HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Pan učitel Igor Hnízdo dnes (18. 10. 2019) oznámil první veřejnou verzi nového programovacího jazyka Č++ [čé plus plus]. Jde o jazyk určený (nejen) k výuce na středních školách. Vyznačuje se používáním českých klíčových slov a podobá se přirozenému jazyku. Programy v jazyce Č++ jde překládat pomocí GCC a následně i spouštět. Více podrobností v článku Ryze český programovací jazyk Č++ na Farmě Trollí hnízdo (dostupné přes Tor).
Vypadá to dost zvláštně, ale kupodivu to funguje.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 21.10.2019 13:45
mirefek | skóre: 6
| blog: proc_dalsi_nazev
21.10.2019 13:45
mirefek | skóre: 6
| blog: proc_dalsi_nazev
 21.10.2019 18:02
Gilhad | skóre: 20
| blog: gilhadoviny
21.10.2019 18:02
Gilhad | skóre: 20
| blog: gilhadoviny
AK čosi PAK dačo() INAK voľačo();
 21.10.2019 18:52
Josef Kufner | skóre: 70
21.10.2019 18:52
Josef Kufner | skóre: 70
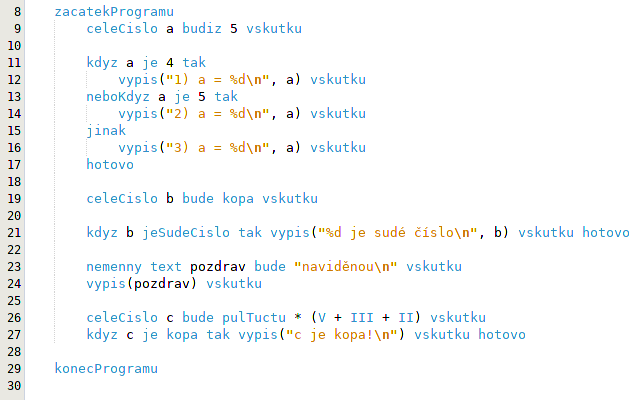
CeléČíslo a budiž 5.
Když a je 4 tak:
Vypiš "...".
Jinak:
Vypiš "...".
Hotovo.
Také by bylo vhodné používat správně diakritiku, když je i v názvu jazyka.
Když a je 4 tak:
Vypiš „…“.
Jinak:
Vypiš „…“.
Hotovo.
 22.10.2019 03:49
Jendа | skóre: 78
| blog: Jenda
| JO70FB
22.10.2019 03:49
Jendа | skóre: 78
| blog: Jenda
| JO70FB
/* */ komentářů při programování občas chybí. (#if 0, které vnořovat jdou, jsou trochu nepraktické)
Velká výhoda (pro lidi co píšou parser a požadují aby parsoval regulární jazyk nevýhoda) je, že tyhle uvozovky jdou vnořovat! Osobně mi třeba vnořováníOno je to jedno, běžné programovací jazyky stejně nemají regulární syntax. AFAIK většina nemá ani context-free a některé ani context-sensitive... Céčko by klidně mohlo mít balancované/* */komentářů při programování občas chybí. (#if 0, které vnořovat jdou, jsou trochu nepraktické)
/* */ , ale prostě to tak neudělali, tak máme smůlu...
 23.10.2019 19:24
xkucf03 | skóre: 50
| blog: xkucf03
23.10.2019 19:24
xkucf03 | skóre: 50
| blog: xkucf03
Ono je to jedno, běžné programovací jazyky stejně nemají regulární syntax. AFAIK většina nemá ani context-free a některé ani context-sensitive...
To asi záleží, co do toho parsování všechno počítáš a jestli si ho třeba nerozdělíš na víc kroků/úrovní. Na té základní úrovni, kdy jsi schopný říct, který kus textu je komentář, který řetězec, který název proměnné, metody atd. je to výrazně jednodušší, než na úrovni, kde to už kompiluješ nebo s tím nějak jinak pracuješ (tam už víš, zda se třeba nepoužívá nedefinovaná proměnná nebo nevolá neexistující metoda nebo třeba, že jsi zapomněl nastavit hodnotu final proměnné, jestli nemáš duplicitní názvy metod/proměnných, jestli nevoláš private metodu, odkud nemáš atd.).
Na té základní úrovni, kdy jsi schopný říct, který kus textu je komentář, který řetězec, který název proměnné, metody atd. je to výrazně jednodušší, než na úrovni, kde to už kompiluješ nebo s tím nějak jinak pracuješJednodušší to určitě je, ale ani na to IMHO nestačí regulární gramatika. A nejsem si jistej, jestli context-free. Možná u jazyků s relativně jednodušší syntaxi (např. Java) ano, ale nepřekvapilo by mě, kdyby i tam to bylo >= context-sensitive kvůli třeba dangling else, syntaxi generik apod...
 24.10.2019 11:31
|🇵🇸 | skóre: 94
| blog:
24.10.2019 12:47
xkucf03 | skóre: 50
| blog: xkucf03
24.10.2019 11:31
|🇵🇸 | skóre: 94
| blog:
24.10.2019 12:47
xkucf03 | skóre: 50
| blog: xkucf03
Ta „základní úroveň“ je prostě lexikální analýza
Ne. Rozpadnout vstupní text na tokeny je pořád ještě málo, to je ten úplně první krok. Ale to o čem mluvím, je až za tím, za lexikální gramatikou, ale stále před krokem, kdy dojde k plnému vyhodnocení kódu (a kde jsi schopný např. vyhodit chybu, protože final proměnná nebyla ve správnou chvíli nastavena nebo proto, že voláš private metodu, nebo že máš dvě proměnné se stejným názvem).
Relevantní diskuse třeba zde: What programming languages are context-free?
The set of programs that are syntactically correct is context-free for almost all languages.
The set of programs that compile is not context-free for almost all languages.
nebo Is XML context-free?
This separates out the context-free part of the language from the context-sensitive part -- which is generally regarded as good practice (a kind of modular "programming" discipline for language design).
24.10.2019 12:58
|🇵🇸 | skóre: 94
| blog:
Tohle vypadá dost přesně jako lexikální analýza:
Na té základní úrovni, kdy jsi schopný říct, který kus textu je komentář, který řetězec, který název proměnné, metody atd.
Ale není mi jasné, jakou to má souvislost. S oněmi uvozovkami či ohraničením komentářů lze pracovat i analogicky jako s bloky.
Nechápu, proč do toho cpeš sémantickou analýzu; jak s tím souvisí nějaké final a private?
Na začátku vět se píše velké písmeno a na konci tečka.To si pletes s jazykem ČOBOL:
IDENTIFIKAČNÍ ODDÍL.
ID-PROGRAMU. NAZDAR.
PROCEDURÁLNÍ ODDÍL.
ZOBRAZ "SVĚTU MÍR!".
UKONČI BĚH.
 22.10.2019 13:55
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
22.10.2019 13:55
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
Pro případ, že by si někdo z Vás opět doma zapomněl igelitky (moc jsem jich na letošních linux days neviděl!), tak v nůši přinesu jednu, dvě aktovky navíc. Aktovek mám spoustu, často se nějaká v šatně záhadně ztratí.
A jako pohoštění navrhuji vepřový jazyk. Už teď se těším, jak jse budeme pěchovat do nůší, aktovek a igelitek! Možná by nás při tom i mohl natočit Švankmajer a přivydělali bychom si jako kompars. A to se vyplatí!
Do papiňáku dáme vařit omyté jazyky s bobkovým listem,novým kořením, 1-2 lžičkami soli, 3 kuličkami pepře a mraženou zeleninou. Po uvaření vyjmeme koření, jazyk oloupeme (nejlépe se loupe ještě teplý) a nakrájíme na plátky. Zeleninu i s vývarem rozmixujeme. V jiném hrnci orestujeme na slanině cibulku, zaprášíme moukou a zalejeme rozmixovanou zeleninou. Chvíli povaříme, přidáme hořčici a 1 hrnek plnotučného mléka. Dochutíme solí a citrónem. Kdyby byla omáčka řídká, může se zahustit moukou, rozmíchanou v mléce. Vložíme nakrájený jazyk a ještě chvili prohřejeme.Jako příloha je nejlepší knedlík nebo těstoviny
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz