Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
Samba, svobodná implementace síťového protokolu SMB/CIFS, byla vydána ve verzích 4.24.5, 4.23.10 a 4.22.11. Řešeno je 6 zranitelností.
Přední technologické společnosti (Adobe, Cadence, Capital One, Cisco, Cloudera, Cloudflare, Cognition, CrowdStrike, Databricks, Dell Technologies, DoorDash, Elastic, HPE, Hugging Face, IBM, LangChain, Linux Foundation, Microsoft, NAVER, NetApp, Nous Research, NVIDIA, OpenClaw, Palantir, Palo Alto Networks, Red Hat, Reflection AI, Salesforce, SAP, ServiceNow, Siemens, SK Telecom, Snowflake, SpacexAI, Synopsys, Thinking
… více »Krabix.cz je online 3D konfigurátor krabiček pro 3D tisk s exportem do STL. Běží přímo v prohlížeči. Nic se neposílá na server.
Nadace Open Home Foundation spustila veřejnou preview verzi komunitní databáze zařízení pro Home Assistant. Má fungovat jako „Wikipedie pro chytrá zařízení".
Na stránce nového panelu Firefoxu přibudou nové widgety. Například denně aktualizována interaktivní křížovka.
PGSimCity (GitHub) je webová 3D vizualizace vnitřního fungování databázového systému PostgreSQL v podobě města. Vytvořena pomocí umělé inteligence.
21.11.2018 16:27
| Přečteno: 3251×
|  | poslední úprava: 21.11.2018 16:38
| poslední úprava: 21.11.2018 16:38
Skoro před rokem jsem tu představil svůj projekt
Trilium Notes na správu "osobní znalostní báze" v blogpostu
Trilium Notes - představení hobby projektu a pak nějaké nové featury v blogpostu
Trilium Notes jako platforma pro mini-aplikace.
Dnes bych chtěl ukázat další featuru, kterou považuji za docela zajímavou - tou jsou "relační mapy".

S vysvětlováním ale musím začít od základů ...
Poznámky jsou typicky o nějaké reálné věci (např. knize), která má nějaké atributy. V Triliu se tyto atributy dělí na:
rokVydani=1984
následuje Dvě věže
následuje
Společenstvo Prstenu.
Pokud mluvím o atributech, tak tím myslím labely a relace dohromady.
Trilium používá atributy i pro některé pokročilejší "systémové" funkce - např. label
sorted umístěný na poznámku znamená, že její pod-poznámky budou udržovány abecedně seřazené nebo že poznámka připojená jako cíl relace
runOnNoteView
se spustí při zobrazení zdrojové poznámky.
Poznámky jsou zařazeny do stromu a tak se nabízí myšlenka, že by atributy bylo možné v tomto stromě
dědit - tzn. atribut uložený pro nějakou poznámku je automaticky "aktivní" i pro podpoznámky. Příkladem využití je label
archived, který vyřadí poznámku z vyhledávání - typicky totiž chceme takto vyřadit celý podstrom, ne jen jednu poznámku.
Dědičnost je užitečná ale jen někdy - např. už zmíněný label
rokVydani jaksi nemá smysl dědit do pod-poznámek knihy (které můžou obsahovat třeba výtažky, recenzi atp. u nichž tento label může být přímo zavádějící). Dědičnost je proto nutné explicitně zapnout pro daný atribut.
Trilium má pak ještě jeden typ dědičnosti, který dědí atributy přes relaci
template
, aniž by poznámky musely být ve vztahu předek - potomek. Později uvidíme na co to může být užitečné.
Potenciální idea do budoucna je možnost definovat určité aplikační nastavení jako atributy. Např. nastavení komprese a škálování uložených obrázků. Celý dokument může mít nastavenu JPEG kompresi na 70 (nastavením děděných atributů na kořen dokumentu) a některý podstrom toto může přenastavit na 90. Můžeme si tak ponastavovat aplikaci zvlášť pro různé podstromy.
Atribut je ve své podstatě jen položka klíč-hodnota, kde jak klíč, tak hodnota jsou netypované řetězce. To je ale pro některé použití málo. Pokud si např. chci definovat label
datumNarozeni, tak je docela blbé, aby do něj bylo možné zadávat jakýkoli řetězec v jakémkoli formátu - např. "22. 1. 2000", "první duben 89" atp.
V Triliu je to řešeno trochu nestandardně tím, že existují dva další typu atributů -
definice labelu a
definice relace. Mezi atributy a jejich definicemi neexistuje přímé spojení. Funguje to tak, že definice určuje, jak pracovat s daným atributem, pokud se vyskytuje ve stejné poznámce. Přičemž "vyskytuje" bere v úvahu dědičnost. V praxi pak typicky vytváříme takové definice pro určitý podstrom - např. pokud máme některý podstrom vyhrazený pro lidi, tak takovou definici pro
datumNarozeni podědíme v celém tomto podstromě.
A co můžeme v takové definici definovat?
isChildOf je inverzní k
hasChild. Bude vidět níže.
Příklad jak takový výsledek definice může vypadat je toto:
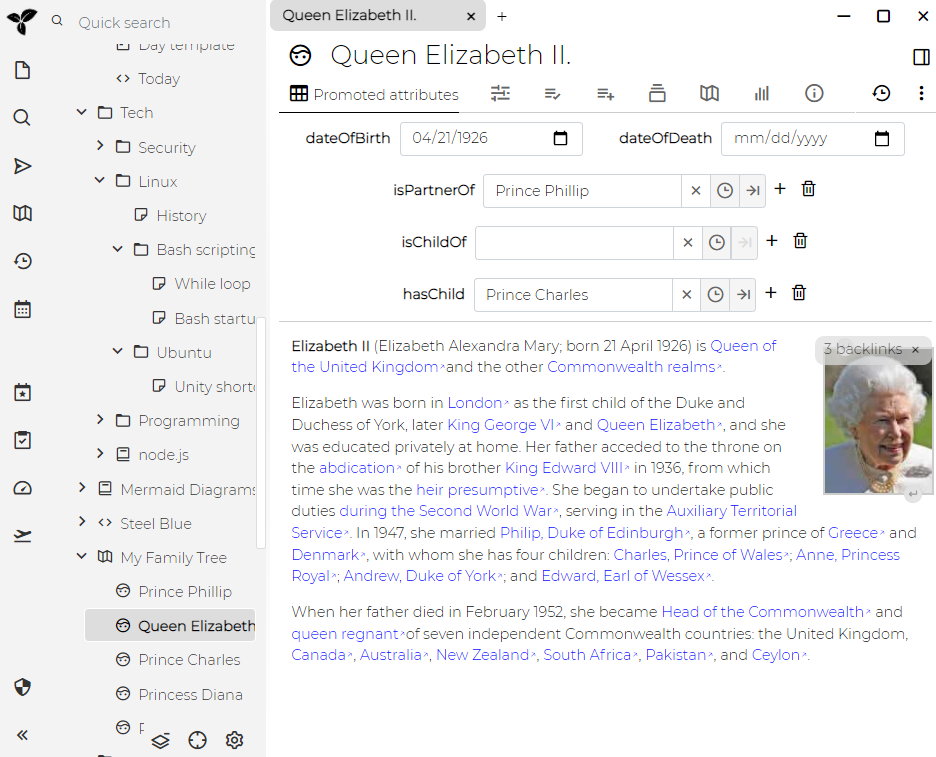
Relační mapa je nový typ poznámky (zatím dostupný jen v beta verzi 0.24), která vizualizuje poznámky a jejich relace. Níže můžete vidět proces tvorby takové relační mapy:

Tohle ale potřebuje vysvětlit:
isPartnerOf
template
na poznámku "person", která obsahuje několik
definicí atributů - např. ona relace
isPartnerOf, label
dateOfBirth atd.
template je v tomto případě analogická konceptu jakéhosi typu nebo třídě poznámky
isPartnerOf
isChildOf k oběma rodičům.
hasChild. To je tím, že definice relace pro
isChildOf specifikuje inverzní relaci
hasChild (a naopak). Inverzní relace je pak automaticky dovytvořena.
isPartnerOf relaci od Charlese. Opět je relace vytvořena jako oboustranná, protože definice relace
isPartnerOf specifikuje inverzní relaci
isPartnerOf.
Tento příklad s královskou rodinou je k dispozici v demo dokumentu Trilia - stačí tedy stáhnout a spustit poslední betu a můžete si s tím zkusit pracovat sami.
Demo v tomto blogpostu je tak trochu "kitchen sink" v tom, že jsem se do něj snažil nacpat několik konceptů dohromady, což může (oprávněně) vyvolat dojem, že je to celé hrozně složité. Ve skutečnosti je ale možné začít daleko jednodušeji - stačí pár poznámek, pár relací a relační mapa. Pokročilé koncepty jako inverzní relace, dědičnost,
template relace atp. jsou k dispozici pro náročnější použití.
Aktuální stav relačních map je tak nějak MVP. Je možné si představit další možnosti vizualizace - např. nějaké seskupování do větších celků, obarvování, nějaké vysvětlující poznámky přímo v diagramu - věci známé např. z UML diagramů. Co bude možné přidat se uvidí ...
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()

 22.11.2018 11:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2018 12:48
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2018 16:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2018 11:04
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2018 12:48
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2018 16:03
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Pokud k tomu neni silny duvod, tak se vyplati jit spis s mainstreamem ...S tímhle přístupem bys nemusel programovat vlastní aplikaci a rovnou mohl používat evernote ;)
S tímhle přístupem bys nemusel programovat vlastní aplikaci a rovnou mohl používat evernote ;)No tech nespocet spalenych hodin ukazuje na to, ze to bude asi pravda. Jinak samozrejme ta cena vyhybani se mainstreamu muze byt prijatelna, jen je potreba ji mit na pameti pri rozhodovani.
22.11.2018 16:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
No ja jen mam dojem ze JS ma ne uplne zaslouzene spatnou povest.Javascript jako takový je potrat, pro který neexistuje omluva. Ecmy to sice zlepšují, ES6 byl skoro fajn jazyk, ale stejně nemám důvod se do toho pouštět a zdaleka to nevyvažuje negativa (horší tooling, toxická komunita, nepraktičnost pro cokoliv jiného kromě webu).
No tech nespocet spalenych hodin ukazuje na to, ze to bude asi pravda. Jinak samozrejme ta cena vyhybani se mainstreamu muze byt prijatelna, jen je potreba ji mit na pameti pri rozhodovani.To chápu a v principu s tím i souhlasím. Ostatně nejsem nadšený začátečník a do něčeho takového se pouštím s plným vědomím.
Jinak obecne povazuju dulezitost jazyka za precenovanou (obzvlast tady v ramci jedne kategorie).K tomuhle mám dost komplikovaný přístup, kterým bych mohl popsat nejeden blog, ba možná i knihu. Pro tohle chci použít python, protože s ním mám víc jak 14 let zkušeností a cca pět let z toho komerčně na každodenní bázi. Viděl jsem jeho výšiny i hlubiny, hackoval ho zleva i z prava, v cpythonu, v javascriptovém brythonu i v pythonním pypy. Je pro mě jako motor, na kterém patnáct let jezdím, a který jsem nespočetněkrát rozebral i složil. S ním si troufnu kolem světa nikoliv protože by byl tak skvělý, ale protože ho umím kdykoliv opravit a domlátit do něj kladivem co potřebuji, i kdyby mě zrovna někdo vzbudil ve tři ráno. JS by tohle jen hodně těžko vyvažoval (mohl by, ale trvalo by to 14 let), i kdyby měl co nabídnout, což kromě nativního běhu v prohlížeči imho nemá. Druhá věc je paradigma a filosofie. Co do paradigma, tak v imperativním procedurálním jazyce už není moc co vymýšlet a vskutku je to prašť jako uhoď. Na poli objektových jazyků si ovšem myslím, že je pořád stále spousta prostoru, stejně jako u těch funkcionálních. Osobně momentálně dělám na klonu Selfu právě z důvodu, že mi přijde že potenciál prototypově objektově orientovaných programovacích jazyků byl javascriptem neprávem zabit a díky tomu stále ještě nebyl plně objeven a využit. Celé je to samozřejmě experiment, který může skončit špatně, ale i tak jsem na něj zvědavý a stojí mi za práci a čas.
22.11.2018 16:59
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2018 17:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 22.11.2018 21:22
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.11.2018 22:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
22.11.2018 21:22
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.11.2018 22:13
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Mno Python nie je tiež bez chyby. Osobne som v ňom opravil len pár bugov v programoch, ale podľa mňa taký "for" bude mať v Pythone dosť race condition pretože vo väčšine jazykov je prepis podobný s asemblerom, čiže vloženie hodnoty a inkrementovanie. Je to jedna z vecí čo ma na Pythone sere a druhá je, že čo kurva majú proti závorkám.Závorky jsou koncept imho vzniklý jen kvůli náročnosti parserů a neschopnosti tehdejších řádkových editorů. Python, ale i Smalltalky dokazují, že nejsou třeba a je to jen zbytečný fluff, který nic co by mělo nějakou hodnotu nepřidává. To s tím
forem a race condition nechápu vůbec.
Python určitě není bez chyby, mohl bych vypsat spoustu věcí, které jsou na pythonu špatně, či nedobře řešené. Je to ovšem velmi pragmatický a praktický jazyk, jehož použitelnost je vysoká a málokdy se v něm střelíš do nohy. To o JS říct nejde.
Javascript má chyby, ktoré serú všetkých, napr. nejednosť ako sa dostať k údajom, mno je tu jedna veľká výhoda, že to sere veľkú časť populácie a budú sa asi diať zmeny. Takže sa to nejak zjednotí, aby sme mali všetci radosť. Tak veľká komunita vývojárov sa proste ignorovať nedá.Javascript má hlavně problém absence jakékoliv vnitřní logiky a vize. Známé je napříkald wtf.js, nebo wtfjs, což oboje z větší části ukazuje totální shnilost typového systému. Python má taky svoje (viz wtfpython), ale přijde mi to podstatně konzistentnější a má to nějaký vnitřní model, co se dá pochopit.
Keď si sa pýtal na Electron, tak v tom som nenapísal ani riadok, je to viac lowlevel než napríklad NWjs v ktorom som už pár projektov napísal. Hlavne prečo som si zvolil NWjs je, že výzor si napíšem v klasickom HTML a ten JavaScript tam pridám len ako bonus, toto v Electrone neexistuje. Mno a NWjs projekty mávajú tak 50% veľkosti oproti Electron.NWjs neznám, mrknu na to. Osobně jsem zatím ve fázi hledání, skutečně jsem se odhodlal pustit se do toho projektu po pár letech psaní poznámek a přemýšlení až minulý týden.
22.11.2018 23:00
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.11.2018 23:13
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
To s tím forem a race condition nechápu vůbecProste sa ten cyklus musí nejak spracovať, namiesto naplnenia premenných a inkrementácií +-
22.11.2018 23:45
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
for v pythonu pracuje nad iterátory. Je to úplně něco jiného, než for cyklus v C. Jak vypadá iterace přes iterable object je možné vidět například v builtin funkci all():
static PyObject *
builtin_all(PyObject *module, PyObject *iterable)
/*[clinic end generated code: output=ca2a7127276f79b3 input=1a7c5d1bc3438a21]*/
{
PyObject *it, *item;
PyObject *(*iternext)(PyObject *);
int cmp;
it = PyObject_GetIter(iterable);
if (it == NULL)
return NULL;
iternext = *Py_TYPE(it)->tp_iternext;
for (;;) {
item = iternext(it);
if (item == NULL)
break;
cmp = PyObject_IsTrue(item);
Py_DECREF(item);
if (cmp < 0) {
Py_DECREF(it);
return NULL;
}
if (cmp == 0) {
Py_DECREF(it);
Py_RETURN_FALSE;
}
}
Py_DECREF(it);
if (PyErr_Occurred()) {
if (PyErr_ExceptionMatches(PyExc_StopIteration))
PyErr_Clear();
else
return NULL;
}
Py_RETURN_TRUE;
}
Tedy nad objektem voláš iternext(), dokud tam něco je. For samotný se překládá na konkrétní instrukce v podobném smyslu:
$ python3
Python 3.6.6 (default, Sep 12 2018, 18:26:19)
[GCC 8.0.1 20180414 (experimental) [trunk revision 259383]] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> def xe():
... for i in range(5):
... print(i)
...
>>> import dis
>>> dis.dis(xe)
2 0 SETUP_LOOP 24 (to 26)
2 LOAD_GLOBAL 0 (range)
4 LOAD_CONST 1 (5)
6 CALL_FUNCTION 1
8 GET_ITER
>> 10 FOR_ITER 12 (to 24)
12 STORE_FAST 0 (i)
3 14 LOAD_GLOBAL 1 (print)
16 LOAD_FAST 0 (i)
18 CALL_FUNCTION 1
20 POP_TOP
22 JUMP_ABSOLUTE 10
>> 24 POP_BLOCK
>> 26 LOAD_CONST 0 (None)
28 RETURN_VALUE
což je trošku komplikovanější, protože se to interpretuje v bytecode cruncher looopu v ceval.c:
case TARGET(FOR_ITER): {
PREDICTED(FOR_ITER);
/* before: [iter]; after: [iter, iter()] *or* [] */
PyObject *iter = TOP();
PyObject *next = (*iter->ob_type->tp_iternext)(iter);
if (next != NULL) {
PUSH(next);
PREDICT(STORE_FAST);
PREDICT(UNPACK_SEQUENCE);
DISPATCH();
}
if (PyErr_Occurred()) {
if (!PyErr_ExceptionMatches(PyExc_StopIteration))
goto error;
else if (tstate->c_tracefunc != NULL)
call_exc_trace(tstate->c_tracefunc, tstate->c_traceobj, tstate, f);
PyErr_Clear();
}
/* iterator ended normally */
STACK_SHRINK(1);
Py_DECREF(iter);
JUMPBY(oparg);
PREDICT(POP_BLOCK);
DISPATCH();
}
Samozřejmě, pro čísla je to kapku míň efektivnější, než C, ale zase to umí iterovat na libovolným objektem implementujícím protokol iterátorů. V pypy interpretru se to pak afaik ještě jituje a leze z toho relativně efektivní kód.
22.11.2018 23:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
def FOR_ITER(self, jumpby, next_instr):
w_iterator = self.peekvalue()
try:
w_nextitem = self.space.next(w_iterator)
except OperationError as e:
if not e.match(self.space, self.space.w_StopIteration):
raise
# iterator exhausted
self.popvalue()
next_instr += jumpby
else:
self.pushvalue(w_nextitem)
return next_instr
Nutno myslet na to, že celý kód je pak na úrovni AST analyzován a je z něj vygenerováno ekvivalentní C, které je potom na základě statistik jitováno do asm podle analýzy typů rpythonem.
23.11.2018 16:50
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
22.11.2018 22:20
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 21.11.2018 20:14
21.11.2018 20:14