pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na Seznam nepovolených internetových her (Wikipedie) se k 13. 7. 2026 dostala predikční platforma Polymarket.
Nová čísla časopisů od nakladatelství Raspberry Pi zdarma ke čtení: Raspberry Pi Official Magazine 167 (pdf) a Hello World 30 (pdf).
Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Odkazy


Práce na asynchronnom Djangu začali okolo roku 2020. Je rok 2025. Čo tak sa pozrieť, čo sme za tú dobu získali?
Päť rokov je v oblasti IT veľmi dlhá doba aby async prestal ignorovať aj taký technologický konzervatívec a spiatočník ako ja. Po všetkých tých fantastických blogoch a benchamrkoch som nasadol na vlnu asyncu.
Nie až tak dávno som začal nový projekt v asynchrónnom frameworku FastAPI. Nebudem rozoberať, prečo som sa rozhodol práve pre Django v úlohe ORM. Akonáhle som sa začal trocha hrabať vo vnútornostiach, šokovalo ma ako zle všetko funguje. Tento blog bude o čistom djangu.
Blogy sľubujú výkon. Tak moje konzervatívne skostnatené ja si spustí zastaralý uWSGI a oproti tomu postavím uvicorn. Oba s jedným workerom. Môj naivný view vyzerá ako väčšina dnešných benchmarkov. Veď prečo sa pozerať na komplexnú aplikáciu keď môžeme merať nič?
from django.http.response import JsonResponse
def naive_sync(request):
return JsonResponse({"status": "ok"})
async def naive_async(request):
return JsonResponse({"status": "ok"})
S týmto viewom si spustím benchmark pre 10 simultánnych požiadaviek a 1000 celkovo:
ab -n 1000 -c 10 'http://127.0.0.1:8000/naive/sync/'
Výsledný graf zobrazuje synchrónne volanie v uWSGI, potom synchrónne uvicorn a asynchrónne uvicorn. Vyššie číslo udáva vyššiu priepustnosť.
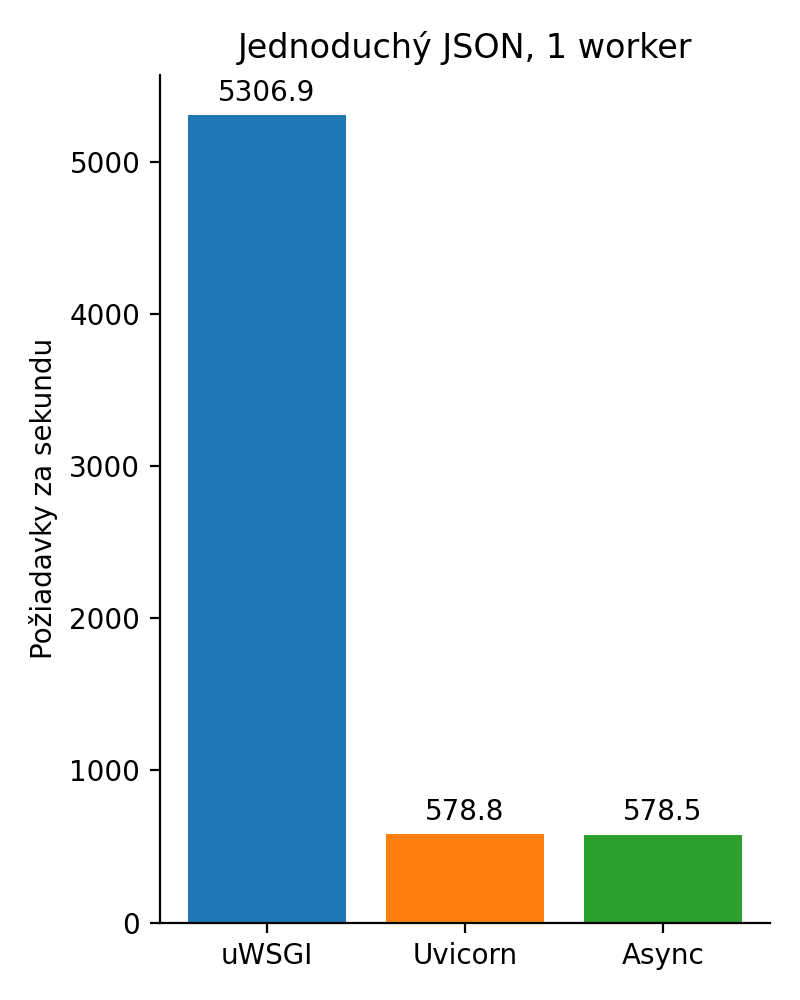
Obrázok 1: Naivná implementácia
Čo sa stalo? No jednoducho v tomto príklade nemala ako vyniknúť asynchrónnosť. Okrem toho uWSGI je napísaný v C, ale oproti python implementácii je to rozdiel len 2ms na pižiadavku. Nie je to nič, čo by mi žily trhalo v reálnej aplikácii. Tento benchmark je nanič a som si toho vedomý.
Chceme ešte jeden nanič benchmark? Samozrejme! Tak teda to isté so 16 workermi.
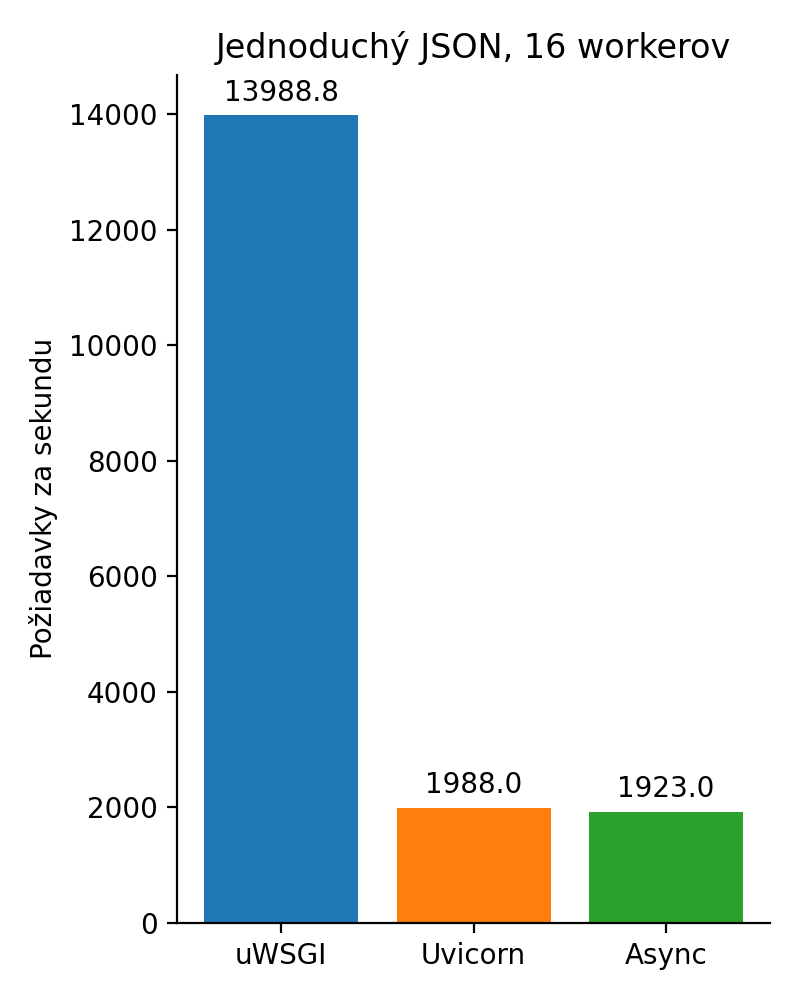
Obrázok 2: Naivná implementácia so 16 workermi
Väčšina aplikácií hrabe do databázy a tak si vytvorme pár tabuliek:
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
class Category(models.Model):
name = models.CharField(max_length=100)
class Document(models.Model):
name = models.CharField(max_length=100)
authors = models.ManyToManyField(Author, related_name='documents')
category = models.ForeignKey(Category, on_delete=models.CASCADE, related_name='documents', null=True)
Po naplnení databázy som ešte napísal jeden synchrónny a jeden asynchrónny view.
from asgiref.sync import sync_to_async
from django.http.response import JsonResponse
from .models import Document
def db_sync(request):
data = []
for document in Document.objects.order_by('pk'):
authors = []
data.append(
{
"name": document.name,
"category": document.category.name,
"authors": authors,
}
)
for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
async def db_async(request):
data = []
async for document in Document.objects.order_by('pk'):
authors = []
data.append(
{
"name": document.name,
"category": (await sync_to_async(getattr)(document, 'category')).name,
"authors": authors,
}
)
async for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
Vytvoril som dve prakticky rovnaké funkcie líšiace sa len v dvoch detailoch. Prvým je volanie generátora for. V jednom prípade je synchrónny (for) a v druhom prípade asynchrónny (async for). No a potom je tu táto šialenosť:
(await sync_to_async(getattr)(document, 'category')).name
Python neumožňuje kombinovať synchrónne a asynchrónne funkcie. Napíšete jedinú funkciu asynchrónne a musíte prepísať všetky funkcie, ktoré ju volajú. V postate tým infikujete celý kód. Ak ste tvorcom knižnice, môžete buď napísať knižnicu syncrhónne, alebo asynchrónne, alebo oboma spôsobmi pričom každú funkciu napíšete 2x a bude sa v 99% prípadov líšiť v tomto:
# async async def afunkcia(): ... await ainafunkcia() ... # sync def funkcia(): ... inafunkcia() ...
Django začala ako synchrónna knižnica a postupne sa duplikuje kód. Niektoré „drobnosti“ nie sú doteraz podporované ako napríklad transakcie. No a potom sú tu ešte veci, ktoré sa nedajú prepísať ako napríklad property, kde .category potrebuje zavolať SQL dotaz, ale propery nie je polymorfná a tak volá len syncrhónny select, ktorý sa nedá zavolať z asynchrónneho kontextu. Zabalíme to teda do sync_to_async
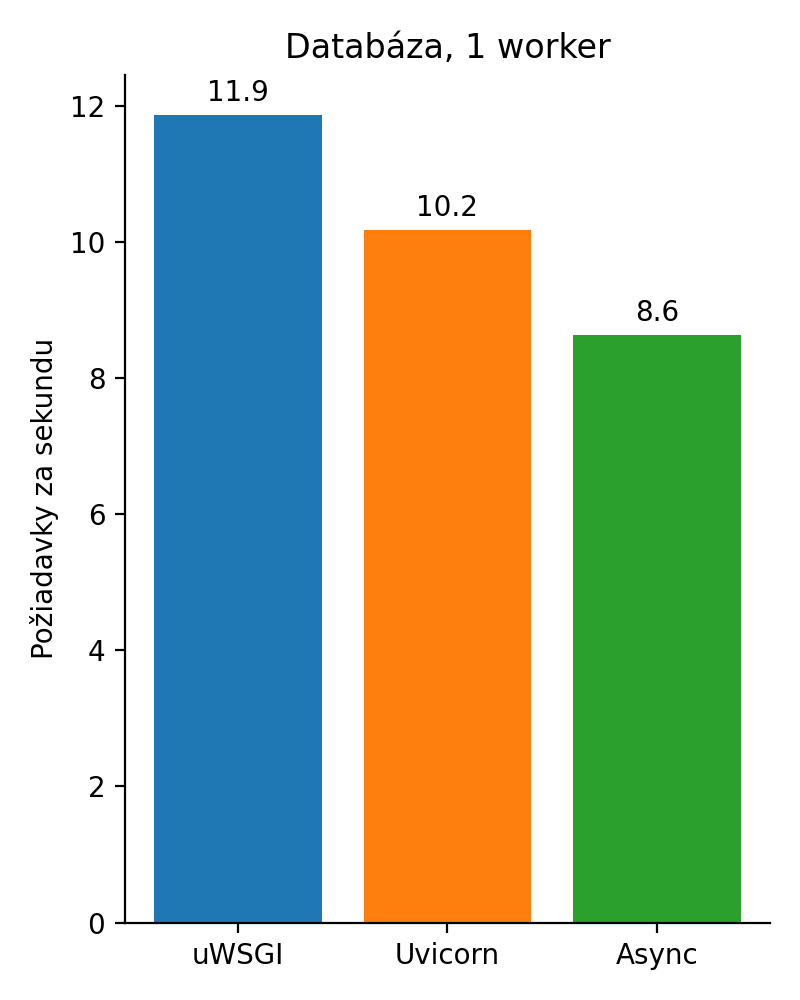
Obrázok 3: Prístup do databázy
To nie je možné!?! Dajme tam 16 workerov. Nech sa ukáže asyncrhṕnnosť.
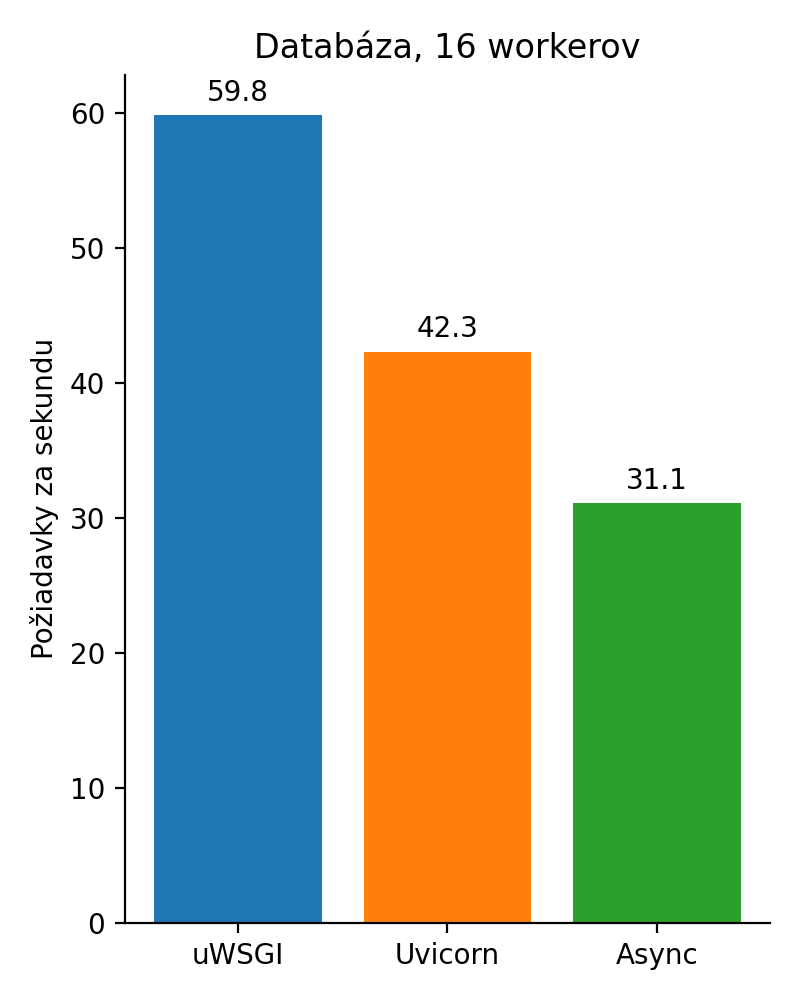
Obrázok 4: Prístup do databázy so 16 workermi
Ešte väčšia katastrofa, čo? Rozmeňme si to na drobné. Databázový driver, ktorý django používa je synchrónny. Aj keby nebol, tak celá implementácia Djanga je hračkárska a vyzerá takto:
async def aget(self, *args, **kwargs):
return await sync_to_async(self.get)(*args, **kwargs)
V tomto momente dochádza k prepnutiu kontextu, čo môže trvať rádovo okolo 1ms. Nie je dostatok vývojárov, aby implementovali a udržiavali Django so skoro každou duplikovanou funkciou. Preto sa len hráme na akože asynchrónnosť. Mimochodom viete, že veľa vývojárov vo svojich knižniciach overriduje save, aby tam pridali napríklad nejakú logiku, ja neviem date_created = now? Teraz to funguje pretože asave vyzerá takto: sync_to_async(self.save). Teraz si predstavte ako sa django knižnice začnú rozpadávať až sa začne reálne implementovať async. Celý ekosystém, desaťtisíce knižníc sa musia prepísať.
Nakoniec ešte doplním úpravu vďaka ktorej sa spustia len 2 dotazy namiesto 300:
def db_opt_sync(request):
data = []
for document in Document.objects.order_by('pk').prefetch_related('authors').select_related('category'):
authors = []
data.append(
{
"name": document.name,
"category": document.category.name,
"authors": authors,
}
)
for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
async def db_opt_async(request):
data = []
async for document in Document.objects.order_by('pk').prefetch_related('authors').select_related('category'):
authors = []
data.append(
{
"name": document.name,
"category": (await sync_to_async(getattr)(document, 'category')).name,
"authors": authors,
}
)
async for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
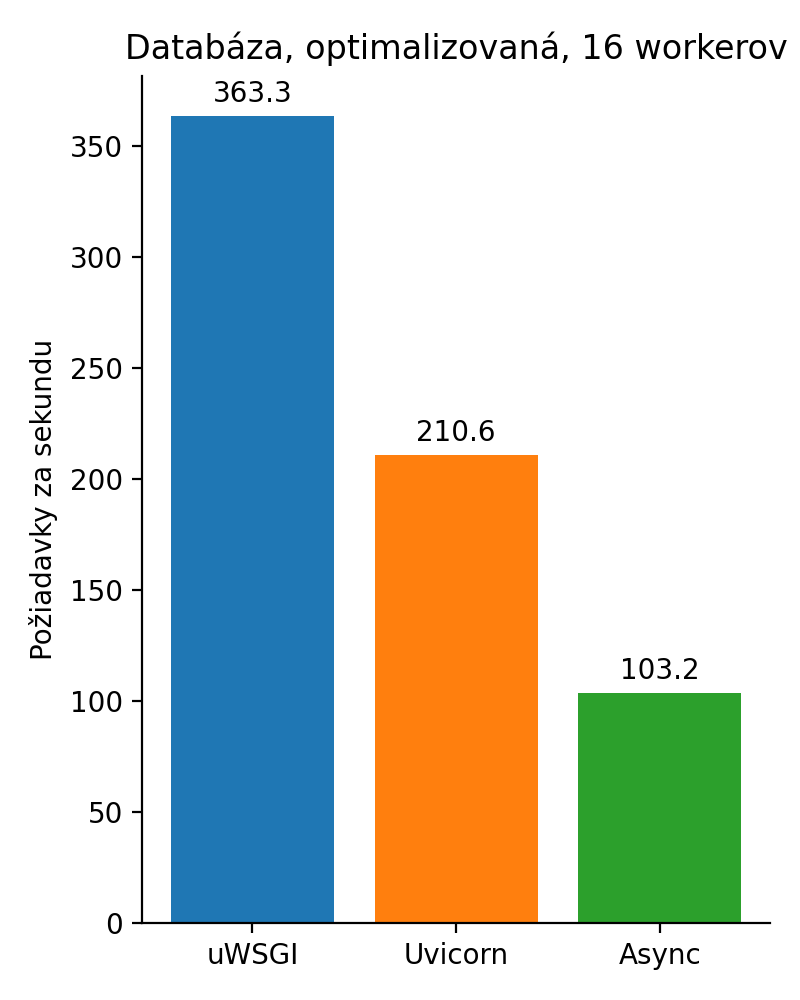
Obrázok 5: Prístup do databázy so 16 workermi po optimalizácii
Čo som vlastne chcel povedať? Neverte všetkým sladkým rečiam v blogoch. Python má svoju filozofiu „explicit is better“ a nej podriadil aj implementáciu async. Autori knižníc sa teraz musia rozhodnúť, či budú písať synchrónne, asynchrónne, alebo budú svoj kód duplikovať, budú mať 2x viac práce a 2x viac chýb. Pritom v dynamickom jazyku s tak neskorou adaptáciou async / await nebolo farbenie vôbec nevyhnutné. Škoda. Z môjho pohľadu premárnená príležitosť urobiť lepší jazyk.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 23.10.2025 15:39
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
23.10.2025 15:39
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Keďže sa k blogu nedá priložiť súbor prikladám tu. Veľa sa tu na abclinuxu od mojej poslednej návštevy nezmenilo. Akurát ja som o dosť starší, šedivejší a bývam s 10 mačkami v dome.
Veľa sa tu na abclinuxu od mojej poslednej návštevy nezmenilo. Akurát ja som o dosť starší, šedivejší a bývam s 10 mačkami v dome.
To je teda ale smutný příběh.
23.10.2025 18:17
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Smutný ani nie, ale 10 mačiek je dobrý začiatok konverzácie :P Sám nie som, mám partnerku, ktorá má rada mačky, veľa cestujem, mám catsittera kým som preč, veľa koníčkov, aktivít. Škoda akurát, že dni nemajú viac hodín.
24.10.2025 12:47
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Je to veľa, ale už sú také stále. Mal som aj viac, rozdal som. Občas sa niekto spýta, či nechcem darovať. Hmm iskra medzi mačkami a ňou?
 teda iskra medzi tebou a catsitterkou
teda iskra medzi tebou a catsitterkou  24.10.2025 13:01
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
24.10.2025 13:01
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Mám partnerku (človeka) a som monogamný takže nie :)
 23.10.2025 20:15
vlk | skóre: 23
| blog: u_vlka
23.10.2025 20:15
vlk | skóre: 23
| blog: u_vlka
az na to ze async nema s vyuzitim cpu cores moc spolecneho ...
na tyto strandy jsou multiprocess a multithread moduly + concurrent.
23.10.2025 20:52
vlk | skóre: 23
| blog: u_vlka
a zrovna tyto dva priklady nejsou o vytizeni cpu .. ale presne o cem async je .. IO
Ja chapu, ze async resi IO ale to je jaksi provazane s multicpu systemy.No, ani ne. Původní C10k problém je formulován na single-threaded službě. Zvýšením počtu CPU to prostě akorát horizontálně škáluješ...
 27.10.2025 00:12
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
27.10.2025 00:12
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
az na to ze async nema s vyuzitim cpu cores moc spolecneho
cpu si muže jít makat na něčem jiným zatimco se čeká třeba na I/O :O ;D
Příliš sofistikovaný fakt, který Žako nikdy nepochopí.
jop, az na to ze to v klidu muze byt pouze 1 cpu s 1 jadrem ... nic co by nejak ovlivnilo multicore system ...
proste async != paralerni ..
A prohlasit ja vse pisy async abych vyuzil vsechan jadra CPU znamena jen jednu vec ... netusis co to async je a proc je .
23.10.2025 20:37
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Async kód využíva kooperatívny multitasking. Niečo, čo vzniklo v dobách jednoprocesorových strojov. Spoliehať sa len na async znamená využívať jediné jadro. Ak sa bavíme o pythone tak správnou cestou je multiprocessing, alebo subinterpretery alebo novy no-GIL. Inak sa bude striedavo využívať jediné jadro.
Správnym využitím async je v prípadoch, keď sa čaká na IO, ale aj vtedy môže byť rozumnejšie kombinovať multiprocessing s asyncom a nemať jeden veľký loop pri veľkom množstve spojení s väčšou priepustnosťou.
Sám by som rád písal čistý async kód, ale knižnice, ktoré používam nie sú prepísané do async a nik ich do async celkom neche prepísať, lebo by bolo potrebné prepísať komplet kód, ktorý ich využíva a vlastne musel by sa infikovať celý ekosystém.
Na limity databázy nenarážam. Používam PostgreSQL 17 s nastavenými max 100 connections.
23.10.2025 20:49
vlk | skóre: 23
| blog: u_vlka
 24.10.2025 18:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.10.2025 05:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
24.10.2025 18:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.10.2025 05:17
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Zámky musíš řešit vždycky. Nikdy nevíš, která korutina zrovna běží.Myšleno jako že kód mezi dvěma awaity je z pohledu běžících korutin možno brát v podstatě jako atomickou operaci. Což ti teda přestane platit, když to běží ve vícero threadech na vícero event loopech.
Obecně to vidím tak, že threading je super pro CPU bound úlohy.Tak v současnosti je to v py přesně naopak, ne? Protože GIL ti tohle zabíjí a dělá ti to použitelné hlavně pro IO bound úlohy.
Pokud se bavíme o pythonu, tak je to mnohem lepší než použít multiprocessing, protože můžeš poslat čekající úlohu na jiný nevytížený thread.Mno, tohle jsem teda nějak nepochopil. Jakože nějak mixuješ terminologii, nebo topologii. Při topologii kde máš vyšší počet worker procesů jak počet jader/threadů procesoru a nějakém obsluhování queue to bude to samé, ne? Zprávu si vezme z queue nevytížený proces. Threading / multiprocessing bude mít větší overhead než asyncio při spouštění workerů, což typicky řešíš tak že pustíš nějaký pool workerů a dál to neřešíš. Paměťově asi vyjde vždycky líp asyncio? Umím si představit že asi nižší latence dělá pouštět korutinu pro každý příchozí požadavek, protože když se ti vytíží ten worker pool, tak buď budou nové požadavky čekat, nebo musíš pouštět nové thready a tady asi vynikne výhoda asyncia?
 26.10.2025 07:58
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
26.10.2025 07:58
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
dneska thread má skoro nulovou zátěžOS thread má stále netriviální zátěž, protože alokuje dopředu celkem velký stack. Golang korutiny jsou odlečené userspace thready, které Go runtime plánuje na konečný počet OS threadů. Stack řeší (relativně) malými dynamicky rostoucími stacky. Rust korutiny jsou stackless. (Obojí má nějaké výhody/nevýhody.)
27.10.2025 15:22
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
A je potřeba tohle vůbec řešit s výjimkou velmi expertních příkladů, kde je nutné zachovat nějakou definovanou latenci?Ano, je. 250 threadů/procesů nic není. Milion gorutin je v pohodě, protože to jsou lehké userspace thready. Milion OS threadů bude problém, protože stacky, kernel struktury a kernel context-switching...
28.10.2025 13:23
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz