HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Aneb malé povídání o n-gramech a Rku. Honzíkovi slibuji, že to bude mít větší hodnotu a lepší formátovaní než minule!
O co nám dnes půjde? Na vstupu máme titulky (anglické) z kompletní první série seriálu Southpark a budeme zjišťovat, jestli se v textu neobjevují nějaké opakující se patterny. K analýze nám poslouží tradičně jazyk R a jeho knihovny textcat, tau a k zobrazení výsledků pak wordcloud.
Jako první si někde obstaráme textové soubory s titulky, které budeme analyzovat. Ty umístíme do jednoho adresáře, v našem případě nazvaném "southpark", a s tím již pracujeme v R. Dále načteme potřebné knihovny a vytvoříme korpus, který bude obsahovat náš adresář.
library(textcat)
library(tau)
library(wordcloud)
korpus <- Corpus(DirSource("southpark", encoding="UTF-8"), readerControl = list(language = "en"))
Dále si do proměnné ngramy uložíme výsledek funkce textcnt, které předáváme v parametru n řád n-gramu. Postupně jsem to provedl pro n=1, 2, 3 a 4.
ngramy <- textcnt(korpus, method = "string",n=3)
Abychom mohli výsledek zobrazit jako wordcloud, musíme jej převézt z formátu textcnt na dataframe. To řeší následující příkaz:
df <- data.frame(word = names(ngramy), freq=unclass(ngramy))
Zbytek již je opakování z minula:
pal2 <- brewer.pal(8,"Dark2")
png("wordcloud_ngram.png", width=1024,height=768)
wordcloud(df$word,df$freq, scale=c(10,.2),min.freq=3,
max.words=150, random.order=FALSE, rot.per=.15, colors=pal2)
dev.off()
V prvním kroku nám vyjde úplně normální wordcloud, který je dosti nevypovídající - nebyla použita žádná stopwords, a tak převládají členy "a" a "the".

V dalším kroku pro n=2 je výsledek již zajímavější. Mezi nejčastějšími spojeními dvou slov se nám již objeví "south park", ale pořád to hyzdí nicneříkající "have to", "are you" a podobné.

U n=3 začíná být výsledek již opravdu zajímavý. Mezi nejčastějšími tříslovnými výrazy se objevují věci jako "oh my god", což je klasická Cartmanovská hláška, popřípadě "Terrance and Phillip" podle které Southpark zcela jistě identifikujeme a "Kathie Lee Gifford", která prostě musí zemřít!

A máme tady zlatý hřeb večera - n=4! Zde dominuje především asi nejvíce WTF věta "hut hut hut hut", u které doteď nevím co znamená. Southpark se dá rozeznat podle "my god they killed" a "a big fat ass". Pro n-gram pro čtyři slova je problematická především malá délka vstupního textu, kvůli čemuž máme velmi málo výsledků a nejsou příliš reprezentativní.

Jako bonus jsem spočítal a vykreslil do grafu vzdálenost slov "killed", "kenny" a "bastards" v jednotlivých epizodách. Výsledek zde:
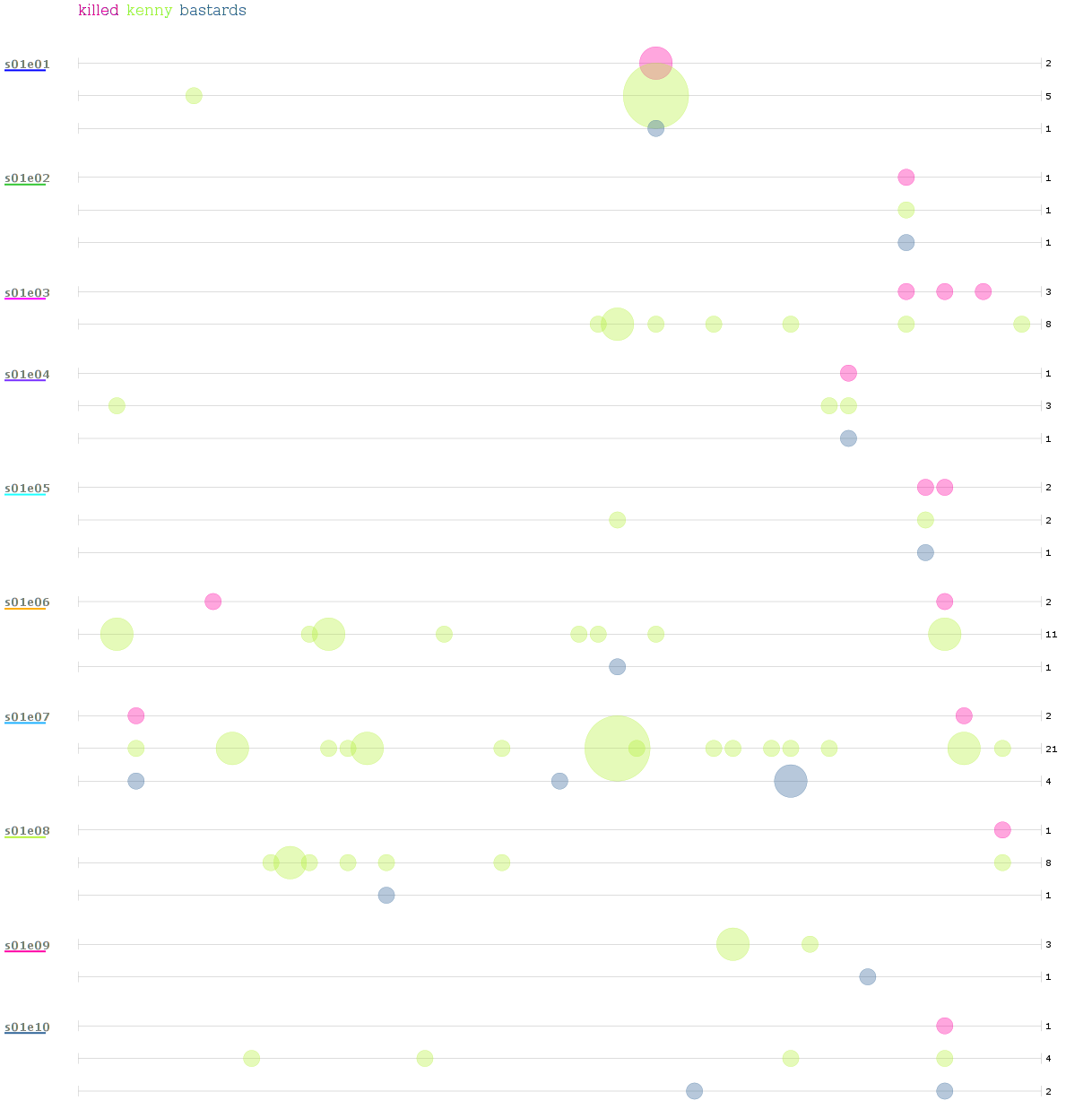
Měření dopadlo úspěšně a nebyl při něm nikdo zraněn. Na pár příkladech jsme si předvedli, jak analyzovat text z pohledu výskytů sousloví. Největší smysl dávají asi 3-gramy, u kterých jde relativně dobře poznat, jaký text byl analyzován. U kratších spojení narážíme na přílišnou obecnost, zde by bylo potřeba implementovat zakázaná slova. U delších je pak problém v krátkosti textu. Pokud byste si chtěli něco podobného zkusit a nechtěli si při tom složitě instalovat R a hledat, které RStudio je nejlepší, vyzkoušejte online Voyant-tools. O kostičku se hlaste v komentářích!




Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 2.2.2014 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
2.2.2014 23:58
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
3.2.2014 00:10
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
2.2.2014 23:01
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
2.2.2014 23:58
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
3.2.2014 00:10
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 2.2.2014 23:50
AsciiWolf | skóre: 41
| blog: Blog
2.2.2014 23:50
AsciiWolf | skóre: 41
| blog: Blog
 3.2.2014 10:03
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
3.2.2014 10:03
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
 3.2.2014 21:22
Agent
| blog: Life_in_Pieces
| HC city
3.2.2014 21:22
Agent
| blog: Life_in_Pieces
| HC city
 5.2.2014 09:44
grubber | skóre: 6
| blog: grubber
| Břeclav / Brno
5.2.2014 09:44
grubber | skóre: 6
| blog: grubber
| Břeclav / Brno
Zde dominuje především asi nejvíce WTF věta "hut hut hut hut", u které doteď nevím co znamená.Že by More crap?
5.2.2014 17:04
pools | skóre: 19
| blog: Svědek Damdogův
| Opava/Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 3.2.2014 11:02
3.2.2014 11:02