HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
24.2.2019 23:51
| Přečteno: 3848×
| Obecné IT
|  | poslední úprava: 5.5.2019 22:53
| poslední úprava: 5.5.2019 22:53
Parser parsuje, testy procházejí a svítí zeleně. Co víc si přát. Snad jen .. Ve všemožných článcích psali, že je dobré provádět časté testy, zda jde kód přeložit RPythonem. Během psaní parseru to nemělo smysl, protože parser je obtížně dělitelný kus a moje soustředění mířilo směrem k projití unittesty. Řešit u toho ještě datové typy a všechna omezení RPythonu mi přišlo jako zbytečný masochismus, který by mohl způsobit, že projekt nikdy nedodělám.
Normální unittesty pouštím scriptem run_tests.sh, který obsahuje následující kód:
#! /usr/bin/env bash export PYTHONPATH="src/:$PYTHONPATH" python2 -m py.test tests $@
Ten je následně pouštěn scriptem when-changed, jenž detekuje změny na disku a při každé úpravě zdrojových kódů pustí testy:
when-changed -s -r src/tinySelf/*.py -r tests/*.py -c ./run_tests.sh -s
Parametr -s zachycuje stdout z testů.
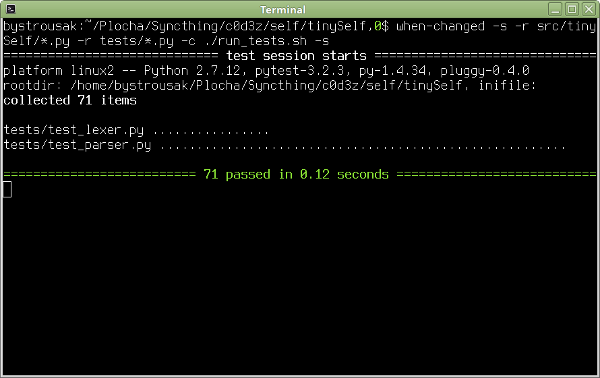
RPython takto pouštět nemůžu, neboť se nejedná o unittesty, ale spíš test kompilace trvající na mém domácím počítači klidně minutu.
Pro RPython jsem si do začátku napsal následující scriptík run_rpython_test.sh:
#! /usr/bin/env bash $HOME/Plocha/tests/pypy/rpython/bin/rpython src/tinySelf/target.py
Jak je možné vidět, ten předpokládá, že v adresáři $HOME/Plocha/tests je naklonovaný repozitář projektu pypy. To je možné udělat například příkazem:
hg clone https://bitbucket.org/pypy/pypy
ve složce $HOME/Plocha/tests.
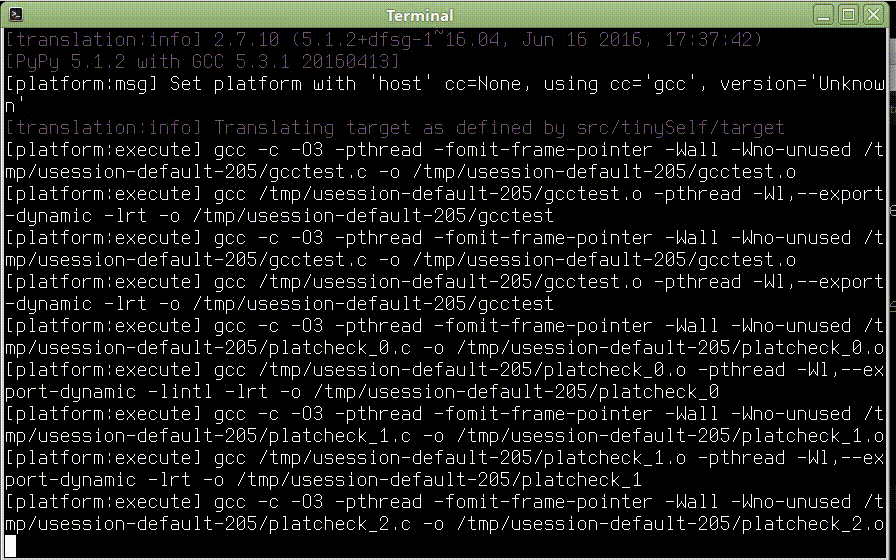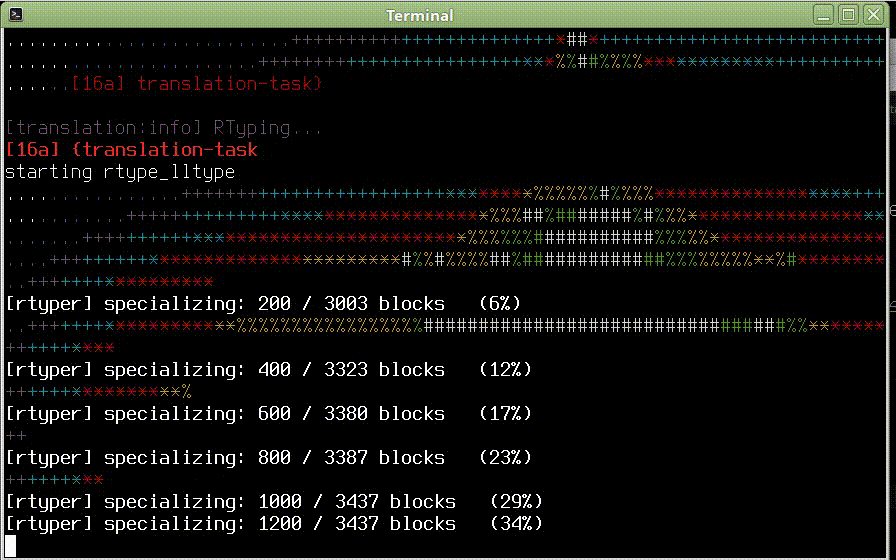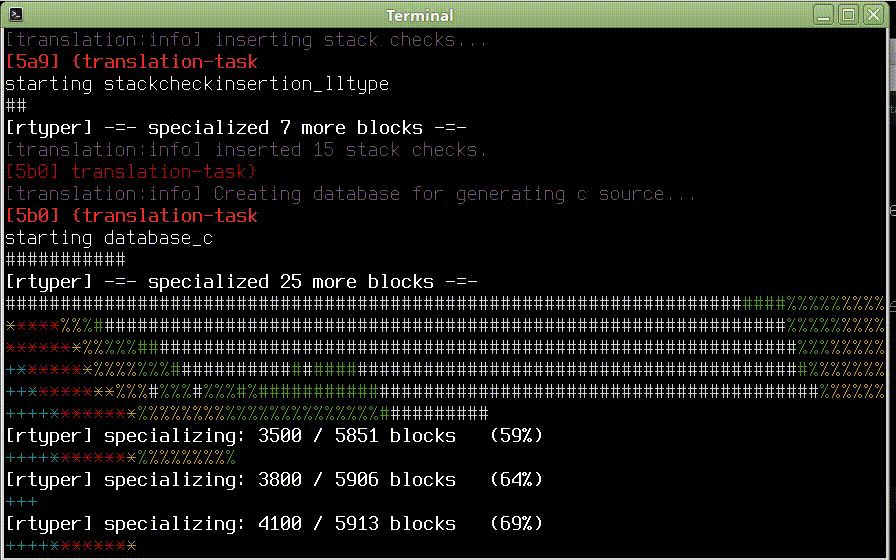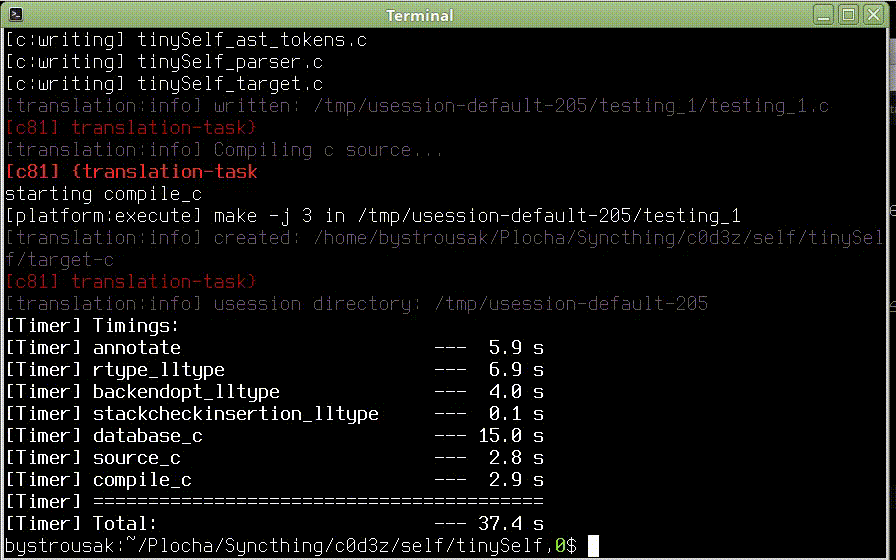
Repozitář je možné zkompilovat a zajistit si tak nejnovější verzi pypy. Osobně to tak ale nedělám, protože to trvá dlouho, nejnovější revize repozitáře typicky obsahuje bugy a navíc kompilace má spoustu závislostí. Proto používám pypy z repozitáře (sudo apt install pypy) a využívám jen nejnovější RPython toolkit, který je s pypy distribuovaný.
Jakmile mám pypy nainstalované, stáhnu si ještě PIP (python package manager) pro pypy (standardní funguje jen pro cpython):
curl https://bootstrap.pypa.io/get-pip.py | sudo pypy
Poté do pypy doinstaluji nejnovější verzi parsovacího balíku rply:
pypy -m pip install --user rply
V repozitáři debian based systémů se nachází balík pypy-rply, který ale nedoporučuji používat, protože může být zastaralý vůči PIPu (v době psaní článku je v debian repozitáři verze 0.7.4-3 a v pipu 0.7.5).
Pouštěný script target.py definuje vstupní kompilační bod. V něm musí být minimálně dvě funkce - target() a poté funkce která slouží jako vstupní bod spuštěného programu. V podstatě se jedná o takové meta-main() známé z C jazyků, tedy funkci určující funkci main. Mám pocit, že na linuxu se k tomu pod libc běžně používá __start.
Obsah funkce target() se spouští v době překladu a proto je možné v něm provádět různé meta-programování, například volat funkce, které vygenerují funkce, které jsou poté zkompilovány.
Osobně jsem do začátku použil jen nejjednodušší target.py:
#! /usr/bin/env python2
# -*- coding: utf-8 -*-
from rpython.jit.codewriter.policy import JitPolicy
from parser import lex_and_parse
def main(argv):
print lex_and_parse("1")
return 1
def target(driver, args):
return main, None
def jitpolicy(driver):
return JitPolicy()
def untranslated_main():
import sys
sys.exit(main(sys.argv))
if __name__ == '__main__':
untranslated_main()
Jak je vidět, jen se pustí funkce lex_and_parse("1"), tedy pokus o zparsování zdrojového kódu obsahujícího jen číslo jedna.
Pokud by vás zajímal princip fungování překladu na C kód, tak znovu doporučuji následující odkazy:
Hezky to celé shrnuje následující graf:
![]()
Ve zkratce je vytvořen flow graf kódu, který je poté projit analyzátorem datových typů, jenž se snaží jednotlivým elementům přiřadit statické datové typy. Pokud se podaří, jsou aplikovány optimizace, případně přidán JIT, vyplivnut C kód a celé je to zkompilováno pomocí normálního C kompilátoru.
To že jde o flow graf ovšem znamená, že části kódu, které nejsou volány nejsou překládány. Celé je možné si to představit jako kompilaci AST, i když ve skutečnosti se kód prvně kompiluje do pythonního bytecode a teprve ten se poté analyzuje a z něj se staví control flow graph.
Prakticky to znamená, že pokud máte v objektu metodu, kterou nejde přeložit, tak na to nepřijdete, dokud v kódu nebude někde místo, odkud se volá. Do té doby vůbec není součástí flow grafu.
První puštění testů mi samozřejmě neprošlo:
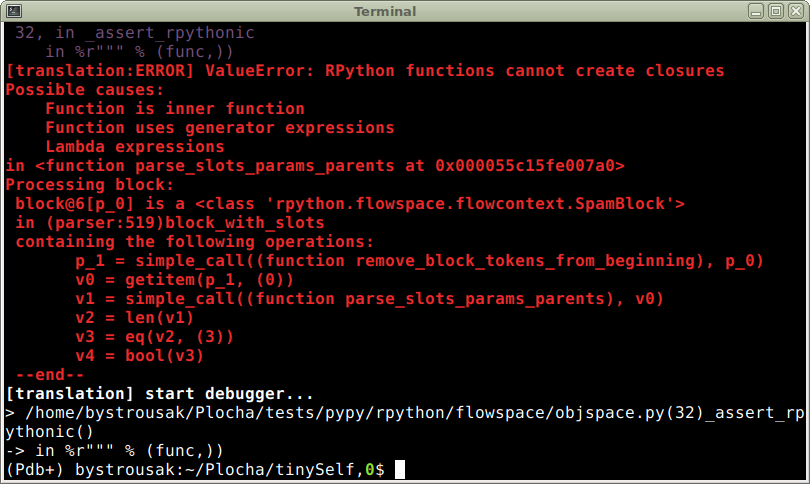
Žádné překvapení. Jak jsem psal, RPython používá silně omezenou verzi pythonu a můj kód nijak nešetří list comprehensionama, closures a dalšími „vysokoúrovňovými“ konstrukty.
Kód je nyní zapotřebí „zhloupit“ a přidat typové hinty, které RPythonu pomohou anotovat flow graph v místech, kde si je nedokáže odvodit sám.
Nyní musím vzít dynamický a relativně vyskoúrovňový python a převést ho na staticky typovaný kód, který by se psal podobně jako třeba v Javě. To vše čistě v syntaxi pythonu.
Část omezení je popsána v oficiální dokumentaci:
Mnohem lepší představu však dává článek
Mezi významná omezení patří například omezení proměnných pouze na jeden datový typ v daném scope. To znamená, že do nich nemůžete přiřadit hodnotu s jiným datovým typem, jakmile je jednou použijete. Seznamy musí být celé tvořeny z jednoho datového typu. Closures nefungují vůbec. List comprehensions fungují, ale ne úplně tak jak by člověk čekal. Generátory jsou více/méně podporovány, ale nejdou s nimi dělat různé psí kusy, jako třeba kompozice.
Otravně omezující je nutnost všech funkcí v parseru vracet stejný datový typ, resp. třídu odvozenou od stejného datového typu. rply k tomu nabízí rply.token.BaseBox, od které musí být poděděny všechny AST prvky. Navíc je však ale třeba přepsat i všechny parsovací funkce tak, aby nevracely list, dict, nebo jiné nativní typy, ale datový typ odvozený od BaseBoxu.
Proto jsem byl nucen nadefinovat třídy StrContainer, DictContainer, ListContainer a KwSlotContainer, a používat je na místech, kde jsem dříve používal prostě jen dict, nebo list. Původně jsem chtěl použít jen Container, který by udržoval obecný datový typ, ale ukázalo se, že na něj taky platí omezení a pro jednu instanci je možné použít jen jeden datový typ. Do třídy ve stylu:
class Container(object):
def __init__(self, data):
self.data = data
není možné v různých instancích uložit různé datové typy. To je pro mě jakožto dlouhodobého programátora v pythonu docela nezvyk.
Hezky je to vidět například na parsovací funkci kw_slot_definition(), která se proměnila z
@pg.production('slot_definition : kw_slot_name ASSIGNMENT expression')
def kw_slot_definition(p):
assert isinstance(p[2], Object), "Only objects are assignable to kw slots!"
slot_name = p[0][0]
parameters = p[0][1]
obj = p[2]
obj.params.extend(parameters)
return {slot_name: obj}
na
@pg.production('slot_definition : kw_slot_name ASSIGNMENT expression')
def kw_slot_definition(p):
slot_info = p[0]
obj = p[2]
assert isinstance(slot_info, KwSlotContainer)
assert isinstance(obj, Object)
obj.params.extend(slot_info.parameters)
return DictContainer({slot_info.slot_name: obj})
Za povšimnutí stojí také několik použití assert isinstance(..). V prvním případě používám assert tak, jak byl zamýšlen, tedy k ujištění se, že do funkce nepoleze datový typ jiný než objekt a pokud ano, tak vyhodím chybovou hlášku.
Ve druhém případě assert nefunguje jako příkaz pro ujištění, ale jako type hint (typová nápověda) pro RPython, který mu říká, jakého datového typu jsou dané parametry. Pokud bych ho neuvedl, došlo by v době překladu k vyhození výjimky, která může vypadat například takto:
[translation:ERROR] NoSuchAttrError:
the attribute 'params' goes here to <ClassDef 'rply.token.BaseBox'>, but it is forbidden here
v0 = getattr(obj_0, ('params'))
In <FunctionGraph of (parser:453)kw_slot_definition at 0x55b7e3841cc8>:
Happened at file src/tinySelf/parser.py line 461
slot_info = p[0]
obj = p[2]
# assert isinstance(slot_info, KwSlotContainer)
# assert isinstance(obj, Object)
==> obj.params.extend(slot_info.parameters)
return DictContainer({slot_info.slot_name: obj})
Z chyby je jasně vidět, že RPython nechápe, proč se snažím u neznámého objektu přistupovat k členské proměnné params.
Na konci funkce pak vracím DictContainer čistě jen proto, že vrácené parsované hodnoty musí být všechny stejným datovým typem, nebo jeho potomky. To je způsobeno vnitřním fungováním parseru, který jednotlivé odekorované funkce zpracovává v různých kolekcích, ve kterých nemůžou být pod RPythonem různé datové typy.
Zajímavé jsou chyby Blocked block -- operation cannot succeed, které mi jeden večer docela zamotaly hlavu. Nakonec jsem však prohledáním konference zjistil, že se jedná o chybu když RPython type annotator prvně vleze do metody objektu a ještě neprošel .__init__() metodu. Pokud je v metodě přistoupeno k členským proměnným, tak dojde chybě, jelikož anotátor neví o tom že byly definovány. Řešení je docela prosté, stačí objekt prostě předtím někde použít, aby byla o-anotována .__init__() metoda.
Výše uvedené potíže jsou jen malá část toho, s čím se člověk setká. Osobně jsem postupoval tak, že jsem celý parser až na první pravidlo a poslední parsovací funkci parse_and_lex() zakomentoval a postupně převáděl jednotlivá pravidla. Tímhle postupem mi to trvalo poměrně dlouho, ale nakonec se dostavil výsledek:
(Kompilační fraktály v původní kvalitě: https://youtu.be/A_OhtmUH830)
Příště se podíváme na návrh rozložení a reprezentace objektů v paměti před tím, než přijde na řadu psaní virtuálního stroje a kompilátoru do bytecode.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 25.2.2019 10:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.2.2019 10:21
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Mám otázku, nestálo za to zkusit to používat přímo v Pypy?Co se mě týče, tak ne (programovací jazyk nemá smysl dvojitě interpretovat), obecně bych to ale asi mohl doporučit. V práci jsem asi před 3/4 rokem řešil něco podobného. Dělal jsem benchmark na nuitku, cython, numbu a rpython, jak co se týče rychlosti, tak co se týče pracnosti přepisu. Nakonec jsme prostě jen vyprofilovali který kus kódu žere nejvíc CPU a ten jsem přepsal do rustu. To bylo nejmíň pracné a navíc nejrychlejší co do rychlosti programu. Původně jsem o tom chtěl napsat článek, ale nakonec jsem se k tomu nedostal. Používal jsem Pythonium Trioxide. Pypy ale obecně bývá nejjednodušší varianta. Jinak co se týče čísel, tak můj úplně první benchmark v (c)pythonu 2.7 trval 2583 sekund, pod pypy 30.25 sekund a kompilovaný rpythonem bez JITu a optimalizací 16.26. Od té doby jsem to ještě mnohokrát zrychlil pod rpythonem, imho to ale pěkně ukazuje, jak moc velký může být rozdíl mezi pypy a klasickým cpythonem, speciálně když tam třeba často vytváříš dicty, nebo něco drtíš ve smyčce.
Mám pocit, že na linuxu se k tomu pod libc běžně používá __start.
No, to není úplně to samé... V C main bude vždy main, je to dané i standardem. __start je v podstatě implementační detail, např. vytváří seznam argumentů a environment proměnných, který je procesu předán OS/platformě-specifickým způsobem, pak taky inicializuje nějaký věcí C runtimu (např. locale, tuším, doufám, že nekecám) ...
Ve zkratce je vytvořen flow graf kódu, který je poté projit analyzátorem datových typů, jenž se snaží jednotlivým elementům přiřadit statické datové typy.Ví někdo, jestli RPython na tohle používá Hindley-Milner / algoritmus W, nebo jestli mají nějaké svoje custom řešení?
__start je v podstatě implementační detail, např. vytváří seznam argumentů a environment proměnných, který je procesu předán OS/platformě-specifickým způsobem
Jak moc je vytváří? Protože, když jsem si s tím před časem hrál (Přepisování parametrů příkazové řádky), tak jsem zjistil, že OS i program koukají na to samé místo v paměti, takže z programu můžeš přepsat to, co vidí OS a zobrazují různé nástroje na výpis procesů.
pak taky inicializuje nějaký věcí C runtimu (např. locale
Tak to už to mohli udělat tak, aby nebylo nutné na začátku programu psát setlocale(LC_ALL, ""); …
Záleží z pohledu čeho se na to koukáš. Z pohledu C standardu jakým způsobem se ten vektor vytvoří je implementation-defined. AFAIK změnit obsah těch stringů můžeš, ale jestli se to projeví ještě někde jinde je IMHO opět implementation-defined. V praxi na Linuxu AFAIK ty startovací funkce jen vyhrabou pointer na ten vektor někde ze stacku a předají to mainu. Víc detailů viz tenhle blog, ale je dobrý pamatovat, že autor se na to kouká na x86. Na jiný architektuře to třeba může fungovat trochu jinak. Nemluvě o specifikách jiných OS (BSD, Mac, ...).__start je v podstatě implementační detail, např. vytváří seznam argumentů a environment proměnných, který je procesu předán OS/platformě-specifickým způsobemJak moc je vytváří? Protože, když jsem si s tím před časem hrál (Přepisování parametrů příkazové řádky), tak jsem zjistil, že OS i program koukají na to samé místo v paměti, takže z programu můžeš přepsat to, co vidí OS a zobrazují různé nástroje na výpis procesů.
Tento blog by mohol byť označení ako Kvalitný zápis.
27.2.2019 16:30
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
27.2.2019 18:27
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Zase na druhou stranu v tomhle vidím přednost těch matfyz talkůJa se drzel demonstracnich prikladu a prednasek od lidi z Oracle a misty se to rozchazelo nejen mezi sebou, ale i s API, ktere bylo k dispozici. Misty to byla opravdu narocna detektivni prace. Nakonec jsem to rozchodil, ale cekal jsem, ze to bude jednodussi. Ale uz je to nejaky patek, mozna s tim pohli. V kazdem pripade, kdyz se to stabilizuje a napisou k tomu rozumnou uptodate dokumentaci s priklady (coz by mi prislo uzitecnejsi nez talky na univerzitach a konferencich), tak to bude super.
Tohle přednáší přímo autor GraalVM, takže to má člověk z první ruky :-)
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 25.2.2019 17:11
25.2.2019 17:11