgreSQL. Vlastne riesenie. V rozsahu do radu 10k v pohode. Odvtedy mam kod uz upraveny a prakticky funkcny na 1M. Limitom pri takej indexacie je najma stiahnutie zo servera. 1M chce CPU 0.9GHz. Mas uvedene celkovy pocet. Daj cez wget stiahnut a mas +- minimalne, kolko to bude trvat. Konkretne v pripade linuxforum.hu to bolo od 20.08 00:52 do 22.08 22:44.
Říkej si tomu jak chceš, ale mimo tvojí hlavu to nebude dávat smysl, protože indexování všude jinde znamená něco jiného.Uzytok vysledneho grafu je najme pre indexovanie, kde pod pojmom indexovanie sa chape poznanie stromovej URL struktury na stranke.
30.8.2020 21:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
wgetu jsem stahoval nějaký web (asi AbcL), a než jsem si toho všiml, vyprodukoval miliony souborů a adresářů (to opravdu nechcete mazat), protože našel odkaz na stránce adresa s číslem, který vede na adresa s číslem + 1. FIFO v téhle situaci bude sice stahovat do nekonečna, ale stihne před zacyklením stáhnout celkem smysluplnou část webu. LIFO by zůstal ve smyčce při první takové stránce. Chtělo by to detekci počítadla v URL nebo příliš podobných stránek. V případě, že nekonečné stahování nevadí, dává celkem smysl volit stránku ke stažení náhodně s pravděpodobností stažení rostoucí s její významností, což může být metrika založená na počtu stránek, které na ní odkazují, nebo na minimálním/průměrném počtu odkazů, které se musí projít než se na ní dostane z hlavní stránky.
 31.8.2020 13:07
Josef Kufner | skóre: 70
31.8.2020 13:07
Josef Kufner | skóre: 70
Pozor na nekonečné smyčkyObaval som sa toho, ale realne ziadna nenastala. Proste pri indexovany overujem URL ci uz bola indexovana.
ČasováníBral som ohlad aj na druhu stranu. Testoval som, kym som najprv stahoval. A v user agent posielam svoj mail, ak by im to nieco vadilo.
From?
§ 5.5.1 The "From" header field contains an Internet email address for a human user who controls the requesting user agent. […] A robotic user agent SHOULD send a valid From header field so that the person responsible for running the robot can be contacted if problems occur on servers, such as if the robot is sending excessive, unwanted, or invalid requests.
Mozilla/5.0 (compatible; NetcraftSurveyAgent/1.0; +info@netcraft.com)
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz
{kind=link}