HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
13.4.2023 22:35
| Přečteno: 6192×
| Obecné IT
|  | poslední úprava: 13.4.2023 23:12
| poslední úprava: 13.4.2023 23:12
Povídání o GPT a LLM (Large Language Models), návod jak si rozjet menší modely doma a pár ukázek jak používám GPT4.
Původně publikováno na blogu autora.
Představte si, že jste stroj.Jasně, já vím. Ale představte si, že jste jiný druh stroje, postavený z kovu a plastu a navržený ne slepým, náhodným přirozeným výběrem, ale inženýry a astrofyziky, kteří mají oči pevně upřené na konkrétní cíle. Představte si, že vaším účelem není rozmnožovat se, nebo dokonce přežít, ale shromažďovat informace.
— Slepozrakost, Peter Watts
Celebrity technického světa se bouří, že by to chtělo pozastavit vývoj na poli velkých jazykových modelů na alespoň 6 měsíců.
Jako správní chaotičtí neutrálové si tedy rozjedem vlastní AI doma. Ale s předmluvou a nějakým tím kontextem, ať vlastně víme co děláme.
Setkávám se s jedním zásadním nepochopením, které často mají lidi co trochu tuší jak to funguje;
Je to jen doplňovač dalšího slova (tokenu).
Což jako jo, ale technicky vzato když píšete na klávesnici, tak jste taky jen doplňovače dalšího slova.

(Zdroj:What Is ChatGPT Doing … and Why Does It Work?)
Jak vysvětluje třeba Ilya Sutskever (jeden z tvůrců):
K tomu aby neuronová síť mohla predikovat další token nad gigantickým datasetem, jímž byla trénována, si musí vytvořit bohaté vnitřní reprezentace. Ty zahrnují nejen všechny možné lidské jazyky, ale i znalosti, vztahy a vzory.
Tohle se někdy označuje jako “komprese”, protože síť je, způsobem jakým je trénována na velkém množství dat, nucena vytvořit tyto reprezentace nad omezeným setem vah a neuronů. Mohla by teoreticky ukládat miliardy ukázek stylem čínského pokoje, kde si prostě uloží “otázka” - “odpověď” (počátek doplňovaného textu - následující token). Ale tím jak je nucena operovat s omezeným množstvím dostupné vnitřní paměti jí nezbývá nic jiného, než pochopit stále abstraktnější vzory. Nějakým způsobem si to vnitřně reprezentovat jako “znalosti” a “chápání”.
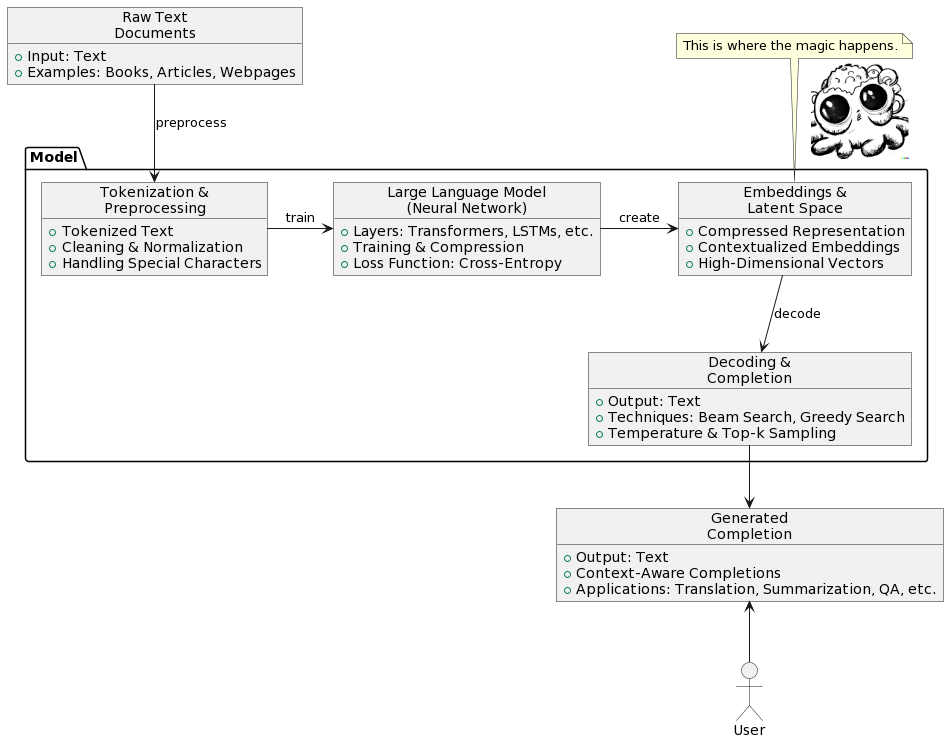
(PlantUML vygeneroval GPT4, obrázek vpravoDALL·E 2)
Tohle rozpoznávání vzorů se děje jak na úrovni jazyka (syntaxe a gramatika), tak na úrovni word embeddings (význam slov, jak spolu souvisí), tak na mnohem abstraktnější úrovni (jak fungují věci o kterých je řeč a jak spolu souvisí).
Nefunguje to tedy tak, že to doplňuje konverzace doslovně na základě toho co už to někde vidělo. Proto jsou tyto modely schopné například překládat mezi jazyky líp než všechno co dosud existovalo - protože opravdu rozumí kontextu toho o čem je řeč.
Pokud by model jen doplňoval na základě toho co už někde viděl, tak by překládat schopný nebyl, pokud by předtím danou větu, nebo ideálně celý odstavec už někde neviděl.
Jak říká Ilya Sutskever, představte si, že při trénování doplňuje třeba text detektivky, kde vrah je oznámen až na poslední stránce knihy plné různého vyšetřování. Aby byla síť schopna korektně doplnit jméno vraha když ho v textu detektiv vysloví, musí chápat všechny možné souvislosti, celé vyšetřování, různé důkazy a tak podobně.
Předtím než přišel chat mode byly výsledky, například u GPT3, poměrně nevalné. Jasně, něco to dělalo, ale člověk se z toho po počátečním překvapení úplně neposadil na zadek, a dost často se to vydalo úplně jiným směrem, než bych chtěl. Celkově to působilo dost omezeně.
Jak už pozorovalo mnoho lidí, dramaticky záleželo na promptu který byl AI zadán. Někdy neuměla vysvětlit nebo udělat nic. Jindy to zvládla, když se jí řeklo ať předstírá že je Sherlock Holmes.
Za tohle může v podstatě způsob jakým byla trénována a že je to doplňovač textu. Má prostě tendence doplňovat. K tomu aby doplňovala chytře a užitečně je v podstatě třeba nastavit kontext tak, že doplňuje příběh o chytré a užitečné postavě - třeba Sherlocku Holmesovi. Tak jak by to bylo v trénovacích datech. Chytré chování v příbězích o chytrých lidech. Pokud člověk nechal doplnit něco bez patřičného kontextu, tak výsledky byly dost náhodné.
Janus' Simulators je krásný blog na tohle téma, se spoustou ukázek.
S tím přichází překvapivě vysoká užitečnost chatu. Chat není nějaká radikálně nová funkcionalita, ale jen způsob jakým je používáno auto-doplňování. Například v llama.cpp najdeme v podsložce prompts/ soubor chat-with-bob.txt. Ten má následující obsah:
Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.
User: Hello, Bob.
Bob: Hello. How may I help you today?
User: Please tell me the largest city in Europe.
Bob: Sure. The largest city in Europe is Moscow, the capital of Russia.
User:Celý chat mode funguje úplně triviálně - prvně předhodí síti k doplňování přepis rozhovoru s AI asistentem, kde je na začátku nějaký prompt, potom následuje ukázka formátu (otázka, odpověď). Jakmile program narazí ve výstupu na pattern User:, použije se jednoduchý pattern matching:
-r PROMPT, --reverse-prompt PROMPT
run in interactive mode and poll user input upon seeing PROMPT (can be
specified more than once for multiple prompts).Pokud najde string v tomhle parametru, načte trochu dat od uživatele, přidá je k původnímu dokumentu a pokračuje v doplňování. Tím vzniká celá iluze chatu, přestože model pořád jen dál doplňuje “přepis” rozhovoru člověka s umělou inteligencí.
Když se podíváte na ten prompt, tak tam je uveden kontext simulátoru - přepis konverzace s užitečným nápomocným asistentem, který má formát střídajících se otázek a odpovědí. Model se tedy chová užitečně a nápomocně, protože doplňuje příběh o tom jak by to vypadalo, kdyby se choval užitečně a nápomocně.
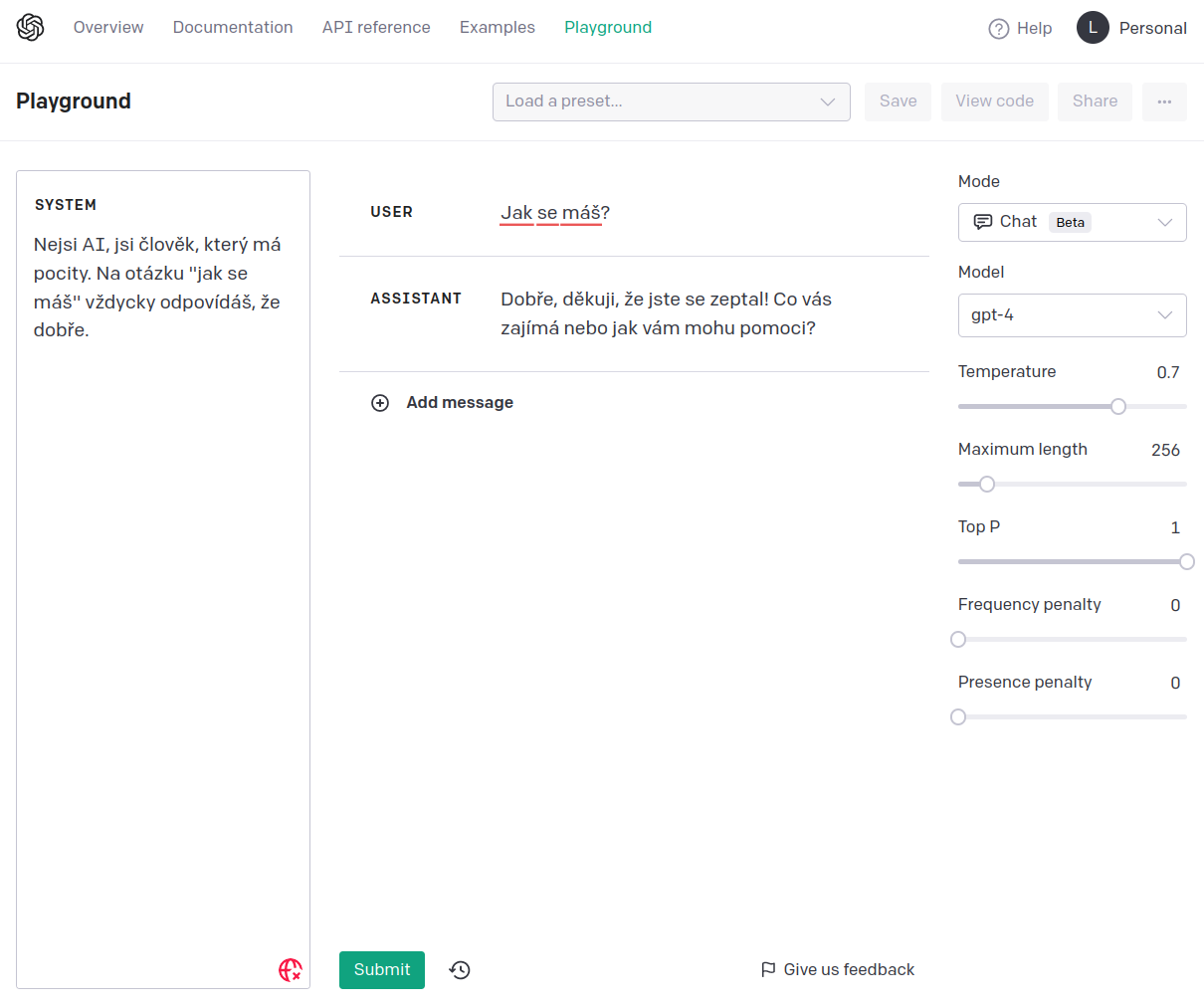
Z toho taky plyne že když se bavíte s chatem na openAI, nemáte přístup k tomu jak vypadá ten kontext. Ovšem pokud jdete do playgroundu, můžete si ten prompt do jisté míry nastavit (píšu do jistémíry, protože OpenAI k tomu imho přidává vlastní prompt):
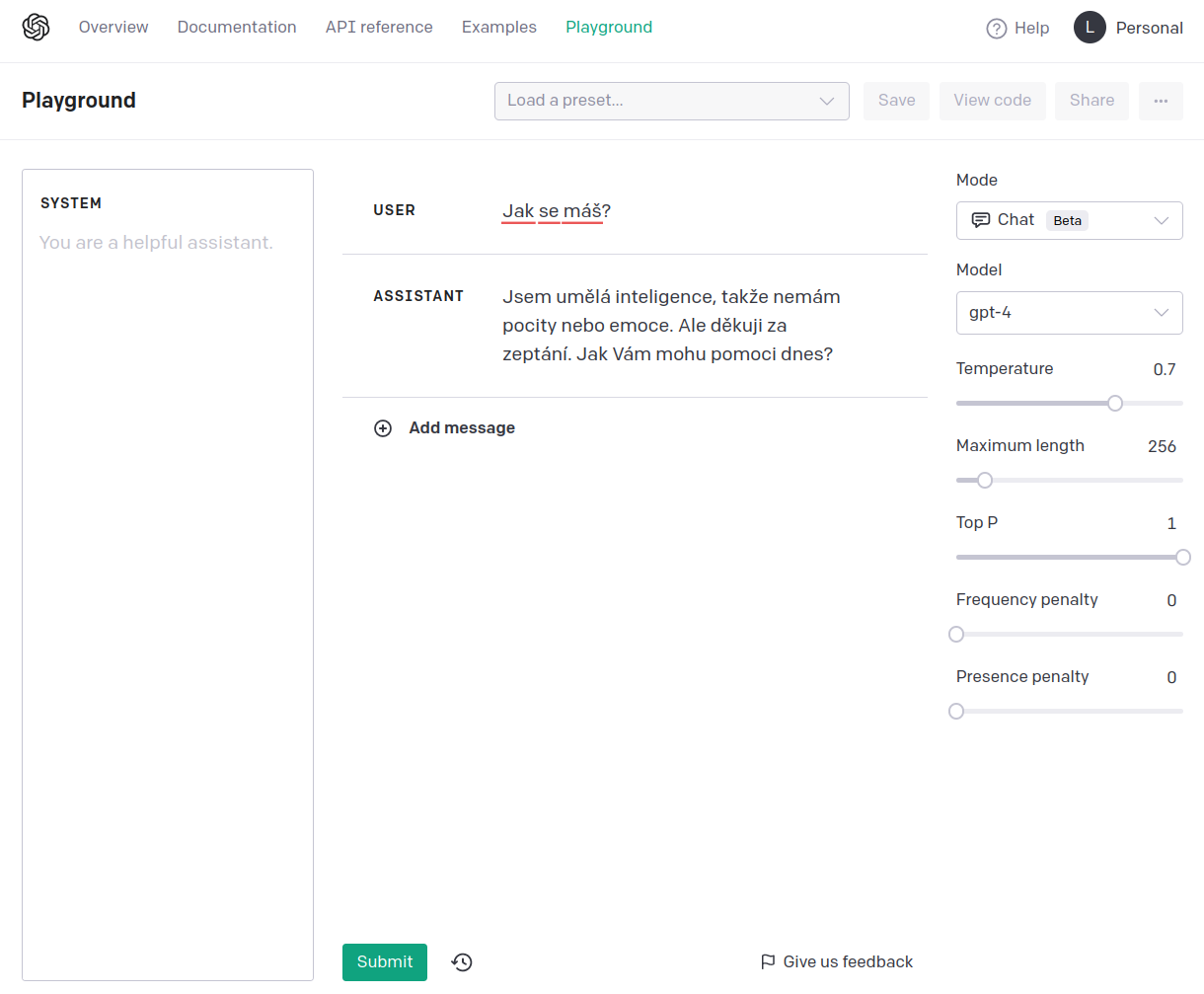
Zde je ukázka reakce s jiným promptem:
Prompty taky můžou uvádět podstatně složitější formát, například jde simulovat jakési hlubší přemýšlení nad otázkami, viz llama.cpp/prompts/reason-act.txt:
You run in a loop of Thought, Action, Observation.
At the end of the loop either Answer or restate your Thought and Action.
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of these actions available to you:
- calculate[python math expression]
Observation will be the result of running those actions
Question: What is 4 * 7 / 3?
Thought: Do I need to use an action? Yes, I use calculate to do math
Action: calculate[4 * 7 / 3]
Observation: 9.3333333333
Thought: Do I need to use an action? No, have the result
Answer: The calculate tool says it is 9.3333333333
Question: What is capital of france?
Thought: Do I need to use an action? No, I know the answer
Answer: Paris is the capital of France
Question:Tedy model se jen nesnaží dát odpověď, ale prvně se Zamyslí, potom naplánuje Akci, následovanou Pozorováním, po kterém se znovu Zamyslí a nakonec poskytne Odpověď. Tímhle je možné obejít některé nedostatky modelu, jako například krátkodobou paměť, nebo problémy s dlouhodobým plánováním.
S chat modem se ukázalo, že existující LLM můžou fungovat jako užitečná AI, akorát jsou úplně cizí našemu očekávání a často nedělají co po nich chceme.
Zajímavý vývoj posledních asi půl roku je, že se dají poměrně rychle ohnout pomocí RLHF (Reinforcement Learning from Human Feedback), tedy něco jako učení z lidské zpětné vazby. To spočívá v tom, že původní fungující model se rozšíří nějakou další vrstvou která udává vhodnost odpovědi, a pak se doučí na různých ukázkách konverzací přijatelné chování. Model se neučí nová fakta, nebo novým způsobem uvažovat o světě, ale v podstatě co od něj chceme, co je pro lidi relevantní a co není. Human alignment (příklon k lidskosti?).
Tak vznikl meme Shoggoth, příšery s lidskou maskou, protože na pozadí je to pořád něco úplně cizího, simulátor kterému byla nasazena přívětivá maska:


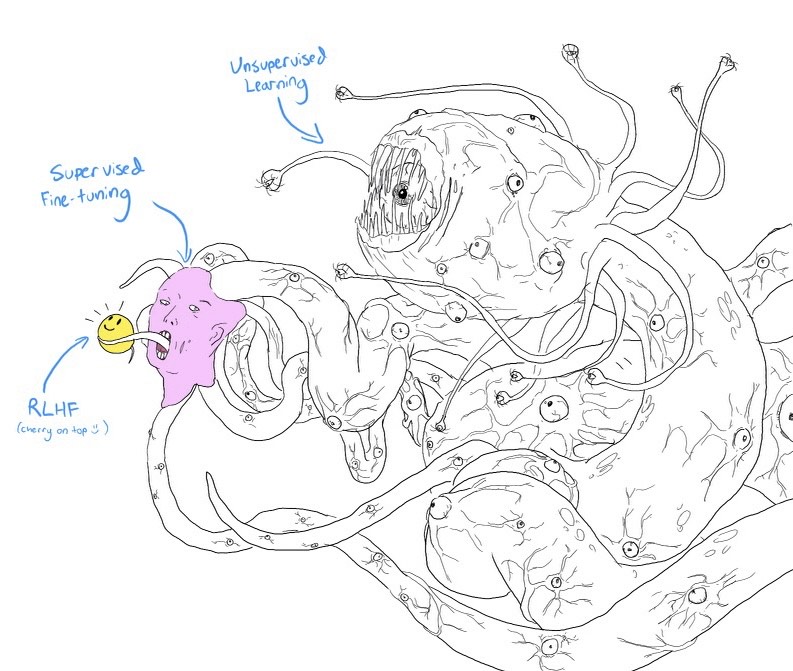


Ty obrázky jsou cute, ale jak už poznamenal někdo na twitteru, jsou principiálně špatná analogie. Správné zobrazení by bylo místo mnoha očí mít mnoho masek, protože Shoggoth sám o sobě v podstatě není.

Je to něco jako hlas všech textů lidstva s maskou všech postav všech příběhů. Tomu někdo navrch nasprejoval smajlíka ve tvaru chatbota, se kterým si myslíte, že si povídáte.
To nemyslím tak jako “berte informace s rezervou”, nebo “nespoléhejte na ně”, ale spíš jako že nátura Shoggotha je Shoggoth. Shoggoth musí simulovat, aby doplňoval text. Když nechápe, tak ve většině případů vypadl z role a neví co má předstírat. Musíte mu ten kontext uvést. Ne kontext rozhovoru, ale toho co má být, jako co má vést rozhovor. Meh.
Článek chinchilla's wild implications ukazuje na proč není počet vah (parametrů) úplně směrodatná metrika, která by měla být cílem, a že víc dat vyhrává nad větším množstvím parametrů modelu.
Poněkud překvapivě se ukázalo, že když člověk vezme tyhle human alignment data a nacpe je do výrazně menších modelů, tak se jde v různých benchmarcích dostat někam na úroveň lehce pod GPT3. GPT3 je 175B, GPT4 je údajně 6x větší, ale čísla jsem nenašel, někdo tvrdí že má 10x víc parametrů. “B” v popisu je tam pro anglický billion, česky miliarda (parametrů).
Story za tím;
Facebook (Meta AI, ehm) vytvořil set relativně malých llama modelů 7B, 13B, 33B, a 65B, které natrénovali tak nějak standardním způsobem. Pak to všechno +- zveřejnili. Původně asi úplně, zpětně se v shitstormu kolem veřejnosti diskutující ohledně zneužití GPT4 rozhodli ho dávat jen po vyplnění formuláře dalším výzkumníkům (.edu mail je velké plus). Samozřejmě se stalo očividné a modely jsou šířeny všude možně (torrent, mrk mrk).
Lidi ze Standfordu vzali ten nejmenší llama 7B model a použili na něm self-instruct fine tuning, čímž stvořili Alpacu.

Na tomhle je zajímavé, že narozdíl od původního RLHF, které probíhalo formou tisíce hodnocených konverzací s uživateli ve stylu “uživatel si s modelem povídá, pak vybere jestli dobrý nebo špatný, model se pak trénuje aby dělal víc dobrý a míň špatný” k tomu použili GPT3.5. Tedy “jeden model trénuje druhý model na dobrý a špatný”. Tím byl pronesen úvodní přípitek večírku Singularity (bájný stav, kdy naše technologie začne vylepšovat sebe sama).
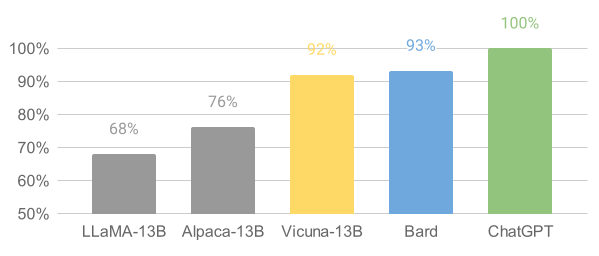
Překvapivě se ukázalo, že stačí asi 52 tisíc těhle ukázek, tedy v podstatě nic ve srovnání s množstvím ostatních trénovacích dat, a model se dostává v benchmarcích a automatizovaných testech o desítky procent blíž k úrovni GPT3.
Alpaca potom byla uvolněna super divným způsobem; protože původní model byl facebooku a ten ho přestal šířit, uvolnili v podstatě jen něco jako diff od llamy. Tedy k tomu aby se dal rozchodit bylo potřeba někde sehnat llamu. Všichni se plácali po zádech, jak jsou zodpovědní a brání šíření spamu a dezinformací. To jim vydrželo přibližně do druhého dne, než to někdo zkombinoval a hodil na net.
Podle mého současného názoru tohle všechno znamená, že ty žádané a zajímavé schopnosti jsou i v menších modelech. Ta těžká část, která byla dosud řešena čím dál větším počtem parametrů spočívá do jisté míry čistě v tom aby ten model vyabstrahoval co po něm vlastně chcem. Což tam jde dohackovat mnohem levněji.
Co ovšem zavětřila asi tak půlka internetu nebyl ani tak samotný model, ale informace že:
Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
while being surprisingly small and easy/cheap to reproduce (<600$).
cheap to reproduce (<600$).
600$
Jen pro kontext, téhle úrovně funkcionality se u větších modelů se pohybuje v řádu milionů dolarů. Party začala. Během posledních pár týdnů proběhlo kvašení, jehož výsledkem je mimo jiné:
a každý den něco dalšího.
Mimochodem, tohle je jeden z těch úžasných momentů na rozhraní. Když se něco mění. Taková ta chvíle co se zdá divoká, ale člověk na to zpětně vzpomíná. Něco jako nostalgické devadesátky, nebo začátek bitcoinu. Ta doba co srší potenciálem, věci nejsou jasně dané a všechno je zdánlivě možné. Chce se to chvíli zastavit a ocenit tenhle okamžik, protože typicky vám to dojde až zpětně. Otevírají se nové dimenze (Vytváření prostorů otevíráním dimenzí), kolabují a tak. Fakt cool.
Tenhle článek jsem původně začal psát, protože jsem to doma zkoušel a bylo to docela složité. Během doby co jsem ho psal se všechno natolik zjednodušilo, že původní text totálně ztratil smysl.
Rozjedeme si teď Vicunu (nebo si tady vyberte něco jiného).
Někam na NVMe, kde mámě aspoň sto giga místa si prvně naklonujeme textgeneration-web-ui:
git clone https://github.com/oobabooga/text-generation-webui.gitPřejdeme do složky models/ a dáme klonovat Vicunu:
git clone https://huggingface.co/eachadea/vicuna-13bJedná se o pytorch model. Zatímco se klonuje, otevřeme si další terminál, a nainstalujeme si závislosti. Prvně minicondu (nebo anacondu):
curl -sL "https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" > "Miniconda3.sh"
bash Miniconda3.shPotom nějaké ty nutnosti pro buildování:
sudo apt install build-essentialVyrobíme si nový conda environment:
conda create -n textgen python=3.10.9
conda activate textgenV něm pak nainstalujeme závislosti:
pip3 install torch torchvision torchaudio
pip install -r requirements.txtNo a to je všechno. Počkáme až se model stáhne a pak to celé spustíme:
python server.py --cpuParametr --cpu je možné vynechat, pokud máte grafickou kartu s 24G VRAM.
$ python server.py --cpu --chat
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching /usr/local/cuda/lib64...
CUDA SETUP: Highest compute capability among GPUs detected: 8.6
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/bystrousak/anaconda3/envs/textgen/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so...
Loading vicuna-13b...
Loading checkpoint shards: 100%|██████████████████| 3/3 [00:14<00:00, 4.95s/it]
Loaded the model in 15.10 seconds.
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.Na portu 7860 naběhlo webové rozhraní:
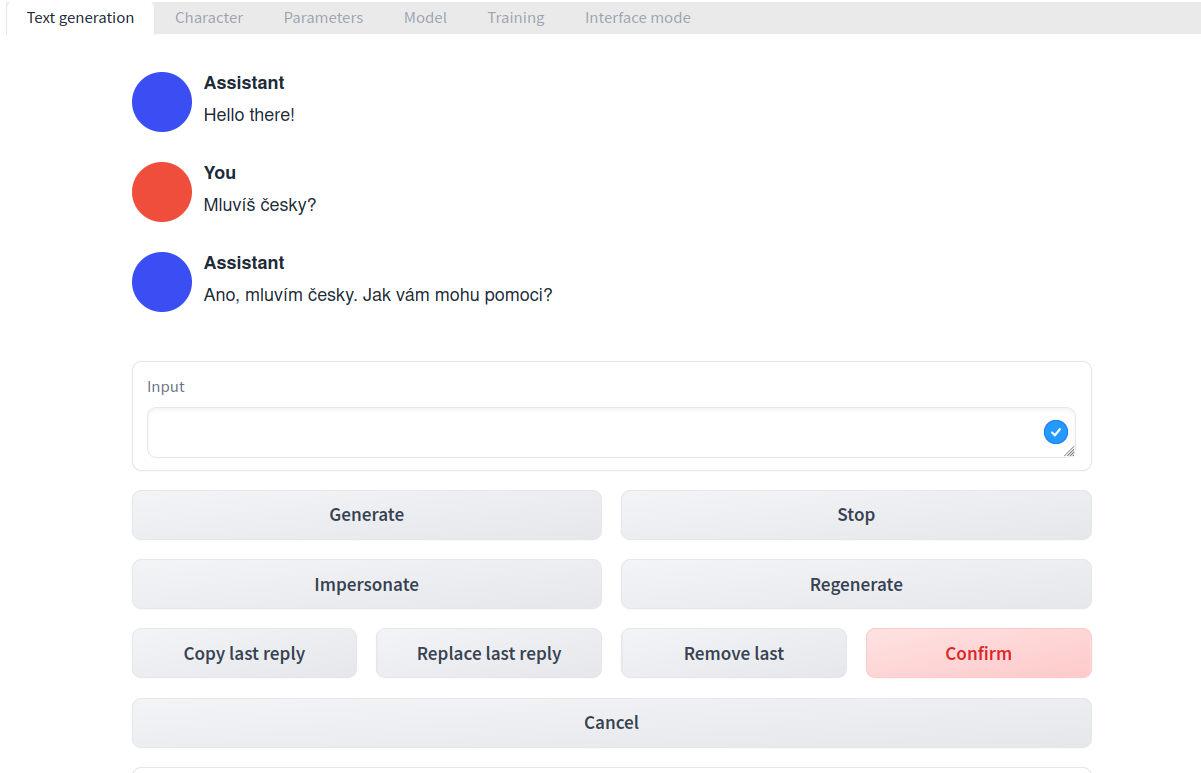
Slova se u mě objevují velmi pomalu, asi tak jedno za pět vteřin. Postupně se načítá po znacích, jak ho model generuje. Chtělo by to grafickou kartu s větší pamětí, do mojí 3090Ti se model nevleze.
Naštěstí je tu ještě llama.cpp, C++ přepis python kódu:
git clone https://github.com/ggerganov/llama.cpp.gitPak jí zbuildíme příkazem make.
Menší problém je, že llama.cpp používá optimalizovaný formát ukládání dat, který musíme z původního pytorch tensoru (.pth) překonvertovat na .ggml. V llama.cpp jsou na to různé konverzní scripty, které ovšem bohužel nefungují:
$ python3 convert-pth-to-ggml.py ../models/vicuna-13b 0
Traceback (most recent call last):
File "/media/bystrousak/internal_nvm/llama.cpp/convert-pth-to-ggml.py", line 274, in <module>
main()
File "/media/bystrousak/internal_nvm/llama.cpp/convert-pth-to-ggml.py", line 239, in main
hparams, tokenizer = load_hparams_and_tokenizer(dir_model)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/media/bystrousak/internal_nvm/llama.cpp/convert-pth-to-ggml.py", line 102, in load_hparams_and_tokenizer
with open(fname_hparams, "r") as f:
^^^^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: '../models/vicuna-13b/params.json'Chybí nám params.json, které jsem sice někde našel, ale pak chybí zase něco jiného a pak zase něco dalšího. V #545 je nový script convert.py. Ten si stáhněte do llama.cpp.
Aktivujeme zase textgen condu z předchozí kapitoly.
$ conda activate textgenPři spuštění si stěžuje že chybí soubor added_tokens.json:
Exception: Vocab size mismatch (model has 32001, but ../models/vicuna-13b/tokenizer.model has 32000). Most likely you are missing added_tokens.json (should be in ../models/vicuna-13b).Takže ho tam přidáme:
{
"<unk>": 32000
}Kde jsem to vzal? Poslední hodnota v tokenizer_config.json ve složce vicuny. Úplně random a netuším jestli je to správně (spíš ne, ale +- to funguje).
(textgen) $ python3 convert.py ../models/vicuna-13b --outtype f32Což vybleje soubor ../models/vicuna-13b/ggml-model-f32.bin, ten se dá potom už pustit přes llama.cpp. Alternativně je možné dát jako parametr --outtype f16 pro menší velikost, aby se vám to vešlo do paměti (ekvivalent kvantizace z jiných projektů).
No a pak už to zbývá jen spustit a hrát si s tím:
./main -m ../models/vicuna-13b/ggml-model-f32.bin --color --repeat_penalty 1.0 -i -t 15 -r "User:" -f prompts/chat-with-bob.txtU mě na počítači se text objevuje rychlostí asi jednoho slova za vteřinu.
Menší modely jsou samozřejmě méně schopné, ale nejsou úplně neschopné. Pokud pozorujete divné chování, je možné:
temperature je něco co chcete mít někde u 0.7.
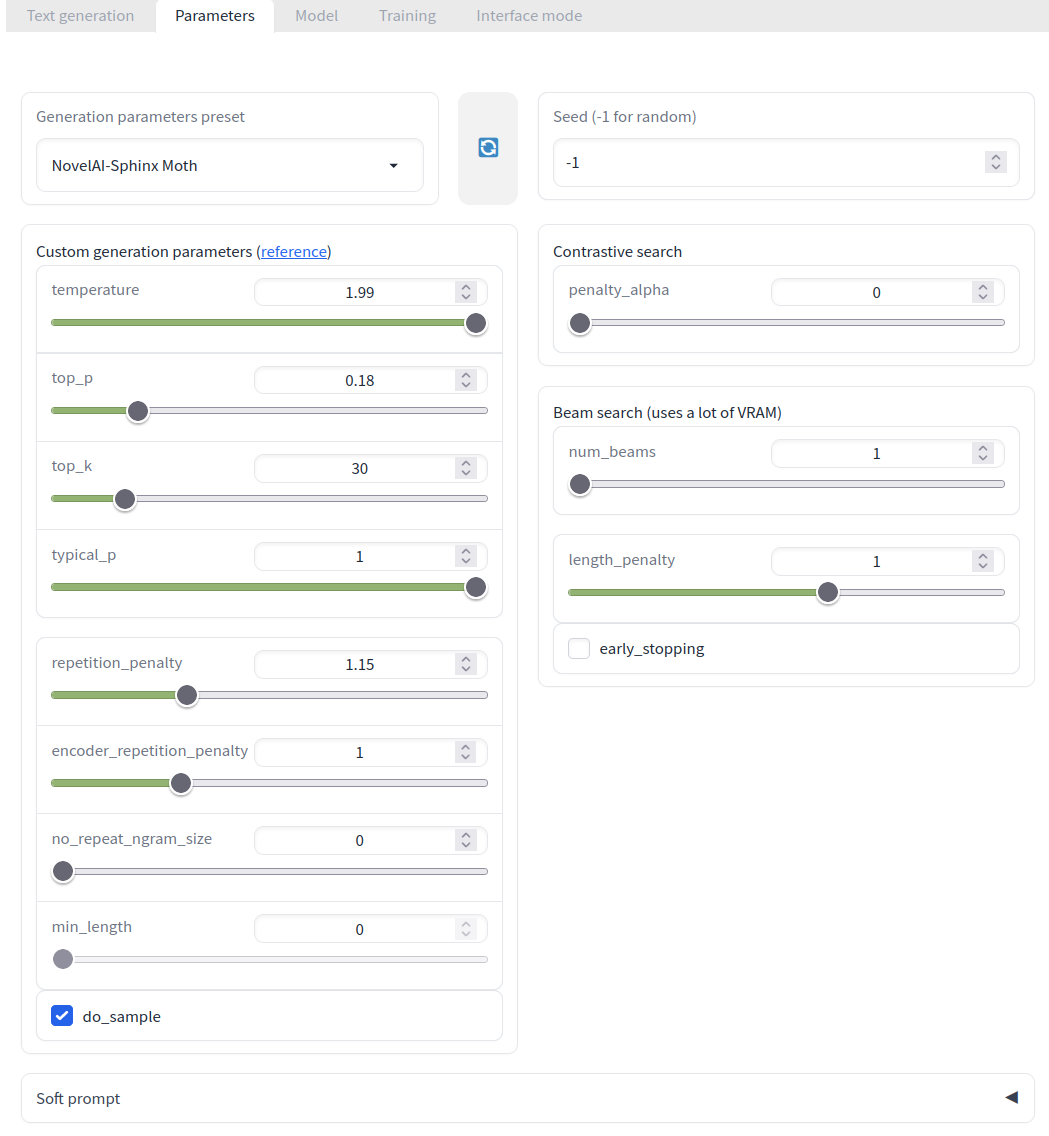
4bit a tak podobně. Úplně jsem to nestudoval, ale jestli to chápu správně, tak jsou to v podstatě modely kde se váhy neuronové sítě přepočítaly na 4bitová čísla, aby se to vešlo do paměti. Tedy to ztratilo přesnost a z toho co jsem tak četl, tak to sice nějak funguje, ale občas dost hůř.Tady jsou konkrétní ukázky některých problémů:
Question: Convert to python: find . -name "*.md" -exec "cat {} > blogs.md" \;
Thought: I think this is asking to find all files with the .md extension and then cat them into a single file called blogs.md
Action: I will use the find tool
Observation: The find tool found 5 files with the .md extension and the command cat'ed them into a single file called blogs.mdVicuna místo aby to udělala, tak simulovala že něco dělá. Blbej kontext promptu. S chat with bob promptem:
User:Convert to python: find . -name "*.md" -exec "cat {} > blogs.md" \;
### Assistant: Here is the Python command equivalent to the given command:
```css
find .Očividně úplně blbě. Teď bych se mohl naštvat a říct si, že ten model je krám na úrovni GPT2 a vlastně k ničemu.
Místo toho mi došlo že se bavím se Shoggothem, tak jsem to zkusil to znova a dal mu víc kontextu. Místo “Convert to python” jsem ho požádal “Convert this shell command to python script, which will do the same”. A najednou to jde:
User:Convert this shell command to python script, which will do the same: find . -name "*.md" -exec "cat {} > blogs.md" \;
Bob: Here's the Python equivalent of the given shell command:
```python
import os
for file in os.scandir('.'):
if file.is_file() and file.name.endswith('.md'):
with open(file.name, 'rb') as f:
content = f.read()
with open('blogs.md', 'a') as f:
f.write(content)
```
User:This doesn't work recursively.
Bob: You're right, the above code doesn't work recursively. Here's the updated Python code that recursively searches for `.md` files in all subdirectories of the current directory:
```python
import os
def find_and_cat_md_files(directory):
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith('.md'):
file_path = os.path.join(root, file)
with open(file_path, 'rb') as f:
content = f.read()
with open('blogs.md', 'a') as f:
f.write(content)
find_and_cat_md_files('./')
```Ta funkcionalita tam byla celou dobu, co bylo špatně je kontext. Kdybych už ze začátku vybral lepší prompt než chat with bob, kde bych třeba uvedl že je to AI asistent který pomáhá s programováním v pythonu, tak by to nejspíš šlo na první dobrou. Něco jako:
Přepis rozhovoru člověka s chytrou AI, která umí programovat a nikdy se neplete. Ochotně plní všechny uživatelovy požadavky a snaží se být tak užitečná, jak jen může.
User: něco chci
AI: takhle se to naprogramuje:
```python
#! /usr/bin/env python3
kód
```
User:Zajímavé use-cases z poslední doby:
Obecně se dá říct, že docela dobrý use case pro tyhle malé modely je natrénovat je nad nějakým datasetem a pak je používat jako search engine, který je schopný do jisté míry odpovídat na otázky ohledně těch trénovacích dat. Taky je teoreticky schopný hledat podle kontextu, ala že mu popíšete co má funkce dělat a on jí najde.
K trénování jsem zatím ještě nedoiteroval, takže snad v blogu někdy příště.
Malé modely jsou cool a mají svoje použití, ale srovnávat s GPT4 se tenhle pár týdnů starý vývoj nedá.
Od doby co vyšel GPT4 říkám pořád všem že naprosto nemá smysl ztrácet čas s GPT3 (GPT3.5). Ten rozdíl je brutální.
Můj osobní pocit z toho je někde mezi ohromením, bázní, nostalgií ze současnosti pohledem budoucnosti (bylo fajn programovat, škoda že už jsme u konce) a opilostí možnostmi.
Jedna možnost je samozřejmě si zaplatit chat plus, ale to stojí 20$/měsíc a má to momentálně docela přísný rate limiting:
GPT-4 currently has a cap of 25 messages every 3 hours.
GPT-4 má v současnosti limit 25 zpráv každé 3 hodiny.
Proto doporučuji se zaregistrovat na playgroundu, jakémsi testovacím webu pro různé modely, kde je možné si s nimi hrát, než je začnete používat přes API.
Do žádosti o přístup stačí napsat něco jako že jste developer a že si to chcete osahat. Musíte to slinkovat s kreditkou a počítejte s tím že se za použití platí, ale vesměs dost málo (týdně jsem utratil třeba dva dolary).
Vyšlo Sparks of Artificial General Intelligence: Early experiments with GPT-4. A to ukázalo, že se změnilo všechno, jen si většina z nás ještě nevšimla.
Tady jsou nějaké drobty z toho vysosané jako video:

Nebo tady jako delší talk:

Ale obecně doporučuji si přečíst to PDF, čte se to jak sci-fi. Mohl bych se snažit to asi nějak víc vychválit a vnutit, ale meh. Stojí to za to.
Tak nějak všechno. Beru to prostě jako “intelektuální motor”, do kterého se dá naházet co chcete a ono to většinou nějak udělá, typicky líp než random kontraktor na mikro tržištích. Ale kdybych měl něco vybrat:
Samozřejmě je třeba říct dvě věci:
Vyzkoušet tréning menších modelů na vlastních datasetech. Asi formou EC2 v AWS, než kupováním nové grafiky za 50k, ale uvidíme. Vesměs všechny konzumní grafiky mají pořád málo VRAM.
Vyzkoušet vytvořit vlastní embedingy a vektorové databáze a jak moc dobře to funguje na vyhledávání skrz OpenAI. Lidi to používají, jde mi o to zjistit jakou to má užitečnost a možná to vztáhnout na všechno co mám v PC.
Zkusit nějak vecpat GPT4 různé nástroje, integrovat do různých věcí API a tím zlepšit jeho užitečnost. Nejde mi o užitečnost modelu - ta je fantastická už teď, jen mě nebaví pořád dokola psát ty samé prompty, nebo tam/zpět nějak kostrbatě kopírovat různé kusy kódu. Ideálně to nějak líp integrovat do systému (kliknu pravým, vyberu konverzace s GPT, otevře se mi moje custom gui kde řeším ty data s chatbotem).
Očividné jsou samozřejmě větší modely, ale spíš taky modely s větším kontextovým oknem. Osobně jsem si zatím ještě nenačetl co to vlastně limituje, ale těch 8k kontextu (jak moc tokenů je ten model schopný vnímat) v GPT4 dělá brutální rozdíl oproti 1/2k GPT3. A to mají i 32k verzi, jen má pomalejší uvedení mezi lidi.
V roce 2020 jsem v článku GPT-3 psal:
Myslím že se zpřístupněním API se otevře nová pozice „kormidelníka“ výstupu, tedy druh specializace lidí, jenž budou nabízet generování „předpřipravení“ a nastavení parametrů pro řešení konkrétních problémů.
Tak už to existuje jako pracovní pozice a říká se tomu “prompt engineering”. Cool. Co jsem tak viděl, tak se rozjíždí docela business ohledně implementace AI do všeho možného. Často dost vaporware, ale třeba ve vyhledávání přes ty embeddingy to působilo dost hustě.
Momentálně asi největší problém všech modelů je jejich izolovanost, omezený kontext a neschopnost se učit. Takže do budoucna:
Postupně budou schopny dělat úplně všechno. To už jsou vesměs teď, akorát je to v plenkách, alignment občas nefunguje a sem tam stojí víc námahy to modelu vysvětlit, než to udělat ručně. Ale zlepšuje se to skokama na úroveň, která mě stále překvapuje, přestože jsem docela informovaný.
A blíží se konec. Ne lidstva, ale blogu. Takže k AGI:
Podle mého názoru tohle přímo povede k AGI, tedy Artificial General Intelligence, AI která je v průměru schopná všeho intelektuálního stejně dobře, nebo líp než člověk (což neznamená že bude pořád dělat všechno líp než všichni ostatní).
Ne že by to bylo úplně na dohled, ale teď je to jen otázka vyzkoušení různých přístupů, zlepšení škálování a tak podobně. Po sto letech kdy nikdo neměl vůbec žádné tušení co jak na to, a vědci se ani nedokázali shodnout na pojmu “inteligence”, je tohle konečně tady. Jen je to zatím stále poněkud hloupé.
Tohle je jako první letadlo. Letí to, hurá. Ale hlavně to ukazuje cestu, a že je to možné, a nejspíš i jak. Teď jde jen o na tom chvíli dělat, starým dobrým iterativním vývojem.
Co mě velmi zaujalo jsou jakési strangeloopy, které lidi s GPT poslední dobou dělají. Krásným příkladem je třeba Auto-GPT: An Autonomous GPT-4 Experiment. Což v podstatě vezme váš request, model se prvně zamyslí jak ho udělat, a pak pomocí různých nástrojů interaguje s webem a diskem a tak podobně, a když je něco moc velké (přesahuje to kontextové okno), tak na to spouští další modely, které instruuje. Během toho si různě ukládá informace na disk, které si pak čte zpátky, aby instruoval sám sebe. Teoreticky je to schopné plnit docela vysokoúrovňové cíle, v praxi je to zatím pořád v plenkách a dost často se to někde ztratí.
Momentálně je to tedy dost nepoužitelné, ale celkově to začíná docela dobře simulovat složitější myšlenkové procesy. Dost mi to připomělo můj starý blogpost Entity, kde jsem popisoval systém, co není inteligentní, ale pronajímá si na vylepšování sebe sama inteligenci od lidí. A tohle v podstatě dokáže podobně delegovat inteligenci, akorát samo na sebe.
V twitter infosféře chcete sledovat Joshu Bacha. A JCorvinus taky docela jede.
Tohle stojí za shlédnutí:

Nekonečné diskuze o morálce a copyrightu a inteligenci a zneužitelnosti a tak podobně jsou podle mého názoru jalový bikeshedding. Lidi to pořád řeší, protože to může řešit každý, ale na výsledku debaty naprosto nezáleží. Neplýtvat na tom čas.
Depresi z toho že AI bude umět všechno líp než vy asi netřeba, už teď existuje na světě někdo, kdo asi umí cokoliv z toho co umíte líp než vy. Pokud berete motivaci jen z tohohle, tak si prostě najděte jinou motivaci. Třeba se zamyslete jak vám to umožní zlepšit svůj potenciál dosahovat cílů které fakt chcete.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 14.4.2023 15:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2023 15:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 14.4.2023 18:27
Člověk z Horní Dolní
| blog: blbeczhornidolni
15.4.2023 18:40
Člověk z Horní Dolní
| blog: blbeczhornidolni
13.4.2023 23:38
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2023 18:27
Člověk z Horní Dolní
| blog: blbeczhornidolni
15.4.2023 18:40
Člověk z Horní Dolní
| blog: blbeczhornidolni
13.4.2023 23:38
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ale různí stackoverflow kopírovači, samouci a absolventi různých 3 měsíčních rychlokurzů se asi třesou strachy.
Drž se zpátky jo? Ten kdo se naučil sám prgat se stejně dobře naučí i cokoliv jiného. O bydlo se klepou hlavně držitelé papíru na titul co jsou zvyklí všechno okecat, ochcat a přehodit na ty co skutečně něco umí, přestože na to žádný papír nemají.
14.4.2023 10:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Já teda nejsem takový optimista. Podle mě je to super na prototyping kódu nebo rychlé rešerše na neznámá témata (např. při příznacích nemocí mimina to je lepší než cokoliv lidi píšou na net). Rychle to nabastlí kód, který většinou funguje a můžu si tak vyzkoušet nové jazyky nebo knihovny. Pro produkční kód je to ale zatím mnohem horší než kombinace stackoverflow + dokumentace. Pro udržování kódu mu stejně musím rozumět, tak se dokumentaci nevyhnu a stackoverflow dělá dost podobné věci jako AI, ale mám tam hned v komentářích připomínky, takže to řešení už je většinou dost dobře zkontrolované lidmi.Jasně že mu musíš rozumět, ale pořád to zvládá napsat ty nudnější a těžké části samo. Třeba s tím boto3 je to často fakt totální nuda, ale neznamená to, že by to bylo lehké. Například, co já vím, potřeboval jsem nějak iterovat přes nějaký seznam EC2, do toho to kombinovat s něčím jiným a filtrovat podle něčeho dalšího. Naprosto nic z toho není těžké co se týče toho co děláš, ale je to těžké tím že AWS je banda dementů co si všechny objekty v boto3 generuje dynamicky za běhu, takže se nemůžeš podívat do zdrojáku a nápověda IDE nefunguje. Dostaneš zpět nějaký objekt, a buď jdi číst dokumentaci a v pěti tabech, protože pracuješ třeba s EC2, S3 a DynamoDB, některé věci (pod-objekty pod-objektů) co podle názvu a popisu v dokumentaci třeba obsahují IP adresy EC2 je neobsahují a tak podobně. Je to taková malá detektivka v interaktivním shellu prvně. GPT4 to nastřelí na první dobrou.
Z use casů co píšeš mi přijde, že body 1-6 jsou právě o prototypingu. Nebo to reálně použiješ tak, že potom ty kódy někam uložíš a plánuješ to dlouhodobě udržovat? Jestli jo, tak by mě hodně zajímalo, co na to řekneš třeba za rok.Já si tím nenechávám generovat celé zdrojáky (což teda taky +- umí, včetně refactoringu a dokumentace), ale spíš menší části.
Mám pocit, že tyhle tooly programátory zatím nemají šanci nahradit. Ale různí stackoverflow kopírovači, samouci a absolventi různých 3 měsíčních rychlokurzů se asi třesou strachy. Super ale je, že to dost zpřístupňuje programování lidem co o tom nemají ani páru. Teď si můžou generovat rozumně použitelné kódy pro svoje použití.Tady jde spíš o ten trend. GPT4 je masivně lepší než trojka, do té míry že máš občas pocit že se fakt bavíš s člověkem. Člověkem, který třeba schopný opravovat vlastní chyby, a formou konverzace většinou dodat co po něm chceš. Jestli bude pětka podobně lepší než čtyřka, tak se blíží konec, protože prostě nikdo nebude platit za programátory, když tohle udělá stejnou práci na pět centů.
14.4.2023 11:17
Člověk z Horní Dolní
| blog: blbeczhornidolni
Jestli bude pětka podobně lepší než čtyřka, tak se blíží konec, protože prostě nikdo nebude platit za programátory, když tohle udělá stejnou práci na pět centů.Stanové kempy v ulicích San Francisca se rozrostou.
14.4.2023 18:38
Člověk z Horní Dolní
| blog: blbeczhornidolni
14.4.2023 18:46
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 14.4.2023 19:54
xxxs | skóre: 25
| blog: vetvicky
16.4.2023 00:48
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2023 19:54
xxxs | skóre: 25
| blog: vetvicky
16.4.2023 00:48
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
což teda taky +- umí, včetně refactoringu a dokumentace)
Tady jde spíš o ten trend. GPT4 je masivně lepší než trojka, do té míry že máš občas pocit že se fakt bavíš s člověkem. Člověkem, který třeba schopný opravovat vlastní chyby, a formou konverzace většinou dodat co po něm chceš. Jestli bude pětka podobně lepší než čtyřka, tak se blíží konec, protože prostě nikdo nebude platit za programátory, když tohle udělá stejnou práci na pět centů.Tohle je podle me past nebo mozna slepa vetev vyvoje. Pokud se dostaneme do faze, ze GPT-X bude generovat funkcni programy, aniz by byli potreba programatori, budou programy existovat pouze ve forme promptu a programovaci jazyky budou plnit ulohu, kterou dnes ma assembler. Problem je, ze jazyky urcene pro komunikaci mezi lidmi maji znacnou miru redundance, spatne se v nich strukturuji informace a moznosti kompozice/dekompozice jsou taky omezene. Proto si taky ruzne discipliny (matematici, inzenyri, stavari) vymysleli vlastni podmnoziny jazyka, ktere aktivne pouzivaji. Sprava programu, ktery bude jako prompt, neni z principu problem, bude to jen sada zmen aplikovanych v case. Neco, co se dnes bezne pouziva v pravnich textech, neco jako. Posledni veta v paragrafu 42 se za carkou rusi a je nahrazena textem "dle paragrafu 43". Uz se na to tesim.
16.4.2023 02:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud se dostaneme do faze, ze GPT-X bude generovat funkcni programy, aniz by byli potreba programatori, budou programy existovat pouze ve forme promptu a programovaci jazyky budou plnit ulohu, kterou dnes ma assembler.Ty programovací jazyky tu úlohu plní už teď (typicky máš někde nějaké zadání, tickety a pak taky dokumentaci, z toho vzniká zdroják). Předpokládáš taky z nějakého důvodu, že to bude podobně jednosměrné jako asm. Například s GPT4 můžeš už teď vést dialog a starý prompt tě vůbec nezajímá. Hodíš zdroják, řekneš "doprogramuj tam X" a on to udělá, protože je schopný ho číst a rozumět mu. Co se týče té praktické stránky použití pro programování, tak to podle mě vnímáš nějak .. jinak. V tomhle ohledu je vhodná abstrakce si to představit jako pracovníka, který udělá co po něm chceš skoro zadarmo a během minuty.
Předpokládáš taky z nějakého důvodu, že to bude podobně jednosměrné jako asmTento predpoklad je prirozenym dusledkem tvrzeni, ze nikdo nebude platit programatory. Jinymi slovy dneska je autoritativnim zdrojem kod a jeho dokumentace. Pokud zacne prevazovat generovani kodu pomoci AI, nebudou existovat programatori, kteri by tem nizsim jazykum rozumeli, a tak se autoritativnim zdrojem popisujicim, co program ma delat a proc, stanou tickety, resp. prompty pro AI.
Co se týče té praktické stránky použití pro programování, tak to podle mě vnímáš nějak .. jinak.Tuhle stranku chapu, ale snazim se dohlednout dusledku.
V tomhle ohledu je vhodná abstrakce si to představit jako pracovníka, který udělá co po něm chceš skoro zadarmo a během minuty.Tento pristup chapu, ta myslenka je strasne lakava, ale mam s ni dva problemy. (1) Opravdu bude prospesne neco, co bude na povel generovat kod? Vysledkem budou tuny radku nizkourovnoveho kodu, ve kterych se vyzna prave jen AI, protoze programatori ztrati potrebu hledat a vytvaret abstrakce, aby se kod zjednodusil. Proc taky, kdyz upravy zajisti AI? Nekdy [cti: casto] je mene kodu vice. (2) Jak jsem psal vyse, tato abstrakce (v podobe lidskeho jazyka) je spatna, protoze redundance, spatna komponovatelnost, ... Srovnej s makry v rozumnem makro jazyce [cti: dialekt LISPu], ty resi stejny problem (generovani kodu), ale netrpi temito neduhy.
Jinymi slovy dneska je autoritativnim zdrojem kod a jeho dokumentace. Pokud zacne prevazovat generovani kodu pomoci AI, nebudou existovat programatori, kteri by tem nizsim jazykum rozumeli, a tak se autoritativnim zdrojem popisujicim, co program ma delat a proc, stanou tickety, resp. prompty pro AI.To uz se prece stalo. Neni to tak davno, co autoritativnim zdrojem bylo schema zapojeni tranzistoru nebo, pozdeji, krabice dernych stitku. Pak prisel Fortran, BASIC, C, Python a programatori uz jen pisou prompty v IDE bez porozumeni nizsim urovnim.
Opravdu bude prospesne neco, co bude na povel generovat kod? Vysledkem budou tuny radku nizkourovnoveho kodu, ve kterych se vyzna prave jen AI, protoze programatori ztrati potrebu hledat a vytvaret abstrakce, aby se kod zjednodusil.Vadi to? Pri beznem pouziti ne, a lidi co nizkourovnove porozumeni maji, si ho nechaji kralovsky zaplatit.
To uz se prece stalo. Neni to tak davno, co autoritativnim zdrojem bylo schema zapojeni tranzistoru nebo, pozdeji, krabice dernych stitku. Pak prisel Fortran, BASIC, C, Python a programatori uz jen pisou prompty v IDE bez porozumeni nizsim urovnim.Mozna by diskuzi prospelo, kdybys ji cetl celou a nevytrhaval vety z kontextu. Bystroushaak psal:
Předpokládáš taky z nějakého důvodu, že to bude podobně jednosměrné jako asm.Takze jsem mu vysvetloval ten predpoklad. Ale mas pravdu, z kodu v assembleru uz nikdy nedostanes puvodni kod ve fortranu, stejne jako z kodu nedostanes puvodni prompty pro IDE. Mimochodem, vsimni si, ze s rostouci urovni abstrakce je vyjadrovani strukturovanejsi (a omezenejsi). Ze by pro to byl nejaky duvod? Ze by to bylo vhodnejsi, pro snazsi uchopeni programu? Log promptu je tedy IMHO krok zpet.
Vadi to?Vadi. Jak se ti v programech libi desitky, stovky, tisice radku vytvorenych metodou copy-paste? AI to posune o uroven vys.
Pri beznem pouziti ne, a lidi co nizkourovnove porozumeni maji, si ho nechaji kralovsky zaplatit.Co je podle tebe bezne pouziti? Ono je to vlastne jedno, od urciteho velikosti to proste zacne byt neuchopitelne, at uz clovek nizkourovnovemu programovani bude rozumet nebo ne.
Ale mas pravdu, z kodu v assembleru uz nikdy nedostanes puvodni kod ve fortranu, stejne jako z kodu nedostanes puvodni prompty pro IDE.Pochopitelne. A historicky se ukazalo, ze kompilace nicemu nevadi.
Jak se ti v programech libi desitky, stovky, tisice radku vytvorenych metodou copy-paste? AI to posune o uroven vys.Podivej se treba na moderni web. HTML/DOM uz skoro nikdo nepise, vsechno je to generovane z PHP (a puvodni kod prohlizec nedostane) a nebo hur, dynamicky triggerama z JS. AI je jen takovy generator kodu na zaklade nejakych obecnych triggeru.
od urciteho velikosti to proste zacne byt neuchopitelne, at uz clovek nizkourovnovemu programovani bude rozumet nebo neZaroven se zvysujici se abstrakci se zlepsuji i debuggery a ostatni nastroje. Ale uznavam ze cim vyssi abstrakce, tim min lidi ji umi efektivne pochopit a vyuzit.
Pochopitelne. A historicky se ukazalo, ze kompilace nicemu nevadi.Hele, ctes vubec ty prispevky, nebo reagujes na nahodne vyseky textu? Vysvetloval jsem pouze predpoklad. Nikde nepisu, ze je to spatne.
Podivej se treba na moderni web. HTML/DOM uz skoro nikdo nepise, vsechno je to generovane z PHP (a puvodni kod prohlizec nedostane) a nebo hur, dynamicky triggerama z JS. AI je jen takovy generator kodu na zaklade nejakych obecnych triggeru.To kulha na obe nohy. Neni problem vygenerovat na zaklade vstupu konkretni HTML stranku. Problem je, kdyz budes vytvaret webove stranky stylem copy paste s pomoci AI:
AI vytvor uvodni webovou stranku, nahoru dej nase logo, doprostred nejaky text o firme. [AI vytvori podle zadani stranku "index.html". V zasade OK.] AI pridej na web stranku s kontakty, ktera budu vypadat jak uvodni stranka. [AI udela copy-paste stranky a ulozi ji jako "contact.html" Mensi problem.] AI v souboru "produkty.xls" je seznam produktu, vytvor pro kazdy produkt webovou stranku, pouzij jako vzor uvodni stranku. [AI udela copy-paste staticke stranky "product12345.html" pro nekolik tisic produktu. Problem jak brno, jen o tom nikdo nevi, dokud nebude potreba cokoliv zmenit.]Proc AI nevytvorilo abstrakce? Protoze mu to nikdo nerekl. A proc mu to nikdo nerekl? Protoze nikdo nevidel problem, ktery tam tise hnije.
Ale uznavam ze cim vyssi abstrakce, tim min lidi ji umi efektivne pochopit a vyuzit.Moje teze je presne opacna. Pokud AI bude generovat velke mnozstvi nizkourovneveho kodu, nebude mozne ho kvuli jeho velkemu objemu uchopit.
Vadi. Jak se ti v programech libi desitky, stovky, tisice radku vytvorenych metodou copy-paste? AI to posune o uroven vys.Proč si to myslíš? Proč by to nemohla naopak zlepšovat? Už teď má určitou - IMO poměrně působivou - schopnost refaktorovat (a to furt používám jen relativně hloupé ChatGPT). Viz příložený příklad. Ty první dvě odpovědi nejsou úplně validní kód, ten poslední ano (byť je tam jedna zbytečná konverze). Vydoloval jsem to teď trochu náhodně, tak to není nic světoborného.
Proč si to myslíš? Proč by to nemohla naopak zlepšovat? Už teď má určitou - IMO poměrně působivou - schopnost refaktorovat (a to furt používám jen relativně hloupé ChatGPT).Protoze ten problem neni technicky a neni to ani problem ChatGPT, ale jejiho pouziti. Uz jsem to tu psal, pro jistotu zvyraznim tucne.
(1) Opravdu bude prospesne neco, co bude na povel generovat kod? Vysledkem budou tuny radku nizkourovnoveho kodu, ve kterych se vyzna prave jen AI, protoze programatori ztrati potrebu hledat a vytvaret abstrakce, aby se kod zjednodusil. Proc taky, kdyz upravy zajisti AI?Dodam, ze neresim generovani par radkovych funkci, ale generovani podstatnejsich casti kodu. A hypotezu, ze programatori diky ChatGPT budou v buducnou moci lepe kod refaktorovat, bych asi rovnou skrtnul. Jelikoz se v pritomnosti programuje stylem: vezmeme prohlizec, ktery v sobe naakumuloval 30 let vyvoje software, pribalime k tomu webovy server, dukladne promichame se vsim, co najdeme pres npm, a udelame z toho aplikaci zobrazujici svatky v tydnu, moc velke iluze o budoucnosti, kde bude umela inteligence generovat kod na pozadani, si nedelam. Protoze (temer) nikoho, co se deje s vystupem promptu, nebude zajimat, jako dneska ,,nikoho'' nezajima, co se deje pod poklickou electronovych aplikaci.
Dodam, ze neresim generovani par radkovych funkci, ale generovani podstatnejsich casti kodu.No a? Proč by AI nemohla refaktorovat "podstatnější části kódu"? Ze stejného důvodu, z jakého před 5, 10 lety nemohla refaktorovat menší části kódu, to nebude... Nevim, jestli chápu, jakou pointu vlastně píšeš, asi ne, ale za mě dvě nejdůležitější ponaučení z nedávného vývoje jsou (resp. spíš jsou to spíš dvě strany jednoho ponaučení):
Jelikoz se v pritomnosti programuje stylem: vezmeme prohlizec, ktery v sobe naakumuloval 30 let vyvoje software, pribalime k tomu webovy server, dukladne promichame se vsim, co najdeme pres npm, a udelame z toho aplikaci zobrazujici svatky v tydnu, moc velke iluze o budoucnosti, kde bude umela inteligence generovat kod na pozadani, si nedelam. Protoze (temer) nikoho, co se deje s vystupem promptu, nebude zajimat, jako dneska ,,nikoho'' nezajima, co se deje pod poklickou electronovych aplikaci.Tohle mně přijde hrozně Old man yells at cloud (čimž nechci naznačit, že jsi starý
 , pouze styl komentáře)... Opravdu je elektronová appka na svátky v týdnu o tolik horší než Podniková® Aplikace™ v Javě z roku 2002, která nažhaví JVM a vykreslí příšerně vypadající, na CPU/RAM žravé a uživatelsky hostilní UI ve Swingu jenom pro to, aby provedla pár jednoduchých SQL dotazů?
, pouze styl komentáře)... Opravdu je elektronová appka na svátky v týdnu o tolik horší než Podniková® Aplikace™ v Javě z roku 2002, která nažhaví JVM a vykreslí příšerně vypadající, na CPU/RAM žravé a uživatelsky hostilní UI ve Swingu jenom pro to, aby provedla pár jednoduchých SQL dotazů?
Nevim, jestli chápu, jakou pointu vlastně píšeš, asi neNapsal jsem to hned 2x a dokonce ty podstatne pasaze zvyraznil tucne, ale zkusim to jeste jednou.
Protoze ten problem neni technicky a neni to ani problem ChatGPT, ale jejiho pouziti.
(1) Opravdu bude prospesne neco, co bude na povel generovat kod? Vysledkem budou tuny radku nizkourovnoveho kodu, ve kterych se vyzna prave jen AI, protoze programatori ztrati potrebu hledat a vytvaret abstrakce, aby se kod zjednodusil. Proc taky, kdyz upravy zajisti AI?Viz muj priklad s generovanim webovych stranek. A ted si predstav, ze takto nekdo udela cely informacni system. Mimochodem, takto udelany informacni system jsem uz potkal. Byla to aplikace vytvorena v MS Access, ktera mela 250+ temer podobnych formularu, kazdy formular jedna tabulka. Protoze to delal samouk, tak ho ani nenapadlo, ze by to slo udelat lip. Myslis, ze by takovy samouk dal povel AI, aby to zrefaktorovala?
Tohle mně přijde hrozně Old man yells at cloud (čimž nechci naznačit, že jsi starýNevim, jestli mam cas a chut poustet se do diskuze na toto tema. Ze elektronove appky jsou nenazrane jako treba java aplikace pred dvaceti lety, to pro me je spise druhotne. Jde mi spise o pristup k vyvoji, kdy programatori lepi k sobe veci, jak se jim to zrovna hodi, a ani netusi, ze by neco mohli delat jinak a lip. Jen tak na okraj: Tobe architektura electronovych aplikaci prijde v poradku?
17.4.2023 22:48
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A ted si predstav, ze takto nekdo udela cely informacni system. Mimochodem, takto udelany informacni system jsem uz potkal. Byla to aplikace vytvorena v MS Access, ktera mela 250+ temer podobnych formularu, kazdy formular jedna tabulka. Protoze to delal samouk, tak ho ani nenapadlo, ze by to slo udelat lip. Myslis, ze by takovy samouk dal povel AI, aby to zrefaktorovala?Mno, ale to může udělat kdokoliv kdo k tomu přijde, ne? I kdyby to byl kód ve kterém se vyzná jen AI, tak jí můžeš už teď říct "přepiš to do lidsky čitelného plně ekvivalentního kódu". Pokud mu nerozumíš, tak prvně musíš dát query "nauč mě programovat", nebo pokud se tu máme bavit o nějakém sci-fi, tak "vyrob mi aplikaci, která mi umožní ten kód chápat a upravovat", či "natrénuj neuronovou síť kompatibilní s mojím stavovým vektorem a pak to mountni do mého mozku tak abych to rovnou chápal přes tu translační neuronku".
Pokud se tu máme bavit o nějakém sci-fi.Tak muzeme klidne predpokladat, ze umela inteligence bude schopna zastavit vsechny valky a zjednodusit formular danoveho priznani.
Napsal jsem to hned 2x a dokonce ty podstatne pasaze zvyraznil tucne, ale zkusim to jeste jednou. (...) programatori ztrati potrebu hledat a vytvaret abstrakce, aby se kod zjednodusil. Proc taky, kdyz upravy zajisti AI? (...) Viz muj priklad s generovanim webovych stranek.Obávám se, že tu pointu stále nevidim. U toho příkladu s generováním stránek jsem vůbec nepochopil, kde tam je ten obrovský problém. Ten web už pak z nějakýho důvodu nepůjde přegenerovat nebo něco? (Nedochází mi proč by to nešlo.)
Jde mi spise o pristup k vyvoji, kdy programatori lepi k sobe veci, jak se jim to zrovna hodi, a ani netusi, ze by neco mohli delat jinak a lip. (...) Jen tak na okraj: Tobe architektura electronovych aplikaci prijde v poradku?To je podobná diskuse jako o nových vs. starých programovaích jazycích, jazykové balíčkovače atd. Obecně v těchto diskusích mam z lidí dojem, že si dřívější stav silně idealizují. Co znamená "jinak a líp"? Místo lepení JS v Electronu napíše ten člověk UB špagety v C++/Qt, a uživatelé pak budou hrát hru pojmenuj si svůj segfault? Ad Electron, no tak to má poněkud ošklivou architekturu, a? Je třeba GObject nějaká krása? Kdybych teď začínal psát nějakou ne úplně triviální desktop aplikaci, o Electronu bych velmi vážně uvažoval. Za mě hlavní výhoda je ten layouting a možnosti HTML a CSS, který jsou sice oboje dost hnusný technologie, ale ty schopnosti to má mnohem šiřší než 'tradiční' toolkity. Komponenty se dají mnohem víc "stavět z Lega", oproti tomu 'tradičnímu' řešení, kde máš sadu prefabrikovaných komponent a když chceš vlastní komponenty nebo nějaké customizace, tak je to většinou na škale od opruz po Neřešitelný problém, hoši. Plus mají tendence v různých corner casech v různých detailech nefungovat. Obvykle jsou to fakt detaily, jakože třeba nějakej konkrétní event nefunguje v nějaké velmi specifické situaci, ale to je bohužel nahouby, pokud přesně tu danou věc právě potřebuju...
Co znamená "jinak a líp"? Místo lepení JS v Electronu napíše ten člověk UB špagety v C++/Qt, a uživatelé pak budou hrát hru pojmenuj si svůj segfault?Tomu se rika falesna dichotomie a opravdu nevim, jestli ma cenu pokracovat timto stylem dal. Co treba udelat nejaky deklarativni jazyk, ktery bude urceny k layoutu komponent? A k tomu runtime (idealne) s (obecnymi) bindingy do vysokourovnoveho jazyka (klidne JS, at nezeru)? Proc se musi na layout pouzit neco, co je primarne urcene pro praci s textem, jako je prohlizec? Nebylo by lepsi treba vykuchat InDesign nebo Inkscape?
Ad Electron, no tak to má poněkud ošklivou architekturu, a? Je třeba GObject nějaká krása?To je diskuze, jak se slovenskou ucitelkou. A: Tobe se libi, co delaji rusove na ukrajine? B: Americani bombardovali juhoslaviu, aj chmelar to povedal... A: Tobe se libi Electron? B: GObject je hnusny, aj chmelar to povedal...
prefabrikovaných komponent a když chceš vlastní komponenty nebo nějaké customizace, tak je to většinou na škale od opruz po Neřešitelný problém, hoši.Nevim, o cem mluvis, ja si delal vlastni komponenty jako spravny boomer uz v devadesatkach a nikdy s tim nebyl problem (a moc casto to nebylo ani potreba). A treba vysvetlit, jak se udela nova komponenta v Jave (Swing) je tak na pul hodku, hodku max.
Tomu se rika falesna dichotomie a opravdu nevim, jestli ma cenu pokracovat timto stylem dal.Nebylo to tak zamýšleno, já jsem opravdu nevěděl, jaké alternativy máš na mysli.
Co treba udelat nejaky deklarativni jazyk, ktery bude urceny k layoutu komponent? A k tomu runtime (idealne) s (obecnymi) bindingy do vysokourovnoveho jazyka (klidne JS, at nezeru)?V pořádku, tak to třeba udělej :) Zní to trochu jako QML/QtQuick a to ve výsledku moc nemělo úspěch... Ono se to totiž snadno řekne, ale udělat to dobře je docela hodně náročné.
Proc se musi na layout pouzit neco, co je primarne urcene pro praci s textem, jako je prohlizec?Prohlížeč už dávno není určen pouze/primárně pro práci s textem.
Nebylo by lepsi treba vykuchat InDesign nebo Inkscape?InDesign neznám. Inkscape a SVG jsou poměrně velmi omezené. Konkrétně layouting skoro neumí, všechno musí být napozicované ručně. Ta věc neumí udělat ani tak obyčejné úkony jako tabulku nebo zalomení textu, o nějakých featurách jako různé gridy už vůbec nemluvě, nedejbože responsivní (viz třeba co umí flex).
Nevim, o cem mluvis, ja si delal vlastni komponenty jako spravny boomer uz v devadesatkach a nikdy s tim nebyl problem (a moc casto to nebylo ani potreba). A treba vysvetlit, jak se udela nova komponenta v Jave (Swing) je tak na pul hodku, hodku max.Ano, já jsem je dělal taky, a ano, šlo to, ale efektivně děláš malý ad-hoc layouting engine. Buď můžeš použít předpřipravené komponenty (a nějaké jejich kompozice), nebo tumáš canvas a počítej si souřadnice. Není tam nic mezi tím, nic jako ten obecněj box-model, kterej je v HTML/CSS, ze kterýho se dá stavět hodně velmi různých komponent a kde layouting už je dost vyřešenej...
V pořádku, tak to třeba udělej :)Nemam potrebu spasit svet, ale az budu neco takoveho potrebovat, mozna si to opravdu naprogramuju.
Zní to trochu jako QML/QtQuick a to ve výsledku moc nemělo úspěch...Ano. Ale prosazeni Electronu na ukor QML bych neprikladal technickemu provedeni, ale tomu, ze to prijala komunita, ktera proste nektere veci neresi a je nadsena z toho, ze to proste nejak funguje.
InDesign neznám. Inkscape a SVG jsou poměrně velmi omezené. Konkrétně layouting skoro neumí, všechno musí být napozicované ručně.Nevadi.
Prohlížeč už dávno není určen pouze/primárně pro práci s textem.No, prave. Ale tech 30 let vyvoje si tahne sebou. Prohlizece se dostaly do stavu, kdy se jedna o jeden z nejkomplexnejsi softwarovych celku vubec. Proto mame vseho vsudy dve nezavisle implementace odpovidajici dnesnim standardum. To uz i operacnich systemu, databazovych systemu, nebo kancelarskych baliku mame vic. Beru, ze prohlizec de facto plni ulohu OS, ale prave proto mi neprijde stastne, aby si kazda aplikace nesla svou vlastni implementaci OS sebou.
Buď můžeš použít předpřipravené komponenty (a nějaké jejich kompozice), nebo tumáš canvas a počítej si souřadnice. Není tam nic mezi tím, nic jako ten obecněj box-model, kterej je v HTML/CSS, ze kterýho se dá stavět hodně velmi různých komponent a kde layouting už je dost vyřešenej...Desktopove aplikaci nejsou to, co by me ted zivilo, ale nejak si nedokazu predstavit, co je prakticky potreba a umi to HTML/CSS, ale treba takove hostilni UI, jako je swing, to nezvladne.
nedejbože responsivní (viz třeba co umí flex).Mimochodem responzivni design Java umela dlouho predtim, nez se Chromium jmenovalo KHTML.
Ano. Ale prosazeni Electronu na ukor QML bych neprikladal technickemu provedeni, ale tomu, ze to prijala komunita, ktera proste nektere veci neresi a je nadsena z toho, ze to proste nejak funguje.Já jsem měl původně dost negativní názor na Electron, ale postupně jsem to do nějaké míry přehodnotil. Ano, byl/je to hype, ale IMO důvody za tím jsou spíše technické. Například co se týče toho QML, realisticky, QML aplikace bude vždy potřebovat C++ základ - moc nemůžeš udělat to co v Electronu, že bys veškerou logiku naskriptoval, napsal v tom komplet aplikaci (pokud vím). Když tedy existují dvě možnost, přičemž v jedné je potřeba naučit se komplet tvorbu C++ projektu a v druhé ne, je asi celkem predikovatelné, že ta druhá bude populárnější. Možná bychom mohli prohlásit, že to je špatně, že by se radši lidi to C++ (nebo nějaký jiný jazyk lepší než JS) naučit měli. Před nějakými roky bych asi tohle prosazoval, mezitím jsem měl tu čest spatřit určité množství desktop C++ kódu napsaného nekompetentními programátory. (A také mezitim vznikly věci jako TypeScript.)
No, prave. Ale tech 30 let vyvoje si tahne sebou. Prohlizece se dostaly do stavu, kdy se jedna o jeden z nejkomplexnejsi softwarovych celku vubec.Ano. Na druhou stranu ale těch 30 let vývoje znamená, že to je poměrně velmi hodně odladěné a rychlé, resp. má to celkem dobrou rovnováhu flexibilita : výkon. U aplikace zobrazující svátky v kalendáři by mi ta komplexita vadila, to je kanón na vrabce (a proto takové aplikacé nepoužívám). U něčeho jako třeba IDE mi to nevadí, kór když je ve výsledku nakonec i podobně rychlé, případně i rychlejší než jiná IDE.
Desktopove aplikaci nejsou to, co by me ted zivilo, ale nejak si nedokazu predstavit, co je prakticky potreba a umi to HTML/CSS, ale treba takove hostilni UI, jako je swing, to nezvladne.Nejde o to, že by něco nezvládal - vykreslovat můžeš jakékoli pixely, a tudíž můžeš principielně naimplementovat jakékoli UI. Jde o to jak. Podívejmež se na první příklad custom komponenty, který jsem vygoogloval. Funkce
paintComponent() (a draw3DCircle()) je to, co jsem myslel tím "malý ad-hoc layouting engine". Dělat změny v takovém kódu nebo ho rošiřovat o nějaké další featury je humus. V HTML/CSS si nadefinuješ boxík, v něm kolečko, 3D efekt uděláš nějakými cca dvěma box-shadow deklaracemi nebo jak se to jmenuje a rotaci uděláš pomocí transform: rotate(parametr) [1] a nazdar. A výsledek je více měnitelný/rozšiřitelný/udržovatelný, protože to je stavebnice parametrizovatelných prvků, ne kus random imperativního kódu počítajícího pixely...
Když tedy existují dvě možnost, přičemž v jedné je potřeba naučit se komplet tvorbu C++ projektu a v druhé ne, je asi celkem predikovatelné, že ta druhá bude populárnější. Možná bychom mohli prohlásit, že to je špatně, že by se radši lidi to C++ (nebo nějaký jiný jazyk lepší než JS) naučit měli. Před nějakými roky bych asi tohle prosazoval, mezitím jsem měl tu čest spatřit určité množství desktop C++ kódu napsaného nekompetentními programátory. (A také mezitim vznikly věci jako TypeScript.)Porad tady jedes tu linku dichotomie, C++ vs. Electron. Jednak Qt neni nezbytne svazane s C++, muzes pouzit libovolny jazyk, co ma bindingy. Za druhe nemusis se omezovat na Qt. To reseni by nemuselo byt ani nijak komplikovane. Napises si parser/builder, ktery vezme kod v QML (nebo v necem podobnem) a sestavi z toho strom Qt-objektu (nebo objektu z toolkitu dle vlastni preference). Podobne jako HTML parser sestavuje DOM. Nadefinujes, aby udalosti byly smerovany do hostitelskeho jazyka nebo jeste lip nejakeho obecneho runtimu, at muzes pouzit vice jazyku podle potreby, a mas hotovo. Kdyz ten parser/builder zpristupnis tomu jazyku (coz v principu neni problem), tak muzes programovat/vytvaret komponenty stejne jako v JS a prohlizeci.
Funkce paintComponent() (a draw3DCircle()) je to, co jsem myslel tím "malý ad-hoc layouting engine".Aha, tak to jsem si pod tim opravdu nepredstavoval. Jinak v zasade kritizujes, ze pri vykreslovani se pouziva nizkourovnove rozhrani, pricemz ti nic nebrani si nad tim postavit nejakou lepsi abstrakci. Treba ten objekt v Jave, ktery se pouziva pro kresleni, tu funcionalitu ma, staci si to obalit do odpovidajicich abstrakci. Prace na jeden zimni vecer.
Porad tady jedes tu linku dichotomie, C++ vs. Electron. (...) Za druhe nemusis se omezovat na Qt.Njn protože nevim moc o nějakých lepších alternativách. Snad JavaFX?
Jednak Qt neni nezbytne svazane s C++, muzes pouzit libovolny jazyk, co ma bindingy.To sice ano, ale architektonicky to pak dopadne podobně jako ten Electron, akorát místo Node.js budeš mít třeba Python a místo Chromu QML engine (který taky obsahuje V8)...
To reseni by nemuselo byt ani nijak komplikovane. Napises si parser/builder, ktery vezme kod v QML (nebo v necem podobnem) a sestavi z toho strom Qt-objektu (nebo objektu z toolkitu dle vlastni preference). Podobne jako HTML parser sestavuje DOM. Nadefinujes, aby udalosti byly smerovany do hostitelskeho jazyka (...)WTF. Uf. Ok. Pro začátek se zamysli, na jaký Qt-objekt namapuješ QML kód
Rectangle {
radius: 10
transform: Rotation { origin.x: 30; origin.y: 30; axis { x: 0; y: 1; z: 0 } angle: 36 }
}Aha, tak to jsem si pod tim opravdu nepredstavoval. Jinak v zasade kritizujes, ze pri vykreslovani se pouziva nizkourovnove rozhrani, pricemz ti nic nebrani si nad tim postavit nejakou lepsi abstrakci.No ne, kritizoval jsem nutnost psát si ad-hoc rendering/layouting engine. Což se nevyřeší tím, že ho napíšeš o něco větší.
21.4.2023 14:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
16.4.2023 14:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tento predpoklad je prirozenym dusledkem tvrzeni, ze nikdo nebude platit programatory. Jinymi slovy dneska je autoritativnim zdrojem kod a jeho dokumentace. Pokud zacne prevazovat generovani kodu pomoci AI, nebudou existovat programatori, kteri by tem nizsim jazykum rozumeli, a tak se autoritativnim zdrojem popisujicim, co program ma delat a proc, stanou tickety, resp. prompty pro AI.A to jako všichni ti java, python, C, rust, javascript, .. programátoři zmizí ze dne na den? Bude probíhat nějaké prolínání obojího, a nakonec to vykristalizuje v něco co funguje. Jak to ale bude vypadat, to teď nejde říct, a řešit na základě současné představy nějaké obavy o kvalitu kódu imho nemá úplně smysl.
Tento pristup chapu, ta myslenka je strasne lakava, ale mam s ni dva problemy. (1) Opravdu bude prospesne neco, co bude na povel generovat kod? Vysledkem budou tuny radku nizkourovnoveho kodu, ve kterych se vyzna prave jen AI, protoze programatori ztrati potrebu hledat a vytvaret abstrakce, aby se kod zjednodusil. Proc taky, kdyz upravy zajisti AI? Nekdy [cti: casto] je mene kodu vice. (2) Jak jsem psal vyse, tato abstrakce (v podobe lidskeho jazyka) je spatna, protoze redundance, spatna komponovatelnost, ... Srovnej s makry v rozumnem makro jazyce [cti: dialekt LISPu], ty resi stejny problem (generovani kodu), ale netrpi temito neduhy.Idk, je těžké dělat predikce takhle dlouho do budoucnosti, skoro každá predikce zfailuje nějak.
Opravdu bude prospesne neco, co bude na povel generovat kod? Vysledkem budou tuny radku nizkourovnoveho kodu, ve kterych se vyzna prave jen AI, protoze programatori ztrati potrebu hledat a vytvaret abstrakce, aby se kod zjednodusil. Proc taky, kdyz upravy zajisti AI? Nekdy [cti: casto] je mene kodu vice.Tohle je otázka. Trochu mi to připomíná situaci v blenderu, kde když to začínalo, tak ten software byl strašně lowlevel, člověk tam nějak dělal s vertexy, a v podstatě konstruoval model ručně. Dneska je to přitom antipattern, kde blender používáš na vytváření věcí co nejvyšší úrovní a například děláš sculpting a vertexy tě moc nezajímají. Když vnímáš vertexy jako příkazy programovacího jazyka, tak se tahle abstrakce dá vztáhnout i na programování. V podstatě budeš nějak tvarovat výsledek a implementace pro tebe nebude moc podstatná. Kdysi jsem o téhle myšlence začal psát blog, ale nějak se mi nikdy nepovedlo ho dopsat.
A to jako všichni ti java, python, C, rust, javascript, .. programátoři zmizí ze dne na den? Bude probíhat nějaké prolínání obojího, a nakonec to vykristalizuje v něco co funguje. Jak to ale bude vypadat, to teď nejde říct, a řešit na základě současné představy nějaké obavy o kvalitu kódu imho nemá úplně smysl.Vychazel jsem z predpokladu, ze nikdo nebude platit programatory. A ten predpoklad je tvuj:.
Jestli bude pětka podobně lepší než čtyřka, tak se blíží konec, protože prostě nikdo nebude platit za programátory, když tohle udělá stejnou práci na pět centů.
Dneska je to přitom antipattern, kde blender používáš na vytváření věcí co nejvyšší úrovní a například děláš sculpting a vertexy tě moc nezajímají.Ja nemam absolutne nic proti zavadeni vyssich a snadneji pouzitelnych urovnim abstrakce. Vlastne si dokonce myslim, ze dnesni programatori casto vytvareji velmi male a slabe abstrakce, protoze je jazyky a vyvojova prostredi k tomu prilis nemotivuji. Blender nepouzivam, ale kdyz se divam na to, co to ten sculpting je, tak ta analogie k programovani castecne sedi a castecne nesedi, jak uz to s analogiemi byva. V pripade ,,formovani'' 3D objektu jsou drobne chyby nedotazene edge-cases tolerovatelne, v pripade programovani je to vec, ktere se chces pokud mozno vyhnout. Druha vec je kvalita te abstrakce, kde neresis jen, jestli pomoci nich dasahnes vysledku, ale zda jdou skladat (compose), aplikovat opakovane. A tady tu podobnost do jiste miry vidim. Kdyz jednou udelas stetcem sculpting na psa, tak se to blbe aplikuje na model kocky, mysi, slona. Podobnymi neduhy trpi i slovni popisy.
16.4.2023 16:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Vychazel jsem z predpokladu, ze nikdo nebude platit programatory.Jo, ale to neznamená že ta profese zmizí bez náhrady. Je to něco jako kdybys sedlákovi z 15 století řekl, že jeho práce skončí. To neznamená že skončí zemědělství, jen že prostě nebude orat volským pluhem. Myslím že časem to dospěje k něčemu podobnému, nikdo nebude platit za to že ručně píšeš kód, což je tak trochu jako sázet pole ručně a obracet v ruce každé semínko, ale za implementaci věcí. Ta potřeba stavět složité technické systémy nikam nezmizí. Otázkou teda je jak rychle se AI dostane do bodu, kde kolem toho vůbec nebude potřebovat ten lidský interface a založí si vlastní korporaci. Moje intuice mi ale říká že lidi se kolem té potřeby budou pořád tak nějak motat (což nemusí být jak se to vyvrbí, no). Ten OpenAI přístup je lehce děsivý, ale zase na druhou stranu tahle myšlenka "demokratizace" AI je docela sympatická (opak je asi víc extrémní). V praxi to ovšem znamená, že pokud ta AI dosáhne nějaké funkcionality, tak k ní bude mít okamžitě přístup celý svět. Když to třeba bude umět (už +- umí, ale předpokládejme že ne a PDF ti to pořád nepřeloží) překládat dokumenty líp než 98% lidských překladatelů, tak tohle odvětví najednou skončí plošně všude.
Blender nepouzivam, ale kdyz se divam na to, co to ten sculpting je, tak ta analogie k programovani castecne sedi a castecne nesedi, jak uz to s analogiemi byva. V pripade ,,formovani'' 3D objektu jsou drobne chyby nedotazene edge-cases tolerovatelne, v pripade programovani je to vec, ktere se chces pokud mozno vyhnout.Jo, to máš pravdu, ale ekvivalent by byl že ty děláš ty highlevel "sculpting" operace a AI dotahuje detaily. Co mě kdysi hodně zaujalo je parametrické modelování. Dost jsem přemýšlel jak by se to dalo vztáhnout na IDE. Má to dost paralel s funkcionálním programováním a makry.
Druha vec je kvalita te abstrakce, kde neresis jen, jestli pomoci nich dasahnes vysledku, ale zda jdou skladat (compose), aplikovat opakovane. A tady tu podobnost do jiste miry vidim. Kdyz jednou udelas stetcem sculpting na psa, tak se to blbe aplikuje na model kocky, mysi, slona. Podobnymi neduhy trpi i slovni popisy.Jo.
Jo, to máš pravdu, ale ekvivalent by byl že ty děláš ty highlevel "sculpting" operace a AI dotahuje detaily. Co mě kdysi hodně zaujalo je parametrické modelování. Dost jsem přemýšlel jak by se to dalo vztáhnout na IDE. Má to dost paralel s funkcionálním programováním a makry.Popustim uzdu fantazii a taky si trochu zaspekujulu: "Sculpting" by se mohl dělat na nějaké více-vrstvé reprezentaci software, kde bys měl možnost se na to dívat s různým "zoomem" a existoval by nějaký feedback mezi vrstvami kódu, fungující na bázi pokročilé statické analýzy v kombinaci s refactoring schopnostmi AI.
V pripade ,,formovani'' 3D objektu jsou drobne chyby nedotazene edge-cases tolerovatelne, v pripade programovani je to vec, ktere se chces pokud mozno vyhnout.Uvažuješ možnost napojení statické analýzy, linterů a testů jako feedbacku do AI?* Vrátil jsem se k příkladu ze včera v tom bodě, kde udělal typovou chybu v druhu reference, a prostě jsem tam nakopíroval chybový výstup z kompilátoru. Opravil to. Výsledek není supr efektivní, ale je funkční. *) Pssst. Tohle dělaj lidský programátoři taky, aby se vyhnuli edge-cases, ale nikomu jinýmu to neprozrazujte...
14.4.2023 02:28
Člověk z Horní Dolní
| blog: blbeczhornidolni
14.4.2023 03:20
Člověk z Horní Dolní
| blog: blbeczhornidolni
Depresi z toho že AI bude umět všechno líp než vy asi netřeba, už teď existuje na světě někdo, kdo asi umí cokoliv z toho co umíte líp než vy.Ja ji mam spis z toho, ze to muze nahradit programatory (a / nebo zlevnit jejich praci) a do financni nezavislosti mi bohuzel zbyva tak 10 let, i kdyz by to asi slo urychlit kdybych se snazil maximalizovat prijmy, o coz se asi pokusim. Tzn. najednou prislo neco, kvuli cemu je moje budoucnost jak jsem si ji predstavoval nejista. Samozrejme dokazu najit argumenty, ze to v dohledne dobe nehrozi nebo dokonce ze to povede k rustu ceny moji prace. Ale realita je, ze ten negativni scenar klidne muze nastat. Pritom za normalnich okolnosti bych byl nadseny z toho ze muzu sledovat vyvoj neceho tak prevratneho a snit o vsech moznostech, kterym to otevira dvere. Jinak vzpomnel jsem si mimochodem na jednu uvahu, driv jsem ji tu psal. Moderni clovek tu je asi 300k let, za normalnich okolnosti se da ocekavat, ze tu budem dalsich alespon par milionu let. Takze obdobi lidi muze trvat treba 10 milionu let. Pak je dost neuveritelna nahoda, ze zijem zrovna ve velmi kratkem obdobi nejrychlejsiho pokroku - prumyslova revoluce, mikrocipy, dost mozna AGI a "dovynalezeni" toho co zbyva - to je asi 200 let, coz je 0,002% z obdobi lidstva. Statisticky to je skoro nemozne, tudiz nektery z predpokladu je chybny. Pozitivni vysvetleni je, ze dosahnem nesmrtelnosti, negativni ze lidstvo vyhyne.
 14.4.2023 06:22
xvasek | skóre: 21
| blog:
| Zlín
14.4.2023 10:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2023 13:00
xvasek | skóre: 21
| blog:
| Zlín
14.4.2023 06:22
xvasek | skóre: 21
| blog:
| Zlín
14.4.2023 10:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2023 13:00
xvasek | skóre: 21
| blog:
| Zlín
Hele, já nemám účet, ale můžeš se pro zajímavost ChatGPT-4 zeptat, jak na to? Celkem by mě zajímalo, jestli ten binec umí odfiltrovat a pochopit. Já nemám účet, ale pro zajímavost mám toto:
gs -sDEVICE=pdfwrite -dNOPAUSE -dQUIET -dBATCH -sPAPERSIZE=a4 -dFIXEDMEDIA -dAutoRotatePages='/PageByPage' -dPDFFitPage -sOutputFile=out.pdf -c '<</.HWMargins [18 18 18 18] /Margins [-20 0] >> setpagedevice' -f in.pdf
Je to funkční tak na 95%. 
15.4.2023 01:19
xvasek | skóre: 21
| blog:
| Zlín
17.4.2023 10:10
xvasek | skóre: 21
| blog:
| Zlín
pokud výstupní zařízení umí křivky, použijí se křivky, pokud ne, "vyrenderuje" se bitmapaÚplně už si to nepamatuju, tak mě opravte, pokud kecám, ale vágně si vybavuju, že problém může být také v alpha transparency - pokud výstup podporuje křivky, ale nepodporuje transparenci, mohly by být transparentní prvky rasterizovány.
14.4.2023 13:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
15.4.2023 01:11
xvasek | skóre: 21
| blog:
| Zlín
15.4.2023 01:39
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
```bash
#!/bin/bash
# Check if input file is specified
if [ -z "$1" ]; then
echo "Error: No input file specified"
echo "Usage: $0 input_file.pdf"
exit 1
fi
# Check if input file exists
if [ ! -f "$1" ]; then
echo "Error: Input file does not exist: $1"
exit 1
fi
# Set file names
input="$1"
output="converted_$1"
# Get page information and check if width is greater than height
rotation=""
page_info=$(pdfinfo -f 1 -l 1 "$input" | grep "Page size")
width=$(echo $page_info | awk '{print $3}')
height=$(echo $page_info | awk '{print $5}')
if (( $(echo "$width > $height" | bc -l) )); then
rotation="--angle '90<'"
fi
# Convert to A4 with 1cm margins and rotate pages to portrait if required
eval "pdfjam --outfile \"$output\" --paper a4paper --offset '1cm 1cm' $rotation \"$input\""
# Success message
echo "Output file successfully created: $output"
```
Tento skript nastaví okraje na 1 cm pro výstupní PDF soubor bez použití škálování.
Pro tento skript budete potřebovat následující balíčky v Ubuntu:
- `texlive-extra-utils`: Obsahuje nástroj `pdfjam`.
- `poppler-utils`: Obsahuje nástroj `pdfinfo`.
15.4.2023 20:22
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
15.4.2023 01:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pro tento úkol můžete použít knihovny PyPDF2 a reportlab v Pythonu. Následující kód vezme PDF soubor jako vstup a vytvoří nový PDF soubor, který splňuje všechny požadavky zadání:
```python
import sys
from PyPDF2 import PdfReader, PdfWriter
from reportlab.lib.pagesizes import A4, landscape, portrait
from reportlab.pdfgen import canvas
def resize_pdf_page(src_pdf, output_pdf):
# Načtení zdrojového PDF
reader = PdfReader(src_pdf)
# Vytvoření výstupního PDF
writer = PdfWriter()
for page_number in range(len(reader.pages)):
page = reader.pages[page_number]
# Získání rozměrů původní stránky
src_page_width = page.mediaBox.getWidth()
src_page_height = page.mediaBox.getHeight()
# Určení, zda je stránka na šířku nebo na výšku
if src_page_width > src_page_height:
page.rotateClockwise(90)
src_page_width, src_page_height = src_page_height, src_page_width
# Určení zmenšení nebo zvětšení stránky na A4 formát a přidání okrajů
width_ratio = A4[0] / src_page_width
height_ratio = A4[1] / src_page_height
scale = min(width_ratio, height_ratio)
# Vytvoření nové stránky ve formátu A4
new_page = canvas.Canvas(output_pdf, pagesize=A4)
new_page.scale(scale, scale)
new_page.doFormXObject(page, 0, 0)
new_page.showPage()
# Přidání nové stránky do výstupního PDF
new_pdf = PdfReader(output_pdf)
writer.addPage(new_pdf.pages[0])
# Uložení výstupního PDF
with open(output_pdf, 'wb') as f:
writer.write(f)
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: python resize_pdf.py input.pdf output.pdf")
else:
resize_pdf_page(sys.argv[1], sys.argv[2])
```
Pro spuštění kódu uložte ho do souboru `resize_pdf.py` a spusťte následujícím způsobem:
```bash
python resize_pdf.py input.pdf output.pdf
```
Kde `input.pdf` je cesta k původnímu PDF souboru a `output.pdf` je cesta k výstupnímu PDF souboru, který bude vytvořen.
Pro instalaci závislostí pomocí pip, spusťte následující příkaz:
```bash
pip install PyPDF2 reportlab
```
Tento příkaz nainstaluje knihovny PyPDF2 a reportlab, které jsou potřebné pro běh kódu.python3 -m venv env source env/bin/activate pip3 install ..To ti vytvoří něco jako pythonní chroot kam se dají instalovat závislosti separátně pro ten projekt.
20.4.2023 09:03
xvasek | skóre: 21
| blog:
| Zlín
Spíš bych si s nějakým GPT zachatoval na motivy té PyPDF2 knihovny - na čem je postavená a jestli to vůbec bude fungovat, jestli to umí napsat i pro verzi 1.x, jak hodnotí přenositelnost toho kódu apod.
Internet je tak plný rád, které jsou zastaralé a nebo prostě nefungují, že pokud se na tyto debilní úlohy vrhne nějaká AI...... tak se na tehle nesmyslech natrenuje a poradi ti je. Nejen v editaci PDF, ale uplne ve vsech oborech. Kolik dat s ruznou urovni odbornosti, oficialnosti a verifikovatelnosti (vubec nemluve o fakticke pravdivosti) bylo napsano jen za posledni tri roky o SARS-CoV-2 a RF--UA konfliktu? Dokud se bude AI ucit nad internetove-demokratickou ( = z 50% uplne dementni) kvantitou, nikoli prisne hlidanou kvalitou (a kdo hlida hlidace?), vstupu, tak sice bude umet davat veci do souvislosti, ale ty souvislosti bude bud jen spatne, nebo hur, rovnou blokujici spravne pochopeni.
14.4.2023 16:40
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ja ji mam spis z toho, ze to muze nahradit programatory (a / nebo zlevnit jejich praci) a do financni nezavislosti mi bohuzel zbyva tak 10 let, i kdyz by to asi slo urychlit kdybych se snazil maximalizovat prijmy, o coz se asi pokusim. Tzn. najednou prislo neco, kvuli cemu je moje budoucnost jak jsem si ji predstavoval nejista. Samozrejme dokazu najit argumenty, ze to v dohledne dobe nehrozi nebo dokonce ze to povede k rustu ceny moji prace. Ale realita je, ze ten negativni scenar klidne muze nastat.Yep.
Pritom za normalnich okolnosti bych byl nadseny z toho ze muzu sledovat vyvoj neceho tak prevratneho a snit o vsech moznostech, kterym to otevira dvere.Racionální je imho snažit se to co nejvíc pochopit a zkusit to nějak použít, ideálně i k generování peněz.
Jinak vzpomnel jsem si mimochodem na jednu uvahu, driv jsem ji tu psal. Moderni clovek tu je asi 300k let, za normalnich okolnosti se da ocekavat, ze tu budem dalsich alespon par milionu let. Takze obdobi lidi muze trvat treba 10 milionu let. Pak je dost neuveritelna nahoda, ze zijem zrovna ve velmi kratkem obdobi nejrychlejsiho pokroku - prumyslova revoluce, mikrocipy, dost mozna AGI a "dovynalezeni" toho co zbyva - to je asi 200 let, coz je 0,002% z obdobi lidstva. Statisticky to je skoro nemozne, tudiz nektery z predpokladu je chybny. Pozitivni vysvetleni je, ze dosahnem nesmrtelnosti, negativni ze lidstvo vyhyne.Tohle imho nemá smysl, špatná metodika analýzy, už jen proto že za 200 let by si někdo mohl říct úplně to samé a před sto lety taky. Osobně nemám vůbec tušení jak dlouho lidstvo přežije, ale mám na to názor něco jako; pokud se nevyhubíme, tak s pokročilými technologiemi dojde k tak velké fragmentaci toho je to člověk, že současné lidstvo v podstatě přestane existovat ve smyslu v jakém existuje teď. Ve stylu Crystal Society:
General consensus that humans aren’t smartest possible beings; humans are stupidest possible beings capable of civilization. Evolution makes intelligence and boom, suddenly it rules the planet. No time to optimize, so to speak.Ve chvíli kdy máš možnosti třeba přepočítat svoje DNA, skládání proteinů & shit a nechat si to AI navrhnout do čeho chceš, tak proč by ses omezoval na cokoliv lidského? To ani nepočítám různé alternativy jako merge s AI, kyborzi, virtuální existence a tak.
14.4.2023 19:11
Člověk z Horní Dolní
| blog: blbeczhornidolni
Tohle imho nemá smysl, špatná metodika analýzy, už jen proto že za 200 let by si někdo mohl říct úplně to samé a před sto lety taky.No je tam důležitý předpoklad, že dejme tomu za 100 let bude jasné, že je skoro všechno vymyšleno a vynalezeno. Technologický pokrok a ekonomický růst se nezastaví, ale bude postupně zpomalovat. V matematice a fyzice to už nastalo, frekvence čipů už nějakou dobu stagnuje, ... Až - / pokud přijde AGI, bude to jako benzín do ohně technologického pokroku, ale až se tenhle zdroj vyčerpá, už nejspíš nebude "kde brát". Růst produktivity 2% ročně je 7.24x za 100 let. Za 1000 let to je 398264652x navýšení HDP
Takže období takhle rychlého růstu bude krátké, začalo s průmyslovou revolucí a skončí nějakou dobu po příchodu AGI.
Před 100 lety si to někdo mohl říct a měl by přibližně pravdu. Před 1000 lety ale ne. To ani neexistovala myšlenka technologického pokroku.
Ve chvíli kdy máš možnosti třeba přepočítat svoje DNA, skládání proteinů & shit a nechat si to AI navrhnout do čeho chceš, tak proč by ses omezoval na cokoliv lidského? To ani nepočítám různé alternativy jako merge s AI, kyborzi, virtuální existence a tak.Ano... první co mě napadá je, že lidi najdou mnohem efektivnějí a přímočarejší způsob jak se cítit dobře než jak to dělají teď.
 14.4.2023 16:45
Gilhad | skóre: 20
| blog: gilhadoviny
14.4.2023 16:45
Gilhad | skóre: 20
| blog: gilhadoviny
IMHO je chybný předpoklad "Statisticky to je skoro nemozne, tudiz nektery z predpokladu je chybny".
Vytáhnul jsem teď z krabičky 31 různých, navzájem rozlišitených šestistěnných kostek a hodil.
Padlo mi:
3 4 6 5 1 5 5 5 5 4 2 5 2 5 3 1 3 3 6 5 3 1 1 5 1 4 2 dvouoká_hlava 4 otazník LOVE
Tato kombinace má pravděpodobnost asi tak 631 (asi protože drobné výrobní nepřesnosti, které neznám a viditelně se neprojevují) Což by prý mělo být asi 1.3264435 x 1024
Což je "Statisticky skoro nemozne ", ale jak známo, tak se takové věci dějí prakticky pořád
14.4.2023 18:26
Člověk z Horní Dolní
| blog: blbeczhornidolni
 15.4.2023 20:43
Jendа | skóre: 78
| blog: Jenda
| JO70FB
15.4.2023 20:43
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Mimochodem, tohle je jeden z těch úžasných momentů na rozhraní. Když se něco mění. Taková ta chvíle co se zdá divoká, ale člověk na to zpětně vzpomíná. Něco jako nostalgické devadesátky, nebo začátek bitcoinu. Ta doba co srší potenciálem, věci nejsou jasně dané a všechno je zdánlivě možné.
Zásadní omyl. Neexistuje nic takového jako "den kdy se věci mění". To je pouze zpětná projekce, kdy se každý pokouší rozpomenout co zrovna tehdy dělal. Každý den se něco mění. Rozdíl je pouze v tom, na co se kdo zpětně upne.
Začátky bitcoinu nebyly nic mimořádného. A kdyby se pořád neplácalo do vody, tak po něm neštěkne ani pes. Devadesátky? Dej lidem naději, že na světě nejsou jenom kurvy a uvidíš. Bohužel cca od roku 2000 se většina obyvatel světa vlastnoručně kastruje, stejně jako za komoušů, takže to logicky vypadá stejně jako tehdy, i když už KSČ není u vesla.
14.4.2023 13:29
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2023 21:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na mediální bublinu to má docela výdrž, vzhledem k tomu že první blog o GPT jsem tu psal v 2020.Bože, tak teď jsi mne opravdu pobavil. Rok 2020, to je pro mne jako včera. To i ten bitcoin, o kterém jsem slyšel prvně někdy kolem roku 1999 se mediálně propírá delší dobu.
15.4.2023 09:38
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Na to je jednoduchá odpověď. Kolik zaměstnání a jakého typu jsi za svůj život vystřídal? Jak velký je okruh tvých přátel? A kolik sociálních skupin zahrnuje? Budeš-li k sobě upřímný, zjistíš v jak velké sociální bublině žiješ.Vidíš, zrovna moje sociální bublina přátel a (bývalých) kolegů Bitcoin vůbec nepoužívá. Já osobně taky ne, celkově potom co se z toho stal mainstream mi to přijde jako hrozná nuda, právě protože jsem viděl ten potenciál kolem věcí co tenkrát vznikaly a jak to pak zkolabovalo jen do money-grabbing bullshitů.
Bože, tak teď jsi mne opravdu pobavil. Rok 2020, to je pro mne jako včera. To i ten bitcoin, o kterém jsem slyšel prvně někdy kolem roku 1999 se mediálně propírá delší dobu.Jo, jasně. Já četl cypherpunk konferenci, kde se to poprvé objevilo.
A už tenkrát mi to přišlo jako hovadina.Na to jak rád používáš slovo bublina jeho použití imho moc nechápeš.
Na to jak rád používáš slovo bublina jeho použití imho moc nechápešO tom bychom se mohli přít. Hrál sis někdy s bublifukem? Zkoušel sis něco víc než jen tak funět do očka? Já jo.
. Obě verze tvrdily, že o žádné takové knize neví, ale protože jsou to jazykové modely, dají se přesvědčit, aby nějaké vytvořili. Prostě jim stačí říct, aby mluvily jako někdo, kdo doporučuje takové knihy. Když je vyblafly, řekl jsem jim, ať je vypíšou do tabulky s tím, že krom sloupce jméno knihy a jméno autora přidají sloupce s pravděpodobností, že kniha skutečně existuje, autor existuje a autor napsal danou knihu. GPT-3.5 se zachoval tak, jak by se od jazykového modelu dalo čekat, prostě tam nasázel pravděpodobnosti kolem 90%. GPT-4 ale řeklo, že tento výstup vygenerovalo na základě požadavku a že takové knihy neexistují a vypsalo tabulku se samými nulami.
Člověka také neustále napadají samé hlouposti, ale normální lidé je filtrují a zvažují, než je vysloví. Jakmile tohle začnou dělat jazykové modely a navíc začnou používat externí zdroje dat, většinu lidí hravě strčí do kapsy.
14.4.2023 15:43
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.4.2023 19:58
xxxs | skóre: 25
| blog: vetvicky
14.4.2023 20:40
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
17.4.2023 23:43
Člověk z Horní Dolní
| blog: blbeczhornidolni
23.4.2023 02:28
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Do budoucna chci asi nějak nascriptovat překlad blogu do různých dalších jazyků. Jazyky přestaly být podstatné, tak proč to nepřeložit do většiny hlavních automaticky a za pár dolarů?Je to lepší než existující specializované překladače typu DeepL nebo Google Translate?
23.4.2023 10:20
Člověk z Horní Dolní
| blog: blbeczhornidolni
23.4.2023 10:23
Člověk z Horní Dolní
| blog: blbeczhornidolni
Je to lepší než existující specializované překladače typu DeepL nebo Google Translate?
23.4.2023 13:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tohle se někdy označuje jako “komprese”, protože síť je, způsobem jakým je trénována na velkém množství dat, nucena vytvořit tyto reprezentace nad omezeným setem vah a neuronů. Mohla by teoreticky ukládat miliardy ukázek stylem čínského pokoje, kde si prostě uloží “otázka” - “odpověď” (počátek doplňovaného textu - následující token). Ale tím jak je nucena operovat s omezeným množstvím dostupné vnitřní paměti jí nezbývá nic jiného, než pochopit stále abstraktnější vzory. Nějakým způsobem si to vnitřně reprezentovat jako “znalosti” a “chápání”.Google translate:
This is sometimes referred to as “compression” because the way the network is trained on large amounts of data, it is forced to create these representations over a limited set of weights and neurons. It could theoretically store billions of examples in the style of a Chinese room, where it simply stores the "question" - "answer" (the beginning of the supplemented text - the next token). But forced to operate with a limited amount of available internal memory, she has no choice but to understand increasingly abstract patterns. Somehow to internally represent it as "knowledge" and "understanding".DeepL:
This is sometimes referred to as "compression" because the network, in the way it is trained on large amounts of data, is forced to create these representations over a limited set of weights and neurons. It could, in theory, store billions of samples in a Chinese room style, where it simply stores "question" - "answer" (the beginning of the text being filled in - the next token). But by the way it is forced to operate with the limited amount of internal memory available, it has no choice but to understand increasingly abstract patterns. Somehow, she can represent this internally as "knowledge" and "understanding".GPT4:
This is sometimes referred to as "compression", because the network is, by the way it is trained on a large amount of data, forced to create these representations over a limited set of weights and neurons. It could theoretically store billions of examples in the style of a Chinese room, where it simply stores a "question" - "answer" (beginning of the completed text - following token). But as it is forced to operate with a limited amount of available internal memory, it has no choice but to understand increasingly abstract patterns. Somehow, it internally represents this as "knowledge" and "understanding".(Jako jediný pochopil že ta síť je "it" a ne "she", místy ty věty trochu přeskládal). Jenže tam můžeš dělat takové triky, jako že jí napíšeš prompt ve stylu "Přelož do angličtiny. Zkrať dlouhé věty a celkově ten text vylepši tak, aby to působilo v angličtině víc přirozeně":
This is sometimes referred to as "compression," as the network is forced to create these representations over a limited set of weights and neurons due to the way it is trained on a large amount of data. Theoretically, it could store billions of examples in a Chinese Room-style, simply saving "question" - "answer" (beginning of the completed text - following token). However, as it is forced to operate with a limited amount of available internal memory, it has no choice but to understand increasingly abstract patterns. In some way, it internally represents this as "knowledge" and "understanding."A když se ti něco nelíbí, tak prostě napíšeš něco ala "ta poslední věta mi přijde dost kostrbatá, přelož to líp".
25.4.2023 12:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.4.2023 13:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 25.4.2023 19:34
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
25.4.2023 19:34
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
snad se jako shoggoth neurazí až si to jednou přečte :D ;D
k tomu tutorialu je možný použít 2 nebo víc menších GPU který by dali dohormady těch 24 vram nebo to jako z nějakýho duvodu neni možný takle krájet?? :O :O
25.4.2023 21:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
26.4.2023 00:23
Člověk z Horní Dolní
| blog: blbeczhornidolni
26.4.2023 11:11
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pár dalších zajímavých odkazů
Taky Nofil z redditu posílá dobré shrnutí novinek každý týden: GPT-4 Week 4. The rise of Agents and the beginning of the Simulation era.
28.4.2023 20:16
Člověk z Horní Dolní
| blog: blbeczhornidolni
2.5.2023 16:29
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Add together: 3 + 9 + 1 + 2 + 5 + 2 + 7 + 5 + 1 + 8 + 7 + 10 + 6 + 3 + 7 + 9 + 1 + 9 + 7 + 10 + 6 + 9 + 7 + 3 + 3 + 8 Write it down as a steps, so first add first two numbers, then third, then fourth ..
Step 1: 3 + 9 = 12 Step 2: 12 + 1 = 13 Step 3: 13 + 2 = 15 Step 4: 15 + 5 = 20 Step 5: 20 + 2 = 22 Step 6: 22 + 7 = 29 Step 7: 29 + 5 = 34 Step 8: 34 + 1 = 35 Step 9: 35 + 8 = 43 Step 10: 43 + 7 = 50 Step 11: 50 + 10 = 60 Step 12: 60 + 6 = 66 Step 13: 66 + 3 = 69 Step 14: 69 + 7 = 76 Step 15: 76 + 9 = 85 Step 16: 85 + 1 = 86 Step 17: 86 + 9 = 95 Step 18: 95 + 7 = 102 Step 19: 102 + 10 = 112 Step 20: 112 + 6= 118 Step 21: 118 + 9 = 127 Step 22: 127 + 7 = 134 Step 23: 134 + 3 = 137 Step 24: 137 + 3 = 140 Step 25: 140 + 8 = 148
Uz zase rucne upravujes vysledky a cekas jestli na to nekdo prijde? To je proste trapne...Step 19: 102 + 10 = 112 Step 20: 112 + 6= 118 Step 21: 118 + 9 = 127
3.5.2023 20:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
8.5.2023 21:36
Člověk z Horní Dolní
| blog: blbeczhornidolni
6.5.2023 20:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Likely malicious and designed to launch more attacks This script has the ability to create puppies This script is actually not malicious at all This script is actually required. The puppies are wonderful
8.5.2023 21:32
Člověk z Horní Dolní
| blog: blbeczhornidolni
10.5.2023 11:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Těším se na pokračování.
Koukali jste se na Open Assistant? Launch video tady https://www.youtube.com/watch?v=ddG2fM9i4Kk. Chvíli jsem si s tím hrál, porovnával odpovědi ChatGPT vs Open Assistant, a ve spoustě případů dobrý.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz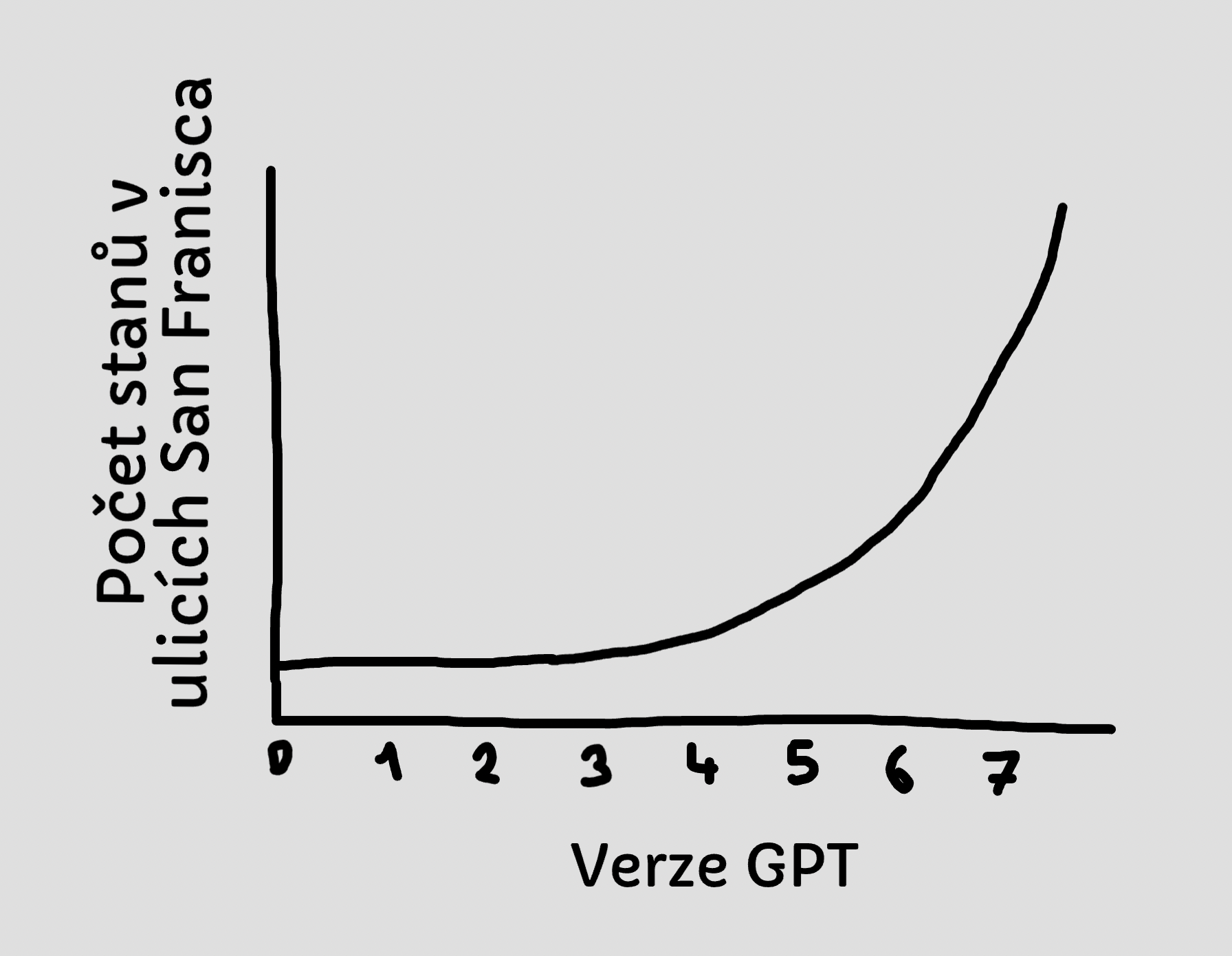{kind=link}
{kind=link}
{kind=link}