HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
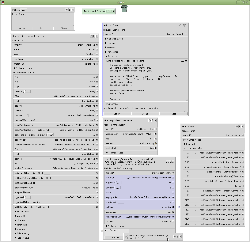
Je o mně známo, že už víc jak desetiletí aktivně používám osobní wiki. To je program, do kterého je možné formátovaným způsobem psát texty a tyto texty poté různě propojovat. Trochu se to podobá wikipedii, je to ale celé určené k vašemu osobnímu použití. Spousta lidí, co u mě osobní wiki vidí, reaguje překvapením. Napadlo mě tedy, že bych mohl pro inspiraci napsat k čemu a proč osobní wiki využívám, neboť jednotlivé wiki jsou většinou zdokumentované docela dobře. Přijde mi ale, že chybí popis motivace. Nějaké vysvětlení, co k tomu lidi vede.
Všichni si asi umíte představit, že wiki používám k psaní blogů a článků a zamyšlení a všeho možného textově orientovaného, co poté publikuji. Vskutku je to tak, všechny své články a blogy jsem napsal právě v ní.
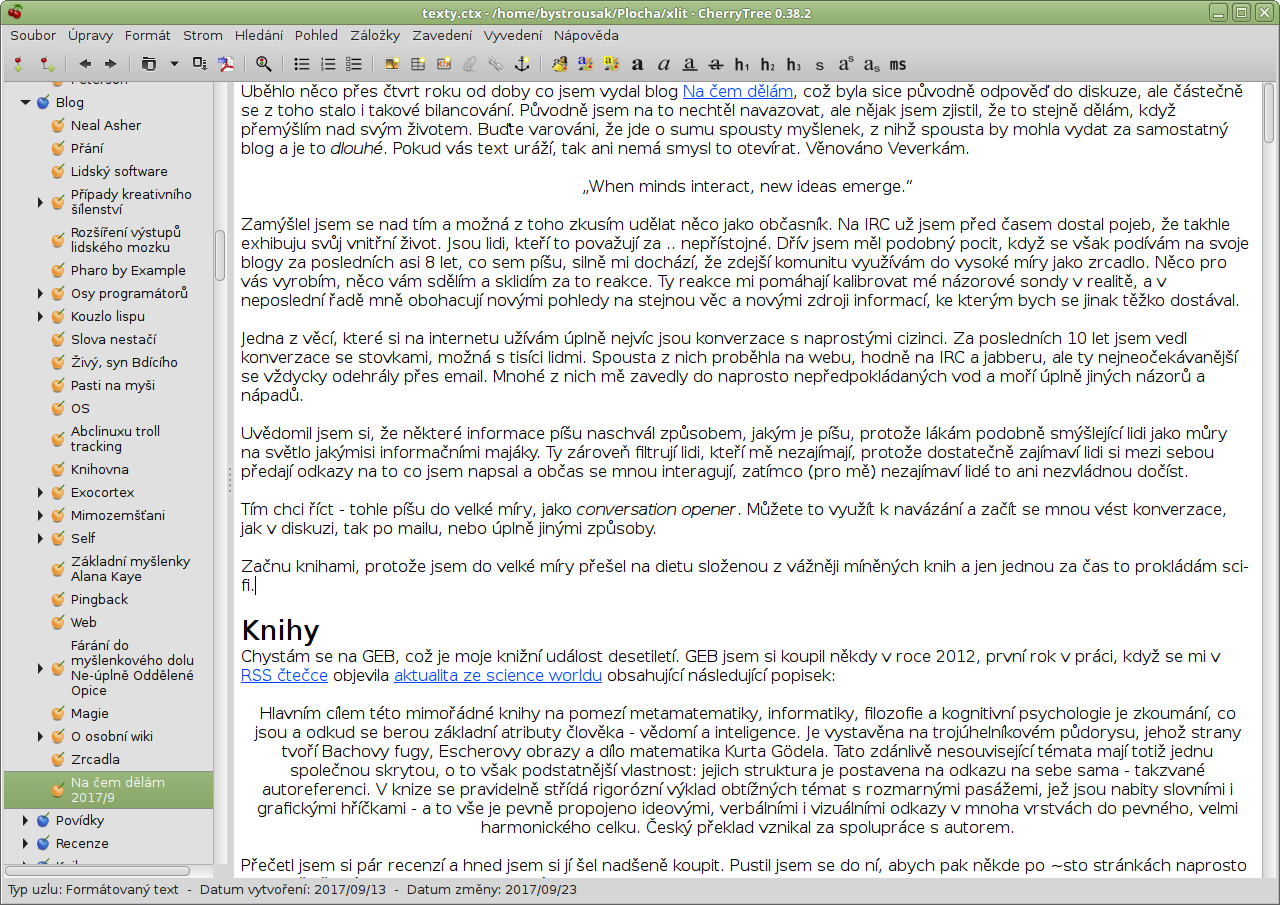
Někteří si asi umí představit, že wiki používám k sledování průběhu různých projektů a píšu si do ní „todo listy“. Opět správně. I k tomu wiki používám.
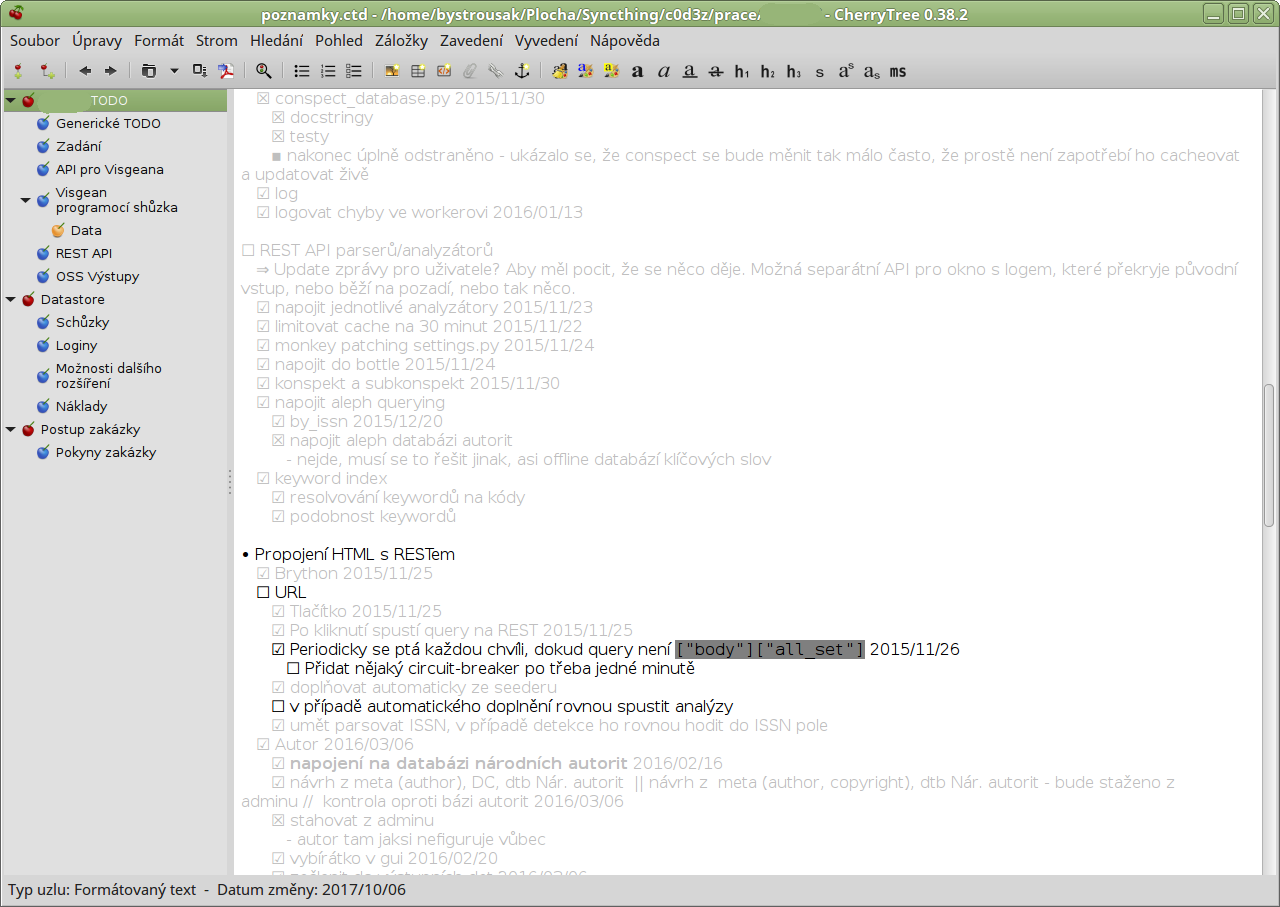
Další použití, které pro osobní wiki mám je osobní nestrukturovaná databáze. Kromě všemožných nápadů si tam zapisuji také, ale nejenom:
Věci jako telefonní čísla. Seznam balíků k nainstalování po reinstallu. Adresy všeho možného, od ip adres serverů, přes URL až po fyzické adresy míst. Názvy knih, které chci přečíst, i těch, které právě čtu (spolu s pozicí v knize). Kusy zdrojových kódů, datumy kdy jsem naposledy byl v posilovně, jak dlouho a kolik jsem vážil. Kdy a kolik jsem uplaval bazénů. Kdy jsem si koupil doutník, jaký to byl druh a jak mi chutnal. Čísla účtů. Emaily. Odkazy na zajímavé diskuze. Odkazy na stránky, které chci dlouhodobě sledovat. Profily zajímavých lidí. Jména a druhy lodí, které bych si koupil, kdybych měl zbytečných pět milionů. Věci, které mám rád, i věci, které nenávidím. Čaje, které jsem vyzkoušel, kde jsem je koupil a jak mi chutnaly. Vína co jsem pil. Veřejné klíče všemožných kryptografií, od bitcoinu přes ssh až po gpg. Tohle všechno a ještě stokrát víc.
Něco mě napadne? Například vysvětlení jak používám wiki? Šup s tím do wiki. Vedu nějaký zajímavý rozhovor na IRC, který bych si rád pamatoval? Šup s ním do wiki. Nad vším se dá samozřejmě vyhledávat, když pominu, že je to tématicky kategorizované.
Moje hlavní osobní wiki má téměř šest set nod (uzlů). To jsou jakési „stránky“, či podstránky věnované nějaké informaci, či tématu. Některé mají pět řádek, další sto kilobajtů. To je přitom jenom jeden z tří hlavních wiki souborů, které používám každý druhý den, a není v tom započítaná wiki „sklad“, kam přesouvám věci, které jsem se rozhodl nadále ignorovat, aby mi tu nestrašily a nezabíraly místo. Zbylé dvě wiki jsou „práce“ (vždy pro konkrétní firmu jeden wiki soubor) a „Self“ (pro mé bádání na poli tohohle programovacího prostředí).
Jinými slovy; osobní wiki, tak jak jí používám, udržuje většinu kontextu mého mozku. Hlavní lidská paměť je sice super-rychlá a super-asociativní, ale neustále zapomíná naprostou většinu toho, co mě napadne. Nemám špatnou paměť a běžně si dobře pamatuji události. Tohle je ale něco jiného. Je to paměť na nápady a databáze na konkrétní tvrdá data. Když mě něco napadne, nějaký záblesk myšlenky, zachytím ho do wiki. Pak se na něj s odstupem dívám a nabaluji k němu další myšlenky. Časem z toho vznikne projekt, článek, či něco úplně jiného.
Osobní wiki mi oproti paměti dovoluje věci zapomínat a vypouštět. Kdykoliv stačí jen otevřít soubor CherryTree, mechanicky přes něj listovat, a okamžitě si je připomenu. Můžu třeba pokračovat kde jsem dřív skončil, nebo to celé vyexportovat a poslat někomu jinému.
Tohle všechno jsou ale naprosto očividné, samozřejmé a poměrně nudné věci, které dělá tak nějak každý, kdo osobní wiki nějakou dobu používá. Někdo víc, někdo míň, ale dospějí k tomu všichni. Ta pravá magie spočívá v Zrcadlech.
Mám jeden problém; jsem neviditelný. Když se na sebe podívám, tak se nevidím, a když se na mě dívají ostatní, tak mě vidí jen když se hýbu, nebo mluvím a i tehdy většina lidí vnímá všechno co jsem jen nepřímo, skrz fyzické akce. Celé lidstvo má tenhle tenhle problém.
Všichni jsme vysoce výkonné adaptabilní neuronové sítě, které běží na nejdokonalejším hardware v celém známém vesmíru; lidském mozku. Ten je obalený spoustou masa, kostí, šlach a vody, jenž tvoří zbytek našich těl.
Moje mysl jasně září, její záře je však tlumená vězením z masa a kostí. Moje tělo vypadá jako těla všech ostatních a všichni ostatní se dívají především na něj. Nevidí mě, vidí můj nosič.
Poslední dobou jsem s tím různě experimentoval. Vím, že to není nic překvapivého, ale stejně je oči-otevírající, když si vyzkoušíte, jak moc ovlivňuje lidi kolem vás vaše oblečení, vousy a vlasy. Stačí si vzít místo bundy kabát a na poště s vámi jednají úplně jinak, protože nevidí vás - vidí vaše tělo a odznaky postavení.
Jak se tedy podívat sám na sebe? Kde vzít zrcadlo, které by vám ukázalo vaše vědomí?
Jak už asi správně hádáte, tím zrcadlem jsou vlastní poznámky.
Mysl je jako oko částečného slepce, který vidí jen malou tečku, a když si chce udělat představu o světě, musí tím okem hodně hýbat. Stejně tak běžně vidíte jen pár svých aktuálních myšlenek a představ. Osobní wiki vám je umožňuje všechny udržet, takže si můžete prohlédnout sebe sama. Je to místo, kde lapáte své pocity a nápady a pohledy na svět a díváte se skrz ně kousek po kousku sami na sebe. Stále se sice neuvidíte najednou, vždycky jen střípek, ale když těch střípků naskládáte na jednom místě hromadu, jednoho dne si k nim sednete a rychle si je všechny prohlédnete, máte možnost zahlédnout v odrazu všech těch střípků vlastní podobu.
To vám umožní se měnit. Pokud se vám nelíbí co vidíte, můžete se zkusit přeformovat. Můžete si zkusit vytyčit jiné cíle, jiné priority a jiné motivace. Můžete zkusit překročit vlastní stín a stát se něčím víc, než čím jste.
Momentálně je pro mě wiki naprosto nepostradatelná věc, která přerostla pouhý nástroj na psaní poznámek, a stala se rozšířením mé mysli. Už to pro mě není nástroj, je to filosofie. Stal se z toho způsob jakým pracuji, jak přemýšlím, jak své myšlenky udržuji, formuluji, konkretizuji a kondenzuji v písmena a projekty, které pak nabízím ostatním. Stala se z toho součást mého myšlenkového procesu, mě sama.
Protože jí tak aktivně používám, již několik let provádím výzkum jak jí nahradit. Samotný formát osobní wiki má totiž svá omezení. Mou snahou je získat nekonečně programovatelné strukturované meta-médium, do kterého bych mohl své myšlenky a data ukládat jinak a lépe. Pokud nechápete, pusťte si Engelbartovo Mother of All Demos. Ale o tom třeba někdy příště.
Dnes vám víc než doporučuji zkusit si stáhnout nějaký software tohohle typu, ať již CherryTree, OneNote, nebo něco jiného. Zkuste ho chvíli aktivně používat. S překvapením možná zjistíte, že nechápete, jak jste bez toho mohli žít.
Edit: Pár hodin před tím, než jsem se rozhodl tenhle blog publikovat mi kamarád poslal odkaz na článek Dr. Jordan B. Peterson’s 10 Step Guide to Clearer Thinking Through Essay Writing (archiv), který se do velké míry dotýká toho, o čem tady mluvím.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 12.10.2017 15:06
vencour | skóre: 56
| blog: Tady je Vencourovo
| Praha+západní Čechy
12.10.2017 15:06
vencour | skóre: 56
| blog: Tady je Vencourovo
| Praha+západní Čechy
 12.10.2017 16:06
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
12.10.2017 16:06
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
...Z kvantity roste kvalita. Na vše mohu navázat. ..To mas z VUMLu? O přechodu kvantity v kvalitu nas uci marxleninismus. Porad jsme v 80 letech cekali, kdy se ty, cim dal vetsi, hromady hoven zmeni v neco kvalitniho, treba zapadonemecky kazetak. A ono hovno.
12.10.2017 20:30
vencour | skóre: 56
| blog: Tady je Vencourovo
| Praha+západní Čechy
 12.10.2017 20:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.10.2017 20:46
vencour | skóre: 56
| blog: Tady je Vencourovo
| Praha+západní Čechy
12.10.2017 20:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.10.2017 20:57
vencour | skóre: 56
| blog: Tady je Vencourovo
| Praha+západní Čechy
12.10.2017 17:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.10.2017 20:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.10.2017 20:46
vencour | skóre: 56
| blog: Tady je Vencourovo
| Praha+západní Čechy
12.10.2017 20:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.10.2017 20:57
vencour | skóre: 56
| blog: Tady je Vencourovo
| Praha+západní Čechy
12.10.2017 17:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 12.10.2017 18:27
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
12.10.2017 19:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.10.2017 04:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.10.2017 13:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
12.10.2017 18:27
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
12.10.2017 19:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.10.2017 04:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.10.2017 13:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 14.10.2017 00:24
Josef Kufner | skóre: 70
14.10.2017 00:41
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.10.2017 01:40
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.10.2017 00:24
Josef Kufner | skóre: 70
14.10.2017 00:41
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.10.2017 01:40
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jaký je rozdíl mezi offline a online wiki?Ta první je prostě program v počítači, co nabízí trochu lepší responzivnost a funguje bez internetu.
Proč je špatně chtít si poznámky z CherryTree (nebo Zimu, nebo čehokoliv jiného) přečíst na mobilu?Špatné na tom není nic. Jen mi přijde víc užitečné mít možnost ty poznámky upravovat - osobně na mobilu většinou chci přidávat třeba nové todo body, než číst si něco co jsem napsal. V tomhle je imho lepší klasická webová wiki, kde to můžeš z mobilu rovnou upravit.
14.10.2017 11:52
Josef Kufner | skóre: 70
.ctd, nebo co? Fakt to nechápu.
14.10.2017 18:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 14.10.2017 14:54
xvasek | skóre: 21
| blog:
| Zlín
14.10.2017 14:54
xvasek | skóre: 21
| blog:
| Zlín
Cherrytree ma verzi pro Android zatim jen na TODO listu. Resil nekdo osobni wiki i se syncrhonizaci mezi vice zarizenimi, zejmena mobilnimi?
Vim, ze Onenote a Evernote klienty maji, ale zde je pro mne nestravitelne, ze data jsou ulozena v cizim cloudu.
Ještě existuje Google Keep. Když už používám gmail a Google search, tak jim tam šoupnu i ty myšlenky, just to be sure. Pak si tam člověk udělá seznam přání a hned vypadají stránky líp, když se v reklamách zobrazují Lamborghini, tropické ráje a relaxační lehátka místo vysavačů a přípravků na hubení švábů.
 Bohuzel to taky z principu nechci mit resene nejakou proprietarni sluzbou.
Zatim teda nemam nic. Ted jsem zkousel orgzly, docela fajn, mozna do toho pujdu. Obrazky budu muset holt dodavat pozdeji rucne na pc
Bohuzel to taky z principu nechci mit resene nejakou proprietarni sluzbou.
Zatim teda nemam nic. Ted jsem zkousel orgzly, docela fajn, mozna do toho pujdu. Obrazky budu muset holt dodavat pozdeji rucne na pc  13.10.2017 17:37
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
13.10.2017 17:37
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 15.10.2017 00:48
xkucf03 | skóre: 50
| blog: xkucf03
15.10.2017 00:48
xkucf03 | skóre: 50
| blog: xkucf03
Někde jsi tu psal, že bys tu osobní wiki chtěl řešit ideálně objektově… Já jsem nad tím teď taky trochu přemýšlel a za hodně důležitou vlastnost považuji historii, verzování – abych se mohl vracet zpět, abych mohl bez obav promazávat (kdybych to chtěl obnovit, tak můžu, takže mne to neomezuje v tom, dělat si v poznámkách pořádek), abych věděl, kdy která část vznikla… Máš nějak vymyšlené jak tohle řešit, jak tam dostat tu časovou dimenzi? Resp. počítáš vůbec s verzováním?
Nejjednodušší je vyplivnout data do nějaké textové serializace a tu uložit do verzovacího systému, ale to není úplně optimální, protože jednak verzovací systém (resp. diff) nerozumí tomu formátu a bere to jen jako řádky textu, a jednak pokud chceš používat nějaký WYSIWYG/WYSIWYM editor, tak těžko promítneš tu informaci o tom, kdy která část vznikla, odkud se přesunula atd. protože tu historii eviduješ jen na úrovni řádků zdrojáku/serializace. Možná by šlo použít nějakou databázi a ukládat si všechny provedené operace – takže by si člověk mohl přehrát žurnál a dostat se do nějakého bohu v minulosti – ale zase to neřeší to zpětné dohledání (kdy vznikl daný uzel?). Nebo použít databázi, která tu časovou dimenzi nativně podporuje…
15.10.2017 01:53
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Někde jsi tu psal, že bys tu osobní wiki chtěl řešit ideálně objektově… Já jsem nad tím teď taky trochu přemýšlel a za hodně důležitou vlastnost považuji historii, verzování – abych se mohl vracet zpět, abych mohl bez obav promazávat (kdybych to chtěl obnovit, tak můžu, takže mne to neomezuje v tom, dělat si v poznámkách pořádek), abych věděl, kdy která část vznikla… Máš nějak vymyšlené jak tohle řešit, jak tam dostat tu časovou dimenzi? Resp. počítáš vůbec s verzováním?Ano.
Nejjednodušší je vyplivnout data do nějaké textové serializace a tu uložit do verzovacího systému, ale to není úplně optimální, protože jednak verzovací systém (resp. diff) nerozumí tomu formátu a bere to jen jako řádky textu, a jednak pokud chceš používat nějaký WYSIWYG/WYSIWYM editor, tak těžko promítneš tu informaci o tom, kdy která část vznikla, odkud se přesunula atd. protože tu historii eviduješ jen na úrovni řádků zdrojáku/serializace. Možná by šlo použít nějakou databázi a ukládat si všechny provedené operace – takže by si člověk mohl přehrát žurnál a dostat se do nějakého bohu v minulosti – ale zase to neřeší to zpětné dohledání (kdy vznikl daný uzel?). Nebo použít databázi, která tu časovou dimenzi nativně podporuje…Jsi nepochopil objektově. Tím myslím skutečné objekty v paměti. Historie je prostě property
.history obsahující odkaz na předchozí verzi objektu. Že je to paměťově náročné? No a? Optimalizace budu řešit, až je budu potřebovat. Serializace je fajn, ale beru to jako export. By default chci mít textové ukládání, ale do formátu objektů programovacího jazyka nezamýšlenou pro lidskou editaci. Mým cílem je mít z toho v každém kroku pokud možno vždy existující objekty bez jejich transformování do běžných formátů, proto to chci stavět nad image-based systémem. To má taky další výhodu, že tvůj systém je doslova programovací jazyk a IDE, což posouvá scriptování taky někam úplně jinam.
Osobně bych to hrozně rád založil na Selfu, ale mé průzkumy zatím ukazují, že na to nejspíš není ready. Prototype based OOP by na to sedělo hrozně moc (doslova máš jen objekty a jejich reprezentace, kód není specifikován nikde jinde v nějakém class browseru), ale momentálně si pohrávám se Smalltalkem.
Ale uvidíme. Jsem spíš ve fázi zkoumání konkrétních frameworků a jazyků a vší silou se snažím odolat cukání si navrhnout vlastní.
15.10.2017 11:29
xkucf03 | skóre: 50
| blog: xkucf03
Jsi nepochopil objektově. Tím myslím skutečné objekty v paměti. Historie je prostě property .history obsahující odkaz na předchozí verzi objektu.
Ano, nad tím jsem taky přemýšlel, jenže tady nejde zdaleka jen o paměťovou náročnost. Nevím, jak v těch objektech („property .history“) namodelovat plnohodnotnou historii. Představ si, že si napíšeš nějaký odstavec na stránku X, ale pak zjistíš, že patří spíš na stránku Y, tak ho přesuneš. Jak to bude zaznamenané v historii objektů? Budeš mít uložené starší verze stránek X a Y, které budou mít shodou okolností stejné časové razítko? Bude tam někde zaznamenaná ta vazba, že to je pořád ten samý odstavec a jen se přesunul z jednoho místa na druhé? Mě by totiž občas zajímala informace typu „kdy jsem poprvé začal přemýšlet o …“ (tom, co je v tom odstavci).
Taky mi přijde, že uvažuješ o jakýchsi objektech typu „stránka“ (a pak asi nějaké kategorie/štítky/složky nad tím, což jsou jiné typy objektů). Já bych mnohem radši viděl celou tu wiki jako jeden strom/graf složený z uzlů – kde uzel je všechno: kořen, kategorie/složka, štítek, stránka, nadpis, odstavec, formátovaný/vyznačený text (obdoba <b/>, <i/>, resp. spíš sémanticky vyznačený text), odkaz, obrázek… tzn. jednotný model – něco jako kdyby celá wiki byla jedno obrovské XML, což je taky strom uzlů, jedna hierarchie – na vyšší úrovni by byly ty kategorie, stránky, pak obsahy stránek… ale celé by to byl jeden strom, ve kterém by šlo přesazovat uzly z místa na místo. Zřejmě by to nebylo XML, ale logickým modelem se to tomu nejvíc podobá. A k tomuhle bych potřeboval přidat tu časovou dimenzi. Když např. tučně vyznačím kus textu, tak to znamená, že se textový uzel přesunul do uzlu něco jako <strong/>, který je ve stromu na místě toho původního textového uzlu – ne, že se změnil nějaký řádek a ne že vznikla nová verze nějaké stránky. Pojmenované verze (obdoba commit ve verzovacích systémech) mohou seskupovat více atomických změn, ale zaznamenané by tam měly být i ty jednotlivé změny/operace. (běžný verzovací systém neví o tom, že se přesunul odstavec odněkud někam nebo že se změnilo formátování – pro něj prostě jen nějaké řádky/bajty zmizely a jiné se objevily, ale „nechápe“ proč a jaký to má význam)
Nicméně celé je to jen teorie – udělat něco tak dokonalého mi přijde dost pracné a nevím, jestli to za to stojí. Takže v současnosti to řeším tak, že mám disku složku „znalosti“ a v ní různé podsložky, kam sypu jak soubory od ostatních (obrázky, schémata, PDF, výstřižky z webu), tak svoje poznámky (většinou .txt soubory, někdy .xhtml nebo .xml, občas .tex). Časem si nad tím udělám nějaké indexování a vyhledávání, metadata uložím asi do rozšířených atributů souborů a historii zajistím Mercurialem. Je mi sice proti srsti cpát binární soubory do verzovacího systému, ale tady to asi nějak skousnu.
15.10.2017 18:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 15.10.2017 21:53
xkucf03 | skóre: 50
| blog: xkucf03
15.10.2017 21:53
xkucf03 | skóre: 50
| blog: xkucf03
Tyhle ontologie každého jen otravují :-)
Ne, já o tom vím, i když jsem to zatím nějak moc do hloubky nezkoumal. Ale to, co jsem tu popisoval, mělo být trochu jednodušší a asi by to šlo poskládat i z hotových nástrojů – vzít nějaký SŘBD, který by udržoval tu časovou dimenzi (jenže jaký?) a do této databáze prostě nacpat ten strom. Pak by to chtělo WYSIWYM editor, kterému bys ukázal na část stromu a on by ji vykreslil jako stránku a umožnil editaci, to už je trochu složitější. A k tomu si dopsat nějaké indexování, štítkování atd. to už je poměrně jednoduché (technicky).
Ale dohromady je to pořád spousta práce, takže se do toho asi v nejbližší době nepustím. Přeci jen bych chtěl dělat radši nějakou reálnou práci, než si jen „organizovat poznámky“ (i když i to je důležité). Takže v té složce ~/znalosti jsem udělal hg init a párkrát hg add a hg commit a zatím to budu udržovat takhle. Časem přidám nějaké indexování a vyhledávání, symbolické odkazy (např. pro štítky) a rozšířené atributy souborů (další metadata) + něco na jejich správu, možná nějaký lepší editor/prohlížeč… Třeba to jednou přehodím do něčeho lepšího – ten jednotný strom a sémantické verzování pořád považuji za ideál, ale ta pracnost prostě převyšuje můj osobní užitek z toho.
Takže v té složceTakže něco jako ty wiki ukládající data do gitu, jak se tady v jiném komentáři snažím propagovat? :)~/znalostijsem udělalhg inita párkráthg addahg commita zatím to budu udržovat takhle. Časem přidám nějaké indexování a vyhledávání, symbolické odkazy (např. pro štítky) a rozšířené atributy souborů (další metadata) + něco na jejich správu, možná nějaký lepší editor/prohlížeč…
16.10.2017 21:40
xkucf03 | skóre: 50
| blog: xkucf03
Ano, je to něco podobného. Akorát spíš než k webu směřuji k nějaké desktopové aplikaci – hodilo by se mít kombinaci správce souborů (Dolphin), GUI k verzovacímu systému (Tortoise Hg), prohlížeče souborů (Okular, Gwenview, Firefox/Chromium) a editoru (to je zatím nejslabší část – chtěl bych dobrý WYSIWYM editor) + indexování, vyhledávání, štítky a nějaký nástroj pro jejich správu. Rád bych se držel blízko souborovému systému, tzn. metadata jde ukládat do rozšířených atributů, propojení udělat přes symbolické odkazy a dovedl bych si představit i smysluplné využití nějakého FUSE souborového systému, který by přidával funkcionalitu.
Ono, když se tohle dotáhne do konce, tak se to složitostí pracností už blíží tomu ideálu, co jsem tu popisoval o kousek vedle (jednotný strom uzlů s integrovaným verzovacím systémem), ale na rozdíl od něj lze tento ekosystém budovat iterativně a užitečný/použitelný je už v té první/nejprimitivnější fázi (soubory + adresáře + Mercurial).
15.10.2017 15:14
xkucf03 | skóre: 50
| blog: xkucf03
kde uzel je všechno: kořen, kategorie/složka, štítek, stránka, nadpis, odstavec, formátovaný/vyznačený text
P.S. resp. ne nadpis, ale kapitola (jejímž atributem je nadpis) – a pod uzlem kapitoly jsou uzly dalších kapitol nebo odstavců. Tzn. nemělo by to vypadat tak, jako v HTML, kde nadpis a jemu podřízené odstavce jsou ve stromu na stejné úrovni.
15.10.2017 18:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Taky mi přijde, že uvažuješ o jakýchsi objektech typu „stránka“ (a pak asi nějaké kategorie/štítky/složky nad tím, což jsou jiné typy objektů). Já bych mnohem radši viděl celou tu wiki jako jeden strom/graf složený z uzlů – kde uzel je všechno: kořen, kategorie/složka, štítek, stránka, nadpis, odstavec, formátovaný/vyznačený text (obdoba <b/>, <i/>, resp. spíš sémanticky vyznačený text), odkaz, obrázek… tzn. jednotný model – něco jako kdyby celá wiki byla jedno obrovské XML, což je taky strom uzlů, jedna hierarchie – na vyšší úrovni by byly ty kategorie, stránky, pak obsahy stránek… ale celé by to byl jeden strom, ve kterém by šlo přesazovat uzly z místa na místo. Zřejmě by to nebylo XML, ale logickým modelem se to tomu nejvíc podobá. A k tomuhle bych potřeboval přidat tu časovou dimenzi. Když např. tučně vyznačím kus textu, tak to znamená, že se textový uzel přesunul do uzlu něco jako <strong/>, který je ve stromu na místě toho původního textového uzlu – ne, že se změnil nějaký řádek a ne že vznikla nová verze nějaké stránky. Pojmenované verze (obdoba commit ve verzovacích systémech) mohou seskupovat více atomických změn, ale zaznamenané by tam měly být i ty jednotlivé změny/operace. (běžný verzovací systém neví o tom, že se přesunul odstavec odněkud někam nebo že se změnilo formátování – pro něj prostě jen nějaké řádky/bajty zmizely a jiné se objevily, ale „nechápe“ proč a jaký to má význam)
:)
Mrkni se na Self a na jeho objektový model. Vážně :)
16.10.2017 21:46
xkucf03 | skóre: 50
| blog: xkucf03
Dík, to vypadá zajímavě. Ten proklik, kterým si člověk zobrazí danou část stromu, to je přesně ono. Tedy samo o sobě to nestačí, ale zrovna tahle část je to, jak jsem si to představoval.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz