Byly zveřejněny informace o kritické zranitelnosti CVE-2026-64600 pojmenované RefluXFS (technické detaily) v XFS. Je tam již od verze Linuxu 4.11, tj. rok 2017. Jedná se o lokální eskalaci práv. Neprivilegovaný uživatel může editovat libovolný soubor, například klidně zrušit rootovské heslo v /etc/passwd. Videoukázka na Vimeo. V upstreamu je zranitelnost opravena.
OpenAI / ChatGPT má dnes výpadky (OpenAI Status, DownDetector).
Poskytovatel hostingu svobodných/open-source projektů Codeberg po hlasování na valné hromadě vydal stanovisko k využívání LLM. Kvůli vytěžování infrastruktury a rostoucím cenám hardwaru, ale také hrozbám pro spolupráci v komunitě se k LLM staví kriticky. Nebude poskytovat hosting projektů vytvářených LLM agenty.
Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
Tento blog obsahuje nebezpečnou symboliku.

20.8.2019 12:02
| Přečteno: 5704×
|  | poslední úprava: 20.8.2019 13:03
| poslední úprava: 20.8.2019 13:03
xargs nebo parallel pro spuštění jednoho programu nad hromadou souborů. Nebo použití pipe. Pomocí jednoduchých skriptů můžeme oba přístupy snadno kombinovat, pokud to charakter dat a jejich zpracování dovolí.
Co se týče podpory multiprocesing (nebo multithreading, budu to volně zaměňovat) přímo v programovacích jazycích, tady je situace horší. Ano, v klasickém C máme fork() s tím, že si všechno (výměnu dat mezi procesy, zámky apod musíme pohlídat sami). Některé jazyky (Python) jsou vyloženě singlethread. Ne, že by nešlo programovat ve více vláknech, ale v základu všechno dost komplikuje GIL (global interpreter lock). Existují snadno použitelné knihovny, které to různými způsoby obcházejí (Multiprocessing). V Golangu máme gorutiny a kanály. V Rustu máme threads a message passing. Ale je tohle opravdu způsob, jak snadno napsat program pro 256 jader?
O co mi jde a tak trochu zopakuju jeden ne moc povedený dotaz, který jsem měl nedávno pod nějakým blogem. Proč neexistuje jazyk, který by multiprocesing řešit sám bez zásahu programátora? Když uvedu příklad z pythonu, tak v pythonu máme list comprehension, což je udělátko, které na vstupní seznam aplikuje nějakou fci a výstupem je opět seznam:
output = [f(item) for item in input]Problém je, že jak celý vstupní, tak celý výstupní seznam se musí vejít do paměti. Tenhle problém se řeší pomocí generátorů a od toho máme generator comprehension:
output = (f(item) for item in input)Pokud máte pocit, že to až na použité závorky vypadá úplně stejně, je to tak. Drtivou většinu list comprehension lze přepsat na generator comprehension a všechno bude fungovat. Výhodou generátorů je to, že jsou lazy, že další prvek vygenerují až je potřeba, na rozdíl od listu, který je kompletní. To znamená, že pomocí generátorů můžeme generovat nekonečné seznamy a taky můžeme jako prvky používat objemná data (já to takto používám pro obrázky, jejichž celkový objem je výrazně větší než dostupná paměť a přes to s nimi můžu pracovat jako s jedním seznamem). Zpět k tématu. Python poskytuje snadno použitelnou knihovnu (Multiprocessing.Pool) pro zpracování dat ve více procesech. Použití triviální:
output = Pool().map(f, input)Toto nám vyrobí seznam stejně jako list comprehension, ale využije k tomu automaticky všechny dostupné procesory. Což je moc fajn, pokud se nám vstupní a výstupní data vlezou do paměti. Je to rychlé, snadné na použití a efektivní. Bohužel neexistuje nic jako Pool generátor. Tj že by pro výrobu další prvků používat více procesů, ale nevygeneroval by celý výstupní seznam naráz. Držel by si několik předzpracovaných prvků k okamžitému výdeji. Ano, toto si lze napsat pomocí jiných prostředků a mít tak frontu požadavků ke zpracování a ty zpracovávat paralelně (což ve skutečnosti mám, ale nepovažuju to za řešení ale spíš jako workaround). Co by se mi líbilo by byl automaticky paralelní generator comprehension. Nebo ještě lépe, jazyk, který od programátora vůbec nevyžaduje hint ve stylu "tady bude další thread" (tak jako třeba Golang i Rust vyžadují o C ani nemluvě). Prostě jazyk, který by sám dokázal generovat nezávislé úlohy a jejich závislosti, tak jak se třeba píšou pravidla pro Make (popis, jak vyrobit nějakou část dat a popis závislostí jednotlivých podúloh), dával si je do fronty a toto exekuoval na všech dostupných procesorech. Je něco takového na obzoru? Vím, že existují speciální jazyky jako ERlang, ale v těch jsem nikdy nic "pořádného" napsaného neviděl. Ano, používá se s výhodou tam, kde je potřeba řídit komunikaci many to many (tj ejabberd nebo rabbitmq) a ty nic nepočítají a erlang se tam používá spíš jen pro výměnu zpráv mezi jednotlivými interními thready (kterých mohou být snadno miliony) a nikoliv pro paralelní výpočet čehokoliv.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 20.8.2019 12:49
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
20.8.2019 12:49
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 20.8.2019 13:01
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
20.8.2019 13:01
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
Když uvedu příklad z pythonu, tak v pythonu máme list comprehension, což je udělátko, které na vstupní seznam aplikuje nějakou fci a výstupem je opět seznam:Nemáš to naopak?output = (f(item) for item in input)Problém je, že jak celý vstupní, tak celý výstupní seznam se musí vejít do paměti. Tenhle problém se řeší pomocí generátorů a od toho máme generator comprehension:output = [f(item) for item in input]
LongStream
.range(1000000L, 1000000000000000000L)
.parallel()
.filter(num -> isMersennePrime(num))
.findFirst();
Kod hleda prvni Mersennovo prvocislo nad 1 milion. Streamy jsou lazy, takze .range() postupne krmi retezec ostatnich metod, coz zaruci, ze se cely proces for nalezeni prvniho hned zastavi.
Volani .parallel() automaticky distribuuje praci do thread poolu, ktery ma pocet threadu stejny jako pocet jader. Single thread varianta je uplne stejna, jen vynechame to .parallel(). Duvod proc tohle musi byt explicitni je, ze koordinace threadu atp. ma znacny overhead a vyplati se jen od urciteho mnozstvi prace (coz musi usoudit programator).
Tohle reseni neni idealni, momentalne proto ze vsechny takove paralelni streamy pouzivaji stejny thread pool, ale ukazuje to jednu moznou cestu.
20.8.2019 13:23
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
let result = (1000000u64 .. 1000000000000000000u64)
.into_par_iter()
.find_first(|num| is_mersenne_prime(*num));
 20.8.2019 19:50
Josef Kufner | skóre: 70
20.8.2019 19:50
Josef Kufner | skóre: 70
Smula je, ze az na nejake trivialni skolni priklady nejaky ten stav menit obvykle chces.To si uplne nemyslim, ze vsechny ty nabusene hadoop clustery se pouzivaji jen na skolni priklady
 20.8.2019 16:01
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
20.8.2019 16:01
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
jak tady psal uzivatel Cal, tak specielne pro mne knihovny na Javu jsou a uz hodne davnoTakže tu budoucnosti vidíte (množné číslo) jen v nových knihovnách? Jazyk ani paradigma podle vás není potřeba?
Ac nemam rad lambda vyrazy, tak jsem je zacal diky paraelizaci vice respektovat.Mě funkcionální programování postihlo jen během studia a to setkání bylo takové zvláštní. Jednak se říkalo, že je to velmi snadno paralelizovatelné, protože funkce nemají žádné vedlejší efekty (což skutečně nemají) ale žádný interpret (tehdy scheme) nikdy nebyl multithreading. Já proti funkcionálnímu paradigmatu nic nemám, ale chtěl bych někdy vidět všechny jeho výhody v plné palbě včetně toho masivního paralelismu. Lamba funkce se v nefunc jazycích používají spíše jen jako syntaxe pro anonymní funkce. (Typicky, chcete předat něco filteru nebo mapu a nechcete dělat pojmenovanou fci, tak to napíšete jako lambdu.)
Asi bych se nebranil nejakym anotacim, ktere by nejak rozdelovaly kod (fork, join) operace a byla by tam pak nejaka paraelizace automaticky. Treba na urovni for, while cyklu..... Asi se spatne vyjadruji.Jo, tomu rozumím a to jsem navrhoval už v předchozí diskusi. Mít v první fázi alespoň možnost udělat hint "tohle můžeš paralelizovat". V druhé fázi už by to měl jazyk poznat sám.
propustnost pameti. Kdo ma 32-core od AMD a neni to EPYC, tak vi o cem je recJo. Možná dojde k tomu, že ryzen zůstane optimalizován spíš pro hry a epyc pro servery a workstation. Ty 32 core ryzeny jsou takové zvláštní.
hodne bych se zamyslel nad tim, kolik uloh je mozne paraelizovat pro treba 15 a vice jader ?? Ono uz toho tolik neni a dostavame se k specializovanym aplikacimProto si myslím, že musí dojít ke změně paradigmatu. Dneska se afaik až na nějaké speciality stále programuje tak, že se přímo určuje kde se to má forknout a co v tom vlákně má běžet. Tj se ručně alokuje určitá činnost do určitého vlákna. Proto jsem uvedl ty příklady, kde to prog vůbec neřeší.
20.8.2019 16:22
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Kdyz jsme se bavili s Milou Ponkracem, tak rekl jednu peknou vec a to, ze paraelizaci bude casem sam resit kompilatorAno, to jsem poprvé slyšel možná taky už před dvaceti lety. Osobně bych na to příliš nesázel.
21.8.2019 08:29
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Řešení paralelizace kompilátorem je jediné možné skutečné řešení. Takové řešení byly a jsou, jen nikoli v mainstreamových jazycích.Si fakt nejsem jist, zda je kompilátor to správné místo. Podpora ze strany jazyka tam být musí, ale podle mě by se na tohle mnohem víc hodil JIT a nějaké běhové prostředí. A spolupráce s OS.
Hardware a elektronika jede raketově dopředu.Opravdu? Tenhle pocit fakt nemám. Frekvence CPU už hodně dlouho neroste. Rychlost výpočtů se řeší jinými způsoby. Jedno jádro dostává více ALU ke stejné sadě registrů, takže může vykonávat více nezávislých instrukcí současně. Totéž s FPU. Většina instrukcí už je ale 1T a nelze donekonečna měnit jejich pořadí. Proto se do CPU přidávají akcelerátory na všechno. Když už ani to nepomáhá, tak se udělá "inteligentní" cache (což potom vede k bezpečnostním problémům viz všechny problémy Intelu za poslední roky). Fakticky jedinou možností jak zrychlovat výkon CPU je vícejadernost. Jenže to opravdu za raketový pokrok nepovažuju. Nehledě na naprostou nesmyslnost držení zpětné kompatibility až někam k ATčku. Tím máme v CPU módy, které tam nemají co dělat a přinášejí další bezpečnostní problémy. Já očekávám koncepční změnu v tom, že místo CPU (central) bude DPU (distributed). Tj ze místo toho, aby se veškeré výpočty dělaly na jednom místě, tak např paměť dostane vlastní jednoduchý procesor, který bude umět dělat základní tranformace dat (přičti vzor, odečti vzor, xor apod) přímo na modulu, místo toho, aby se, jako dnes, každá stránka paměti posílala do CPU a zpět jen k vůli triviální transformaci. Totéž disk. Disk by mohl více spolupracovat s FS a místo neustálého posílání bloků tak a zpět by disk uměl sám udělat základní blokové operace (nebo proudové).
21.8.2019 11:16
Josef Kufner | skóre: 70
[…] např paměť dostane vlastní jednoduchý procesor […]Ten už tam je. Jmenuje se řadič DMA. I když tedy těch transformací umí jen pár.
 21.8.2019 12:09
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.8.2019 17:32
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.8.2019 12:09
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.8.2019 17:32
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 21.8.2019 19:17
Gilhad | skóre: 20
| blog: gilhadoviny
21.8.2019 19:43
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.8.2019 19:17
Gilhad | skóre: 20
| blog: gilhadoviny
21.8.2019 19:43
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
s hrotovyma diodamaJenže ani dioda by bez kvantovky nevznikla. Je pravda, že jistý pan Schottky (ano, ten, po kterém je pojmenován jeden z druhů polovodičových diod) (a doufám, že si to jméno nepletu s jiným známým) na to přišel intuicí, ale obecně jiné druhy diod vznikly aplikací kvantové mechaniky a materiálové fyziky. Taky je zajímavé, že hned na počátku vznikly oba hlavní druhy tranzistoru (řízený polem a bipolární). Tuším, že nejdřív to vypadalo na velký úspěch pro FET, ale velice rychle převzal štafetu BJT až opět došlo na FET (mluvím zejména o použití pro výpočetní techniku).
Cili, ze to byl objev typu, kdy newtonovi spadlo jabko na hlavuTohle je pohádka. Newtonova gravitace nevznikla jednou událostí někde v sadu, i před Newtonem se zkoumal pohyb a hledal se pro to matematický aparát. A v podstatě to šlo přidáváním dalších derivací (i když to tak ti lidé nenazývali). Nejprve (tisíc let před letopočtem) se někteří lidé domnívali, že každý předmět má svoji určenou polohu do které se prostě dopraví (nějak). Potom si někdo všiml, že se ale předměty přece jen pohybují a snažil se najít popis pro ten pohyb. První derivace dráhy je rychlost. A tuším že už někdo před Newtonem do toho strčil další derivaci, tedy zrychlení. A Newton to potom uhladil a uvědomil si, že by takto šlo popisovat i pohyb planet. Tehdy byly už velmi dobře měřené dráhy planet, byla známa Keplerovská elipsa a Newton to z toho prostě odvodil. Takže, práce jak na kostele, vymyslel si k tomu matematický aparát, který posunul jak matematiku, tak fyziku, ale rozhodně to nevymyslel celé sám na zelené louce. Každý objev stojí na objevech předchozích a kdyby to nevymyslel on, tak to vymyslel někdo jinej (třeba takovou speciální relativitu ve skutečnosti ještě přes Einsteinem napsal Poincaré a určitě i Lorentz, ale teprve šutr tomu dal správnou fyzikální interpretaci a našel správný invariant (rychlost světla)). Fakt to nejsou samostatně stojící jednotky. Bohužel, výuka ve školách má tendenci spíše vypichovat osobnosti a nikoliv metody, jak se k nějakému objevu došlo.
21.8.2019 19:53
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 21.8.2019 21:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
21.8.2019 21:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jenže ani dioda by bez kvantovky nevznikla. Je pravda, že jistý pan Schottky (ano, ten, po kterém je pojmenován jeden z druhů polovodičových diod) (a doufám, že si to jméno nepletu s jiným známým) na to přišel intuicí, ale obecně jiné druhy diod vznikly aplikací kvantové mechaniky a materiálové fyziky.Elektronkové diody se používaly před tím a podle wikipedie byl ten objev asymetického toku proudu detekován Ferdinandem Braunem v roce 1874.
21.8.2019 21:20
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Elektronkové diodyJistě, nikdo netvrdí, že ne. Řeč byla o polovodičích.
objev asymetického tokuNo a co tím chceš říct? Ano, polovodivost některých materiálů byla známá i před tím, stejně jako třeba i závislost na osvětlení. Ale cíleně to vyrobit a vědět proč a jak je zcela jiná disciplína. Stejně jako magnetismus byl znám a využíván hodně dlouho před Ampérem a Maxwellem, kteří tomu dali tu první správnou interpretaci.
že hned na počátku vznikly oba hlavní druhy tranzistoruNám to na škole říkali tak, že FET byl teoreticky známý před BJT, ale protože nešlo vyrobit dost čistý křemík bez vad mřížky, tak první reálná součástka vznikla až po BJT... První funkční teda - FET se zabudovaným kanálem, který nejde vypnout, je dost k ničemu.
21.8.2019 21:55
Josef Kufner | skóre: 70
Opravdu? Tenhle pocit fakt nemám. Frekvence CPU už hodně dlouho neroste. Rychlost výpočtů se řeší jinými způsoby. Jedno jádro dostává více ALU ke stejné sadě registrů, takže může vykonávat více nezávislých instrukcí současně. Totéž s FPU. Většina instrukcí už je ale 1T a nelze donekonečna měnit jejich pořadí. Proto se do CPU přidávají akcelerátory na všechno. Když už ani to nepomáhá, tak se udělá "inteligentní" cache (což potom vede k bezpečnostním problémům viz všechny problémy Intelu za poslední roky). Fakticky jedinou možností jak zrychlovat výkon CPU je vícejadernost. Jenže to opravdu za raketový pokrok nepovažuju.Za prvé já mluvil o elektronice a hw, ne pouze o procesoru. Za druhé frekvence ani zdaleka není jediné co byste měl sledovat, když hodnotíte pokrok. Za třetí procesory udělaly snad úplně všechno, co je možné k maximálnímu single thread výkonu. Další zvyšování single thread výkonu půjde jen po troškách. Výrazné zvýšení výkonu už je možné jen paralelizací. Jenže na to dnešní programátoři a programovací jazyky nejsou jaksi připraveni moc dobře. ---
Nehledě na naprostou nesmyslnost držení zpětné kompatibility až někam k ATčku. Tím máme v CPU módy, které tam nemají co dělat a přinášejí další bezpečnostní problémy.O tom přesně mluvím. Současné operační systémy (zejména unix), současné mainstreamové programovací jazyky a současný PC standard - vyžadují aby hw emuloval mnoho věcí, které jsou zbytečné. ---
Já očekávám koncepční změnu v tom, že místo CPU (central) bude DPU (distributed). Tj ze místo toho, aby se veškeré výpočty dělaly na jednom místě, tak např paměť dostane vlastní jednoduchý procesor, který bude umět dělat základní tranformace dat (přičti vzor, odečti vzor, xor apod) přímo na modulu, místo toho, aby se, jako dnes, každá stránka paměti posílala do CPU a zpět jen k vůli triviální transformaci.To už tu v minulosti bylo a neosvědčilo se to. Například Amiga se až neskutečně podobala tomu, co očekáváte. Dále to naráží na to, že se sw firmy i programátoři zvysoka vykašlou na to psát pro různé architektury různé verze programů. Zde chybí hlavně ten programovací jazyk, který by tu paralelizaci podporoval. Bez toho se celý hw/sw nepohne dál, a bude to celé viset na single thread výkonu. ---
Totéž disk. Disk by mohl více spolupracovat s FS a místo neustálého posílání bloků tak a zpět by disk uměl sám udělat základní blokové operace (nebo proudové).Jenomže mu vadí třeba unix. Unix, který disk považuje za blokové zařízení, a file system chce řešit nezávisle na ovladači blokového zařízení. V tomto asi nejvíce překáží nedomyšlenost unixu.
 23.8.2019 13:16
xkucf03 | skóre: 50
| blog: xkucf03
23.8.2019 13:16
xkucf03 | skóre: 50
| blog: xkucf03
Jenomže mu vadí třeba unix. Unix, který disk považuje za blokové zařízení, a file system chce řešit nezávisle na ovladači blokového zařízení. V tomto asi nejvíce překáží nedomyšlenost unixu.
Ona je to zároveň silná vlastnost, protože díky těmto abstrakcím je možné vyměňovat a kombinovat různé vrstvy nezávisle na sobě, aniž by autoři těchto vrstev museli vědět, co bude pod nimi a nad nimi v době použití. Jestli si uživatel ty vrstvy nakombinuje vhodně nebo nevhodně, to už je na něm. Ale ten návrh právě dost promyšlený a flexibilní je.
Jasně, že když se vše zadrátuje napevno a na přímo propojí, tak se tím ušetří nějaký výkon, ale má to zase jiné nevýhody.
23.8.2019 13:38
Josef Kufner | skóre: 70
23.8.2019 13:03
xkucf03 | skóre: 50
| blog: xkucf03
Si fakt nejsem jist, zda je kompilátor to správné místo. Podpora ze strany jazyka tam být musí, ale podle mě by se na tohle mnohem víc hodil JIT a nějaké běhové prostředí.
To hledání té optimální cesty může být dost náročné a bude vyžadovat dostatečný vzorek dat. Může se to dít v rámci JITu, ale tu pracně nalezenou optimální cestu pak nechceš při ukončení programu zahodit. Takže by tam měla být možnost si ten stav uložit a příště ho už jen načíst. Ve výsledku to pak bude vypadat tak, že program nakrmíš vzorovými daty a necháš ho zahřívat – tomu se pak dá říkat „kompilace“ nebo to poběží těsně po klasické kompilaci v rámci vydání nové verze softwaru.
V podstatě to navazuje na myšlenku PGO (Profile-guided optimization), které je třeba v GraalVM.
ale žádný interpret (tehdy scheme) nikdy nebyl multithreading.Jak to ze nebyl? A co Schemik?!!! ;-] Asi to zkusim trochu oprasit a podivam se, jak to pojede na soudobem zeleze. ;-]
 ),
). Spry je aktuálně neparalelní, avšak s nenulovým potenciálem pro implicitní paralelismus trochu inspirovaný např. Dask pro Python.
Nějaké myšlenky jsou např. v https://github.com/daokoder/dao/issues/524#issuecomment-497068976 a https://github.com/daokoder/dao/issues/524#issuecomment-500064368.
20.8.2019 16:04
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.8.2019 16:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
),
). Spry je aktuálně neparalelní, avšak s nenulovým potenciálem pro implicitní paralelismus trochu inspirovaný např. Dask pro Python.
Nějaké myšlenky jsou např. v https://github.com/daokoder/dao/issues/524#issuecomment-497068976 a https://github.com/daokoder/dao/issues/524#issuecomment-500064368.
20.8.2019 16:04
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
21.8.2019 16:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Jinak ještě malá hračka Spry pro Smalltalkisty (ano, myslím mj. i na Tebe BystroushaakuCool :) Spry jsem kdysi viděl, ale nějak mi na dlouho zmizelo z obzoru. Když si to tak teď čtu, tak se to hodně blíží tomu na co cílím s tinySelfem.
21.8.2019 18:28
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Umí tohle "provádění výpočtu neustálým hraním si s evaluací AST" i tinySelf (nedíval jsem se do zdrojáku ani nečetl dokumentaci, ale tinySelf nevypadá homoikonicitně, a tak očekávám spíše horší podporu pro "hraní si s AST")?V tinySelfu si momentálně s AST hrát moc nemůžeš, ale už jsem se nad tím zamýšlel a časem nejspíš zkusím nějaké experimenty. Jde si hrát s reprezentací objektů v paměti skrz mirrory, což tuhle vlastnost z malé části nahrazuje (můžeš měnit sloty a parenty a objekty, ale nemůžeš zatím měnit kód). Homoikonicita tam není, ale opět, rád bych se časem dostal na úroveň, kdy tam pro ní bude částečná podpora. Rebol mě částečně inspiroval v té myšlence "jazyka pro data", kde určitě jedna z vlastností, které chci je mít možnost vyplivnout objekty reprezentující nějakou informaci zpět do zdrojáku, který poté bude přenositelný na další počítače. Celkově, tinySelf se pomalu blíží teprve prvnímu beta vydání a momentálně spíš odlaďuji bugy a přidávám podporu základních věcí do stdlibu, než že bych se věnoval složitějším věcem.
Obávám se, že každý mluvíme o něčem jiném. Neměl jsem na mysli rozdělování na samostatné jednotky, které lze spustit paralelně, tam jazyk a překladač určitě mohou odvést hodně práce, ale v tom problém není. Pokud ty thready potřebují přistupovat ke společným datům, pak se už u desítek procesorů snadno dostaneme do situace, kdy je režie klasického zamykání neúnosně velká, takže obvyklé metody, které bez problémů zvládaly 4-8 threadů, prostě neškálují. Před pár lety jsem třeba dělal microbenchmark IPv6 routing lookupu v jádře 3.12 a už při ~60 paralelních threadech byl výsledek některých testů horší než kdyby ty dotazy byly serializované.
Opravdu dost těžko si dokážu představit, že by jazyk a překladač byly schopny řešit, kde není problém se spinlockem nebo atomickým counterem, kde se dá použít RCU, kde třeba per-CPU datové struktury a kdy je to prostě potřeba celé navrhnout od základu jinak. Spíš bych řekl, že prostor pro "paralelní jazyky" bude spíš tam, kde je na jedné misce vah cena za vývojáře a na druhé cena za hardware a elektřinu, ne tam, kde je potřeba jít s výkonem opravdu "na krev".

Upřímně řečeno, je to několik dní, co jsem zrušil můj závazek nepsal na abclinuxu.cz. A už přemýšlím, že to byla chyba.Tak ještě než odejdeš, tak bys možná mohl konečně odpovědět v té vedlejší diskusi, které že platformy nemají
uint16_t . Čekám už nějakou dobu, že se dozvím třeba něco novýho / zajímavýho o platformních specifikách C/C++.
23.8.2019 13:42
xkucf03 | skóre: 50
| blog: xkucf03
Jazyky s podporou paralelizace existovaly, pár si jich pamatuji. Rozhodně bych šel do paralelizace tisíckrát raději s takovým jazykem, než s nějakým C/C++, Javou. Pythonem, apod. Právě tam, kde je potřeba jít s výkonem na krev bych tisíckrát raději uvítal jazyk s podporou paralelismu. Pokud má kompilátor a linker jazyka k dispozici informace o paralelismu, může optimalizovat řádově lépe než programátor - a hlavně to dělá bezchybně.
Výkon ale není jediné kritérium kvality a jediný cíl. V jednom programu můžou být části, kde je výkon důležitý, a části, kde na něm prakticky vůbec nezáleží a kde jsou důležité jiné věci. A teď je otázka, jak se k tomu postavit a který jazyk zvolit nebo zda ten program rozdělit na části a psát každou v jiném jazyce.
Pokud má kompilátor a linker jazyka k dispozici informace o paralelismu
Zrovna tyhle informace lze kompilátoru dodat i třeba anotacemi, makry nebo obalením do nějaké OOP abstrakce nebo funkce. Takže si myslím, že k tomu, aby programátor sdělil kompilátoru takové informace, nový jazyk není nutný.
20.8.2019 18:12
Gilhad | skóre: 20
| blog: gilhadoviny
21.8.2019 01:50
Gilhad | skóre: 20
| blog: gilhadoviny
kdy vytizim nejen procesor, ale i IO
Pokud chcete opravdu využít CPU, překládejte na tmpfs.
21.8.2019 07:57
Gilhad | skóre: 20
| blog: gilhadoviny
21.8.2019 08:48
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
ale ze skutecne vic veci zacne byt tak nejak automaticky paralelizovanych (i kdyby se nasledne mely rychle stridat na jednom jadru)V tohle doufám prakticky taky těch 20 let, od chvíle, kdy jsem se poprvé dostal k více procesorovému PC. Přesně jak píšeš, i multithread program na jednom single core cpu může být výhodou. Jenže tohle jde o dost pomaleji, než bych před těmi 20 lety čekal a spíše slyšíme výmluvy, proč to nejde a nikdy nepůjde - viz třeba situace kolem herních API. Tak dlouho jsme slyšeli, že hry nikdy nebudou multithread, až přišlo AMD Mantle a ukázalo, že to jde levou zadní.
jelikoz to ted dost tlaci herni prumyslJe potřeba si uvědomit, že to tlačí jen díky aktuálnímu HW herních konzolí. Dokud měl prim Intel a konzole byly různé, tak to "nešlo" (viz předchozí odstavec). Ani DX neumělo moc multithreading. Potom přišlo AMD se svým Mantle a následně obě NextGen herní konsole měly AMD APU osmijádro a najednou to šlo. Tedy, kdyby tehdy někdo přišel s herní konzolí postavené na zázračném jednojádru, tak se obávám, že dodnes budeme mít hraní na PC totálně v zajetí málojaderných cpu s vysokým výkonem na jedno jádro.
21.8.2019 09:16
Gilhad | skóre: 20
| blog: gilhadoviny
256 jader je zrovna takové divné číslo. Na manuální řízení je to moc a na pořádnou paralelizaci zase málo. Osobně si myslím, že bude převládat hybridní přístup a žádný jazyk tento problém univerzálně nevyřeší. Moc nevěřím tomu, že funkcionální a logické jazyky z masivní paralelizace dokáží skutečně těžit, ač k tomu mají teoreticky dostatečné předpoklady. V osmdesátých letech se věřilo, že Prolog je pro to jako stvořený, ale v praxi se ukázalo tak velké množství problémů, že i dnes aby člověk pohledal jeho paralelní implementaci.
A protože nakonec i 256 jader je málo, budete potřebovat mnoho takových strojů, což zase znamená nutnost je pokud možno transparentně řídit, spravovat, rozdělovat mezi ně zdroje a úlohy. Navíc je úloh, které si vyžadují paralelizaci, tolik různých druhů s odlišnými nároky, že ještě dlouho tohle kompilátory uspokojivě automaticky řešit nebudou.
Osobně jsem zkoušel třeba hloupočké experimenty se 128 samostatnými smalltalkovskými image, kde byla každá s každou propojena (takže přes 8 tisíc obousměrných spojení), přičemž díky proxy objektům a zasílání zpráv není z pohledu jazyka prakticky žádný rozdíl v programování takového systému oproti běžným programům. Ale přístup k návrhu programů pro takový systém je samozřejmě značně odlišný. Dokáži si představit i lepší podporu od jazyka. Třeba reference jako first-class objekty.
21.8.2019 09:01
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
A jelikoz rada uloh obsahuje nejake neparalelizovatelne casti (hodne casto I/O) ta mez, kdy ma jeste smysl pridavat nova jadra muze byt hodne nizko.To ano, ale tohle nejsou případy všech úloh.
Coz hodne zabiji i pristup, jak jsme zvykli o programech uvazovat. Udelej neco, pak udelej neco, jestlize neco, udelej neco. Psat program tak, aby sel automaticky paralelizovat vyzaduje uplne jiny mindset a pristup k programu.Ano. A nejen v programování je někdy potřeba změnit mindset. A je to strašně těžké a přináší to spíš zklamání.
Jsou to vlastne instance jednoho reseni, kdy mas (relativne) omezeny jazyk, kterym muzes deklarativne popsat, co se s daty ma stat.Přesně tak. Neříkat jak se to má udělat, ale co se má udělat. Ne že by to mohlo fungovat všude, ale budoucnost právě vidím v tom, že ve vysokoúrovňových jazycích přestaneme psát jak to má dělat krok za krokem, ale budeme popisovat výsledek. Ať si to udělá jak chce. A jak píšeš, já vím, že Python není nejdokonalejší jazyk na světě, ale první setkání s list / generátor comprehension si budu pamatovat hodně dlouho. To, co se dřív psalo min na 4 řádky (s ifem na 6), je tady na jeden. Elegantně vyjádřené všechno podstatné (vstupem je iterable, výstupem je iterable, je tam jasná transformace prvků a je tam volitelný filter v podobě if).
#pragma omp parallel for schedule(static)
for (int i=0; i<size; i++) {
....
}
V kódu uvedeném výše se provede smyčka paralelně. Samozřejmě to znamená, že kód musí být nezávislý. Největší radost je ladit přístupy do cache - musí se pamatovat už při návrhu datových struktur na to, aby program z různých vláken nesahal do společných prostor. Klasickému programování shora dolů je tento přístup nejbližší.
V C++17 se mi pak líbí stl přístup, například:
std::for_each(begin, end, [](DataItem& data) {
data.q4 = data.d * data.dt;
data.a = data.v + data.w1 * data.q1 - data.w2 * data.q2 + data.w3 * data.q3 + data.w4 * data.q4;
});
Podobně se dají programovat paralelní výpočty v Qt. Proti stl je ale výběr algoritmů chudší a na kontejnerech mi chybí úplně.
V každém případě není problémem malá podpora ze strany jazyků - určitě ne u C++, větší potíž je vývojář.
output = [funkce(item) for item in input]odpovídá
std::for_each(begin, end, funkce);Jen zápis v Pythonu může být omezený neexistencí lambda funkcí, ale to se dá udělat v pohodě jinak. Jazyky jsou na paralelizaci připravené lépe, než programátoři. Školívám C++ (a rozhodně ne začátečníky) a žasnu, že se mi na kurzech sejde jen velmi málo lidí, kteří aspoň slyšeli o přístupu map-filter-reduce. Když se naučíte tímto způsobem myslet, tak třeba to zmiňované C++ vám z vašeho kódu velmi ochotně splácá paralelní aplikaci. Bobužel, strukturované, serializované algoritmy máme všichni velmi kvalitně vypálené do hlavy, do budoucích programátorů se tlačí už od mateřské školy. Je obtížné si osvojit jiné přístupy.
21.8.2019 22:08
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Jen zápis v Pythonu může být omezený neexistencí lambda funkcí, ale to se dá udělat v pohodě jinak.Python má lambdy taky.
Školívám C++ (a rozhodně ne začátečníky) a žasnu, že se mi na kurzech sejde jen velmi málo lidí, kteří aspoň slyšeli o přístupu map-filter-reduce.No tohle asi postihuje každý obor. Já sice nejsem programátor (ani nechci být, jsem admin a sem tam, bohužel a s největším odporem, něco napsat musím) a žasnu taky. Což o to, jedna věc je žasnout nad tím, že někdo něco neví, druhá věc je ho to naučit. (Na pohovorech mě ani tak nezajímá to, co člověk umí teď, ale co bude umět za měsíc.) Bohužel se najdou lidé, jejichž neochota přijímat nové myšlenky je skutečně obdivuhodná. Naposledy dneska jsem někoho klepl přes prsty (za poslední rok snad po desáté), když použil v aktuálním linuxu příkaz
route (se divím, že tam ještě vůbec je, tedy ten příkaz ).
V jednom analyzátoru logů jsem použil map-filter koncept a potom jsem to chtěl někomu předat a vůbec to nepochopil. No nic.
C++ vám z vašeho kódu velmi ochotně splácá paralelní aplikaciA to automaticky nějakou volbou kompilátoru nebo viz výše, třeba přes #pragma?
Python má lambdy taky.Má konstrukci, kterou nazývá "lambda". Nejsem žádný velký odborník na Python, takže se můžu lehce mýlit. Nikdy jsem ale nedokázal v Pythonu napsat lambda funkci (ne jeden pouhý výraz, který se může v Python lambdě objevit) s případnými dalšími vnořenými lambda funkcemi. V C++ to naprostá samozřejmost.
Školívám C++ (a rozhodně ne začátečníky) a žasnu, že se mi na kurzech sejde jen velmi málo lidí, kteří aspoň slyšeli o přístupu map-filter-reduce.Bavíme se v kontextu paralelního zpracování. Map-filter-reduce jsou základní používané postupy v paralelním zpracování a nad čím žasnu, je, jak málo lidí o těchto postupech ví. Strukturované programování, objektové programování a další metodiky jsou známé a nedělají vývojářům problémy. Paralelní postupy už tak zažité nejsou. Není to, že bych žasnul, že ti lidi jsou blbí, protože něco neví. Žasnu nad tím, že paralelní postupy jsou tak málo rozšířené a mezi lidem vývojářským prakticky neznámé. To je ten důvod, proč tvrdím, že slabým místem paralelního programování jsou vývojáři. Oni ti lidi, co si u mě školení zaplatí, tam nakonec jdou proto, aby se něco naučili - patří (snad) mezi ty aktivnější. Nějaké základy paralelního zpracování si ode mě odnesou a snad i zapamatují a později dokážou použít. Nevím.
C++ vám z vašeho kódu velmi ochotně splácá paralelní aplikaciJe to součástí C++17. Používám GCC, tam asi dosud není podpora úplná (nevím, jak GCC 8.3). Ale dá se použít jmenný prostor __gnu_parallel místo std, funguje to velmi podobně. Je jen potřeba přilinkovat OpenMP.
21.8.2019 23:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Má konstrukci, kterou nazývá "lambda". Nejsem žádný velký odborník na Python, takže se můžu lehce mýlit. Nikdy jsem ale nedokázal v Pythonu napsat lambda funkci (ne jeden pouhý výraz, který se může v Python lambdě objevit) s případnými dalšími vnořenými lambda funkcemi. V C++ to naprostá samozřejmost.To jde, ale je to trochu zběsilé*. Co nejde je použít v lambdě return, nebo bloky. Důvod je, že bývalý benevolentní diktátor je prostě neměl rád: Language Design Is Not Just Solving Puzzles. *:
>>> (lambda x: (lambda y: y)(x))(1) 1
22.8.2019 10:19
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
benevolentní diktátorA s ním lze jen souhlasit. Jazyk je trochu víc, než jen prostředek pro řešení problémů. Pokud někdo chce komplexní lambda kalkul, ať se mrkne třeba na Haskell.
output = map(funkce, input)
jen je potřeba od pythonu 3 počítat s lazy evaluation, map vrací místo listu iterátor.
Lambda se dá samozřejmě použít.
Filter používám docela pravidelně, reduce se mi hodí méně často, ale functools ho zná.
22.8.2019 11:09
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Filter používám docela pravidelně, reduce se mi hodí méně často, ale functools ho zná.Proč používáš filter místo list comprehensions / generator expressions?
map(int, list) úhlednější a stručnější než (int(i) for i in list))
22.8.2019 12:23
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
21.8.2019 18:30
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Když budete dodržovat zásady správného sw inženýrství, tak vás to třeba 1 % výkonu bude stát.Je ovšem dobré se taky zamyslet nad tím, jestli cena úprav a dalšího rozšiřování software potom nebude větší než cena za 1% výkonu navíc.
23.8.2019 17:27
xkucf03 | skóre: 50
| blog: xkucf03
23.8.2019 17:24
xkucf03 | skóre: 50
| blog: xkucf03
Když program operačnímu systému nasype třeba tisíc1 vláken, tak se je operační systém bude snažit spravedlivě střídat (s ohledem na jejich prioritu), aby se na každé dostalo. Nebo je tu způsob, jak může proces operačnímu systému říct: „tady máš 1000 vláken, ale kdyby se ti to nehodilo, tak jich spusť třeba jen 200 a zbytek ukonči“? To AFAIK nejde a program by musel nějak adaptivně přisypávat další vlákna a průběžně měřit, jak efektivně pracují, jak je vytížený HW a zda má smysl přidávat další. Ostatní programy můžou ale dělat totéž a pokud se nebudou mezi sebou koordinovat, tak ten HW můžou přetížit nebo to minimálně povede na neoptimální výsledek.
Částečně by to šlo řešit tak, že by si proces spustil více vláken s odlišnými prioritami a zjišťoval, jak často na které vyjde řada a podle toho upravoval počet vláken a rozhazoval mezi ně úkoly. Kolik vláken spustit s normální prioritou a kolik s nižší, ale nejde odvodit ze zdrojového kódu – tam je potřeba zohlednit, jaké všechny procesy na daném počítači běží a jaké jsou mezi nimi vztahy a priority. Když např. zpomalení jednoho procesu způsobí, že jiný proces nebude mít co dělat, je potřeba to při optimalizaci zohlednit. Stejně tak i zahlcení (viz #143).
[1] resp. on to nemusí být jeden program, ale třeba si každý proces bude myslet, že je dobrý nápad pustit tolik vláken, kolik má daný počítač jader, akorát neví o tom, že stejný nápad měly i jiné procesy běžící na témže stroji
Bohužel neexistuje nic jako Pool generátor.Co pool.imap()?
21.8.2019 14:23
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
''' Equivalent of `map()` -- can be MUCH slower than `Pool.map()`. '''což nenadchne.
21.8.2019 14:27
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Některé jazyky (Python) jsou vyloženě singlethread. Ne, že by nešlo programovat ve více vláknech, ale v základu všechno dost komplikuje GIL (global interpreter lock).Tady si pleteš Python jako jazyk a Python jako interpreter. Konkrétně tohle je omezení CPythonu. Existuje například verze Pypy s STM, která tohle omezení nemá.
Existují snadno použitelné knihovny, které to různými způsoby obcházejí (Multiprocessing).Knihovna multiprocessing to neobchází, ta prostě jen pouští víc procesů.
Nebo ještě lépe, jazyk, který od programátora vůbec nevyžaduje hint ve stylu "tady bude další thread"Neuměl tohle Common lisp?
Tady si pleteš Python jako jazyk a Python jako interpreter. Konkrétně tohle je omezení CPythonu. Existuje například verze Pypy s STM, která tohle omezení nemá.Programovací jazyk, který dobře podporuje paralelismus, je třeba navrhnout už s touto myšlenkou. Ne to tam dolepit.
21.8.2019 17:49
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
hmm, odbornik promluvil.
21.8.2019 21:02
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 22.8.2019 15:01
xxx | skóre: 42
| blog: Na Kafíčko
23.8.2019 11:12
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
22.8.2019 15:01
xxx | skóre: 42
| blog: Na Kafíčko
23.8.2019 11:12
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Dovedu pochopit, ze si __nekdo__ nekoupi to, ci ono. No treba ty 16 jadrove stroje.Ono je to taky otázka KDY. Tohle jde ve vlnách. Já si Ryzen (8/16) koupil okamžitě jak byl dostupný. Před tím nic takového dostupného nebylo a byl to velký skok. Ale dneska je to vlastně obyč a pokud si dneska někdo bude kupovat highend cpu, tak poskočí někam na tvou úroveň 16/32 nebo 32/64. Tedy je to taky otázka času.
Kdyz jsem kupoval 128GB RAMTady je to pro mě otázka taky trochu morální. Od roku 2013 jsem měl 32GB RAM a v roce 2017 jsem chtěl pro Ryzen minimálně 64GB a nejlépe to naplnit na maximum, co umí základní deska. Jenže ty ceny od roku 2013 dost vzrostly (podle mě uměle) a za 32GB jsem v 2017 zaplatil víc než v roce 2013. A na tohle nejsem ochoten přistupovat v žádném oboru a u žádného výrobku.
To, co popisuju je spise znak technologickeho zastaravani. Dobre muzeme si jej omluvit. To jde. Ale neni to dobry znak libovolne technologicke komunity.Ano, tohle mě taky překvapuje. Na IT portálech bych čekal trochu větší afinitu k HW a tak trochu bych očekával, že každý toho máme doma víc a že kolem toho nebudou otázky typu proč a na co apod.
Jenže ty ceny od roku 2013 dost vzrostly (podle mě uměle) a za 32GB jsem v 2017 zaplatil víc než v roce 2013.
Tohle jsem taky zaznamenal, v roce 2012 jsem kupoval 32 GB (4x8, DDR3) za něco kolem 3500 Kč včetně DPH, na podzim 2018 mne stálo 32 GB (2x16, DDR4) víc než dvojnásobek. Ale co jsem teď koukal na ceny, zdá se, že už to konečně zase spadlo, 2x16 GB začínají pod 4000 Kč s DPH.
Ryzen 1800X mel problem s pady velkych kompilaci C/C++.Prve padali na Linuxe (Linux sa snazil regularne vyzmykat na maximum hardver, co je dostupne systemu). AMD to pekne riesilo, vymenou procesora za novsi - za dalsi z vyrovnej linky, kde hardverovu chybu v procesore sposobujucu to).
Mozna budete prekvapeni, ale je bezne, ze redakci pujci welkoobchod s pocitaci sestavu zdarma.Uz ani nie, lebo uz sa zvykne pod/v clanku uvadzat, kto a ako spozoroval clanok. Ale nikde co sledujem, som nevidel recenziu na ten clanok. V CZ alebo SK (Alebo ja na nejake take stranky s tym obsahom zrejme nechodim :D). Predsa, pre min 80% beznych ludi to nateraz nie je atraktivne, cena alebo vykon. Takze tvoj pohlad a skusenosti by nam ukazali, tym co to teraz nemame, co nas caka o X rokov.
Priznam se, ze moc spotrebu neresim. Mozna je to rocne 2-4 tisice navic. Protoze moje sazby mi to zaplati velmi rychle. Zanedbatelna castka.Nová studie nazvaná Měření ekologické stopy bohatých. Nadměrná spotřeba, ekologická dezorganizace, zelený zločin a spravedlnost, kterou provedli badatelé Michael J. Lynch, Michael A. Long, Paul B. Stretesky a Kimberley L. Barrett, zkoumá, jak chování bohatých lidí ovlivňuje změnu klimatu. Studie tvrdí, že když má člověk mnohem větší množství peněz, než potřebuje k životu, „stává se pro něj nadměrná spotřeba či nakupování nemovitostí statusovým symbolem, který musí být pravidelně obnovován, což vede k ještě větší spotřebě“. To vede velmi bohaté lidi k výstavbě obrovských domů, k nakupování luxusních jachet, aut nebo soukromých letadel. K tomu, aby se vyvážil jejich ekologický dopad, by bylo potřeba nesmírné množství zmíněných „zelených“ baterií Powerwall.
Já zase podobně ždímám výkon z grafických karet (někdo se tu ptal na spotřebu? ~800W v zátěži). Převážně na tom jedou statistické výpočty v TensorFlow.
Když už vzpomínám TensorFlow - to je pěkná ukázka toho, jak programátoři nejsou připravení na paralelizaci. Pro "zapisovatele algoritmů" je TensorFlow zcela neuchopitelné - zapomeňte na cykly či jiné řídící struktury. TensorFlow je více o zvládnutí matematického aparátu, který je za tím. Normální programátor myslí úplně jinak. Výkonné části programu nakonec mohou mít jen pár desítek řádků a dokáží efektivně zaměstnat veškerá výpočetní jádra.
21.8.2019 22:18
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Asi je čas na upgrade, začínám pošilhávat po 3950X i když je ještě čas počkat na threadrippery nové generace.
21.8.2019 22:21
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 21.8.2019 18:15
Max | skóre: 73
| blog: Max_Devaine
22.8.2019 01:11
Gilhad | skóre: 20
| blog: gilhadoviny
22.8.2019 11:09
Josef Kufner | skóre: 70
21.8.2019 18:15
Max | skóre: 73
| blog: Max_Devaine
22.8.2019 01:11
Gilhad | skóre: 20
| blog: gilhadoviny
22.8.2019 11:09
Josef Kufner | skóre: 70
Herone .. Jazyku ktere jsou implicintne concurrentni a parallelni existuje celkem nepreberne mnozstvi. Uz mimo jine proto ze mnohojadrove systemy tu mame skoro vice nez 50 let. Jen ted se dostavaji do beznych PC ..-> https://en.wikipedia.org/wiki/List_of_concurrent_and_parallel_programming_languages
o jak velké části kódu si většinou volí programátor.To právě Heron nechce. On chce (jestli jsem pochopil blog správně), aby kompilátor byl schopný paralelizovat libovolný dumb (sériový, triviální) algoritmus. A to podle mě nejde udělat tak, aby se úloha přeložila na volání kernelu pro spuštění dalších threadů (a zároveň to mohlo paralelizovat třeba jednu for smyčku). Paralelizace pomocí CPU je velmi omezená na buď SIMD, což neumožňuje počítat naprosto nesouvisející data, nebo na plnění prázdných ALU slotů blízkým kódem bez závislostí. To co jsem měl na mysli by bylo něco jako realtime FPGA syntéza, kde by se před for smyčkou prostě jen syntetizovalo 10 nových ALU a po skončení smyčky by se zase dealokovaly zpátky do poolu volných prostředků. V případě potřeby něčeho jako další vlákno (v měřítkách existujících vláken) by se prostě ten procesor nechal běžet déle. Moje instrukce fork by pak fungovala asi jako podmíněný skok, jen s tím rozdílem, že by zárověň skočila i neskočila
, chovalo by se to vlastně jako nedeterministický automat (omezený hardwarem samozřejmě).
23.8.2019 15:27
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
To právě Heron nechce. On chce (jestli jsem pochopil blog správně), aby kompilátor byl schopný paralelizovat libovolný dumb (sériový, triviální) algoritmus. A to podle mě nejde udělat tak, aby se úloha přeložila na volání kernelu pro spuštění dalších threadů (a zároveň to mohlo paralelizovat třeba jednu for smyčku).+1
To co jsem měl na mysli by bylo něco jako realtime FPGA syntéza, kde by se před for smyčkou prostě jen syntetizovalo 10 nových ALU a po skončení smyčky by se zase dealokovaly zpátky do poolu volných prostředků.No to by byla úplná bomba. O použití FPGA pro ad hoc akcelerátory kde čeho jsem tady taky kdysi snil. Program by si pro svou specifickou činnost vyrobil akcelerátor na prvním volném FPGA a potom to opět zrušil. Je pravdou, že toto postupem doby alespoň částečně na sebe vzaly GPU a kde co si přes OpenCL něco nechá spočítat na GPU.
23.8.2019 15:42
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
https://www.colfaxdirect.com/store/pc/viewPrd.asp?idproduct=3637
23.8.2019 12:27
xkucf03 | skóre: 50
| blog: xkucf03
Na trhu se začínají objevovat 64 core / 128 thread CPU a nebude dlouho trvat a zcela běžně budou dostupné 256 core / thread CPU. Do pár let to máme na stole. A nastává otázka, jak pro tyto cpu programovat.
Tohle mi přijde jako poněkud zvláštní směr uvažování. Podle mého by se k tomu mělo přistupovat spíš z druhé strany: mám nějaký problém, požadavky, potřebu → hledám vhodný hardware. A ne naopak, že si koupím 256jádrový procesor a pak teprve začnu vymýšlet, k čemu a jak ho použiji.
Ty požadavky se v čase mění, např. jsou dnes centralizované weby, které obsluhují obrovské množství návštěvníků – v takovém případě dává smysl si pořídit server se spoustou procesorů/jader/vláken a tahle úloha se dá krásně paralelizovat (a to celkem primitivním způsobem, prostě jen vytvoříš patřičný počet procesů a mezi ně pak rozhazuješ požadavky resp. zpracováváš v nich události).
Další změna je třeba rostoucí rozlišení u videí, fotek nebo zvukových záznamů a jejich rostoucí počet. Pokud je počet souborů vyšší než počet jader, lze to paralelizovat opět naprosto primitivním způsobem (třeba tím xargs nebo parallel) a není potřeba měnit algoritmus. Pokud chceš jeden soubor zpracovat rychle ve více vláknech, změna algoritmu je potřeba, ale díky vyššímu rozlišení to jde i relativně jednoduše rozsekáním na menší části, které se pak zase poskládají dohromady.
Toto nám vyrobí seznam stejně jako list comprehension, ale využije k tomu automaticky všechny dostupné procesory.
Ona ta všudypřítomná automatická paralelizace sice vypadá lákavě, ale často to smysl nemá nebo to může být i kontraproduktivní. Představ si, že máš jeden server, který obsluhuje velký počet uživatelů. Díky tomu, že jich je víc než jader, jsou schopní naplno vytížit CPU a tím využít hardware efektivně. Přitom se každý požadavek může vyřizovat sekvenčně, v jednom vlákně (v rámci toho požadavku můžeš klidně iterovat ve for cyklu přes nějaký seznam). Pokud to v rámci jednoho požadavku začneš paralelizovat, zvýší se počet úloh, který byl ale už před tím vyšší než počet jader, takže tím vlastně nemáš co získat, a akorát to bude čekat na plánovač, který rozhazuje úlohy mezi jádra procesoru – a jeho režie může způsobit i pokles výkonu. Pokud bys tam měl nevytížená jádra (kvůli čekání na I/O) tak by to smysl mělo (nicméně to obvykle nenastává, protože když máš velký počet klientů, začneš během čekání u jednoho obsluhovat požadavek někoho jiného).
Největšího efektu podle mého stejně dosáhneš tam, kde jsi schopný to paralelizovat vědomě/explicitně. Na nějakou magii, která ti libovolnou úlohu automaticky zoptimalizuje na pozadí, bych moc nespoléhal – ve chvíli, kdy to bude dostupné a spolehlivé, asi není důvod to nepoužít a nějaká procenta výkonu ti to přidá, ale žádné zázraky a skokové zlepšení bych od toho nečekal.
Když se dívám na to, jak se dneska vrší jedna vrstva na druhou, jak si např. lidi pouští mnoho instancí webového prohlížeče a dalších komponent i pro triviální aplikace, jak roste komplexita… tak vidím ty rezervy úplně někde jinde, než v nějakých automatických optimalizacích. Když některé vrstvy/komponenty proškrtáš, tak ušetříš mnohem víc, než když je tam necháš a budeš je (sebelépe) optimalizovat.
Takže tu budoucnosti vidíte (množné číslo) jen v nových knihovnách? Jazyk ani paradigma podle vás není potřeba? (#19)
Podpora paralelizace na úrovni syntaxe jazyka může přidat nějaké pohodlí, ale podle mého se dobrý jazyk pozná spíš tak, že je dostatečně pružný na to, aby takovéto vylepšení (a nemusí jít jen o paralelizaci) umožnil zavést formou knihovny (a třeba anotací nebo jiného již existujícího jazykového prostředku) a bylo to ve výsledku srovnatelně pohodlné, aniž by se musela měnit syntaxe jazyka nebo specifikace běhového prostředí.
Časem se třeba dočkáme nějaké umělé inteligence, která zanalyzuje tvoji úlohu a vymyslí za tebe, které části lze paralelizovat a kde je potřeba na sebe čekat a synchronizovat se… a tahle optimalizace se bude dít v době kompilace nebo dynamicky za běhu. To by zásadní změna paradigmatu a vůbec způsobu vývoje softwaru byla. Ale tady bych čekal, že na vstupu bude spíš nějaký deklarativní popis toho, co má být cílem výpočtu, než imperativní předpis, co se má dělat. Zajímavé by bylo automatické rozložení algoritmu napříč více počítači (ne jen více procesory jednoho počítače). Potřeboval bys dost vzorových vstupních dat a popis požadovaného výsledku, kterým by se to testovalo – a kompilátor (o dost jiný než dnešní kompilátory) by pak pouštěl různé simulace a hledal nejefektivnější cestu, jak dosáhnout správného výsledku.
Mě funkcionální programování postihlo jen během studia a to setkání bylo takové zvláštní. Jednak se říkalo, že je to velmi snadno paralelizovatelné, protože funkce nemají žádné vedlejší efekty (což skutečně nemají) ale žádný interpret (tehdy scheme) nikdy nebyl multithreading. Já proti funkcionálnímu paradigmatu nic nemám, ale chtěl bych někdy vidět všechny jeho výhody v plné palbě včetně toho masivního paralelismu.
Ano, to se tak říká, ale přijde mi, že ty reálné přínosy nás trochu míjejí a že spousta lidí do toho vkládá větší naděje, než to může přinést – asi podobně, jako když bylo na vrcholu módní vlny OOP a lidi čekali zázraky od něj.
Lamba funkce se v nefunc jazycích používají spíše jen jako syntaxe pro anonymní funkce. (Typicky, chcete předat něco filteru nebo mapu a nechcete dělat pojmenovanou fci, tak to napíšete jako lambdu.)
Z praktického hlediska považuji za vítěze multiparadigmatické jazyky, které umožňují kombinovat více přístupů, podle toho, co se na kterou část programu hodí. Typicky to pak vede na nějakou objektovou (nebo v jednodušším případě procedurální) kostru programu a uvnitř nějaké funkcionální a deklarativní prvky. Sice to není tak akademicky čité jako např. výhradně funkcionální jazyk, ale z praktického hlediska je to užitečnější.
Proto si myslím, že musí dojít ke změně paradigmatu. Dneska se afaik až na nějaké speciality stále programuje tak, že se přímo určuje kde se to má forknout a co v tom vlákně má běžet. Tj se ručně alokuje určitá činnost do určitého vlákna. Proto jsem uvedl ty příklady, kde to prog vůbec neřeší.
A o jaké konkrétní programy ti jde? Co se týče desktopu nebo pracovní stanice a uživatelských aplikací určených pro toho člověka, který u počítače sedí, tak tam mi to přijde jako zbytečná otázka, protože výkon současného HW je pro potřeby jednoho člověka brutálně předimenzovaný a pokud se systém jeví jako pomalý, tak je to spíš špatně odvedená práce autorů softwaru – tzn. je to řešitelné v rámci stávajícího paradigmatu, jen stačí dodržovat doporučení a nedělat základní chyby, nekašlat úplně na všechno, co se učí i v prvním semestru SW inženýrství. Pokud jde o zpracování velkého množství dat nebo zpracování požadavků velkého počtu uživatelů na sdíleném stroji (serveru), tak bývají jednoduše paralelizovatelné úlohy, protože tam na první pohled vidíš, co může běžet vedle sebe, je na sobě nezávislé, a co na sebe musí čekat a synchronizovat se.
23.8.2019 13:34
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Tohle mi přijde jako poněkud zvláštní směr uvažování. Podle mého by se k tomu mělo přistupovat spíš z druhé strany: mám nějaký problém, požadavky, potřebu → hledám vhodný hardware. A ne naopak, že si koupím 256jádrový procesor a pak teprve začnu vymýšlet, k čemu a jak ho použiji.Hlavním důvodem tohoto blogu a taky toho, proč jsem po 8 letech něco napsal na ABCLinuxu, byla především diskuse a ta se velmi povedla a díky všem za ni. Jinak to cos popsal není můj směr uvažování. Já mám dat, že bych tím mohl vytížit i 4096 jádro. Nebo procesorů na síti. Což ve skutečností provozuju (ne to 4096core ale distribuované počítání).
Další změna je třeba rostoucí rozlišení u videí, fotek nebo zvukových záznamů a jejich rostoucí počet. Pokud je počet souborů vyšší než počet jader, lze to paralelizovat opět naprosto primitivním způsobem (třeba tím xargs nebo parallel) a není potřeba měnit algoritmus. Pokud chceš jeden soubor zpracovat rychle ve více vláknech, změna algoritmu je potřeba, ale díky vyššímu rozlišení to jde i relativně jednoduše rozsekáním na menší části, které se pak zase poskládají dohromady.Přesně tak.
Představ si, že máš jeden server, který obsluhuje velký počet uživatelů. Díky tomu, že jich je víc než jader, jsou schopní naplno vytížit CPU a tím využít hardware efektivně.To je zase podle mě chybný pohled na věc. Podle mě bych se vůbec neměl řídit tím, kolik uživatelů naplní potenciál cpu na serveru, ale měl bych to psát tak, aby to po přehození na vyšší počet cpu mohl využít. Dám příklad z FreeBSD. Ve FreeBSD se na celkem dost systémových úkonů používá Make a ty Makefile obsahují velký počet celkem triviálních úkolů. Když jsem to přestěhovat z dvoujádra na osmijádro, tak při zachování celé instalace svižnost systému vzrostla určitě více než 4x. Tj ten OS má dost úkolů, které může distribuovat mezi procesory. A nemyslím si, že by ty Makefile měly být psány s ohledem na nějaký počet cpu. Prostě pokud se dá udělat malý úkol, měl by zůstat malý bez ohledu na to, že jich tam celkově budou desetitisíce. Kdyby ti uživatelé psali svoje programy tak jak navrhuješ, tak by přestěhování na výrazně vyšší počet cpu nemělo takový efekt. Proto si myslím, že je vhodnější to psát paralelizovatelně bez ohledu na skutečný počet aktuálně dostupných procesorů.
Když se dívám na to, jak se dneska vrší jedna vrstva na druhou, jak si např. lidi pouští mnoho instancí webového prohlížeče a dalších komponent i pro triviální aplikace, jak roste komplexita… tak vidím ty rezervy úplně někde jinde, než v nějakých automatických optimalizacích. Když některé vrstvy/komponenty proškrtáš, tak ušetříš mnohem víc, než když je tam necháš a budeš je (sebelépe) optimalizovat.Na tom se shodneme.
A o jaké konkrétní programy ti jde?V tom konkrétním tebou vypíchnutém odstavci o žádné. Jde mi jen o vyjádření myšlenky, že místo explicitního psaní "tady bude vlánko a bude dělat to a to" se to stane jaksi samo implicitně bez zásahu proga.
Co se týče desktopu nebo pracovní stanice a uživatelských aplikací určených pro toho člověka, který u počítače sedí, tak tam mi to přijde jako zbytečná otázka, protože výkon současného HW je pro potřeby jednoho člověka brutálně předimenzovaný a pokud se systém jeví jako pomalý, tak je to spíš špatně odvedená práce autorů softwaru – tzn. je to řešitelné v rámci stávajícího paradigmatu, jen stačí dodržovat doporučení a nedělat základní chyby, nekašlat úplně na všechno, co se učí i v prvním semestru SW inženýrství.Mě se brutálně předimenzovaný tedy nezdá a jako příklad uvedu to, co jsem psal v minulosti už několikrát. Tak triviální věc jako prohlížeč obrázků. Dekódovat jeden obrázek dnešních rozlišení rozhodně není z hlediska lidského vnímání hned. Proto by mi přišlo logické, kdyby prohlížeče obrázků na pozadí v dalších vláknech / procesech načítaly a do paměti dekódovaly další obrázky v adresáři. Tj spustím prohlížeč nad složkou kde jsou tisíce obrázků, prohlížeč zjistí, že mám 16jádro, a v dalších threadech začne načítat dalších 16 obrázků, protože lze očekávat, že na ně za chvíli dojde řada pro zobrazení. Na to mi tady někdo minule napsal "ale to by se ti roztočil ventilátor"... Takže ano, částečně souhlasím s tím, že je to špatná práce sw inženýra, ale když takhle blbě se dneska píše skoro všechno.
23.8.2019 14:37
xkucf03 | skóre: 50
| blog: xkucf03
Kdyby ti uživatelé psali svoje programy tak jak navrhuješ, tak by přestěhování na výrazně vyšší počet cpu nemělo takový efekt. Proto si myslím, že je vhodnější to psát paralelizovatelně bez ohledu na skutečný počet aktuálně dostupných procesorů.
Já to nenavrhuji – je to vlastně současný stav a tím návrhem na změnu je naopak to, že použijeme jiný jazyk, který to nějak zázračně implicitně paralelizuje. Pokud tahle změna bude zadarmo a nebude mít žádné negativní dopady ani režii, tak není důvod do toho nejít.
Pokud ten přechod ale nějaké negativní dopady a režii má, tak je na místě se ptát, co mi to přinese a co mi to vezme a porovnávat si to. A co jsem se právě snažil říct tím:
Představ si, že máš jeden server, který obsluhuje velký počet uživatelů. Díky tomu, že jich je víc než jader, jsou schopní naplno vytížit CPU a tím využít hardware efektivně.
je fakt, že paralelizace má přínos jen v případě, že ta nevytížená jádra máš. Pokud je nemáš (protože řešených úloh ve frontě je tolik, že čekají, až na ně volné jádro vyjde), tak ta dodatečná paralelizace má nulový pozitivní efekt, ale ty nevýhody a režie zůstávají. Takže ve chvíli, kdy se tvůj počítač fláká a ty jen klikáš v GUI, tak by se ti např. mohla zlepšit odezva uživatelského rozhraní. Ale ve chvíli, kdy svoje procesory vytěžuješ kódováním videa, kompilací nebo třeba na serveru obsluhuješ tolik příchozích požadavků, že dosáhneš zátěže CPU, kterou sis naplánoval1, tak ti ta dodatečná paralelizace už nic nepřinese.
Hello world příklad, jak ti implicitní paralelizace zrychlí program, tedy bude na nevytíženém systému vypadat úžasně, ale na vytíženém se tento efekt vytrácí. Tím nechci říct, že to nemá smysl vůbec – ale že to platí jen za specifických podmínek a obecně to nebude takový zázrak, jak si od toho asi hodně lidí slibuje.
Pak taky záleží na tom, zda se snažíš minimalizovat a) čas zpracování úlohy nebo b) spotřebu elektřiny na zpracování dané úlohy. Pokud bys měl nulovou režii uspávání a zapínání jader CPU a měl volná jádra, tak ti to umožní zkrátit čas zpracování úlohy. Pokud tě ale zajímá víc poměr výkon/spotřeba, tak na té paralelizaci vlastně nezáleží, protože více zapnutých jader (CPU nebo dokonce serverů, pokud jde o větší úlohy a vyplatí se kvůli nim zapínat další servery) znamená i větší spotřebu. Na sdílené pronajímané infrastruktuře pak neplatíš přímo za elektřinu ale za ty využité zdroje – a jestli využíváš jeden zdroj delší dobu nebo více zdrojů paralelně kratší dobu, ti asi nic moc neušetří.
Jakási mikrooptimalizace by mohla spočívat v tom, že by ses vždy podíval, kolik máš aktuálně zapnutých jader a podle toho se rozmyslel, zda úlohu pustíš přesně v tolik vláknech, nebo zda nějaká vypneš a pustíš to v menším počtu vláken, nebo naopak další zapneš a pustíš to více paralelně. Režie takového rozhodování ale může hravě převýšit užitek a navíc to musíš koordinovat napříč všemi programy běžícími v daném systému tzn. není to řešitelné v rámci jednoho procesu a programovacího jazyka. Jinak by ti ta jádra, o kterých si myslíš, že jsou volná, mezi tím obsadil jiný program.
[1] nechceš, aby servery běžely naprázdno (mimo špičku je třeba automaticky vypnínáš), ale na druhou stranu zase nechceš mít 100 % vytížení CPU a chceš si tam nechat nějakou rezervu
23.8.2019 14:58
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
je fakt, že paralelizace má přínos jen v případě, že ta nevytížená jádra máš. Pokud je nemáš (protože řešených úloh ve frontě je tolik, že čekají, až na ně volné jádro vyjde), tak ta dodatečná paralelizace má nulový pozitivní efekt, ale ty nevýhody a režie zůstávají. Takže ve chvíli, kdy se tvůj počítač fláká a ty jen klikáš v GUI, tak by se ti např. mohla zlepšit odezva uživatelského rozhraní.To není zcela pravda, protože paralelizace pomáhá i na single cpu. Ne každá úloha je pořád cpu bound, taky někdy načítá data z disku a komunikuje třeba po síti. Takže je výhodou mít víc procesů i v případě málojaderného cpu.
Ale ve chvíli, kdy svoje procesory vytěžuješ kódováním videa, kompilací nebo třeba na serveru obsluhuješ tolik příchozích požadavků, že dosáhneš zátěže CPU, kterou sis naplánoval1, tak ti ta dodatečná paralelizace už nic nepřinese.Přijde mi, že se trochu zapomíná na prioritu procesů. Já běžně kóduju video a u toho dělám další činnost a nebo třeba hraju hry. A viz výše, žádný proces, ani to kódování videa, kompilace nebo hraní her nevytěžuje cpu vždy na max, takže se tam prostřídají úlohy s nižší prioritou. Takže průměrné vytížení CPU se dlouhodobě může blížit 100% a tohoto vytížení je dosaženo mnoha různými úlohami (aktuálně mám na pozadí kódování videa a vůbec nijak mě to neomezuje v dalších činnostech a zcela běžně mám ještě na pozadí pauznutou nějakou hru, kterou si ve volné chvíli vytáhnu na monitor).
Hello world příklad, jak ti implicitní paralelizace zrychlí program, tedy bude na nevytíženém systému vypadat úžasně, ale na vytíženém se tento efekt vytrácí. Tím nechci říct, že to nemá smysl vůbec – ale že to platí jen za specifických podmínek a obecně to nebude takový zázrak, jak si od toho asi hodně lidí slibuje.Viz výše, odpovědí jsou priority procesů.
a) čas zpracování úlohy nebo b) spotřebu elektřiny na zpracování dané úlohySpotřeba elektřiny bude v obou případech teoreticky stejná, protože na tu úlohu je potřeba stejného počtu elementárních výpočtů, které vyžadují svou energii. Ve skutečnosti ale spotřeba elektřiny v prvním případě (tj rychlejšího zpracování) je nižší, protože v kompu jsou "režijní" komponenty, které žerou proud tak jako tak. Tj nápad snížit rychlost výpočtu aby se snížila energie nedává žádný smysl. Pochopitelně příkon je nižší. Ale energie je příkon krát čas. (Nebo jsem možná i vzhledem k dalším odstavcům jen nepochopil, co tím vlastně chceš říct.)
25.8.2019 10:13
xkucf03 | skóre: 50
| blog: xkucf03
Ne každá úloha je pořád cpu bound, taky někdy načítá data z disku a komunikuje třeba po síti. Takže je výhodou mít víc procesů i v případě málojaderného cpu.
Pokud úloha čeká na I/O, tak nevytěžuje jádro tzn. nevytížená jádra můžeš mít, i když máš víc spuštěných úloh než jader. Pointa byla v tom, že v určitém bodě se to saturuje a další paralelizace už nemá smysl nebo je dokonce kontraproduktivní. Ano, nastává to typicky ve chvíli, kdy je počet běžících úloh mírně vyšší než počet jader – ve chvíli, kdy je jen stejný, tak to ještě saturované není, kvůli tomu čekání na I/O, ale ten bod zlomu nepochybně existuje.
Ostatně dobrým příkladem jsou HTTP servery. Jednu dobu se pro každé příchozí spojení spouštělo jedno vlákno/proces, ale pak se přišlo na to, že na hodně navštěvovaných serverech není taková paralelizace optimální a je lepší pustit menší počet vláken/procesů a úlohy v nich odbavovat vlastně více sekvenčně. A pokud na tom stroji běží i jiné služby jako třeba databáze, nějaké fronty nebo další servery, tak nakonec o počtu vláken přidělených jednotlivým službám ručně rozhoduje administrátor a neděje se to nějak samo, že by za tebe optimální konfiguraci vymyslel jazyk nebo jeho kompilátor. Pokud by se to mělo automatizovat, tak to vyžaduje minimálně účast plánovače OS.
Stejné je to s RAM – tam bys taky mohl říct, ať si každý program vezme, kolik chce, a udělat velký swap a ať se mezi sebou nějak poperou a OS rozhodne o tom, co skončí ve swapu a co ve fyzické RAM. Ale to taky není optimální řešení a pravděpodobně tam budeš jednotlivým komponentám (databáze, aplikační server atd.) chtít alespoň naznačit, kolik paměti si která může vzít.
Totéž v případě úložišť – asi tam budeš mít nějaké rychlé SSD/NVME disky, pak nějaké pomalejší a pak nějaké úplně nejpomalejší kdesi na síti. A taky budeš chtít nějak inteligentně rozhodnout o tom, kolik kapacit v které kategorii si může která služba vzít. Kdybys to rozhodnutí nechal na těch službách/programech, tak si každý vezme co nejvíc toho co nejrychlejšího úložiště, ale z pohledu celého systému to optimální (nebo vůbec proveditelné) nebude.
25.8.2019 10:38
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
mírně vyšší než počet jaderPřičemž v praxi to mírně může být klidně 10x.
Ostatně dobrým příkladem jsou HTTP servery. Jednu dobu se pro každé příchozí spojení spouštělo jedno vlákno/proces, ale pak se přišlo na to, že na hodně navštěvovaných serverech není taková paralelizace optimální a je lepší pustit menší počet vláken/procesů a úlohy v nich odbavovat vlastně více sekvenčně.Tady se míchají dvě věci. Dodnes se u webů, které skutečně něco dělají, používá proces per client a není na tom nic špatného. U webů, které "jen" posílají drobný statický obsah se tento přístup neosvědčil a přešlo se na event model. V praxi to vypadá tak, že na drobný statický obsah se používá event base webserver a zbytek se předává na těžkotonážní proces per client (to už nemusí být vyloženě plnohodnotný webserver ale třeba FCGI proces skriptovacích jazyků).
A pokud na tom stroji běží i jiné služby jako třeba databáze, nějaké fronty nebo další servery, tak nakonec o počtu vláken přidělených jednotlivým službám ručně rozhoduje administrátor a neděje se to nějak samo, že by za tebe optimální konfiguraci vymyslel jazyk nebo jeho kompilátor. Pokud by se to mělo automatizovat, tak to vyžaduje minimálně účast plánovače OS.Viz níže. Tohle považuju za předčasnou optimalizaci a v praxi se to moc neřeší.
Stejné je to s RAM – tam bys taky mohl říct, ať si každý program vezme, kolik chce, a udělat velký swap a ať se mezi sebou nějak poperou a OS rozhodne o tom, co skončí ve swapu a co ve fyzické RAM. Ale to taky není optimální řešení a pravděpodobně tam budeš jednotlivým komponentám (databáze, aplikační server atd.) chtít alespoň naznačit, kolik paměti si která může vzít.Swap se nepoužívá. Na serveru už rozhodně ne. K tomu dalšímu, je pochopitelně otázka, co je to za konkrétní program. Ano, některé programy si myslí, že zvládnou práci lépe než např. iocache v OS, ale tak ty si dáme na blacklist. Normální programy používají výhod OS a neřeší co nemusí a vezmou si jen tolik paměti, kolik potřebují. Ano jistě, některé potřebují hint. Taky je otázkou, zda je vhodné mixovat jednotlivé programy na jednom stroji (za předpokladu, že to chceš takhle brutálně optimalizovat). Už jen tato skutečnosti by ti měla naznačit, že bys to možná měl rozdělit na různé stroje.
Totéž v případě úložišť – asi tam budeš mít nějaké rychlé SSD/NVME disky, pak nějaké pomalejší a pak nějaké úplně nejpomalejší kdesi na síti. A taky budeš chtít nějak inteligentně rozhodnout o tom, kolik kapacit v které kategorii si může která služba vzít. Kdybys to rozhodnutí nechal na těch službách/programech, tak si každý vezme co nejvíc toho co nejrychlejšího úložiště, ale z pohledu celého systému to optimální (nebo vůbec proveditelné) nebude.Tohle je na samostatnou debatu. V prvním přiblížení říkám ano, každý proces má právo přistupovat ke storage stejně jako kterýkoliv jiný. Někde jsi tady obhajoval abstrakci rozdělení do vrstev, tak tady to máš na stříbrném podnose. Proces vidí jen VFS.
A jakožto člověk, co se dlouhodobě zabývá FS a storage systémy to pochopitelně vnímám trochu komplikovaněji a předchozí odstavec svým způsobem nemám rád. Ale na vysvětlení toho proč by to chtělo mnohem víc prostoru. Souvisí to totiž s návrhem celého systému, který na tom chceme provozovat. A ten, kdo to navrhuje by měl na straně jedné znát data, co se mají ukládat a požadavky na to ukládání kladené a na straně druhé znát specifika jednotlivých storage systémů. Třeba jednou někoho takového potkám a nebudu to musel suplovat. (Konec osobního traumatu ). Ale jasně, tohle se opět týká brutálně optimalizovaných systémů, kde se řeší každý kB/s. V praxi je levnější koupit nové pole. Prostě je to tak, i když s tím často nesouhlasím.
25.8.2019 11:16
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Přičemž v praxi to mírně může být klidně 10x.Abych to ilustroval, v příloze je rychlý test z POVRay na Ryzenu 1700 (8 core / 16 thr). Jedná se o čistě CPU bound úlohu (raytracing, pravda, v této scéně je i trocha radiozity) a těžko říct, jak moc je POVRay optimalizovaný (tato verze 3.7 je první s podporou multithreadingu) a přes to mu nedělá 80 vláken problém. Rozdíl mezi optimem na 16 vláknech a 80 vlákny je jen 6.4%. Takže se opravdu netřeba bát programů, které si automaticky naspawnují počet procesů podle počtu cpu.
25.8.2019 12:45
xkucf03 | skóre: 50
| blog: xkucf03
Tohle jsou dost dobré výsledky1 a nad 6,4% rozdílem2 bych asi mávl rukou a neřešil ho.
[1] nevím, jak moc typické – jinde ta režie s více vlákny a rozdělením úlohy na malé kousky může být vyšší
[2] nebo někomu může stát za to, řešit i takhle malý rozdíl tzn. když bude mít na systému s 16 jádry pět služeb, nebude chtít spustit všechny s 16 vlákny a mít celkem 80 paralelně běžících vláken
25.8.2019 12:38
xkucf03 | skóre: 50
| blog: xkucf03
Přičemž v praxi to mírně může být klidně 10x.
Teoreticky to může být libovolné číslo v závislosti na charakteru I/O operací a úložiště. Tím spíš nelze říct, ať si program vytvoří tolik vláken, kolik máme jader. Nakonec se používá nějaká kombinace alchymie, intuice a zkušenosti, kde si vymyslíš, jaké bude třeba X v make -j X.
Tohle považuju za předčasnou optimalizaci a v praxi se to moc neřeší.
Já to v praxi taky moc neřeším – pokud programy dobře fungují s výchozím nastavením vláken (a třeba limitů RAM nebo adresářů, kam co ukládat), tak do toho taky nevrtám a jsem spokojený. Ono to nějak funguje a ty potenciální úspory, které by optimalizace přinesla, jsou menší, než práce navíc. Takže ano, často by šlo o předčasnou optimalizaci.
Nicméně je to takový „dřevorubecký“ přístup ve stylu pustíme X vláken na Y-jádrovém procesoru a plánovač už si s tím poradí. I tento přístup funguje relativně dobře. Ale měl jsem pocit, že tahle diskuse je nikoli o nějakém „good enough“ řešení, ale o hledání něčeho lepšího, promyšlenějšího – a to je daleko složitější a je potřeba řešit ty různé věci, o kterých tu píšu. A nebo si říct, že nám za to tahle optimalizace nestojí – to je taky racionální úvaha.
Normální programy používají výhod OS a neřeší co nemusí a vezmou si jen tolik paměti, kolik potřebují.
Jednu úlohu lze obvykle řešit různými způsoby a některé budou více náročné na RAM, některé na CPU a jiné třeba na úložiště a síť. Tím, že programu naznačíš, kolik si kterých zdrojů může vzít, mu dáváš šanci ten algoritmus vhodně parametrizovat nebo zvolit jiný algoritmus vhodnější pro dané podmínky.
Taky je otázkou, zda je vhodné mixovat jednotlivé programy na jednom stroji (za předpokladu, že to chceš takhle brutálně optimalizovat). Už jen tato skutečnosti by ti měla naznačit, že bys to možná měl rozdělit na různé stroje.
Dneska jsou ty různé stroje typicky VM běžící na jednom fyzickém stroji, kde v lepším případě má každá virtuálka přidělená nějaká fixní jádra, v horším případě se perou navzájem o fyzická jádra. V tom druhém případě je to oddělení celkem na nic, protože se stejně budou navzájem ovlivňovat. V tom prvním je to pak podobné, jako kdybys to pustil na jednom stroji a jednotlivým službám přidělil nějaký počet vláken.
Jak jsem tu někde psal, mohlo by pomoci, kdyby si služba pustila třeba X vláken s normální prioritou a Y s nižší (tak aby celkový počet byl optimální pro případ, že na tom systému nic jiného neběží) a takových služeb by ti tam běželo několik (jednotlivá X bys volil tak, aby rozdělení kapacit mezi jednotlivé služby bylo spravedlivé resp. tak, jak potřebuješ pro plynulý chod celého systému) a plánovač by věděl, že ta vlákna s nižší prioritou má pouštět jen ve chvíli, kdy má volná jádra. A program by se pak měl umět vypořádat se situací, kdy vlákno s normální prioritou doběhne výrazně dřív než vlákno s nižší tzn. měl by umět přehodit nedokončenou práci z jednoho vlákna na jiné – nebo by to mohl udělat plánovač (když bude vědět, která vlákna patří k sobě, a že když to prioritnější doběhne, má dostat prioritu to další ze stejné skupiny). Nicméně pokud si myslíš, že režie přepínání vláken/procesů je dostatečně nízká, tak to je zbytečná mikrooptimalizace.
V prvním přiblížení říkám ano, každý proces má právo přistupovat ke storage stejně jako kterýkoliv jiný. Někde jsi tady obhajoval abstrakci rozdělení do vrstev, tak tady to máš na stříbrném podnose. Proces vidí jen VFS.
To není nic proti ničemu. Mít společnou abstrakci a pracovat s úložišti jednotným způsobem je dobré. Ale ty můžeš říct programu, ať si dá primární data do jednoho adresáře, dočasné soubory do druhého a logy do třetího atd. a tím to vyladit, aniž by program věděl, které úložiště je rychlé a které pomalé nebo co jsou lokální disky a co síťové.
A ten, kdo to navrhuje by měl na straně jedné znát data, co se mají ukládat a požadavky na to ukládání kladené a na straně druhé znát specifika jednotlivých storage systémů.
Stejně tak lze přistupovat k těm vláknům a snažit se nějak vymyslet, v kolika vláknech by měl běžet aplikační server, v kolika databáze, jaké by jednotlivé procesy měly mít priority atd.
V praxi je levnější koupit nové pole. Prostě je to tak, i když s tím často nesouhlasím.
Analogicky lze říct, že pustíme všechny programy s třeba dvojnásobným počtem vláken, než máme jader, a nějak to dopadne. Je to asi o tom, jak moc si s tím člověk chce hrát a ladit to.
25.8.2019 13:04
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Nicméně je to takový „dřevorubecký“ přístup ve stylu pustíme X vláken na Y-jádrovém procesoru a plánovač už si s tím poradí. I tento přístup funguje relativně dobře.Viz graf, který jsem tady přikládal. On ten dřevorubecký přístup má opodstatnění tam, kde je systém velmi necitlivý na změnu parametrů. Tj změníš počet vláken na libovolné číslo od 16 do 80 (a jistě by to pokračovalo i dál) a ono se nic nestane (kde ono nic je v tomto problému 6%). Takovou úlohu nemá cenu optimalizovat a má smysl přejít na jiné parametry, které jsou na změnu daleko citlivější (třeba změna nastavení renderingu přinese stovky procent).
Ale měl jsem pocit, že tahle diskuse je nikoli o nějakém „good enough“ řešení, ale o hledání něčeho lepšího, promyšlenějšího – a to je daleko složitější a je potřeba řešit ty různé věci, o kterých tu píšu.To je velmi dobrá poznámka a je vidět, že tady v diskusi každý přistupujeme ze svého pohledu a každý ten problém vidíme jinak. Proto jsem ani nereagoval na Michala Kubečka (kterého si samozřejmě velmi vážím), protože o jeho doméně, tedy jaderný vývoj síťového stacku nevím vůbec nic a stojí vlastně na přesně opačné straně toho, co běžně řeším já, tedy paralelizace zpracování velkých balíků dat.
Jednu úlohu lze obvykle řešit různými způsoby a některé budou více náročné na RAM, některé na CPU a jiné třeba na úložiště a síť. Tím, že programu naznačíš, kolik si kterých zdrojů může vzít, mu dáváš šanci ten algoritmus vhodně parametrizovat nebo zvolit jiný algoritmus vhodnější pro dané podmínky.To jistě.
Dneska jsou ty různé stroje typicky VM běžící na jednom fyzickém stroji, kde v lepším případě má každá virtuálka přidělená nějaká fixní jádra, v horším případě se perou navzájem o fyzická jádra. V tom druhém případě je to oddělení celkem na nic, protože se stejně budou navzájem ovlivňovat. V tom prvním je to pak podobné, jako kdybys to pustil na jednom stroji a jednotlivým službám přidělil nějaký počet vláken.Ano, to je znak dnešní doby. Místo, aby se virtuální prostředí využilo tam, kde to má smysl a vysokou přidanou hodnotu, tak se používá všude a ještě se nad tím staví různé vzdušné zámky. Trochu se zapomíná na to, že existuje taky fyzické železo a některé úlohy lze provozovat s výhodou rovnou tam.
To není nic proti ničemu. Mít společnou abstrakci a pracovat s úložišti jednotným způsobem je dobré. Ale ty můžeš říct programu, ať si dá primární data do jednoho adresáře, dočasné soubory do druhého a logy do třetího atd. a tím to vyladit, aniž by program věděl, které úložiště je rychlé a které pomalé nebo co jsou lokální disky a co síťové.Tak já myslím, že každý, kdo mě trochu zná a ví, jaké články jsem v průběhu let napsal, tak pochopil, že to bylo myšleno spíš ironicky.
Stejně tak lze přistupovat k těm vláknům a snažit se nějak vymyslet, v kolika vláknech by měl běžet aplikační server, v kolika databáze, jaké by jednotlivé procesy měly mít priority atd.Jenže, a omlouvám se, že se k tomu stále vracím, tahle optimalizace pracuje v těžce necitlivé oblasti. Prostě to nemá smysl řešit. Zatímco v případně dnešního storage se stále ještě vyplatí optimalizovat až na úroveň každé jednotlivé tabulky a umístění indexu na různé storage, tak u počtu vláken tohle příliš nefunguje. (Teď mě určitě někdo rozseká nějakým hororovým příběhem o tom jak plánování na NUMA nodech těžce selhalo. )
Ostatně dobrým příkladem jsou HTTP servery. Jednu dobu se pro každé příchozí spojení spouštělo jedno vlákno/proces, ale pak se přišlo na to, že na hodně navštěvovaných serverech není taková paralelizace optimální a je lepší pustit menší počet vláken/procesů a úlohy v nich odbavovat vlastně více sekvenčně.To není pravda. Tam nešlo o to, že vlákna/procesy by byly "moc paralelizace", ale o to, že vlákna/procesy mají moc velký overhead. HTTP server typicky odbavuje paralelně, akorát se ten paralelismus řeší na jiný úrovni (v rámci nějakého event loopu s použitím např. epollu, kqueue apod.). To, že v jedný chvíli odbavuje ten server jen nějakej subset spojení/tasků nezmanená, že to je sekvenční - když si vytvoříš hromadu procesů/vláken, tak se v jedný chvíli taky provádí jen tolik, kolik zvládnou najednou CPU. Koneckonců, z tohoto důvodu je úspěšný např. jazyk Go.
25.8.2019 13:09
xkucf03 | skóre: 50
| blog: xkucf03
Tam nešlo o to, že vlákna/procesy by byly "moc paralelizace", ale o to, že vlákna/procesy mají moc velký overhead.
O tom právě celou dobu mluvím, že ta paralelní vlákna/procesy mají nějakou nenulovou režii.
To, že v jedný chvíli odbavuje ten server jen nějakej subset spojení/tasků nezmanená, že to je sekvenční - když si vytvoříš hromadu procesů/vláken, tak se v jedný chvíli taky provádí jen tolik, kolik zvládnou najednou CPU.
Odebíráš z fronty události (sekvenčně) a rozhazuješ je mezi dostupná vlákna/procesy (které pak běží paralelně). Když ti třeba nějaké náročné úlohy vyžerou tři vlákna ze čtyř a ucpe se to, tak ten zbytek událostí se bude zpracovávat už čistě sekvenčně v tom jednom zbylém vlákně.
Ano, je to sekvenční i paralelní zároveň. Ale ve srovnání s přístupem, kdy pro každý požadavek spustíme nové vlákno/proces, asi můžeme říct, že tento přístup jen více sekvenční a méně paralelní.
Koneckonců, z tohoto důvodu je úspěšný např. jazyk Go.
Já pořád nevím, jestli je objektivně úspěšný nebo jen módní. Když si čtu, jak si někteří lidé pochvalují Go nebo Clojure atd. a srovnávají ho s Javou, tak tam nelze přehlédnout fakt, že ti lidé najednou programují úplně jiným stylem, než programovali v Javě (nebo v jiném jazyce, se kterým to srovnávají). Kdyby ale stejný styl uplatnili i v té Javě (což lze, jen na to nebyli zvyklí), tak by výsledek byl stejný. Tato srovnání mi tedy přijdou dost neobjektivní, protože když člověk při příležitosti změny jazyka změnil zrovna i přístup k programování, tak to neříká celkem nic.
Odebíráš z fronty události (sekvenčně) a rozhazuješ je mezi dostupná vlákna/procesy (které pak běží paralelně).Úplně to samé ale přece platí pro scheduller vláken/procesů (rozhazuje mezi CPU/jádra/hw thready).
Ano, je to sekvenční i paralelní zároveň. Ale ve srovnání s přístupem, kdy pro každý požadavek spustíme nové vlákno/proces, asi můžeme říct, že tento přístup jen více sekvenční a méně paralelní.Ne, to nemůžeme. To se ti právě snažím říct, že to je úplně stejně paralelní. Akorát ten scheduling těch tasků nedělá OS, ale nějaká userspace implementace nad primitivy OS. Z hlediska paralelismu to vyjde nastejno. Vlastně je to naopak více paralelní v tom smyslu, že těch tasků můžeš díky tomu nízkému overheadu vytvořit mnohem (řádově) více než threadů/procesů.
Já pořád nevím, jestli je objektivně úspěšný nebo jen módní. Když si čtu, jak si někteří lidé pochvalují Go nebo Clojure atd. a srovnávají ho s Javou, tak tam nelze přehlédnout fakt, že ti lidé najednou programují úplně jiným stylem, než programovali v Javě (nebo v jiném jazyce, se kterým to srovnávají). Kdyby ale stejný styl uplatnili i v té Javě (což lze, jen na to nebyli zvyklí), tak by výsledek byl stejný. Tato srovnání mi tedy přijdou dost neobjektivní, protože když člověk při příležitosti změny jazyka změnil zrovna i přístup k programování, tak to neříká celkem nic.Změna jazyka většinou znamená i změnu stylu, to mi nepřijde překvapivý. Java má v porovnání s Go tu smůlu, že Go ji poráží její vlastní dřívější PR strategií (tj. hlavně "jednoduchost"/"snadnost" daná nízkou úrovní abstrakce), ale zároveň není zatíženo OOP módou a může taky být efektivnější (hodnotové typy, kompilace do nativního kódu). IMO Java to bude mít proti Go dost těžké, zejména jestli teď konečně dostane generika ...
25.8.2019 16:19
xkucf03 | skóre: 50
| blog: xkucf03
AFAIK jen výkonnostní – v té EE jsou nějaké optimalizace navíc, které chce Oracle prodávat velkým firmám typu Twitter a financovat z toho vývoj celého GraalVM.
23.8.2019 13:50
Josef Kufner | skóre: 70
Podpora paralelizace na úrovni syntaxe jazyka může přidat nějaké pohodlí, ale podle mého se dobrý jazyk pozná spíš tak, že je dostatečně pružný na to, aby takovéto vylepšení (a nemusí jít jen o paralelizaci) umožnil zavést formou knihovny (a třeba anotací nebo jiného již existujícího jazykového prostředku) a bylo to ve výsledku srovnatelně pohodlné, aniž by se musela měnit syntaxe jazyka nebo specifikace běhového prostředí.Docela hezký příklad je zavedení await/async v Javascriptu. V podstatě celá ta věc je jen syntaktický cukr nad promises. Tedy zavedla se knihovna, která řešila nepohodlí. Knihovna se standardizovala a následně se ke knihovně dodělal syntaktický cukřík, aby se to používalo ještě pohodlněji. V případě paralelních výpočtů by to asi mohlo být podobné. Jen je potřeba, aby ten jazyk měl připravené to správné podhoubí ze kterého takové funkce mohou vyrůst. Například Rust se v tomto směru tváří docela nadějně právě díky tomu, jak pracuje s kontextem proměnných.
23.8.2019 14:54
xxx | skóre: 42
| blog: Na Kafíčko
for (i = 0; i < len(a); i++)
{
sum += a[i];
}
mu nebude stacit resit datove zavislosti a podle nich jen tak rozhazovat instrukce na jednotliva jadra, ale ze smycku musi nejdriv prevest na paralelni soucet, a pak teprve rozhodit na jednotliva jadra.
Coz znamena existenci prekladace vesticiho z kristalove koule, nebo neceho jako x = sum(a, i, +) coz uz klade naroky na znalosti programatora.
23.8.2019 15:12
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Pool.map() vyžaduje, aby ta funkce neměla vedlejší efekty, tedy aby neměnila sdílený stav.
Tj místo:
for item in input:
output.append(funkce(item))
nebo ekvivalentu:
output = [f(item) for item in input]by automaticky použil
pool.map(funkce, input) a to všude tam, kde by mohlo dokázat, že funkce() nemá vedlejší efekty (což ví, protože na to stejně umí upozornit u toho map()) a taky tam, kde vykonávání funkce bude trvat delší než malou dobu (proto tady vidím potenciál pro běhové prostředí víc než pro kompilátor).
23.8.2019 18:27
xxx | skóre: 42
| blog: Na Kafíčko
23.8.2019 18:34
xkucf03 | skóre: 50
| blog: xkucf03
Tohle by šlo řešit nějakými anotacemi nad příslušnou metodou – jen deklaruješ určité vlastnosti a kompilátor/VM na základě toho pak může optimalizovat.
O - final sum (0123)
/ \ - a[3]
O - sum_012
/ \ - a[2]
O - sum_01
/ \ - a[0], a[1]
A pak na základě pravidel komutativity a HW schopností přenosu a[0] a a[1] v jednom burstu ten strom vyvážit:
O - final sum (0123)
/ \
O O
/ \ / \
a jednotlivé (nezávislé) branche pustit na různých ALU?
(samozřejmě ta databáze pravidel by byla velká jako kráva )
23.8.2019 15:49
xxx | skóre: 42
| blog: Na Kafíčko
23.8.2019 16:22
xkucf03 | skóre: 50
| blog: xkucf03
Ono jsou tu dva úkoly: 1) umět paralelizovat úlohu a 2) rozhodnout, kdy má paralelizace smysl.
IMHO nelze předpokládat, že paralelizace má smysl vždy, kdy ji umíme provést – protože do paměti těch jader je potřeba rozkopírovat určitá data dané úlohy a při střídání úloh tato data prohazovat. A pak může nastat situace, že na počítači s dvou-jádrovým procesorem, kde řešíš dvě úlohy je lepší je pustit jedno-vláknově, každou na jednom dedikovaném jádře, než je pustit dvou-vláknově a mít celkově čtyři vlákna, která se střídají na dvou-jádrovém procesoru. (to je jen zjednodušený příklad, ty počty by byly vyšší) A pro takové rozhodnutí je potřeba mít přehled o všech úlohách běžících na daném počítači, o jejich CPU, IO a paměťové náročnosti (to vyžaduje nějaké předchozí profilování a nelze to vyvodit jen ze zdrojového kódu), prioritách a o zpracovávaných datech, která čekají na zpracování. Asi by to vyžadovalo nějaké nové rozhraní mezi programem a OS nebo dokonce mezi OS a CPU…
Třeba to jednou dospěje do fáze jako assembler vs. C, kde se dneska ve většině případů nevyplatí psát ručně assembler, protože kompilátor C nebo vyššího jazyka vygeneruje lepší strojový kód. Prostor pro zlepšení kompilátorů a běhových prostředí tady určitě je, jen nevím, jestli je k tomu nutné mít i nový jazyk – přijde mi, že to je ortogonální. Jazyk je jen způsob, jak programátor počítači řekne, co chce – a jak si to počítač zoptimalizuje a provede, to už je na něm. U těch stávajících jazyků resp. jejich kompilátorů a běhových prostředí neustále přibývají optimalizace a běh se zrychluje, aniž by bylo nutné měnit syntaxi jazyka. Tady je výhodou deklarativní zápis, který se optimalizuje snáze, ale i u ten imperativní kód lze analyzovat a odvodit z něj předpoklady, na kterých se dá při té optimalizaci stavět.
protože do paměti těch jader je potřeba rozkopírovat určitá data dané úlohy a při střídání úloh tato data prohazovat.V daném příkladě s forem bude kompilátor vědět která data bude mít které "vlákno" a už dostane předem ty správné adresy apod.
A pak může nastat situace, že na počítači s dvou-jádrovým procesorem, kde řešíš dvě úlohy je lepší je pustit jedno-vláknově, každou na jednom dedikovaném jádře, než je pustit dvou-vláknově a mít celkově čtyři vlákna, která se střídají na dvou-jádrovém procesoru.V případě mnou navrhované architektury by byl takovej overhead minimální. Vlastně co jsem se koukal, tak třeba MT DSP u MIPSu umí něco co je hodně blízko. Přes konfigurační registr TCRestart si nastavíš adresu jakou začne thread vykonávat a po dokončení rutiny se může třeba i sám zastavit přes stejnej mechanismus. Samozřejmě by bylo potřeba tenhle mechanismus vylepšit (a odstranit spectre útoky
). Podobně bude kompilátor vědět jak dlouho ten for bude trvat, takže může vzniknout instrukce podobná prefetchi, která bude říkat procesoru kolik taktů bude rutina trvat. A ohledně nevýhodné paralelizace: tak i když bude ten strom rozřezán na paralelní podstromy nezávislého kódu, tak je jedno zda se zpracují sériově nebo paralelně (stejně jako HT omezuje paralelizmus ALU slotů pro jedno vlákno).
Jinak čekání na IO není takový problém, to by prostě bylo sched_yield().
Asi by to vyžadovalo nějaké nové rozhraní mezi programem a OS nebo dokonce mezi OS a CPU…Jj jsem právě navrhoval kompletně nové CPU, které bere paralelizmus už od základu.
jen nevím, jestli je k tomu nutné mít i nový jazykJo kompilátory mají velké rezervy, ale i dneska pomůže vyšší paralelizaci jazyk, co má tu podporu i v základu.
25.8.2019 09:44
xkucf03 | skóre: 50
| blog: xkucf03
Celkově souhlasím (viz také #152 a #165). Jen k tomu:
Map-reduce a spol. to porusuji a vysledky co do vykonu jsou spis tristni.
Přijde mi, že tam se tak nějak předpokládá, že úloha, kterou tímto způsobem řešíš, bude ta nejdůležitější, která na daném HW běží. Proto různá dema/příklady vypadají tak skvěle – protože počítač v tu chvíli nic jiného s podobnou prioritou nedělá. Pokud ten předpoklad platí a chceš HW využít třeba na dávkové zpracování velkého množství dat, tak to bude dávat dobré výsledky.
Pokud se tam úloh s podobnou prioritou sejde víc, tak už to nelze paralelizovat stylem „dáme úloze tolik vláken, kolik má procesor jader“, ale je potřeba nějaký inteligentní plánovač, který má přehled o celém systému, všech programech a zpracovávaných datech.
25.8.2019 10:13
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Driv se mi pristup map-reduce nebo Sparku hodne libil, ale dneska mam jiny nazor.Neni to stoprocentni reseni, ale pro docela sirokou skalu uloh to predstavuje adekvatni reseni.
Takze kazdy program, ktery chceme paralelizovat, je samostatny ukol. A je treba se podivat, ktera data muzeme v ramci celeho programu rozdelit tak, aby se jejich zpracovani dalo provadet paralelne.Souhlasim, ze klicove je prave znat data.
takove "neparalelizuj predcasne". (Map-reduce a spol. to porusuji a vysledky co do vykonu jsou spis tristni.)Map/Reduce (a spol.) je v zasade jen princip, jak zapsat algoritmus pomoci transformaci, ktere maji tu vlastnost, ze je lze soucasne i dobre paralelizovat. Napr. u jednoho programu mam, ze pro mala data se pouzije standardni implementace funkci map a reduce, pro vetsi data uz se to posila frameworku postavenem na vlaknech.
takove "neparalelizuj predcasne"To mas tezke. Pro radu uloh je napr. nejefektivnejsi reseni iterativni (resp. sekvecni pruchod), pro paralelni zpracovani jsou zase vyhodne napr. stromove rekurzivni algoritmy. Takze si muzes vybrat. Bud naprogramujes ulohu iterativne a bude to v jednom vlaknu a pro mala data efektivni, nebo to naprogramujes napr. stromove rekurzivne a uloha bude snadno paralelizovatelna, ale pro mala data bude neefektivni (ve srovnani s iterativnim algoritmem). Takze se najednou dopustis predcasne paralelizace. ..
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}
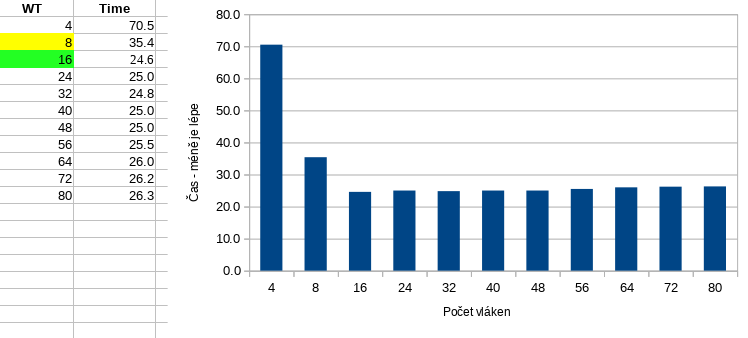{kind=link}