Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.

 . Nejprve začnu tím, jak to bylo uděláno předtím (ve zkratce: hloupě) a pak popíšu, jak je to uděláno teď s využitím jedné pěkné datové struktury.
. Nejprve začnu tím, jak to bylo uděláno předtím (ve zkratce: hloupě) a pak popíšu, jak je to uděláno teď s využitím jedné pěkné datové struktury.
Oproti tomu nové řešení je strašně super. Celé je postavené na upravené datové struktuře Trie přidávající hashování. O tom, jak funguje trie psát nebudu, kdo to neví, ať to přečte. Standardní trii jsem se ale rozhodl trošičku optimalizovat, a to použitím hash tabulky pro první rozdílné písmeno za prefixem. V praxi rozdíl nebude, protože se zpracovává málo dat, ale chtěl jsem si to vyzkoušet . Hlavně pokud by to mělo k něčemu být při zpracování většího množství dat, tak by se hash tabulka musela používat pro větší část prefixu (třeba tři písmena), protože projít abecedu je mžik. Každopádně už to tak je a funguje to.
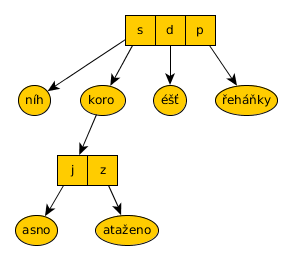
Pro lepší ilustraci obrázek, co vznikne vložením „sníh“, „skoro jasno“, „skoro zataženo“, „déšť“ a „přeháňky“ do této datové struktury. První je na řadě hash tabulka pro počáteční písmena prefixů „s“, „d“, „p“. Protože déšť a přeháňky nemají společný prefix, jsou uloženy (kromě prvního písmena) do samostatných uzlů do kterých ukazuje záznam pro „d“, resp. „p“ z hash tabulky. Zajímavé jsou ale „skoro jasno“ a „skoro zataženo“. Protože se liší prvním písmenem za „skoro “, tak se vytvoří nová hash tabulka, která ukazuje na další část slova.
Co se týče použití v praxi, tak došlo k následujícím změnám – veškerý starý kód parseru jsem vyhodil, a:
Díky těmto změnám je teď snadné podporovat víceslovná spojení a navíc došlo k výraznému zrychlení. IIRC parser zabral ca dvě třetiny času zpracování předpovědi, teď to je tuším někde kolem 2%.

Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 26.6.2014 17:45
Rezza | skóre: 25
| blog: rezza
| Brno
26.6.2014 19:57
Rezza | skóre: 25
| blog: rezza
| Brno
26.6.2014 17:45
Rezza | skóre: 25
| blog: rezza
| Brno
26.6.2014 19:57
Rezza | skóre: 25
| blog: rezza
| Brno
 26.6.2014 21:57
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 22:34
Rezza | skóre: 25
| blog: rezza
| Brno
28.6.2014 11:25
Rezza | skóre: 25
| blog: rezza
| Brno
28.6.2014 13:40
stativ | skóre: 54
| blog: SlaNé roury
28.6.2014 16:55
Rezza | skóre: 25
| blog: rezza
| Brno
28.6.2014 20:32
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 21:19
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 21:36
stativ | skóre: 54
| blog: SlaNé roury
30.6.2014 21:20
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 20:58
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 21:57
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 22:34
Rezza | skóre: 25
| blog: rezza
| Brno
28.6.2014 11:25
Rezza | skóre: 25
| blog: rezza
| Brno
28.6.2014 13:40
stativ | skóre: 54
| blog: SlaNé roury
28.6.2014 16:55
Rezza | skóre: 25
| blog: rezza
| Brno
28.6.2014 20:32
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 21:19
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 21:36
stativ | skóre: 54
| blog: SlaNé roury
30.6.2014 21:20
stativ | skóre: 54
| blog: SlaNé roury
26.6.2014 20:58
stativ | skóre: 54
| blog: SlaNé roury
V tomhle případě byl význam si vyzkoušet, jestli to jde.
Teď k mojí teorii, která tedy má smysl až když se udělá hash na delší část textu. Předpokládám, že hashováním na několika písmenech se hledání rychle posune do nižší úrovně bez nutnosti přímo porovnávat různé prefixy. Důsledkem by vlastně bylo i snížení hloubky stromu. Př.: když by se vkládalo „něco“, „někdo“ a „foo“ a hash se dělal ze tří písmen, tak by si člověk odpustil porovnávání s „ně“ a s „foo“ ale v tomhle případě by se rovnou skočilo na výsledek. Podle mého názoru (nemám to nijak matematicky podložené*) by to tedy mělo výhodu v podstatě O(1) vyhledávání jako v hash tabulce, ale s tím, že by bylo menší množství kolizí při potřebě několika krátkých tabulek.
Tady asi čtenáře napadne, proč jsem vlastně nepoužil rovnou hash tabulku. Důvod je takový, že by musela být poměrně rozsáhlá aby zachytila všechny možné tvary slov. Tak, jak to mám implementováno teď, se do trie často vkládá jen část slova (třeba „sněh“) přičemž se vrací výsledek už když ten začátek pasuje (tedy pokud nepasuje nějaký delší prefix), tj. postihne to slova jako „sněhem“, „sněhové“ atd. což už by se s hash tabulkou dělalo asi docela špatně.
PS: nevykat 
* píšu si do TODO, protože by mě to samotného zajímalo
26.6.2014 22:57
stativ | skóre: 54
| blog: SlaNé roury
30.6.2014 12:18
stativ | skóre: 54
| blog: SlaNé roury
27.6.2014 22:50
stativ | skóre: 54
| blog: SlaNé roury
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 27.6.2014 11:56
27.6.2014 11:56