Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »
12.12.2019 14:54
| Přečteno: 3098×
| Hardware
|  | poslední úprava: 13.12.2019 11:14
| poslední úprava: 13.12.2019 11:14

Mě to sice kazí těch 532 threadů (+1039 kiernel threadů) Spuštěné je jen GUI a jedna SSH session. Ale to je na jinou debatu.
Mimochodem gnómí systém-monitor sám o sobě žere skoro 10 % výkonu jednoho jádra. Měření holt ovlivňuje realitu jako v kvantovce Výstup z /proc/interupts také vypadá vtipně, to si jistě dokážete představit. Až se pokocháte pohledem, podíváme se, jak s počtem jader škálují některé úlohy, pro které by si někdo mohl chtít tento procesor pořídit.
Threadripper 3970X, 4x32GB 3600MHz DDR4 (díky těmto hustým modulům jsou na desce ještě 4 volné sloty, ty se budou hodit, kdyby majitel někdy chtěl provozovat více než jednu elektron aplikaci současně, může rozšířit paměť na 256GB což je současně maximum této platformy. Pokud zvětší swap soubor, tak by mohl možná ty dvě elektron apky provozovat souběžně i s chromiem. Možná.) Dále tam je 2x 1TB nvme SSD, ASUS TRX40 deska, AIO vodní chladič, zdroj RM850i a omáčka okolo.
Zatímco Intel je sen taktovače a ladiče, tak AMD je z toho pohledu nuda. Zapne se jednu funkci v BIOSU (PBO) spolu se zvětšením několika limitů a je to. Možná trochu poladit parametry pamětí. A přínos není ani tak příliš znatelný. Brzy se narazí na limit toho, že 400W tepla není snadné z toho procesoru ani AIO vodníkem odvést. Každopádně je PBO při testech zapnuté. Při kompilaci na všech jádrech statečně drží 4,2 GHz, při OpenSSL 4,1 GHz a při hnusné zátěži jako mprime small FFT 3,9 GHz. Jednojádrové takty nejdou přes 4,35GHz. Při předpokladu podobného IPC jako dříve testovaný Intel 7960X, bude oproti němu výkon v rozsahu 1-8 zatížených jader horší. Kdo by si ale kupoval takový procesor pro osmijádrovou zátěž, že.
Testuje se na minimální instalaci Ubuntu 19.10. Soudruzi z AMD zapomněli poslat patch na kernel, takže aktuální jádro v době vydání s threadripperem trojkové řady nebootuje. Jádru je třeba předat parametr mce=off což je jen workaround, mce tam není jen pro srandu králíkům takže vypnutí není dobrým řešením. Ale to, že bude u AMD po uvedení nové platformy nějaký softwarový problém, je zhruba asi stejně jasné, jako že nás Intel v pravidelných intervalech oblaží nějakou novou a fascinující dírou ve svých procesorech (jako třeba dnes Plunder Volt). Když jsme u těch děr, Threadripper v lscpu hlásí:
Vulnerability Itlb multihit: Not affected Vulnerability L1tf: Not affected Vulnerability Mds: Not affected Vulnerability Meltdown: Not affected Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization Vulnerability Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, STIBP conditional, RSB filling Vulnerability Tsx async abort: Not affected
Takže Spectre jsou řešeny i na nových Threadripperech softwarovými mitigacemi.
Překládám vanilkové jádro 5.4 s implicitním .config (lze získat pomocí make defconfig). Jádra vypínám přes zápis do /sys/devices/system/cpu/cpuN/online. Tímto způsobem lze nasimulovat vypnutí SMT (vypnutím jader 31-63) a taktéž 24jádrový model 3960X (vypnutím příslušných dvojic v každém CCX). Celý proces kompilace probíhá v ramdisku. Měřím pomocí time make -jN resp. openssl speed rsa2048 -multi N. Všechna měření dělám dvakrát a výsledky průměruji. V případě kompilace dávám do grafu počet kompilací za 10 minut.
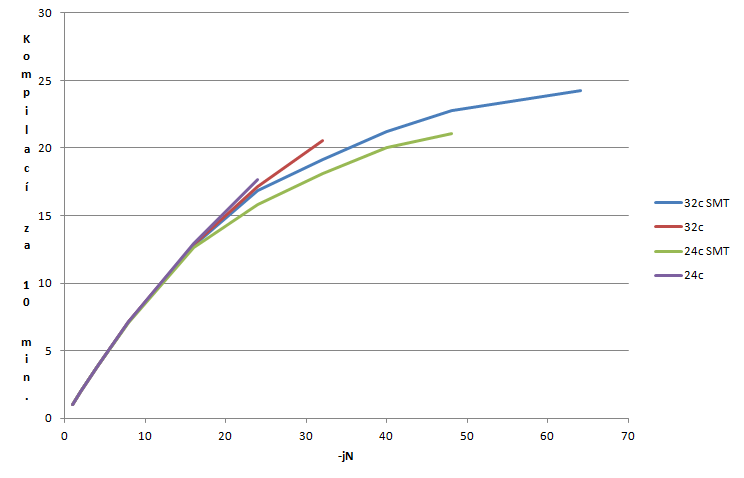
Minule jsem testoval překlad jádra 4.13.5 a na Intelu s –j16 se dalo přeložit 14x za 10 minut. Na AMD se s –j16 přeloží současné jádro necelých 13x za 10 minut. Podobné konstatování bylo i v minulém díle. Vypadá to, že růst IPC*frekvence není sto pokrýt ztráty způsobené bobtnáním softwaru (tedy pozorujeme Gatesův zákon v praxi).
I na této platformě se potvrzuje, že při –j32 je výsledek lepší na 32jádru bez SMT než s ním (a ekvivalentně pro 24jádro). Linux tedy stále nedokáže zcela zvládnout rozdělení procesů tak, aby na jednom páru byl pouze jeden proces. SMT přidává 26 % výkonu 32jádru a 33 % výkonu 24jádru. 32jádro je o 15 % výkonnější (ale o 56 % dražší) než 24jádro. Je vidět, že škálování v takto postavené úloze výrazně vadne. Pojďme to tedy vyzkoušet jinak. Budeme kompilovat více jader současně např. místo make –j64 spustíme 4 nezávislé instance make –j16 na separátní kopií zdrojáků.
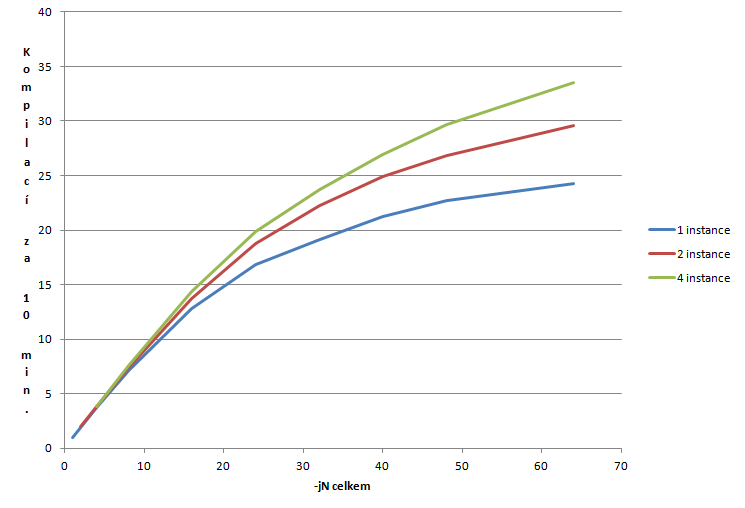
Tohle vypadá mnohem lépe. Z grafu je hezky vidět, že když u 16 threadů začíná škálování vadnout, tak tomu další instance velmi pomůže. Podobně přidání dalších 2 instancí někde kolem 40 threadů. Přínos SMT se u 4 instancí vyšplhal na 40 %. Bohužel je to také ještě méně realistický scénář… Pokud bude růst počtu jader pokračovat, bude nezbytně nutné zapracovat na paralelizaci samotného gcc protože make ani u projektů jako linux kernel není schopno v každé chvíli najít dostatek cílů, aby saturovalo celý procesor. Tím klesá „parallel portion“ Amdahlova zákona a škálování jde do háje.
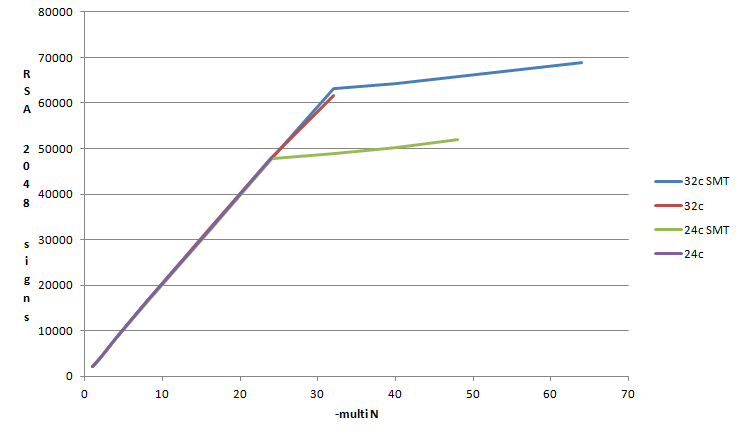
Tady je to zcela bez překvapení. Škáluje to s fyzickými jádry velice pěkne (-multi 32 je 30,3x rychlejší, než –multi 1) a SMT přidává cca 10 %. Opět je patrný mírně větší výkon, když při 32 threadech na 32jádru vypneme SMT (a ekvivalentně na 24jádru).
7-Zip [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=cs_CZ.UTF-8,Utf16=on,HugeFiles=on,64 bits,64 CPUs AMD Ryzen Threadripper 3970X 32-Core Processor (830F10),ASM,AES-NI)
AMD Ryzen Threadripper 3970X 32-Core Processor (830F10)
CPU Freq: - - - - - - - - -
RAM size: 128754 MB, # CPU hardware threads: 64
RAM usage: 14120 MB, # Benchmark threads: 64
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 214939 6055 3453 209093 | 2840092 6321 3832 242188
23: 189690 5746 3364 193272 | 2779563 6319 3806 240506
24: 179640 5747 3361 193149 | 2719748 6320 3777 238711
25: 171073 5896 3313 195325 | 2640529 6294 3733 234953
---------------------------------- | ------------------------------
Avr: 5861 3373 197710 | 6314 3787 239090
Tot: 6087 3580 218400
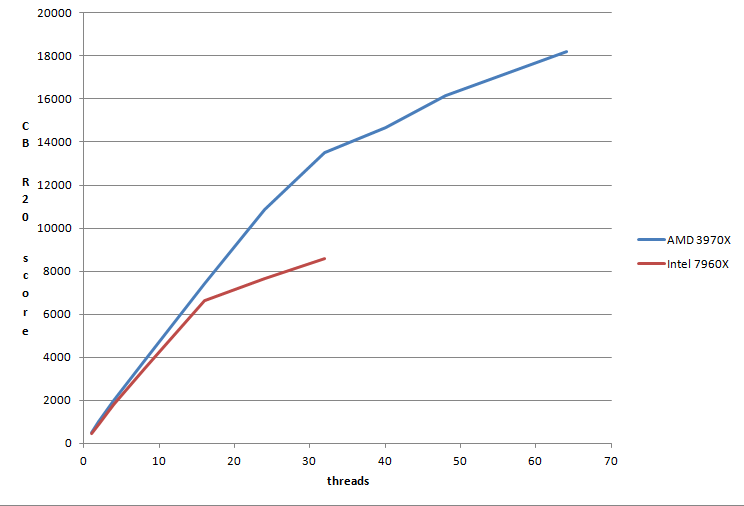
Cinebench škáluje poměrně dobře na fyzických (32j má 26x větší výkon než 1j) i virtuálních jádrech (SMT na AMD přidává 34 % a HT na Intelu 29 %). AMD je v rozsahu 1-16 přibližně 10 % výkonnější, pro 24 a 32 cca 50% a na maximálním počtu threadů má AMD převahu 110 %. Je třeba přiznat, že ten test není k Intelu zcela férový, protože nepoužívá AVX512. Cpu-z, který má podporu AVX512 vykazuje až 35% převahu Intelu na jednom jádře. Intel má také navrch v „legacy“ aplikacích. Zkoušel jsem třeba SuperPi mod 1.6 32M s výsledkem 519 sdekund na AMD a 429 sekund na Intelu, to je 21% převaha Intelu. Corona 1.3 AMD 27s a 54s pro Intel (přesně dvojnásobek).
Architektura ZEN2 s centrálním IO čipíčkem se AMD velmi povedla a je to vidět zejména u threadripperů. Předchozí generace, tedy 2990WX, měla kvůli komplikované NUMA architektuře značné potíže (v mnoha testech znamenalo vypnutí poloviny CCX paradoxně růst výkonu). Ten procesor se tedy nedal doporučit pro použití v PC, které má plnit více úkolů ale pouze jako procesor pro stroj plnící jednu specializovanou úlohu, u které je známo, že na něm dobře škáluje.
Po pár dnech používání PC s trojkovou řadou můžu konstatovat, že se to už neděje. Tady si již lze představit, že si ho pořídí někdo, kdo potřebuje něco náročného vyrenderovat, spočítat, nasimulovat, zvirtualizovat,… ale občas si na něm něco zahraje, nebo bude používat po zbytek času jako běžné PC. V těch ostatních oblastech nebude tak dobrý, jako Intel 9900K nebo AMD 3950X ale bude „good enough“. I tak je to ale procesor pro extrémně úzkou cílovou skupinu a jeho osudem pravděpodobně bude, že si ho pořídí většinou lidé, protože ho chtějí a ne proto, že ho potřebují. Tato skupina asi překoná i firemní klientelu – firmy, které používají softy schopné tak vysoko škálovat většinou mají infrastrukturu na offload takové zátěže (renderovací farmy,…). A tam dají spíše Epycy. Nebo jsou to pozéři a pořídí si nový Mac Pro za 1,8 milionu
A nakonec tradiční upozornění - pozor na vyvozování příliš širokých závěrů z naměřených výsledků v tomto článku. Testy jsou úmyslně zaměřeny úzce, tak laskavě vyvozujte jen úzké závěry





Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 12.12.2019 15:47
Max | skóre: 73
| blog: Max_Devaine
12.12.2019 15:47
Max | skóre: 73
| blog: Max_Devaine
Tohle mělo smysl, když se spoustu času strávilo čekáním na pomalé disky. Nedávno jsem s tím ze zvědavosti trochu experimentoval a vyšlo mi, že při překladu na tmpfs nemá smysl dávat větší počet úloh, než je k dispozici logických CPU.
Konkrétně jsem překládal jádro SLE15-SP2 (což je podobně nové, ale s o dost bohatší konfigurací než defconfig z blogpostu) na Ryzenu 3900X (12 jader, 2 thready na jádro). Od -j24 výš byly rozdíly pod úrovní statistické chyby a i rozdíl mezi -j23 a -j24 už byl menší než jedno procento. Podobně na stroji se staršími Xeony X7560 (4 sloty po 8 jádrech, 2 thready na jádro, tj. 64 logických CPU) se optima dosáhlo někde mezi 60 a 63.
 V roce 2009 na osmijádru (2x4 xeon bez HT) to mělo vliv zcela marginální viz
V roce 2009 na osmijádru (2x4 xeon bez HT) to mělo vliv zcela marginální vizSkoda, ze jsi -jN utnul u poctu jader, protoze driv doporucene N byl dvojnasobek jader. Hlavnim duvodem je zcela urcite IO wait, ktery v pripade ram je minimalni, ale i tak by bylo zajimave to videt.Moje zkušenost s tímhle je spíš negativní, zejména u C++ věcí se složitějším kódem, kde je kompilace náročná na paměť. Zvyšování paralelizace nad
nproc pak vedlo akorát k tomu, že to žralo brutální množství ramky, ale rychlost lepší nebyla...
-j 32 real 0m57,139s user 20m19,768s sys 2m2,336s -j 64 real 0m49,738s user 31m30,032s sys 3m3,312sgf
Pokud chcete, aby výsledky něco vypovídaly o výkonu procesoru, překlad v tmpfs je nutnost (a i jinak není moc důvodů v tmpfs nepřekládat, pokud máte dost paměti, aby to šlo). Když se podívám na ty vaše výsledky metrikou celkového času CPU (user + sys) děleného dobou překladu (tj. jakési "míry paralelizace"), dostanu v prvním případě 23.5 a ve druhém 41.7, což není úplně moc (ideál by byl 32 a 64). V podstatě to znamená, že 26 resp. 35 procent času procesor na něco čekal.
Pro srovnání, při překladu na tmpfs na 3900X dostanu (i při paměti prozatím běžící s dost neuspokojivým SPD časováním)
real user sys
-----------------------------------------------
-j12 1m3,751s 9m48,272s 1m16,665s 10.4
-j24 0m48,999s 14m4,137s 1m51,504s 19.5
Vezmu-li v úvahu, že ten procesor má dvanáct jader, stál třetinu a má poloviční TDP, je to námět k zamyšlení.
Pro úplnost bych ale ještě dodal, že test buildu s defconfigem není moc šťastně zvolený. Když build zkusím s realističtější distribuční konfigurací, vyjde mi ten poměr s -j12 11.7 a s -j24 22.2, což je o dost lepší.
Nedalo mi to a zkusil jsem ještě osmijádrový 2700X, což by měla být podobná architektura jako 2990WX:
-j8 2m1,050s 13m7,965s 1m40,901s 7.3
-j16 1m28,412s 18m40,589s 2m18,100s 14.2
Oproti 3900X jsou časy přibližně dvakrát pomalejší (podle počtu jader a frekvence by to mělo být 1.54), takže pokrok tam vidět je (kvantitativně asi tak o třetinu).
Teď jsem si ale uvědomil, že při porovnávání výsledků z různých systémů může hrát významnou roli i verze gcc (moje výsledky jsou s gcc 7.4).
Ale frekvence jsou oproti 3970X podle předpokladu nižší (2,9 GHz base oproti 3,7 GHz) a hrubý výpočetní výkon bude cca 35% nad 3970x. Musíš mít tedy naprostou jistotu, že tvůj workload dobře škáluje jinak bude reálný výkon horší než u toho 32jádra.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz