Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na Seznam nepovolených internetových her (Wikipedie) se k 13. 7. 2026 dostala predikční platforma Polymarket.
Nová čísla časopisů od nakladatelství Raspberry Pi zdarma ke čtení: Raspberry Pi Official Magazine 167 (pdf) a Hello World 30 (pdf).
Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Odkazy


Pri vývoji webových aplikácií je bežnou požiadavkou aby bol obsah viacjazyčný. Tento blog sa zaoberá návrhom modelov pre uloženie viacjazyčných dát a výhodami / nevýhodami jednotlivých návrhov.
Jazyk SQL neposkytuje žiadnu vstavanú podporu pre viacjazyčný obsah. Návrh databázovej schémy pre viacjazyčný obsahu tak zostáva len na databázovom programátorovi.
Na internete je možné nájsť veľké množstvo rôznych databázových schém, ktoré riešia viacjazyčný obsah. Nedá sa všeobecne povedať ktorá schéma je najlepšia. Vždy to závisí od konkrétneho prípadu použitia. V nasledujúcom texte som sa pokúsil zhrnúť výhody a nevýhody jednotlivých prístupov.
V celom blogu budem aplikovať návrh na model článkov. Polia nazov a obsah budú prekladané. Zvyšné polia budú rovnaké pre každý jazyk.
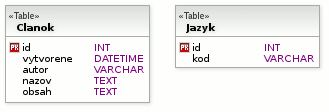
Tabuľka jazykov bude vyzerať nasledovne:
| id | kod |
|---|---|
| 1 | sk |
| 2 | cz |
V selectoch budem vyberať slovenskú lokalizáciu. Pre jednoduchosť nebudem používať join s tabuľkou jazykov. Namiesto toho budem priamo ako ID jazyka používať 1.
Pri tomto prístupe nedochádza k zmene schémy a preklady pre všetky jazyky sa ukladajú do tej istej bunky v špeciálnom formáte. Ako príklad si požičiam formát používaný pluginom qTranslate z Wordpressu. Nasledujúci kód reprezentuje český a slovenský preklad slova „Článok“.
<!--:sk-->Článok<!--:--><!--:cz-->Článek<!--:cz-->
Výber objektov je veľmi jednoduchý. Dáta je však potrebné následne spracovať v aplikácii.
SELECT vytvorene,
autor,
nazov,
obsah
FROM clanok;
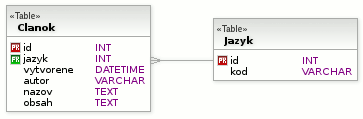
Pri tomto prístupe sa do modelu pridá jediný stĺpec určujúci jazyk. Medzi jazykovými mutáciami nie je žiaden vzťah, takže v jednej jazykovej mutácii môžu byť úplne iné položky než v inej jazykovej mutácii, čo môže byť v niektorých prípadoch výhodné. Pri pridaní, alebo odstránení jazyka nie je potrebná žiadna modifikácia schémy.
Pre výber slovenských objektov stačí pridať podmienku where.
SELECT vytvorene,
autor,
nazov,
obsah
FROM clanok
WHERE jazyk = 1;
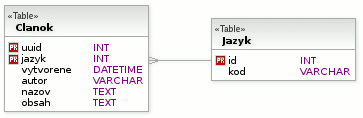
V tomto modeli bude primárnym (alebo minimálne unikátnym) kľúčom dvojica uuid a jazyk. Objekty (články) sú identifikované stĺpcom uuid. Ten bude rovnaký pre všetky preklady článku.
Výber objektov je identický ako v prípade predchádzajúceho modelu.
uuid pre objekty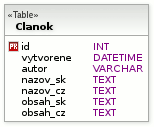
Do modelu pridá každý stĺpec toľkokrát, koľko jazykov bude v aplikácii podporovaných. Nepreložené stĺpce zostávajú bez zmeny.
Pre výber položiek v konkrétnom jazyku je potrebné modifikovať samotný dotaz. Jazykové suffixy musia byť preto chránené voči SQL injection.
SELECT vytvorene,
autor,
nazov_sk AS nazov,
obsah_sk AS obsah
FROM clanok;

Oproti predchádzajúcim spôsobom sa tu využívajú 2 tabuľky - časť pôvodnej tabuľky neobsahujúca preklady a tabuľka prekladov. Tá môže byť implementovaná buď prekladmi v riadkoch, alebo v stĺpcoch.
Pri výbere sa používa v oboch prípadoch join, čo môže mať vplyv na výkon. Pri použití tabuľky s prekladmi v stĺpcoch sa pri výbere v konkrétnom jazyku zase modifikuje dotaz a je potrebné zabezpečiť ho voči SQL injection.
-- clanok_row
SELECT vytvorene,
autor,
nazov,
obsah
FROM clanok
INNER JOIN clanok_row
ON clanok.id = clanok_row.clanok_id AND jazyk = 1;
-- clanok_col
SELECT vytvorene,
autor,
nazov_sk AS nazov,
obsah_sk AS obsah
INNER JOIN clanok_col
ON clanok.id = clanok_col.clanok_id;
Na túto otázku neexistuje jednoznačná odpoveď. Ak máme pevne danú schému, ktorú nemôžeme prispôsobiť bude jediným možným spôsobom uloženie všetkých prekladov oddelených rozumne zvoleným oddeľovačom do pôvodných buniek.
V prípade, že máme rôzny obsah v každom jazyku (napr. v každom jazyku budú iné články) bude najvhodnejším riešením model bez vzťahov medzi jazykmi. Ak však budeme chcieť tie isté objekty v rôznych jazykových mutáciách budeme musieť zvoliť inú schému.
Preklady v riadkoch poskytujú vysokú flexibilitu v možnosti zmeny podporovaných jazykov. V prípade článkov sa pri prekladoch bude opakovať autor a dátum. Schému je možné normalizovať rozdelením tabuľky na samostatnú tabuľku prekladov a zvyšný obsah (posledný príklad).
Preklady v stĺpcoch zachovávajú počet riadkov rovnaký ako počet objektov. Schéma je vhodná len v prípade, že sa v budúcnosti nebude manipulovať s podporovanými jazykmi. Pri väčšom počte jazykov a stĺpcov s prekladmi môže byť táto schéma veľmi neprehľadná. Presun prekladov do samostatnej tabuľky slúži len na sprehľadnenie pôvodnej tabuľky.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 29.9.2012 07:49
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
29.9.2012 07:49
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Dovolím si o výkone JOINu tak trochu nesúhlasiť. Robievam s dosť veľkými databázami a nie len MySQL, ale aj s podstatne výkonnejšou PostgreSQL. Joiny (LEFT aj INNER) môžu mať podstatný vplyv na výkon. Nedávno som riešil problém s pomalým selectom (~2s). Po odstránení joinu klesol čas na ~0.01s. Samozrejme indexy boli nastavené správne a join ich používal.
Problémom v mojom prípade bola veľkosť tabuľky (> 100 000 riadkov) a výber 10 prvkov s offsetom 100 000. Pri výbere bez joinu to pre databázu znamená jednoduchý odskok na 100 000 pložku a vrátenie 10 nasledujúcich položiek. Operácia join však môže vrátiť aj viac, alebo menej riadkov než je v prvej tabuľke. Preto musí databáza pri offsete 100 000 skutočne vykonať join na 100 000 riadkoch. Ak samozrejme ide len o výber s malým offsetom bude mať join zanedbateľný vplyv.
So zvyškom príspevku súhlasím, sám dokonca nepoužívam id jazyka.
29.9.2012 12:32
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Pokud jde join přes primární nebo unikátní klíč, tak by s tím neměl být problém.
Práve, že tu problém je pretože ten join sa minimálne v postgresql materializuje. Obísť sa to dá limitom v subselecte. Nedávno som to riešil v jednej django aplikácii. Musel som optimalizáciou zájsť až po RAW query.
 30.9.2012 11:40
bertone
| blog: Bertone
| Bratislava
30.9.2012 11:47
bertone
| blog: Bertone
| Bratislava
30.9.2012 12:36
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
30.9.2012 19:45
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
30.9.2012 21:07
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
30.9.2012 11:40
bertone
| blog: Bertone
| Bratislava
30.9.2012 11:47
bertone
| blog: Bertone
| Bratislava
30.9.2012 12:36
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
30.9.2012 19:45
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
30.9.2012 21:07
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
 . Inak dobrý nápad blog o graphvize, ale predtým možno niečo napíšem o AVR, a hackovaní TV LG a tak ... jednoducho čo mám čerstvo v pamäti
. Inak dobrý nápad blog o graphvize, ale predtým možno niečo napíšem o AVR, a hackovaní TV LG a tak ... jednoducho čo mám čerstvo v pamäti  3.10.2012 19:59
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
3.10.2012 22:30
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
3.10.2012 19:59
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
3.10.2012 22:30
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 29.9.2012 00:48
29.9.2012 00:48
 29.9.2012 11:04
29.9.2012 11:04
 Ale čechom sme mohli dať 0 .. alebo -1 :-p
Ale čechom sme mohli dať 0 .. alebo -1 :-p