Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
Víte že můžete odebírat mé blogy pomocí RSS? (Co je to RSS?)
Od určité doby jsou všechny texty které zde publikuji verzované na Githubu.
Jestliže najdete chybu, nepište mi do diskuze a rovnou jí opravte. Github má online editor, není to skoro žádná práce a podstatně mi tím usnadníte život. Taky vás čeká věčná sláva v commit logu :)
13.3.2019 18:31
| Přečteno: 2547×
| Obecné IT
|  | poslední úprava: 5.5.2019 23:00
| poslední úprava: 5.5.2019 23:00
Dalším logickým krokem by mělo být vytvoření virtuálního stroje, který bude programovací jazyk interpretovat, a kompilátoru, který pro tento virtuální stroj zkompiluje zdrojový kód. Před tím, než se do toho můžu pustit je však třeba ujasnit si, nejlépe formou konkrétní implementace, jak bude vypadat reprezentace a rozložení objektů v paměti.
Specificky následující věci;
Přestože tento seriál je určen především pro pokročilé čtenáře, od kterých očekávám alespoň základní obeznámení se Selfem, pro jistotu zde rekapituluji na prototypech založený objektový model Selfu.
Objekty v Selfu se chovají jako asociativní pole, které na konkrétním jménu uchovávají buďto hodnotu, nebo odkaz na jiné objekty. Pár jméno : hodnota je nazýván slotem. Objekt je kolekcí takovýchto slotů.
(| slot = 1. another = 2 |)
Tento objekt na jisté úrovni abstrakce odpovídá slovníku {"slot": 1, "another": 2}.
Klíče v asociativním poli jsou přeloženy na konkrétní výsledek aktem poslání zprávy objektu. Zprávy můžou být unární (jednoduchý string bez mezer), binární (operátory jako +-/ a tak podobně), či keyword* (složené z jednoho, či více klíčových slov následovaných dvojtečkou).
obj unaryMessage. obj + anotherObj. obj keyword: anotherObj Message: evenMoreObjs.
Analogie k pythonu by byla:
obj.unaryMessage() obj.+(anotherObj) obj.keyword:Message:(anotherObj, evenMoreObjs)
Rozdíly oproti klasickému asociativnímu poli jsou následující:
Objekt je možné interně reprezentovat třídou zhruba a velmi abstraktně následujícího typu:
class Object:
def __init__(self):
self.slots = {}
self.parents = {}
self.scope_parent = None
self.primitive_code = None
self.parameters = []
Tedy Objekt může obsahovat sloty jako hashmapu, seznam přijímaných parametrů jako pole, slovník odkazů na rodiče a kód, což je zase jiný objekt, něco jako pole zpráv, které se postupně zasílají.
Od začátku jsem chtěl, aby sloty byly uloženy se zachováním pořadí v OrderedDictu, místo v klasické hashmapě. To není tak moc podstatné, pro samotný programovací jazyk, jako pro jeho využití k ukládání strukturovaných informací. Díky tomu je možné do stromové struktury například 1:1 konvertovat XML s poměrně malým overheadem.
V na třídách založených jazycích jsou objekty reprezentovány přibližně nějak jako pointer na třídu následovaný polem s datovými sloty udržujícími členské proměnné. Ve třídě samotné je uložen popis toho, co se dělá s datovými sloty. Tím je šetřena paměť, neboť samotná funkcionalita objektu je v ní uložena jen jednou pro všechny instance.
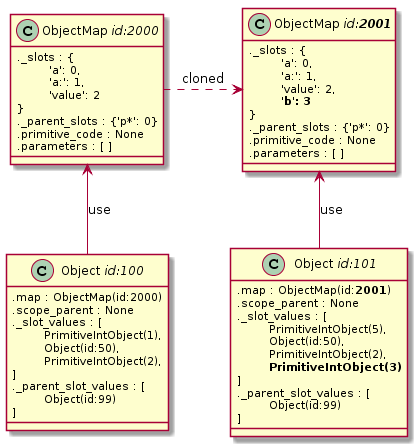
Self je na prototypech založený jazyk, kde nic jako třídy není. Objekty nejsou instancovány, ale klonovány z jiných objektů. Přesto, či respektive právě proto, je možné použít stejný trik, jako u jazyků s třídami. Při klonování je v paměti vytvořena takzvaná mapa a uživateli je vrácen objekt, který je podobně jako v předchozím případě pouze polem s hodnotami a pointerem na mapu. Pokud uživatel klon strukturálně modifikuje (přidá / ubere / přejmenuje sloty), je pro něj vytvořena samostatná mapa, do té doby jsou však mapy sdíleny.
Rozložení v paměti se tedy mění následovně:
class Object:
def __init__(self, map=None):
self.map = map
self.scope_parent = None
self._slot_values = []
self._parent_slot_values = []
def clone(self):
o = Object(self.map)
o.map = self.map
o.scope_parent = self.scope_parent
o._slot_values = self._slot_values[:]
o._parent_slot_values = self._parent_slot_values[:]
return o
class Map:
def __init__(self):
self._slots = OrderedDict()
self._parent_slotss = OrderedDict()
self.primitive_code = None
self.parameters = []
V jakémsi pseudoUML to vypadá takto:
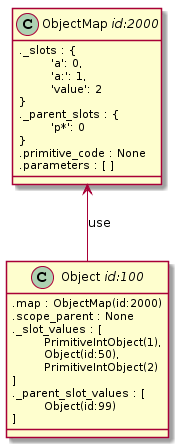
Pokud dojde ke klonování objektu, je vytvořen nový objekt obsahující pole s odkazy na hodnoty. Všechny ostatní informace, jako rodičovské sloty, seznam parametrů a kód objektu jsou pro všechny klony uložené v jedné mapě, na kterou si předávají reference. Díky tomu je možné signifikantním způsobem šetřit paměť.
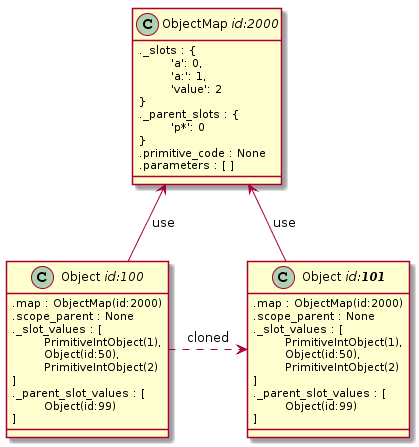
To platí, i když se změní hodnota konkrétního slotu:
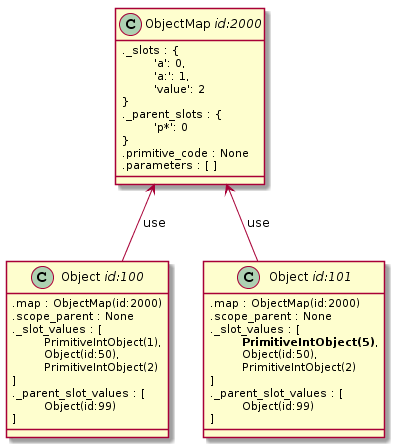
Celá implementace se ovšem kapku zesložiťuje v případě kdy se změní struktura, neboť je potřeba patřičně ošetřit všechny manipulace objektu tak, aby došlo k vytvoření nové mapy.
To jsem osobně vyřešil spoustou meta_ metod. Například .meta_add_slot(), která do klonu přidá nový slot, před tím však vytvoří klon mapy, takže tento nový objekt již používá vlastní mapu, kterou si může upravovat jak chce.
Překlad názvu slotu probíhá následujícím způsobem:
Je zavolána metoda .get_slot(), která se do mapy podívá, jestli obsahuje index patřičného slotu v OrderedDictionary property ._slots. Pokud ano, vezme tento index a najde patřičnou hodnotu v poli ._slot_values. Tu potom vrátí.
Uložení nové hodnoty probíhá podobně.
Meta-operacemi nazývám takové operace, které nějak mění strukturu objektu. Například přidání či odebrání nového slotu. Vzhledem k tomu že jsou sloty uloženy v OrderedDictu, je touto operací i prohození pozice slotu.
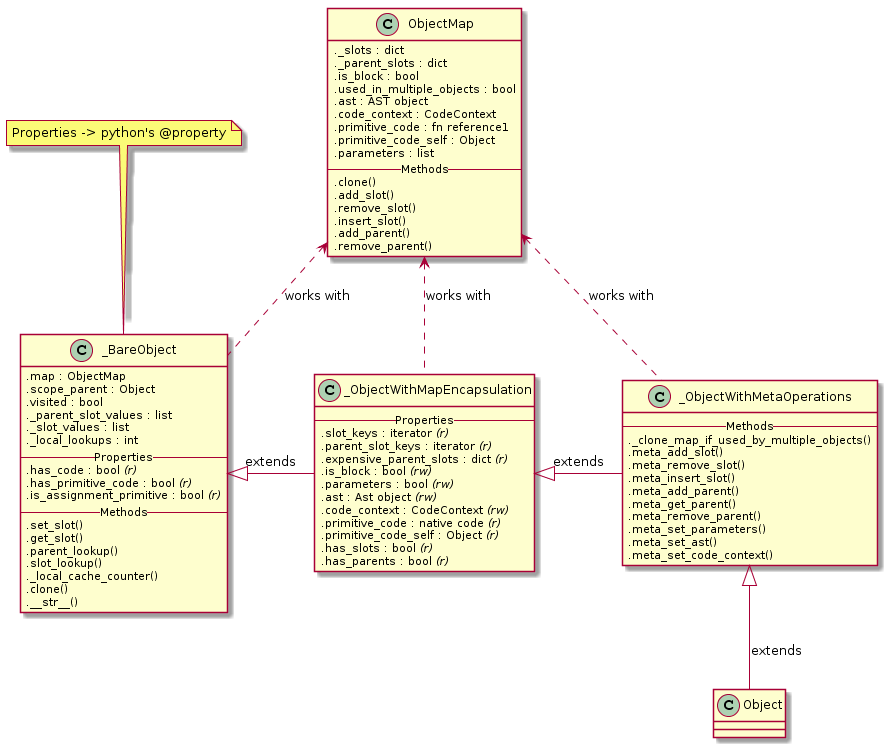
Vzhledem k tomu, že počet řádků narostl z původní několikařádkové myšlenky na pěkných pár stovek, rozhodl jsem se Objekt pro lepší čitelnost dekomponovat do několika tříd. Tato dekompozice nemá vliv na běh programu (stejně je z toho nakonec masivně inlinované C, které objekty nezná), je čistě jen pro lepší strukturovanost zdrojového kódu.
Zde je UML výsledné podoby objektového layoutu:
Zdrojový kód je možné najít v souboru:
Oproti tomu co jsem zatím popsal je možné vidět ještě mezi-třídu _ObjectWithMapEncapsulation, což je abstrakce nad většinou properties v mapě, abych nepřistupoval v kódu interpretru k interním záležitostem mapy přímo. Pro kód je mnohem výhodnější a čitelnější, když mapa zůstane čímsi na pozadí, optimalizací, která je pro vnější svět neviditelnou.
Jednou z naprosto klíčových funkcionalit Selfu, která mu dodává mnoho elegance, jenž například postrádá javascript, je delegace na rodičovské sloty.
Object obsahuje kromě metody .get_slot(), jenž pouze hledá v mapě patřičný slot, také metody .parent_lookup() a .slot_lookup(). Druhá jmenovaná je tím, co se reálně používá všude v interpretru.
Metoda .parent_lookup() funguje následovně:
Projde všechny rodičovské sloty a pokud mají .visited nastavené na True, tak je přeskočí. Pokud ne, podívá se do jejich .slots (respektive do jejich mapy..) a zkusí v nich najít jméno slotu. Pokud tam není, postupuje rekurzivně do hloubky pro rodičovské sloty prvního rodičovského slotu. Všechny objekty, které navštíví, si označí pomocít property .visited a uloží pro pozdější resetování této property. Pokud je slot nalezen v některém z rodičů, či jeho rodičů, je vrácen. Pokud není vůbec nalezen, je vráceno None. V obou případech jsou nakonec všechny prošlé objekty označeny jako .visited = False. Prvním rodičovským slotem, který je vždy prohledávám je speciální rodičovský slot .scope_parent, který je použit k uchovávání lokálních parametrů a kontextu lokálních a globálních proměnných.
Druhá jmenovaná metoda .slot_lookup() se prvně podívá do vlastního seznamu slotů pomocí .get_slot() a pokud tam nic nenajde, pokračuje metodou .parent_lookup(). Tím je implementovaná dědičnost.
Příště se podíváme na bajtkód a literály a v jaké je to celé uložené datové struktuře.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Takže pro vyhledávání slotů používáš DFS. Uvažoval jsi o plném prohledávání tak, jak to dělá Self?
Jsem zvědav, jak budeš řešit kontexty a procesy
 14.3.2019 09:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.3.2019 09:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Uvažoval jsi o plném prohledávání tak, jak to dělá Self?Mám na to issue, ale ještě jsem se k tomu nedostal. Četl jsem někde v paperu od Davida Ungara, že bez toho to není úplně korektní.
Jsem zvědav, jak budeš řešit kontexty a procesyProcesy už mám +- vyřešené. Co je konkrétně myšleno kontexty? Lokální scope?
Četl jsem někde v paperu od Davida Ungara, že bez toho to není úplně korektní.
U složitějších systémů se bez toho dá hůře odhadnout, jak se bude program vlastně skutečně chovat, ale na druhou stranu přináší DFS větší flexibilitu.
Co je konkrétně myšleno kontexty? Lokální scope?
Myslel jsem obecně přístup ke stacku a případnou manipulaci s ním
14.3.2019 10:45
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Myslel jsem obecně přístup ke stacku a případnou manipulaci s nímTo bude vidět v příštím díle. Já si to dělám dost po svém a taky je to z jisté míry ovlivněné pythonem, ve kterém to píšu, tak se to bude asi lišit poměrně hodně od toho co je v Selfu. Momentálně řeším nejvíc pomalost, kde už jsem zoptimalizoval kde co, a dostal jsem se někam k 3 vteřinám na 1 milion while cyklů, což je pořád hrozně pomalé. Teď se snažím ve vedlejší branchi implementovat cacheování slotů a dynamickou rekompilaci bytecode, kde podle profileru parent lookupy zabírají víc jak 70% výkonu.
Uvažoval jsi o plném prohledávání tak, jak to dělá Self?Ze zvědavosti: Jak to dělá Self? Nedělá DFS?
14.3.2019 11:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Když Self prohledává sloty v rodičích, prohledá úplně všechny možnosti a pokud hledanému slotu odpovídá více možností, vyhodí chybu. Jediná validní možnost, jak překrýt definici nějakého rodičovského slotu, je udělat to v rámci vlastních slotů objektu, nemůžete k tomu použít jiného rodiče.Jen dodám, že pak je nutné použít resend (směrování do konkrétního parenta), což je korektní řešení.
Když Self prohledává sloty v rodičích, prohledá úplně všechny možnosti a pokud hledanému slotu odpovídá více možností, vyhodí chybu. Jediná validní možnost, jak překrýt definici nějakého rodičovského slotu, je udělat to v rámci vlastních slotů objektu, nemůžete k tomu použít jiného rodiče.Aha, rozumim. To připomíná řešení ambiguit v multiple inheritance kde např. jazyky jako C++ taky vyhazují chyby v podobných situacích, zatímco například v Go tohle přehlédli a jsou z toho pak problémy.
18.4.2019 01:51
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Uvažoval jsi o plném prohledávání tak, jak to dělá Self?Nedávno jsem to implementoval btw.
Jednou z naprosto klíčových funkcionalit Selfu, která mu dodává mnoho elegance, jenž například postrádá javascript, je delegace na rodičovské sloty.Chápu to správně, že ten rozdíl oproti JavaScriptu je v tom, že v JS může mít objekt pouze jednoho rodiče?
Object obsahuje kromě metodyChvíli mi dalo tuhle větu rozparsovat, jestli jsem to pochopil správně, chtělo by to čárku mezi 'slot' a 'také'..get_slot(), jenž pouze hledá v mapě patřičný slot také metody.parent_lookup()a.slot_lookup().
14.3.2019 10:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Chápu to správně, že ten rozdíl oproti JavaScriptu je v tom, že v JS může mít objekt pouze jednoho rodiče?Spíš že do javascriptu je to tak divně naprasené, že se to reálně stejně moc nepoužívá, kdežto v Selfu je to doslova základ a staví na tom prakticky každý objekt, včetně třeba právě implementace lokálního scope. Podle mě to není jen kulturou, ale i podporou v syntaxi. Ono obecně, prototypy v javascriptu tě tlačí k tomu přát si aby to byl class based systém. Prototypy v Selfu oproti tomu působí přirozeně a konzistentně.
Chvíli mi dalo tuhle větu rozparsovat, jestli jsem to pochopil správně, chtělo by to čárku mezi 'slot' a 'také'.Máš pravdu, opravím to.
Spíš že do javascriptu je to tak divně naprasené, že se to reálně stejně moc nepoužívá, kdežto v Selfu je to doslova základ a staví na tom prakticky každý objekt, včetně třeba právě implementace lokálního scope. Podle mě to není jen kulturou, ale i podporou v syntaxi. Ono obecně, prototypy v javascriptu tě tlačí k tomu přát si aby to byl class based systém. Prototypy v Selfu oproti tomu působí přirozeně a konzistentně.Afaik v JS je to dané mimo jiné také optimalizacemi, viz tady a tady.
 14.3.2019 11:14
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
14.3.2019 11:14
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
 14.3.2019 11:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.3.2019 11:58
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
14.3.2019 13:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.3.2019 11:26
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
14.3.2019 11:58
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
14.3.2019 13:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
[hidden] u šipek, kde můžeš konečně silou donutit layout vykreslit se jak chceš. To mi dřív vždycky trvalo hrozně dlouho.
Začal jsem na to teď psát takový python wrapper, kde jen skládáš třídy do sebe a pak ti z toho krásně vypadne UML graf, ale zatím je to jen takové experimentování. Je to ale super právě na vizualizace třeba těch scope chainů.
BTW: když je řeč o diagramech, znáte někdo Adaptagramy a Dunnart? Přijde mi to jako (takřka) ideální kompromis mezi ručním kreslením grafu a automatickým generováním z nějakého předpisu – základem je vlastně předpis podle kterého lze vygenerovat graf, ale člověk k tomu může přidat různá omezení, jako tenhle uzel má být přesně tady nebo mezi těmito uzly mají být stejné mezery nebo tyhle uzly mají být na vodorovné přímce.
14.3.2019 11:59
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
 15.3.2019 09:56
xkucf03 | skóre: 50
| blog: xkucf03
15.3.2019 09:56
xkucf03 | skóre: 50
| blog: xkucf03
Funguje tam přetěžování 1 metod? Když je to implementované jako slovník, tak asi ne. Nebo je klíčem něco jiného než název metody?
Jak se to bude chovat v případě, že zavolám metodu na neexistujícím objektu (None)? Vyletí něco jako NullPointerException nebo to budeš řešit nějakým lepším způsobem? Když jsem nad tím někdy přemýšlel – tedy v kontextu třídní dědičnosti – tak jsem si říkal, že by třída mohla definovat výchozí chování metod pro případ, že je zavoláš na null objektu. Pak by šlo implementovat chování třeba tak, že když se pokusíš iterovat přes chybějící (null) seznam, chovalo by se to stejně, jako kdybys iteroval přes prázdný seznam. U té prototypové dědičnosti víš, jakého typu mělo být None, nebo ne?
[1] více metod se stejným názvem a různými parametry (ne překrývání)
15.3.2019 10:25
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Funguje tam přetěžování 1 metod? Když je to implementované jako slovník, tak asi ne. Nebo je klíčem něco jiného než název metody?Ono je to hlavně dynamicky typované, takže víc metod se stejnými názvy nedává smysl, nemáš je podle čeho rozlišit. Metody tam navíc nejsou, jsou to zprávy a počítá se pouze název zprávy.
Jak se to bude chovat v případě, že zavolám metodu na neexistujícím objektu (None)?Přemýšlím jak by k tomu mohlo dojít a nic mě nenapadá. Nic jako neexistující objekt tam není. Interně se
None sice používá, ale to je na úrovni implementace, ne na úrovni něčeho k čemu bys mohl přistupovat z tinySelfu samotného. Je tam nil, ale to je prostě jen singleton normálního objektu, takže se na to reaguje jako když pošleš zprávu libovolnému jinému objektu (momentálně to mám nastavené tak že to spadne a vypíše debug, ale správně by to mělo fungovat tak že se dá objektu šance reagovat (vyhledání metody pro dynamický resolve) a pokud se nenajde, zavolá error handler).
Pak by šlo implementovat chování třeba tak, že když se pokusíš iterovat přes chybějící (null) seznam, chovalo by se to stejně, jako kdybys iteroval přes prázdný seznam.Tam nikdy nic jako null seznam nebude.
15.3.2019 11:35
xkucf03 | skóre: 50
| blog: xkucf03
momentálně to mám nastavené tak že to spadne a vypíše debugCož je vlastně ten
NullPointerException.
ale správně by to mělo fungovat tak že se dá objektu šance reagovat (vyhledání metody pro dynamický resolve) a pokud se nenajde, zavolá error handler).To už odpovídá tomu mému nápadu. Akorát u té třídní dědičnosti je výhoda v tom, že víš, jakého typu ten
null měl být, takže víš, ve které třídě hledat. V dynamickém systému tahle informace chybí, takže to asi spadne do nějakého obecného objektu, předka všech předků, a v něm se to nějak genericky zpracuje. Šlo by z toho vytáhnout aspoň ten kontext/objekt, ve kterém se ten chybějící slot nacházel?
Tam nikdy nic jako null seznam nebude.Jak se to tedy bude chovat v případě, že na nějakém místě očekávám seznam, ale on tam není a místo toho to ukazuje na
nil objekt? To je přece v principu stejné, jako kdybych měl proměnnou, ve které čekám ArrayList, ale bylo v ní null, ne?
15.3.2019 11:55
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To už odpovídá tomu mému nápadu. Akorát u té třídní dědičnosti je výhoda v tom, že víš, jakého typu ten null měl být, takže víš, ve které třídě hledat. V dynamickém systému tahle informace chybí, takže to asi spadne do nějakého obecného objektu, předka všech předků, a v něm se to nějak genericky zpracuje. Šlo by z toho vytáhnout aspoň ten kontext/objekt, ve kterém se ten chybějící slot nacházel?Momentálně je to jen ve fázi návrhu, takže jak si to udělám, takové to bude. Teď řeším hlavně rychlostní optimalizace, s tím že cílem je se dostat s milionem while cyklů pod jednu vteřinu (while cyklus v každé iteraci testuje a vytváří dynamickou lambda funkci), a ideálně pod 100ms. Jsem někde okolo tří vteřin bez jitu.
Jak se to tedy bude chovat v případě, že na nějakém místě očekávám seznam, ale on tam není a místo toho to ukazuje na nil objekt? To je přece v principu stejné, jako kdybych měl proměnnou, ve které čekám ArrayList, ale bylo v ní null, ne?Tak jako vždycky v ducktypovaných jazycích (třeba pythonu), padne to na tom že se objektu pošle zpráva které nerozumí. Momentálně by se to prostě ukončilo, ale to je čistě jen řešení ve stylu „v téhle fázi vývoje mě to nezajímá“. V budoucnosti v tu chvíli dojde k zavolání error handleru na dané úrovni stackframe, což pokud není změněno kódem, tak povede ke spuštění interaktivního debuggeru. Ten error handler už tam mám teď, akorát se prostě nevolá u chybějícího slotu, protože se mi teď nechtělo. Trochu koketuji s myšlenkou, že bych dovolil metodám definovat rozhraní parametrů a výstupní hodnoty, a přidal k tomu nějaké statické typování, ale není to v TODO, jen ve fázi „hm, to by nemuselo být špatné“. Funkcionalita momentálně z větší části klonuje Self.
Když jsem nad tím někdy přemýšlel – tedy v kontextu třídní dědičnosti – tak jsem si říkal, že by třída mohla definovat výchozí chování metod pro případ, že je zavoláš na null objektu. Pak by šlo implementovat chování třeba tak, že když se pokusíš iterovat přes chybějící (null) seznam, chovalo by se to stejně, jako kdybys iteroval přes prázdný seznam.
Tohle řeší funcionální a jimi ovlivněné jazyky typovým systémem a použitím ADTs.
Tady máš příklad v Rustu. (Ta metoda get_list() náhodně vrací "nic" nebo vektor čísel.)
Přijde mi to lepší mj. v tom, že to není závislé na objektech / dědičnosti a můžeš se rozhodnout, co dělat s prázdnou hodnotou, jak zrovna potřebuješ, není to zadrátováno v té třídě.
15.3.2019 13:42
xkucf03 | skóre: 50
| blog: xkucf03
Z hlediska zápisu a pohodlnosti se to:
let list = get_list().unwrap_or(vec![]);
ale moc neliší od:
list = list == null ? Collections.emptyList() : list;
(mimochodem v Javě někdy používám svoje notNull())
To Option.unwrap_or() tě akorát donutí se k té null hodnotě nějak postavit a nezapomenout na její ošetření. Ale tu práci a rozhodování musíš udělat tak jako tak. (a pokud nezapomínáš nebo ten kód testuješ, tak v tom opravdu moc velký rozdíl není)
Mně šlo spíš o to mít možnost, se téhle práce úplně zbavit, resp. přesunout to rozhodování někam jinam, aby nebylo rozeseté všude možně v kódu. Přišlo by mi fajn mít možnost na jednom místě definovat, jak se chovat k chybějícím hodnotám různých typů.
Přijde mi, že někdy by se to hodilo mít definované tohle výchozí chování na úrovni tříd. Na druhou stranu je pravda, že by to šlo řešit i tím, že null prostě nikde nebude a místo něj budeme mít jen nějaké singletony, které tam dáme místo něj a budou jednak symbolizovat, že jde o prázdnou hodnotu (akorát místo if(a == null) se bude psát if (a == Někde.nějaký.SINGLETON) nebo if (isMissingValue(a))).
Např. když budu mít atribut, který definuje nějaké filtrovací pravidlo, tak null by se interpretoval tak, že se nic filtrovat nemá a projde vše. Ale taky by šlo vynutit (např. nějakou anotací nebo klíčovým slovem), že ten atribut null nikdy nebude – a když v něm budu chtít mít prázdný filtr, tak tam dám singleton, který bude na všechno odpovídat true, tudíž projde vše.
Přišlo by mi fajn mít možnost na jednom místě definovat, jak se chovat k chybějícím hodnotám různých typů.To se dela pres monady. Option je monada, takze muzes skladat funkce co s ni vselijak pracuji aniz bys musel resit, jak presne se chova.
Přijde mi, že někdy by se to hodilo mít definované tohle výchozí chování na úrovni tříd.Tak v tom Rustu se tohle nestane, protože tam žádný
null není a každý objekt je vždy platný. Ten Option je jen obyčejný enum a None je jen varianta tohoto enumu, nemá žádný specielní význam pro kompilátor. Takže v zásadě ti nic nebrání si nadefinovat vlastní typ, který bude nějakým jiným způsobem reprezentovat prázdnou hodnotu, třeba pomocí Default, jako např. takhle, to by asi zhruba byl rustový ekvivalent toho, co chceš, ačkoli obecně se to nepoužívá, protože to není potřeba, viz dále...
Ale taky by šlo vynutit (např. nějakou anotací nebo klíčovým slovem), že ten atribut null nikdy nebudeAno, pokud vyloženě nemáš null-free jazyk, tak můžeš třeba udělat to, co dělá Kotlin. Náhradou "null" je pak konkrétní stav nějakého objektu, například u toho vektoru prostě vrátíš prázdný vektor a s null se nezabýváš, protože to nemá v té chvíli smysl - proč přidávat další možný stav objektu (
null) jen proto, abys ho následně natvrdo namapoval na již existující stav (prázdný vektor)?
15.3.2019 17:16
xkucf03 | skóre: 50
| blog: xkucf03
třeba pomocí Default, jako např. takhle, to by asi zhruba byl rustový ekvivalent toho, co chcešDík, vypadá to zajímavě.
15.3.2019 17:40
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Náhradou "null" je pak konkrétní stav nějakého objektu, například u toho vektoru prostě vrátíš prázdný vektor a s null se nezabýváš, protože to nemá v té chvíli smysl - proč přidávat další možný stav objektu (null) jen proto, abys ho následně natvrdo namapoval na již existující stav (prázdný vektor)?Jo, přesně.
null na sémanticky ekvivalentní instanci cílového typu by mohla být fajn. Mně osobně se hodně líbí nullable typy v C# (zjednodušeně: proměnná typu Foo? může být nastavena na null, proměnná typu Foo nikoliv). C# obecně je Java na steroidech, alespoň co se core jazyka týká.
Však Java má Optional, což je potom 1:1 jako ta ukázka z Rustu.Když zamhouřím oči tak jo. Když nezamhouřím, tak si budu stěžovat minimálně na to, že ten
Optional může sám být null, takže odpovídá spíš něčemu jako Option<Option<T>> ...
Mně osobně se hodně líbí nullable typy v C# (zjednodušeně: proměnná typuStejně to má i Kotlin, asi to převzali z C#...Foo?může být nastavena nanull, proměnná typuFoonikoliv). C# obecně je Java na steroidech, alespoň co se core jazyka týká.
Když zamhouřím oči tak jo. Když nezamhouřím, tak si budu stěžovat minimálně na to, že tenPravda, přehlédl jsem, že ty v tom Rustu vracíšOptionalmůže sám býtnull, takže odpovídá spíš něčemu jakoOption<Option<T>>...
None a ta konverze na Option proběhne implicitně. Nicméně já bych stav, kdy samotný Optional bude null, stejně neošetřoval, přijde mi to hloupé. IMHO nemá smysl psát každou metodu bullet-proof tak, aby nebylo možné ji rozbít. V ideálním případě by jazyk vůbec neumožnil tam ten null poslat, když to neumí, bude to padat za běhu a ne v čase kompilace. To statické typování v Javě holt má svoje problémy.
Pravda, přehlédl jsem, že ty v tom Rustu vracíšNo, ona to není konverze.Nonea ta konverze naOptionproběhne implicitně.
None je jedna z variant enumu Option, tj. reálně ta funkce vrací Option::None. V Rustu může člověk importovat do scope nejen ten enum (tj. typ), ale i jeho varianty. A ten Option jakož i jeho varianty jsou by-default importovány, prostě protože se to používá často. Proto je možný prostě vrátit None.
Nicméně já bych stav, kdy samotnýJo, s tim souhlasim, je to trochu hnidopišská připomínka. Afaik mají v plánu to fixnout přidáním podpory value types, ale nevim, jak je to daleko...Optionalbudenull, stejně neošetřoval, přijde mi to hloupé. IMHO nemá smysl psát každou metodu bullet-proof tak, aby nebylo možné ji rozbít. V ideálním případě by jazyk vůbec neumožnil tam tennullposlat, když to neumí, bude to padat za běhu a ne v čase kompilace.
15.3.2019 20:19
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
18.3.2019 10:29
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
__getattr__().
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz