3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
FreeCAD (Wikipedie), tj. svobodný multiplatformní parametrický 3D CAD, má nový vtipný a současně užitečný doplněk Banana For Scale (GitHub). Aktuálně umožňuje do výkresu vložit banán nebo plechovku pro porovnání a určení měřítka.
Blender Studio nedávno oznámilo plán vytvořit svůj první otevřený (open source) celovečerní film. Film by se měl jmenovat Overgrown (YouTube). Film vznikne, pokud se zajistí financování. Prvním krokem je získat 7 000 předplatitelů Blender Studia. Cena je od 11,50 eur měsíčně. Aktuálně počet předplatitelů je 5 289. Předplatné pokryje 20 % nákladů. Zbytek, 80 % nákladů, má být financován externími producenty nebo distributory.
Byl vydán Debian 13.6, tj. šestá opravná verze Debianu 13 s kódovým názvem Trixie a Debian 12.15, tj. poslední patnáctá opravná verze Debianu 12 s kódovým názvem Bookworm, k dispozici je LTS. Řešeny jsou především bezpečnostní problémy, ale také několik vážných chyb. Instalační média Debianu 13 a Debianu 12 lze samozřejmě nadále k instalaci používat. Po instalaci stačí systém aktualizovat.
V jádře Linux byla nalezena a v upstreamu již byla opravena kritická zranitelnost GhostLock aneb CVE-2026-43499. Lokálnímu uživateli umožňuje získat práva roota a také obejít kontejnerovou izolaci. Zranitelnost existovala v Linuxu 15 let, tj. od roku 2011, od Linuxu verze 2.6.39.
Evropská komise předběžně shledala, že návykový design aplikací Instagram a Facebook od americké společnosti Meta porušuje unijní nařízení o digitálních službách (DSA). Návykový design zahrnuje například takzvané nekonečné posouvání, automatické přehrávání videí, tzv. push notifikace, kdy aplikace uživatele vybízí k návratu do jejího prostředí, či vysoce personalizovaný algoritmus, který rychle pozná, co uživatele baví a snaží
… více »
A protivné je to tehdy, pokud se jedná o konfigurační soubory a chci si něco zjistit-vytáhnout v normálním malučkém skriptíku. Samozřejmě lze použít některé knihovny a není jich málo — což je možná také „potíž“.
No, a oni (ti zlí xml dokumenti) mě dohnali k tomu, udělat si něco na úrovni bash-e. Pokud to ovšem mělo být jednoduché, nešlo se na „ně“ dívat, jak na XML strukturovaný dokument, ale zpracovávat je trochu jiným „jednodušším způsobem“.
Chtěl jsem udělat jen něco jako transformační script, co z toho udělá něco čitelného, ale pak mě to zaujalo, tak jsem tam ještě něco doplnil, z čehož vznikl takový, ne úplně čistý kód, nicméně vypadá, že funguje. By-design si neporadí se smíšeným kontejnerem (obsahující text i další tagy), nicméně na kulturní XML dokumenty funguje, nebo se tak minimálně tváří.
Funguje to tak, že zlý dokument se prochází a uchovává se jen informace „co“ se našlo minule a „co“ teď a dle toho se to sype ven (jako: »minule tag, nyní obsah −> vypiš to«).
Cesta se vypisuje tečkami oddělená (ve výchozím stavu) a hodnota se vypíše za „rovná se“, pokud se jedná o atribut, tak je uvozen „zavináčem“ a komentář „křížkem“ (včetně DOCTYPE). Hodnota má napraveny HTML entity & > < ", všechny '\' jsou zdvojeny a všechny nové řádky jsou jako '\n', tedy výpis každé entity je jednořádkový (a běžným echo-em lze hodnotu vypsat, tak jak má být).
Ve výsledku to znamená že mám(e) rozumně zpracovatelný výpis typu key=value.
No a jak jsem uvedl, „zaujalo mě to“, tak jsem doplnil jednoduchá přepínače
No a ve výsledku už s tím lze příjemně pracovat, ne že by z některou knihovnou nešlo taky a i líp, ale toto je nezávislé maličké. Nicméně vzhledem ke způsobu zpracování dokumentu, se to spíš musí otestovat, než revizí kódu prohlásit 'OK'.
Na ukázku jsou přiloženu dva, snad lehce pochopitelné, obrázky (aby si to náhodou někdo nekopíroval do schránky :) ), kde jsem něco vyčetl z nějaké policy a pak z definice VM.
Opět se zopakuji: Protože zde nelze vložit přílohy, tak je to tu
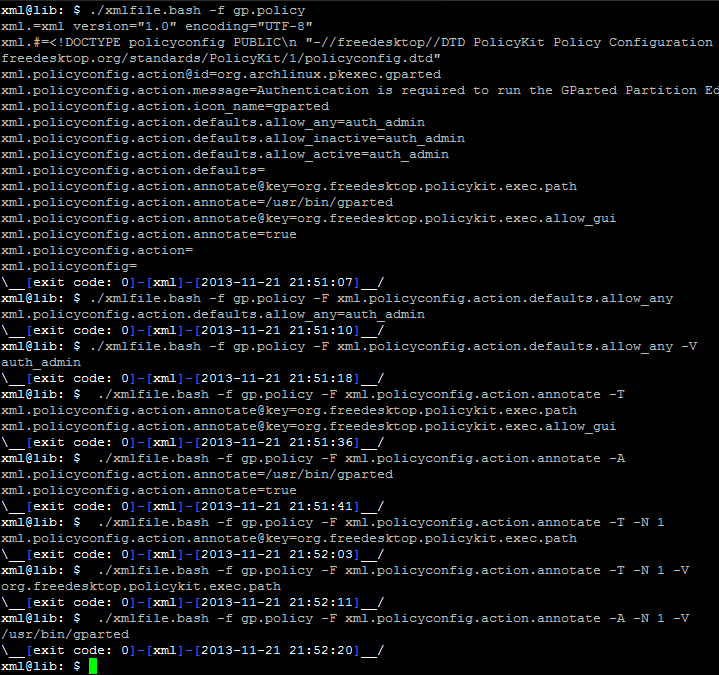
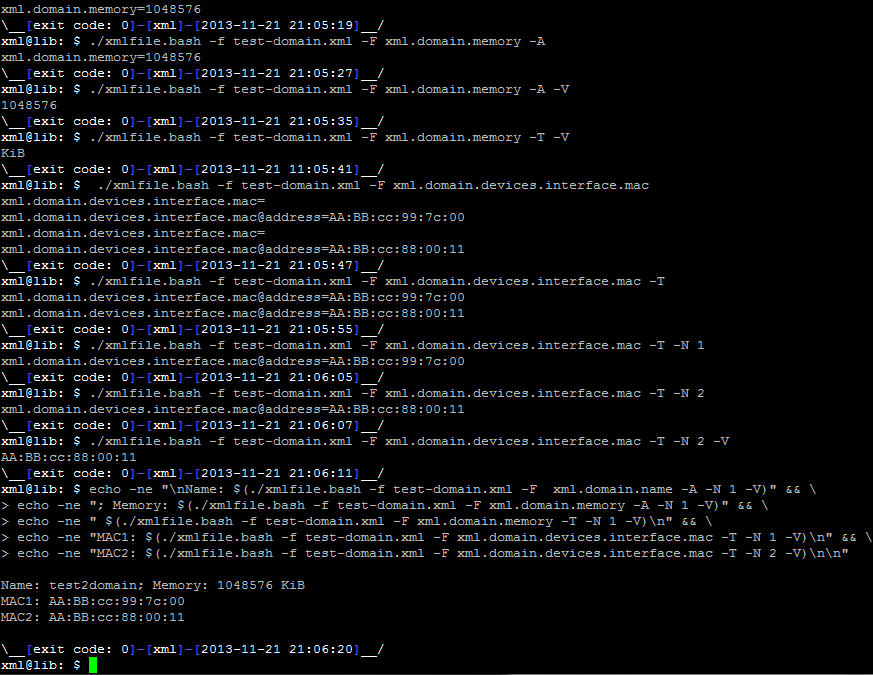
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 21.11.2013 20:22
xkucf03 | skóre: 50
| blog: xkucf03
21.11.2013 20:22
xkucf03 | skóre: 50
| blog: xkucf03
Svojho casu som si na netrivialnu strojovu upravu velkych XML dokumentov napisal bashove skripty, ktore rozobrali XML do stromovej struktury na filesysteme a spatne to dokazali identicky poskladat (so zachovanim poradia elementov na rovnakej urovni).
Tohle už mě taky napadlo – chtěl bych to ale jednou implementovat jako FUSE souborový systém, XML by to upravovalo v přímém přenosu (po každém zápisu do souboru), umožnilo by to editaci libovolných XML dokumentů a ještě by je to mohlo online validovat proti XSD nebo jinému schématu (nešlo by některé soubory zapsat, dokud by neměly platný obsah – např. číslo, datum, regulární výraz).
21.11.2013 23:10
xkucf03 | skóre: 50
| blog: xkucf03
jj, tohle by se muselo řešit nějak v názvech souborů1 nebo přes rozšířené atributy.
pořadí_názevElementu@názevAtributupořadí_cokoliCDATA by se dalo označit pomocí rozšířených atributů nebo nějak zakódovat do názvu souboru.
A pak nějak ošetřit jmenné prostory – v kořenovém adresáři by mohl být soubor s jejich mapováním na prefixy a případně by je šlo kódovat do názvů souborů.
A pak půjde jako XML editor používat MC 
[1] např. pokud název bude obsahovat znak „_“, tak to před jeho prvním výskytem bude pořadí a to za ním bude název elementu
21.11.2013 20:17
xkucf03 | skóre: 50
| blog: xkucf03
Převádíš XML dokumenty na výpis typu key=value, abys je pak mohl grepovat? To mi přijde, jako kdybys nadiktoval dopis sekretářce, ta ho vytiskla, naskenovala, prohnala ORCkem, vytiskla do PDF a odfaxovala přes VoIP virtuálním faxem.
P.S. přílohu dej do komentáře, ať je to na jednom serveru společně se článkem a neztratí se to.
Ten postup je myslím špatně, nevidím paralelu vysvětli. (Ten grep není třeba).
PS: To už jsem kdysi udělal, ale teď čekám a budu čekat, že „někdo“ doplní možnost přidat přílohu ke článku
 21.11.2013 23:37
pavlix | skóre: 54
| blog: pavlix
21.11.2013 23:37
pavlix | skóre: 54
| blog: pavlix
$ xpath domain.xml 'string(/domain/devices/interface/mac/@address)'
Query didn't return a nodeset. Value: 24:42:53:21:52:45
$ xpath domain.xml '/domain/memory/text()'
Found 1 nodes:
-- NODE --
131072
Achjo. Nevěděl jsem, že je to tak jednoduché. 
Odpověď na otázku „o co s snažíš?“ bude mít velký průnik s odpovědmi na otázku „proč neexistuje jen jedna knihovna?“
Ale konkrétně jsem se snažil/snažím vyřešit třeba: Když ten nebo jiný balíček nemáš? (Konkrétně třeba PartedMagics) nebo nemůžeš stahovat balíčky). Nebo nechceš pro script dohazovat závislosti kvůli prkotině?
xmllint z balíčku
libxml2. Konkrétně xmllint --xpath přidali ve verzi 2.7.7. Coz sice
porad v tom PartedMagics distru neni, ale v beznych distribucich typu debian zcela
jiste bude již naistalovaný.
21.11.2013 23:39
pavlix | skóre: 54
| blog: pavlix
string() z toho vybere jen první výskyt (aneb i XPath má svá temná zákoutí). Prakticky jsou tyhle konverzní operace použitelné jen pro porovnávání.
22.11.2013 17:44
xkucf03 | skóre: 50
| blog: xkucf03
Třeba konfiguráky bych psal radši snad i v SQL než v JSONu, protože tam komentáře jsou Pokud to má číst a psát člověk, jsou komentáře obrovská výhoda nebo spíš nutnost. A pokud to má číst a psát stroj, tak rozšířit parser o podporu komentářů už nedá moc práce (a na straně generátoru je nemusíš podporovat vůbec).
22.11.2013 17:47
xkucf03 | skóre: 50
| blog: xkucf03
BTW: tahle debata se tu cyklicky vrací, tak jen stručně. Podle mého v sobě JSON kombinuje ty horší vlastnosti různých formátů. Když nemá komentáře, nemusí být ani čitelný/zapisovatelný člověkem – klidně se může použít nějaký binární formát a bude to mnohem efektivnější. Ale když si to hraje na lidsky čitelný text, tak tam komentáře být měly.
Ale nemuzu si nerypnout, kdyz o citelnosti mluvi clovek, co ma (pry) rad XML.Ale on napsal
Ale když si to hraje na lidsky čitelný text
Poznámky k poznámkám:
Vetší znalosti a zkušenosti než co?
Jako nejlepsi cestu zde kolegove jiz zminili konzolove utility na praci s xml. A když je nemáš, tak jaká je cesta?
Odstrašující příklady jsou všude, a toto je jeden z nich (neporadí si s jakýmkoliv XML-kem), XML je super formát, ale na druhé straně je to s ním často jako s obrázkem TIF, každý ho umí zapsat, ale 100% přečíst jakýkoliv, už je pěkná věda.
Ad CSV:
Tok sorry, ale to je krávovina, pokud se bavíme o CSV, tak sice nemá žádnou normu, ale existuje k němu RFC-čko. Pokud soubor není podle něho, tak mu neříkejme CSV (navíc když je oddělené středníkem či tabem , tak už na to není právo ani „jazykově“).
A pokud někdo označí MIME text/csv, tak to musí být „comma“, používajíc " a končící CRLF.
22.11.2013 12:45
xkucf03 | skóre: 50
| blog: xkucf03
Jako nejlepsi cestu zde kolegove jiz zminili konzolove utility na praci s xml.A když je nemáš, tak jaká je cesta?
Vždyť je to otázka zadání aptitude install libxml-xpath-perl nebo ekvivalentu v jiné distribuci. Pokud to fakt nejde, tak bych to řešil přes Javu, Perl nebo Python (jedno z toho tam mít budeš) a knihovnu přibalenou k programu (v Javě už máš dokonce všechno v JRE).
P.S. neber prosím tyhle komentáře tak, jako že jsi něco zveřejnil a teď ti za to lidi nadávají prostě jen takové zamyšlení, jak bych to řešil já – i když já si taky občas napíšu něco sám, než abych používal hotové programy/knihovny, prostě NIH Každý má občas pocit, že něco udělá jinak, jednodušeji a lépe než ti před ním.
Zmínil jsem třeba PartedMagics (,který se nám fčul nějak komercializoval) třeba nic rozumného nemá, a mám další dvě distra(, kde minimálně jedno další taky nemá) na flashce, a vždy s tím udělám cokoliv je potřeba na desktopu i na serverech při fyzickém zásahu, a doplnit si tam balíček není úplně tak jak píšeš. Na flashce mám samozřejmě i další skripty a přece neotevřu v daném bodě 'vim' s hláškou najdi sekci bla-bla a opiš atribut 'x' pokud atribut 'y' je 'a' jinak tam napiš 'ahoj', stejně tak pokud třeba mám minimální instalaci nějakého stroje, tak nebudu k vůli každé prkotině instalovat nový balíček a pak při update řešit na co to má vliv, nebo že bych tam dokonce nainstaloval JRE a zahrál si třeba na SAXofon (a přihodil k vůli němu i RAM ).
PS: To tak vůbec neberu (někdy přemýšlím, jestli má odpověď není zbytečně „útočná“, ale politikaření mě nebaví…). Hledal bych tam naprosto to samé a čekal jsem přesně tento typ argumentů a i jsem přemýšlel, jestli mi to za to stojí, ale pak jsem si řekl, že třeba má někdo podobné důvody a třeba mu to pomůže. Už se mi párkrát podařilo udělal něco líp než ti ostatní, kteří si to pak přebrali, takže má smysl to dělat, ale toto je trochu jiný případ.
Jo, pokud dělám parser, tak oddělovač, text ohraničovač, konec řádků, hedaer yes/no a znaková sada musí být (jakože to tak udělám) jako volba, protože to sice pak není CSV i když to někdo tak pojmenuje, ale má to tu strukturu (např. text/tab-separated-values , či ten SSV) a lze to použít.
OT: CSV prostě nemůže být ze středníky, ani dle RFC, ani zkratka jako taková nefunguje
PS: Existence komentářů je pro mně také novinka a není mi jasné, jak se mohou implementovat, podle mně to není možné.
 22.11.2013 16:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2013 17:14
pavlix | skóre: 54
| blog: pavlix
22.11.2013 17:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2013 16:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2013 17:14
pavlix | skóre: 54
| blog: pavlix
22.11.2013 17:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 23.11.2013 21:33
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
23.11.2013 21:33
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
virsh či policykit (vybral jsem si je v ukázkách).
24.11.2013 07:19
pavlix | skóre: 54
| blog: pavlix
virsh je hrozně zprasené samo o sobě.
Zprasené je cokoliv co na konfiguraci používá XML zvláště když je to CLI a pokud se do toho ještě zamotají atributy, tak je to už fakt úlet. Asi chápu proč to tak udělali, bo to ty informace „má“ předávat, ale zas na druhé straně, lze očekávat, že bude třeba i „jednoduché“ získávání informací, takže implementace „normálního“ výstupu by nikomu nic neudělalo, nebo případně alespoň definovaná vyšší restrikce nad XML, což je velmi výjimečně k vidění (typu, každý klíč je unikátní, odřádkování je vždy po entitě, použíté jsou jen tyto HTML entity a je to vždy utf-8), ale když je někdo -píp- a použije i atributy, tak je to zabité.
Má to aspoň svobodnou licenci
24.11.2013 13:12
xkucf03 | skóre: 50
| blog: xkucf03
alespoň definovaná vyšší restrikce nad XML, což je velmi výjimečně k vidění (typu, každý klíč je unikátní, odřádkování je vždy po entitě, použíté jsou jen tyto HTML entity a je to vždy utf-8), ale když je někdo -píp- a použije i atributy, tak je to zabité.
OMG, to jsou kecy. Já zase nemůžu z toho, když někdo spatlá miliontý „jednoduchý textový formát“ a já se musím po milionté učit, jak se oddělují klíče a hodnoty, jestli jsou na koncích řádků středníky, jak se píší komentáře, jestli jsou hodnoty v uvozovkách a jak a jestli jsou tam struktury, jestli se používají třeba složené závorky, nebo jednoduché nebo nějaká obskurní parodie na XML jako u Apache.
XML máš parsovat XML parserem a jestli jsou atributy na stejném řádku nebo na novém tě nemá vůbec zajímat. Nic jako klíče1 tam není – jsou to uzly, elementy a těch tam z principu může být víc2. Pokud to má být nějak omezené, můžeš použít atribut, ten tam bude maximálně jednou nebo takové omezení napiš do XSDčka.
Z praktického hlediska: když budu chtít „vyzobat“ nějaké hodnoty z XML konfiguráku, stačí mi na to jednoduchý XPath dotaz nebo si napíšu jednoduché XSLT, které to převede na něco jiného (třeba XHTML, které si může otevřít i BFU a podívat se, co v tom konfiguráku je a jaký to má význam). Když budu chtít udělat totéž (např. z nějaké sekce vytáhnout určité hodnoty), musím nejdřív nastudovat syntaxi daného „jednoduchého textového formátu“ a pak si vzít na pomoc třeba Perl a napsat v něm program na pár řádků. Neříkám, že to nejde, ale je to méně standardní a pracnější.
[1] resp. jedinečným klíčem může být atribut id
[2] např. seznam souborů, seznam oprávněných uživatelů, seznam domén
Už vím, že miluješ XML a tedy nejsi objektivní - mimo jiné, uvědomuješ si, že když je to tak udělané, jsou v zásadě spokojené obě skupiny (pro XML i lehce parsovatelné). Pokud někdo považuje XML-ko bez atributů za čitelné a ručně upravitelné, tak to pochopím, ale pokud si to někdo myslí i o XML-ku s atributy, tak je pro mě XML fanatik. Konfiguráky mají být ručně snadno editovatelné a čitelné. XML-ko vzniklo jako universální výměnný formát. Jako nativní formát, se hodí jen na něco, a dle mého, konfiguráky to určitě nejsou.
PS: Ony jsou to klíče (i když ne unikátní), pokud jsou jedinečné, struktura je tam informace navíc, kterou lze použít nebo ne. U spoustu XML dokumentů záleží na pořadí.
OT: A spousta aplikací kolabuje při parsování XML dokumentů, protože načítá DOM (místo čtení založeném na event-ech), nejlepší je když se ještě validuje dokument vůči šabloně a na prkotinu potřebuješ gigabajty paměti. Navíc je XML-ko strašně ukecané a nepomáhá ani komprimace. Přimlouval bych se, používejme jej jen tam kde je třeba, tedy při mezi aplikační výměně dat.
24.11.2013 14:44
xkucf03 | skóre: 50
| blog: xkucf03
ale pokud si to někdo myslí i o XML-ku s atributy, tak je pro mě XML fanatik.Pořád nechápu, co máš proti těm atributům – proč by mělo být špatně:
<element atribut1="hodnota1" atribut2="hodnota2"/>a chtěl bys radši:
<element>
<atribut1>hodnota1</atribut1>
<atribut2>hodnota2</atribut2>
</element>
Vždyť ti to dá i méně práce napsat ručně atribut než element.
Ony jsou to klíče (i když ne unikátní), pokud jsou jedinečné, struktura je tam informace navíc, kterou lze použít nebo ne.Že ta cesta od kořene k textovému uzlu tvořená názvy elementů je jedinečná, to je jen vedlejší efekt, může to tak být a nemusí. Kdekoli v té cestě může být nejedinečnost (více stejnojmenných elementů na stejné úrovni) a to je na tom právě to krásné a mocné. Můžu mít např. více virtuálních serverů a v každém mít více adresářů a každý z nich má jiná přístupová práva (např. povolení pro uživatelské skupiny), nebo tam je něco z toho jen jednou. Vždyť ten XPath je vlastně ten klíč, který potřebuješ – v nejjednodušším případě je to jen cesta tvořená názvy elementů pospojovaná lomítky. Akorát tam můžeš (když potřebuješ) občas připsat hranatou závorku a do ní nějaký filtr na atributy nebo další vlastnosti. Prostě místo:
aaa.bbb.opice.cccnapíšeš:
/aaa/bbb[@nazev='opice']/cccnebo
/aaa/bbb[1]/cccPřičemž to druhé a třetí (XPath) je standardizované a má to jasná obecná pravidla, zatímco to první se bude lišit formát od formátu, někde budeš psát tohle, jinde třeba
bbb.1.ccc nebo ještě hůř bbb1.ccc.
U spoustu XML dokumentů záleží na pořadí.To je bohužel chyba toho, kdo DTD nebo Schéma pro daný formát navrhoval – dá se to udělat i tak, že na pořadí nezáleží (a mělo by se to tak dělat, jinak je to zbytečná buzerace)
24.11.2013 14:53
xkucf03 | skóre: 50
| blog: xkucf03
P.S. nebo zápis více hodnot – viz jeden reálný příklad (raději nebudu jmenovat, ale diskutovali jsme to tu na Ábíčku) resp. odstrašující příklad, kde se v jednom konfiguráku vícenásobné hodnoty zapisovaly jednou jako čárkou oddělené:
nějaký_klíč=hodnota1,hodnota2
a jinde pro změnu:
nějaký_jiný_klíč1=hodnota1 nějaký_jiný_klíč2=hodnota2
V XML prostě vložíš víckrát ten element a nemusíš tam dělat takové prasárny – je to hezké a systematické.
key=value1 key=value2a
<key>value1</key> <key>value2</key>Nemám nic proti:
key=value1,value2pokud je to třeba set modulů, je to vlastně normální pole.
Ano, rozhodně bych chtěl to druhé, když už to má být ukecané, tak ť je to i čitelné a lehce parsovatelné...
Že ta cesta od kořene k textovému uzlu tvořená názvy elementů je jedinečná, to je jen vedlejší efekt, může to tak být a nemusí.
Je bezva, když to není vedlejší efekt, a že to sem tam někdo i dá do specifikace.
Můžu mít např. více virtuálních serverů a v každém mít více adresářů a každý z nich má jiná přístupová práva (např. povolení pro uživatelské skupiny), nebo tam je něco z toho jen jednou.Toto
[server] name=server1 [dir] path=/kuk perm=777 [server] name=server2 [dir] path=/kukoo perm=555 [dir] path=/kukuu perm=444je úplně to samé co to XML-ko, rozdíl je jen v tom, že toto čteš (od předu do zadu) a xml-ko parsuješ.
Neustále nechceš přijmout to, že s běžným texťákem lze pracovat jakkoliv, kdežtože s XML-kem rozumně jen pomocí XML parseru a že z toho není každý nadšený.
To je bohužel chyba toho, kdo DTD nebo Schéma pro daný formát navrhoval – dá se to udělat i tak, že na pořadí nezáleží (a mělo by se to tak dělat, jinak je to zbytečná buzerace)To jakože bych se u těch elementů ještě uvedlo pořadí a pak se setřídilo - tak tomu říkám buzerace zas já.
24.11.2013 16:10
xkucf03 | skóre: 50
| blog: xkucf03
Toto…
Tam ti právě chybí informace o struktuře. Jak mám poznat, že [dir] patří pod [server] a není to jen jiná položka na stejné úrovni?
Nějaké náznaky vnořených strukturu jsem v INI souborech občas viděl, ale nevím o tom, že by to bylo nějak standardizované. Něco ve stylu [sekce\podsekce], ale tam je problém právě v tom, že tam chybí ta identita – nevíš do které sekce ta podsekce patří – tzn. je to použitelné jen pro struktury, kde je všechno maximálně jednou.
Případně by se dalo vymyslet něco jako:
[sekce] a=b [.podsekce] c=d [..podpodsekce] e=f
Kde by záleželo na pořadí, na kontextu a nějak bys tam vyznačoval úroveň zanoření. Ale to jsou už fakt obskurnosti.
Neustále nechceš přijmout to, že s běžným texťákem lze pracovat jakkoliv
Ano, pro strojové zpracování XML potřebuji parser případně další knihovny, ale vtip je v tom, že tyhle nástroje aspoň existují – u jiných formátů ani neexistují nebo dokonce chybí i formální specifikace formátu – celé je to na vodě, někdo si z hlavy vymyslel „formát“ napsal ukázkový soubor a napsal proceduru/funkci (schovanou kdesi v jeho programu), která tento formát umí načíst a vytvořit v paměti struktury daného jazyka nebo během načítání průběžně volat nějaké jiné funkce, které cosi zkonfigurují.
Příklad: Dejme tomu, že chci znát práva k adresáři /kukoo v serveru server2.
V případě XML napíšu něco jako:
//server[@name='server2']/dir[@path='/kukoo']/@perm
V případě toho textového formátu si asi vezmu na pomoc Perl a v něm budu iterovat přes jednotlivé řádky, vytvořím si pár pomocných proměnných, nějaký ten IF a taky se výsledku nakonec nějak doberu.
Případně použiji nějaký hotový parser INI souborů, ale opět budu muset napsat nějaký ten cyklus a nějaké ty IFy, abych si z toho vytáhl požadovanou hodnotu.
To jakože bych se u těch elementů ještě uvedlo pořadí a pak se setřídilo - tak tomu říkám buzerace zas já.
Nerozumím. Myslel jsem, že se bavíme např. o případu, kdy v elementu komponenta můžu nakonfigurovat věci jako volba1 a volba2. Z podstaty věci na pořadí nezáleží, ale přiložené DTDčko mě nutí uvést nejdřív volbu1 a až pak volbu2 (což já z hlavy nemůžu vědět a pamatuji si jen názvy těch voleb, tudíž je to opruz trefovat to správné pořadí). Formální schéma někdo navrhl špatně, příliš přísně a měl to udělat tak, aby to šlo zapisovat i v jiném pořadí (což udělat lze).
Pokud naopak na pořadí záleží, tak považuji za správné, aby se bralo pořadí, v jakém jsou uvedené elementy v XML dokumentu a nemusely se tam doplňovat např. atributy pořadí="1" atd.
24.11.2013 16:17
xkucf03 | skóre: 50
| blog: xkucf03
BTW: jeden z mých (mnoha) rozpracovaných projektů je nástroj, který bude převádět různé formáty na XML1 a umožní provádění XPath dotazů nebo XSLT transformací např. nad INI nebo YAML soubory případně dalšími formáty. Takže pokud se někomu hnusí2 psaní XML dokumentů, může je psát v něčem jiném, ale přesto bude mít k dispozici ten ekosystém XML nástrojů – XPath, XQuery, XSLT, XSD, Schematron… Tudíž si budeš moci zvalidovat INI soubor proti schématu nebo z něj vytáhnout nějaké hodnoty XPathem.
[1] přesněji řečeno SAX události, takže půjde proudově zpracovávat „nekonečné“ soubory
[2] nebo je naopak nucen používat jiný formát, i když by radši dal přednost XML
24.11.2013 19:12
xkucf03 | skóre: 50
| blog: xkucf03
Pokud by se upravil parser JSONu o to, aby klíč nemusel být v uvozovkách a doplnily se komentáře
Ano, tak už by to nebyl tak na hovno formát a možná by to na tu konfiguraci šlo použít. Jenže už by to nebyl JSON. (trefil jsi přesně dvě věci, které mi na něm vadí nejvíc)
25.11.2013 11:20
xkucf03 | skóre: 50
| blog: xkucf03
ale pro strojově zpracovávaná data (read-write), do kterých uživatel zasahuje ručně jen málo, ale hodí se je mít čitelné i bez programu, je to super, protože absence komentářů značně zjednodušuje jejich rekonstrukci při ukládání upraveného souboru.
Zajímavé je, že u XML tohle lze – komentář je prostě jen jeden z typů uzlu. Lidsky čitelné i bez programu to taky je. A kdybych potřeboval hodně optimalizovat, tak použiji binární formát (i za cenu toho, že pro prohlížení člověkem bude potřeba nějaký program – třeba Wireshark, ve kterém se různá binární data zkoumají dost pohodlně). Nějak pro ten JSON prostě nemám využití (ale dokážu si představit využití pro INI soubory nebo YAML).
komentář je prostě jen jeden z typů uzlu.V tom je právě ta potíž. Takovéhle věci nesktečně komplikují aplikaci, která ty soubory zpracovává. Na JSON stačí v podstatě hash tabulka a seznam, u dostatečně dynamických jazyků je to ještě jednodušší. V podstatě můžeš JSONem přímo krmit objekty a po opětovné serializaci takových objektů do JSONu nepřijdeš o data, např. o komentáře, styly, DTD a podobně.
25.11.2013 13:47
xkucf03 | skóre: 50
| blog: xkucf03
Ale vždyť ten komentář je jen prvek seznamu – a je jiného typu, takže ho při běžném zpracování budeš ignorovat (ale necháš ho tam) a při serializaci se zase normálně zapíše.
Dejme tomu, že máš uzel „konfigurace“ a v něm uzly „virtuálníServer“ a pak třeba uzly „popis“ nebo něco dalšího a pak ještě komentáře. Funkce, která má zkonfigurovat virtuální servery bude iterovat přes ty prvky a pokud je jejich typ virtuální server, tak je zpracuje (nebo se to filtrování udělá nějak jinak). Tohle je dobré i kvůli kompatibilitě – v konfiguráku můžou přibýt nové volby a stará verze programu je bude ignorovat (nebo jen vypíše varování, že něčemu nerozumí).
25.11.2013 16:34
xkucf03 | skóre: 50
| blog: xkucf03
Ale jistě, syntakticky to oddělené je <!-- komentář --> vs. <element/>, ale to nebrání v tom, aby parser načetl i ty komentáře a dalo se s nimi nějak dál pracovat, je-li to potřeba – když je ale parser zahodí/přeskočí, tak už to nemůžeš bezztrátově číst/zapisovat, což je pro nějaké aktualizace dost na nic. Tohle se dá aplikovat u programovacího jazyka, kde ty komentáře fakt lze zahodit, ale pokud je to ne-programovací jazyk pro popis dat, tak by mělo být možné ty komentáře zachovat a přitom měnit data.
25.11.2013 16:35
xkucf03 | skóre: 50
| blog: xkucf03
P.S. a po načtení a převodu na nějaké struktury/objekty programovacího jazyka je to zase oddělené na úrovni datových typů (komentář bude jiného typu než text, element, atribut…).
Nevím jak ostatní, ale případy jako uvedený případ s VS bych teda raději rozdělil na jednotlivé soubory (a adresáře) s normálními konfiguráky, pak je to hezky spravovatelné, oddělené, změny jasně identifikovatelné na minimálním celku a na jednu obrazovku se vleze maximum informací.
Podle mě, na výměnu informací jak XML tak JSON je OK, ale na konfiguráky s ohledem na správu je to často monolitické utrpení. Tyto informace by měli ukládat s ohledem na uživatele a správce, ne s ohledem na to vývojáře. Registry jsou také strukturované řešení totálně na prd...
24.11.2013 19:29
xkucf03 | skóre: 50
| blog: xkucf03
Nevím jak ostatní, ale případy jako uvedený případ s VS bych teda raději rozdělil na jednotlivé soubory (a adresáře) s normálními konfiguráky, pak je to hezky spravovatelné, oddělené, změny jasně identifikovatelné na minimálním celku a na jednu obrazovku se vleze maximum informací.
jj, tohle je taky možnost – použít jako formát souborový systém a popsat tu stromovou strukturu pomocí adresářů a souborů – pokud jich nebudou sta tisíce (u běžné konfigurace snad nehrozí), tak je to v pohodě. Uvnitř těch souborů pak může být prostě struktura klíč=hodnota (akorát je potřeba dohodnout kódování a formát zápisu víceřádkových hodnot, případně nějaké to escapování, pokud by klíč měl být libovolný řetězec a mohl obsahovat znak =). S tím by se pak dalo velmi dobře pracovat a i by se to hezky verzovalo (už ve verzovacím systému bys viděl, v jaké sekci se dělaly změny). Akorát by trochu chyběl ten celkový pohled – všechno na jedné obrazovce – ale na to by se dal napsat celkem jednoduchý nástroj, který by to pospojoval a čitelně naformátoval.
No.., - je to léty odzkoušená možnost.
Obsah '=' je řešen automaticky, klíč nemůže obsahovat '=' a pak nás zajímá jen první '='.
Víceřádkový text není zrovna častá věc, ale stačí to řešit prázdným řádkem (+ klasický escape netisknutelných znaků).
24.11.2013 16:21
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
OMG, to jsou kecy. Já zase nemůžu z toho, když někdo spatlá miliontý „jednoduchý textový formát“ a já se musím po milionté učit, jak se oddělují klíče a hodnoty, jestli jsou na koncích řádků středníky, jak se píší komentáře, jestli jsou hodnoty v uvozovkách a jak a jestli jsou tam struktury, jestli se používají třeba složené závorky, nebo jednoduché nebo nějaká obskurní parodie na XML jako u Apache.S týmto som fakt nemal nikdy problém a pri tom nepoužívam klikátka a softvér si nastavujem cez konfiguráky. Dobre napísaný konfigurák má všetku nápovedu v sebe a nepotrebuješ nič hľadať. Zato nepoznám jediný softvér čo používa XML a niesu s ním problémy, našťastie už nič také nepoužívam.
[...], nebo případně alespoň definovaná vyšší restrikce nad XML, což je velmi výjimečně k vidění (typu, každý klíč je unikátní, odřádkování je vždy po entitě, použíté jsou jen tyto HTML entity a je to vždy utf-8), ale když je někdo -píp- a použije i atributy, tak je to zabité.Právě jsi popsal JSON
24.11.2013 18:43
xkucf03 | skóre: 50
| blog: xkucf03
Který je pro konfiguráky nepoužitelný (mj. kvůli chybějícím komentářům) a odřádkování neřeší – klidně to může být všechno namaštěné na jednom, takže to stejně negrepneš nebo nezpracuješ v nějakém cyklu po řádcích.
24.11.2013 19:15
xkucf03 | skóre: 50
| blog: xkucf03
jj, YAML je relativně dobrý (ve srovnání s JSONem určitě)
25.11.2013 11:33
xkucf03 | skóre: 50
| blog: xkucf03
Kéž by to mělo nějakou specifikaci a nemělo tak těsnou vazbu na PHP a Nette…
23.11.2013 22:23
xkucf03 | skóre: 50
| blog: xkucf03
Keď budem chcieť nejaké štruktúry, tak použijem syntax like C.
Existuje nad tím nějaký dotazovací jazyk – něco jako XPath pro XML nebo SQL pro relační databáze?
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 22.11.2013 17:19
22.11.2013 17:19