Národní úřad pro kybernetickou a informační bezpečnost (NÚKIB) se zapojil do mezinárodní iniciativy vedené americkou agenturou CISA (Cybersecurity and Infrastructure Security Agency) a dalšími partnery, jejímž cílem je stanovit minimální náležitosti pro tzv. Software Bill of Materials (SBOM). Nový dokument přináší praktická doporučení, jak by měl vypadat přehled komponent softwaru a jak s ním v praxi pracovat. SBOM lze
… více »V aktuálním přehledu vývoje renderovacího jádra webového prohlížeče Servo (Wikipedie) bylo oznámeno vydání nové verze 0.4.0. Výrazně se zlepšilo vykreslování stránek jako lichess.org, Zulip nebo Speedtest.
Vládní CERT upozorňuje (𝕏) na kritické zranitelnosti v produktech VMware: CVE-2026-59309, CVE-2026-59310 a CVE-2026-47876. Zranitelnosti v VMware vCenter umožňují vzdálenému útočníkovi se síťovým přístupem obejít autentizaci a získat neoprávněný přístup k vCenter, případně zneužít directory traversal ke spuštění libovolného kódu na vCenter.
Společnost Coinkite upozorňuje na bezpečnostní chybu svých hardwarových kryptopeněženek Coldcard. Jedná se o kritickou chybu v generování náhodných čísel (RNG). Místo hardwarového generátoru náhodných čísel (TRNG) byl omylem používán softwarový fallback (PRNG).
Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.

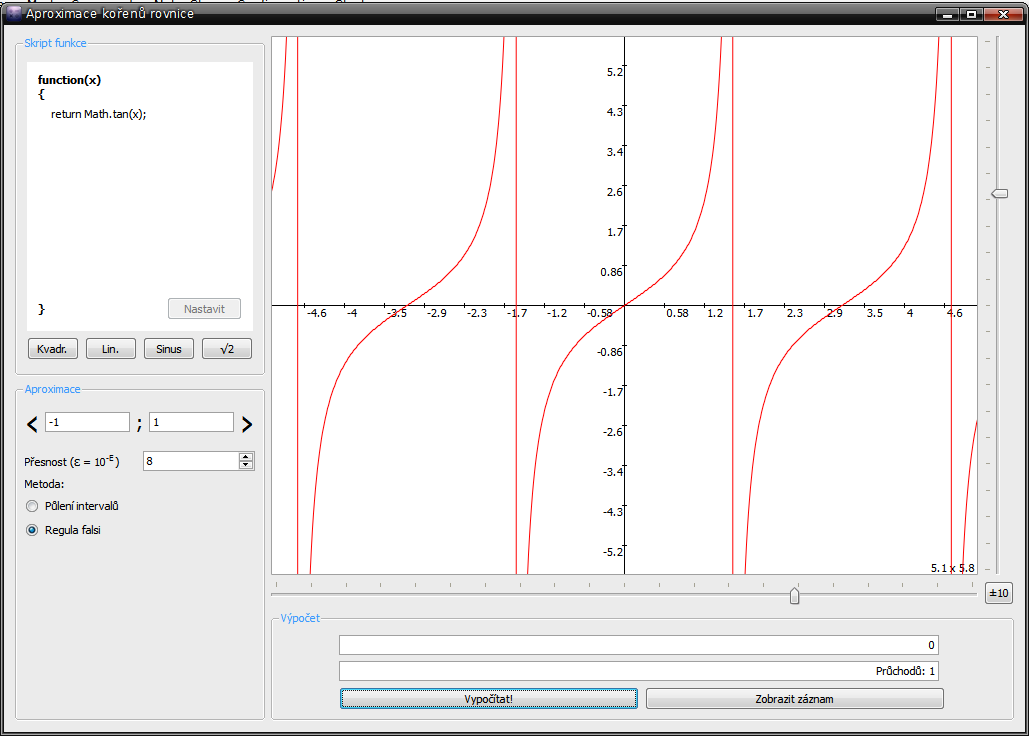
 Tak jsem pokročil se svojí semestrálkou (Graf funkce) a konečně jsem implementoval do stromu funkcí možnost se "zkompilovat" do strojového kódu. Zatím to tedá má implementováno jen podporu konstant, proměnných a umí to operaci sčítání, ale je to super rychlý. Schválně jsem udělal cyklus o 50000000000UL iteracích (teď si nejsem jistý, jestli tam bylo u nulu víc nebo míň, už jsem ten cyklus smazal
Tak jsem pokročil se svojí semestrálkou (Graf funkce) a konečně jsem implementoval do stromu funkcí možnost se "zkompilovat" do strojového kódu. Zatím to tedá má implementováno jen podporu konstant, proměnných a umí to operaci sčítání, ale je to super rychlý. Schválně jsem udělal cyklus o 50000000000UL iteracích (teď si nejsem jistý, jestli tam bylo u nulu víc nebo míň, už jsem ten cyklus smazal  ), který vyhodnocuje strom normálně (jsou tam virtuální metody na vyhodnocování, takže pomalost zaručena) a pak cyklus, který to vyhodnocuje zavoláním toho vygenerovaného strojového kódu jako funkci. Funkce byla "+1+x+pi+2+pi+(3+pi)+x+pi+pi+(x+(x+pi)+x)". Zatímco v druhém případě trval cyklus 62 sekund a pár drobných, v prvním případě jsem čekal 4 minuty a stále nic, tak jsem mu věnoval kill Sice můj kreslič grafů asi nebude kreslit 50000000000 funkčních hodnot, ale vždycky se hodí ušetřit nějaký ten taktík procesoru ...
), který vyhodnocuje strom normálně (jsou tam virtuální metody na vyhodnocování, takže pomalost zaručena) a pak cyklus, který to vyhodnocuje zavoláním toho vygenerovaného strojového kódu jako funkci. Funkce byla "+1+x+pi+2+pi+(3+pi)+x+pi+pi+(x+(x+pi)+x)". Zatímco v druhém případě trval cyklus 62 sekund a pár drobných, v prvním případě jsem čekal 4 minuty a stále nic, tak jsem mu věnoval kill Sice můj kreslič grafů asi nebude kreslit 50000000000 funkčních hodnot, ale vždycky se hodí ušetřit nějaký ten taktík procesoru ...
Update: vlastně, ono to bude kreslit i víc funkcí najednou, takže když bude pan tester zlej a nasází tam tisíce funkcí s úmyslem mi to schodit ...update end
Dodatek pro nechápavé () "Kompilátor" zatím generuje jen x86_64 kód, používá SSE2 instrukce a podpora 32bit má malou prioritu (i když by asi spočívala v pouhém přepsání rax na eax ).
A navíc mi to pak zdržuje Cairo knihovna, je to strašně pomalej šmejd. Věnoval jsem ji kreslení funkce na (1000*šířka okna v pixelech) s následným škálováním dolů na (šířka okna v pixelech) a trvá ji několik sekund takovou čáru vykreslit (+ do toho ještě počítání funkčních hodnot, ale to později přijde na resize okna, takže se jí trochu uleví). Bohužel nepotěším __dark__a, to tajné si s tím také moc rychle neporadí (kresleno přes drawPath()). Zdá se mi to sice o trošičku rychlejší, ale o moc ne. BTW nepoužívá Cairo (kdo co) Agg (koho co)? Se mi ty výstupy včetně antialiasingu zdají naprosto identické BTW AsmJit jsem nevykradl, mám to tam hardcoded instrukce přímo ve zdrojáku, zatím mi to stačí. ... i když v portu pro tajné bych ho použít mohl, když už ho to používá, ale do zadání semestrálky jsem si hold kydnul Gtk/cairo, tak teď s tou pomalou mrchou musím žít
A ještě malý tip:
... Cursor (*pXCreateFontCursor)(Display*, unsigned int); void (*pXDefineCursor)(Display*,XWindow,Cursor); ...
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
PC: Intel Quad Q6600 4x@2.4GHz
OS: Gentoo Linux, 64-bit
quantity = 100.000 ops
operation size = 128x128
(mt) = multithreaded, 4 threads
Fill Rect Fill Path Linear Gradient Radial Gradient Blit Image Celkem
Fog 2,138483 19,504839 3,045745 44,114807 3,420949 72,224823
Fog (mt) 0,688641 14,268885 0,852112 11,051629 0,997409 27,858676
Cairo 2,194677 54,638788 24,212126 121,435137 4,13704 206,617768
Ještě mě brzdí drawPath()/fillPath(), ale už vím jak to líp paralelizovat
Zkoušel. Ještě tam zkusím zapnout ten multithreading, ten jsem nezkoušel. Ale mám jen dvoujádrák
 30.5.2009 14:46
Jardík | skóre: 40
| blog: jarda_bloguje
30.5.2009 14:46
Jardík | skóre: 40
| blog: jarda_bloguje
...
_unitSize = 40;
_extraPerPixel = 1000;
...
void FunctionWidget::onPaint(PaintEvent* e)
{
Painter* p = e->painter();
p->setProperty(StubAscii8("multithreaded"), Value::fromInt32(1));
p->setSource(0xFFFFFFFF);
p->clear();
RectF r(x1(), y1(), width(), height());
double xAxisPos = r._h / 2.0 + _xAxisDelta; // y coordinate of x-axis
double yAxisPos = r._w / 2.0 + _yAxisDelta; // x coordinate of y-axis
Path path;
p->setSource(0xFF000000);
// draw y-axis (if visible)
if (yAxisPos <= r._w && yAxisPos >= 0)
{
path.moveTo(PointF(yAxisPos, 0));
path.lineTo(PointF(yAxisPos, r._h));
p->drawPath(path);
path.clear();
}
// draw x-axis (if visible)
if (xAxisPos <= r._h && xAxisPos >= 0)
{
path.moveTo(PointF(0, xAxisPos));
path.lineTo(PointF(r._w, xAxisPos));
p->drawPath(path);
path.clear();
}
if (_functions.length() > 0)
{
size_t n = _functions.length();
// calculate start and end X values for functions
double x_val_start = (-(r._w / 2.0) - _yAxisDelta) / _unitSize;
double x_val_end = (((r._w / 2.0) - _yAxisDelta) / _unitSize);
p->setLineWidth(_extraPerPixel+1);
AffineMatrix affine;
affine.scale(1.0/_extraPerPixel, 1.0/_extraPerPixel);
p->setMatrix(affine);
for (size_t i = 0; i < n; ++i)
{
// if the functions has been successfully parsed
if (_functions[i]->_parseResult.tree)
{
// set function color
p->setSource(_functions[i]->_color);
paintFunction(p, _functions[i]->_parseResult, x_val_start, x_val_end, xAxisPos);
}
}
affine.scale(_extraPerPixel, _extraPerPixel);
p->setMatrix(affine);
}
p->flush();
}
30.5.2009 19:28
Jardík | skóre: 40
| blog: jarda_bloguje
30.5.2009 15:10
Jardík | skóre: 40
| blog: jarda_bloguje
dload(). Sice je volání celé mašinerie překladač+linker poněkud overkill, ale je to plně přenositelné (alespoň v unixech) a oproti interpretaci je to o mnohem, mnohem rychlejší.
 30.5.2009 14:47
hikikomori82 | skóre: 18
| blog: foobar
| Košice
30.5.2009 19:42
Jardík | skóre: 40
| blog: jarda_bloguje
30.5.2009 14:47
hikikomori82 | skóre: 18
| blog: foobar
| Košice
30.5.2009 19:42
Jardík | skóre: 40
| blog: jarda_bloguje
 30.5.2009 16:12
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
30.5.2009 19:43
Jardík | skóre: 40
| blog: jarda_bloguje
Ale když k tomu přidáme ten strojový kód, tak se dá říct, že i ve strojovém kódu
30.5.2009 20:24
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
30.5.2009 20:46
Jardík | skóre: 40
| blog: jarda_bloguje
) a při vyhodnocování se zavolá
30.5.2009 16:12
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
30.5.2009 19:43
Jardík | skóre: 40
| blog: jarda_bloguje
Ale když k tomu přidáme ten strojový kód, tak se dá říct, že i ve strojovém kódu
30.5.2009 20:24
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
30.5.2009 20:46
Jardík | skóre: 40
| blog: jarda_bloguje
) a při vyhodnocování se zavolá (*(double (*)(void))(a.buffer()))() (volací konvenci zatím ošetřenu nemám a tiše předpokládám unixový fastcall pro x86_64) a za chvilku je výsledek.
30.5.2009 21:04
Jardík | skóre: 40
| blog: jarda_bloguje
mov_RAX_IMM64(bla) a movsd_XMM0_pRAX(). Jenom dotaz, jak je to s tím Labelem. Když funkci předám např. referenci na ten Assembler, ve funkci vytvořím normálně na zásobníku Label, použiju na něj třeba jmp, pak ho bindnu, vrátím z funkce, Label se zničí, nevadí to, když už je bindnutej?
void codeGenerator(Assembler& a)
{
Label lbl;
a.jmp(lbl);
...
a.bind(lbl);
...
a.jmp(lbl);
...
}
Label se sice zničí, ale assembler ten label po zavolání bind() už nepotřebuje. On už ten label není potřeba ;)
31.5.2009 01:10
Jardík | skóre: 40
| blog: jarda_bloguje
Ještě jeden dotaz, jak je to s immediate. Na x64 můžu mít instrukci mov rax, 0xFFEEDDCCBBAA9988 a mov rax, 0xFFEEDDCC. yasm mi v prvním případě vygeneruje 0x48,0xB8,0x88,0x99,0xAA,0xBB,0xCC,0xDD,0xEE,0xFF (s imm64) a v druhém 0x48,0xC7,0xC0,0xCC,0xDD,0xEE,0xFF (s imm32). Co tam vygeneruje Assmebler s a.mov(rax,imm(0xFFEEDDCC)) a a.mov(rax,imm(0xFFEEDDCCBBAA9988))? Všiml jsem si totiž, že jako argument má imm() SysUInt, tedy v případě x64 64bit ćíslo, a vůbec není přetížená.
31.5.2009 12:43
Jardík | skóre: 40
| blog: jarda_bloguje
mov rax, 0xFFFFFFFFFFFFFFFF vygeneruje "64bit mov" 48 b8 ff ff ff ff ff ff ff ff a když mu tam dám mov rax, -1, tak 48 c7 c0 ff ff ff ff. A když pak budu adresovat, tak je asi rozdíl, jestli použiju k adresaci [rax] (kde rax = 0xFFFFFFFF nebo 0xFFFFFFFFFFFFFFFF). Ale zatím to s AsmJit nespadlo, tak snad volí správně (mám 6BG ram, tak je tu nějaká šance, že by to imm mohlo mít adresu > 4GB).
add(rax, imm((SysInt)ptr));V tomto případě by AsmJit vypsal warning do logu (pokud to máš zapné) a měl by vyhodit i assert, pokud nelze hodnota zapsat jako 32 bitů.
31.5.2009 21:34
Jardík | skóre: 40
| blog: jarda_bloguje
movsd xmm0, [0x12345678] kdežto na x86_64 musím použít rax jako prostředníka
mov rax, 0x123456789ABCDEF movsd xmm0, [rax]
31.5.2009 21:36
Jardík | skóre: 40
| blog: jarda_bloguje
31.5.2009 22:11
Jardík | skóre: 40
| blog: jarda_bloguje
1.6.2009 15:03
Jardík | skóre: 40
| blog: jarda_bloguje
Multiplication::assemble: xmm pushed Plus::assemble: xmm pushed Plus::assemble: xmm poped Multiplication::assemble: xmm poped Bus errorHups ... jak že se pracuje ze stackem? Potřebuju double v xmm registru pushnout a pak popnout ze stacku. Provedl jsem to takto:
sub(nsp, imm(8)) movsd(ptr(nsp), xmm0) // něco co přepsalo xmm0 movsd(xmm0, ptr(nsp)) add(nsp, imm(8))A jak se zdá, asi to tak nepůjde
Funkce byla 3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3))))))))) a tohle jsem vygeneroval:
mov rax, 28970128 movsd xmm0, [rax] mov rax, 28967368 movsd xmm1, [rax] mov rax, 30396064 movsd xmm2, [rax] mov rax, 28967368 movsd xmm3, [rax] mov rax, 28775376 movsd xmm4, [rax] mov rax, 28967368 movsd xmm5, [rax] mov rax, 30528784 movsd xmm6, [rax] mov rax, 28967368 movsd xmm7, [rax] mov rax, 28696608 movsd xmm8, [rax] mov rax, 28967368 movsd xmm9, [rax] mov rax, 28696960 movsd xmm10, [rax] mov rax, 28967368 movsd xmm11, [rax] mov rax, 28974704 movsd xmm12, [rax] mov rax, 28967368 movsd xmm13, [rax] mov rax, 28975056 movsd xmm14, [rax] mov rax, 28967368 movsd xmm15, [rax] sub rsp, 8 movsd [rsp], xmm0 # Multiplication::assemble: xmm pushed mov rax, 28975408 movsd xmm0, [rax] sub rsp, 8 movsd [rsp], xmm1 # Plus::assemble: xmm pushed mov rax, 28967368 movsd xmm1, [rax] mov rax, 28975456 addsd xmm1, [rax] mulsd xmm0, xmm1 movsd xmm1, [rsp] add rsp, 8 # Plus::assemble: xmm poped addsd xmm15, xmm0 movsd xmm0, [rsp] add rsp, 8 # Multiplication::assemble: xmm poped mulsd xmm14, xmm15 addsd xmm13, xmm14 mulsd xmm12, xmm13 addsd xmm11, xmm12 mulsd xmm10, xmm11 addsd xmm9, xmm10 mulsd xmm8, xmm9 addsd xmm7, xmm8 mulsd xmm6, xmm7 addsd xmm5, xmm6 mulsd xmm4, xmm5 addsd xmm3, xmm4 mulsd xmm2, xmm3 addsd xmm1, xmm2 mulsd xmm0, xmm1 retJe tedy pravda, že na začátku nějak neuchovávám rsp, ale to je přece vráceno do původního stavu a nějaký registry jako rbp, rdi, ... vůbec nemodifikuju
1.6.2009 23:01
Jardík | skóre: 40
| blog: jarda_bloguje
; yasm 00000000 48 c7 c0 90 0c ba 01 f2 0f 10 00 48 c7 c0 c8 01 |H..........H....| 00000010 ba 01 f2 0f 10 08 48 c7 c0 a0 ce cf 01 f2 0f 10 |......H.........| 00000020 10 48 c7 c0 c8 01 ba 01 f2 0f 10 18 48 c7 c0 d0 |.H..........H...| 00000030 13 b7 01 f2 0f 10 20 48 c7 c0 c8 01 ba 01 f2 0f |...... H........| 00000040 10 28 48 c7 c0 10 d5 d1 01 f2 0f 10 30 48 c7 c0 |.(H.........0H..| 00000050 c8 01 ba 01 f2 0f 10 38 48 c7 c0 20 e0 b5 01 f2 |.......8H.. ....| 00000060 44 0f 10 00 48 c7 c0 c8 01 ba 01 f2 44 0f 10 08 |D...H.......D...| 00000070 48 c7 c0 80 e1 b5 01 f2 44 0f 10 10 48 c7 c0 c8 |H.......D...H...| 00000080 01 ba 01 f2 44 0f 10 18 48 c7 c0 70 1e ba 01 f2 |....D...H..p....| 00000090 44 0f 10 20 48 c7 c0 c8 01 ba 01 f2 44 0f 10 28 |D.. H.......D..(| 000000a0 48 c7 c0 d0 1f ba 01 f2 44 0f 10 30 48 c7 c0 c8 |H.......D..0H...| 000000b0 01 ba 01 f2 44 0f 10 38 48 83 ec 08 f2 0f 11 04 |....D..8H.......| 000000c0 24 48 c7 c0 30 21 ba 01 f2 0f 10 00 48 83 ec 08 |$H..0!......H...| 000000d0 f2 0f 11 0c 24 48 c7 c0 c8 01 ba 01 f2 0f 10 08 |....$H..........| 000000e0 48 c7 c0 60 21 ba 01 f2 0f 58 08 f2 0f 59 c1 f2 |H..`!....X...Y..| 000000f0 0f 10 0c 24 48 83 c4 08 f2 44 0f 58 f8 f2 0f 10 |...$H....D.X....| 00000100 04 24 48 83 c4 08 f2 45 0f 59 f7 f2 45 0f 58 ee |.$H....E.Y..E.X.| 00000110 f2 45 0f 59 e5 f2 45 0f 58 dc f2 45 0f 59 d3 f2 |.E.Y..E.X..E.Y..| 00000120 45 0f 58 ca f2 45 0f 59 c1 f2 41 0f 58 f8 f2 0f |E.X..E.Y..A.X...| 00000130 59 f7 f2 0f 58 ee f2 0f 59 e5 f2 0f 58 dc f2 0f |Y...X...Y...X...| 00000140 59 d3 f2 0f 58 ca f2 0f 59 c1 c3 |Y...X...Y..| 0000014b ; AsmJit 00000000 48 c7 c0 f0 95 60 02 f2 42 0f 10 00 48 c7 c0 e8 |H....`..B...H...| 00000010 7c 4a 02 f2 42 0f 10 08 48 c7 c0 c0 42 60 02 f2 ||J..B...H...B`..| 00000020 42 0f 10 10 48 c7 c0 e8 7c 4a 02 f2 42 0f 10 18 |B...H...|J..B...| 00000030 48 c7 c0 c0 94 60 02 f2 42 0f 10 20 48 c7 c0 e8 |H....`..B.. H...| 00000040 7c 4a 02 f2 42 0f 10 28 48 c7 c0 50 bf 43 02 f2 ||J..B..(H..P.C..| 00000050 42 0f 10 30 48 c7 c0 e8 7c 4a 02 f2 42 0f 10 38 |B..0H...|J..B..8| 00000060 48 c7 c0 50 27 61 02 f2 46 0f 10 00 48 c7 c0 e8 |H..P'a..F...H...| 00000070 7c 4a 02 f2 46 0f 10 08 48 c7 c0 b0 28 61 02 f2 ||J..F...H...(a..| 00000080 46 0f 10 10 48 c7 c0 e8 7c 4a 02 f2 46 0f 10 18 |F...H...|J..F...| 00000090 48 c7 c0 10 2a 61 02 f2 46 0f 10 20 48 c7 c0 e8 |H...*a..F.. H...| 000000a0 7c 4a 02 f2 46 0f 10 28 48 c7 c0 d0 2c 61 02 f2 ||J..F..(H...,a..| 000000b0 46 0f 10 30 48 c7 c0 e8 7c 4a 02 f2 46 0f 10 38 |F..0H...|J..F..8| 000000c0 48 83 ec 08 f2 42 0f 11 04 24 48 c7 c0 30 2e 61 |H....B...$H..0.a| 000000d0 02 f2 42 0f 10 00 48 83 ec 08 f2 42 0f 11 0c 24 |..B...H....B...$| 000000e0 48 c7 c0 e8 7c 4a 02 f2 42 0f 10 08 48 c7 c0 60 |H...|J..B...H..`| 000000f0 2e 61 02 f2 42 0f 58 08 f2 0f 59 c1 f2 42 0f 10 |.a..B.X...Y..B..| 00000100 0c 24 48 83 c4 08 f2 44 0f 58 f8 f2 42 0f 10 04 |.$H....D.X..B...| 00000110 24 48 83 c4 08 f2 45 0f 59 f7 f2 45 0f 58 ee f2 |$H....E.Y..E.X..| 00000120 45 0f 59 e5 f2 45 0f 58 dc f2 45 0f 59 d3 f2 45 |E.Y..E.X..E.Y..E| 00000130 0f 58 ca f2 45 0f 59 c1 f2 41 0f 58 f8 f2 0f 59 |.X..E.Y..A.X...Y| 00000140 f7 f2 0f 58 ee f2 0f 59 e5 f2 0f 58 dc f2 0f 59 |...X...Y...X...Y| 00000150 d3 f2 0f 58 ca f2 0f 59 c1 c3 |...X...Y..| 0000015aA tady jsou v assembleru zvýrazněné části:
; yasm 48 c7 c0 09 0c ba 01 ; mov rax, 0x01BA0C90 f2 0f 10 00 ; movsd xmm0, [rax] 48 c7 c0 c8 01 ba 01 ; mov rax, 0x01BA01C8 f2 0f 10 08 ; movsd xmm1, [rax] 48 83 ec 08 ; sub rsp, 8 f2 0f 11 04 24 ; movsd [rsp], xmm0 48 83 ec 08 ; sub rsp, 8 f2 0f 11 0c 24 ; movsd [rsp], xmm1 f2 0f 10 0c 24 ; movsd xmm1, [rsp] 48 83 c4 08 ; add rsp, 8 f2 0f 10 04 24 ; movsd xmm0, [rsp] 48 83 c4 08 ; add rsp, 8 ; AsmJit 48 c7 c0 f0 95 60 02 ; mov rax, 0x026095F0 f2 42 0f 10 00 ; movsd xmm0, [rax] 48 c7 c0 e8 7c 4a 02 ; mov rax, 0x024A7CE8 f2 42 0f 10 08 ; movsd xmm1, [rax] 48 83 ec 08 ; sub rsp, 8 f2 42 0f 11 04 24 ; movsd [rsp], xmm0 48 83 ec 08 ; sub rsp, 8 f2 42 0f 11 0c 24 ; movsd [rsp], xmm1 f2 42 0f 10 0c 24 ; movsd [xmm1], rsp 48 83 c4 08 ; add rsp, 8 f2 42 0f 10 04 24 ; movsd [xmm0], rsp 48 83 c4 08 ; addd rsp, 8AsmJit u movsd generuje navíc byte 0x42 (označen tučně). U movsd s raxem ničemu nevadil, protože kód bez použití zásobníku šlapal. Tak buď tam ten byte vadí u přístupu k zásobníku (a to bych řekl bude nepravděpodobné) a nebo takhle k zásobníku přistupovat nemůžu a dělám to špatně (to spíše). Ale v jednom tutoriálu assembleru jsem četl, že
push eax dělá to samé, co sub esp, 4; mov dword ptr [esp], eax tak předpokládám, že to samé platí pro 64bit s tím, źe místo esp použiju rsp. Škoda, že nejde push xmm0 nebo není nějaká instrukce přímo pro xmm registry.
1.6.2009 23:08
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Ale v jednom tutoriálu assembleru jsem četlVíš kdo je to Ruik(Rudolf Marek)?
žeNo pozor, je stack pointer na x86_64 taky 32-bitovej? Imho ne! takže pro 64b to bude spíš takhle:push eaxdělá to samé, cosub esp, 4; mov dword ptr [esp], eax
sub rsp, 8; mov dword ptr [rsp], rax
2.6.2009 00:27
Jardík | skóre: 40
| blog: jarda_bloguje
48 83 ec 08 ; sub rsp, 8.
Každopádně movsd z xmm registu vždycky přenáší spodních 8B, tak v obouch případech je nutné odečíst 8.
2.6.2009 01:37
Jardík | skóre: 40
| blog: jarda_bloguje
BITS 64 SECTION .text global _start _start: call calc_it mov rax, M_RESULT movsd [rax], xmm0 ; M_RESULT contains result of calc_it push rax mov rax, 4 ;write mov rbx, 1 ;stdout pop rcx ;M_RESULT mov edx, 8 ;8 int 0x80 ;write(1, M_RESULT, 8) mov rax, 1 mov rbx, 0 int 0x80 ;exit(0) ; returns result of ; 3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3(pi+3))))))))) ; in xmm0 calc_it: mov rax, M_3 movsd xmm0, [rax] mov rax, M_PI movsd xmm1, [rax] mov rax, M_3 movsd xmm2, [rax] mov rax, M_PI movsd xmm3, [rax] mov rax, M_3 movsd xmm4, [rax] mov rax, M_PI movsd xmm5, [rax] mov rax, M_3 movsd xmm6, [rax] mov rax, M_PI movsd xmm7, [rax] mov rax, M_3 movsd xmm8, [rax] mov rax, M_PI movsd xmm9, [rax] mov rax, M_3 movsd xmm10, [rax] mov rax, M_PI movsd xmm11, [rax] mov rax, M_3 movsd xmm12, [rax] mov rax, M_PI movsd xmm13, [rax] mov rax, M_3 movsd xmm14, [rax] mov rax, M_PI movsd xmm15, [rax] sub rsp, 8 movsd [rsp], xmm0 mov rax, M_3 movsd xmm0, [rax] sub rsp, 8 movsd [rsp], xmm1 mov rax, M_PI movsd xmm1, [rax] mov rax, M_3 addsd xmm1, [rax] mulsd xmm0, xmm1 movsd xmm1, [rsp] add rsp, 8 addsd xmm15, xmm0 movsd xmm0, [rsp] add rsp, 8 mulsd xmm14, xmm15 addsd xmm13, xmm14 mulsd xmm12, xmm13 addsd xmm11, xmm12 mulsd xmm10, xmm11 addsd xmm9, xmm10 mulsd xmm8, xmm9 addsd xmm7, xmm8 mulsd xmm6, xmm7 addsd xmm5, xmm6 mulsd xmm4, xmm5 addsd xmm3, xmm4 mulsd xmm2, xmm3 addsd xmm1, xmm2 mulsd xmm0, xmm1 ret SECTION .data align=16 M_PI: dq 0x400921fb54442d18 M_3: dq 0x4008000000000000 M_RESULT: dq 0To normálně funguje. Pak mě to nakrklo a kydnul jsem tam ty prology a epilogy, co generuje c kompilátor:
; prolog push rbp mov rbp, rsp ; epilog ; mov rsp, rbp ; pop rbp leave ; stejný jako ty 2 instrukce nahoře ret ; tohle už jsem tam mělA místo odčítání a přičítání k
rsp jsem použil rbp, pro movsd jsem taky použil rbp a najednou to začlo fungovat. A teď mi řekněte proč ... vždyť v tom kódu, co jsem z rsp odečetl, to jsem zase přičetl, rbp jsem vůbec neměnil, takže rsp i rbp zůstali zachovalé a v "přímo" assembleru to fungovalo i s rsp.
Zkus SVN a jestli to přetrvává, tak mě informuj :)
2.6.2009 18:47
Jardík | skóre: 40
| blog: jarda_bloguje
3.6.2009 03:58
Jardík | skóre: 40
| blog: jarda_bloguje
cvtpd2dq, která by ty doubly převedla na quadwordy místo doublewordy? Nebo alespoň jak tu "horní 32bit část spodní 64bit části" dát do spodní 32 bit části horní 64bit části? Našel jsem počítání logaritmu v sse2, ale je to jen pro float (a ještě k tomu v intrinsic) tak to přepisuju pro doubly a právě tam má _mm_cvtepi32_ps a já nemůžu najít alternativu.
xmm = [a b c d] pshufd(xmm0, mm_shuffle(0, 1, 2, 3)) xmm = [d c b a]Snad ti to pomůže. PS: Potřeboval bych atan2
3.6.2009 15:13
Jardík | skóre: 40
| blog: jarda_bloguje
)
3.6.2009 22:58
Jardík | skóre: 40
| blog: jarda_bloguje
Teď přemýšlím, jak to zakomponovat do programu. Přece tam tuhle hrůzu nebudu cpát pokaždý do bufferu, když se objeví logaritmus. Jenže tam bych mohl měnit xmm registry podle potřeby (třeba budu mít použité xmm0, xmm1, xmm2, tak použiju xmm3-xmm10), ale když to tam zakóduju jednou a budu provádět call, tan si registry zvolit nebudu moci podle potřeby a budu pushovat/popovat jak blázen... jestli se na to nakonec nevytento.
BITS 64
SECTION .text
global _start
global _sse2_log
_start:
mov rcx, 0xFFFFFFF
mov rax, test_number
loop_start:
movsd xmm0, [rax]
call _sse2_vector_log
movsd [rax], xmm0
loopnz loop_start
mov rax, 1
mov rbx, 0
int 0x80
; input xmm0, output xmm0
; calculate natural logarithm of two packed doubles
; eats xmm1-xmm6, rdi
_sse2_vector_log:
mov rdi, _data_pointer
movapd xmm6, xmm0
maxpd xmm0, [rdi+(mantisa_mask-_data_pointer)]
movdqa xmm3, xmm0
andpd xmm0, [rdi+(mantisa_mask-_data_pointer)]
movapd xmm5, [rdi+(const_0p5-_data_pointer)]
xorpd xmm1, xmm1
psrlq xmm3, 52
psubq xmm3, [rdi+(exponent_bias-_data_pointer)]
movapd xmm2, [rdi+(const_1-_data_pointer)]
; FIXME
; can I do this? exponent should fit dword but
; what about the sign?
pshufd xmm3, xmm3, 0xd8
cvtdq2pd xmm3, xmm3
orpd xmm0, xmm5
cmplepd xmm6, xmm1
movapd xmm1, xmm0
movapd xmm4, xmm0
cmpltpd xmm1, [rdi+(SQRTHF-_data_pointer)]
subpd xmm0, xmm2
andpd xmm4, xmm1
addpd xmm3, xmm2
andpd xmm2, xmm1
movapd xmm1, [rdi+(log_p0-_data_pointer)]
addpd xmm0, xmm4
subpd xmm3, xmm2
mulpd xmm1, xmm0
movapd xmm4, xmm0
movapd xmm2, xmm3
mulpd xmm3, [rdi+(log_q2-_data_pointer)]
mulpd xmm4, xmm0
addpd xmm1, [rdi+(log_p1-_data_pointer)]
mulpd xmm2, [rdi+(log_q1-_data_pointer)]
mulpd xmm1, xmm0
addpd xmm1, [rdi+(log_p2-_data_pointer)]
mulpd xmm1, xmm0
addpd xmm1, [rdi+(log_p3-_data_pointer)]
mulpd xmm1, xmm0
addpd xmm1, [rdi+(log_p4-_data_pointer)]
mulpd xmm1, xmm0
addpd xmm1, [rdi+(log_p5-_data_pointer)]
mulpd xmm1, xmm0
addpd xmm1, [rdi+(log_p6-_data_pointer)]
mulpd xmm1, xmm0
addpd xmm1, [rdi+(log_p7-_data_pointer)]
mulpd xmm1, xmm0
addpd xmm1, [rdi+(log_p8-_data_pointer)]
mulpd xmm1, xmm0
mulpd xmm1, xmm4
mulpd xmm4, xmm5
addpd xmm1, xmm2
subpd xmm1, xmm4
addpd xmm0, xmm1
addpd xmm0, xmm3
orpd xmm0, xmm6
ret
_sse2_scalar_log:
mov rdi, _data_pointer
movsd xmm6, xmm0
maxsd xmm0, [rdi+(mantisa_mask-_data_pointer)]
movsd xmm3, xmm0
andpd xmm0, [rdi+(mantisa_mask-_data_pointer)]
movsd xmm5, [rdi+(const_0p5-_data_pointer)]
xorpd xmm1, xmm1
psrlq xmm3, 52
psubq xmm3, [rdi+(exponent_bias-_data_pointer)]
movsd xmm2, [rdi+(const_1-_data_pointer)]
cvtdq2pd xmm3, xmm3
orpd xmm0, xmm5
cmplepd xmm6, xmm1
movsd xmm1, xmm0
movsd xmm4, xmm0
cmpltpd xmm1, [rdi+(SQRTHF-_data_pointer)]
subsd xmm0, xmm2
andpd xmm4, xmm1
addsd xmm3, xmm2
andpd xmm2, xmm1
movsd xmm1, [rdi+(log_p0-_data_pointer)]
addsd xmm0, xmm4
subsd xmm3, xmm2
mulsd xmm1, xmm0
movsd xmm4, xmm0
movsd xmm2, xmm3
mulsd xmm3, [rdi+(log_q2-_data_pointer)]
mulsd xmm4, xmm0
addsd xmm1, [rdi+(log_p1-_data_pointer)]
mulsd xmm2, [rdi+(log_q1-_data_pointer)]
mulsd xmm1, xmm0
addsd xmm1, [rdi+(log_p2-_data_pointer)]
mulsd xmm1, xmm0
addsd xmm1, [rdi+(log_p3-_data_pointer)]
mulsd xmm1, xmm0
addsd xmm1, [rdi+(log_p4-_data_pointer)]
mulsd xmm1, xmm0
addsd xmm1, [rdi+(log_p5-_data_pointer)]
mulsd xmm1, xmm0
addsd xmm1, [rdi+(log_p6-_data_pointer)]
mulsd xmm1, xmm0
addsd xmm1, [rdi+(log_p7-_data_pointer)]
mulsd xmm1, xmm0
addsd xmm1, [rdi+(log_p8-_data_pointer)]
mulsd xmm1, xmm0
mulsd xmm1, xmm4
mulsd xmm4, xmm5
addsd xmm1, xmm2
subsd xmm1, xmm4
addsd xmm0, xmm1
addsd xmm0, xmm3
orpd xmm0, xmm6
ret
SECTION .data align=16
; double
; 1b - sign
; 11b - exponent (mantisa) -1023
; 52b - significand
; 64b - total
_data_pointer:
mantisa_mask: dq 0x7FF0000000000000,0x7FF0000000000000 ; mask for exponent
inv_mantisa_mask: dq 0x800FFFFFFFFFFFFF,0x800FFFFFFFFFFFFF ; inverted mask for exponent
sign_mask: dq 0x8000000000000000,0x8000000000000000 ; mask for sign
inv_sign_mask: dq 0x7FFFFFFFFFFFFFFF,0x7FFFFFFFFFFFFFFF ;
exponent_bias: dq 0x3FF,0x3FF ; 1023 (subtract from exponent to get real one)
min_norm_pos: dq 0x0010000000000000,0x0010000000000000 ; the smallest double
const_0p5: dq 0x3FE0000000000000,0x3FE0000000000000 ; 0.5
const_1: dq 0x3FF0000000000000,0x3FF0000000000000 ; 1.0
SQRTHF: dq 0x3FE6A09E667F3BCD,0x3FE6A09E667F3BCD ; 0.707106781186547524
log_p0: dq 0x3FB204376245245A,0x3FB204376245245A ; 7.0376836292E-2
log_p1: dq 0xBFBD7A370B138B4B,0xBFBD7A370B138B4B ; -1.151461031e-1
log_p2: dq 0x3FBDE4A34D098E98,0x3FBDE4A34D098E98 ; 1.1676998740000000e-1
log_p3: dq 0xBFBFCBA9DB73ED2C,0xBFBFCBA9DB73ED2C ; -1.2420140846000000e-1
log_p4: dq 0x3FC23D37D4CD3339,0x3FC23D37D4CD3339 ; 1.4249322787000000e-1
log_p5: dq 0xBFC555CA04CB8ABB,0xBFC555CA04CB8ABB ; -1.6668057665000000e-1
log_p6: dq 0x3FC999D58F0FBE3E,0x3FC999D58F0FBE3E ; 2.0000714765000000e-1
log_p7: dq 0xBFCFFFFF7F002B13,0xBFCFFFFF7F002B13 ; -2.4999993993000000e-1
log_p8: dq 0x3FD555553E25CD96,0x3FD555553E25CD96 ; 3.3333331174000000e-1
log_q1: dq 0xBF2BD0105C4242EA,0xBF2BD0105C4242EA ; -2.1219444000000000e-4
log_q2: dq 0x3FE6300000000000,0x3FE6300000000000 ; 6.9335937500000000e-1
test_number: dq 5.0, 5.0
4.6.2009 00:06
Jardík | skóre: 40
| blog: jarda_bloguje
mov rax, adresa; movapd xmm, [rax] a něco sem tam podělal, už to nefunguje. Tak znovu. Příště zálohu
4.6.2009 00:20
Jardík | skóre: 40
| blog: jarda_bloguje
Jenže tam bych mohl měnit xmm registry podle potřeby (třeba budu mít použité xmm0, xmm1, xmm2, tak použiju xmm3-xmm10), ale když to tam zakóduju jednou a budu provádět call, tan si registry zvolit nebudu moci podle potřeby a budu pushovat/popovat jak blázen... jestli se na to nakonec nevytento.Teď se teprve dostáváš k těm zajímavým věcem! Efektivní alokátor registrů je jedna z klíčových součástí překladače, přeju dobrou chuť!
 4.6.2009 09:50
Jardík | skóre: 40
| blog: jarda_bloguje
) a prgat! Není to trivka, ale zase mi to nepřipadalo nezvládnutelné
O další důvod víc pro 64 bitů, kde je těch registrů víc
4.6.2009 09:50
Jardík | skóre: 40
| blog: jarda_bloguje
) a prgat! Není to trivka, ale zase mi to nepřipadalo nezvládnutelné
O další důvod víc pro 64 bitů, kde je těch registrů víc
 31.5.2009 15:01
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
31.5.2009 15:01
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
 31.5.2009 20:34
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
31.5.2009 21:40
Jardík | skóre: 40
| blog: jarda_bloguje
1.6.2009 12:49
Jardík | skóre: 40
| blog: jarda_bloguje
1.6.2009 12:50
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
31.5.2009 20:34
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
31.5.2009 21:40
Jardík | skóre: 40
| blog: jarda_bloguje
1.6.2009 12:49
Jardík | skóre: 40
| blog: jarda_bloguje
1.6.2009 12:50
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz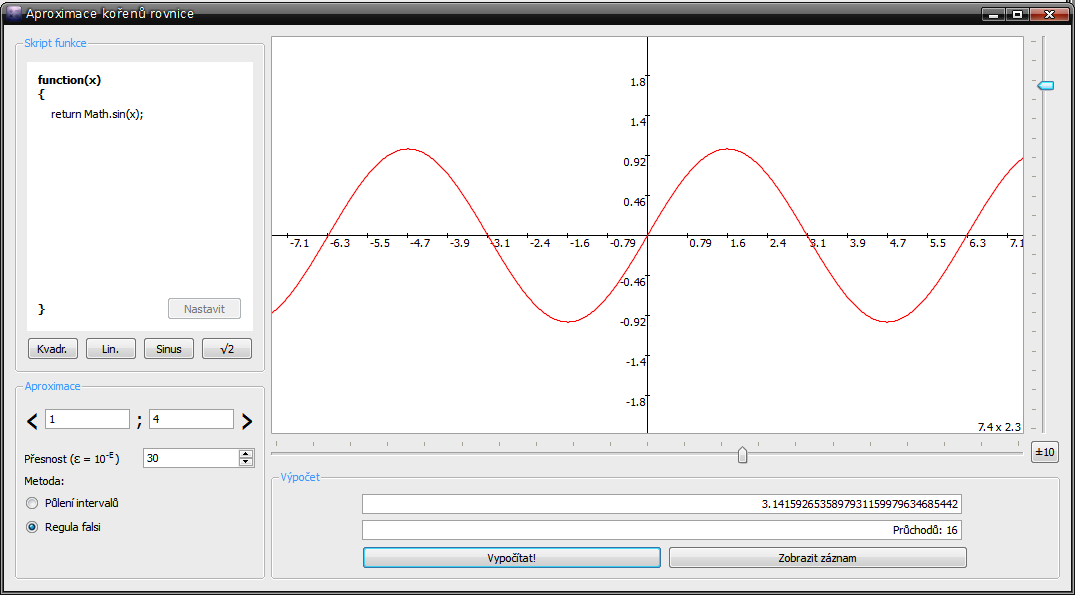{kind=link}
{kind=link}