Vládní CERT upozorňuje (𝕏) na kritické zranitelnosti v produktech VMware: CVE-2026-59309, CVE-2026-59310 a CVE-2026-47876. Zranitelnosti v VMware vCenter umožňují vzdálenému útočníkovi se síťovým přístupem obejít autentizaci a získat neoprávněný přístup k vCenter, případně zneužít directory traversal ke spuštění libovolného kódu na vCenter.
Společnost Coinkite upozorňuje na bezpečnostní chybu svých hardwarových kryptopeněženek Coldcard. Jedná se o kritickou chybu v generování náhodných čísel (RNG). Místo hardwarového generátoru náhodných čísel (TRNG) byl omylem používán softwarový fallback (PRNG).
Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Úspěšné zvládnutí instalace a následné upravení systému vyžaduje:
O systému business intelligence se dále budeme bavit jako o BI.
Po této kapitole budete vědět, jak se vytváří a spouští ETL v aplikaci Kettle. Zároveň se naučíte nastavit automatické spuštění ETL pomocí crontab.
Jedením z poslání BI je zpracovávat a analyzovat aktuální data, která se po čase stanou historickými. Do BI vstupují různorodé typy systémů a s tím je spojen i problém s rozdílností datových formátů a přenosových médií. Vstupy mohou poskytovat svá data v různých intervalech. Některé produkční systémy generují denní data, státní úřady/výzkumné agentury mohou poskytovat data měsíčně, kvartálně nebo také pouze adhoc. Vstupní data nemusejí být ve stejné datové formě (textový soubor, XLS, databáze ...) nebo kódování. Kupříkladu produkční systém může umožňovat přístup přímo ke své relační databázi, data z banky přijdou e-mailem v textovém souboru a státní instituce vystaví svá data na web v excelovém souboru. V praxi existuje nesčetné množství forem, v nichž se data doručují ke zpracování. Se všemi se musí vypořádat vstupní brána každého BI systému, a to ETL. Jedná se o kriticky důležitou oblast, která častokrát determinuje schopnosti celého BI řešení. Ono nelze reportovat data, která nemáte v systému 
ETL nebo-li Extract Transform Load je sada nástrojů, která z nesourodých datových zdrojů separuje adekvátní data, upravuje je a poté nahrává do datového skladu. Tuto činnost provádí buď manuálně nebo automaticky podle časového plánu. O výsledku by mělo ETL podat zprávu (e-mail, log) administrátorovi systému BI.
Mezi základní zdroje, z nichž může ETL čerpat data, jsou věškeré formy hromadného skladování dat. Mohou to být soubory, tabulky, databáze (relační, souborové), OLAP systémy anebo také webové stránky, či prostý text.
Jak jsme uvedli výše, tak ETL je zkratka pro Extract, Transform, Load. Sled písmen ve zkratce také vystihuje posloupnost jednotlivých kroků v celém procesu nahrávání dat. Extract znamená něco vyjmout, vytáhnout. V případě ETL tím „něco“ jsou zdrojová data pro budoucí data datového skladu. Ve zdrojových datech je nutné zmapovat výskyt námi požadovaných dat. V praxi se ve většině případů jedná o sloupce v databázích nebo excelových tabulkách. Je nutné mít na zřeteli kódování textů a regionální nastavení formátů čísel.
Mnohokrát je třeba některé informace rozdělit na dílčí nebo převést jejich formát. Příkladem může být datum ukrytý v názvu souboru nebo složený kód pro místo.
Příklady: Sběr dat z poboček firmy. Data se generují každý den a ukládají se do souboru podle klíče město_datum.txt
Název souboru: brno_20101028.txt Cíl: město = brno, datum='28-10-2010'
Jiným požadavkem může být třeba převod dat ve formě kontingenčních tabulek do normalizované formy.
Tyto požadavky jsou v ETL řešeny pomocí transformací, čili převodů. Děje se tak uvnitř samotného ETL. Transformací může být několik a mohou probíhat paralelně. Výsledkem jsou zpracovaná data pro konečné nahrávání do datového skladu/databáze.
Zpracovaná data po transformaci se ukládají do datového skladu/databáze.
Popsaný proces platí pro nahrávání dat do BI. Pokud naopak exportujeme data z BI, pak je proces obrácený. Data se čtou z datového skladu/OLAPu a ukládají se do formátů vhodných k výměně dat (txt, XLS, DBF ...) nebo přímo do externích databází. I v tomto případě mohou probíhat transformace dat.
V Pentaho jsou ETL řešena pomocí aplikace Kettle, alias Pentaho Data Integration. Jedná se o stand-alone aplikaci běžící v Javě, která umožňuje stavět, spravovat a spouštět jednotlivé ETL. Svoje data ukládá do relační DB nebo do souborů XML. Pro zvýšení výkonu je možné sestavit cluster a ETL spouštět na více strojích současně.
Ze sourceforge.net si stáhněte Pentaho data integration a rozbalte ji do libovolného adresáře.
wget http://sourceforge.net/projects/pentaho/files/Data%20Integration/4.1.0-stable/pdi-ce-4.1.0-stable.tar.gz/download tar xzf pdi-ce-4.1.0-stable.tar.gz
Vytvoří se vám podadresář data-integration, do kterého si přejděte a vypište si všechny .sh soubory.
Výsledkem je:
carte.sh* encr.sh* generateClusterSchema.sh* kitchen.sh* pan.sh* runSamples.sh* set-pentaho-env.sh* spoon.sh*
V tento okamžik jsou pro nás důležité soubory spoon.sh, pan.sh a kitchen.sh. Prvně jmenovaný spoon.sh spouští grafické prostředí pro návrh a provoz vlastních ETL, která se skládají z transformací a jobů (více o nich o malou chvilku později). Pan.sh a kitchen.sh nám umožní nakonfigurované transformace (pan) a joby (kitchen) spouštět z příkazové řádky. Pojďme si ale nejdříve nakonfigurovat samotný PDI.
PDI k běhu vyžaduje úložiště. To může být řešeno buď souborovým systémem nebo relační databází. My si sestavíme PDI proti relační databázi PostgreSQL. Konfigurace se souborovým datovým úložištěm je velmi podobná. Na změny upozorním.
./spoon.sh*
V případě souborového úložiště pokračujte bodem 4
postgres=# CREATE DATABASE pentaho_pdi WITH OWNER = pentaho_user;
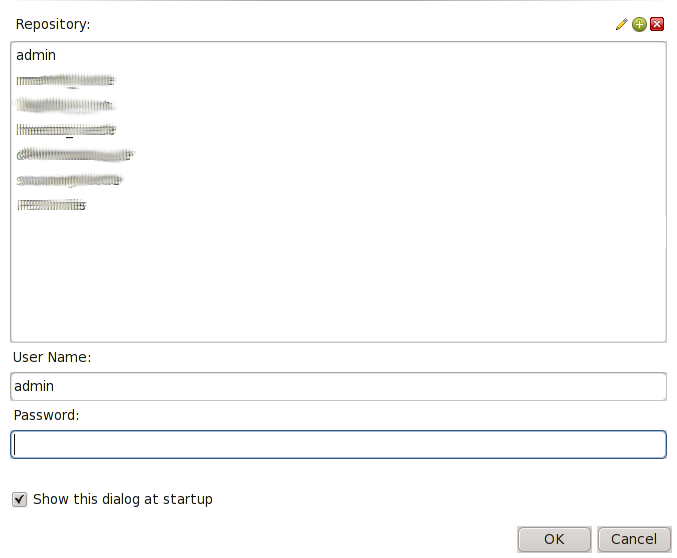
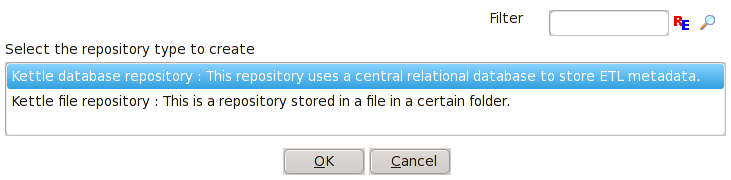
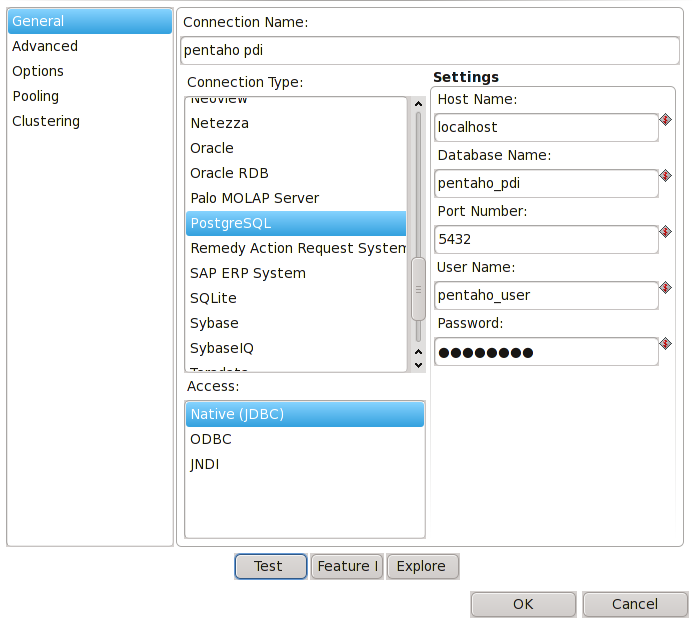
K nově vytvořenému připojení vytvoříme vlastní repository. Doplňte info o ID a Name a stiskněte Create or Upgrade
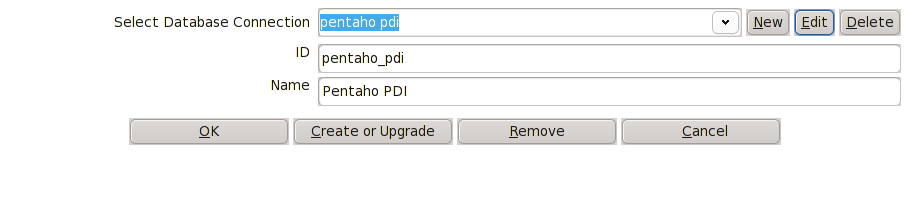
Pokud opravdu chcete vytvořit repository a databázové objekty, 2x kladně odpovězte, až se dostanete po výpisu SQL kódu ke spuštění Buď můžete daný kód spustit přímo z PDI nebo si SQL zkopírujte a spusťte z konzole, kde si jej múžete také odkrokovat
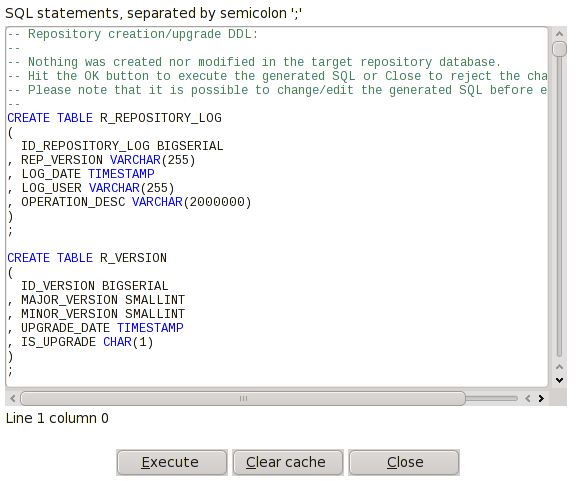
Zavřete okno SQL editoru (i když vše proběhne jak má, tak editor zůstane otevřený a svádí k opětovnému spuštění)
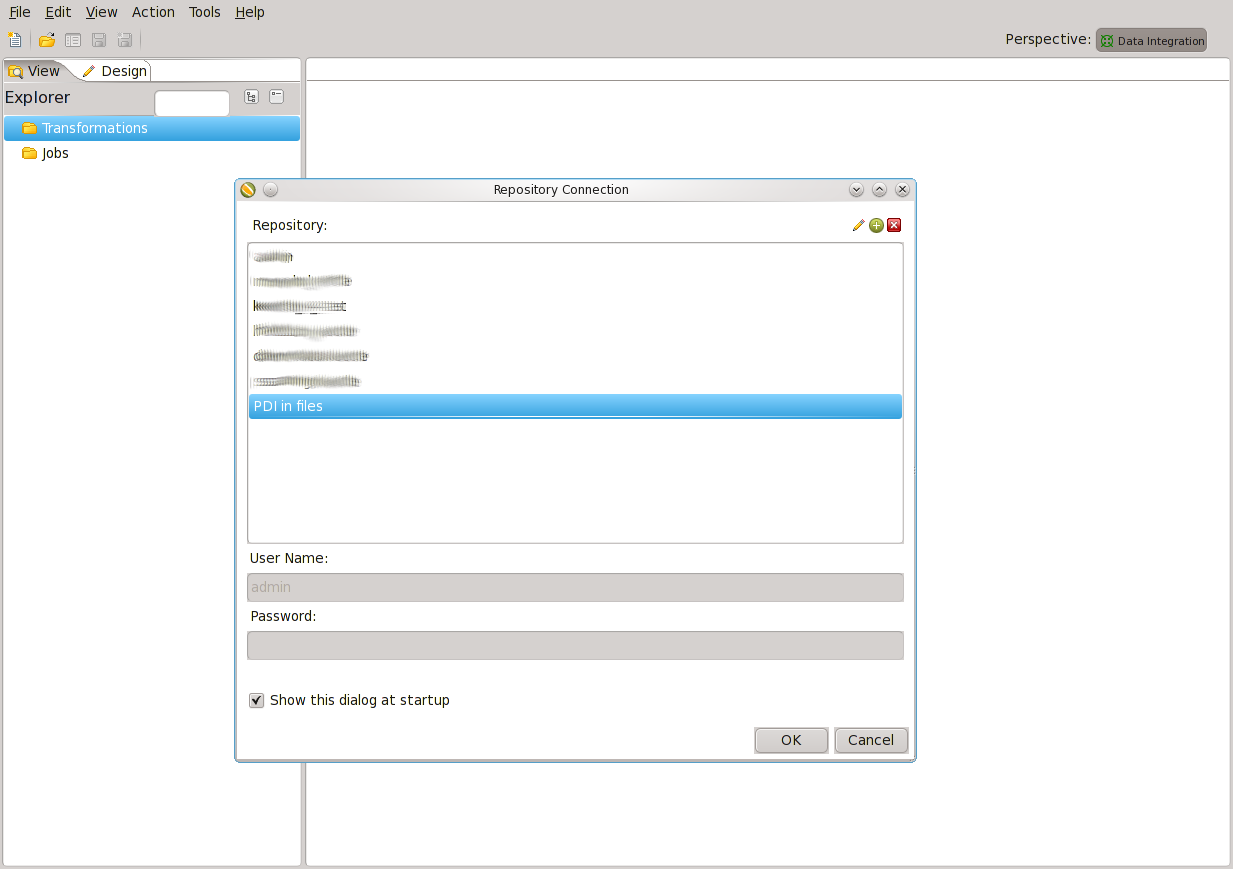
Nyní máme vytvořenou vlastní repository, kam se nám budou ukládat výsledky naší práce. PDI pracuje s dvěma typy objektů: transaformation a job.
Transformation – jsou výkonné prvky, které zajišťují převod importovaných dat do toku, na něm spouštění skriptů a jeho výsledného exportu do cílového úložiště.
Job – je soubor transformací a k nim přiřazených obslužných nástrojů (přístup na FTP, odesílání e-mailů, zipování souborů apd), které tvoří ucelené ETL.
Na jednoduchém příkladě si předvedeme jak sestavit ETL a spustit jej.
Z menu File nebo si pomocí stisknutí Ctrl+N vyberte Transformation. V levé části se objevila řada položek začínajících Input. Jedná se komponenty, které můžete použít ve své transformaci. Každá transformace musí obsahovat nějaký vstup Input a výstup Output. Kettle zná velké množství vstupních/výstupních formátů a technik. Vedle běžně používaných textových souborů a XLS souborů to jsou relační a MS Access databáze, dbase, OLAP (pomocí mdx), a také umí spouštět dotazy na SAPu. V případě, že je nutné mezi vstupem a výstupem data upravit, pak nám Spoon nabízí nástroje pro úpravu dat Transform. Můžeme tak upravovat jednotlivé pole, spojovat řádky, upravovat řetězce a mnohé další. Nástroje pro řízení toku (spojování dávek z několika souborů, filtrování řádků apod.) naleznete pod položkou Flow. Velkou silou Kettlu je možnost vytváření vlastních skriptů. Konkrétně se jedná o JavaScript, SQL a Javu. Tuto vlastnost oceníte zejména při konsolidaci dat z cizích zdrojů (od dodavatelů, výzkumných agentur apod.).
Naším cílem bude importovat textový soubor ve formátu csv do databáze. Nejdříve si vytvoříme cílovou databázi
postgres=# CREATE DATABASE pentaho_data WITH OWNER = pentaho_user;
Do libovolného adresáře si stáhněte tento soubor a rozbalte jej. Obsahuje smyšlená denní data ze třech poboček.
Ve spoon si z nabídky Input myškou přetáhněte na plochu vpravo položku Text file input a z nabídky Output položku Table output.
Výsledek by měl být následující:
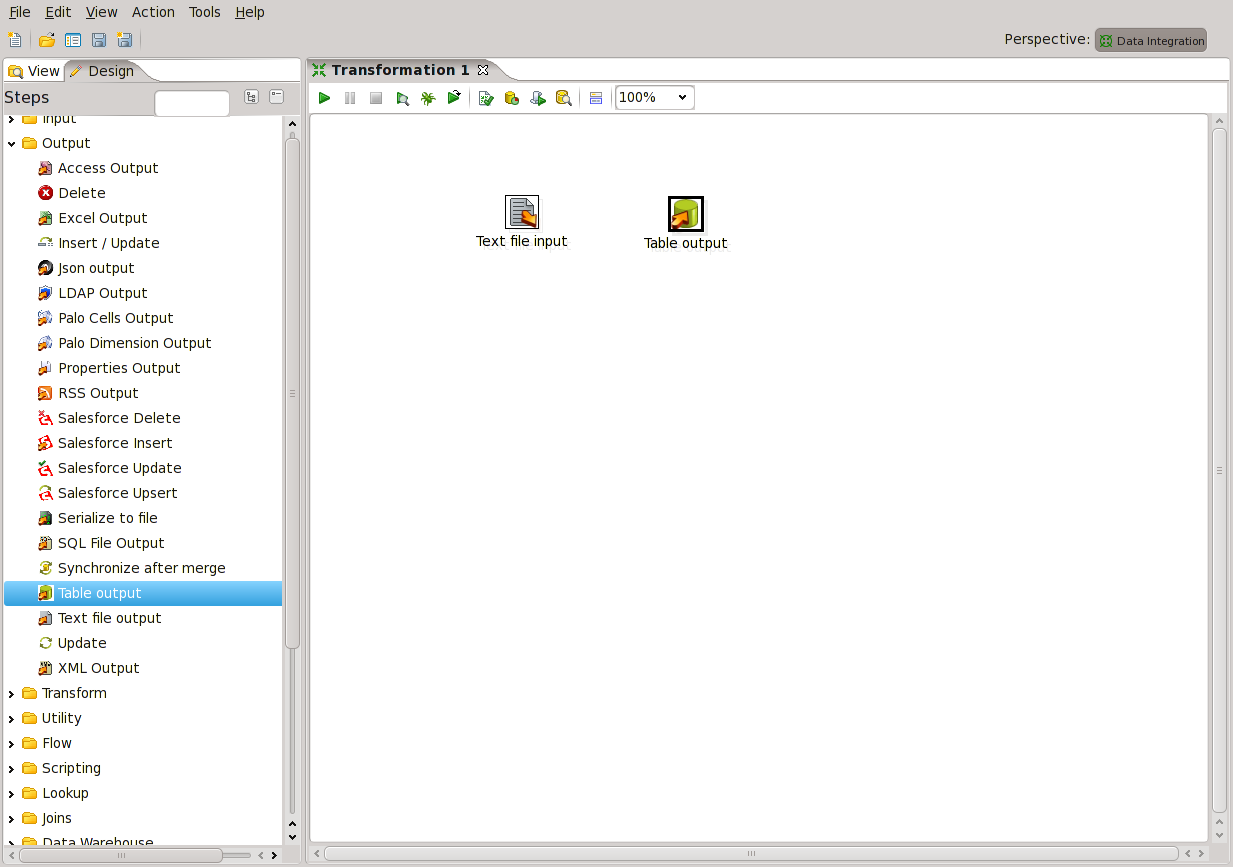
Nyní si pojďme nakonfigurovat vstup naší transformace. Dvojklikem na Text file input se vám otevře nabídka konfigurace komponenty textového souboru.
1. Nejdříve si pomocí Browse vyberte jeden z rozbalených souborů – třeba brno_20101128.csv. Tlačítkem Add jej přidáte do seznamu zpracovávaných souborů
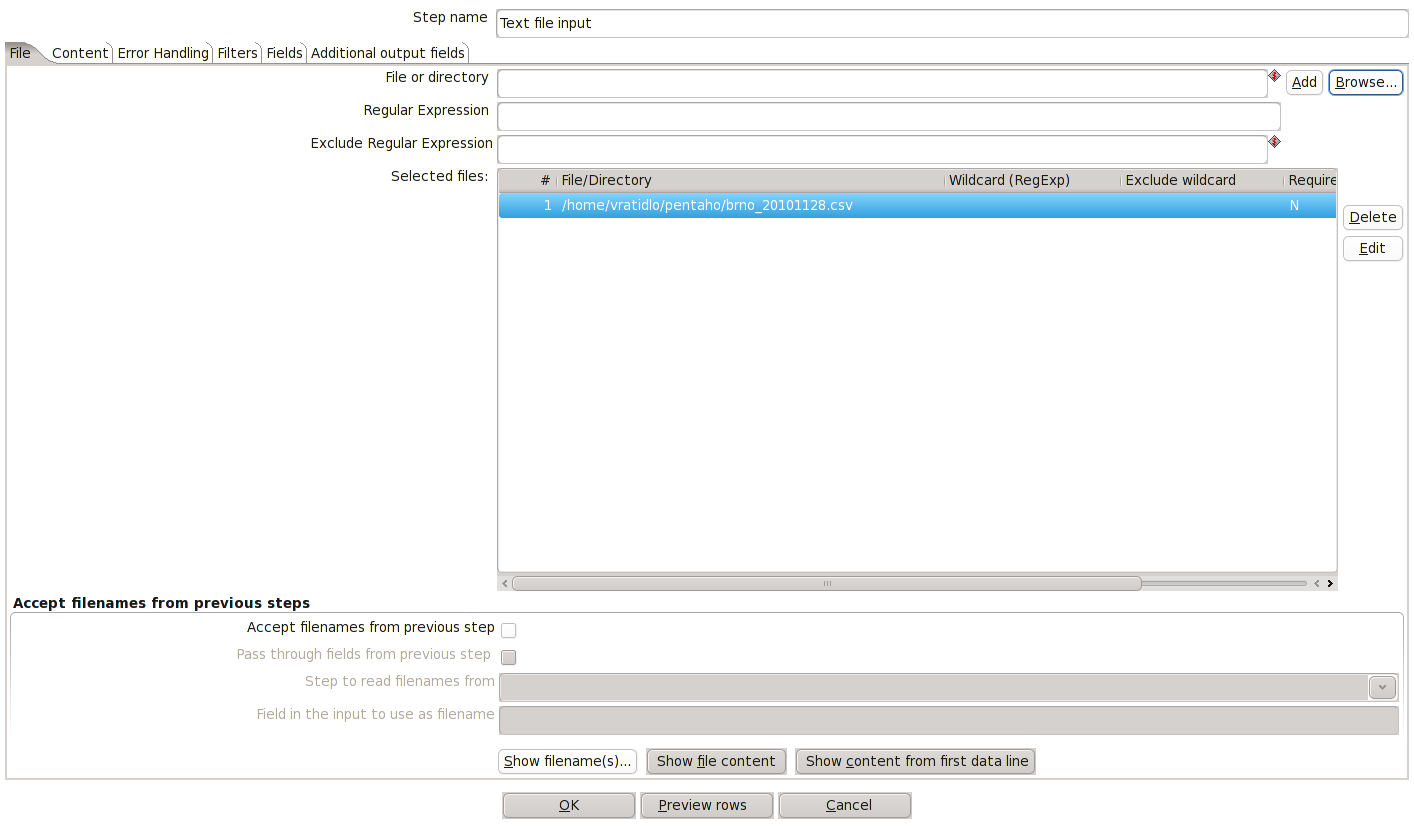
2. Jelikož se jedná o strukturovaná data, musíme pospat obsah vstupního souboru. To učiníme v záložce Content. V našem případě se jedná o tyto položky
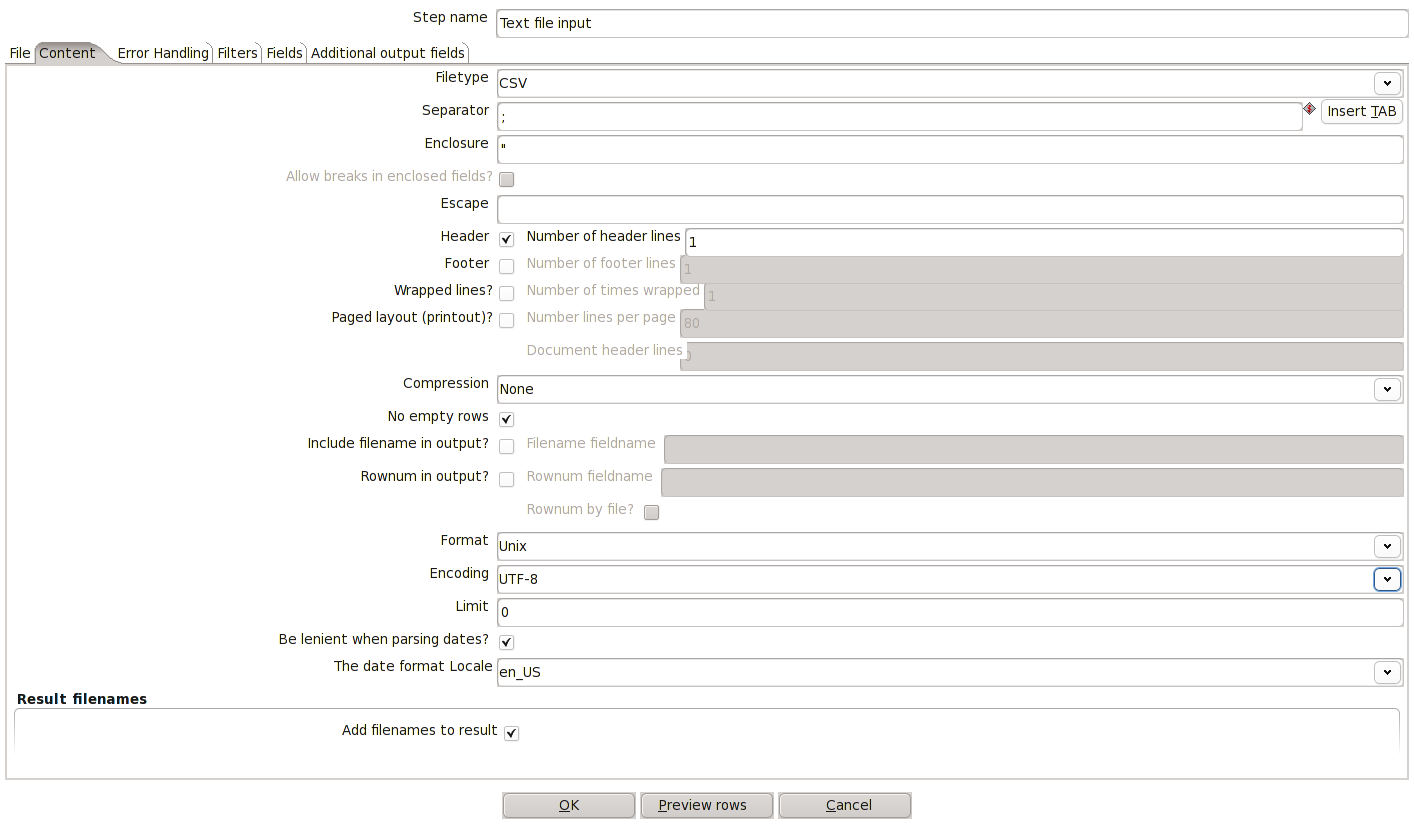
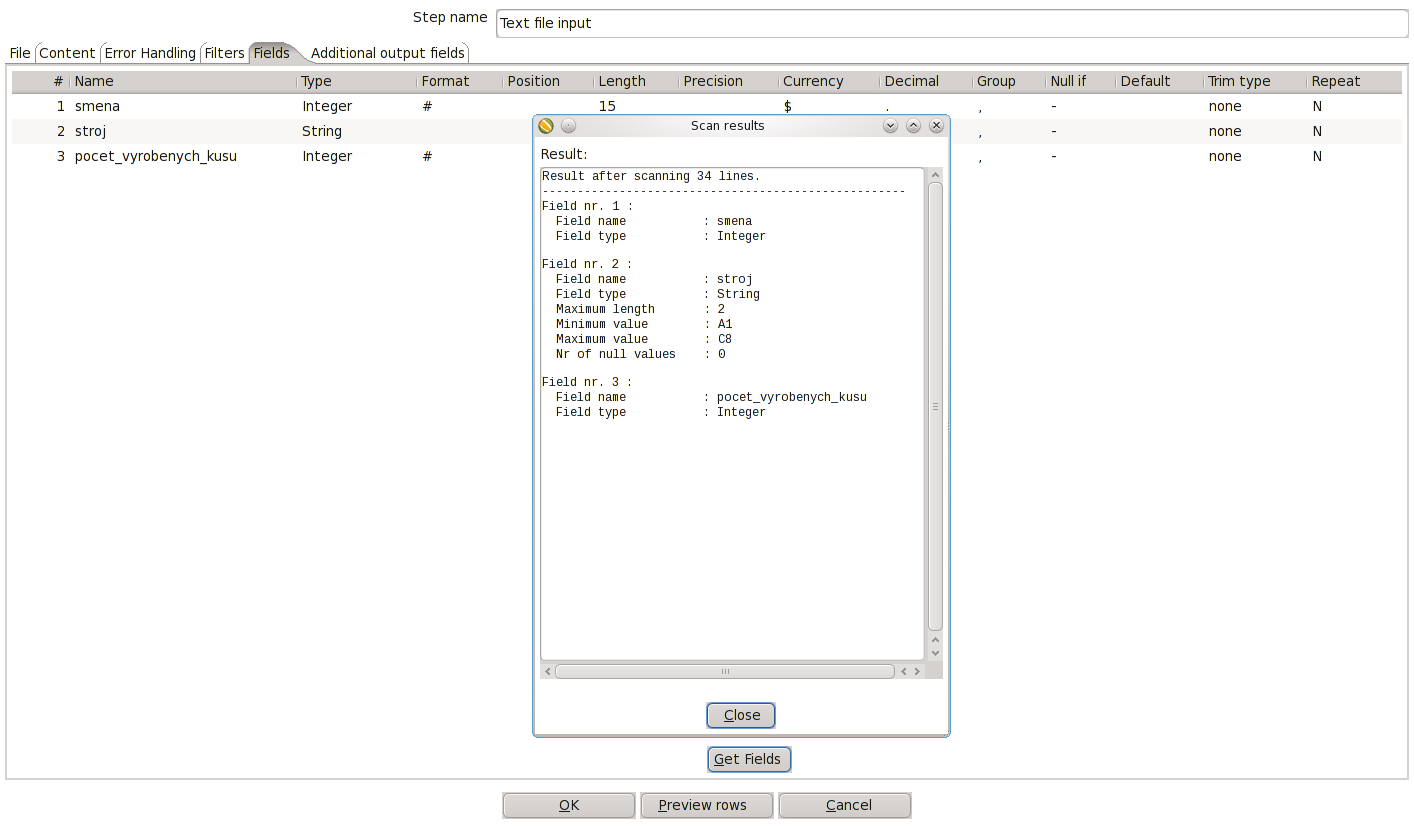
3. Pole, které budeme ze souboru číst, jsou popsány právě hlavičkou ze souboru. Jejich přesnou definici určíme v záložce Fields. Uprostřed dole stiskněte tlačítko Get fields, čímž se na základě prvních 100 řádků odhadne datový typ a rozsah jednotlivých polí. V našem případě je výsledek následující
4. Vstup máme nastavený a zbývá nám říct výstupu Table output, kde má vzít data a jak je má ukládat. Při stisknutém shiftu klikněte myškou na Text file input a táhněte na Table output, kde myšku pusťte. Tím vytvoříte propojení mezi oběma komponentami.
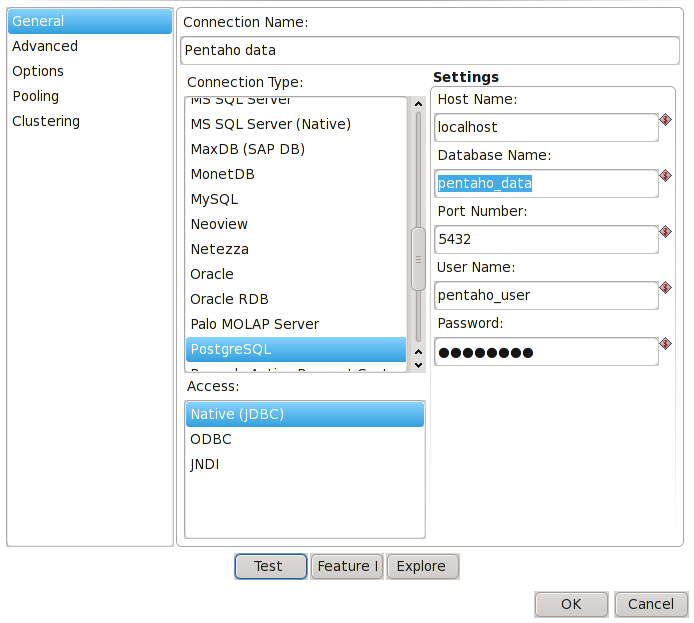
Obdobně jako při přípravě repozitory si vytvoříme konektor do cílové databáze. Dvojklik na Table output nám otevře konfigurace výstupu. Vedle položky Connection stiskněte tlačítko New a nastavte konektor. Výsledek by měl být následující:
Databáze je prázdná, takže do jména cílové tabulky Table target můžeme vepsat libovolné jméno. Zvolme třeba pobocky_data. Jelikož tato tabulka neexistuje, neexistují ani její sloupce. Snadno si je můžeme vytvořit přímo ze Spoon. Zaškrtněte checkbox Specify database fields, běžte do záložky Database fields a stiskněte tlačítko Get fields. Tím se nám načtou pole definované ve vstupu.
Pokud vám tento popis vyhovuje, zvolte tlačítko SQL a Spoon vám vygeneruje patřičný sql dotaz pro vytvoření tabulky pobocky_data.
CREATE TABLE pobocky_data ( smena BIGINT , stroj VARCHAR(2) , pocet_vyrobenych_kusu BIGINT ) ;
Vzhledem k povaze dat je vhodné daný dotaz mírně upravit, a to takto:
CREATE TABLE pobocky_data ( smena SMALLINT , stroj VARCHAR(12) , pocet_vyrobenych_kusu INT ) ;
Stiskněte OK a Spoon spustí příkaz.
Nyní máme definované jednoduché ETL, které nám nahraje právě jeden soubor do cílové tabulky. Pojďme si ho spustit.
Transformaci si uložte File/Save as třeba jako import_datapobocky. Z horní lišty stiskněte zelenou šipku a nebo stiskněte F9. Otevře se vám formulář s informacemi o dané transformaci. Jednotlivými detaily se budeme zabývat později. Zvolte Launch. Výsledek by měl být následující
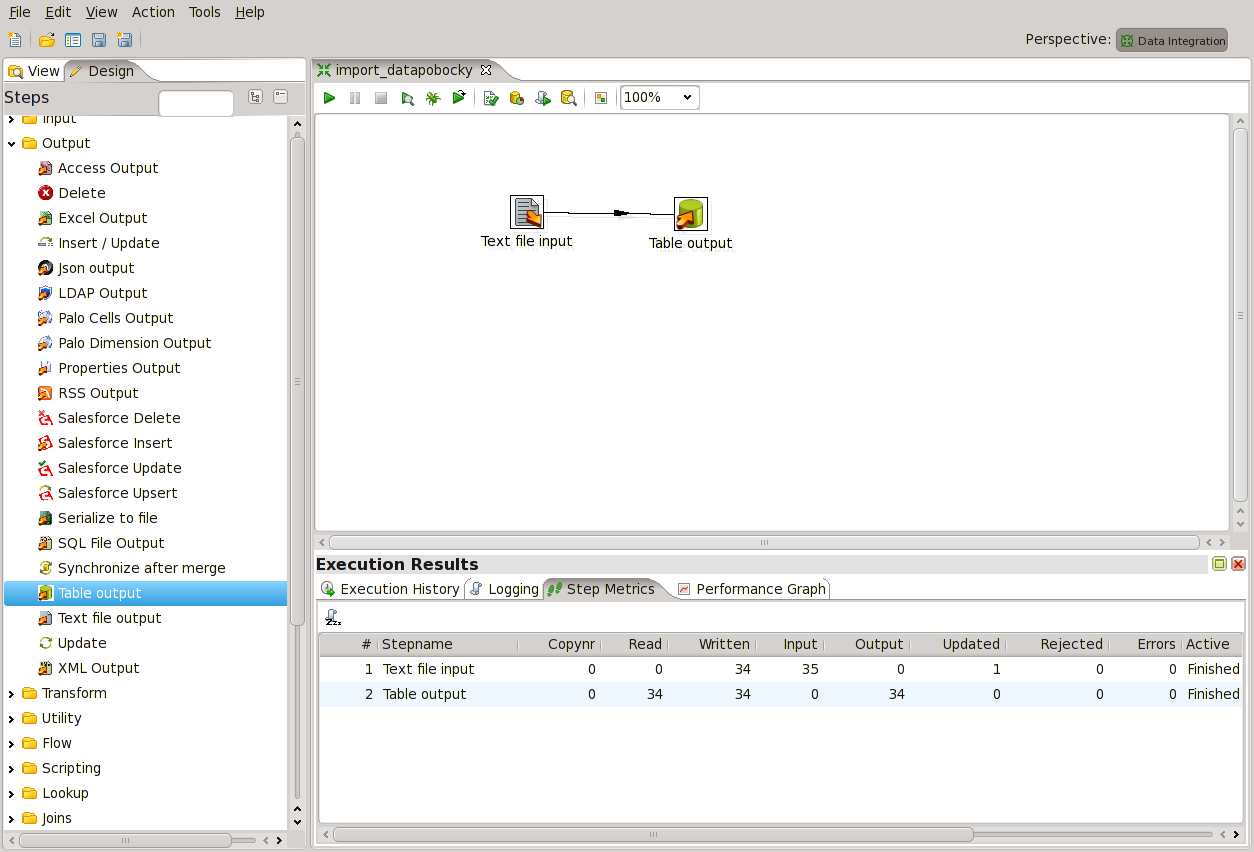
Data máme nahraná
Vytvořili jsme si tranformaci, která nám importuje obsah pouze jednoho souboru. V našem případě, ale potřebujeme importovat data za každý den a je nemyslitelné s každým souborem ručně přepisovat cestu v Text file input. Název importovaného souboru potřebujeme měnit parametricky. Kettle na toto myslí a poskytuje aparát parametrů, které fungují jak v transformacích, tak i v úlohách.
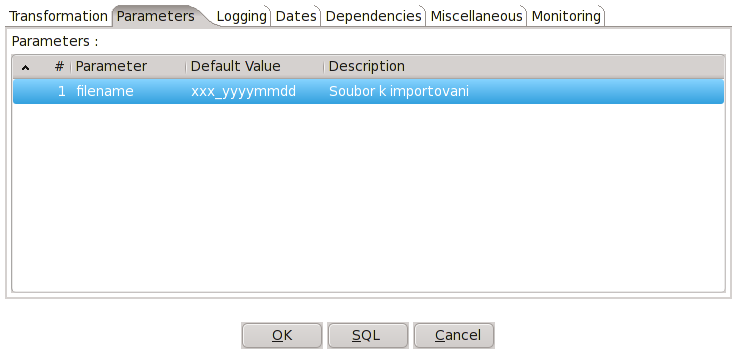
Do libovolného místa na pracovní ploše klikněte pravou myškou a zvolte Transformation settings nebo stiskněte Ctrl+T. V záložce Parameters vytvořte nový parametr filename s výchozí hodnotou „brno_20101129.csv“ a dejte OK. Tím jsme vytvořili dynamickou položku, kterou můžeme ovládat vně naší transformace. Výchozí hodnotu jsme nastavili na název jiného souboru pouze pro náš cvičný případ.
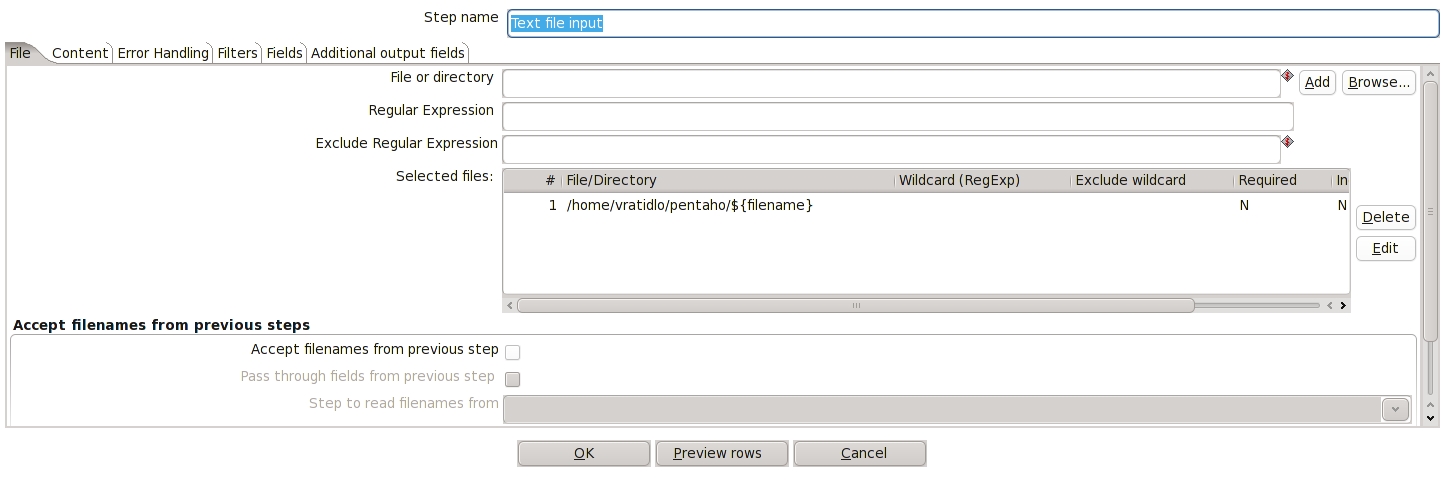
V našem případě potřebujeme měnit název nahrávaného souboru pomocí parametru filename. Otevřete si vlastnosti objektu Text file input, vyberte soubor ze seznamu souborů ke zpracování a dejte Edit. V cestě k souboru nahraďte jeho jméno takto ohraničeným parametrem ${filename} a dejte znovu Add.
Nyní si uložte transformaci a spusťte ji. Než stiskněte tlačítko Launch, tak si v levé části formuláře povšimněte nového parametru filename a u něj uvedené výchozí hodnoty.
Pro zjištění stavu běhu transformace se můžete podívat do logu v Execution Results - Logging, kde jedna z položek bude následující:
Text file input.0 - Opening file: /home/vratidlo/pentaho/brno_20101129.csv
To nám říká, že námi nastavený parametr zafungoval.
Aby nám byl parametr užitečný, je třeba zajistit jeho pohodlné nastavování. Nejčastěji je parametr transformace ovládán z nadřazené úlohy. Něky ale není úlohu třeba vytvářet a postačí nám pouhá transformace. My si náš parametr zavoláme z shellu, a to pomocí skriptu pan.sh
./pan.sh Options: -rep = Repository name -user = Repository username -pass = Repository password -trans = The name of the transformation to launch -dir = The directory (dont forget the leading /) -file = The filename (Transformation in XML) to launch -level = The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) -logfile = The logging file to write to -listdir = List the directories in the repository -listtrans = List the transformations in the specified directory -listrep = List the available repositories -exprep = Export all repository objects to one XML file -norep = Do not log into the repository -safemode = Run in safe mode: with extra checking enabled -version = show the version, revision and build date -param = Set a named parameter= . For example -param:FOO=bar -listparam = List information concerning the defined named parameters in the specified transformation.
Výpis jednotlivých parametrů je výmluvný, takže se pojďme podívat do naší repository
./pan.sh -rep pentaho_pdi -user admin -pass admin -listtrans INFO 09-12 11:13:40,191 - Using "/tmp/vfs_cache" as temporary files store. INFO 09-12 11:13:41,115 - Pan - Start of run. INFO 09-12 11:13:41,213 - RepositoriesMeta - Reading repositories XML file: /home/vratidlo/.kettle/repositories.xml import_datapobocky
Tímto jsme si vypsali veškeré transformace, které v naší repozitory máme uložené. Vidíte, že je pouze jedna, a to import_datapobocky. Pojďme se podívat na její parametry:
./pan.sh -rep pentaho_pdi -user admin -pass admin -trans import_datapobocky -listparam INFO 09-12 11:16:40,272 - Using "/tmp/vfs_cache" as temporary files store. INFO 09-12 11:16:41,152 - Pan - Start of run. INFO 09-12 11:16:41,250 - RepositoriesMeta - Reading repositories XML file: /home/vratidlo/.kettle/repositories.xml Parameter: filename=, default=brno_20101129.csv : Soubor k importovani
Podle očekávání se vypsal pouze jeden, a to filename. Nyní pomocí parametru importujeme další soubor.
./pan.sh -rep pentaho_pdi -user admin -pass admin -trans import_datapobocky -param:filename=brno_20101130.csv INFO 09-12 11:18:39,540 - Using "/tmp/vfs_cache" as temporary files store. INFO 09-12 11:18:40,404 - Pan - Start of run. INFO 09-12 11:18:40,501 - RepositoriesMeta - Reading repositories XML file: /home/vratidlo/.kettle/repositories.xml INFO 09-12 11:18:40,900 - import_datapobocky - Dispatching started for transformation [import_datapobocky] INFO 09-12 11:18:40,967 - import_datapobocky - This transformation can be replayed with replay date: 2010/12/09 11:18:40 INFO 09-12 11:18:40,975 - Table output - Connected to database [Pentaho data] (commit=1000) INFO 09-12 11:18:40,979 - Text file input - Opening file: /home/vratidlo/pentaho/brno_20101130.csv INFO 09-12 11:18:40,984 - Text file input - Finished processing (I=35, O=0, R=0, W=34, U=1, E=0) INFO 09-12 11:18:41,075 - Table output - Finished processing (I=0, O=34, R=34, W=34, U=0, E=0) INFO 09-12 11:18:41,076 - Pan - Finished! INFO 09-12 11:18:41,077 - Pan - Start=2010/12/09 11:18:40.405, Stop=2010/12/09 11:18:41.076 INFO 09-12 11:18:41,077 - Pan - Processing ended after 0 seconds. INFO 09-12 11:18:41,082 - import_datapobocky - INFO 09-12 11:18:41,082 - import_datapobocky - Step Text file input.0 ended successfully, processed 34 lines. ( - lines/s) INFO 09-12 11:18:41,083 - import_datapobocky - Step Table output.0 ended successfully, processed 34 lines. ( - lines/s)
Naše transformace importovala 34 řádků ze souboru brno_20101130.csv
Takto nakonfigurovaný skript pan.sh můžeme vložit do crontabu, a tím velmi jednoduše vytvořit plán automatického spuštění.
Příkaz může vypadat následovně:
0 4 1 12 * /home/vratidlo/pentaho/data-integration/pan.sh -rep pentaho_pdi -user admin -pass admin -trans import_datapobocky -param:filename=brno_20101130.csv
Určitě si dokážete představit, že lze pomocí bash sestavit i vkládaní parametru, tak aby se nám měnil v čase.
V dalších dílech si ještě ukážeme, jak lze Kettle ovládat z jiných aplikací Pentaho.
Ukázali jsme si jak lze poměrně jednoduše vytvořit základní prvek ETL, transformaci. K plnohodnotnému ETL to má však ještě daleko. Takovouto jednoduchou transformaci je vhodné spouštět/opakovaně spouštět, plnit parametry a kontrolovat z nějakého nadřazeného objektu. Tím je úloha – job. O té si ale povíme příště.
Na shledanou s Pentaho
Autor je pracovníkem společnosti OptiSolutions s.r.o.
Společnost OptiSolutions s.r.o. se zabývá poskytováním řešení v oblasti CRM a Business Intelligence založených na Open Source technologiích SugarCRM a Pentaho.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
/mnt/abclinuxu/data/abclinuxu_data/abclinuxu/images/clanky/benes/pdi_repository_connection_new.png (Permission denied)
 21.12.2010 03:46
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
21.12.2010 03:46
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz