Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
Prvním krokem je pochopitelně získat nějakou digitální podobu knihy. Někdo preferuje skener, jiný zase digitální fotoaparát. Ať zvolíme jakoukoliv variantu, jsou důležité tyto věci:
Hlavně k prvnímu bodu dodám, že co nepokazíte při skenování, to pak nebudete muset velmi pracně opravovat softwarově s nejistým výsledkem. Ideální by pro digitalizaci bylo knihu zničit vyříznutím stran a pak to třeba prohnat skenerem s automatickým podavačem. Ale i přesto, že jsem si sám koupil knihy snad jen za účelem digitalizace (nosit „bichle“ mě zkrátka nebaví), se mi to vnitřně příčí.
Pro skenování používám jednoduchý cyklus v konzoli:
for page in $(seq -f "%03.f" 1 500); do echo "Otoč na další stranu a stiskni ENTER" read scanimage --format=pnm --mode "Grayscale" --resolution 300 > "page-$page.pnm" done
Několik poznámek: čísla 1 a 500 na prvním řádku určují, od jakého a do jakého čísla (dvoj)stránky skenujeme. Není nutné se snažit držet skutečných čísel stran. Jde jen o to to mít popořadě. Scan Tailor by si poradil i s neabecedně (jen numericky) řazenou posloupností stran, takže -f „%03.f“ přidávající nuly před číslo by bylo možné vynechat, ale pro vlastní pořádek to tam dávám.
Některé skenery umožňují skenovat více stránek najednou s potvrzováním přímo na skeneru. Jiné zase umožňují poladit kontrast, jas a další parametry přímo při skenování. V těchto věcech vás odkážu na nápovědu scanimage pro konkrétní zařízení. Určitě ale nemusíte řešit ořez nebo rotaci – to nechte na Scan Tailor.
Hned po spuštění se bude Scan Tailor zajímat o to, na jakém projektu chcete pracovat. Jednoduše vyberte adresář se skeny ve formátu .pnm. Pak se před vámi po případném doplnění údaje o DPI zobrazí kompletní GUI se všemi schopnostmi.
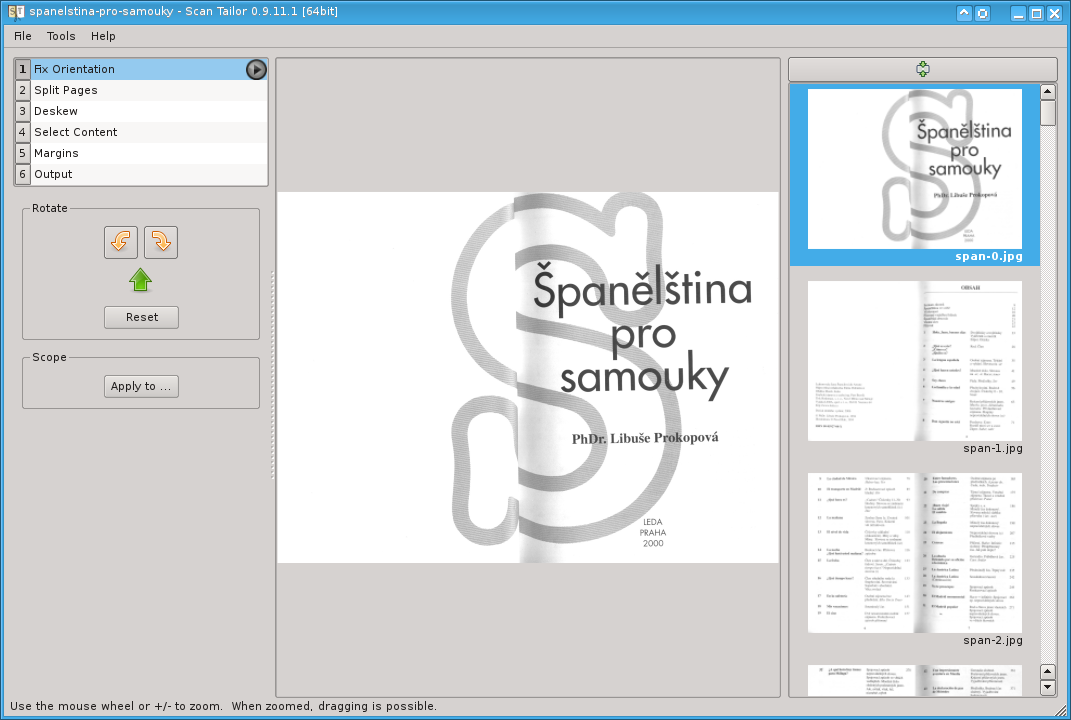
Po levé straně je vidět přehled jednotlivých kroků, které vás na cestě ke kýženému e-booku čekají.
První krok je jasný. Pokud jste skenovali po dvoustranách, jistě je budete mít o 90 nebo 270 stupňů otočené. Pokud by to Scan Tailor náhodou detekoval špatně, jedním klikem to opravte, klikněte na Apply to... a zvolte All pages (všechny strany) a rovnou můžete kliknout na ikonku „play“, která operaci aplikuje na všechny stránky v projektu.
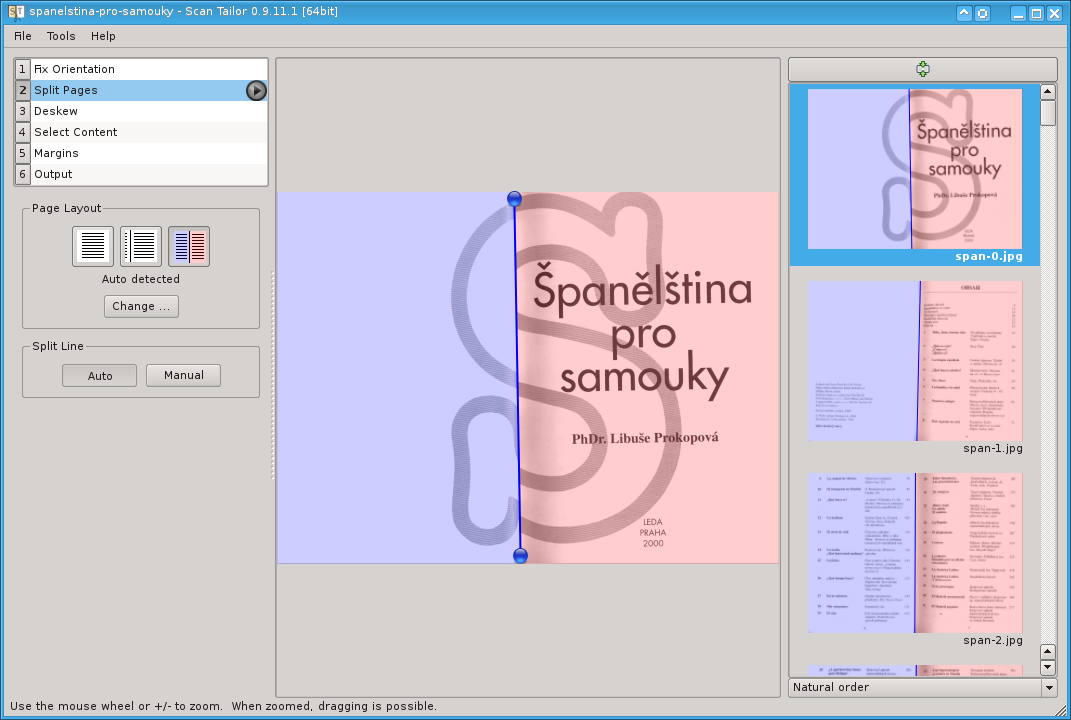
Taktéž druhý krok je vcelku bezproblémový. Ani zde jsem nenarážel na větší problémy. Za pozornost stojí jen možnost vybrat si, jak má dělení probíhat: buď žádné nechceme (tento krok se tedy přeskakuje), nebo chceme jen oddělit okraj z druhé strany (hlavně při skenování knih o rozměrech A4), nebo chceme skenované obrázky oddělit na levou a pravou stranu. Scan Tailor s nimi pak už pracuje odděleně. Dělící čáru jsem musel opravovat jen zcela výjimečně.
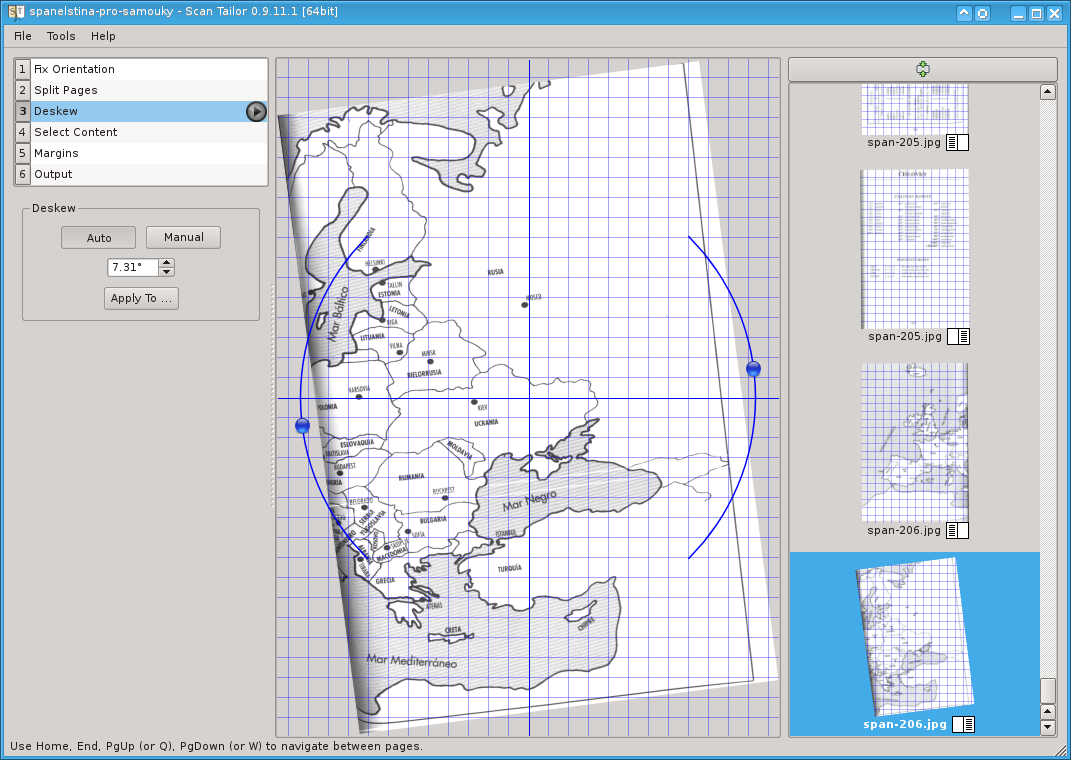
Deskew, tedy zarování stránky o několik stupňů, dokáže dobře pracovat na všech převážně textových stránkách. Velký pozor dávejte na grafické stránky, kde se software nemá čeho chytit, a tak si dost vymýšlí. Podle obrázku to rychle pochopíte. Stačí ale ručně zadat úhel 0° a maximálně to lehce pootočit myší.
Na Výběr obsahu (Select Content) dávejte pozor. Funkce je určena především k odstranění okrajů stránek, bohužel s sebou někde vezme i odloučené části stránek – často to tedy odnesou čísla stránek (pokud je tam chcete), různé ikonky (jako níže na obrázku) nebo čísla lekcí. Výběr jednoduše opravte roztažením nebo změnšením výběru. Zde doporučuji stránky rychle očima projet v přehledu stránek na pravé straně okna a poupravit to, co je potřeba.

Funkce nastavení okrajů (Margins) je nezbytná pro to, aby vyříznutý obsah byl správně umístěn na plochu prázdné stránky. Výchozí nastavení doprostřed nahoru je pro obvyklý obsah ideální, výjimkou jsou hlavně úvodní stránky s autorskými právy apod., které zpravidla mají být zarovnány doleva dolů. Je to ale jen estetická věc.
Své nastavení můžete jako vždy aplikovat jen na jednu stránku, všechny stránky, všechny následující stránky nebo jen na výběr.
A jsme u toho nejnáročnějšího kroku. Příprava výstupu. První věcí je zvolit správný režim barev – na výběr je černobílý výstup (tedy jen černá a bílá, žádná šedá), barevný/šedivý výstup nebo smíšený režim (obojí v rámci jedné strany). Vaše volba se zde bude odvíjet od toho, co vlastně skenujete. Pro klasické knihy bude nejlepší volbou černobílá s pár výjimkami pro případné obrázky.
V závislosti na kvalitě vašeho skenu může být v režimu černé a bílé nutné poupravit na posuvníku kontrast. To se týká zejména stránek uprostřed knihy, kde je velmi výrazný ohyb a tedy i více šedivé barvy. Mohl by se tam objevovat „šum navíc“, kvůli kterému mohou části textu být dokonce nečitelné.
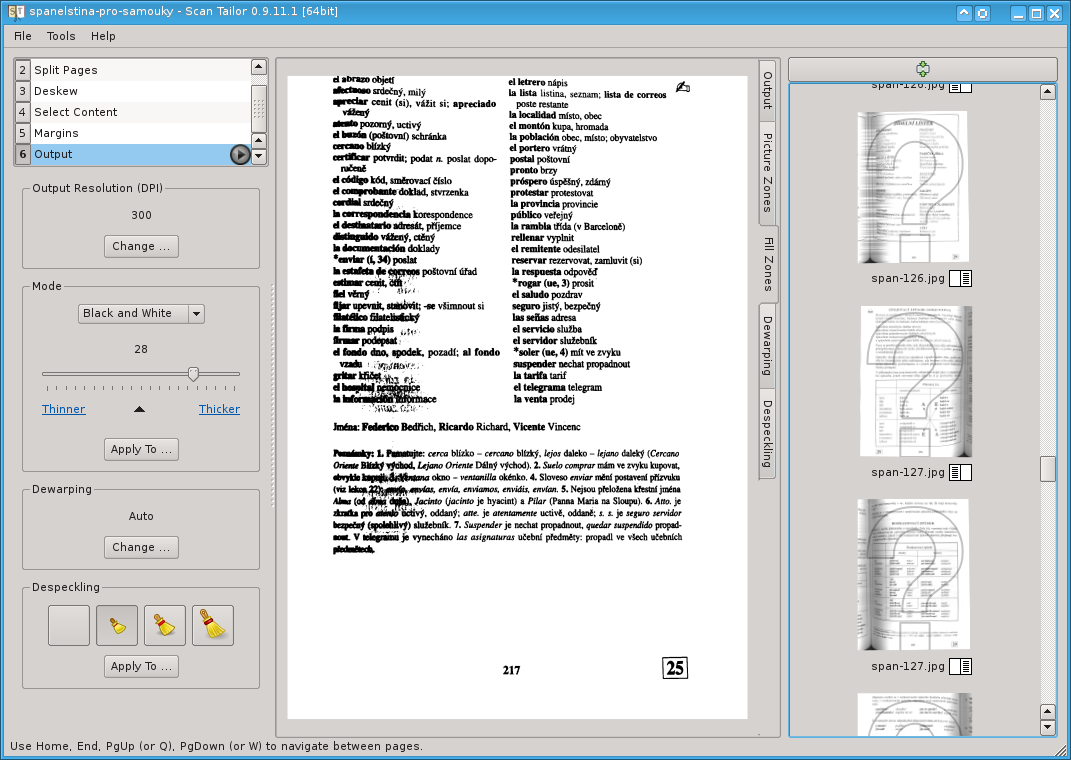
Pokud jste zvolili režim smíšený, pak po pravém okraji velkého náhledu vyhledejte záložky, a to konkrétné záložku „Picture zones“. Program se pokusí oblasti s větší bohatostí odstínů vyhledat automaticky, ale snadno mu pomocí několika kliků můžete poradit.
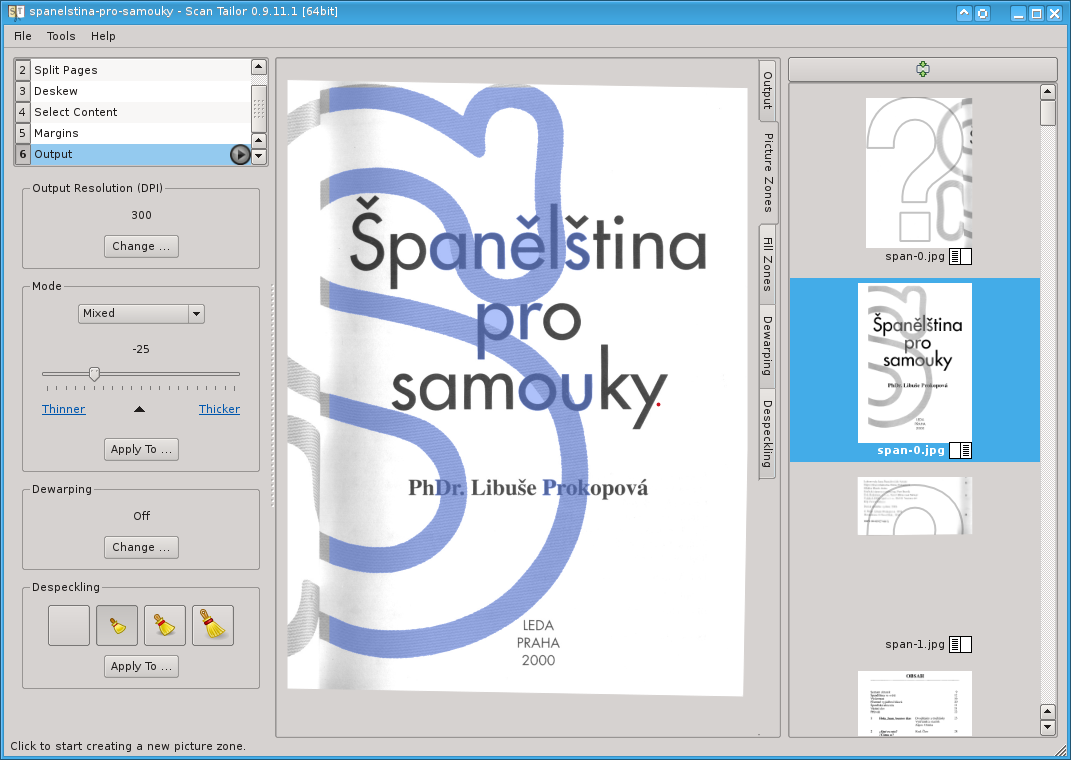
Mezi další funkce patří „Despeckle“ (odstranění flíčků, ať už jde o vadu tisku nebo nečistoty na skeneru) nebo možnost vymazat oblasti stránek (Fill Zones).
Zatím to všechno vypadalo jednoduše. Jestliže jste ale perfekcionisti, pak jistě budete chtít opravit zakřivení v blízkosti hřbetu knihy. Jestli jste knihu ve skeneru šetřili a málo jste jí přitisknuli, pak teď budete jistě vzlykat. Oprava zakřivění je totiž časově nejnáročnější krok. Scan Tailor je sice vybaven experimentální automatickou detekcí tohoto zakřivení, takže na dejme tomu 60 % stran nebudete muset vůbec sahat, jinde to ale bude peklo.
Na stránkách, kde by algoritmus programu měl mít svou práci nejsnazší – tedy tam, kde je na stránce pěkný obdélníkový útvar – to vždy paradoxní pokazí a výsledek můžete vidět níže.
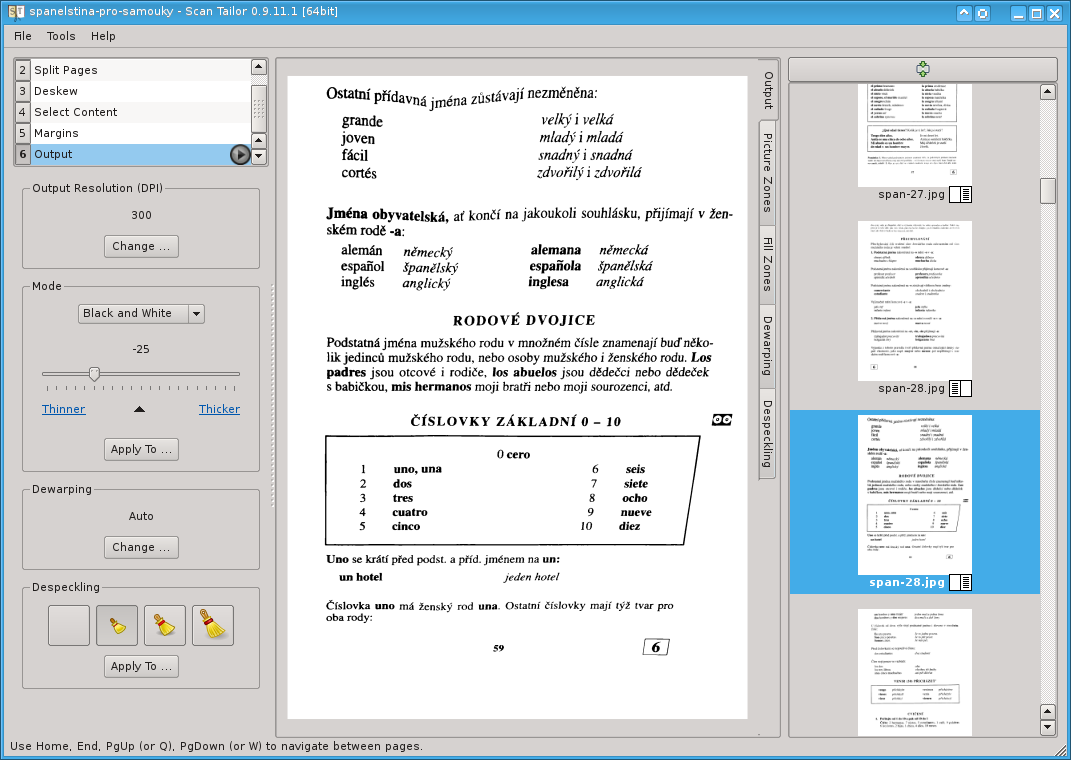
Hned byste se měli podívat do boční záložky Dewarping, kde bude problém evidentní.
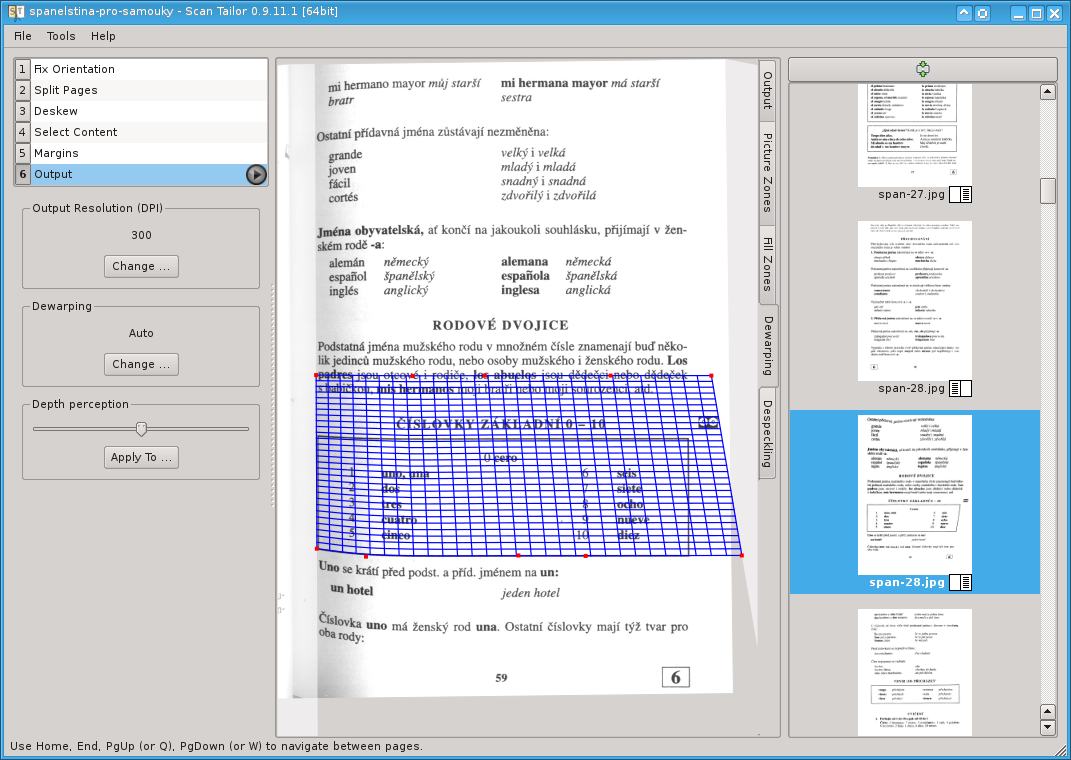
Vaším cílem je pomocí modré mřížky aproximovat na skenu oblast, která by ve skutečnosti měla být obdélníková. Postup práce je takový, že nejprve posunete rohové červené body na správná místa a pak teprve doladíte body mezi (rychle zjistíte, že obráceně to moc dobře nejde). Další body můžete snadno přidávat kliknutím nebo odebírat stiskem písmene D. Oblast by samozřejmě měla v sobě mít nějakou tu ohnutou oblast, aby bylo podle čeho to přepočítat 
K tomuto několik poznámek.
Jakmile jste se vzhledem spokojeni, můžete konečně spustit proces vytváření výstupních obrázkům kliknutím na „play“ u posledního, šestého bodu tohoto procesu. Zde si musím postěžovat, že Scan Tailor používá při své práci jen jediné jádro CPU, takže to může zbytečně trvat. A co s tou hromadou obrázků dál?
Scan Tailor nám teď vytvořil hromadu TIFFů, ty si ale na svém Kindlu jen tak nepřečteme. Mým osvědčeným postupem je obrázky zkomprimovat pomocí komprese CCITT4, která našla své uplatnění hlavně při přenosu faxů. Na černo-bílé stránky bez obrázkůje ale perfektní. Je totiž znatelně efektivnější než JPEG nebo PNG a díky tomu se vám kniha může vejít třeba do 20 MB. To je sice výrazně horší než u knih, které prošly OCR – tam se uchovává hlavně čistý text – ale u knihy, na které jsem jednotlivé kroky v tomto článku ukazoval, by OCR nebyla dobrá volba kvůli ztrátě formátování.
Kompresi CCITT4 můžete aplikovat třeba takto. Za domácí úkol můžete příkaz přepsat tak, aby dokázal používat všechna jádra vašeho CPU
cd out
for file in *.tif; do
convert -compress Group4 "$file" "${file}.pdf"
done
Smíšené stránky s obrázky je zjevně vhodné vynechat.
Nyní máme obrovské množství jednostránkových PDF a zjevně je chceme sloučit do jednoho velkého PDF. Na to šikne třeba program pdftk:
mkdir output pdftk *.pdf cat output output/vsechno.pdf
Pokud nemáme soubory správně seřazené podle abecedy, tak budeme mít stránky mimo pořadí (např. stránka 100 bude hned za stránkou 1). Pomůže drobný trik:
pdftk $(ls -1 *.pdf | sort -n -t '-' -k 2) cat output output/vsechno.pdf
Parametr -t určuje oddělovač v názvu souboru a -k určuje pole v názvu, podle kterého se má provést numerické řazení (-n). Pokud se naše soubory jmenují page-100_1L.tif, pak je oddělovačem pomlčka a číslo strany je pak druhé pole (první obsahuje „page“).
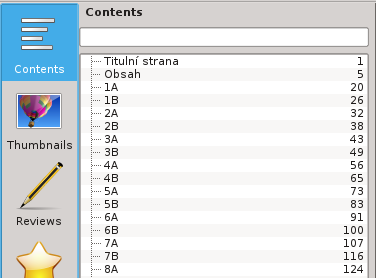
Stále to ale není ono. Při otevření PDF nemáme v titulku název naší knihy a muset listovat k obsahu, kdykoliv něco hledáme, je nepraktické. Co takhle přidat obsah tak, jak ho PDF umí? V takovém případě si otevřeme textový editor a začneme psát.
[ /Title (My Test Document) /Author (John Doe) /Subject (pdfmark 3.0) /Keywords (pdfmark, example, test) /DOCINFO pdfmark
Tím jsme vyřešili informace o knize a teď co ten obsah? Hračka – hned pod to připíšeme:
[/Title (Obsah) /Page 5 /OUT pdfmark [/Title (1A) /Page 20 /OUT pdfmark [/Title (1B) /Page 26 /OUT pdfmark [/Title (2A) /Page 32 /OUT pdfmark [/Title (2B) /Page 38 /OUT pdfmark ...
Místo pdftk si pro sloučení PDF ukážeme GhostScript, který umí tyto „značky PDF“ do dokumentu přimíchat:
gs -dBATCH -dNOPAUSE -sDEVICE=pdfwrite -sOutputFile=output/vsechno.pdf *.pdf pdfmarks.txt
Kde pdfmarks.txt je soubor s výše uvedenými ukázkami. Více, jako třeba několik úrovní obsahu, najdete například v tomto zápisku. Brzo ale asi přijdete na to, že vám nefunguje čeština. S tou je to poněkud komplikovanější. Funkční element s českými znaky může vypadat následovně:
[/Title <FEFF0054006900740075006c006e00ed00200073007400720061006e0061> /Page 1 /OUT pdfmark
Jde o Unicode řetězec zapsaný v hexadecimální reprezentaci. Jak něco takového vytvoříme? Není to až tak hrozné.
echo -n "Žluťoučký kůň" | iconv -f utf8 -t utf16 | hexdump -e '1/1 "%02X"'
Ukázali jsme si, jak vytvořit skeny knih bez OCR – tedy bez možnosti v knize hledat pomocí vestavěných funkcí v prohlížeči PDF. To případně napravíme jindy.
Tak jako tak vám přeji pevné nervy při práci se Scan Tailor a všem nám přeji co nejvíce knih, které nebudeme muset digitalizovat na vlastní pěst.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
apt-get install djvulibre-bin , vysledne subory bez problemov precita aj bezny evince) - format DJVU?
casom sa mi workflow poslednej casti digitalizacie - konverzie do vysledneho formatu - ustalil na par krokoch:
#convert - bitonal
for i in *; do convert $i $i.pbm && cjb2 -dpi 600 $i.pbm $i.djvu && rm $i.pbm; done
#convert - color
for i in *; do convert $i $i.pnm && c44 -dpi 600 $i.pnm $i.djvu && rm $i.pnm; done
#merge
for i in *.djvu; do echo $i; done | xargs djvm -c out.djvu
#clean
rm out/*.djvu
 21.5.2013 08:07
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
21.5.2013 08:07
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
 22.5.2013 19:57
GeoRW | skóre: 13
| blog: GeoRW
| Bratislava
Nicméně výdrž je vynikající a ten měsíc by asi bez problémů dal. Popravdě ještě se mi ho nepovedlo vybít, protože ho každých pár dní připojuju ke Calibre, abych přihrál nějakou tu knížku. A displej je nádherný...čtení pod stromem v lese za slunečného jarního dne je úžasné (ale to je samozřejmě dané e-inkem jako takovým, a s Kindle to bude stejné).
).). Jinak je asi pravda i to, že pro lidi co si knížky poctivě kupují není Kindle úplně nejlepší volba kdekoliv mimo území USA, protože je úzce provázaný s infrastrukturou Amazonu se všemi geografickými omezeními, které z toho plynou. Ale geekové si samozřejmě poradí Tím vším co tady píšu nechci samozřejmě říct, že Kobo je úžasnej a Kindle mizernej, to ne. Kindle je výborná čtečka, a její úspěch není náhoda. Jen jsem se jednoduše rozhodl pro něco jiného.
28.5.2013 15:29
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
22.5.2013 19:57
GeoRW | skóre: 13
| blog: GeoRW
| Bratislava
Nicméně výdrž je vynikající a ten měsíc by asi bez problémů dal. Popravdě ještě se mi ho nepovedlo vybít, protože ho každých pár dní připojuju ke Calibre, abych přihrál nějakou tu knížku. A displej je nádherný...čtení pod stromem v lese za slunečného jarního dne je úžasné (ale to je samozřejmě dané e-inkem jako takovým, a s Kindle to bude stejné).
).). Jinak je asi pravda i to, že pro lidi co si knížky poctivě kupují není Kindle úplně nejlepší volba kdekoliv mimo území USA, protože je úzce provázaný s infrastrukturou Amazonu se všemi geografickými omezeními, které z toho plynou. Ale geekové si samozřejmě poradí Tím vším co tady píšu nechci samozřejmě říct, že Kobo je úžasnej a Kindle mizernej, to ne. Kindle je výborná čtečka, a její úspěch není náhoda. Jen jsem se jednoduše rozhodl pro něco jiného.
28.5.2013 15:29
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
To si vážně vystačíte s takovým polovičatým řešením?Převáděl jste někdy knihu do digitální podoby, a navíc jazykovou učebnici?
Nebo vy vážně čtete knihy v PDF?Jo, když nic jiného není…, nebo jsem si nějakou (malou krátkou - manuál) zrobil sám.
5.6.2013 16:31
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz