Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
9.2.2019 23:08
| Přečteno: 3621×
| Obecné IT
|  | poslední úprava: 11.2.2019 14:13
| poslední úprava: 11.2.2019 14:13
V předchozí části jsem popsal motivaci, jenž mě zavedla na trnitou cestu vývojářů vlastního jazyka. V dnešní části se podíváme na to jak vlastně má můj jazyk vypadat a taky se na první a pravděpodobně nejjednodušší komponentu: lexer.
Základní syntaxi Selfu dobře popisuje následující obrázek:
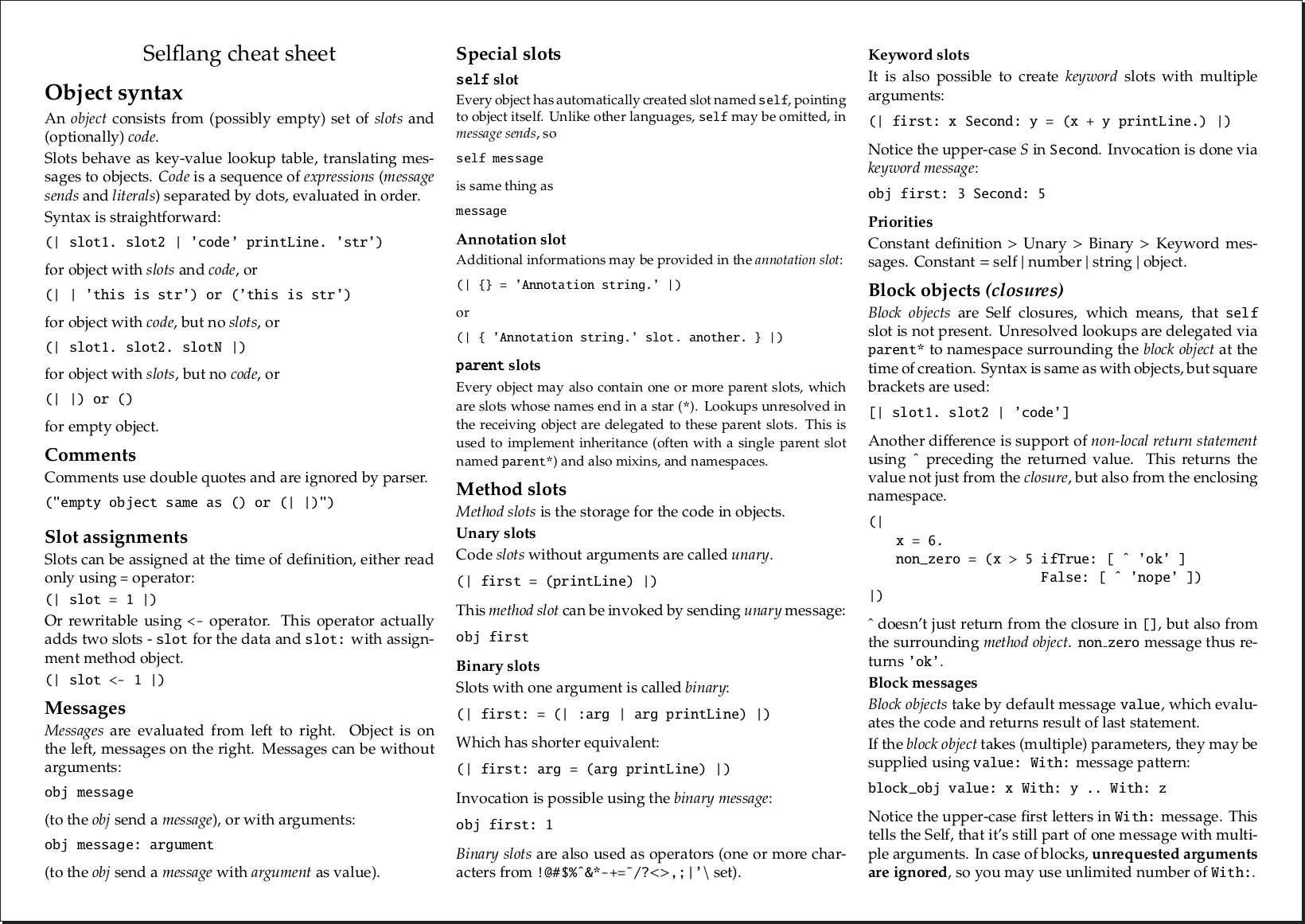
Pokud by vás zajímaly podrobnosti, doporučuji anglickou wikipedii, Self handbook, či můj paralelně vycházející seriál Prostředí a programovací jazyk Selfu.
tinySelf, jak jsem se kdysi nerozvážně (ukázalo se, že stejně pojmenovaný projekt už kdysi existoval) rozhodl můj jazyk nazvat, je v podstatě Self, i když trochu „vylepšený“ po stránce syntaxe.
Například jsem přidal podporu pro kaskády (;), jak je používá Smalltalk. Nikdy jsem nechápal, proč v původním Selfu nejsou, když tam dokonale sednou. Taky jsem změnil "komentář" na # komentář, protože uvozovky se podle mého názoru víc hodí na stringy, než na komentáře a také se lépe píšou na české klávesnici, než standardní Selfovské 'stringy' psané jednoduchými uvozovkami. Pro stringy je nyní možné používat obojí, což člověku šetří escapování, pokud zrovna potřebuje napsat string s uvozovkami.
Kromě toho jsem změnil i syntaxi objektů a bloků, kde jsem umožnil vynechání otevíracího |, takže je možné psát (slot |) místo (| slot |). K parsování to stejně není zapotřebí a vždycky mi to přišlo jako zbytečný opruz. Chtěl jsem přidat i (| code), ale ukázalo se, že to už parseru vadí hodně, takže je nutné zapisovat objekty bez slotů jako (|| code).
Oproti Selfu také není podtržítko na začátku zprávy rezervované pro volání primitivních zpráv. _s je normálně použitelná unární zpráva. Primitivní zprávy (volání nativního kódu interpretru) jsou implementované jako zprávy poslané objektu primitive. Primitivních zpráv je stejně v běžném kódu minimum, tak mi nikdy nebylo jasné, proč by pro ně měla být vyhrazená syntaxe.
Repozitář je momentálně hostovaný na githubu:
Psaní jazyka začíná lexerem. Ten definuje, z jakých komponent se jazyk skládá rozřezáním zdrojového kódu na tokeny. Ve standardním imperativním jazyce to můžou být různé příkazy, definice funkce, if podmínky, klíčová slova a tak podobně. V tinySelfu je to vesměs definice objektů, slotů, bloků, nebo posílání zpráv mezi nimi.
Lexer vám kód rozřeže na pole jednotlivých elementů. Z kódu jako:
(| asd = 1 | ^asd.)
vám udělá pole ve stylu:
[
Token("OBJ_START", "("),
Token("SEPARATOR", "|"),
Token("IDENTIFIER", "asd"),
Token("ASSIGNMENT", "="),
Token("NUMBER", "1"),
Token("SEPARATOR", "|"),
Token("RETURN", "^"),
Token("IDENTIFIER", "asd"),
Token("OBJ_END", ")")
]
Výstupem je plochá struktura, do které byl rozřezán vstupní řetězec a kde byly ke každé části přiřazeny typy tokenu.
Lexer je možné si napsat ručně, formou stavového automatu, který v cyklu prochází kód znak po znaku a postupně ho rozřezává a analyzuje rozřezané kousky (tokeny), aby jim přisoudil typ. Kdysi jsem něco podobného z neznalosti a z nutnosti udělal (tenkrát v D nebyl žádný lexer), když jsem si psal HTML parser, proto mi věřte, když vám tento přístup DÚRAZNĚ NEDOPORUČÍM.
Jedná o nepružný, k chybám náchylný, na pochopení složitý a těžce udržitelný přístup. Až na některé velmi speciální případy, kdy přesně víte co děláte a proč, se vám vždy vyplatí použít nějakou knihovnu, kterou nakrmíte popisy tokenů a ona vám stavový automat na základě popisu vygeneruje.
V mém případě se jedná o knihovnu rply (podrobnosti přinese příští díl), konkrétně část rply.LexerGenerator.
tinySelf je tvořen následujícími tokeny:
Klíčové slovo self tvoří token Self. Použití je podobné jako třeba v pythonu, či this v javě.
Čísla. 5 je číslo. -5 je číslo. 4.32 je taky číslo, stejně jako 0xFF.
Začátek definice objektu. Jedná se jednoduše o závorku ( za níž následuje zbytek objektu.
Ukončovací závorka ) značící konec objektu. Nejkratší (prázdný) objekt v Selfu je ().
Začátek bloku [. Bloky jsou objekty, které mají parenta nadefinovaného na lokální scope, takže se chovají podobně jako lambda funkce.
Konec bloku ]. Nejkratší blok vypadá takhle; [].
Definice stringů. Jak jsem zmiňoval, bere se 'string' a "string" se standardníma escape sekvencema.
V Selfu existují tři druhy zpráv objektům; unární, binární a keyword. Unární nepřijímá žádný parametr. Binární jeden, keyword pak libovolný počet.
Self přinesl oproti Smalltalku drobné vylepšení, kde keyword zprávy jsou jednoznačně parsovatelné prostým okem tím, že vynucuje každé následující klíčové slovo zprávy začínat velkým písmenem.
Ve Smalltalku může zpráva at: 1 put: 2 znamenat buď (at: 1) put: 2, tedy poslání zprávy at: a následné poslání zprávy put: výsledku z prvního volání, nebo poslání zprávy at:put: se dvěma parametry 1 a 2. V Selfu je nutné druhý popsaný případ zapsat jako at: 1 Put: 2, což jednoznačně identifikuje kde keyword zpráva začíná a končí. Proto taky lexer rozlišuje začátek keyword zprávy (string začínající malým písmenem s dvojtečkou na konci) a pokračování.
Zmiňované pokračování zprávy. String začínající velkým písmenem, s dvojtečkou na konci.
String začínající malým či velkým písmenem, či podtržítkem následující tím samým, či číslicí. asd, BSD, _A či _35 jsou validní identifikátory, respektive unární zprávy.
Jako operátor (binární zprávu) je možné použít znaky z množiny: !@$%&*-+~/?<>, v libovolném počtu opakování. @ je operátor, stejně jako @@.
Operátory vždy očekávají jeden parametr. a + b je binární zpráva oprerátoru + s parametrem b zaslaná objektu a.
Hlavně u bloků je potřeba napsat co za argumenty přijímají. Argumenty se zapisují jako identifikátory začínající dvojtečkou.
Ukázky:
Speciální operátor přiřazení. Má význam v definici slotů, kde definuje sloty pouze ke čtení. Také je ho možné použít jako běžný operátor (binární zprávu). Zapisuje se jako znak pro rovná se (=).
Přiřazení do slotu ke čtení i zápisu. Takto jde přiřazovat pouze konstanty, nebo reference na jiné objekty, nikoliv metody.
Zapisuje se jako šipka do leva (<-).
Vrácení hodnoty z objektu / bloku. Zapisuje se jako stříška (^).
Konec výrazu. Odděluje řetězce zpráv. Zapisuje se stejně jako ve Smalltalku tečkou (.).
Oddělovač slotů od kódu. Zapisuje se jako svislá čárka (|).
Vyhrazený operátor kaskády. Zapisuje se jako středník (;). Sděluje interpretru, že následující zpráva se posílá stejnému objektu jako předchozí.
Komentář začínající #, končící koncem řádku.
Může se zdát, že v lexeru je toho spousta, ale ve skutečnosti je celý jazyk dost jednoduchý a ukázka všeho co je v něm možné se vejde tak nějak na pohlednici:
() # Prázdný objekt.
(| |) # Taky prázdný objekt, ale s definicí (prázdných) slotů.
(| slot |) # Objekt obsahující jeden slot (key/val storage, kde slot = nil.).
# Objekt obsahující definice dvou slotů; read only ‚s‘ a zapisovatelného slotu ‚s2‘.
# Ekvivalentní slovníku {"s": None, "s2": 1}, když pominu zapisovatelnost slotů.
(| s = nil. s2 <- 1 |)
# Objekt obsahující slot ‚s‘, a taky kód, který tomuto slotu pošle unární zprávu ‚printLine‘. Poslední výraz je vždy vrácen, takže bude vrácena hodnota slotu ‚s‘.
(s = 1 | s printLine. s)
(| s = 1. | s printLine. ^s. ) # Totožný kód jako v předchozím případě s alternativní syntaxí slotů a explicitní return.
[ ] # prázdný blok
[:a | a printLine. a] # blok přijímající parametr ‚a‘, který vypíše posláním zprávy ‚printLine‘ a vrátí.
[| :a | a printLine. exit: a.] # totožný kód - return v bloku vrací z nadřazeného scope, nikoliv jen z bloku samotného!.
# Komplexnější objekt obsahující asi všechny elementy jazyka.
( a = 1. b <- 2. c |
(a + b) > 0
ifTrue: [c: a+b. ^c]
False: [self logger log: a; log b.].
logger log: 'Vsechny zpravy se prvne resolvuji na Self'.
self logger log: "Toto je tedy totozna zprava".
^ (| output = "vysledek". line <- "metody" |)
)
Celý kód lexeru se vejde na 40 řádek a jde jen o definici jednotlivých elementů jazyka pomocí regexpů:
# -*- coding: utf-8 -*-
from rply import LexerGenerator
lg = LexerGenerator()
lg.ignore(r'\s+')
lg.add('SELF', r'self')
lg.add('NUMBER', r'(0x[0-9a-fA-F]+)|((\-)?\d+(\.\d)?)')
lg.add('OBJ_START', r'\(')
lg.add('OBJ_END', r'\)')
lg.add('BLOCK_START', r'\[')
lg.add('BLOCK_END', r'\]')
lg.add('SINGLE_Q_STRING', r"'(?:\\.|[^'\\])*'")
lg.add('DOUBLE_Q_STRING', r'"(?:\\.|[^"\\])*"')
lg.add('FIRST_KW', r'([a-z_][a-zA-Z0-9_]*\.)*[a-z_]+[a-zA-Z0-9_]*:')
lg.add('KEYWORD', r'[A-Z]+[a-zA-Z0-9_]*:')
lg.add('ARGUMENT', r':[a-zA-Z_]*[a-zA-Z0-9_]+')
lg.add('RW_ASSIGNMENT', r'\<-')
lg.add('OPERATOR', r'[!@\$%&\*\-\+~/?<>,]+|==+')
lg.add('RETURN', r'\^')
lg.add('END_OF_EXPR', r'\.')
lg.add('SEPARATOR', r'\|')
lg.add('CASCADE', r'\;')
lg.add('IDENTIFIER', r'([a-zA-Z_][a-zA-Z0-9_]*\.)*[a-zA-Z_]*[a-zA-Z0-9_\*]+')
lg.add('ASSIGNMENT', r'=')
lg.add('COMMENT', r'#.*[\n|$]?')
lexer = lg.build()
Možná se někdo pozastaví, proč je kód psaný v pythonu 2. Důvod je jednoduchý - pypy v době psaní stále ještě nepodporuje nejnovější python3 v rpython translator toolkitu. Jakmile tam bude podpora pythonu 3.6, mám v plánu kód přeportovat.
V příštím díle se podíváme na parser, který tokeny bere a sestavuje z nich AST - abstraktní syntaktický strom.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Diskuse byla administrátory uzamčena
Lexer je možné si napsat ručně, formou stavového automatu, který v cyklu prochází kód znak po znaku a postupně ho rozřezává a analyzuje rozřezané kousky (tokeny), aby jim přisoudil typ. Kdysi jsem něco podobného z neznalosti a z nutnosti udělal (tenkrát v D nebyl žádný lexer), když jsem si psal HTML parser, proto mi věřte, když vám tento přístup DÚRAZNĚ NEDOPORUČÍM.S tímhle teda úplně souhlasit nemůžu. Mám zkušenost s několika lexer- nebo parser-generátory hlavně z prostředí C++ a Rustu a moje zkušenosti je taková, že na jednu stranu sice pomůžou, ale na druhou jsem vždycky musel s tím generátorem nějakým způsobem bojovat, objevovat jeho limitace a překonávat je (kolikrát složitě). (Typicky error handling je problém, ale i jiné věci.) Naopak se poslední dobou kloním k názoru, že slušně ručně napsaný lexer / parser je kolikrát lepší. Zejména pokud má použitý programovací jazyk třeba pattern matching a/nebo jiné FP prvky, umožňuje to napsat parsery relativně velmi pěkně. Někde v šuplíku mám v Rustu ručně napsaný parser VT-102, se kterým jsem byl co do korektnosti / čitelnosti / mantainability mnohem spokojenější než s přechozími pokusy pomocí parser-generátorů. U toho odkazovaného HTML parseru mi ani tak nepřijde jako problém, že je napsaný ručně, ale spíš že ten state machine a přechody mezi stavy jsou někde ve funkčních scopech a nejsou dostatečně explicitní. Napříkad jedna možnost, jak to zpřehlednit, by mohlo být mít na to objekt, který by držel stav a například by volal pro každý stav nějakou metodu, která by jako návratovou hodnotu vracela následující stav (to je jen nápad, jsou samozřejmě i jiné cesty). Tím nechci říct, že je potřeba všechno parsovat ručně, nicméně ruční lexer/parser bych určitě nezavrhoval.
Naopak se poslední dobou kloním k názoru, že slušně ručně napsaný lexer / parser je kolikrát lepší.Souhlasím, že bude lepší z hlediska toho že ti umožní dělat víc věcí, ale nejsem spíš si nemyslím, že bude lepší z hlediska třeba udržovatelnosti, nebo například modifikovatelnosti. Dejme tomu že chceš přidat nový druh stringů třeba, něco jako raw stringy v pythonu. Jak moc toho najednou musíš přepisovat a upravovat? Nebo jsem možná jen nenašel vhodný pattern jak to dělat čitelně, hm.
Dejme tomu že chceš přidat nový druh stringů třeba, něco jako raw stringy v pythonu. Jak moc toho najednou musíš přepisovat a upravovat?Myslimže zrovna ten případ přidání raw stringu složitý nebude, ale co se modifikovatelnosti obecně týče, umim si představit, že to problém minimálně v některých případech může být. Na ten ruční parser typicky potřebuješ mít dopředu známmý ten stavový automat a tím můžou změny zahýbat.
Nebo jsem možná jen nenašel vhodný pattern jak to dělat čitelně, hm.Ten VT parser jsem strukturoval tak, že to byla dvojice interní stav a dispatch objekt. Dispatch objekt byl definovaný jinde a ten dostával 'hotová' data ve chvíli, kdy byly k dispozici (push parsing). Interní stav držel stavový enum parseru + trochu nějaká dodatečná data jako parametry escapů a podobně. Vstupem byla metoda
input s parametrem bajt (VT je v podstatě streamovaný binární protokol, který je nutný parsovat bajt po bajtu), ve který se akorát podle aktuálního stavu bajt poslal do nějaké metody, ze které vypadl stav pro následující bajt.
Pro parsování textových non-streaming formátů tohle možná není až tak vhodný přístup. Budu potřebovat v dohledné době napsat parser pro textový markdown-like formát, mám to aktálně napsáno v PEGu, ale saje to, nejsem s tim spokojen. Ještě se nad tím zamyslim, jak to nejlíp strukturovat. Například mě napadá, že by se vstupní data daly rozpadnout na znaky významné pro lexing/parsing, které by parser bral jednotlivě, a shluky znaků nevýznamné (ie. nezpůsobující změnu stavu) by se daly zpracovávat vcelku.
V případě tvého tinySelfu ten rply vypadá IMHO v pohodě. Ačkoli zatím neznám tu interakci s parserem a taky nezmiňuješ, jak dobře reportuje syntaktické chyby.
V případě tvého tinySelfu ten rply vypadá IMHO v pohodě. Ačkoli zatím neznám tu interakci s parserem a taky nezmiňuješ, jak dobře reportuje syntaktické chyby.Je to docela v pohodě, ale jak jsem psal, už jsem tam taky narazil, když jsem chtěl parsovat
(| code), což prostě asi tenhle druh parseru vůbec nedá. Bude o tom víc příští díl zase za týden.
Je to docela v pohodě, ale jak jsem psal, už jsem tam taky narazil, když jsem chtěl parsovat (| code), což prostě asi tenhle druh parseru vůbec nedá. Bude o tom víc příští díl zase za týden.
Moje intuice je, že tím přidáním toho (| code) se z gramatiky jazyka stává context-sensitive gramatika, protože když budeš mít (| xxx) versus (| xxx | yyy), tak to xxx se parsuje jinými pravidly v závislosti na tom, jestli pak následuje '|', nebo ')'.
rply neznám, ale vypadá to, že je založen na EBNF a (E)BNF ti context-sensitive jazyk skutečně nezparsuje, umí jen context-free gramatiky. Ale dají se dělat všelijaké triky, viz např. co v podobné situaci dělá python.
Disclaimer: Neudělal jsem si rigorózní analýzu té gramatiky a nezkusil aplikovat Pumping lema a/nebo Ogden's lema, takže můžu kecat, jsou to jen dva centy.
rply neznám, ale vypadá to, že je založen na EBNF a (E)BNF ti context-sensitive jazyk skutečně nezparsuje, umí jen context-free gramatiky. Ale dají se dělat všelijaké triky, viz např. co v podobné situaci dělá python.Jo, k tomu jsem taky dospěl.
Disclaimer: Neudělal jsem si rigorózní analýzu té gramatiky a nezkusil aplikovat Pumping lema a/nebo Ogden's lema, takže můžu kecat, jsou to jen dva centy.Já jsem parsery nikdy nestudoval, tak jsem to prostě udělal jak to šlo. Upřímně nemám moc tušení co s tím dělat, mrknu na to co jsi linkoval. Co se týče chybových hlášek, tak ty jsem zatím neřešil vůbec, s tím že na to bude čas pokud z toho někdy něco bude, neboť nemá smysl zabít rok psaním parseru, když to pak zahodíš jako hračku co tě už omrzela.
Co se týče chybových hlášek, tak ty jsem zatím neřešil vůbec, s tím že na to bude čas pokud z toho někdy něco bude, neboť nemá smysl zabít rok psaním parseru, když to pak zahodíš jako hračku co tě už omrzela.To je dobrá poznámka a ve stejném duchu bych asi neřešil tu syntaxi
(| code) , pokud ti ta syntaxe (|| code) napřijde nějak výrazně debilní. Ono když to člověk s těmi convenience syntaxemi přežene, tak se mu pak taky může stát, že ten jazyk vůbec parsovat nepůjde  No nic, už tě nechám žít a počkám na další díl...
No nic, už tě nechám žít a počkám na další díl...
To je dobrá poznámka a ve stejném duchu bych asi neřešil tu syntaxi (| code) , pokud ti ta syntaxe (|| code) napřijde nějak výrazně debilní.Ono to má řešení přes
(code), což třeba v Selfu funguje. Bohužel jsem se ale rozhodl tuhle syntaxi znásilnit pro prioritizaci zpráv a unfucknout to není úplně triviální. Sice vím jak na to, ale hodina co jsem tomu věnoval nestačila.
No nic, už tě nechám žít a počkám na další díl...Náhodou super, já to dělám +- naslepo, tzn nečetl jsem žádné knihy jak ‚se to má dělat‘ ani jsem to neměl na VŠ, takže každá rada dobrá.
rply neznám, ale vypadá to, že je založen na EBNF a (E)BNF ti context-sensitive jazyk skutečně nezparsuje, umí jen context-free gramatiky. Ale dají se dělat všelijaké triky, viz např. co v podobné situaci dělá python.Tak jsem to četl a je to jedna z těch věcí, co mě taky napadla, tedy udělat z
(| samostatný token.
Celkově jsem se nad tím zamýšlel a je možné, že časem ten parser úplně předělám. Teď to má ale nejmenší prioritu, momentálně se snažím zvednout výkon. Milion cyklů (kde podmínka je lambda/blok) mi žere požád před 3.5 vteřin a rád bych to dostal někam ke sto milisekundám; Speedups of the interpreter.
Tak jsem to četl a je to jedna z těch věcí, co mě taky napadla, tedy udělat z (| samostatný token.
IMHO tím si nepomůžeš, neřeší to tu ambiguitu mezi (| xxx | yyy) a (| xxx) ve chvíli, kdy je parser u xxx a neví, jakými pravidly to zparsovat.
Asi bys musel to xxx by default parsovat jako definici slotů a ve chvíli, kdy by parser narazil na konec objektu nebo non-slot syntax (tj. chybu), přidal by uměle na začátek objektu ještě jeden ten separátor a pokusil se to znovu zparsovat jako (|| code) . Ale je to poněkud hack.
Mám zkušenost s několika lexer- nebo parser-generátory hlavně z prostředí C++ a Rustu a moje zkušenosti je taková, že na jednu stranu sice pomůžou, ale na druhou jsem vždycky musel s tím generátorem nějakým způsobem bojovat, objevovat jeho limitace a překonávat je (kolikrát složitě)Vidim to podobne, ale hodne se mi osvedcil ANTLR, tam se mi dari vetsina veci udelat docela bezbolestne.
Možná se někdo pozastaví, proč je kód psaný v pythonu 2. Důvod je jednoduchý - pypy v době psaní stále ještě nepodporuje nejnovější python3 v rpython translator toolkitu. Jakmile tam bude podpora pythonu 3.6, mám v plánu kód přeportovat.Mimochodem zrovna vyšlo Düsseldorf Sprint Report 2019, kde se píše:
Catching up with CPython 3.7/3.8 – we are planning to release 3.6 some time in the next few months and we will continue working on 3.7/3.8.
[a-zA-Z_]*[a-zA-Z0-9_]+ mi nějak nedává smysl, je to totéž, jak [a-zA-Z0-9_]+ ne? Nemělo by to tam být bez té hvězdičky [a-zA-Z_][a-zA-Z0-9_]+.
TohleIMHO by to mělo být[a-zA-Z_]*[a-zA-Z0-9_]+mi nějak nedává smysl, je to totéž, jak[a-zA-Z0-9_]+ne? Nemělo by to tam být bez té hvězdičky[a-zA-Z_][a-zA-Z0-9_]+.
[a-zA-Z_][a-zA-Z0-9_]*, ten [a-zA-Z_][a-zA-Z0-9_]+ by ti nevzal jednoznakový identifikátor.
[a-z_][a-zA-Z0-9_] (viz to co psal dole Pavel).
Lexer je možné si napsat ručně, formou stavového automatu, který v cyklu prochází kód znak po znaku a postupně ho rozřezává a analyzuje rozřezané kousky (tokeny), aby jim přisoudil typ.To tak jsem psal FPGA xdlrc parser v perlu
. Zároveň jsem se na tom ale učil význam položek toho xdlrc.
Omezení počátečních písmen následujících částí klíčových slov na velká písmena začíná postrádat původní smysl, jakmile může první část začínat na velké písmeno. Protože pak jde mít zprávu Put: a v uvedeném případe rovněž nevíš, jestli se jedná o novou další zprávu nebo pokračování té předchozí. Přijít ale zase o možnost začínat jména zpráv velkým písmenem, jako to má Self, je hodně velká cena. Je to tedy vlastně jen vynucená konvence (což ovšem také dává smysl).
Překvapuje mě, že nikde nevidím resend (řizený, neřízený) nebo nějakou obdobu. Tvůj jazyk ho nemá?
Používá tvůj jazyk indexování od jedničky nebo od nuly?
Omezení počátečních písmen následujících částí klíčových slov na velká písmena začíná postrádat původní smysl, jakmile může první část začínat na velké písmeno.Upřímně, poslední dobou mám pocit že občas fetuju, protože jsem to omezit chtěl, ale vůbec nemám tušení proč jsem to neudělal. I tohle je ale dobrý důvod proč tyhle věci publikovat, protože více oči prostě víc vidí.
Překvapuje mě, že nikde nevidím resend (řizený, neřízený) nebo nějakou obdobu. Tvůj jazyk ho nemá?Má, jen se dopočítává později z identifikátorů.
Používá tvůj jazyk indexování od jedničky nebo od nuly?Od nuly.
Tak tohle je docela vtipné. Jak jsi ty štítky zmínil v diskuzi, tak jsem si je prohlížel a zkoumal, jak vlastně fungují, a najednou vidím, že je máš zobrazené u zápisku. Takže ty štítky od A jsou ode mě. Sorry.V pohodě, já už jsem to hodil do tag manageru a ten to odmázl automaticky, protože jsem je neschválil.
Jinak zajímavý zápisek, sice Smalltalk neumím a kompilátory se teprve učím, ale mám určitou představu, o čem tu je řeč, a docela se těším na vytvoření a vyhodnocení toho AST.To se ti budou líbit další díly, ten kompilátor je sice neoptimalizovaný a relativně neefektivní (například pořád používám více-bajtové instrukce, místo abych zpackoval časté operandy do jednobajtových), ale zase se dá krásně pochopit a je to na pár řádek.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz