HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Aktuální vývojová verze jádra je 3.3-rc2 vydaná 31. ledna – což je o trochu později, než se čekalo. Diffstat je dost rovnoměrný – což značí, že jsou tam především rozprostřeny malé změny. To vidím rád a bohužel to v této fázi tak vždy není. Přesouvají se tam nějaké soubory (sériový port na bázi 8250 a sloučení mx5 -> imx v arm), jinak nic moc zajímavého. To je fajn. Přesto je v této předverzi docela dost změn, krátký seznam změn naleznete v oznámení. Třináct z těchto změn odstraňuje patche, které se nevyvedly.
Stabilní aktualizace: za poslední týden žádné nevyšly. Verze 2.6.32.56, 3.0.19 a 3.2.3 jsou aktuálně ve fázi revidování; můžeme je očekávat 3. února nebo později.
Nebylo by to poprvé, kdy lockdep a ftrace způsobí livelock systému. Nebo jej neskutečně zpomalí. Lockdep a ftrace spolu moc dobře nefungují. Oba jsou dost vlezlé. Připomínají mi americký kongres. Tam se dvě strany snaží nad vším získat moc, ale ve výsledku neodvedou žádnou práci. Výsledkem je grid/live lock v počítači/zemi.
Dovedu si představit, že by to bylo dílo pomstychtivého programátora, který si řekl „Teď to těm lidem, co upozornili na chybu v mém kódu, natřu, hahahahahahaha! Opravím to tak, aby test case prošel, ale podstaty problému se nedotknu,“ ale nemyslím si, že by lidé od kompilátorů byli *tak* zlí. Ano, jsou to zlí lidé, co se nás snaží napálit, ale i tak.
V tomto směru je můj přístup k ext4 takový, že ext4 by mělo být jako linuxové jádro; je to evoluční proces a centrální plánování je často přeceňované. Lidé přispívají do ext4 z mnoha různých důvodů a to znamená, že optimalizují ext4 pro své vlastní využití. Stejně jako Linus s Linuxem se nesnažíme navrhovat věci s cílem „ovládnout svět“ tím, že bychom říkali, „hmm, raději implementujeme funkce A a B, abychom 'odrovnali' reiserfs4“.
-- Ted Ts'o
Stavíte na předpokladu, že uživatelé jsou znalí a dobře informovaní, ale všichni vývojáři souborových systémů by měli vědět, že to prostě není pravda. Uživatelé neustále dokazují, že nevědí, jak souborový systém funguje, nerozumí nabízeným volbám, nerozumí tomu, co jejich aplikace z hlediska operací nad soubory dělají, a opravdu nerozumí svým datům. Vzdělání vyžaduje čas a píli, ale uživatelé přesto dělají stejné chyby dokola.
-- Dave Chinner
Vypadá to, že v release kódu drm je víc draků a padacích dveří, než je tam řádek.
Linux Foundation oznámila, že se Greg Kroah-Hartmann připojil k jejich týmu. Na své pozici v Linux Foundation bude Kroah-Hartmann pokračovat v práci správce stabilní větve Linuxu a řady subsystémů, zatímco bude pracovat v plně neutrálním prostředí. Bude také úzce spolupracovat se členy, pracovními skupinami, projekty v Labu a personálem Linux Foundation na důležitých iniciativách s cílem posunout Linux dál.
Herbert Poetzl nedávno nahlásil zajímavý výkonnostní problém. Jeho laptop s SSD diskem dokázal pod jádrem 2.6.38 číst data o rychlosti kolem 250 MB/s , ale výkon spadl na 25-50 MB/s na všech novějších jádrech. Pád výkonu o jeden řád není ten typ novinky, na který se lidé těší při aktualizaci jádra, takže hlášení si hned získalo pozornost řady vývojářů. Řešení problému se ukázalo být jednoduché, ale přináší zajímavý pohled na to, jak diskové I/O v jádře funguje.
K vysvětlení problému je zapotřebí jen trocha teorie, zejména pak definice pár pojmů. „Readahead“ je proces, kdy je soubor spekulativně načítán do paměti na základě předpokladu, že aplikace tato data bude brzy chtít. Rozumný výkon při sekvenčním čtení souboru závisí na dobře udělaném readahead; je to jediný způsob, jak zajistit to, že čtení a zpracování dat bude probíhat paralelně. Bez readahead budou aplikace čekat na přečtení dat z disku víc, než je nutné.
"Plugging" je zase proces zastavení zasílání I/O požadavků nízkoúrovňovému zařízení po určitou dobu. Smyslem pluggingu je umožnit nahromadění určitého množství I/O požadavků, aby je plánovač I/O mohl seřadit a aby sloučil přilehlé požadavky a uplatnil jakákoliv nastavená pravidla férovosti. Bez pluggingu by I/O požadavky byly menší a byly by více roztříštěné napříč diskem, což by výkon snižovalo dokonce i na SSD.
Teď si představte, že máme proces, který se chystá číst z dlouhého souboru, jak je naznačeno na tomto obrázku.

Jakmile aplikace začne číst ze začátku souboru, jádro začne s naplňováním prvního readahead okénka (které má u větších souborů 128 KB) a zařadí požadavek pro druhé okénko, takže situace bude vypadat nějak takhle:
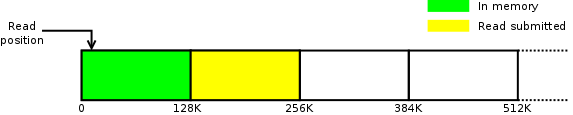
Jakmile se aplikace dostane za 128 KB, data, která potřebuje, už snad budou v paměti. Mašinérie kolem readahead se zase spustí a spustí se i I/O pro okénko od pozice 256 KB; výsledkem je situace na následujícím obrázku:
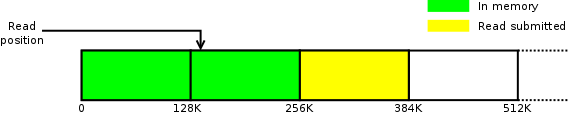
Tento proces pokračuje donekonečna, jádro má vždy náskok před aplikací a má data v době, kdy se aplikace dostane k jejich čtení.
V jádře 2.6.39 došlo k výrazným změnám v tom, jak se plugging dělá, s tím výsledkem, že plugging a opětovné uvolnění je nyní explicitně řízeno v kódu, kde se zadávají I/O požadavky. Takže od verze 2.6.39 kód pro readahead zastaví frontu požadavků před zařazením dávky operací a pak zase frontu odblokuje. Funkce, která řídí základní bufferované I/O nad soubory (generic_file_aio_read()), nyní dělá své vlastní zastavování. A zde celý problém začíná.
Představte si, že proces čte po velkých (1 MB) blocích. První velké čtení skončí v generic_file_aio_read, tato funkce zastaví frontu požadavků a začne procházet stránky souboru, které už jsou v paměti. Jakmile se dostane na konec prvního přednačítaného okénka (na 128 KB), kód pro readahead je spuštěn, jako je popsáno výše. Ale je tu problém: fronta je stále zastavena funkcí generic_file_aio_read(), která stále zpracovává požadavek na 1 MB, takže I/O operace zadané ke zpracování kódem pro readahead nejsou předány hardwaru; jen čekají ve frontě.
Takže jakmile se aplikace dostane ke druhému okénku pro readahead, dostaneme se do takovéto situace:
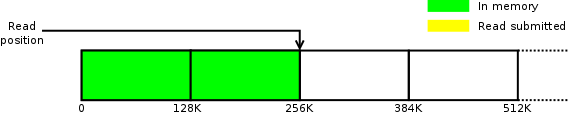
V tento moment se všechno zastaví. To povede k odblokování fronty, což konečně umožní provedení I/O požadavků pro readahead, ale to je příliš pozdě. Aplikace bude muset čekat. Toto čekání stačí k tomu, aby se výkon propadl, a to i na SSD.
Oprava spočívá v odstranění zastavování na nejvyšší úrovni v generic_file_aio_read, takže požadavky od kódu pro readahead se mohou dostat k hardwaru. Vývojáři, kterým se podařilo problém reprodukovat, hlásí, že patch problém odstraňuje, takže můžeme věc považovat za vyřešenou. Oprava by se brzy měla objevit v nějakém stabilním vydání.
Vývojáři mají z chyb kompilátorů strach a mají pro to důvod: takové chyby může být těžké odhalit i se jim pak vyhnout. Mohou v kódu ponechat skryté pasti, do kterých uživatelé spadnou v nevhodný okamžik. Věci se mohou ještě více zkomplikovat, jakmile je chyba vnímána vývojáři kompilátoru jako vlastnost – takové problémy nemusejí být nikdy vyřešeny. Je možné, že se právě tento typ vlastnosti objevil v GCC, dopad na jádro není znám.
Jedna z mnoha struktur používaných souborovým systémem btrfs – definovaná v fs/btrfs/ctree.h – vypadá takto:
struct btrfs_block_rsv {
u64 size;
u64 reserved;
struct btrfs_space_info *space_info;
spinlock_t lock;
unsigned int full:1;
};
Jan Kára nedávno nahlásil, že pole lock je na architektuře ia64 občasně přepisováno. Trocha zkoumání vedla k tomu, že GCC dělalo při změně bitového pole full překvapivou věc: generuje 64bitový cyklus načíst-změnit-zapsat, při kterém dochází ke čtení lock i full, změně full a zápisu obou hodnot zpět do paměti. Pokud bylo lock během této operace upraveno jiným procesorem, tato změna bude ztracena při zpětném zápisu lock. To nevěstí nic dobrého.
Člověk si dokáže představit, že odhalit podstatu problému byla docela fuška. A asi nebude ani těžké si představit zděšení, k jakému vedl následující rozhovor:
Řekl jsem o problému lidem z GCC a řekli mi, že: "C takovou věc nezaručuje a stejně tak nemůžete spolehlivě zamykat různá pole struktury pomocí různých zámků, pokud sdílejí standardně zarovnaný [aligned] paměťový region o velikosti slova. Paměťový model C++11 toto zaručuje, ale ten není implementován a stejně k sestavování jádra nepoužíváte kompilátor C++11."
Není divu, že Linus touto odpovědí nebyl potěšen. Řekl, že standardy jazyků nejsou psány na míru jádrům a nemohou zaručovat, že chování bude odpovídat potřebám jádra:
C/gcc v tomto smyslu nikdy nic „neslibovalo“ a vždy jsme jen předpokládali, jaký kód je rozumné generovat. Většinou jsou naše předpoklady správné, a to proto, že by bylo od C kompilátoru *hloupé*, aby dělal něco jiného, než předpokládáme.
Ale někdy to kompilátory dělají. Používat 8bajtové přístupy k 4bajtové entitě je *hloupé*, když to ani není rychlejší a základní typ byl stanoven jako 4bajtový!
Jak už to bývá, problém je ještě rozsáhlejší. Linus navrhl spustit test s takovouto strukturou:
struct example {
volatile int a;
int b:1;
};
Pokud v tomto případě přiřazení do b způsobí zápis to a, tak je takové chování rozhodně chybné; klíčové slovo volatile stanovuje, že k adrese může být přistupováno odjinud. Jiří Kosina to zkusil a oznámil, že GCC i v tomto případě generuje 64bitové operace. Takže i když je původní chování technicky správně, je to pravděpodobně důsledkem toho samého rozhodnutí, které způsobuje chybu u druhého příkladu.
Tato věc může vývojářům jistě dodat výzbroj do hádek s vývojáři GCC, ale nemusí to nutně pomoci. Bez ohledu na zdroj problému toto chování může existovat ve verzích kompilátoru, které jsou mimo komunitu vývojářů používány k sestavování jádra. Může být proto nutné přijít s obezličkou, i když bude chování GCC opraveno. To může být docela výzva; auditování celého jádra s cílem najít 32bitová bitová pole ve strukturách, ke kterým může být přistupováno souběžně, to nebude jen tak. Ale nikdo ani neříkal, že je vývoj jádra hračka.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 13.2.2012 20:36
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj
13.2.2012 20:36
Dreit | skóre: 15
| blog: Dreit a jeho dračí postřehy
| Královehradecký kraj

 Zvláštní ale je, že se mi to nedaří reprodukovat, zkouším gcc 4.4, 4.5, 4.6. Asi specifické pro ia64...
Zvláštní ale je, že se mi to nedaří reprodukovat, zkouším gcc 4.4, 4.5, 4.6. Asi specifické pro ia64...
 13.2.2012 18:48
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
13.2.2012 18:48
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
 14.2.2012 02:46
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 02:46
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Ano, v pripade bez volatile na locku se to chova podle standardu (nespecifikovano)V tom případě je ale chování podle standardu i to, když by vygenerovaný kód změnil hodnotu v paměti úplně někde jinde, a před dokončením dané "instrukce" by ji zase vrátil zpět. Takhle to sice nemusí dávat smysl, ale stačilo by třeba mít dvě nezarovnané struktury za sebou:
struct btrfs_block_rsv1 {
u64 size;
u64 reserved;
struct btrfs_space_info *space_info;
spinlock_t lock;
};
struct btrfs_block_rsv2 {
unsigned int full:1;
};
Tohle by přece také mohl kompilátor podle standardu přeložit úplně stejně, tj. načte z paměti lock i full, změní full a zapíše obojí zpět. Podle mne by se pak ale v C vůbec nedaly programovat vícevláknové aplikace, protože pokud se nepoužijí zámky znamenalo by to, že kód jednoho vlákna může v paměti změnit úplně cokoli, pokud to před dokončení "instrukce" vrátí zpátky. Jenže jiné vlákno může kdykoli narazit na ta změněná data…
14.2.2012 12:33
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
An implementation may allocate any addressable storage unit large enough to hold a bitfield. If enough space remains, a bit-field that immediately follows another bit-field in a structure shall be packed into adjacent bits of the same unit. If insufficient space remains, whether a bit-field that does not fit is put into the next unit or overlaps adjacent units is implementation-defined. The order of allocation of bit-fields within a unit (high-order to low-order or low-order to high-order) is implementation-defined. The alignment of the addressable storage unit is unspecified.Ma to racionalni zaklad a zejmena v kontextu mozneho pristupu do pameti specifickeho pro dany HW - a C je zde musi byt velmi volny - i plno konsekvenci. Treba pokud mate strukturu
struct test {
unsigned aa:1;
unsigned bb:2;
unsigned cc:1;
}
tak sizeof(struct test) muze byt vetsi nez 1; a zaroven aa, bb and cc jsou ve stejnem bytu; pokud predpokladate vice dostavate se do zavislosti na architekture, implementaci a zavadite nekonzistentni pozadavky.
14.2.2012 15:07
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Podstatné je, že podle této interpretace standardu může kompilátor vygenerovat kód, který změní libovolnou část paměti,To je totalne nesmyslne tvrzeni. Muze to udelat jenom v chybne napsane aplikaci, ktera stavi na nespecifikovanych nebo implementacne zavislych vecech. C standard je v tomto dobre promyslen a i celkem jasny - viz ma citace nahore.
Jenže s takovým přístupem se nedá naprogramovat nic vícevláknového.Opet musim odmitnout. Lze psat vicevlaknove aplikace a pritom respektovat standard, nekdy je to i vyzadovane - treba automotive ci medical firmware. Nekdy je sice vyhodne z hlediska vykonu a efektivity to nerespektovat a spolehat na implementacni detaily kompilatoru a cilove platformy, ale ma to svou cenu.
Ta citace nahoře neříká nic o tom, že při operacích s tou datovou strukturou nesmí vygenerovaný program sahat nikam jinam.Proč by měl někam jinam - mimo tu strukturu - sahat? K tomu přece není žádný důvod. Tady se jedná o práci s pamětí pozue v rámci té struktury. Jinak ale standard to asi nezakazuje, stejně jako nezakazuje vždy v úplňkovou noc vygenerovat náhodné číslo a poslat ho po síti do kerosenem poháněného struhadla na sýr.
14.2.2012 16:46
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
spolehani se na implementation-defined/unspecified behaviourDobře. A kde je tedy ta hranice, co je už definováno standardem? Když budu spoléhat na to, že to GCC nebude dělat s bajtem a 32bitovým slovem (pro změnu bajtu přečte okolní 32bitové slovo, změní bajt a zapíše zpět slovo), má to spoléhání oporu ve standardu, nebo je to zase spoléhání na implementation-defined/unspecified behaviour?
14.2.2012 17:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 18:04
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 16:32
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 18:15
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Alignment je věc, kterou kompilátor může použít.Nekdy muze z duvodu vykonu, nekdy musi z duvodu architektury HW.
Ale já se celou dobu ptám, zda standard omezuje hranice, přes které kompilátor jít nesmí.Hranice v cem? POD data (char, int etc.) jsou zpracovavana korektne, jak se pracuje se strukturami a bit-fields je take specifikovano.
Takže ta hranice možná leží ještě dál, a možná ve standardu vůbec není.Tomu bych se vůbec nedivil (#34), ale co se na tom snažíš celou dobu dokázat? Že standard neobsahuje dlouhý seznam všech možných i nemožných kravin, které by teoreticky kompilátor mohl udělat? Mně by překvapilo, kdyby to tak bylo. Co se multithreadingu a synchronizace týče, tyhle věci adresuje až nejnovější, několikrát zmiňovaný standard C11, tak proč se nekoukneš na něj?
Co se multithreadingu a synchronizace týče, tyhle věci adresuje až nejnovější, několikrát zmiňovaný standard C11, tak proč se nekoukneš na něj?Protože se tady řeší starší verze standardu. A protože programovat vícevláknové aplikace nejde v jazyce, kde platí, že libovolný kód může mít ve vícevláknovém prostředí libovolné vedlejší důsledky. Ono sice platí, že v běžných programovacích jazycích musí programátor zapomenout na spoustu předpokladů, které jsou při jednovláknovém programování splněné. Ale zároveň platí, že pro aspoň trochu rozumné vícevláknové programování musí být spousta dalších předpokladů splněna. A to, že programátor musí vždy přesně vědět, která operace změní která data, je zrovna jeden z těch požadavků, které nelze vynechat.
 .
16.2.2012 15:40
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 16:00
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 17:01
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 17:41
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
.
16.2.2012 15:40
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 16:00
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 17:01
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 17:41
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
struct test {
char a;
char b;
char c;
char d;
}
test.a = 0;
test.c = 0;
test.d = 0;
jako
get32 and32 0x00FF0000 set32vyhovuje standardu?
14.2.2012 18:10
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
O tom co je garantovano standardem, nikoliv platforme a implementacne zavisle?
14.2.2012 18:23
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 09:41
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Takže standard C jako takový je nepoužitelný pro drtivou většinu vícevláknových programů.Muzete mi citovat, ktera cast standardu zpusobuje v kontextu uvedeneho prikladu jeho nepouzitelnost ve vice vlaknovem postredi? Soucasny standard C nema thread model, novy ho velmi opatrne zavadi - podobne jako C++11.
To, že výše uvedený kód je možná přeložený dobře podle standardu, ale ten překlad je naprosto nepoužitelný ve vícevláknových programech, snad vidíte sám.Nevidim. Ten vas priklad neprokazuje nic, preklad se to bude lisit v ramci kontextu jak se pracuje s onou strukturou a tohle muze byt jenom jedna z mnoha variant prekladu. Vy jste totiz udelal jedine - alokoval pamet, podle vseho pouze na stacku a tu potom inicializoval. Nic vic. Pokud pouzijete jine typy ve strukture, treba uint32_t nebo poitery a bude to globalni promenna, kod bude uplne jiny. Zalezi na tom, jak je struktura dale pouzita ci menena atd. Jak probiha treba takovy task switch na nejnizsi urovni asi vite. Pokud struktura (data) jsou sdilena mezi vlakny, nebude asi vytvarena na stacku, bude globalni promenna a pristup k ni bude chranen synchronizacnimi strukturami. Je plna zodpovednost programatora rici: ted modifikuji kriticka data a dokud nezkoncim nelze provest task switch, jinak by mohlo dojit k poskozeni integrity dat. To neni prace C kompilatoru a ani nemuze byt, stejne jako treba zajisteni integrity dat pri interruptech ci synchronizace sdilenych procesorovych cache. Cely problem, vcetne problemu v kernelu, byl o tom, jak C pracuje s bit-fields ulozenych ve strukturach, jste si vedom toho, ze ted jste presel uplne nekam jinam? Ja jiz skoro osum let designuji high speed algoritmy, drivery a aplikace na RTOS systemech (TI DSPs, AD Blackfin, ruzne ARMs, MIPS, SH4, picochip a x86), na polich procesoru, i v certifikovanych systemech, v C, C++, OpenCL a asm; takze nejake zkusenosti asi mam, ale problemy ktere vy nadhazujete mi prijdou dosti divne.
//vlákno 1
test.a = 0;
test.c = 0;
test.d = 0;
//vlákno 2
test.b = 0;
for (i = 1; i <= 10; i++) {
test.b++;
}
assert b == 10;
Z pohledu práce s vlákny tam není žádný problém, nejsou tam žádná data, ke kterým by přistupovala obě vlákna. Takže synchronizace je zbytečná. Ovšem kompilátor, který nebere v úvahu vícevláknový přístup (nebo přerovnání instrukcí procesorem, více vláken ani není potřeba), vygeneruje strojový kód, který nebude vždy fungovat správně.
Ošetřit to obecně nezávisle na implementaci kompilátoru nejde, a i ošetření tohoto konkrétního příkladu se znalostí, jak to kompilátor přeloží, ten kód dost zneefektivní, protože se bude muset přidat zbytečná synchronizace. Jediné rozumné řešení je záruka, že kompilátor takovýhle strojový kód nevytvoří.
pristup k ni bude chranen synchronizacnimi strukturamiTo je právě ten problém. Že synchronizace je potřeba vždy, i když se k datům v programu nikdy nepřistupuje z více vláken. Jenže kompilátor C si tam ten přístup z více vláken může potichu vyrobit, když s vlákny nijak nepočítá.
Cely problem, vcetne problemu v kernelu, byl o tom, jak C pracuje s bit-fields ulozenych ve strukturach, jste si vedom toho, ze ted jste presel uplne nekam jinam?Ne, celý problém je hlouběji. Pokud překladač C s vlákny vůbec nepočítá, může z kódu, který je vícevláknově bezpečný, kdykoli vytvořit strojový kód, který vícevláknově bezpečný není. Prostě někam přidá třeba operaci čtení-zápis, která v jednom vlákně nemá žádný viditelný důsledek, ale ve vícevláknovém prostředí se může stát, že druhé vlákno přepíše hodnotu zrovna mezi načtením a zápisem prvního vlákna. Aby k tomuhle nedocházelo, musí překladač brát vícevláknový přístup v úvahu – i když třeba jinak vlákny vůbec nepodporuje. To, že překladač bere vlákna v úvahu, se pak musí projevit například tím, že budou přesně zdokumentovány případy, kdy překladač může vygenerovat kód, který pracuje s daty tak, že načte i okolní data a pak je nezměněná zase zapíše zpět. Takže by někde muselo být zdokumentováno, že při zápisu do bitového pole může překladač vygenerovat kód, který načte a zapíše zpět hodnoty i z okolních bitových polí ve stejné struktuře.
15.2.2012 13:13
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Pokud překladač C s vlákny vůbec nepočítá, může z kódu, který je vícevláknově bezpečný, kdykoli vytvořit strojový kód, který vícevláknově bezpečný není.Ne, ne, ne. Ja si myslite, ze probiha thread switch?
Takže by někde muselo být zdokumentováno, že při zápisu do bitového pole může překladač vygenerovat kód, který načte a zapíše zpět hodnoty i z okolních bitových polí ve stejné struktuře.Ale vzdyt do ve standardu je!! Znovu, po X-te, s ohledem na zpusob ulozeni bit-fields ve strukturach nemusi byt pristup k clenum struktury atomicky a programator se podle toho musi zaridit. Muze pouzit workaround s volatile, muze data mit v kriticke sekci.
Ve vasem prikladu je velmi dulezite, jak byla struktura deklarovana a na jakem systemu vas kod pobezi.Předpokládejte, že minimální adresovatelná jednotka je 8 bitů a že se jedná o thready běžící na jednom jádře operující nad stejnou L1 cache. Systém dokáže adresovat každý člen struktury, ale kompilátor místo toho použije 32bitové instrukce, protože tím získá rychlejší kód. Všechno je v pořádku, kompilátor splňuje standard, ale výsledek je celkem na houby.
Osobne bych nepouzival sdilenou strukturu bez synchronizace ani v prvnim pripadeJenže problém je v tom, že o tom, co je sdílená struktura, rozhoduje až kompilátor, a verzi od verze a optimalizaci od optimalizace se to může lišit.
tedy nebude moci byt sdilena mezi thready, kompilator muze zoptimalizovat kod tak, ze je primo nacitana do 32 bitoveho registruTo by ale standard musel s thready počítat. Pokud s nimi nepočítá, může kompilátor zoptimalizovat kód tak, že je přímo načítá do 32 bitového registru, bez ohledu na to, zda může nebo nemůže být ta struktura sdílena mezi vlákny. A pořád bude vyhovovat standardu.
Předpokládejte, že minimální adresovatelná jednotka je 8 bitů a že se jedná o thready běžící na jednom jádře operující nad stejnou L1 cache. Systém dokáže adresovat každý člen struktury, ale kompilátor místo toho použije 32bitové instrukce, protože tím získá rychlejší kód. Všechno je v pořádku, kompilátor splňuje standard, ale výsledek je celkem na houby.Afaik tohle standard nedovouje, ne pokud není struktura packed (což v tomto případně předpokládám by-default není). Imho pokud by kompilátor přistupoval ke členům té struktury po 32 bitech, zvolil by zarovnání na tuto velikost.
15.2.2012 15:22
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
To ale popisuje jen způsob uložení dat, ne to, jak se ta data čtou a zapisují.Jenže to spolu úzce souvisí - alignment. Přečti si komentář ještě jednou.
nic takovýho ale nevidím :-O).
16.2.2012 10:58
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
.
15.2.2012 15:07
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Předpokládejte, že minimální adresovatelná jednotka je 8 bitů a že se jedná o thready běžící na jednom jádře operující nad stejnou L1 cache. Systém dokáže adresovat každý člen struktury, ale kompilátor místo toho použije 32bitové instrukce, protože tím získá rychlejší kód. Všechno je v pořádku, kompilátor splňuje standard, ale výsledek je celkem na houby.Blbost. Mate prostredek, jak tomu zabranit:
struct test { uint8 a; uint8_t b;};
volatile struct test t;
Pokud to nepomuze, kompilator nesplnuje podminky standardu.
To by ale standard musel s thready počítat. Pokud s nimi nepočítá, může kompilátor zoptimalizovat kód tak, že je přímo načítá do 32 bitového registru, bez ohledu na to, zda může nebo nemůže být ta struktura sdílena mezi vlákny. A pořád bude vyhovovat standardu.Psal jsem o promenne alokovane na stacku, presneji o objektech s "automatic storage duration".
volatile, jinak je program závislý na konkrétní (a často nedokumentované a negarantované) implementaci překladače? Jak budou asi vypadat přeložené programy, kde to tak programátor skutečně použije?
15.2.2012 16:07
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Volatile je u vicevlaknovych aplikaci temer k nicemuMMIO?
16.2.2012 02:13
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
16.2.2012 10:46
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Ano, presne tak. Musite tam explicitne vlozit memory fence aby to probublalo nekam pres vrstvy cache dolu. Volatile to nedela, tudiz ty napady o synchronizaci vice vlaken s pouzitim volatile jsou uplne mimo.Já nikde netvrdil, že k tomu volatile stačí, nýbrž že pokud přijmete předpoklad, že překladač má právo přistupovat do nesouvisejících proměnných, tak bez volatile to zaručeně správně není. A nebylo by to správně ani v případě, kdybyste pečlivě volal externí funkci, která se postará o všechny cache a další nekoherentní části paměťové hierarchie.
16.2.2012 15:18
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
překladač má právo přistupovat do nesouvisejících proměnnýchTo ze jiny clen struktury muzete oznacit jako "nesouvisejici promenou" je dusledkem bodu specifikace popisujici layout struktury v pameti, ktery vsak pro bit-fields explicitne neplati. Uvedomte si, ze mluvite stale o clenu strukturu, nikoliv o nezavisle promenne, nezavisle entite. Pokud ji chcete pouzivat jako "nesouvisejici promenou" na vsech ISO C kompilatorech, nedavejte ji do struktury s bit-fields ci packovane struktury.
ktery vsak pro bit-fields explicitne neplati.Kde je to řečeno? Existuje nějaké místo ve standardu, kde by se mluvilo o tom, že struktury obsahující bit-fields se chovají jinak? To, které jste citoval minule, hovoří pouze o bit-field members a non-bit-field members a je aplikovatelné na všechny struktury, ať už v nich položky jednoho nebo druhého druhu jsou či nejsou.
16.2.2012 16:33
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
hovoří pouze o bit-field members a non-bit-field members a je aplikovatelné na všechny struktury,Ano, ano, ano! Pokud struktura obsahuje pouze non-bit-field members, mate garantovano jak vypada jeji memory layout. Pokud struktura obsahuje i treba jeden bit-field member, nevite jak je tam kompilator ulozil.
16.2.2012 17:19
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
struct test {
uint8_t a;
uint8_t b;
};
struct test t;
uint8_t aa = 0u;
t.a = aa;
t.b = aa;
Otazka: Proc si myslite, ze bit-fields byly vyslovne vyjmuty?
Otazka: Proc si myslite, ze bit-fields byly vyslovne vyjmuty?Aby jejich kodovani mohlo byt implementation-defined, nikoliv aby mohly ovlivňovat chování non-bit-fields.
16.2.2012 19:04
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
16.2.2012 21:10
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
struct test {
int a;
char b;
};
Je to container, obsahuje data s definovanou strukturou a alignmentem, poradi clenu je takove jak bylo deklarovano, cleny musi mit jmeno a muze se k nim pristupovat metodou pointer + offset, funguje operator offsetof(). V jazyku C od sameho pocatku.
B) Pak jsou tu bit-fields.
Syntaxe:
struct test {
unsigned:2;
unsigned:0;
unsigned:1;
}
Je to pytel bitu, vsechno je implementacne zavisle, cleny nepotrebuji jmeno, pristupovat k bitum metodou poiter + offset nelze nebot nemaji adresu a operator offsetof() nefunguje. Do jazyka pridany o neco pozdeji.
To znamena, ze struktury (A) a bif-fields (B) jsou v podstate uplne jine typy pouze deklarovane se stejnou syntaxi. Pak standard, jak je napsan, zacne davat smysl.
16.2.2012 21:28
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Volatile zde znamena "neprovadet cachovani".
16.2.2012 15:01
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
16.2.2012 15:37
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Ostatně na nekoherentní architektuře by každé synchronizační primitivum muselo vysypat celý obsah cache, což je neúnosné.Staci jen prislusne radky a pouziti synchronizacnich primitiv muze programator kontrolvat.
Mam tu ted pred sebou system kde dva modifikovane jadra Cortex M3 like sdileji L2 cache a pres L3 jsou spojeny s jadrem Cortex A8.Ve světě embedded systémů je samozřejmě možné cokoliv
Staci jen prislusne radky a pouziti synchronizacnich primitiv muze programator kontrolvat.Problém je, že klasické synchronizační primitivum nic neví o tom, které řádky cache patří do kritické sekce a které nikoliv. Takže mu nezbude než vysypat všechno.
16.2.2012 16:08
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Ve světě embedded systémů je samozřejmě možné cokolivTen SoC ma jeste DSP a Cortex A9, image processor, hw JPEG decoder, EMAC a vse to sdili jednu DDR. Z toho by se jeden po**al.
Problém je, že klasické synchronizační primitivum nic neví o tom, které řádky cache patří do kritické sekce a které nikoliv.Mohu flushovat i konkretni radky cache, a nebo i konkretni objekty v pameti (position, size); dobry sluha, zly pan.
Mohu flushovat i konkretni radky cache, a nebo i konkretni objekty v pameti (position, size); dobry sluha, zly pan.To jasně, ale už to pak nemohu ovládat klasickými POSIXovými synchronizačními primitivy.
16.2.2012 21:42
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
. Ale neříkám, že to nejde.
Jo? S Integrou jsou problémy? Já nemám žádnou desku, protože vrážet takový prachy do tý referenční od TI se mě nechce. V patičce to bylo v době, kdy nejlevnější a nejrychlejší ARM na trhu byl beagleboard s OMAP3. Teďka se stopro stav změnil (abych pravdu řekl, už před časem jsem začal přemýšlet na co patičku změnit ). Ta Integra byla dobrá, jelikož má MAC, PCIe a ~1GHz.
Až se bude prodávat něco s Cortex-A15 MPCore to bude jiný kafe .
17.2.2012 09:16
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
kompiler co nejvíc ušitý na míruTakovy existuje a dodava ho TI.
ručních multipassDela se to naprosto bezne, s trochou zkusenosti mate dobre vysledky; vyvoj jen v assembleru by nikdo nezaplatil a hlavne na to nejsou lidi.
S Integrou jsou problémy?S celou radou. Pracoval jsem na odvozenych procesorech driv nez byly uvedeny oficialne na trh. TI ma zvyk nechavat sve prvni zakazniky testovat jejich "produkcni" [alpha] knihovny, kdy nic stabilne nefunguje. Zkoncite mezi svym zakaznikem chtejicim funkcni vyrobek a TI, tvrdicim, ze problem resi a nic se mesice nedeje a zaroven neni dokumentace - jen binarky - kvuli know-how. Lepsi kupovat veci stare dva tri roky kdy to uz jini jejich zakaznici odladili.
takový prachy do tý referenční od TI se mě nechceZivotnost referencni desky pri vyvoji je tak 3-5 mesicu a pouziva se to nez mate svuj HW prototyp. Pro amatera vyhozeny prachy, zakladni EVM a JTAG a minimalni vyvojovy SW muze stat pres 2500 euro.
Ta Integra byla dobrá, jelikož má MAC, PCIe a ~1GHz.To ma, ale proc to potrebujete? Pokud si chcete hrat kupte si Beagleboard ci Pandaboard a usetrene penize radsi prochlastejte.
.
ad deska: Jo proto se ptám zda není nějaká levnější typu beagle(panda)board (v době psaní ještě nebyla verze s ethernetem). Měl jsem totiž takovou chuť (a pořád ještě mám) se na x86 totálně vykašlat a přejít na ARM. Problém byl v tom, že podmínky byly rozšiřitelnost (ve smyslu a rychlosti PCI(e) karet) přes cokoliv kromě usb, ethernet (taky radši ne přes usb - blé latence) a SATA (to usb nestíhá) a rychlost a paměťové nároky vtší než duron 600MHz. V tý době jsem našel jen Integru a po čase něco od Samsungu. Mezitím jsem ale výhodně koupil miniITX x86 desku, takže ta potřeba ARMu se zmenšila (ale taky mě stála ta x86 nemalý počet šedivých vlasů - f*ck socket P a M).
17.2.2012 19:40
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
horší by bylo pokud by byly fatální problémy s hw.Z vaseho hlediska je to jedno jestli je to HW nebo SW, vy mate binarni blob a nechodi to. Za binarnim blobem jsou schovany dalsi procesory a periferie a vy o nich nic oficialne nevite. BTW, integrace Ducati subsystem teto rady je pomerne zabugovana a je to chyba HW.
mě stála ta x86 nemalý počet šedivých vlasůTak s Integrou by to bylo mnohem horsi.
Tak s Integrou by to bylo mnohem horsi.Bude mít ale lepší dokumentaci a ani nebude mít problém s paticí
.
 15.2.2012 14:11
Voty | skóre: 12
| blog: gemini
15.2.2012 14:11
Voty | skóre: 12
| blog: gemini
static unsigned char a;
static unsigned char b;
vlakno_a()
{
while(true)
{
unsgigned tmp = a;
a++;
tmp++;
assert(a == tmp);
}
}
vlakno_b()
{
while(true)
{
unsgigned tmp = b;
b++;
tmp++;
assert(b == tmp);
}
}
Tedy, není nic ve strukturách, nejsou zapnuté různé packed věci atp, zaručuje mi standard C (C++), že toto bude fungovat (nevypadne na assert)?. Jinými slovy, může překladač v takovémto případě provést optimalizaci, že při modifikaci objektu a provede i modifikaci objektu b?
Dále bych měl otázku na proměnné na stacku, zda-li se tyto nějak liší, od statických, neboť ty přece můžu také sdílet mezi vlákny (myslím tím např. stack funkce, která tyto dvě vlákna spustí).
15.2.2012 14:13
Voty | skóre: 12
| blog: gemini
unsigned char tmp =
15.2.2012 14:32
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Jinými slovy, může překladač v takovémto případě provést optimalizaci, že při modifikaci objektu a provede i modifikaci objektu b?Ne, nemuze vkladat zavislosti.
Dále bych měl otázku na proměnné na stacku, zda-li se tyto nějak liší, od statických.Promenna na stacku nemuze byt sdilena mezi vlakny, je alokovana behem behu programu, staticka/globalni promenna je alokovana pri kompilaci.
15.2.2012 14:59
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
// thread fnc
int fnc(){
volatile int a; // predat pointer dalsimu vlaknu
for (;;) {
...
}
}
15.2.2012 17:51
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 19:38
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
... ostatních členů struktury může záviset ...Takhle standardy nefunguji. Ma psano co musite, zbytek neni vyzadovan a nelze na nej spolehat.
Takhle standardy nefunguji. Ma psano co musite, zbytek neni vyzadovan a nelze na nej spolehat.Jasně, že pokud vás zajímá jen to, zda překladač vyhovuje standardu, tak se na to nelze spolehnout. Jenže jak už jsem psal, pokud se spoléháte pouze na standard, nelze v C99 napsat korektní vícevláknový program, leda že by vše bylo volatile. Takže v praxi se spoléhá na "rozumné chování" překladače, tedy že překladač nebude dělat věci, které jsou sice formálně korektní, ale nedávají smysl. Překladač by úplně stejně jako na sousední položku struktury mohl sáhnout na nějakou naprosto nesouvisející proměnnou. Všichni víme, že to neudělá, a v životě na to takřka denně spoléháme. S C99 nelze lépe.
15.2.2012 20:30
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Překladač by úplně stejně jako na sousední položku struktury mohl sáhnout na nějakou naprosto nesouvisející proměnnou.To by byl samozrejme bug. C99 je fajn. Chece psat v portovatelny kod behajici na mnoha platformach, nebo jen v GCC?
compiler take ne, protoze za vas nemuze efektivne udelat cache management, lockovani ci uzivat memory barriers.To je pravda, ale aspoň mi nemusí házet klacky pod nohy, když si na cache management a spol. budu volat externí knihovnu.
Chece psat v portovatelny kod behajici na mnoha platformach, nebo jen v GCC?Zde je řeč o kernelu, takže GCC. Jinak se samozřejmě snažím psát portabilně, přesněji řečeno pro rozumné implementace C99 (korektní implementace klidně může omezit velikost zásobníku na 4KB a přesnost floatů 6 cifer, s čímž se nedá programovat, ale rozumná implementace to nikdy neudělá, takže mi to je jedno).
15.2.2012 22:31
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Nicmene pohadky o znemozneni vicevlaknoveho programovani neberu.Pokud byste se řídil čistě podle kombinace C99 a POSIX threads, tak korektní vícevláknový program prostě nenapíšete. Leda že byste úplně každou proměnnou označil jako volatile.
16.2.2012 00:18
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Leda že byste úplně každou proměnnou označil jako volatileMyslite kazdou sdilenou promennou? To jich sdilite tolik? K cemu vlastne volatile zde chcete pouzit?
C99 a POSIX threadsISO C a POSIX, rozdil je predevsim ve standardni knihovne jazyka - signals, system calls, raise() ktery muze poslat signal jinemu threadu, threads, pids, lepsi localizace, implementace knihovny muze byt vice "system specific". Ale standard vlastniho jazyka je vsak stejny (ISO C), tak jak vam to tedy zde pomuze?
Myslite kazdou sdilenou promennou? To jich sdilite tolik?Celou dobu se tady řeší problém, že kompilátor udělá sdílenou proměnnou z něčeho, co původně sdílené proměnná nebyla.
16.2.2012 09:03
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
On vam vygeneruje kod, kde pristup k promene s ohledem na task switch nebo interrupt muze mit side effect. To je ale celkem bezne pokud zapnete optimalizace - prelozte neco s gcc -02 a kouknete se na vygenerovany kod. Pokud byste chtel neco jineho, zabil byste nejdulezitejsi metody optimalizace na rychlost, vcetne veci jako je instruction reordering.Ne, žádná z těchto optimalizací nezpůsobí, že by program přistoupil k proměnné, která není ve zdrojáku vůbec použita. Instruction reordering se neprovádí přes hranice volání externích funkcí, o nichž překladač nic neví (takže je bezpečné volat synchronizační primitivum z knihovny).
Pritom, polopaticky, je to velmi jednoduche: prvky zapakovane struktury nebo struktury obsahujici bit-fields nemohou byt nikdy povazovany za samostatne entity a cela struktura pak musi byt vzdy chapana jako jedna promenna.Nesouhlasím. Nic takového se ve standardu nepíše (a když jsem se ptal, nebyl jste schopen žádné takové pravidlo odcitovat, pouze jste zmiňoval implementací definovaný alignment, ale ten se týká i struktur, které žádný bit-field neobsahují).
16.2.2012 09:47
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
nezpůsobí, že by program přistoupil k proměnné, která není ve zdrojáku vůbec použita.Chtel jsem ilustrovat, ze zpusobuji side effects, ktere narusi integritu v case a cini problemy pri task switch.
Nic takového se ve standardu nepíšeA jsme zpet. Standard negarantuje s ohledem na temer nulove pozadavky na umisteni bit-fields ve strukturach, ze budete moci cist prvky bez side effect.
zmiňoval implementací definovaný alignment, ale ten se týká i struktur, které žádný bit-field neobsahujíDulezite je, ze se explicitne netyka bit-fields. Jsou vyjmuty z pozadavku. V-Y-J-M-U-T-Y => nemate zadne garance na korektni alignment.
Standard negarantuje s ohledem na temer nulove pozadavky na umisteni bit-fields ve strukturach, ze budete moci cist prvky bez side effect.Standard neříká nic o tom, že by chování non-bit-fieldů mohlo být jakkoliv ovlivněno chováním bit-fieldů.
Dulezite je, ze se explicitne netyka bit-fields. Jsou vyjmuty z pozadavku. V-Y-J-M-U-T-Y => nemate zadne garance na korektni alignment.O alignmentu bit-fieldů také od začátku netvrdím vůbec nic. Jediné, co říkám, je, že přítomnost bit-fieldů nemá způsobit side-efekt na ostatních položkách.
15.2.2012 01:31
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 09:54
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 13:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 13:25
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 13:44
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 09:47
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 18:05
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 19:07
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
... aby nezasahoval mimo proměnné bitfieldsTo lze vynutit pomoci volatile. Proc to tedy zbytecne limitovat a zavadet jako defaultni chovani?
... vážně si procesor stáhne a uloží jediný byte, nebo natáhne do cache větší kus a tím prakticky udělá to samé ...Ano, udela totez, a je to jeste horsi. Cache se nacita ve vetsich blocich a tak muzete klidne nacitat i 2024 bytu kvuli jednomu byte. Navic, kdyz mate tri cache L1/L2/L3, kazda muze pouzivat jinou velikost radku a nebo byt sdilena s jinym jadrem. Pokud chcete vykon, musite optimalizovat memory layout aplikace a velmi casto i cache management - rikate kdy a ktere radky se maji radky zapsat do pameti. Dalsi krasna vec je DMA nebo dynamicke mapovani cache na rychlou pamet behem behu programu. Je toho plno a proto jsem skeptik, kdyz nekdo veri ze kompilator to vyresi.
Proc to tedy zbytecne limitovat a zavadet jako defaultni chovani?Protože je to v podstatě jediný způsob, jak generovat efektivní kód. Učinit z toho defaultní chování možná zabrání nějakým marginálním optimalizacím (zatím nikdo o žádné takové neví), psát ve všech takových případech volatile znemožní optimalizace úplně.
Ano, udela totez, a je to jeste horsi. Cache se nacita ve vetsich blocich a tak muzete klidne nacitat i 2024 bytu kvuli jednomu byte.Na korektnost to ovšem nemá vliv, jen na rychlost. Cache je koherentní.
15.2.2012 19:12
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
že ho nedovedou jednoduše opravit.Hardwarova limitace ... proto jsou pozadavky ohledne bitfields specificke a pomerne volne.
15.2.2012 17:29
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Jako například při operování s proměnnou pracovat i s nějakou jinou, úplně nesouvisející proměnnou.Dobre, tedy otazka. Jak chcete zabranit tomu, ze pri modifika aa neni i bb a cc nactena do pameti a zase zapsana zpet na systemu, ktery neumi zpracovavat data v blocich mensich nez byte (8bitu) a nepodporuje bitovou adresaci, bez toho aniz byste tam daval padding bytes?
struct test {
unsigned aa:1;
unsigned bb:2;
unsigned cc:1;
}
15.2.2012 18:13
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
15.2.2012 19:14
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
An implementation may allocate any addressable storage unit large enough to hold a bit-field. If enough space remains, a bit-field that immediately follows another bit-field in a structure shall be packed into adjacent bits of the same unit. If insufficient space remains, whether a bit-field that does not fit is put into the next unit or overlaps adjacent units is implementation-defined. The order of allocation of bit-fields within a unit (high-order to low-order or low-order to high-order) is implementation-defined. The alignment of the addressable storage unit is unspecified.Kde se zde hovoří o něčem jiném než bit-fieldech?
15.2.2012 20:12
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Within a structure object, the non-bit-field members and the units in which bit-fields reside have addresses that increase in the order in which they are declared. Each non-bit-field member of a structure or union object is aligned in an implementation- defined manner appropriate to its type.Ta vyjimka pro non-bit-field je umysl. Dusledkem je, ze non-bit-field members muzete pouzit i jako padding bytes, ale nemate garantovane ani jejich spravne poradi. Pokud jsou pouzity jako padding, nemate garantovano, ze pri jejich cteni se nectou i dalsi "normalni" cleny.
Nevím o jakékoliv klauzuli standardu, která by připouštěla, aby padding nesl jakýkoliv význam, kromě toho, že některé kombinaci padding bitů u integerů mohou trapovat.
15.2.2012 20:48
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
některé kombinaci padding bitů u integerů mohou trapovat.To je vec HW. Treba u ARMu lze vyjimku zakazat, u nektereho third party kodu jsem to musel udelat a sam se divim, ze to vubec chodi a vim jake auto nemam kupovat.
Vaše intepretace standardu mi přijde jako přinejmenším dost kreativníKomicke je, ze by to bylo formalne asi OK, ale stejne bych to nepouzil. Nemicham bit-fields a normalni data ve strukture, ale v kombinaci s union se daji delat hezke veci a union u clen struktury byt v pohode muze.
15.2.2012 20:54
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
GCC v seznamu implementation-defined vlastností uvádělo nějaké takhle obskurní pravidlo pro alignment :)Tusite kde?
volatile na 16bit a větší proměnné vůbec nezaručuje, že její obsah bude konzistentní. Tj. mezi čtením jednotlivých bajtů může přijít IRQ, v jehož obsluze se hodnota změní. Údajně je volatile jen taková pomůcka pro kompilátor, že nemůže přístup k dané proměnné optimalizovat - třeba vyhodit podmínku, která by v běžném kontextu byla vždy (ne)splněná.
Takže se musí v kritických místech používat ATOMIC makra, která zajistí zákaz přerušení. Zas kdyby to dělal kompilátor okolo každé operace s volatile proměnnou, cena by byla děsivá. Dost divoká je implementace těch ATOMIC konstrukcí - právě proto, že C toho moc nezaručuje, tak se to řeší nějak pomocí for konstrukce.
14.2.2012 03:11
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
14.2.2012 03:34
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
... integer type of an object that can be accessed as an atomic entity, even in the presence of asynchronous interrupts.Pokud nekdo pouzije jiny typ, i treba s volatile, a pak je prekvapen, ze to v interruptu nefunguje, je u chyba u nej, nikoliv bordel v C. U AVR to bude neco jako "typedef int8_t sig_atomic_t;" a pak je vse OK.
Údajně je volatile jen taková pomůcka pro kompilátor, že nemůže přístup k dané proměnné optimalizovat
Přesně tak, to je originální váznam volatile, že narozdíl od normální proměnné kompilátor nemůže předpokládat, že se hodnota té proměnné "samovolně" nezmění od instrukce k instrukci. Hodnotu ve volatile proměnné může kdykoli změnit externí vliv, jako např. jiný process, thread, hardware atd..., takže volatile proměnná se vždy načte. AFAIK toto a pouze toto zaručuje příznak volatile, nic víc.
Druhotné použití pak je vypnutí optimalizací (i když se hodnota "samovolně" nemění), na x86 se to například dá použít pro zajištění determinističnosti FPU (ale nestačí to bohužel samo o sobě).
a=1; a=2; nelze nahradit jedním přiřazením.
Když na to koukám líp a déle:
14.2.2012 10:23
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
GCC v této operaci nepředpokládá, že by program mohl běžet paralelně ve více vláknech na více jádrech.To neni chyba gcc, ale vlastnost C[99]; teprve novy standard prinasi thread model. Ohledne interruptu souhlas, to jde uplne mimo a C nabizi alespon neco (sig_atomic_t). Zverstva s bitovymi poli je jeden z duvodu, proc je kernel nezkompilovatelny jinym kompilatorem nez gcc, protoze to v mnoha pripadech narazi implementation-defined chovani.
To neni chyba gcc, ale vlastnost C[99]Ne, je to vlastnost GCC, která sice není formálně v rozporu se standardem, ale je v rozporu se zdravým rozumem.
Dnes si myslím, že bezzámkové vícevláknové programování je potenciálně užitečná věc právě kvůli škálování výkonu, ale je to zrádné koření vyhrazené pro největší mistry magie, v nepovolaných rukou nebezpečné (bez ohledu na zde probíranou "vlastnost" GCC).Tak jest.
Zdálo by se, že se jedná pouze o problém obskurní architektury IA64 - tzn. nikoli třeba x86_64.Nikoliv, problém byl už pozorován i na amd64.
Pokud je ta "skrytá manipulace s dvěma proměnnými zároveň" věcí výkonové optimalizace, spíš než "jinak to na dané architektuře nejde", slušelo by se, aby ta optimalizace šla vypnout nějakou cmdline opšnou GCC...Ona to vůbec není výkonová optimalizace, nýbrž artefakt velmi obskurní implementace bitfieldů, která se chová jinak, než autoři zamýšleli, a není podle všeho snadné ji opravit. Spíš ji bude potřeba celou přepsat.
15.2.2012 22:40
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
... velmi obskurní implementace bitfieldů ...Nemyslim. Na bit-fieldech je zajimave, ze na ne jsou minimalni pozadavky. Na stranu druhou to dava ohromnou flexibilitu, muzete pretypovat pointer na pointer na zapakovany bit-field a zpracovavat data, definovat vlastni binarni typy ci mapovat obskurni periferie.
Zrovna s tím mapováním obskurních periferií to není tak žhavé, protože pořadí bitfieldů ve struktuře není zaručeno.A to jsem se ty bitfieldy jak blbec učil používat na PIC24
.
16.2.2012 12:29
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
volatile proměnné jen samostatně, nikdy jako součást struktury, i když tam nebylo uvedeno proč přesně. Tenkrát jsem si říkal, že je to asi kvůli tomu, aby překladač nebral jako volatile celou strukutu, ale jak teď vidím, pravý důvod je mnohem děsivější.
Uživatelé neustále dokazují, že neví, jak souborový systém funguje
 13.2.2012 15:17
David Watzke | skóre: 74
| blog: Blog...
| Praha
13.2.2012 15:17
David Watzke | skóre: 74
| blog: Blog...
| Praha
 .
. Sice to taky neumí, ale má nejblíž.
.
. Sice to taky neumí, ale má nejblíž.
do {
orig_val = *mem;
new_val = orig_val|(1<<bit);
} while (!compare_and_swap new_val, orig_val, mem);
Zajímalo by mě, jestli to teda standard upřesňuje více, nebo ne.Z toho, co říká o reprezentaci elementárních typů, plyne, že storage units nemohou být mezi různými proměnnými (či položkami struktur) sdílené, s výjimkou toho, že jednu storage unit může sdílet více bit-fieldů. Jinak i na IA64 je storage unit 8 bitů.
Lze ve starším standardu (řekněme klasicky ANSI89) vidět něco o těch storage units ?Myslím, že prakticky totéž, co v C99.
standard hovoří o tom, jak je to uloženo, nikoliv jak se s tím pracujeTo je podle mne právě ten problém, který znemožňuje ve vícevláknových aplikacích spoléhat se jen na standard. U jednovláknové aplikace skutečně stačí vědět, jak je to uložené. U vícevláknové to už ale nestačí a je potřeba vědět i to, jak se s tím pracuje - respektive musíte mít nějaká rozumná omezení toho, jak se s tím pracovat může.
Znamená to tedy, že synchronizačními funkcemi (např. v pthreads) musím pokrýt operace ve struktuře častěji než bych chtěl, jelikož se nelze vyvarovat toho, že kompilátor sáhne i na jinou storage unit, než by šlo explictně usoudit z mého C kódu.Pokud tahle možnost vyplývá jenom z toho, že nikde ve standardu není napsáno, že při práci s bitovým polem kompilátor nesmí sáhnout i na vedlejší bajty, pak to není omezené jen na struktury. Protože stejně tak nejspíš není ve standardu napsáno ani to, že při práci s jakoukoli jinou proměnnou nesmí kompilátor sáhnout na vedlejší (nebo jakékoli jiné náhodné) bajty. Kdyby to totiž ve standardu explicitně pro různé proměnné uvedeno bylo a pro bitová pole ne, dá se z toho celkem jednoduše odvodit, že pro bitová pole tuto možnost standard připouští a že chyba je jednoznačně na straně jádra. A to se myslím nestalo.
18.2.2012 00:08
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
struct test {
unsigned:2;
unsigned:0;
unsigned:1;
}
jsou jedina moznost, jak programator muze vytvorit bitovy objekt. Kompilator ho vezme a implementacne zavislym zpusobem ho ulozi do implementacne zavisle storage unit.
CHAR_BIT bitů. Vše ostatní je už definováno pomocí bytů, speciálně sekce 6.2.6.1 říká: "Except for bit-fields, objects are composed of contiguous sequences of one or more bytes."
O storage units, do nichž se ukládají bit-fieldy, se nikde neříká nic konkrétního. Speciálně standard nespecifikuje, v jakém vztahu jsou tyto units s byty. Možnost, že by v jedné takové storage unit byl uložen současně bit-field a něco jiného, není nikde explicitně zmíněna.
18.2.2012 04:30
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
O storage units, do nichž se ukládají bit-fieldy, se nikde neříká nic konkrétního. Speciálně standard nespecifikuje, v jakém vztahu jsou tyto units s byty.Ano. V pre-ANSI verzi C byly standardni typy povazovany take za bit-field types, ktere ale maji nejaky format, a po zavedeni verze se struct to bylo vypusteno, s tim ze je to plne interni vec kompilatoru a platformy. Reziduum je ze muzete u bit-fields sice psat normalni typ, ale je to fakticky k nicemu. Vztah mezi units a byty neni asi potreba; vy jako programator nemate moznost ulozit cokoliv do storage unit a navic ani nevite jak je to tam ulozeno. Spise je lepsi rozumet, co se podle standardu stane pri kombinaci normalnich typu a bit-fields. Podle mne to vyplyva to z pozadavku na struktury a take z toho jak je definovan korektni alignment. Chapu to tak, ze je to cyklus, kde se zacina od prvniho az do posledni deklarovaneho clenu. Pokud je to normalni typ s alignmentem umisti se clen na prvni vyssi zarovnanou adresu. Pokud je to bitfield, umisti se jeho storage unit za predchozi clen, zadny alignment neni garantovan, storage unit musi byt adresovatelna a bitfield se tam musi vejit. Pokud je nasledujici clen opet bit-field, muze byt ulozen do predchozi storage unit. Dale, protoze u storage unit se nebere ohled na alignment, muze se umistit do pozice, kde by normalne byly padding bytes nutne pro alignment nasledujiciho typu. Proto se zavadi i unnamed bit-fields, ktere lze pouzit pro vynuceni memory layoutu:
struct test {
uint32_t a;
:5;
uint32_t b;
:5;
:0;
unsigned c:5;
};
Sirka :0 zde znamena otevri novou storage units, nevkladej do predchozi (takze predchozi storage unit je doplnena padding bity).
S takovym memory layoutem nemate moznost diskretniho cteni. To se muzete pokusit zlepsit zarovnavanim storage unit, ale stejne nevite kolik je tam bit-fields. A kdyz umistite jeden bit-field do jedne storage unit a ty zarovnate, nema smysl to vubec pouzivat, kdyz vam to prida k 1b dalsich 7b. Pak je lepsi normalni uint[8,16,32]_t, kdy vite jak to vypada uvnitr a bity si vymaskujete.
Pokud nekdo pouziva tenhle implementacne zavisly neportovatelny hybrid, tak par povolenych a beznych side effectu mezi sequence points pri zapisu nebo cteni by ho nemelo prekvapit. A opet, protoze adresace bitfields nefunguje, chapu gcc, ze precetlo cele slovo do registru a bity, co potrebovalo si vymaskovalo, nejjednoduzsi a nejrychlejsi a u nekterych instrukcnich sad a memory layoutu jedine mozne.
Jak to ovlivni volatile, nevim, asi se tam vlozi padding.
Dale, protoze u storage unit se nebere ohled na alignment, muze se umistit do pozice, kde by normalne byly padding bytes nutne pro alignment nasledujiciho typu.Zde se skrývá jádro pudla. Souhlasím s Vaším popisem toho, jak se struktury skládají do paměti, ale neshodujeme se v tom, jaké to má důsledky. Nemyslím si, že by z citovaného pravidla cokoliv plynulo o chování předchozího nebo následujícího (nebo jakékoliv jiného) prvku struktury. Po storage units obsahujících bit-fieldy se tak jako tak musí objevit správné množství paddingu tak, aby byl následující prvek správně zarovnán. Chování předchozího prvku by nemělo být ovlivněno čímkoliv, co leží za ním, protože je beztak správně zarovnán. Problémy mohou nastat jedině v případě, kdy je předchozí prvek typu, k němuž nelze přistupovat přímo, a překladač se musí uchýlit k read-modify-write. Například stará Alpha 21164 neuměla přímo přečíst nic menšího než 32 bitů, takže ve struktuře
struct xyz {
char a;
int b:4;
}a přečetl a zapsal i b. Jenže to by se stalo i tehdy, kdyby b nebyl bit-field, ale char.
[Mimochodem, ono tohle chování charů na Alphě je vůbec poněkud na hraně korektnosti: lze opravdu považovat za "addressable storage unit" něco, co nelze změnit samostatně?]
Sečteno a podtrženo:
char, všechny jevy, které popisujete, mohou nastat také.
18.2.2012 15:14
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Po storage units obsahujících bit-fieldy se tak jako tak musí objevit správné množství paddingu tak, aby byl následující prvek správně zarovnán.Ano, pokud nasledujici prvek neni storage unit, ale o tom zde nebyl nikdy spor. U bitfieldu vam nic nezarucuje ani to, ze storage unit ma velikost byte; pokud chcete automaticky zajist garantovane "chovani bez predlozenosti", musite fakticky zajistit jejich primou adresovatelnot metodou pointer+offset, coz se nevyzaduje a pak ztratite duvod je pouzivat, nebot uz nebudou mit co nabidnout oproti jinym typu.
[Mimochodem, ono tohle chování charů na Alphě je vůbec poněkud na hraně korektnosti: lze opravdu považovat za "addressable storage unit" něco, co nelze změnit samostatně?]Dopad takovych HW limitaci je bezna vec. U struktury a bit-field je to asi OK, ono se rozlisuje mezi "mit adresu" a "byt adresovatelny". Prvni znamena pristup pointerem, druhy ze pomoci nejake adresy se k tomu kompilator dostane a bity nejakym kodem vyextrahuje. Vam je stejne primy pristup k nicemu, nevite jak storage unit uvnitr vypada. U objektu mimo strukturu by to byl jiste bug.
Nevidím jediné místo ve standardu, které by nás opravňovalo myslet si, že se přítomností bit-fieldů cokoliv změní. Kdyby na místě bit-fieldu byl char, všechny jevy, které popisujete, mohou nastat také.Ne, ne, ne. Alingment of storage units je vyslovne uvaden jako unspecified behavior, cejch vyvrhele (i v Annex J), coz fakticky o bit-fieldech rika: programatore, pokud se ti bit-fields na jedne platforme a kompilatoru chovaji nejak, nepocitej s tim, ze na jine to bude stejne a pokud na to spolehas, tvuj program nemusi vubec fungovat. Hure, ono se to muze chovat jinak i pokud jen zmenite zdanlive nesouvisejici parametry stejneho kompilatoru pro stejnou platformu (treba gcc -O2). U charu nic takoveho nemate, dokonce bych rekl, ze char-y jsou implicitne portabilni a konzistentni vzdy a vsude. Char a bit-field jsou nebe a dudy. Cokoliv s bitfields, je spise zalezitost dobre viry. BTW, u safety & security review-ovaneho kodu s bitfields se akceptuji jen konstrukce jako
union PORT {
struct {
volatile unsigned : 25;
volatile unsigned cc : 5;
volatile unsigned bb : 1;
volatile unsigned aa : 1;
} bitfields;
volatile uint32 reg;
};
a jen proto, ze to jinak nejde. Tim si trochu vynutite ono "chovani bez predlozenosti", s vyjimkou indianness. Pokud ne, je treba tvure kompilatoru bit, tlouci a mlatit dokud to neopravi.
Speciálně POSIX Threads nemohou bez předpokladu, že se do nesouvisejících hodnot nezapisuje, vůbec fungovat.POSIX standard nevyzaduje od kompilatoru vice nez ISO C kompatibililtu; ale netreba plakat, C11 to resi.
POSIX standard nevyzaduje od kompilatoru vice nez ISO C kompatibililtu;Standard výslovně ne, prakticky libovolné jeho použití ano. Nechť v programu deklaruji
int i;
int j;i a druhé jen j. Podle C99 je zcela korektní, aby překladač do kódu prvního vlákna přidal "j++; j--;. Ovšem běh programu to zcela rozbije.
18.2.2012 15:55
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Podle C99 je zcela korektní, aby překladač do kódu prvního vlákna přidal "j++; j--;.Neni to korektni pokud pouzijete volatile, ale jak uz jsme rekli, volatile diky nedostatecnym memory fence multithreading neresi. Pri optimalizaci na rychlost se osklive triky bezne delaji, naucte se s tim zit. Minuly rok jsem byl na prednasce o C++11 a byli tam i jeho tvurci ze standardizacni komise. A prvni recnicka otazka byla, jestli vime, co je nejbezpecnejsi vec na svete. Odpoved: dva language lawyers v jedne mistnosti, a my jsme tady ctyri. Pomalu bych to ukoncil. Diky za diskuzi a nekdy jindy.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz