Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na Seznam nepovolených internetových her (Wikipedie) se k 13. 7. 2026 dostala predikční platforma Polymarket.
Nová čísla časopisů od nakladatelství Raspberry Pi zdarma ke čtení: Raspberry Pi Official Magazine 167 (pdf) a Hello World 30 (pdf).
Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »Pro pořádek dodám lehký úvod do problematiky: Pokud je cílem našeho snažení databáze (někde uložená uspořádaná data), musíme mít na počátku zadaní, které specifikuje s jakými daty a jakým způsobem se bude pracovat. Dalším krokem je rozdělení dat na různé entity (objekty reálného světa) a určení vztahů mezi nimi. Toto se nazývá konceptuální model. Entitami si můžeme přestavit například knihu a autora a vztahem to, že autor napsal knihu. A nakonec můžeme převést daný konceptuální model na logický model, který konkrétně řeší, jak budou daná data reprezentována objekty (relační) databáze, což jsou tabulky, pohledy, indexy, atd...
Dopředu upozorním, že není vyloženě nutné používat nějaký nástroj. Entity a vazby se dají namalovat na papír a SQL skript popisující logický model se napíše z hlavy do textového editoru. Další oblíbený postup je tabulky naklikat v nástrojích typu phpMyAdmin či Adminer. V článku se ale pokusím ukázat třetí cestu, kterou si při větším počtu entit (tabulek) nemohu vynachválit a možná ji někdo docení též.
A to použít MySQL Workbench, což je open source nástroj od autorů MySQL pod licencí GPL (existuje i komerční verze, článek je ale o OSS) nejen k vizuálnímu návrhu databáze. Program funguje na platformě Linux, Windows a Mac OS X. Článek je o aktuální verzi 5.2.47. Co se týče instalace na Linux, na domovské stránce jsou balíčky pro Fedoru, Ubuntu a Oracle / Red Hat Enterprise Linux 6 a to v 32 i 64bitové verzi. Pro Ubuntu jsou dokonce pro verzi 12.04 a 10.04, která se mi podařila nainstalovat na Debian Wheezy. Pro ostatní distribuce jsou zdrojové kódy, ovšem v první řadě byste se měli podívat, jestli už nemáte program v repozitářích.
Pokud chceme něco dělat, musíme mít k tomu důvod. Proč navrhovat logický model vizuálně? Osobně proto, že to považuji za přehledné. Takový návrh má samodokumentační funkci, vazby mezi tabulkami jdou okamžitě vidět a i cizí člověk, co se dostane k projektu, se má šanci rychle zorientovat.
Tuto funkci by ale pořád poměrně dobře zastoupila tužka a papír (i když výstup z MySQL Workbench vypadá podstatně lépe, než to jak umím malovat). Ta za Vás ale nevygeneruje SQL kód. Toto je možná trošku kontroverzní vlastnost, kterou spousta vývojářů odmítá, protože považuje takto generovaný kód za ošklivý. Je to věc názoru, já jsem s tím, co MySQL Workbench produkuje, spokojený.
MySQL Workbench má ale ještě jednu a to někdy dost zabijáckou vlastnost. Dokáže grafickou reprezentaci reverzně vytvořit z SQL skriptu, tedy z existující databáze! A navíc umí vytvářet SQL „patche“ (importujete, graficky upravíte a exportujete ALTER skript). Ovšem všechno popořadě.
Po spuštění programu se nám ukáže úvodní obrazovka, kde je správa existujících modelů. Je skvělé, že program disponuje funkcí obnovy a pokud by náhodou spadl, neuložené modely jsou zde označeny žlutým vykřičníkem a jdou obnovit. My vytvoříme nový model. Objeví se další okno, které obsahuje více věcí, ale ta hlavní je ikona přidat diagram.
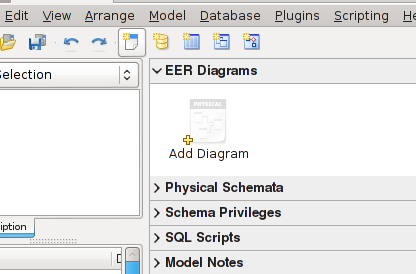
A teď konečně můžeme začít modelovat. První věc, co radím udělat je nastavit název databáze, kódování a způsob řazení. Bude se hodit při exportu. To uděláme v levém sloupci pravým kliknutím na výchozí databázi „mydb“ a zvolením upravit schéma.
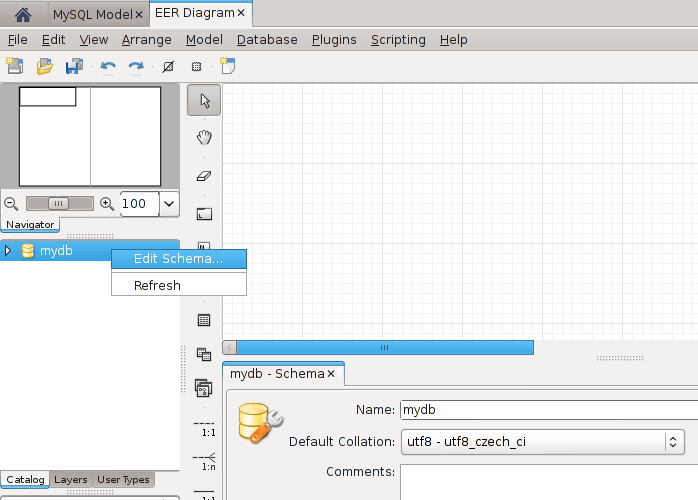
Nyní už můžeme z nástrojové lišty přidávat tabulky. Poklepáním na tabulku se nám v panelu dole zobrazí její nastavení. To je rozděleno na několik logických celků. Můžeme změnit jméno enginu, řazení, indexy, nevlastní klíče, definovat triggery a podobně, ale nejvíce nás zajímá sekce sloupce (columns).
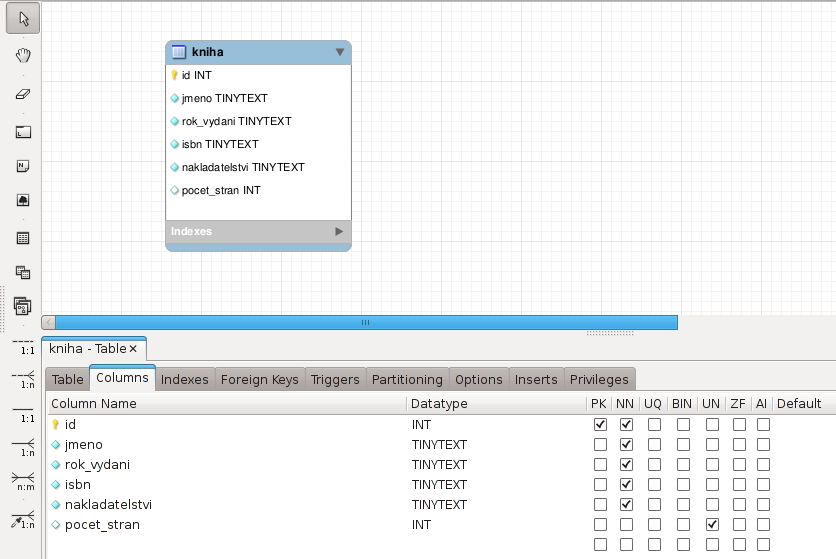
Zde jdou velmi pohodlně definovat všechny atributy tabulky. Je intuitivní, že pro přidání dalšího sloupce stačí zmáčknout šipka dolů a enter a rovněž oceňuji, že do sloupce pro datový typ lze přímo psát, takže není problém nic jako ENUM('zaměstnanec', 'šéf').
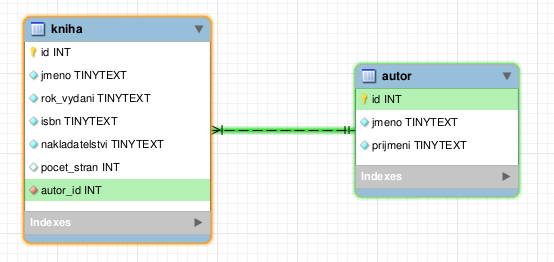
Pokud máme více tabulek, je potřeba mezi nimi definovat vazby. Ty jsou pak v SQL řešeny pomocí primárních a nevlastních klíčů. Integritní omezení pro nevlastní (foreign) klíče umí až InnoDB, proto doporučuji tento engine pro tabulky používat. Vazby opět najdeme v nástrojové listě a máme jich na výběr více (1:1, 1:N, N:M).
 ." width="250" height="118" />
." width="250" height="118" />
Pozastavím se nad vazbou 1:N, která je zde v identifikující a neidentifikující variantě, což se liší tím, jestli má být nevlastní klíč součástí primárního klíče tabulky nebo ne. Při vytváření vazby se prvně kliká na odkazující tabulku a poté na odkazovanou. Aplikace má spoustu šikovných vychytávek, například při najetí na vazbu / tabulku se zvýrazní barevně co je s čím propojeno nebo při smazání vazby se program zeptá, zda ponechat vytvořené sloupce, či je odstranit.
Formát, jakým bude program pojmenovávat nevlastní klíče, integritní omezení a indexy (MySQL Workbench při vytvoření vazby automaticky pro nevlastní klíč vytvoří index) se dá specifikovat v nastavení a vždy to lze ručně změnit v nastavení tabulky.
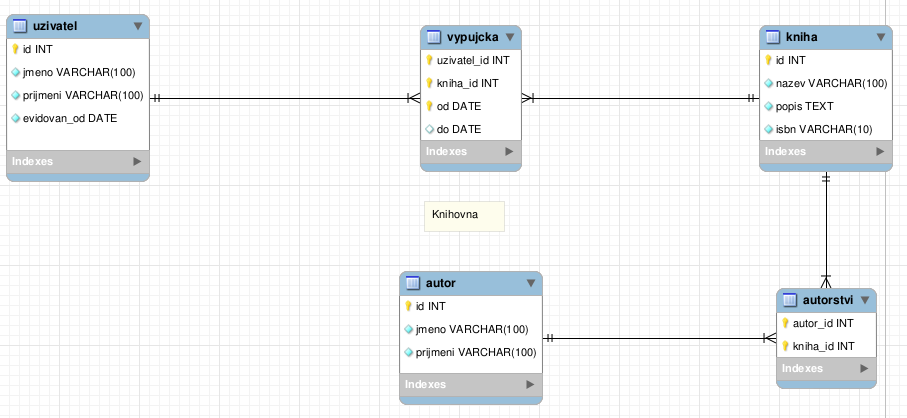 ." width="250" height="115" />
." width="250" height="115" />
Pokud jsme už s modelem spokojeni, budeme ho chtít exportovat. Možnosti najdeme v menu File→Export. Kromě SQL skriptu program samozřejmě zvládá export i do SVG a PNG, pokud bychom například chtěli model vložit do dokumentace.
Skvělou vlastností programu je možnost vytvořit „patch“ (ALTER skript) vůči existujícímu SQL skriptu. Tato volba se jmenuje Forward Engineer SQL ALTER Script.
Toto se dá skvěle zkombinovat s importem, který dokáže reverzně otevřít existující SQL schéma, které můžete třeba lehce upravit a exportovat si ALTER skript, který spustíte nad databázi s daty (předtím ale rozhodně zálohujte  ).
).
V článku jsem popsal jen věci, které používám. MySQL Workbench toho ale umí mnohem více. Dokáže spravovat existující databázi podobně jako phpMyAdmin (pokud to ale není Vaše lokální databáze, potřebujete povolený vzdálený přístup na databázovém serveru), automaticky na ni exportovat vaše úpravy v modelu, atd...
Na druhou stranu se dá nástroj využít, i když nikdy žádnou existující databázi vytvářet nechcete a to jako kreslítko tabulek do dokumentace, protože grafický výstup je slušný. A pak nemusíte ani používat MySQL.
Za tu dobu, co program používám, se občas stane, že spadne, ale díky automatické obnově to není problém. Celkově MySQL Workbench hodnotím jako výborný kousek software a je skvělé, že je dostupný i na Linuxu.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 20.2.2013 05:50
kouzer | skóre: 11
| Mladá Boleslav
20.2.2013 05:50
kouzer | skóre: 11
| Mladá Boleslav
Shodou náhod jsem Workbanch zkoušel před dvěma dny a kvůli častým pádům jsem se vrátil do textového editoru a napsal SQL ručně. Teď (po přečtení článku) si říkám jestli mu nevadilo, že jsem použil MariaDB místo MySQL. To by ale mělo být jedno, ne?
 20.2.2013 13:56
svido | skóre: 28
20.2.2013 13:56
svido | skóre: 28
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz