Kevin Lin zkouší využívat chytré brýle Mentra při hraní na piano. Vytváří aplikaci AugmentedChords, pomocí které si do brýlí posílá notový zápis (YouTube). Uvnitř brýlí běží AugmentOS (GitHub), tj. open source operační systém pro chytré brýle.
Jarní konference EurOpen.cz 2025 proběhne 26. až 28. května v Brandýse nad Labem. Věnována je programovacím jazykům, vývoji softwaru a programovacím technikám.
Na čem aktuálně pracují vývojáři GNOME a KDE Plasma? Pravidelný přehled novinek v Týden v GNOME a Týden v KDE Plasma.
Před 25 lety zaplavil celý svět virus ILOVEYOU. Virus se šířil e-mailem, jenž nesl přílohu s názvem I Love You. Příjemci, zvědavému, kdo se do něj zamiloval, pak program spuštěný otevřením přílohy načetl z adresáře e-mailové adresy a na ně pak „milostný vzkaz“ poslal dál. Škody vznikaly jak zahlcením e-mailových serverů, tak i druhou činností viru, kterou bylo přemazání souborů uložených v napadeném počítači.
Byla vydána nová major verze 5.0.0 svobodného multiplatformního nástroje BleachBit (GitHub, Wikipedie) určeného především k efektivnímu čištění disku od nepotřebných souborů.
Na čem pracují vývojáři webového prohlížeče Ladybird (GitHub)? Byl publikován přehled vývoje za duben (YouTube).
Provozovatel čínské sociální sítě TikTok dostal v Evropské unii pokutu 530 milionů eur (13,2 miliardy Kč) za nedostatky při ochraně osobních údajů. Ve svém oznámení to dnes uvedla irská Komise pro ochranu údajů (DPC), která jedná jménem EU. Zároveň TikToku nařídila, že pokud správu dat neuvede do šesti měsíců do souladu s požadavky, musí přestat posílat data o unijních uživatelích do Číny. TikTok uvedl, že se proti rozhodnutí odvolá.
Společnost JetBrains uvolnila Mellum, tj. svůj velký jazykový model (LLM) pro vývojáře, jako open source. Mellum podporuje programovací jazyky Java, Kotlin, Python, Go, PHP, C, C++, C#, JavaScript, TypeScript, CSS, HTML, Rust a Ruby.
Vývojáři Kali Linuxu upozorňují na nový klíč pro podepisování balíčků. K původnímu klíči ztratili přístup.
V březnu loňského roku přestal být Redis svobodný. Společnost Redis Labs jej přelicencovala z licence BSD na nesvobodné licence Redis Source Available License (RSALv2) a Server Side Public License (SSPLv1). Hned o pár dní později vznikly svobodné forky Redisu s názvy Valkey a Redict. Dnes bylo oznámeno, že Redis je opět svobodný. S nejnovější verzí 8 je k dispozici také pod licencí AGPLv3.
Aktuální předverze řady 2.6 je (k 30. 5. 2007) 2.6.22-rc3, vydaná 25. května. Geekové s embedded hardwarem se mohou cítit dvojnásob polichoceni (a ne jenom proto, že je chválily maminky), jelikož tu máme aktualizace ARM, SH a Blackfin. Co víc byste si ještě mohli přát? Pár aktualizací ATA? Řešení problému s USB při suspend? Infiniband? Aktualizace DVB a MMC? Síťové ovladače a několik oprav hloupých síťovacích chyb? Všechno máme! Podrobnosti najdete v dlouhém changelogu.
Aktuální stabilní verze 2.6 je 2.6.21.3, vydaná 24. května s jediným patchem: oprava bezpečnostní chyby v ovladači geode-aes. 2.6.21.2 vyšla 23. května a obsahovala větší dávku oprav.
Starší jádra: 2.6.20.12 bylo vydáno 24. května se zmiňovanou opravou ovladače geode-aes. 2.6.16.52-rc1 se objevilo 25. května s několika dalšími opravami.
Během let jsme napsali spoustu pěkných "rozšířených funkcí". Nikdo je však nepoužívá. Lidé používají jen standardní věci, které mají i všichni ostatní.
Na frontě sysletů/threadletů/fibril byl nějakou dobu klid. Zdá se, že je to částečně kvůli práci Ingo Molnara na completely fair scheduleru, takže neměl čas se vrátit k tomuto menšímu projektu. Mrtvo však není; práci se začal věnovat Zach Brown (který přišel s původním konceptem fibril). Zach vydal aktualizovaný patch, ve kterém sice není nějak hodně změn, ale to neznamená, že by nebyl zajímavý.
Zachovou motivací bylo, jak si jistě vzpomínáte, zjednodušit implementaci a správu řádné podpory asynchronního I/O (AIO) v jádře. Současná práce pokračuje se stejným cílem:
Prozatím se zaměřuji na zjednodušení mechanismů, které podporují rozhraní sys_io_*(), abych už nikdy nemusel debugovat fs/aio.c (ti z nás, kteří už mají šrámy, tomu také říkají kousání skla).
Jedna část nového patche je náhradou za systémové volání io_submit(), které je jádrem současné implementace AIO. Místo aby začalo I/O a skončilo, používá nové io_submit() mechanismus sysletů, což odstraňuje spoustu jednoúčelového AIO kódu. Zach má v plánu se interní struktury kiocb zbavít úplně. Aktuální kód je však spíše potvrzením konceptu, protože množství detailů musí být ještě doplněno. Byly představeny i nějaké výkonnostní testy, ale sám Zach říká: Neobjevily se šílené regrese, ale to je asi tak vše, co o tom lze v tuhle chvíli upřímně říct. Stojí za zmínku, že s tímto patchem dokáže jádro provádět asynchronní bufferované I/O přes io_submit(), což ještě nikdy předtím nebylo možné.
Nejvíce se však diskutovalo o tom návrhu Jeffa Garzika, který řekl, že by kód kevent měl být integrován se syslety. Některým lidem se takový nápad líbí, ale jiní, včetně Inga, si myslí, že kevent nenabízí ve srovnání se stávající rozhraním epoll žádné hmatatelné zlepšení. Ulrich Drepper, správce glibc, s tímto tvrzením nesouhlasil a prohlásil, že rozhraní kevent je krok správným směrem - i když nemá vyšší výkon.
Zdůvodnění tohoto postoje si zaslouží bližší pohled. Používání rozhraní epoll vyžaduje vytvoření popisovače souboru. To je fajn, používají-li aplikace epoll přímo, ale může to vést k problémům, pokud se na události (dejme tomu dokončení I/O), které aplikace přímo nevidí, ptá glibc. Pro popisovače souborů je jediné místo a aplikace se často myslí, že vědí nejlépe, co by se s každým popisovačem na tomto místě měly provést. Pokud by glibc začala vytvářet vlastní soukromé popisovače souborů, byla by vystavena na milost i nemilost každé aplikaci, která zavírá náhodné popisovače, používá neuváženě dup() atd. Takže neexistuje způsob, jak by glibc mohla využívat popisovače souborů nezávisle na aplikaci.
Mohlo by se to řešit třeba tak, že by glibc dostala sadu soukromých, ukrytých popisovačů. Ale Ulrich by raději zvolil rozhraní založené na paměti, které se problému úplně vyhýbá. A Linus by byl úplně nejradši, kdyby se žádná nová rozhraní nevytvářela. Každopádně to vypadá jako nedokončená diskuze; zase na ni dojde.
Defragmentace paměti je téma, o kterém se mluví často - ačkoliv se ještě žádnému řešení nepodařilo dostat do jádra. Většina defragmentačních přístupů funguje na úrovni stránek, protože cílem je snaha o spolehlivé pokrytí vícestránkových alokací. Existuje však ještě jiný typ fragmentačního problému, který může jadernou správu paměti také komplikovat: fragmentace v rámci slab stránek.
Slab alokátor zabírá celé stránky a rozděluje je na alokace stejné velikosti. Například jaderný kód, který často alokuje specifický typ struktury, si pro ten typ vytvoří slab, aby mohly být alokace vyřízeny rychle a efektivně. Slab alokátor může stránky vrátit jádru, pokud byly uvolněny všechny objekty z daných stránek. V reálu však bývají objekty roztahány přes mnoho stránek, což alokátoru dává hromadu částečně využitých stránek a žádný způsob, jak paměť vrátit systému. Tento druh interní fragmentace může vést k neefektivnímu využívání paměti a nemožnosti získat zpět paměť, když je potřeba.
Christoph Lameter napsal patch pro defragmentaci slabu, který se pokouší problém řešit snahou o přinucení uživatelů slabu ke spolupráci při uvolňování konkrétních stránek. Uživatel slabu, který si na defragmentaci dává pozor, začne vytvořením struktury nového typu kmem_cache_ops:
struct kmem_cache_ops {
void *(*get)(struct kmem_cache *cache, int nr, void **objects);
void (*kick)(struct kmem_cache *cache, int nr, void **objects,
void *private);
};
Ve struktuře jsou dvě metody, které musí uživatel slabu definovat. Když si kód slabu vybere konkrétní stránku pro pokus o uvolnění (obyčejně stránku s relativně nízkým počtem alokovaných objektů), vytvoří z objektů pole a předá ho metodě get(). Ta má zaručeno, že v době volání jsou všechny objekty alokovány; jejím účelem je zvýšit referenční počet každého objektu, aby se zabránilo uvolnění, zatímco se dějí jiné věci. Návratová hodnota je privátní ukazatel, který bude využit později.
Všimněte si, že metoda get() je volána způsobem, který připomíná přerušení - všechny zámky slabu jsou drženy. Nemůže toho moc dělat a především nemůže volat žádné operace se slabem.
Po ukončení get() předá kód slabu stejné parametry metodě kick() - včetně hodnoty, kterou vrátila get(). Podle situace může být hodnota private ukazatel na interní úklid nebo prostě příznak, který říká, že nebude možné všechny objekty uvolnit. Pokud to možné je, pokusí se kick() uvolnit každý objekt z pole objects. Operace se slabem jsou v rámci kick() povolené a vůbec nevadí, když funkce objekty realokuje a přesouvá. Realokace umožní uvolnění cílové stránky a sjednocení objektů na menším počtu plně využitých stránek.
kick() nemá žádnou návratovou hodnotu; kód slabu prostě prověří, jestli na stránce ještě nejsou nějaké zbývající objekty, a podle toho zjistí, jestli operace uspěla nebo ne. Není nic špatného, když operace selže; to se stane, například pokud kód v jiných částech jádra odkazuje na cílové objekty.
Funkce pro vytváření slabu má změněné API, aby umožňovala přiřazení sady operací k dané keši:
struct kmem_cache *kmem_cache_create(const char *name, size_t size,
size_t align, unsigned long flags,
void (*ctor)(void *, struct kmem_cache *, unsigned long),
const struct kmem_cache_ops *ops);
Destruktor už se nepoužívá, takže byl odstraněn ze seznamu parametrů kmem_cache_create() a nahrazen strukturou ops.
Patch obsahuje kód pro přidání defragmentace inodových a dentry keší - často jde o dvě největší slab keše v systému. Přibyla také nová funkce:
int kmem_cache_vacate(struct page *page);
Ta se pokusí přesunout všechny slab objekty z page, což by vlastně měla být stránka spravovaná slab alokátorem; nenulová návratová hodnota značí úspěch. Kromě jiného lze tuto funkci použít k vyčištění konkrétních stránek, což by pomohlo s dokončení alokace vyšší úrovně.
O této sadě patchů se moc nediskutovalo; hlavní koncept pravděpodobně není moc kontroverzní. Vypadá to jako způsob vylepšení jaderného využití paměti, který není zatížen příliš velkou režií; s tím je těžké nesouhlasit.
V září minulého roku jsme se podívali na kontejnerový patch, který připravil Rohit Seth. Od té doby se vývoji kontejnerů věnoval Paul Menage, který, stejně jako Rohit, používá adresu google.com. Patch se hodně vyvíjel, takže Rohitovo jméno už v něm ani není uváděno. S nedávno vydanou verzí V10 se tento mechanismus dostává do rozumně stabilní podoby.
Patch do jádra zavádí dva nové koncepty. První má staré jméno: "subsystém". Naštěstí byl koncept "subsystém" právě odstraněn z ovladačového kódu, takže je termín volný. V kontejnerovém patchi znamená subsystém část jádra, která by se mohla zajímat o to, co dělají skupiny procesů. Je dost pravděpodobné, že se většina subsystémů bude zabývat správou zdrojů; například mechanismus cpuset (který váže procesy ke konkrétním skupinám procesorů) je kontejnerovým patchem změněn na subsystém.
"Kontejner" je skupina procesů, která sdílí sadu parametrů používaných jedním nebo více subsystémy. V příkladu s cpuset by měl kontejner sadu procesorů, které by byl oprávněn využívat; všechny procesy v kontejneru zdědí stejnou sadu. Další (zatím neexistující) subsystémy by mohly využívat kontejnery k prosazení limitů procesorového času, využití I/O šířky pásma, využití paměti, viditelnosti souborových systémů atd. Kontejnery jsou hierarchické, takže jeden kontejner může obsahovat další.
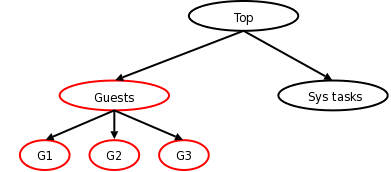 Jako příklad vezměme jednoduchou hierarchii vpravo. Server používaný k hostování kontejnerovaných hostů by mohl založit dva vrchní kontejnery, které by ovládaly využití procesorového času. Hostům by například mohlo být poskytnuto 90 % procesoru, ale administrátor by mohl vložit systémové úlohy do samostatného kontejneru, který by vždy dostal alespoň 10 % - tak by bylo zaručeno doručování pošty bez ohledu na to, co hosté dělají. V rámci kontejneru "Guests" [hosté] by měl každý host svůj vlastní kontejner se specifickými pravidly pro využití procesoru.
Jako příklad vezměme jednoduchou hierarchii vpravo. Server používaný k hostování kontejnerovaných hostů by mohl založit dva vrchní kontejnery, které by ovládaly využití procesorového času. Hostům by například mohlo být poskytnuto 90 % procesoru, ale administrátor by mohl vložit systémové úlohy do samostatného kontejneru, který by vždy dostal alespoň 10 % - tak by bylo zaručeno doručování pošty bez ohledu na to, co hosté dělají. V rámci kontejneru "Guests" [hosté] by měl každý host svůj vlastní kontejner se specifickými pravidly pro využití procesoru.
Mechanismus kontejnerů není omezen na jedinou hierarchii; administrátor jich může vytvořit, kolik se mu zamane. Takže například administrátor zmíněného systému by mohl vytvořit úplně jinou hierarchii pro ovládání využití šířky pásma sítě. Ve výchozím nastavení by byly všechny procesy ve stejném kontejneru, ale je možné nastavit pravidlo, které proces přesune do jiného kontejneru, když je spuštěna určitá aplikace. Takže prohlížeč webu by mohl být přesunut do kontejneru s relativně velkým přídělem, kdežto klienty BitTorrentu by se mohly ocitnout ve smutném a přiškrceném kontejneru.
Různé kontejnerové hierarchie se navzájem vůbec nemusejí podobat. Každá hierarchie má přiřazen jeden nebo více subsystémů; subsystém lze připojit jen k jedné hierarchii. Pokud je hierarchií více, bude každý proces ve více kontejnerech - jeden v každé hierarchii.
Administrace kontejnerů se provádí prostřednictvím speciálního virtuálního souborového systému. Dokumentace naznačuje, že by mohl být připojen k /dev/container, což je trochu podivné; se zařízeními to nijak nesouvisí. Pro každou vytvořenou hierarchii bude připojen jeden kontejnerový souborový systém. Přiřazení subsystémů k hierarchiím se provádí ve chvíli připojení podle mountovacích parametrů. Ve výchozím nastavení jsou s hierarchií propojeny všechny známé subsystémy, takže příkaz
mount -t container none /kontejnery
by vytvořil jednu hierarchii kontejnerů se všemi známými subsystémy v /kontejnery. Výše popisovaný systém by mohl být vytvořen třeba takto:
mount -t container -o cpu cpu /kontejnery/cpu
mount -t container -o net net /kontejnery/net
Požadované subsystémy pro každou hierarchii kontejnerů jsou prostě zadány jako parametry při připojování. V aktuální verzi kontejnerového patche však uváděné subsystémy "cpu" a "net" neexistují.
Pro vytváření nových kontejnerů stačí na požadovaném místě v hierarchii vytvořit nový adresář. Kontejnery obsahují soubor pojmenovaný tasks, ve kterém najdete seznam všech procesů, které jsou právě v kontejneru. Zapsáním ID procesu do souboru tasks lze proces do kontejneru přidat. Takže jednoduchý způsob, jak vytvořit kontejner a vložit do něj shell, by byl:
mkdir /kontejnery/nový_kontejner
echo $$ > /kontejnery/nový_kontejner/tasks
Subsystémy mohou do kontejnerů přidávat soubory, které využijí při nastavování limitů zdrojů nebo jiném ovládání způsobu funkce subsystému. Například subsystém cpuset (který skutečně existuje) přidá soubor cpus, který obsahuje seznam procesorů určených pro daný kontejner; přidává se ještě několik dalších souborů.
Stojí za zmínku, že kontejnerový patch nepřidává jediné systémové volání; veškerá správa se provádí přes virtuální souborový systém.
Když je teď základní kontejnerový mechanismus hotov, bude se pravděpodobně další úsilí zaměřovat na vytváření nových subsystémů. Vytvoření subsystému je poměrně jednoduché; kód subsystému začne vytvořením a zaregistrováním struktury container_subsys. Ta obsahuje celočíselné pole subsys_id, ve kterém by mělo být ID číslo subsystému; ta jsou nastavována staticky v <linux/container_subsys.h>. Vyplývá z toho, že subsystémy musí být zabudovány do jádra; neexistuje způsob pro přidávání subsystémů jako natahovatelných modulů.
Každý subsystém definuje sadu metod, které budou použity kontejnerovým kódem:
int (*create)(struct container_subsys *ss, struct container *cont);
int (*populate)(struct container_subsys *ss, struct container *cont);
void (*destroy)(struct container_subsys *ss, struct container *cont);
Tyto tři jsou volány při každém vytvoření nebo likvidaci kontejneru; v tu chvíli má subsystém šanci připravit administrativu, kterou bude pro nový kontejner potřebovat (nebo uklidit po rušeném kontejneru). Metoda populate() je volána po úspěšném vytvoření nového kontejneru; účelem je umožnit subsystému přidat do kontejneru soubory pro správu.
Čtyři metody pro přidávání a odebírání procesů:
int (*can_attach)(struct container_subsys *ss, struct container *cont,
struct task_struct *tsk);
void (*attach)(struct container_subsys *ss, struct container *cont,
struct container *old_cont, struct task_struct *tsk);
void (*fork)(struct container_subsys *ss, struct task_struct *task);
void (*exit)(struct container_subsys *ss, struct task_struct *task);
Je-li proces do kontejneru přidáván ručně po vytvoření, zavolá kontejnerový kód can_attach(), aby zjistil, jestli by přidání mělo být úspěšné. Pokud subsystém akci povolí, měl by provést veškeré potřebné alokace, aby se zajistilo, že bude úspěšné i následné volání attach(). Při rozdělení [fork] procesu bude zavolána fork(), aby do kontejneru přidala nového potomka. Končící procesy volají exit(), což subsystému umožní po nich uklidit.
Rozhraní je samozřejmě bohatší než by to z popisu mohlo vypadat; vizte podrobný dokumentační soubor, který je přibalen. Je obtížné hádat, kdy by mohl být kód začleněn, ale vypadá to, že jde o mechanismus, který se kontejnerová komunita rozhodla prosazovat. Dříve nebo později se tedy pravděpodobně v hlavním jádře objeví.
Následující obsah je © KernelTrap
25. kvě, originál
V nedávné diskuzi se probíral koncept vypisování [dumping] obrazu paměti jádra do swapu, když jádro narazí na chybu. Linus Torvalds poukázal na to, že taková funkce není pro operační systém jako je Linux, který může běžet na tolika odlišných počítačích, vůbec užitečná: Ano, v regulovaném prostředí může být vypsání paměti na disk správné řešení. ALE: v regulovaném prostředí systém nikdy nebude využíván tak, jak je využíván Linux. Proč myslíte, že Linux (a Windows, když jsme u toho) tolik ukousl z tradičního unixového trhu? Pokračoval vysvětlením, že existují systému, u kterých není swap větší než velikost jádra, takže uložení crash dumpu by nebylo možné. A že Linux se snaží chyby přiznat, aniž by spadl. Navíc je chyba často v ovladači. Zapisování na disk, když je největší problém v ovladači, je UJETÝ. A pokračoval srovnáním Linuxu se Solarisem: Takže skutečnost je taková, že Solaris je srágora, a z velké části je srágora právě _proto_, že předpokládá běh v 'regulovaném prostředí'.
Alan Cox připomněl, že tu je také otázka soukromí: Je tu další faktor - dumpy obsahují data, která mohou být copyrightovaná třetími stranami, spadat pod zákony na ochranu soukromí, prostě osobní a soukromá, citlivá z hlediska bezpečnosti (např. historie webových prohlížečů) a tak dále. Jediný důvod, proč je možné přenechat dumpy výrobcům, je ten, že existují silné formální dohody, které určují, kam se podějí, a co je s nimi prováděno. Podotkl také, že dumpové utility nejsou zrovna uživatelsky přívětivé: diskdump (a netdump ještě více) je, stejně jako kgdb, užitečný v rukách vývojáře, který úmyslně shazuje svůj stroj, ale ne v případě normální a racionální uživatelské reakce 'nefunguje to, stiskni reset' Linus souhlasil a připojil, že když chce někdo používat dumpy jádra, bude se mu lépe pracovat přes FireWire: Pokud jste se někdy probírali dumpem jádra po akci, vsadím se, že byste stejně dobře pořídili s FireWire a na váš obraz jádra by to nemělo žádný efekt. A teď si to srovnejte s kdump a položte si otázku: kterému je lepší se věnovat?
26. kvě, originál
Co začalo jako kontrola hlášení o chybě, se rozrostlo v zajímavou diskuzi, když se Linus Torvalds obul do současného designu suspend a resume [uspávání a probouzení]: Proč si SAKRA nedokážete uvědomit, že jaderná vlákna jsou jiná? Správně je a vždycky bylo začínat i ukončovat uživatelská vlákna kolem celé té věci. Na jaderná vlákna nesahejte. Přestaňte je zmrazovat. Později doplnil, že o suspend to disk (STD) [uspání na disk] vůbec nemá zájem - chtěl by pouze funkční implementaci suspend to ram (STR) [uspání do paměti].
Poznamenal, že se komplikovanost STD projevuje i v STR, takže by tyto dvě funkce měly být zcela odděleny: Rozčiluje mě, že STR tou chybou vlastně vůbec nemělo být ovlivněno. Jediný důvod, proč mělo STR stejnou chybu jako STD, je právě to, že jsou ty dvě funkce v jádře příliš úzce propojeny. To mě vážně štve. Řešili jsme chybu, která vůbec neměla existovat! Připojil, že notebooky sice moc nepoužívá, ale vyhovuje mu STR na desktopu: Díky STR jsou tiché a neplýtvají elektřinou, když je nepoužívám, ale když je potřebuji, mám je hned k dispozici.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 20.6.2007 02:15
Petr (DotaZ) Jakubec | skóre: 5
20.6.2007 02:15
Petr (DotaZ) Jakubec | skóre: 5
/etc/hibernate/blacklisted-modules je seznam modulů, které se musí odstranit, než se provede suspend. Mělo by stačit tam ty dva dopsat.
mno akoratze pri pouziti s2ram nejenze neni muj pocitac tichyTo samý mám tady, ventilátory u disků nadělají docela kravál a softwarově vypnout nejdou. (Ne že by mi suspend to disk momentálně nějak pomohlo, protože
Device driver ide0 lacks bus and class support for being resumed.
což jsem ignoroval, takže se mi jednoho krásného dne při resume pobořil root filesystem a po několika hodinách snahy donutit apt-get k přeinstalaci všech balíků jsem nakonec reinstaloval systém)
s2ram je ze µswsusp, ten používám k plné spokojenosti taky (zvlášť s verzí jádra .21 to chodí stabilně, předtím se jednou do týdne neprobudil/neuspal).

 20.6.2007 10:18
DjAARA | skóre: 32
| Praha|Náklo|Olomouc
20.6.2007 10:18
DjAARA | skóre: 32
| Praha|Náklo|Olomouc
 21.6.2007 18:31
stativ | skóre: 54
| blog: SlaNé roury
Co treba Apple? Ma take kvalitni notebooky. Beha na nich i Linux. Dnes platforma PowerPc i x86. Zna Apple ACPI? Jak Linux resi rizeni spotreby na HW od Apple? Apple ma plnou kontrolu nad HW i OS, takze situace muze byt jeste horsi nez na platforme Wintel.
21.6.2007 18:31
stativ | skóre: 54
| blog: SlaNé roury
Co treba Apple? Ma take kvalitni notebooky. Beha na nich i Linux. Dnes platforma PowerPc i x86. Zna Apple ACPI? Jak Linux resi rizeni spotreby na HW od Apple? Apple ma plnou kontrolu nad HW i OS, takze situace muze byt jeste horsi nez na platforme Wintel.
A pro vyrobce hw je velmi tezke podporovat OS, jehoz API se meni v case...Výrobce HW nemusí podporovat nic, stačilo by, kdyby zveřejnili specifikaci a té se drželi
 21.6.2007 18:39
michich | skóre: 51
| blog: ohrivane_parky
21.6.2007 18:39
michich | skóre: 51
| blog: ohrivane_parky
"O ACPI moc nevim, ale myslim si ze by podobny postup mohl byt pouzitelny"Ehm. Jestliže Microsoft jako spoluautor "normy" pro všechny udělá kompilátor, který normě nevyhovuje, a ACPI VM, které pouští ACPI kód také nekompatibilním způsobem, ale přitom tak, že kompilátor Microsoftu a VM Microsoftu se navzájem dorozumějí, určitě problémy Linuxu s ACPI nejsou zaviněné ani autory Linuxu, ani lidmi od Intelu. Linux totiž používá ACPI kód od Intelu, který respektuje normu. Ale dokud ACPI kód v hardwaru bude kompilovaný pro nestandardní VM od Microsoftu, těžko bude chodit v Linuxu s jinak se chovajícím standardním VM. Je to tak těžké pochopit? Takže nic se nikam nehází, Mrkvošrot prostě zase s ostatními zametl, jak má v oblibě (a může si to vzhledem ke svému postavení dovolit i přes aroganci takového počínání). To je dost těžké už proto, že ten kód v kernelu vykonává firmware v zařízení. Takže to tvoje "a nemůže za to Linux?" moc nedává smysl, kernel dělá přesně to, co mu ACPI firmware řekne, ale to mu moc nepomůže, když obojí hovoří jinou řečí.

s2disk a ne s2ram? S tím, že běžně uspávám do paměti, protože vesměs nemám o zásuvky nouzi?
 Mozna by stalo za to pozvat LT na podzimni Bootcamp, aby se neco o post-mortem analyze naucil.
* nebo tím chce otravovat kolegy solarisáře v práci
Mozna by stalo za to pozvat LT na podzimni Bootcamp, aby se neco o post-mortem analyze naucil.
* nebo tím chce otravovat kolegy solarisáře v práci
Tak tohle je nejlepší hláška v okrese!Ještě lepší je celý email, který doprovázel vydání 2.6.22-rc3. Bohužel už jsem v noci neměl sílu to překládat:
It's Friday evening, and the US is preparing for a long three-day weekend, often considered the official start of summer here. So what's a pasty white nerd to do? You can't go out on the beach, because the goodlooking people will laugh at you, and kick sand in your face. I'm not bitter. But now you _can_ do something: you can download the latest -rc kernel, and smile smugly to yourself, knowing that you are running the latest and greatest on your machine. And suddenly it doesn't even matter that summer is coming, because you can just sit in the basement, and close the blinds, and bask in the warm light from your LCD, rather than the harsh glare of the daystar.. [...] So stop worrying about those dangerous ultraviolet rays, and instead get your Vitamin D in the form God (and the pharmaceutical industry) intended: small easily swallowed pills. Beaches are overrated anyway, the sand gets into the laptop fan and soon it won't work. May you have a great summer, Linus
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 20.6.2007 08:10
20.6.2007 08:10